この記事のポイント
 全社ナレッジマネジメントAIは「個別の暗黙知抽出」ではなく、SECIサイクル全体を組織的に回すための体系設計
全社ナレッジマネジメントAIは「個別の暗黙知抽出」ではなく、SECIサイクル全体を組織的に回すための体系設計- 6038(現場の暗黙知)・6075(設計部門の流用設計)の上位に位置する「全社×体系×Phase」レイヤーの取り組み
- AIによるナレッジマネジメントは収集→構造化→検索配信→活用学習の4レイヤーに分解して設計するのが実務的
- パナソニックPX-AIは現在約18万人規模、コネクトConnectAIは年間18.6万時間削減、旭化成は月2,157時間削減、日清製粉はFabricで全社統合
- 全社展開はPhase1(パイロット部門PoC)→Phase2(部門横展開)→Phase3(PLM/MES連携)の段階設計が現実解

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
製造業のナレッジマネジメントAIとは、設計・購買・製造・品質・保全と分断された部門知識を、SECIサイクルとAIの組み合わせで全社の共通資産として運用できる状態に変える取り組みです。
2025年問題(団塊世代の後期高齢者化と生産年齢人口減少)と既存ナレッジ基盤の機能不全が同時に進行する2026年、現場の暗黙知抽出や設計部門の流用設計だけでなく、全社レベルでナレッジ流通を設計し直すフェーズに入っています。
本記事では、全社・体系レイヤーで再定義したナレッジマネジメントの考え方、AIが変える4つのレイヤー(収集・構造化・検索配信・活用学習)、Microsoft Fabric/Copilot Studio/Glean等の主要プロダクト、パナソニック・旭化成・トヨタ・日清製粉・NECの先行事例、Phase1〜3の全社展開ロードマップ、KPI設計、典型的な失敗パターンまでを2026年5月時点の最新情報で整理します。
自社のどこから着手すべきかを判断するための、実務的な手順をケース別に提示します。
目次
製造業のナレッジマネジメントとは|全社・体系レイヤーで再定義
基盤層|Microsoft Fabric / Copilot Studio / Teams
横断検索層|Glean / Notion AI / Stock
SECI支援層|Confluence AI / Guru / 業界特化
パナソニックグループのPX-AIとパナソニックコネクトConnectAI
旭化成|全社業務で月2,157時間削減+研究開発のナレッジ承継
NEC Obbligato AI|PLM × 生成AIで設計ナレッジを全社化
Phase 2|部門横展開+ナレッジ基盤統合(6〜12ヶ月)
製造業のナレッジマネジメントとは|全社・体系レイヤーで再定義
製造業のナレッジマネジメントとは、設計・購買・製造・品質・保全と部門ごとに分断された知識を、SECIサイクルとAIで全社の共通資産として運用できる状態に変える経営活動です。
単なる「ナレッジ共有ツールの導入」や「個別現場の暗黙知抽出」とは別レイヤーの取り組みで、組織横断のナレッジ流通設計までを含みます。
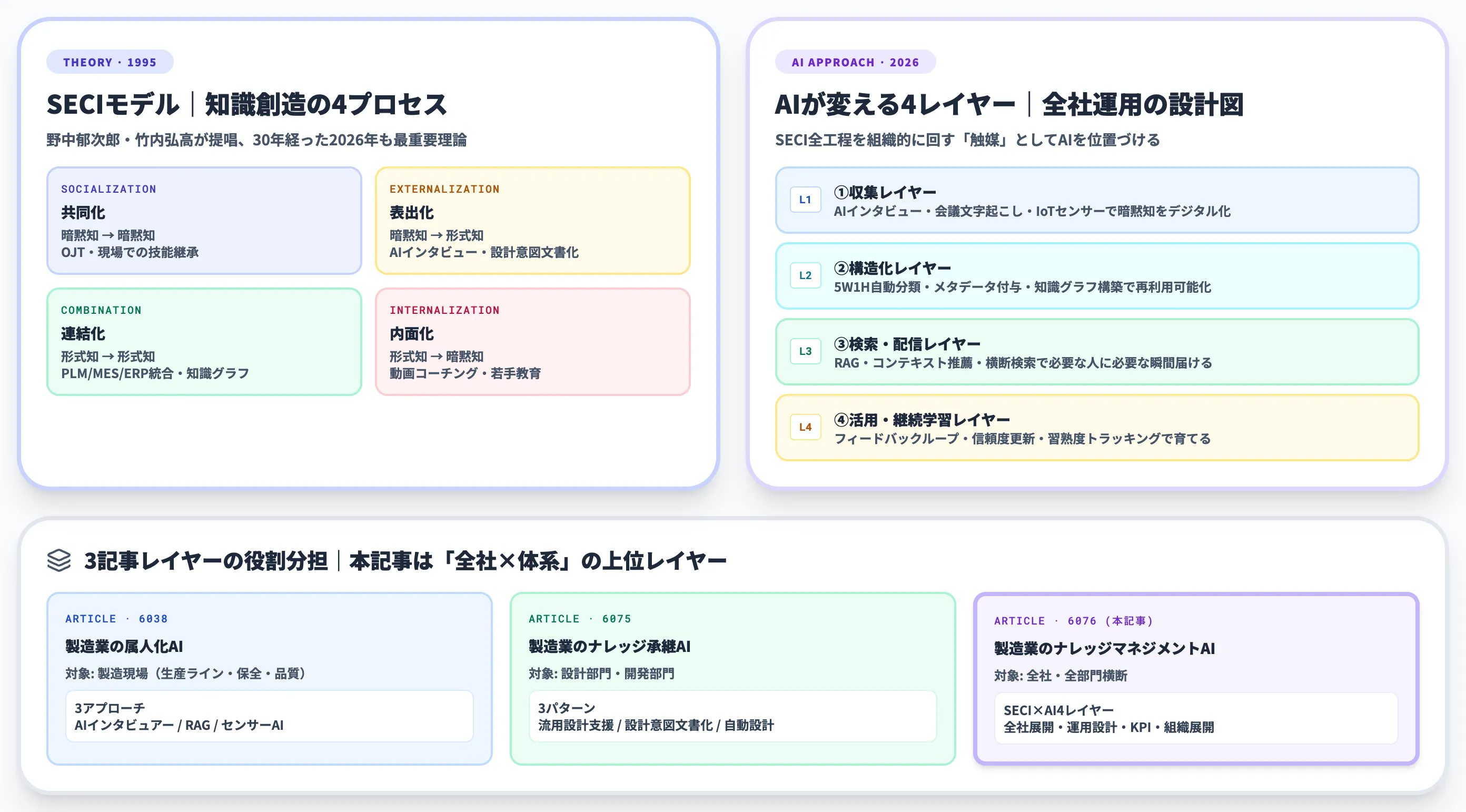
本セクションでは、ナレッジマネジメントの基本理論であるSECIモデル、全社・体系レイヤーで捉え直す3つのポイント、そして既存記事との位置づけ差別化(後述)を整理します。製造業のAIエージェント全体の俯瞰像については製造業のAIエージェント活用を別途参照ください。
ナレッジマネジメントとSECIモデルの基本
ナレッジマネジメントの理論的基盤は、一橋大学の野中郁次郎名誉教授と竹内弘高教授が1995年に著書「The Knowledge-Creating Company(知識創造企業)」で提唱したSECIモデルです。SECIモデルとは・暗黙知の形式知化の基礎概念は別記事でも解説しています。
暗黙知と形式知の相互変換を通じて、組織が新たな知識を生み出すプロセスを4段階で体系化したもので、30年経った2026年現在もナレッジマネジメントの最重要理論として参照され続けています。

以下の表で、SECIモデルの4プロセスと、製造業で典型的に発生するアクティビティを整理しました。
| プロセス | 知識変換 | 製造業の典型アクティビティ |
|---|---|---|
| 共同化(Socialization) | 暗黙知 → 暗黙知 | OJT、現場での技能継承、ベテランへの同行 |
| 表出化(Externalization) | 暗黙知 → 形式知 | AIインタビュー、Teams会議の構造化、設計意図の文書化 |
| 連結化(Combination) | 形式知 → 形式知 | PLM/MES/ERPの統合、ナレッジグラフ構築、横断検索 |
| 内面化(Internalization) | 形式知 → 暗黙知 | 動画コーチング、シミュレーション学習、若手教育 |
従来のナレッジマネジメントが「表出化」と「連結化」の段階で人手の壁にぶつかっていたのに対し、AIは4プロセス全てを加速できる点が2026年の本質的な変化です。
AIは個別プロセスを置き換える単発ツールではなく、SECIサイクル全体を組織的に回す触媒として位置づけるのが正しい捉え方になります。
全社・体系レイヤーで捉え直す3つのポイント
ナレッジマネジメントを実務で機能させるには、テーマを「個別の暗黙知抽出」と「全社ナレッジマネジメント体系」の2層に分けて整理する必要があります。
本記事が扱う全社レイヤーには、以下の3つの特徴があります。
-
組織横断のナレッジ流通を扱う
設計部門で生まれたナレッジが製造・品質・保全に流れ、現場で得たフィードバックが設計に戻る循環を、組織として設計する取り組み
-
ツール導入ではなく、SECIサイクルの組織的運用が目的
Confluence・Notion・Glean等のツールは手段にすぎず、SECI4プロセスを誰が・どのタイミングで・どの基盤で回すかという運用設計が本質
-
経営KPIに直結する仕組み設計
新製品立ち上げスピード、若手育成期間、属人化リスクの定量化、技能継承の事業継続価値など、経営層が判断材料として使える指標を最初から組み込む
個別の暗黙知抽出に閉じた取り組みは、対象部門で成果が出ても他部門に波及しにくく、結果として「ナレッジマネジメント基盤を入れたが全社では機能していない」という典型的な失敗に陥ります。
実務支援の経験からは、最初から全社レイヤーで設計し、対象部門は段階的に広げる順序の方が定着率が高い傾向があります。
既存記事との位置づけ差別化
製造業のナレッジマネジメントAIは、対象部門と扱う暗黙知の性質によって、3つの記事レイヤーで整理しています。
以下の表で、本記事と既存の2記事の役割分担をまとめました。
| 記事 | 対象部門 | 中核論点 |
|---|---|---|
| 製造業の属人化AI(6038) | 製造現場(生産ライン・保全・品質) | AIインタビュアー型/RAG型/センサー×AI型 の3アプローチ。熟練工の身体知 |
| 製造業のナレッジ承継AI(6075) | 設計部門・開発部門 | 流用設計支援/設計意図文書化/自動設計 の3パターン。図面・設計仕様 |
| 本記事 | 全社・全部門横断 | SECIサイクルとAI4レイヤーの全社展開・運用設計・KPI・組織展開 |
個別のAI実装手法を比較したい場合は製造業の属人化AI、設計部門の流用設計を深掘りしたい場合は製造業のナレッジ承継AIが該当します。
本記事は、それらを束ねる上位レイヤーとして、全社ナレッジマネジメントの体系設計を扱います。

製造業のナレッジマネジメントが直面する3つの構造課題
全社レベルのナレッジマネジメントが行き詰まる原因は、技術的な問題ではなく組織構造に根ざした3つの壁にあります。
ツールの選定だけで解決しようとすると、いずれも壁の手前で頓挫します。
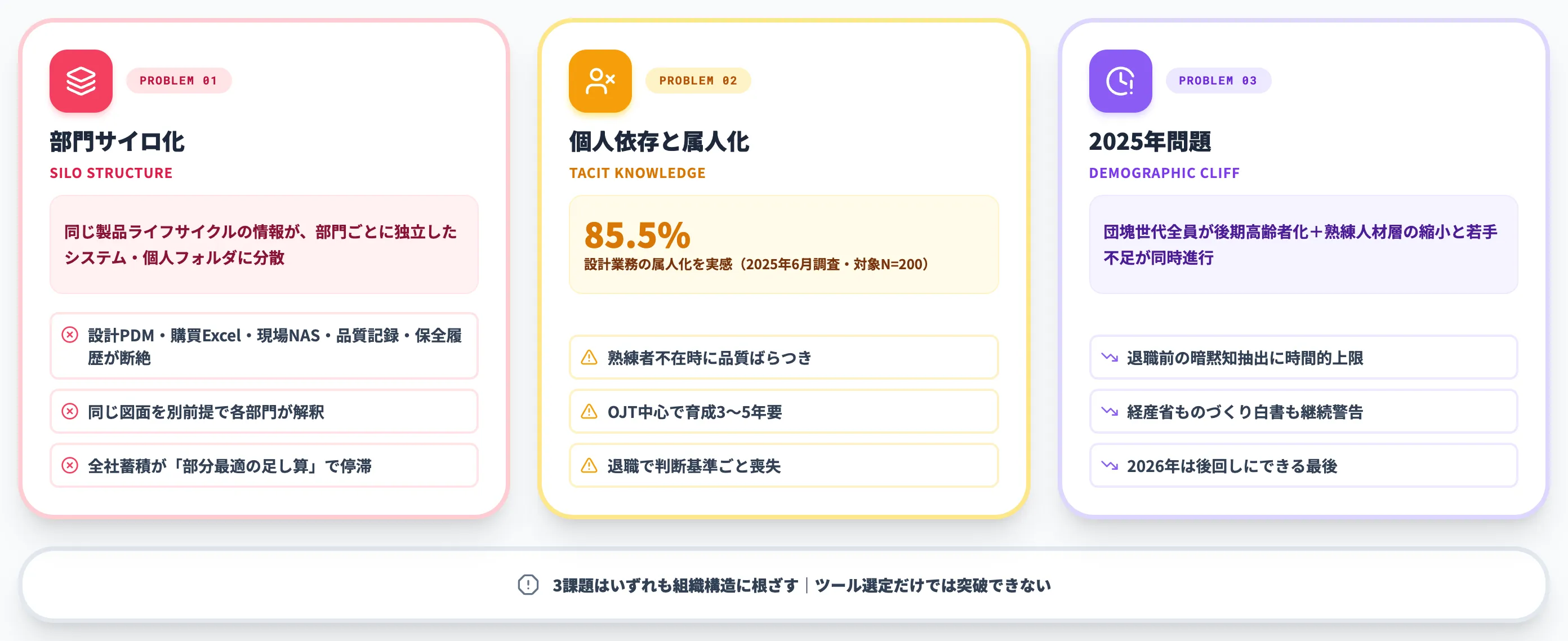
本セクションでは、部門サイロ化/個人依存と属人化/2025年問題という3つの構造課題を順に整理し、なぜこれまでのナレッジマネジメント施策では届かなかったのかを明らかにします。
部門サイロ化と知識分断
第一の壁は、同じ製品・同じ図面・同じ顧客に関する情報が部門ごとに別々の場所・別々の形式で残っている現実です。
設計部門のPDM、購買部門のExcel台帳、製造現場の紙図面・NAS、品質部門の検査記録、保全部門のトラブル履歴。同じ製品ライフサイクルに関わる情報が、部門ごとに独立したシステムや個人フォルダに分散しています。
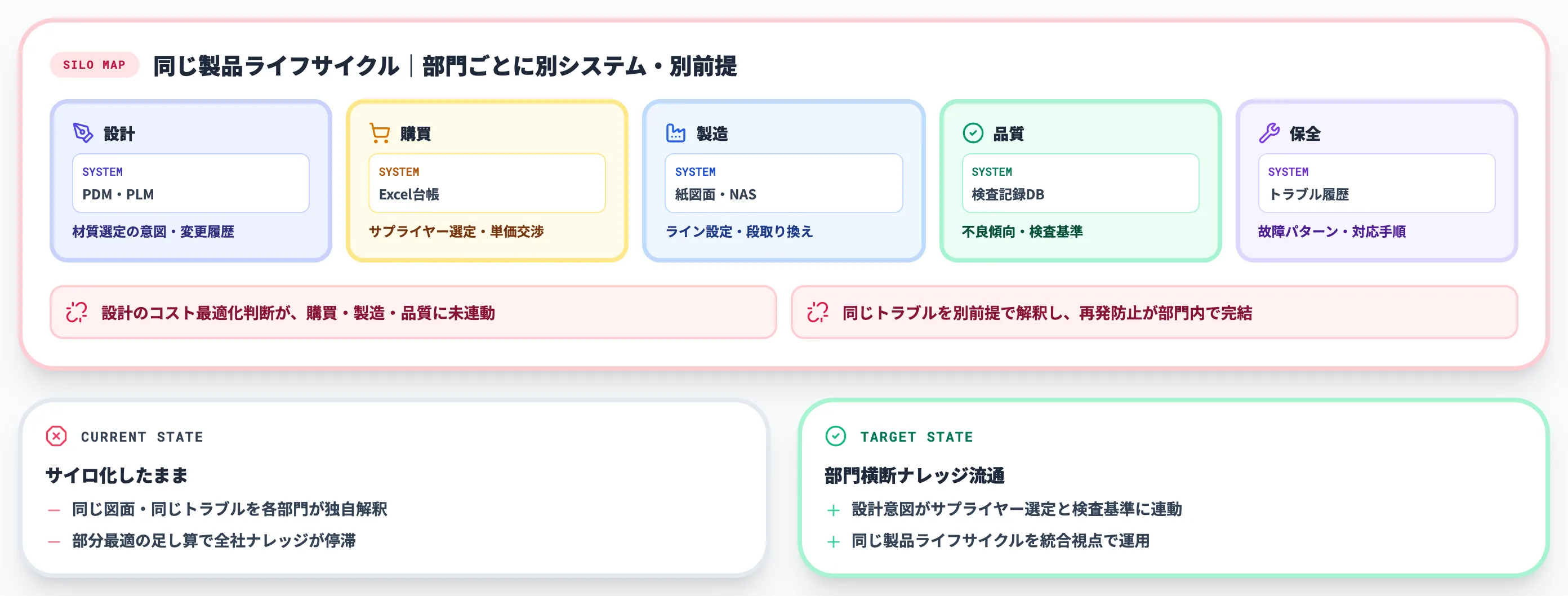
問題は保管場所の多さではなく、設計・購買・製造・品質・保全が同じ図面や同じトラブルを別々の前提で見ていることにあります。
設計者が「コスト最適化のためにこの材質を選んだ」と判断した背景は、購買部門のサプライヤー選定にも、製造現場のライン設定にも、品質部門の検査基準にも本来は連動するべき情報です。
それが部門サイロのまま分断されているため、全社のナレッジ蓄積が「部分最適の足し算」で終わっています。
個人依存と属人化の蓄積
第二の壁は、設計業務・現場判断・トラブル対応の意思決定が、特定個人の頭の中に閉じている状態です。
株式会社New Innovationsが2025年6月に実施した「製造業×AI」調査では、設計業務の属人化を「非常によくある」と回答したのが35.0%、「ときどきある」が50.5%で、合計85.5%が属人化を実感しています。
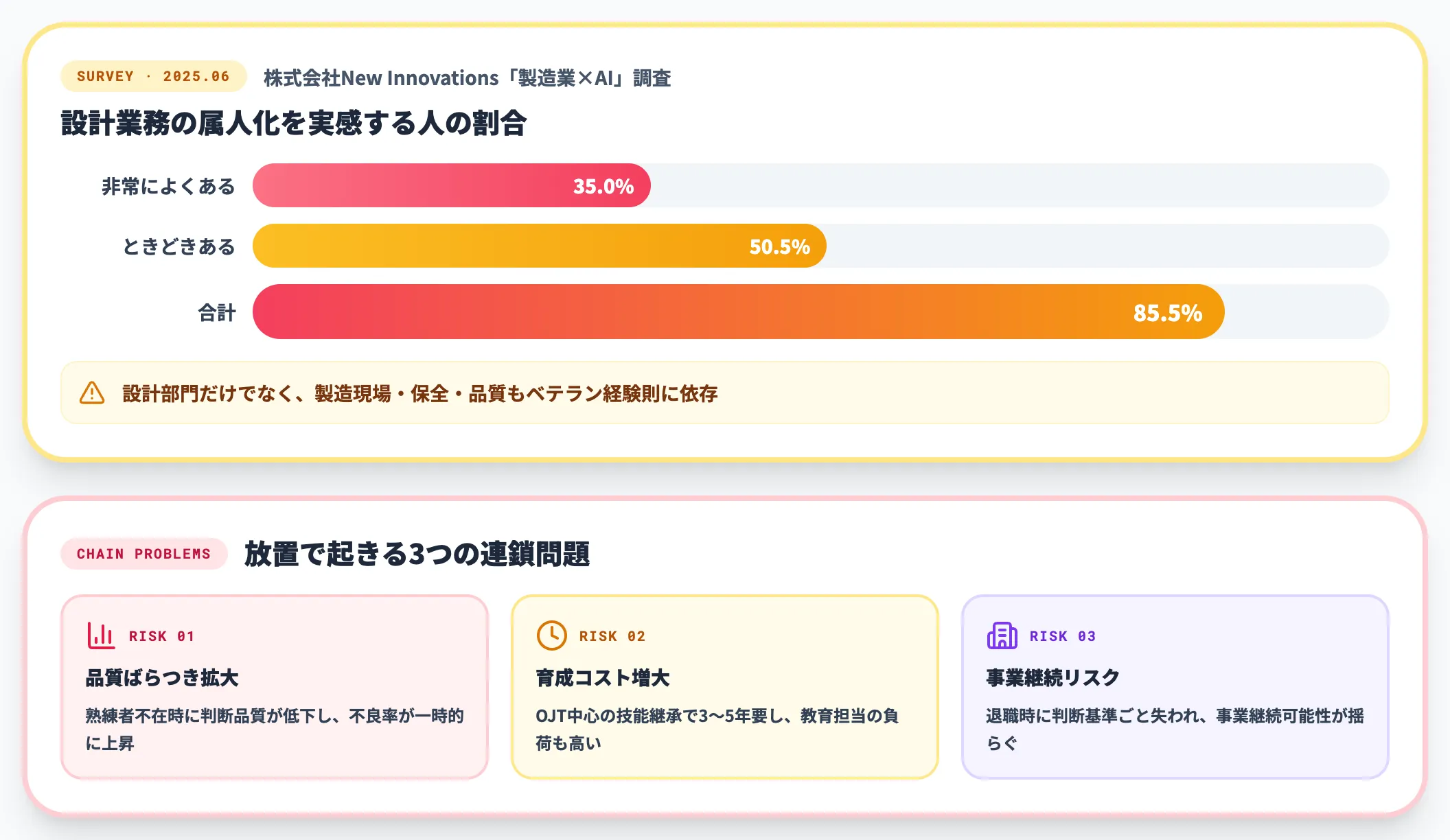
設計部門だけでなく、製造現場・保全・品質の判断もベテランの経験則に強く依存しており、文書化されないまま日々の業務が回っているのが現実です。
属人化を放置すると、3つの連鎖的な問題が起きます。
-
品質ばらつきの拡大
熟練者不在時に判断品質が低下し、不良率が一時的に上昇
-
育成コストの増大
OJT中心の技能継承は3〜5年の期間を要し、教育担当者の負荷も高い
-
事業継続リスクの顕在化
退職時に判断基準ごと失われ、事業の継続可能性自体が揺らぐ
これらは1部門のローカルな問題に見えて、実際には全社の競争力を蝕む構造問題です。
ナレッジマネジメントを全社レイヤーで再設計する必要があるのは、属人化が部門単位で起きている以上、部門単位の対処では足りないからです。
2025年問題(団塊世代の後期高齢者化と生産年齢人口減少)
第三の壁は、属人化したまま熟練人材層の縮小が一段と進むタイミングが2026年現在に重なっている事実です。
厚生労働省の整理によれば、2025年問題とは団塊世代(1947〜1949年生まれ)がすべて75歳以上の後期高齢者となる節目で、生産年齢人口の減少と医療・介護需要の急増が同時に進む構造問題を指します。製造業では団塊世代の退職局面は2012年頃から段階的に進んでおり、現在はその次の世代も含めた熟練人材層の縮小と若手不足の同時進行が課題になっています。経済産業省「2025年版ものづくり白書」でも、ものづくり人材の育成・学び直しの重要性が継続的に扱われています。
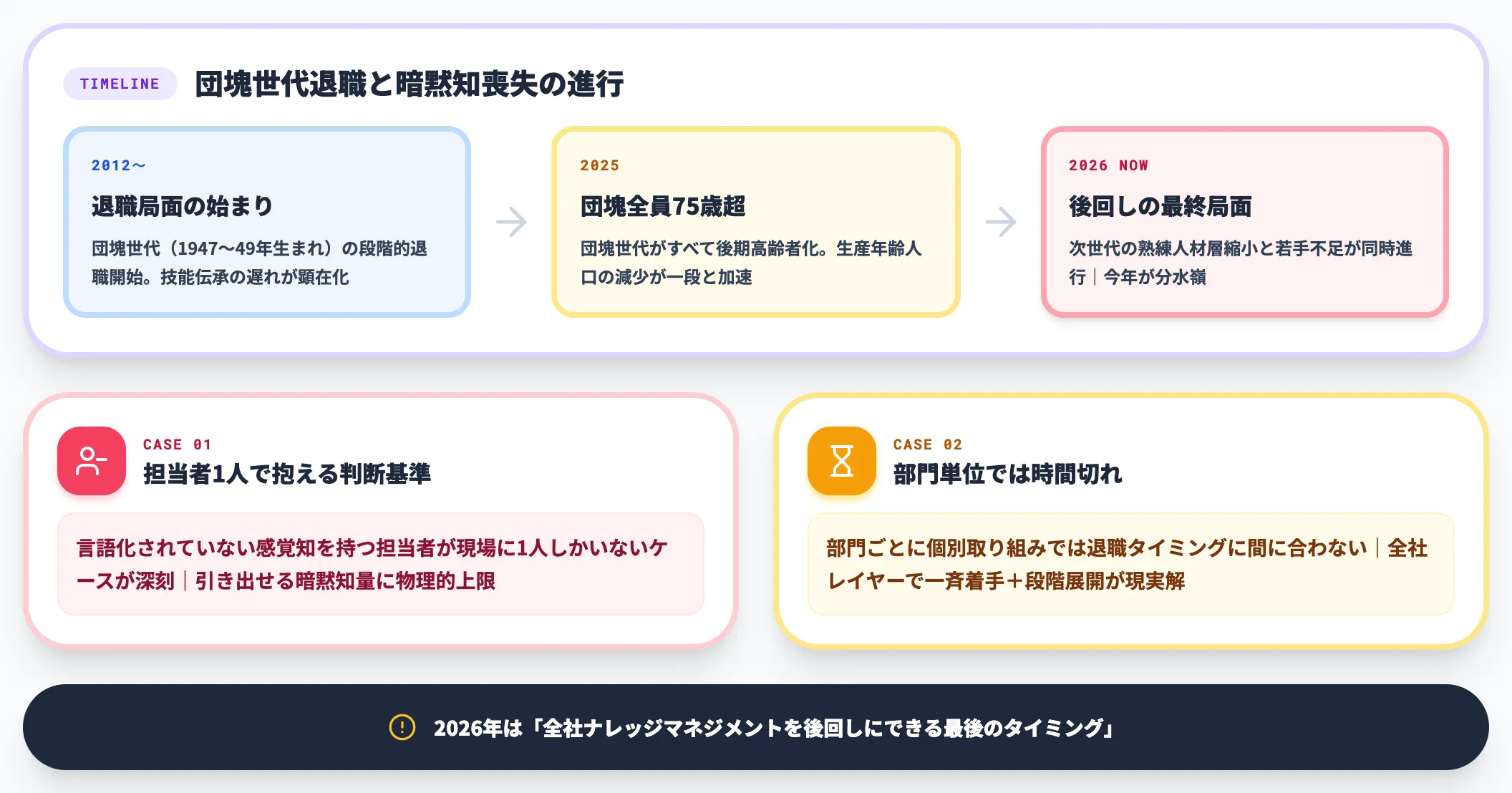
特に深刻なのは、言語化されていない判断基準・感覚知を持った担当者が現場に1人しかいないケースです。
退職までの期間で引き出せる暗黙知の量には物理的な上限があり、今年中に着手しなければ失われる知識が目の前にある企業が少なくありません。
支援現場の肌感としては、2026年は「全社ナレッジマネジメントを後回しにできる最後のタイミング」になりつつあります。
部門単位での個別取り組みでは時間的に間に合わないため、全社レイヤーでの一斉着手と段階展開が現実解になります。
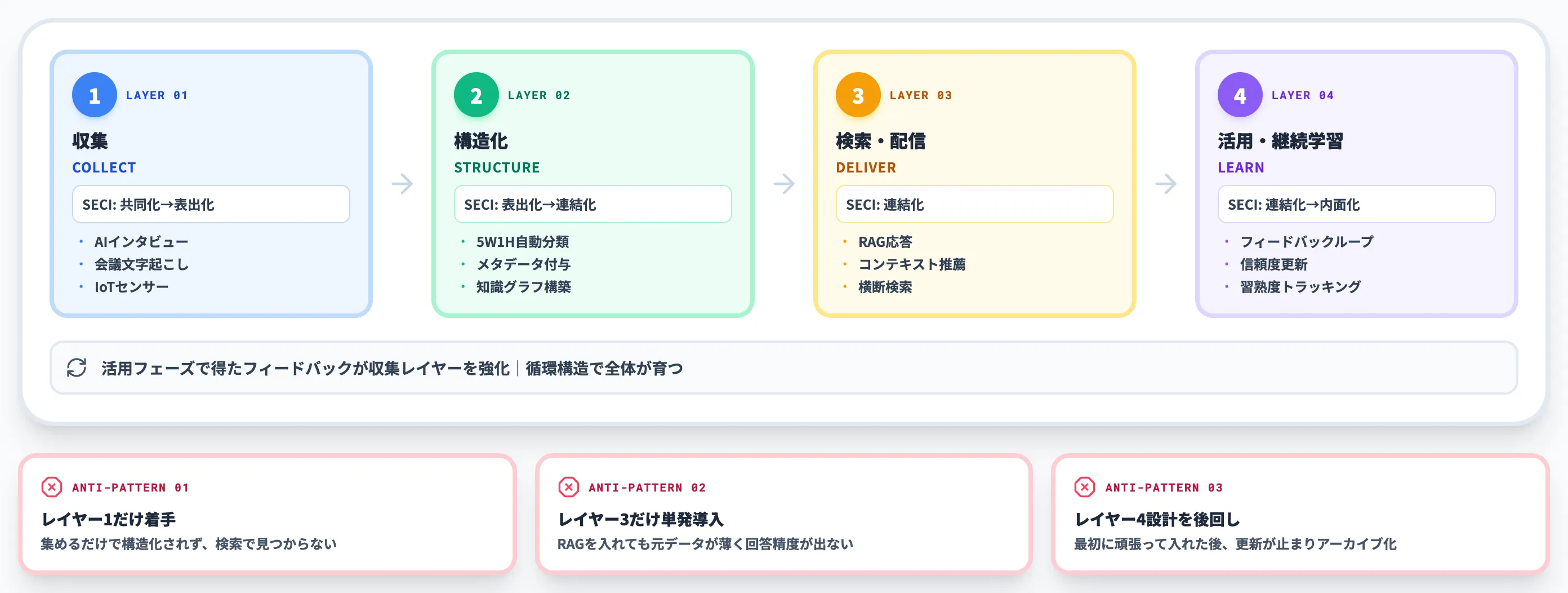
AIがナレッジマネジメントを変える4つのレイヤー
全社ナレッジマネジメントAIは「AIで全部置き換える」ではなく、SECIサイクルの各段階をAIで強化する4レイヤー構造として設計するのが2026年の主流です。
レイヤー分解しないまま「生成AIを入れる」と進めると、収集だけ・検索だけといった部分最適に終わります。
本セクションでは、収集→構造化→検索配信→活用学習 の4レイヤーを順に解説し、6038/6075で扱った3手法・3パターンが各レイヤーのどこに位置づくかも示します。
以下の表で、4レイヤーとSECI4プロセスの対応、各レイヤーで使われる技術を一覧化しました。
| レイヤー | 主な役割 | 対応するSECIプロセス | 代表技術・アプローチ |
|---|---|---|---|
| ①収集 | 暗黙知をデジタル化 | 共同化→表出化 | AIインタビュー、Teams会議文字起こし、IoTセンサー |
| ②構造化 | デジタル化情報を再利用可能な形に | 表出化→連結化 | 5W1H自動分類、メタデータ付与、図面OCR、知識グラフ |
| ③検索・配信 | 必要な人に必要な知識を届ける | 連結化 | RAG、コンテキスト推薦、エンタープライズ検索 |
| ④活用・継続学習 | 現場の結果でナレッジを育てる | 連結化→内面化 | フィードバックループ、信頼度更新、習熟度トラッキング |
この4レイヤーは独立した別物ではなく、収集レイヤーで集めた情報が構造化を経て検索・配信され、活用フェーズで得たフィードバックが収集を強化する循環構造になっています。
レイヤーを意識せず単一ツールで全部を賄おうとすると、いずれかのレイヤーで詰まって全体が止まる失敗パターンに陥ります。
レイヤー①|収集レイヤー(暗黙知をデジタル化)
収集レイヤーは、現場・会議・センサーから暗黙知をデジタル形式で取り込む段階です。
ベテランの口頭説明、Teams会議の議論、IoTセンサーから流れる稼働データ。これらを「人が記録する」のではなく「AIが自動で取り込む」ことで、収集の粒度と頻度が桁違いに上がります。
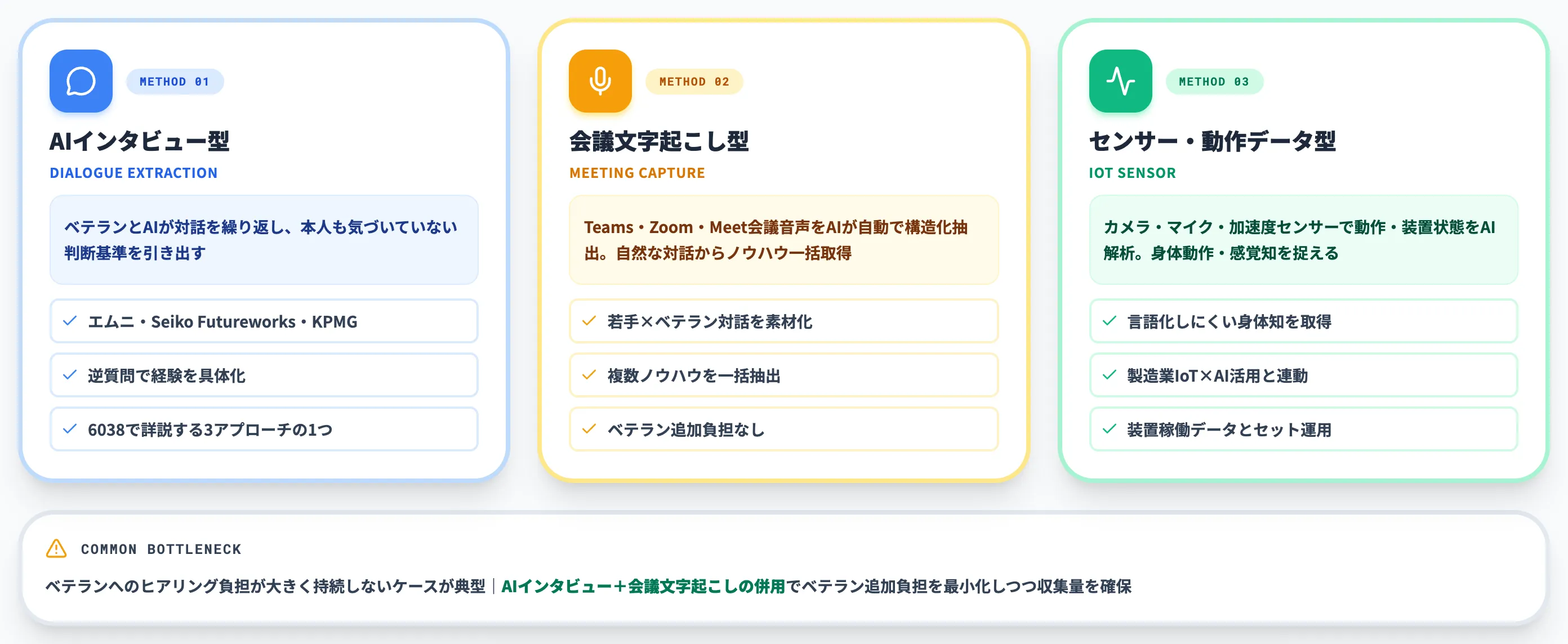
代表的な収集手法は3つあります。
-
AIインタビュー型
ベテランとAIが対話を繰り返し、本人も気づいていない判断基準を引き出す。6038(製造業の属人化AI)で扱ったエムニ・Seiko Futureworks・KPMG等のプロダクトがここに位置づく
-
会議・議事録の文字起こし型
Teams・Zoom・Meet等の会議音声をAIが自動で構造化抽出。若手とベテランの自然な対話から複数のノウハウを一括抽出できる
-
センサー・動作データ型
カメラ・マイク・加速度センサーで作業動作や装置状態をデジタル化し、AIでパターン解析。言語化できない身体動作・感覚知を捉える有力な方法。製造業IoT × AI活用事例で示しているデータ収集の仕組みと組み合わせるのが定番
収集レイヤーで詰まる典型パターンは、ベテランへのヒアリング負担が大きく持続しないケースです。AIインタビューと会議文字起こしを併用すれば、ベテランの追加負担を最小化しながら収集量を確保できます。
レイヤー②|構造化レイヤー(再利用可能な形に)
構造化レイヤーは、収集したデジタル情報を後で検索・活用できる形に整理する段階です。
文字起こしテキストや音声データのまま積み上げても、いざ必要な瞬間に取り出せません。5W1H分類、メタデータ付与、知識グラフ構築などの構造化処理が、再利用性を決定づけます。

製造業で重要な構造化要素は以下の3点です。
-
5W1H自動分類
誰が・いつ・どこで・何を・なぜ・どうやったか、をAIが対話・文書から抽出して構造化登録。ノウハウの再利用性を決める基盤
-
メタデータ自動付与(図面OCR含む)
先述の設計部門向け流用設計支援型AIがここに位置づく。図面・設計仕様・変更理由を構造化属性として保存
-
知識グラフ構築
製品・部品・工程・トラブル・サプライヤーといったエンティティ間の関係性をグラフで表現し、関連情報の探索を可能にする
構造化レイヤーは「最初に手間がかかる地味な工程」ですが、ここを飛ばすと検索・配信レイヤーで「情報はあるはずだが見つからない」状態が続きます。
PoC段階から構造化フォーマットを決めておくと、Phase 2の部門横展開で標準化のコストが大きく下がります。
レイヤー③|検索・配信レイヤー(必要な人に届ける)
検索・配信レイヤーは、構造化されたナレッジを、必要なタイミングで必要な人に届ける段階です。
このレイヤーで使われる技術が、近年急速に進化したRAG(Retrieval-Augmented Generation)と、エンタープライズ横断検索です。

代表的なアプローチは以下の通りです。
-
RAGによる自然言語応答
先述のRAG型・流用設計支援型がここに含まれる。社内の構造化ナレッジを参照しながら、生成AIが自然言語で回答する仕組み
-
コンテキスト推薦
今いるユーザーの業務文脈(編集中の図面・参加中の会議・対応中のトラブル)から、関連ナレッジをプッシュ通知する。検索を待たず、必要な瞬間に情報が出てくる設計
-
エンタープライズ横断検索(Glean / Notion AI等)
M365・Slack・Salesforce・PLMなど100以上のアプリを横断検索。サイロ化したSaaS群を一つの検索窓口で扱える
検索・配信レイヤーで詰まる典型パターンは、データの権限設計が後回しになるケースです。Phase 1の段階から「誰がどの情報を見られるか」を設計に組み込まないと、Phase 2でセキュリティ要件が破綻します。
レイヤー④|活用・継続学習レイヤー(現場の結果で育てる)
活用・継続学習レイヤーは、AIが提示したナレッジが現場で「効いた/効かなかった」をフィードバックとして取り込み、ナレッジの信頼度を継続的に更新する段階です。
ここを設計に組み込まないと、最初に登録したナレッジが古びていき、AIの回答精度が時間とともに下がっていきます。
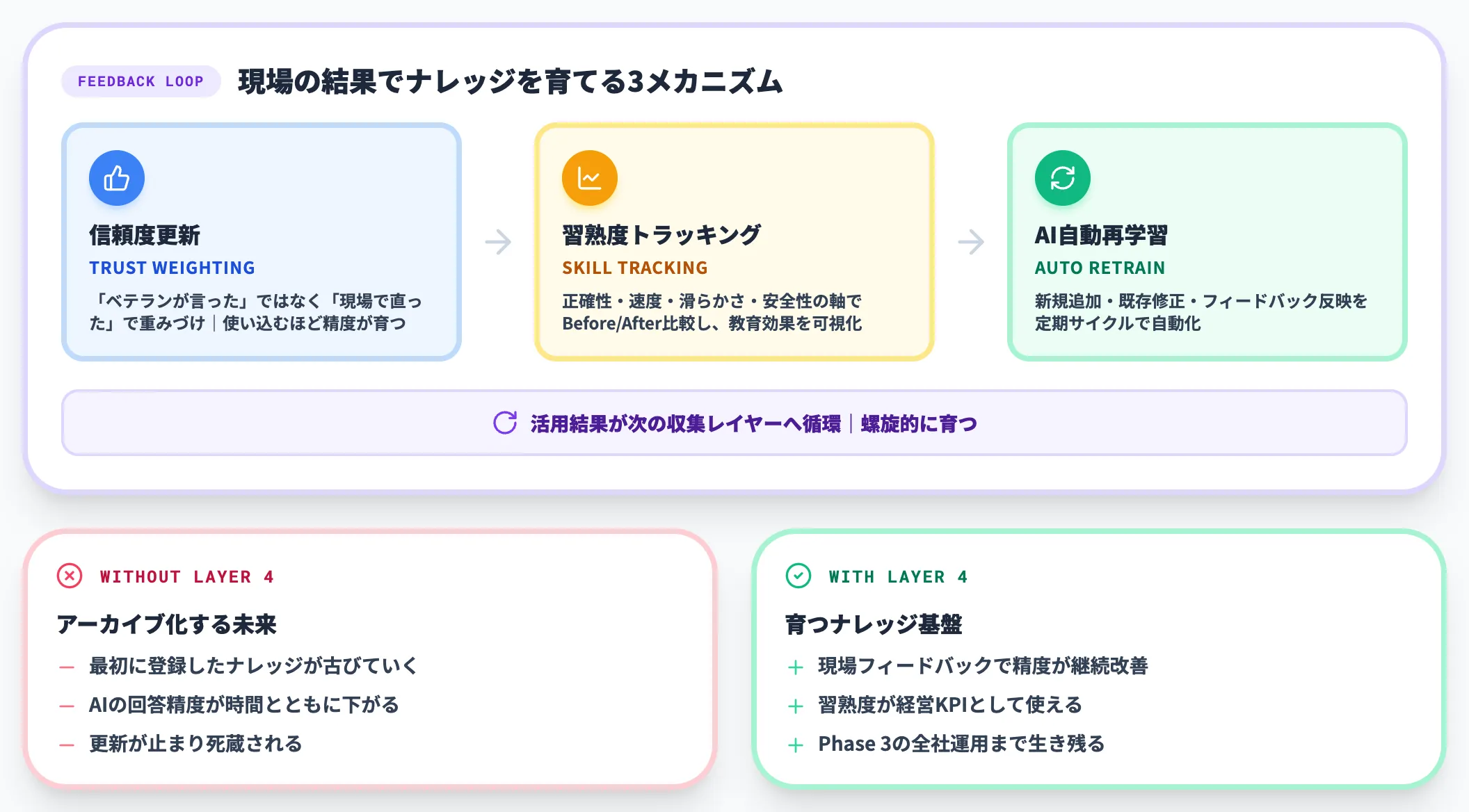
代表的なメカニズムは以下の通りです。
-
フィードバックループによる信頼度更新
「ベテランが言ったから正しい」ではなく「現場で直ったから信頼できる」で重みづけ。使い込むほど精度が育つ設計
-
習熟度トラッキング
若手がナレッジを参照して実務で再現できているかを定量計測。正確性・速度・滑らかさ・安全性などの軸でBefore/After比較し、教育効果を可視化
-
AIの自動再学習
新規ナレッジの追加・既存ナレッジの修正・現場フィードバックの反映を定期サイクルで自動化
このレイヤーがないと、ナレッジマネジメントは「最初に頑張って入れたが、その後は更新されないアーカイブ」になります。
実務では、活用ループの設計を Phase 1のPoC段階から組み込むことが、Phase 3の全社運用まで生き残るための分かれ目になります。
製造業×ナレッジマネジメントAIの主要プロダクト・基盤
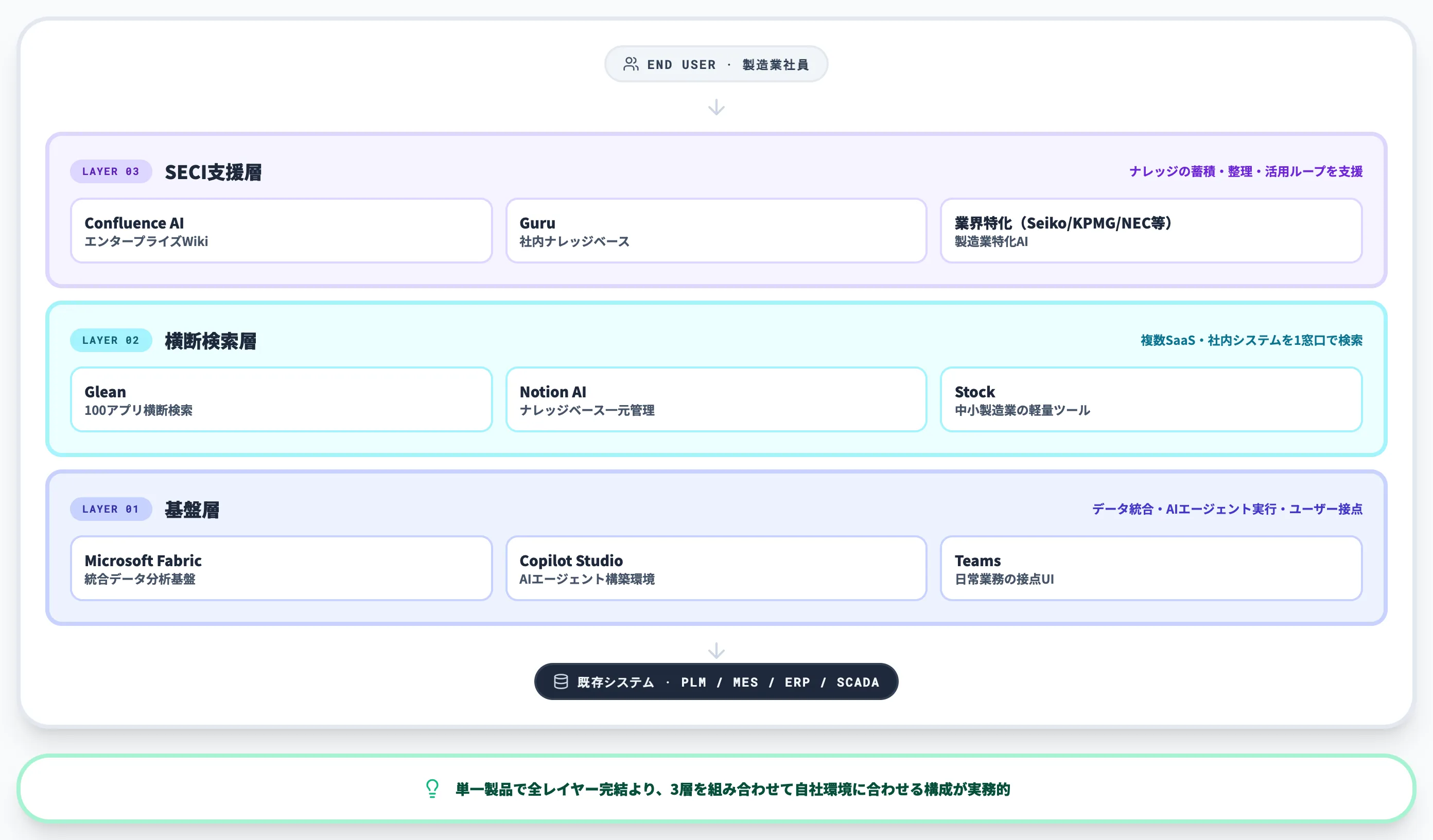
全社ナレッジマネジメントAIを支えるプロダクト群は、役割で分けると「基盤層/横断検索層/SECI支援層」の3層に整理できます。
単一製品で全レイヤーを完結させるよりも、3層を組み合わせて自社のシステム環境に合わせて構成するのが実務的です。
本セクションでは、3層の代表プロダクトと、選定軸(社内データ統合度・コスト・運用負担)を順に整理します。
基盤層|Microsoft Fabric / Copilot Studio / Teams
基盤層は、データ統合・AIエージェント実行・ユーザー接点を担う中核です。
製造業の基幹システム(PLM/MES/ERP/SCADA)と接続できる統合データ基盤と、その上で動くAIエージェント実行環境がここに位置づきます。
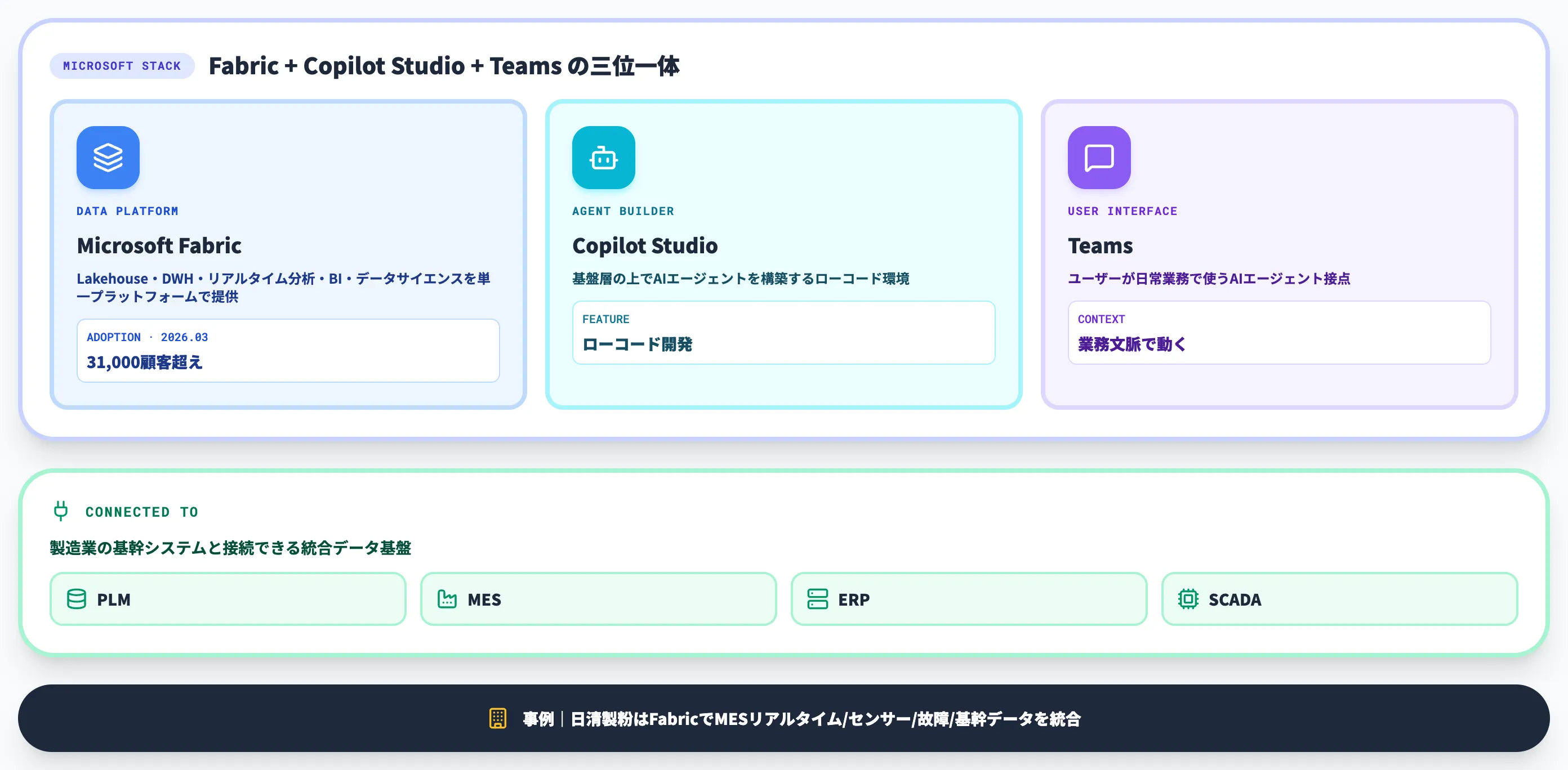
Microsoft Fabricは、SaaS型の統合データ分析基盤として、Lakehouse・データウェアハウス・リアルタイム分析・BI・データサイエンスを単一プラットフォームで提供します。2026年3月時点で31,000を超える顧客がFabricを採用しており、製造業を含めて広く導入が進んでいます。
製造業の代表事例として、日清製粉がMicrosoft Fabricで全社データ活用を加速し、MESのリアルタイムデータ・センサーデータ・生産設備故障データ・基幹システムデータを単一プラットフォームに統合した事例があります。
Copilot Studioは基盤層の上でAIエージェントを構築するローコード環境、Teamsはユーザーが日常業務で使う接点として機能します。Teams上でのAIエージェント実装パターンはTeams AIエージェントの作り方も参照すると、構成の具体像が見えてきます。
横断検索層|Glean / Notion AI / Stock
横断検索層は、複数のSaaS・社内システムを跨いで一つの検索窓口でナレッジを引き出すレイヤーです。
製造業のように複数の基幹システム・SaaSが並列で動いている環境では、サイロを統合せずに「検索面」だけ一本化するアプローチが現実的です。
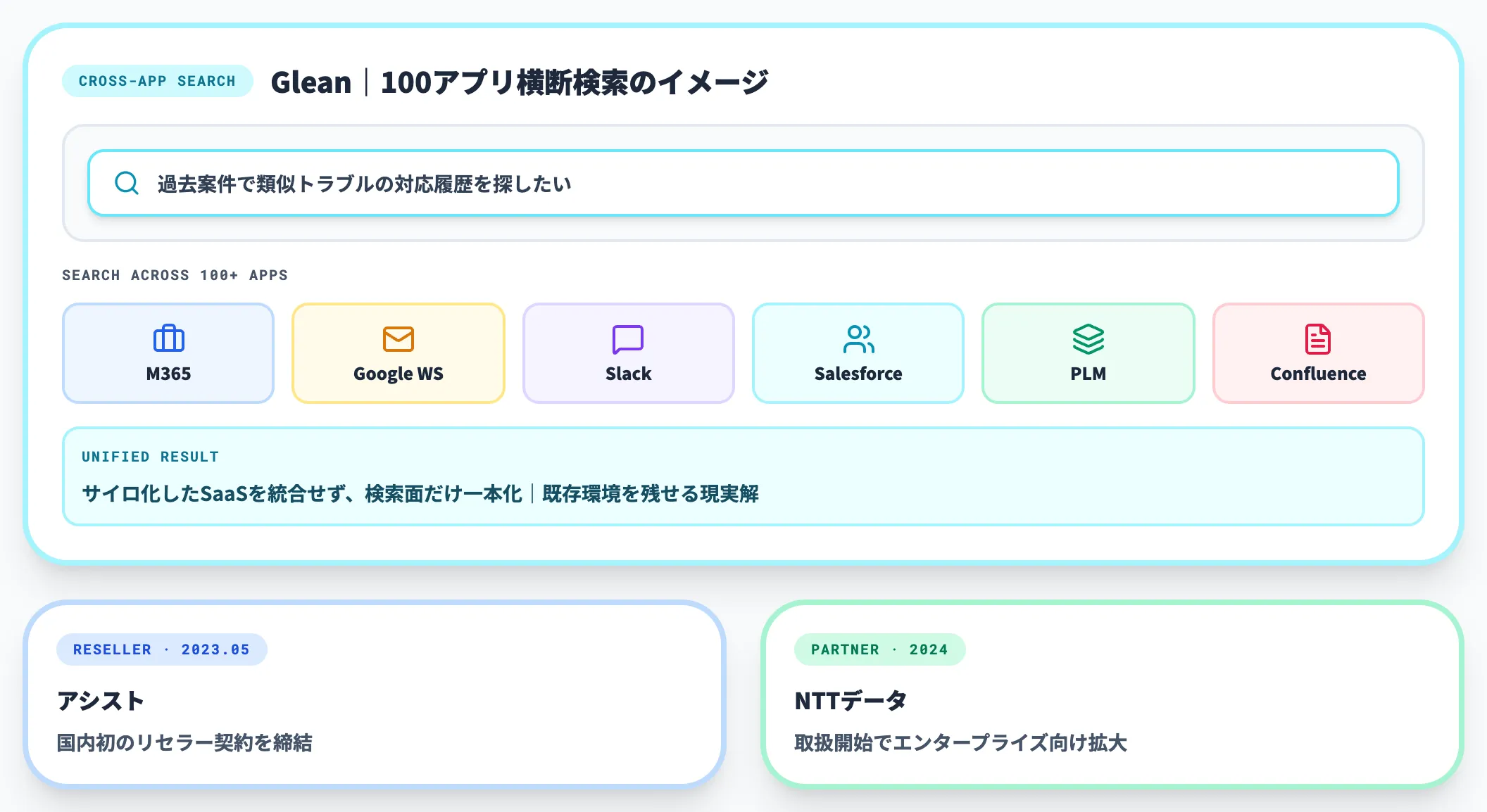
Gleanは、Microsoft 365・Google Workspace・Slack・Salesforceなど約100アプリを横断検索できるエンタープライズAI検索プラットフォームです。日本ではアシストが2023年5月に国内初のリセラー契約を締結し、NTTデータも2024年から取扱を開始しています。
Notion AIはナレッジベースとして社内ドキュメントを一元管理しつつAI検索を提供、Stockは中小製造業で導入が進む軽量なナレッジ共有ツールとして位置づきます。
SECI支援層|Confluence AI / Guru / 業界特化
SECI支援層は、ナレッジの蓄積・整理・活用ループを支援する専門ツール群です。
エンタープライズWiki(Confluence)、社内ナレッジベース(Guru)、業界特化型のナレッジマネジメントSaaSがここに含まれます。
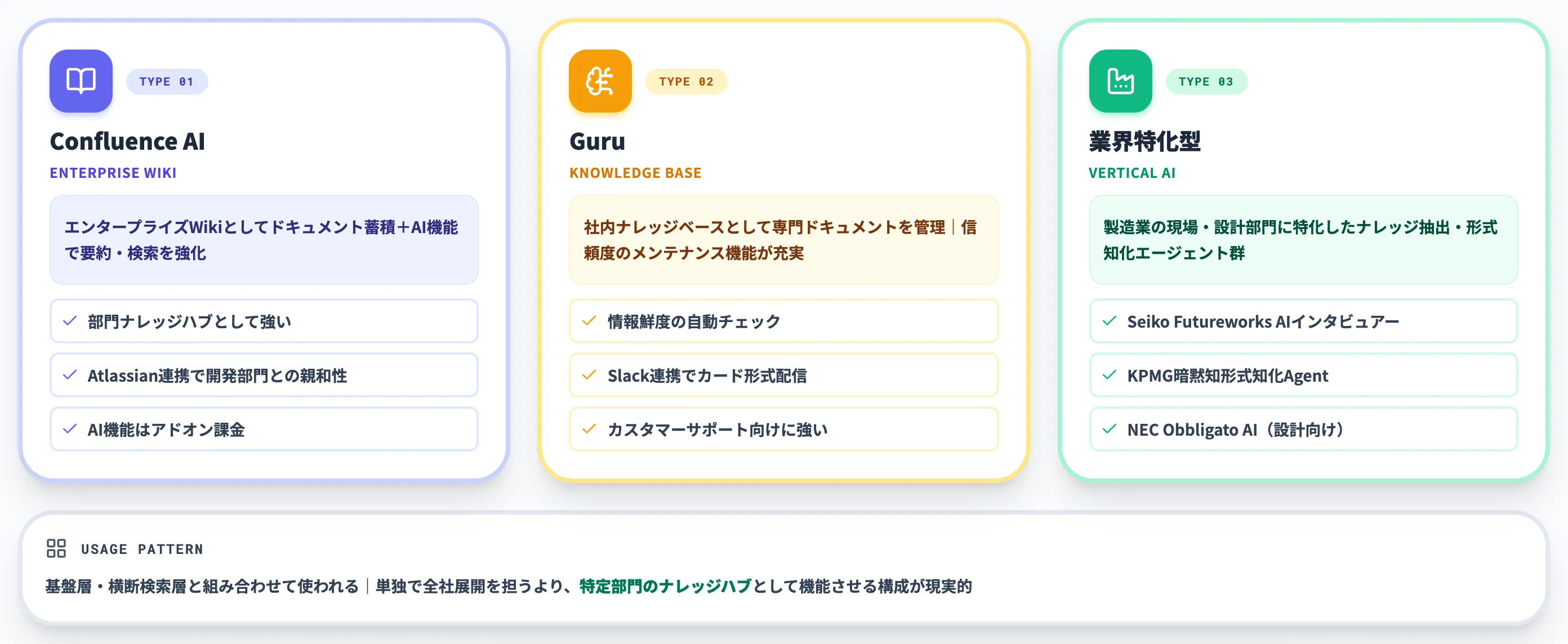
これらは基盤層・横断検索層と組み合わせて使われることが多く、単独で全社展開を担うよりも、特定部門のナレッジハブとして機能させる構成が現実的です。
製造業特化のSECI支援系としては、6038で扱ったSeiko Futureworks AIインタビュアーやKPMGの暗黙知形式知化エージェント、設計部門向けにはNEC Obbligato AIなどが該当します。
製品選定の3つの軸
3層から自社の構成を組む際に、判断軸として効くのは以下の3点です。
以下の表で、3つの選定軸と、それぞれが効くケースを整理しました。
| 選定軸 | 重視すべきケース | 軽視できるケース |
|---|---|---|
| 社内データ統合度 | 既存PLM/MES/ERP/基幹システムが多く、サイロ統合が経営課題 | 単一クラウド環境で完結している小規模組織 |
| コスト構造 | ユーザー数千人以上、長期運用前提 | PoC段階で短期間の効果検証 |
| 運用負担 | 専任のDX推進部・情シスのリソースが限定的 | 内製開発リソースが豊富な大手製造業 |
この3軸は独立しておらず、組織規模と既存システム環境によってトレードオフが発生します。
たとえば、Microsoft 365を全社展開済みの企業はMicrosoft Fabric+Copilot Studio中心の構成でコスト・運用負担を抑えやすい一方、複数クラウド環境を併用する企業はGleanのような横断検索層を厚くする選択が合理的です。
実務支援の場面では、「最初から完璧な構成を組まず、Phase 1で基盤層+1つの検索エントリだけに絞る」のが定着の近道になります。
全社ナレッジマネジメントAIの先行事例
公開情報から見えてくる先行事例は、多くが「一部門のPoC→部門横展開→全社統合」の段階展開を志向しています。
ここでは2026年5月時点で公表情報が充実している5事例を、全社設計の視点で整理します。

個別技術の単発導入ではなく、部門展開から全社基盤化までの参考になる公開事例に絞っています。
パナソニックグループのPX-AIとパナソニックコネクトConnectAI
パナソニックグループは、独自のAIアシスタントサービス「PX-AI」を2023年4月から全社展開しています。
ホールディングス公式情報によれば、Microsoft Azure OpenAI Serviceをベースに自社構築し、提供開始時点で国内グループ約9万人へ展開、その後利用範囲が広がり現在は約18万人規模で活用されています。
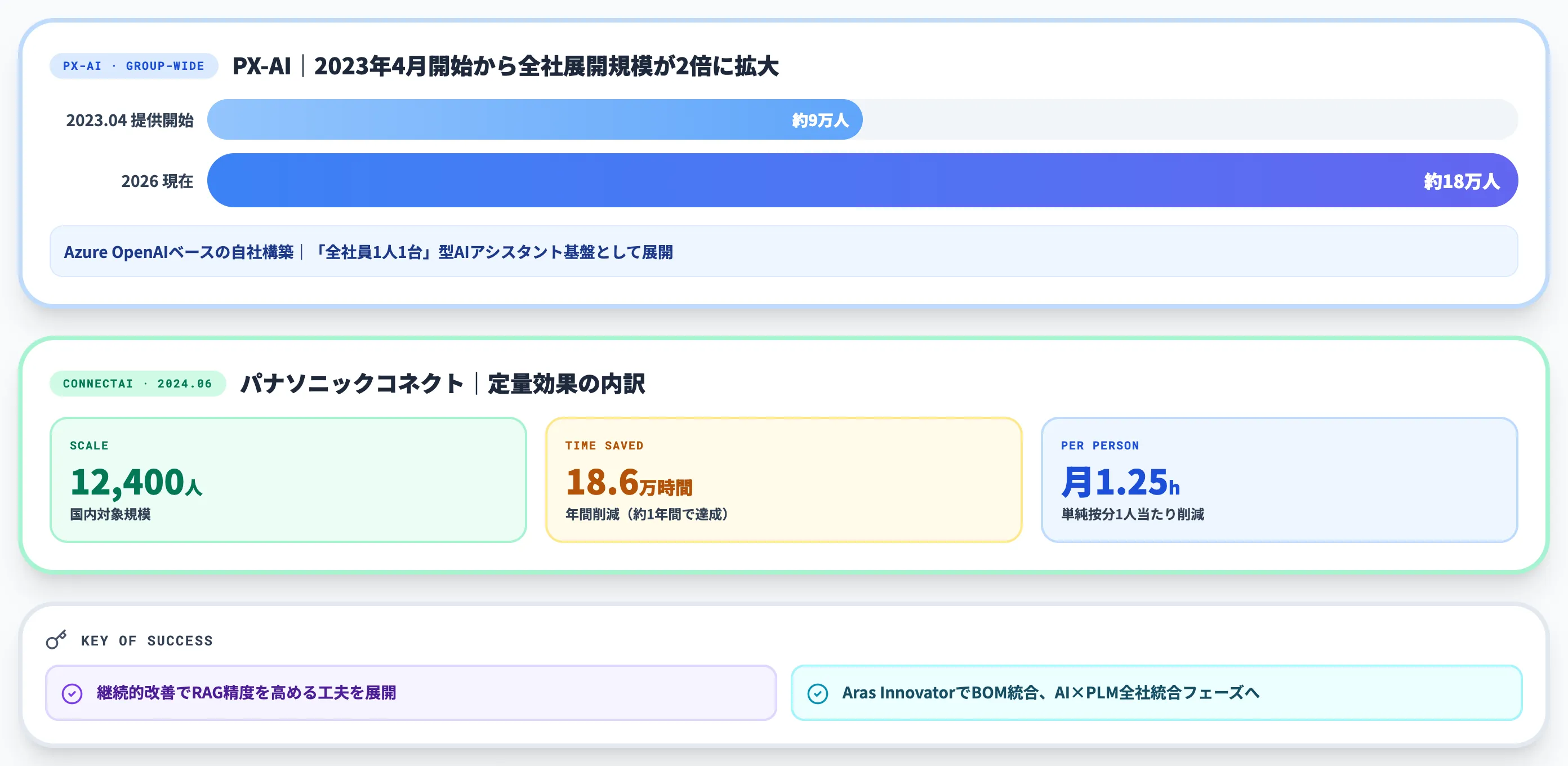
PX-AIは「全社員に1人1台」型のAIアシスタント基盤として位置づけられており、グループ全体での組織的活用が進んでいる事例です。
加えて、傘下のパナソニックコネクトでは別途「ConnectAI」を展開しており、2024年6月の発表で国内約12,400人を対象に、提供開始から約1年間で約18.6万時間の労働時間削減を達成したと報告されています。単純按分すると1人当たり年約15時間、月換算で約1.25時間に相当します。
公開されている主な成果を整理すると以下の通りです。
- PX-AI(ホールディングス): 2023年4月開始、国内グループ約9万人から現在約18万人規模へ拡大
- ConnectAI(パナソニックコネクト): 国内約12,400人対象で年間約18.6万時間の労働時間削減、単純按分で1人当たり年約15時間(月約1.25時間相当)
- 継続的改善: RAGの精度を高めた工夫を継続展開
パナソニックHDは加えて、Aras Innovator活用によるBOM統合とレガシー変革を進めており、AI×PLM(Adaptive PLM)の全社統合フェーズに入っています。
全社展開の鍵は、自社構築のAI基盤を持ち、PLMやMESといった基幹システムとの統合を経営層が主導している点です。単発のChatGPT利用とは設計思想が根本的に異なります。
旭化成|全社業務で月2,157時間削減+研究開発のナレッジ承継
旭化成は、研究開発と製造現場の両面で生成AIの全社活用を進めています。
2024年12月のプレスリリースでは、書類作成や社内資料検索などの全社業務で月2,157時間の時間短縮を達成、業務全体の効率化が定量的に確認されています。

研究開発・製造現場での具体的な取り組みは以下の通りです。
-
材料の新規用途探索
文献データ解析AIと生成AIの組み合わせで、6,000以上の用途候補を創出。ある材料では選別作業時間を従来の約40%に短縮
-
製造現場のリスク管理
過去の危険事例データから危険予知チェック項目を自動作成。経験の浅い従業員でも危険予知に参加可能に
-
書類監査の効率化
書類監査システムで年間1,820時間の業務削減を達成
旭化成の取り組みは、生成AI活用を「全社業務効率化」と「研究開発のナレッジ承継」の両軸で組織横断展開している点で、製造業のナレッジマネジメントAI事例として参照価値が高い水準にあります。
詳細な取り組みは旭化成、研究開発や製造現場での技能継承に生成AIの利用を本格化で公開されています。
トヨタ自動車「O-Beya」とAIエージェント
トヨタ自動車は、マイクロソフトとの協働でデジタル協働プラットフォーム「O-Beya」を構築し、その上で生成AIエージェントを運用しています。
Microsoftの公開事例によれば、2024年11月時点でパワートレイン開発部門の約800名がO-Beyaを利用しており、24時間365日AIエージェントにアクセスできる環境が構築されています。
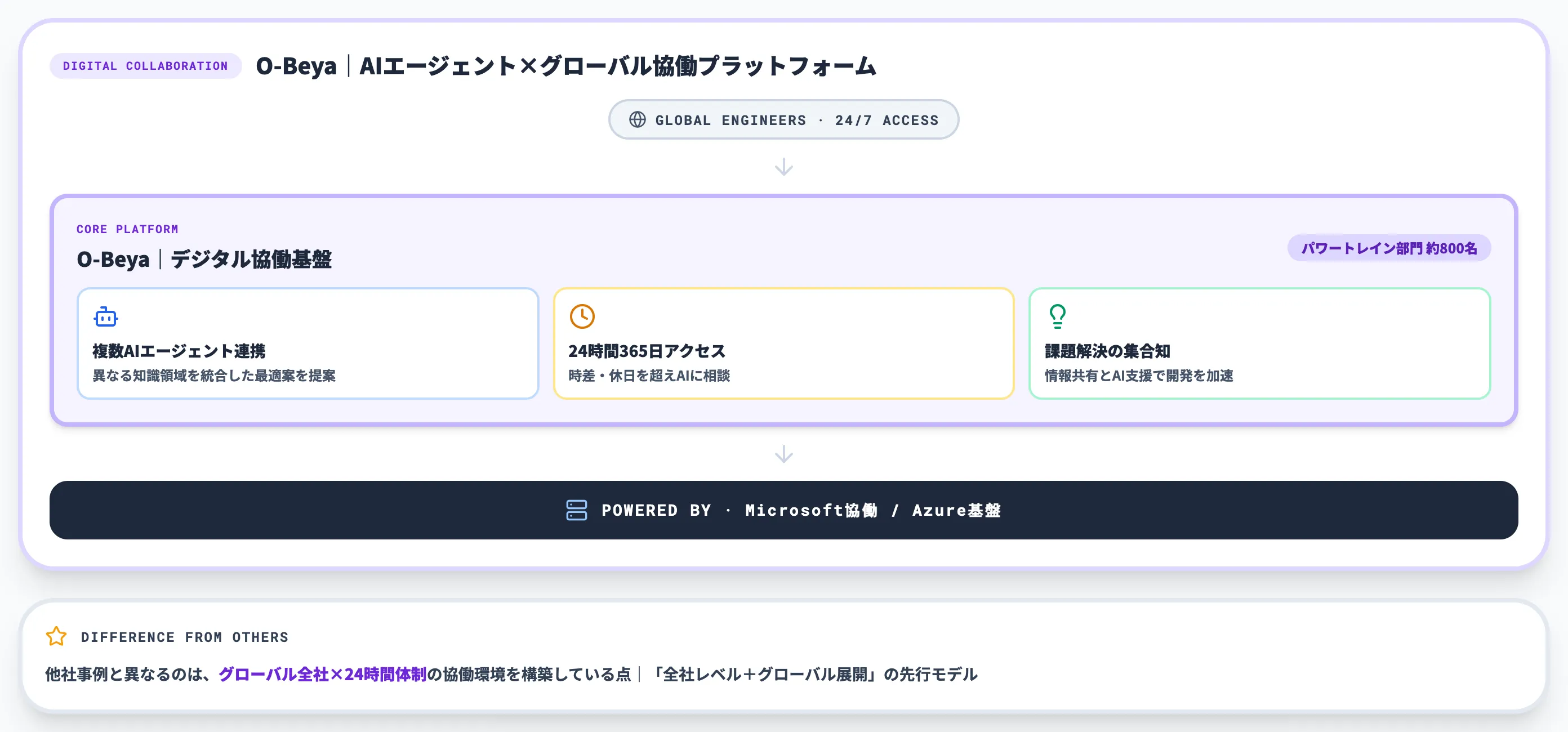
O-Beyaが他社事例と異なるのは、24時間365日、世界中のエンジニアがAIを通じて情報共有や課題解決を行える環境を構築している点です。
複数のAIエージェントが連携して異なる知識領域から統合した最適案を提案できる設計になっており、ナレッジマネジメントAIの「全社レベル+グローバル展開」の先行モデルとして注目されています。
日清製粉|Microsoft Fabricで全社データ統合
日清製粉は、Microsoft Fabricを基盤に全社データ統合を進めている事例です。
MESのリアルタイムデータ・センサーデータ・生産設備故障データ・基幹システムデータを単一プラットフォームに統合し、多角的なデータ分析を全社で実現しています。
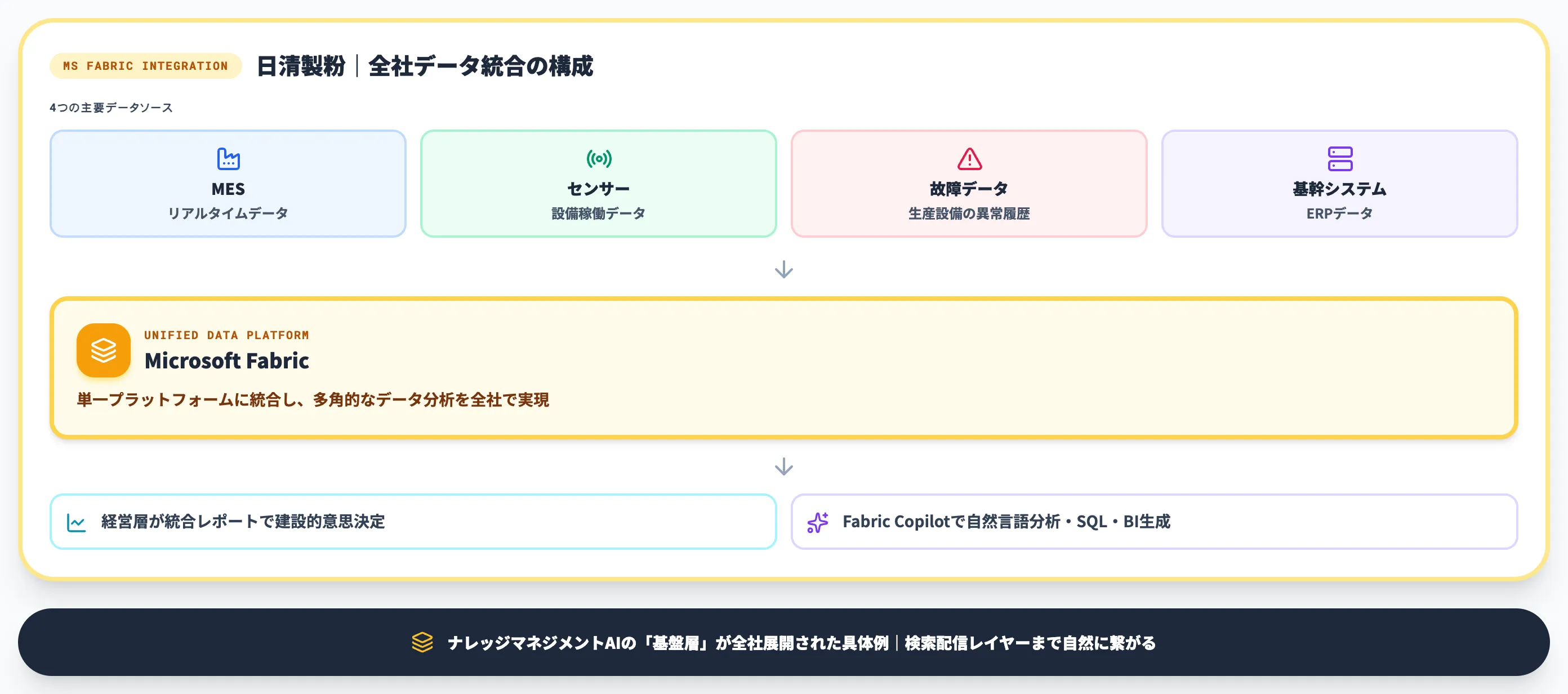
経営層が統合レポートに基づいて意思決定の建設的な議論ができる状態になっており、ナレッジマネジメントAIの「基盤層」が全社展開された具体例として参考になります。
Fabricに含まれるCopilot機能を使えば、自然言語による分析操作・データフロー生成・SQL/BI/MLモデル作成が可能になり、ナレッジマネジメントの「検索・配信レイヤー」までシームレスに繋がります。
NEC Obbligato AI|PLM × 生成AIで設計ナレッジを全社化
NECは、PLMソフトウェア「Obbligato」の生成AI連携機能を強化し、2026年4月から「Obbligato AI」の提供を開始しました。
PLMに蓄積された膨大な技術情報を、生成AIによって部門横断で活用できる状態に変える取り組みです。
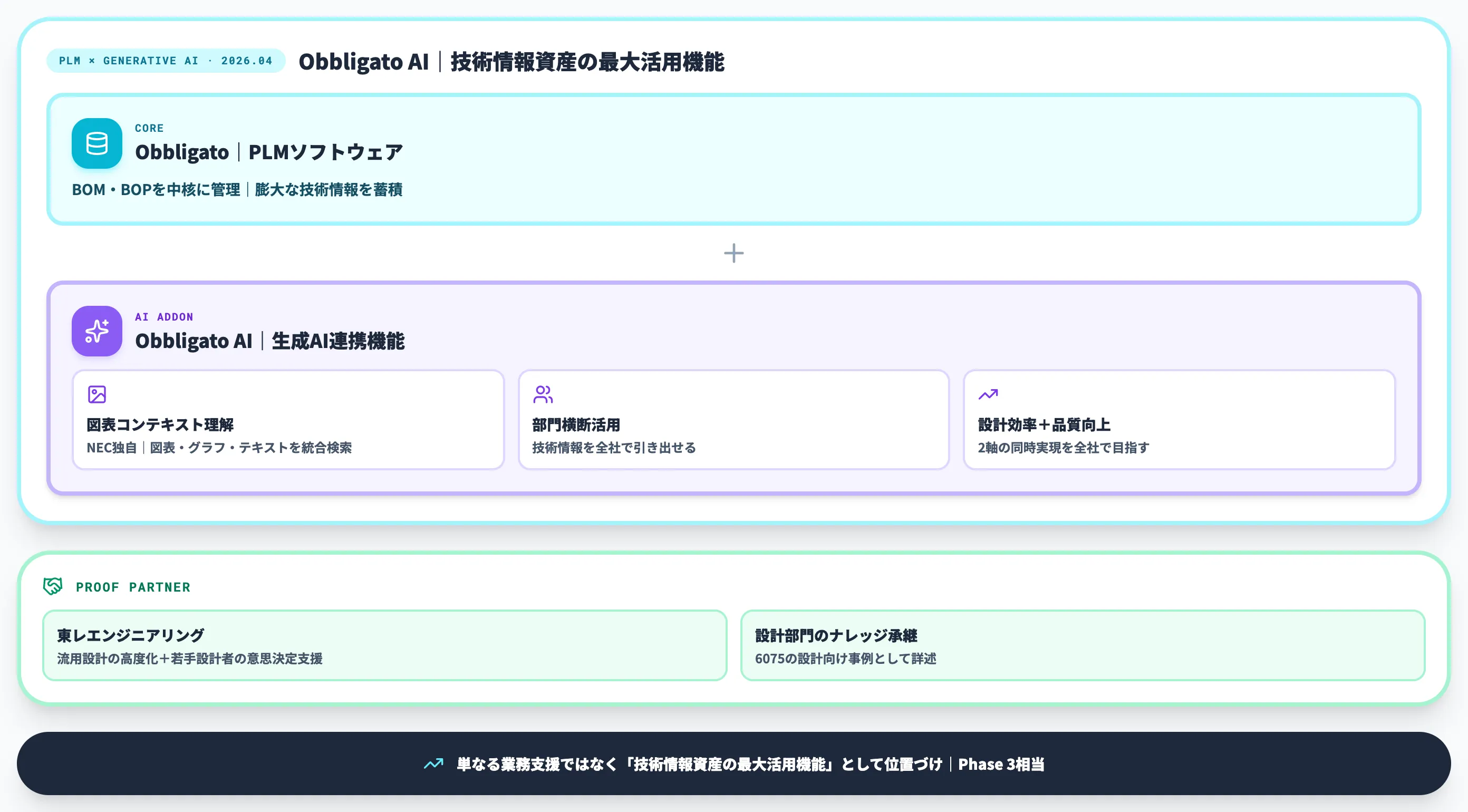
NEC独自の図表コンテキスト理解機能により、図表・グラフ・テキストを統合した検索が可能になり、これまで生成AIで活用しづらかった技術情報が引き出せるようになっています。
NECの公式説明では、生成AIを単なる業務支援ツールではなく「技術情報資産の最大活用機能」として位置づけており、設計効率化と品質向上の同時実現を全社レベルで目指す方針です。
実証パートナーの東レエンジニアリングとの取り組みでも、流用設計の高度化と若手設計者の意思決定支援が進んでいます。設計部門のナレッジ承継については、記事冒頭の位置づけ整理で示した別記事で詳述しています。

全社展開のステップとPhase設計
全社ナレッジマネジメントAIの展開は、3Phaseで設計し、それぞれ目標・体制・予算規模を分けるのが現実的です。汎用的な製造業AI導入ステップを踏襲しつつ、ナレッジマネジメント特有のレイヤー分解を組み込んでいきます。
最初から全社一斉展開を狙うと、データ整備不足・部門間の温度差・PoC設計の甘さなどが原因で、投資対効果が見えないまま頓挫するケースが少なくありません。
本セクションでは、各Phaseのアクション・期間・体制・予算規模目安を順に整理し、Phase間の移行判断のポイントも併記します。
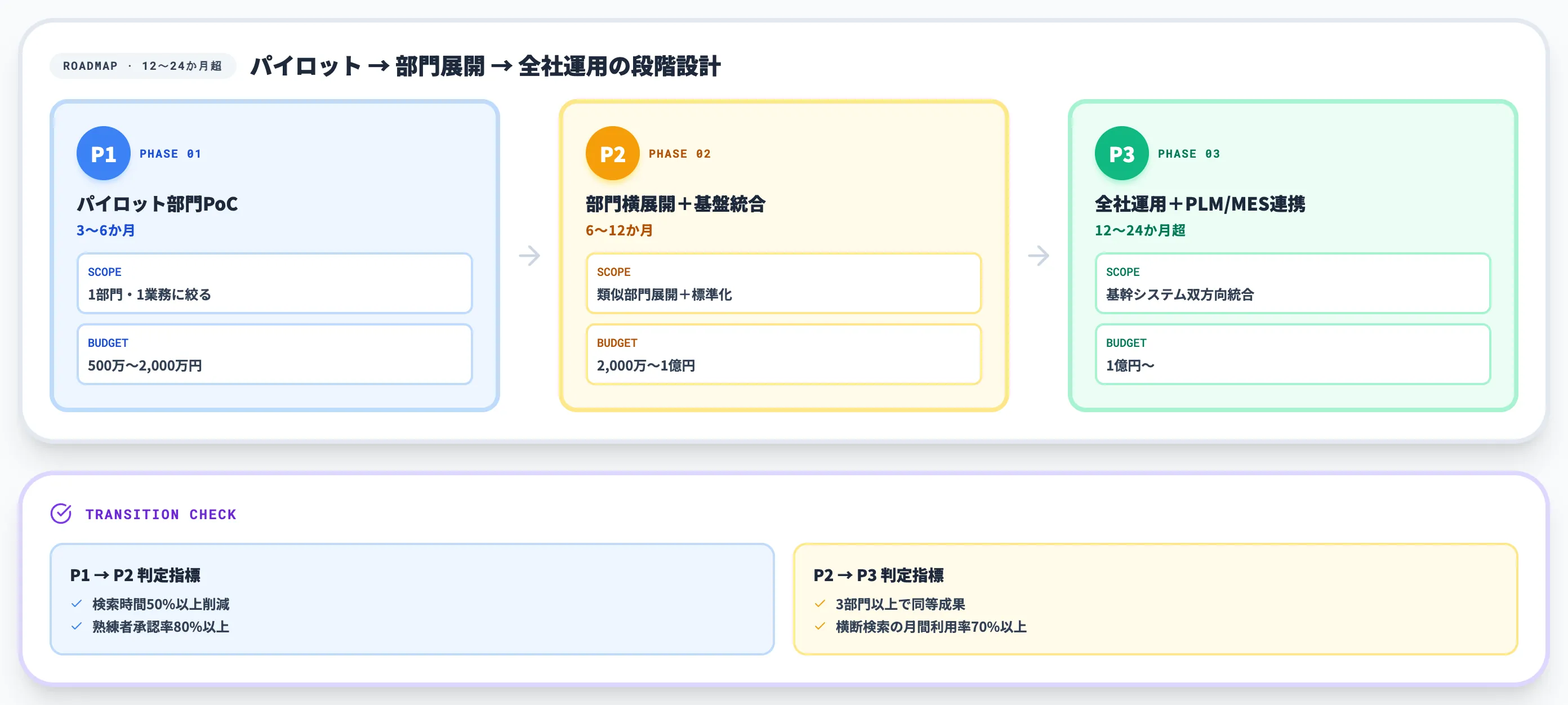
Phase 1|パイロット部門PoC(3〜6ヶ月)
最初の3〜6ヶ月は、1部門・1業務に絞ったPoCから始めます。
対象業務は、属人化が顕在化していて、退職・休職リスクが明確で、効果検証指標を数値化しやすいテーマを選びます。
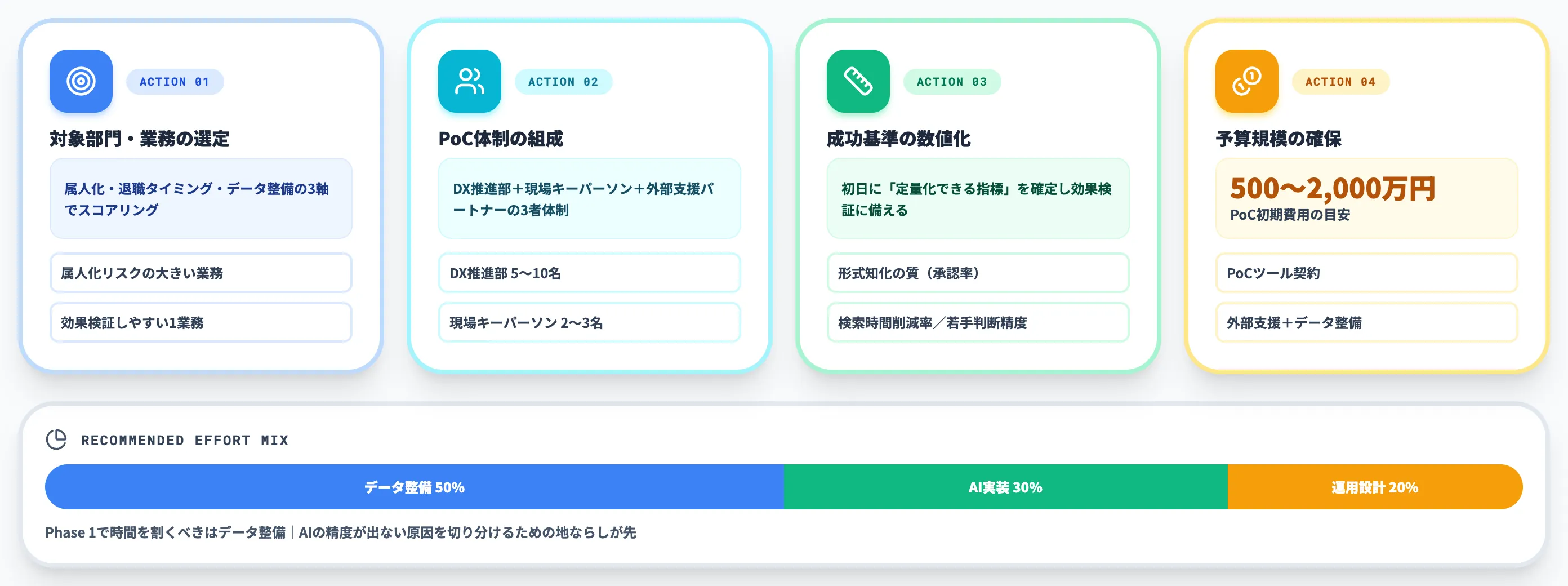
このフェーズの具体的なアクションは以下の通りです。
-
対象部門・業務の選定
属人化リスク・退職タイミング・データ整備状況の3軸でスコアリングし、最も効果検証しやすい業務を1つ選ぶ
-
PoC体制の組成
DX推進部5〜10名、対象部門のキーパーソン2〜3名、外部支援パートナー1社の3者体制が標準
-
成功基準の数値化
「対話による形式知化の質(熟練者承認率)」「検索・参照時間の削減率」「若手の判断精度」などの指標を初日に定義
-
予算規模目安
500万〜2,000万円(PoCツール契約+外部支援+データ整備の初期費用)
Phase 1で重要なのは、効果検証よりもデータ整備の地ならしです。図面ファイルの命名・保管場所・属性付与ルールが整っていない状態でPoCに入ると、AIの精度が出ない原因が「AIの問題」なのか「データの問題」なのかが切り分けられません。
支援現場でも、Phase 1で時間を割くべきはデータ整備50%・AI実装30%・運用設計20%の配分が現実的でした。PoC設計の詰まりポイントを深掘りしたい場合は製造業のAI PoCの進め方も併せてご参照ください。
Phase 2|部門横展開+ナレッジ基盤統合(6〜12ヶ月)
Phase 1で成果が確認できたら、6〜12ヶ月程度をかけて類似部門への展開と、ナレッジ基盤の標準化を進めます。
この段階で、AIモデルのチューニングよりも、ナレッジ構造化フォーマットと運用ルールの標準化に時間を割く必要があります。
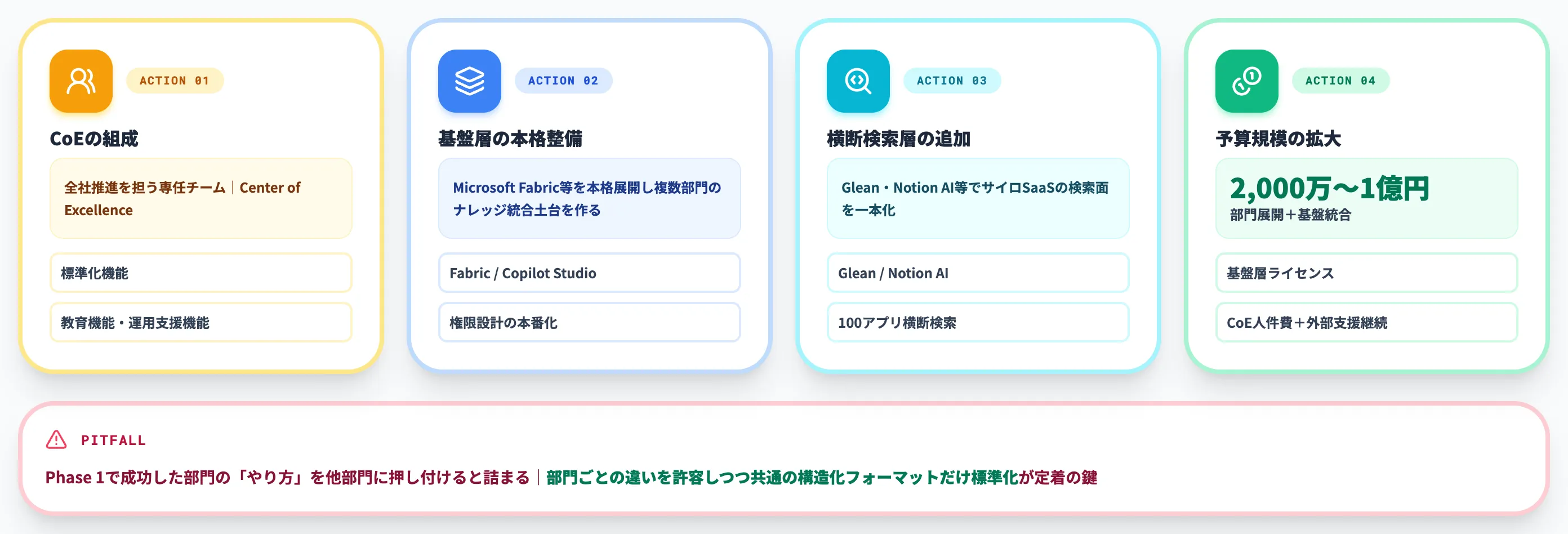
主なアクションは以下の通りです。
-
CoE(Center of Excellence)の組成
全社のナレッジマネジメントAI推進を担う専任チーム。標準化・教育・運用支援の3機能を担う
-
基盤層の本格整備
Microsoft Fabric等の基盤層を本格展開し、複数部門のナレッジを統合できる土台を作る
-
横断検索層の追加
GleanやNotion AIのような横断検索層を導入し、サイロ化したSaaS群の検索面を一本化
-
予算規模目安
2,000万〜1億円(基盤層ライセンス+横断検索ツール+CoE人件費+外部支援継続)
Phase 2で詰まりやすいのは、Phase 1で成功した部門の「やり方」を他部門にそのまま押し付けてしまうケースです。製品カテゴリーごとに図面の特性や属性体系が違うため、テンプレートをそのまま流用できないことが多くあります。
部門ごとの違いを許容しつつ、共通の構造化フォーマットだけは標準化する設計が定着の鍵になります。
Phase 3|全社運用+PLM/MES連携(12〜24ヶ月以降)
12〜24ヶ月以降は、設計部門だけでなく調達・購買・生産技術・品質保証・保全まで広げ、PLM/MES/ERP等の基幹システムとの統合を進めます。
設計ナレッジが部門を超えて流通すると、サプライヤー選定・コスト見積・品質トラブル対応の精度が一段上がります。
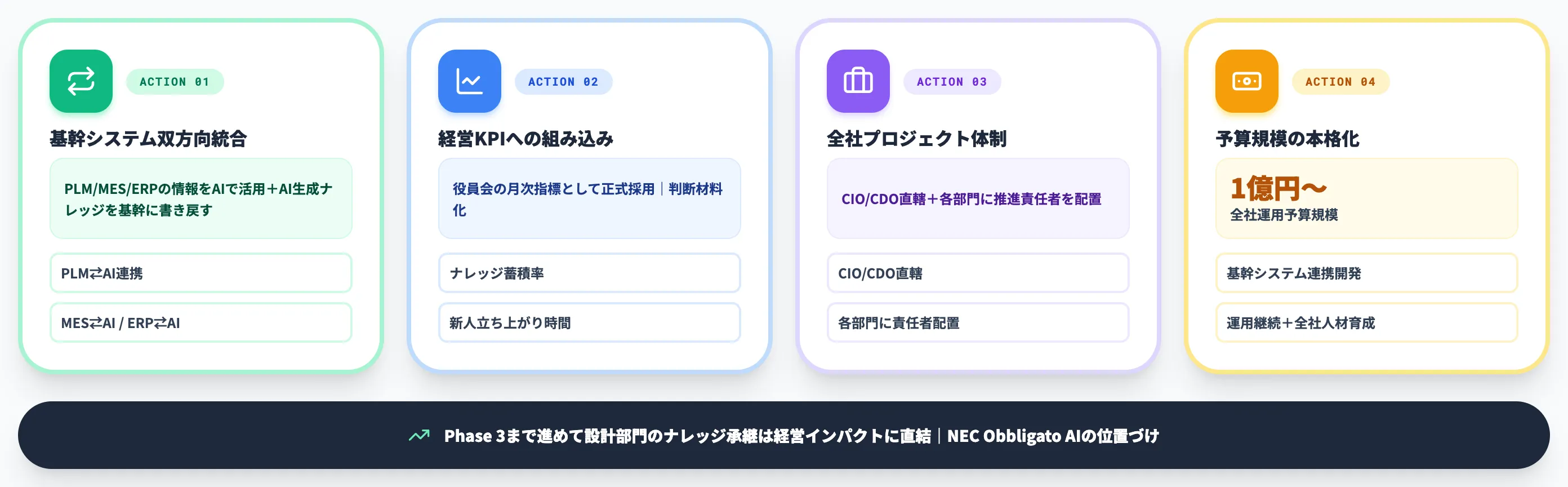
主なアクションは以下の通りです。
-
基幹システムとの双方向統合
PLM/MES/ERPに蓄積された情報をAIで活用し、AI側で生成したナレッジを基幹システムに書き戻す双方向連携
-
経営KPIへの組み込み
ナレッジ蓄積率・部門横断利用率・新人立ち上がり時間などを役員会の月次指標に組み込む
-
全社プロジェクト体制
CIO/CDO直轄の全社プロジェクト化、各部門に推進責任者を配置
-
予算規模目安
1億円〜(基幹システム連携開発+運用継続+全社人材育成)
NECがBOM・BOPを中核に管理するObbligato上でObbligato AIを提供しているのも、PLMに蓄積された技術情報の検索・活用を全社の意思決定に繋げるという思想です。さらに製造現場との繋ぎ込みでは生産管理AIが連携対象として組み込まれていきます。
設計部門のナレッジ承継は、Phase 3まで進めてようやく経営インパクトに直結します。
Phase移行判断のチェックポイント
PhaseからPhaseへの移行は、定性的な手応えではなく定量指標で判断します。
以下の表で、Phase間の移行判断ポイントを整理しました。
| 移行 | 判断指標 | 移行を遅らせるべきサイン |
|---|---|---|
| Phase 1 → Phase 2 | 対象業務の検索時間50%以上削減、熟練者承認率80%以上 | データ整備が部分的、運用ルールが現場に浸透していない |
| Phase 2 → Phase 3 | 3部門以上での同等成果、横断検索の月間利用率70%以上 | 経営層のスポンサーシップ不安定、CoE機能が単一拠点に依存 |
Phase移行を急ぐと、後段で必ず破綻します。
特にPhase 2 → Phase 3への移行は基幹システム改修を伴うため、Phase 2の段階で経営層が明確にコミットしていない場合は、Phase 2の延長戦に切り替える判断が必要です。
全社ナレッジマネジメントAIのKPI設計とROI
全社レベルのKPIは、個別業務効率ではなく組織のナレッジ流通能力を測定するように設計します。
部門単位の業務時間削減だけ追っていても、全社レイヤーで成果が見えず、経営層への説明力が落ちます。
本セクションでは、主要プロダクトの料金感、4つの全社特有KPI、ROI試算の組み立て方を順に整理します。
主要プロダクトの料金感
全社展開のコストは、基盤層・横断検索層・SECI支援層・AIエージェント基盤の4カテゴリで見積もるのが実務的です。
以下の表で、2026年5月時点の代表製品と課金体系の傾向を整理しました。
| カテゴリ | 代表製品 | 課金体系 | 料金目安 |
|---|---|---|---|
| 基盤層 | Microsoft Fabric | 容量CU(F2=2CU〜F2048=2048CU)のリージョン別月額従量 | 公式価格計算ツールで要見積 |
| 横断検索層 | Glean | ユーザー数ベース・年間契約 | 個別見積(公開価格なし) |
| SECI支援層 | Confluence AI / Guru | ユーザー数×月額、AI機能はアドオン | ユーザーあたり月1,000〜3,000円帯 |
| AIエージェント基盤 | Copilot Studio | Copilot Credits制(25,000 Credits = 200USDパック等) | パック単位で要見積。Microsoft 365 Copilotライセンス利用時は一部内部エージェント利用が別扱い |
2026年5月時点では公開価格を出していない製品が多く、組織規模・利用範囲・既存契約に応じた個別見積が前提になります。
全社展開の経済合理性は、単年度の料金比較ではなく3〜5年累積のROIと併せて見るのが妥当です。
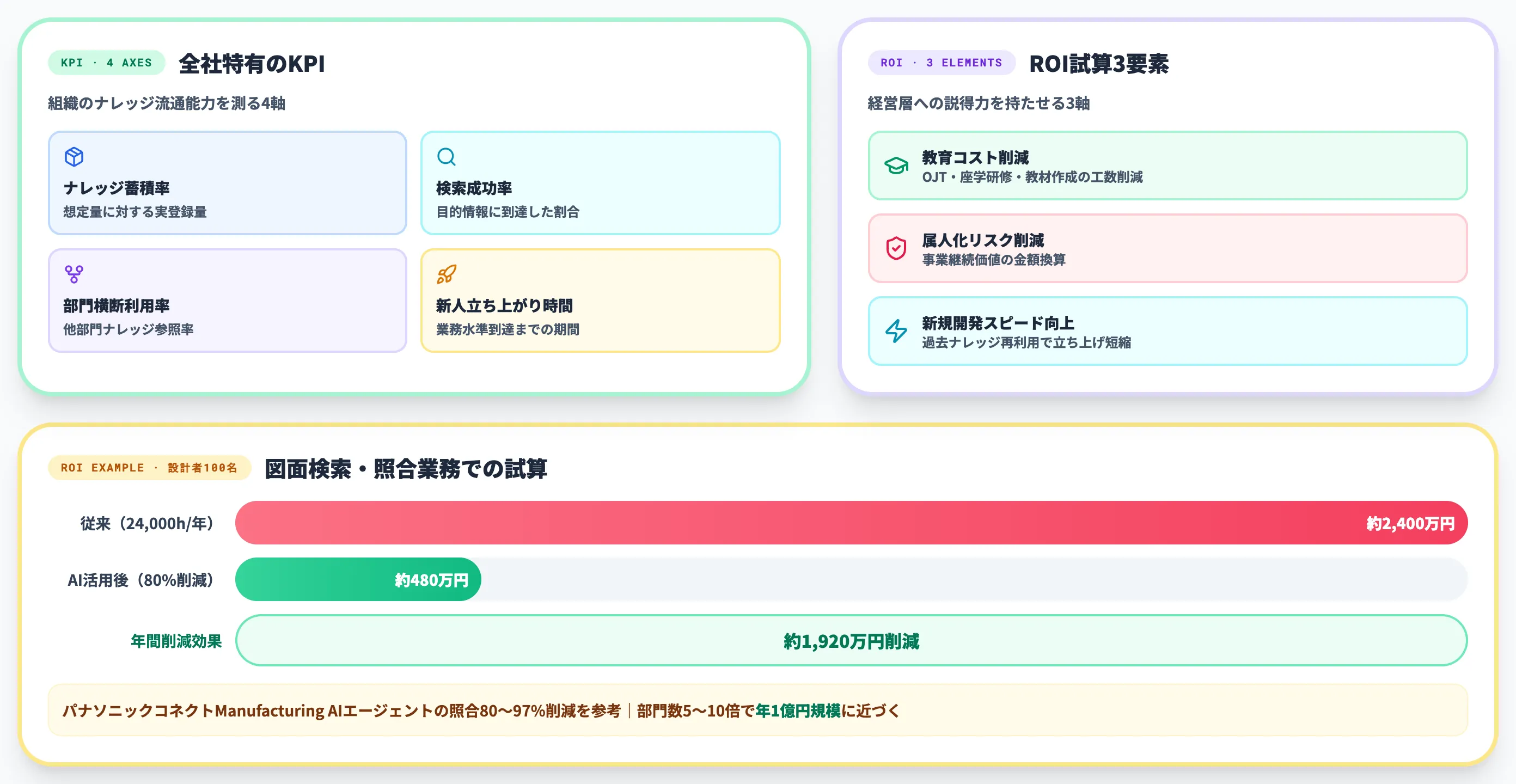
全社特有の4つのKPI
全社ナレッジマネジメントAIの効果測定は、以下の4つのKPIを軸に組み立てるのが実務的です。

-
ナレッジ蓄積率
各部門で想定されるナレッジ量に対し、実際に登録された量の割合。部門間のばらつきを見ると、組織課題が浮かびやすい
-
検索成功率
検索回数のうち、目的の情報に到達した割合。50%以下なら構造化レイヤーの設計に問題がある
-
部門横断利用率
ある部門のメンバーが、自部門以外のナレッジを参照した割合。サイロ化の解消度合いを定量的に測れる
-
新人立ち上がり時間
新任メンバーが業務水準に到達するまでの期間。暗黙知が形式知化されたあとの短縮率で測る
これら4つのKPIは、いずれも個別業務の効率指標ではなく、組織のナレッジ流通能力を測る指標になっています。
経営層への報告では「月◯時間削減」だけでなく、「部門横断利用率がN%向上した結果、新人立ち上がり時間がN%短縮した」という連鎖を示すと、全社レベルの価値が伝わります。
ROI試算の3要素
ROI試算は、以下の3要素で組み立てます。
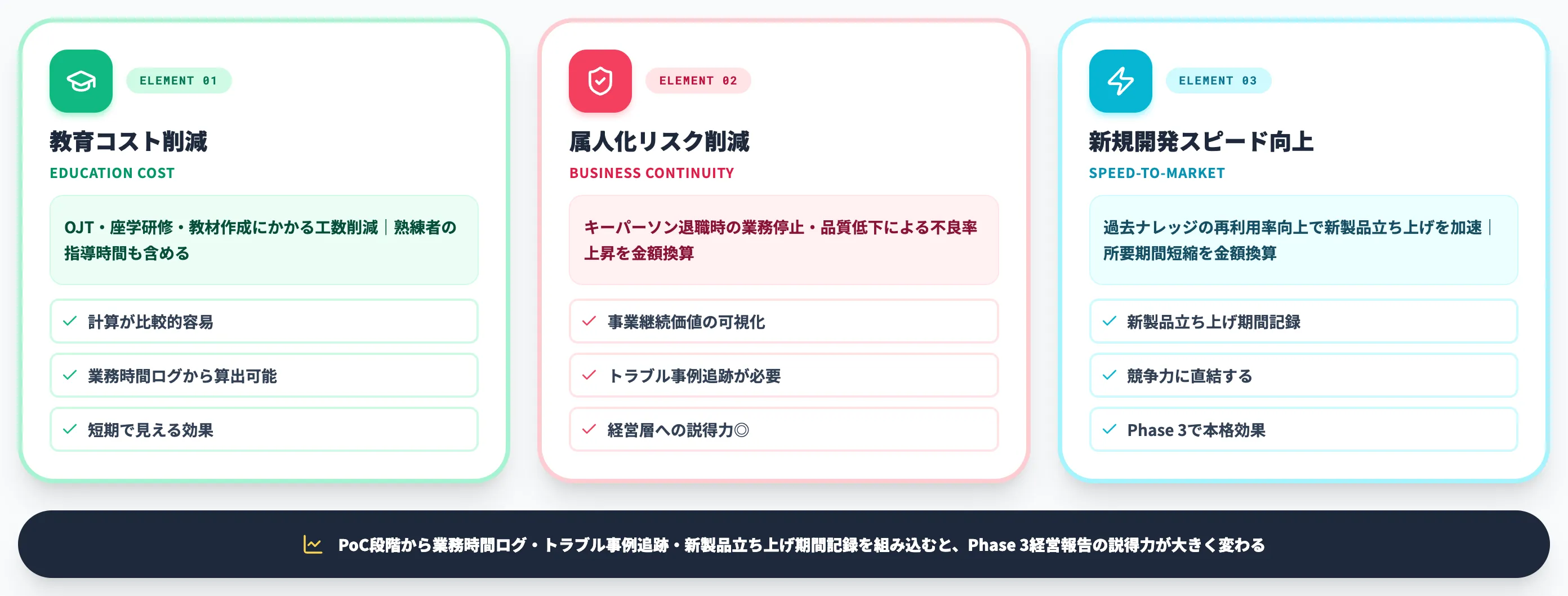
-
教育コスト削減
OJT・座学研修・教材作成にかかる工数の削減効果。熟練者の指導時間も含めて計算
-
属人化リスク削減(事業継続価値)
キーパーソン退職時の業務停止リスク、判断品質低下による不良率上昇リスクを金額換算
-
新規開発スピード向上
過去ナレッジの再利用率向上による新製品立ち上げの加速。新規開発1件あたりの所要期間短縮を金額換算
1番目の教育コスト削減は計算が比較的容易ですが、2番目の事業継続価値と3番目の開発スピード向上は経営層への説得力を持つ反面、定量化が難しい領域です。
PoC段階から、これら3要素を定量化する仕組み(業務時間ログ・トラブル事例追跡・新製品立ち上げ期間記録)を組み込んでおくと、Phase 3の経営報告で説得力が大きく変わります。
全社ROI試算例
具体的な数値感を整理すると、全社展開の経済合理性が見えてきます。
2026年2月発表のパナソニックコネクトManufacturing AIエージェントでは照合業務を80〜97%削減した実績があります。これを参考に、仮に設計者100名の組織で図面検索と照合に1人あたり月20時間(年240時間)かけている前提で計算します。
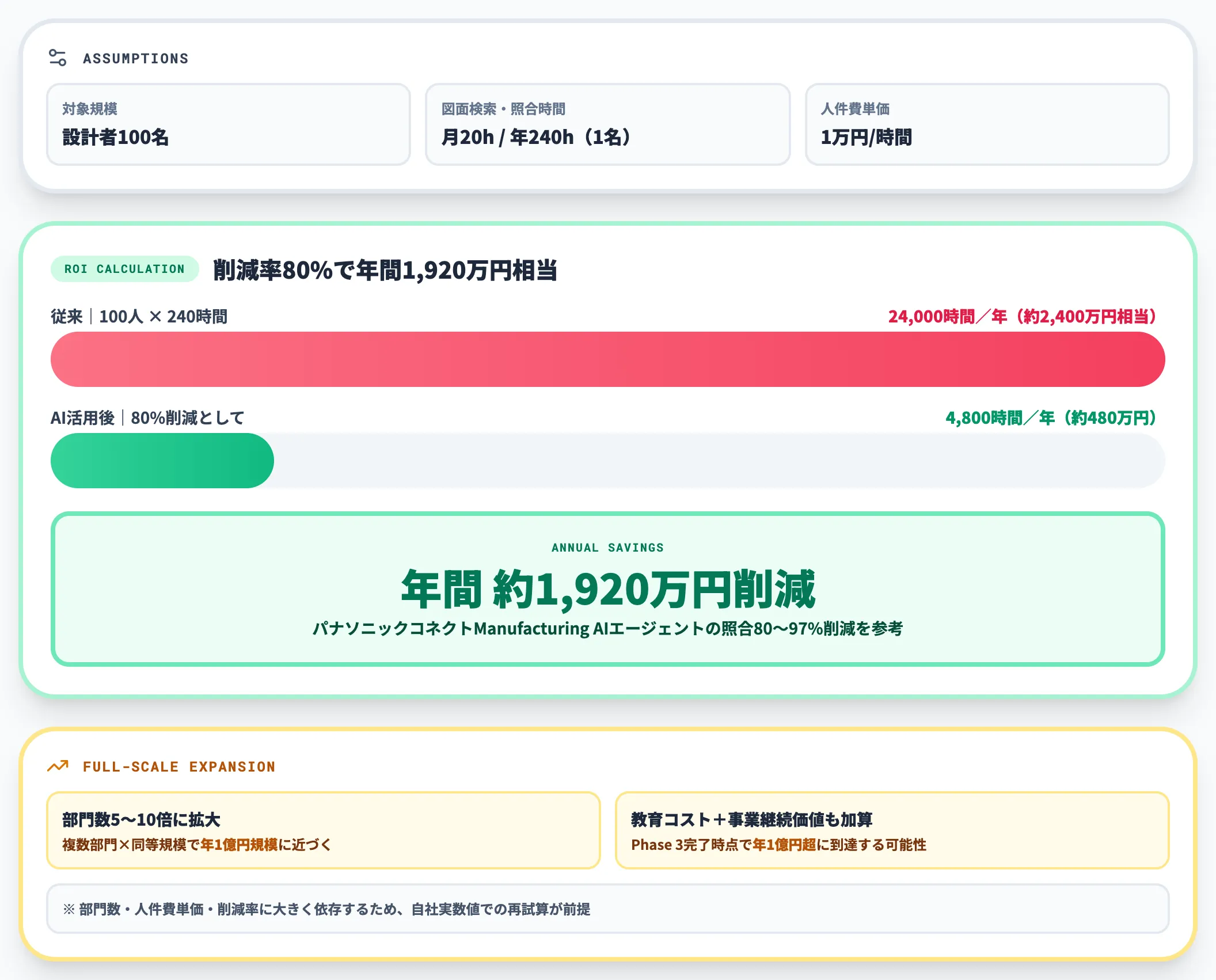
- 従来: 100人 × 240時間 = 年間24,000時間(人件費1万円/時間換算で約2,400万円相当)
- AI活用後(80%削減として): 年間4,800時間(約480万円)
- 削減効果: 年間1,920万円
この計算には設計品質向上や手戻り削減の効果は含まれていません。
全社展開で部門数が5〜10倍に広がれば、複数部門×同等規模となり、年1億円規模に近づく削減効果が見込まれます。
加えて、教育コスト削減・事業継続価値・新規開発スピード向上を加算すると、Phase 3完了時点で総削減効果が年1億円を超える水準に到達する可能性が出てきます。ただしこれは前提条件(部門数・人件費単価・削減率)に大きく依存するため、自社の実数値で再試算するのが妥当です。
ROI試算は単年度ではなく3〜5年の累積効果で組み立てるのが、経営層への報告で正確な判断材料を提供する書き方になります。
全社ナレッジマネジメントAIの向き不向きと失敗パターン
全社ナレッジマネジメントAIは万能ではなく、組織文化・データ整備状況・経営コミットが揃わないと典型的な失敗パターンに陥ります。
導入前に向き不向きを冷静に判断することで、Phase 1の失敗リスクを大きく下げられます。

本セクションでは、向いている場面・向いていない場面・典型的な3つの失敗パターンを順に整理します。
向いている場面
全社ナレッジマネジメントAIの効果が出やすいのは、経営層のコミットメントとデータ整備の素地が揃っている組織です。
以下の3条件のうち2つ以上に該当する場合、Phase 1で成果が出やすい傾向があります。
| 条件 | 効果が出やすい理由 |
|---|---|
| 経営層がDX推進をトップダウンで主導している | 部門間の調整コストが下がり、Phase移行がスムーズに進む |
| 既存のナレッジ基盤がワークせず明確な痛みがある | 現場の協力を得やすく、PoCの成功基準が定量化しやすい |
| 部門横断のCoE組成が可能な人材プールがある | Phase 2の標準化フェーズで詰まりにくく、全社展開の速度が上がる |
逆に、これら3条件が揃わないままPhase 1に入っても、ツールだけが導入されて運用が定着しない結果に終わりやすいのが現実です。
支援現場の経験では、経営層のスポンサーシップが最も重要な変数で、ここが弱いとPhase 2以降で必ず失速します。
向いていない場面
逆に、以下の状況に該当する場合は、全社ナレッジマネジメントAIの導入を急がず、組織側の準備を先行させる選択が現実的です。
| 状況 | 効果が出にくい理由 |
|---|---|
| 経営層のスポンサーシップが弱い | Phase 2以降の基盤投資判断が下りず、Phase 1の延長で頓挫しやすい |
| 部門ごとにバラバラのKPIが設定されている | 部門間の協力動機が成立せず、ナレッジ流通の循環が起きない |
| 既存システム統合が政治的に難しい | Phase 3でPLM/MES連携が必要になるが、部門権限の壁で進まない |
| データ整備が手付かず(紙図面・命名規則ばらつき大) | Phase 1のPoCでAI精度が出ず、効果検証ができない |
これらに該当する場合は、AIツールを選ぶ前に、経営層のコミット形成・部門間のKPI整合・データ整備の3点を半年〜1年かけて先行整備する方が、結果的に早く成果が出るケースが多くあります。
「AI導入が目的」ではなく「ナレッジ流通の改善が目的」と位置づけ直すことが、判断の出発点になります。
典型的な3つの失敗パターン
全社ナレッジマネジメントAIで頻発する失敗パターンを3つ整理します。
ナレッジマネジメントの失敗事例でも整理されている通り、失敗の多くはツール選定ではなく組織設計に原因があります。製造業特有のAI導入失敗パターンは製造業のAI導入が失敗する理由も併せて確認すると、より具体的な回避策が見えてきます。

-
ツール先行で文化が追いつかない
ナレッジマネジメントツールを導入したが、情報が入力されずに形骸化。「使う動機」「使う時間」「使った結果のフィードバック」を組織として用意しないまま導入したケース
-
経営コミット無しでの全社展開
経営層が「ナレッジマネジメントは重要」と発信せず、現場任せで進めるパターン。業務の優先順位が変わる中で、ナレッジ共有が後回しにされ継続的な運用が崩れる
-
部門サイロを壊さずに導入する罠
既存の部門権限・部門KPIを温存したままツールだけ全社に展開。結果として「部門ごとに別々のナレッジ基盤」が並列で動き、サイロが温存される
これら3パターンに共通するのは、AIツールの問題ではなく、組織設計の問題である点です。
特に3つ目の「部門サイロを壊さずに導入する罠」は、製造業特有の縦割り組織で頻発します。Phase 2のCoE組成段階で、部門間のKPI整合と権限再配置を経営層が主導しないと、必ずこの罠にハマります。
導入判断で詰まる論点
最後に、導入判断で詰まる典型的な論点を3つ整理します。
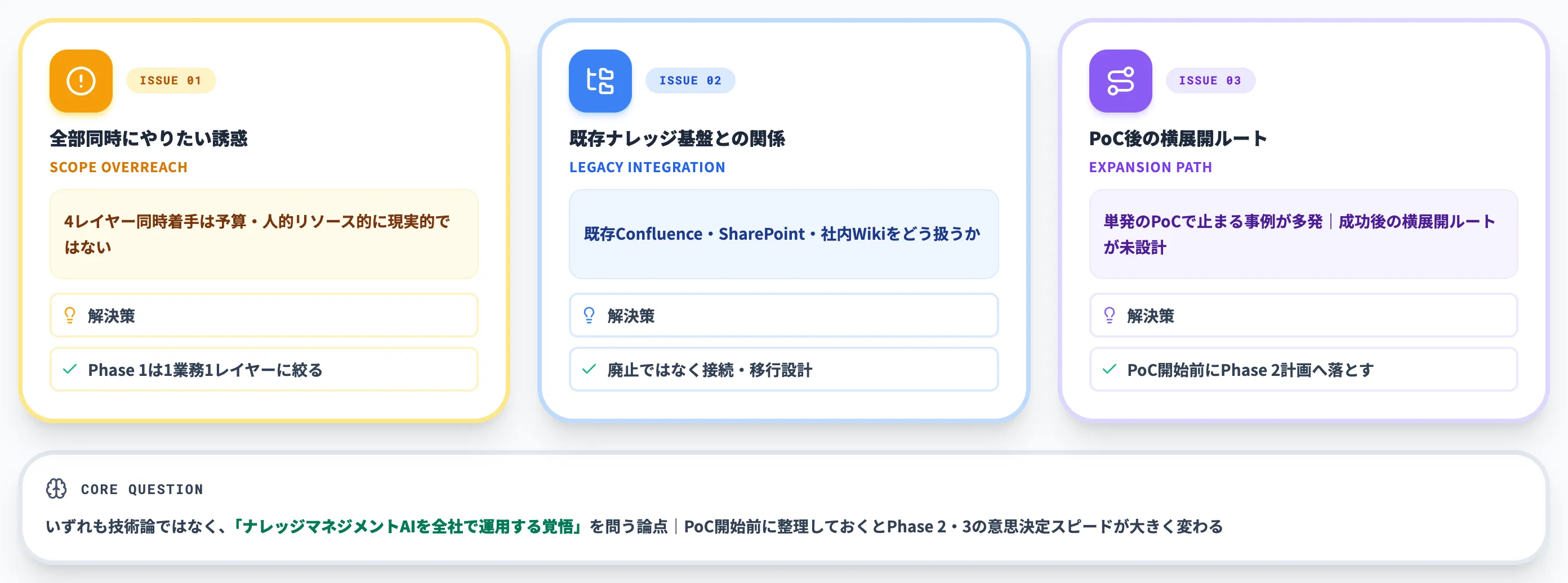
-
全部同時にやりたいという誘惑
4レイヤー同時着手は予算・人的リソース的に現実的ではない。Phase 1は1業務1レイヤーに絞る
-
既存ナレッジ基盤との関係整理
既存のConfluence・SharePoint・社内Wikiをどう扱うか。多くの場合、廃止ではなく接続・移行で対応する設計が現実的
-
PoC成功後の横展開ルートの事前設計
単発のPoCで止まる事例が多い。PoC開始前に、成功したらどの部門・拠点に展開するかを Phase 2の計画に落とし込んでおく
これらは技術的な論点というより、組織として「ナレッジマネジメントAIを全社で運用する覚悟」があるかを問う論点です。
支援現場では、これら3論点をPhase 1のPoC開始前に整理しておくと、Phase 2・3の意思決定スピードが大きく変わります。

製造業のナレッジマネジメントAIを業務に組み込むなら
ここまで整理してきたように、全社ナレッジマネジメントAIはSECIサイクルとAI4レイヤーを束ね、Phase 1〜3で段階的に展開していく取り組みです。
ただし、AIインタビュアー・横断検索・センサーAIといった個別ツールを単体導入で止めると、2025年問題への対応スピードでは間に合わず、現場の暗黙知が他業務と連携しないまま埋没してしまうのが現実です。
このレイヤーを束ねるのが、SECIサイクルをMicrosoft Teams上で回せるエンタープライズAIエージェント基盤です。AI総合研究所のAI Agent Hubに含まれる暗黙知Agentは、収集レイヤー(AI対話インタビュー・Teams会議文字起こし・動画コーチング)から、構造化レイヤー(5W1H自動分類・工程ステップ分解)、活用・継続学習レイヤー(信頼度フィードバック・Before/After習熟度可視化)までを1つのAIエージェントで束ね、熟練工のノウハウを組織として継承可能な形に変えます。
-
AI対話インタビューで曖昧な経験を逆質問で具体化
「組立で『これはダメ』と判断した瞬間はありましたか?」のようにAIが文脈に沿って深掘りし、本人も言語化していなかった判断軸を引き出します。回答候補チップで入力負担も最小化します。
-
Teams会議・文字起こしから熟練ノウハウを一括抽出
若手がベテランにインタビューしたTeams会議の文字起こしを貼り付けるだけで、AIが複数の熟練ノウハウ候補を構造化抽出します。
-
動画コーチングと動作ステップ分析で身体知まで継承
お手本動画と学習者動画を骨格overlayで並べて比較し、AIが作業工程ステップに自動分解。文章では残しにくい身体技能まで継承可能な形にします。
-
正確性・速度・滑らかさ・安全性の4軸で習熟度を可視化
レーダーチャートでBefore/After比較し、どの軸が伸びどこに課題が残るかを定量的に追えます。技能継承の進捗が経営KPIとして扱えるようになります。
-
自社のAzureテナント内で管理する設計
蓄積した暗黙知は御社のMicrosoft Azure環境内・テナント完結で管理する設計で、外部SaaSへの保存を避けられる構成です。競争力の源泉であるノウハウを安心して預けられます。
AI総合研究所の専任チームが、SECIサイクルとAI4レイヤーの設計、PLM・MES連携、Phase設計まで一気通貫で支援します。
まずは無料の資料で、全社ナレッジマネジメントAIの実装イメージをご確認ください。
製造業のナレッジマネジメントAIを業務に組み込むなら

熟練工のノウハウを構造化登録し、現場の結果で精度が育つ
暗黙知Agentは熟練工の段取り・材質選定・トラブル対応のノウハウをAI対話で形式知化し、Teams会議文字起こしから一括抽出、動画コーチングで身体知の差まで可視化します。AI総合研究所では、SECIサイクルとAI4レイヤーの設計、PLM・MES連携、Phase設計までを一気通貫で支援します。
まとめ|全社ナレッジマネジメントを製造業×AIで実現するために
本記事では、製造業のナレッジマネジメントを全社・体系レイヤーで再定義し、SECIサイクルとAIの組み合わせで設計する方法を整理しました。
各セクションの結論を改めて整理すると以下の通りです。
- 製造業のナレッジマネジメントは、現場の暗黙知抽出(6038)や設計部門の流用設計(6075)の上位に位置する「全社×体系×Phase」レイヤーの取り組み
- 全社が直面する3つの構造課題は、部門サイロ化/属人化/2025年問題で、いずれも組織構造に根ざしているためツール選定だけでは解決しない
- AIによるナレッジマネジメントは収集→構造化→検索配信→活用学習の4レイヤーに分解して設計するのが実務的で、SECI4プロセス全体を組織的に回す触媒として位置づける
- 全社展開はMicrosoft Fabric等の基盤層、Glean等の横断検索層、Confluence AI等のSECI支援層の3層を組み合わせ、社内データ統合度・コスト・運用負担の3軸で選定する
- パナソニックグループPX-AI 9万人→現在18万人規模・旭化成2,157時間/月削減・トヨタO-Beyaパワートレイン部門約800名・日清製粉Fabric全社統合・NEC Obbligato AIが全社展開・部門横展開の参考事例
- 展開はPhase 1(パイロット部門PoC・3〜6ヶ月)→Phase 2(部門横展開+ナレッジ基盤統合・6〜12ヶ月)→Phase 3(全社運用+PLM/MES連携・12〜24ヶ月)の段階設計が現実解
- KPIはナレッジ蓄積率/検索成功率/部門横断利用率/新人立ち上がり時間の4軸、ROI試算は教育コスト削減+事業継続価値+新規開発スピード向上の3要素で組み立てる
- 失敗パターンの典型は「ツール先行で文化が追いつかない」「経営コミット無し」「部門サイロを壊さずに導入」の3つで、いずれも組織設計の問題
2025年問題に伴う熟練人材層の縮小と既存ナレッジ基盤の機能不全が同時に進む2026年、製造業の全社ナレッジマネジメントは「後回しにできる最後のタイミング」を迎えています。
まずは自社の対象部門を1つ選び、属人化リスク・退職タイミング・データ整備状況の3軸でPhase 1のPoCテーマを決めるところから着手すると、Phase 2・3への展開が見えてきます。










