この記事のポイント
 既存S3バケットをファイルシステムとして使いたいなら、マイグレーション不要のAmazon S3 Filesが第一候補
既存S3バケットをファイルシステムとして使いたいなら、マイグレーション不要のAmazon S3 Filesが第一候補- AIエージェントのワークスペースや機械学習のデータ準備のように、ファイル単位の編集が頻発する用途で本領を発揮
- 全データではなく「アクティブな作業セットだけ」高性能ストレージ料金が課金されるため、ペタバイト級バケットでもコストを抑えやすい
- Linuxの標準ファイル操作で動くレガシーアプリをコード変更なしでS3上に載せ替えたい組織にとって、移行コストを大幅に削減できる
- EFS単体やFSx for Lustre、S3 Mountpointとの使い分けは「データの真の住処をどこに置きたいか」で決めるのが実務的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Amazon S3 Filesは、AWSが2026年4月7日に一般提供を開始した、S3バケットを共有ファイルシステムとして直接利用できる新機能です。内部はAmazon EFSをベースに構築され、既存のS3バケットをマイグレーションなしでマウントでき、最大25,000台のコンピュートリソースから同時アクセスが可能です。
本記事では、Amazon S3 Filesの主要機能、stage and commitセマンティクスを採用したアーキテクチャ、従来のS3との違い、EFSやFSx for Lustre・S3 Mountpointとの比較、料金体系、AIエージェント時代におけるユースケースまでを体系的に解説します。
Amazon S3 Filesとは?
Amazon S3 Files(エススリー ファイルズ)は、AWSが2026年4月7日に一般提供を開始した、S3バケットを共有ファイルシステムとして直接マウントできる新機能です。データを別ストレージに複製・同期する手間なしに、既存のS3バケットへ「普通のファイル」として読み書きできるのが最大の特徴です。
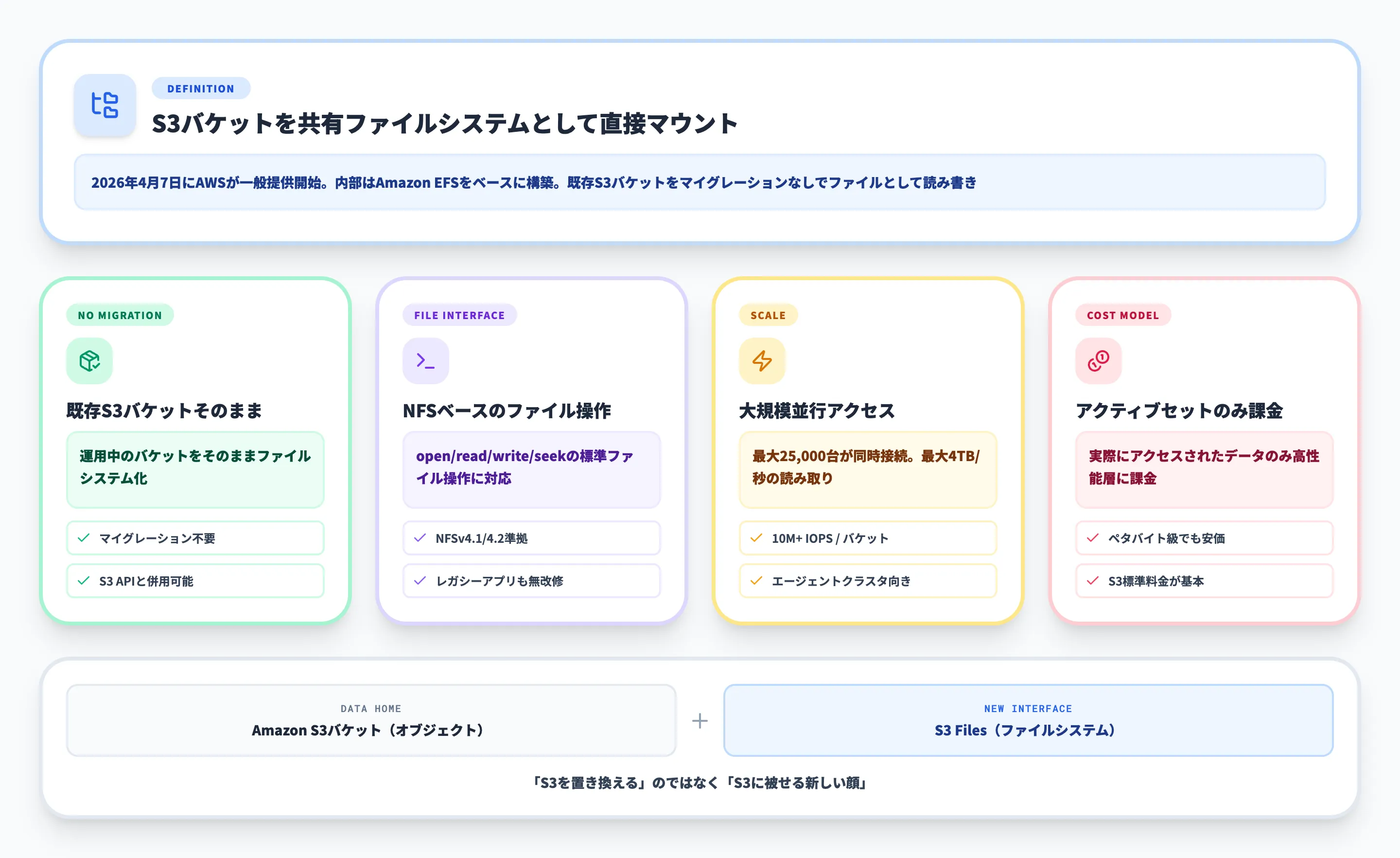
S3 Filesは内部的にAmazon EFSを基盤としており、アクティブに使っているデータだけを高性能ストレージにキャッシュし、低レイテンシでアクセスできるようになっています。バケットのデータ本体はS3にあるため、S3の堅牢性・スケーラビリティ・コスト効率はそのまま継承されます。
S3 Filesの主な特徴は次の通りです。
-
既存S3バケットをそのまま利用
マイグレーション不要で、すでに運用中のバケットをファイルシステムとしてマウントできます
-
NFSv4.1/4.2ベースの共有ファイルシステムアクセス
open/read/write/seekといったLinuxの標準的なファイル操作に対応し、レガシーアプリやファイルベースのツールがコード変更なしで動きます(hard linkやACL、Kerberosなど一部の高度なPOSIX機能には未対応)
-
大規模並行アクセス
1つのS3ファイルシステムに対して最大25,000台のコンピュートリソースが同時接続でき、最大4TB/秒の読み取りスループットを実現します
-
アクティブセットだけ課金される高性能ストレージ層
バケット全体ではなく、実際にアクセスされたデータだけがEFSベースの高性能層にキャッシュされ、課金対象になります
これらの特徴を踏まえると、S3 Filesは「S3を完全に置き換える」ものではなく、S3の上に被せる新しいインターフェースと理解するのが正確です。データの真の住処はあくまでS3バケットであり、S3 Filesはそこに「ファイルシステム的なアクセス経路」を追加する役割を担います。

Amazon S3との位置付けの違い
従来のAmazon S3はオブジェクトストレージであり、HTTPベースのAPI(PUT/GET/LIST Object)でファイル全体を読み書きするのが基本でした。フォルダの概念はキーのプレフィックスで擬似的に表現され、ファイルの一部だけを書き換える操作(partial write/append)や効率的なrenameは苦手な領域でした。
S3 Filesはこのギャップを埋める形で登場し、S3のオブジェクト面を維持したまま「ファイルシステムとしての顔」を追加します。AWSのAndy Warfield氏は公式ブログで、S3が長年抱えていた「データ摩擦——一方にS3、もう一方にファイルシステム、その間に手動コピーパイプライン」という課題が、S3 Files開発の出発点になったと述べています。
なぜAmazon S3 Filesが必要なのか?
S3 Filesが投入された背景には、AIエージェント時代の到来によるストレージ要件の変化があります。従来のオブジェクトストレージのままでは対応しづらい新しい使い方が、ここ数年で急速に増えてきました。

AIエージェントが生む新しいI/Oパターン
AIエージェントやコーディングエージェントは、人間の開発者と同じように「ファイルを開き、読み、編集し、保存する」操作を前提に動きます。エージェントが一時メモリを書き出したり、複数のステップにまたがってstateを共有したり、生成したコードや中間データをワーキングディレクトリに置いたりといった操作は、本質的にファイルシステム的なアクセスを必要とします。
ところがS3はオブジェクトストレージなので、ファイルの一部だけを差し替えたいだけでもオブジェクトを丸ごとPUTし直す必要があり、エージェントが扱うには摩擦が大きすぎました。「それなら別のファイルシステムを用意して、終わったらS3にコピーする」というワークフローも、複数エージェントが並行で動く環境では同期コストが膨れ上がります。
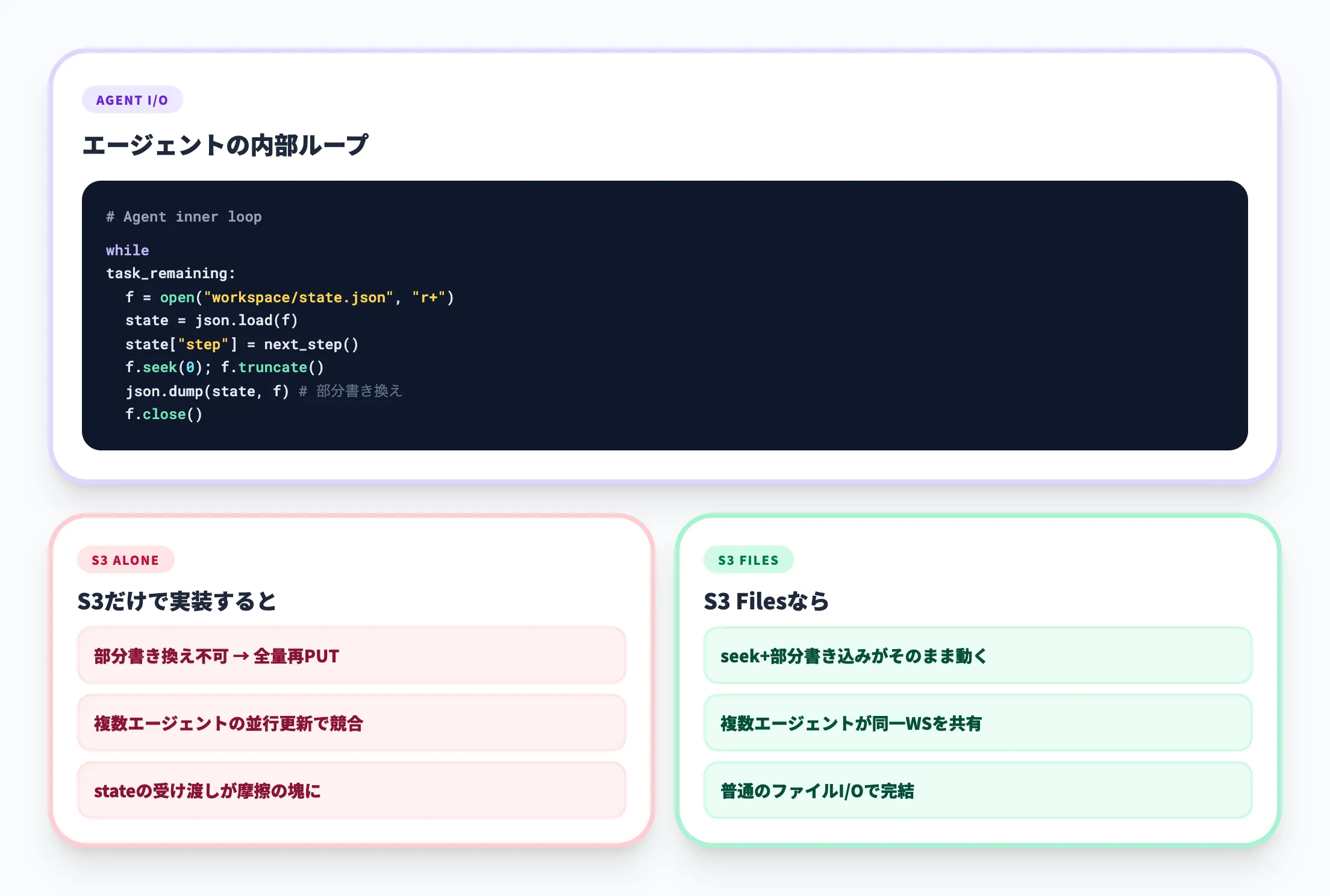
従来は別々のストレージを束ねる必要があった
S3 Files登場以前にも、S3とファイルシステムを橋渡しする選択肢はいくつか存在しましたが、いずれも一長一短がありました。
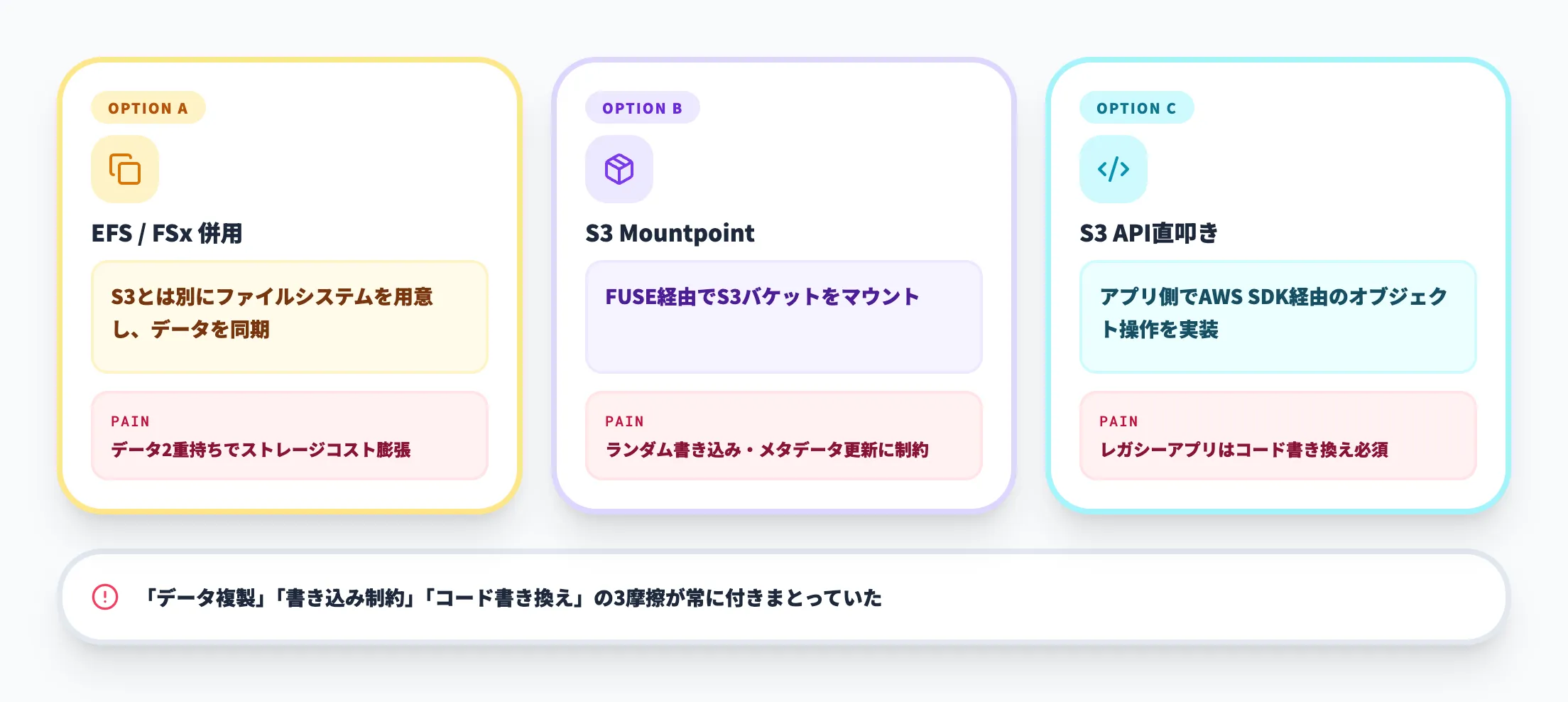
-
EFSやFSx for Lustreを併用してデータを同期
ファイルシステムは手に入るが、データを2重に持つことになりストレージコストが膨らむ
-
S3 Mountpoint(mountpoint-s3)でFUSEマウント
読み取り中心なら使えるが、ランダム書き込みやメタデータ更新に制約が多い
-
アプリケーション側でS3 APIを直接叩く
レガシーアプリやファイルベースのツールにそのままは適用できず、コード書き換えが必要
S3 Filesは、これらの選択肢が抱えていた「データ複製」「書き込み制約」「コード書き換え」という3つの摩擦を、S3そのものに正式なファイルシステムインターフェースを加えることで一括して解消するアプローチです。
The New Stackも、S3 Filesは「20年近く分離されてきたオブジェクトとファイルの世界をついに同じ箱に収めた」とその意義を強調しています。
Amazon S3 Filesの主要機能
S3 Filesが提供する機能は、大きく「ファイルシステムインターフェース」「高性能キャッシュ層」「並行アクセス」「データ管理ポリシー」の4つに整理できます。それぞれ単独でも有用ですが、組み合わせることで「AIエージェントや機械学習向けの共有ワークスペース」として機能します。
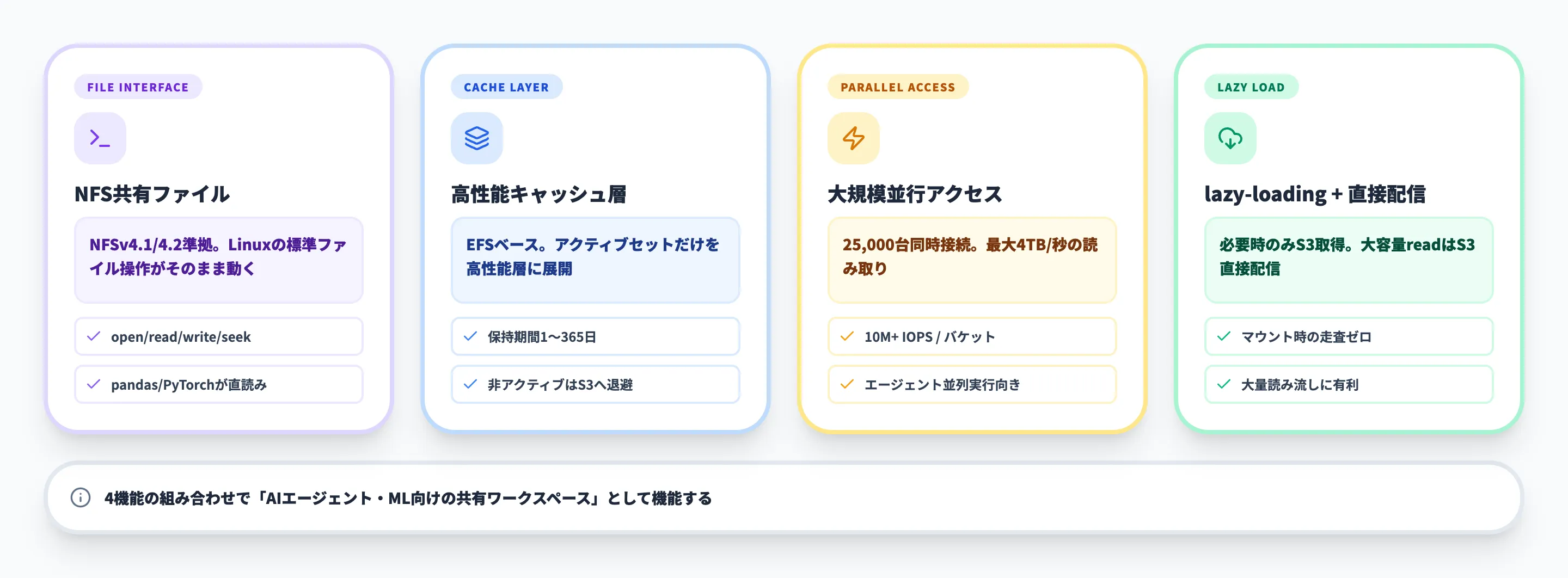
NFSv4.1/4.2ベースの共有ファイルシステムアクセス
S3 Filesは、Linuxベースのコンピュートリソース上でNFSv4.1/4.2プロトコルによる共有ファイルシステムアクセスを提供します。openしてファイルハンドルを取得し、seekで任意のオフセットへ移動し、その位置から書き込んでcloseするといった、Linux上のアプリケーションが当然のように行う標準ファイル操作がそのまま動きます。
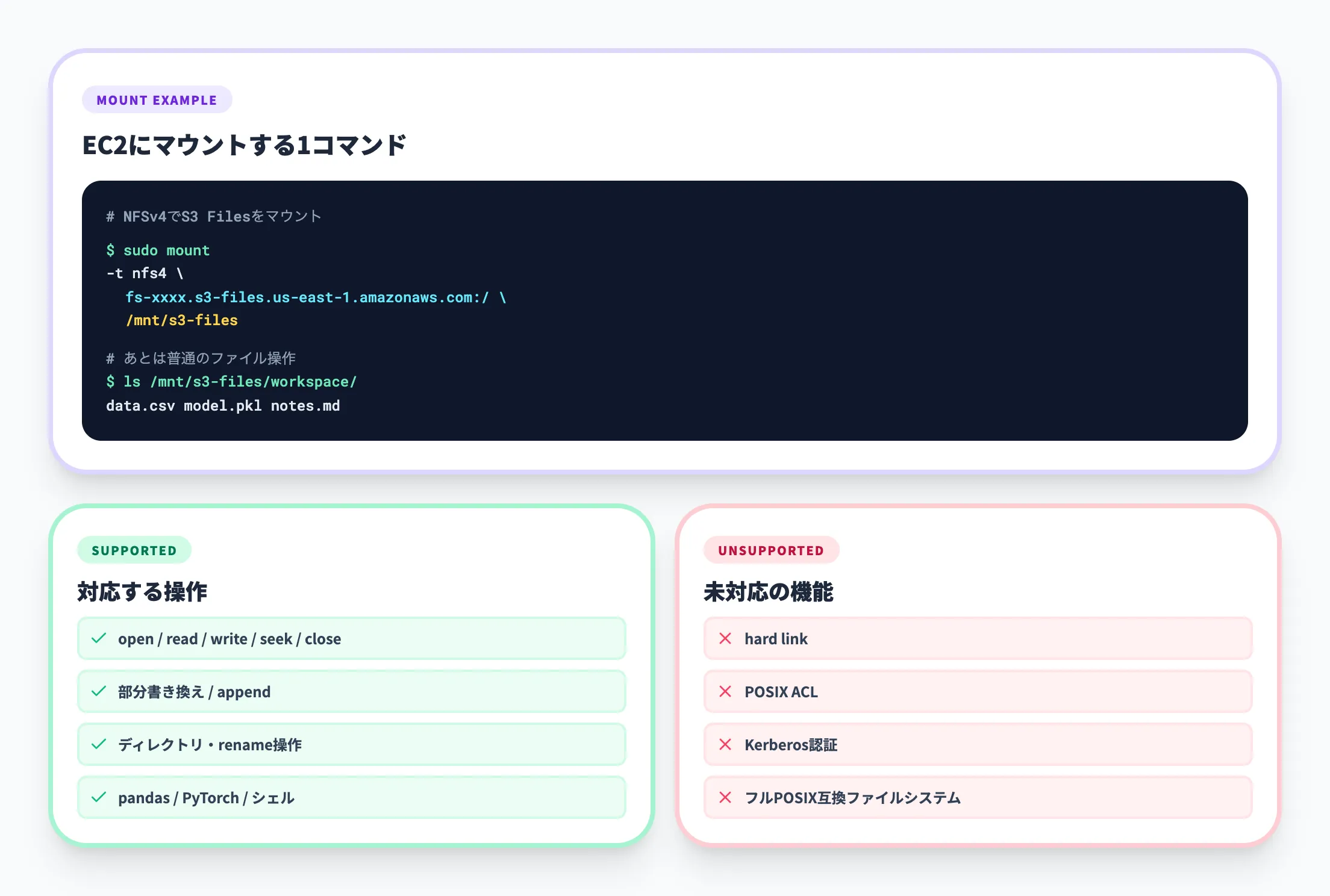
このため、PythonのpandasやPyTorch、シェルスクリプト、CLIユーティリティなどがコード変更なしでS3上のデータを直接読み書きできます。ファイルベースで動いている既存ツールチェインがあるなら、置き換えコストはほぼゼロに近いと言えます。
ただし「完全なPOSIXファイルシステム」ではない点には注意が必要です。hard linkやPOSIX ACL、Kerberos認証など一部の高度な機能には対応しておらず、レガシーアプリの移行時はこれらに依存していないかを事前に確認する必要があります。
高性能ストレージ層によるキャッシュ
S3 Filesは内部的にAmazon EFSをキャッシュ層として使い、アクティブにアクセスされたデータだけを高性能ストレージに展開します。これにより、ファイルシステム経由のレイテンシが大きく下がります。
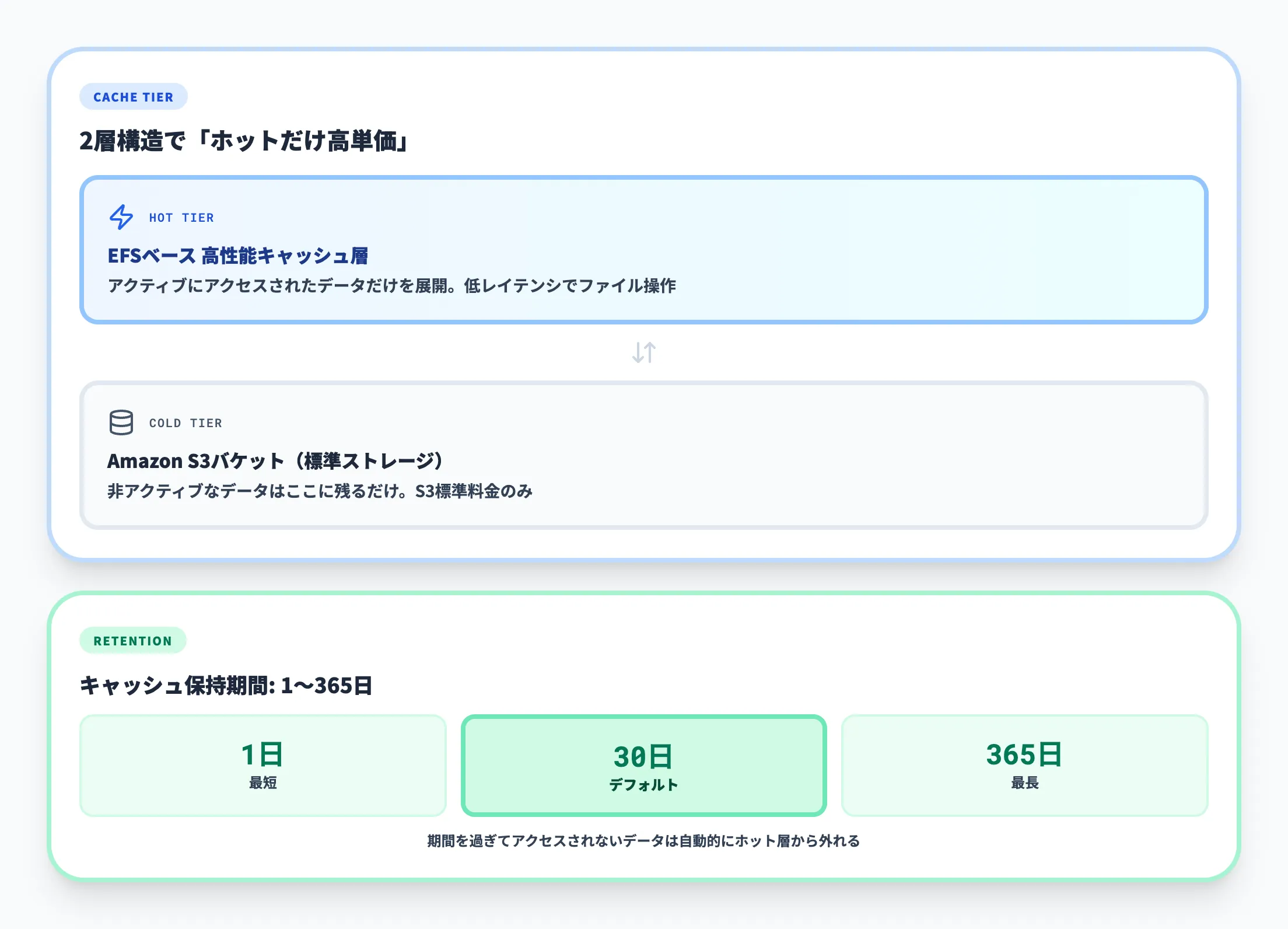
注目すべきは、キャッシュの保持期間が1〜365日の範囲で設定可能(デフォルト30日)な点です。一定期間アクセスのなかったデータは自動的に高速層から外れ、S3本体に戻ります。これにより、ペタバイト級のバケットをマウントしても、課金される高性能ストレージは実際の作業セット分だけに収まります。
大規模並行アクセス
S3 Filesは1つのファイルシステムに対して最大25,000台のコンピュートリソースが同時接続でき、ピーク時には最大4TB/秒の読み取りスループット、1バケットあたり1,000万以上のIOPSを処理できます。

機械学習の分散学習や、数百〜数千エージェントが並列でデータを参照するエージェントクラスタのような用途でも、I/Oがボトルネックになりにくい設計です。これは従来のNFSアプライアンスでは到達が難しいスケールでした。
lazy-loadingと大規模リードのS3直接配信
S3 Filesはメタデータとファイルコンテンツをlazy-loadingします。ファイルが必要になった瞬間に初めてS3から取得するため、マウント時にバケット全体を走査するコストは発生しません。
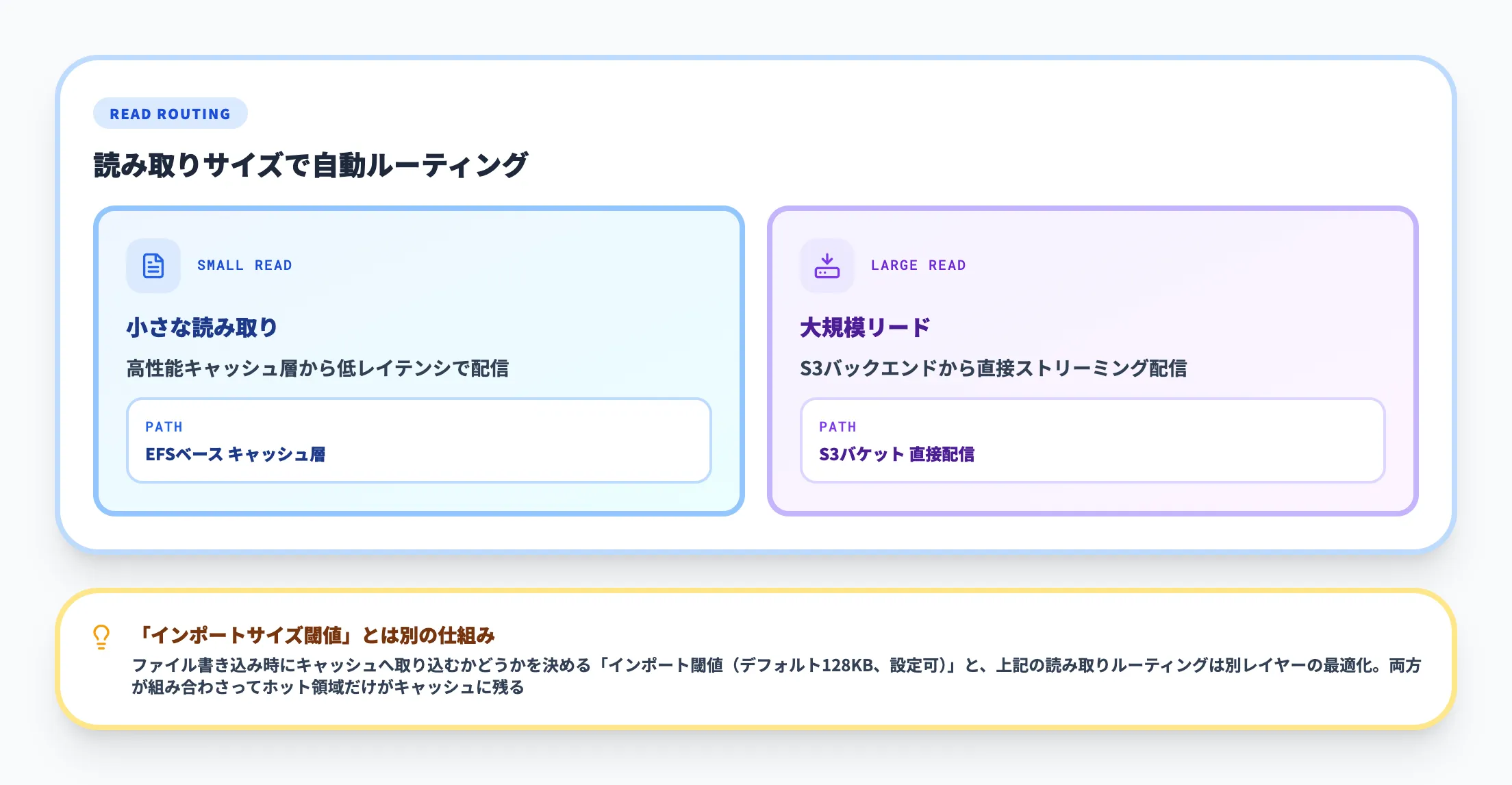
さらに、大きなサイズの読み取りに対しては、キャッシュ層を経由せずS3から直接ストリームする経路が用意されています。大規模なログファイルや機械学習データセットのように一気に読み流すワークロードでは、キャッシュを汚さずに済むため、コストとパフォーマンスの両立が図られています。
なお、これとは別に、S3バケットからキャッシュ層へオブジェクトを取り込む際の「インポートサイズ閾値」も存在し、デフォルトは128KBで設定変更が可能です。両者は別の仕組みなので混同しないよう注意してください。
Amazon S3 Filesの仕組み(アーキテクチャ)
S3 Filesの内部設計には、「stage and commit」セマンティクスと呼ばれる独特のアプローチが採用されています。これはバージョン管理ツールから着想を得た仕組みで、ファイルとオブジェクトという2つのデータモデルを矛盾なく共存させる工夫です。

stage and commit セマンティクス
S3 Filesは、ファイルシステム経由の書き込みをまずキャッシュ層(EFS)にステージし、その後S3バケットへコミット(同期)します。この「ステージ→コミット」の2段階構造により、エージェントやアプリケーションが小刻みに書き込みを行っても、その都度S3にPUTを発行する必要がありません。
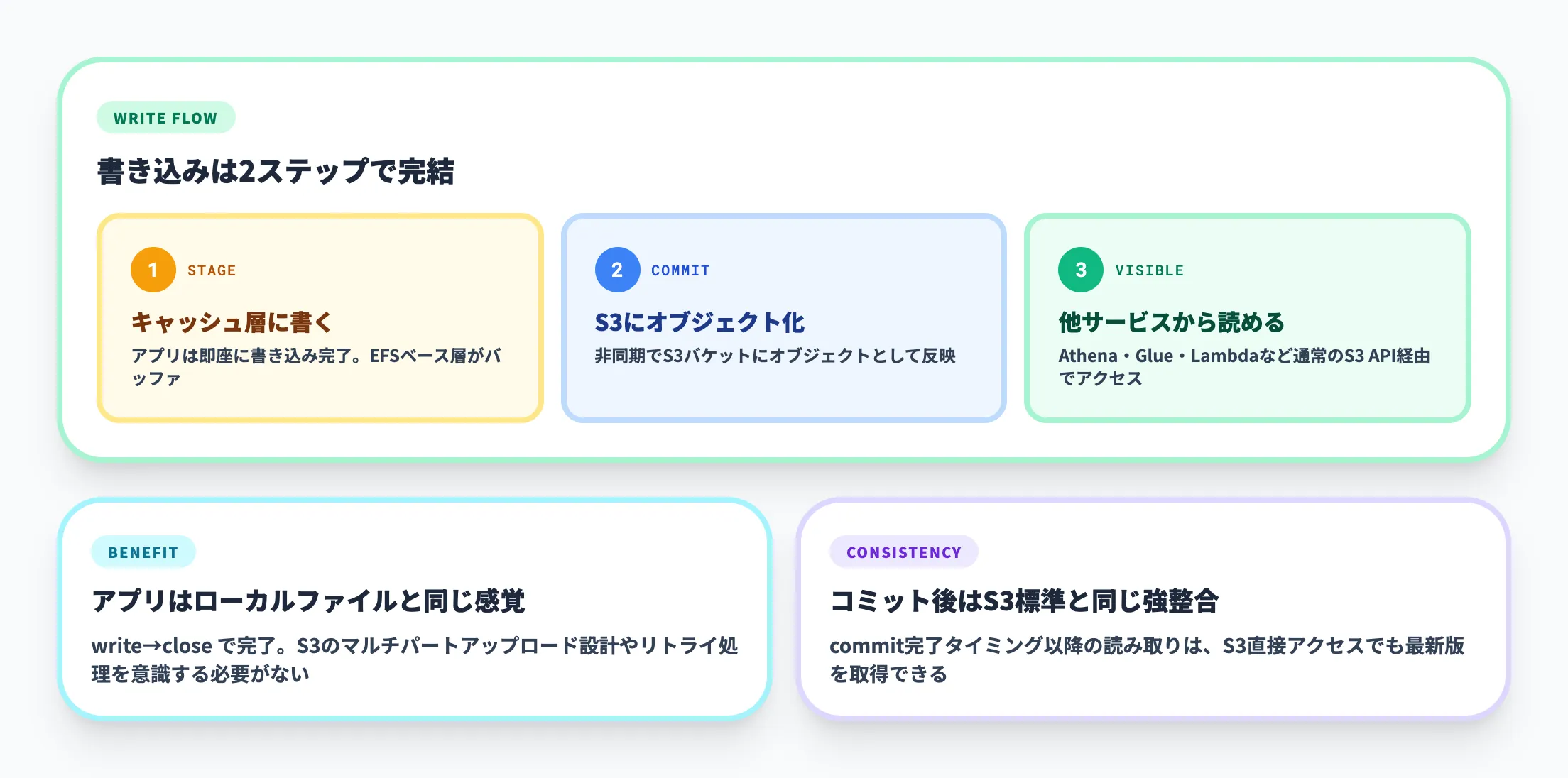
Andy Warfield氏の解説では、ファイルとオブジェクトの境界を隠さずに明示的に扱うという設計思想が語られています。境界を曖昧にしてどちらかの整合性を犠牲にするのではなく、両方のセマンティクスを保ったまま、変更がEFS上で蓄積されてからS3に同期される仕組みです。
S3バケットとの対応関係
S3 Filesは、対象のS3バケット内のオブジェクトのビューを保持し、ファイルシステム操作を効率的なS3リクエストに変換します。バケット側に保存されているオブジェクトは、S3 Files経由でも従来のS3 API経由でもアクセスでき、両者は併存可能です。
つまり、既存のS3 APIで動いているデータレイクパイプラインやアナリティクスはそのまま継続させつつ、新しく追加するエージェントワークロードだけをS3 Filesで動かす、といった段階的な導入が可能です。
キャッシュ層の役割
S3 Filesにおける高性能キャッシュ層(EFSベース)は、書き込みのバッファリングだけでなく、再アクセスされるホットデータの保持役も担います。読み取りがキャッシュにヒットすれば、S3に問い合わせる必要がなく低レイテンシで応答できます。
逆に長期間アクセスのないデータはキャッシュから自然に追い出され、S3 Standard料金だけが残ります。AIエージェントのように「直近の作業中ファイルは何度もアクセスするが、過去ログはほとんど触らない」アクセスパターンとは相性の良い設計です。

Amazon S3とAmazon S3 Filesの違い
ここまでの内容を踏まえて、従来のS3とS3 Filesの違いを整理します。両者は競合するサービスではなく、同じバケットを別の角度から見るインターフェースの関係にあります。

以下の表で、主要な観点別にS3とS3 Filesの違いを比較しました。
| 観点 | Amazon S3(従来) | Amazon S3 Files |
|---|---|---|
| データモデル | オブジェクトストレージ | ファイルシステムインターフェース |
| アクセス方式 | HTTP API(PUT/GET/LIST Object) | NFSv4.1/4.2ベースのファイル操作(open/read/write/seek) |
| 部分書き換え | 不可(オブジェクト全体を再PUT) | 可能(任意オフセットへ書き込み) |
| ファイル単位のrename | 実質コピー+削除 | ファイルシステムネイティブ |
| 同時接続 | 大量だがオブジェクト単位 | 最大25,000台が同一ファイルシステムを共有 |
| 課金対象 | 標準ストレージ+リクエスト課金 | S3標準料金+アクティブセットの高性能層料金 |
| 主用途 | 静的ファイル・データレイク・バックアップ | AIエージェント・MLデータ準備・レガシーFS移行 |
| マイグレーション | — | 不要(既存バケットをそのまま使える) |
この比較から分かるのは、S3 Filesはあくまで「S3の操作スタイルを拡張した姿」だという点です。データを別の場所に移すわけではなく、同じバケットに対する新しい読み書きの口が増えると考えるのが正確です。
実務的には、データレイクや配信用静的ファイルなど「丸ごと書く・丸ごと読む」が中心の用途は従来通りのS3 APIで運用し、エージェントワークスペースのように「細かく編集する」ワークロードだけをS3 Files経由で扱う、というハイブリッド構成が現実的になります。
Amazon S3 Files vs EFS / FSx for Lustre / S3 Mountpoint
S3 Filesと近い役割を持つAWSのストレージサービスには、Amazon EFS、Amazon FSx for Lustre、そしてOSSのS3 Mountpoint(mountpoint-s3)があります。それぞれ得意分野が異なるため、選定の判断材料を整理しておきます。

以下の表で、代表的な4サービスの違いをまとめました。
| サービス | データの主の住処 | アクセスモデル | 主な強み | 想定ワークロード |
|---|---|---|---|---|
| Amazon S3 Files | S3バケット | NFSv4.1/4.2ベースのファイル操作+S3 API | S3バケットそのままに、ファイル操作で扱える | AIエージェント、MLデータ準備、レガシーアプリ移行 |
| Amazon EFS | EFSファイルシステム | NFS | フルPOSIX、Linux標準のNFS互換 | コンテンツ管理、開発環境、Webサーバー共有 |
| Amazon FSx for Lustre | FSxファイルシステム(S3連携可) | Lustreプロトコル | HPC向け超低レイテンシ・超高スループット | 大規模シミュレーション、ハイパフォーマンスML学習 |
| S3 Mountpoint | S3バケット | FUSE(読み取り中心) | OSSで導入が手軽 | 読み取り中心の分析、シーケンシャルアクセス |
表だけでは判断しづらいので、選び方の指針を補足します。**「データの真の住処をどこに置きたいか」**を起点に考えるのが実務的です。
- データはS3に置きたい、でもファイル操作したい → S3 Files
- データもアクセスもS3を意識せず、純粋なNFSで運用したい → EFS
- HPCのような極端な性能要求があり、計算ジョブの間だけ高速ストレージが必要 → FSx for Lustre
- 読み取り中心で十分、できるだけシンプルに済ませたい → S3 Mountpoint
特にS3 FilesとEFSは内部基盤を共有していますが、**S3 Filesは「アクティブセットだけ高性能層に展開し、非アクティブなデータはS3 Standardの単価で寝かせておける」**点が決定的に異なります。EFSを単体で使う場合、保管しているデータすべてに$0.30/GB-月(Standard)が課金されますが、S3 Filesなら同じバケットを丸ごとマウントしてもS3標準料金が基本になります。
Amazon S3 Filesの主要ユースケース
S3 Filesは「ファイルシステム的アクセスが必要だが、データの本体はS3に置きたい」シナリオで特に強みを発揮します。代表的な活用パターンを4つ紹介します。

AIエージェントのワークスペース・メモリ永続化
AIエージェントが思考プロセスや中間生成物を保存し、別のステップ・別のエージェントと共有する用途は、S3 Filesがもっとも狙っている領域です。エージェントは人間の開発者と同じく「ファイルを開いて、編集して、閉じる」操作を前提とするため、S3 FilesのNFSv4.1/4.2ベースの共有ファイルアクセスが直接フィットします。
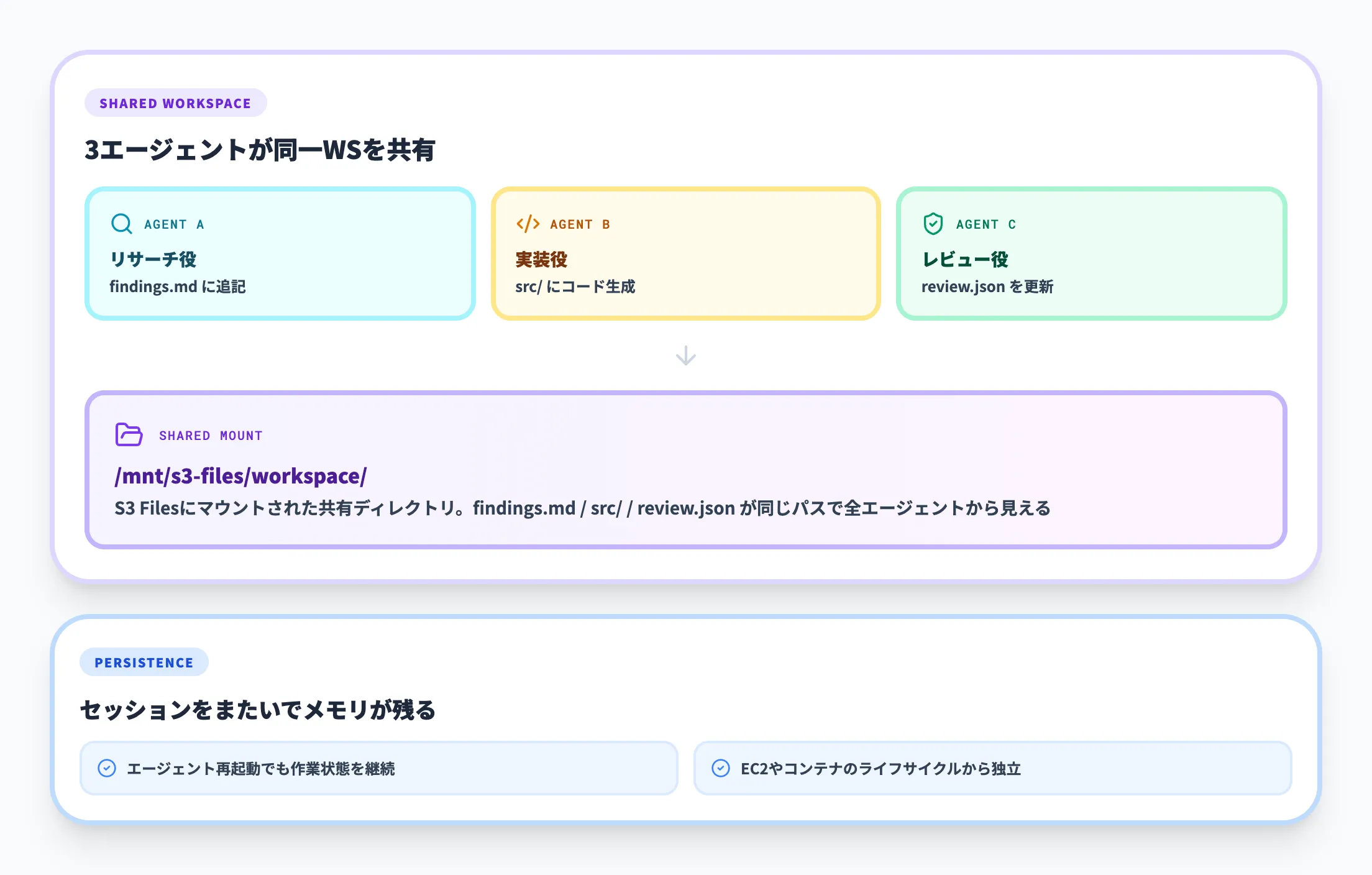
AWS公式ブログでも、「AIエージェントがメモリを永続化し、パイプラインを横断してstateを共有する」ことが主要ユースケースとして筆頭に挙げられています。複数のエージェントが同一ワークスペースを共有しながら並行作業するエージェントクラスタを構築する場合、S3 Filesは現実解の1つになります。
具体的なシナリオを1つ挙げると、たとえばコード生成エージェント・テスト実行エージェント・レビューエージェントの3体が、s3://my-bucket/workspaces/project-A/ を共通の /workspace としてマウントし、生成された.pyファイル・テスト結果のログ・中間ビルド成果物を同じディレクトリツリー上で受け渡す構成が組めます。各エージェントは普通のファイルI/Oで読み書きするだけでよく、別途のメッセージングや共有DBを設計しなくても並行作業のstateが揃います。終了後はそのままS3バケットに成果物が残るため、後続の分析や監査にもそのまま使えます。
機械学習のデータ準備
機械学習プロジェクトでは、生データの前処理・特徴量エンジニアリング・データセット分割といった工程で、ファイル単位の細かな操作が頻発します。従来はS3からEFSやローカルディスクへデータをステージングし、加工後にまたS3に戻すパイプラインが必要でしたが、S3 Filesを使えばステージングを省略できます。
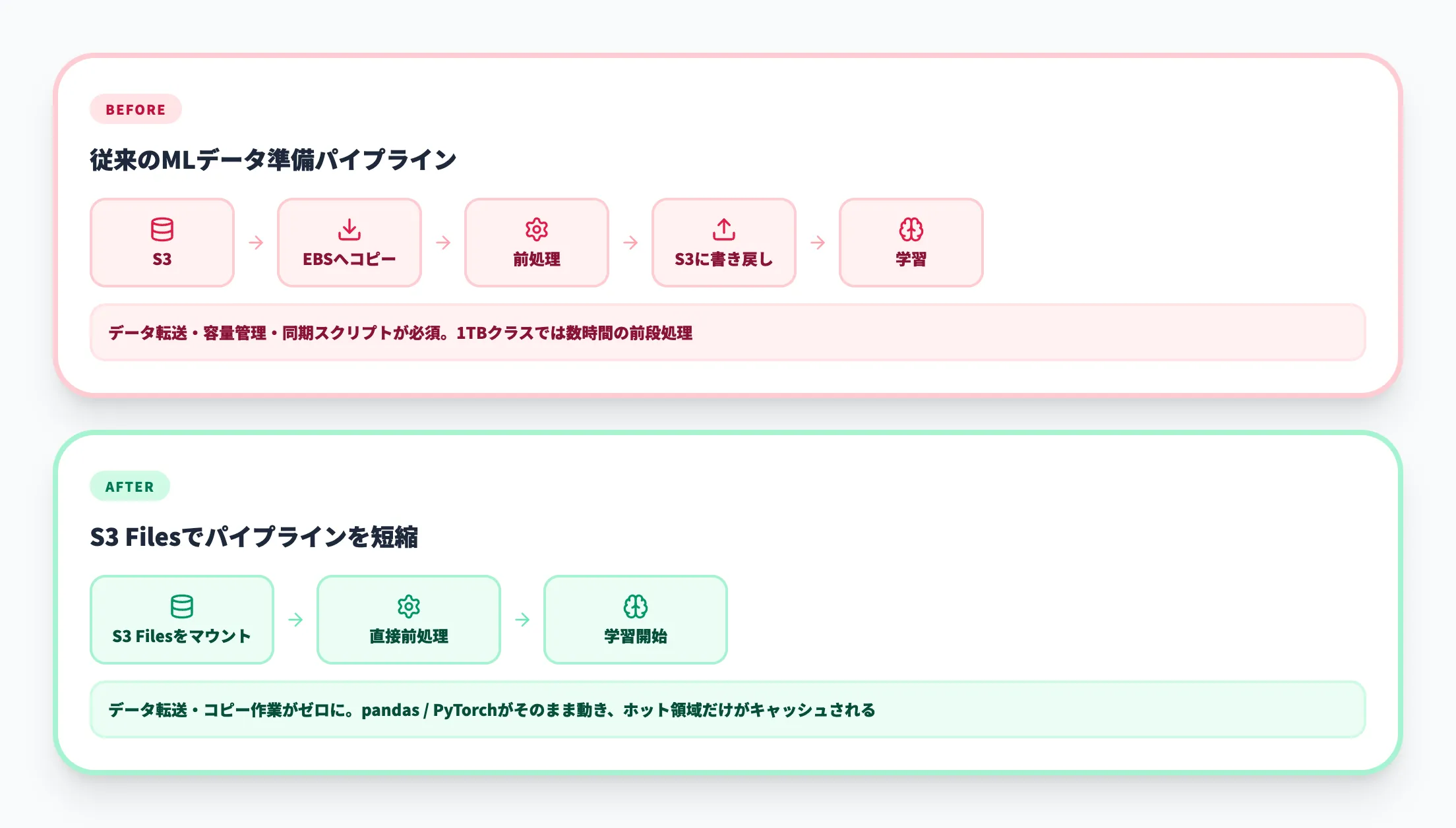
Amazon SageMaker AIなどのML基盤と組み合わせれば、データ準備からモデル学習までを単一のS3バケット上で完結させやすくなります。
ファイルベース分析ツールでの直接利用
PythonのpandasやApache Spark、各種BIツールなど、ファイルパスを前提に動くツールチェインは数多く存在します。これらは「S3バケットからファイルを読む」という操作を、内部的にはAWS SDK経由で行う必要がありました。
S3 Filesを利用すれば、ツール側からはローカルファイルと区別なく扱えるため、追加のSDK統合やコネクタ実装なしで分析処理を回せるようになります。アドホックな分析や、データサイエンティストが手元のスクリプトでバケットを直接触る用途で大きな効果が出ます。
レガシーアプリケーションのS3移行
NFSや既存のファイルサーバーで動いているレガシーアプリケーションをクラウド移行する際、これまでは「アプリ側のコードをS3 API向けに書き換える」あるいは「EFSやFSxを別途プロビジョニングしてデータを2重持ちする」ことが必要でした。

S3 Filesを使えば、既存アプリのコードをそのまま動かしながらバックエンドだけS3に切り替えることができます。長年動いてきた業務システムの移行コストを大幅に下げたい組織にとって、現実的な選択肢が1つ増えた形です。
複数の業務システムを抱える企業で、AIエージェント基盤の整備と並行してレガシーアプリのクラウド移行を進めているなら、S3 Filesを「両者の交差点」として位置付けると投資の重複を抑えられます。これは単なる新機能の評価ではなく、ストレージ戦略全体を見直すタイミングの合図と捉えるべき変化です。
Amazon S3 Filesが向いている場面 vs 向かない場面
主要ユースケースを押さえたうえで、「自社のどのワークロードに当てるべきか」を判断するには、向いている場面と向かない場面の両方を知っておく必要があります。

以下の表で、S3 Filesが効果を発揮しやすいケースと、別の選択肢のほうが適切なケースを整理しました。
| 分類 | 向いている場面 | 向かない場面 |
|---|---|---|
| データの本体 | データの真の住処をS3に統一したい | データはEFSやFSxに置く前提で設計済み |
| アクセスパターン | アクティブセットがデータ全体の一部に偏る | ほぼ全データに常時アクセスがある |
| ワークロード | AIエージェント共有ワークスペース/MLデータ準備/レガシーFS移行 | S3 APIだけで十分な静的配信・データレイク参照 |
| アプリ要件 | Linuxの標準ファイル操作で動くアプリ | hard linkやACLなどフルPOSIX機能に強く依存するアプリ |
| 性能要件 | 数千〜数万コンピュートの並行アクセスが要件 | HPC級の超低レイテンシ・超高スループットが必須(FSx for Lustreが本命) |
表で見ると、向き不向きの分かれ目は**「データの真の住処をS3に置きたいか」と「アクセスパターンが偏っているか」**の2点に集約されます。この2つに当てはまる用途であれば、S3 Filesは高い確率で第一候補になります。
逆に、ほぼ全データが常時ホットでEFSのように使い倒したい場合は、S3 Filesの「アクティブセットだけ高単価」モデルの旨みが消えるため、素直にEFS単体で構成したほうが管理もシンプルです。フルPOSIX依存の特殊なアプリも、無理にS3 Filesに寄せるより既存FSをそのままクラウドに持ち上げるほうが安全です。
Amazon S3 Filesの制約と非対応事項
導入判断の前に、S3 Filesにはいくつかの前提条件と未対応機能があることを押さえておく必要があります。メリットだけで決めず、これらの制約に自社ワークロードが抵触しないかを必ず確認してください。
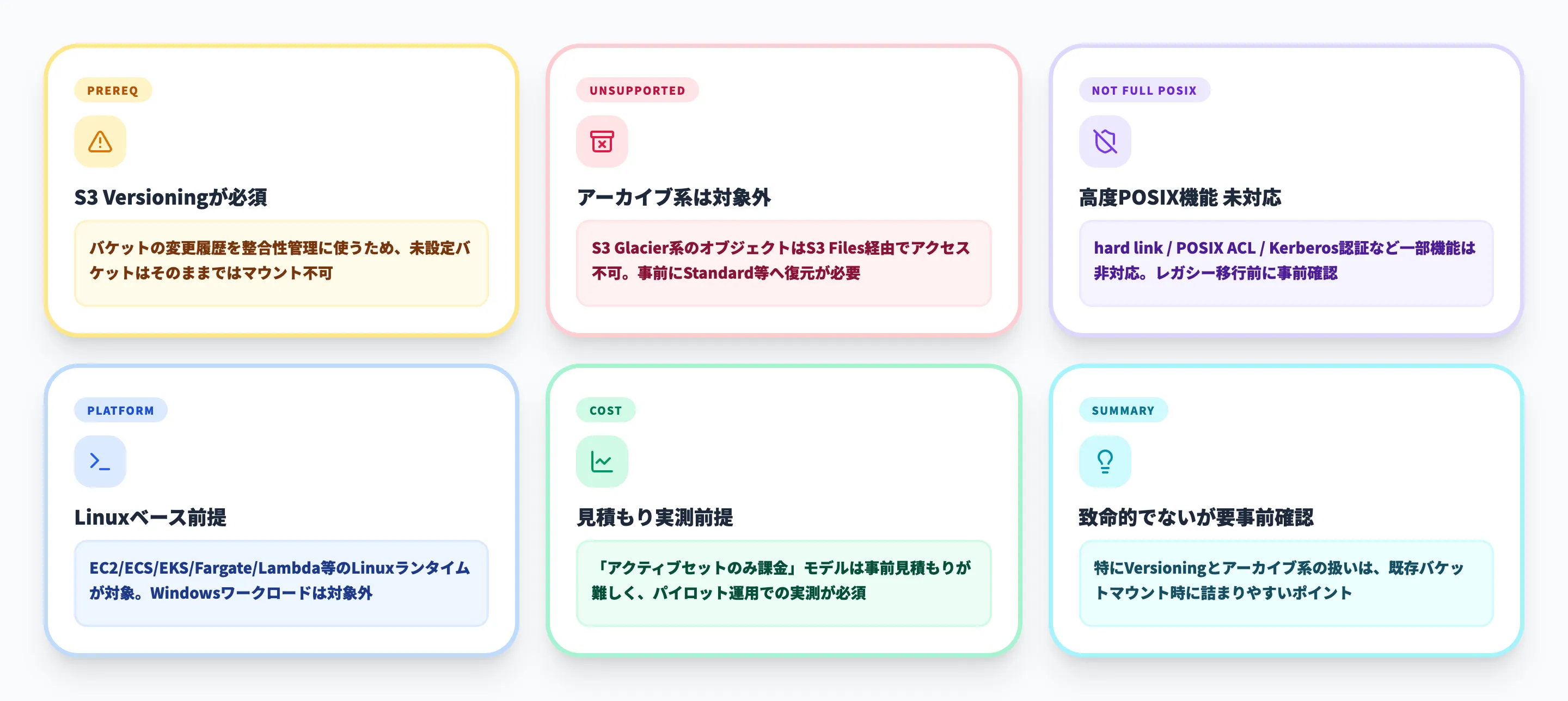
主要な制約は次の通りです。
-
リンク対象のS3バケットでS3 Versioningが必須
S3 Filesはバケットのオブジェクト変更履歴を整合性管理に使うため、Versioning未設定のバケットはそのままではファイルシステム化できません
-
アーカイブ系ストレージクラスのオブジェクトはそのまま扱えない
S3 Glacier系のオブジェクトはS3 Files経由ではアクセス対象外です。アーカイブ済みデータを扱う場合は、事前にStandard等へ復元しておく必要があります
-
hard link・POSIX ACL・Kerberos認証など一部の高度機能に未対応
完全なPOSIXファイルシステムではないため、これらに依存しているレガシーアプリを移行する際は事前確認が必須です
-
Linuxベースのコンピュートが前提
EC2/ECS/EKS/Fargate/LambdaのLinux系ランタイムからの利用が想定されており、Windowsベースのワークロードは対象外です
-
コスト見積もりに実測フェーズが必要
「アクティブセットのみ課金」というモデルは結果的に安くなりますが、事前見積もりだけで決め打ちするのは難しく、パイロット運用で実測を取る前提で計画する必要があります
これらの制約は致命的というほどではありませんが、**「本番採用してから気づくと痛い」**部類の項目です。特にVersioningとアーカイブ系の扱いは、既存バケットをそのままマウントしようとした際に詰まりやすいポイントなので、事前確認を強く推奨します。
Amazon S3 Filesの導入手順
S3 Filesは2026年4月7日のGA時点で34のAWSリージョンで利用可能です。導入は概ね以下の流れで行います。
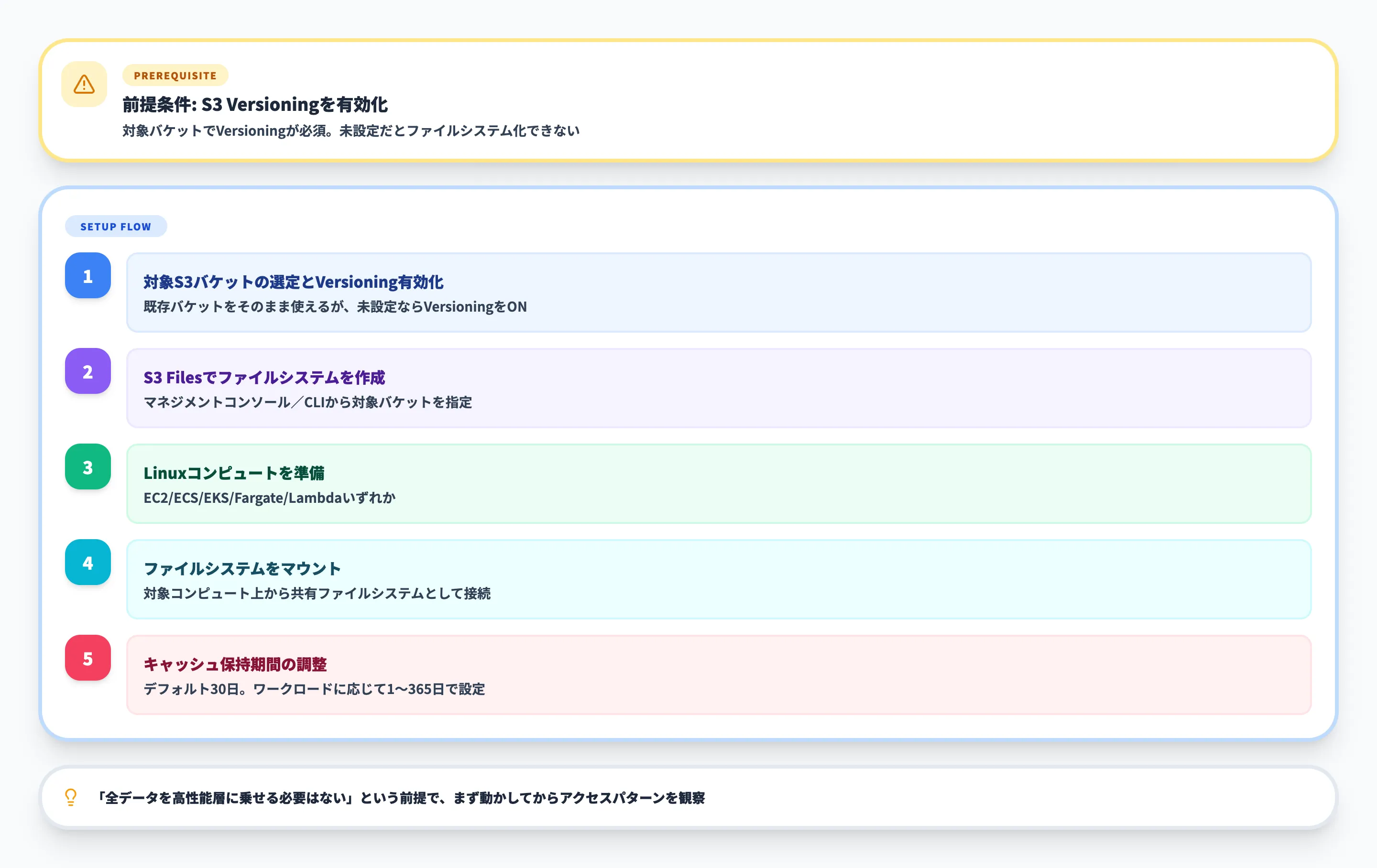
導入前にひとつだけ前提条件があります。リンク対象のS3バケットでは事前にS3 Versioningを有効化しておく必要があります。S3 Filesはバケットのオブジェクト変更履歴を整合性管理に使うため、Versioning未設定のバケットはそのままではファイルシステム化できません。既存バケットを利用する場合は、まずVersioningの状態を確認してください。
S3 Filesを導入する際の基本的な流れは次の通りです。
-
対象のS3バケットを決め、Versioningを有効化する
既存バケットをそのまま使えますが、未設定の場合はS3 Versioningを有効化しておきます
-
S3 Filesでファイルシステムを作成する
AWS Management Consoleまたはコマンドラインから、対象バケットを指定してファイルシステムを作成します
-
アクセス先のコンピュートリソースをLinuxベースで用意する
EC2、ECS、EKS、Fargate、Lambdaなど、AWS上のLinux系コンピュートを準備します
-
ファイルシステムをマウントする
作成したS3ファイルシステムを、対象のコンピュートリソースにマウントします
-
必要に応じてキャッシュ保持期間を設定する
デフォルトは30日ですが、ワークロードに応じて1〜365日の範囲で調整できます
導入時に最初から押さえておくべきは、**「全データを高性能層に乗せる必要はない」**という考え方です。アクティブにアクセスするデータだけがキャッシュ層へ自然に展開されるため、最初から綿密な階層設計をする必要はありません。むしろ、一定期間運用したうえでアクセスパターンを確認し、必要ならキャッシュ保持期間や閾値を調整するのが現実的です。
導入判断で詰まる論点
S3 Filesの導入を検討する際、特に判断に迷いやすい論点を3つ整理します。
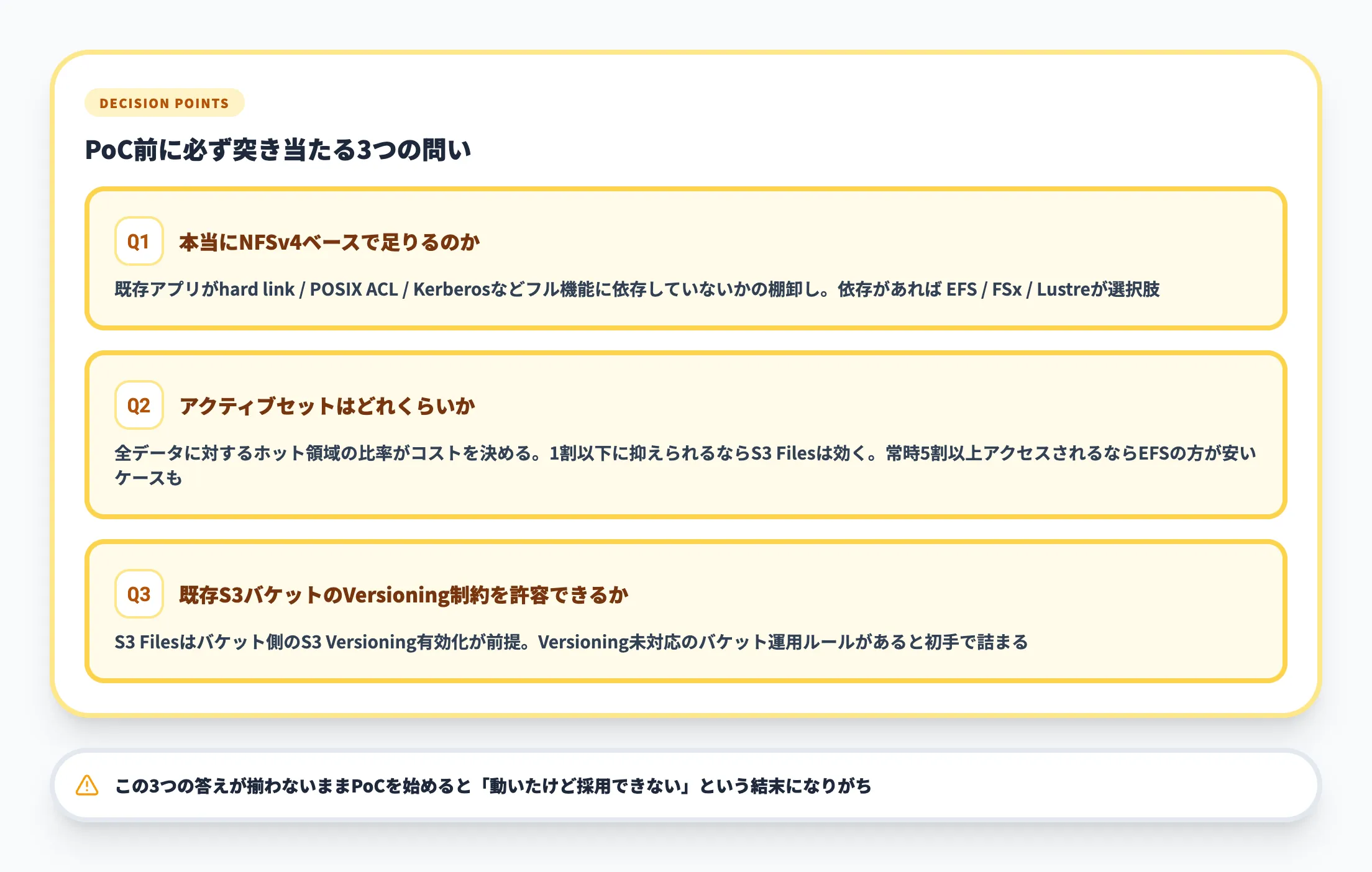
既存のEFSやFSxからS3 Filesに乗り換えるべきか
すでにEFSやFSx for Lustreで安定運用できているワークロードを、無理にS3 Filesに移す必要はありません。乗り換えを検討すべきは、**「データの真の住処をS3に統一したい」**という戦略的な動機があるケースです。データレイクとしてS3に集約し、その上でファイル操作も統合したい組織なら、移行の意味が出てきます。
どのワークロードから始めるべきか
最初に試すべきは、新規のAIエージェント/MLワークロードです。既存の安定運用システムには手を入れず、新しく立ち上げるワークロードからS3 Filesを採用すれば、リスクを最小化しながら効果を測定できます。レガシーアプリの大規模移行をいきなり進めるのは、コスト試算と並行アクセス時の挙動を十分に検証してからが安全です。
コストの見積もりが読みづらい
「アクティブセットのみ課金」という料金モデルは結果的にコストを下げますが、事前の見積もりが難しいという副作用があります。最初の1〜2か月はパイロット運用で実際のキャッシュ使用量を測定し、その実績をもとに本格導入時のコストを試算するのが現実的なアプローチです。AWSの料金計算機だけで決め打ちせず、必ず実測値を組み合わせてください。
Amazon S3 Filesの料金体系
S3 Filesの料金は、S3そのものの標準料金に加えて、S3 Files独自の「高性能ストレージ料金」と「読み書き料金」が上乗せされる構造です。料金は時期やリージョンで変動するため、本番採用時は必ず最新の公式情報を確認してください。

ざっくりとした月額試算は、次の1行で押さえられます。
月額 ≒ S3標準ストレージ料金 + アクティブセットGB × $0.30 + 小さなread GB × $0.03 + write GB × $0.06
実際の見積もりではリージョン単価やリクエスト料金、データ転送料も入りますが、桁感を掴むだけならこの式で十分です。自社のワークロードに当てはめて、まずは「アクティブセットがどれくらいか」「読み書きのGB量がどう積み上がるか」を概算してみてください。
料金の主要構成要素
S3 Filesの料金は次の3要素で構成されます。
-
S3標準ストレージ料金
データ本体のストレージはS3バケットに保管されるため、これまで通りS3 Standardなどの単価で課金されます
-
S3 Files高性能ストレージ料金
キャッシュ層に展開されたアクティブセットに対してのみ、$0.30/GB-月(EFS Standard相当)が課金されます
-
S3 Files読み書き料金
ファイルシステム経由の読み取りに$0.03/GB、書き込みに$0.06/GB程度が課金されます。S3 Filesにはユーザーが設定可能な「インポートサイズ閾値」(デフォルト128KB)があり、それより小さいオブジェクトはキャッシュ層へ取り込まれて通常のファイルとして扱われます。一方で大きなサイズのread要求は、S3 Files側のキャッシュを介さずS3バケットから直接ストリームされる経路があり、その場合はS3 Files側の読み取り料金が発生しません
価格例(2026年4月時点)
たとえば、10TBのデータセットを「アクティブにアクセスされるのはその一部だけ」という典型的なワークロードで運用する場合、S3 Filesの月額コストはS3標準ストレージ料金+実際にキャッシュ層へ展開されたGB分のS3 Files料金+読み書き料金の合計になります。ComputingForGeeksの一例の試算では、この構成でS3 Filesの月額コストは数百ドル規模に収まり、同じ10TBをすべてEFS Standardに置いた場合と比較して大幅に低くなると報告されています。
ただしこの数値はあくまで第三者の試算であり、AWS公式のS3料金ページに同条件の例があるわけではありません。実際の金額はホットデータの割合・読み書きパターン・リージョンで大きく変わるため、本番採用時は必ず公式pricing pageとAWS料金計算機で自社条件に合わせて見積もり直してください。
逆に、ほぼすべてのデータに常時アクセスがある特殊なワークロードでは、キャッシュ層に乗るデータ量が多くなりEFS単体に近いコスト感になる可能性もあります。

コスト試算のポイント
実務でS3 Filesのコストを見積もる際は、次の3点に注意してください。

-
アクティブセットのサイズを過大評価しない
全データ量ではなく、実際にキャッシュに乗るホットデータの量で計算する
-
読み書きのGB単価が積み上がる用途を見落とさない
小さなファイルを大量に書き込む用途では、書き込み料金($0.06/GB)が積み上がる可能性がある
-
大規模リード時の挙動を理解する
大きなサイズのread要求はS3バケットから直接ストリームされる経路があり、その場合はS3 Files側の読み取り料金が発生しません。シーケンシャルな大量読み取り中心のワークロードには有利に働きます
S3 Filesは「アクティブセットのみ高単価で残りは安価」という特性が強いため、ワークロードの読み書きパターンを丁寧に分析することが、無駄のない運用への近道です。クラウド全体の料金最適化やマルチクラウドの選定基準を整理したい場合は、AzureとAWSの比較記事も参考になります。
AWSで設計したAIエージェントを本番業務に組み込むなら
S3 Filesでエージェントのワークスペースが整備できても、実際に業務へ組み込む段階では、Teamsなどユーザー接点の設計、SAPやSalesforceといった基幹システムとの接続、実行ログや権限管理を含めた運用設計まで必要になります。S3 Files単体ではここまでカバーしません。
- AWS上で構築したエージェントワークロードを、Microsoft Teamsなど現場の使い慣れたチャットツールから呼び出せる業務インターフェースに統合
- SAP Concur / Salesforce / freee会計 / Dynamics 365など既存の業務システム側との接続設計を、要件に応じて支援
- 実行ログ・アクセス権限・セキュリティスキャンを単一ダッシュボードで一元管理し、シャドーAIの乱立を防ぐガバナンス基盤を整備
- PoCや検証段階で止まらず本番運用へ進めるための運用設計を、専任チームが伴走支援
特に**「S3 Filesのようなデータ基盤までは自社で整備できても、業務システム接続・権限設計・運用ガバナンスまで含めて本番運用まで持っていきたい」**と感じている企業は、一度ご相談ください。AI総合研究所では、S3 Filesのようなクラウドネイティブのデータ基盤を活かしながら、AIエージェントを業務に定着させるためのAI Agent Hubをご用意しています。AWSで動くワークロードを業務システムへ接続していく進め方は、無料の資料からご確認ください。
S3 Files基盤を業務実装につなぐ

モデル検証から業務システム接続・運用設計まで一元化
S3 FilesでAIエージェントのワークスペースを整備しても、実運用ではTeamsなどユーザー接点、SAPやSalesforceとの接続、権限・実行管理まで必要です。AI Agent HubのLPで、AWS上で設計したエージェントを業務に定着させるための全体像をご確認ください。
まとめ
Amazon S3 Filesは、既存のS3バケットを共有ファイルシステムとして直接マウントできる新しいインターフェースであり、AIエージェント時代のストレージ要件に正面から応える機能です。EFSをキャッシュ層として活用しつつ、データの本体はS3に置いたままにできるため、コストとパフォーマンスのバランスが取りやすい点が最大の魅力です。
本記事の要点を改めて整理します。
- S3 Filesは「S3の置き換え」ではなく「S3の新しい顔」——既存バケットをマイグレーションなしで使え、従来のS3 APIと併用できる
- アクティブセットだけ高性能ストレージ料金が課金されるため、ペタバイト級バケットでもコストを抑えやすい
- AIエージェント、MLデータ準備、レガシーアプリ移行の3領域で本領を発揮する
- EFS / FSx for Lustre / S3 Mountpointとの使い分けは、データの真の住処をどこに置きたいかで決めるのが実務的
S3 Filesに興味を持った方が次に取るべき一歩としては、まずは新規のパイロットワークロードで試すことを強くおすすめします。既存の安定運用システムは触らず、新しく立ち上げるエージェント基盤や機械学習プロジェクトでS3 Filesを採用してみてください。1〜2か月のパイロット運用でアクセスパターンとコストを実測すれば、自社のワークロードに本当にフィットする領域が見えてきます。
Amazon SageMaker AIやAmazon Bedrock、Amazon Bedrock AgentsといったAWSのAIサービスと組み合わせれば、データ基盤からエージェントワークロードまでを一貫してAWS上で構築できます。AIエージェントとデータ基盤の関係性について詳しくは、AIエージェント×データ基盤もあわせてご覧ください。










