この記事のポイント
 大規模LLMの学習でGPU障害による中断が課題なら、HyperPodの自動復旧が有力な選択肢
大規模LLMの学習でGPU障害による中断が課題なら、HyperPodの自動復旧が有力な選択肢- Checkpointless Trainingで障害回復を15〜30分から2分以内に短縮、95%以上のtraining goodputを実現
- 2026年は新CLI/SDK(hyp)とRIG Observability(Grafana/Prometheus統合)で運用負荷を更に軽減
- Perplexityは学習時間40%削減・スループット2倍。Hexagon・Salesforce・Hugging Faceも採用
- 東京リージョンでFlexible Training Plans対応済み。Spot Instancesで最大90%のコスト削減も可能

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Amazon SageMaker HyperPodは、AWSが提供する大規模AI/MLモデルの学習に特化したマネージドクラスターサービスです。数百から数千のGPU・AIアクセラレータをまとめたクラスターを構築し、障害が発生しても自動で検出・復旧する耐障害性を備えています。
本記事では、SageMaker HyperPodの基本概念から、Checkpointless TrainingやElastic Trainingといった主要機能、Slurm/EKSによるアーキテクチャ構成、Perplexityなどの導入事例、料金体系、そして導入判断で詰まりやすいポイントまでを体系的に解説します。
目次
RIG Observability — クラスター可観測性の強化
SageMaker HyperPodのアーキテクチャと使い方
SlurmとAmazon EKS — 2つのオーケストレーター
SageMaker HyperPod vs 他の大規模学習基盤
SageMaker HyperPod利用時の注意点と導入判断
Amazon SageMaker HyperPodとは?
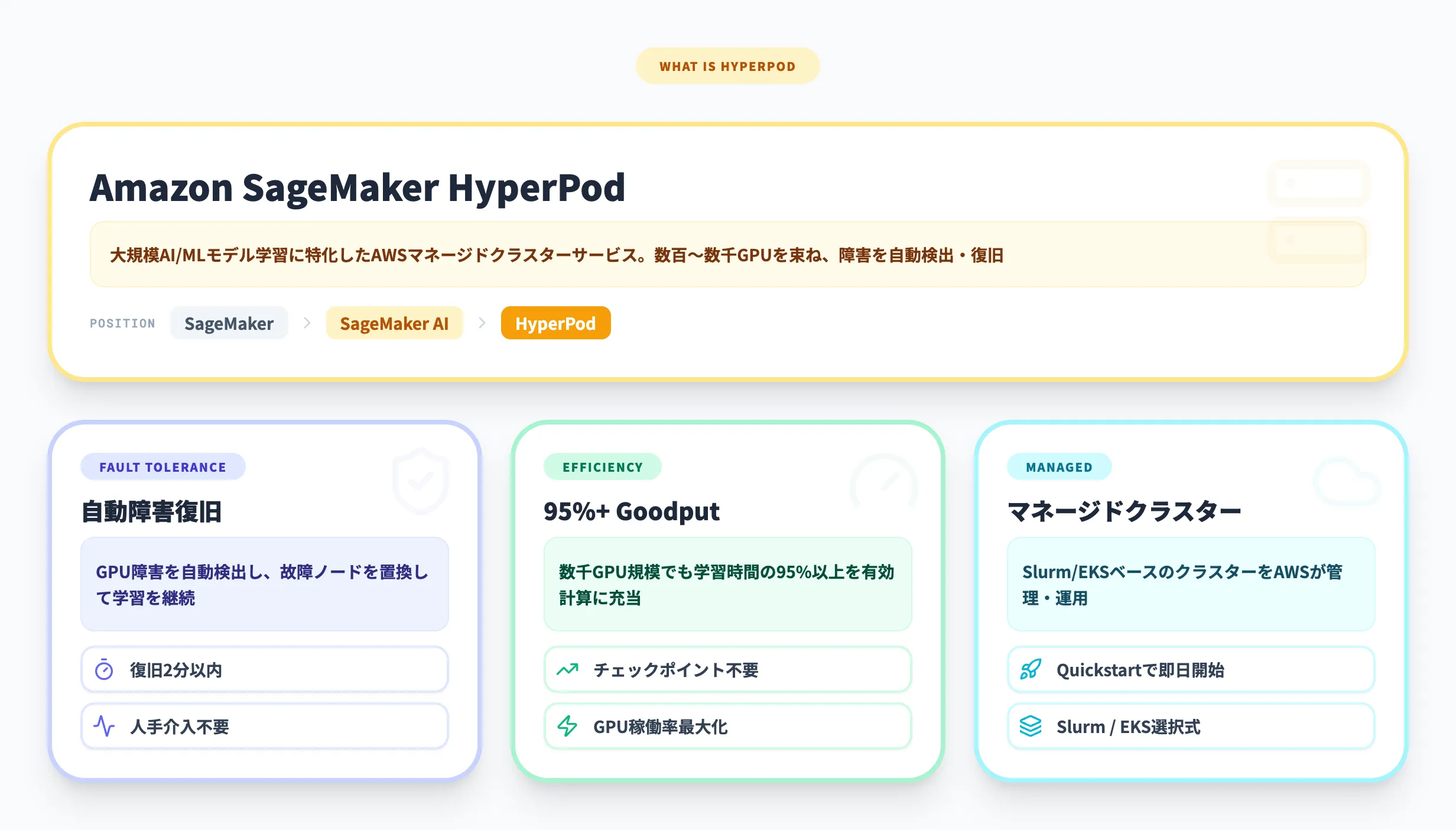
Amazon SageMaker HyperPodは、AWSが提供する大規模AI/MLモデルの学習に特化したマネージドクラスターサービスです。
大規模言語モデル(LLM)や拡散モデル、基盤モデルといった最先端のAIモデルを学習するには、数百から数千のGPUを束ねたクラスター環境が必要です。しかし、これだけの規模になるとハードウェア障害は「起きるかどうか」ではなく「いつ起きるか」の問題になります。
SageMaker HyperPodは、このインフラ障害の問題を根本から解決するために設計されました。障害を自動的に検出・診断し、故障したノードを置換して学習を継続する仕組みを備えています。数週間から数か月にわたる長期の学習ジョブを、人手による介入なしで安定して実行できる環境を提供するサービスです。
2024年12月のre:Invent 2024でSageMakerの次世代アーキテクチャが発表されて以降、HyperPodはSageMaker AIの中核コンポーネントの一つとして位置づけられています。

従来のML学習環境との違い
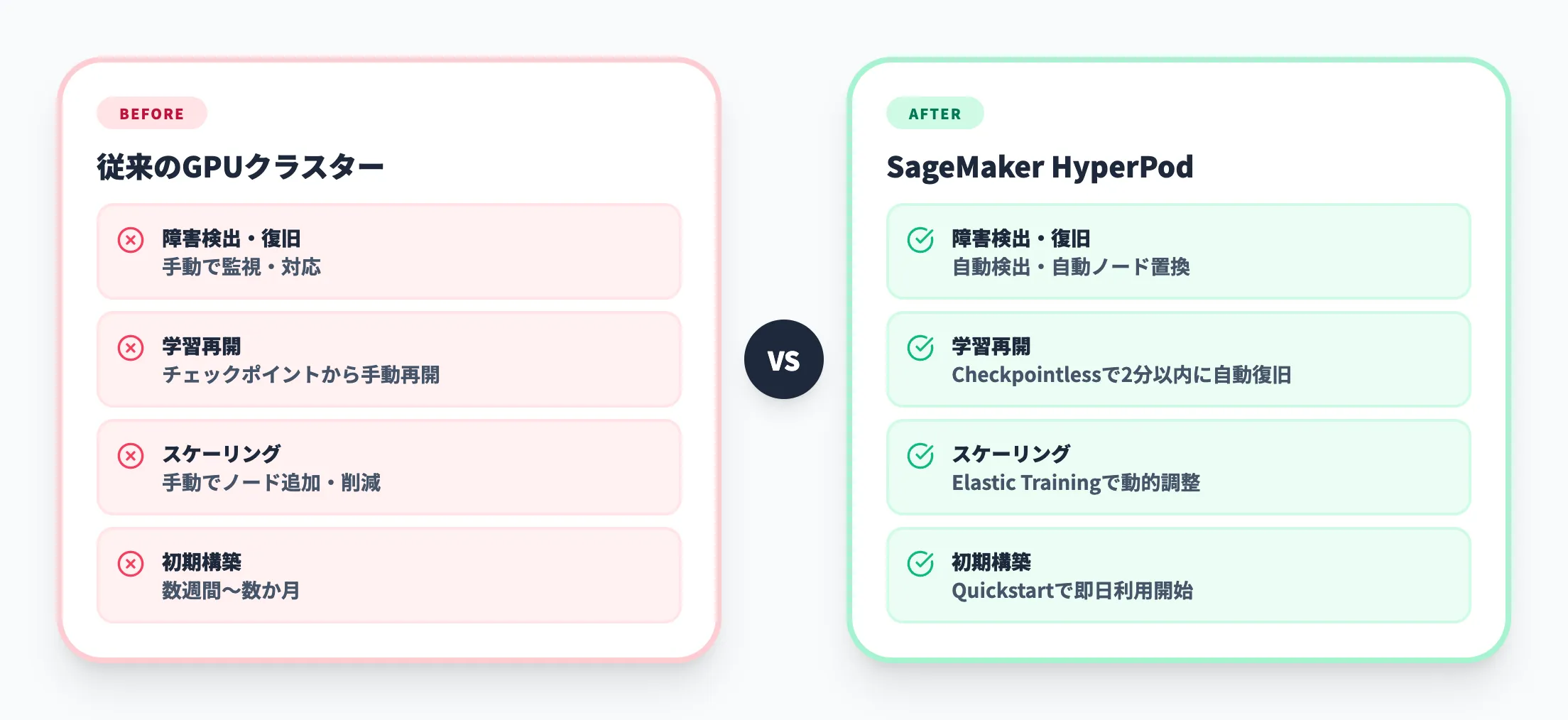
自社でGPUクラスターを構築・運用する従来のアプローチでは、障害対応やノード管理に多大なエンジニアリング工数がかかります。以下の表で、従来環境とHyperPodの違いを整理しました。
| 項目 | 従来のGPUクラスター | SageMaker HyperPod |
|---|---|---|
| 障害検出・復旧 | 手動で監視・対応 | 自動検出・自動ノード置換 |
| 学習再開 | チェックポイントから手動再開 | Checkpointless Trainingで自動復旧 |
| クラスター管理 | Slurm/Kubernetes環境を自前構築 | AWSマネージドで提供 |
| スケーリング | 手動でノード追加・削減 | Elastic Trainingで動的調整 |
| GPU利用効率 | 障害停止時間分のロス | 95%以上のtraining goodput |
| 初期構築コスト | 数週間〜数か月 | Quickstartで即日利用開始 |
特に差が出るのが障害復旧の部分です。従来環境では、障害発生→原因特定→ノード交換→チェックポイントからの再開という一連の流れに数十分から数時間かかることも珍しくありません。HyperPodでは、この一連の処理が自動化され、後述するCheckpointless Trainingを使えば2分以内に学習を再開できます。
SageMaker AIの中での位置づけ
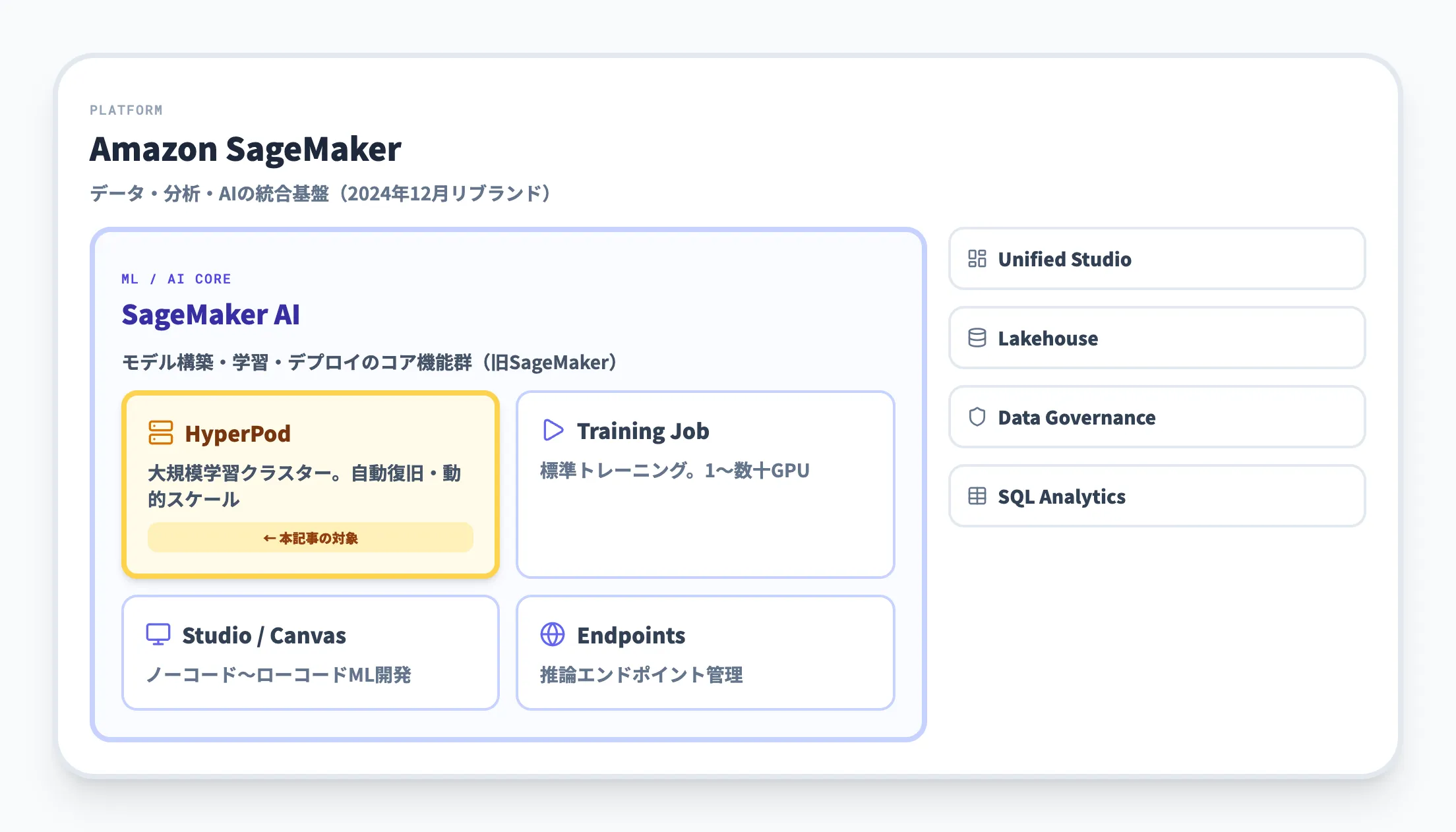
SageMakerは2024年12月のリブランドにより、データ・分析・AIの統合基盤へと進化しました。次世代SageMakerは、Unified Studio、Lakehouse、データガバナンス、SQL分析などの機能を統合した広範なプラットフォームです。
このうちSageMaker AIは、旧SageMakerの機能群を引き継いだML/AIモデルの構築・学習・デプロイのためのコア機能で、HyperPodはこのSageMaker AIに含まれる大規模学習向け機能です。
つまり、SageMaker(統合基盤)→ SageMaker AI(ML/AIのコア機能群)→ HyperPod(大規模学習クラスター)という階層関係になっています。通常のML学習ジョブであればSageMaker AIの標準トレーニング機能で十分対応できますが、数百GPU以上を使う基盤モデルの事前学習やファインチューニングには、HyperPodの耐障害性とスケーラビリティが不可欠になります。
【関連記事】
Amazon SageMakerとは?機能や料金、導入事例を解説
SageMaker HyperPodの主要機能
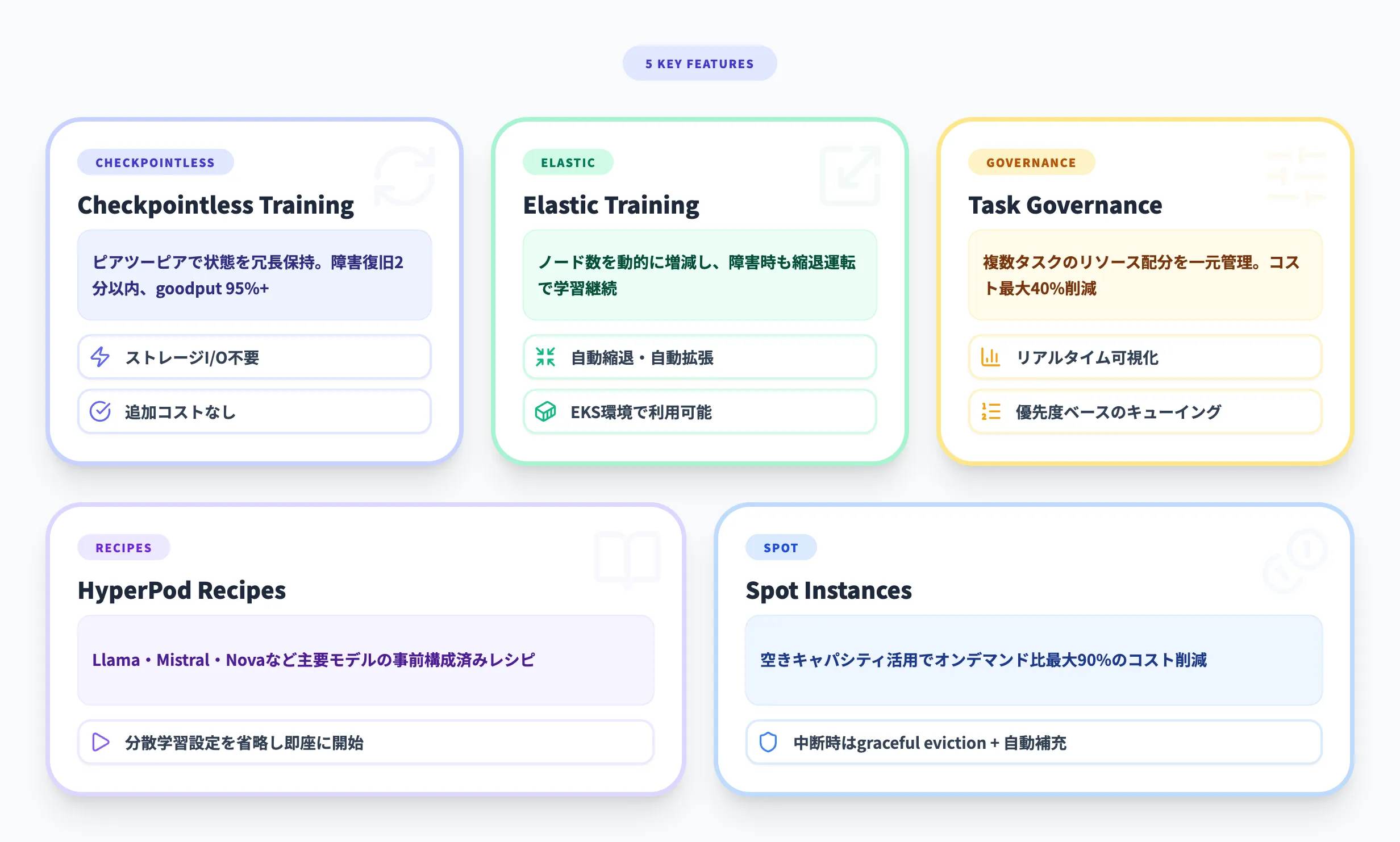
SageMaker HyperPodは、大規模学習を効率化するための5つの主要機能と、2026年に拡充された運用支援機能(HyperPod CLI/SDK、RIG Observability)を備えています。ここでは各機能の仕組みと、実際の運用でどのような効果が得られるかを解説します。
Checkpointless Training

Checkpointless Trainingは、2025年12月にGAとなったHyperPodの中核機能です。従来の大規模学習では、障害に備えて定期的にモデルの状態をストレージに保存する「チェックポイント」が必須でした。しかし、この保存処理自体がGPUの稼働を止め、学習効率を下げる原因になっていました。
Checkpointless Trainingは、このアプローチを根本から変えます。各GPUが保持するモデルの状態を、ピアツーピアで他の健全なGPUに冗長コピーとして保持します。障害発生時には、中央ストレージからの読み込みではなく、隣接するGPUから高速ネットワーク(EFA)経由で直接状態を復元します。
この仕組みにより、以下の改善が実現しています。
-
障害回復時間
従来の15〜30分以上から、2分以内に短縮
-
training goodput
数千アクセラレータ規模のクラスターで95%以上を達成
-
追加コスト
なし。対応リージョンで追加料金なく利用可能
AWSの基盤モデルAmazon Novaの学習にも使われた技術であり、数万アクセラレータ規模での実績があります。
Elastic Training
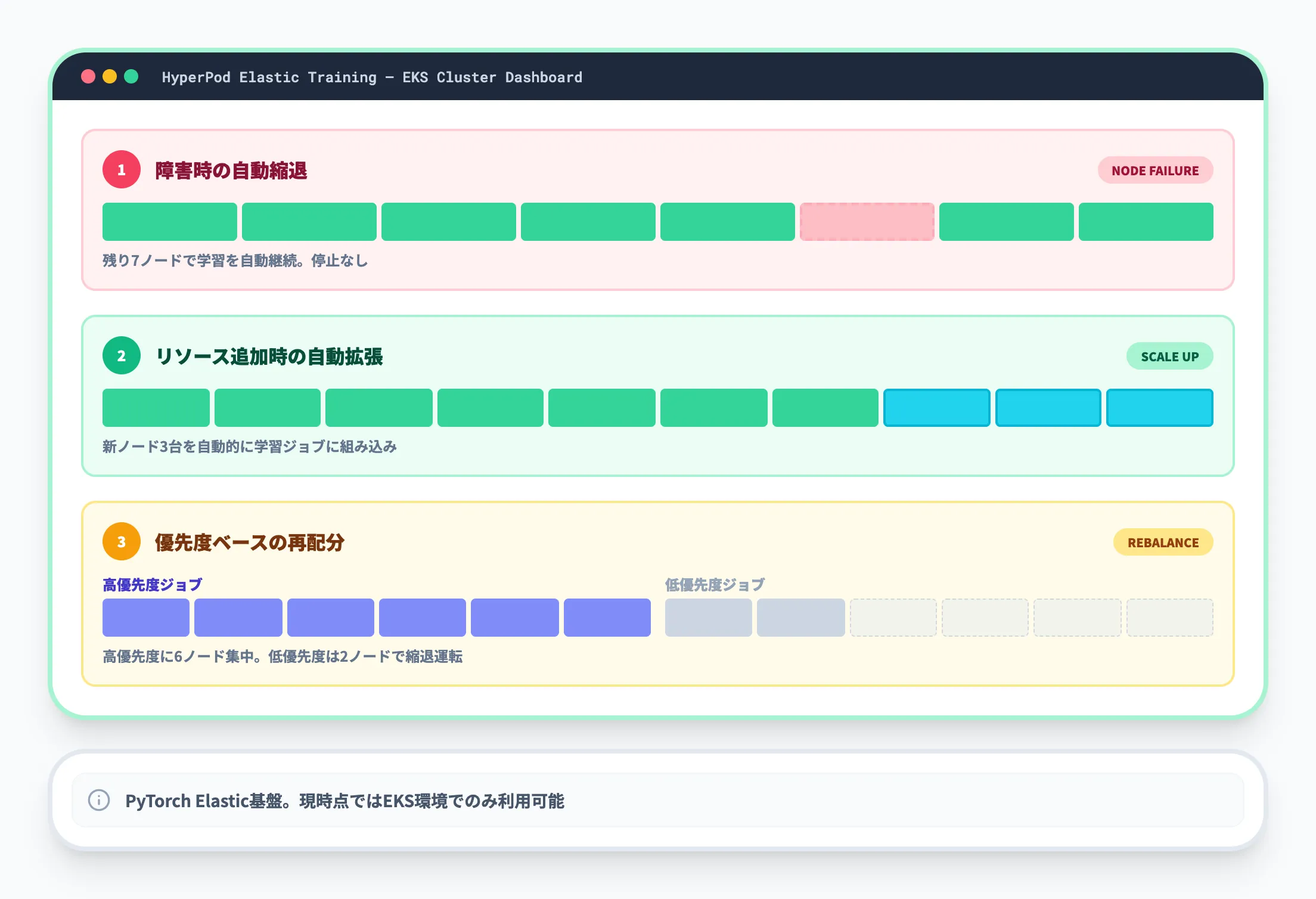
Elastic Trainingは、クラスターの容量変化に応じて学習ジョブのノード数を動的に増減する機能です。2025年12月にCheckpointless Trainingと同時にGAとなりました。
具体的には、以下のシナリオに対応します。
-
障害時の自動縮退
ノード障害が発生した場合、残りの健全なノードだけで学習を自動的に継続する
-
リソース追加時の自動拡張
新たなノードが利用可能になった場合、自動的に学習ジョブに組み込む
-
優先度ベースのリソース再配分
高優先度のジョブにリソースを動的に移動し、低優先度ジョブは縮退運転する
Elastic TrainingはPyTorch Elasticを基盤技術として採用しており、現時点ではAmazon EKS環境でのみ利用可能です。
Task Governance
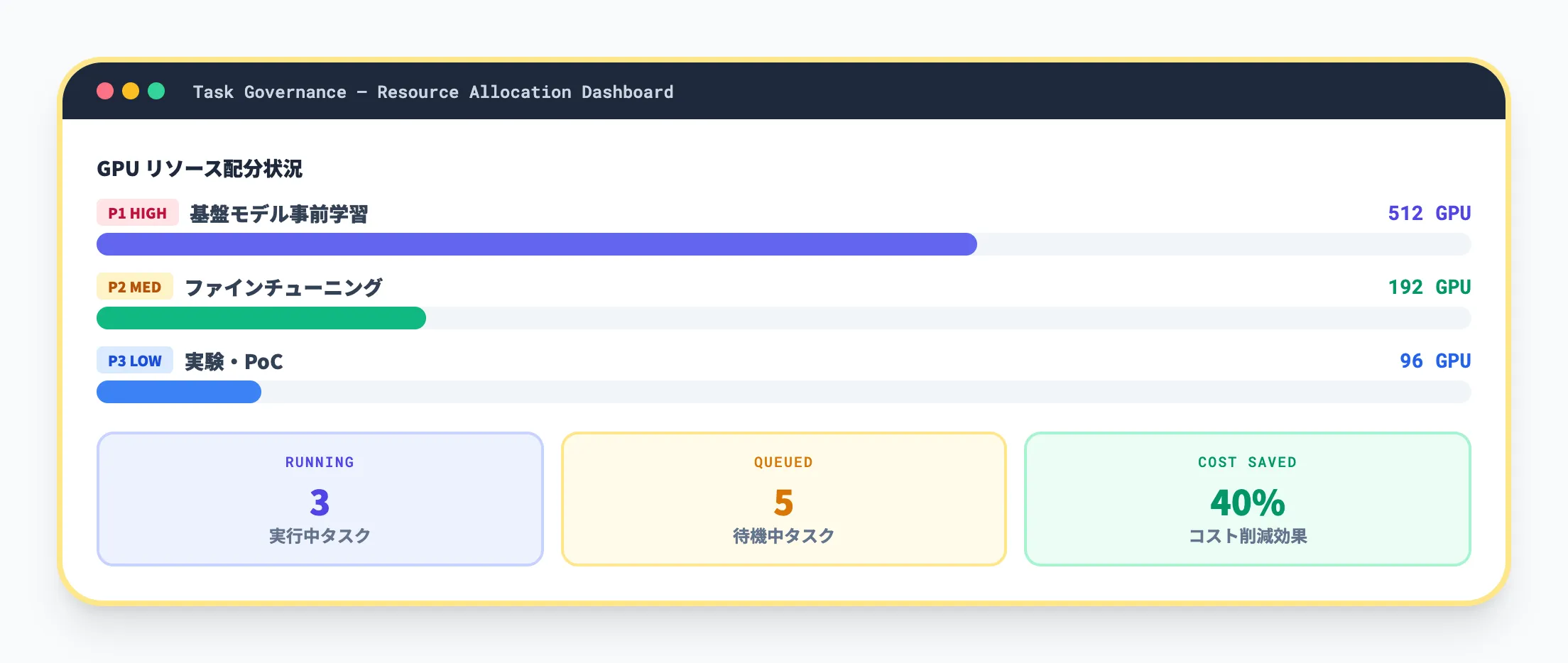
Task Governanceは、複数のAIモデル開発タスクにまたがるコンピュートリソースの配分を一元管理する機能です。
大規模な組織では、複数のチームが同時にモデル学習やファインチューニングを実行します。リソースの奪い合いが起きると、重要度の高いタスクが遅延したり、低優先度のタスクがリソースを占有したりする問題が発生します。
Task Governanceでは、タスクごとに優先度とリソース割当量を設定し、自動キューイングで最適なリソース配分を実現します。AWSの公式情報によると、この機能によりモデル開発コストを最大40%削減できるとされています。
リアルタイムのダッシュボードでリソース利用状況を可視化し、監査ログも取得できるため、コストの説明責任を果たしやすい設計になっています。
SageMaker HyperPod Recipes
SageMaker HyperPod Recipesは、主要な基盤モデルの学習・ファインチューニングを素早く開始するための事前構成済みレシピです。
Amazon NovaシリーズのモデルをはじめLlama、Mistralといったオープンモデルにも対応しており、分散学習の構成やハイパーパラメータのチューニングを自分でゼロから設定する必要がありません。
レシピを使うことで、分散学習ライブラリの選定やGPU間のデータ分割方法、学習率のスケジューリングといった設計判断を省略し、機械学習モデルの改良や評価に集中できます。
なお2026年には、レシピをCLI/SDKから直接呼び出せるHyperPod CLIとSDKが一般提供されました。hypコマンドで学習ジョブと推論ジョブを統一インターフェースから実行でき、PythonスクリプトやCI/CDパイプラインへの組み込みも容易になっています。コンソール操作を介さずにジョブ投入を自動化したいチームには有力な選択肢です。
RIG Observability — クラスター可観測性の強化
2026年3月にGAとなったRestricted Instance Group(RIG)向けObservabilityは、Amazon Nova ForgeなどのRIG構成クラスターに統合監視ダッシュボードを提供する機能です。Amazon Managed GrafanaとAmazon Managed Service for Prometheusを土台に、GPU使用率、NVLink帯域、CPU圧迫、FSx for Lustre使用量、Podライフサイクルといった指標をひとつのダッシュボードから確認できます。
従来は各メトリクスを手動で集約して相関分析する必要がありましたが、新クラスターでは自動的にオブザーバビリティスタックが有効化されるため、追加実装なしで以下のような運用が可能になります。
-
GPU性能の継続監視
ノードごとの利用率と温度、HBMメモリ消費を可視化し、ボトルネック特定を容易にする
-
トレーニングジョブのライフサイクル追跡
エポック進捗・ステップごとのログ・パイプラインエラー・Pythonトレースバックをキュレーションされたログとして集約
-
障害時の根本原因分析の短縮
ネットワーク・GPU・ストレージのメトリクスを横断的に追跡し、トラブルシューティング時間を「数日から数分」へ短縮
運用負荷の高い大規模クラスターでは、SREチームの監視業務を自動化できる効果が大きく、監査・コスト報告のエビデンスとしても活用しやすい設計です。
Spot Instances
HyperPodはSpot Instancesに対応しており、オンデマンド料金と比較して最大90%のコスト削減が可能です。
Spot Instancesは空きキャパシティを利用する仕組みのため、AWSの需要状況によってインスタンスが中断される可能性があります。HyperPodはSpot中断を検知すると、graceful evictionによるチェックポイント保存とキャパシティの自動補充を行います。Elastic Training(EKS環境)を使う場合は、保存したチェックポイントから学習を再開できます。なお、Checkpointless Trainingはノード障害時のピアツーピア状態復元を担う別系統の耐障害機能であり、Elastic Trainingとは現時点で併用できません。
コスト最適化を重視するケースでは、Spot Instancesを軸にしつつ、中断リスクの許容できない最終段階のみオンデマンドに切り替える、という運用が現実的です。

SageMaker HyperPodのアーキテクチャと使い方

SageMaker HyperPodのクラスターは、オーケストレーターとハードウェア構成を選択して構築します。ここでは2つのオーケストレーター、最新のUltraServers、そしてセットアップの流れを解説します。
SlurmとAmazon EKS — 2つのオーケストレーター
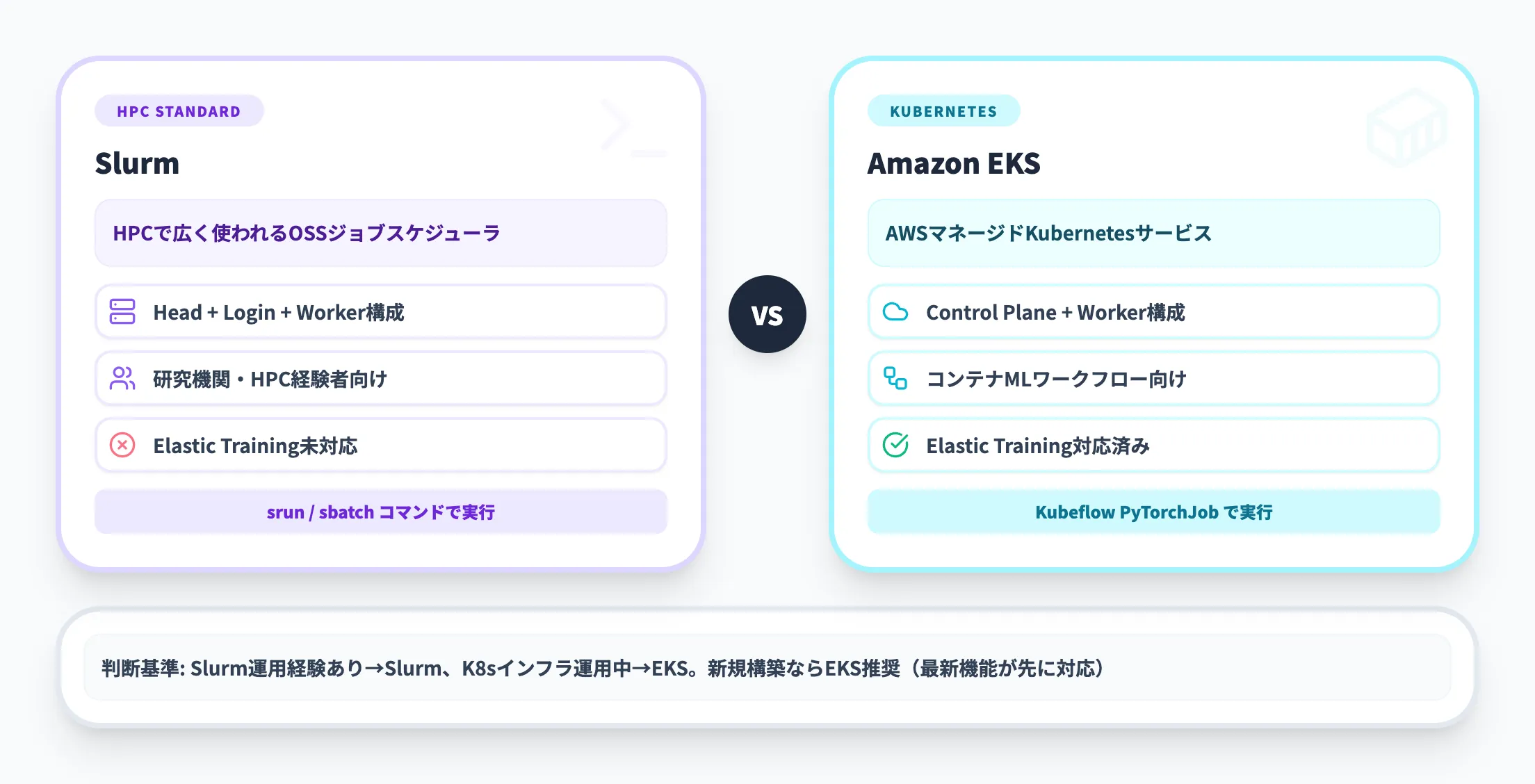
HyperPodでは、クラスターのワークロード管理にSlurmまたはAmazon EKSのいずれかを選択できます。
| 項目 | Slurm | Amazon EKS |
|---|---|---|
| 概要 | HPCで広く使われるオープンソースのジョブスケジューラ | AWSのマネージドKubernetesサービス |
| クラスター構成 | Headノード + Loginノード + Workerノード | EKS Control Plane + HyperPod Workerノード |
| 向いている用途 | 研究機関やHPC経験者のチーム | コンテナ化されたMLワークフロー |
| Elastic Training | 未対応 | 対応済み |
| 主なメリット | HPCの知見をそのまま活用可能 | 既存のKubernetes運用と統合しやすい |
選び方の判断基準はシンプルです。チーム内にSlurmの運用経験があるならSlurm、Kubernetesベースのインフラを既に運用しているならEKSを選ぶのが自然です。Elastic Trainingのような最新機能はEKS側から先に対応される傾向があるため、新規構築であればEKSを選択するメリットが大きくなっています。
P6e-GB200 UltraServers
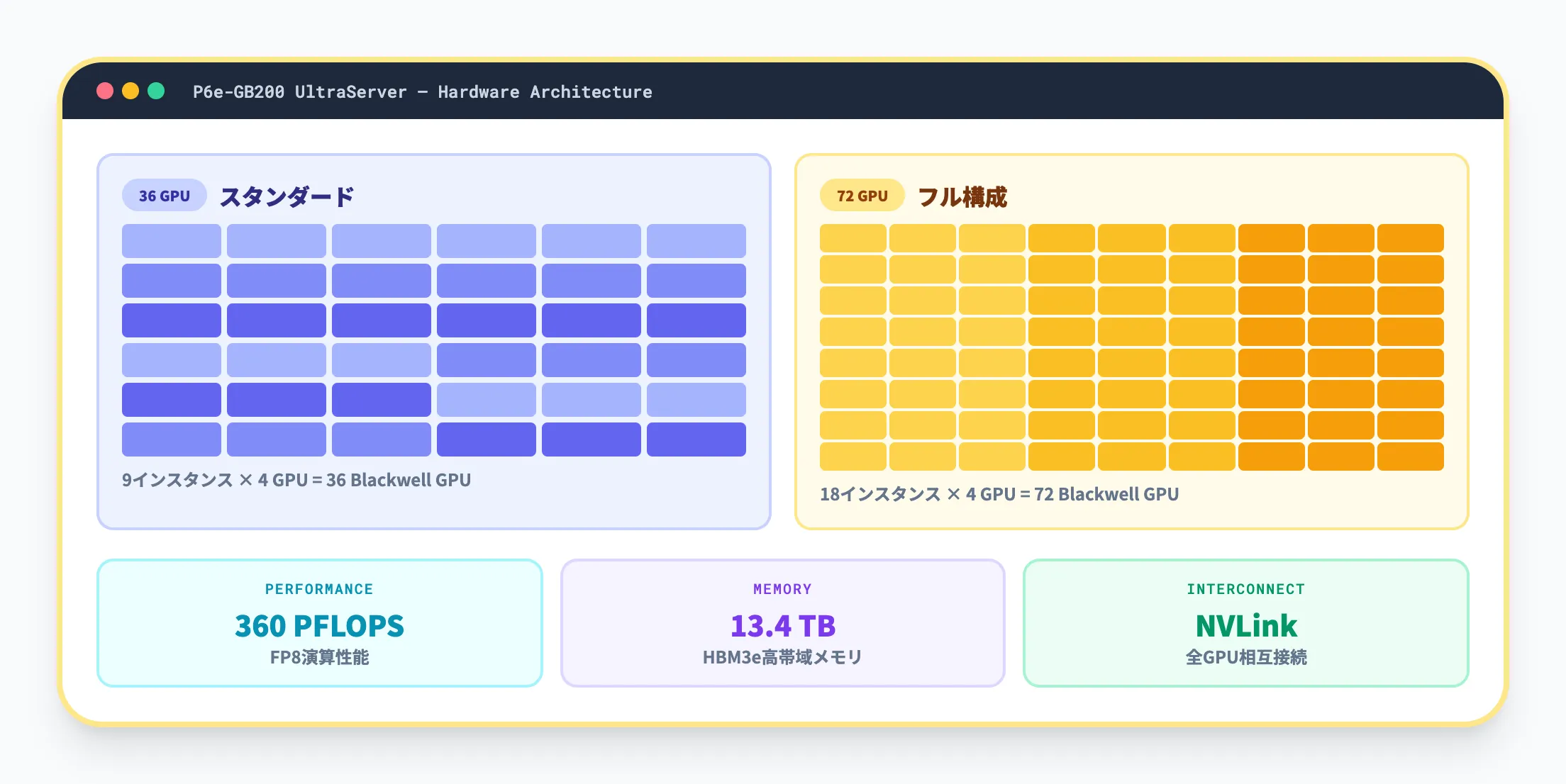
2025年中頃にGAとなったP6e-GB200 UltraServersは、HyperPodで利用できる最上位のハードウェア構成です。
UltraServerには2つのサイズがあり、36 GPU構成(9インスタンス)と72 GPU構成(18インスタンス)から選択できます。いずれもNVIDIA Grace CPUとBlackwell GPUがNVLinkで相互接続されています。72 GPU構成の主なスペックは以下のとおりです。
-
演算性能
FP8で360 PFLOPS(スパーシティなし)
-
メモリ
合計13.4TBのHBM3e高帯域メモリ
-
用途
1兆パラメータ規模のモデル学習と推論
HyperPodはUltraServer内のトポロジーを認識したスケジューリングを行い、同一NVLinkドメイン内にインスタンスを配置することで、GPU間の通信遅延を最小化します。障害発生時には、あらかじめクラスター構成でスペアインスタンスを確保しておくことで、同じNVLinkドメイン内での自動置換が可能です。
なお、UltraServersは大規模な基盤モデルの事前学習を想定した構成であり、中小規模のファインチューニングであればp5.48xlarge(NVIDIA H100搭載)やp4d.24xlarge(A100搭載)で十分対応できます。
セットアップの手順

HyperPodクラスターの構築は、以下の流れで進めます。
1. 前提条件の準備
IAMロールの作成、VPCとサブネットの設定、サービスクォータの引き上げ申請を行います。特にGPUインスタンスのクォータはデフォルトで低く設定されているため、余裕を持って申請しておく必要があります。
2. クラスターの作成
SageMakerコンソール、AWS CLI、またはSDKからクラスターを作成します。Quickstartを利用すれば、対話形式で基本構成を自動生成できます。
3. ライフサイクルスクリプトの設定
クラスターノード起動時に実行されるカスタムスクリプトを設定します。Conda、Docker、venv、enrootなど複数の実行環境に対応しています。2026年1月のアップデートでデバッグ機能が強化され、CloudWatchログとの連携でトラブルシューティングが容易になりました。
4. ジョブの実行
Slurm環境ではsrunやsbatchコマンド、EKS環境ではKubeflow PyTorchJobでジョブを投入します。HyperPod Recipesを使えば、事前構成済みのテンプレートで素早く学習を開始できます。
実際のワークショップでの報告によれば、FSx for LustreとNAT Gatewayはクラスター稼働中は課金が継続するため、検証後のリソース削除を忘れないよう注意が必要です。
SageMaker HyperPodの導入事例

SageMaker HyperPodは、AIスタートアップから大手企業まで幅広く採用されています。ここでは、公式に公開されている事例から定量データのある4社を紹介します。
Perplexity AI

Perplexity AIは、会話型回答エンジンを提供するAIスタートアップです。約1,000万人の月間アクティブユーザーを抱え、大規模なLLMを継続的に改善する必要がありました。
HyperPodの導入により、以下の成果を達成しています。
| 指標 | 改善効果 |
|---|---|
| モデル学習時間 | 最大40%削減 |
| 学習スループット | 2倍に向上 |
| クエリ処理能力 | 10万クエリ/時間以上に対応 |
SageMakerの分散学習ライブラリによるGPU間データ転送の最適化(1,600Gbps超)が、スループット向上の主因です。PerplexityのCEOは「SageMaker HyperPodの組み込みライブラリがGPU学習を最適化し、スループットを倍増させた」と述べています。
Salesforce
Salesforceは、エンタープライズAI研究の文脈でHyperPodを活用しています。Checkpointless Trainingの採用により、障害発生時のジョブ再設定にかかっていた時間を大幅に削減しました。
大規模学習インフラの迅速な展開と、障害復旧の自動化が導入の決め手です。研究チームがインフラ管理ではなくモデル改善に集中できる環境を実現しています。
Hugging Face
オープンソースAIプラットフォームのHugging Faceは、StarCoder(コード生成モデル)、IDEFICS(マルチモーダルモデル)、Zephyr(対話モデル)といった基盤モデルの開発にHyperPodを利用しています。
インフラ管理をAWSに任せることで、研究チームがイノベーションに集中できる点を評価しています。
Hexagon — 地理空間AIの自社モデル開発
測量・地理空間ソリューションを提供するHexagonは、点群(ポイントクラウド)データを扱う特化型セグメンテーションモデルの事前学習にSageMaker HyperPodを採用しました。粉塵やセンサーノイズの除去、地形タイプの分類、移動物体の検出といった用途で、汎用大型モデルではなく業務特化モデルを自社で構築しています。
導入の決め手となったポイントは以下のとおりです。
-
長期学習の安定稼働
ノードのヘルスチェックと自動置換、ジョブの自動再開により、数週間から数か月にわたる学習を中断なく実行
-
データ基盤との統合
S3に格納した学習データをFSx for Lustreから遅延ロードし、チェックポイントの自動S3エクスポートも実現
-
柔軟なGPU予約
SageMaker Training Plansで1日から6か月までの範囲でGPUキャパシティを確保し、実験フェーズと長期学習を予算内で両立
Hexagonの事例は、汎用基盤モデルではなく業務特化モデルを継続的に開発したい製造・エンジニアリング業界にとって、HyperPodの「インフラ運用を自動化しモデル開発に集中する」という価値が活きる典型例です。
このほか、映像AI企業のLuma AIやAI文書生成のWriterなど、大規模モデルの開発を手がけるスタートアップの採用が目立ちます。
Amazon SageMaker HyperPodの成果を業務実装までつなぐ

学習基盤の先にある業務接続・運用設計を整理
Amazon SageMaker HyperPodで学習基盤を整えても、実運用では推論導線、業務システム連携、権限設計、実行管理まで含めた設計が必要です。AI Agent HubのLPで、学習成果を業務実装につなぐ全体像をご確認ください。
SageMaker HyperPod vs 他の大規模学習基盤
HyperPodの導入を検討する際、SageMakerの標準トレーニング機能との違いや、他クラウドの学習基盤との比較は避けて通れません。ここでは2つの軸で整理します。
SageMaker標準トレーニングジョブとの違い

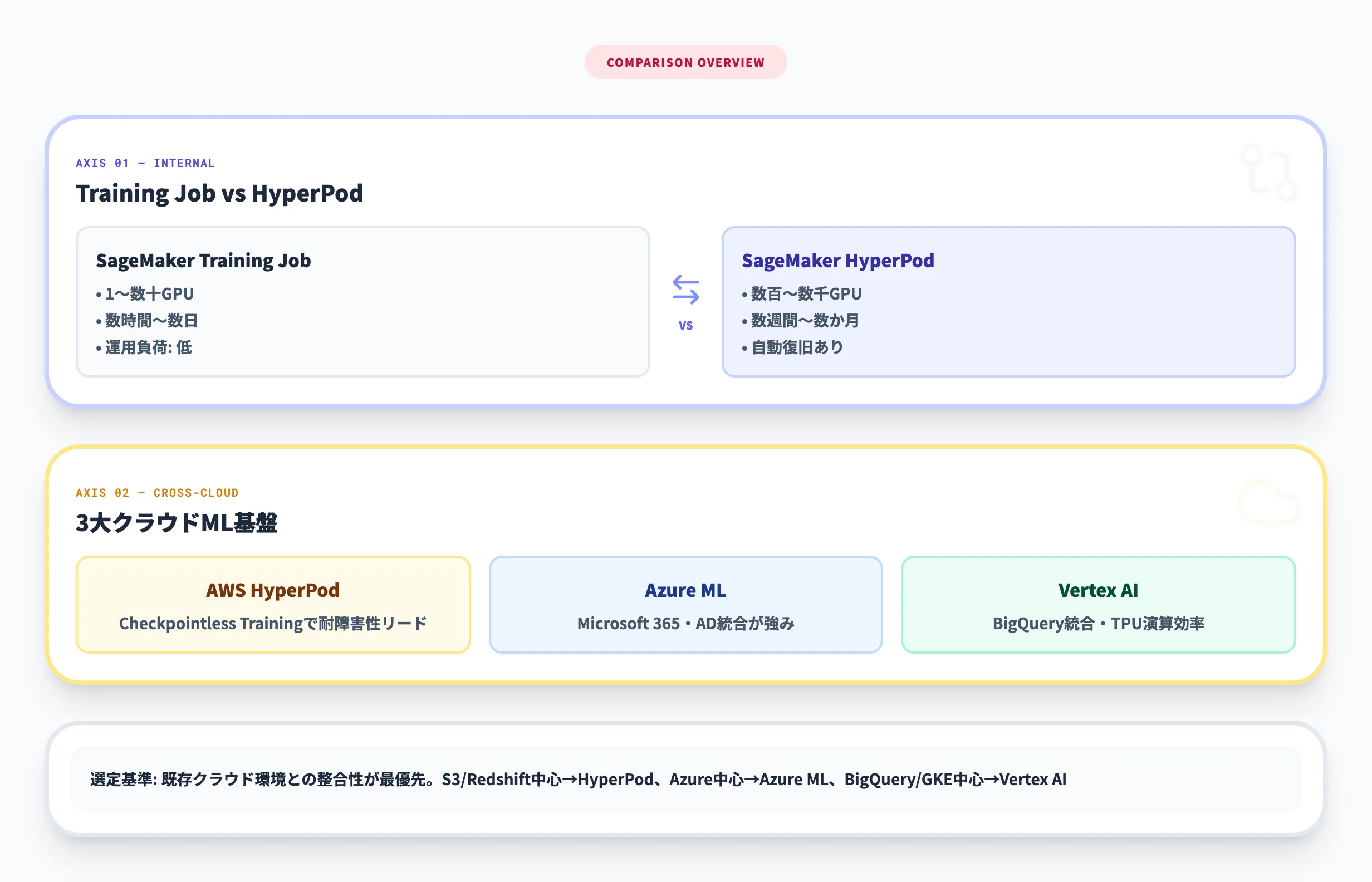
SageMaker AIには、HyperPodとは別にTraining Jobという標準的なモデル学習機能があります。以下の表で使い分けの判断基準を示します。
| 項目 | SageMaker Training Job | SageMaker HyperPod |
|---|---|---|
| 想定規模 | 1〜数十GPU | 数百〜数千GPU |
| 学習期間 | 数時間〜数日 | 数週間〜数か月 |
| クラスター管理 | ジョブ単位で自動起動・終了 | 常駐クラスターを管理 |
| 障害復旧 | チェックポイントからの再実行 | 自動復旧(Checkpointless対応) |
| オーケストレーター | 不要(マネージド) | Slurm or EKS |
| 運用負荷 | 低い | 中〜高い |
| 向いている用途 | PoC、小規模学習、推論エンドポイント | 基盤モデルの事前学習、大規模ファインチューニング |
つまり、「MLの学習ジョブを手軽に実行したい」ならTraining Job、「数百GPU規模で数週間の学習を安定して回したい」ならHyperPod、という切り分けになります。多くの企業では、PoCや小規模実験はTraining Jobで始め、本格的な基盤モデル開発に進む段階でHyperPodに移行するパターンが一般的です。
3大クラウドML基盤の比較
AWS以外にも、Azure Machine LearningやGoogle Vertex AIが大規模学習の基盤を提供しています。
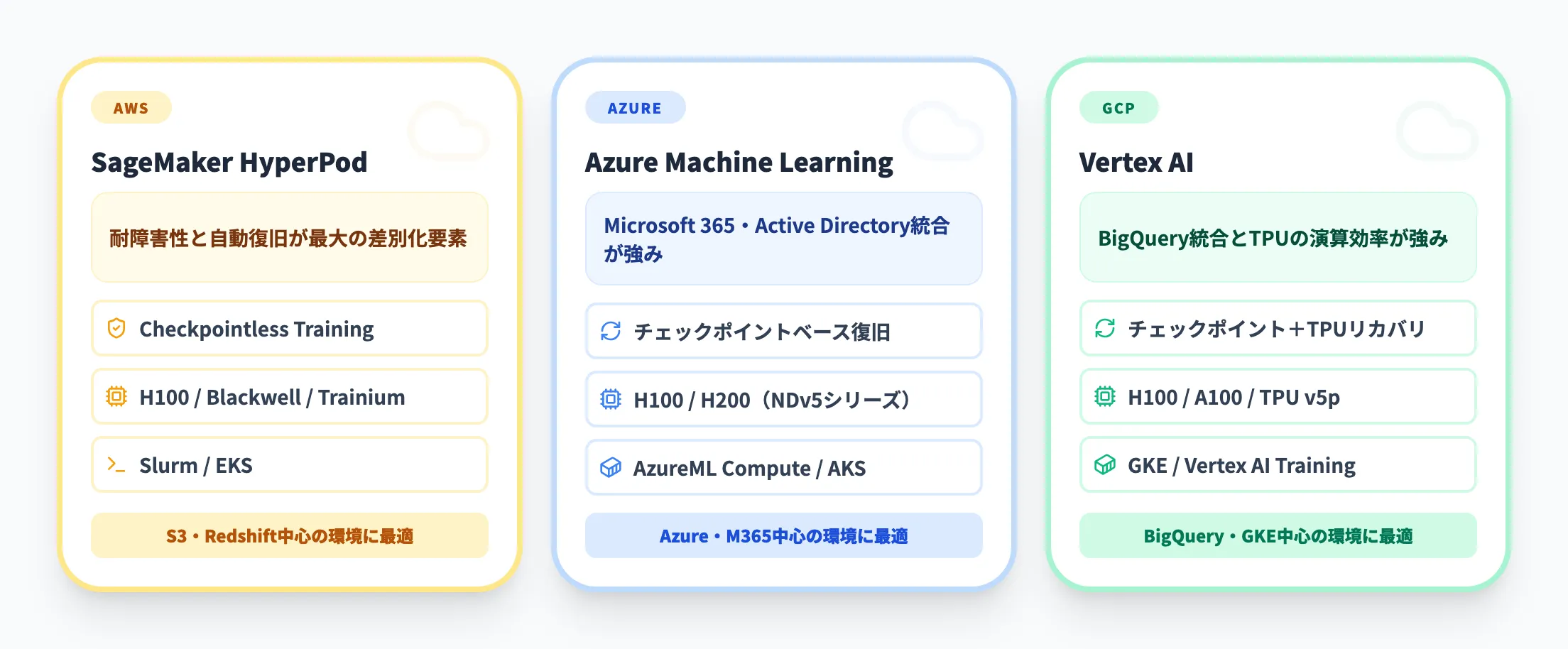
| 項目 | SageMaker HyperPod | Azure Machine Learning | Vertex AI |
|---|---|---|---|
| 最大GPU規模 | 数千GPU(UltraServerで最大72GPU/ドメイン) | 数千GPU(NDv5シリーズ) | 数千TPU(TPU v5p Pod) |
| 耐障害性 | Checkpointless Training(自動復旧2分以内) | チェックポイントベースの復旧 | チェックポイント+TPUリカバリ |
| GPU種類 | NVIDIA H100/H200/Blackwell、AWS Trainium | NVIDIA H100/H200 | NVIDIA H100/A100、Google TPU |
| オーケストレーター | Slurm / EKS | AzureML Compute / AKS | GKE / Vertex AI Training |
| 独自チップ | AWS Trainium(学習用) | なし | Google TPU v5p |
| 強み | 耐障害性と自動復旧の成熟度 | Microsoft 365・Active Directory統合 | BigQuery統合とTPUの演算効率 |
プラットフォーム選定で最も重要なのは、既存のクラウド環境との整合性です。S3やRedshiftにデータが集約されているならSageMaker HyperPod、Microsoft 365やAzure環境が中心ならAzure ML、BigQueryやGoogle Workspaceを基盤にしているならVertex AI、というのが基本的な判断ラインです。
純粋な耐障害性の観点では、Checkpointless Trainingを持つHyperPodが一歩リードしています。他のプラットフォームではチェックポイントベースの復旧が主流であり、復旧時間に差が出ます。
【関連記事】
Azure Machine Learning(ML)とは?使い方や料金、Notebookを解説
【関連記事】
Vertex AIとは?主要機能・料金体系・他Googleサービスとの違いを徹底解説
SageMaker HyperPodの料金体系

SageMaker HyperPodの料金は、使用するインスタンスタイプと利用形態によって決まります。公式の料金ページでは、インスタンスごとの時間単価が公開されています。
オンデマンド料金
HyperPodのオンデマンド料金は、クラスターにプロビジョニングしたインスタンスのキャパシティ割当期間に対して課金されます。以下は代表的なGPUインスタンスの参考価格です。
| インスタンスタイプ | 搭載GPU | 参考価格(時間単価) |
|---|---|---|
| ml.p4d.24xlarge | NVIDIA A100 x 8 | 約$37.69/時間 |
| ml.p5.48xlarge | NVIDIA H100 x 8 | 公式料金ページを参照 |
| ml.p5e.48xlarge | NVIDIA H200 x 8 | 公式料金ページを参照 |
| ml.trn2.48xlarge | AWS Trainium2 | 公式料金ページを参照 |
上記はHyperPod単体の料金であり、Amazon EKS、Amazon FSx for Lustre、Amazon S3、NAT Gatewayなど接続サービスの料金は別途発生します。特にFSx for LustreとNAT Gatewayはクラスター稼働中は継続的に課金されるため、コスト計算に含める必要があります。
2026年4月時点の正確な料金はSageMaker AI料金ページで確認してください。
Flexible Training Plans
Flexible Training Plansは、re:Invent 2024で発表されたコスト最適化オプションです。指定した期間とタイムライン内でGPUキャパシティを確保し、オンデマンドより割安な料金でリソースを利用できます。
東京リージョン(ap-northeast-1)でもFlexible Training Plansが利用可能になっており、日本国内の学習ワークロードにも対応しています。
「いつまでに学習を完了させたいか」「最大いくらまで支出できるか」を指定すると、SageMakerが自動的にインフラ設定・ワークロード実行・障害復旧を管理してくれる仕組みです。
コスト最適化のポイント
HyperPodのコストを管理するための主要な手段をまとめます。
-
Spot Instances
オンデマンド比で最大90%の割引。中断リスクはあるが、Checkpointless Training併用で影響を最小化できる
-
ML Savings Plans
1年または3年の利用コミットメントで最大64%の割引が適用される
-
AWS Budgetsアラート
GPU利用時間が想定を超過する前に通知を受け取る設定を推奨
-
Task Governance
リソース配分の最適化でモデル開発コストを最大40%削減
大規模学習のコストは月額数万ドルに達することも珍しくないため、AWS Budgetsによるアラート設定は必須です。Spot InstancesとFlexible Training Plansを組み合わせることで、オンデマンドのみの場合と比較して大幅にコストを抑えられます。
なお、HyperPodには初回リソース作成月から2か月間、月間50時間のm5.xlargeインスタンスが無料枠として提供されています。GPU学習には不十分ですが、クラスターの基本的な操作やセットアップの検証に活用できます。

SageMaker HyperPod利用時の注意点と導入判断

HyperPodは強力なサービスですが、導入すれば全て解決するわけではありません。セットアップのハマりどころと、そもそも導入すべきかの判断ポイントを整理します。
セットアップで詰まりやすいポイント
実際にHyperPodクラスターを構築する際に、エンジニアがつまずきやすいポイントがいくつかあります。
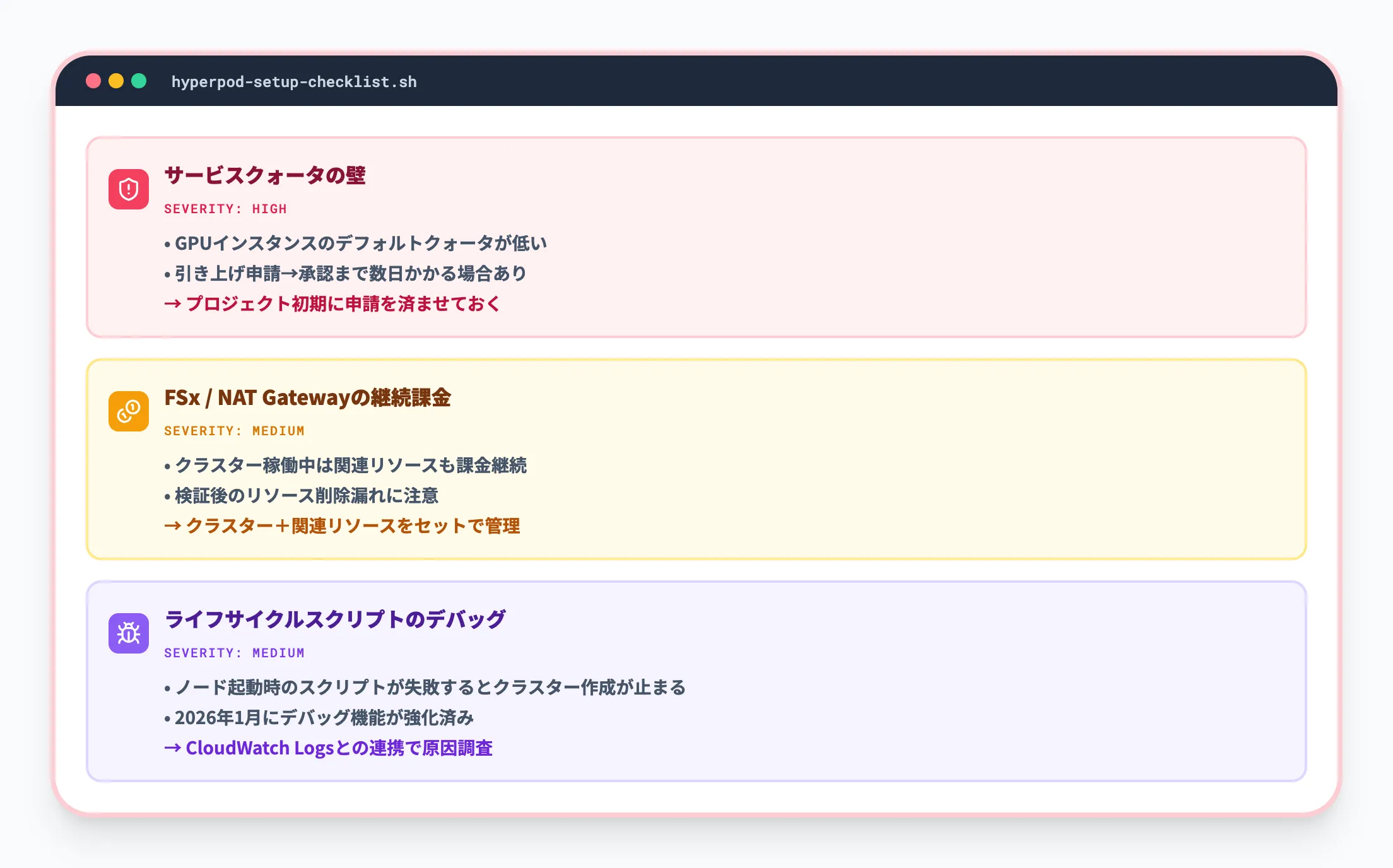
-
サービスクォータの壁
GPUインスタンスのデフォルトクォータは低く設定されているため、クラスター構築前にAWSへの引き上げ申請が必要です。申請から承認まで数日かかることがあるため、プロジェクト初期に済ませておくべきです
-
FSx for LustreとNAT Gatewayの課金
クラスター稼働中はこれらのリソースが継続課金されます。検証が終わったらクラスターだけでなく関連リソースも含めて削除する必要があります
-
ライフサイクルスクリプトのデバッグ
カスタムスクリプトのエラーはクラスター起動の失敗につながります。2026年1月のアップデートでCloudWatchログとの連携が強化されましたが、初回はエラーの切り分けに時間がかかることがあります
-
SSH接続のユーザー設定
セッションマネージャーで接続した場合、デフォルトがrootユーザーになります。学習ジョブの実行にはubuntuユーザーへの切り替えが必要です
導入判断で詰まる3つの論点
HyperPodの導入を検討する際、多くの企業が以下の3つの論点で判断に迷います。
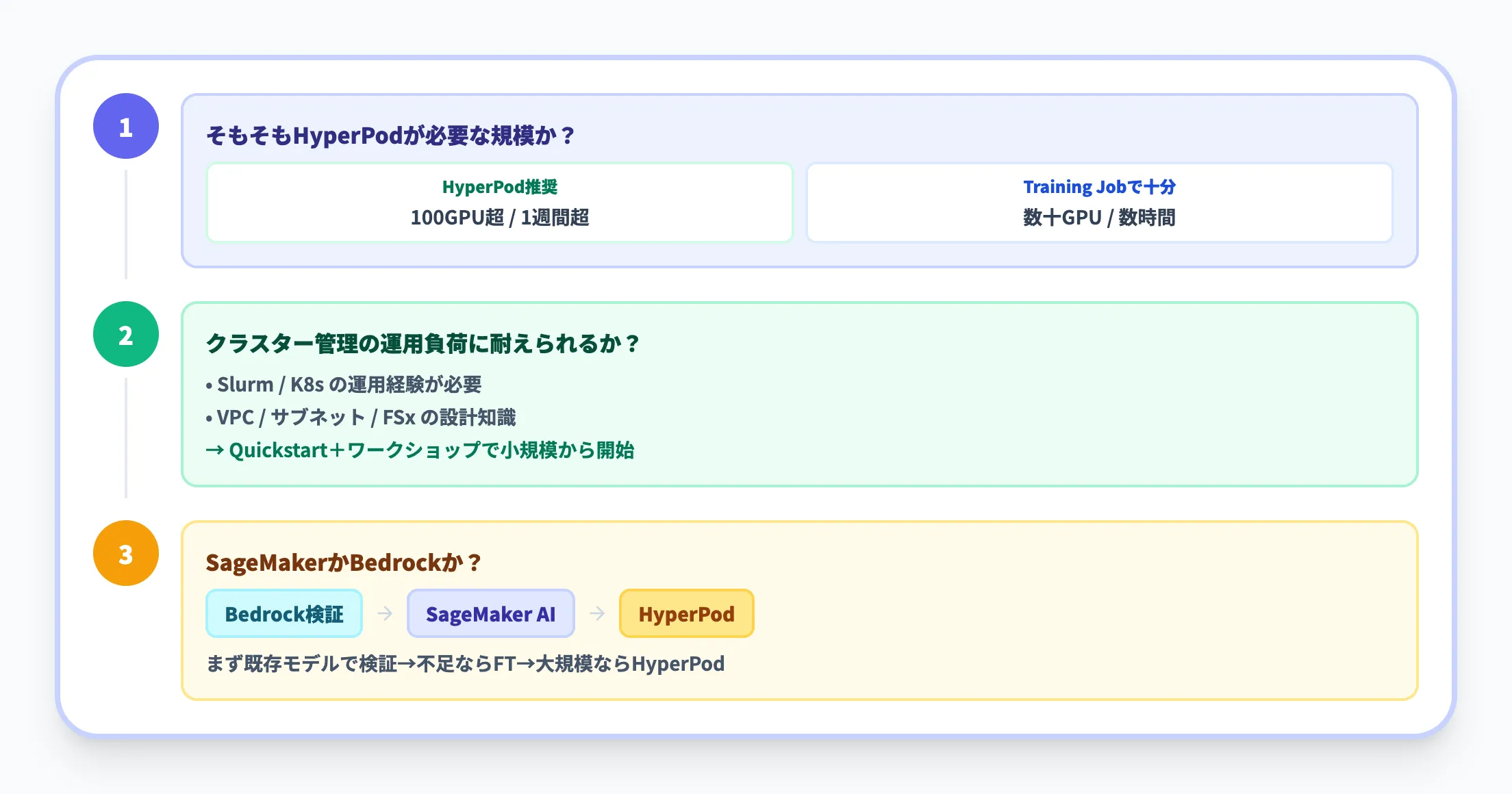
論点1 — そもそもHyperPodが必要な規模か
HyperPodは大規模学習に特化したサービスであり、すべてのMLプロジェクトに必要なわけではありません。SageMaker AIの標準Training Jobで対応できる規模(数十GPUまで)であれば、HyperPodを導入する意味は薄いです。
目安として、以下の条件に1つでも当てはまるならHyperPodの検討を推奨します。
- 100GPU以上を使った学習を計画している
- 学習ジョブの実行期間が1週間を超える
- 学習中のGPU障害による中断が深刻な問題になっている
逆に、PoCレベルの実験や数時間で終わる学習であれば、標準トレーニングジョブで十分です。
論点2 — クラスター管理の運用負荷
HyperPodはマネージドサービスですが、クラスターの設計・運用にはインフラエンジニアリングの知識が求められます。SlurmやKubernetesの運用経験、ネットワーク設計(VPC/サブネット)、ストレージ設計(FSx for Lustre)などの専門知識が必要です。
チーム内にこうした知見がない場合、Quickstartと公式ワークショップから小規模に始め、段階的にスキルを積み上げるアプローチが現実的です。
論点3 — SageMakerかBedrockか
AWSのAI/MLサービスには、HyperPodが属する統合基盤SageMakerと、基盤モデルをAPI経由で利用するAmazon Bedrockがあります。
判断の順序は経験的にはシンプルです。まず既存の基盤モデルで要件を満たせるかをClaudeなどを含むBedrockで検証し、精度が不足する場合にSageMaker(必要に応じてHyperPod)でファインチューニングや独自モデル開発に進む、という順序が現実的です。
独自データでの学習が不要な用途(チャットボット、文書要約、コード生成など)であれば、Bedrockだけで完結するケースが多くあります。さらに業務オーケストレーションが必要な場合はAmazon Bedrock Agentsを組み合わせる選択肢もあります。
【関連記事】
Amazon Bedrockとは?主要機能や料金、導入事例を解説
社内にMLエンジニアがいない段階であれば、まずBedrockとSageMaker Canvasで検証を始め、独自モデルの必要性が明確になった時点でSageMaker AI → HyperPodと段階的に移行する流れが、初期投資とリスクのバランスを取りやすい進め方です。
Amazon SageMaker HyperPodの成果を業務実装までつなぐなら
Amazon SageMaker HyperPodで大規模学習基盤を整えても、価値が出るのは、その学習成果を実際の業務フローへ載せられたときです。モデル精度だけでなく、どの推論導線で使うか、どのシステムと接続するか、誰が運用責任を持つかまで決める必要があります。
特に、独自モデルを部門横断で使う段階では、権限、監査ログ、例外時の切り戻しまで含めた運用設計が欠かせません。学習基盤と本番利用の間にあるこの設計を飛ばすと、研究用途で止まりやすくなります。
AI総合研究所のAI Agent Hub資料では、Amazon SageMaker HyperPodのような既存AI基盤を前提に、業務システム連携、管理ダッシュボード、実行導線の整備をどう進めるかを整理しています。学習成果を業務実装へつなぐ判断材料としてご確認ください。
Amazon SageMaker HyperPodの成果を業務実装までつなぐ
学習基盤の先にある業務接続・運用設計を整理
Amazon SageMaker HyperPodで学習基盤を整えても、実運用では推論導線、業務システム連携、権限設計、実行管理まで含めた設計が必要です。AI Agent HubのLPで、学習成果を業務実装につなぐ全体像をご確認ください。
まとめ
Amazon SageMaker HyperPodは、大規模AIモデルの学習における「障害による中断」という構造的課題を、Checkpointless TrainingやElastic Trainingで解決するマネージドクラスターサービスです。2026年は新CLI/SDK・RIG Observability・Hexagonの業界事例など、現場で使える機能と参照例がさらに揃ってきました。
本記事のポイントを4つに集約します。
-
自動復旧による学習効率の最大化
Checkpointless Trainingで障害回復を2分以内に短縮し、95%以上のtraining goodputを実現。GPU障害によるコストロスを構造的に抑えられる
-
2026年の運用支援機能で人手の負担をさらに軽減
HyperPod CLI/SDKでジョブ投入をスクリプト化し、RIG Observabilityでクラスター状態を一元監視できる。SREチームや少人数ML基盤チームでも回しやすくなった
-
段階的な導入が現実的
すべてのMLプロジェクトにHyperPodが必要なわけではない。標準Training Jobで始め、100GPU超の学習が必要になった段階でHyperPodに移行する流れが、過剰投資を避けつつスケールしやすい
-
コスト管理の手段が充実
Spot Instances(最大90%オフ)、Flexible Training Plans、ML Savings Plans(最大64%オフ)を組み合わせることで、オンデマンドのみの場合と比較して支出を大幅に抑えやすい
まずはSageMaker HyperPod Quickstartで小規模なクラスターを構築し、学習ジョブの実行からCheckpointless Trainingの動作確認までを一通り体験してみてください。







