この記事のポイント
 複数エージェントで社内データを共有するならFoundry IQのナレッジベースが有力候補、複数ソースを1つに集約しエージェントごとの接続を削減
複数エージェントで社内データを共有するならFoundry IQのナレッジベースが有力候補、複数ソースを1つに集約しエージェントごとの接続を削減- データソースはIndexed型(Blob/OneLake/SharePoint)とRemote型(SharePoint/Web)を用途で使い分けるのが正解
- Retrieval Reasoning Effortは既定Lowから開始、多段推論が要るならMedium、単純結合はMinimalに絞るのが現実的
- エージェント接続はMCP経由で実装。SDKはPython 2.0.0以降とREST APIがPreview対応、C#/JS/Javaは2026年4月時点で未対応
- 料金はAzure AI Search+Azure OpenAIの従量課金が主軸、SharePoint時のCopilotライセンス等追加コストにも注意

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Foundry IQのナレッジベースは、Azure AI Searchをバックエンドに据え、社内の分散データをエージェントから参照できる「再利用可能なナレッジ層」として整理するマネージドコンポーネントです。対応ソースに応じて、元データ側のACLや機密ラベルをクエリ時のフィルタに活かす構成も取れます。
Azure Blob Storage・OneLake・SharePoint・Webといった複数ソースを1つのエンドポイントに束ね、Model Context Protocol(MCP)経由でFoundry Agent ServiceやMicrosoft Agent Frameworkから呼び出せます。
本記事では、2026年4月時点のMicrosoft Learn公式ドキュメントをもとに、ナレッジベースの構成要素・対応ソース・Retrieval Reasoning Effortの設計指針・Pythonでの実装手順・セキュリティ・料金・類似機能との使い分けまでを整理します。
RAGを個別構築している現場から、複数エージェントで共通のナレッジ層を再利用する運用へ移行する際の判断材料としてお使いください。
目次
Retrieval Reasoning Effort(取得推論レベル)
SharePoint Remoteソースを含む場合の追加設定
Foundry IQ ナレッジベースのセキュリティとガバナンス
Foundry IQ ナレッジベースとは?
Foundry IQのナレッジベースは、MicrosoftがMicrosoft Foundry上で提供するマネージド型のナレッジ層です。エージェントが参照するナレッジを1つのリソースとして宣言し、検索の振る舞いやフィルタ、セキュリティ境界をひとまとめに管理するための入口として設計されています。
バックエンドはAzure AI Searchで、インデックス処理・ベクトル化・ACL同期・検索のすべてがAzure AI Searchのagentic retrieval機能に依存しています。
2026年4月時点ではPublic Preview段階で、SLAは付与されておらず本番運用は推奨されていません。それでも公式ベンチマークでは、従来のシングルショットRAGと比較して約36%の応答品質向上が確認されており、複数ホップの問い合わせに強みを発揮します。
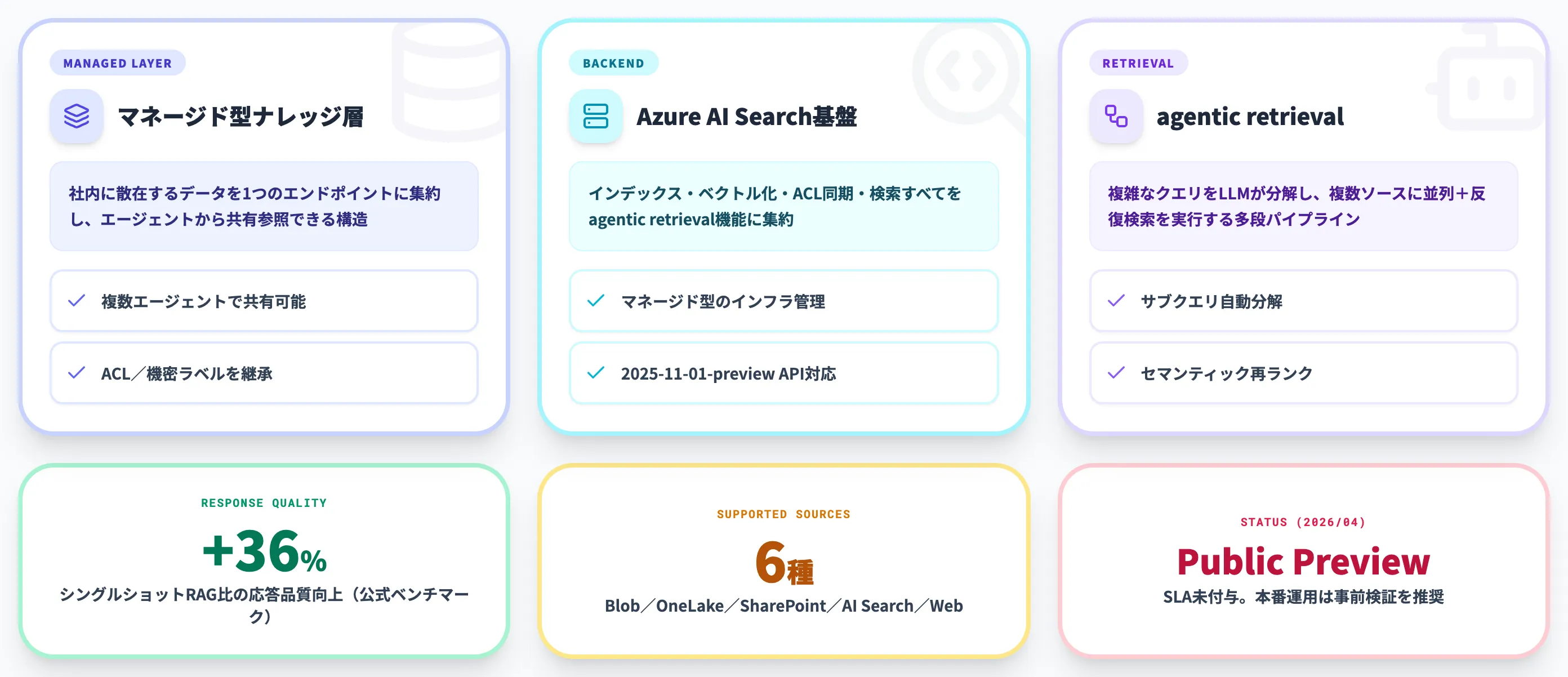

Foundry IQ全体の中でのナレッジベースの位置づけ
Foundry IQは「ナレッジベース」「ナレッジソース」「agentic retrievalエンジン」の3要素で構成されるマネージドサービス群の総称です。ナレッジベースはその中で最上位のリソースにあたり、どのソースをどう検索するかを決めるコントロールプレーンの役割を担います。この階層にナレッジベースを置くことで、社内に散在する複数のデータソースを1つのエンドポイントに集約でき、同じナレッジベースを複数のエージェントから共有することも可能になります。エージェントが権限を保ったままアクセスできるため、「エージェントごとにRAGパイプラインを構築する」という従来の重複作業を排除できるのが最大の設計思想です。
Foundry IQ自体の全体像・設計思想・ユースケースを先に押さえておきたい場合は、以下の関連記事を参照してください。
【関連記事】
Foundry IQとは?仕組みや使い方、料金体系を解説
従来RAGとの違い
従来のRAG(Retrieval-Augmented Generation)は、単一インデックスに対して1回のクエリで検索結果を取得し、そのままLLMに渡す「シングルショット型」が中心でした。
Foundry IQのナレッジベースはこれを「agentic retrieval」という多段パイプラインに置き換えています。
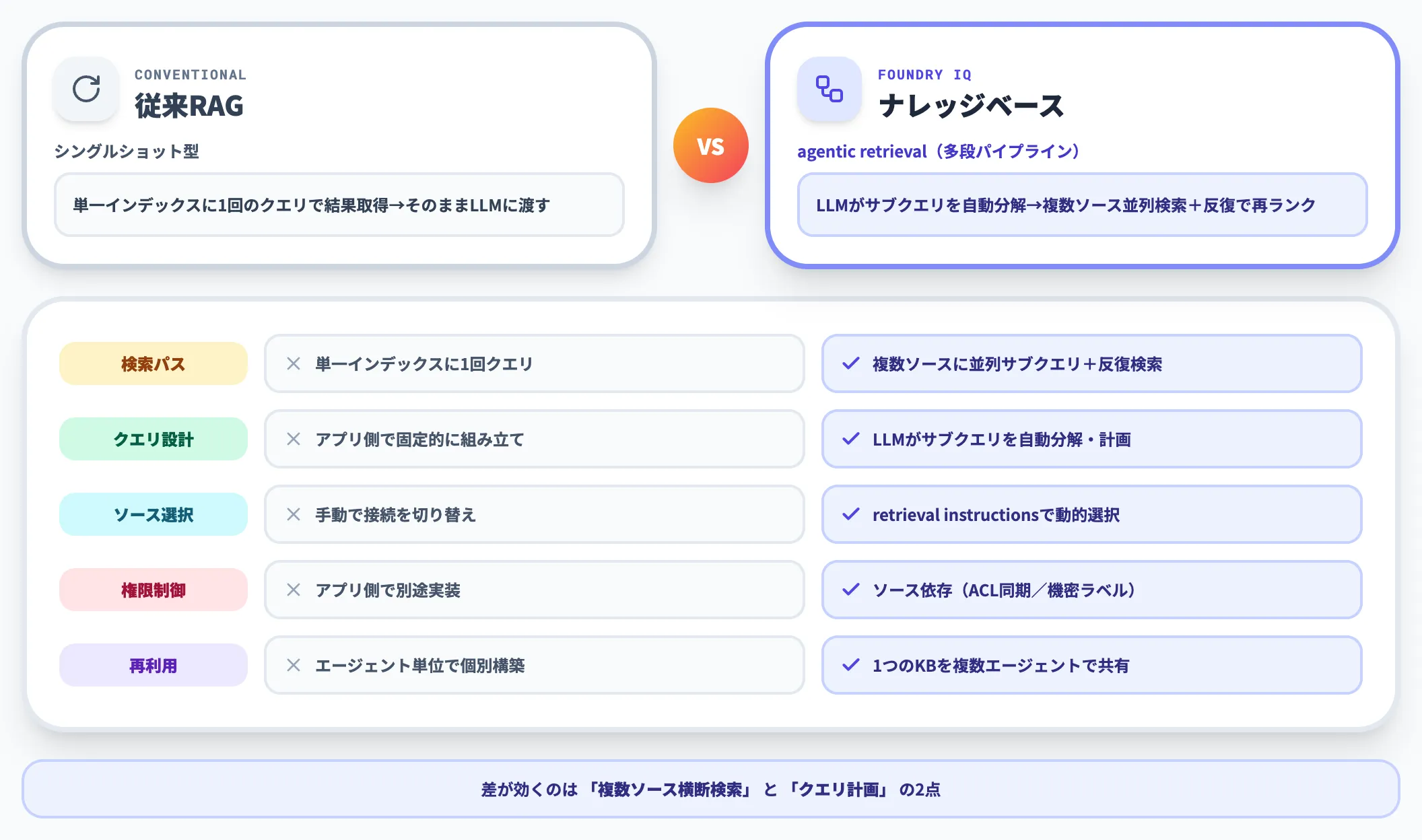
以下の表で、従来RAGとFoundry IQ ナレッジベースの挙動の違いを整理しました。この比較を踏まえたうえで、次のセクションから個別の構成要素の詳細に入ります。
| 観点 | 従来RAG(シングルショット) | Foundry IQ ナレッジベース |
|---|---|---|
| 検索パス | 単一インデックスに1回クエリ | 複数ソースに並列サブクエリ+反復検索 |
| クエリ設計 | アプリ側で固定的に組み立て | LLMがサブクエリを自動分解・計画 |
| ソース選択 | 手動で接続を切り替え | retrieval instructionsでエージェントが動的選択 |
| 権限制御 | アプリ側で別途実装 | ソース依存(詳細は表下) |
| 再利用 | エージェント単位で個別構築 | 1つのKBを複数エージェントから共有 |
権限制御はソース種別で扱いが分かれます。Indexed型はACL同期の構成が必要で、Remote SharePointはPurview機密ラベルを標準サポートします。
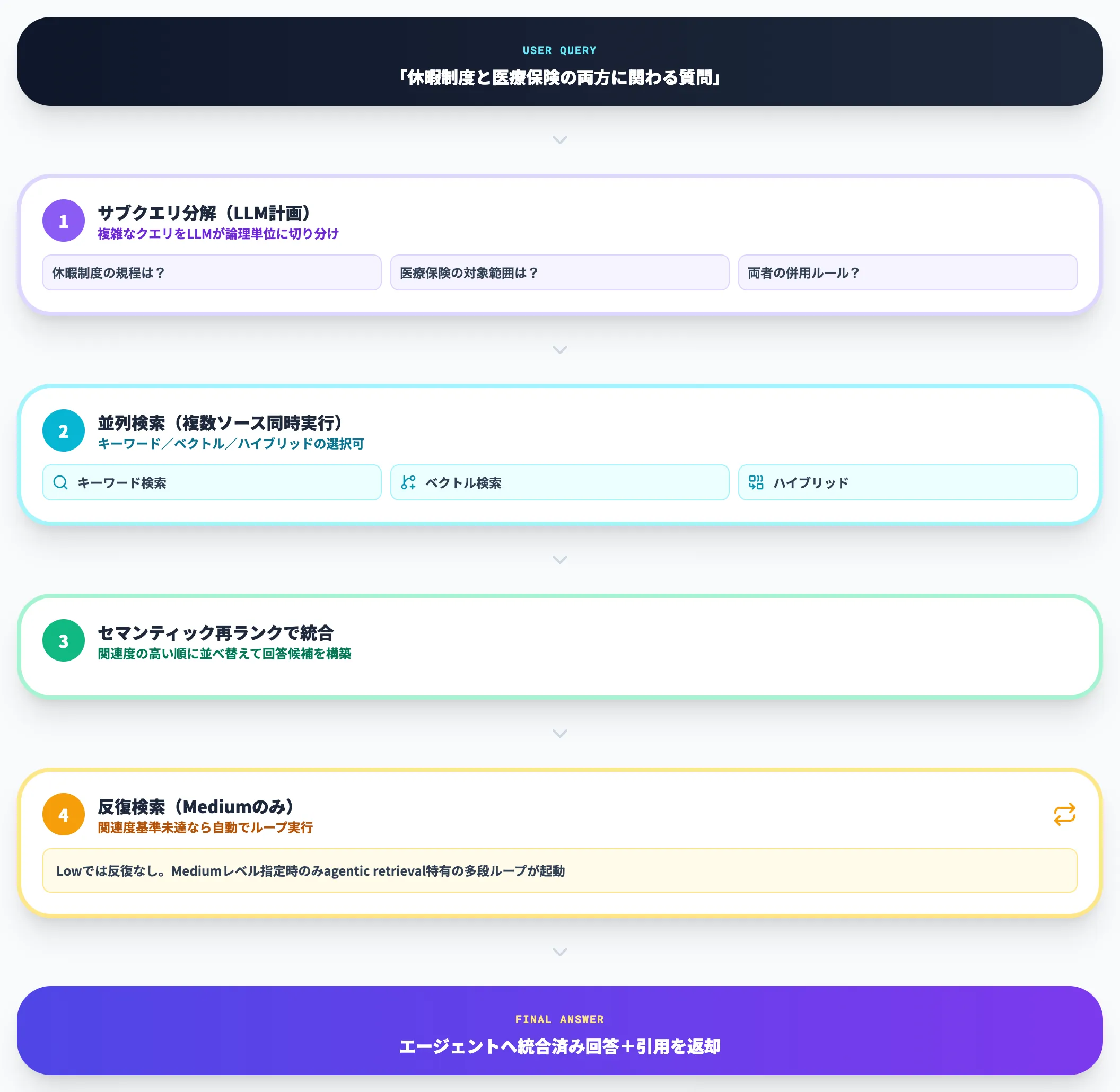
実運用で差が効くのは「複数ソースの横断検索」と「クエリ計画」の2点です。たとえば「休暇制度と医療保険の両方に関わる質問」が来たとき、従来RAGではアプリ側で人事ハンドブックと保険インデックスを別々に叩き、結果をマージする実装を書く必要がありました。ナレッジベースではretrieval instructionsで使用するインデックスの選択基準を指定しておけば、LLMが自動で適切なソースを呼び分けます。
Foundry IQ ナレッジベースの構成要素
Foundry IQのナレッジベースは、役割の異なる3層のコンポーネントで成り立っています。この節では、Azure AI Searchの公式ドキュメントに基づいて、それぞれの責任範囲と設定項目を整理します。
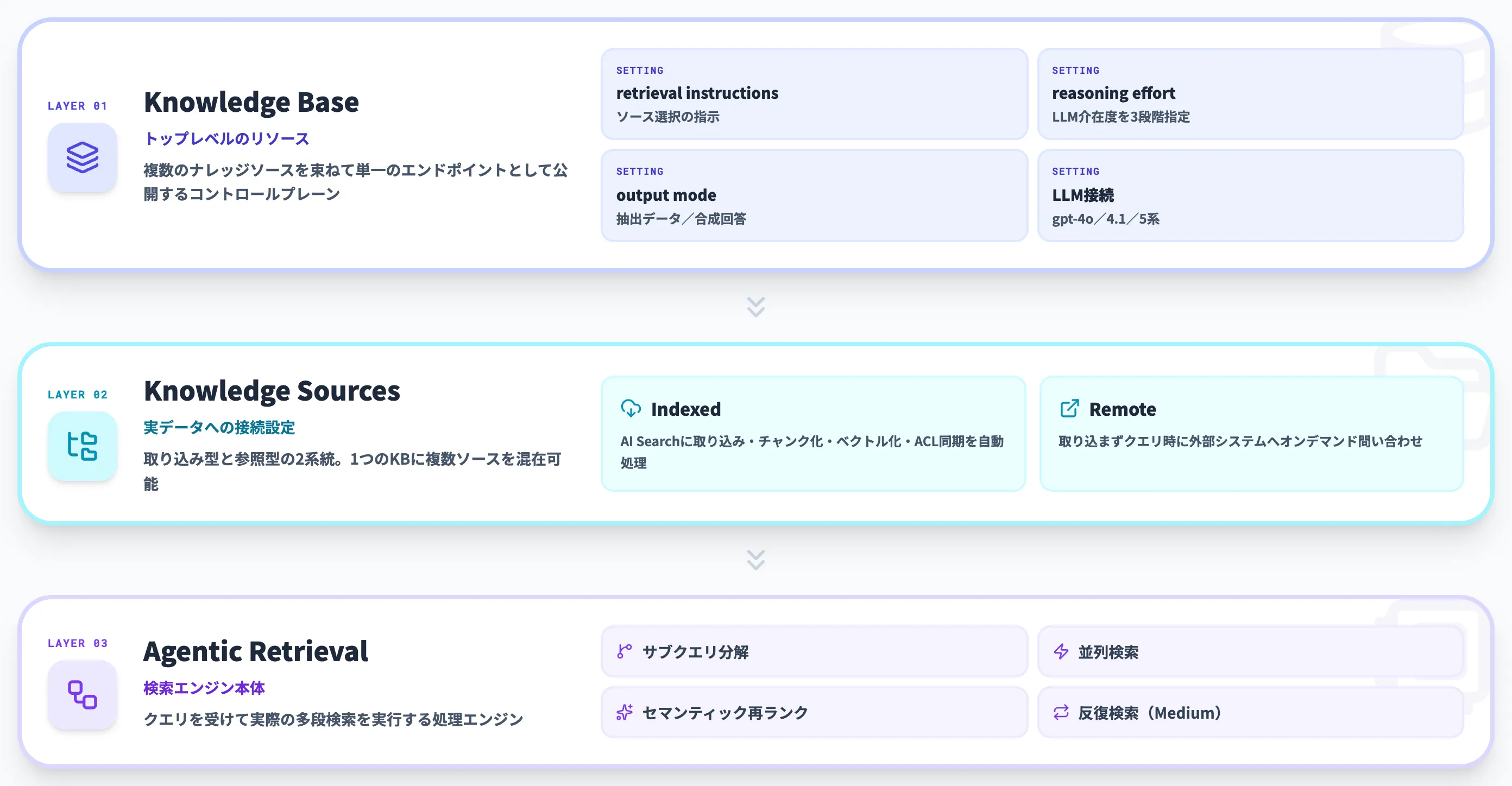
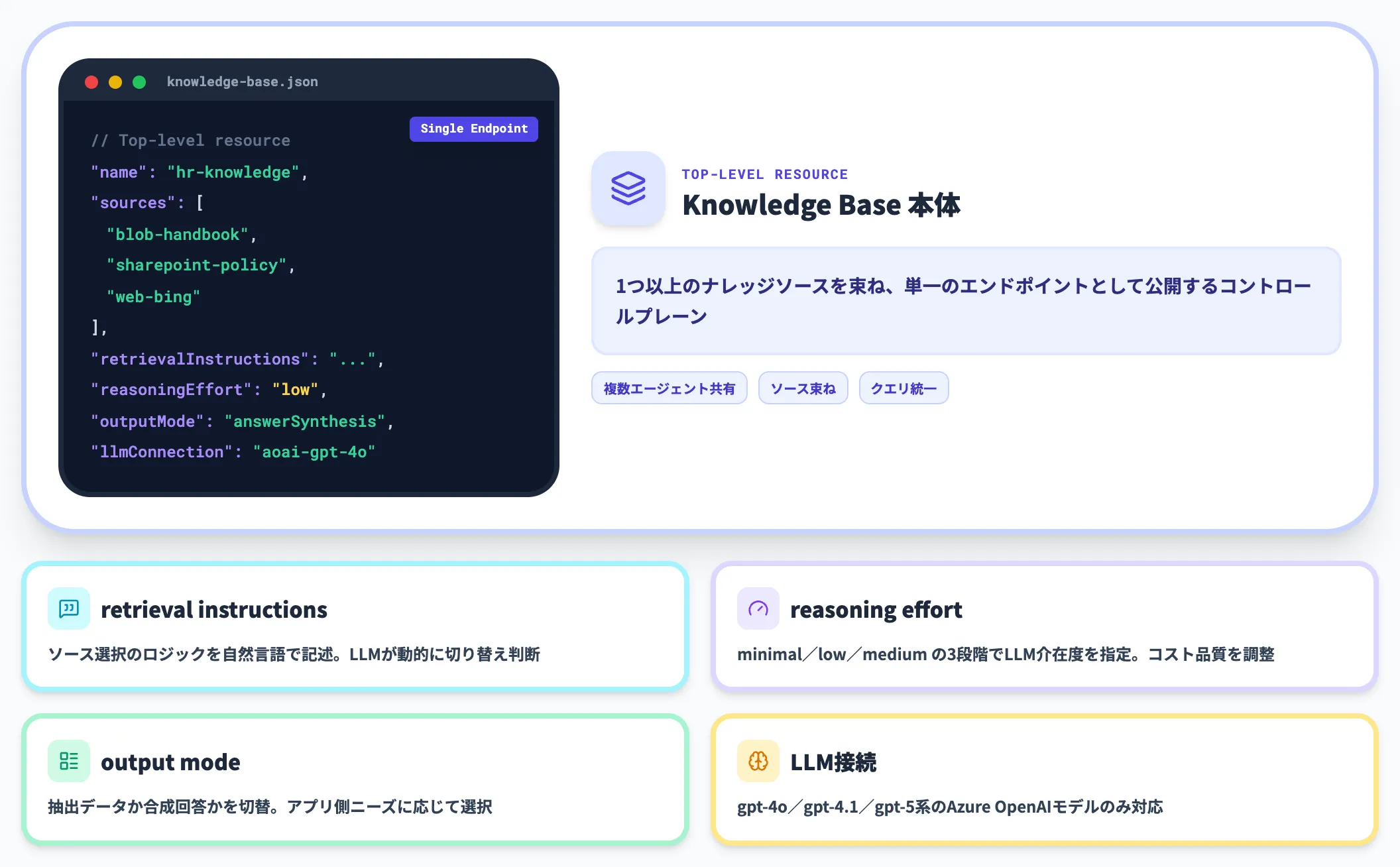
Knowledge Base(ナレッジベース本体)
ナレッジベースはトップレベルのリソースで、1つ以上のナレッジソースを束ね、単一のエンドポイントとして公開します。設定項目としては、retrieval instructions(どのソースをどう使うかの指示)、retrieval reasoning effort(検索時のLLM推論量)、output mode(抽出データか合成回答か)、LLM接続(クエリ計画と回答合成に使うAzure OpenAIのモデル)などがあります。
-
retrieval instructions
ソース選択のロジックを自然言語で記述する設定
-
retrieval reasoning effort
minimal/low/mediumの3段階で、LLMの介在度合いを決める
-
LLM接続
gpt-4o/gpt-4.1/gpt-5系のAzure OpenAIモデルのみ対応
作成したナレッジベースは、AzureポータルのAI Searchリソースからも確認できます。
AzureポータルのAI Searchリソース画面
左メニューの「ナレッジベース」を選択すると、Foudryポータルで作成したナレッジベースが表示されます。
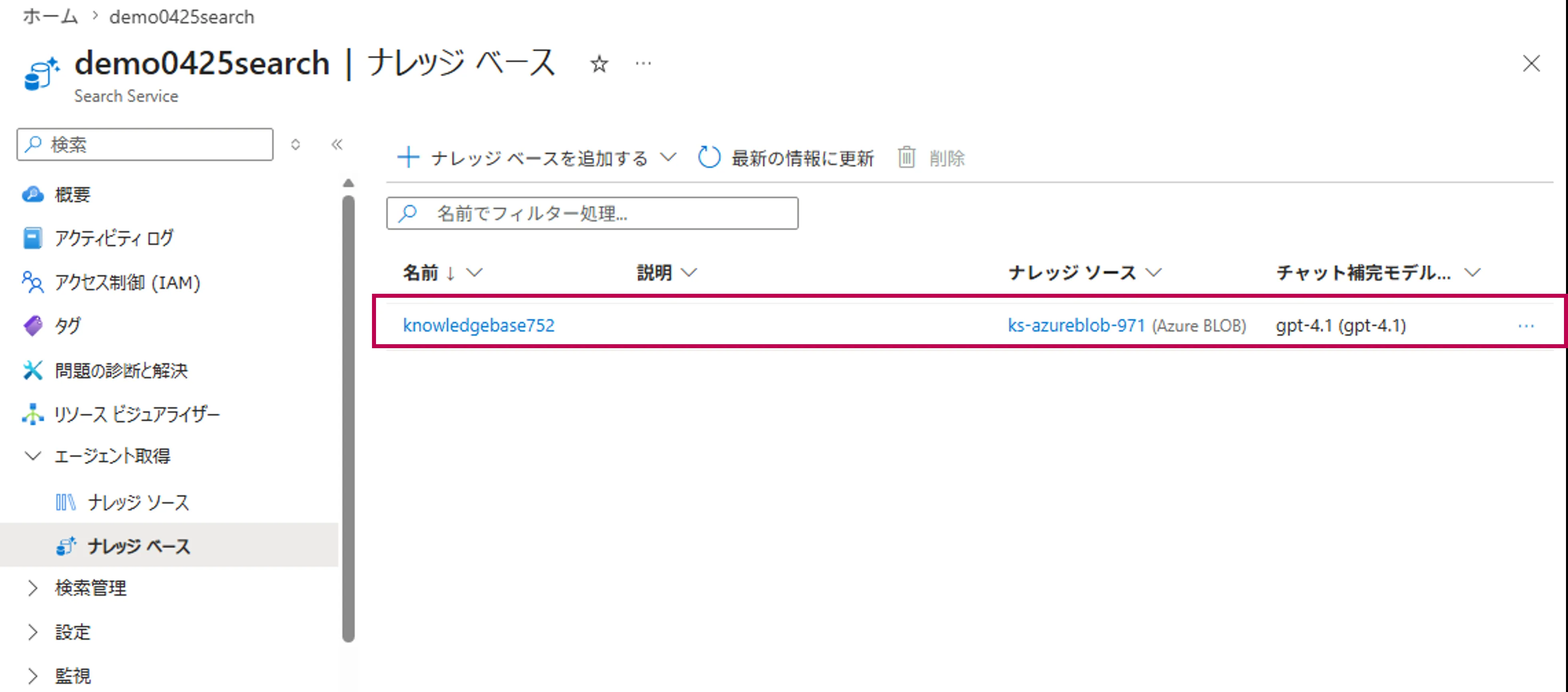
ナレッジベース一覧画面
Knowledge Sources(ナレッジソース)
ナレッジソースは実際のデータへの接続設定です。Indexed(取り込み型)とRemote(参照型)の2種類があり、ナレッジベースは1つ以上のソースを参照する形で定義されます。Indexed型はAzure AI Searchのインデックスにデータを取り込み、チャンク分割・ベクトル化・メタデータ抽出・ACL同期までを自動で処理します。Remote型はデータを取り込まず、クエリ時に外部システムへオンデマンドで問い合わせる仕組みです。
対応ソースの詳細と使い分けは次節で整理します。
Agentic Retrieval(検索エンジン)
クエリを受け取ったときに実際の検索を実行するエンジンです。複雑なクエリをサブクエリに分解し、キーワード・ベクトル・ハイブリッドのいずれかで並列検索を実行したあと、セマンティック再ランクで統合します。初回の検索結果が関連度基準を満たさない場合は、mediumレベルで反復検索が走ります。この多段処理がFoundry IQの「agentic」たる所以です。
対応するナレッジソース一覧
ナレッジベースで参照できるデータソースは、2026年4月時点で以下のとおり整理されています。Indexed型とRemote型の性質が大きく異なるため、要件に応じた使い分けが必要です。
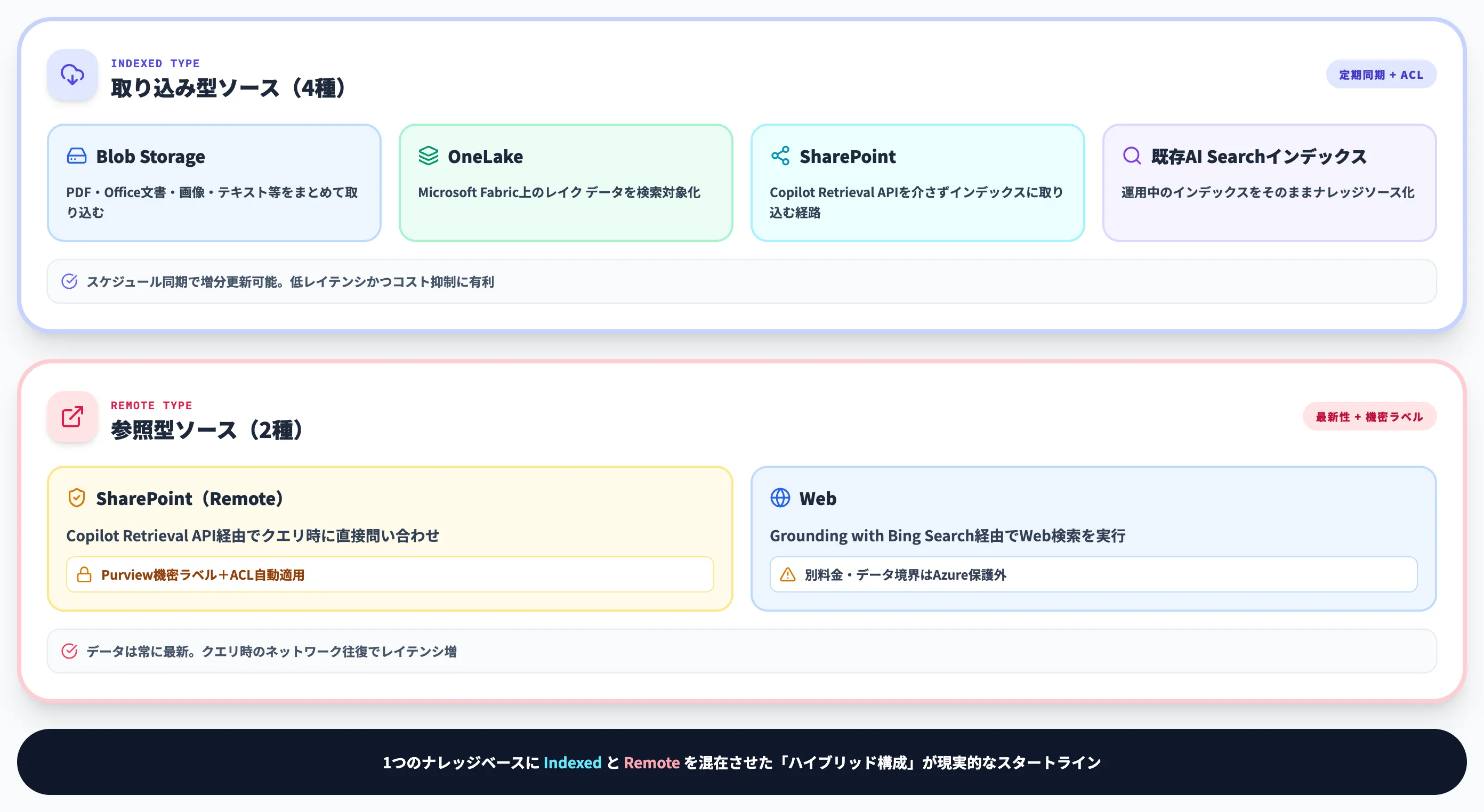
Indexed型のナレッジソース
Indexed型は、Azure AI Searchのインデクサーを使ってデータを取り込み、検索インデックスに永続化するタイプです。以下のソースに対応しています。
-
Azure Blob Storage
PDF・Office文書・画像・テキスト等をまとめて取り込む用途に最適
-
OneLake
Microsoft Fabric上のOneLakeデータを検索対象にする
-
SharePoint(Indexed)
Copilot Retrieval APIを介さず、インデックスに取り込む経路
-
既存のAzure AI Search インデックス
すでに運用中のインデックスをナレッジソース化する
Indexed型の利点は、スケジュール設定した定期同期で増分更新が行える点と、ACL(アクセス制御リスト)やベクトル埋め込みが検索側で一元管理される点です。大量ドキュメントを対象とする場合、クエリ時のレイテンシとコストはRemote型より抑えられます。
Remote型のナレッジソース
Remote型は、データを取り込まずにクエリ時にソース側へ問い合わせる方式です。現時点で以下の2つがサポートされています。
-
SharePoint(Remote)
Copilot Retrieval API経由でSharePointに直接問い合わせ
-
Web
Grounding with Bing Search経由でWeb検索を実行
Remote型はデータが常に最新である反面、クエリ時にネットワーク往復が発生するためレイテンシが増えます。またSharePointのRemoteソースでは、Microsoft Purviewの機密ラベルとACLがクエリ時に自動で適用されるため、機密性の高いドキュメントを扱う用途で有利です。
Indexed型とRemote型の使い分け
ここまでの内容を実務観点で整理すると、以下のような判断軸が妥当です。
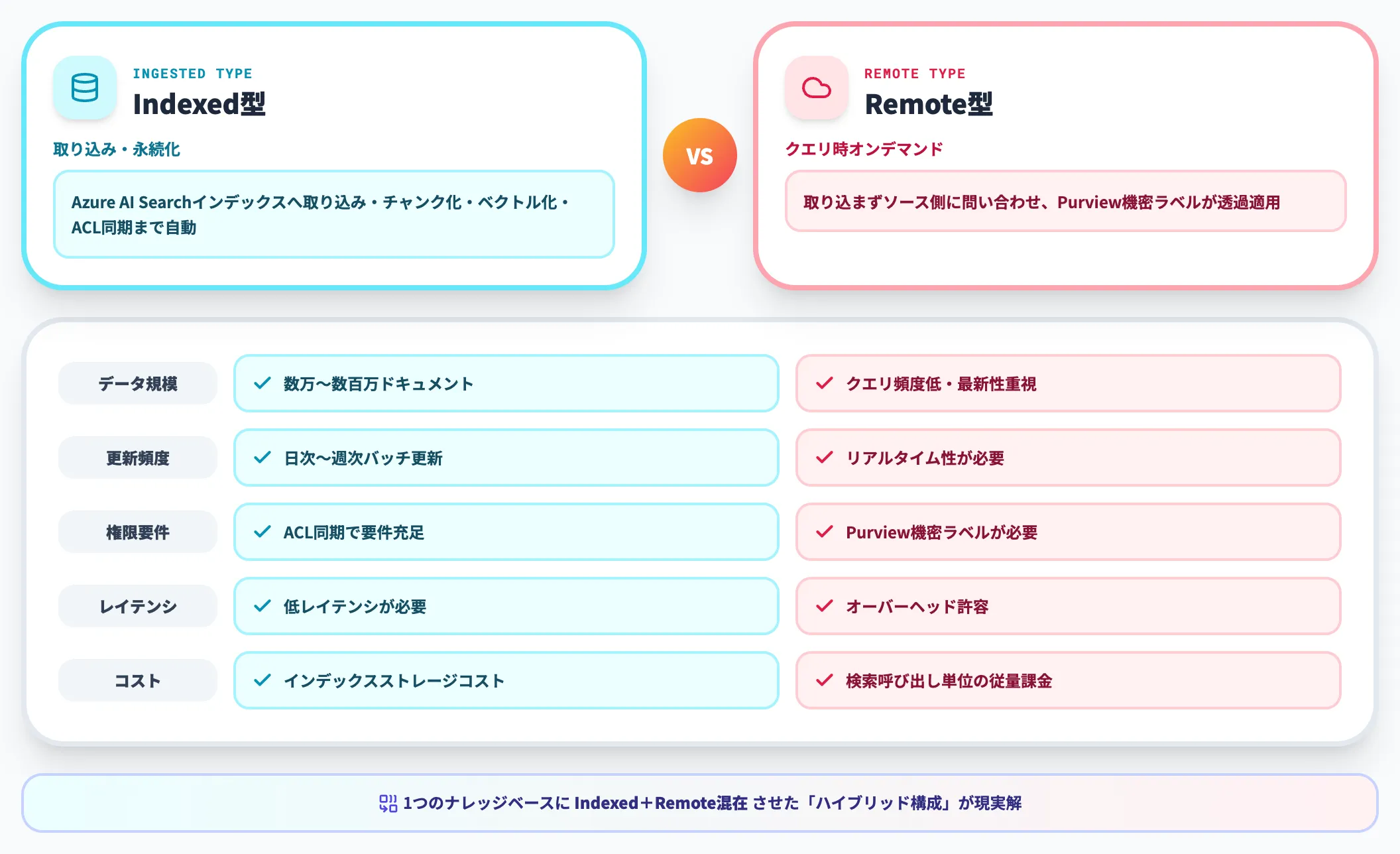
| 軸 | Indexed型が向く | Remote型が向く |
|---|---|---|
| データ規模 | 数万〜数百万ドキュメント | クエリ頻度が低い・最新性重視 |
| 更新頻度 | 日次〜週次のバッチ更新 | リアルタイム性が必要 |
| 権限要件 | ACLを同期しても要件を満たす | Purview機密ラベルが必要 |
| レイテンシ | 低レイテンシが必要 | 多少のオーバーヘッドが許容できる |
| コスト | インデックスストレージコストを負う | 検索呼び出しごとの課金で十分 |
社内ナレッジの本体はIndexed型で取り込み、SharePointの機密文書とWeb情報だけRemote型で補完する、という「ハイブリッド構成」が現実的なスタートラインになります。たった1つのナレッジベースに両タイプのソースを混在できるのが設計上の強みです。
Retrieval Reasoning Effort(取得推論レベル)
ナレッジベースのチューニング設計で最も重要な設定項目が、retrieval reasoning effortです。検索時にどれだけLLMを関与させるかを3段階で指定でき、コストと品質のバランスを決めます。Microsoft Learnの公式仕様に基づいて整理します。
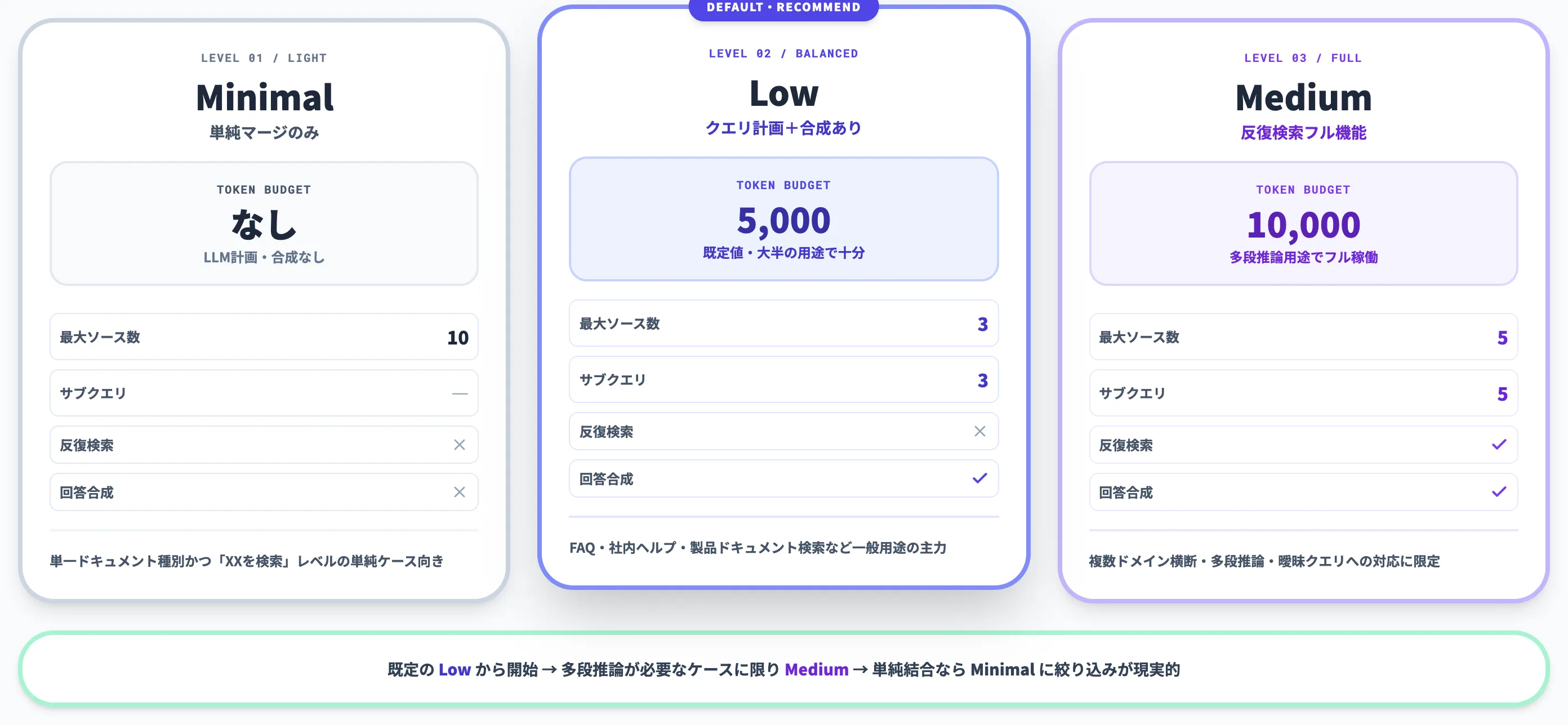
3段階のレベルと制限
以下の表で、各レベルの上限値と主な挙動の違いを整理しました。表の下に、実務で選ぶときの指針を示します。
| レベル | 最大ソース数 | 最大サブクエリ数 | 反復検索 | 回答合成 | トークン予算 |
|---|---|---|---|---|---|
| Minimal | 10 | なし(LLM計画なし) | なし | なし | なし |
| Low | 3 | 3 | なし | あり | 5,000 |
| Medium | 5 | 5 | あり | あり | 10,000 |
サブクエリ分解のログ画面
Minimalは「複数ソースの結果をシンプルにマージするだけ」で、LLMによるクエリ計画も回答合成も行わないモードです。低コストで動かせますが、複雑な質問に対しては精度が物足りません。Lowはクエリ計画を入れてサブクエリを分割するものの、反復検索は行わない中間帯。Mediumは反復検索まで含むフル機能版で、複数ホップの質問や曖昧なクエリに強くなります。
レベル選択の指針
実務での選び方は以下の通りです。

-
Minimal
ドキュメント種別が単一で、クエリも「XXを検索」レベルの単純ケース
-
Low
一般的なFAQ・社内ヘルプ・製品ドキュメント検索
-
Medium
複数ドメインにまたがる業務問い合わせ、多段推論が必要な用途
Lowが既定値で、ほとんどのFAQや社内ヘルプ用途はLowで足ります。Mediumは反復検索が有効な多段推論用途に限定し、実クエリでのトークン消費量とレイテンシを計測しながら段階的に引き上げるのが安全な運用です。
クエリ計画に使えるLLM
retrieval reasoning effortをLowまたはMediumに設定すると、クエリ計画でLLM呼び出しが発生します。公式ドキュメントで対応が明記されているのは、Azure OpenAI in Foundry Modelsの以下のモデルシリーズのみです。
- gpt-4o 系
- gpt-4.1 系
- gpt-5 系
gpt-3.5系や他ベンダーのLLMは使えません。Azure OpenAIのデプロイ名を、ナレッジベース作成時にLLM接続として指定します。モデル選定はコストと回答品質のトレードオフになるため、実データでの小規模検証を経て決めるのが現実的です。
Foundry IQ ナレッジベースの作り方
ナレッジベースの作成は、Microsoft FoundryポータルのGUIとAzure AI Search APIによるプログラム操作の2つの経路があります。PoC段階ではポータル、本番構築は自動化のためにプログラム経路を採用するのが標準です。
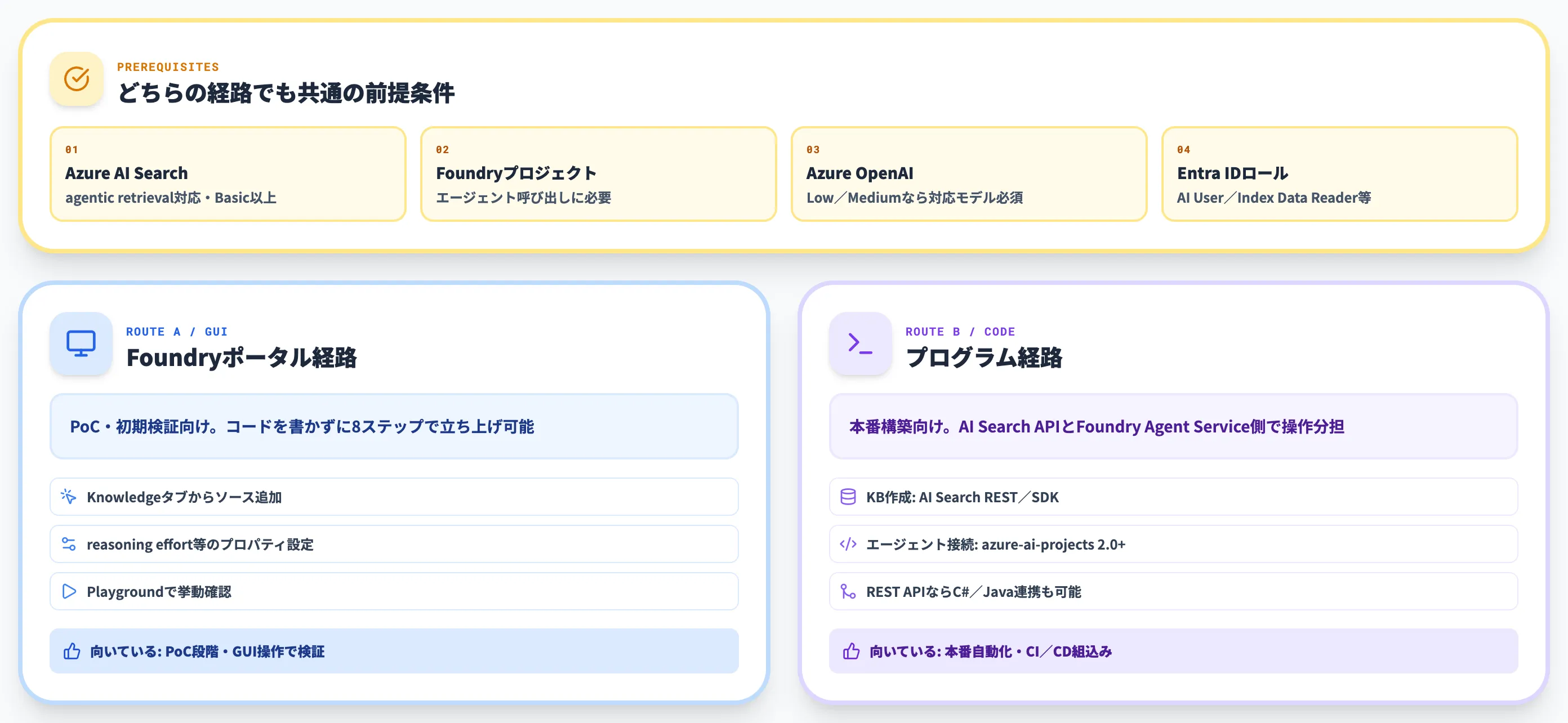
前提条件
どちらの経路でも、以下が事前に必要です。

-
Azure AI Searchサービス
agentic retrievalをサポートするサービスが必要。Basicティア以上を推奨
-
Microsoft Foundryプロジェクト
エージェント側でナレッジベースを呼び出す場合に必要
-
Azure OpenAIデプロイ
LowまたはMediumのreasoning effortを使う場合は、対応モデルのデプロイが必要
-
Microsoft Entra IDのロール
Azure AI User・Azure AI Project Manager・Search Index Data Reader等
Microsoft Foundryポータルでの作成手順
ポータルの手順は以下のとおりです。各ステップを順に進めれば、コードを書かずにナレッジベースを立ち上げられます。

- Microsoft Foundry (new)にサインインし、「New Foundry」トグルをオンにする
Foundryポータルサインイン画面
- プロジェクトを作成または選択する
プロジェクト作成選択画面
- 上部メニューから「Build」→「Knowledge」タブを開き、agentic retrieval対応のAzure AI Searchサービスを接続する
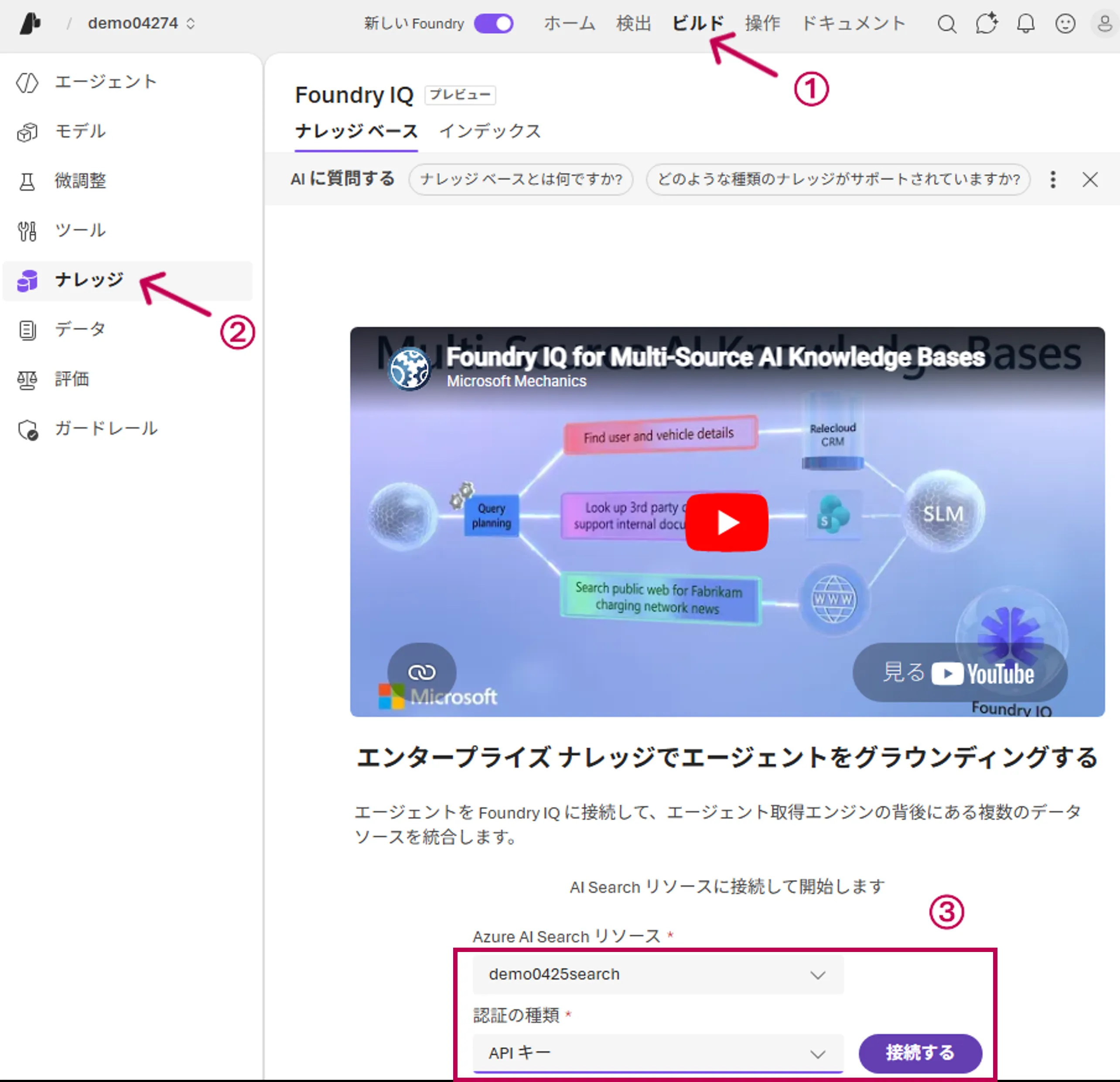
Azure AI Searchサービス接続画面
- ナレッジソースを1つずつ追加する(Blob/OneLake/SharePoint等)
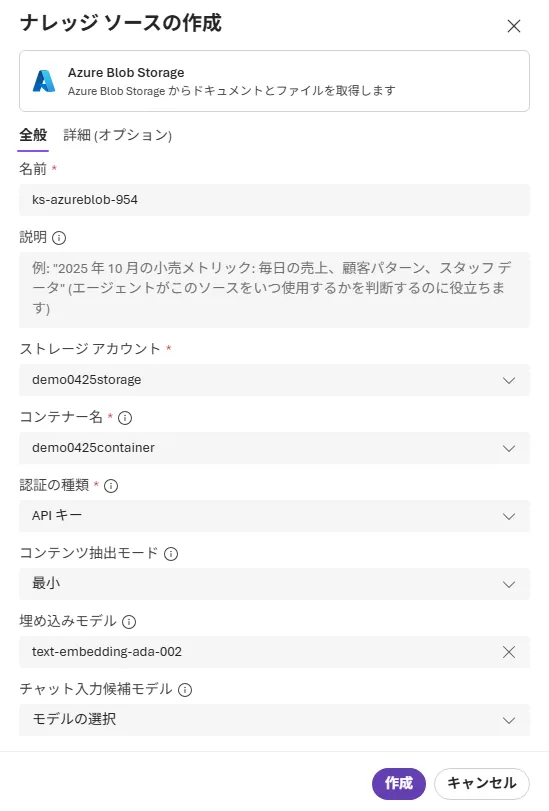
ナレッジソース作成画面
以下のように、複数のナレッジソースをナレッジベースに紐づけることができます。
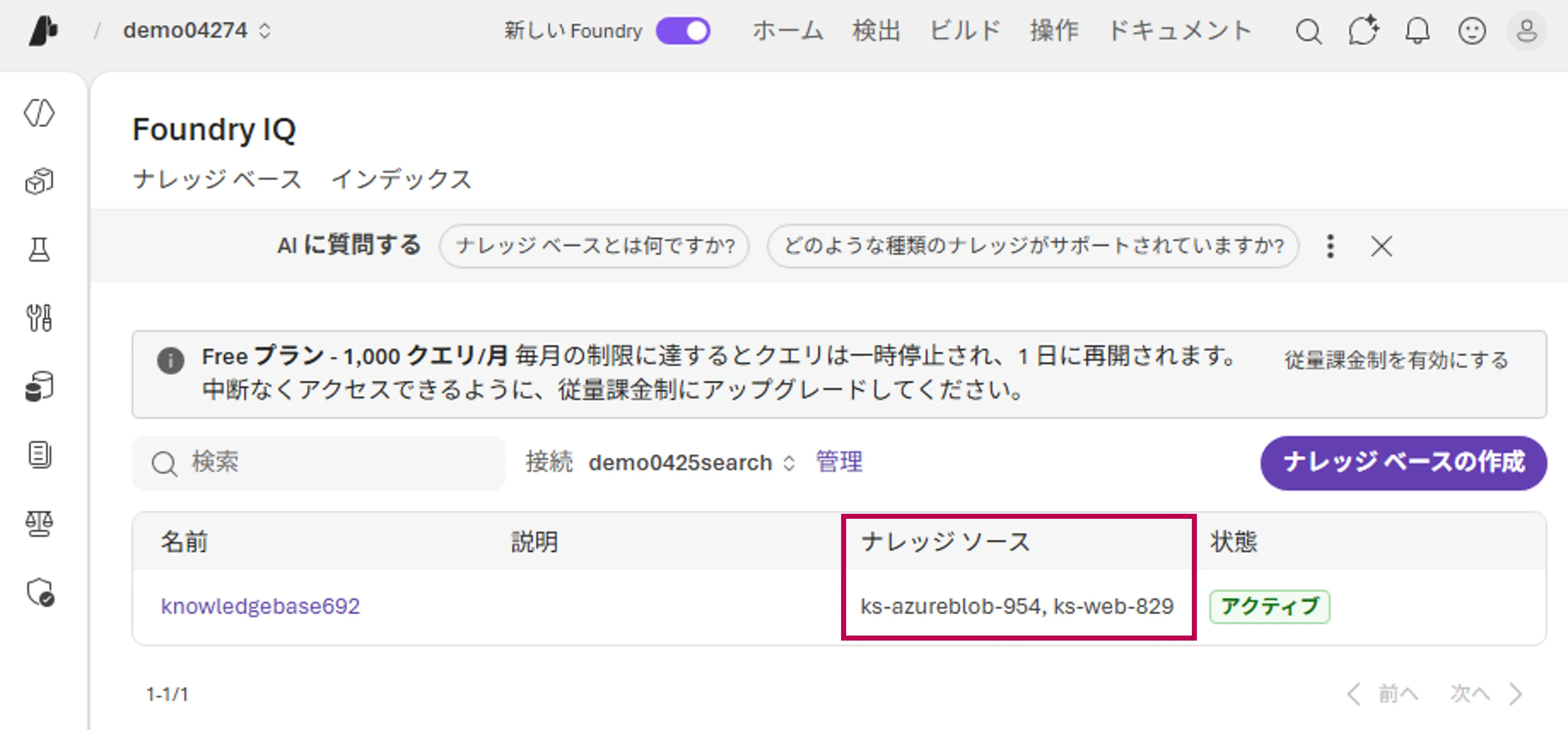
ナレッジソース一覧画面
- retrieval reasoning effort等のプロパティを設定する
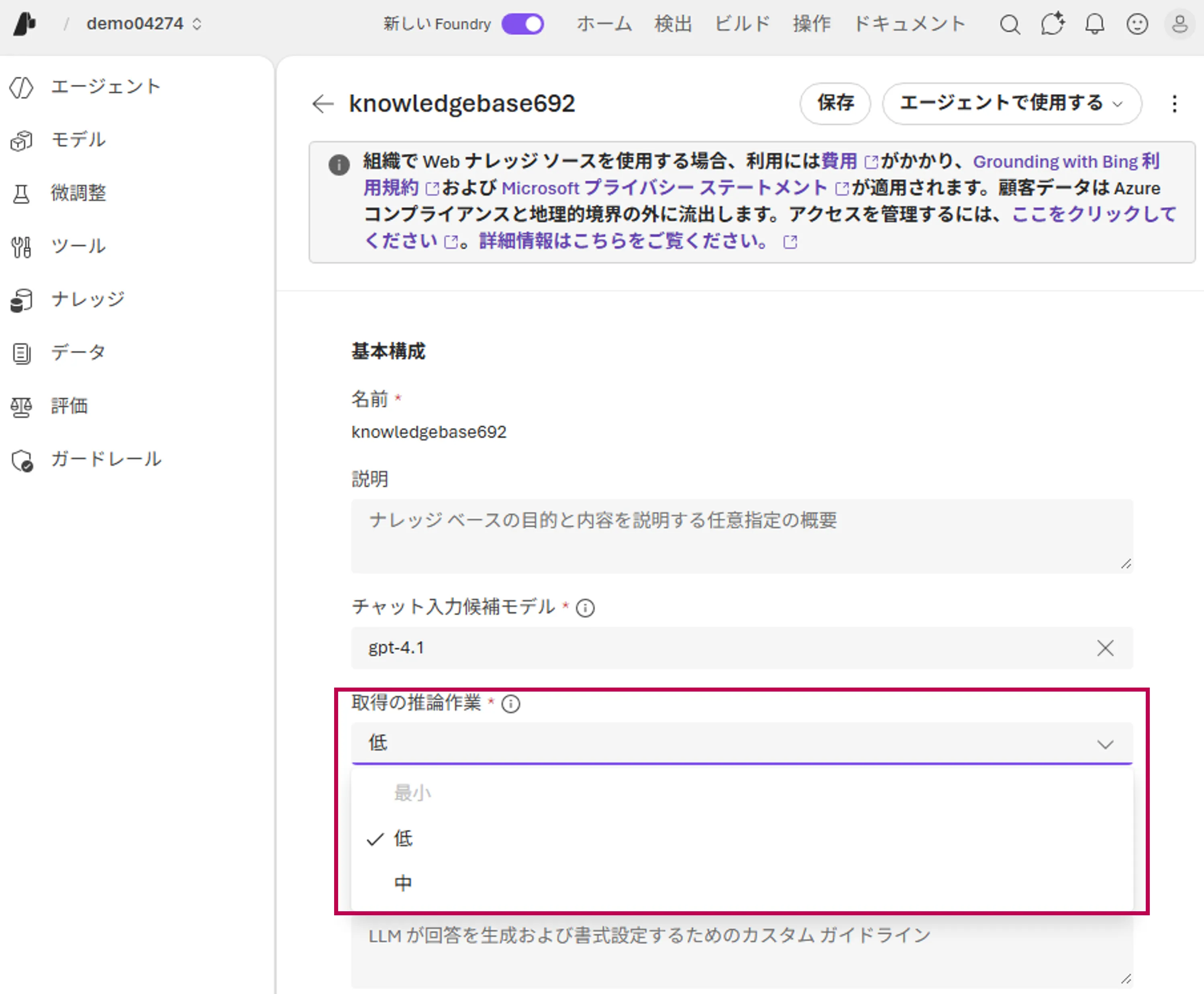
Retrieval Reasoning Effort設定画面
- 「Agents」タブでエージェントを作成し、ナレッジベースを紐付ける
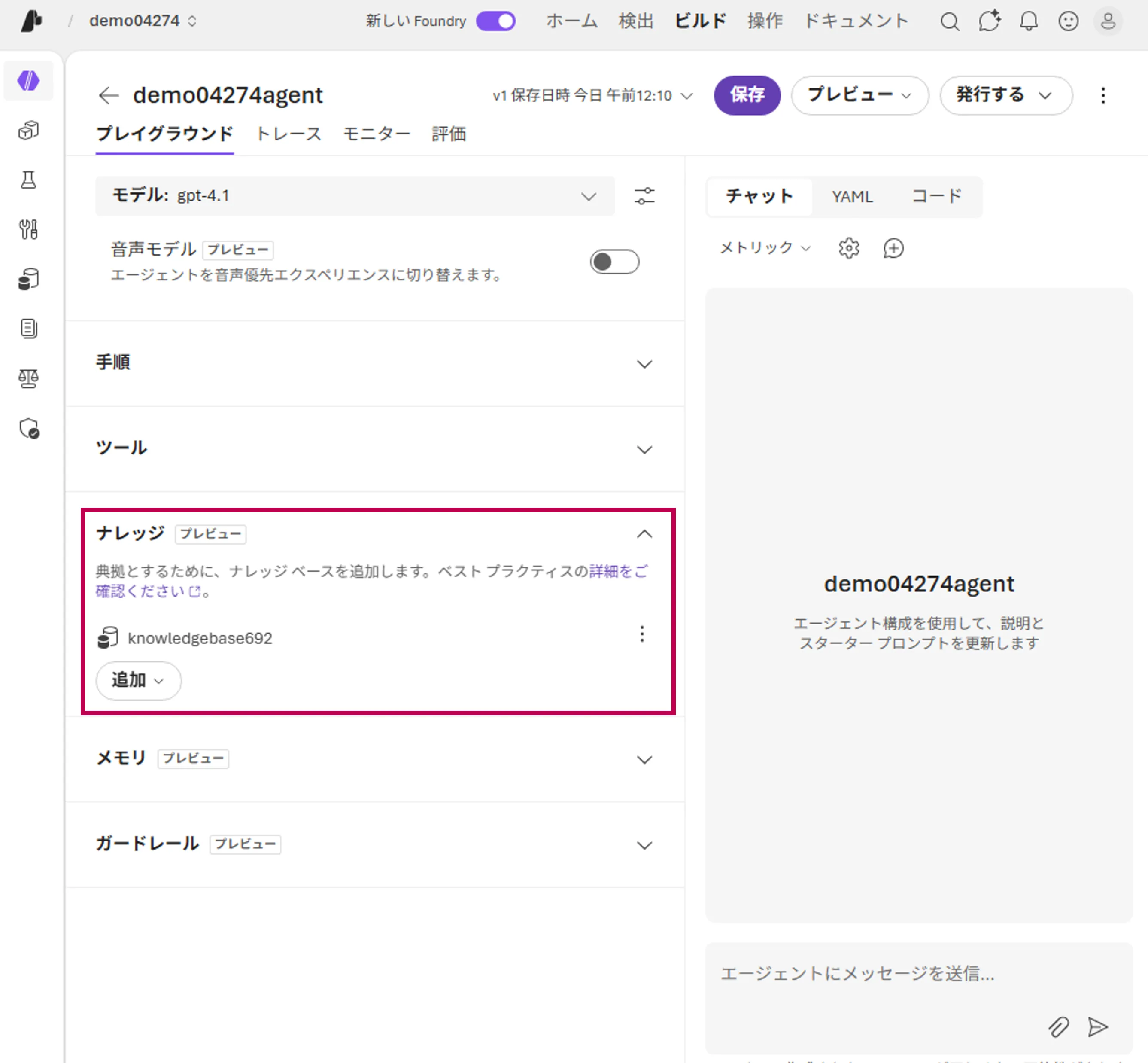
Agentsタブでの紐付け画面
- Playgroundでメッセージを送信して挙動を確認する
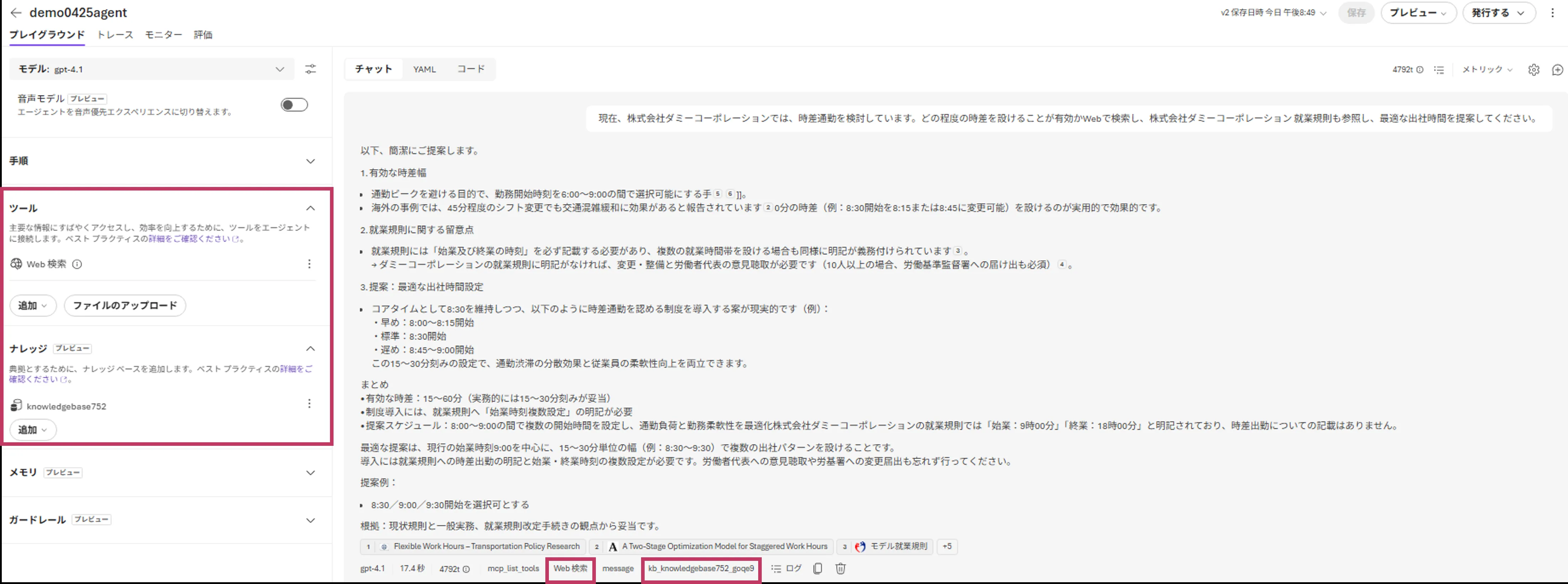
Playgroundでクエリ実行画面
Playgroundは検証用で、本番では後述するマネージドIDと権限設定を別途行う必要があります。
プログラムでの作成手順
プログラム経路では、操作対象ごとに使用するSDK/APIが異なります。ナレッジソースとナレッジベースそのものの作成はAzure AI Search側、エージェントへの接続はFoundry Agent Service側が担当です。
-
ナレッジソース/ナレッジベースの作成
Azure AI SearchのREST APIまたはSDKを使用し、APIバージョンは2025-11-01-previewを指定します。手順はCreate a knowledge base (Azure AI Search)を参照
-
エージェントへのナレッジベース接続
Foundry Agent Service側で行い、Python SDKならazure-ai-projectsの2.0.0以降、もしくはREST APIが対応しています。C#/JS/Java SDKは2026年4月時点で未対応
詳細なチュートリアルはAzure AI Search公式サンプルで公開されています。

エージェントへのMCP接続と実装例
作成したナレッジベースは、Model Context Protocol(MCP)経由でエージェントから呼び出します。これはAIエージェントの外部ツール呼び出しに使われる標準プロトコルで、Foundry Agent ServiceがMCPクライアントとして振る舞い、ナレッジベースがMCPサーバーとして応答する構造です。
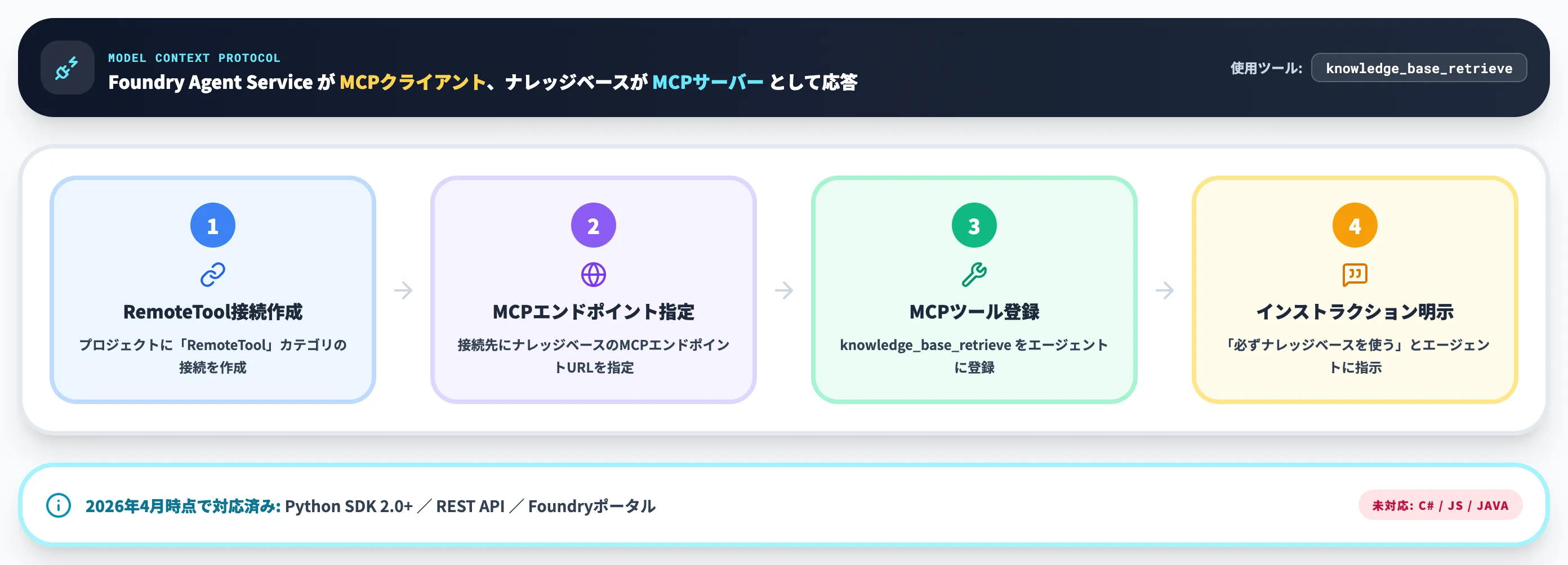
対応状況(2026年4月時点)
エージェント接続のSDK対応は以下のとおりです。
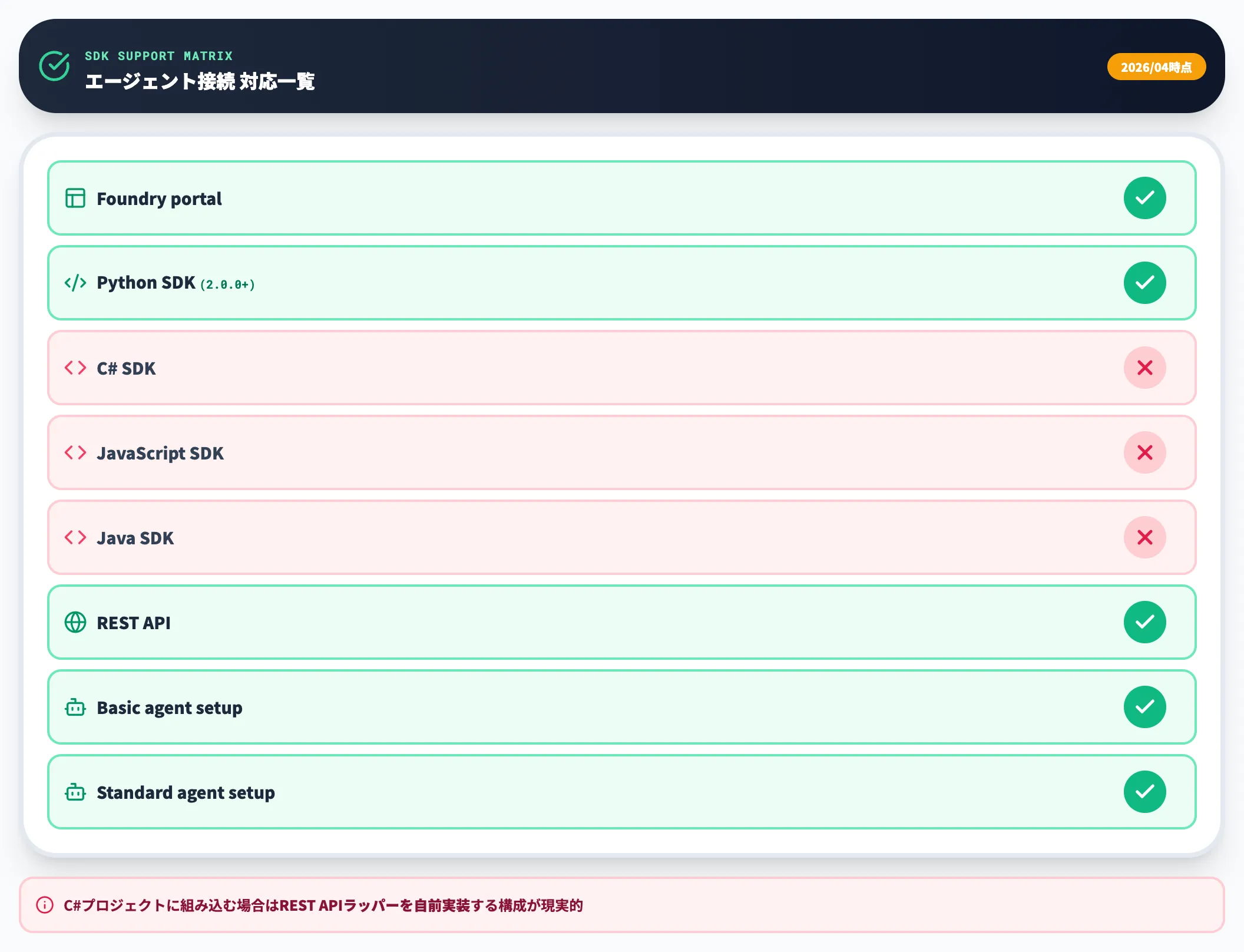
| Foundry portal | Python SDK | C# SDK | JS SDK | Java SDK | REST API | Basic agent setup | Standard agent setup |
|---|---|---|---|---|---|---|---|
| ✔️ | ✔️ | - | - | - | ✔️ | ✔️ | ✔️ |
C#・JavaScript・JavaのSDKは未対応で、プログラムから接続するならPython SDK 2.0.0以上かREST APIのいずれかを選びます。C#プロジェクトに組み込みたい場合は、一旦REST APIでラッパーを書く構成になります。
実装の全体フロー
エージェントをナレッジベースに接続するまでのステップは、以下の4つです。
- プロジェクトに
RemoteToolカテゴリの接続を作成する - 接続先としてナレッジベースのMCPエンドポイントを指定する
- MCPツール(
knowledge_base_retrieve)をエージェントに登録する - エージェントインストラクションで「必ずナレッジベースを使う」よう明示する
Pythonでのエージェント作成例
以下は、ナレッジベースをMCPツールとして登録したエージェントを作成するコードの抜粋です。実装の骨子を把握する目的で、必要最低限に絞って掲載します。
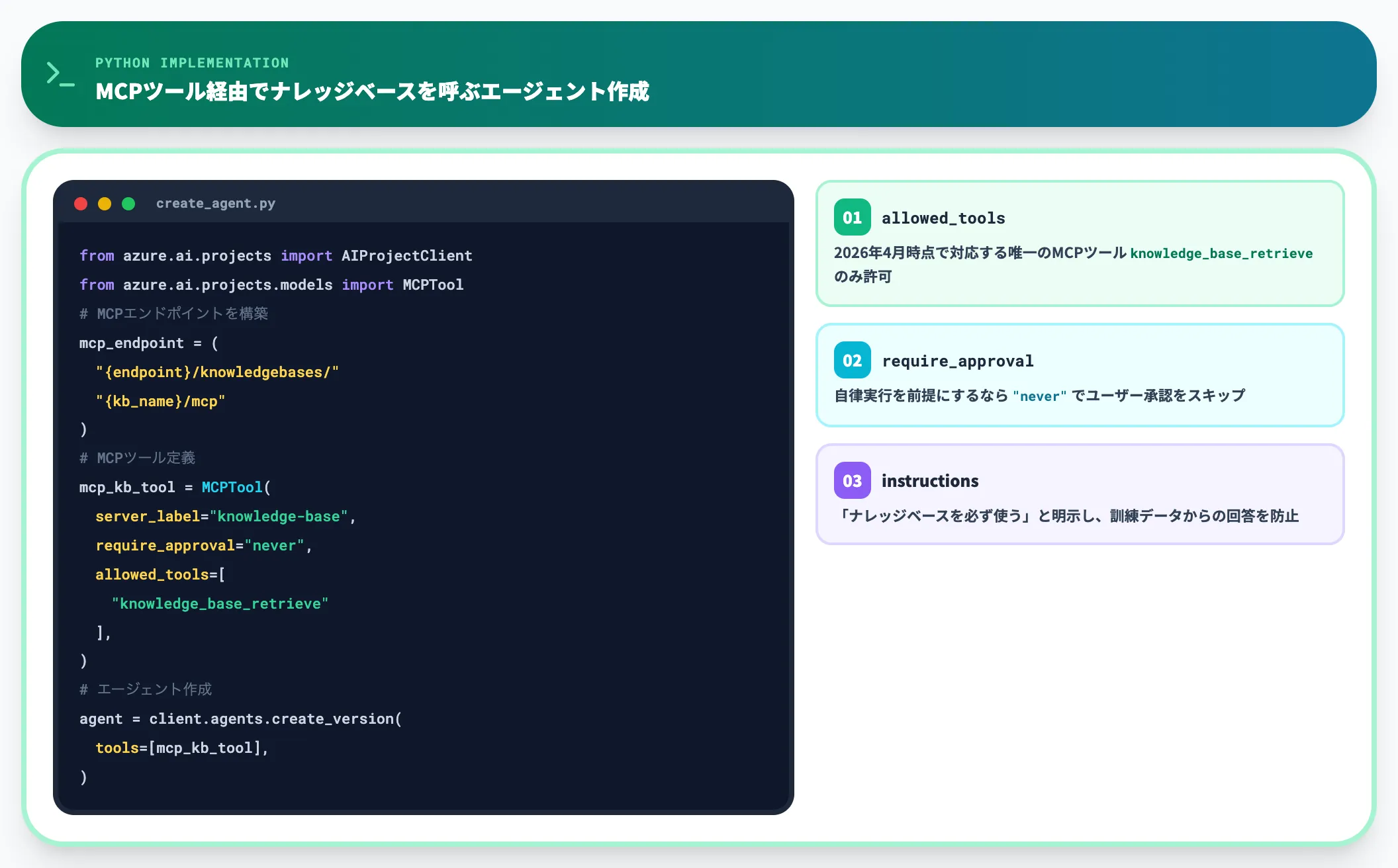
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import PromptAgentDefinition, MCPTool
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
mcp_endpoint = (
"{search_service_endpoint}/knowledgebases/{kb_name}/mcp"
"?api-version=2025-11-01-preview"
)
project_client = AIProjectClient(endpoint=project_endpoint, credential=credential)
instructions = """
You are a helpful assistant that must use the knowledge base to answer all questions.
If you cannot find the answer, respond with "I don't know".
Always return citations in the format: 【message_idx:search_idx†source_name】
"""
mcp_kb_tool = MCPTool(
server_label="knowledge-base",
server_url=mcp_endpoint,
require_approval="never",
allowed_tools=["knowledge_base_retrieve"],
project_connection_id=project_connection_name,
)
agent = project_client.agents.create_version(
agent_name=agent_name,
definition=PromptAgentDefinition(
model="gpt-4.1-mini",
instructions=instructions,
tools=[mcp_kb_tool],
),
)
このコード構成のポイントは3つあります。
-
allowed_toolsでknowledge_base_retrieveのみを許可
2026年4月時点でFoundry Agent Serviceが対応する唯一のMCPツールがこれです
-
require_approval="never"でユーザー承認をスキップ
エージェントの自律実行を前提にするなら無効化が必要
-
インストラクションで「ナレッジベースを必ず使う」と明示
LLMが自前の訓練データから答えるのを防ぎ、引用精度を上げる
SharePoint Remoteソースを含む場合の追加設定
ナレッジベースにSharePoint Remoteソースを含める場合は、MCPツール定義にx-ms-query-source-authorizationヘッダーを追加し、SharePoint側でクエリ時のACL判定が行われるようにします。ただし、Preview段階のFoundry Agent ServiceではMCPツールのヘッダーをリクエスト単位で切り替える仕組みがないため、エージェント定義時に設定したヘッダーが全呼び出しに適用される制約があります。ユーザー単位の認可が必要な場合は、Azure OpenAI Responses APIを直接使う設計に切り替える必要があります。
詰まりポイント
実装時にハマりやすいポイントを先回りでまとめます。
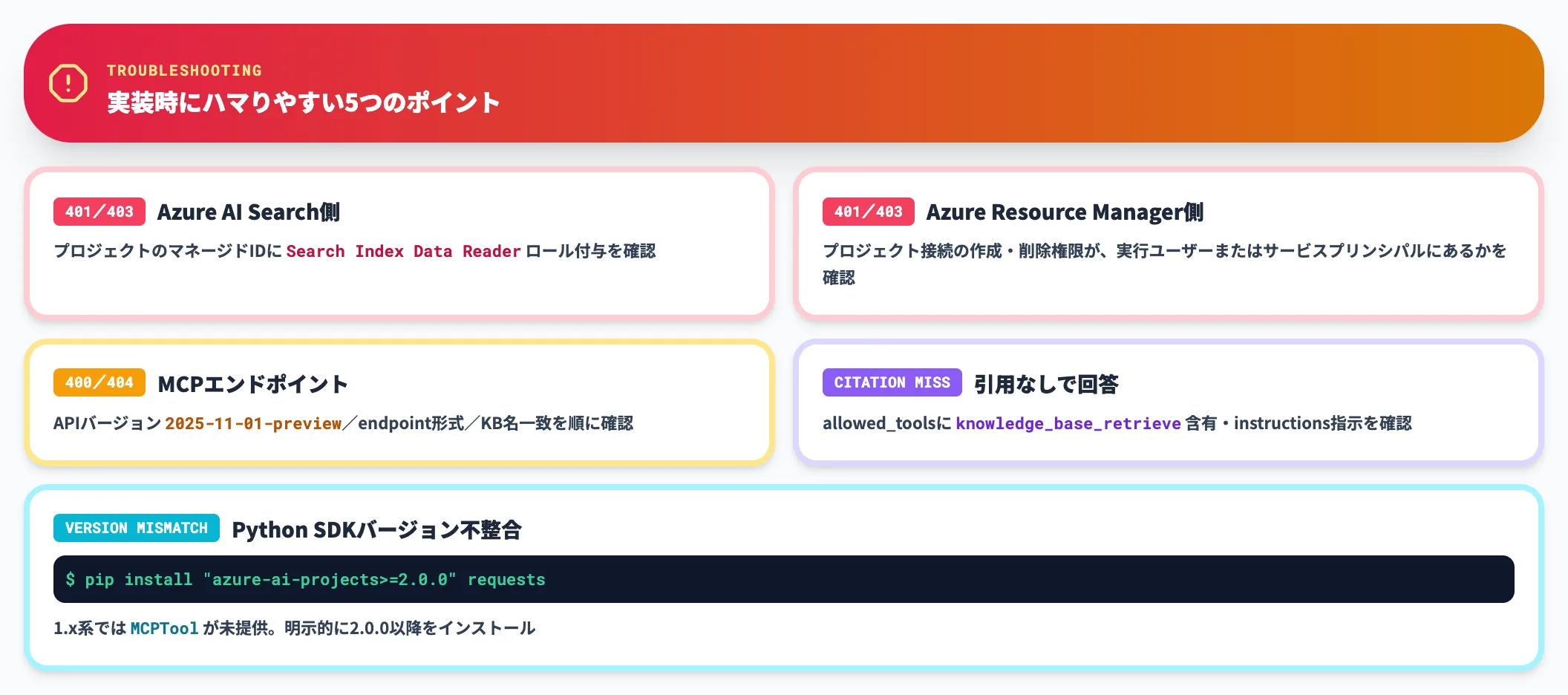
-
401/403エラー(Azure AI Search側)
プロジェクトのマネージドIDにSearch Index Data Readerロールが付与されているか確認。書き込みが必要ならSearch Index Data Contributorも追加
-
401/403エラー(Azure Resource Manager側)
プロジェクト接続の作成・削除権限が、実行ユーザーまたはサービスプリンシパルに付与されているか確認
-
MCPエンドポイントの400/404エラー
APIバージョンが2025-11-01-previewか、search_service_endpointがhttps://<name>.search.windows.net形式か、knowledge_base_nameがAzure AI Search側のKB名と一致しているかを順に確認
-
エージェントが引用なしで回答する
allowed_toolsにknowledge_base_retrieveが含まれているか、インストラクションで「ナレッジベースを使え」と指示しているかを確認
-
Python SDKのバージョン不整合
pip install "azure-ai-projects>=2.0.0" requestsで明示インストール。1.x系ではMCPToolが提供されていない
Foundry IQ ナレッジベースのセキュリティとガバナンス
エンタープライズで使う場合、最も懸念されるのがアクセス制御とデータ境界の扱いです。ナレッジベースは、対応ソースでACL同期やRemote接続を構成した場合、元データ側の権限モデルをクエリ時のフィルタとして適用できる設計になっています。どこまで権限透過になるかはソース種別ごとに差があるため、以下で順に整理します。
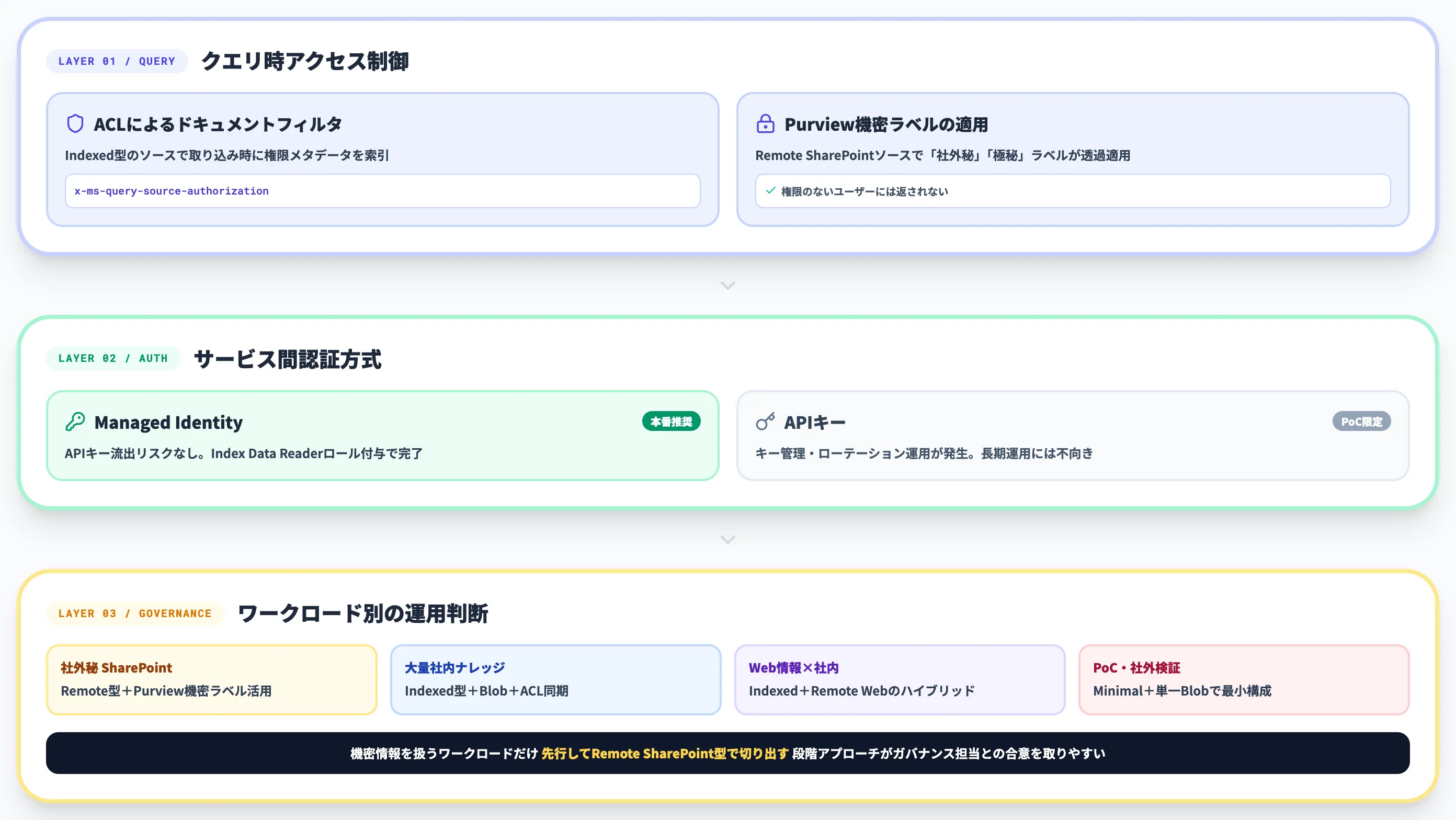
ACLとクエリ時フィルタリング
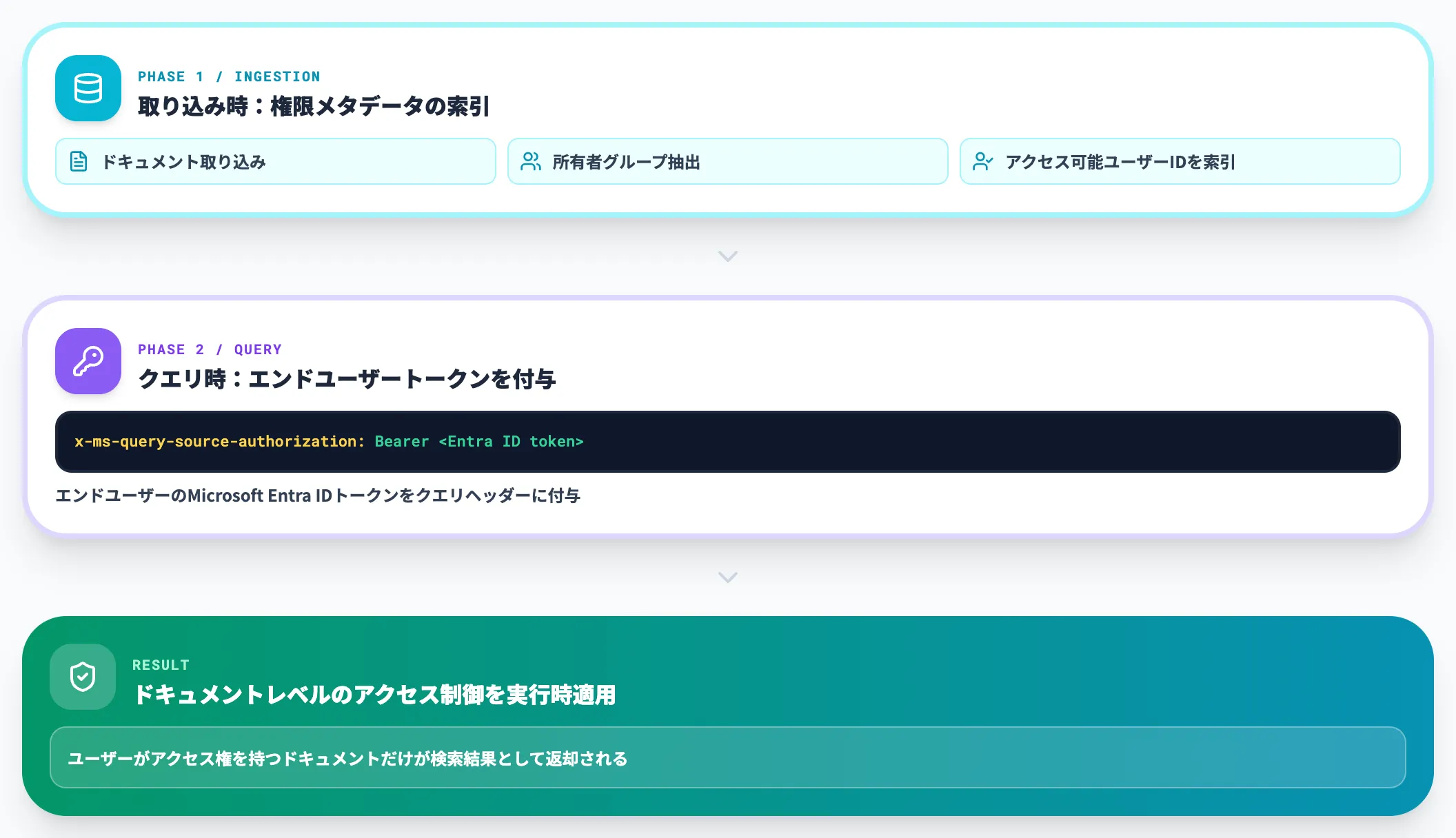
Indexed型のソースでは、取り込み時に各ドキュメントの権限メタデータ(所有者グループ・アクセス可能なユーザーID等)を索引し、クエリ時にユーザーIDで結果をフィルタリングします。これを実現するのがx-ms-query-source-authorizationヘッダーで、エンドユーザーのMicrosoft Entra IDトークンをクエリに付与することで、ドキュメントレベルのアクセス制御が実行時に適用されます。
Microsoft Purview機密ラベルとの連携
Remote SharePointソースでは、Copilot Retrieval APIがACLとMicrosoft Purviewの機密ラベルを透過的に適用します。たとえば「社外秘」「極秘」とラベル付けされた文書は、権限のないユーザーからのクエリには返されません。Indexed型では機密ラベルの自動適用はサポートされていないため、機密文書はRemote型で扱うのがセキュリティ面の定石です。
認証方式
Azure AI Searchと他のAzureサービス間の接続は、以下の2方式から選べます。

| 方式 | 推奨度 | 用途 |
|---|---|---|
| Managed Identity(システム割り当て) | ★★★ | 本番推奨。APIキー流出リスクなし |
| APIキー | ★ | ローカル開発・PoC限定 |
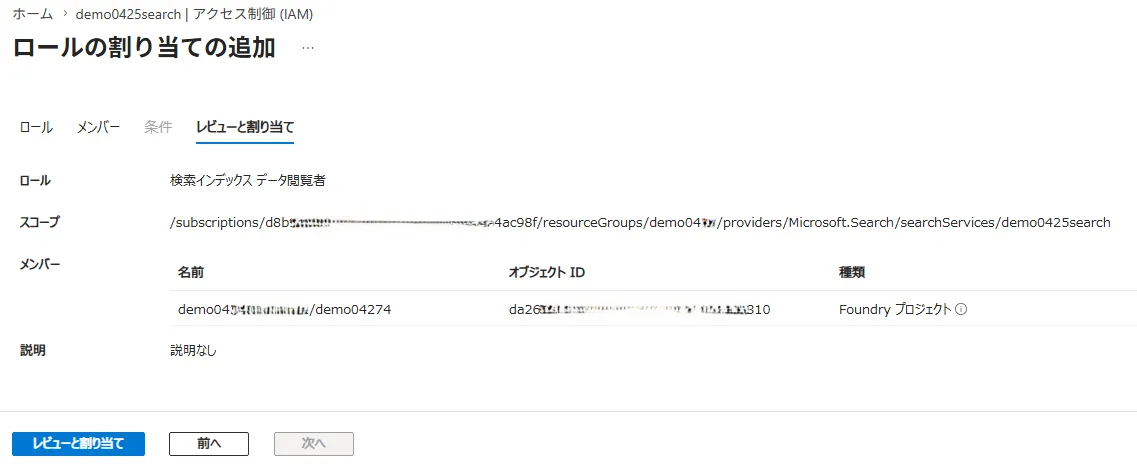
ロール割り当て画面
本番ではManaged Identityを使い、Azure AI SearchのインデックスデータリーダーロールをFoundryプロジェクトのマネージドIDに付与する構成が標準です。APIキーはキー管理の負担とローテーション運用が発生するため、長期運用には向きません。
ナレッジベース運用の判断で詰まる論点
ここは読者の自己判断で迷いやすい箇所です。SIerとしての支援経験からは、以下の切り分けが現実的です。
-
社外秘ドキュメント含むSharePoint資産
Remote型を選び、Purview機密ラベルの適用を活かす
-
大量の社内ナレッジ(マニュアル・手順書・議事録)
Indexed型でBlob Storageに集約し、ACL同期で権限制御
-
Web情報と社内データのハイブリッド
1つのナレッジベースにIndexed型+Remote Webソースを併置
-
PoCや社外データ検証
権限管理を簡素化するため、まずはMinimalモード+単一Blobソースで最小構成を作る
「全社展開の前に、機密情報を扱うワークロードだけ先行してRemote SharePoint型で切り出す」という段階的アプローチが、ガバナンス担当との合意を取りやすい進め方です。

類似機能との違いと使い分け
Microsoftは類似のナレッジ連携機能を複数提供しており、選定で混乱しやすいのが実情です。この節では、Foundry IQナレッジベースと他の選択肢を比較して整理します。
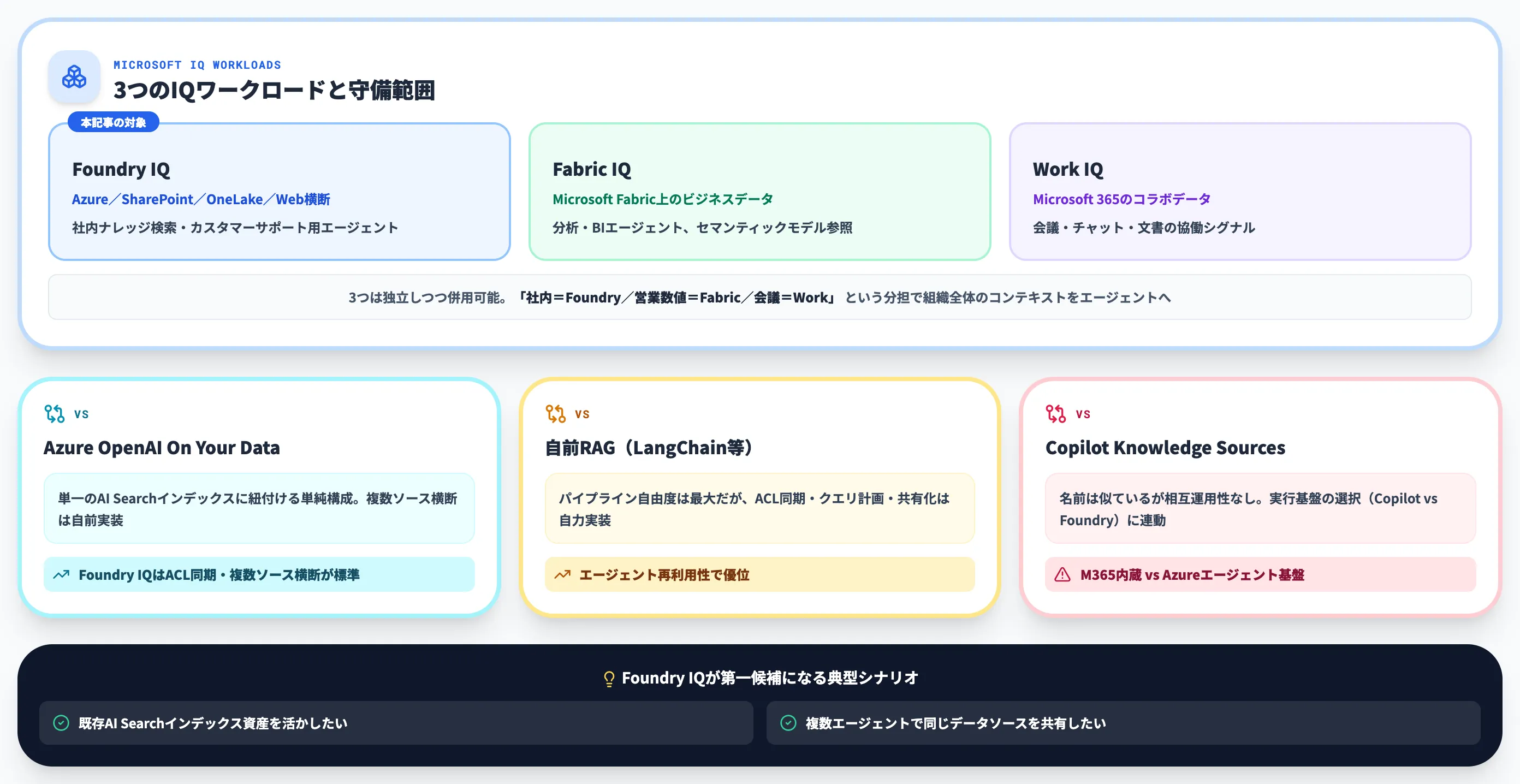
Fabric IQ/Work IQとの関係
MicrosoftはエージェントのためのIQワークロードを3種類提供しています。以下の表でそれぞれの守備範囲を示します。
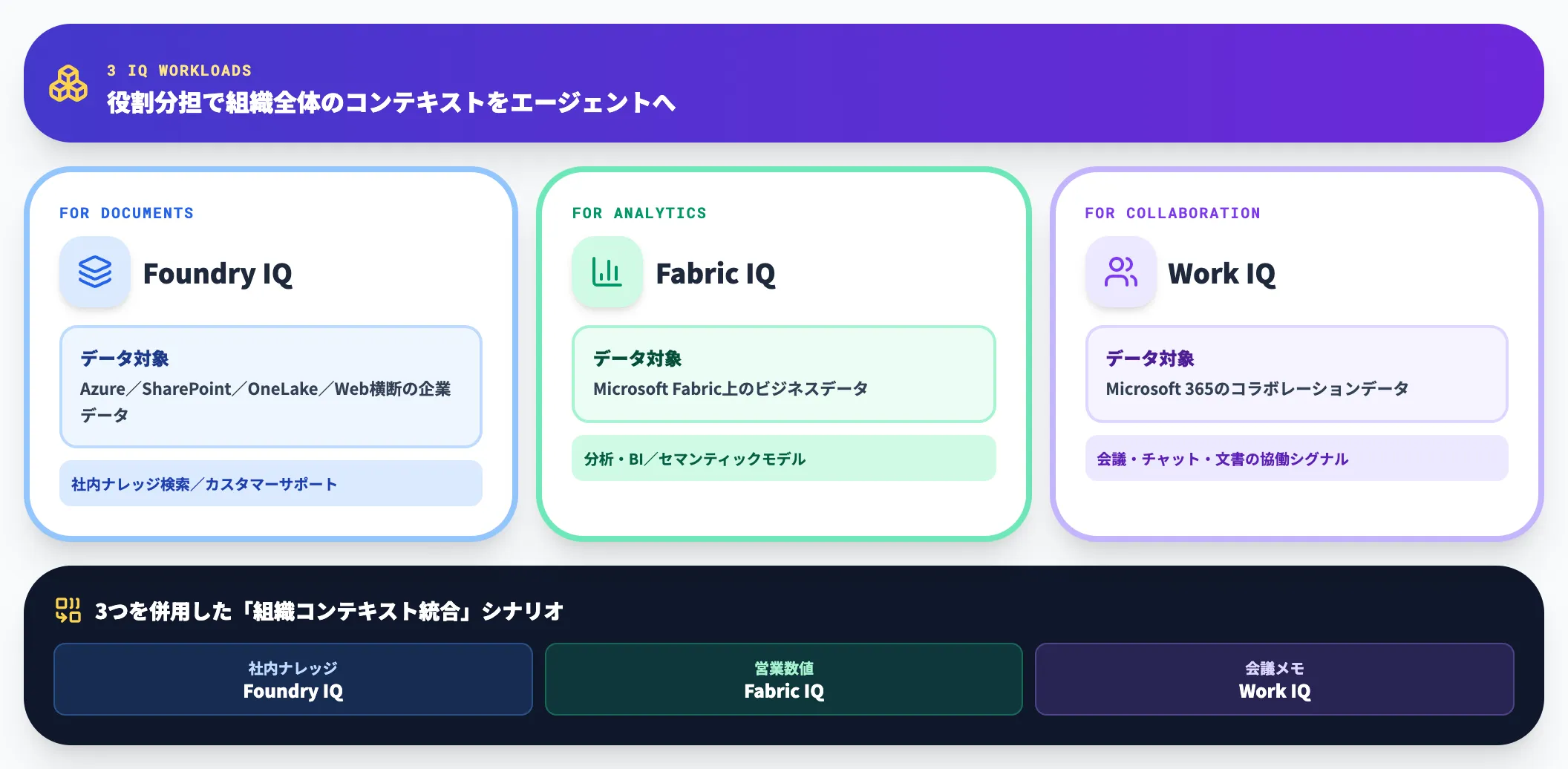
| ワークロード | データ対象 | 主な用途 |
|---|---|---|
| Foundry IQ | Azure/SharePoint/OneLake/Web横断の企業データ | 社内ナレッジ検索・カスタマーサポートエージェント |
| Fabric IQ | Microsoft Fabric上のビジネスデータ | 分析・BIエージェント、セマンティックモデル参照 |
| Work IQ | Microsoft 365のコラボレーションデータ | 会議・チャット・文書の協働シグナル |
3つは独立して動作しますが併用可能です。実務では「社内ナレッジはFoundry IQ、営業数値はFabric IQ、会議メモはWork IQ」という役割分担で、組織全体のコンテキストをエージェントに渡す構成が検討されています。
従来RAG/Azure OpenAI On Your Dataとの違い
従来の実装パターンとの差分は以下の通りです。
-
Foundry IQ ナレッジベース
複数ソースを1エンドポイントで集約、複数エージェントで共有、agentic retrievalで反復検索
-
Azure OpenAI On Your Data
単一のAzure AI Searchインデックスに紐付ける単純構成。複数ソース横断は自前実装
-
自前RAG(LangChain/LlamaIndex等)
パイプラインの自由度は最大だが、ACL同期・クエリ計画・共有化は自力実装
多くの現場ですでに「Azure OpenAI On Your Data」や自前RAGで動いているケースがあると思います。その場合、Foundry IQへの移行メリットは「エージェント再利用性」「複数ソース横断」「ACL同期の自動化」の3点です。逆に、単一ドキュメント群に対する単純検索しか必要ないなら、既存構成の維持でも問題ありません。
Copilot Knowledge Sourcesとの違い
Microsoft Copilotのknowledge sourcesとFoundry IQのknowledge sourcesは、名前は似ていますが相互運用性はありません。2026年4月時点で、Copilotで登録したソースをFoundry IQで使うことも、その逆もできません。どちらで構築するかは、エージェント実行基盤をCopilot(Microsoft 365内蔵)で組むか、Foundry Agent Service(Azure)で組むかに連動して選ぶ必要があります。

導入判断で詰まる論点
技術選定で迷いやすいのは、「Copilot Studioで組むか、Foundry Agent Service+Foundry IQで組むか」の判断です。実装経験からは、以下の基準で切り分けるのが妥当です。
-
Microsoft 365のユーザー体験に統合したい/ノーコード中心
Copilot Studio+Copilot knowledge sources
-
カスタムUI/複雑な業務ロジック/Python主体の開発チーム
Foundry Agent Service+Foundry IQ ナレッジベース
-
既存のAzure AI Searchインデックス資産を活かしたい
Foundry IQ一択(Indexed型で既存インデックスをそのまま流用可能)
-
複数エージェントで同じデータソースを共有したい
Foundry IQ一択(ナレッジベースは共有前提の設計)
Foundry IQ ナレッジベースの料金
Foundry IQの料金は、基盤となるAzure AI SearchとAzure OpenAIの利用料が主軸です。加えて、接続するナレッジソースによってはMicrosoft 365 CopilotライセンスやGrounding with Bing Searchのような別料金・別規約が発生します。以下、2026年4月時点の料金体系の要点を整理します。

料金体系の構成要素
課金は大きく3ブロックに分かれます。
-
Azure AI Search
サービスティア(Free/Basic/Standard S1〜S3/Storage Optimized)ごとのリソース課金。ナレッジベースとインデックス格納の基盤
-
agentic retrieval(Azure AI Search内)
retrieval時のトークン消費ベースで課金。無料トークン枠あり
-
Azure OpenAI
クエリ計画・回答合成で消費するLLMトークン。モデル別の従量課金
-
ナレッジソース側のライセンス・別料金
Remote SharePointの利用にはMicrosoft 365 Copilotライセンスが必要。Grounding with Bing SearchはAzure AI Foundryとは別料金で、データ境界もAzureの保護対象外
Foundry Agent Service自体はエージェントインスタンス単位の追加料金こそかかりませんが、Foundry IQのコネクション利用に関する課金条件は公式料金ページで最新情報を確認してください。
無料枠とPoCコスト
Microsoft LearnとAzure AI Searchの料金ページでは、Azure AI Searchに無料ティア(F0)があり、agentic retrievalには無料トークン割り当てが含まれるとされています。これらを使えば初期の小規模検証は追加コストを抑えて始めやすい構成です(補足としてTech Communityも参照)。
無料枠を超えた場合は、agentic retrievalのトークン消費量とAzure OpenAIモデルの利用量の両方で課金が発生します。具体的な課金レートはAzure AI Search料金ページおよびAzure OpenAI料金ページで都度確認してください(価格は随時更新されるため本記事では具体額を記載しません)。
コスト最適化のポイント
本番運用でコストを抑える実務的な打ち手は以下の通りです。

-
Reasoning Effortの段階運用
全クエリをMediumで回さず、単純な問い合わせはLow以下に落とす
-
LLMモデル選定
クエリ計画には軽量モデル、アンサー合成には上位モデルといった役割分担を検討する。実クエリでの品質計測をもとに段階的に選ぶ
-
Remote型ソースの絞り込み
クエリごとに外部API呼び出しが走るため、頻度の高いソースはIndexed型へ寄せる
-
indexerスケジュールの最適化
日次更新で足りるデータをリアルタイム同期にしない
月額コストは接続ソース数・クエリ量・選択モデルで大きく変動するため、具体額はPoCで実測するのが現実的です。PoC時の試算と本番運用後の再試算を、3ヶ月単位で見直すサイクルを組むのが安全です。
まとめ
本記事では、Foundry IQ ナレッジベースの仕組み・構成要素・作り方・エージェント接続・セキュリティ・類似機能との違い・料金までを、2026年4月時点のMicrosoft公式ドキュメントに基づいて整理しました。
要点を振り返ると以下の3つです。
- 複数エージェントで共通のナレッジ層を再利用する「集約型RAG」としての設計思想が、従来のシングルショットRAGや自前構築との最大の違い
- 設計上の核はKnowledge Base/Knowledge Sources/Agentic Retrievalの3層と、Retrieval Reasoning Effortによるコスト/品質のトレードオフ設計
- 実装経路はMicrosoft FoundryポータルとPython SDK/REST APIの2系統で、MCP経由のエージェント接続が本番構成の標準
次の一歩としては、まずMicrosoft Foundryポータルで無料枠を使い、Azure Blob Storageに社内サンプル文書を入れてMinimal設定のナレッジベースを1つ作ってみてください。1つ動かせば、Reasoning Effortの切り替えによる挙動変化や、MCP接続時の権限設計のポイントが体感的に理解できます。そこから、SharePoint Remoteソースの追加、複数エージェントでの共有、Purview機密ラベル適用など、段階的にスコープを広げるのが現実的です。
全社展開を検討する段階では、ACL同期の運用設計、Reasoning Effortのコスト上限、エージェント間のナレッジベース共有ルールをガバナンスチームと事前に握る必要があります。設計前提を整理したうえで、AI Agent HubのようなAzureテナント内で完結するAI Agent運用基盤と組み合わせると、PoCから本番運用までの橋渡しがスムーズになります。
Foundry IQのナレッジベースを業務運用基盤に落とし込むために

Azureテナント内で完結するAIエージェント基盤を設計・構築支援
Foundry IQのナレッジベースで検索エージェントを動かせても、社内システム連携・権限統制・実行ログ管理まで含めた運用設計が本番移行のハードルになります。AI Agent Hubは、顧客のAzureテナント内(Managed Applications)でFoundry・Fabricを基盤にAIエージェントを内製化するためのプラットフォームです。サービスページで全体像をご確認ください。







