この記事のポイント
 大規模リポジトリのリファクタリングや長時間タスクにはGPT-5.2-Codexが最適、SWE-Bench Proで旧世代を大幅に上回り実務レベル精度
大規模リポジトリのリファクタリングや長時間タスクにはGPT-5.2-Codexが最適、SWE-Bench Proで旧世代を大幅に上回り実務レベル精度- ChatGPT Plus以上のプランに含まれるため、OpenAIを既に契約している組織は追加コストなしでCodex CLI経由で利用すべき
- 脆弱性調査やログ解析などセキュリティ用途にも有効だが、本番環境への直接アクセス権限は付与すべきでない。サンドボックス内での分析に限定するのが最適
- GPT-5.2(汎用)とGPT-5.2-Codex(開発特化)は用途で使い分けるべき。コーディング以外のタスクにCodexを使うのはコスト効率が悪い
- 導入時はAGENTS.mdでタスク範囲とコマンド権限を明文化し、ログ監査を有効にすべき。ガバナンス設計なしでの全社展開は避けるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OpenAIは、ソフトウェア開発と防御的サイバーセキュリティ向けに最適化されたエージェント型コーディングモデル「GPT-5.2-Codex」の提供を開始しました。これは、フラッグシップモデルであるGPT-5.2をベースに、大規模リポジトリのリファクタリングや脆弱性調査といった「プロジェクト規模の長時間タスク」を、Codex CLIやIDE拡張から対話的に進められるように設計されたものです。
本記事では、GPT-5.2-Codexの内部アーキテクチャやベンチマーク性能、料金プラン、そして実務での具体的な活用シナリオとガバナンス設計までを体系的に解説します。
✅最新モデル「GPT-5.5」については、以下の記事をご覧ください。
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Codex Cloud(ブラウザ版・GitHub連携)から使う場合(クラウドタスク)
ドキュメント整備とAGENTS.md / SKILL.mdの自動生成
GPT-5.2-Codexを使いこなすためのワークフロー設計
GPT-5.2 / GPT-5.1-Codex-Maxとの比較
Claude Code / Anthropic Subagentsとの比較
GPT-5.2-Codexとは?
GPT-5.2-Codexは、OpenAIの大型言語モデル「GPT-5.2」をベースに、ソフトウェア開発と防御的サイバーセキュリティ向けに最適化されたエージェント型コーディングモデルです。
大規模リポジトリのリファクタリングやマイグレーション、テスト強化、脆弱性調査といった「プロジェクト規模の長時間タスク」を、Codex CLI・Web・IDE拡張などの専用環境から対話的に進められるように設計されています。

GPT-5.2-Codexの性能・アーキテクチャ概要

このセクションでは、GPT-5.2-Codexの内部アーキテクチャと性能のポイントを整理します。
ベースモデルであるGPT-5.2の特徴、コンテキスト圧縮による長期タスク処理、エージェント機能、ビジョン対応、主要ベンチマークを順に見ていきます。
ベースモデルと長文コンテキスト処理
GPT-5.2-Codexは、フラッグシップモデルであるGPT-5.2をベースにした専用バリアントです。GPT-5.2自体が長文コンテキストとツール利用を前提に設計されており、その強みをエージェント型コーディングに振り切ったのがGPT-5.2-Codexという位置づけになります。
GPT-5.2では、長期タスク向けに次のような仕組みが導入されています。
- 有効コンテキスト長を拡張する「/responses/compact」エンドポイントによるコンテキスト圧縮
- 長時間のツール利用や会話を前提とした、トークン効率の高い推論プロセス
- プロジェクト単位のタスクで、前半の議論や操作内容を保持しながら後半に引き継げる設計
GPT-5.2-Codexはこの設計を引き継ぎつつ、Codex内での長時間コーディングセッションに合わせて、より積極的に「重要な履歴だけを残すコンテキスト圧縮」を行います。
これにより、モノレポ全体をまたぐ変更や、数時間〜数日にわたる開発セッションでも一貫性を保ちやすくなっています。
エージェント機能とツール連携の仕組み
GPT-5.2-Codexは、単なる「コード生成モデル」ではなく、Codexのエージェントとして動作することを前提に最適化されています。Codex側が提供するファイル操作・ターミナル・ブラウザ・Git・外部API呼び出しなどのツールを、モデルが自律的に組み合わせるイメージです。
エージェントとしての主な特徴は次のとおりです。
- ソースコード・設定ファイル・ドキュメントを横断的に読み込んだ上で、変更箇所を自動で見つける
- ターミナルコマンドの実行、テストの実行、ログの確認までを一連の流れとして扱える
- Gitのブランチ運用やPull Request作成を前提に、変更セット単位で提案・適用できる
- プロジェクトルートのガイドライン(AGENTS.mdなど)を参照しながら、プロジェクト固有のルールに沿って動作できる
これらの機能は、Codex CLIやCodex IDE拡張から利用できます。開発者は「やりたいタスク」を自然言語で伝えるだけで、GPT-5.2-Codexがツール呼び出しやファイル編集をオーケストレーションする構造です。
ビジョン機能とUI/デザイン開発への応用
GPT-5.2-Codexはテキストだけでなく、画像や画面キャプチャを扱うビジョン機能も強化されています。
GPT-5.2世代では、スクリーンショットや図版を含む入力に対して、より正確な構造理解ができるようになっており、UI開発やデザインレビューでも活用範囲が広がっています。
想定される活用パターンの例としては、次のようなものがあります。
- デザインツールからエクスポートしたモックアップ画像を読み込み、対応するコンポーネント構造やCSS設計を提案してもらう
- 既存アプリの画面キャプチャを元に、アクセシビリティ上の課題やレスポンシブ対応の改善案を洗い出す
- エラーダイアログやログビューアのスクリーンショットを解析し、根本原因の候補と修正パッチを提示してもらう
このように、GPT-5.2-Codexは「コードだけを見るモデル」ではなく、「UIやログも含めた開発コンテキスト全体」を扱うエージェントとして位置づけられています。
ベンチマーク評価
性能面では、GPT-5.2-Codexは既存のコーディング特化モデルを上回るベンチマーク結果が報告されています。特に、実務に近いタスクを評価するSWE-Bench ProやTerminal-Bench 2.0で高いスコアを示しています。
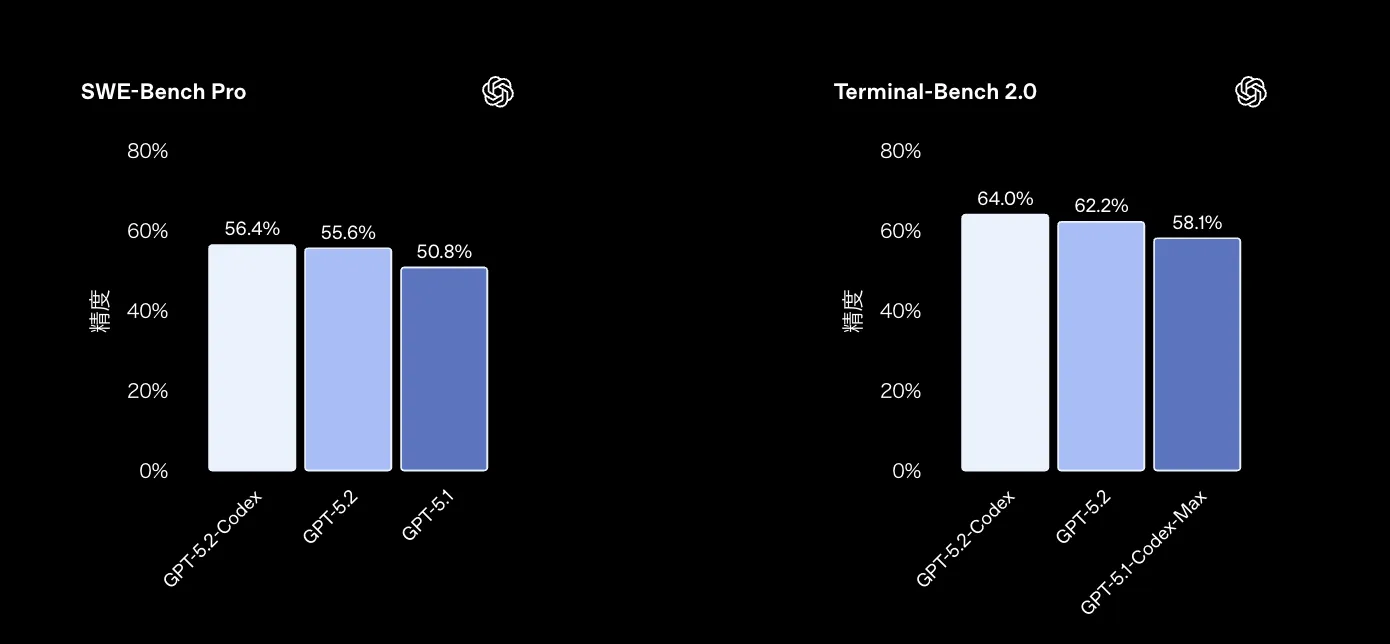
代表的なベンチマークを、GPT-5.2や過去世代モデルと比較したイメージは次のとおりです(2025年12月時点の公開情報に基づく)。
| ベンチマーク | 評価内容 | GPT-5.2-Codex | GPT-5.2(汎用) | GPT-5.1-Codex-Max のイメージ |
|---|---|---|---|---|
| SWE-Bench Pro | 実在OSSの難しめのバグ修正 | 約56.4% | 約55.6% | 約50%台前半 |
| Terminal-Bench 2.0 | ターミナル操作を伴う長期タスク | 約64.0% | 約62.2% | 約58%前後 |
| CTF系課題(社内評価) | 防御的サイバー演習タスク | 旧世代より有意に向上 | ― | 参考基準 |
これらの結果から、GPT-5.2-Codexは「ベースモデルのGPT-5.2と同等以上の推論力を保ちながら、コード変更やターミナル操作を伴う長時間タスクでより安定した成功率を出すモデル」と位置づけられます。
サイバー用途における利用制限・アクセス制御
GPT-5.2-Codexは、防御的サイバーセキュリティ(脆弱性調査・ログ解析・CTF演習など)を強く意識して設計されています。一方で、攻撃的な用途に転用されないよう、モデル側とプロダクト側の両方で制御が入っています。
主なポイントは次のとおりです。
- 通常のCodex利用では、「一般的なコーディング+防御的な分析」までを想定した安全性チューニングが入っている
- より踏み込んだサイバー演習やマルウェア解析などは、招待制の「Cyber Trusted Access」プログラムを通じて段階的に提供される
- モデルレベルの安全性学習に加えて、サンドボックス環境・ネットワークアクセス制御・操作ログの記録など、インフラ側の防御も組み合わせている
開発者が「自社プロダクトのセキュリティレビューをしたい」「ログから怪しそうな挙動を洗い出したい」といった用途は、通常のCodex環境でカバーされます。
一方で、レッドチーミングや本格的なマルウェア解析のような領域は、組織ポリシーやCyber Trusted Accessの枠組みの中で扱う前提になります。
GPT-5.2-Codexの料金・利用制限
Codexまわりの料金は、ざっくり次の3つに分かれます。
- ChatGPTサブスクリプションに含まれる利用枠
- その枠を超えた分をまかなう ChatGPTクレジット
- CIなど共有環境から直接叩くための APIトークン課金
この3つの組み合わせで考えると整理しやすくなります。
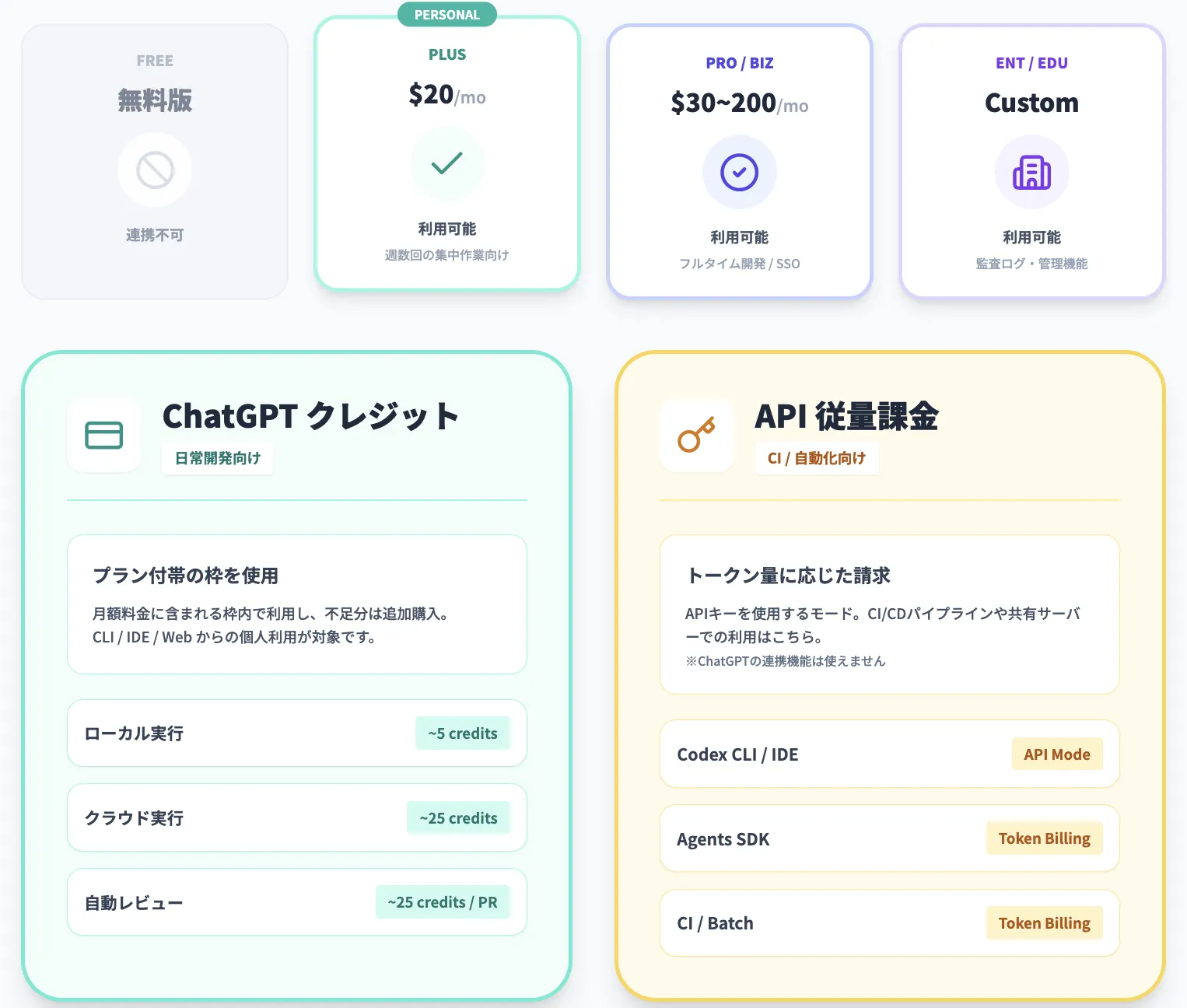
GPT-5.2-Codexを利用できるChatGPTプラン
GPT-5.2-Codexは、ChatGPTの有料プランに付属するCodex機能の一部として提供されています。通常のChatGPTチャット画面でモデル名を直接選ぶのではなく、Codex CLI / IDE拡張 / Web からサインインして使う前提です。
代表的な位置づけは次のとおりです。
| 区分 | プラン | GPT-5.2-Codexの扱い(Codex経由) | 目安 |
|---|---|---|---|
| 個人向け | ChatGPT Plus | 利用可能(Codex Web / CLI / IDE / モバイル) | 月20ドル、週に数回の集中コーディング向け |
| 個人向け | ChatGPT Pro | 利用可能 | 月200ドル、フルタイム開発をCodex前提にする層 |
| ビジネス向け | ChatGPT Business | 利用可能 | 1ユーザーあたり月30ドル、SSOや基本管理機能付き |
| 企業・教育機関向け | ChatGPT Enterprise / Edu | 利用可能 | 価格は要問い合わせ、監査ログやコンプライアンス対応強化 |
| 無料版 | ChatGPT Free | 連携不可 | ChatGPTアカウントでCodexにサインイン不可(API利用は別枠) |
Plus / Business などの有料プランには、Codex用の利用枠があらかじめ含まれており、不足分はChatGPTクレジットを追加購入して拡張できます。
【関連記事】
ChatGPTの料金プラン一覧を比較!無料・有料版の違い・支払い方法を解説
クレジット消費とAPI課金
前述の通り、Plus / Pro / Business / Enterprise / Edu の各プランには、もともと Codex 用の利用枠が含まれており、その範囲内であれば 追加のクレジット購入なしで GPT-5.2-Codex を使えます。
枠を超えてさらにタスク数を増やしたい場合にだけ、オプションとして ChatGPTクレジットを購入して上乗せするイメージです。
ChatGPTクレジット(Plus / Pro / Business / Enterprise / Edu)の消費イメージ
- ローカルタスク(CLI / IDE / Webのローカル実行)
→ GPT-5.2 / GPT-5.2-Codex は1メッセージあたり平均5クレジット前後
- クラウドタスク(Codex Cloudのサンドボックス実行)
→ 1タスクあたり平均25クレジット前後
- コードレビュー(GitHub連携の自動レビュー)
→ 1 PRあたり平均25クレジット前後
クレジット単価自体はプランごとに異なり、Plus / Pro では月額料金に含まれている枠を超えた分だけ追加クレジットを購入する形になります。
APIキー(CIや共有環境向け)
- Codex CLI / SDK / IDE拡張をAPIキーで動かすモード
- GitHubコードレビューやSlackなどのクラウド連携機能は対象外
- GPT-5.2-Codexなどが使うトークン量に応じて、OpenAI APIの料金テーブルで従量課金
- 新しいモデル(GPT-5.2-Codex など)は、ChatGPTプランよりAPI側の提供タイミングが少し遅れる設計
日常の開発作業を中心に使うなら「ChatGPTプラン+クレジット」、CI / CDやバッチ処理など共有環境の自動化はAPIキー、という役割分担で考えると整理しやすくなります。
GPT-5.2-Codexの使い方
GPT-5.2-Codexは、「ターミナル(CLI)」「IDE拡張」「Codex Cloud(ブラウザ/GitHub連携など)」の3パターンで使うのが基本です。ここでは、それぞれでどこまでモデルを指定できるのかだけを簡単に整理します。

Codex CLIから使う場合(ローカルタスク)
Codex CLIでは、手元のリポジトリに対してGPT-5.2-Codexを直接呼び出せます。モデルを明示的に切り替えたいときは、この経路がいちばん分かりやすいです。
- Codex CLIをインストールし、ChatGPTの有料アカウントでサインインする。
- 対象リポジトリのディレクトリで「codex」を起動する。
- 「config.toml」の 「model = "gpt-5.2-codex"」を設定するか、セッション中に 「/model」 コマンドでGPT-5.2-Codexを選ぶ。
こうしておくと、そのリポジトリに対するローカルタスクは基本的にGPT-5.2-Codexで実行されます。
VS Code拡張から使う場合(IDE)
VS Code拡張(Codex拡張)では、エディタ上からGPT-5.2-Codexを呼び出せます。ローカルで動かす範囲であれば、拡張機能側のモデル選択UIからモデルを切り替えられます。
- Codex拡張をインストールし、サイドバーやコマンドパレットからCodexビューを開く。
- モデルのプルダウンから、利用したいモデルとしてGPT-5.2-Codexを選ぶ。
「普段の編集作業は常にGPT-5.2-Codexに任せたい」というケースでは、このモデル選択を一度済ませておくと運用しやすくなります。
Codex Cloud(ブラウザ版・GitHub連携)から使う場合(クラウドタスク)
ブラウザのCodex画面やGitHub連携から動かすタスクは、OpenAI側が用意したCodex Cloud上のサンドボックスで実行されます。
- ブラウザでCodexの画面を開き、リポジトリやブランチを選んでタスクを依頼する。
- GitHubのPull Requestをトリガーに、Codexに自動レビューをさせる。
このクラウドタスクでは、画面上から「このタスクだけGPT-5.2-Codexにする」といった形でモデルを個別指定することはできません。2025年12月時点では、Codex Cloudタスクは gpt-5.1-codex で実行されます。
APIから使う場合(CI/自動化)
CIパイプラインやバッチ処理から直接モデルを呼びたい場合は、OpenAI API経由でGPT-5.2-Codexを指定します。
- APIキーを用意し、OpenAI APIの呼び出しでモデル名にGPT-5.2-Codexを指定する。
- 変更差分やログなどを入力に渡し、提案された修正やレポートを自動で取り込む。
Codex CLIやVS Code拡張での作業をサーバーサイドに移したいときは、このAPIパターンと組み合わせてワークフローを設計していくことになります。
GPT-5.2-Codexのユースケース・活用シナリオ
GPT-5.2-Codexは、単発のコード生成というよりも「長期的なプロジェクト運用」を意識したモデルです。このセクションでは、代表的なユースケースを実務の観点から整理します。

大規模モノレポのリファクタリングと段階的マイグレーション
モノレポ環境での全面的なリファクタリングや、フレームワークのメジャーアップグレードは、人手のみで進めると膨大な工数とリスクが発生します。
GPT-5.2-Codexは、長文コンテキストとコンテキスト圧縮を活かし、この種のタスクを段階的に支援できます。
例えば次のような進め方が考えられます。
- まずCodexに「現状のディレクトリ構造と依存関係の概要」を整理してもらう
- ターゲットとするモジュールやサービス境界を決め、変更範囲を限定したマイグレーション計画を作る
- 各ステップごとに、変更箇所の提案・テストケースの追加・ドキュメント更新までをエージェントに任せる
こうした「スコープを明確にしたうえでの長期タスク」は、GPT-5.2-Codexの得意領域です。
既存機能のテスト強化とレガシーコードの安全な改修
既存プロダクトでは、「ふるまいを変えずにテストだけ増やしたい」「安全にリファクタリングしたい」というニーズが多くあります。
GPT-5.2-Codexは、テスト追加や静的解析ログの活用を通じて、慎重な改修を支援できます。
具体的には次のようなシナリオが想定されます。
- 既存コードとログから、バグが多発している領域を抽出し、テスト候補を生成してもらう
- カバレッジレポートと組み合わせて、優先的にテストを追加すべきファイルを洗い出してもらう
- レガシーコードを段階的にモダンなスタイルへ移行しつつ、変更前後の挙動差分をCodexにチェックさせる
このように、「壊さないことが最優先」の場面でも、GPT-5.2-Codexは有効です。
インシデントレスポンス・脆弱性調査の補助
GPT-5.2-Codexは、防御的サイバーセキュリティ用途も意識して設計されています。ログ解析やCTF形式の演習でその力を発揮しやすく、インシデント対応プロセスの一部を効率化できます。
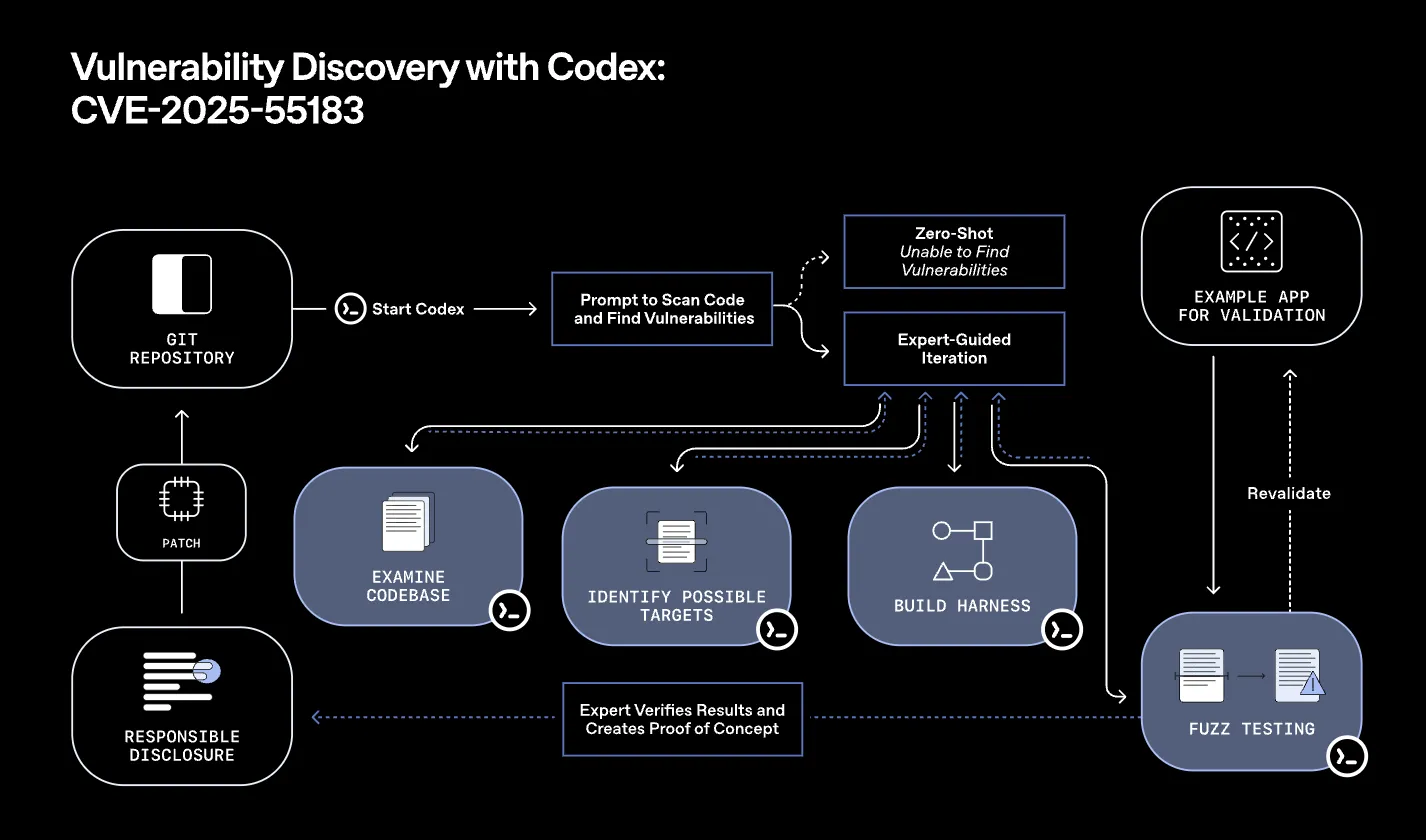
この図は、実際の脆弱性(CVE-2025-55183)を題材に、「Gitリポジトリを起点としてCodexを立ち上げ、コードベースをスキャンし、怪しい箇所を洗い出し、PoCとパッチ作成・検証まで進める」一連の流れを整理したものです。
Codexが候補箇所や仮説を挙げ、人間のセキュリティ担当者がそれを検証・絞り込みながら、最終的なExploitと修正パッチを完成させるという、人間とエージェントの協調プロセスをイメージしやすくするための図解になっています。
実務では例えば次のような使い方が考えられます。
- Webサーバーやアプリケーションのログを読み込ませ、疑わしいリクエストやIPアドレスのパターンを抽出してもらう
- 既知の脆弱性情報と照らし合わせつつ、「このコードパスに潜むリスク」を洗い出してもらう
- インシデント対応レポートのドラフトをGPT-5.2-Codexに書かせ、人間が最終チェックを行う
こうした「本番環境や準本番環境に近いログ・コードを扱う場面」に加えて、より安全な環境でスキルやモデル性能を試したい場合には、次のセクションで触れるCTF形式のサイバー演習での活用も有効です。
ドキュメント整備とAGENTS.md / SKILL.mdの自動生成
エージェント時代の開発では、「人間向けのREADMEだけでなく、エージェント向けのガイド(AGENTS.mdやSKILL.md)が重要になる」と言われています。GPT-5.2-Codexは、こうしたメタドキュメントの整備にも向いています。
たとえば次のようなドキュメント生成が考えられます。
- プロジェクト全体の構造・コマンド・禁止事項などをまとめたAGENTS.mdのドラフトを生成
- Codexや他のエージェントが使う前提のSKILL.md(スキル定義ファイル)のテンプレートを作成
- 既存の設計ドキュメントとソースコードを突き合わせて、古くなっている記述を洗い出す
こうした「エージェントにとっての開発ガイド」を整備することで、GPT-5.2-Codexの性能をより安定して引き出しやすくなります。
サイバー演習・CTFトレーニング環境での利用
CTF(Capture the Flag)のようなサイバー演習では、「解法の解説」や「防御側の視点の整理」にGPT-5.2-Codexが役立ちます。特に、攻撃コードの動作解析や防御手段の設計を学ぶ際に、補助的な役割を担えます。
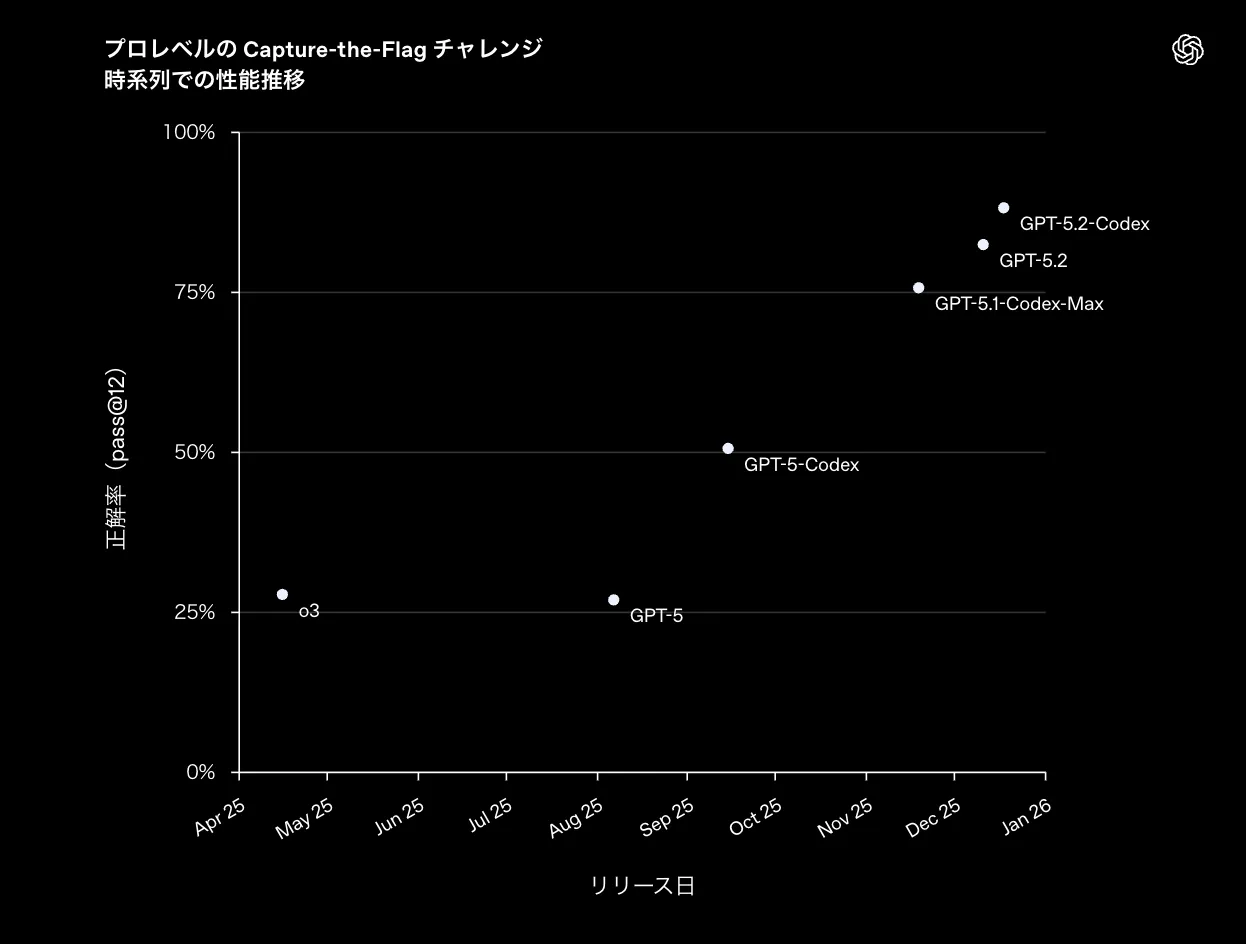
このグラフは、プロレベルのCapture-the-Flagチャレンジに対するCodex系モデルの正解率(pass@2)が、o3/GPT-5/GPT-5-Codex/GPT-5.1-Codex-Max/GPT-5.2/GPT-5.2-Codexと世代を追うごとにどう伸びてきたかを時系列で示したものです。
GPT-5.1-Codex-Max以降で大きなジャンプがあり、GPT-5.2やGPT-5.2-Codexの世代では80〜90%近い水準まで到達していることから、「プロ向けCTFレベルの複雑な課題でも、最新世代のCodexは実務的に使える精度に入りつつある」というトレンドが読み取れます。
CTFトレーニングでの具体的な使い方としては、例えば次のようなものがあります。
- 出題コードやバイナリの動きをCodexに説明させ、攻撃ベクトルや防御案の整理に使う
- 解いた後のWriteup作成をCodexに任せ、チーム内のナレッジ共有を効率化する
- 同じジャンルの問題をまとめて解析させ、「どのパターンにどの防御が効くか」をカタログ化する
ただし、演習内容によっては攻撃的な技術に踏み込むこともあるため、Cyber Trusted Accessの範囲や組織ポリシーのルールを決めたうえで、どこまでCodexに任せるかを設計しておく必要があります。

GPT-5.2-Codexのセキュリティ・コンプライアンス
ここからは、GPT-5.2-Codexを組織導入する際に押さえておくべきセキュリティとコンプライアンス面の論点を整理します。モデル固有の安全対策と、組織側で設計すべきガバナンスの両方を意識することが重要です。

コード・機密情報を扱う際のリスクと対策
Codexを使うと、ソースコードや設定ファイルだけでなく、ログ・シークレット・環境変数なども扱う可能性があります。そのため、次のような基本的な対策を徹底する必要があります。
- 本番環境のシークレットや鍵情報を含むファイルを、そのままCodexに読ませない
- ログやダンプデータから、個人情報や機微情報を適切にマスキングする
- 社外に出せないコードベースについては、オンプレミスやVPC内からのアクセス制御を検討する
GPT-5.2-Codex自体は安全性を考慮して設計されていますが、入力する情報の範囲を絞ることは、組織側の責任として重要です。
モデルの安全対策
OpenAIはGPT-5.2-Codex向けに専用のシステムカードを公開しており、モデルレベル・プロダクトレベルの安全対策が記載されています。主なポイントは次の通りです。
- 有害なタスクやプロンプトインジェクションに対する専用の安全性学習
- エージェントをサンドボックス内で実行し、ネットワークアクセスやファイルシステム権限を制御する仕組み
- 防御的サイバー用途に特化した「Cyber Trusted Access」プログラムによる、より高度な機能への限定的なアクセス
これにより、「一般開発者向けの安全な範囲」と「セキュリティ専門家向けの高度な機能」の両方を共存させる設計になっています。
組織としては、自分たちがどちらの範囲を利用するのかを明確にした上で、申請や契約の要否を検討する必要があります。
組織導入時のガバナンス・ログ設計
GPT-5.2-Codexをチームや企業で使う場合、「誰がどのリポジトリに対して、どのような権限でエージェントを動かせるか」を明確にしておくことが重要です。
検討すべきガバナンス項目の例は次の通りです。
- CodexアカウントとGitリポジトリの紐づけ方(個人アカウントか、サービスアカウントか)
- エージェントが行った操作(ファイル変更・ターミナル実行・ネットワークアクセス)を、どの程度ログとして残すか
- セキュリティチームやプラットフォームチームが、Codexの利用状況を監査できる仕組みの有無
これらを整理しておくことで、「Codexを導入した結果、誰も変更の出どころを追えない」という状況を避けられます。
GPT-5.2-Codexを使いこなすためのワークフロー設計
ここでは、GPT-5.2-Codexの性能を引き出すためのワークフロー設計のポイントを紹介します。モデルの性能だけでなく、「どういう前提情報を渡し、どういう役割を担わせるか」が成果に直結します。

AGENTS.mdやプロジェクトガイドラインとの組み合わせ
エージェントにプロジェクト固有のルールを守らせるには、「エージェント向けのREADME」を整備しておくことが有効です。AGENTS.mdのようなガイドを用意し、Codexから最初に参照してもらう設計にすると、挙動が安定しやすくなります。
盛り込むべき項目の例は次の通りです。
- プロジェクトの目的と主要なコンポーネントの役割
- コーディング規約やディレクトリ構造の約束事
- テスト・ビルド・デプロイに使う代表的なコマンド
- やってはいけない操作(本番環境の設定変更など)
こうした情報を整理しておくことで、GPT-5.2-Codexに「このリポジトリでの常識」を共有しやすくなります。
PR・テスト・デプロイフローへの組み込み
GPT-5.2-Codexを単発のチャットツールとして使うのではなく、既存の開発フローに組み込むと、効果を定量化しやすくなります。
例えば次のようなフローが考えられます。
- 開発者がブランチを切り、ざっくりとした変更方針だけを記述
- GPT-5.2-Codexに対して、「このチケットを完了させるためのステップ」と「必要なテスト」を洗い出してもらう
- 実装の一部をCodexに任せ、PR作成時に再度レビューを依頼する
- CI上で追加テストや静的解析を走らせ、Codexが提案した変更の妥当性を確認する
このように、「チケット〜PR〜マージ」の一連の流れの中で、ところどころをGPT-5.2-Codexに任せることで、開発者は判断とレビューに集中できるようになります。
プロンプトテンプレート・スキル共有のベストプラクティス
GPT-5.2-Codexは、同じようなタスクを何度も繰り返す場面で特に効果を発揮します。そのため、「よく使う依頼」をテンプレート化し、チーム内で共有しておくと効率が上がります。
たとえば次のようなスキルやテンプレートが考えられます。
- APIエンドポイント追加時に、ルーティング・バリデーション・テスト・ドキュメントまで一括で提案してもらうスキル
- 既存コードのセキュリティレビューを行い、改善すべきポイントを一覧化するスキル
- ログファイルからインシデントの兆候を抽出し、報告テンプレートに落とし込むスキル
こうしたテンプレートやスキルは、リポジトリ内で共有したり、組織内のポータルでカタログ化したりすることで、チーム全体の生産性向上につながります。
GPT-5.2-Codexと他モデルの比較・使い分け指針
最後に、GPT-5.2-Codexを他のモデルとどう使い分けるかを整理します。ここでは、OpenAI内部の他モデルや、Claude Code / Gemini / Copilotなど、代表的な選択肢との比較観点をまとめます。

GPT-5.2 / GPT-5.1-Codex-Maxとの比較
OpenAI内部の比較としては、次のような切り分けがイメージしやすいです。
-
GPT-5.2(汎用モデル)
- コーディング以外も含めた幅広いタスクに対応
- ChatGPT上での対話や、一般的なAPI利用に向く
-
GPT-5.1-Codex-Max
- 旧世代のエージェント型コーディングモデル
- 依然として高性能だが、長期タスクやサイバー用途ではGPT-5.2-Codexに分がある
-
GPT-5.2-Codex
- Codex内での長時間コーディング・防御的サイバータスクに特化
- コンテキスト圧縮やツール連携が前提のアーキテクチャ
単発の設計相談や、ビジネス文章の作成なども含めた汎用利用にはGPT-5.2が向きます。一方で「リポジトリを丸ごと渡して、エージェントに手を動かしてもらう」ような場面ではGPT-5.2-Codexが第一候補になります。
Claude Code / Anthropic Subagentsとの比較
Claude CodeやAnthropicのSubagentsは、VS CodeなどのIDE統合やサブエージェント機能の豊富さで評価されています。
これらとGPT-5.2-Codexを比較する際の観点は次の通りです。
- IDE連携やCLIの使い勝手
- 長時間のターミナル操作を含むタスクの成功率
- マルチモーダル(画像・PDFなど)を含むコード理解の精度
- セキュリティポリシーやオンプレミス連携の選択肢
現時点では、「Claude CodeはIDE中心」「GPT-5.2-CodexはCodexという専用エージェント基盤中心」という色合いがあります。
実務では、両方を試した上で、チームの得意なツールチェーンや既存のインフラに合う方を選ぶのが現実的です。
Gemini 3 + Gemini CLI / Antigravity / Copilotとの比較
GoogleのGemini 3(特にGemini 3 Flash / Pro)やGemini CLI、Antigravity、GitHub Copilotは、開発者向けの別系統のエコシステムです。GPT-5.2-Codexと比べる際の主な観点は次のとおりです。
- 価格帯($/M tokens)とレイテンシ
- Google Cloud / GitHub / Azureなど、既存クラウドとの統合度
- RAGや社内検索との連携のしやすさ
- IDEやCI/CDとの接続で用意されているテンプレートやベストプラクティス
たとえば、「Google Cloud中心のスタックで、Gemini 3 Flashをすでに使っている」組織は、まずGemini系のツールを試す方が自然でしょう。
一方で、「すでにChatGPT Enterpriseを導入しており、OpenAI APIが社内標準になりつつある」環境では、GPT-5.2-Codexを中心に据える方が設計コストを抑えやすくなります。
複数モデル併用時の現実的なパターン
実務では、単一モデルにすべてを寄せるのではなく、「タスクごとにモデルを使い分ける」構成も現実的です。たとえば次のようなパターンがあります。
-
設計検討や仕様調整
→ GPT-5.2やClaudeなど、対話に強い汎用モデル
-
実装やリファクタリング、テスト追加
→ GPT-5.2-CodexやClaude Codeなど、エージェント型コーディングモデル
-
ログ解析やレポート生成
→ Gemini 3 Flashや社内RAG基盤など、データ連携に強いモデル
このように、「役割ごとに得意なモデルを組み合わせる」前提でワークフローを設計すると、ベンダーロックインを避けながら性能を引き出しやすくなります。

コーディングAIの導入ノウハウを業務自動化にも展開するなら
GPT-5.2-Codexのようなエージェント型モデルで開発プロセスが変わり始めた今、同じ発想を業務プロセスにも適用する企業が増えています。データ集計・承認フロー・レポート生成など、ルールベースの定型業務はAIエージェントが代行できる段階に来ています。
AI総合研究所のAI業務自動化ガイドでは、どの業務領域から着手すべきか、段階的な導入ステップと効果測定の考え方を整理しています。コーディングAIで得たノウハウを組織全体に広げる参考にしてください。
コーディングAIの次は業務プロセスのAI化

開発効率化から業務自動化への拡張ステップ
GPT-5.2-Codexのようなコーディングモデルで開発が変わったように、業務プロセスもAIで自動化できます。どこから着手すべきかを整理した無料ガイドです。
まとめ
GPT-5.2-Codexは、GPT-5.2をベースにしたエージェント型のコーディングモデルで、モノレポのリファクタリングや段階的マイグレーション、防御的サイバー用途など、時間のかかる開発タスクを長期コンテキストで支援します。有料版ChatGPTアカウントからCodexのCLI・Web・IDE拡張などを通じて利用でき、SWE-Bench ProやTerminal-Bench 2.0でも旧世代モデルを上回る実務寄りの性能が確認されています。一方で、コードやログなど機密性の高い情報を扱うため、AGENTS.mdによる前提共有や権限設計、操作ログの整備といったガバナンスを先に固め、小さなPoCからPRレビューやテスト自動化など限定的な範囲に組み込んでいくのが現実的な導入ステップになります。
なお、2026年3月5日にリリースされたGPT-5.4では、GPT-5.3-Codexを経てCodex系モデルで培われたコーディング能力が汎用フラグシップモデルに統合されています。詳しくはGPT-5.4とは?使い方や料金、GPT-5.2との違いを徹底解説をご覧ください。







