この記事のポイント
 GPU並列処理の導入にはCUDAが第一候補。NVIDIA GPU資産を活かすならCUDA以外の選択肢はコスト面で非現実的
GPU並列処理の導入にはCUDAが第一候補。NVIDIA GPU資産を活かすならCUDA以外の選択肢はコスト面で非現実的- AI・HPCワークロードではCUDA-Xライブラリ群を活用すべき。cuDNN・cuBLASだけで推論速度が数倍改善するケースが多い
- 開発環境はCUDA Toolkit+VS Codeの組み合わせが最適。Docker公式イメージを使えば環境構築の工数を大幅に削減できる
- 性能ボトルネックの大半はメモリアクセスパターンに起因するため、協調アクセスとシェアードメモリ最適化を最優先で取り組むべき
- Blackwell世代への移行を見据えるなら、CUDA 13.1のタイルベースAPIに早期対応しておくのが有効

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AI、ビッグデータ解析、科学技術計算など、現代のコンピューティングにおいて、高速な並列処理は不可欠です。その鍵を握るのが、NVIDIAが開発した「CUDA」です。
CUDAは、GPUの計算能力を汎用的な目的で活用するためのプラットフォームであり、2025年にはBlackwellアーキテクチャへの対応やCUDA 13のリリースなど、大きな進化を遂げています。
この記事では、CUDAの基本概念から、その特徴、プログラミングの基礎、開発環境の構築方法、さらには性能を最大限に引き出すための最適化手法までを、初心者にも分かりやすく解説します。
また、実際に手を動かしながら学べるサンプルプログラムや、2026年最新の動向も紹介しています。
目次
行列積(Matrix Multiplication)のサンプルコード
1. Blackwellアーキテクチャの本格出荷と性能の飛躍
NVIDIA CUDAとは
CUDAとは、GPUの並列処理能力を活かして、C/C++ベースで汎用計算を高速化できる、NVIDIA独自の並列コンピューティングプラットフォームです。
もともとGPUは、画像処理やグラフィックス描画など特定用途に最適化されたプロセッサでした。しかしCUDAの登場により、GPUを一般的な計算処理にも応用できる「GPGPU(General-Purpose computing on GPUs)」という新たな活用法が広まりました。
これにより、科学技術計算、AI、ビッグデータ解析といった幅広い分野で、飛躍的な処理性能の向上が実現しています。特に、近年の生成AIの爆発的な進化を支える計算基盤として、その重要性はかつてないほど高まっています。

引用元:NVIDIA
現在では、CUDAは単なる開発ツールの枠を超え、GPUコンピューティングの事実上の標準プラットフォームとして確立されています。
NVIDIAの継続的な技術革新とエコシステムの拡充により、CUDAは高性能計算、機械学習、シミュレーション、3Dレンダリングなど、あらゆる分野における最適な選択肢となっています。

CUDAの主な特徴
CUDAが単なるプログラミングツールに留まらず、AIやHPC(ハイパフォーマンスコンピューティング)分野で圧倒的な標準基盤となったのには、明確な理由があります。
ここでは、その核心となる3つの特徴を深く掘り下げて解説します。
1. C/C++をベースとした直感的なプログラミングモデル
CUDAの最大の功績の一つは、GPUプログラミングの敷居を劇的に下げたことです。
それまで専門家でなければ難しかったGPUの並列計算を、多くの開発者が慣れ親しんだC/C++言語を拡張するというアプローチで実現しました。具体的には、以下のような直感的な仕組みを提供しています。
- 最小限の追加構文
「global」キーワードでGPUで実行する関数(カーネル)を定義し、「<<<...>>>」という構文でそのカーネルを起動する、といった数個の拡張機能を学ぶだけで、基本的な並列プログラムを記述できます。
- CPUコードとの共存
1つのソースファイル内に、プログラム全体を制御するCPU側のコード(ホストコード)と、GPUで並列実行されるコード(デバイスコード)を混在して記述できます。これにより、処理の分担が分かりやすく、開発効率が大幅に向上します。
この親しみやすさが、大学の研究室から企業の開発現場まで、爆発的にCUDAプログラマを増やす原動力となりました。
2. ハードウェアの性能を最大限に引き出すスケーラビリティ
CUDAはNVIDIAのGPUアーキテクチャと密接に連携して進化してきました。新しいGPUが登場するたびに、その新機能を最大限に活用するためのCUDAバージョンが提供されます。
-
ハードウェアへの直接的なアクセス
CUDAは、開発者がGPUのメモリ階層やスレッドの動作を細かく制御できる、比較的低レベルなAPIを提供します。これにより、性能を極限まで追求する最適化が可能です。
-
アーキテクチャの進化と共に成長
例えば、近年のGPUに搭載されている「Tensorコア」のようなAI専用演算ユニットも、CUDAライブラリを通じて簡単に利用できます。
最新のBlackwellアーキテクチャ(Compute Capability 10.0)もCUDA 12.8以降で正式にサポートされており、FP4やFP6といった超低精度データ型を活用した高効率な演算が可能です。
-
圧倒的なスケーラビリティ
CUDAで書かれたプログラムは、デスクトップPCに搭載された1基のGPUから、数千基のGPUで構成されるスーパーコンピュータまで、基本的に同じコードで動作させることができます。
この拡張性の高さが、小規模な実験から世界レベルの大規模計算まで、あらゆるニーズに応えられる理由です。
3. 圧倒的なエコシステム「CUDA-X」
CUDAの最も強力な点であり、競合が追随できない最大の強みが、「CUDA-X」というブランドで体系化された、長年の技術の蓄積からなる巨大なエコシステムです。
CUDA-Xは、単なるツールの集合体ではありません。CUDAを基盤として、特定の応用分野(ドメイン)における開発を劇的に加速させるために最適化されたライブラリ、ツール、そしてマイクロサービスの集合体です。
これにより、開発者は低レベルなGPUプログラミングを意識することなく、高度なアプリケーションを迅速に構築できます。
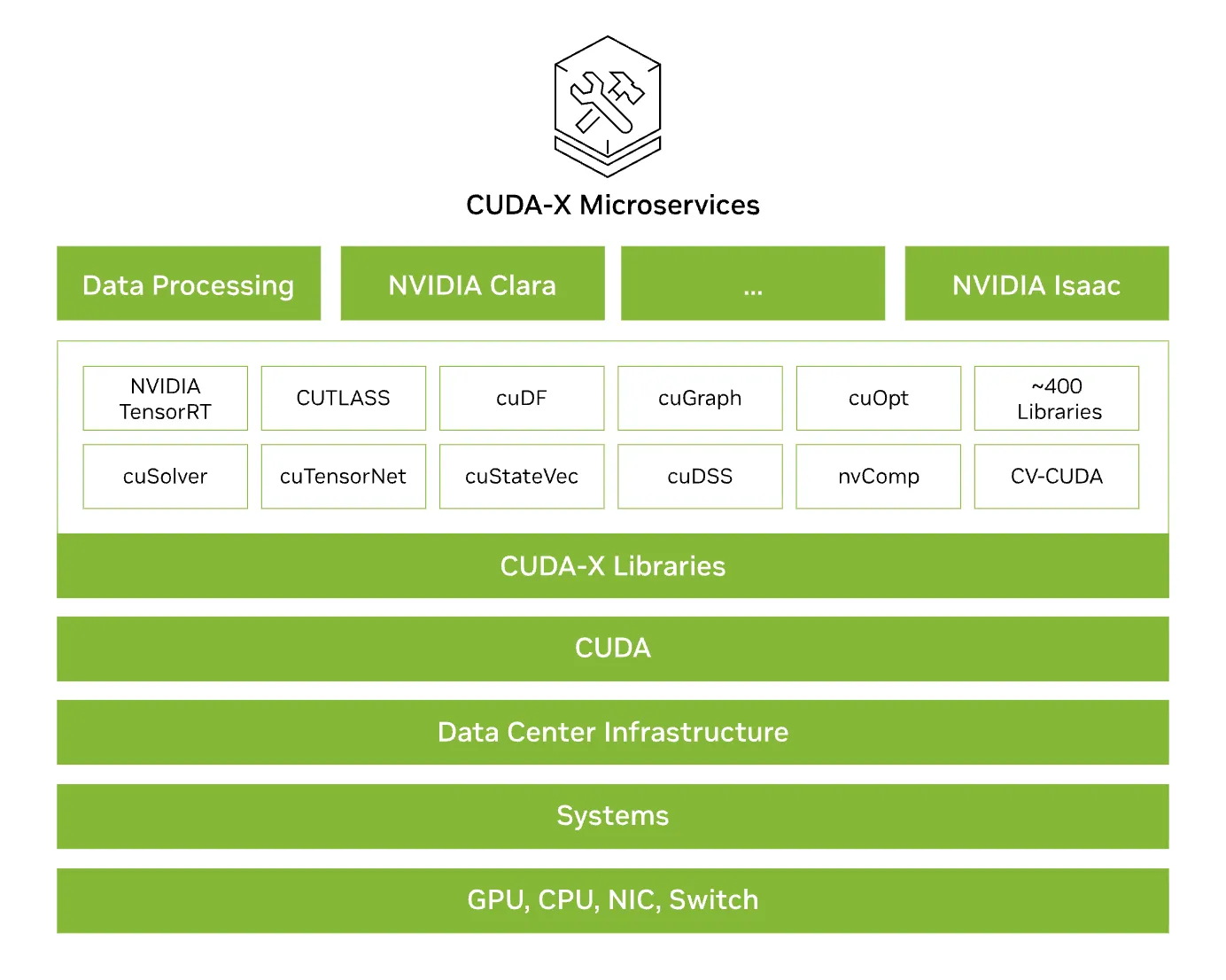
ハードウェアからマイクロサービスまでを網羅するCUDA-Xの階層構造。CUDAを基盤に約400以上のライブラリやマイクロサービスを統合。 (参考:NVIDIA
CUDA-Xは、主に以下の3つの領域をカバーしています。
CUDA-X AI
現代のAI開発ワークフロー全体を支援します。データの前処理、モデルの学習、そして推論(デプロイ)の各段階で必要となる膨大な計算を高速化します。
基礎となる「cuDNN」ライブラリから、LLM開発を支援する「NVIDIA NeMo」フレームワークまで、AI開発に必要なあらゆるツールを提供します。
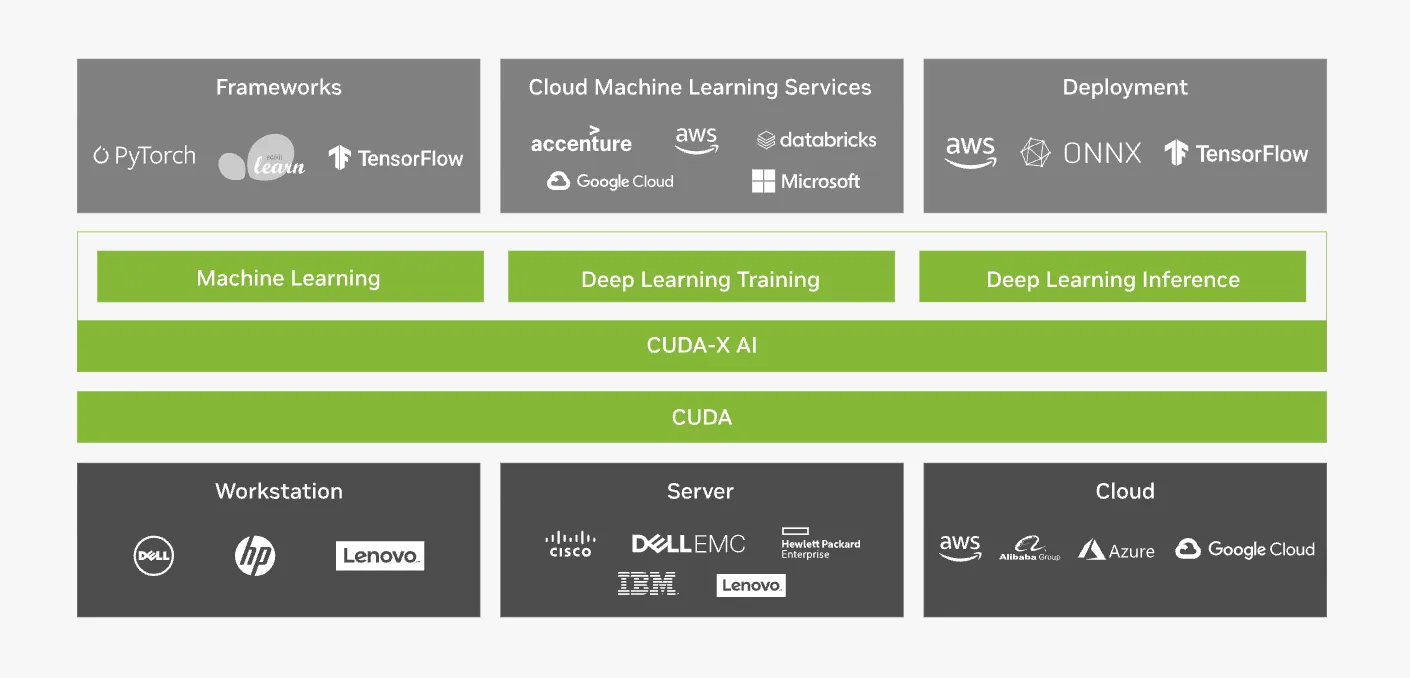
CUDA-X AIはPyTorchやTensorFlowなど主要フレームワークと統合され、クラウドサービス上でも利用可能。(参考:NVIDIA
CUDA-X HPC
科学技術計算やシミュレーションなど、伝統的なハイパフォーマンスコンピューティング(HPC)領域を支えます。
流体力学、分子動力学、気象シミュレーションといった分野で不可欠な、線形代数(cuBLAS)や信号処理(cuFFT)などの高度にチューニングされたライブラリ群が含まれています。
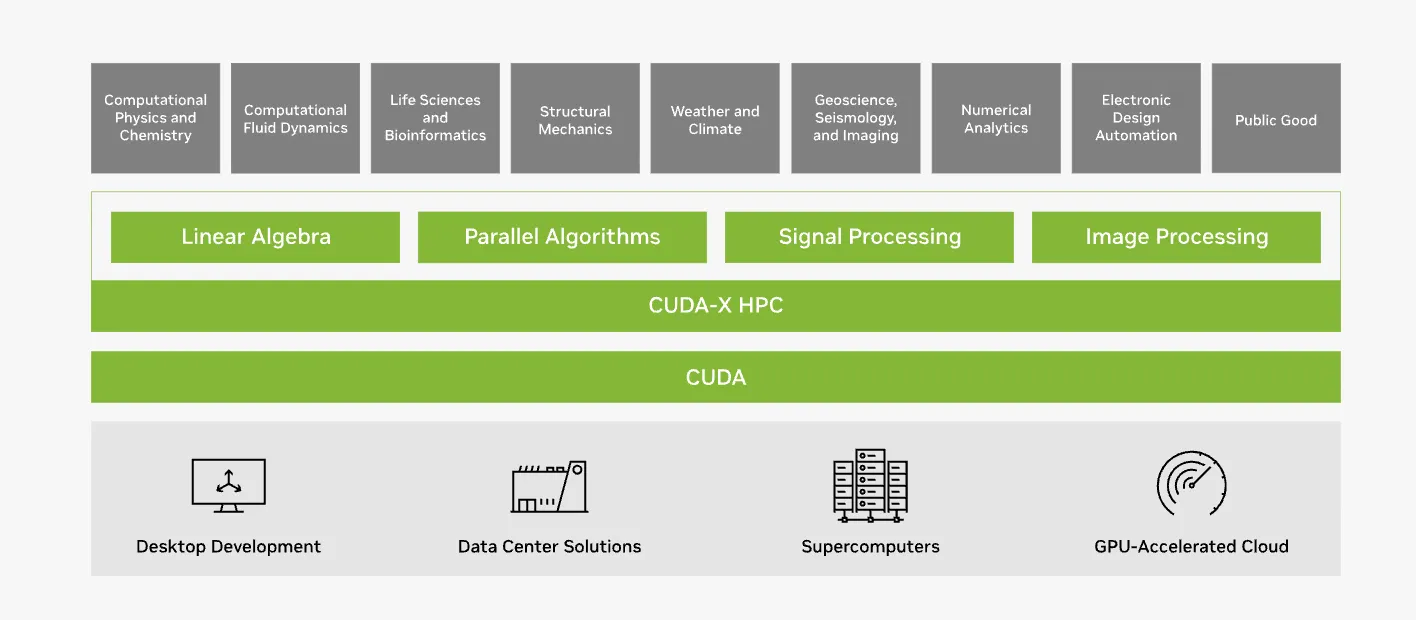
CUDA-X HPCは物理・流体・気象などの科学技術分野における大規模シミュレーションを支える。 (参考:NVIDIA
CUDA-X Data Processing
AIやHPCの計算を始める前段階として、爆発的に増加するデータを効率的に処理するための基盤です。
画像、テキスト、表形式データなど、様々な形式の巨大なデータセットに対するETL(抽出、変換、読み込み)処理をGPUで高速化します。
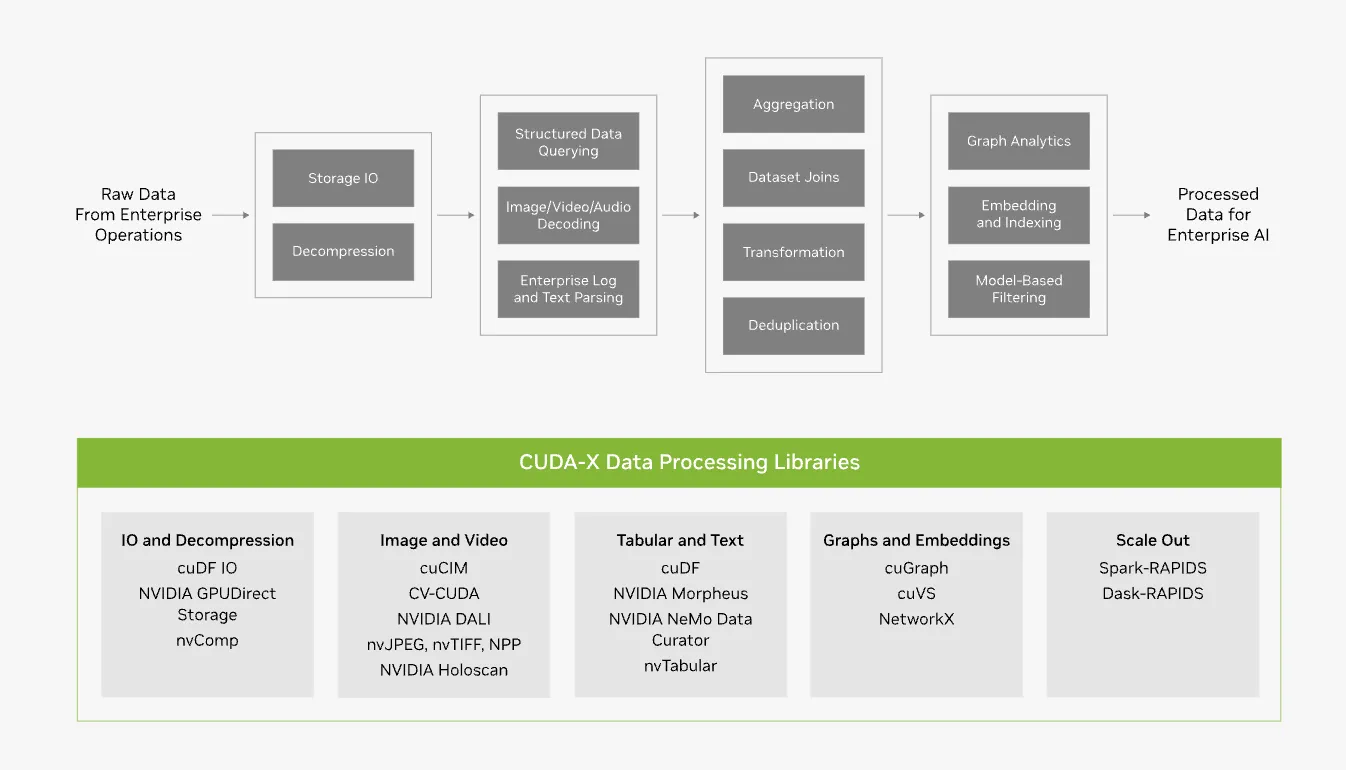
*CUDA-X Data Processingは画像・動画・テキストなど多様なデータのETL処理をGPUで高速化する。(参考:NVIDIA
進化するエコシステム:CUDA-X マイクロサービス
近年NVIDIAは、これらの技術をさらに使いやすくするため、「CUDA-X マイクロサービス」として提供する動きを加速させています。これは、特定の機能(音声認識、ルート最適化など)を、クラウドネイティブなAPIとしてパッケージ化したものです。
例えば、対話AIを構築するための「NVIDIA Riva」や、検索拡張生成(RAG)システムを構築するため「NVIDIA NeMo Retriever」などが提供されており、開発者はこれらのサービスを組み合わせるだけで、GPUのパワーを活用した高度なアプリケーションをサービスに組み込むことができます。
この重層的で進化し続けるエコシステムこそが、CUDAを単なるプログラミング言語から、あらゆる場所に展開可能なAI・HPC開発の標準プラットフォームへと押し上げている最大の理由なのです。
CUDAプログラミングモデルの基本
CUDAプログラミングモデルは、GPUを利用した並列計算を効率的に行うための基本的な枠組みを提供します。
Kernel, Grid, Block, Threadの概念
CUDAでは、並列計算をスレッド(Thread)という単位で処理します。
これらのスレッドはBlockにグループ化され、さらに複数のBlockが集まってGridを形成します。この構造により、GPU上で大規模なデータ処理を効率的に並列化できます。
1.Kernel関数
CUDAプログラムでは、GPU上で実行される関数を Kernel関数(カーネル関数) と呼びます。
通常、ホスト(CPU)側から呼び出され、デバイス(GPU)上で並列に実行されます。
__global__ void myKernelFunction(int *data) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
data[idx] = idx * 2; // 各スレッドが異なる計算を担当
}
【関連記事】
Kernel関数については、こちらの記事で詳しく解説しています。
→サポートベクターマシン(SVM)とは?その種類や利点、実装方法を解説
2.Grid, Block, Threadの階層構造
CUDAの並列計算は、以下の3つの階層構造で管理されます。
| 要素 | 役割 |
|---|---|
| Grid | すべてのBlockをまとめた構造。処理全体を指す。 |
| Block | いくつかのスレッドをグループ化した単位。 |
| Thread | 実際に計算を行う最小単位。個々のデータを処理する。 |
3. CUDAのスレッドインデックス計算
各スレッドは、threadIdx を使用して、自分のインデックスを特定できます。
例えば、1次元のデータを扱う場合、スレッドのインデックスは次のように計算できます。
int idx = threadIdx.x + blockIdx.x * blockDim.x;
例えば、blockDim.x = 256 の場合、Blockごとに256個のスレッドが割り当てられ、スレッドのインデックスは0~255(1つのBlock内)になります。
異なるBlockのスレッドは、全体のインデックスを求めるために blockIdx.x * blockDim.x を考慮する必要があります。
ホスト(CPU)とデバイス(GPU)の関係
1.CUDAにおけるCPUとGPUの役割
CUDAプログラムは、ホスト(CPU)とデバイス(GPU)の2つの側面を持ちます。それぞれの役割を明確にすることで、効率的なコードを書くことができます。
| コンポーネント | 役割 |
|---|---|
| ホスト(CPU) | プログラムの管理・制御を担当し、GPUの計算処理を指示 |
| デバイス(GPU) | 大量のデータ処理を並列で実行する |
2.ホストからデバイスへのデータ転送
CPU(ホスト)からGPU(デバイス)へデータを転送し、GPUで計算を実行した後、結果をCPUに戻す流れが一般的です。
int *d_data; // GPU側のポインタ
cudaMalloc((void**)&d_data, size); // GPUメモリ確保
cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice); // CPU→GPUにデータ転送
myKernelFunction<<<numBlocks, threadsPerBlock>>>(d_data); // Kernel関数を実行
cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost); // GPU→CPUにデータ転送
cudaFree(d_data); // GPUメモリの解放
このデータ転送はオーバーヘッドになるため、できるだけ転送回数を減らすことがCUDAプログラムの最適化の鍵となります。
CUDAプログラムを書く際の制約
CUDAプログラムを書く際には、いくつかの制約があります。これらの制約を理解することで、より効率的なコードを書くことができます。
1.スレッド並列数の制約
| 制約項目 | 内容 |
|---|---|
| 1 Block内の最大スレッド数 | 最大1024(通常は256または512が推奨) |
| GridのBlock数 | 理論上は制限なし(ハードウェアに依存) |
2.メモリ使用量の制限
- **各GPUの共有メモリ(Shared Memory)**のサイズ制限。
- **グローバルメモリ(Global Memory)**の使用量が多いと性能が低下。
- テクスチャメモリやコンスタントメモリを活用して最適化可能。
NVIDIA CUDA Toolkitのインストール手順
CUDA Toolkitの構成要素を理解し、スムーズにインストールを進めるための手順を詳しく解説します。
これからCUDAを用いた開発を始める方は最初の一歩を踏み出しましょう!
CUDA Toolkitに含まれる主要コンポーネント
GPUコンピューティングを効率的に実現するために、NVIDIAが提供する CUDA Toolkit は、開発者に必要なツールとリソースを一つにまとめた強力なパッケージです。
このセクションでは、CUDA Toolkitに含まれる主要なコンポーネントを紹介し、その機能や活用方法について詳しく解説します。
1.コンパイラ
nvcc(NVIDIA CUDA Compiler)は、CUDAコードをGPUで実行可能なバイナリにコンパイルするためのツールです。
nvccの特徴
C/C++に対するCUDAの拡張構文を処理します。
CPUとGPUのコードを統合してコンパイル可能。
2.ライブラリ
CUDA Toolkitには、さまざまな分野で利用可能な高性能ライブラリが含まれています。
- cuBLAS
行列計算を効率化するためのライブラリ。ディープラーニングや科学計算で広く使用されています。
- cuDNN
ディープラーニングフレームワーク(TensorFlow、PyTorchなど)で使用される深層ニューラルネットワーク向けのライブラリです。
- Thrust
C++テンプレートベースの並列アルゴリズムライブラリです。簡単な記述で大規模なデータ処理を実現します。
これらのライブラリを使用することで、開発者はGPU向けのコードを一から書く手間を省き、高度な計算を迅速に実装できます。
WindowsとLinuxでのインストール手順
NVIDIA CUDA Toolkitをインストールする際には、WindowsとLinuxで手順が異なります。このセクションでは、それぞれの環境での具体的なインストール方法と注意点について解説します。
Windowsでのインストール手順
1.NVIDIAドライバのインストール
CUDA Toolkitを使用するには、GPUに対応したNVIDIAドライバが必要です。
まずNVIDIA公式サイトにアクセスします。
上記からGPUモデルとOSに合ったドライバをダウンロード、そこからインストーラーを実行し、指示に従ってインストールしていきます。
2.CUDA Toolkitのダウンロードとインストール
CUDA Toolkit公式ページにアクセスして最新バージョンをダウンロードします。
インストーラーを実行し、「Express(推奨)」または「Custom」を選択してインストールしていきます。
3.環境変数の設定
インストール後、CUDAの実行ファイルにパスを通す必要があります。「スタート」メニューで「環境変数」と検索し、「環境変数の編集」を選択します。
「システム環境変数」の「Path」に以下のディレクトリを追加します。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA<バージョン>\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA<バージョン>\libnvvp
4.インストール確認
コマンドプロンプトを開き、以下を実行してインストールが正しく行われたか確認します。

nvcc --version
CUDAのバージョン情報が表示されれば成功です。
Linuxでのインストール手順
Linuxの場合、gccやmakeなどの開発ツールが必要です。事前にインストールしておきましょう!
sudo apt install -y build-essential
1.NVIDIAドライバのインストール
Windowsと同様にNVIDIA公式サイトからGPUに適したNVIDIAドライバをインストールします。
- Debian/Ubuntuの場合
sudo apt update
sudo apt install -y nvidia-driver-<バージョン番号>
- RHEL/CentOSの場合
sudo yum install -y nvidia-driver-<バージョン番号>
2.CUDA Toolkitのインストール
Windowsと同様CUDA Toolkit公式ページにアクセスしてLinux用のインストーラーをダウンロードします。
ダウンロードしたファイルを実行し、インストール時のオプションに従って進めます。
sudo sh cuda_<バージョン番号>_linux.run
環境変数の設定
まず、.bashrcまたは.zshrcファイルを編集します。
nano ~/.bashrc
以下を追加して
export PATH=/usr/local/cuda-<バージョン>/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-<バージョン>/lib64:$LD_LIBRARY_PATH
設定を反映します。
source ~/.bashrc
4.インストール確認
以下のコマンドでCUDA Toolkitが正しく動作しているか確認します。
nvcc --version
インストール時の注意点
インストール時の注意点をご紹介します。
ドライバとCUDAのバージョン互換性
使用するCUDA Toolkitのバージョンが、インストールしたNVIDIAドライバのバージョンと互換性があるか確認する必要があります。
互換性のリストは、NVIDIAの公式ドキュメントから確認しましょう!
GPUの対応モデルの確認
お使いのGPUがCUDA対応である必要があります。
対応しているモデルは、CUDA対応GPUリストから確認しましょう!
CUDA開発環境 構築の実例
CUDAプログラミングを行うためには、適切な開発環境を整えることが重要です。
本では、「CUDA 開発環境」 の構築手順や、Visual Studio Code CUDA設定方法、nvccを使ったコンパイル、CMakeによるビルド設定、そしてデバッグやプロファイリングツールの活用方法について詳しく解説します。
CUDA開発環境に適したIDEの選択
CUDAプログラミングでは、C/C++の開発環境が必要になります。以下のIDE(統合開発環境)を使用すると、効率的に開発が行えます。
| 開発環境 | 特徴 |
|---|---|
| Visual Studio Code (VSCode) | 軽量で拡張機能が豊富、CUDAプラグインやCMake拡張が利用可能 |
| Visual Studio | WindowsでのCUDA開発に最適、NVIDIAが公式にサポート |
| Eclipse | クロスプラットフォーム開発向け、CUDAプラグインあり |
| CLion | CMakeベースの開発に強く、CUDAと組み合わせやすい |
特に、「Visual Studio Code CUDA」の組み合わせは、拡張機能を利用することで非常に快適な開発環境を構築できておすすめです!
CMakeを使ったCUDAプロジェクト設定
CUDAプロジェクトでは、CMakeを利用すると、異なるプラットフォームでのビルドが容易になります。以下は、CMakeLists.txtを使ってCUDAプロジェクトを設定する方法です。
CMakeとは?
CMake(シーメイク)は、C/C++のプログラムを簡単にビルド(コンパイル&リンク)できるツールです。
通常、C/C++のプログラムを実行可能なファイルにするには、手動でコンパイラ(gcc や clang など)を呼び出したり、複雑なMakefileを書いたりする必要があります。
CMakeを使うと、プロジェクトのビルドを簡単に管理できるようになります!
cmake_minimum_required(VERSION 3.18)
project(MyCUDAProject LANGUAGES CXX CUDA)
set(CMAKE_CUDA_STANDARD 14)
# CUDAアーキテクチャの設定
set(CMAKE_CUDA_ARCHITECTURES 75)
# 実行ファイルを作成
add_executable(my_cuda_program main.cu)
# CUDAコンパイラオプションを設定
set_target_properties(my_cuda_program PROPERTIES
CUDA_SEPARABLE_COMPILATION ON)
CMakeを使ったビルド手順は以下のようになります。
mkdir build
cd build
cmake ..
make -j$(nproc)
nvccコマンドを使ったコンパイル
CUDAのコンパイラnvccを直接使用して、CUDAコードをビルドする方法を解説します。
1.nvcc での基本的なコンパイル
nvcc -o my_cuda_program my_cuda_code.cu
2.nvcc のオプション例
nvcc -arch=sm_75 -O3 -Xcompiler "-Wall" -o optimized_program my_cuda_code.cu
ビルドエラーへの対処方法
CUDA開発では、以下のようなビルドエラーに遭遇することがあります。その時の対処法とともにまとめました。
| エラー | 原因 | 対処法 |
|---|---|---|
| nvcc: command not found | CUDA Toolkitが正しくインストールされていない | export PATH=/usr/local/cuda/bin:$PATH を追加 |
| cuda_runtime.h: No such file or directory | ヘッダーファイルが見つからない | CPLUS_INCLUDE_PATHにCUDAのincludeパスを設定 |
| unsupported gpu architecture 'compute_86' | nvccのバージョンが古い | 最新のCUDA Toolkitにアップデート |
| fatal error: cudnn.h: No such file or directory | cuDNNライブラリが見つからない | CUDNN_INCLUDE_DIRにCUDAのincludeパスを設定 |
| nvcc fatal : Unsupported gpu architecture 'sm_90' | 使用しているGPUがCUDA Toolkitのバージョンに未対応 | 最新のCUDA Toolkitにアップデート |
| Error: identifier "__shfl_down" is undefined | 旧バージョンのCUDAで新しいAPIを使用している | -arch=sm_xx を適切な値に変更 |
| relocation R_X86_64_32 against '.rodata' can not be used | ホストとデバイスのメモリ管理の設定ミス | -Xcompiler -fPIC をコンパイルオプションに追加 |
| undefined reference to '__cudaRegisterFatBinary' | CMake設定のミス、またはCUDAライブラリが適切にリンクされていない | target_link_librariesにcudaを追加 |
デバッグ・プロファイリングツールの活用
CUDAプログラムの最適化やデバッグには、NVIDIAの公式ツールが非常に有用です。ここではツールをいくつか紹介します!
1.Nsight Systems(プロファイリングツール)
「Nsight Systems」は、CUDAプログラムの全体的なパフォーマンスを解析するためのツールです。
Nsight Systemsを使ったプロファイリング手順
nsys profile -o my_profile_report ./my_cuda_program
2.Nsight Compute(カーネルプロファイラ)
「Nsight Compute」は、CUDAカーネルごとの詳細な実行パフォーマンスを分析するツールです。
Nsight Computeの基本的な実行
nv-nsight-cu-cli ./my_cuda_program
GPUメモリの使用状況や、スレッドの実行効率を可視化します。
CUDAのメモリモデルと最適化の考え方
CUDAを使ってGPUプログラムを高速化する際、メモリの使い方がパフォーマンスを大きく左右します。
特に、適切なメモリを選択し、効率的なメモリアクセスを実装することで、計算速度を飛躍的に向上させることができます。
CUDAのメモリモデルを解説し、最適なメモリアクセスの設計、バンク競合の回避、データ転送の効率化といった最適化手法について詳しく説明していきます!
CUDAのメモリ種類と特徴
CUDAには、さまざまな種類のメモリがあり、それぞれ異なる特性を持っています。以下の表に、それぞれのメモリの特徴をまとめました!
| メモリ種類 | アクセス可能範囲 | 遅延(レイテンシ) | 特徴 |
|---|---|---|---|
| グローバルメモリ (Global Memory) | GPU全体で共有 | 高 (400~600サイクル) | メインメモリ、サイズが大きいが遅い |
| シェアードメモリ (Shared Memory) | 各ブロック内のみ | 低 (~30サイクル) | 高速だが、各SM内で共有(48KB~96KB) |
| レジスタ (Register Memory) | 各スレッド専用 | 非常に低 (1サイクル) | 最高速だが、数に制限あり |
| テクスチャメモリ (Texture Memory) | GPU全体で共有 | 中 (キャッシュ付き) | 画像処理向け、2Dキャッシュを持つ |
| コンスタントメモリ (Constant Memory) | GPU全体で共有 | 低 (キャッシュ付き) | 読み取り専用、キャッシュを持つ |
メモリアクセスパターンと最適化手法
CUDAでは、メモリアクセスの最適化が非常に重要です。特に、グローバルメモリへのアクセスを最適化することで、大幅なパフォーマンス向上が期待できます。
1.Coalesced Access(協調アクセス)
グローバルメモリは 128バイト単位でデータをフェッチするため、連続したメモリアドレスにアクセスすることで転送の無駄を減らす ことができます。
スレッドが 連続したメモリアドレスを順番にアクセスする ように設計することが重要。
int idx = threadIdx.x + blockIdx.x * blockDim.x;
data[idx] = input[idx]; // 連続アクセス → 高速
悪いメモリアクセス
int idx = threadIdx.x;
data[idx] = input[idx * STRIDE]; // 非連続アクセス → 非効率
2.バンク競合(Bank Conflicts)の回避策
シェアードメモリ(Shared Memory) は、スレッド間でデータを共有できるため、グローバルメモリよりもアクセスが高速です。
しかし、適切に設計しないと バンク競合(Bank Conflicts) が発生し、スレッドが同時にアクセスできずに処理が遅くなることがあります。
【バンク競合の発生条件】
- シェアードメモリは、32個の バンク(Bank) に分かれており、スレッドが同じバンクの異なるアドレスに同時アクセスすると競合が発生。
- 競合すると、メモリアクセスがシリアル化 され、遅延が発生する。
バンク競合を回避する方法はパディング(Padding) を使い、各スレッドが異なるバンクを使うように調整することです。
__shared__ float sharedData[32 + 1]; // 1つ余分に確保し、バンクをずらす
int idx = threadIdx.x;
sharedData[idx] = input[idx]; // 競合を回避!
バンク競合が発生する例
__shared__ float sharedData[32]; // 32スレッドが1つのバンクに集中
int idx = threadIdx.x;
sharedData[idx] = input[idx]; // 同じバンクにアクセス → 競合発生!
3.メモリコピー (cudaMemcpy) と転送帯域幅の最適化
CPUとGPU間のメモリ転送は、大きなボトルネック になり得ます。以下の最適化手法を活用することで、転送時間を短縮できます。
デバイスメモリ(GPU)⇔ホストメモリ(CPU)間のデータ転送には、cudaMemcpy を使用します。
cudaMemcpy(device_data, host_data, size, cudaMemcpyHostToDevice); // CPU → GPU
cudaMemcpy(host_data, device_data, size, cudaMemcpyDeviceToHost); // GPU → CPU
プログラムのボトルネックになりやすいため、以下の方法で最適化すると、データ転送のオーバーヘッドを減らし、処理速度を向上できます。
| 最適化手法 | 効果 |
|---|---|
| ピン留めメモリ(pinned memory)を使う | cudaHostAlloc() を使用し、CPU-GPU間のデータ転送を高速化 |
| 非同期コピーを活用 | cudaMemcpyAsync() を使い、データ転送とカーネル実行を並行処理 |
| ページロックメモリを利用 | cudaMallocHost() でページロックメモリを確保し、転送効率を向上 |
| 転送回数を減らす | 大きなデータを一括転送し、小さな転送回数を減らす |
| ゼロコピー(Zero-Copy)を活用 | cudaHostRegister() を使い、ホストメモリを直接GPUで利用(低レイテンシ) |
統合メモリ(Unified Memory, cudaMallocManaged)を使用 |
自動的にデータを管理し、明示的なcudaMemcpyを削減 |
CUDA実践例:簡単なサンプルプログラム
CUDAを使ったGPUプログラミングの基本を学ぶには、実際のコードを書いて動かしてみるのが最も効果的です。
ここでは、CUDAの基本を理解するために、ベクトル加算、行列積、画像のグレースケール変換という3つの簡単なサンプルプログラムを紹介します。
それぞれのプログラムで、CUDAの基本構文 (<<<>>>)、スレッドとブロックの割り当て、メモリ管理のコツを学びながら、GPUを活用する方法を身につけましょう。
ベクトル加算のサンプルコード
ベクトル加算とは?
ベクトル加算は、2つのベクトル(配列)の各要素を加算し、結果を新しいベクトルに格納する処理です。各要素の加算は独立しているため、CUDAの並列処理に適しています。
以下のサンプルコードを実際に実行してみましょう!
#include <cuda_runtime.h>
#include <iostream>
// __global__ を使ってGPU上で実行するカーネル関数
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
int N = 1000;
size_t size = N * sizeof(float);
// ホストメモリの割り当て
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// データの初期化
for (int i = 0; i < N; i++) {
h_A[i] = i;
h_B[i] = i * 2;
}
// デバイスメモリの割り当て
float *d_A, *d_B, *d_C;
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
// ホストからデバイスへデータを転送
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// スレッドとブロックの設定
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// カーネル関数の実行
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 結果をホストにコピー
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 結果の確認
for (int i = 0; i < 10; i++) {
std::cout << "C[" << i << "] = " << h_C[i] << std::endl;
}
// メモリの解放
free(h_A); free(h_B); free(h_C);
cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);
return 0;
}
実際に以下のような出力が出たでしょうか?
| Index | A | B | C (GPU Expected) |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 |
| 1 | 1.0 | 2.0 | 3.0 |
| 2 | 2.0 | 4.0 | 6.0 |
| 3 | 3.0 | 6.0 | 9.0 |
| 4 | 4.0 | 8.0 | 12.0 |
| 5 | 5.0 | 10.0 | 15.0 |
| 6 | 6.0 | 12.0 | 18.0 |
| 7 | 7.0 | 14.0 | 21.0 |
| 8 | 8.0 | 16.0 | 24.0 |
| 9 | 9.0 | 18.0 | 27.0 |
行列積(Matrix Multiplication)のサンプルコード
行列積とは?
行列積は、2つの行列AとBを乗算し、新しい行列Cを作成する計算です。CUDAではスレッドごとに1つの行列要素を計算するように設計することで、効率的に処理できます。
以下のサンプルコードを実際に実行してみましょう!
#include <cuda_runtime.h>
#include <iostream>
#define TILE_SIZE 16
// シェアードメモリを利用した行列積
__global__ void matrixMulShared(const float* A, const float* B, float* C, int N) {
__shared__ float Asub[TILE_SIZE][TILE_SIZE];
__shared__ float Bsub[TILE_SIZE][TILE_SIZE];
int row = blockIdx.y * TILE_SIZE + threadIdx.y;
int col = blockIdx.x * TILE_SIZE + threadIdx.x;
float sum = 0.0f;
for (int tile = 0; tile < (N + TILE_SIZE - 1) / TILE_SIZE; tile++) {
Asub[threadIdx.y][threadIdx.x] = A[row * N + tile * TILE_SIZE + threadIdx.x];
Bsub[threadIdx.y][threadIdx.x] = B[(tile * TILE_SIZE + threadIdx.y) * N + col];
__syncthreads();
for (int k = 0; k < TILE_SIZE; k++)
sum += Asub[threadIdx.y][k] * Bsub[k][threadIdx.x];
__syncthreads();
}
C[row * N + col] = sum;
}
以下のような結果はでましたか?
| Col 0 | Col 1 | Col 2 | Col 3 | |
|---|---|---|---|---|
| Row 0 | 4.0 | 4.0 | 4.0 | 4.0 |
| Row 1 | 4.0 | 4.0 | 4.0 | 4.0 |
| Row 2 | 4.0 | 4.0 | 4.0 | 4.0 |
| Row 3 | 4.0 | 4.0 | 4.0 | 4.0 |
画像をグレースケールに変換する簡単なサンプルコード
画像のグレースケール変換とは?
カラー画像(RGB)を、1つの輝度値(グレースケール)に変換する処理です。各ピクセルのRGB値を、Y = 0.299R + 0.587G + 0.114B の式で変換します。
以下のサンプルコードを実際に実行してみましょう!
__global__ void rgbToGrayscale(unsigned char* rgbImage, unsigned char* grayImage, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int idx = (y * width + x) * 3;
unsigned char r = rgbImage[idx];
unsigned char g = rgbImage[idx + 1];
unsigned char b = rgbImage[idx + 2];
grayImage[y * width + x] = static_cast<unsigned char>(0.299f * r + 0.587f * g + 0.114f * b);
}
}
【内容例】
- ベクトル加算プログラムでGPUの基本的な動かし方を実践
<<<>>>構文によるスレッドの割り当て、__global__関数の書き方など
- 行列積(matrix multiplication)のサンプルでBlock・Threadの割り当て方のコツを説明
- 画像をグレースケールに変換する簡単なサンプルコードを紹介
以下のような結果はでましたか?
| R | G | B | Grayscale (GPU Expected) |
|---|---|---|---|
| 73 | 113 | 221 | 113 |
| 114 | 129 | 132 | 124 |
| 190 | 208 | 0 | 178 |
| 140 | 49 | 247 | 98 |
| 69 | 151 | 59 | 115 |

CUDAのユースケース
CUDAは、さまざまな分野で活用されています。以下に、いくつかの具体的なユースケースを紹介します。
ディープラーニング(例:Pinterest)
ディープラーニングや機械学習の分野では、大量のデータを高速に処理する必要があります。特に、大規模言語モデル(LLM)や画像生成AIの学習・推論には、膨大な計算が不可欠です。
CUDAを活用することで、GPUの並列処理能力を最大限に引き出し、モデルのトレーニング時間を大幅に短縮できます。
例えば、PinterestはGPUを活用したディープラーニングで大量の画像を認識し、ユーザーがピンを作成し、注釈をつける際の支援を行っています。
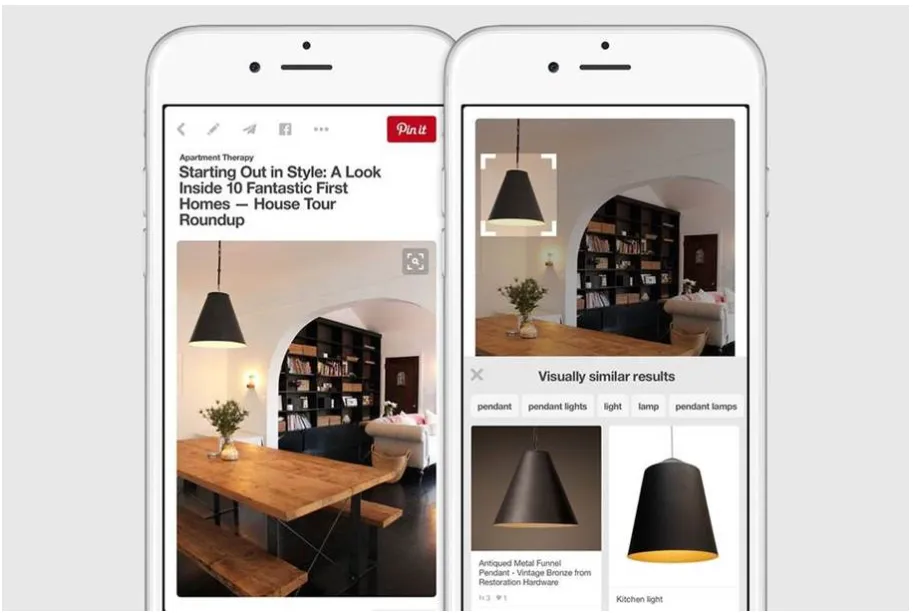
引用元:NVIDIA
数値シミュレーション
科学技術計算、流体解析、分子動力学などの数値シミュレーションでは、膨大な計算量が求められます。
CUDAを用いることで、これらの計算を効率的に並列処理し、シミュレーションの精度と速度を向上させることが可能です。
具体的な企業事例として、カナダのフィンテック企業 Wealthsimple が、機械学習モデルのデプロイと推論のパフォーマンス向上のために NVIDIA Triton Inference Server を活用しています。
Wealthsimpleは、CUDAを活用することで、モデル推論のスループットを向上させ、運用コストを削減しました。特に、金融市場の動向分析やユーザー向けのカスタマイズサービスの改善に貢献しています。

引用元:NVIDIA
画像処理
映像編集ソフトや3Dレンダリングなどの分野でも、CUDAは重要な役割を果たしています。
GPUの並列処理能力を活用することで、リアルタイムでの高品質なレンダリングやエフェクトの適用が可能となり、クリエイティブな作業の効率化が図れます。
例えば、AdobeのDeepFontは、GPUを活用してキャプチャした画像の曲線やその他の特性を調べ、20,000種類ものフォントを抱えるデータベースと照合することで、デザイナーを支援しています。

引用元:NVIDIA
CUDAの最新動向と将来展望
CUDAはNVIDIAの最新GPUアーキテクチャと共に進化を続けており、2025年から2026年にかけて、ハードウェアとソフトウェアの両面で大きな進展がありました。
ここでは、CUDAエコシステムの最新動向と、それが切り拓く未来について解説します。
1. Blackwellアーキテクチャの本格出荷と性能の飛躍
2024年3月のGTCで発表されたGPUアーキテクチャ「Blackwell」は、2024年末から出荷が始まり、2025年には本格的な量産体制に入りました。前世代の「Hopper」から大きな進化を遂げ、生成AIのワークロードに特化して設計されています。
Blackwellの主な特徴は以下の通りです。
-
第2世代Transformer Engine
LLMの学習と推論をさらに加速させるため、FP4やFP6などの超低精度データ型(マイクロスケールフォーマット)に対応しました。これにより、メモリ使用量と計算コストを削減しつつ、モデルの実行効率を向上させます。
-
高速なインターコネクト技術
チップ内の2つのダイをNV-HBI(NVIDIA High Bandwidth Interface)で接続し、10TB/sの超高速な通信を実現しています。また、次世代NVLinkも搭載され、1兆パラメータを超える巨大モデルの学習におけるボトルネックを解消します。
-
Blackwell Ultraへの進化
2025年3月のGTC 2025で発表された「Blackwell Ultra」(B300/GB300)は、288 GB HBM3eメモリを搭載し、FP4で15PFLOPSの性能を実現します。初代Blackwellと比較して約1.5倍の推論性能向上が見込まれています。
Blackwellの出荷は2025年に約520万基と予測されており、データセンター向けAI計算基盤の主力として急速に普及しています。
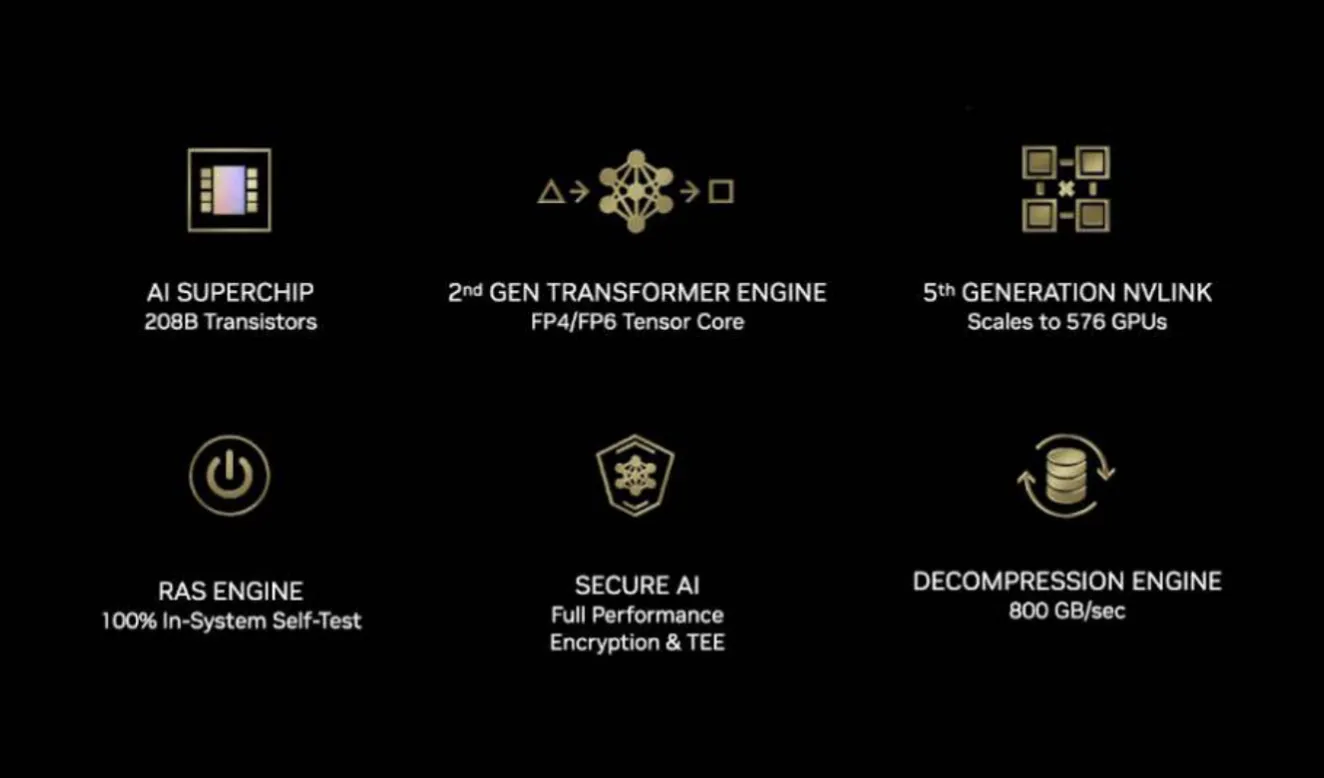
*Blackwellアーキテクチャの概要 (参考:NVIDIA)
2. Grace Blackwell SuperchipによるCPU/GPU統合の進化
前世代のGrace Hopper Superchipに代わり、NVIDIAの高性能CPU「Grace」とGPU「Blackwell」をNVLink-C2C(Chip-to-Chip)で直接結びつけた「Grace Blackwell Superchip」が新たなフラグシップとして出荷されています。
CPUとGPUのメモリがコヒーレントに(矛盾なく)接続されることで、CUDAプログラミングにおけるメモリ管理が大幅に簡素化され、cudaMemcpyのような明示的なデータ転送の必要性を低減させます。
主な製品ラインナップは以下の通りです。
-
GB200 NVL72
1つのGrace CPUと2つのB200 GPUを組み合わせたSuperchipを72基搭載するラックスケールシステムです。HPEが2025年2月に最初のシステムを出荷しました。
-
DGX Spark
デスクトップサイズのGrace Blackwellシステムで、2025年10月に3,999ドルで発売されました。開発者が手元でGPUコンピューティングを体験できる環境として注目されています。
Grace Blackwellは、同等の電力条件下でGrace Hopperと比較して、HPC処理で約2.2倍、AI学習で約1.8倍の性能向上を実現しています。
3. CUDA 13の登場と新しいプログラミングモデル
2025年8月にリリースされたCUDA 13.0は、約20年ぶりとなるCUDAプログラミングモデルの大幅な刷新を含む節目のアップデートとなりました。2026年1月時点の最新バージョンはCUDA 13.1.1です。
CUDA 13の主な新機能は以下の通りです。
-
CUDA Tile(タイルベースプログラミング)
従来のスレッド単位のプログラミングに代わり、データの「タイル(かたまり)」単位で処理を記述する新しいモデルです。開発者はタイルとその操作を定義するだけで、コンパイラとランタイムが最適なスレッド配分を自動的に決定します。現在はBlackwellアーキテクチャ(Compute Capability 10.x / 12.x)でサポートされています。
-
cuTile Python DSL
CUDA Tileカーネルをpythonで記述できるドメイン固有言語です。C++版は将来のリリースで提供予定とされています。
-
Green Contexts
Runtime APIで公開された新機能で、特定のStreaming Multiprocessor(SM)を特定のコンテキストに割り当てることにより、レイテンシに敏感なワークロードの性能を向上させます。
なお、CUDA 13.0ではMaxwell、Pascal、Voltaアーキテクチャのオフラインコンパイルおよびライブラリサポートが廃止されました。これらの旧アーキテクチャ向けの開発にはCUDA 12.x系を使用する必要があります。
4. 生成AIに最適化されるソフトウェアスタック
CUDA-Xエコシステムは、生成AIの潮流に合わせて急速に進化を遂げています。特に、LLMの開発と運用を効率化する以下のソフトウェアが、その進化を牽引しています。
-
NVIDIA NeMo
企業の独自データを使ったLLMのカスタマイズ、ガードレール(安全性確保)機能の実装、そして推論まで、LLMのライフサイクル全体を管理するための統合プラットフォームへと進化しています。
-
TensorRT-LLM
TensorRTをベースとしたLLM推論高速化ライブラリで、BlackwellアーキテクチャのFP4/FP6/FP8といった超低精度データ型をサポートしています。推論時のレイテンシを極限まで削減し、より応答性の高いAIサービスの実現を可能にします。
-
NVIDIA Triton Inference Server
AIモデルの実サービス展開用サーバーで、特にLLM運用で重要となる「In-flight batching」といった高度な機能をサポートしています。
最新のハードウェアの能力を最大限に引き出すソフトウェアが常に提供され、両者が一体となって進化し続けることが、CUDAプラットフォームの最大の強みです。
5. 次世代アーキテクチャ「Rubin」の展望
NVIDIAは2025年3月のGTC 2025で、Blackwellの次世代となるGPUアーキテクチャ「Rubin」を発表しました。2026年1月のCES 2026では量産開始が確認され、2026年後半のパートナー出荷が予定されています。
Rubinは、TSMCの3nmプロセスで製造され、HBM4メモリ(288 GB、13 TB/s帯域幅)を搭載します。FP4で50PFLOPSの性能が見込まれ、Blackwellの約2.5倍に相当します。新たに設計されたARMベースCPU「Vera」と組み合わせ、推論性能でBlackwell比5倍、トークンあたりコスト10分の1の実現を目指しています。
このように、NVIDIA CUDAを取り巻くハードウェアとソフトウェアの両面が、生成AI時代の要求に応えるべく急速に進化しています。
GPU並列処理の知見からAI業務活用の構想を進める
CUDAによるGPU並列処理の仕組みを理解したことで、AIの計算基盤がどう動作するかの解像度が高まったはずです。こうした技術基盤への理解は、組織がAIを業務に導入する際に、適切なインフラ選定と実装計画を立てるための土台になります。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階設計する実践ガイド(220ページ)を無料で提供しています。部門別のBefore/After付きユースケースから、PoC→全社展開のロードマップまで、技術選定だけでなく業務設計の視点で解説しています。
AI総合研究所が、AIインフラの知見を組織の業務自動化に結びつける計画策定を支援します。
GPU知識をAI基盤の導入設計に活かす

Microsoft環境でのAI業務自動化ガイド
CUDAやGPU技術の理解を、組織としてのAI業務自動化基盤の設計に展開するための220ページの実践ガイドです。インフラ選定からROI設計まで収録しています。
NVIDIA CUDAの料金体系
CUDAは無償で利用できるプラットフォームですが、実際の開発・運用にはハードウェアやクラウド環境のコストが発生します。ここでは、CUDA関連の費用構造を整理します。
CUDA Toolkitと主要ライブラリの費用
CUDA Toolkit、CUDA-Xライブラリ群(cuDNN、cuBLASなど)は、すべて無償で提供されています。NVIDIAの公式サイトからダウンロードでき、商用利用もEULAの範囲内で無料です。
以下の表で、CUDA関連ソフトウェアの費用を整理しました。
| 項目 | 費用 | 備考 |
|---|---|---|
| CUDA Toolkit | 無料 | コンパイラ、ライブラリ、デバッグツール一式 |
| CUDA-Xライブラリ | 無料 | cuDNN、cuBLAS、TensorRT等 |
| NVIDIA AI Enterprise | 有償(年額制) | 企業向けサポート・セキュリティパッチ・認定済みコンテナ |
CUDA自体は無料ですが、実行にはNVIDIA製GPUが必須である点に注意が必要です。CUDAのライセンス規約では、NVIDIA GPU以外のハードウェアでの実行が明確に禁止されています。
CUDA開発に必要なGPU調達の選択肢
CUDAを利用するためのNVIDIA GPU調達には、主にオンプレミス購入とクラウド利用の2つの方法があります。
-
オンプレミス(GPU購入)
開発用途であれば、GeForce RTXシリーズ(数万円〜)で始められます。本格的なAI学習には、データセンター向けのA100やH100、最新のB200といったGPUが必要になりますが、これらは数百万円以上の投資となります。
-
クラウドGPU
AzureやAWSなどの主要クラウドプロバイダーが、NVIDIA GPUインスタンスを提供しています。初期投資を抑えつつ、必要な期間だけGPUリソースを利用できるため、プロジェクトの規模に応じた柔軟な選択が可能です。
CUDA自体のソフトウェア費用はかからないため、予算の大部分はGPUハードウェアまたはクラウド利用料に充てられることになります。開発の規模と期間に応じて、オンプレミスとクラウドを使い分けるのが現実的な選択肢です。
まとめ
CUDAは、GPUの並列処理能力を活用することで、ディープラーニング、数値シミュレーション、画像処理、自動運転、ゲーム開発などの分野で計算速度を飛躍的に向上させます。特に、TensorFlowやPyTorchといったフレームワークとの統合により、AIモデルのトレーニングや推論を効率的に行うことが可能になります。
また、CUDAプログラムを開発する際には、適切なメモリアクセスの設計や最適化が重要であり、共有メモリの活用や協調アクセス(coalesced access)によって、処理性能を最大限に引き出すことができます。さらに、開発環境の構築、コンパイルエラーやGPUドライバの問題解決についても理解を深めることで、スムーズな開発が可能になります。
もしCUDAに興味を持ったら、次は実際にコードを書いてみることをおすすめします。まずは簡単なベクトル加算や行列積のプログラムからスタートし、徐々に最適化や実践的なアプリケーションにチャレンジしていきましょう!
また、AI総合研究所は企業のAI導入をサポートしています。導入の構想段階から、AI開発はもちろんのことRPAなどのシステム開発まで一気通貫で支援いたします。お気軽に弊社にご相談ください。
CUDAをマスターすれば、あなたのプログラムはもっと速く、もっとパワフルになります。ぜひ、GPUの可能性を最大限に活かして、新しいチャレンジを楽しんでください!











