この記事のポイント
 データセンター規模のLLM推論を最適化するなら、NVIDIA Dynamoが2026年時点で最も有力なオープンソースの選択肢
データセンター規模のLLM推論を最適化するなら、NVIDIA Dynamoが2026年時点で最も有力なオープンソースの選択肢- SGLang・TensorRT-LLM・vLLMのいずれを使っていてもDynamoで統合管理できるため、推論エンジンの乗り換えリスクを避けられる
- Prefill/Decode分離型サービングにより推論性能が最大7倍向上するため、Blackwell GPU導入時にはDynamoとの併用が不可欠
- Apache 2.0で無料利用可、将来的にNVIDIA AI Enterpriseに組み込まれる予定で商用サポート必要な企業はライセンス移行計画を準備
- Perplexity AI・ByteDance・SoftBankの本番採用実績で大規模トラフィック環境の信頼性は実証済み、PoCを省略した段階導入も妥当

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
NVIDIA Dynamoは、データセンター規模のGPUクラスタ上でLLM・推理モデル・マルチモーダルモデルの推論を効率的にスケーリングするために設計されたオープンソースの分散推論フレームワークです。2026年3月のGTC 2026でDynamo 1.0として本番環境向けのGA(一般提供)が発表されました。
本記事では、NVIDIA Dynamoの4つのコアコンポーネント(GPU Planner・Smart Router・NIXL・KV Block Manager)の仕組み、分離型サービングによるパフォーマンス向上の原理、導入手順、Perplexity AIやByteDanceなどの採用企業、そして料金体系までを体系的に解説します。
目次
NVIDIA Dynamoが必要な理由 — LLM推論スケーリングの課題
NVIDIA Dynamoの分離型サービングとパフォーマンス
Kubernetes(Grove / Dynamo Operator)でのプロダクション運用
NVIDIA Dynamoとは?
NVIDIA Dynamoは、データセンター規模のGPUクラスタ上で生成AIモデルの推論を効率的にスケーリングするためのオープンソース分散推論フレームワークです。2026年3月16日のGTC 2026で、Jensen Huang CEOがDynamo 1.0の本番提供開始を発表しました。

NVIDIAはDynamoを「AIファクトリーのための推論オペレーティングシステム」と位置づけています。コンピューターのOSがハードウェアとアプリケーションを仲介するように、DynamoはGPUクラスタ全体のリソース(計算・メモリ・ネットワーク)を一元管理し、複雑な推論ワークロードを効率的に分配する役割を担います。
ライセンスはApache 2.0で、商用利用を含めて無償で利用可能です。以下の表にDynamo 1.0の基本情報をまとめました。
| 項目 | 内容 |
|---|---|
| 初回リリース | 2025年3月(GTC 2025) |
| GA版リリース | 2026年3月16日(Dynamo 1.0) |
| 最新バージョン | v1.0.1(Release Artifactsで最新タグを確認) |
| ライセンス | Apache 2.0 |
| GitHubコントリビューター | 255人以上 |
| 対応推論エンジン | SGLang、TensorRT-LLM、vLLM |
| 対応GPUアーキテクチャ | Blackwell / Hopper推奨、Ada Lovelace / Ampereもサポート |
| 開発言語 | Rust、Python |
Dynamoの重要な特徴は、既存の推論エンジンを「置き換える」のではなく、それらを「統合管理する」オーケストレーション層であるという点です。SGLang、TensorRT-LLM、vLLMといった推論エンジンは引き続きモデルの実行を担当し、Dynamoはその上位レイヤーとして複数ノード間のリクエストルーティング、メモリ管理、GPU割り当てを最適化します。

Triton Inference Serverからの進化

DynamoはNVIDIAのTriton Inference Serverの後継として位置づけられています。Tritonは100万回以上のダウンロードを記録した汎用推論サーバーですが、DynamoはTritonの実績を基盤に、LLM時代に求められる分散推論の課題を解決するために再設計されたフレームワークです。
TritonとDynamoの主な違いを以下の表で整理しました。
| 比較項目 | Triton Inference Server | NVIDIA Dynamo |
|---|---|---|
| 設計思想 | 汎用的な推論サービング | LLM・生成AI特化の分散推論 |
| スケーリング | 単一ノード中心 | マルチノード・データセンター規模 |
| 主な最適化 | モデル並列、バッチング | 分離型サービング、KVキャッシュルーティング |
| GPUリソース管理 | 静的な割り当て | 動的なGPU追加・削除(GPU Planner) |
| 名称変更 | Dynamo-Triton(旧名:Triton)に改名 | NVIDIA Dynamo |
既存のTritonユーザーに対しては、NVIDIA AI Enterpriseを通じてプロダクションブランチのサポートが継続される方針が示されています。つまり、Tritonが即座に廃止されるわけではなく、既存環境を維持しつつ新規プロジェクトでDynamoへの移行を進めるという段階的な移行が想定されています。
推論OSとしての位置づけ
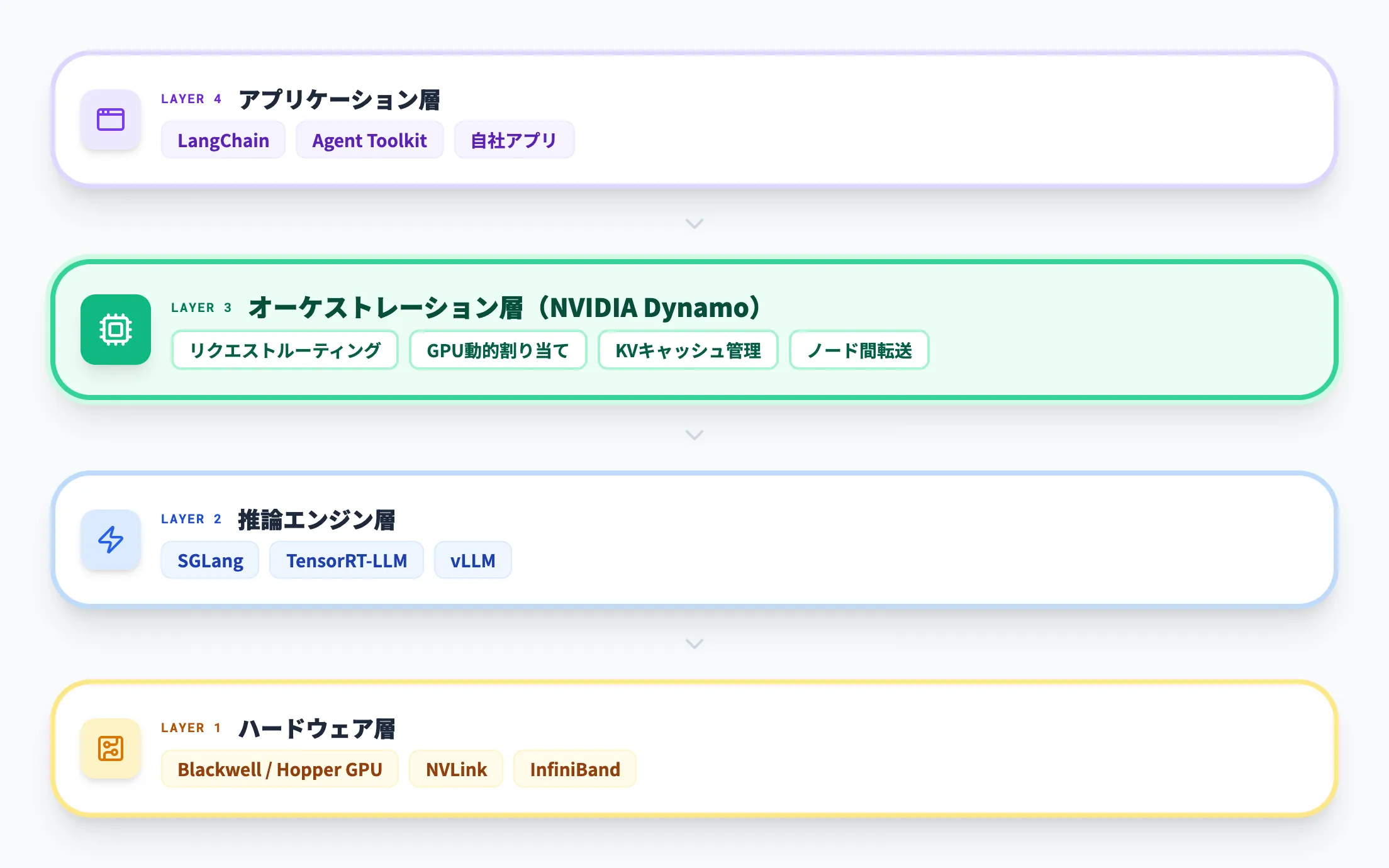
Dynamoを理解するうえで最も重要な概念は、「推論エンジンの上位にあるオーケストレーション層」という位置づけです。
以下に、AI推論の技術スタックにおけるDynamoの位置を整理しました。
-
アプリケーション層
LangChain、NVIDIA Agent Toolkit、自社アプリケーションなど、エンドユーザーにAI機能を提供するレイヤー
-
オーケストレーション層(NVIDIA Dynamo)
リクエストのルーティング、GPU動的割り当て、KVキャッシュ管理、ノード間データ転送を統括するレイヤー
-
推論エンジン層
SGLang、TensorRT-LLM、vLLMなど、実際にモデルを実行してトークンを生成するレイヤー
-
ハードウェア層
NVIDIA GPU(Blackwell / Hopper)、NVLink、InfiniBand、ストレージなどの物理インフラ
この構造から分かるように、Dynamoは推論エンジンそのものではありません。SGLangやvLLMをすでに使っている環境でも、その上にDynamoを導入することで、マルチノードへのスケールアウトやKVキャッシュの最適化といった恩恵を得られる設計です。
NVIDIA Dynamoが必要な理由 — LLM推論スケーリングの課題
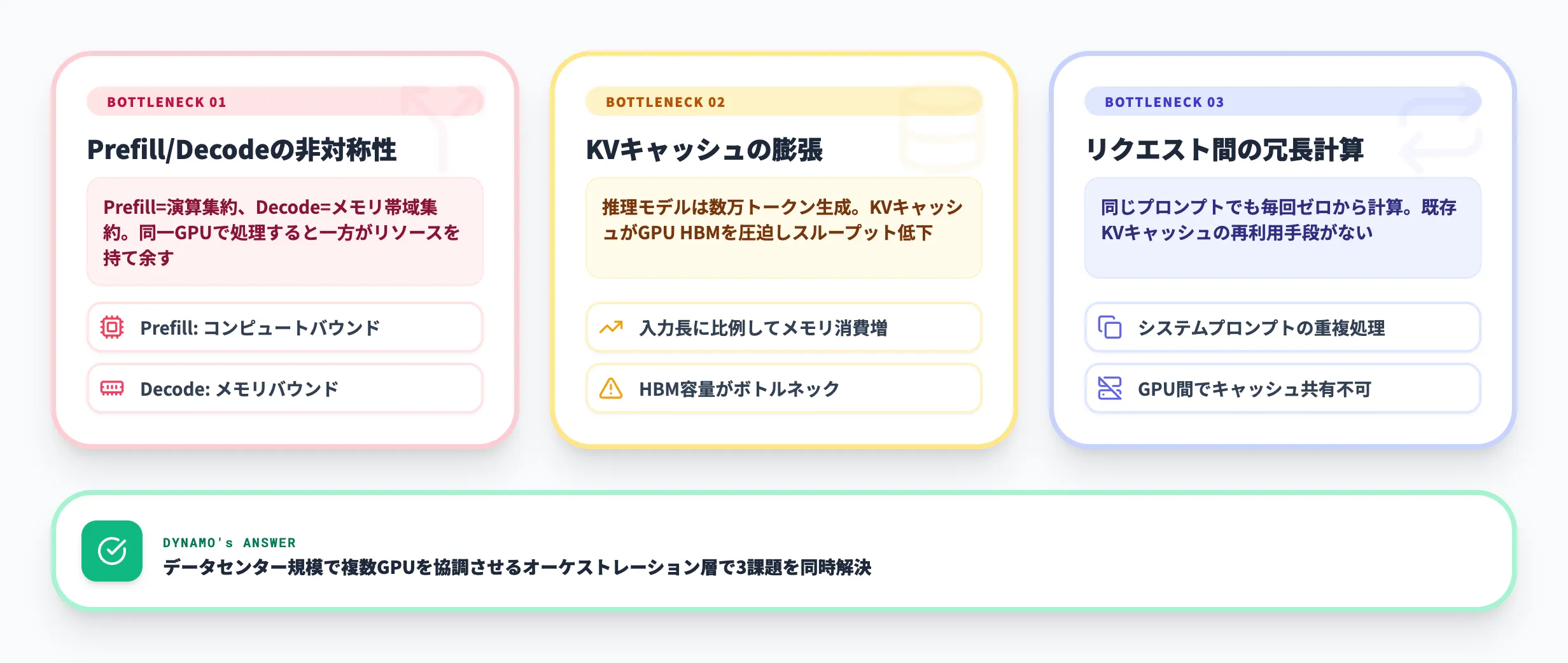
Dynamoが生まれた背景には、LLM推論が従来の推論インフラでは効率的に処理できないという構造的な問題があります。このセクションでは、Dynamoが解決しようとしている課題を整理します。
LLM推論の3つのボトルネック
LLMの推論は、画像分類やテキスト分類といった従来のAI推論とは根本的に異なる特性を持っています。
-
Prefill/Decodeの非対称性
LLM推論は「Prefill(入力トークンの一括処理)」と「Decode(出力トークンの逐次生成)」の2フェーズに分かれる。PrefillはGPUの演算能力(コンピュートバウンド)、Decodeはメモリ帯域(メモリバウンド)がボトルネックになるため、同じGPU上で両方を処理すると一方が常にリソースを持て余す
-
KVキャッシュの膨張
LLMは入力が長くなるほどKVキャッシュ(推論中間データ)が巨大になる。DeepSeek-R1のような推理モデルでは入出力合計で数万トークンに達することもあり、GPU HBM(高帯域メモリ)を圧迫してスループットが低下する
-
リクエスト間の冗長計算
同じシステムプロンプトや類似の入力を持つリクエストが連続しても、従来のサーバーはリクエストごとに独立して処理する。すでに計算済みのKVキャッシュが別のGPUに存在していても、それを再利用する仕組みがなければ毎回ゼロから計算し直すことになる
これらの課題は、単一ノードの推論サーバーで個別に最適化しても根本的には解決しません。データセンター規模で複数GPUを協調させるオーケストレーション層が必要になる——これがDynamoの設計思想です。
推理モデル・エージェンティックAI時代の要件
2025年以降、DeepSeekのR1シリーズに代表される推理モデル(reasoning model)の登場により、推論ワークロードの特性が大きく変化しています。
推理モデルは「考える」プロセスに長い思考トークンを生成するため、出力トークン数が従来のLLMの数倍から数十倍に膨らむことがあります。また、AIエージェントが複数のツールを呼び出しながら多段階の推論を行うワークフローでは、同一セッション内でKVキャッシュを保持し続ける必要があり、メモリ管理の効率がサービス全体のコストに直結します。
Dynamoの公式ブログでは、こうしたワークロードの変化に対応するために「OSレベルのアプローチ」で推論インフラを再設計したと説明されています。
NVIDIA Dynamoの4つのコアコンポーネント
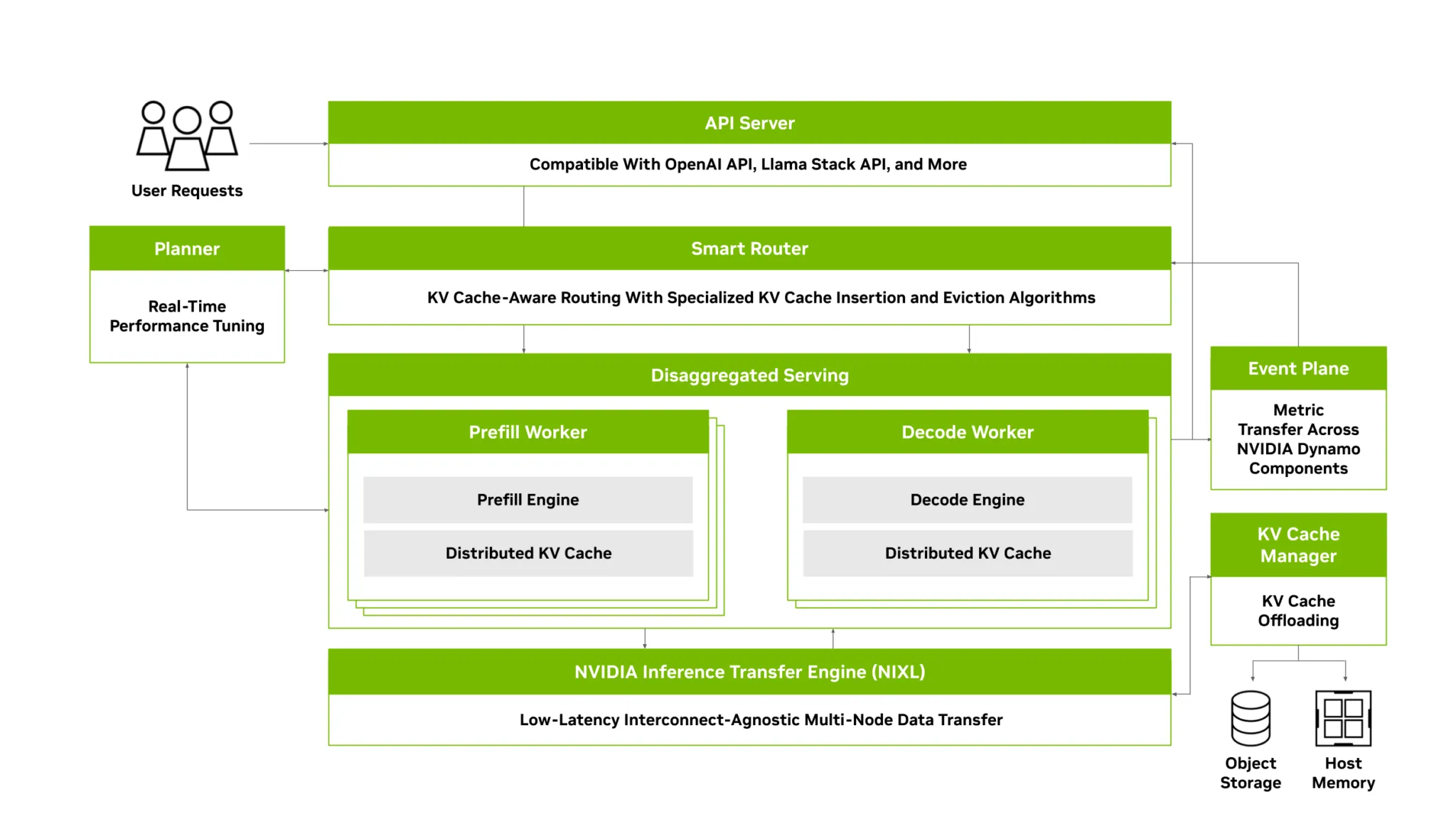
NVIDIA Dynamoのアーキテクチャ(出典:NVIDIA Developer Blog)
Dynamoの技術的な核は、GPU Planner・Smart Router・NIXL・KV Block Managerの4つのコンポーネントです。KVBMやNIXLなど一部のビルディングブロックはスタンドアロン利用にも対応しており、必要なものだけを段階的に導入できるモジュール設計になっています。
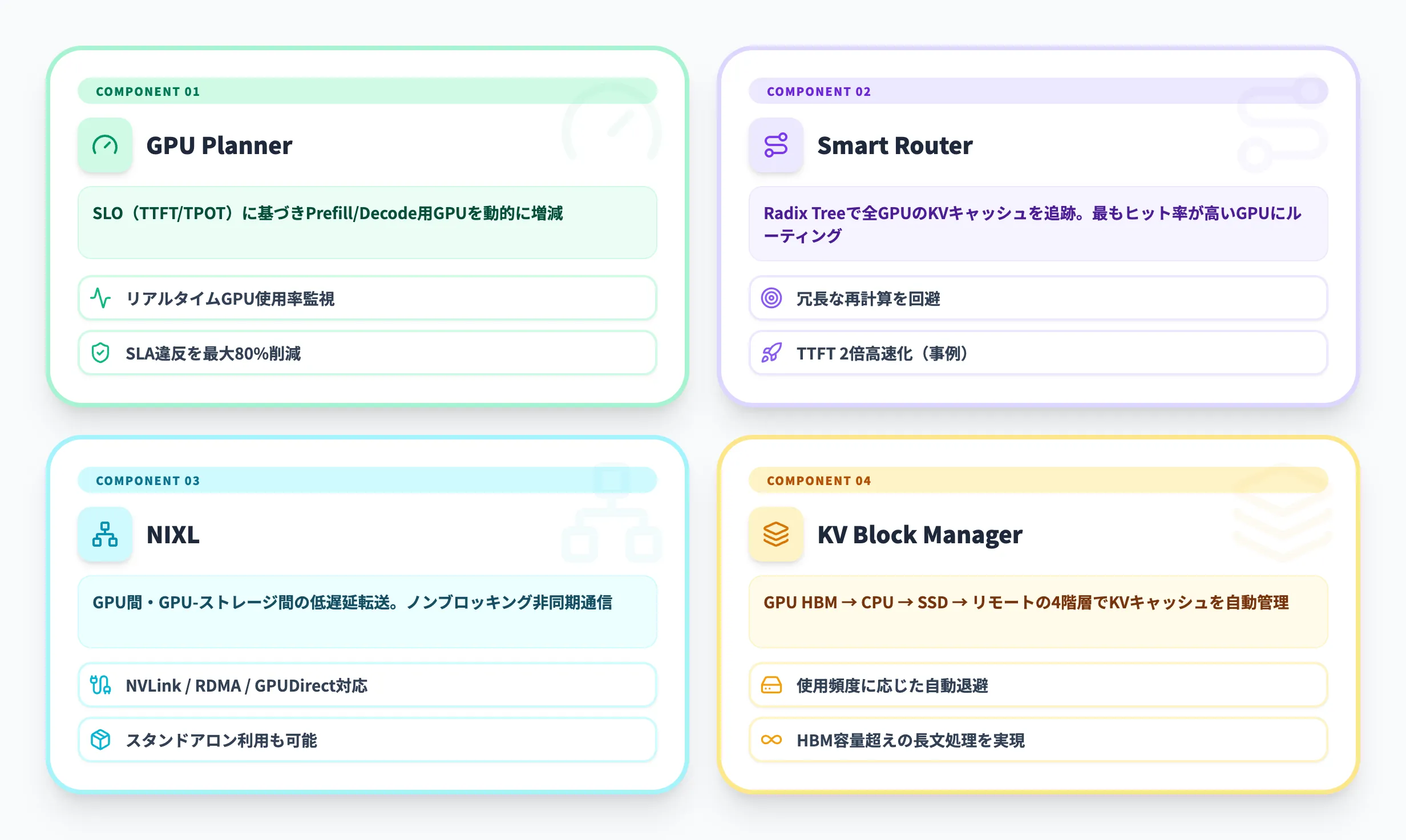
GPU Planner(動的GPUスケジューラー)
GPU Plannerは、GPUの使用状況をリアルタイムで監視し、ワークロードに応じてGPUの追加・削除を自動で行うコンポーネントです。
TTFT(最初のトークンまでの待ち時間)やTPOT(トークン間の生成間隔)といったSLO(サービスレベル目標)を入力として受け取り、PrefillとDecodeそれぞれに割り当てるGPU数を動的に調整します。ユーザーリクエストが集中する時間帯にはPrefill用GPUを増やし、負荷が下がればDecodeに再割り当てするといった制御が自動で行われます。
Dynamo 1.0のブログによると、このPlannerによりSLA違反を最大80%削減できるとされています。
Smart Router(KV対応ルーター)
Smart Routerは、受信したリクエストを最適なGPUワーカーに振り分けるルーティングエンジンです。
一般的なロードバランサーとの最大の違いは、各GPU上のKVキャッシュの状態を把握している点です。Radix Tree(基数木)というデータ構造を使い、クラスタ全体のGPU上にどのKVキャッシュブロックが存在するかをリアルタイムで追跡します。
新しいリクエストが届くと、Smart Routerはそのリクエストとクラスタ内の各GPUが保持するKVキャッシュとの「重なり度合い(overlap score)」を計算し、最もキャッシュヒット率が高いGPUにルーティングします。これにより、すでに計算済みのKVキャッシュを再利用でき、冗長な再計算を回避できます。
Baseten社の事例では、KVキャッシュ対応ルーティングによりQwen3 Coder 480BのTTFTが2倍高速化し、スループットが1.6倍向上したと報告されています。
NIXL(低遅延通信ライブラリ)
NIXL(NVIDIA Inference Xfer Library)は、GPU間やGPU-ストレージ間のデータ転送を高速に行うための通信ライブラリです。
分離型サービングではPrefill GPUで生成したKVキャッシュをDecode GPUに転送する必要がありますが、この転送がボトルネックになると分離型サービングのメリットが相殺されます。NIXLはノンブロッキングの非同期転送を実現し、GPUの推論処理を中断せずにバックグラウンドでデータを移動させます。
NIXLが対応するデータ転送経路は以下のとおりです。
| 転送方式 | 用途 |
|---|---|
| NVLink(C2C / NVSwitch) | 同一ノード内のGPU間高速転送 |
| GPUDirect RDMA | ノード間のGPU-GPU直接転送 |
| GPUDirect Storage | GPU-SSD間の直接データ転送 |
| InfiniBand / RoCE / Ethernet | ネットワーク経由のノード間通信 |
| S3 / オブジェクトストレージ | リモートストレージへのKVキャッシュ退避 |
NIXLはDynamoとは別のGitHubリポジトリ(ai-dynamo/nixl)で管理されており、単独でも利用可能です。NVIDIA BlueField-4 DPU(データ処理ユニット)との連携にも対応しており、ホストCPUを介さずにKVキャッシュの入出力を加速できる構成も発表されています。
KV Block Manager(多階層メモリ管理)
KV Block Managerは、KVキャッシュをGPU HBMだけでなく、CPUメモリ・SSD・リモートストレージまで含めた多階層のメモリに分散管理するコンポーネントです。
GPU HBMは推論速度に直結する最重要リソースですが、容量には限りがあります。KV Block Managerは使用頻度の低いKVキャッシュを自動的にコストの低いストレージ階層に退避させ、必要になったときにGPUに呼び戻します。
管理対象となる4つのメモリ階層は以下のとおりです。
-
G1(GPU HBM)
最も高速なメモリ。アクティブに推論中のKVキャッシュを保持
-
G2(CPUホストメモリ)
GPUメモリの次に高速。短期的に再利用される可能性があるKVキャッシュの退避先
-
G3(ローカルSSD)
大容量だがアクセス速度はメモリより遅い。中期的なKVキャッシュの保存先
-
G4(リモートストレージ)
S3やAzure Blob Storageなどのオブジェクトストレージ。ペタバイト規模のKVキャッシュを永続的に保存可能
この多階層管理により、GPU HBMの容量制限を超えた長文コンテキストの処理が可能になります。たとえばエージェンティックAIのワークフローでは、セッションの途中で生成されたKVキャッシュをG3やG4に退避させておき、後続のステップで必要になったときにGPUに戻すことで、メモリ不足によるリクエスト拒否を回避できます。
推論基盤の最適化を業務成果につなげる

インフラ投資のROIを最大化する設計
Dynamoのような高性能推論基盤を導入しても、業務側の使いこなし設計がなければコスト削減効果は限定的です。PoCから全社展開までの段階設計、部門別ユースケース、インフラ投資のROI測定まで整理したAI業務自動化ガイド(220ページ)を無料で公開中です。
NVIDIA Dynamoの分離型サービングとパフォーマンス
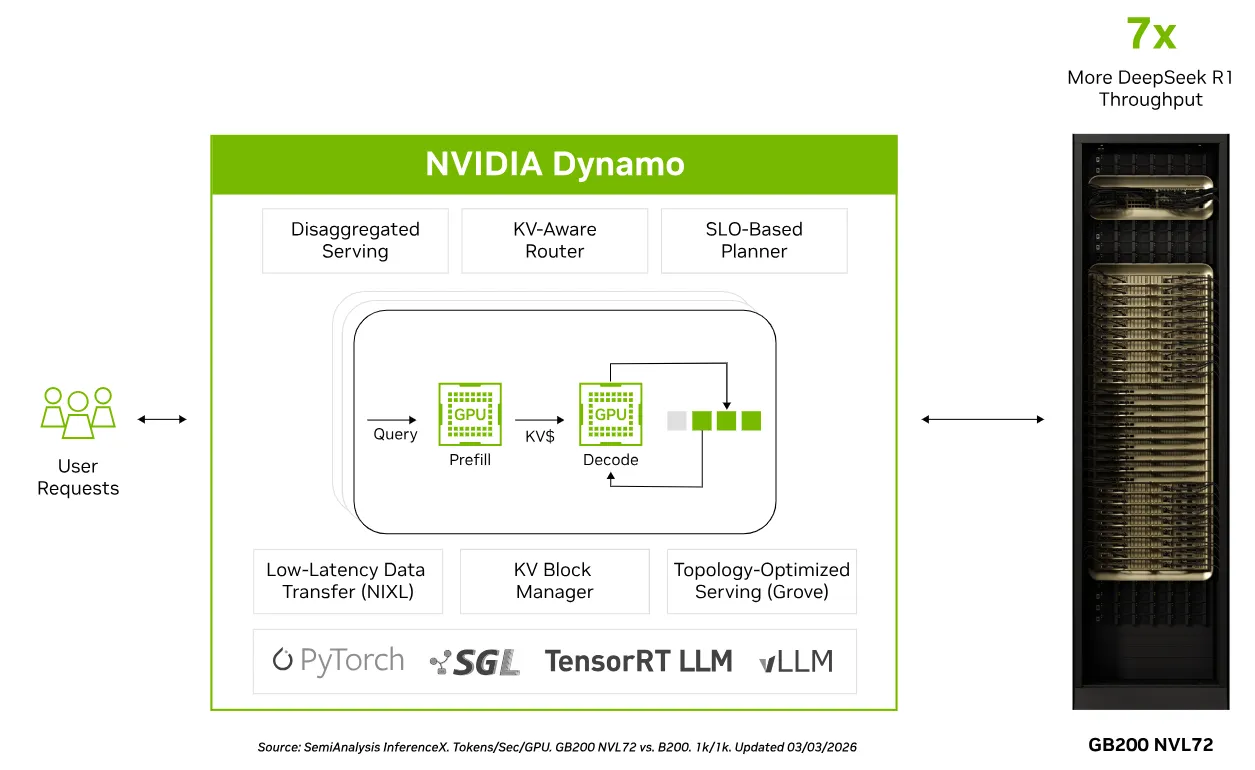
NVIDIA DynamoにおけるPrefill / Decode分離の構成(出典:NVIDIA)
Dynamoの最大の技術的特徴は、推論処理のフェーズを分離して異なるGPU群に割り当てる「分離型サービング(Disaggregated Serving)」です。このセクションでは、その仕組みとパフォーマンスへの影響を解説します。
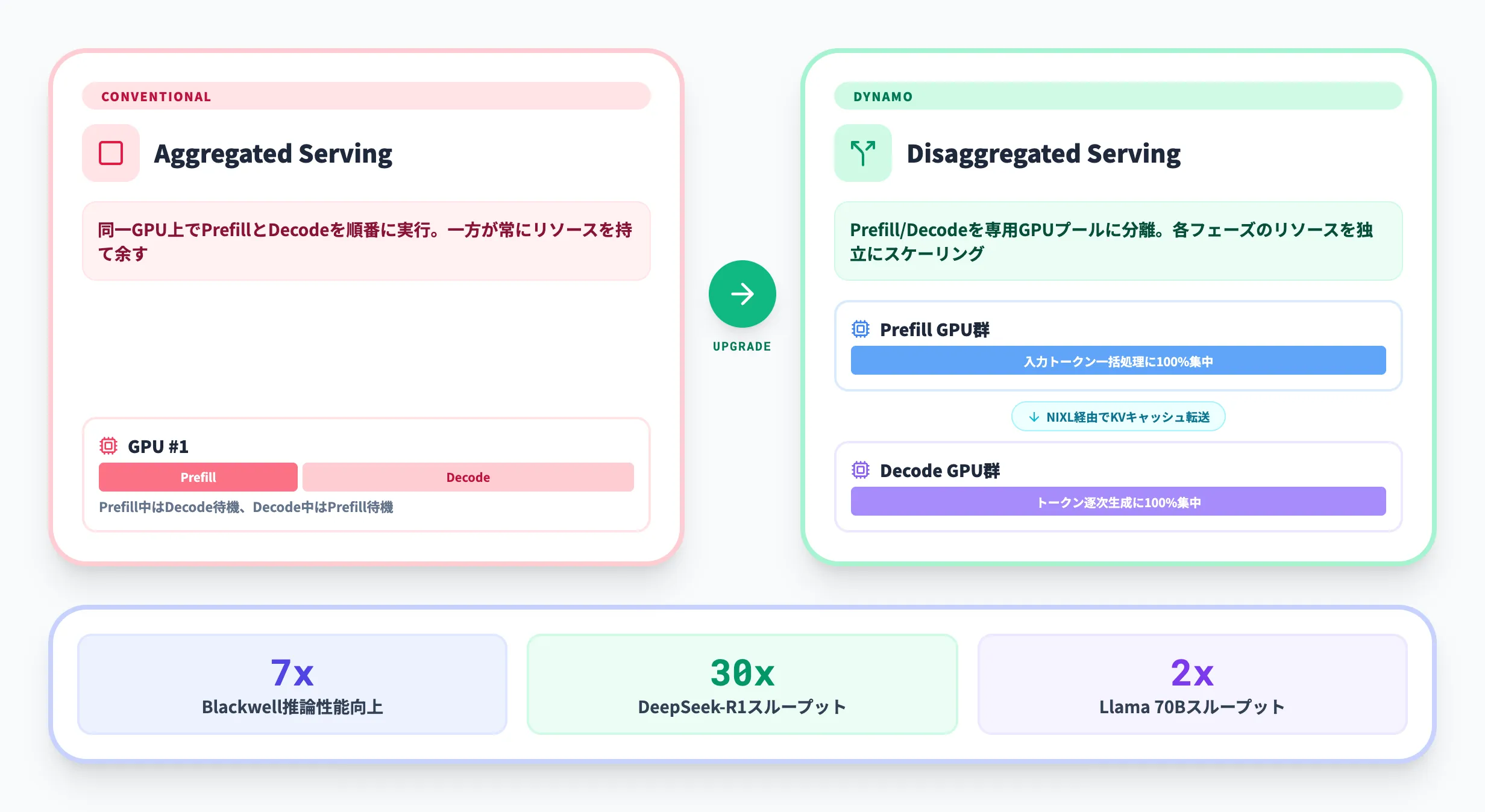
Prefill/Decode分離の設計思想
従来の推論サーバーでは、PrefillとDecodeは同じGPU上で順番に実行されます。この方式(Aggregated Serving)では、Prefillが実行されている間、Decode処理は待機させられます。逆も同様です。
Dynamoの分離型サービングでは、PrefillとDecodeをそれぞれ専用のGPUプールで実行します。
-
Prefill GPU群
入力トークンの一括処理に特化。低いテンソル並列度(通信オーバーヘッドを削減)で構成し、演算スループットを最大化する
-
Decode GPU群
出力トークンの逐次生成に特化。高いテンソル並列度(メモリ帯域を拡大)で構成し、トークン生成速度を最大化する
Prefillが完了すると、生成されたKVキャッシュはNIXL経由で非同期にDecode GPUに転送されます。この分離により、各フェーズのGPUリソースを独立にスケーリングでき、GPU使用率の向上とレイテンシの低減を両立させることが可能になります。
パフォーマンスベンチマーク
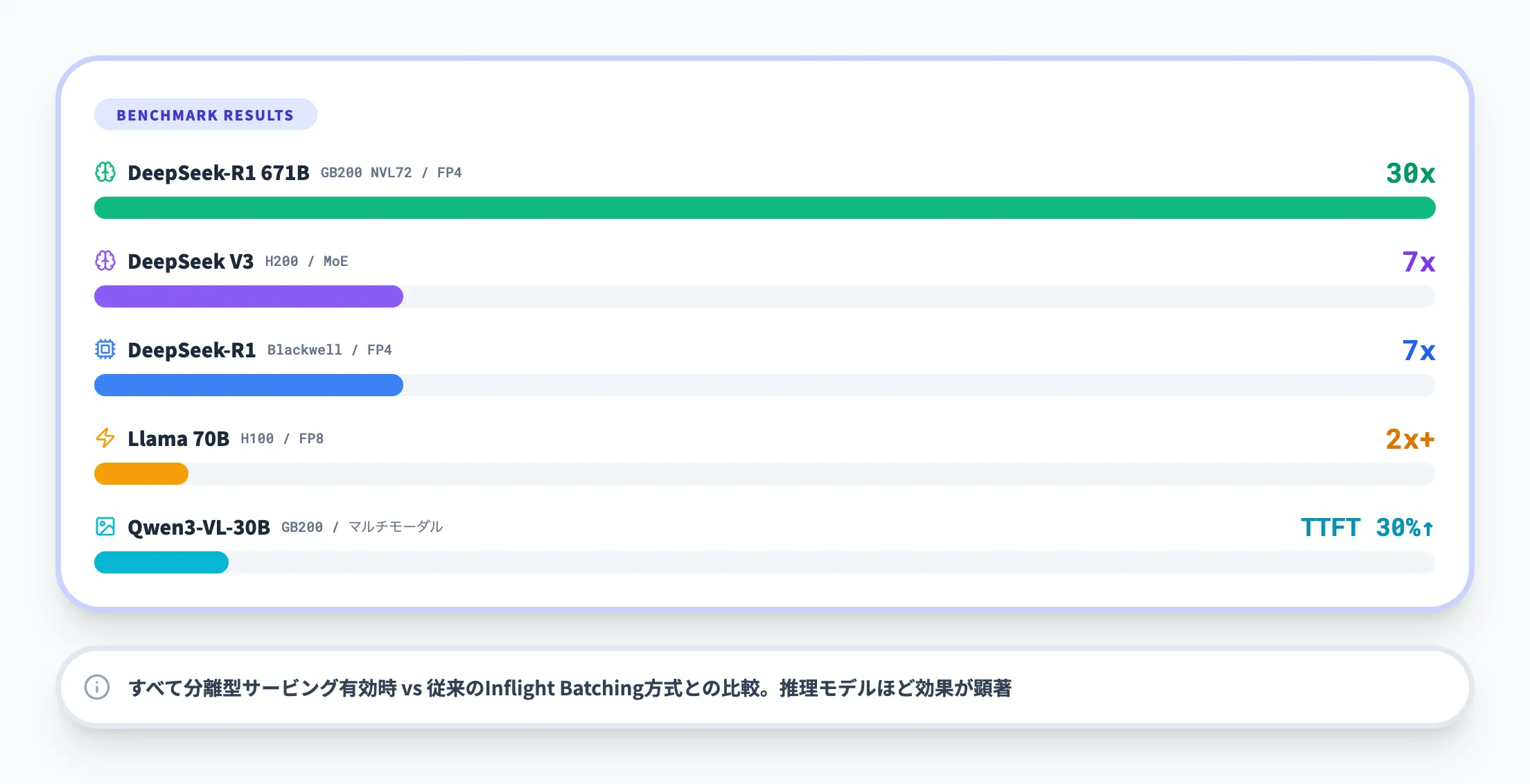
Dynamo 1.0のブログおよび初期の技術ブログで公開されているベンチマーク結果を以下にまとめました。
| モデル | GPU | 条件 | 改善効果 |
|---|---|---|---|
| DeepSeek-R1 671B | GB200 NVL72 | FP4、ISL/OSL 32K/8K | スループット最大30倍 |
| DeepSeek-R1 | Blackwell | FP4、分離型サービング | 推論性能最大7倍 |
| Llama 70B | H100(Hopper) | FP8、ISL/OSL 3K/50 | スループット2倍以上 |
| DeepSeek V3 | H200 | 分離型+エキスパート並列 | GPU当たりスループット約7倍 |
| Qwen3-VL-30B | GB200 | マルチモーダル、FP8 | TTFT 30%高速化、スループット25%向上 |
上記の数値は、いずれもDynamoの分離型サービングを有効にした場合と従来のInflight Batching方式を比較した結果です。特にDeepSeek-R1のような長い思考トークンを生成する推理モデルでは、Prefill/Decode分離の効果が顕著に表れます。
また、ModelExpressというコンポーネントにより、DeepSeek V3のような大規模MoE(Mixture of Experts)モデルのロード時間を従来比で約7倍高速化できるとも報告されています。
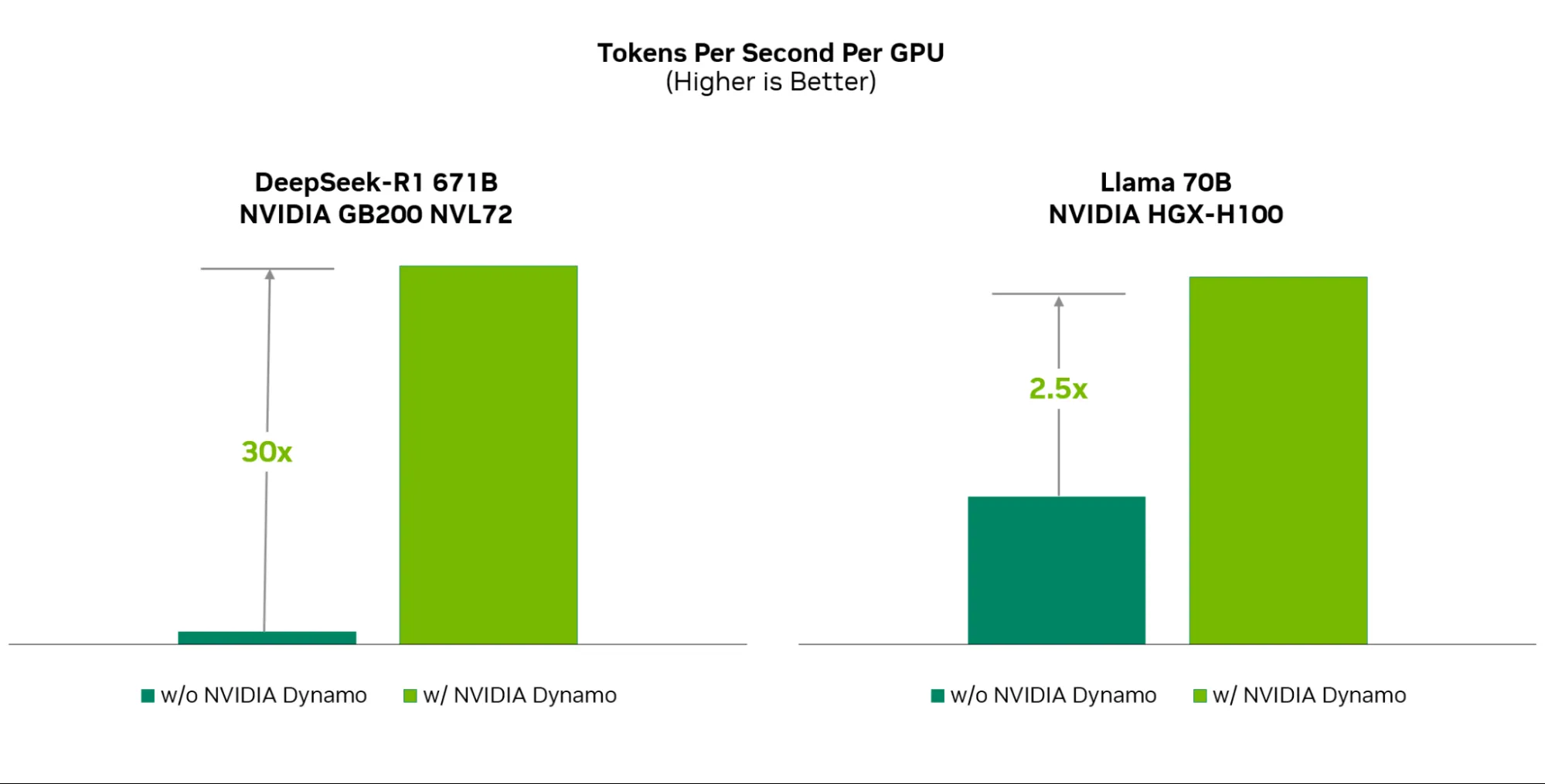
NVIDIA Dynamoあり/なしのスループット比較(出典:NVIDIA Developer Blog)
NVIDIA Dynamoの導入手順と使い方
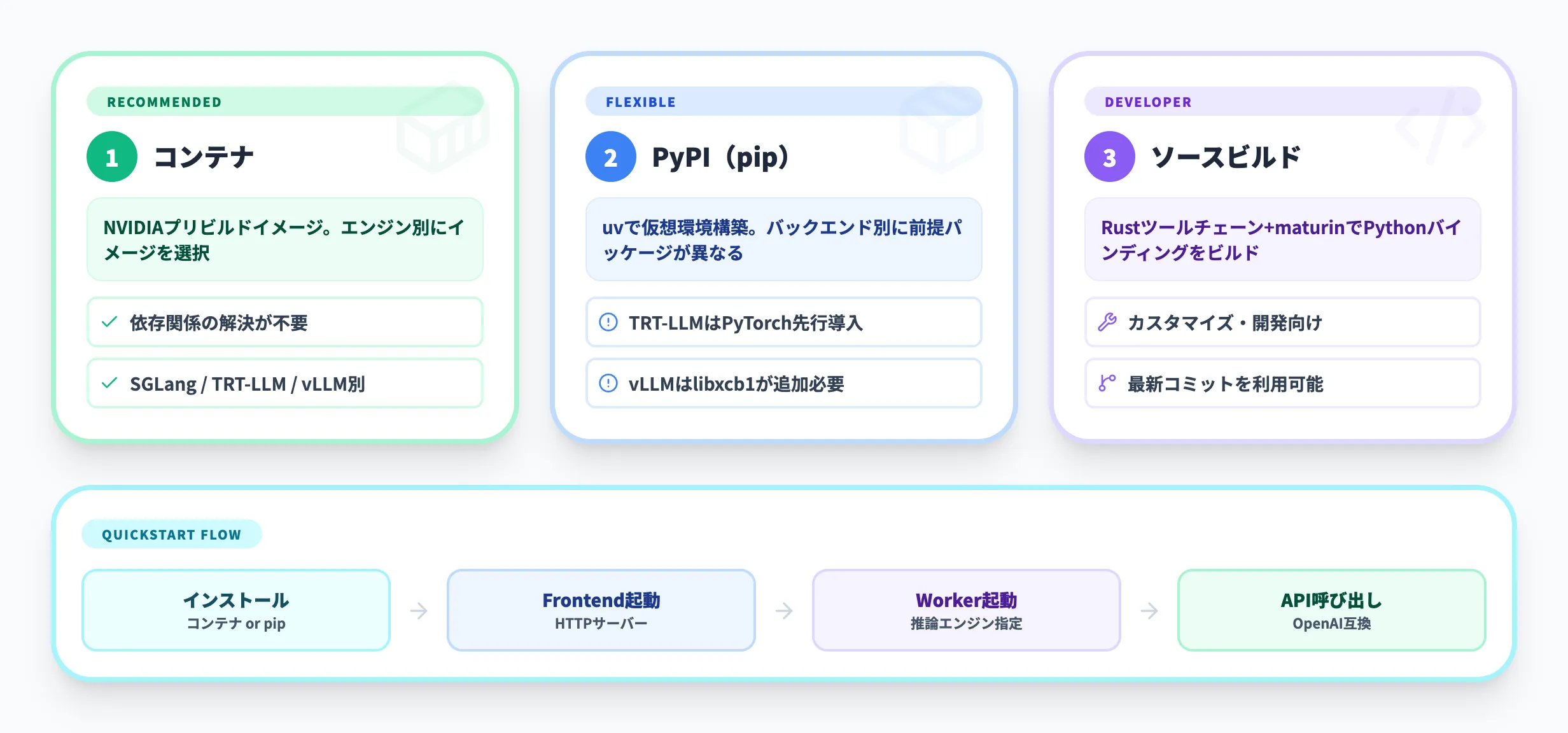
DynamoはGitHubリポジトリ(ai-dynamo/dynamo)から入手でき、コンテナ、PyPI、ソースビルドの3つの方法でインストールできます。ここでは公式ドキュメントとQuickstartに沿って導入手順を整理します。
システム要件
Dynamoの導入にあたって必要な環境は以下のとおりです。
| 要件 | 詳細 |
|---|---|
| GPU | NVIDIA GPU(CUDA対応)。Blackwell / Hopper推奨、Ada Lovelace / Ampereもサポート |
| OS | Ubuntu 22.04 / 24.04(x86_64)、Ubuntu 24.04(ARM64)。CentOS Stream 9は実験対応 |
| Docker | GPU対応のDockerランタイム(コンテナ利用時) |
| Kubernetes | 本番マルチノード環境向け(Grove / Dynamo Operator利用時) |
| Python | Python 3.10〜3.12(KVBMは3.12前提) |
2026年3月時点ではLinuxが前提であり、WindowsやmacOSでの直接実行は公式にサポートされていません。
インストール方法
3つの導入方法から環境に合ったものを選択できます。
方法1:コンテナ(推奨)
NVIDIAが提供するプリビルドコンテナを使う方法です。推論エンジンごとにイメージが用意されています。以下はQuickstartの例(1.0.0タグ)ですが、最新タグはRelease Artifactsで確認してください。
# SGLangバックエンド
docker run --gpus all --network host --rm -it \
nvcr.io/nvidia/ai-dynamo/sglang-runtime:1.0.0
# TensorRT-LLMバックエンド
docker run --gpus all --network host --rm -it \
nvcr.io/nvidia/ai-dynamo/tensorrtllm-runtime:1.0.0
# vLLMバックエンド
docker run --gpus all --network host --rm -it \
nvcr.io/nvidia/ai-dynamo/vllm-runtime:1.0.0
NVIDIA DynamoのSGLangランタイムコンテナを取得する画面
方法2:PyPI(pip install)
uvパッケージマネージャーを使って仮想環境にインストールする方法です。バックエンドごとに前提パッケージが異なるため、使用するエンジンに応じた手順を選択してください。
# 共通:uvのインストールと仮想環境の作成
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv venv && source venv/bin/activate
SGLangバックエンド
sudo apt install python3-dev
uv pip install --prerelease=allow "ai-dynamo[sglang]"
vLLMバックエンド
sudo apt install python3-dev libxcb1
uv pip install --prerelease=allow "ai-dynamo[vllm]"
TensorRT-LLMバックエンド
TensorRT-LLMではpython3-devとPyTorch(CUDA 13.0対応)を先にインストールする必要があります。
sudo apt install python3-dev
pip install torch==2.9.0 torchvision --index-url https://download.pytorch.org/whl/cu130
pip install --pre --extra-index-url https://pypi.nvidia.com "ai-dynamo[trtllm]"
方法3:ソースビルド
開発者向けの方法です。Rustツールチェーンとビルドツールが必要になります。
# Rustのインストール
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
# 仮想環境の作成とビルドツールの導入
uv venv dynamo && source dynamo/bin/activate
uv pip install pip maturin
# Pythonバインディングのビルド
cd lib/bindings/python && maturin develop --uv
Quickstart — 最初のモデルをデプロイする
コンテナまたはpipでのインストールが完了したら、以下の手順でモデルをデプロイし動作確認できます。
# フロントエンド(HTTPサーバー)の起動
python3 -m dynamo.frontend --http-port 8000 \
--discovery-backend file > /dev/null 2>&1 &
# ワーカー(SGLangバックエンド)の起動
python3 -m dynamo.sglang --model-path Qwen/Qwen3-0.6B \
--discovery-backend file &
--discovery-backend fileフラグを指定すると、etcd(分散KVストア)なしでローカル環境だけで動作確認ができます。
起動が完了したら、OpenAI互換のAPIエンドポイントにリクエストを送信します。
curl -s localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [{"role": "user", "content": "Hello!"}],
"max_tokens": 100
}' | jq
レスポンスが返ってくれば、Dynamoが正しく動作しています。
Kubernetes(Grove / Dynamo Operator)でのプロダクション運用
本番環境でのマルチノード運用では、GroveとDynamo Operatorという2つのコンポーネントが連携して動作します。Groveは高度なマルチノードオーケストレーションAPIとしてKubernetes上のリソース管理を担当し、Dynamo OperatorはDGDR(Dynamo Graph Deployment Request)を監視してプロファイリングを実行し、最適なDGD(Dynamo Graph Deployment)を生成・反映する制御を担います。
以下のようなDGDRカスタムリソースを作成するだけで、最小限の設定でデプロイが可能です。
apiVersion: nvidia.com/v1beta1
kind: DynamoGraphDeploymentRequest
metadata:
name: my-model
spec:
model: Qwen/Qwen3-0.6B
backend: vllm
sla:
ttft: 200.0
itl: 20.0
autoApply: true
ttft(Time To First Token)とitl(Inter-Token Latency)のSLO目標値を指定すると、AIConfiguratorが10,000以上のデプロイ構成を20〜30秒でシミュレーションし、推奨構成を生成します。なお、AIConfiguratorによる高速シミュレーションは2026年3月時点ではTensorRT-LLMバックエンドのみ対応しており、vLLM・SGLangへの対応は今後予定されています。
AWS EKS、Azure AKS、Google Cloud GKEなど、主要なマネージドKubernetesサービスへのデプロイガイドも公式ドキュメントで提供されています。

NVIDIA Dynamoの導入企業と活用事例

Dynamo 1.0のリリース時点で、クラウドプロバイダーからAIスタートアップ、エンタープライズまで幅広い企業が本番環境で採用しています。ここでは、具体的な活用内容が明らかになっている事例を紹介します。

NVIDIA Dynamoのエコシステムパートナー(出典:NVIDIA Dynamo)
【関連記事】
AIエージェントとは──日本・世界の事例を徹底紹介
クラウドプロバイダーの対応状況
主要なクラウドプロバイダーはすでにDynamoの統合・サポートを開始しています。
| プロバイダー | 対応状況 |
|---|---|
| AWS | Amazon EKSでのDynamoデプロイガイドを公開 |
| Microsoft Azure | AKSでのマルチノード推論ガイドを公開 |
| Google Cloud | AI HypercomputerでのDynamoレシピを公開 |
| Oracle Cloud Infrastructure | Dynamoサポートを発表 |
| Alibaba Cloud | ACK(Alibaba Container Service)でのサポートを発表 |
各プロバイダーが独自のドキュメントやブループリントを提供しており、既存のKubernetesインフラにDynamoを統合する導線が整っています。
AI企業・エンタープライズの採用
Dynamoを本番環境で運用している企業の中から、具体的な効果が公開されているケースを紹介します。
-
Perplexity AI
CTOのDenis Yarats氏は、月間数億件のリクエストを処理する環境で、Dynamoにより推論処理の効率を向上させ、新しいAI推論モデルの計算要求にも対応できるとコメントしている
-
Baseten
推論エンドポイントプロバイダーであるBaseten社は、Qwen3 Coder 480BモデルにDynamoのKVキャッシュ対応ルーティングを適用し、TTFTを2倍高速化、スループットを1.6倍向上させた
-
Cursor
AI開発支援ツールのCursor社が、Dynamoを採用してコード補完・生成の推論基盤を最適化している
-
SoftBank Corp.
日本のSoftBank Corp.もDynamoを本番環境に導入している企業として公式発表に名前が挙がっている
上記以外にも、ByteDance、Meituan、PayPal、Pinterest、AstraZeneca、BlackRockといった企業がDynamoの本番採用を公表しています。
ストレージ連携パートナーとしては、Dell、HPE、NetApp、VAST Data、WEKA、DDNなどがDynamoのKVキャッシュオフロード機能との統合を進めています。
NVIDIA Dynamoの料金と必要コスト
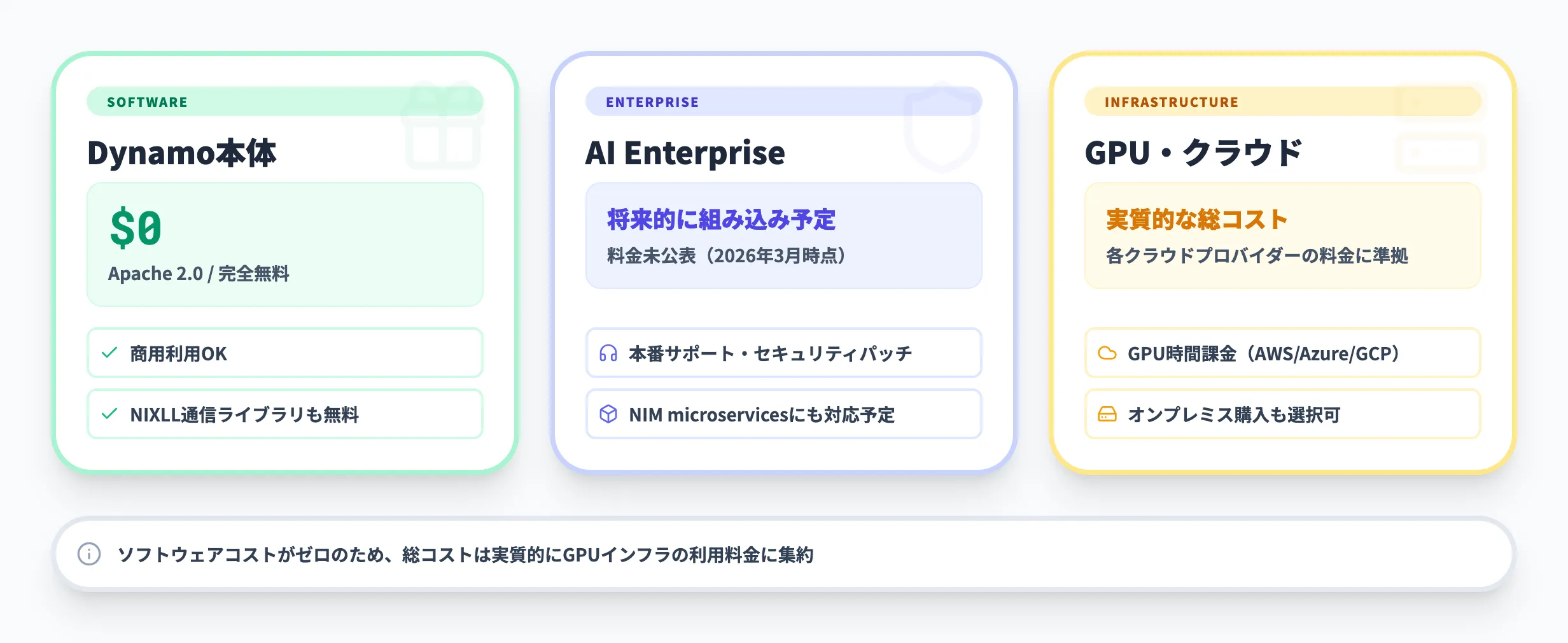
Dynamoのコスト構造は「ソフトウェアは無料、ハードウェアとクラウドは別途」というモデルです。企業で導入を検討する際に把握しておくべき費用項目を整理します。
オープンソースライセンス(無料)
Dynamo本体はApache 2.0ライセンスで提供されており、ダウンロード・インストール・商用利用のいずれにも費用は発生しません。NIXL通信ライブラリも同様にオープンソースで無料です。
エンタープライズサポート(NVIDIA AI Enterprise)
NVIDIA公式では、Dynamoは将来的にNVIDIA AI Enterpriseに組み込まれる予定であり、NVIDIA NIM microservicesにもDynamoの機能が含まれる予定とされています。
2026年3月時点では、エンタープライズ版のDynamoに関する具体的な料金や提供時期は公表されていません。本番環境でのサポートが必要な場合は、NVIDIA AI Enterpriseの動向を確認してください。
GPU・クラウドインフラのコスト
Dynamoの利用にはNVIDIA GPUが必須です。推論するモデルのサイズに応じて、必要なGPUの種類と台数が変わります。
以下の表は、代表的な構成パターンとコストの目安をまとめたものです。
| 構成 | 用途 | コストの考え方 |
|---|---|---|
| 単一GPU(H100 / A100) | 小〜中規模モデルの検証 | クラウドのGPUインスタンス時間課金 |
| マルチGPU(HGX-H100 x 2ノード以上) | 70Bクラスモデルの本番運用 | 各クラウドプロバイダーのGPUインスタンス料金に準拠 |
| GB200 NVL72 | DeepSeek-R1クラスの大規模推論 | オンプレミス購入またはクラウド予約インスタンス |
Dynamoのソフトウェアコストがゼロであるため、総コストは実質的にGPUの利用料金に集約されます。具体的な費用は利用するクラウドプロバイダーの料金体系やオンプレミス構成によって大きく異なるため、各プロバイダーの料金ページで最新情報を確認してください。
NVIDIA Dynamoの注意点と現時点の制限
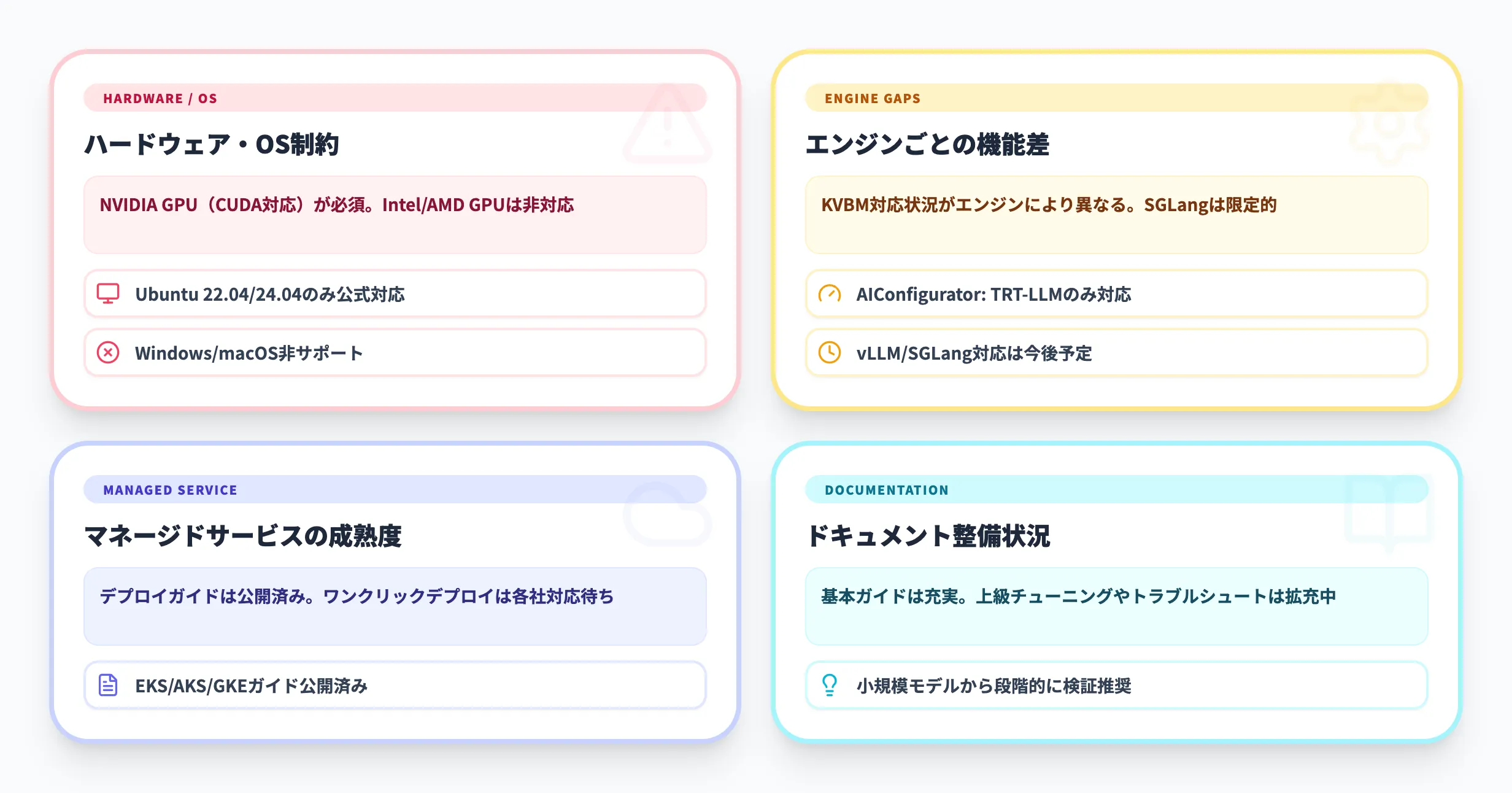
Dynamo 1.0は本番環境向けのGA版として公開されていますが、導入に際して把握しておくべき制約があります。
ハードウェア・OS要件
Dynamoの実行にはNVIDIA GPU(CUDA対応)が必須です。2026年3月時点で公式にサポートされているのはNVIDIA GPU(Blackwell / Hopper / Ada Lovelace / Ampere)のみであり、IntelやAMDのGPUには対応していません。
対応OSはUbuntu 22.04 / 24.04(x86_64)およびUbuntu 24.04(ARM64)が公式サポートされており、CentOS Stream 9は実験対応です。WindowsやmacOSでの直接実行は公式にサポートされていません。
まだ発展途上の領域
Dynamo 1.0は本番利用に耐える品質に達していますが、以下の点は今後のリリースで改善が見込まれる領域です。
-
対応推論エンジンごとの機能差
SGLang、TensorRT-LLM、vLLMの3エンジンをサポートしていますが、KV Block Manager(KVBM)の対応状況はエンジンによって異なる。2026年3月時点ではSGLangのKVBM対応が他2エンジンに比べて限定的
-
マネージドサービスの成熟度
AWS EKS、Azure AKS、GKEでのデプロイガイドは公開されているが、フルマネージドなワンクリックデプロイは各プロバイダーの対応待ちの部分がある
-
ドキュメントの整備
公式ドキュメントは急速に拡充されているものの、上級者向けのチューニングガイドやトラブルシューティング情報はまだ網羅的ではない
初めてDynamoを検証する場合は、公式のQuickstartガイドに沿って小規模なモデル(Qwen3-0.6Bなど)で動作確認を行い、段階的にスケールアップしていくアプローチが推奨されます。

AIインフラの進化を組織の業務自動化の機会として捉える
NVIDIA Dynamoの技術を理解したことで、AI推論インフラの最前線が見えてきました。こうした基盤技術の進化を、自社の業務効率化にどう結びつけるかが次の論点です。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。部門別の導入ユースケースとBefore/After事例で、AI活用の投資判断を支援します。
AI総合研究所が、AI基盤技術の動向を踏まえた業務自動化の全体設計をお手伝いいたします。
推論基盤の最適化を業務成果につなげる
インフラ投資のROIを最大化する設計
Dynamoのような高性能推論基盤を導入しても、業務側の使いこなし設計がなければコスト削減効果は限定的です。PoCから全社展開までの段階設計、部門別ユースケース、インフラ投資のROI測定まで整理したAI業務自動化ガイド(220ページ)を無料で公開中です。
まとめ
NVIDIA Dynamoは、LLM・推理モデル・マルチモーダルモデルの推論をデータセンター規模でスケーリングするために設計されたオープンソースのオーケストレーションフレームワークです。
GPU Planner・Smart Router・NIXL・KV Block Managerの4つのコンポーネントが連携し、Prefill/Decode分離型サービング、KVキャッシュ対応ルーティング、多階層メモリ管理を実現します。Blackwell GPUでの推論性能を最大7倍向上させ、DeepSeek-R1では処理リクエスト数を最大30倍に増加させるベンチマーク結果が公開されています。
Apache 2.0ライセンスで無料利用可能であり、AWS・Azure・Google Cloudなどの主要クラウドプロバイダーが統合を進めています。Perplexity AI、ByteDance、SoftBank Corp.をはじめとする多数の企業がすでに本番環境で運用しており、LLM推論のインフラ基盤として急速に標準化が進んでいるソフトウェアです。










