この記事のポイント
 月500ページまでの無料枠で試せるため、OCR導入検証はDocument Intelligence Studioから始めるのが最も効率的
月500ページまでの無料枠で試せるため、OCR導入検証はDocument Intelligence Studioから始めるのが最も効率的- 請求書・領収書・契約書なら事前構築済みモデルで即時対応可能。独自帳票にはカスタムニューラルモデルが有効
- Amazon TextractやGoogle Document AIとの比較ではカスタムモデルの柔軟性とAzure連携の深さが本サービスの強み
- Power AutomateやLogic Appsと組み合わせれば、ノーコードでOCR処理を業務パイプラインに組み込める
- Content Understanding(2025年11月GA)でテキスト・画像・音声・動画のマルチモーダル処理にも拡張可能

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure AI Document Intelligence(旧Azure Form Recognizer)は、Microsoftが提供するクラウドベースのAI文書処理サービスです。
OCRと機械学習を組み合わせ、請求書・領収書・契約書などの紙帳票やPDFから、テキスト・表・キーバリューペアを自動で抽出します。
2024年11月にAPI v4.0がGA(一般提供)となり、バッチ処理や検索可能PDFなどの実務向け機能が大幅に強化されました。
さらに2025年11月には後継サービスContent Understandingが登場し、テキストに加えて画像・音声・動画のマルチモーダル処理にも対応しています。
本記事では、Document Intelligenceの主要機能からDocument Intelligence Studioでの始め方、料金体系、Amazon TextractやGoogle Document AIとの比較、導入時の注意点までを2026年4月時点の情報で解説します。
目次
Azure AI Document Intelligenceとは?
Azure AI Document Intelligenceが求められる背景
Azure AI Document Intelligenceの主な機能
Content Understanding(次世代のマルチモーダル処理)
Azure AI Document Intelligenceの使い方
Document Intelligence Studioでの試用
Azure AI Document Intelligenceと他OCRサービスの比較
Azure AI Document Intelligenceの活用シーン
Azure AI Document Intelligenceの注意点と制限事項
Azure AI Document Intelligenceとは?

Azure AI Document Intelligenceは、Microsoft Azureが提供するAI文書処理サービスです。
機械学習ベースのOCR(光学式文字認識)とドキュメント理解技術を組み合わせ、紙帳票やPDF、画像ファイルからテキスト・テーブル・キーバリューペアなどの構造化データを自動抽出します。
このサービスはAzure AI Foundry(旧Azure AI Studio)のToolsとして提供されており、Azure AI servicesの一部として位置づけられています。REST APIやPython・C#・Java・JavaScriptのSDKを通じてアプリケーションに組み込めるほか、Document Intelligence StudioというGUIツールでコードを書かずに試すこともできます。
Form Recognizerからの名称変更
Azure AI Document Intelligenceは、もともとAzure Form Recognizerという名称で2019年から提供されていたサービスです。2023年7月に現在の名称へ変更されました。
名称変更の背景には、サービスの対応範囲が「フォーム認識」を超えて拡大したことがあります。
当初は定型フォームからのデータ抽出が中心でしたが、契約書・請求書・ID・小切手・給与明細など多岐にわたる文書タイプに事前構築済みモデルが追加され、さらにカスタムモデルのトレーニング機能やマルチモーダル処理への拡張が進んだことで、より実態に即した「ドキュメントインテリジェンス」という名称に変わっています。
Azure AI Document Intelligenceが求められる背景

Azure AI Document Intelligenceの導入を検討する企業が増えている背景には、紙帳票のデジタル化が業務効率のボトルネックになっているという現実があります。
紙帳票の手作業がもたらすコスト
経理部門で毎月届く数百枚の請求書を1枚ずつ目視で確認し、金額や取引先名を会計システムへ手入力している——こうした業務は多くの企業でいまだに残っています。人手による入力は1件あたり数分かかるうえ、転記ミスのリスクも避けられません。
金融機関では融資審査のために本人確認書類や収入証明書を大量に処理する必要があり、保険会社では保険金請求書の項目を1件ずつ確認しています。これらの作業を人海戦術で処理し続けることは、人件費とスピードの両面で限界を迎えつつあります。
従来OCRの限界とAI-OCRの登場
従来型のOCR(光学式文字認識)は、決まったレイアウトの文書からテキストを読み取る用途では有効でした。しかし、レイアウトが異なる複数種類の帳票が混在する場合や、手書き文字・傾いたスキャン画像が含まれる場合には精度が大きく低下するという課題がありました。
AI-OCRは、この課題に対して機械学習モデルによるパターン認識で対応します。Document Intelligenceの場合、テキスト抽出だけでなく、テーブル構造の認識、キーバリューペアの抽出、文書分類までを1つのサービスで処理できる点が従来OCRとの大きな違いです。
営業担当が毎日30分以上かけて受注伝票をシステムへ転記しているなら、それはDocument Intelligenceの事前構築済みモデルで自動化できる可能性が高い領域です。まずは無料枠で自社の帳票を試し、精度を確認するところから始めることをおすすめします。

Azure AI Document Intelligenceの主な機能

Document Intelligenceが提供するモデルは、大きく3つのカテゴリに分かれます。
ここでは各カテゴリの特徴と使い分けを整理します。
ドキュメント分析モデル(Read・Layout)

ドキュメント分析モデルは、文書の基本的なテキスト抽出と構造解析を行う汎用モデルです。
以下の表で、ReadモデルとLayoutモデルの違いを整理します。
| モデル | 抽出対象 | 主な用途 |
|---|---|---|
| Read | テキスト、言語検出、手書き文字 | 文書のデジタル化、翻訳前の手書きメモ処理 |
| Layout | テキスト、テーブル、選択マーク、文書構造(セクション・見出し) | 財務レポートの構造分析、文書のインデックス化 |
Readモデルはテキスト抽出に特化しており、コスト効率を重視する場面に向いています。一方、Layoutモデルはテーブルや見出し構造まで認識するため、表を含む帳票やレポートの処理に適しています。
v4.0では、Layoutモデルに図形検出機能が追加され、ドキュメント内の図形を画像ファイルとして取得できるようになりました。また、マークダウン形式での出力にも対応しているため、生成AIとの連携がより容易になっています。
- 対応ファイル形式
PDF、JPEG/JPG、PNG、BMP、TIFF、HEIFに加え、v4.0ではMicrosoft Officeファイル(DOCX、PPTX、XLS)にも対応(Read・Layoutモデルのみ)
事前構築済みモデル(Prebuilt)
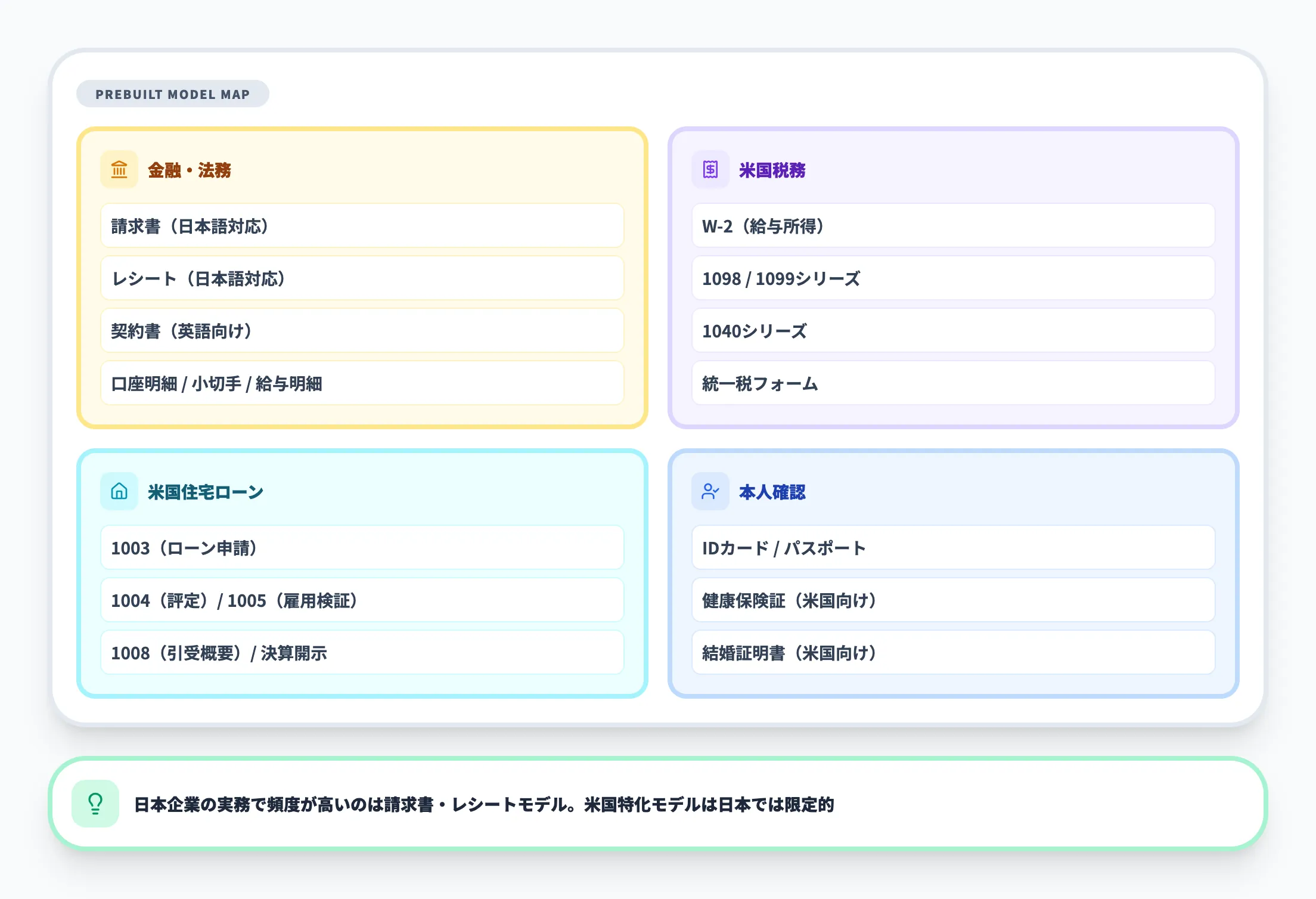
事前構築済みモデルは、特定の文書タイプ向けにMicrosoftがトレーニング済みのモデルです。自社でモデルをトレーニングする必要がなく、APIにドキュメントを送信するだけで構造化データを取得できます。
v4.0時点で利用可能な主な事前構築済みモデルを以下に示します。
| カテゴリ | 対応文書 |
|---|---|
| 金融・法務 | 請求書、レシート、契約書、口座取引明細書、小切手、クレジットカード、給与明細 |
| 米国税務 | W-2、1098シリーズ、1099シリーズ、1040シリーズ、統一税フォーム |
| 米国住宅ローン | 1003(ローン申請)、1004(評定)、1005(雇用検証)、1008(引受概要)、決算開示 |
| 本人確認 | IDカード・パスポート、健康保険証(米国向け)、結婚証明書(米国向け) |
この表からわかるように、金融・税務・住宅ローン関連のモデルが特に充実しています。日本の企業が実務で使う頻度が高いのは請求書モデルとレシートモデルで、日本語を含む多言語に対応しています。
請求書モデルは取引先名、請求金額、支払期日、明細行などのフィールドを自動で識別・抽出します。2024年2月にはアラビア語やロシア語など10言語以上のロケールが追加されたほか、税項目のフィールド対応も拡大しています。
なお、米国税務や住宅ローン関連のモデルは米国固有の書式に特化しているため、日本企業が直接利用する場面は限られます。日本固有の帳票(源泉徴収票、年末調整書類など)を処理する場合は、後述のカスタムモデルを活用します。
カスタムモデル

事前構築済みモデルでカバーされない独自帳票に対応するには、カスタムモデルをトレーニングします。Document Intelligenceでは以下の4種類のカスタムモデルを提供しています。
-
カスタムテンプレートモデル
レイアウトが固定された定型帳票に向いています。少数のサンプル(5件程度〜)で高精度の抽出が可能で、トレーニング時間も短いのが特徴です。自社専用の注文書や検査報告書など、フォーマットが決まっている帳票に適しています。
-
カスタムニューラルモデル
レイアウトが多様な帳票に対応できるディープラーニングベースのモデルです。
構造化・半構造化・非構造化のいずれの文書にも対応し、v4.0では署名検出機能も追加されました。トレーニングには多くのサンプルと時間を要しますが、汎用性の高さが強みです。
-
カスタム分類モデル
抽出の前段階として、ドキュメントの種類を判別する分類モデルです。たとえば、1つのPDFに請求書・納品書・発注書が混在している場合に、ページ単位で文書タイプを自動判別します。
v4.0では増分トレーニング(既存モデルにサンプルを追加して再トレーニング)に対応しました。
-
作成済みモデル(Composed)
複数のカスタムモデルを1つにまとめて、送信されたドキュメントの種類に応じて自動的に適切なモデルで処理するモデルです。
分類モデルと組み合わせることで、多種類の帳票を1つのエンドポイントで処理できます。
自社帳票のレイアウトが概ね固定ならテンプレートモデル、フォーマットにバリエーションがあるならニューラルモデルを選ぶのが基本方針です。
どちらを選ぶか迷う場合は、まずテンプレートモデルで精度を検証し、不十分ならニューラルモデルへ切り替える段階的なアプローチが実務的です。
アドオン機能
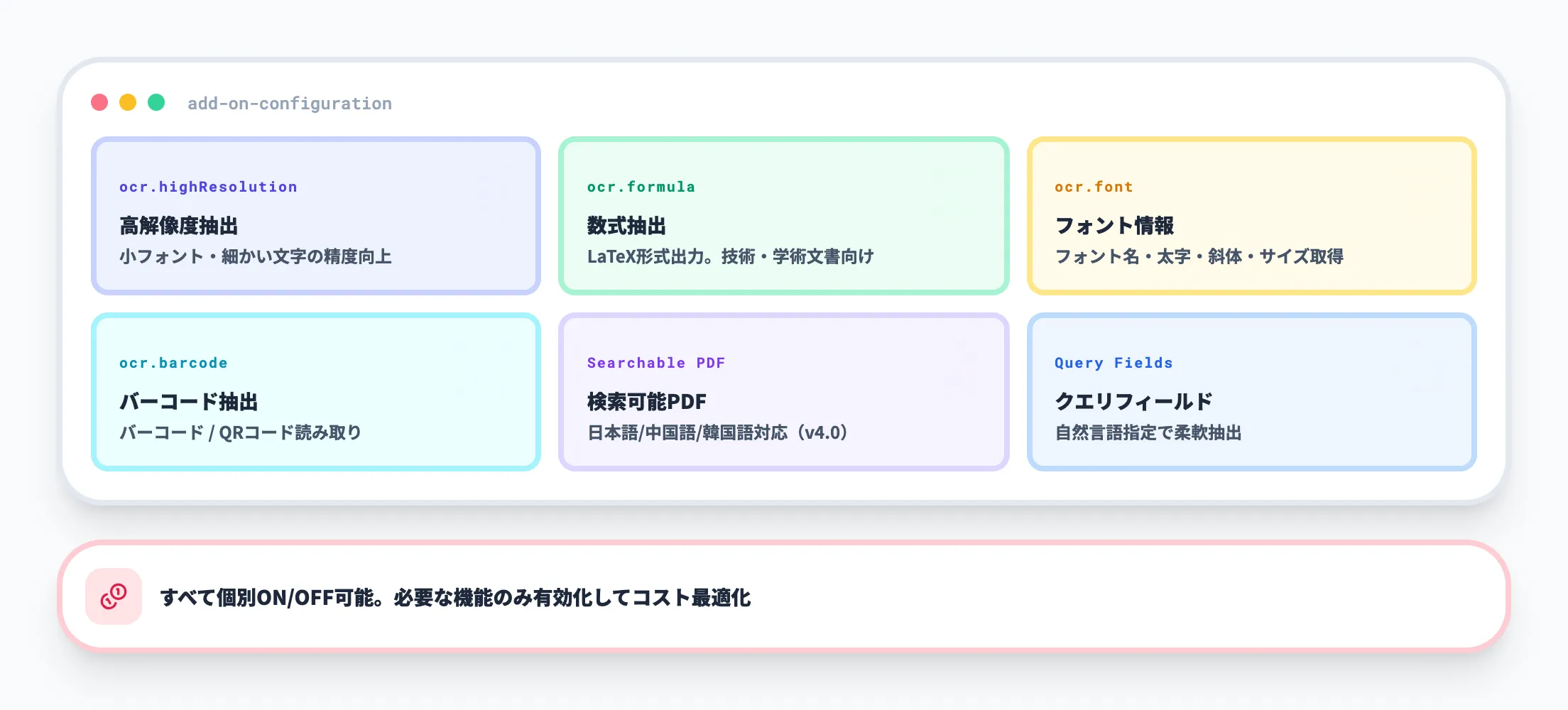
Document Intelligenceには、ドキュメント抽出を強化するオプション機能が用意されています。
-
高解像度抽出(ocr.highResolution)
小さなフォントや細かい文字が含まれるドキュメントで抽出精度を向上させます。
-
数式抽出(ocr.formula)
ドキュメント内の数式をLaTeX形式で抽出します。技術文書や学術論文の処理に有効です。
-
フォント情報抽出(ocr.font)
テキストのフォント名、スタイル(太字・斜体)、サイズなどの書式情報を取得します。
-
バーコード抽出(ocr.barcode)
ドキュメント内のバーコードやQRコードを読み取ります。
-
検索可能PDF(Searchable PDF)
画像ベースのPDFにOCR結果を埋め込み、テキスト検索可能なPDFとして出力します。v4.0で日本語・中国語・韓国語の出力にも対応しました。
-
クエリフィールド(Query Fields)
事前定義されたフィールド以外の情報を、自然言語で指定して抽出できる機能です。カスタムモデルを作成せずに柔軟なデータ抽出が可能です。
これらのアドオンは必要に応じて個別に有効化できるため、コストを抑えながら必要な機能だけを使い分けることができます。
Content Understanding(次世代のマルチモーダル処理)

2025年11月、Document Intelligenceの進化版としてContent UnderstandingのGAバージョン(API 2025-11-01)がリリースされました。
Content Understandingは、テキストだけでなく画像・音声・動画のマルチモーダルコンテンツを統合的に処理できるサービスです。
Azure AI Foundryとの統合がさらに深まり、複数のコンテンツタイプを1つのAPIフレームワークで扱えるようになりました。
現時点でDocument Intelligenceが必要な文書処理案件にはDocument Intelligenceをそのまま使い、将来的にマルチモーダルな処理が必要になった段階でContent Understandingへの移行を検討する、という段階的なアプローチが合理的です。
Azure AI Document Intelligenceの使い方
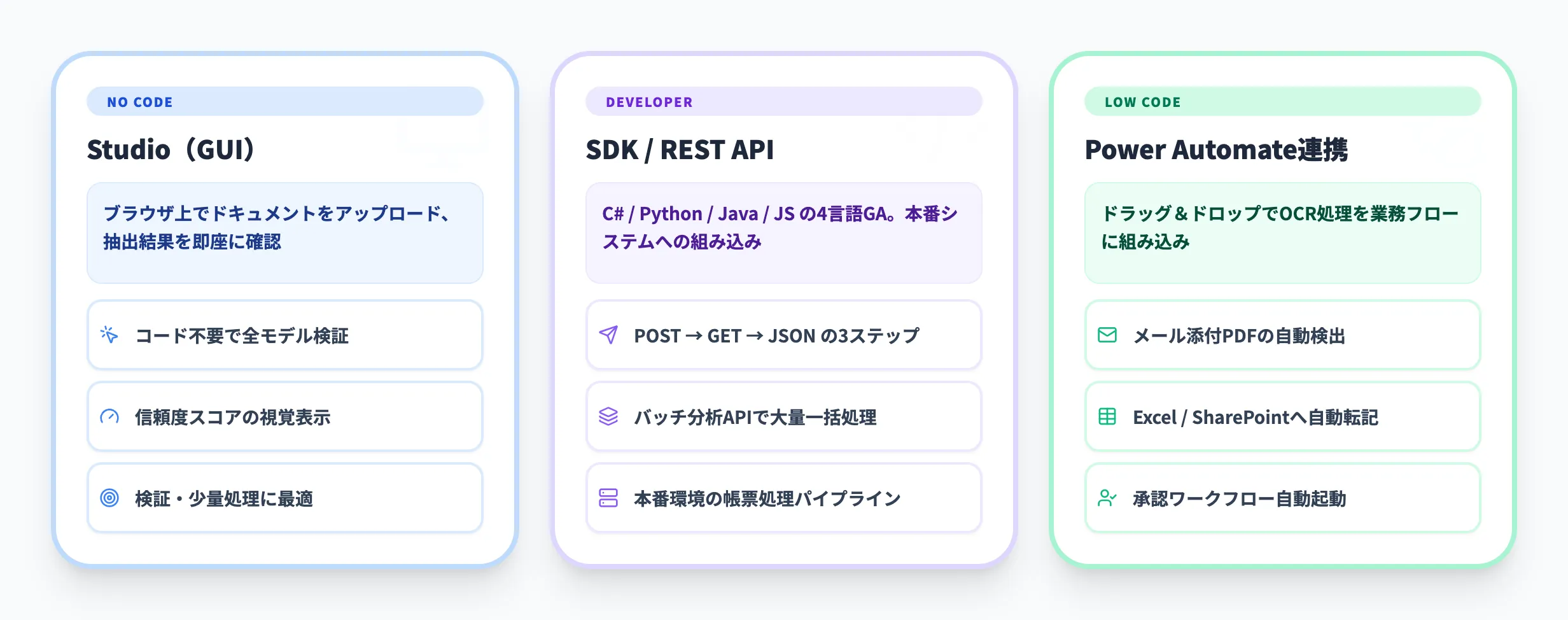
Document Intelligenceを実際に使い始めるには、いくつかの方法があります。ここでは代表的な3つのアプローチを解説します。
Document Intelligence Studioでの試用

Document Intelligence Studioは、ブラウザ上でDocument Intelligenceの全機能を試せるGUIツールです。コードを書かずにドキュメントをアップロードし、各モデルの抽出結果を視覚的に確認できます。
ここでは手書き文字の読み取り(Readモデル)を例に、リソース作成からStudioでの分析実行までを一通り紹介します。
Step 1 Azureポータルにサインイン
Azure Portalにアクセスし、Azureアカウントでサインインします。
Azureポータルのトップ画面
Step 2 Document Intelligenceリソースを作成
Azureポータルの「リソースの作成」から「azure ai document intelligence」で検索し、「Document Intelligence」を選択します。
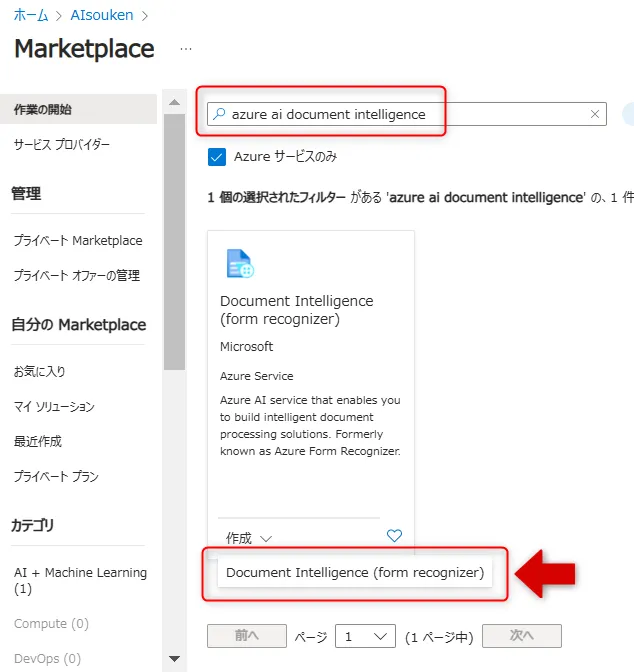
マーケットプレイスでDocument Intelligenceを選択
「基本」タブでサブスクリプション、リソースグループ、リージョン、価格レベル(F0の無料枠またはS0の有料枠)を設定し、「次へ」をクリックします。
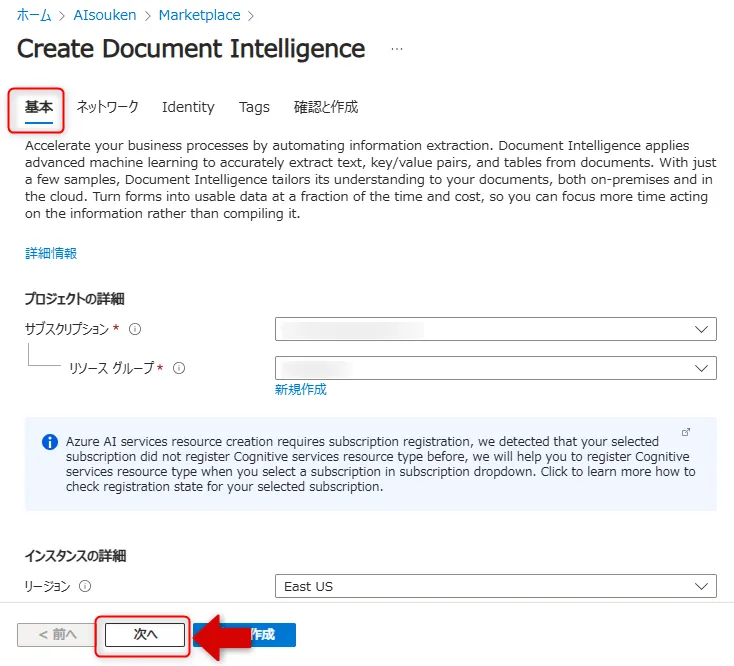
基本タブの設定画面
「ネットワーク」タブでネットワークアクセスの設定を確認し、「次へ」をクリックします。
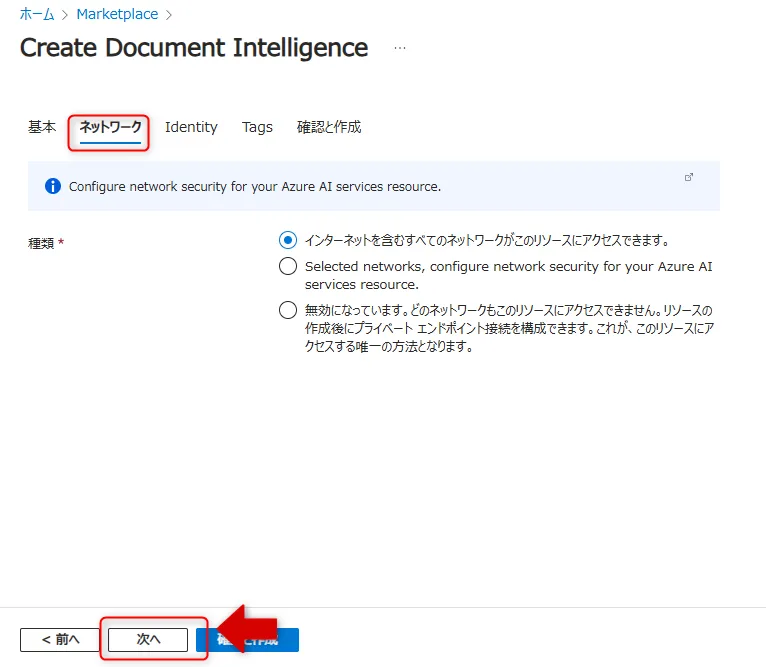
ネットワークタブの設定画面
「Identity」タブでマネージドIDの設定を確認し、「確認と作成」をクリックします。
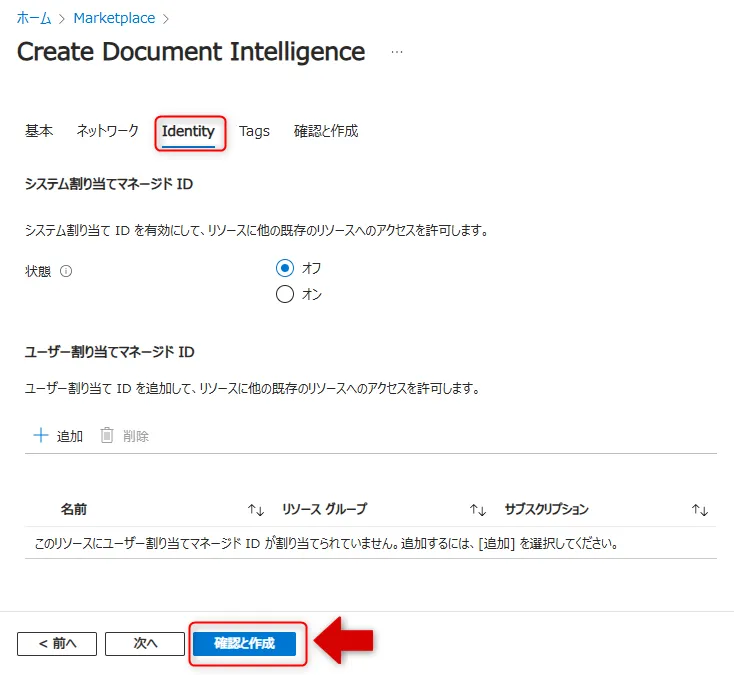
Identityタブの設定画面
設定内容を確認し、「作成」をクリックしてリソースをデプロイします。
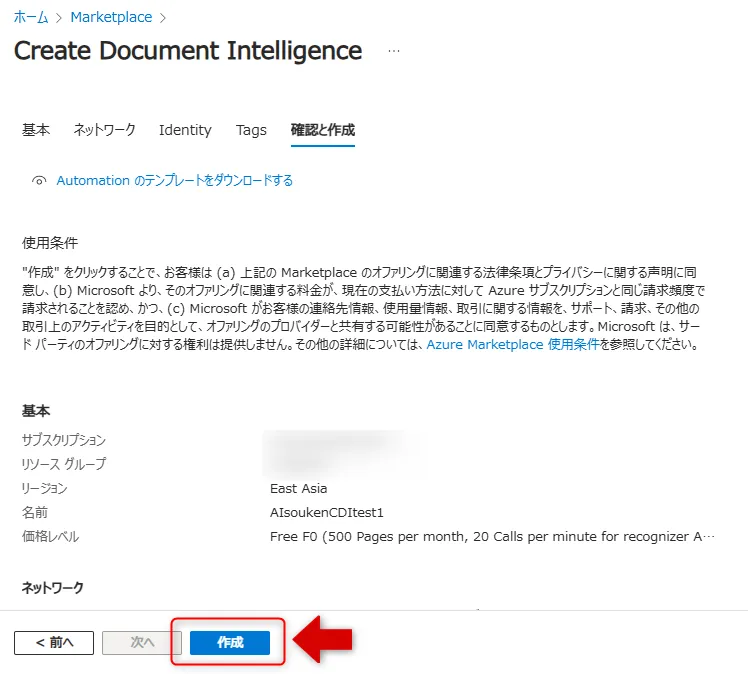
確認と作成タブの画面
デプロイが完了したら「リソースに移動」をクリックします。

デプロイ完了画面
Step 3 Document Intelligence Studioに接続
作成したリソースの概要画面から「Go to Document Intelligence Studio」をクリックし、Document Intelligence Studioを開きます。
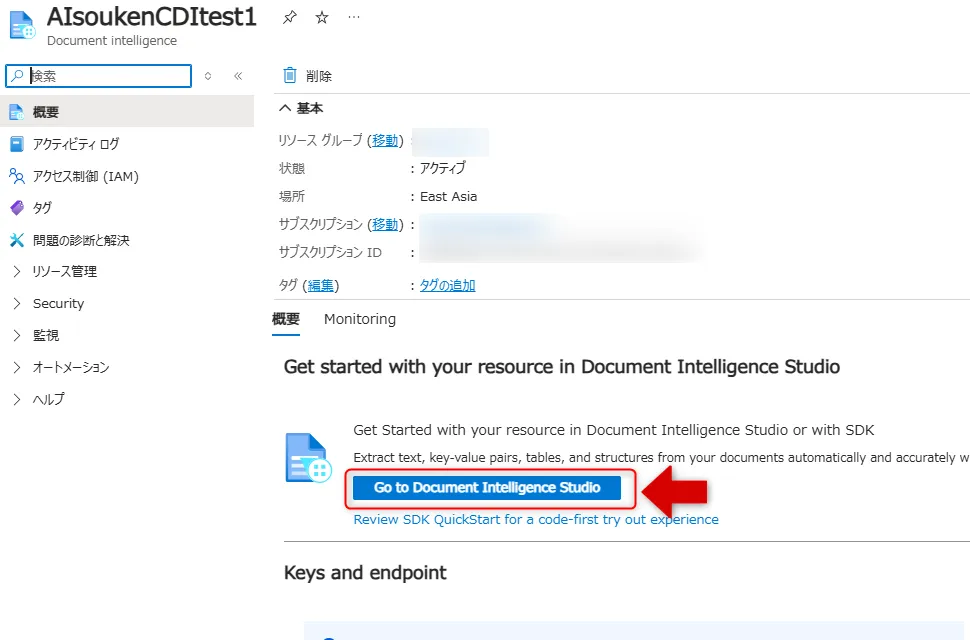
リソース画面からStudioへ移動
Studioのトップ画面が表示されたら、使いたいモデルを選択します。今回は手書き文字を読み取るため「Read」をクリックします。
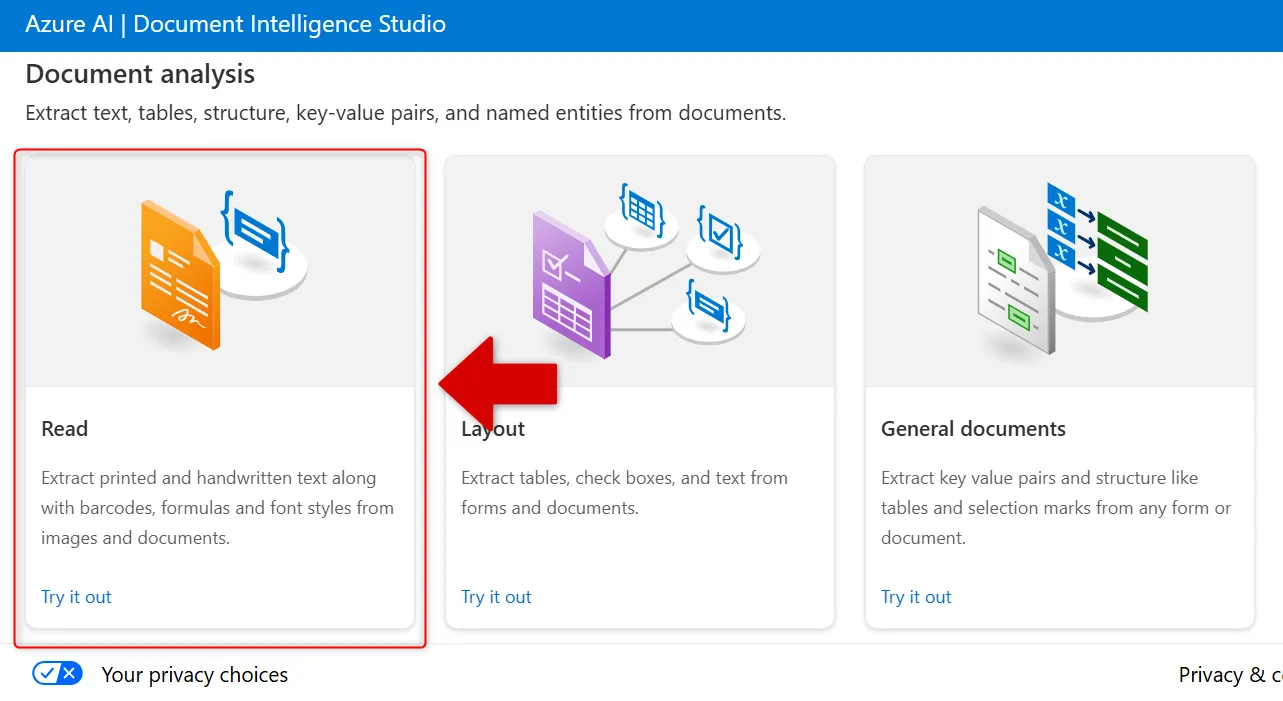
Document Intelligence StudioでReadモデルを選択
初期設定画面で、先ほど作成したAzureリソースを紐付けます。サブスクリプション・リソースグループ・リソース名を選択し、「Continue」をクリックします。
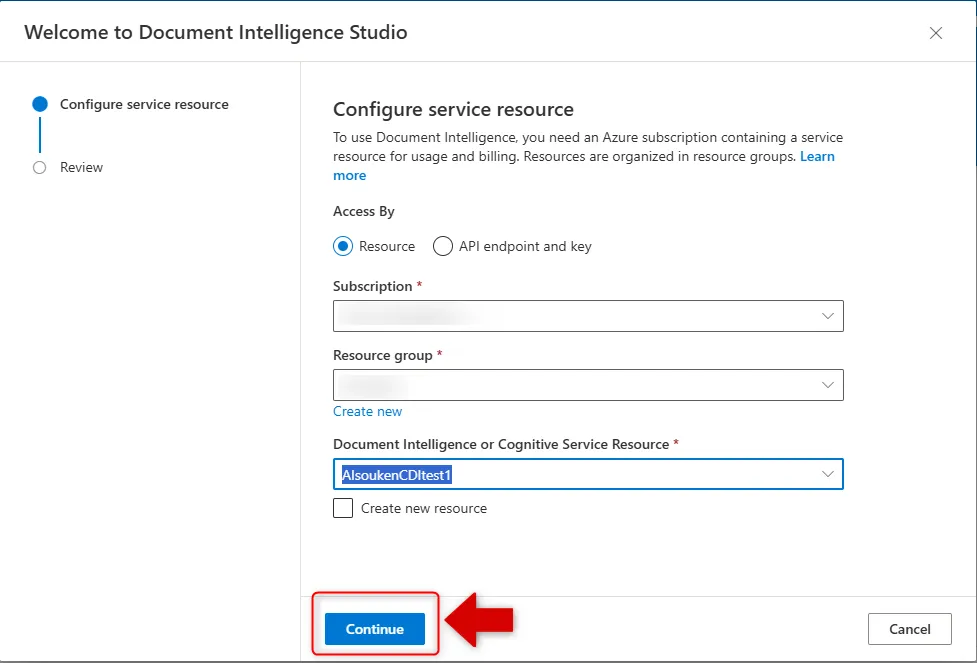
Studioの初期設定でAzureリソースを接続
Step 4 ドキュメントをアップロードして分析を実行
Read画面が表示されたら、「Drag & Drop file」エリアに解析したいファイルをドラッグ&ドロップします。
Readモデルのアップロード画面
ファイルが読み込まれたら「Run analysis」をクリックして分析を実行します。
ファイル読み込み後、Run analysisで分析を開始
分析が完了すると、抽出結果がJSON形式で表示されます。フィールドごとの信頼度スコアも確認でき、抽出精度を定量的に把握できます。
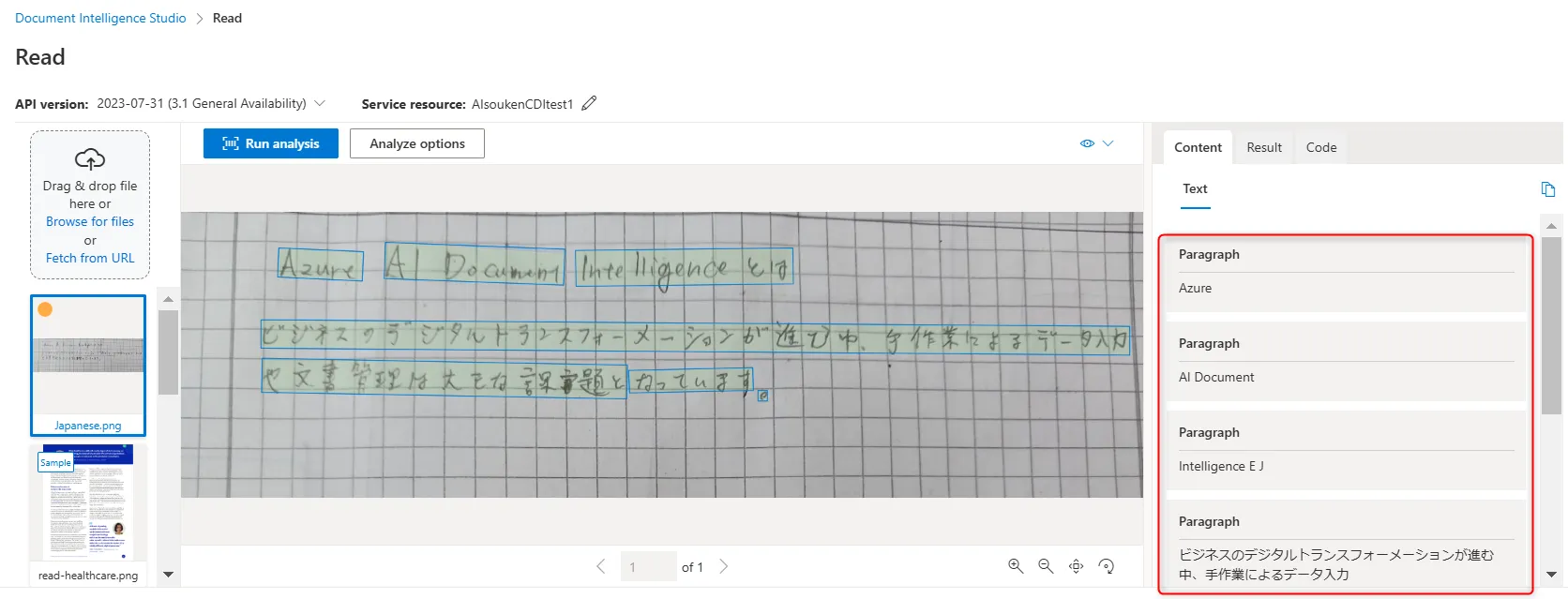
解析結果の出力画面
Studioは検証や少量処理に最適ですが、本番環境では後述のSDKやAPIを使った組み込みが必要です。
SDK・REST APIで組み込む
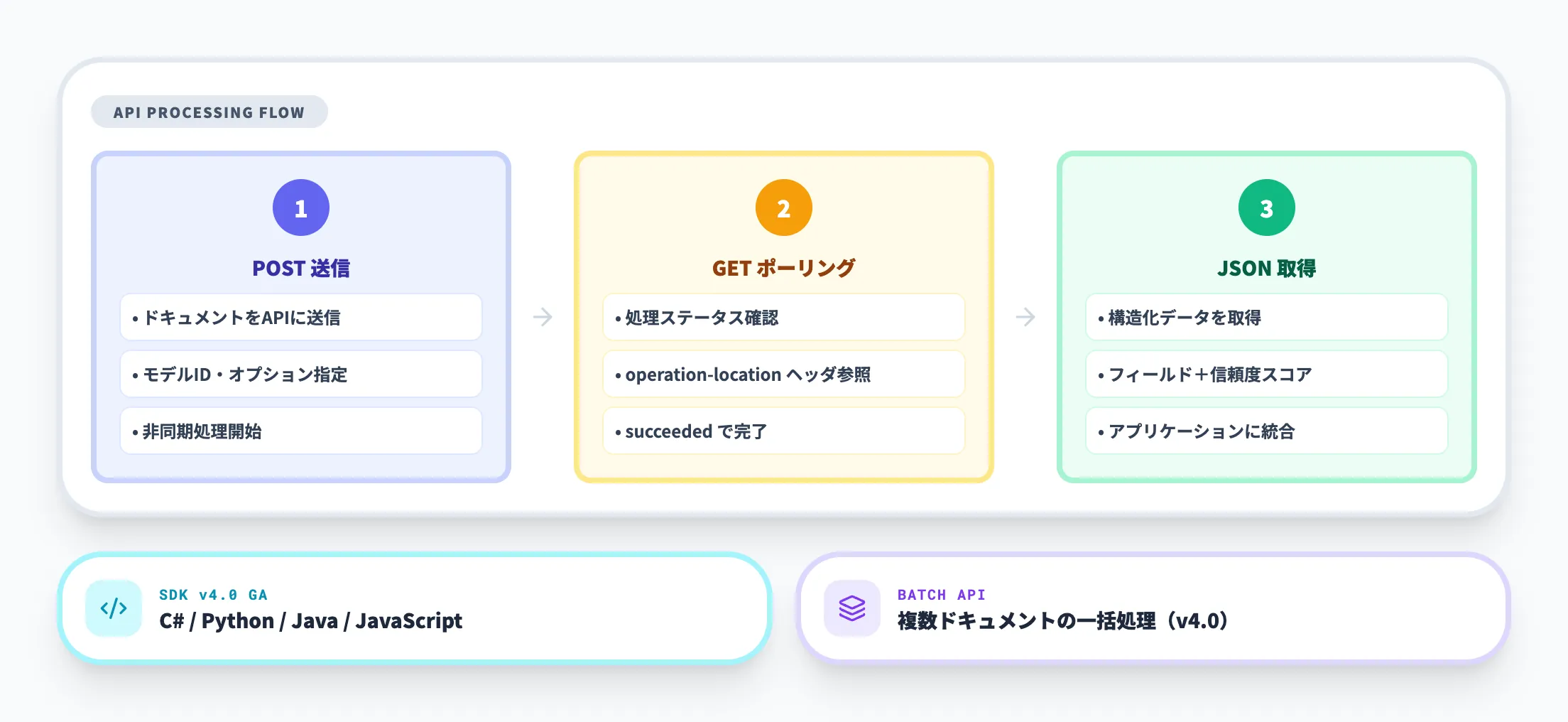
本番システムにDocument Intelligenceを組み込む場合は、SDKまたはREST APIを使用します。v4.0のSDKは以下の4言語でGA版が提供されています。
- C#(.NET)
- Python
- Java
- JavaScript
基本的な処理の流れは、ドキュメントをAPIに送信(POST)→ 処理完了を確認(GET)→ JSON形式の結果を取得、という3ステップです。v4.0ではバッチ分析APIが追加され、複数ドキュメントを一括で処理できるようになりました。大量の帳票を定期的に処理する業務では、バッチAPIの活用がスループットの改善に直結します。
Power AutomateやLogic Appsとの連携

コードを書かずにDocument Intelligenceを業務フローに組み込みたい場合は、Azure Logic AppsやMicrosoft Power Automateとの連携が有効です。
たとえば、以下のような自動化フローを構築できます。
- メールに添付された請求書PDFを自動検出
- Document Intelligenceで金額・取引先・日付を抽出
- 抽出データをExcelやSharePointリストに自動転記
- 金額が一定額を超える場合は承認ワークフローを起動
こうした連携は、Power AutomateのDocument Intelligenceコネクタを使えばドラッグ&ドロップで設定できます。エンジニアのリソースが限られる中小企業や、特定部門での小規模な自動化から始めたい場合に適した方法です。

Azure AI Document Intelligenceと他OCRサービスの比較

クラウドOCRサービスを選定する際、Azure AI Document Intelligenceの主な比較対象となるのがAmazon Textract(AWS)とGoogle Document AI(Google Cloud)です。以下の表で3サービスの特性を比較します。
| 比較項目 | Azure AI Document Intelligence | Amazon Textract | Google Document AI |
|---|---|---|---|
| 事前構築済みモデルの種類 | 30種類以上(請求書、レシート、ID、税務、住宅ローンなど) | 少数(Expense、Lending、ID) | プロセッサ形式で複数提供 |
| カスタムモデル | テンプレート・ニューラル・分類・作成済みの4種類 | Queriesベースのadapter学習に対応(custom extraction/classificationとは範囲が異なる) | カスタムドキュメント抽出に対応 |
| 日本語対応 | Read・Layout・主要Prebuiltモデルで対応 | テキスト抽出は対応、Expense等は英語中心 | 対応あり |
| GUI分析ツール | Document Intelligence Studio | AWSコンソール内のデモ | Document AI Workbench |
| ファイル直接アップロード | 対応 | 対応 | Cloud Storageバケット経由(一部直接アップロード可) |
| リージョン制約 | 60以上のAzureリージョン | AWSリージョン依存 | us/euマルチリージョン中心。限定的なsingle-regionあり(日本リージョンは非対応) |
| コンテナ(オフライン)対応 | Read・Layoutコンテナ提供(v4.0) | 非対応 | 非対応 |
この比較でポイントになるのは、カスタムモデルの柔軟性とリージョンの選択肢の2点です。
Amazon Textract
Queriesベースのadapter学習に対応しており、学習データを使った訓練と推論時の適用が可能です。
ただし、Document Intelligenceのようにテンプレート・ニューラル・分類・作成済みといった複数のカスタムモデル種別を使い分ける構成とは範囲が異なります。自社独自の帳票フォーマットが多岐にわたる場合、Document Intelligenceのカスタムモデル群が選択肢として広い構成です。
Google Document AI
us/euのマルチリージョンが中心で、一部のsingle-region(asia-south1、asia-southeast1など)にも限定対応していますが、日本リージョンは提供されていません。
データの保管場所に制約がある日本企業にとってはハードルになりえます。Document Intelligenceは日本(East Japan)リージョンを含む60以上のリージョンで利用できるため、データ主権の観点でも選択肢に入りやすい構成です。
すでにAWSを主要クラウドとして使っている場合はTextractとの連携コストが低く、Azure環境を中心に運用している企業であればDocument Intelligenceが自然な選択肢になります。
クラウド基盤とは別にOCR精度やカスタマイズ性で選ぶなら、Document Intelligenceのカスタムモデル群が現時点ではカスタマイズの幅が広い構成です。
【関連記事】
おすすめのAI-OCRサービスを徹底比較!選び方・利用時の注意点も紹介
Azure AI Document Intelligenceの活用シーン
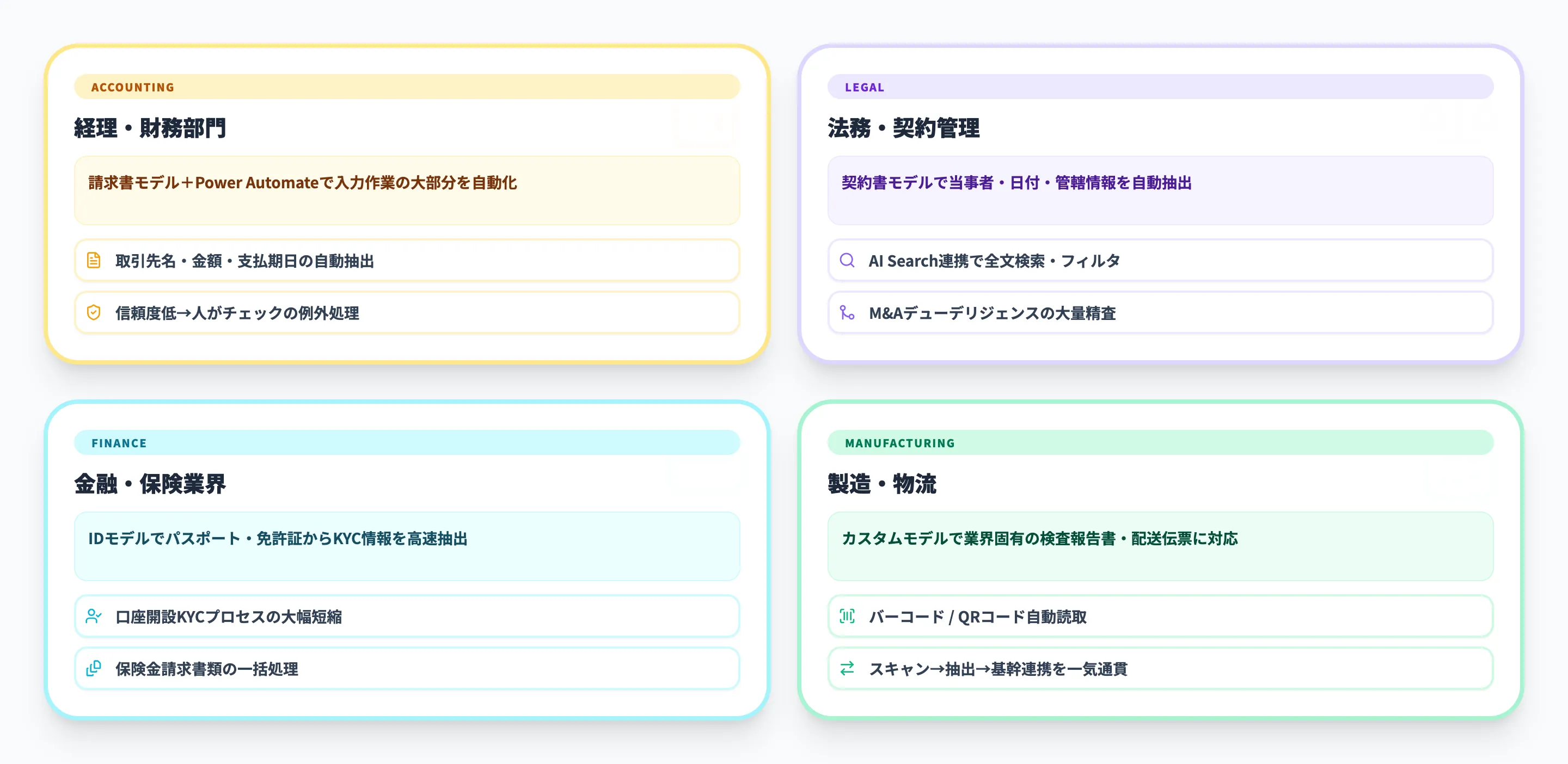
Document Intelligenceの事前構築済みモデルやカスタムモデルは、幅広い業務領域で活用できます。ここでは代表的な4つのシーンを紹介します。
経理・財務部門での請求書・領収書処理

最も導入効果が見えやすい領域です。請求書モデルを使えば、取引先名、請求金額、支払期日、明細行などを自動抽出し、会計システムへの転記を自動化できます。
毎月数百件の請求書を手入力している経理チームであれば、Document Intelligenceの請求書モデル+Power Automateの連携で、入力作業の大部分を自動化できます。抽出結果にはフィールドごとの信頼度スコアが付与されるため、信頼度が低い項目だけを人がチェックする「例外処理フロー」を組むことで、精度と効率のバランスを取れます。
法務・契約管理

契約書モデル(英語契約書向け)では、当事者(Parties)、契約ID、執行日・発効日・満了日などの各種日付、管轄情報(Jurisdictions)などを自動抽出します。大量の契約書を管理する法務部門や、M&A時のデューデリジェンスで多数の契約書を精査する場面で効果を発揮します。
Azure AI Searchと組み合わせれば、抽出したデータをインデックス化し、契約書の全文検索やフィルタリングが可能になります。
金融・保険業界での本人確認
IDモデルは、パスポートや運転免許証から氏名・生年月日・住所・文書番号などを抽出します。口座開設時のKYC(顧客確認)プロセスを大幅に短縮でき、米国の運転免許証では承認情報や車両分類まで取得可能です。
保険金請求の処理では、レシートモデルや健康保険証モデル(米国向け。モデルIDはprebuilt-healthInsuranceCard.us)と組み合わせて、申請書類一式をまとめて処理するワークフローが構築できます。日本の健康保険証には対応していないため、国内で同様の処理を行う場合はカスタムモデルの構築が必要です。
製造・物流での帳票デジタル化
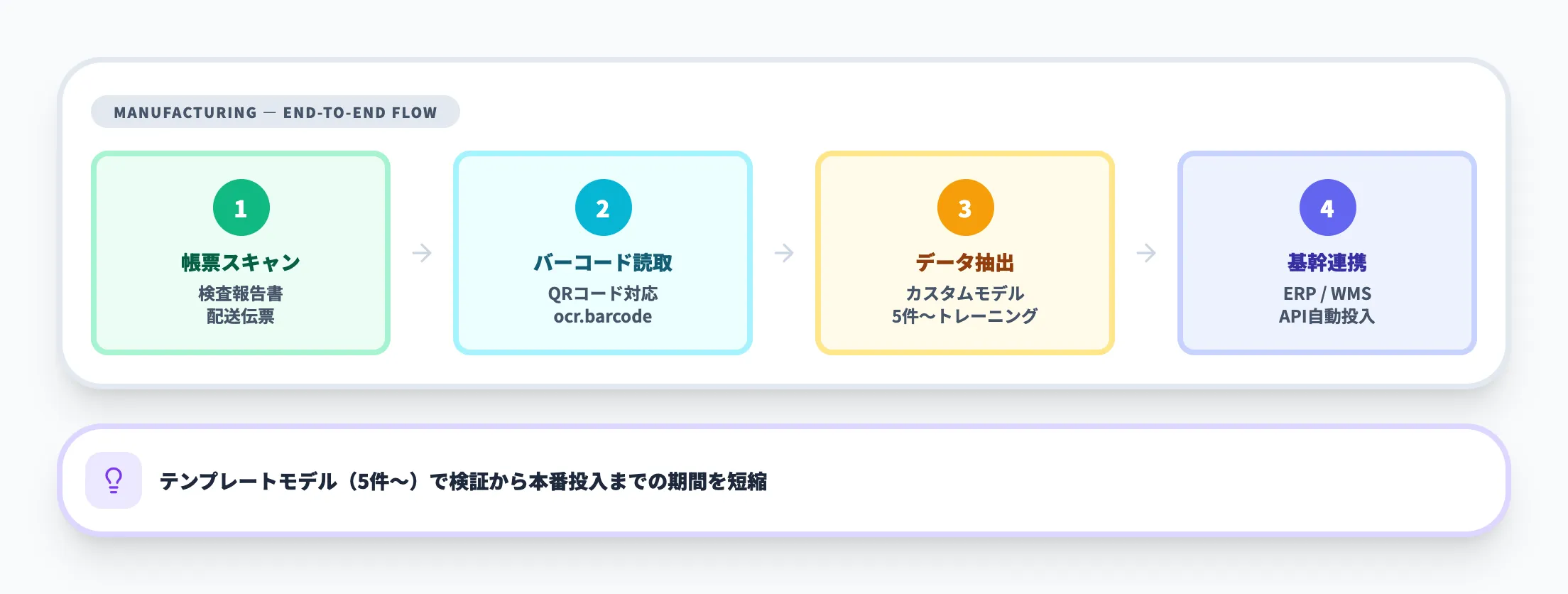
製造現場の検査報告書や物流の配送伝票など、業界固有のフォーマットを持つ帳票はカスタムモデルで対応します。テンプレートモデルなら5件程度のサンプルでトレーニングを開始でき、検証から本番投入までの期間を短縮できます。
v4.0で追加されたバーコード抽出機能は、伝票に印刷されたバーコードやQRコードの読み取りにも対応しており、製造ラインや倉庫での帳票スキャン→データ抽出→基幹システム連携を一気通貫で実現します。
【関連記事】
Azureで使えるAIサービスは?主要サービス一覧・利用メリットを解説
Azure AI Document Intelligenceの注意点と制限事項

Document Intelligenceの導入にあたっては、いくつかの制限事項を事前に把握しておく必要があります。ここでは実務で詰まりやすいポイントを整理します。
ファイルサイズとページ数の上限
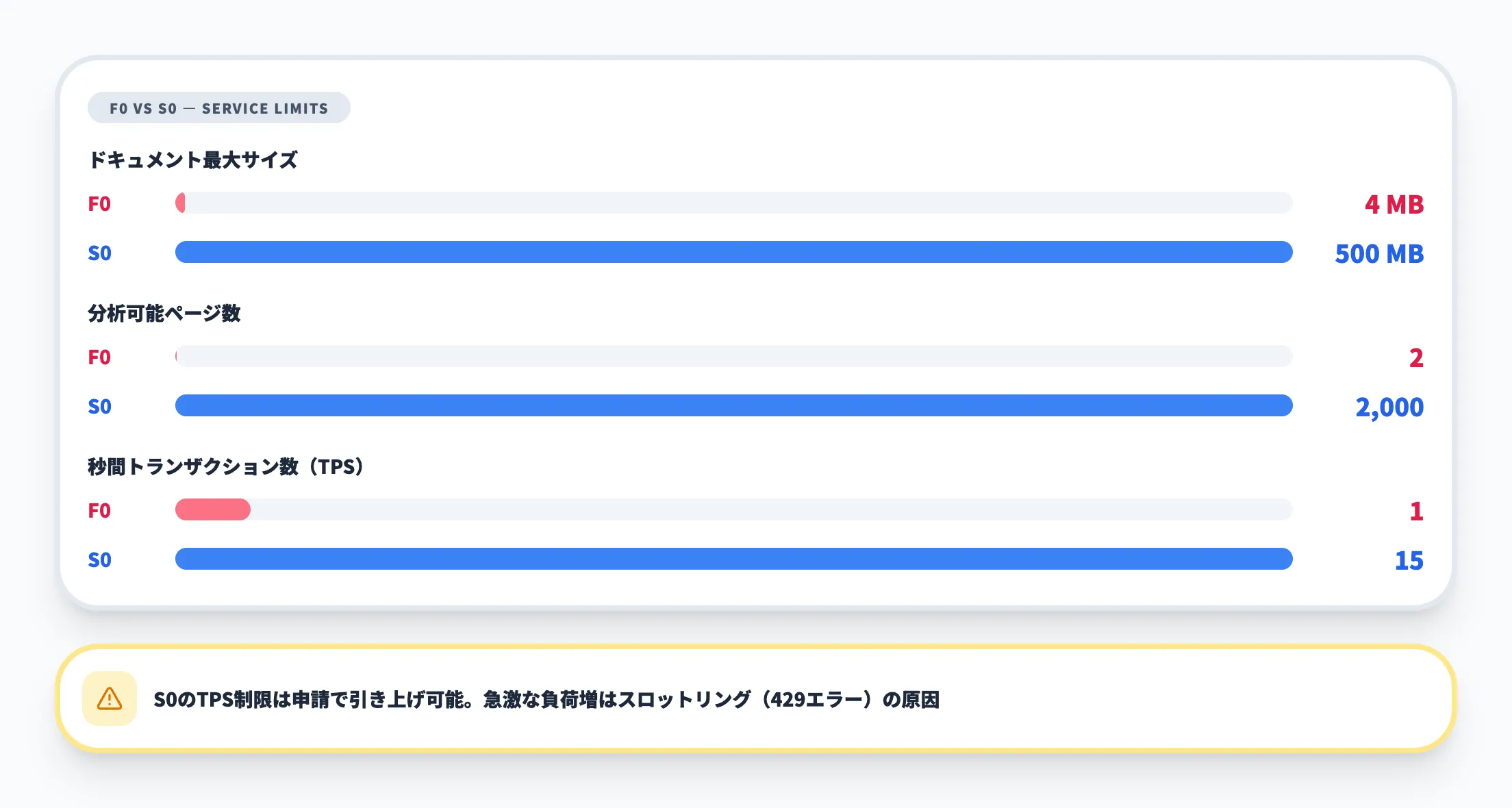
Document Intelligenceでは、価格レベルごとにファイルサイズとページ数の上限が設定されています。
| 制限項目 | Free(F0) | Standard(S0) |
|---|---|---|
| ドキュメントの最大サイズ | 4 MB | 500 MB |
| ページの最大数(分析) | 2ページ | 2,000ページ |
| 1秒あたりの分析トランザクション数 | 1 TPS | 15 TPS(引き上げ可能) |
無料枠(F0)は検証用途に限定されます。分析対象が最大2ページに制限されるため、複数ページの帳票を処理するには有料枠(S0)が必要です。
S0のTPS制限(既定15 TPS)は、Azureサポートへの申請で引き上げが可能ですが、急激なワークロード増加はスロットリング(429エラー)の原因になるため、段階的にスケールアップすることが推奨されています。
カスタムモデルのトレーニング制約
カスタムモデルには以下の制約があります。
-
トレーニングデータセットサイズ
ニューラルモデルは最大1 GB、テンプレートモデルは最大50 MBまで
-
トレーニングページ数
ニューラルモデルは最大50,000ページ、テンプレートモデルは最大500ページ
-
無料トレーニング時間
v4.0では月10時間まで無料。それ以降は有料($3/時間)
-
モデル保存数
テンプレートモデルはS0で最大5,000個、ニューラルモデルは最大500個
特に注意すべきは、無料トレーニング時間の制限です。大量のサンプルでニューラルモデルをトレーニングする場合、10時間を超えるとコストが発生します。最初は少量のサンプルで精度を検証し、効果が確認できてからサンプル数を増やす段階的なアプローチが実務的です。
プレビュー機能と本番利用の注意
Document Intelligenceの一部機能やモデルは、プレビュー(Public Preview)段階で提供されることがあります。プレビュー機能は利用可能なリージョンが限定される場合があるほか、GA前にAPIの仕様が変更される可能性があります。
プレビュー段階の機能を本番システムに組み込む際は、API仕様の変更に備えたバージョン管理と、GA移行時のマイグレーション計画を事前に準備しておくべきです。
導入判断で詰まる論点
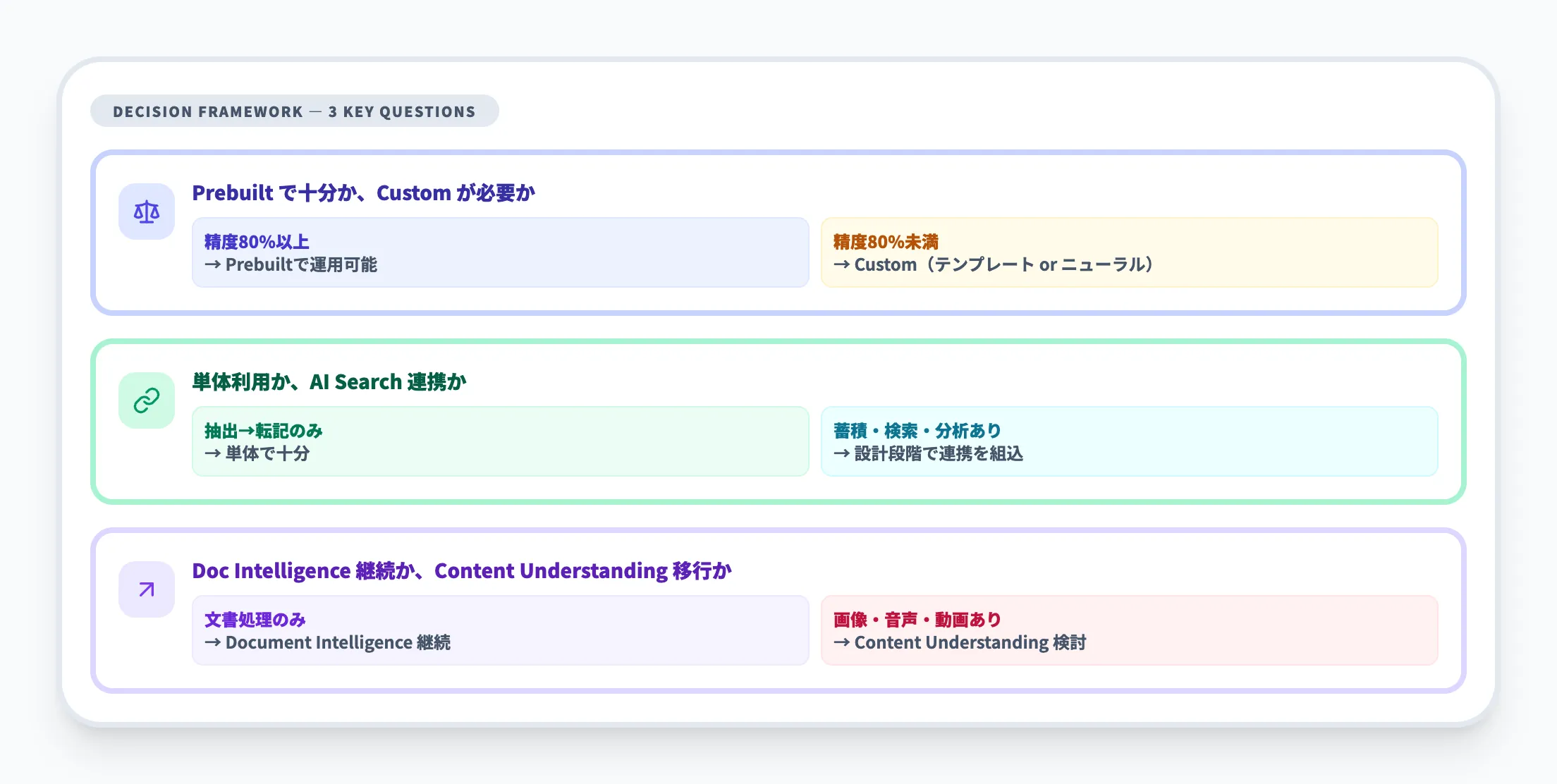
Document Intelligence導入の検討で判断が分かれやすいのは、以下の3点です。
-
事前構築済みモデルで十分か、カスタムモデルが必要か
まずは事前構築済みモデルで自社帳票をテストし、抽出精度が80%以上であれば事前構築済みモデルで運用可能なケースが多いです。それ以下の場合、レイアウトのばらつきが原因であればニューラルモデル、レイアウトが固定なのに精度が出ないならテンプレートモデルの検討に進みます。
-
Document Intelligence単体で使うか、Azure AI Searchと連携するか
抽出したデータを蓄積・検索・分析する用途がある場合は、Azure AI Searchとの連携を最初から設計に入れるべきです。後から連携を追加するより、アーキテクチャ設計段階で組み込むほうが手戻りが少なくなります。
-
Document Intelligenceを使い続けるか、Content Understandingに移行するか
現時点ではDocument Intelligenceが安定しており、テキスト・表・フォーム処理にはDocument Intelligenceが最適です。画像や動画のマルチモーダル処理が要件に含まれる場合のみ、Content Understandingの検討が合理的です。

Azure AI Document Intelligenceの料金

Document Intelligenceは分析したページ数に基づく従量課金を基本としています。以下の表に主なモデルの料金を示します(2026年4月時点。料金はリージョンにより異なる場合があります)。
| モデル | 料金(1,000ページあたり) |
|---|---|
| Read | $1.50(100万ページ以上は$0.60) |
| Layout | $10(Prebuilt料金枠として扱われる) |
| 事前構築済みモデル(請求書、レシート、IDなど) | $10 |
| カスタム分類 | $3 |
| カスタム抽出(テンプレート・ニューラル) | $30 |
| アドオン(高解像度、フォント、数式) | $6 |
| クエリフィールド | $10 |
無料枠(F0)は月500ページまで利用でき、主要なモデルをテストできます。ただし分析は1ドキュメントあたり最大2ページに制限されるほか、premium featuresとQuery Meterは無料枠に含まれません。
カスタムモデルのトレーニングは月あたり最初の10時間が無料で、超過分は$3/時間です。
大量処理を行う場合はコミットメントプラン(一定量を事前に確保する料金モデル)も用意されています。コスト試算にはAzure料金計算ツールが利用可能です。最新の正確な料金は公式料金ページで確認してください。
コスト最適化のポイント
コストを最適化するポイントは以下の3点です。
-
モデルの使い分け
テキスト抽出だけで済む処理にはReadモデル($1.50/1,000ページ)を使い、レイアウト解析や構造化データの抽出が必要な場合にLayout・事前構築済みモデル($10/1,000ページ)を使う。ReadとLayout/Prebuiltの間で約85%のコスト差があるため、用途に応じた使い分けが重要です。
-
ページ範囲の指定
APIリクエスト時にpagesパラメータで処理対象ページを指定できます。10ページのPDFのうち、請求書に該当する1〜2ページだけを分析対象にすれば、課金されるページ数を大幅に減らせます。
-
アドオンの選択的利用
高解像度抽出やフォント情報は必要な場合のみ有効化する。デフォルトでは無効のため、不要なアドオンのコストは発生しません。
【関連記事】
Azureの料金体系を解説!サービスごとの料金例や確認方法も紹介
帳票の読み取りから経理処理までAIで一気通貫にするなら
Document Intelligenceで帳票データを正確に抽出できても、その先の仕訳・転記・承認フローが手作業のままでは、業務全体の効率化にはつながりません。OCRの精度を検証する段階から、抽出後のデータ活用まで見据えた設計が求められます。
AI Agent Hubは、AI-OCRによる読み取りから仕訳・基幹システムへの自動連携までをAIエージェントが一気通貫で実行するエンタープライズAI基盤です。Azure Managed Applicationsとして自社テナント内に構築するため、請求書や契約書など機密性の高い書類も安全に処理できます。
-
請求書・領収書のOCR→仕訳→ERP連携を自動化
AI-OCR Agentが帳票を読み取り、経費仕分けAgentが勘定科目を自動判定。SAP Concur・freee会計・勘定奉行クラウドなどの経理システムへ直接データを投入します。
-
承認フローもTeamsで完結
フロー判定Agentが社内規定に照合し、承認が必要な場合はTeamsに通知。スマートフォンからでも承認・差戻しが可能で、経理業務のリードタイムを短縮します。
-
機密書類の処理も自社テナント内で完結
Azure Managed Applicationsとして顧客テナント内に構築されるため、請求書・契約書のデータが外部に出ることはありません。実行ログとアクセス権限をダッシュボードで一元管理できます。
AI総合研究所では、OCR導入の精度検証から経理業務フロー全体のAI自動化まで、段階的な構築を専任チームが支援しています。まずは資料で、AI-OCRを軸にした業務自動化の全体像をご確認ください。
帳票OCRから経理業務までAIで自動化

読み取りだけで終わらない、仕訳・転記・承認まで一気通貫
Document Intelligenceで帳票データを抽出した後、仕訳・基幹システム連携・承認フローまでをAIエージェントが自動実行。Azure自社テナント内で完結するため、請求書や契約書も安全に処理できます。
まとめ
Azure AI Document Intelligenceは、OCRと機械学習を組み合わせたAI文書処理サービスとして、紙帳票のデジタル化から構造化データの抽出までを1つのサービスでカバーします。
本記事で解説した内容を振り返ると、導入を検討する際の判断軸は以下の3つに集約されます。
まず、事前構築済みモデルの活用範囲を見極めることです。請求書・レシート・ID・契約書など30種類以上の文書タイプに対応しているため、自社の帳票がこれらに該当するなら、カスタムモデルを作る前に事前構築済みモデルの精度を検証すべきです。無料枠(月500ページ)でDocument Intelligence Studioから即座に試せます。
次に、業務フロー全体を見据えたアーキテクチャ設計です。Document Intelligence単体のOCR処理にとどめず、Power AutomateやLogic Appsでの自動化フロー、Azure AI Searchでの検索基盤との連携を最初から設計に含めることで、データ活用の幅が大きく変わります。
そして、将来のマルチモーダル対応への備えです。Content Understanding(2025年11月GA)はDocument Intelligenceの進化版として、テキスト以外の画像・音声・動画処理にも対応しています。現時点ではDocument Intelligenceで十分ですが、将来の要件拡張を見据えた技術選定を行うことが重要です。
AI総合研究所では、Azure AI Document IntelligenceをはじめとするAzureのAIサービスを活用した文書処理の自動化や、業務プロセス全体のDX推進を支援しています。OCR導入の検証から本番環境の構築、カスタムモデルのトレーニングまで、段階的な導入をサポートしていますので、まずはDocument Intelligence Studioで自社帳票の処理精度を試すところから始めてみてください。










