この記事のポイント
 AI単独で生成したコンテンツは原則として著作物に該当せず、人間の「創作的寄与」が認められた範囲だけが著作権で保護される
AI単独で生成したコンテンツは原則として著作物に該当せず、人間の「創作的寄与」が認められた範囲だけが著作権で保護される- 著作権侵害の判断は依拠性・類似性の2要件、出力公開した利用者が原則責任、AI開発企業・サービス提供者も生成態様で責任主体になり得る
- 学習段階は著作権法30条の4で原則適法だが、「享受目的」の併存や権利者の利益を不当に害する場合は例外として違法になる
- Anthropic 15億ドル和解案・千葉県警AI生成画像書類送検・Perplexity提訴等、2025-2026年は企業AI利用に直撃する判決・摘発が連続
- 商用公開する画像生成はIP補償付きAdobe Firefly・ChatGPT Enterpriseが第一候補、Midjourney等は社内チェックフロー別建て

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI生成物の著作権は、文化庁の2段階モデル(学習段階/生成・利用段階)を起点に判断するのが現在の実務的な前提です。
2025年から2026年にかけて、Anthropicの15億ドル規模の和解案合意、Perplexityに対する読売・朝日・日経の提訴、千葉県警によるAI生成画像の書類送検など、企業のAI利用に直接効いてくる動きが立て続けに起きました。
本記事では、AI生成物の著作物性・侵害判断・学習段階の30条の4・国内外の最新訴訟・米国著作権局/EU AI Actの動向・主要AIサービスごとの商用利用と補償・罰則と賠償コスト・企業がいま整備すべき対策までを2026年6月時点の情報で整理します。
法務担当者の方が社内ガイドラインを引くとき、現場担当者がサービス選定の判断軸を持つときに、両方の目線で使える内容を目指しました。
目次
AI著作権の全体像——文化庁の2段階モデルで論点を分けて読む
AI生成物による著作権侵害——依拠性と類似性の2要件で判定する
侵害責任の主体——原則は利用者、ただし開発・提供事業者も態様により
AI学習段階の著作権——著作権法30条の4と「享受目的」の例外
国内外の最新訴訟・事例——2025年から2026年にかけて何が起きたか
Anthropic 15億ドル和解案——米著作権法史上最大規模の大型和解
NYT vs OpenAI——進行中の最大訴訟、1億件超のログ開示命令へ
Getty Images vs Stability AI——英高裁の中間判断
海外の法制度動向——米国Copyright Office・EU AI Actから2026年を読む
米国——Copyright Office Part 2 Reportと最高裁判断
EU——AI Act第50条(透明性表示)と第53条(GPAIモデル提供者義務)
国際的な傾向——「人間の著作性」「学習データ透明性」の2軸が共通土台
主要AIサービスの商用利用と補償——選定段階で差がつくIP indemnity
AI著作権侵害の罰則と損害賠償コスト——リスクを金額で把握する
AI著作権の全体像——文化庁の2段階モデルで論点を分けて読む
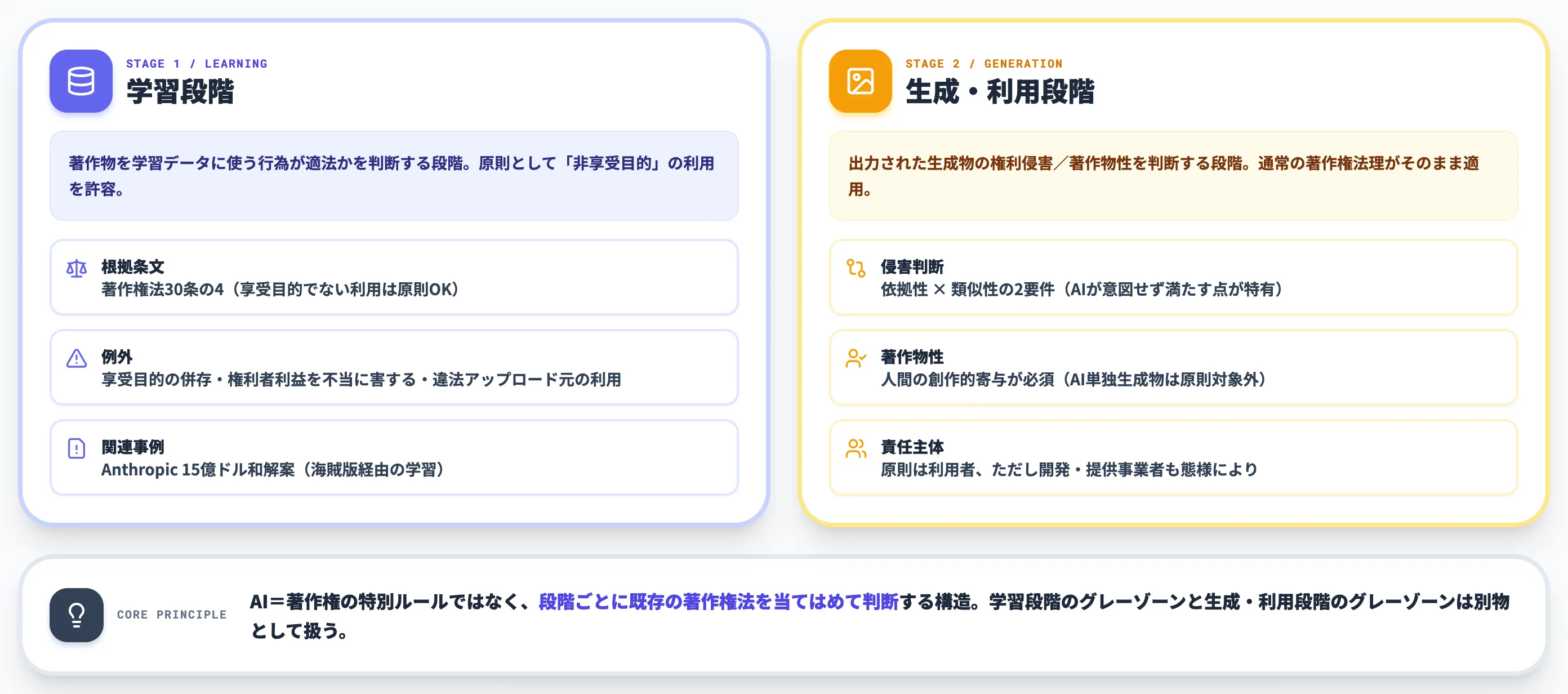
生成AIの著作権を考えるとき、最初に押さえるべきは「学習段階」と「生成・利用段階」を分けて議論するという前提です。
文化庁が2024年3月に公表した「AIと著作権に関する考え方について」はこの2段階モデルで整理されており、日本における実務判断の土台になっています。
両者を混ぜて議論すると「AIに学習させた時点でアウト」「生成したものに著作権は一切ない」のような極端な誤解が生まれます。本記事ではこの2段階を軸に、論点を順番に切り分けて整理していきます。

学習段階と生成・利用段階で論点が変わる
文化庁「AIと著作権に関する考え方について」(令和6年3月15日公表)(出典:文化庁)
文化庁の2段階モデルを表にまとめると、論点の置き場所がはっきり見えてきます。
| 段階 | 主な論点 | 根拠条文・原則 |
|---|---|---|
| 学習段階 | 著作物を学習データに使う行為が適法か | 著作権法30条の4(享受目的でない利用は原則OK) |
| 生成・利用段階 | 出力された生成物が既存著作物の権利を侵害するか/AI生成物自体に著作権が発生するか | 通常の著作権法(依拠性・類似性/創作的寄与) |
この表が示すのは、「AI=著作権の特別ルール」ではなく、段階ごとに既存の著作権法を当てはめて判断するというシンプルな構造です。
学習段階のグレーゾーンと、生成・利用段階のグレーゾーンは別物として扱う必要があります。
この記事で答えを出す3つの問い
本記事では、企業の法務担当者・現場のAI利用者が実務で迷いやすい次の3つの問いに、2026年6月時点の最新情報で答えていきます。

- AIが作った文章・画像に著作権は発生するか、誰のものになるか
- AIで作ったものを公開して、既存作品の著作権侵害になるのはどんな条件か
- 業務でAIを使うために、自社として何を整備しておけばよいか
「AIに何を入れてよいか」と「AIが出したものを何に使ってよいか」は、技術ではなく契約と法律で決まる領域です。技術記事を読むだけでは判断軸が見えないため、本記事は実務担当者がそのまま社内に持ち帰れる粒度で整理しました。
AI生成物の著作物性——誰のものになるのか
AI生成物に著作権が発生するかどうかは、人間の創作的寄与がどこまであったかで判断されます。
文化庁の「AIと著作権に関する考え方について」も、米国著作権局のCopyright and Artificial Intelligence Part 2 Reportも、結論はほぼ一致しています。AIが自律的に生成しただけのものは著作物ではなく、人間の表現上の選択が反映された範囲だけが保護対象になります。
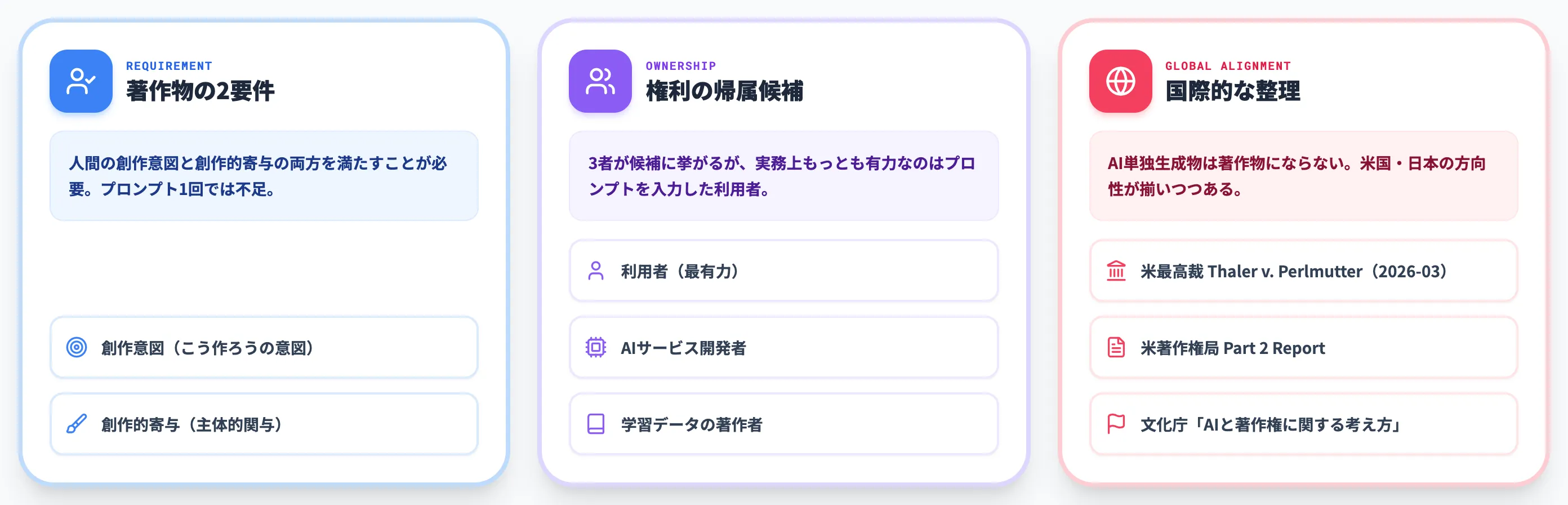
著作物として認められる2つの要件
著作物として認められるためには、文化庁の整理に基づき次の2つの要件を両方満たす必要があります。

| 要件 | 内容 | 満たしやすい例 | 満たしにくい例 |
|---|---|---|---|
| 創作意図 | 「こういうものを作ろう」という意図が人間にあること | 「水彩風の山岳風景画を作ろう」と意図を持って指示 | 「何かいい感じの絵」と指示 |
| 創作的寄与 | 表現の内容・形式に人間が主体的に関与していること | プロンプト改善・出力の選別・修正を何度も重ね、最終形を人間が決めた | プロンプトを1行だけ入力し最初の出力をそのまま採用した |
この表で重要なのは、創作意図だけでは足りないという点です。「水彩風の山岳風景画を作ろう」と思っていても、プロンプト1回・選別なしでは創作的寄与は弱いと評価される可能性が高くなります。
逆に、AI出力を何百枚と生成しその中から1枚を選び、さらにレタッチや構図の調整を加えた場合は、人間がAIを「道具」として使った創作活動と評価され、著作権が発生する余地が出てきます。
AI生成物の著作権は誰に帰属するか
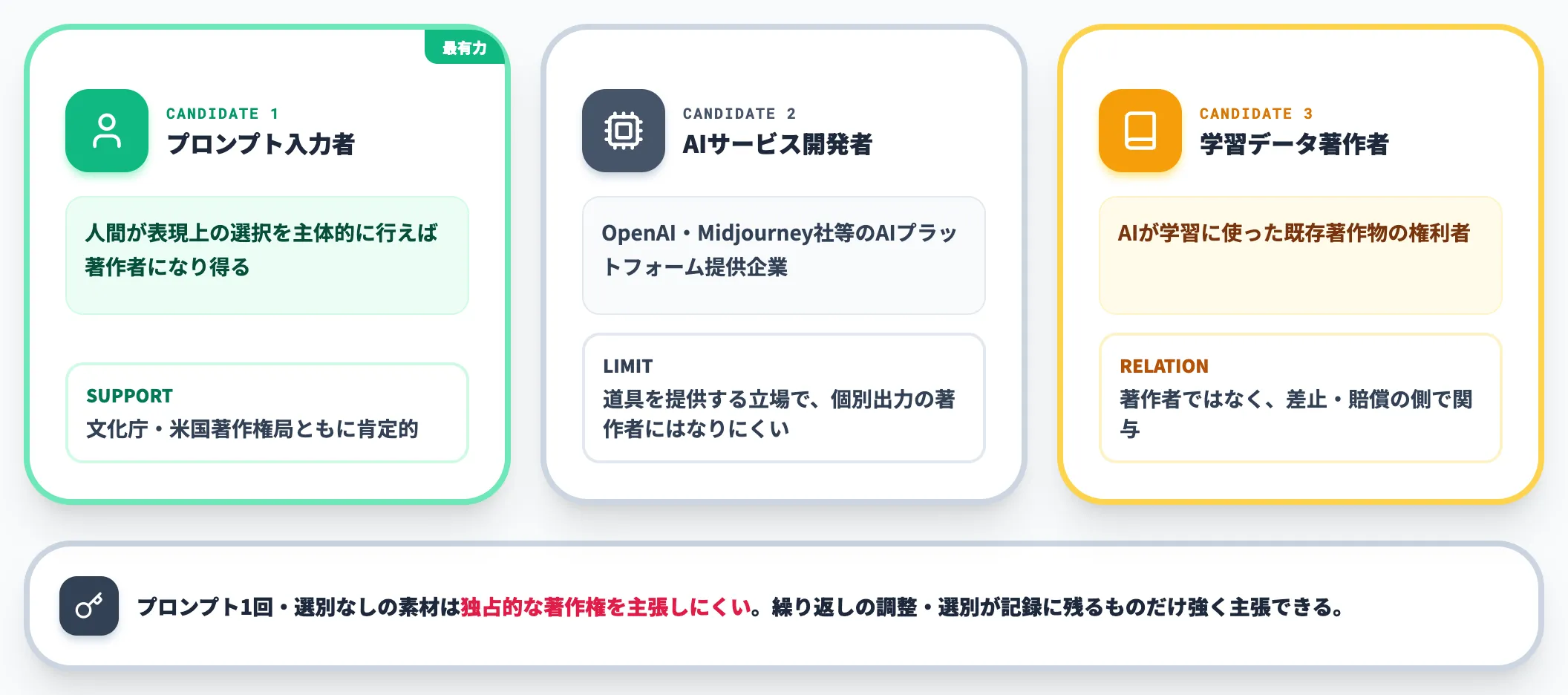
著作権が発生したとして、その権利が誰のものになるかは別の問題です。実務で議論される候補は次の3者です。
-
AIサービスの開発者
ChatGPTのOpenAI、MidjourneyのMidjourney社など、AIプラットフォームを提供する企業。
ただし開発者は道具を提供している立場であり、個別の出力物について著作者と評価されるケースは限定的です。
-
学習データの著作者
AIが学習に使った既存著作物の権利者。
生成物がその著作物に類似しかつ依拠性が認められれば、後述の「侵害」として権利主張が成立する可能性があります。著作者として権利を取得するわけではなく、侵害者に対する差止・賠償の形で関与します。
-
プロンプトを入力した利用者
実務上もっとも有力な候補。文化庁・米国著作権局ともに、人間が表現上の選択を主体的に行ったと認められる場合は、利用者が著作者になる余地を認めています。
実務的な使い分けとしては、「プロンプト1回・選別なし」で生成されたものは著作権法上の保護対象になりにくい素材として扱い、「繰り返しの調整と選別が記録に残るもの」だけ独占的な著作権を主張しやすい素材と整理するのが安全側です。
米国・日本の最新判断——AI単独生成物は著作物にならない


米国Copyright Office「Copyright and Artificial Intelligence Part 2: Copyrightability」レポート(2025年1月公表、出典:U.S. Copyright Office)
2025年から2026年にかけて、AI単独生成物の扱いは国際的にも整合性が高まりました。米国では2026年3月、最高裁が Thaler v. Perlmutter で certiorari を却下し、「AI単独で生成された作品は著作権で保護されない」というルールが事実上確定しました。
米国著作権局の2025年1月のレポートも、「ほとんどのプロンプトは、出力の具体的な表現要素を支配しているとは言えず、著作者性を満たさない」と明言しています。日本の文化庁の整理と方向性は揃っており、実務担当者は**「AIに任せたものは原則として著作権なし」を出発点に置く**のが妥当です。
【関連記事】
ChatGPTの問題点とは?セキュリティや著作権の観点から徹底解説
AI生成物による著作権侵害——依拠性と類似性の2要件で判定する
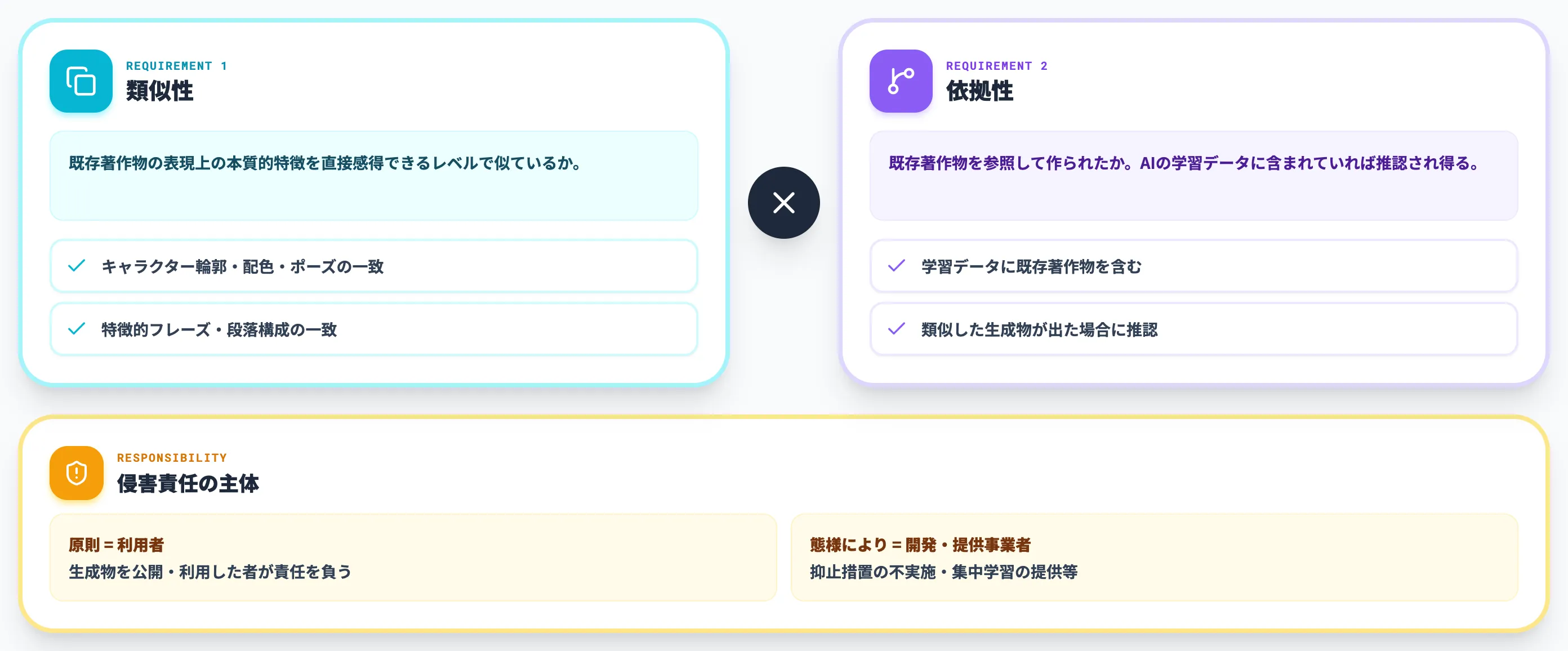
AI生成物に著作権が「ない」場合でも、既存著作物の権利を侵害するリスクは別問題として残ります。ここを混同すると、社内ガイドラインで重大な抜けが生じます。
著作権侵害は、AI利用かどうかにかかわらず①類似性と②依拠性の両方が認められた場合に成立します。AI生成物に特有の論点は、この2つの要件がAIの内部で意図せず満たされ得るという点に集約されます。
類似性——表現が既存著作物とどれだけ重なるか

類似性とは、生成物が既存著作物の「表現上の本質的特徴」を直接感得できるレベルで似ているかどうかという判断です。アイデアやスタイルが似ているだけでは類似性は成立しません。
具体的なキャラクターの輪郭・配色・ポーズや、文章の特徴的なフレーズ・段落構成が一致するレベルで重なると、類似性が認められやすくなります。
商用公開する画像・文章は、リリース前に「既存作品との類似性チェック」をフローに組み込むのが実務的な対策です。逆引き画像検索や、既知の人気作品との比較を最低限の手順として持っておきます。
依拠性——AIが既存著作物に「触れて」いたか
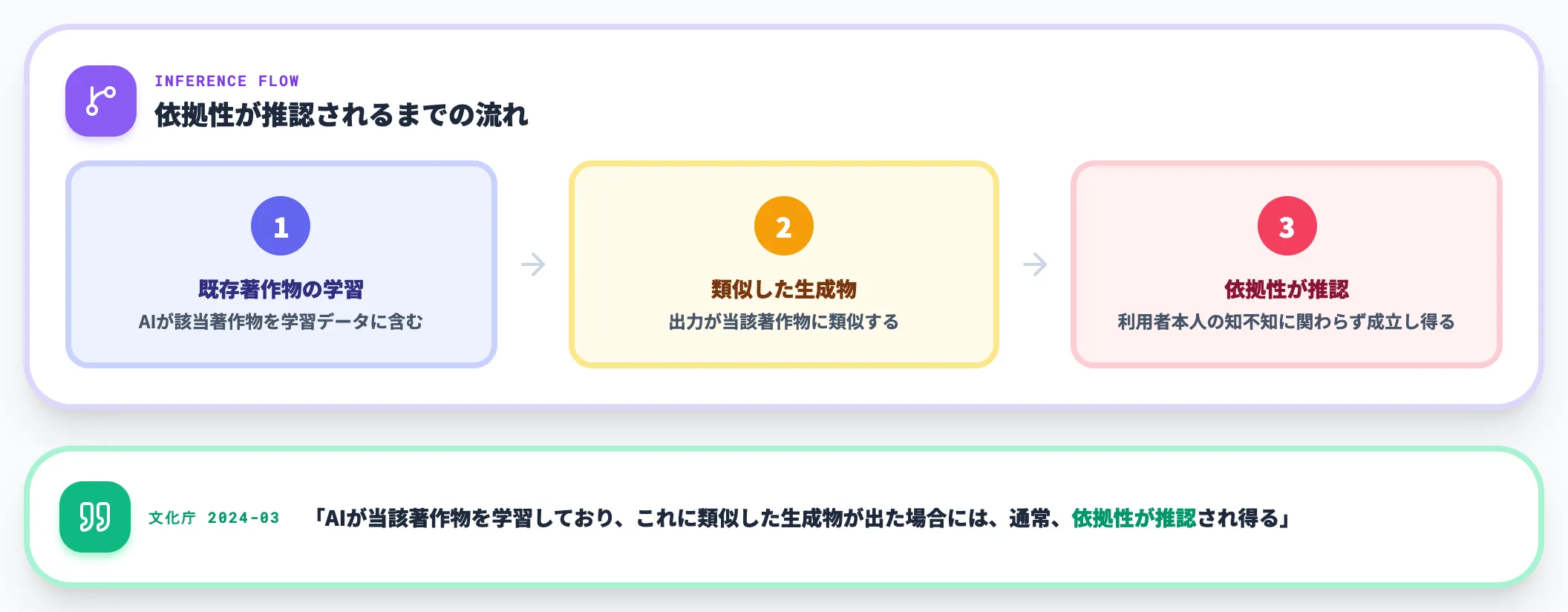
依拠性は、生成物が既存著作物を参照して作られたかどうかの判断です。人間が直接コピーしていなくても、AIの学習データに既存著作物が含まれていれば依拠性が認められる余地がある点が、従来の著作権論との大きな違いです。
日本では2024年3月の文化庁「AIと著作権に関する考え方」で、「AIが当該著作物を学習しており、これに類似した生成物が出た場合には、通常、依拠性が推認され得る」とする整理が示されました。
つまり利用者本人が元ネタを知らなくても、AIがそれを学習していて、出力が類似していれば侵害が成立し得るということです。条件は「学習している」と「類似した生成物が出た」の両方が揃った場面である点に注意してください。
グレーゾーンの典型——スタイルの模倣・キャラクター類似
実務で判断に悩むのは、次の3パターンです。

-
特定アーティストの画風を意図して指示するケース
プロンプトに「〇〇風」と作家名を含める利用は、当該作家の著作物との類似性が高まりやすく、リスクが上がります。
-
既存キャラクターを連想させる出力
名前を直接入れていなくても、特徴的な配色や髪型を指定すると有名キャラクターに近い出力が出てしまうケースがあります。
-
小説・歌詞・脚本の部分的な再現
LLMがプロンプトに反応して、学習データの一部をほぼそのまま出力してしまうケース。実際の訴訟で繰り返し争点になっています。
これらは「プロンプトに作品名・作家名を直接入れない」「特徴的な固有名詞を出させない」という運用ルールである程度回避可能です。同時に、出力後のチェックフローを別建てで持つことが必要になります。
侵害責任の主体——原則は利用者、ただし開発・提供事業者も態様により
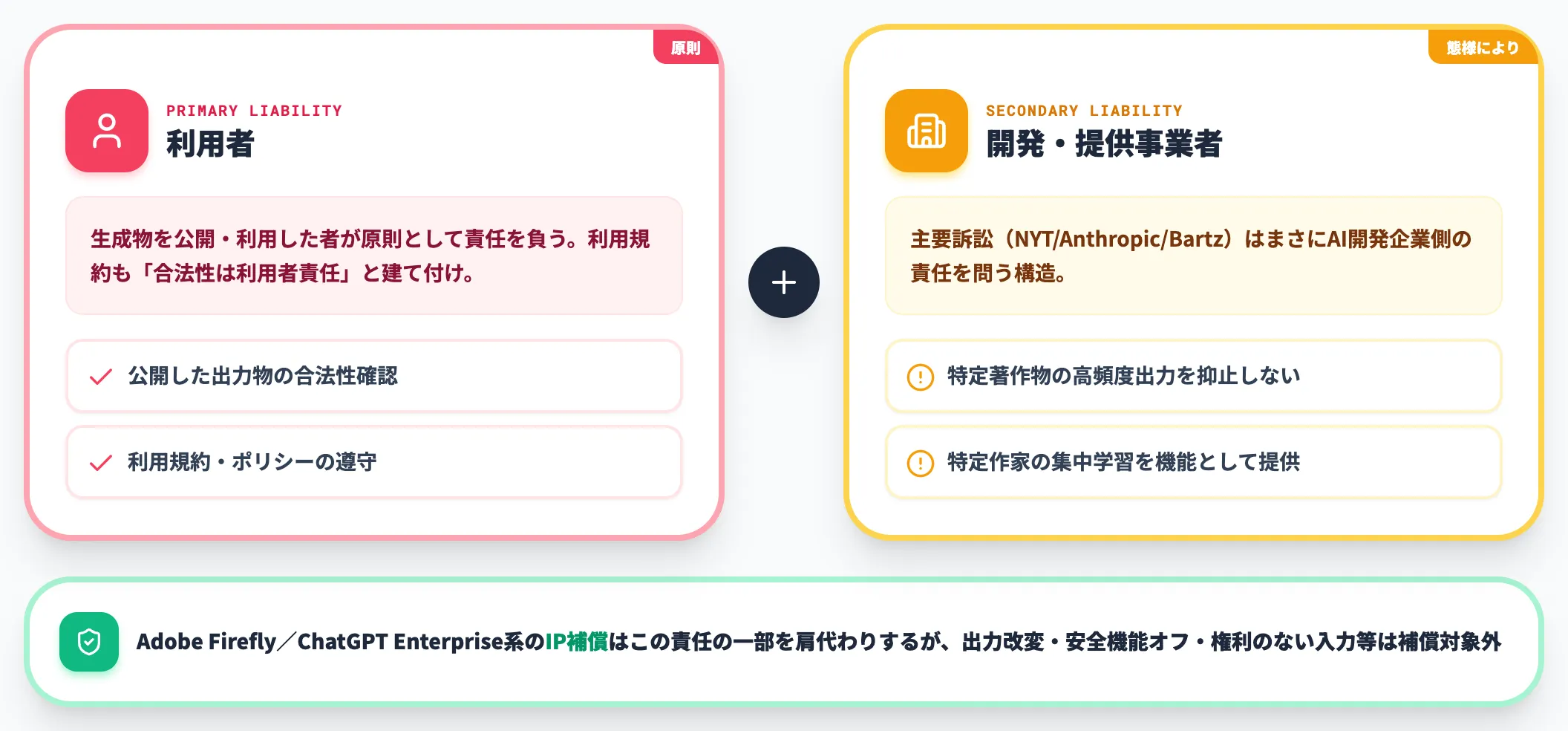
実務でもっとも誤解されているのが、責任の所在です。AIが既存著作物を学習していた場合でも、生成物を公開・利用した責任は原則として利用者にあります。各社の利用規約も、生成物の合法性については利用者の責任で確認するという建て付けです。
ただし**「利用者だけが責任を負う」と言い切れるわけではありません**。文化庁の整理でも、AI開発事業者・サービス提供事業者が侵害の主体として責任を負う場合があるとされています。たとえば、特定の著作物が高頻度で出力されることが知られているのに抑止措置を講じない、特定作家の作品集中学習を機能として提供している、といった態様では、開発側・提供側の責任が問題になります。
後述する一部の有償サービス(Adobe Firefly/ChatGPT Enterprise系)は、IP補償でこの責任の一部を肩代わりしますが、出力の改変・安全機能や引用機能の不使用・権利のない入力の利用など補償対象外条件があります。一方で、係争中の主要訴訟(NYT vs OpenAI/Bartz vs Anthropic 等)はまさにAI開発企業側の責任を問う構造になっており、「開発企業が訴えられているから自社は無関係」という発想は通用しません。利用者と開発・提供事業者の双方が、それぞれの態様に応じて責任を負い得るという立て付けで読むのが安全側です。
AI学習段階の著作権——著作権法30条の4と「享受目的」の例外
ここからは2段階モデルのもう片方、学習段階の話です。日本では著作権法30条の4が学習段階の中心条文になります。
30条の4が許す「非享受目的」の利用
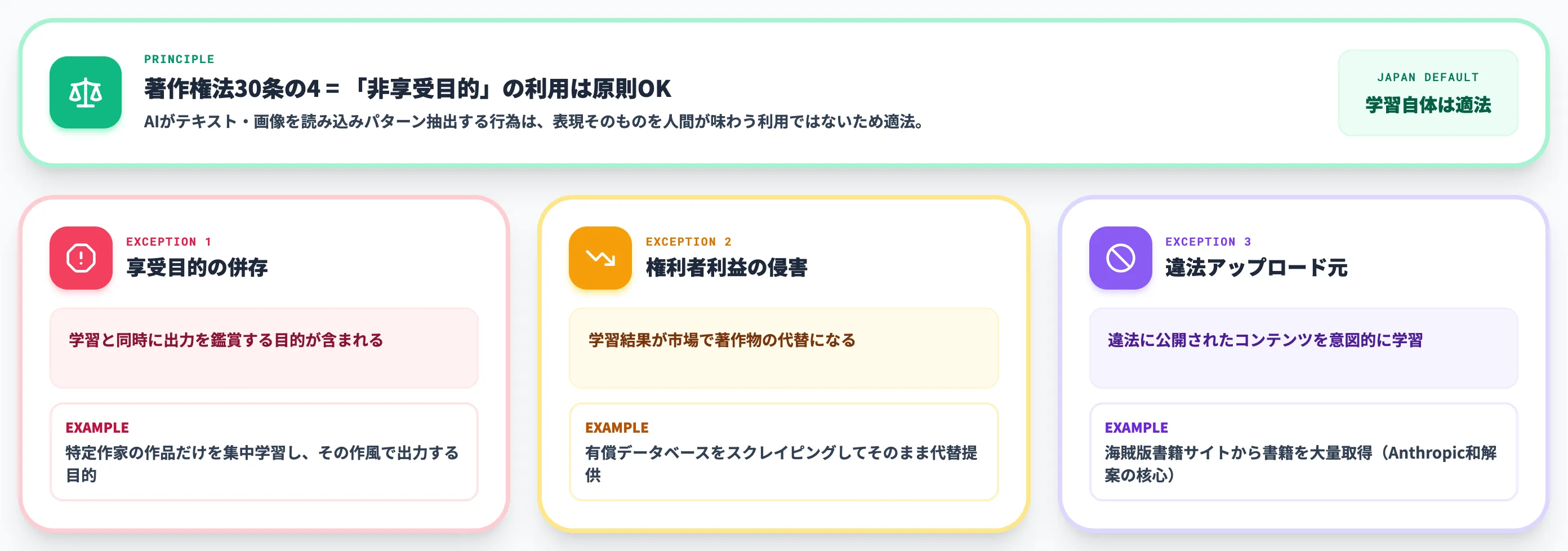
著作権法30条の4は、「著作物に表現された思想又は感情の享受を目的としない利用」については、原則として著作権者の許諾なく著作物を利用できると定めています。
AIが大量のテキストや画像を読み込んでパターン・統計量を抽出する行為は、著作物の表現そのものを人間が味わうための利用ではないため、この「非享受目的」に該当すると整理されています。
この条文があるため、日本国内では生成AIの学習自体は基本的に適法とされ、学習データに権利者の許諾を都度取る必要はありません。これは世界的に見ても日本がAI開発に対して柔軟な法的環境を持つ理由のひとつです。
例外——学習段階でも違法になる3パターン
ただし30条の4は無制限ではなく、文化庁の整理では次の3パターンで例外的に違法になる可能性があります。
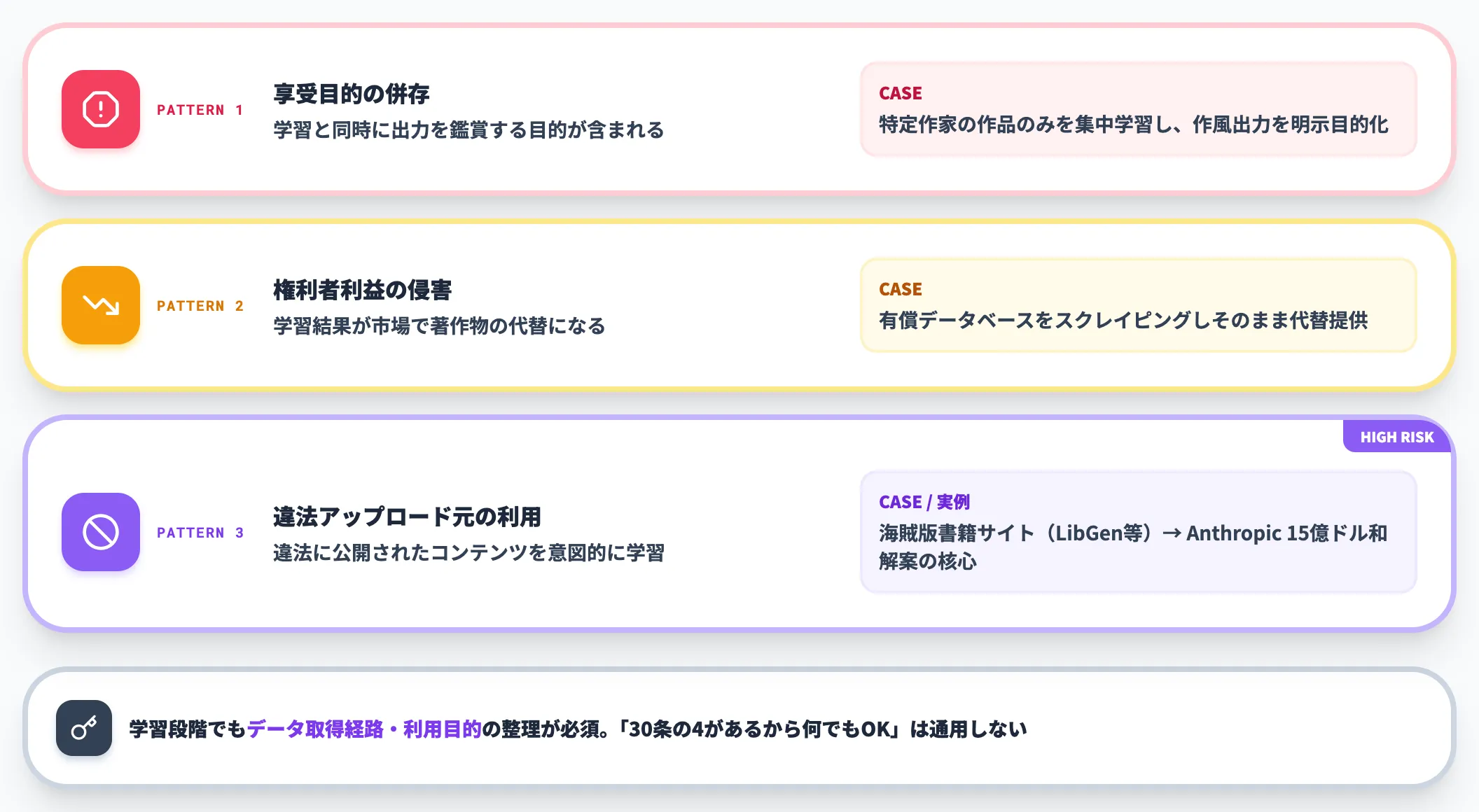
| 例外パターン | 内容 | 例 |
|---|---|---|
| 享受目的の併存 | 学習と同時に出力を鑑賞する目的が含まれる | 特定作家の作品だけを集中学習し、その作家の作風で出力する目的が明示されている |
| 権利者の利益を不当に害する | 学習結果が市場で著作物の代替になる | 有償データベースをスクレイピングしてそのまま代替提供する |
| 違法アップロード元の利用 | 違法に公開されたコンテンツを意図的に学習 | 海賊版書籍サイトから書籍を大量取得して学習 |
この例外の中でも、特に「違法アップロード元の利用」は、後述するAnthropicの和解事例に直結する論点になりました。学習段階だから何でもOKというわけではなく、データの取得経路・利用目的の整理が学習側にも求められます。
企業が学習データを扱うときに確認すべきポイント
自社で生成AIをファインチューニングする、または社内データを学習に使う企業は、次の3点を押さえておくと安全側です。

- 学習に使うデータの取得経路が合法であること(公式API・契約済みデータベース・自社作成データ)
- 学習結果が特定権利者の市場代替にならないこと(社内利用に限定するか、出力に独自性を加える)
- 学習データに違法コンテンツ・海賊版が混入していないこと(データクレンジング工程を組み込む)
これらは現場の判断では難しいため、法務部門と開発部門の合同レビューとして最初のモデル構築前に走らせるのが現実的です。30条の4の整理を法務に説明する材料として、本セクションの内容を引用できる粒度にしています。
国内外の最新訴訟・事例——2025年から2026年にかけて何が起きたか

著作権の議論は、抽象的な条文解釈よりも具体的な訴訟・摘発から流れが決まります。2025年から2026年にかけて、AI著作権の論点を一気に動かす事例が複数発生しました。
ここでは、企業の実務担当者が押さえておくべき主要事例を米国・国際・日本の順で整理します。
Anthropic 15億ドル和解案——米著作権法史上最大規模の大型和解


Authors Guildによる Bartz v. Anthropic 和解案解説。15億ドル・約50万作品・1作品あたり$3,000の配分(出典:Authors Guild)
Bartz v. Anthropicは、ノンフィクション作家・スリラー作家のグループが、Anthropicが書籍を無断学習データに使ったとして提訴した訴訟です。2025年9月5日、両当事者は15億ドル(約2,200億円)規模の和解案で合意したと公表しました。米国著作権法史上最大規模の金額として大きく報じられています。
訴訟の核心は、AnthropicがLibrary Genesis(LibGen)やPiLiMiといった海賊版サイトから書籍を大量にダウンロードしてClaudeの学習に使った点でした。NPRの報道によると、約50万冊が対象で、1冊あたり約3,000ドル、著者と出版社で50:50配分が原則です。
この事例が示すのは、学習段階であっても海賊版経由のデータ利用は決定的に違法判断され得るという事実です。日本の30条の4でも違法アップロード元の利用は例外扱いになっており、この方向性は世界共通の認識になりつつあります。
2026年5月14日には、北カリフォルニア連邦地裁の Martínez-Olguín 判事のもとで最終公平性審理(fairness hearing)が開かれました。判事はその場では判断を留保し、未期限のオプトアウト扱いについて2026年5月21日までの補足意見書提出を命じています。最終承認のorderは2026年6月時点でなお保留中で、続報を待つ段階です。
NYT vs OpenAI——進行中の最大訴訟、1億件超のログ開示命令へ
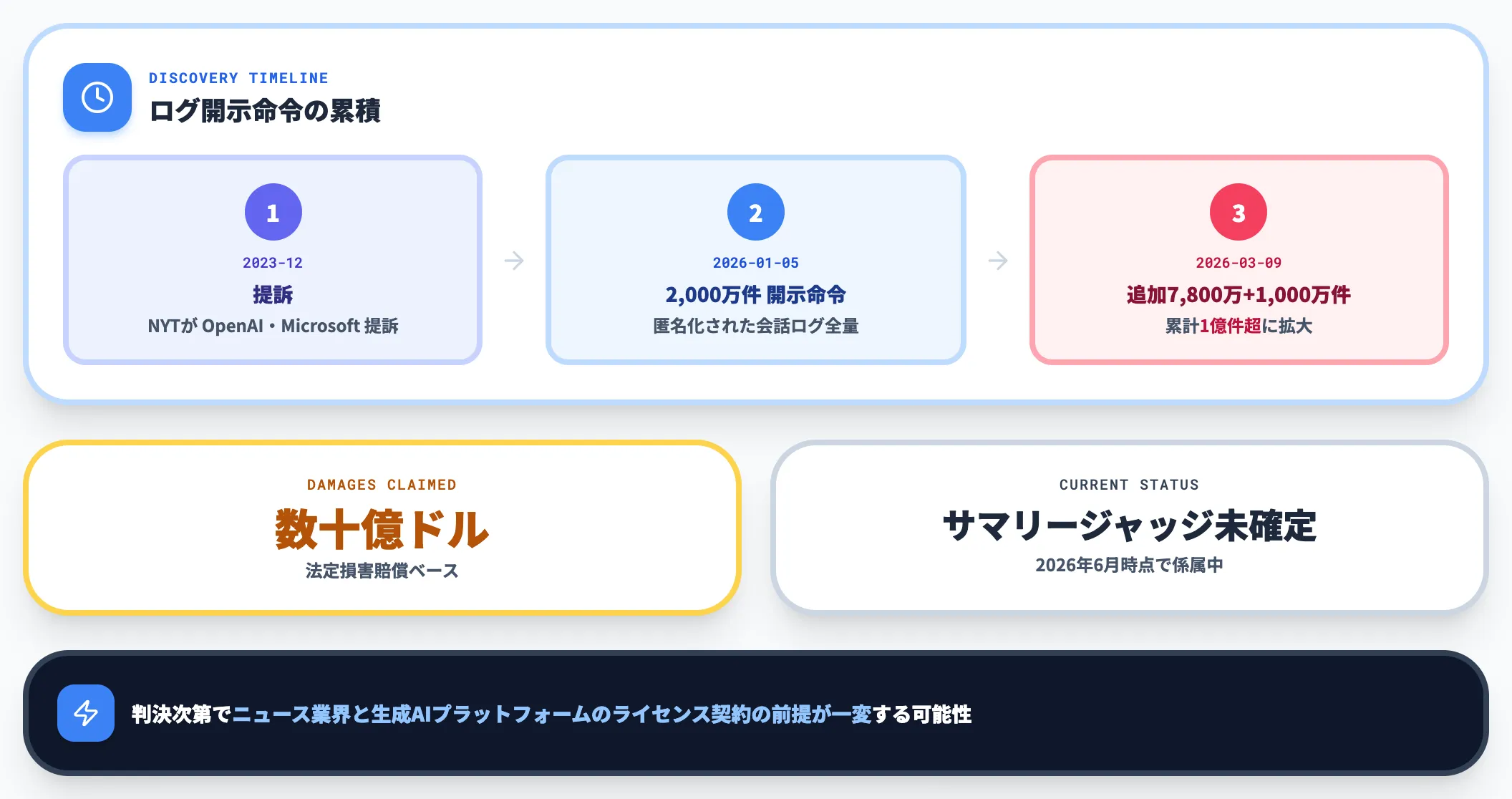
The New York Timesが2023年末にOpenAIとMicrosoftを提訴した事案は、現時点で進行中の最大級の訴訟です。Timesは「数百万本の自社記事を無断でChatGPTの学習に使われた」として、法定損害賠償として数十億ドルを請求しています。
ディスカバリーをめぐる争いは2026年に2段階で大きく動きました。2026年1月5日、Sidney Stein連邦地裁判事は、OpenAIに対し匿名化されたChatGPT会話ログ2,000万件の全量提出を命じるマジストレート判事の決定を支持しました(2026年1月5日order PDF)。OpenAIは原告作品に該当する会話のみを絞り込んで提出する方針を望んでいましたが、これが却下された形です。
さらに2026年3月9日、追加開示命令によりOpenAIに対し、約7,800万件と約1,000万件という2つの追加ログリザーバーの提出が命じられ、累計の開示対象は1億件超の規模に拡大しました(2026年3月9日order)。当初の2,000万件は「規模感の起点」に過ぎず、ディスカバリー段階で訴訟の規模そのものが膨らんでいる構図です。
サマリージャッジは2026年4月に予定されていたものの、2026年6月時点で判決には至っておらず、係属中の段階にあります。学習段階の適法性論を米国の司法がどう整理するかの試金石として、判決次第でニュース業界と生成AIプラットフォームのライセンス契約の前提が一変する可能性があります。
Getty Images vs Stability AI——英高裁の中間判断


Getty Images v Stability AI 英国高等法院判決(2025年11月4日、出典:Judiciary UK)
英国では Getty Images vs Stability AI が、AI著作権の重要判例として進行しています。2025年11月4日、英国高等法院(Mrs Justice Joanna Smith DBE)は判決([2025] EWHC 2863 (Ch))で、二次的著作権侵害(モデル重みが「侵害コピー」に該当するか)の主張を退けました。一方で、Stable Diffusionの過去の出力にGettyのウォーターマークが現れた件については、限定的に商標侵害を認めました。
この判決は、英国の文脈で「モデル重み自体は侵害コピーには当たらない」という整理を本件において示したものです。同時に、出力に既存事業者のウォーターマークが残るケースは別軸のトラブルになり得るという、実務的な線引きも示されました。日本企業として参照するときは、AI著作権論全体への一般化ではなく、本件における判断の射程に留めて受け止めるのが安全側です。

日本——Perplexity提訴と千葉県警の刑事立件

千葉県警が生成AIで作成された画像を無断使用したとして書類送検(2025年11月、出典:千葉日報)
国内でも、2025年から2026年にかけて重要な動きが続きました。2025年8月、読売新聞・朝日新聞・日本経済新聞の3社が生成AI検索サービスPerplexity AIを東京地裁に提訴しました。日本の大手メディアによる本格的なAI著作権訴訟として注目されています。
さらに2025年11月、千葉県警が生成AIで作成された画像を無断で使用したとして著作権法違反容疑で書類送検しました。日本国内では2025年1月にも生成AIで強調したアニメキャラクター画像のポスター販売に関する書類送検が報じられており、千葉県警の事案はそれに続く形で、AI生成画像をめぐる著作権法違反としては全国初の摘発と報じられています(千葉日報は「千葉県警では初とみられる」と慎重表現)。民事の差止・賠償だけでなく刑事責任のリスクが現実化したことを示す動きです。
これまで日本でのAI著作権トラブルは民事の差止・賠償が中心という認識でしたが、こうした摘発の積み上がりを受け、刑事リスクも社内ガイドラインに組み込む必要が出てきています。
【関連記事】
生成AIの問題点とは?実際の事例を踏まえ、解決策を解説
訴訟動向から読み取れる実務インパクト
ここまでの事例を、企業の実務担当者が押さえておくべき観点で整理すると次のとおりです。

- 学習データの取得経路は決定打になる: 海賊版経由は和解金15億ドル級の判断に直結する
- 責任は出力の利用者にも及ぶ: AI開発企業だけが訴えられているわけではなく、Perplexity訴訟のように出力をサービス化した側も対象になる
- 日本でも刑事化のリスクが顕在化: 民事の損害賠償だけでなく、書類送検レベルの刑事責任も意識する必要がある
- 判例が出揃うまでは慎重運用が安全側: 主要訴訟は2026年中に判決・サマリージャッジが続くため、現時点でリスクの高い利用は避けるのが現実的
これらの認識は、社内ガイドラインの根拠として法務部門に説明するときに有効です。AI総研の支援現場でも、ガイドライン策定の議論はこの2年間の事例ベースで進めるケースが増えています。
海外の法制度動向——米国Copyright Office・EU AI Actから2026年を読む

訴訟と並行して、各国の法制度も2026年に大きく動いています。日本企業が海外向けに事業展開している場合、これらの動向は無視できません。
米国——Copyright Office Part 2 Reportと最高裁判断

米国著作権局(U.S. Copyright Office)は、2025年1月に「Copyright and Artificial Intelligence Part 2: Copyrightability」を公表しました。要点は次の3つです。
| 論点 | 米国著作権局の整理 |
|---|---|
| AI単独生成物の著作物性 | 認めない。人間の著作性が必須 |
| AIをツールとして使った場合 | 既存の著作権法理で判断可能(必ずしも著作権を否定しない) |
| プロンプトのみによる著作者性 | 多くの場合、表現要素を支配しているとは言えず著作者性を満たさない |
この整理は、「AI単独生成物の著作物性」「人間の創作的寄与」といった基本方針において、日本の文化庁見解と方向性が揃っています。グローバルに事業展開する企業にとって、社内ガイドラインの著作物性まわりの土台は日本基準と大きく外れにくくなりました。
ただし米国実務にはフェアユース判断・著作権登録・法定損害賠償といった日本にない要素があり、米国での公開・販売を伴う展開では、米国著作権法と各サービスの米国向け契約条件を別途確認する必要があります。著作物性の枠組みが揃ったことと、米国市場特有のリスクが消えたことは別の話として整理しておくのが安全側です。
そして2026年3月、米国最高裁がThaler v. Perlmutterに対する上告を却下し、「AI単独生成物は著作権で保護されない」というルールが事実上確定しました。今後数年は、この判断を前提に米国の実務が動きます。
EU——AI Act第50条(透明性表示)と第53条(GPAIモデル提供者義務)
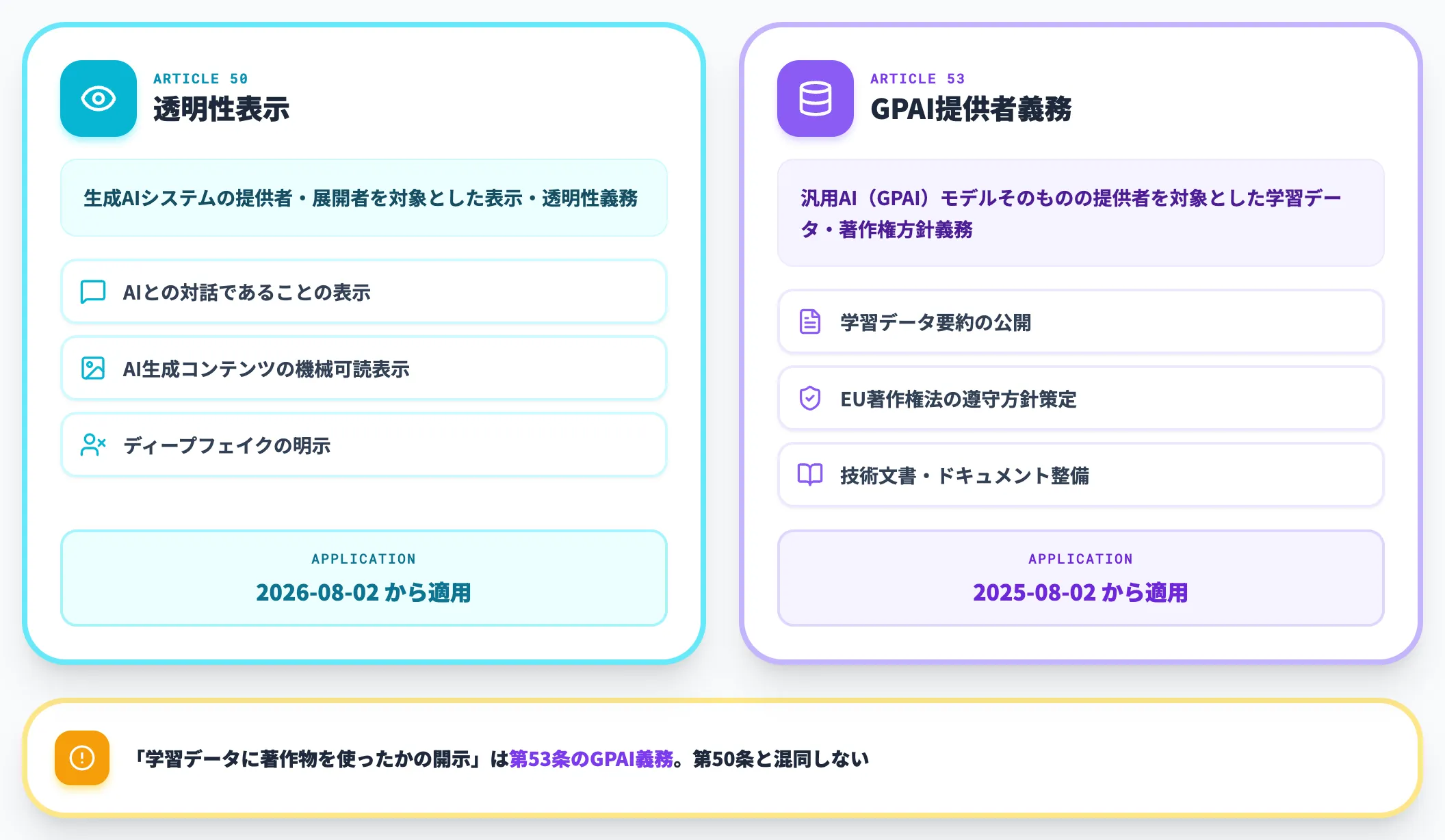
EUではAI Actが2024年に成立し、段階的に施行が進んでいます。著作権との接続では、対象と適用時期が異なる第50条と第53条を分けて押さえる必要があります。
以下の表で、両条文の対象・主な内容・施行時期を整理しました。
| 条文 | 対象 | 主な義務 | 適用時期 |
|---|---|---|---|
| 第50条 | 生成AIシステムの提供者・展開者 | AIとの対話であることの表示/AI生成・操作コンテンツであることの機械可読表示/ディープフェイクの明示 | 2026年8月2日から適用 |
| 第53条 | 汎用AI(GPAI)モデルの提供者 | 学習データ要約の公開/EU著作権法の遵守方針の策定/技術文書・利用者向けドキュメントの整備 | 2025年8月2日から適用開始 |
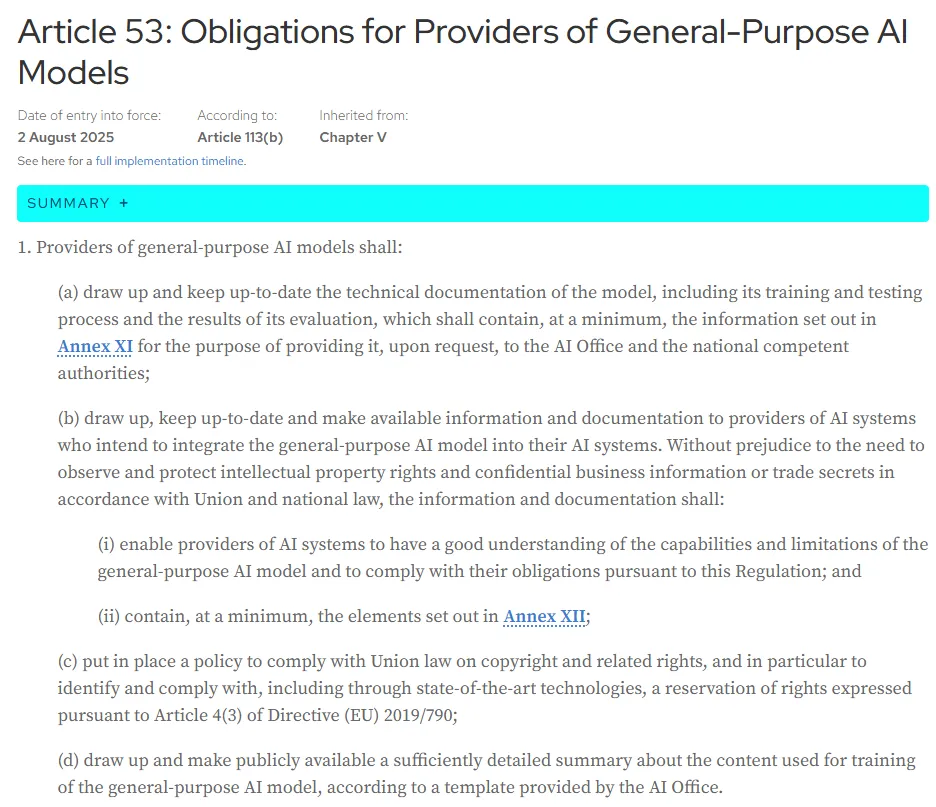
EU AI Act 第53条「Obligations for Providers of General-Purpose AI Models」(2025年8月2日適用開始、出典:Artificial Intelligence Act)

EU AI Act 第50条「Transparency Obligations」(2026年8月2日から適用、出典:Artificial Intelligence Act)
第50条はあくまで「表示・透明性」の義務で、AIが生成・操作したコンテンツであることを利用者やエンドユーザーに伝える設計を求めるものです。「学習データに著作物を使ったかの開示」は第50条ではなく第53条のGPAIモデル提供者向け義務として整理されています。両者を混同して書くと、自社が負う義務の射程を見誤りやすいので注意が必要です。
EUで生成AIシステムを提供する企業は第50条の表示要件を、GPAIモデルそのものを開発・提供する企業は第53条の学習データ・著作権方針を、それぞれ自社の対象範囲に応じて準備する必要があります。日本国内のみの利用なら直接の規制対象ではありませんが、学習データの開示要求は国際的なデフォルトになりつつある点を踏まえると、自社AIの学習データの整理は早めに着手しておく価値があります。
国際的な傾向——「人間の著作性」「学習データ透明性」の2軸が共通土台
ここまでの整理を踏まえると、2026年時点の国際的な傾向は次の2つに集約できます。

- 人間の著作性が著作物性の必須条件(米・日): 米国・日本は「人間の創作的寄与」を軸にAI単独生成物の著作権を認めない方向で揃いつつある。一方、英国はCDPAのcomputer-generated works規定が残っており、人間の著作者がいないコンピュータ生成物が保護され得る建て付けで、米日とは別枠での確認が必要
- 学習データの透明性が今後の論点: EU AI Act第53条(GPAIモデル提供者向け)が先行し、米国のNYT訴訟も学習データ開示が争点。日本でも文化庁の最終ガイドライン策定の中で議論される可能性が高い
グローバル展開を視野に入れる企業は、今のうちから「学習データ何を使ったか」を説明できる状態を整えることが将来の規制対応の余裕につながります。
主要AIサービスの商用利用と補償——選定段階で差がつくIP indemnity
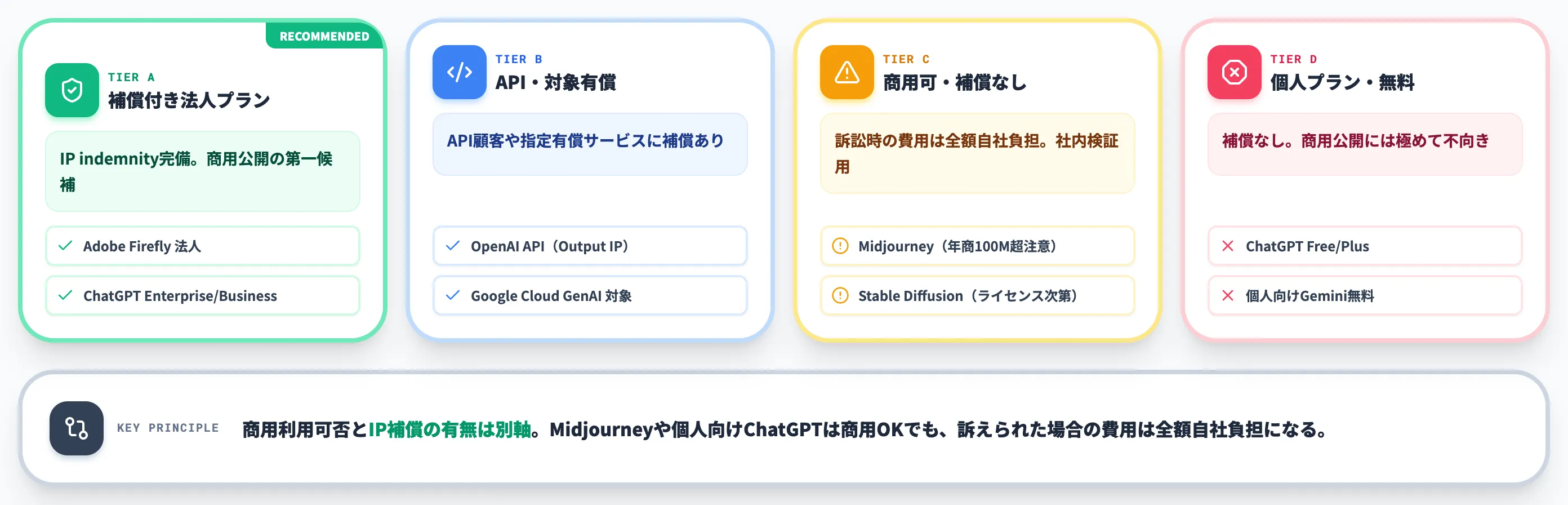
ここからは実務に踏み込みます。主要な生成AIサービスごとに、商用利用の可否とIP補償(IP indemnity)の有無を比較します。商用公開する画像・文章は、ここでサービス選定を間違えると、後段の著作権リスク対策のコストが跳ね上がります。
主要サービスの比較表
主要な生成AIサービスの商用利用条件と補償の有無を整理しました。
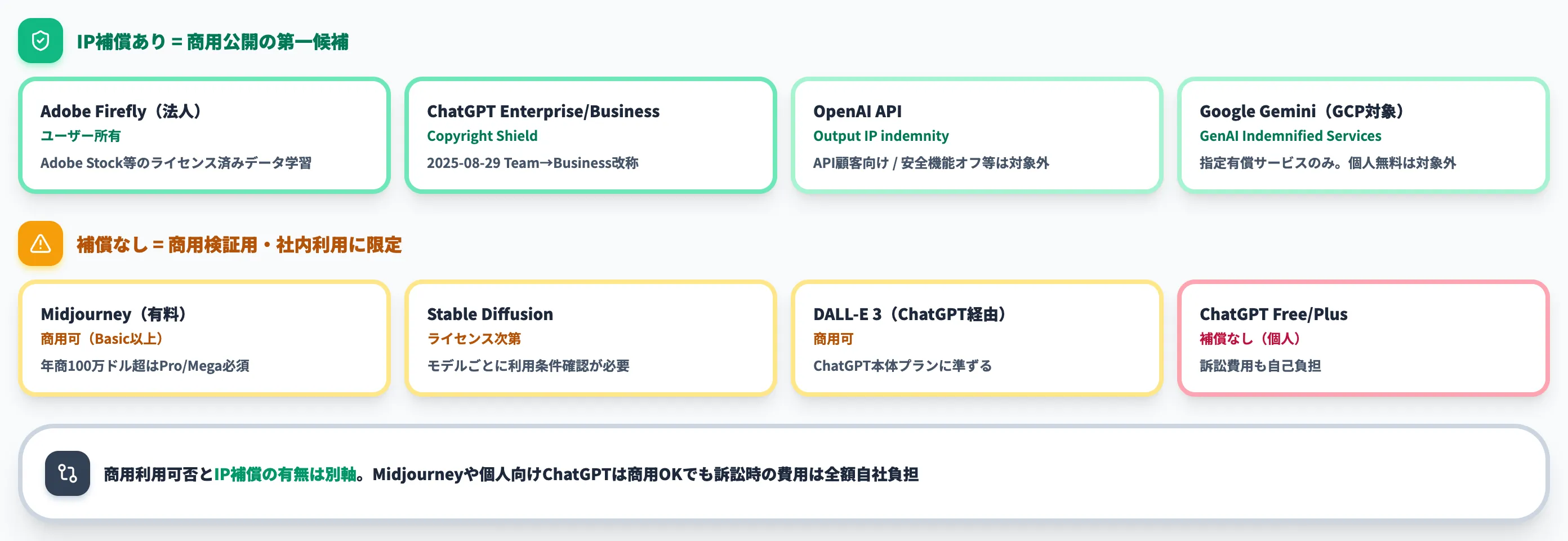
| サービス | 商用利用 | IP補償(著作権侵害時の損害賠償肩代わり) | 主な制約 |
|---|---|---|---|
| OpenAI API | 可(出力はユーザー所有) | API顧客向けにOutput IP claim indemnityあり(OpenAI Service Terms) | 出力の改変・安全機能や引用機能の不使用・権利のない入力の利用・コンテンツポリシー違反等は補償対象外 |
| ChatGPT Enterprise・Business(旧Team・2025-08-29改称) | 可 | Copyright Shield提供(OpenAI Service Terms) | 出力の改変・安全機能や引用機能の不使用・権利のない入力の利用等は補償対象外 |
| ChatGPT Free・Plus(個人) | 可 | 補償なし | 規約・コンテンツポリシー遵守は利用者責任、訴訟費用も自己負担 |
| Adobe Firefly | 可(ユーザー所有) | 法人プラン中心にIP indemnity提供(Firefly for Enterprise) | Adobe Stock等のライセンス済みデータ学習 |
| Midjourney(有料プラン) | 可(Basic以上)/年商100万ドル超の企業はPro・Megaが必要(Midjourney Terms of Service) | 補償なし | 無料版は商用不可。生成物の所有権は有料プランの種別で扱いが変わる |
| Stable Diffusion | モデルライセンス次第 | 通常なし | モデルごとに利用条件確認が必要 |
| DALL-E 3(ChatGPT経由) | 可 | ChatGPT本体に準ずる | 同上 |
| Google Gemini(Google Cloud / Workspaceの対象サービス) | 可 | Generative AI Indemnified Servicesに列挙された有償サービスのみ補償あり | 個人向けGemini無料版は補償対象外。対象サービス・契約条件は公式ページで都度確認 |
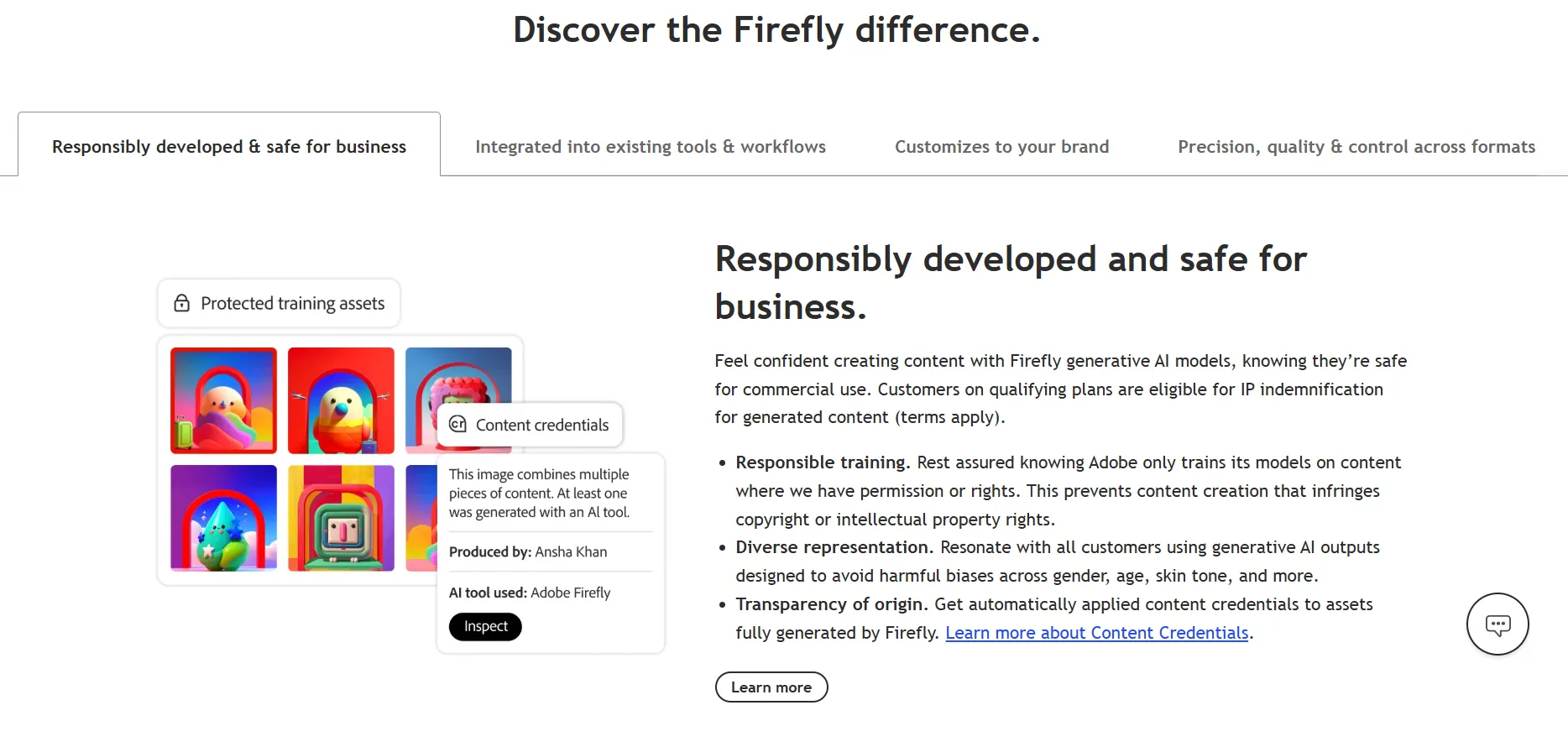
Adobe Firefly 公式のIP補償案内。Adobe Stockのライセンス済みデータ学習で商用利用安心設計(出典:Adobe)
この表で押さえるべきは、商用利用可否とIP補償の有無は別軸という点です。Midjourneyや個人向けChatGPTは商用利用OKですが、訴えられた場合の費用は全額自社負担になります。
IP補償がついたサービスを選ぶ価値
商用公開する画像・文章を扱う企業は、IP補償付きサービスを第一候補にするのが2026年時点の現実解です。理由は次の3点に集約されます。

OpenAIサービス利用規約におけるアウトプットに関する補償条項。APIおよびChatGPT Enterprise/Business等の利用者向けに規定されている(出典:OpenAI)
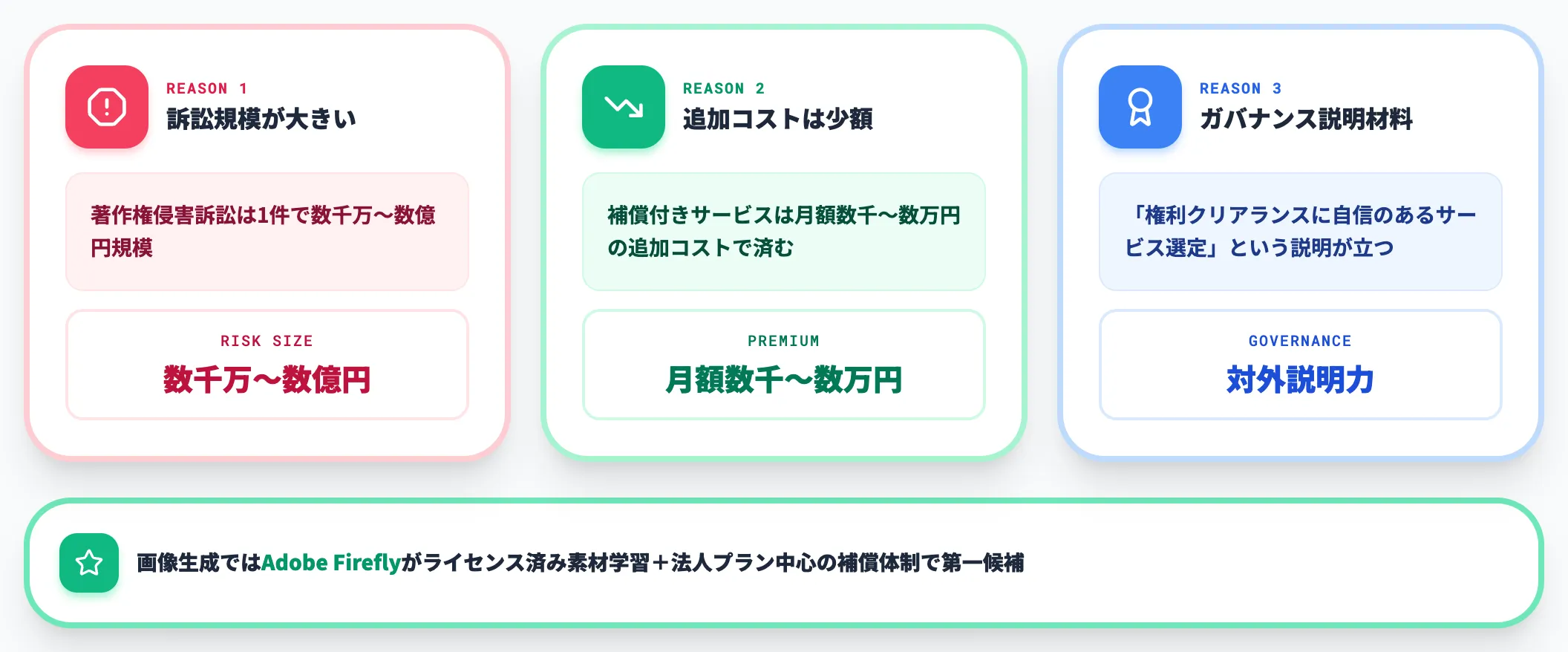
- 著作権侵害訴訟は1件で数千万〜数億円規模になる(後述)
- 補償付きサービスは月額数千〜数万円の追加コストで済む
- 補償の存在自体が「権利クリアランスに自信のあるサービスを選んでいる」というガバナンス上の説明材料になる
とりわけ画像生成では、Adobe Fireflyは学習データに自社Adobe Stockなどのライセンス済み素材を使っており、補償も法人プラン中心に整備されています。リーガル観点でリスクをミニマイズしたい用途で第一候補に挙げやすい構成です。
補償対象外になりやすい条件
IP補償も万能ではありません。OpenAIやGoogle Cloud等の規約を整理すると、補償対象外になりやすい条件は共通しています。
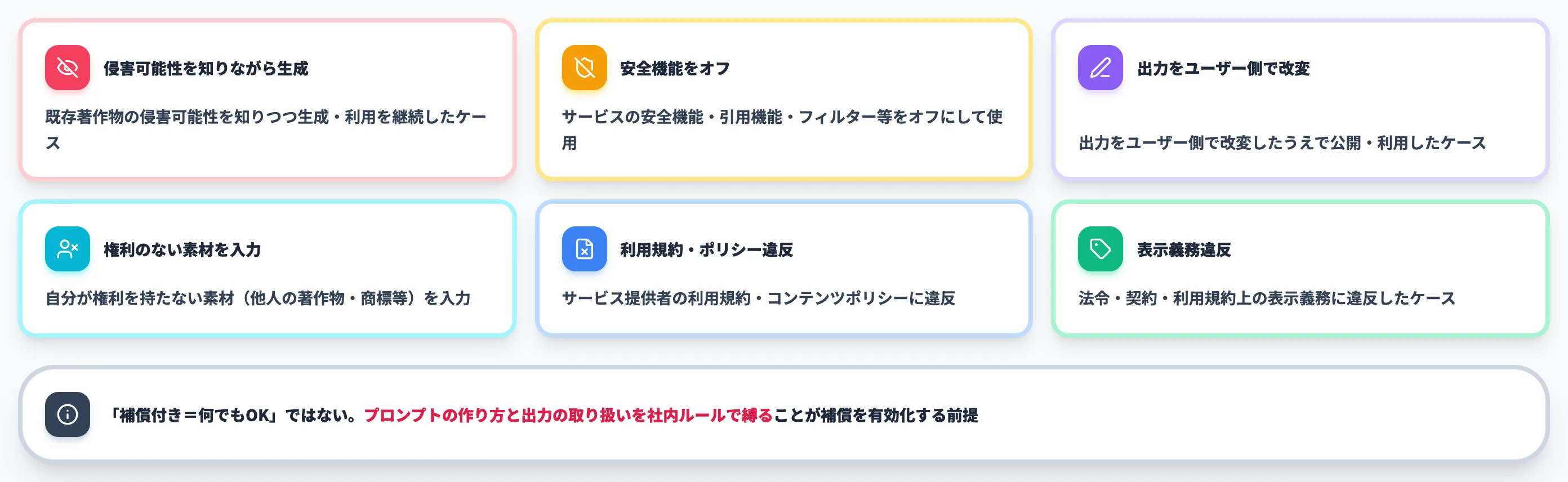
- 既存著作物の侵害可能性を知りつつ生成・利用を継続した場合
- サービスが提供する安全機能・引用機能・フィルター等をオフにした、または無視して使った場合
- 出力をユーザー側で改変したうえで公開・利用した場合
- 自分が権利を持たない素材(他人の著作物・商標等)を入力として使い、それに起因する出力で侵害が生じた場合
- サービス提供者の利用規約・コンテンツポリシーに違反していた場合
- 法令・契約・利用規約上、表示が必要な場合にその表示義務に違反したケース
つまり「補償付きサービスを使えば何でもOK」というわけではなく、プロンプトの作り方と出力の取り扱いを社内ルールで縛ることが補償を有効化する前提になります。AI総研の支援現場でも、補償付きサービスの導入と同時に「補償を無効化しないための社内ルール」を整備するのが定石です。
用途別のサービス選定例
実務上の使い分けの目安として、用途別にケース別推奨を整理しました。

| 用途 | 第一候補 | 補足 |
|---|---|---|
| 商用ビジュアル制作(広告・LP・パッケージ) | Adobe Firefly(法人プラン) | 補償+クリーン学習データの両立 |
| 社内資料・提案書の画像 | ChatGPT(Business/Enterprise) | Copyright Shield対象、業務統合しやすい |
| プロトタイピング・社内検証用 | Midjourney/Stable Diffusion | 表現力優先、対外公開しない前提 |
| 文章生成(記事・コピー) | ChatGPT Enterprise/Claude | 出典確認+人間編集を必須化 |
この使い分けは、外向け公開物と社内検証用で補償付きサービスとそれ以外を切り分けるという設計思想です。社内検証用なら表現力重視のサービスを使い、公開段階では補償付きに乗り換える、という二段構えも現実的な選択肢になります。
AI著作権侵害の罰則と損害賠償コスト——リスクを金額で把握する

ガイドライン整備を社内で稟議に上げるときに最も効くのが、実際にいくらかかるかの数字です。日本の著作権法と国内外の判例から、リスクをコストとして整理します。
日本の著作権法上の罰則
日本の著作権法上、著作権侵害に対する刑事罰の上限は次のとおりです。
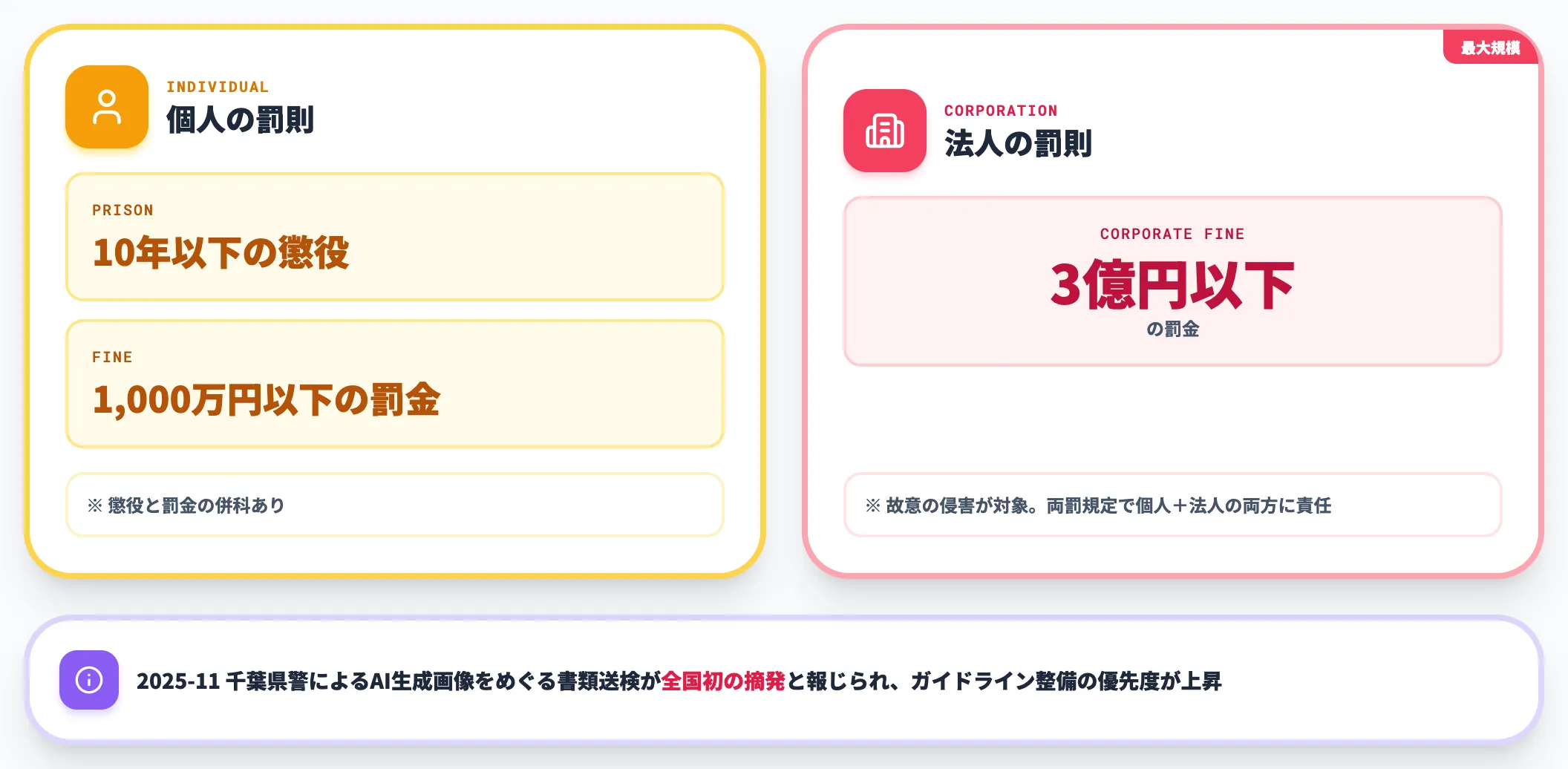
| 対象 | 懲役 | 罰金 |
|---|---|---|
| 個人 | 10年以下 | 1,000万円以下(または懲役と併科) |
| 法人 | — | 3億円以下 |
この罰則は故意の侵害が対象ですが、法人に対しては最大3億円の罰金が科される構造です。2025年11月の千葉県警によるAI生成画像をめぐる書類送検事案は、AI生成画像をめぐる著作権法違反としては全国初の摘発と報じられ(千葉日報は「千葉県警では初とみられる」と慎重表現)、社内ガイドライン整備の優先度を一段引き上げる根拠になりました。
加えて、民事の損害賠償請求・差止請求・名誉回復措置請求が別途あります。
民事の損害賠償額——海外の参考事例
民事の賠償額は、日本国内では判例がまだ蓄積途上ですが、海外の参考事例から規模感をつかめます。
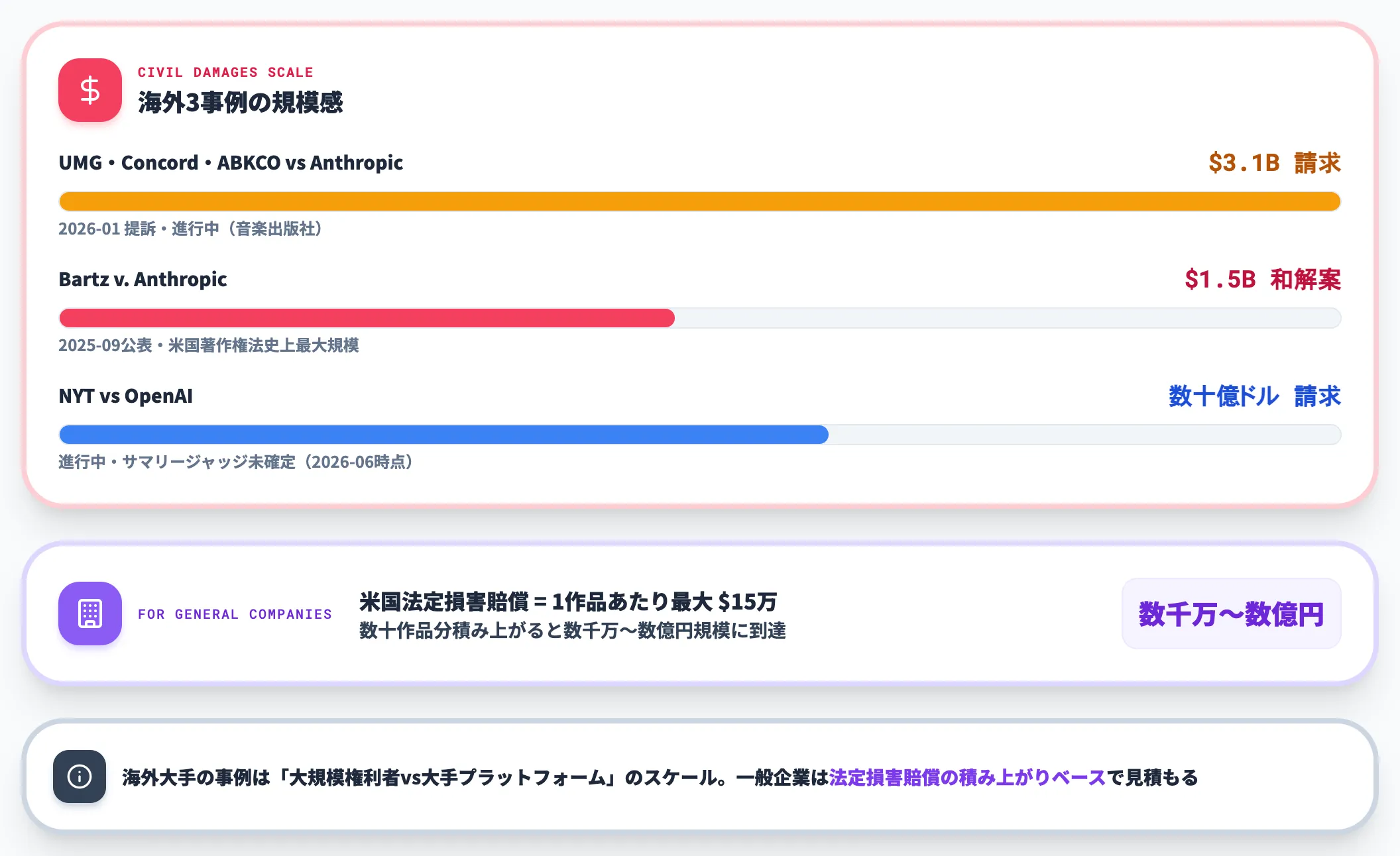
| 事例 | 金額 | 備考 |
|---|---|---|
| Bartz v. Anthropic(米) | 15億ドル規模(約2,200億円) | 2025-09公表の和解案。米国著作権法史上最大規模。2026年6月時点で最終承認待ち |
| UMG・Concord・ABKCO 等 音楽出版社 vs Anthropic(米) | 31億ドル請求 | 2026年1月提訴、進行中 |
| NYT vs OpenAI(米) | 数十億ドル請求(法定損害賠償) | 進行中、2026年6月時点でサマリージャッジ判決未確定。ChatGPT会話ログ開示は2026-01の2,000万件+2026-03の追加命令(OpenAIへ約7,800万件・約1,000万件の2つの追加ログリザーバー)で累計1億件超 |
これらは大手プラットフォーム vs 大規模権利者団体のスケールで、一般企業が同規模の請求を受けるわけではありません。ただし1作品あたりの法定損害賠償が米国では最大15万ドル設定で、これが数十作品分積み上がると数千万〜数億円規模に到達するのは現実的な水準です。
直接コストだけでは終わらない——間接コストの内訳
実際のリスクは、訴訟費用や賠償金だけではありません。AI生成物の著作権侵害が発覚した場合、企業が負う間接コストは次のとおりです。
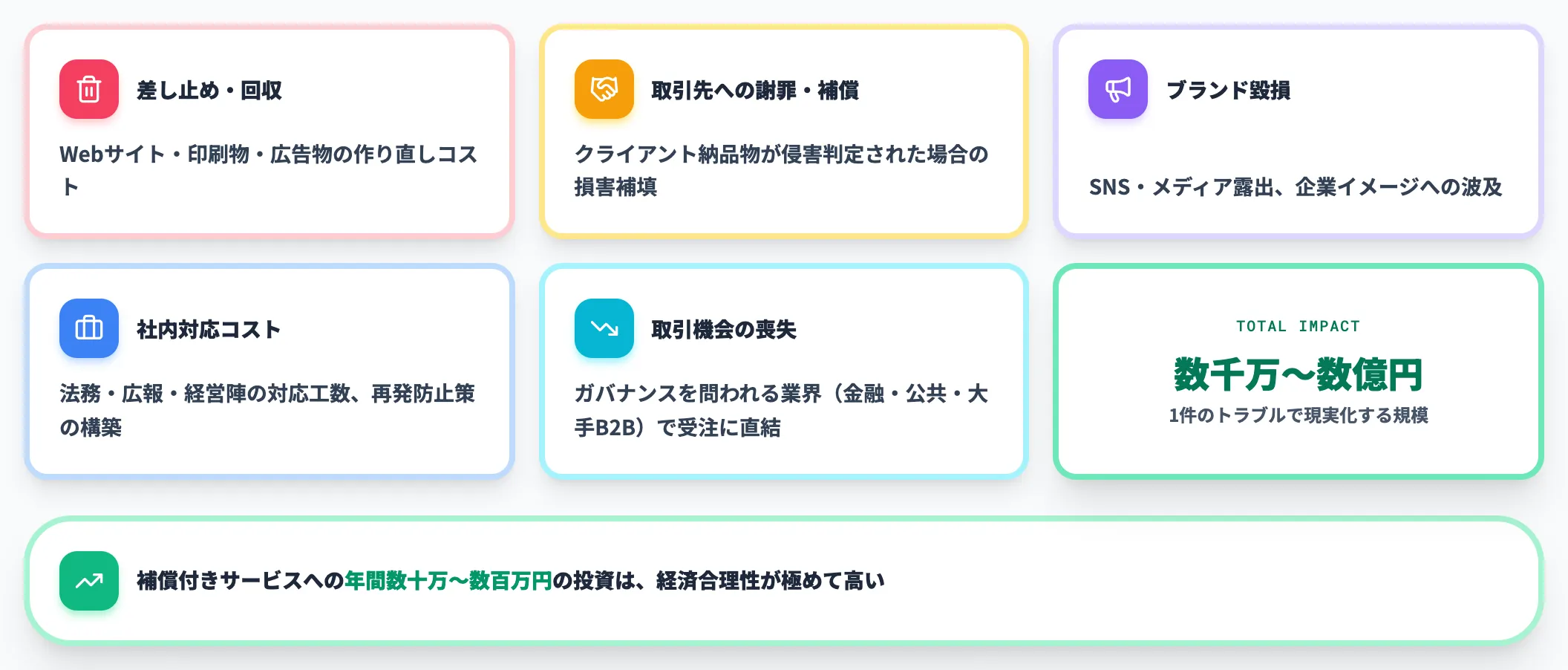
- コンテンツ差し止め・回収: Webサイト・印刷物・広告物の作り直し
- 取引先への謝罪・補償: クライアント納品物が侵害判定された場合の損害補填
- ブランド毀損: SNS・メディアで取り上げられ、企業イメージへ波及
- 社内対応コスト: 法務・広報・経営陣の対応工数、再発防止策の構築
- 取引機会の喪失: ガバナンスを問われる業界(金融・公共・大手B2B)では受注に直結
これらを総合すると、1件のトラブルで数千万円〜数億円規模のコストが現実的になります。ChatGPT EnterpriseやAdobe Firefly法人プランの追加コストが年間数十万〜数百万円であることを踏まえれば、補償付きサービスへの投資は経済合理性が極めて高い領域です。
コスト計算で社内稟議を通す
ガイドライン整備や補償付きサービス導入を社内で承認させるとき、次の3点をセットで提示すると説得力が増します。
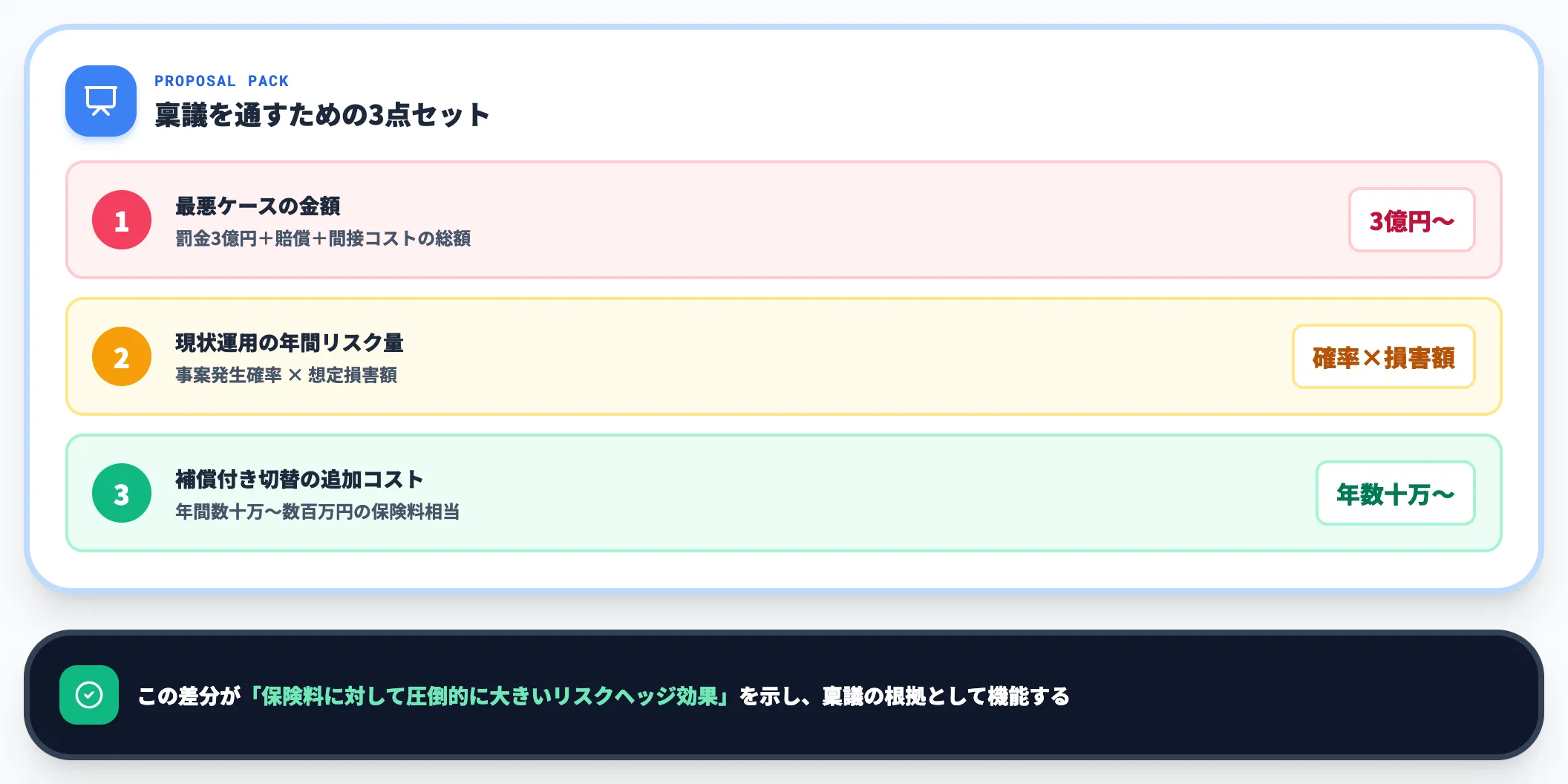
- 想定される最悪ケースの金額(罰金3億円+賠償+間接コスト)
- 現状の補償なし運用が継続した場合の年間リスク量(事案発生確率×想定損害額)
- 補償付きサービスへ切り替えた場合の追加コスト(年間数十万〜数百万円)
この差分が「保険料に対して圧倒的に大きいリスクヘッジ効果」を示すため、稟議の根拠として機能します。AI総研の支援現場でも、この3点セットでガイドライン稟議を進めるとほぼ通る感覚があります。
企業がいま取るべき著作権リスク対策——ガイドライン整備とチェックフロー

ここまでの法的整理・訴訟事例・サービス比較を踏まえ、企業が今日から着手できる対策を整理します。AI総研の支援現場で実際に動いている内容をベースに、優先度順で示します。
優先度高——すぐ着手すべき3つ
最優先で進めるべき対策は次の3つです。これらが揃わないまま生成AIの全社展開に進むと、後で必ずトラブルが起きます。
-
社内AI利用ガイドラインの策定
プロンプトの作り方・出力の取り扱い・商用公開時のチェック手順を明文化する。
文化庁の考え方やガイドライン事例を参考にすると、自社ガイドラインのたたき台がつくりやすくなります。
-
補償付きサービスへの段階的移行
商用公開する画像・文章は、IP補償付きサービス(Adobe Firefly法人プラン/ChatGPT Enterprise・Business(旧Team))に集約。
社内検証用は表現力重視のサービスを残しつつ、対外公開フローには通さないルートを設計します。
-
法務レビューを通す公開フローの整備
商用公開前に、類似性チェック・依拠性リスク評価を法務またはコンプライアンス担当のレビューに通す。
重要度の低い社内利用は省略でよいが、対外公開は必ずレビューを通す二段構えにします。
これらは「**やる・やらない」ではなく「いつまでに整備するか」**の問題として扱うべきフェーズに入りました。
社内ガイドラインに入れるべき10項目
ガイドラインのテンプレートとして、最低限カバーすべき10項目を整理しました。
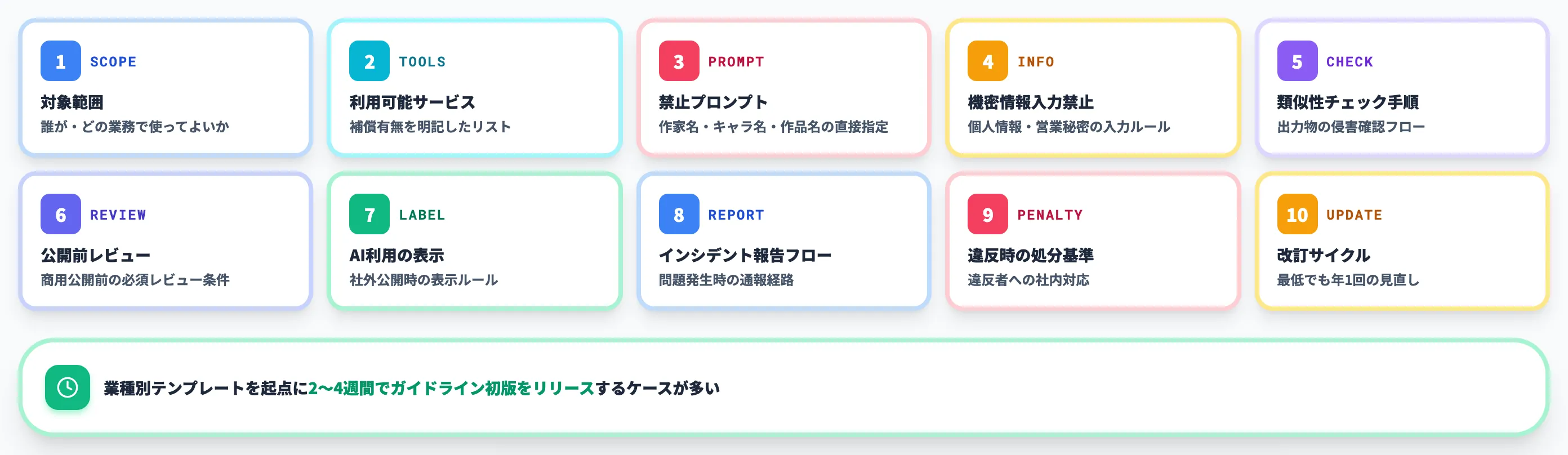
- 対象範囲(誰が・どの業務で生成AIを使ってよいか)
- 利用可能なAIサービス一覧(補償有無を明記)
- 禁止プロンプト(特定アーティスト名・キャラクター名・既存作品名の直接指定)
- 機密情報の入力禁止ルール
- 出力物の類似性チェック手順
- 商用公開前のレビュー必須条件
- 生成AI利用の表示ルール(社外公開時)
- インシデント発生時の報告フロー
- 違反時の社内処分基準
- ガイドライン改訂サイクル(少なくとも年1回)
このリストはガイドラインの「目次」レベルで、各項目の具体的な記述は自社の業種・利用シーンに合わせて作り込みます。AI総研の支援では、業種別のテンプレートを起点に2〜4週間でガイドライン初版をリリースするケースが多くなっています。
チェックフロー——出力から公開までの4ステップ
ガイドラインだけでは現場が動きにくいため、チェックフローを4ステップで明文化しておきます。
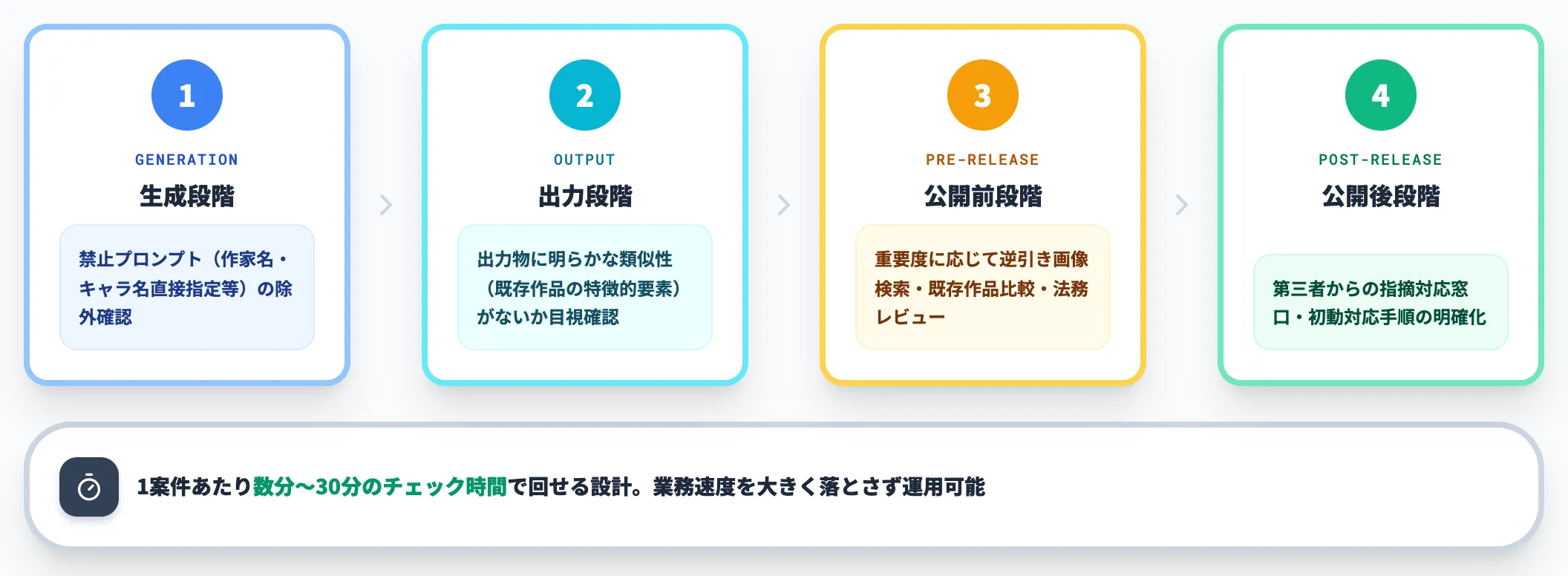
- 生成段階: 禁止プロンプト(作家名・キャラ名直接指定等)が含まれていないことを確認
- 出力段階: 出力物に明らかな類似性(既存作品の特徴的要素)がないかを目視確認
- 公開前段階: 重要度に応じて逆引き画像検索・既存作品との比較を実施。法務レビューが必要な案件はここで通す
- 公開後段階: 万一第三者から指摘があった場合の対応窓口・初動対応の手順を明確化
このフローは1案件あたり数分〜30分のチェック時間で回せる設計で、現場の業務速度を大きく落とさずに運用可能です。重要度に応じた段階的レビュー設計が、運用負荷とリスクヘッジを両立させるコツになります。
ケース別推奨——業種・利用シーンで判断を変える
AI総研の支援経験から、業種・利用シーンごとに最適な打ち手は変わります。整理すると次のとおりです。

| ケース | 第一候補の対策 |
|---|---|
| 受託制作会社(広告・デザイン) | Adobe Firefly法人プラン+クライアント別の生成AI利用合意書 |
| 大手企業の広報・マーケ部門 | ChatGPT Enterprise/Business+法務レビュー必須フロー、社外発信は人間最終チェック |
| スタートアップのプロダクト開発 | 補償付きサービスを最低1つは契約、社内検証は表現力重視サービスで分離 |
| 公共セクター・金融機関 | 全社統一ガイドライン+AIサービスはホワイトリスト方式で限定 |
| 個人事業主・フリーランス | 補償付きサービス1つに集約、納品物にAI利用の旨を契約書で明記 |
業種ごとに「ガバナンスをどこまで効かせるか」のバランスが異なり、画一的なルールよりケース別に判断軸を持つ方が現実的です。
詰まりポイント——導入判断で迷いやすい論点
最後に、ガイドライン策定や運用設計で詰まりやすい論点を先回りで整理しておきます。
- 「人間の創作的寄与」をどう証跡として残すか: プロンプト履歴・修正履歴の保存ルールが必要
- 過去にAI生成物を使った公開物の遡及対応: 全件チェックは現実的でないため、リスク評価に基づく対応範囲の線引きを決める
- クライアント納品物にAI利用をどう開示するか: 業界慣行が固まっていないため、契約段階で個別合意を取る運用が安全側
- 海外サービスのIP補償の準拠法・管轄: 米国法準拠が多く、日本国内で執行できるかは別問題。補償が「あるかないか」だけでなく「どこで請求できるか」も確認
これらは法務部門の判断が必要になる論点ですが、現場担当者が問いを持っていることが議論の起点になります。「ガイドラインを作る前に、何を決めなければならないかを整理する」フェーズを必ず先に置くと、後の運用がスムーズに回ります。

著作権リスクを抑えてAIを業務に組み込むなら
AI著作権の論点を整理できたら、次は「整理した知見をどう業務設計に落とすか」が論点に変わります。ガイドライン・サービス選定・チェックフローを揃えても、PoCから全社展開へ進めるステップ設計がなければ業務効果は出ません。
そこで踏むべき段階設計を、Microsoft環境を起点に体系化したのが、AI総合研究所の「AI業務自動化ガイド」(220ページ)です。Copilot Chat・M365 Copilot・Copilot Studio・Microsoft Foundryへの段階導入、部門別ユースケース、セキュリティ・ガバナンス・権限設計、PoCから全社展開までの進め方を1冊で整理しています。
法務・情シス・現場の3者で同じ地図を共有するための実務ガイドとして、本記事の著作権整理と並行して活用ください。
著作権リスクを踏まえたAI業務導入

社内ガイドラインから全社展開までの設計を1冊で
AI生成物の著作権リスクを把握した次は、ガイドラインを軸にAIを業務へ組み込むフェーズです。AI業務自動化ガイド(220ページ)では、PoCから全社展開までの段階設計、部門別ユースケース、セキュリティ・ガバナンス・権限設計の進め方を整理しています。法務・情シスと現場をつなぐ実務ガイドとして活用ください。
まとめ
本記事では、AI生成物の著作権を、文化庁の2段階モデルを起点に、著作物性・侵害判断・学習段階・国内外訴訟・海外法制度・サービス補償・罰則と賠償コスト・企業対策まで、2026年6月時点の最新情報で整理しました。要点を改めて整理します。
-
AI単独生成物は原則として著作物にならない——日本・米国とも「人間の創作的寄与」が必須。プロンプト1回で生成したものは独占的な著作権を主張しにくい素材として扱う
-
著作権侵害は依拠性・類似性の2要件で判断され、原則として出力を公開した利用者が責任を負う——ただしAI開発企業・サービス提供事業者も態様により責任主体になり得るため、利用者側のガイドラインとチェックフロー整備に加え、補償付きサービス選定が必須
-
学習段階は30条の4で原則適法だが、海賊版経由・享受目的併存は例外——Anthropic 15億ドル和解案(2025年9月公表・最終承認待ち)が示すように、データの取得経路は決定打になる
-
2025-2026年は訴訟と摘発が連続している——Anthropic和解案は2026年5月14日fairness hearing後に最終承認order保留中、NYT vs OpenAIはChatGPT会話ログ開示が累計1億件超の規模に拡大しつつサマリージャッジ判決待ち、千葉県警によるAI生成画像をめぐる書類送検(報道ではAI生成画像をめぐる著作権法違反としては全国初の摘発)など、企業のAI利用に直撃する事案が続発。判例が出揃うまではリスクの高い利用を避けるのが安全側
-
商用公開はIP補償付きサービスを第一候補に——Adobe Firefly・ChatGPT Enterprise/Business(旧Team)の追加コストは、罰金3億円+賠償+間接コストのリスクヘッジ効果から見て合理的
-
企業対策は「ガイドライン・補償付きサービス・法務レビュー」の3点セット——いつ着手するかの問題であり、後回しにすると訴訟・摘発の波に巻き込まれる
AI著作権は「使ってよいかどうか」ではなく「どう整備すれば安全に使えるか」を考えるフェーズに入りました。本記事の整理を起点に、自社のガイドライン・サービス選定・チェックフローを2026年中に整える動きが、最も現実的な打ち手になります。










