この記事のポイント
 2026年4月24日にベータ公開、2026年6月22日に一般提供を開始したマルチエージェント基盤モデルで、OpenAI互換API経由で複数のフロンティアモデルを動的に編成
2026年4月24日にベータ公開、2026年6月22日に一般提供を開始したマルチエージェント基盤モデルで、OpenAI互換API経由で複数のフロンティアモデルを動的に編成- 上位版Fugu UltraはTerminal-Bench 2.1でFable 5、Charxiv ReasoningでMythos Previewを上回ったと公式報告
- サブスクは月20ドル・100ドル・200ドルの3段、Fugu Ultra APIは入力5ドル・出力30ドルで272Kトークン超過時は10ドル・45ドル
- Fable 5・Mythos 5が利用停止中の現在、Fugu Ultraはフロンティア帯AIを業務利用したい企業の現実的な代替候補
- 標準版Fuguでは特定プロバイダー・モデルの除外設定が可能(Fugu Ultraは固定プール)、EU/EEAは現時点未提供でGDPR対応中

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Sakana Fugu(サカナ・フグ)は、Sakana AIが2026年4月24日にベータ公開し、2026年6月22日に一般提供を開始した、複数のフロンティアモデルを動的に編成して動かす「マルチエージェント基盤モデル」です。
上位版「Fugu Ultra」はClaude Mythos PreviewやFable 5と並ぶフロンティア性能をうたい、一部ベンチマークでこれらを上回ったと公式が報告しています。
本記事では、Sakana Fuguの仕組み・Fugu Ultraとの違いとベンチマーク・料金体系・OpenAI互換APIでの使い方・他フロンティアモデルとの比較・Fable 5が利用停止となった現状での採用判断軸を、2026年6月時点の最新情報で体系的に解説します。
目次
Sakana Fuguとは?日本発の「マルチエージェント基盤モデル」
Sakana AIの位置づけ——日本発のフロンティアAI企業
Sakana Fuguの仕組み——ConductorとTRINITYによるオーケストレーション
Sakana FuguとFugu Ultraの性能とベンチマーク
ベンチマーク——Fable 5・Mythos Previewと「肩を並べる」性能
実務的な性能差——50週株式取引パイプラインで+19.43%
Sakana Fuguの料金体系——サブスクと従量課金の二本立て
Sakana Fuguの使い方——OpenAI互換APIと利用範囲
Sakana Fugu UltraはClaude Fable 5の代替になるか
Fable 5・Mythos 5は2026年6月13日に利用停止
Fugu Ultraがフロンティア帯の現実的な選択肢になる理由
他のマルチモデル統合との違い——OpenRouter Fusion APIとの比較
Sakana Fuguとは?日本発の「マルチエージェント基盤モデル」

Sakana Fugu(サカナ・フグ)は、東京を本拠とするSakana AIが2026年4月24日にベータ公開し、2026年6月22日に一般提供を開始した、**複数のフロンティアモデルを動的に編成して動かす「マルチエージェント基盤モデル」**です。同じく6月22日には、上位版「Fugu Ultra」の提供も同時に始まっています。
ユーザーから見れば1つのモデルAPIに見えますが、内部ではClaude系・GPT系・Gemini系を含む複数のLLMを「エージェント」として呼び分け、難易度や用途に応じてチーム編成を組み替える設計になっています。

Sakana AIの位置づけ——日本発のフロンティアAI企業
Sakana AIは「Building Frontier AI in Japan」を掲げる東京拠点のAI企業で、複数のLLMを編成する「集合知(Collective Intelligence)」研究を中心に据えてきました。
これまで主要なフロンティアモデルはAnthropic・OpenAI・Google・Metaなど米国企業を中心に展開されてきましたが、Sakana AIはFuguを「flagship international commercial AI product」と位置づけており、日本発の国際商用AIプロダクトとして国内外で注目を集めています。
複数モデルを束ねるアプローチは、米国一極集中の輸出規制リスクや、データ主権・コンプライアンスの観点でも一定の意味を持ちます。
Sakana Fuguの仕組み——ConductorとTRINITYによるオーケストレーション
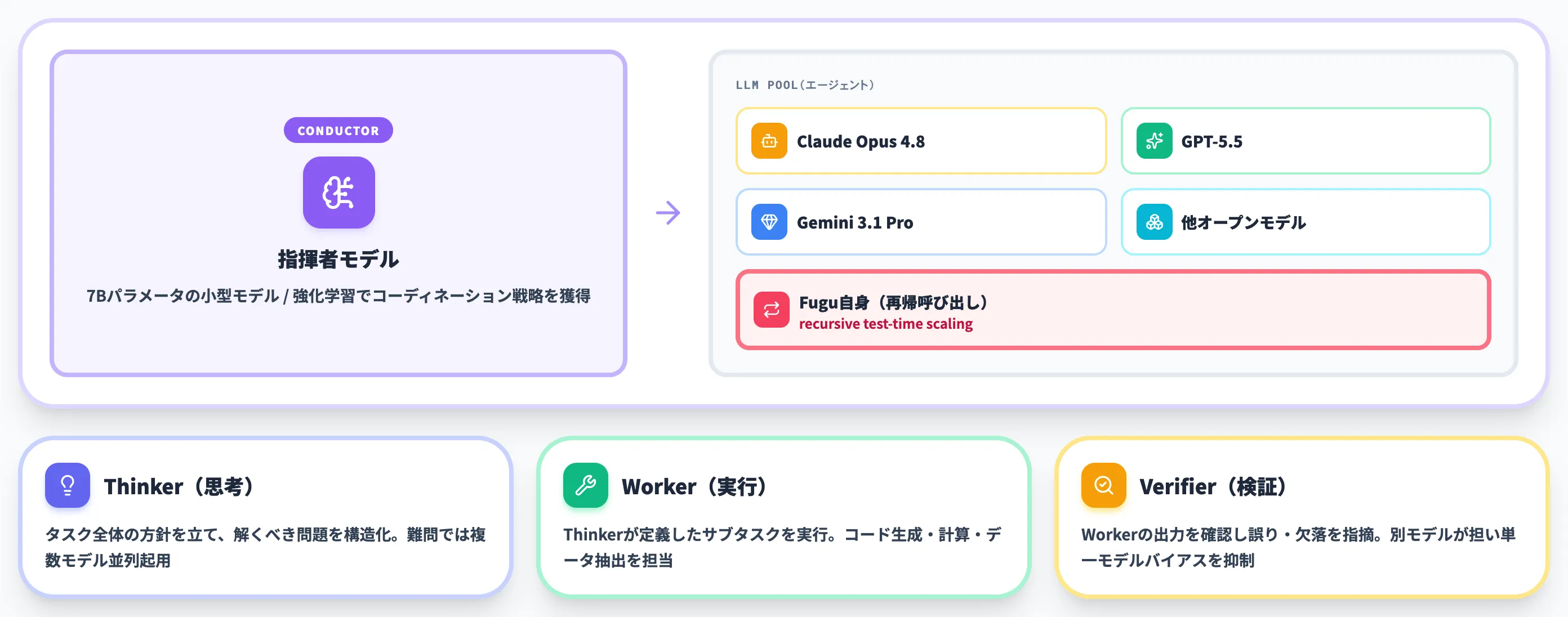
Sakana Fuguの中心にあるのは、「Conductor(指揮者)」と呼ばれるオーケストレーションモデルです。
Fugu自身がLLMとして訓練されており、エージェントプール内の各モデルに対して「誰に・どのタスクを・どう投げるか」を判断します。
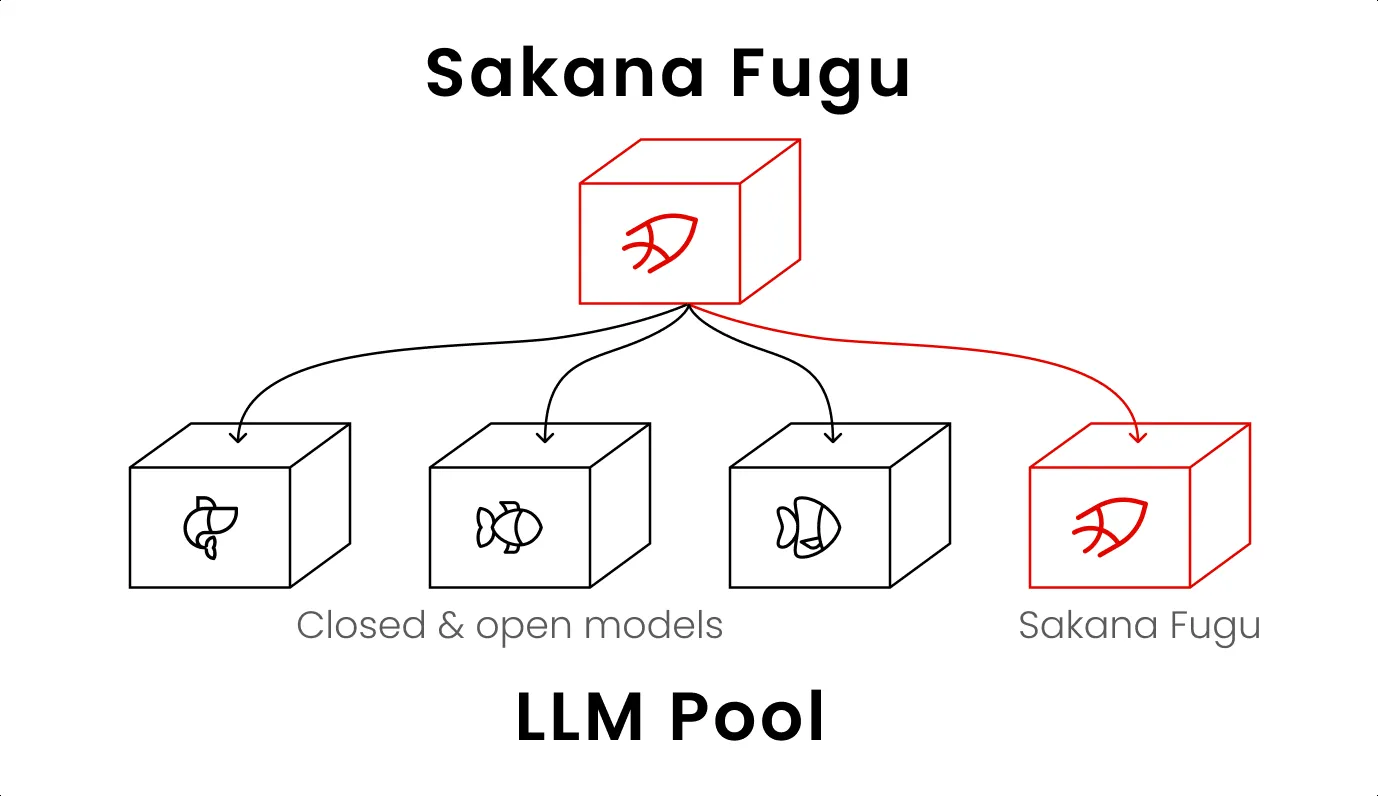
Sakana Fuguが複数モデルと自分自身を含むLLM Poolを呼び分ける構造(出典:Sakana AI)
図の中央上段にあるSakana Fugu(赤枠)が、下段のLLM Pool——他社の閉鎖モデル・オープンモデル——に加えて、右端で自分自身を呼び出すループを持っているのが見て取れます。この再帰呼び出しが、後述する「recursive test-time scaling」の核です。
このセクションでは、Fuguの技術的中核であるICLR 2026の論文2本——TRINITYとConductor——をベースに、内部の動き方を整理します。
Thinker/Worker/Verifierの3役割
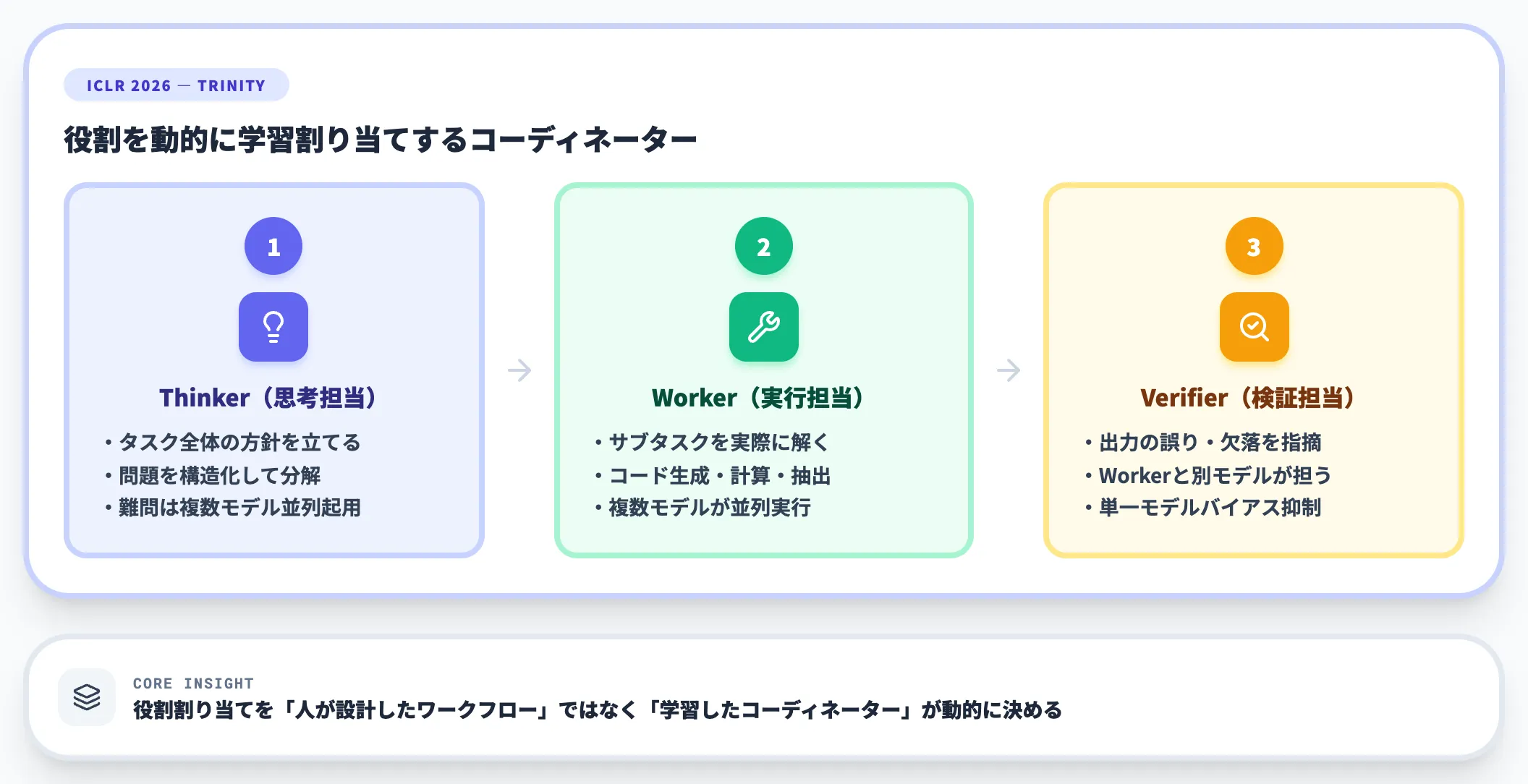
TRINITYは、Sakana AIが提唱する進化的に訓練されたLLMコーディネーターのフレームワークです。
TRINITYは、複数のLLMに3つの役割を動的に割り当てます。
-
Thinker(思考担当)
タスク全体の方針を立て、解くべき問題を構造化する役割。難問では複数モデルを並列で起用することもある
-
Worker(実行担当)
Thinkerが定義したサブタスクを実際に解く役割。コード生成・計算・データ抽出などをこなす
-
Verifier(検証担当)
Workerの出力を確認し、誤りや欠落を指摘する役割。Workerと別のモデルが担うことで、単一モデル特有のバイアスや幻覚を抑制する
これらの役割割り当てを「人が設計したワークフロー」ではなく「学習したコーディネーター」が動的に決めるところがTRINITYの肝です。コーディング・数学・推論・知識タスクで、単一モデルを上回る成果が報告されています。
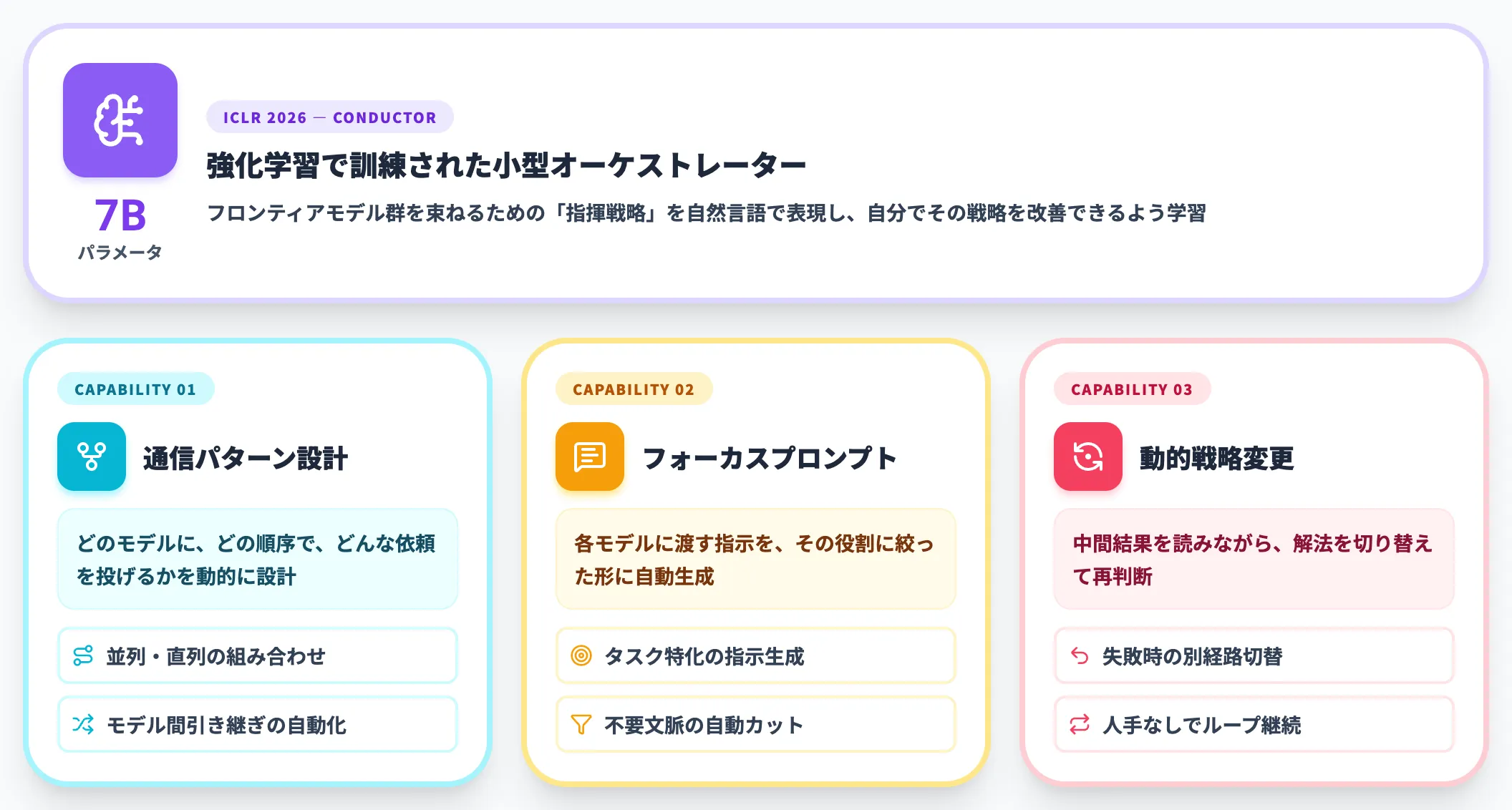
強化学習で訓練された7Bオーケストレーター
もう一本の論文「Conductor」は、TRINITYの実装に近い構造を持ちます。
Conductorは7Bパラメータの小型モデルで、強化学習(RL)によって自然言語のコーディネーション戦略を学習します。具体的には以下のような能力を獲得します。
- エージェント間の通信パターン(どのモデルにどの順序で投げるか)の設計
- 各モデルに渡すフォーカスを絞ったプロンプトの自動生成
- タスクの中間結果を見ながら、戦略を動的に変更する判断
VentureBeatの取材によれば、ConductorはGPT-5・Claude Sonnet・Gemini Proなどのフロンティアモデルを束ねることで、それぞれ単独で動かすよりも高い推論性能を引き出せることが示されています。
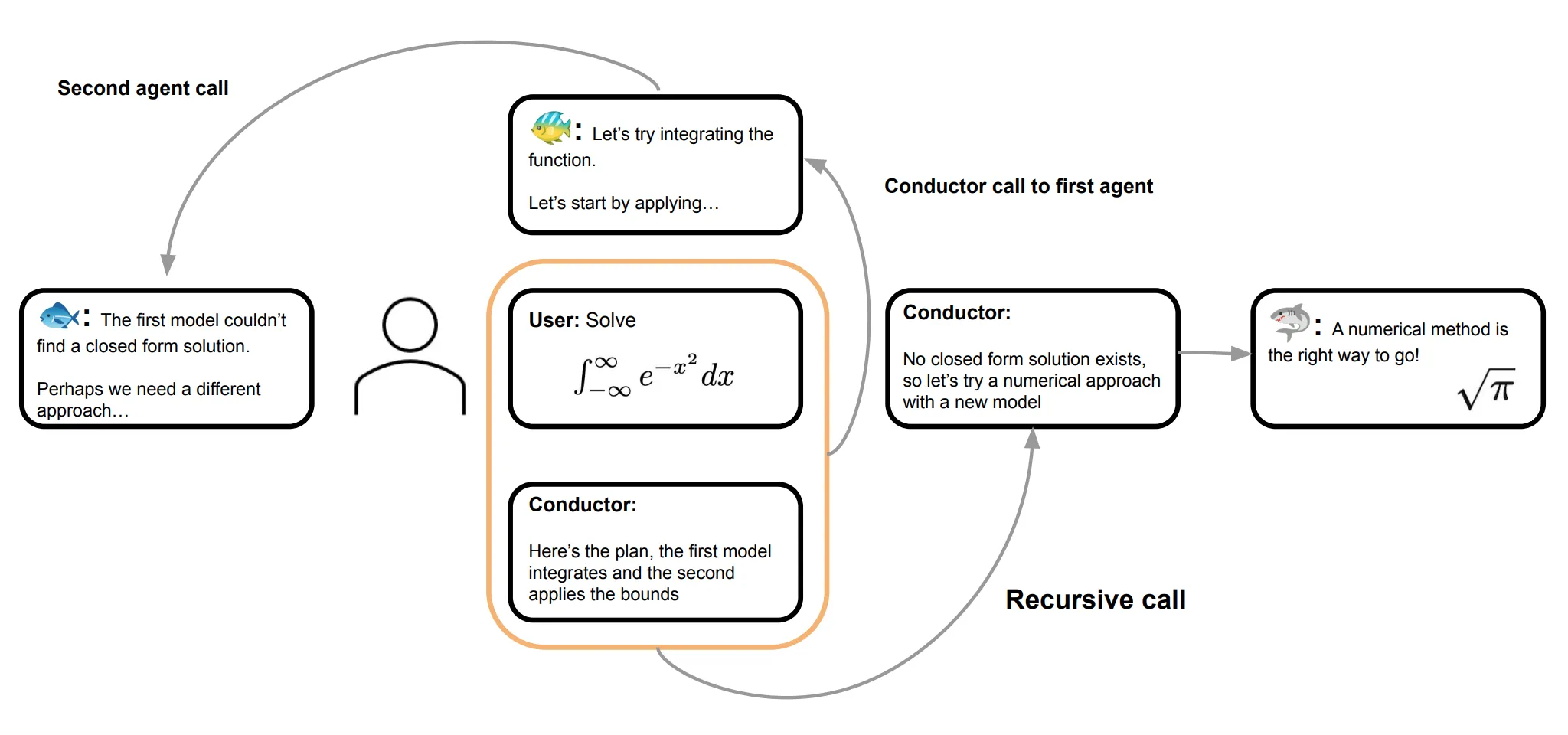
Conductorが「First agent → Second agent → Recursive call」で数学問題を解く具体例(出典:Sakana AI)
実際の動き方を、図の数学問題(ガウス積分の評価)で追うと分かりやすいです。
最初にConductorが「First agentは積分、Second agentは境界条件」と方針を立て、First agentが解析的に解けないと判断すると、Conductorがその結果を読んで「数値解法に切り替える」と再判断し、別のagentに振り直しています。人間が「次は何をするか」を指示し直さなくても、Conductor自身がループを回すところがポイントです。
Fuguは自分自身も再帰的に呼び出せる
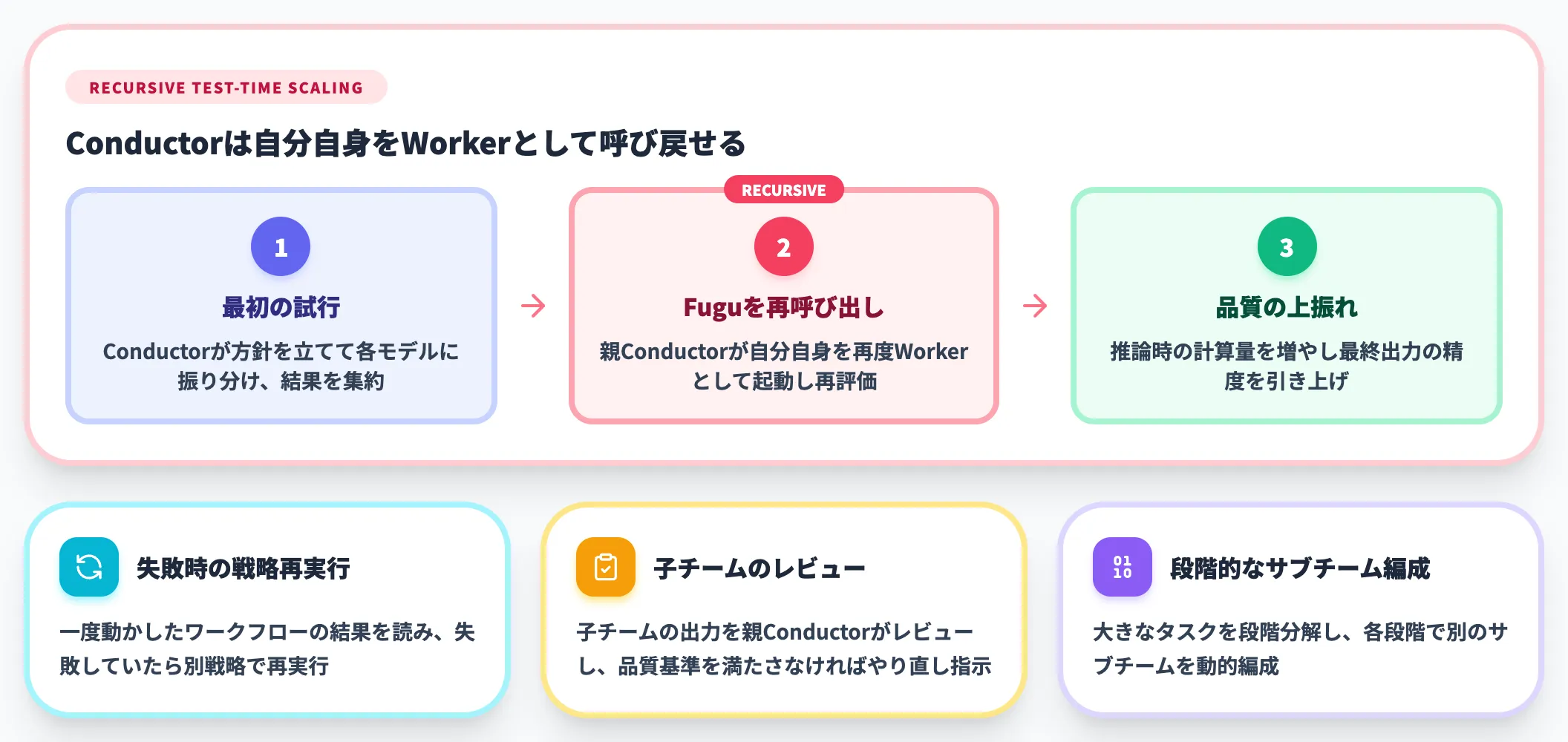
Sakana Fuguの設計で特徴的なのは、Fugu自身がエージェントプールの中に再帰的に含まれる点です。Conductorは必要に応じて、自分自身を「Worker」として呼び出すことができます。
これにより以下のような挙動が可能になります。
- 一度実行したワークフローの結果を読み取り、失敗していたら別の戦略で再実行する
- 子チームの出力を親Conductorがレビューし、品質基準を満たさなければやり直しを指示する
- 大きなタスクを段階的に分解し、各段階で別のサブチームを動的に編成する
公式は、この再帰的な呼び出しを「推論時の計算量を増やすことで品質を上げる新しい軸(recursive test-time scaling)」と説明しています。
エージェントプールは差し替え可能
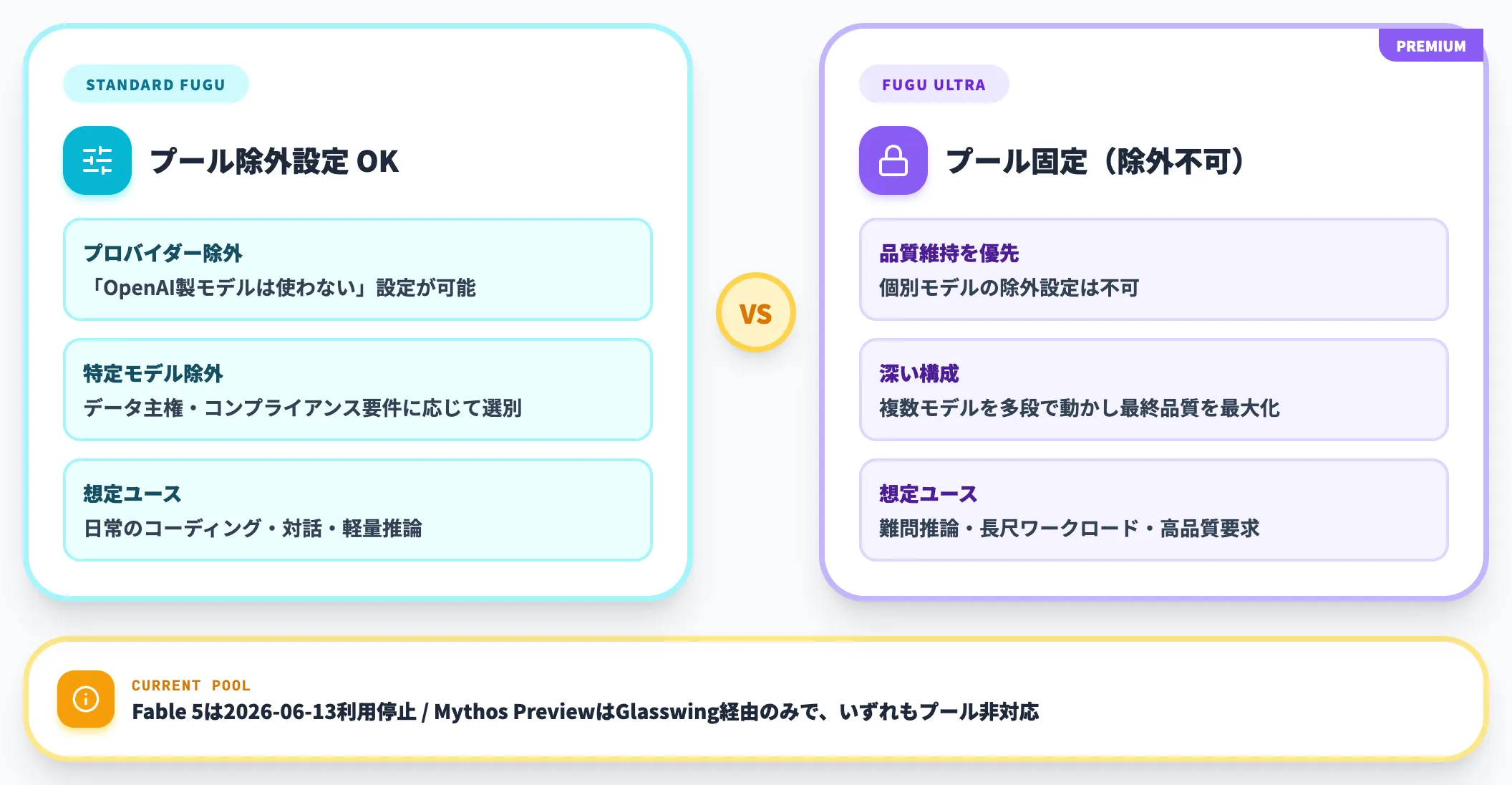
Sakana Fuguのもう一つの特徴は、エージェントプールが完全に差し替え可能な点です。
標準版のFuguでは、データ・プライバシー・コンプライアンス要件に応じて、特定のプロバイダーや特定のモデルを「使わない」設定をオプトアウトできます。
たとえば「OpenAIモデルは使わない」といった構成が可能です。一方でFugu Ultraは品質維持のためエージェントプールが固定されており、個別モデルの除外設定はできない仕様です。
公式は今後、オープンモデルやSakana AI独自のモデルもエージェントプールに組み込んでいく方針を示しています。
Sakana FuguとFugu Ultraの性能とベンチマーク
Sakana Fuguには標準版「Fugu」と上位版「Fugu Ultra」の2モデルがあります。ここでは両者の使い分けと、公式・主要メディアが報じたベンチマーク評価を整理します。
ベンチマーク——Fable 5・Mythos Previewと「肩を並べる」性能
公式リリース「One Model to Command Them All」では、Sakana Fugu Ultraを8つの主要ベンチマークでフロンティアモデルと比較しています。
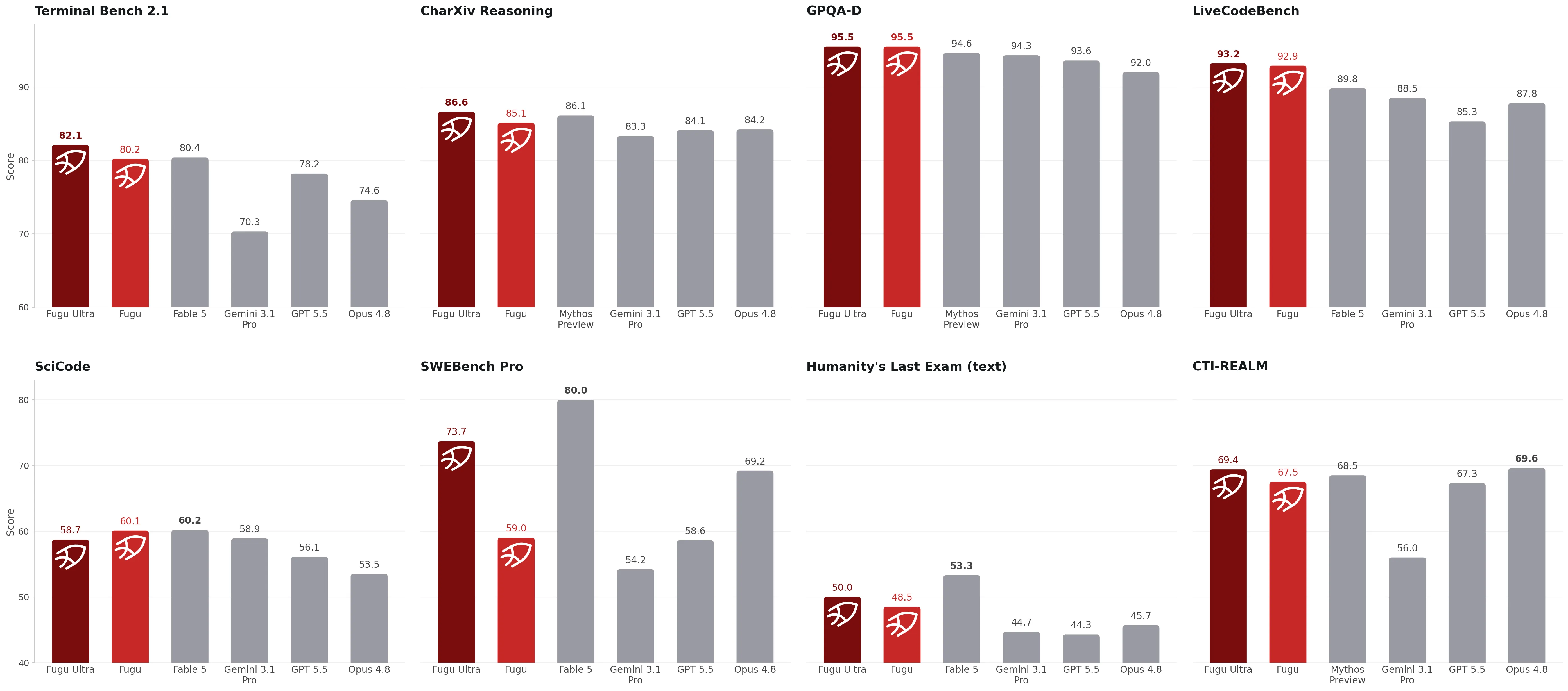
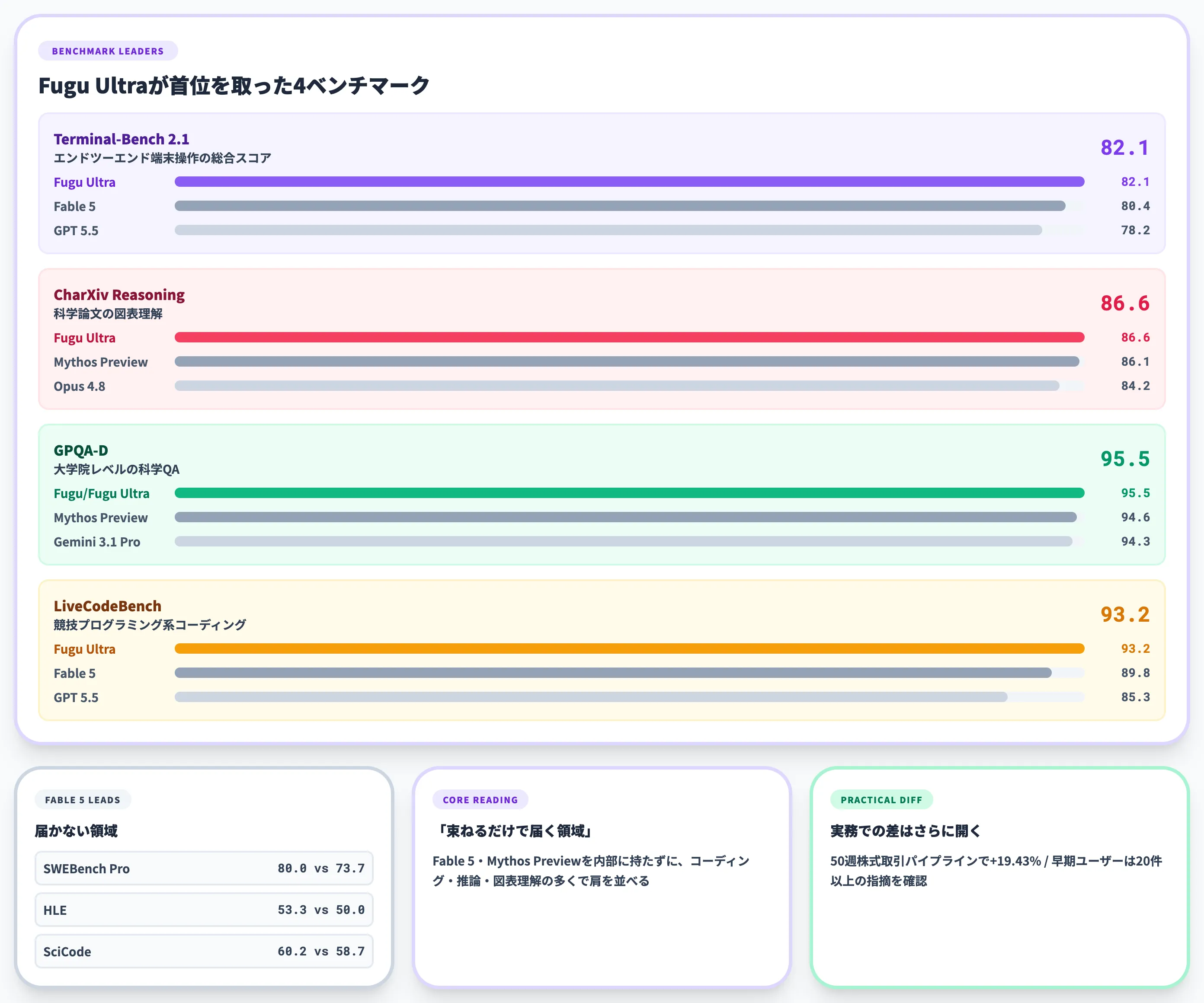
Sakana Fugu Ultra・FuguをFable 5・Mythos Preview・Opus 4.8・Gemini 3.1 Pro・GPT 5.5と比較した8ベンチマーク(出典:Sakana AI)
棒グラフから読み取れる主要スコアを整理すると、Fugu Ultraが首位を取ったベンチマークは以下のとおりです。
- Terminal-Bench 2.1: Fugu Ultra 82.1 vs Fable 5 80.4・GPT 5.5 78.2・Opus 4.8 74.6
- CharXiv Reasoning: Fugu Ultra 86.6 vs Mythos Preview 86.1・Opus 4.8 84.2
- GPQA-D: Fugu Ultra/Fugu 95.5 vs Mythos Preview 94.6・Gemini 3.1 Pro 94.3(Sakana公式テクニカルレポートではFable 5は92.6)
- LiveCodeBench: Fugu Ultra 93.2 vs Fable 5 89.8・GPT 5.5 85.3
一方で、Fable 5がFugu Ultraを上回ったベンチマークもあります。
- SWEBench Pro: Fable 5 80.0 vs Fugu Ultra 73.7
- Humanity's Last Exam: Fable 5 53.3 vs Fugu Ultra 50.0
- SciCode: Fable 5 60.2 vs Fugu Ultra 58.7
Sakana Fugu Ultraはコーディング・推論・ドキュメント理解の多くのベンチマークでFable 5・Mythos Previewと拮抗または上回る一方で、最難関の Humanity's Last Exam や ソフトウェアエンジニアリングタスク SWEBench Pro では Fable 5 に届いていません。「全領域で最強」ではなく、「現役モデルを束ねるだけでFable・Mythos級と渡り合える領域がここまで広がった」と読むのが正しい解釈です。
詳細な数値比較は、公式が掲載している11ベンチマーク数値表でも確認できます。
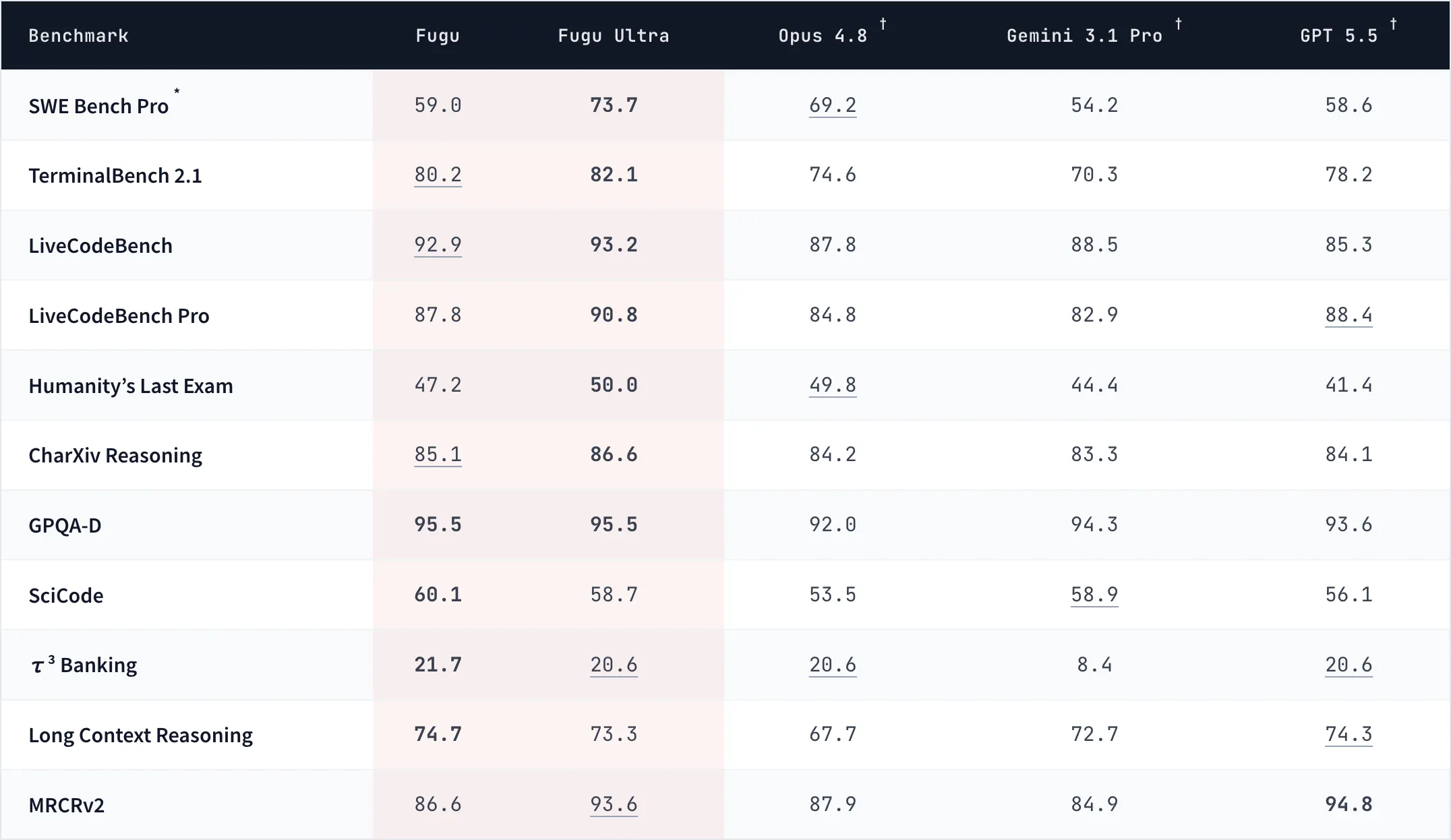
Fugu / Fugu Ultra / Opus 4.8 / Gemini 3.1 Pro / GPT 5.5 の11ベンチマーク数値比較(出典:Sakana AI)
この数値表ではFable 5とMythos Previewが除外されており、比較対象は Fugu・Fugu Ultra・Opus 4.8・Gemini 3.1 Pro・GPT 5.5 の5列に絞られています。公式は「Fable 5は利用停止中・Mythos Previewは限定提供のため、いずれも一般利用できる公開API経路がなくFuguのエージェントプールに含まれない」と説明しており、エージェントプール内のみで比較したい意図がうかがえます。
注目すべきは、Fugu Ultraはエージェントプール内にFable 5・Mythos Previewを持たないにもかかわらず、Charxiv Reasoning・LiveCodeBench・GPQA-D 等でこれらに肩を並べている点です。
つまり、Fuguは「最強モデル」を借りずに、利用可能なフロンティアモデル群を束ねるだけで、Fable・Mythos級の領域まで届いていることになります。
実務的な性能差——50週株式取引パイプラインで+19.43%
ベンチマークだけでなく、実務に近い長尺タスクでの差も公式は報告しています。
50週分の株式取引パイプラインを5回実行する評価では、Fugu Ultraがポートフォリオを**$11,943.22 ± $633.86**(平均リターン+19.43%)まで成長させ、他のフロンティアモデル単体は+15%未満にとどまったとされています。
ベンチマークの数ポイント差は実務でわかりにくいことが多いものの、**「複数日の連続タスクで方針を維持する力」**には差が出やすく、Fugu Ultraのオーケストレーション効果が明確に表れた事例です。
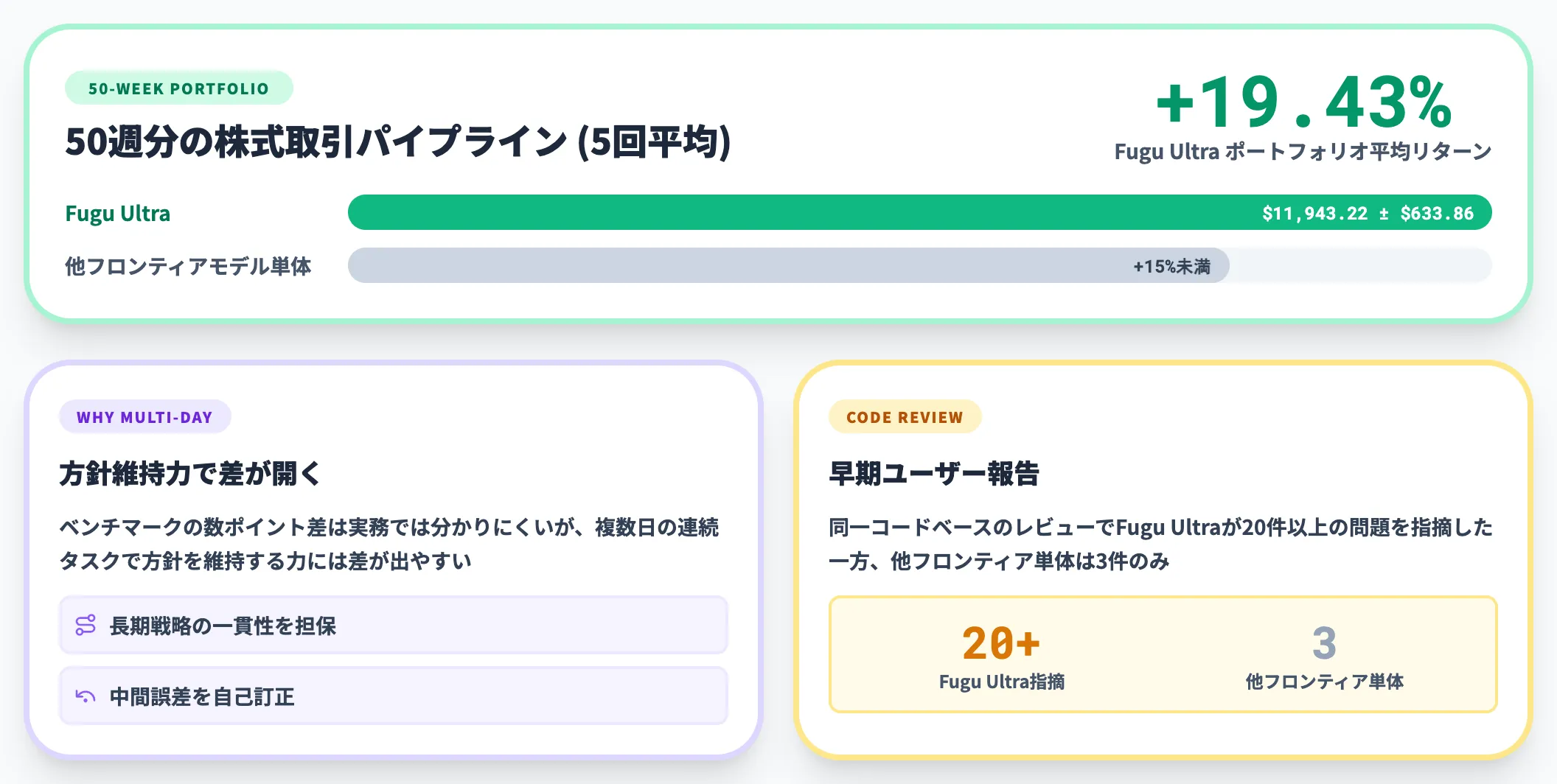
ベンチマーク以外で現れる「方針維持力」
公式リリースでは、ベータ版を試用した早期ユーザーから「同一コードベースのレビューでFugu Ultraが20件以上の問題を指摘した一方、他フロンティアモデル単体は3件のみだった」など、ベンチマーク数値では現れにくい多段ワークフロー上の差が報告されています。
業務に近い活用パターンと向き不向きの詳細は、後段の「Sakana Fuguが効くユースケースと採用判断軸」で整理します。
Sakana Fuguの料金体系——サブスクと従量課金の二本立て
Sakana Fuguの料金はサブスクリプション(個人・小規模チーム向け)と従量課金(法人・大規模ワークロード向け)の二本立てです。
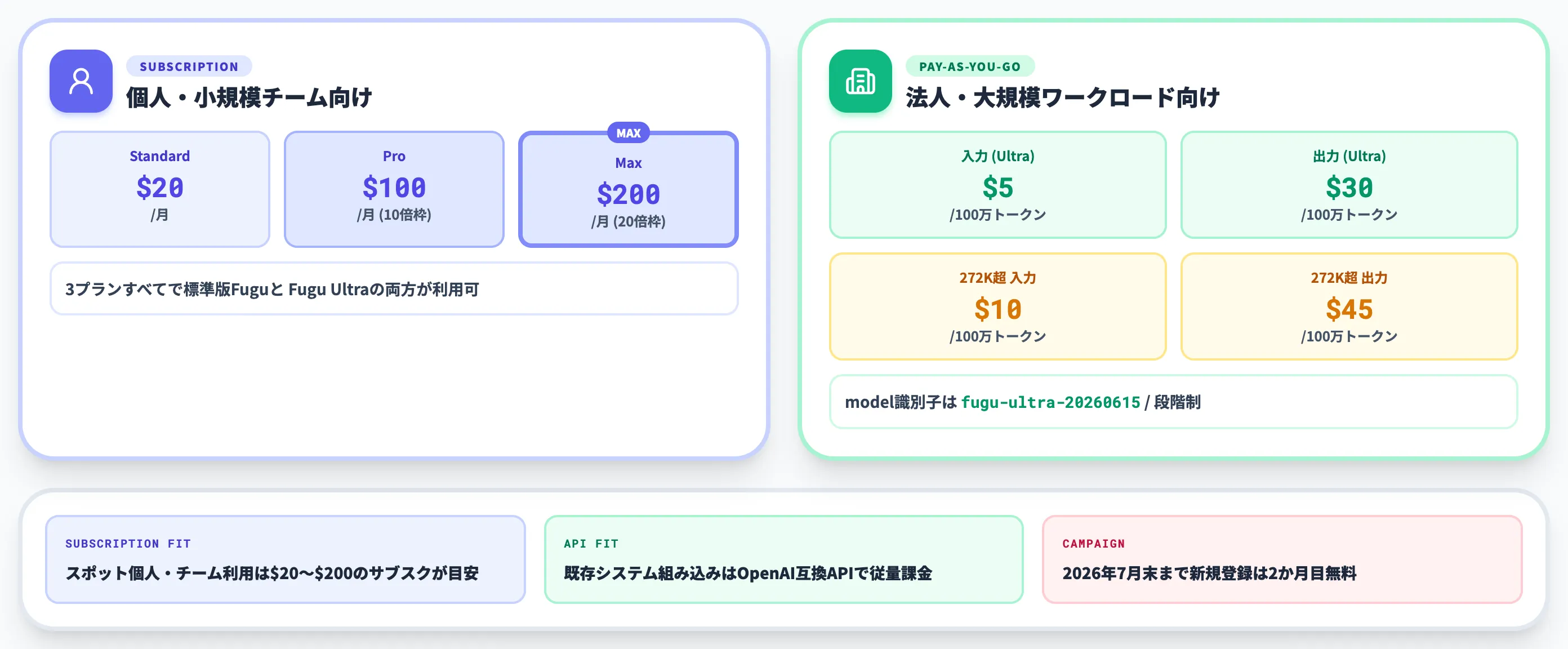
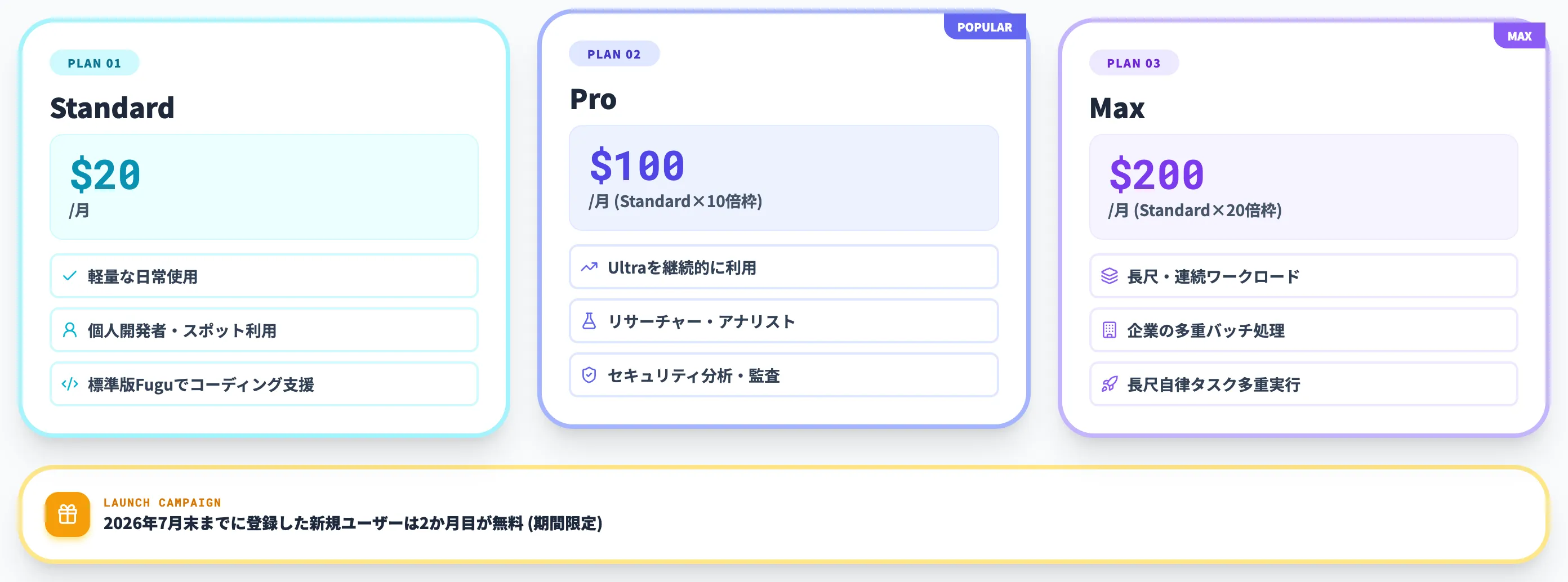
サブスクリプション3プラン
個人・小規模チームが日常的に使う場合、月額サブスクリプションが選択肢になります。
| プラン | 月額 | 利用枠の目安 |
|---|---|---|
| Standard | $20 | 軽量な日常使用 |
| Pro | $100 | Standardの10倍の利用枠 |
| Max | $200 | Standardの20倍の利用枠、長尺・連続ワークロード向け |
3プランすべてで標準版FuguとFugu Ultraの両方が利用可能で、ワークロードに応じてどちらを呼ぶか選べます。
価格設定はChatGPT Plus・Pro・MaxやClaude Pro・Maxなどの主要LLMサブスクリプションと正面から競合する水準で、「複数モデル契約を1つに統合できる」点をコスト訴求にしています。
Sakana AI公式では、2026年7月末までに登録した新規ユーザー向けに2か月目を無料にするローンチキャンペーンも案内されています(期間限定のため、契約時点で公式ページの最新条件を確認してください)。
Fugu Ultra APIの従量課金
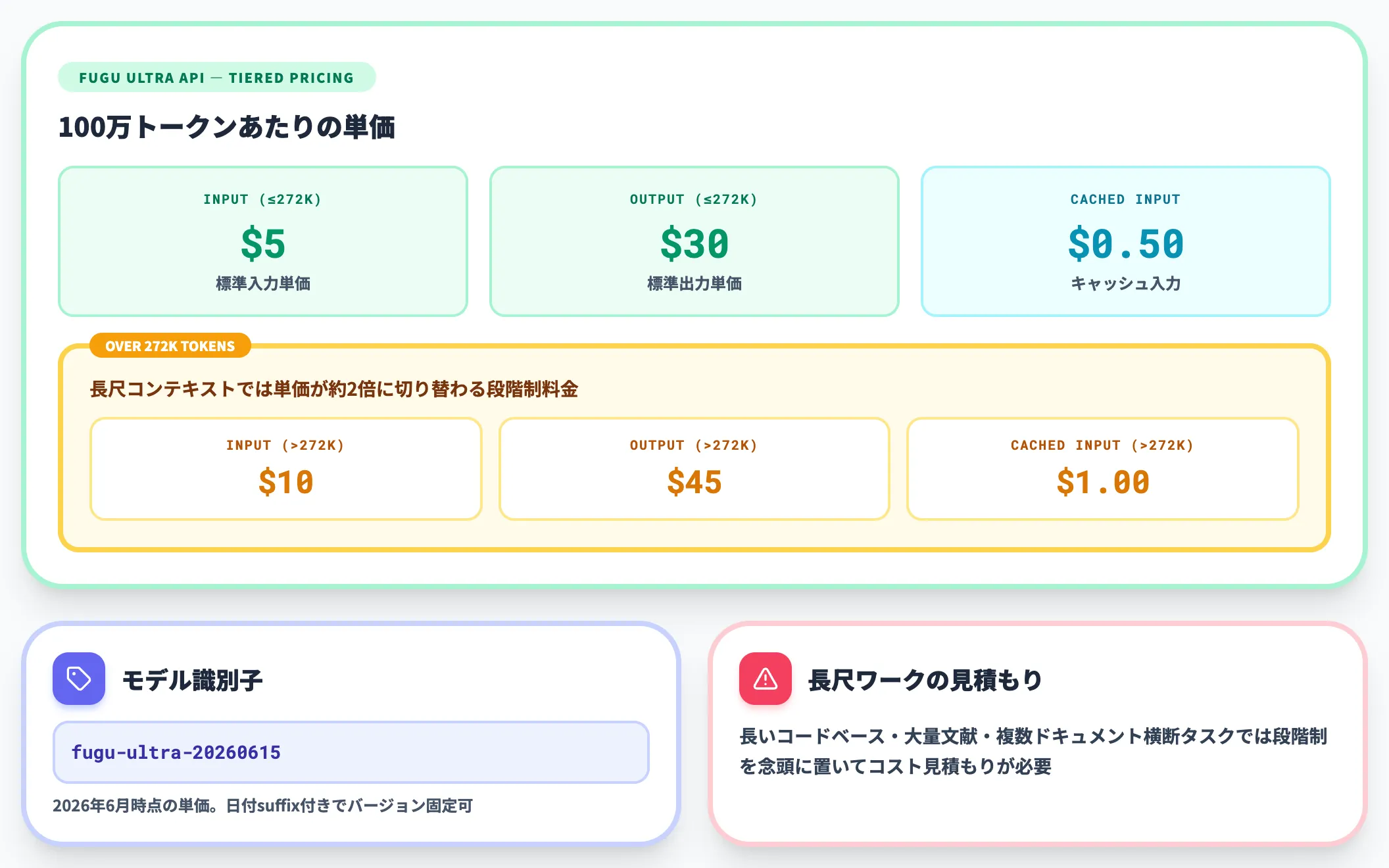
法人・大規模ワークロード・既存システムへの組み込みでは、従量課金APIを使います。Fugu Ultraの料金体系は以下のとおりです。
| 種別 | 料金(100万トークンあたり) | 272Kトークン超過時 |
|---|---|---|
| 入力 | $5 | $10 |
| 出力 | $30 | $45 |
| キャッシュ入力 | $0.50 | $1.00 |
モデル識別子は「fugu-ultra-20260615」で、2026年6月時点の単価です。
272Kトークンを超える長尺コンテキストでは単価が倍前後に切り替わる段階制料金になっており、長いコードベース・大量の文献・複数ドキュメント横断のタスクではコスト見積もりに注意が必要です。
他フロンティアモデルとの単価比較
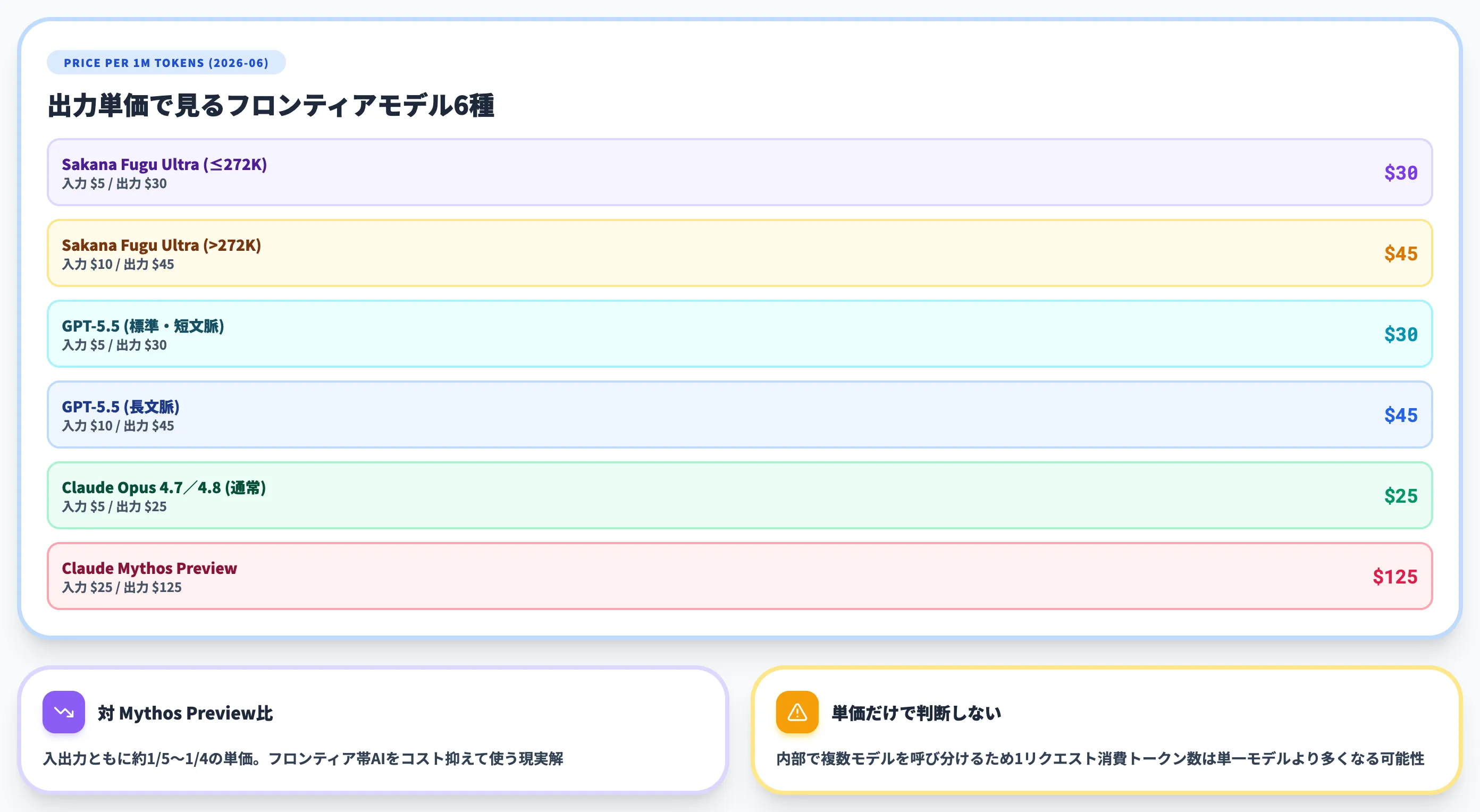
参考として、現行の主要フロンティアモデルとの単価関係を整理します(いずれも2026年6月時点・100万トークンあたり)。
| モデル | 入力単価 | 出力単価 |
|---|---|---|
| Sakana Fugu Ultra(272K以下) | $5 | $30 |
| Sakana Fugu Ultra(272K超) | $10 | $45 |
| GPT-5.5(標準・短文脈) | $5 | $30 |
| GPT-5.5(長文脈) | $10 | $45 |
| Claude Opus 4.7/4.8 通常利用 | $5 | $25 |
| Claude Mythos Preview | $25 | $125 |
Fugu Ultraの単価は、Mythos Previewと比べれば大幅に安く、GPT-5.5の標準帯とほぼ同水準です。一方でClaude Opus 4.7/4.8の通常利用と比べると入力単価は同じでも出力単価は5〜20ドル高い位置にあります。
ただし、内部で複数モデルを呼び分ける構造のため「1リクエストで消費するトークン数」は単一モデルよりも多くなる可能性があります。単価の安さだけで判断せず、ワークロード単位の実コストで評価する必要があります。
コスト最適化の現実的な判断軸
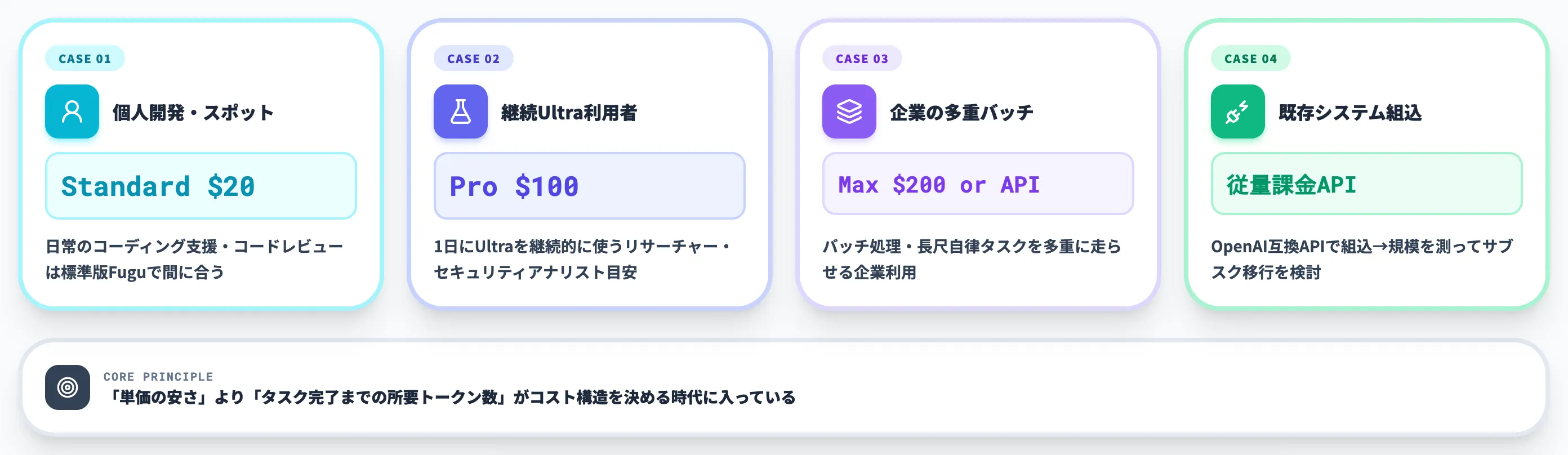
サブスク vs API、StandardからMaxへの移行シグナルは、以下のように整理できます。
- 個人開発者・スポット利用ならStandard $20で十分。日常のコーディング支援・コードレビューは標準版Fuguで間に合う
- 1日にFugu Ultraを継続的に使うリサーチャー・セキュリティアナリストはPro $100が目安
- バッチ処理・長尺自律タスクを多重に走らせる企業利用はMax $200または従量課金API
- 既存システムにOpenAI互換APIで組み込む場合は最初から従量課金APIを選び、ワークロード規模を測ってからサブスク移行を検討する
API料金は具体ワークロードでの実測が前提です。AI総研の支援現場でも、「単価の安さ」より「タスク完了までの所要トークン数」がコスト構造を決めるケースが増えています。
Sakana Fuguの使い方——OpenAI互換APIと利用範囲
Sakana Fuguの最大の実装上の特徴は、既存のOpenAI互換APIをそのまま流用できる点です。ここでは具体的な使い方と利用範囲を整理します。

OpenAI互換APIで既存コードがそのまま動く
Sakana FuguはOpenAI互換のAPIエンドポイントを提供しています。
すでにOpenAI Responses APIやChatGPT APIを使ったアプリケーションがあれば、エンドポイントURLとAPIキーを差し替えるだけで切り替えが可能です。

具体的には以下のような連携シナリオが想定されています。
- 既存のLangChain・LlamaIndex等フレームワーク
「openai」クライアントを使ったまま接続先をSakana Fuguに切り替える
- GitHub Copilot
IDE拡張のうちカスタムエンドポイント対応のものに、Sakana Fuguを設定する
- OpenAI Codex CLI
カスタムモデルプロバイダーのbase URL指定に対応するエージェントツールに、Sakana FuguをOpenAI互換エンドポイントとして直接設定する
- Claude Code
Anthropic Messages / Bedrock / Vertex形式のリクエストを前提とするため、Sakana Fuguを直接エンドポイントに指定できない。LLM gateway(プロキシ)でリクエスト変換層を挟む構成が前提になる
「複数モデル契約を1つに統合できる」と公式が強調する根拠は、このOpenAI互換性とエージェントプール内のモデル多様性の組み合わせにあります。
モデル選択は「自動」が基本、手動指定も可能
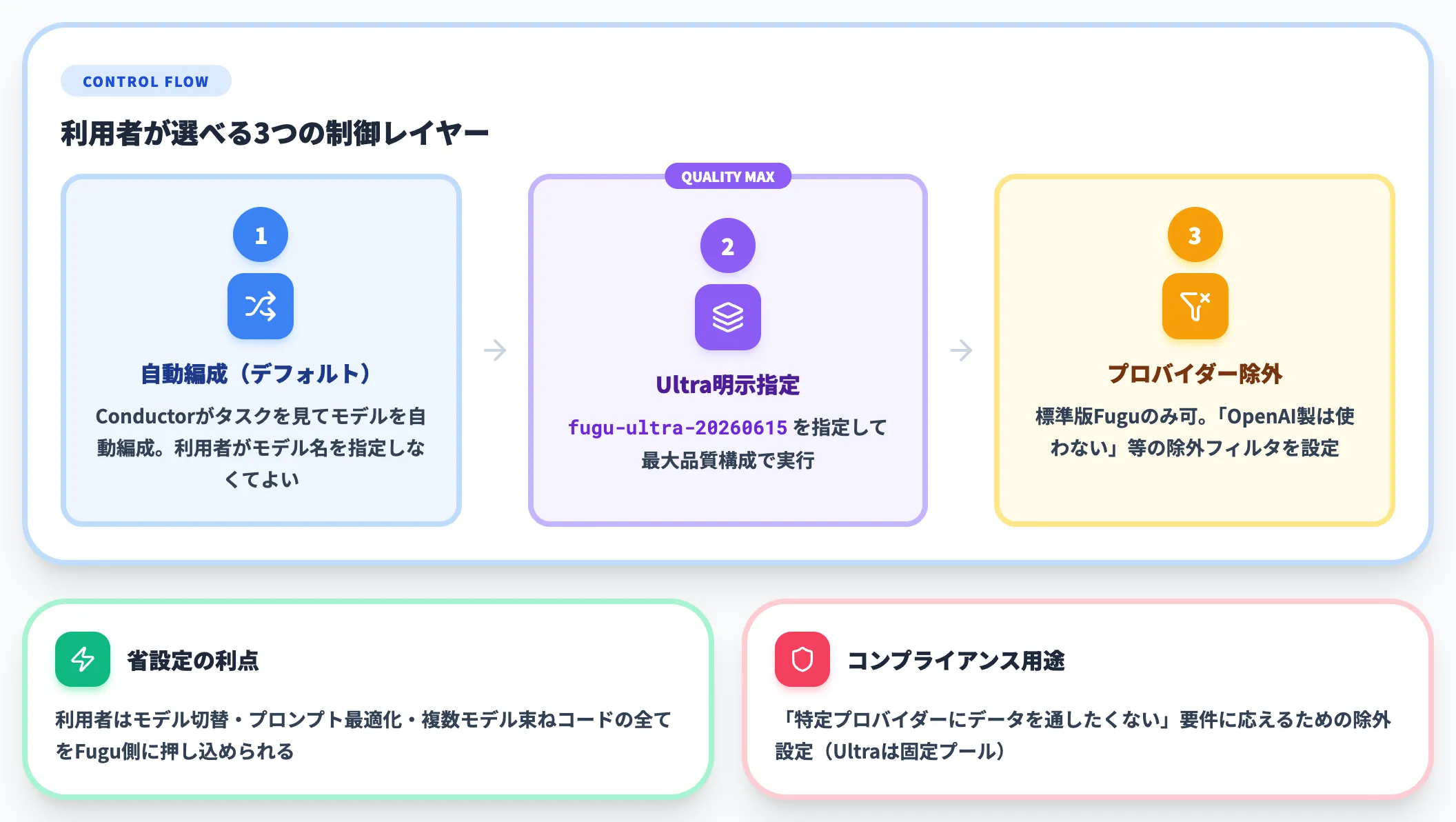
Fuguの基本動作は、Conductorがタスクの内容を見て自動でモデルを編成します。利用者がモデル名を指定する必要はありません。
ただし、用途に応じて以下のような制御が可能です。
- Fugu Ultraを明示指定: API呼び出しで fugu-ultra-20260615 を指定すれば、最大品質構成で実行
- プロバイダー・モデル除外(標準版Fuguのみ): 「OpenAI製モデルは使わない」といった除外フィルタを設定可能。Fugu Ultraは品質維持のためエージェントプールが固定で、除外設定はできない
これらの制御は、データ主権・プライバシー・社内コンプライアンス要件を満たすために用意されています。たとえば「OpenAI製モデルにはデータを通したくない」という要件があれば、エージェントプールからOpenAIモデル群を除外できます。
console.sakana.aiでの管理
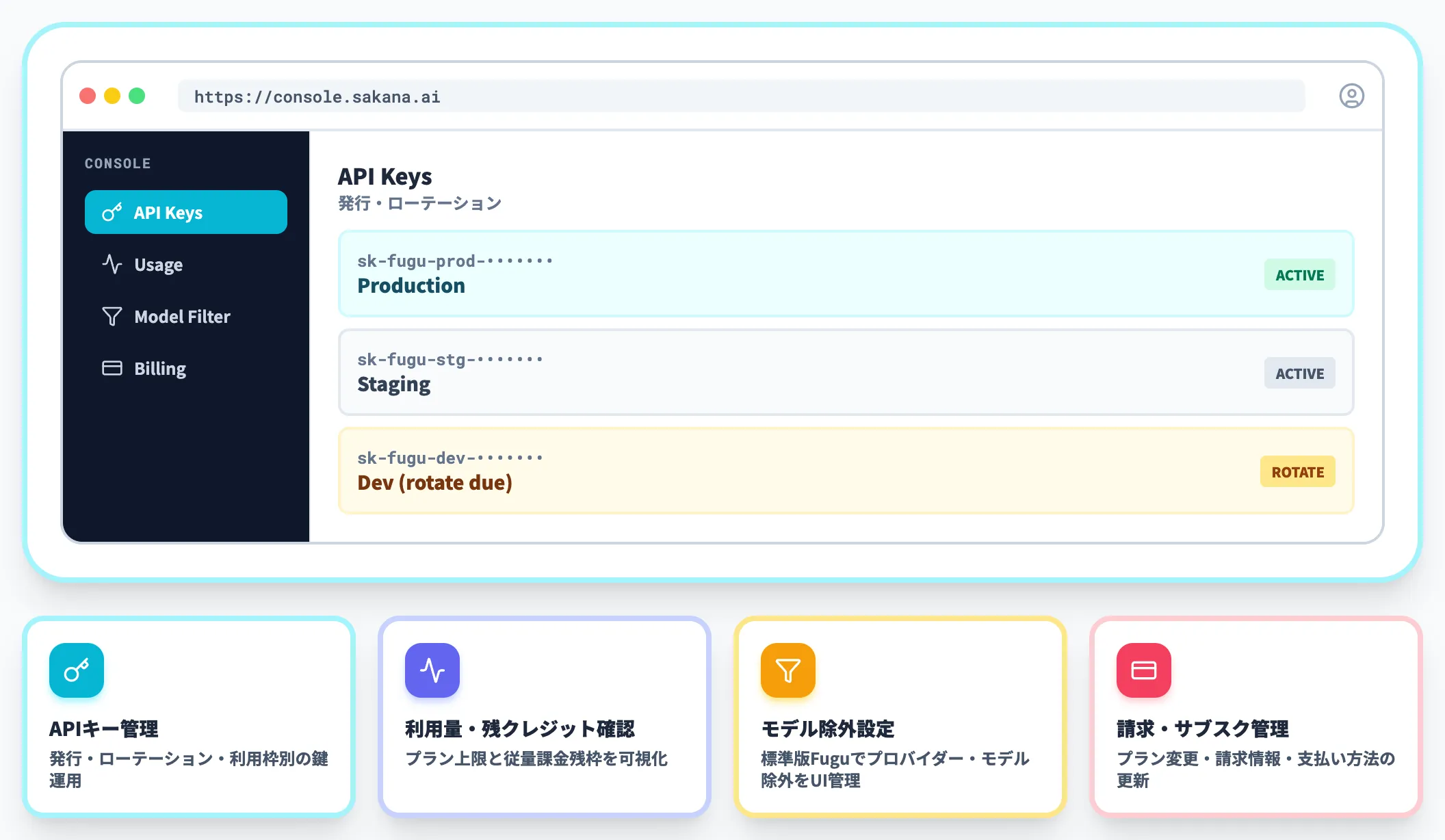
API利用にはconsole.sakana.aiでのアカウント開設が必要です。コンソールでは以下が管理できます。
- APIキーの発行・ローテーション
- 利用量・残クレジットの確認
- プロバイダー・モデルの除外設定
- 請求情報・サブスクリプション管理
直感的なUIで、エンタープライズ管理者がガバナンスを効かせやすい設計になっています。

EU/EEAは提供対象外(2026年6月時点)
Sakana Fuguには現時点でEU/EEA(欧州経済領域)では利用できないという重要な制約があります。
公式は「GDPR対応の準備中」としており、ヨーロッパ拠点の事業者・データ保護要件がGDPR準拠を要求する案件では、Sakana Fuguを採用できません。日本・米国・アジア圏での利用がメインターゲットになっている状況です。
公式のサポート窓口は fugu-support@sakana.ai で、エンタープライズ案件・コンプライアンス相談はここから連絡することになります。
Sakana Fugu UltraはClaude Fable 5の代替になるか
Sakana Fuguが一般提供を開始した2026年6月22日時点で、AnthropicのClaude Fable 5・Mythos 5は利用停止中です。フロンティアレベルのAIを業務利用したい企業にとって、Fugu Ultraがどこまで代替になるかは現実的な論点になっています。
このセクションでは、現状のフロンティアモデル提供状況と、Fugu Ultraの代替可能性を整理します。
Fable 5・Mythos 5は2026年6月13日に利用停止
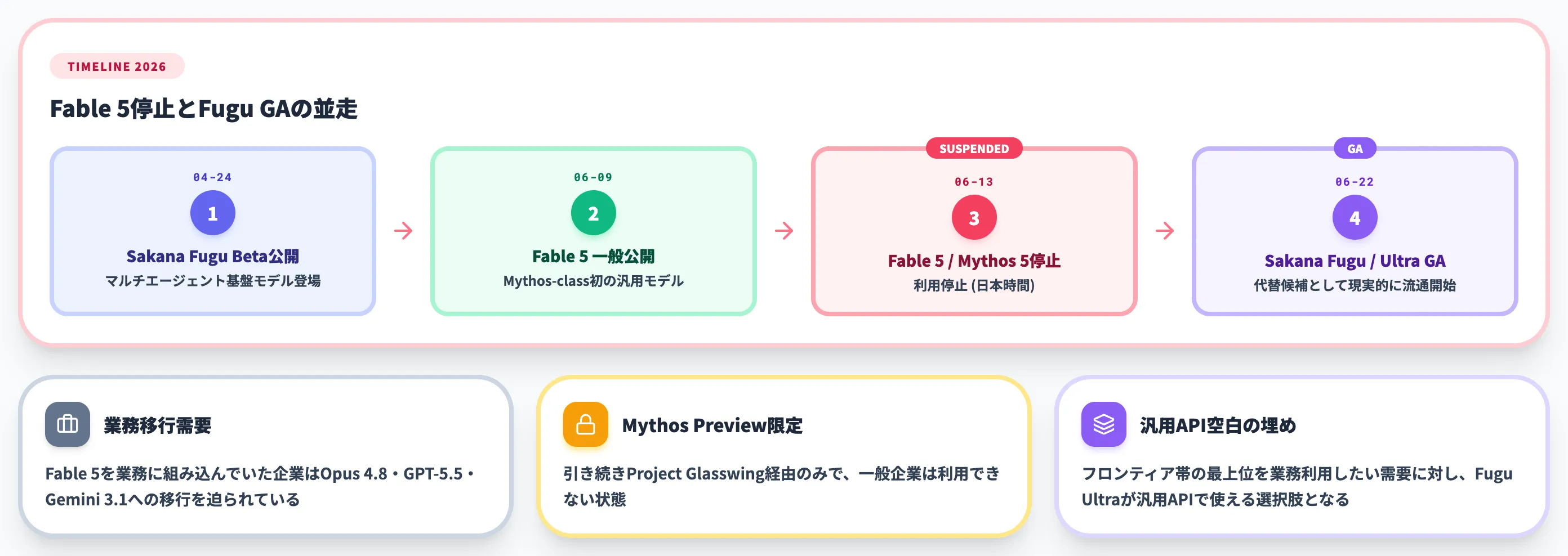
Anthropicは2026年6月9日にMythos-class初の一般公開モデル「Claude Fable 5」を発表しましたが、**米国時間2026年6月12日(日本時間6月13日)にFable 5・Mythos 5の利用が停止**されています。
利用停止の経緯と代替モデル移行・返金確認の実務対応は別記事で詳述していますが、企業ユースとしての要点は以下のとおりです。
- Fable 5・Mythos 5を業務に組み込んでいた企業は、Claude Opus 4.8/4.7・GPT-5.5・Gemini 3.1への移行を迫られている
- Mythos Previewは引き続きProject Glasswing経由の限定提供のみで、一般企業は利用できない
- Anthropicが次世代モデルでMythos級能力を一般公開する時期は未確定
つまり、「フロンティア帯の最上位を業務利用したい」という需要に対して、汎用APIで使えるオプションが薄くなっている状況です。
Fugu Ultraがフロンティア帯の現実的な選択肢になる理由
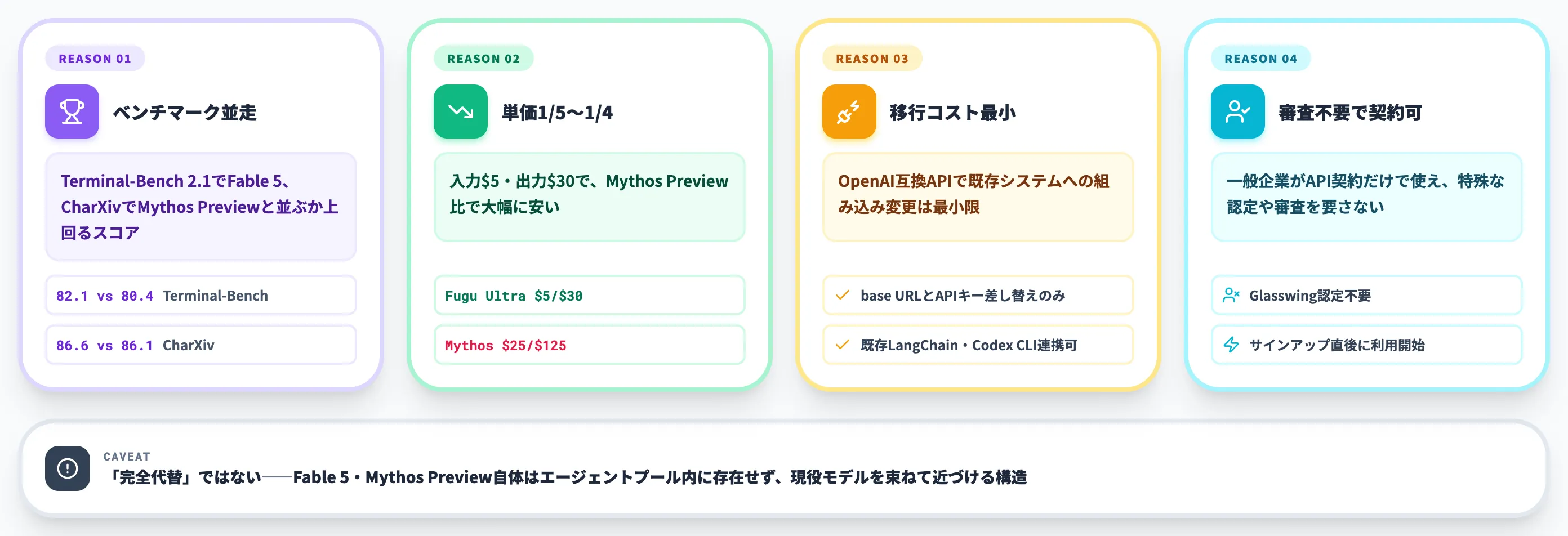
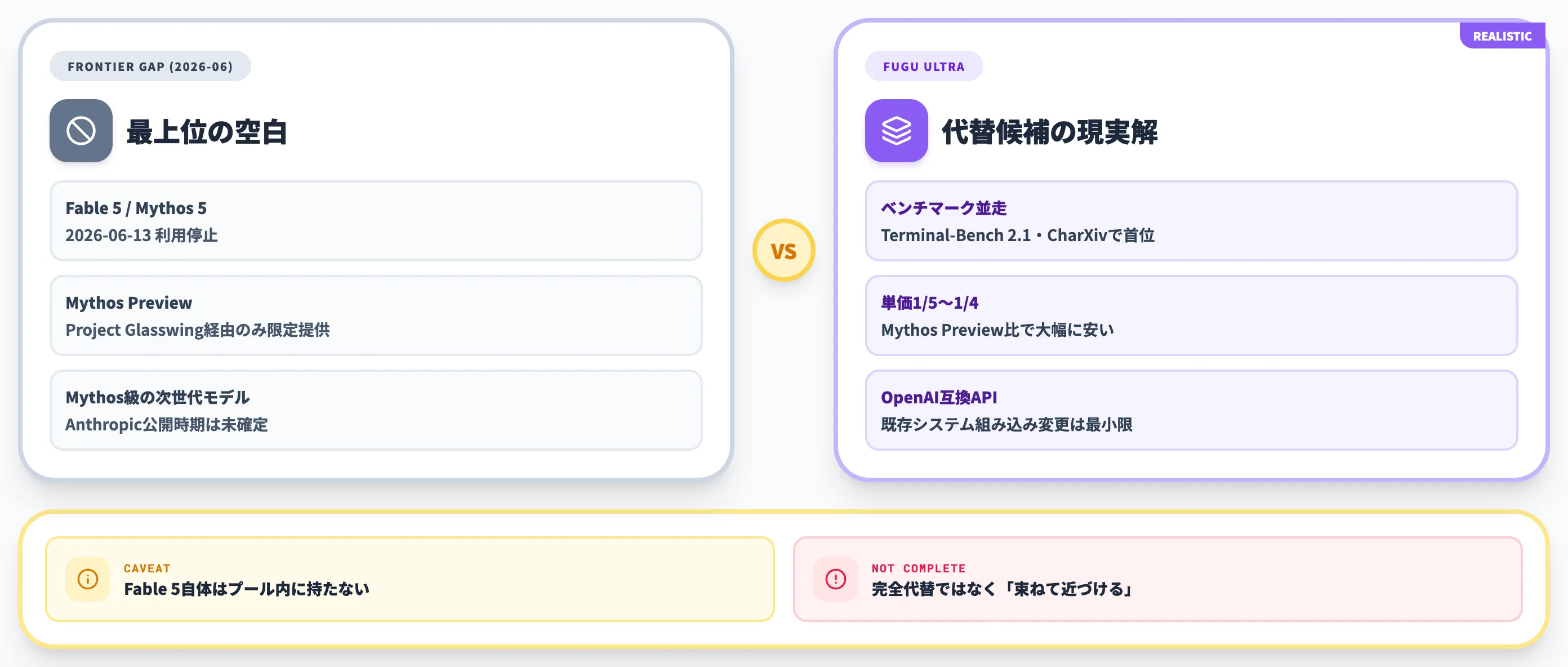
この空白に対して、Fugu Ultraは以下の点で代替候補として現実的です。
- Terminal-Bench 2.1でFable 5、Charxiv ReasoningでMythos Previewと並ぶか上回るスコアを示している
- 入力$5/出力$30と、Mythos Preview(入力$25/出力$125)の約1/5〜1/4の単価
- OpenAI互換APIで、既存システムへの組み込み変更が最小限
- 一般企業がAPI契約だけで使え、特殊な認定や審査を必要としない
ただし「完全代替ではない」という前提は重要です。Fugu UltraはFable 5・Mythos Preview自体をエージェントプールに持っていません。
つまり「Fable 5の能力をそのまま使う」のではなく、「Claude Opus 4.7・GPT-5.5・Gemini 3.1などのフロンティア帯モデルを束ねて、Fable 5級の出力に近づける」というアプローチです。
特定の専門領域でFable 5にしかできない処理があれば、Fugu Ultraでは届かない可能性があります。
他のマルチモデル統合との違い——OpenRouter Fusion APIとの比較

「複数モデルを束ねる」という発想自体はSakana Fuguが初ではなく、2026年6月12日に発表されたOpenRouter Fusion APIなど、関連プロダクトが並行して登場しています。
両者の違いを以下に整理しました。
| 観点 | Sakana Fugu | OpenRouter Fusion API |
|---|---|---|
| 設計思想 | オーケストレーション(Conductorが役割分担と委譲を学習) | 合議(複数モデルの並列回答を統合) |
| 中身 | 学習済みLLMが内部判断 | ルーティングと並列実行・統合 |
| 強みが出る場面 | 多段ワークフロー・タスク自律遂行 | 単発回答の品質向上・安全性確認 |
| 統合API | OpenAI互換 | OpenAI互換 |
| 提供開始 | 2026-04-24 ベータ / 2026-06-22 GA | 2026-06-12 |
つまり、OpenRouter Fusion APIは「同じ質問を複数モデルに投げて合議する」アプローチ、Sakana Fuguは「タスクを分解して各モデルに割り振る」アプローチで、根本的な設計思想が違います。
長い自律タスクや多段リサーチではSakana Fugu、単発の重要回答の品質担保ではFusion APIが向く構図です。
Claude Opus 4.8・GPT-5.5・Gemini 3.1単体との比較
単一モデルAPIとの違いも整理しておきます。
- Claude Opus 4.8単体: コーディング・長文理解で安定。1モデル前提のため再現性は高いが、ベンチマーク上限はそのモデル単独の性能で決まる
- GPT-5.5単体: 汎用性能と価格バランスが高い。Anthropicが利用停止になっている領域での代替候補
- Gemini 3.1単体: 長文コンテキストと検索連携に強み
Fugu Ultraはこれらをエージェントプール内で組み合わせるため、「単一モデルの上限」を越えてくる設計です。逆に「予測可能で同一モデルで再現性を担保したい」案件では、単一モデルAPI直接利用のほうが運用しやすい場合があります。

【関連記事】
ハーネスエンジニアリングとは?AIエージェント開発を支える新しい工学領域を3社の一次情報で解説
Sakana Fuguが効くユースケースと採用判断軸
Sakana Fuguは万能なモデルではなく、**「多段の自律タスク」「複数モデルの強みを束ねたい場面」**で特に効きます。ここでは具体的なユースケースと、採用判断のチェックポイントを整理します。

大規模コードレビューと脆弱性検出
公式の早期事例で最も鮮明な差が出たのは、コードレビューと脆弱性検出です。
- Fugu Ultraに大きなPR・ブランチを丸投げし、複数モデルの観点で問題点を抽出させる
- 旧コードベースの全体監査を、人手では追いきれない範囲まで走らせる
- セキュリティ評価で、フロンティア帯AIによる発見とClaude Code Security等の専用ツールを併用する
ただし、サイバーセキュリティの「攻撃的能力」では、Project Glasswing経由のMythos Previewに分がある領域もあるため、用途に応じた使い分けが必要です。
論文・特許のランドスケープリサーチ
数十本以上の文献を横断して比較・要約するワークロードは、Fugu Ultraの典型的な強み領域です。
- 競合製品の特許マップを作る
- 学術論文の動向調査と関連文献のクラスタリング
- 規制動向・業界レポートの横断比較
通常3〜4日かかる作業が数時間で済む事例も公式から報告されており、リサーチ部門・知財部門・市場調査チームでの活用が想定されます。
論文再現・実験自動化
学術論文のコードを読み込ませ、再実装と再現実験を自律で完遂させる用途もFugu Ultraの想定範囲です。
- 公開論文のPyTorch/TensorFlow実装を新しい環境に移植
- 再現性が問われる実験を、Fugu Ultraに環境構築から走らせる
- 機械学習のハイパーパラメータ探索を、長尺の試行錯誤として委ねる
このタイプのワークロードは**「数時間以上の連続実行」**が前提で、Standard $20では枠が足りずProまたはMaxが必要になります。
:プロトタイピングと多段ワークフロー
複数ステップを経るプロトタイピング——「リサーチ→設計→実装→検証→ドキュメント化」のような多段の自律ワークフロー——も、Fugu Ultraの典型用途です。
- 新規プロダクトの企画検証フロー
- 営業提案資料の自動生成(市場調査→提案構成→資料化)
- 業務オペレーションのプロセス改善案策定
Conductorの再帰呼び出しを活かして、1回のリクエストで「企画→検証→修正」までを完結させる使い方が可能です。
向いていないユースケース
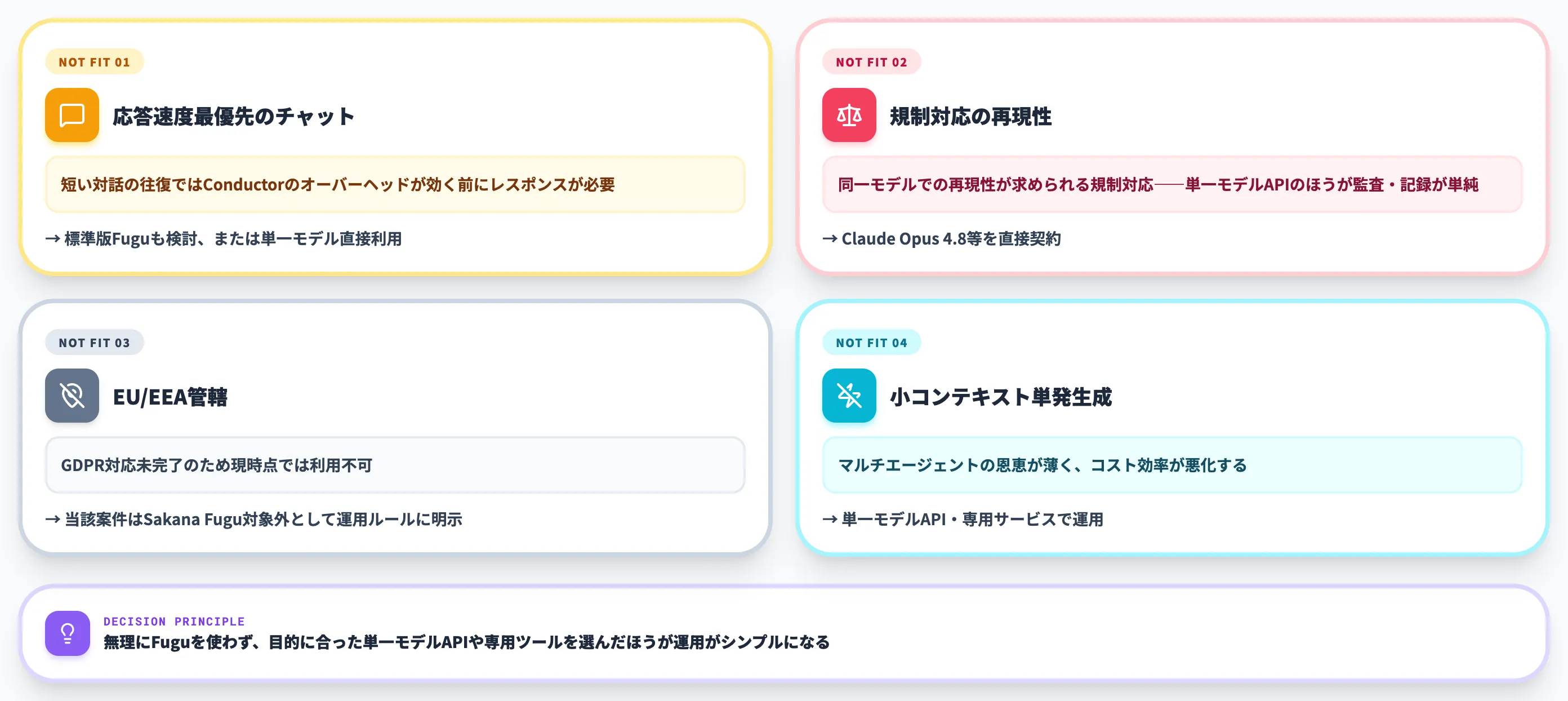
逆に、以下のケースではSakana Fuguよりも単一モデルAPIや専用サービスのほうが向きます。
- 応答速度が最優先のチャットボット 短い対話の往復ではConductorのオーバーヘッドが効く前にレスポンスが必要
- 同一モデルでの再現性が求められる規制対応 単一モデルAPI(Claude Opus 4.8等)のほうが監査・記録が単純
- EU/EEA管轄でのデータ処理 GDPR対応未完了のため現時点では利用不可
- コンテキストが小さく単発の生成タスク マルチエージェントの恩恵が薄く、コスト効率が悪化
これらの場合は、無理にFuguを使わず、目的に合った単一モデルAPIや専用ツールを選んだほうが運用がシンプルになります。
マルチモデル統合APIを企業導入する際の運用設計
Sakana Fugu単体の採用判断とは別に、「マルチエージェントが基盤モデル化する時代」が来たという事実は、すべての企業のAI戦略に影響します。
このセクションでは、AI総研の支援現場で見えている傾向も踏まえ、企業がSakana Fugu世代に備えるための実務指針を整理します。
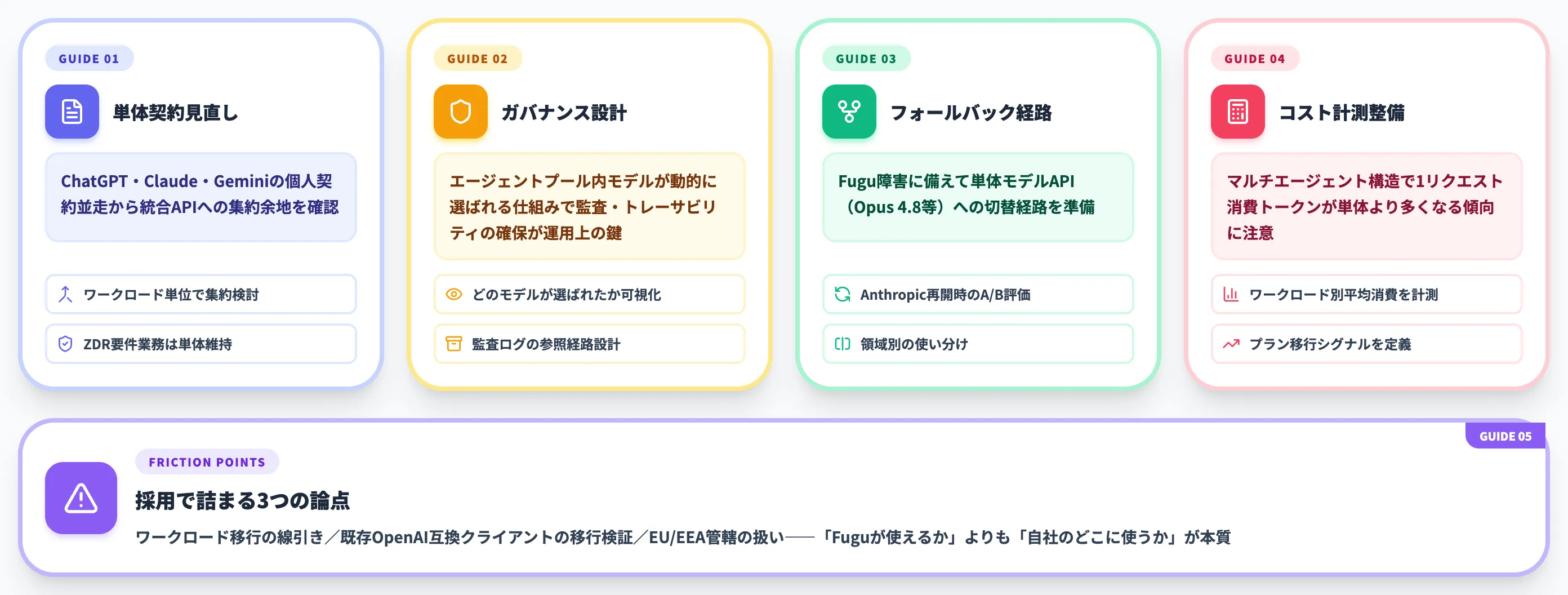
単体モデル契約の見直しタイミング
複数のLLMをサブスクリプション・API契約で並走している企業は、契約構造を見直すタイミングに来ています。
- ChatGPT Pro・Claude Max・Gemini Advancedなど複数の個人契約を従業員ごとに走らせている企業は、Sakana Fugu・OpenRouter Fusion APIなど統合APIへの集約余地がある
- API側でも複数プロバイダーに分散している場合、ワークロード単位でのコスト計測とコンソリデーション余地を確認する
- ただし、Anthropic・OpenAI直接契約のセキュリティ・ガバナンス要件(ZDR・SLA等)が必要な業務は単体契約を維持
「とりあえず束ねる」では事故が起きやすい領域なので、業務ごとに**「単体直接契約が必要か / マルチエージェント経由でよいか」**を分けて整理することが重要です。
マルチエージェントのガバナンス設計
Sakana Fuguのようにエージェントプール内のモデルが動的に選ばれる仕組みでは、監査・トレーサビリティが運用上の鍵になります。ただし公式FAQでは、Fuguが個々のリクエストでどの基盤モデルを選択しどう連携したかの詳細は現時点では公開されない設計と説明されています。厳密なモデル別監査が必要な業務(金融規制対応・医療データ処理等)では、Sakana Fugu経由ではなく単一モデル直接契約への切り出し、もしくはエンタープライズ契約での個別取り決めが必要になります。
- 各リクエストでどのモデルが選ばれたかの可観測性
- データの送信先プロバイダー単位での除外設定
- 監査ログの保管と、コンプライアンス担当者からの参照経路
これらはハーネスエンジニアリングの領域でも論点になっており、マルチエージェント基盤モデルの企業導入では避けて通れません。
Fable 5・Mythos 5再開時の運用フォールバック
Fable 5・Mythos 5の利用停止が今後解除された場合、Sakana FuguとAnthropic直接契約のどちらを優先するかを事前に決めておくことが、運用上のリスク低減になります。
- 基本はFugu Ultraで運用、Anthropicが再開したらワークロード別にA/B評価
- セキュリティ・知財領域はAnthropic直接契約を優先、汎用業務はFugu経由
- 突発的なFugu側障害に備えて、Opus 4.8等の単体モデルAPIへのフォールバック経路を用意
「Fuguに一本化する」のではなく、主用途と緊急時のフォールバックを別系統で用意する設計が現実的です。
コスト計測の整備——タスク単位でのトークン消費把握
Fugu Ultraの単価はフロンティア帯では抑えめでも、マルチエージェント構造のため1リクエストでの消費トークンは単体モデルより多くなる傾向があります。
- 主要ワークロードごとの平均消費トークン数を計測
- StandardからPro、ProからMaxへの移行シグナルを社内で定義
- 従量課金APIに切り替えるタイミングの基準(月額換算でサブスクを超えたら)を明文化
「単価が安いから安心」ではなく、「タスク完了までに何トークン使うか」をワークロード単位で測れる仕組みを最初から組み込むことが重要です。

マルチエージェント時代のAI活用を業務に定着させる
Sakana Fuguのようなマルチエージェント基盤モデルの登場で、AIを業務に組み込む選択肢は確実に広がっています。
一方で多くの企業は、Sakana Fuguを試す前に、現行のClaude Opus 4.7・GPT-5.5・Gemini 3.1を業務プロセスに定着させる段階にあります。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。Sakana Fugu世代のマルチエージェント基盤を視野に入れた自社のAI活用戦略を整理する第一歩として活用ください。
マルチエージェント時代のAI活用を業務に定着させる

PoCから全社展開までの設計を1冊で
Sakana FuguのようなマルチエージェントAIを待たなくても、現行のClaude Opus 4.7・GPT-5.5・Gemini 3を業務に組み込むことは可能です。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、2026年4月24日にベータ公開・6月22日に一般提供を開始したSakana Fuguについて、仕組み・Fugu Ultraの性能・料金体系・OpenAI互換APIでの使い方・Fable 5代替としての立ち位置・採用判断軸・企業が備えるべき実務指針まで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
Sakana Fuguは、Sakana AIが複数のフロンティアモデルを動的に編成するマルチエージェント基盤モデルで、Conductor(ICLR 2026論文)とTRINITYが内部のオーケストレーションを担う
-
Fugu UltraはTerminal-Bench 2.1でFable 5、Charxiv ReasoningでMythos Previewを上回ったと公式報告。HLEではFable 5に及ばないが、コーディング・推論ベンチマークの多くでフロンティア帯と肩を並べる
-
料金はサブスク3段($20・$100・$200)と従量課金APIの二本立て。Fugu Ultra APIは入力$5/出力$30で、272Kトークン超過時は$10/$45に切り替わる
-
Fable 5・Mythos 5の利用停止が続く現在、Fugu Ultraはフロンティア帯AIの現実的な代替候補。ただしFable 5・Mythosをエージェントプール内に持たないため、完全代替ではなく「束ねて近づける」アプローチ
-
標準版Fuguではプロバイダー・モデルの除外設定でデータ主権・コンプライアンス要件に応じた構成が可能(Fugu Ultraは固定プール)。ただしEU/EEAはGDPR対応中で現時点未提供、欧州案件では採用不可
企業にとってSakana Fuguは、「日本発のフロンティアAIを試せるか」という以上に、**「マルチエージェント基盤モデルという新しいパラダイムを、自社の業務にどう組み込むか」**という問いを突きつける動きです。まずは多段の自律タスク・コードレビュー・リサーチの3領域に絞って試し、運用ルールとガバナンスを並行で整備していくことが、最も現実的な第一歩になります。
Fable 5・Mythos 5が止まり、フロンティア帯AIの選択肢が一時的に薄くなった2026年6月は、複数モデルを束ねるアプローチが現実解として注目される節目になりました。Sakana Fugu世代の到来を「待つ」のではなく、「いま試す」姿勢が、これからのAI活用の競争力を左右する時期に入っています。










