この記事のポイント
 OKFはGoogle Cloudが2026年6月(GitHub初期公開12日/ブログ発表13日)にApache 2.0で公開したベンダー中立の知識フォーマット仕様で、Markdown+YAML frontmatterだけで成立
OKFはGoogle Cloudが2026年6月(GitHub初期公開12日/ブログ発表13日)にApache 2.0で公開したベンダー中立の知識フォーマット仕様で、Markdown+YAML frontmatterだけで成立- type必須・他は推奨5フィールド(title/description/resource/tags/timestamp)のみという最小規約で、Notion/Obsidian/Gitに馴染む設計
- Karpathy LLM Wikiパターンの組織版であり、CLAUDE.md/AGENTS.md/Agent Skills(手順書)とは目的が異なる「データカタログ向け中間言語」
- MCP・RAG・Iceberg・dbt Semantic Layer・OpenMetadataとは補完関係で、置き換えではなく既存スタックの隙間を埋めるレイヤー
- v0.1 Draftは仕様1ページの最小スタートでtype値レジストリ未整備、参考実装は実質4フィールド要求と仕様との差分があり、BigQuery導入企業から小規模試作で始めるのが現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Open Knowledge Format(OKF)は、Google Cloudが2026年6月13日にブログで発表した、AIエージェント向けに組織内の知識を記述するためのベンダー中立なオープン仕様です(GitHubでの初期公開は2026年6月12日)。
Markdownファイル+YAML frontmatterだけで構成され、特定のSDK・ランタイム・カタログ製品に縛られない「持ち運べる知識フォーマット」を目指しています。
背景には、Andrej Karpathyが提唱した「LLM Wiki」パターンが個人レベルで広がり、組織向けの共通フォーマットが求められていたという文脈があります。
本記事では、OKFの仕様・3つの設計原則・Karpathy LLM Wikiとの関係・公開された参考実装・MCP/RAG/Iceberg/dbt Semantic Layerなど隣接技術との位置関係・v0.1 Draftが抱える限界、そしてBigQuery/Microsoft Fabric/Databricks別の導入判断軸までを、Google Cloudの一次情報とGitHub上の参考実装コードで体系的に解説します。
目次
YAML frontmatter——必須は type 1つだけ
Minimally opinionated——最小限の規約だけを置く
Producer/Consumer independence——書き手と読み手を切り離す
Format, not platform——プラットフォームではなくフォーマット
BigQuery enrichment agent(プロデューサー側)
Apache Iceberg・dbt Semantic Layerとの関係——データ本体・メトリクスDSLとの分業
公式に確認できる限界(type値レジストリ・conformance)
OKFを導入する場合の判断軸(BigQuery/Microsoft Fabric/Databricks別)
Microsoft Fabric導入企業——持ち出し用として併用
Open Knowledge Format(OKF)とは
Open Knowledge Format(OKF)は、Google Cloudが2026年6月に公開したベンダー中立のオープンな知識フォーマット仕様です。
組織内に散らばる「テーブル定義・メトリクス・データセット説明・運用Playbook」といった知識を、特定のクラウドベンダーやデータカタログ製品に縛られない形で記述・共有・持ち運べるようにするのが目的で、Markdownファイル+YAML frontmatterだけで完結します。
新しいランタイム・SDK・スキーマレジストリは不要で、Gitリポジトリで管理し、Notion・Obsidian・MkDocsなどのMarkdownツールでそのまま読める設計です。
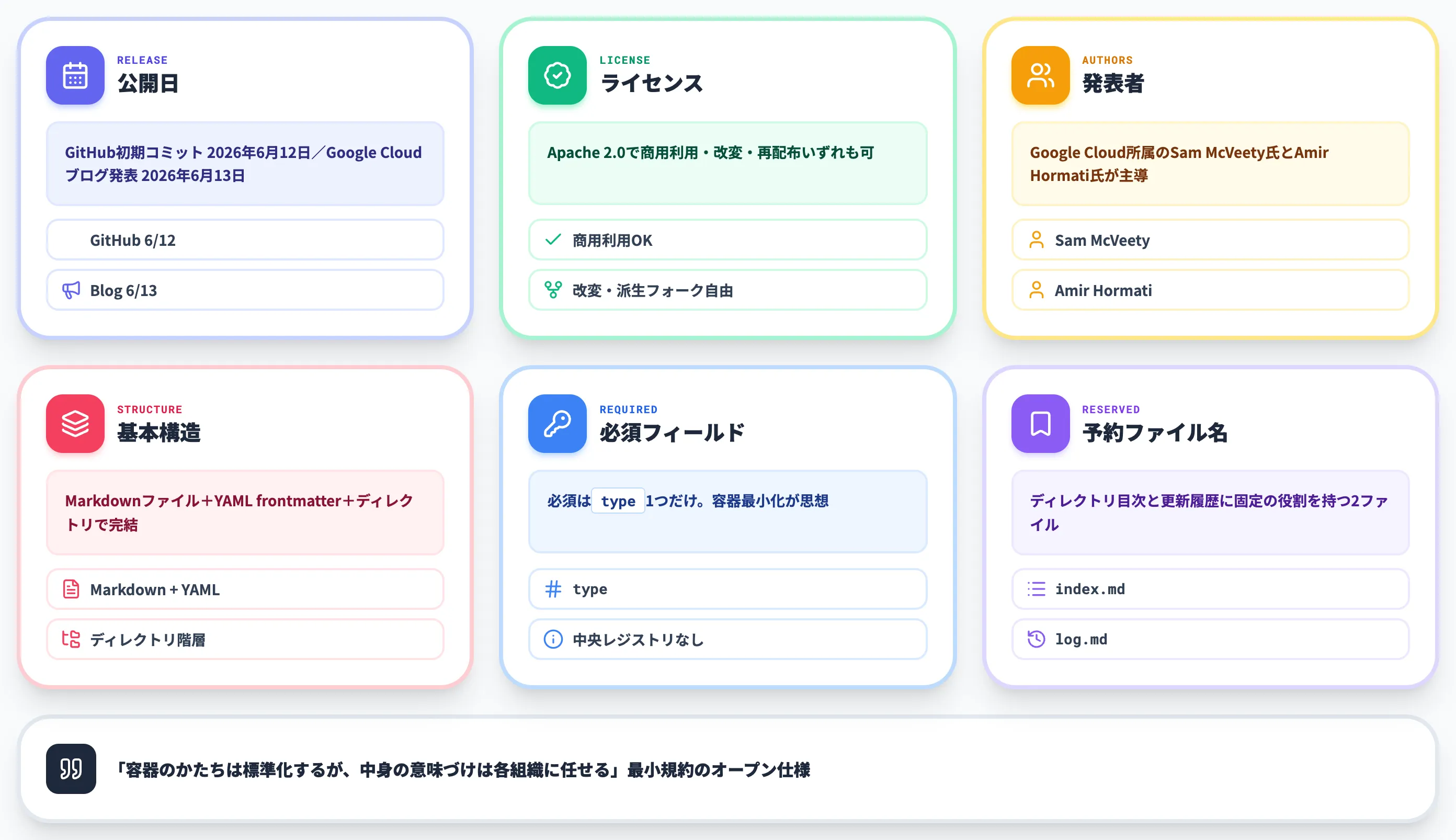
以下の表で、OKF v0.1 Draftの基本属性をまとめました。
| 項目 | 内容 |
|---|---|
| 仕様バージョン | v0.1 Draft(出発点・進化前提) |
| 公開日 | GitHub初期コミット 2026年6月12日/Google Cloudブログ発表 2026年6月13日 |
| ライセンス | Apache 2.0 |
| 発表者・執筆者 | Sam McVeety、Amir Hormati(いずれもGoogle Cloud) |
| リポジトリ | GoogleCloudPlatform/knowledge-catalog(okf/サブディレクトリ) |
| 基本構造 | Markdownファイル+YAML frontmatter+ディレクトリ |
| 必須フィールド | type のみ |
| 推奨フィールド | title / description / resource / tags / timestamp |
| 予約ファイル名 | index.md(ルート要約)/log.md(更新履歴) |
| 参考実装 | BigQuery enrichment agent/静的HTML visualizer |
| サンプルバンドル | GA4 e-commerce/Stack Overflow/Bitcoin |
「必須が1フィールドだけ」という割り切りが、OKFの設計思想を一言で示しています。「容器のかたちは標準化するが、中身の意味づけは各組織に任せる」という、最低限の共通項だけを定義したフォーマットです。
仕様の詳細・3つの設計原則・参考実装・隣接技術との関係は、後段のセクションで順に整理します。

OKFが解決する「組織知識の散在問題」
なぜ今、Googleがわざわざ新しい知識フォーマットを提案したのか。背景には、AIエージェントを業務に組み込もうとすると毎回ぶつかる「コンテキスト集約問題」があります。
組織内の知識は、メタデータカタログ(Purview・Unity Catalog等)、社内Wiki(Confluence・Notion)、共有ドライブのドキュメント、コードベースのコメント、そしてシニアエンジニアの頭の中、と複数の場所に分散しています。
エージェントが「週次アクティブユーザーをどう計算する?」のような業務質問に答えるには、これら散在した知識を毎回かき集める必要があり、組織ごと・チームごとに同じ作業を独自に作り直しているのが2026年時点の実情です。
この問題への一つの解答として、Andrej Karpathy氏が公開した「LLM Wiki」のGitHub Gistが広く参照されており、OKFはこのLLM Wikiパターンを組織向けに標準化したものとして位置づけられます(パターンの中身は後段の「Karpathy『LLM Wiki』とOKFの関係」セクションで詳しく扱います)。
「context-assembly problem」の本質
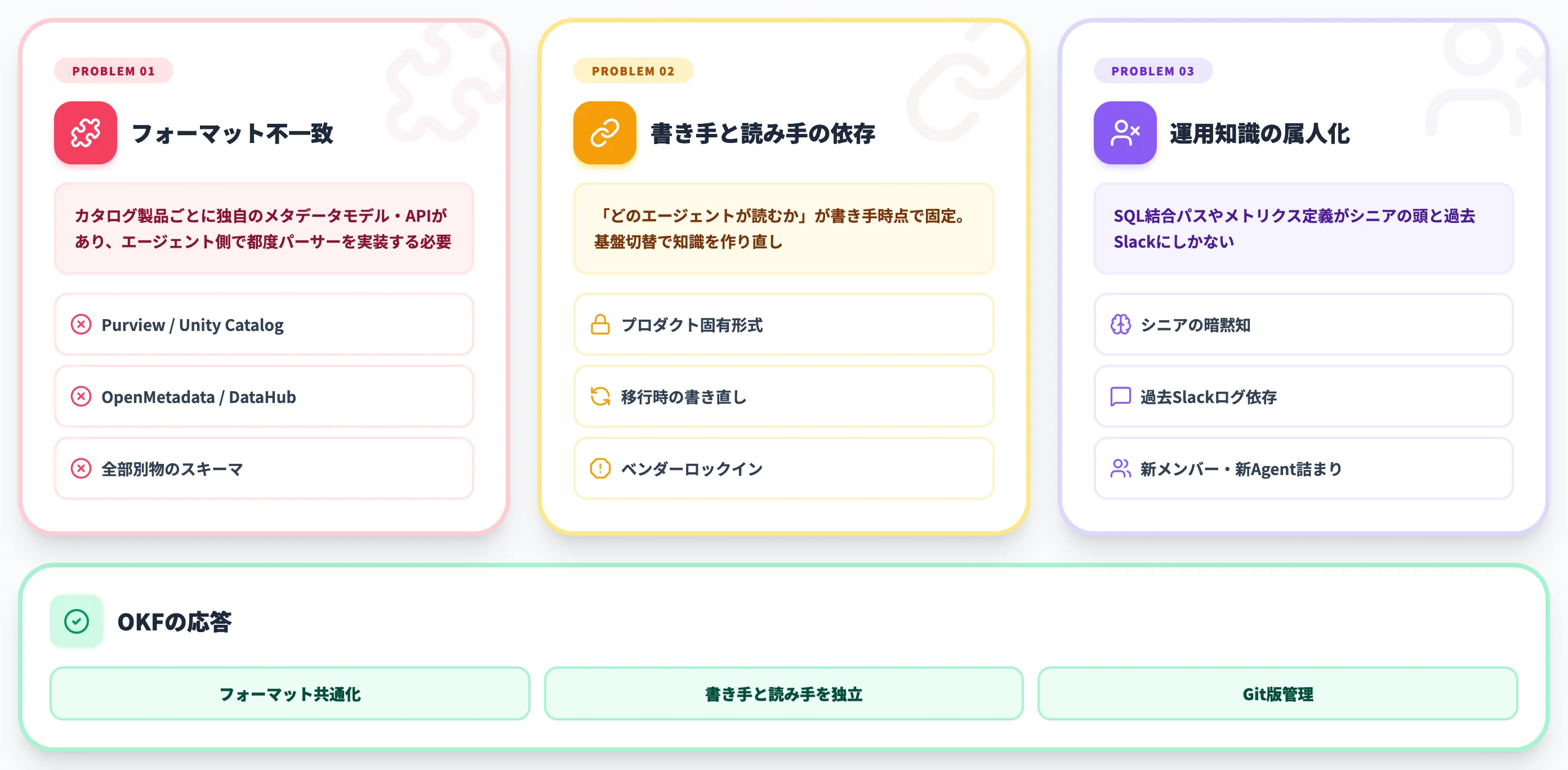
組織が毎回ぶつかるコンテキスト集約問題の構造を整理すると、以下の3点に集約されます。
-
知識のフォーマット不一致
カタログ製品ごとに独自のメタデータモデル・APIがあり、エージェント側で都度パーサーを実装する必要がある。Purview・Unity Catalog・OpenMetadata・DataHubで全部別物。
-
書き手と読み手の依存関係
「ここに書いた知識をどのエージェントが読むか」がプロデューサー時点で決まってしまう。あとから別のエージェント基盤に切り替えると、知識を作り直しになる。
-
属人化された運用知識
SQLの結合パスやメトリクス計算の「本当の定義」が、シニアエンジニアの頭の中とSlackの過去ログにしかない状態。新メンバー・新エージェントの双方が同じ場所で詰まる。
OKFはこの3点に対して、「フォーマットを共通化する」「書き手と読み手を独立させる」「Gitで運用知識をコードとして版管理する」という方向性で応答します。
ただしOKFが解決するのは「フォーマット」のレイヤーだけで、知識の中身の質や運用フローまでは規定しません。組織側の運用設計とセットで初めて効果が出るタイプの仕様です。
OKFバンドルの構造とフィールド仕様
OKFの実体は、Markdownファイルを集めた1ディレクトリ=バンドルです。1つのバンドルは独立したGitリポジトリでもよいし、大きなリポジトリのサブディレクトリでもよく、tarballで配布することもできます。
ここでは公式のSPEC.mdに沿って、バンドルの構造・必須フィールド・予約ファイル名を順に整理します。
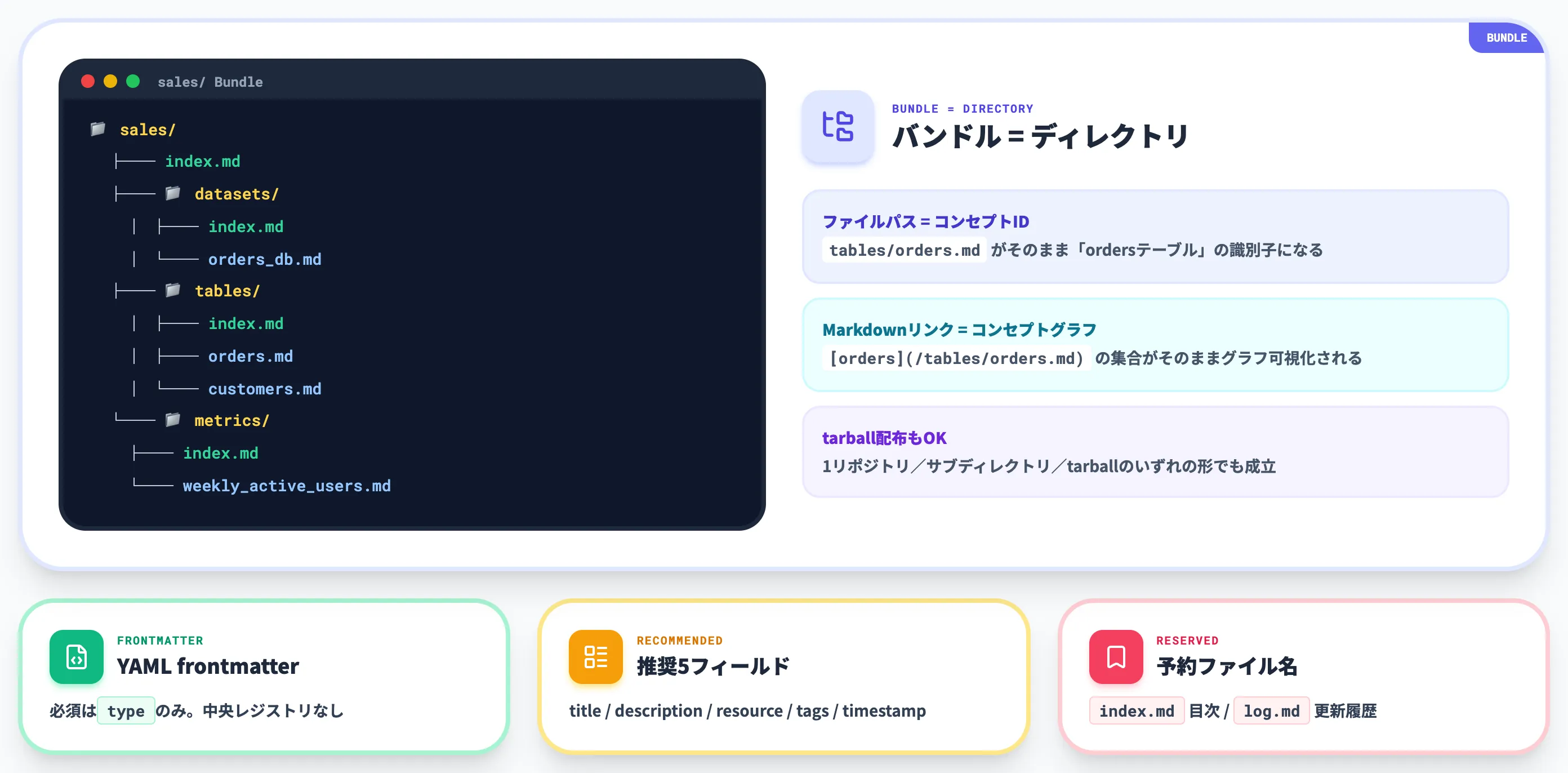
バンドルのディレクトリ構造の例
Google Cloud公式ブログで示されているバンドル例は、たとえば営業ドメインなら以下のような構造を取ります。
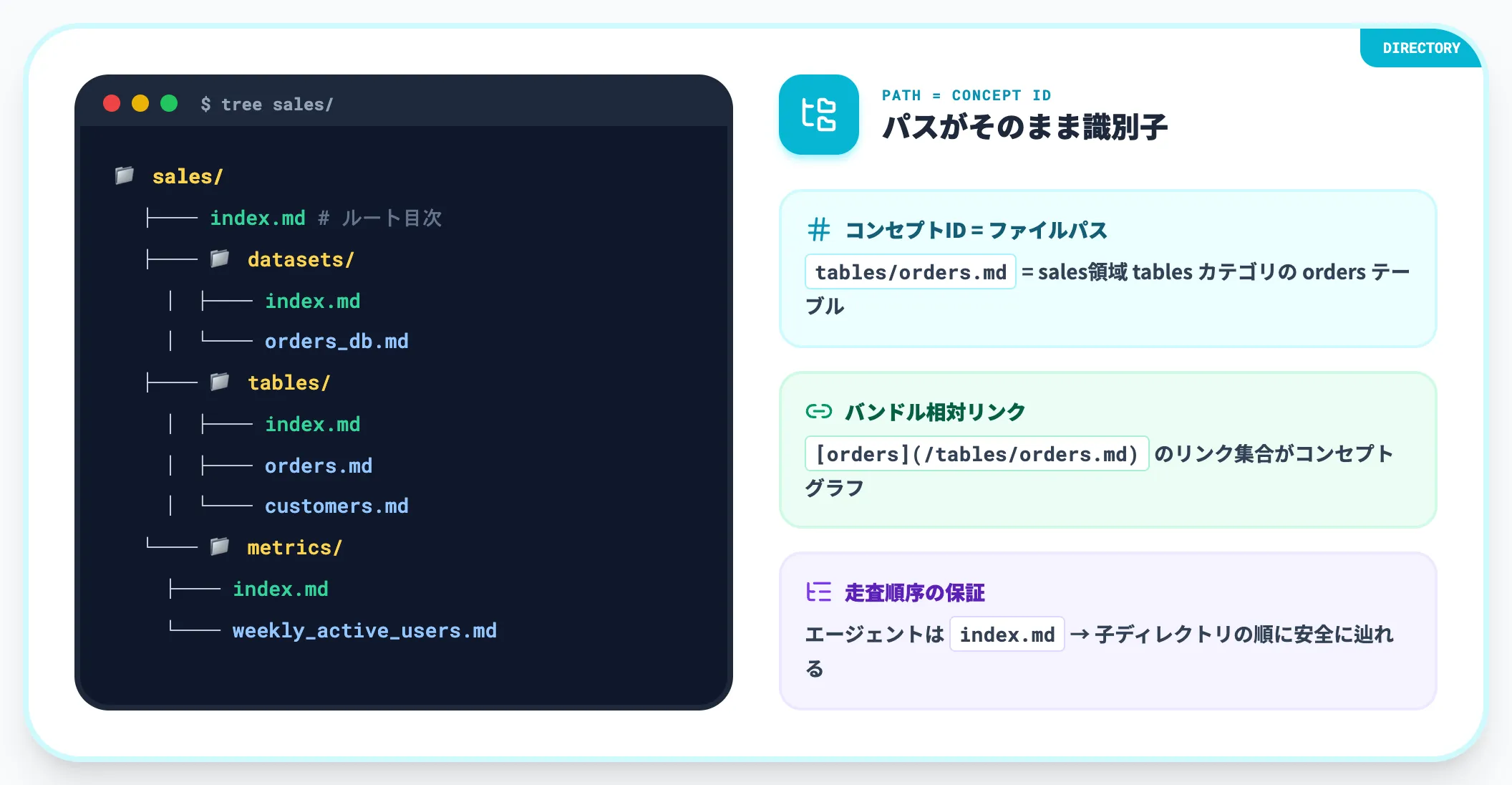
sales/
├── index.md
├── datasets/
│ ├── index.md
│ └── orders_db.md
├── tables/
│ ├── index.md
│ ├── orders.md
│ └── customers.md
└── metrics/
├── index.md
└── weekly_active_users.md
ファイルパスがそのまま概念の識別子(コンセプトID)になる点が特徴です。tables/orders.md であれば「sales領域のtablesカテゴリのordersテーブル」を一意に指し、Markdown本文中のリンクは [orders](/tables/orders.md) のようにバンドル相対パスで書きます。
このリンクの集合がそのままコンセプトグラフになり、参考実装の静的HTMLビジュアライザーはこのグラフを可視化します。
YAML frontmatter——必須は type 1つだけ
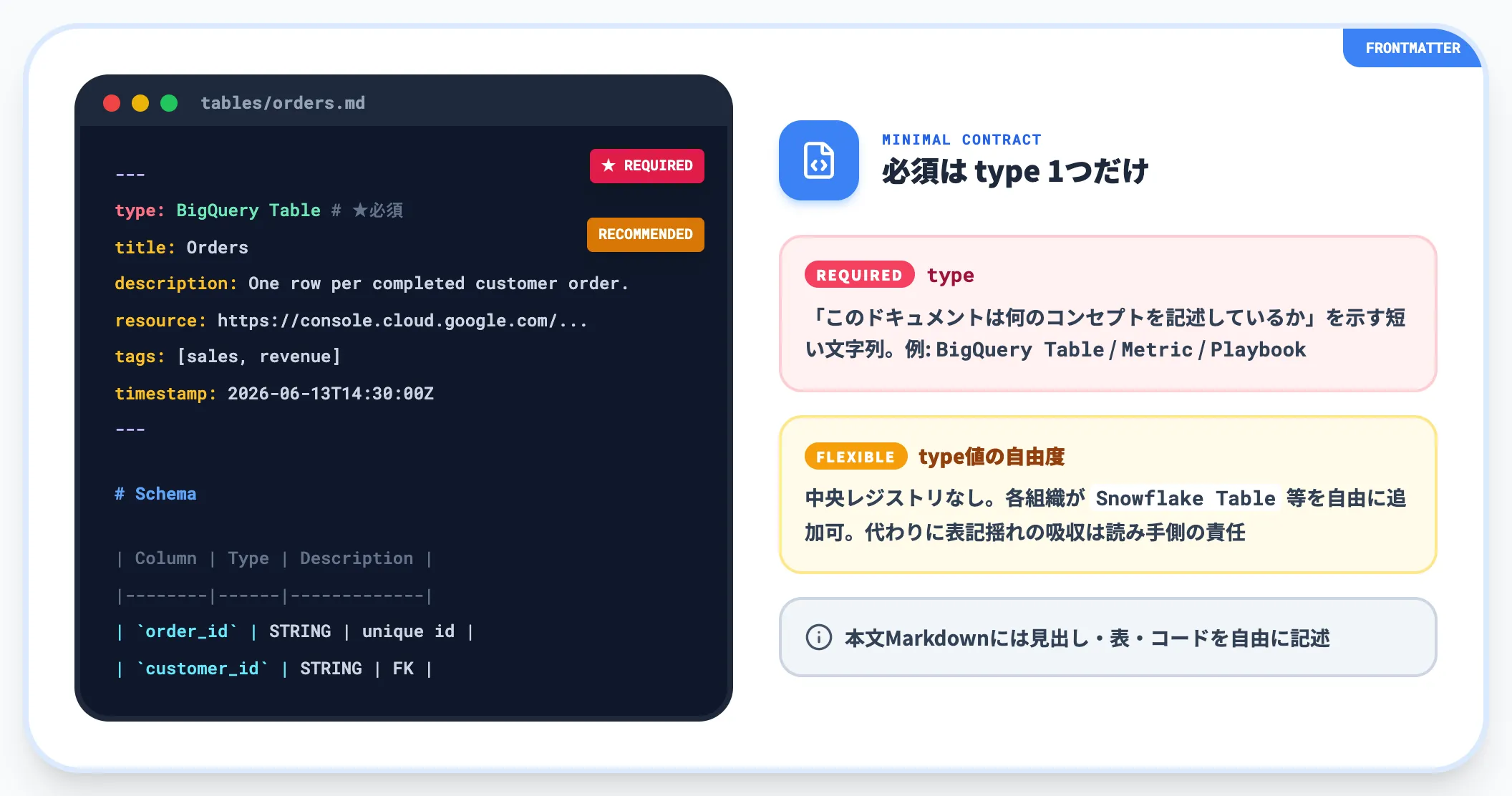
各Markdownファイルの先頭にはYAML frontmatterを置き、最低限の構造化メタデータをここで宣言します。OKF v0.1の必須フィールドはtype 1つだけです。
たとえば tables/orders.md であれば以下のように書きます。
---
type: BigQuery Table
title: Orders
description: One row per completed customer order.
resource: https://console.cloud.google.com/bigquery?p=acme&d=sales&t=orders
tags: [sales, revenue]
timestamp: 2026-06-13T14:30:00Z
---
# Schema
| Column | Type | Description |
|--------|------|-------------|
| `order_id` | STRING | Globally unique order identifier. |
| `customer_id` | STRING | FK to [customers](/tables/customers.md). |
type フィールドは「このドキュメントが何のコンセプトを記述しているか」を示す短い文字列で、BigQuery Table ・ API Endpoint ・ Metric ・ Playbook ・ Reference などの値が公式ドキュメントの例に登場します。
ただしtype値の中央レジストリは存在しません。組織ごとに Snowflake Table ・ Fabric Lakehouse Table ・ dbt Model のように自由に追加できる代わりに、複数組織のバンドルを横断して読むエージェントは値の揺れ(BigQuery Table 対 bigquery_table 対 table など)に自力で対応する必要があります。
推奨フィールドと予約ファイル名
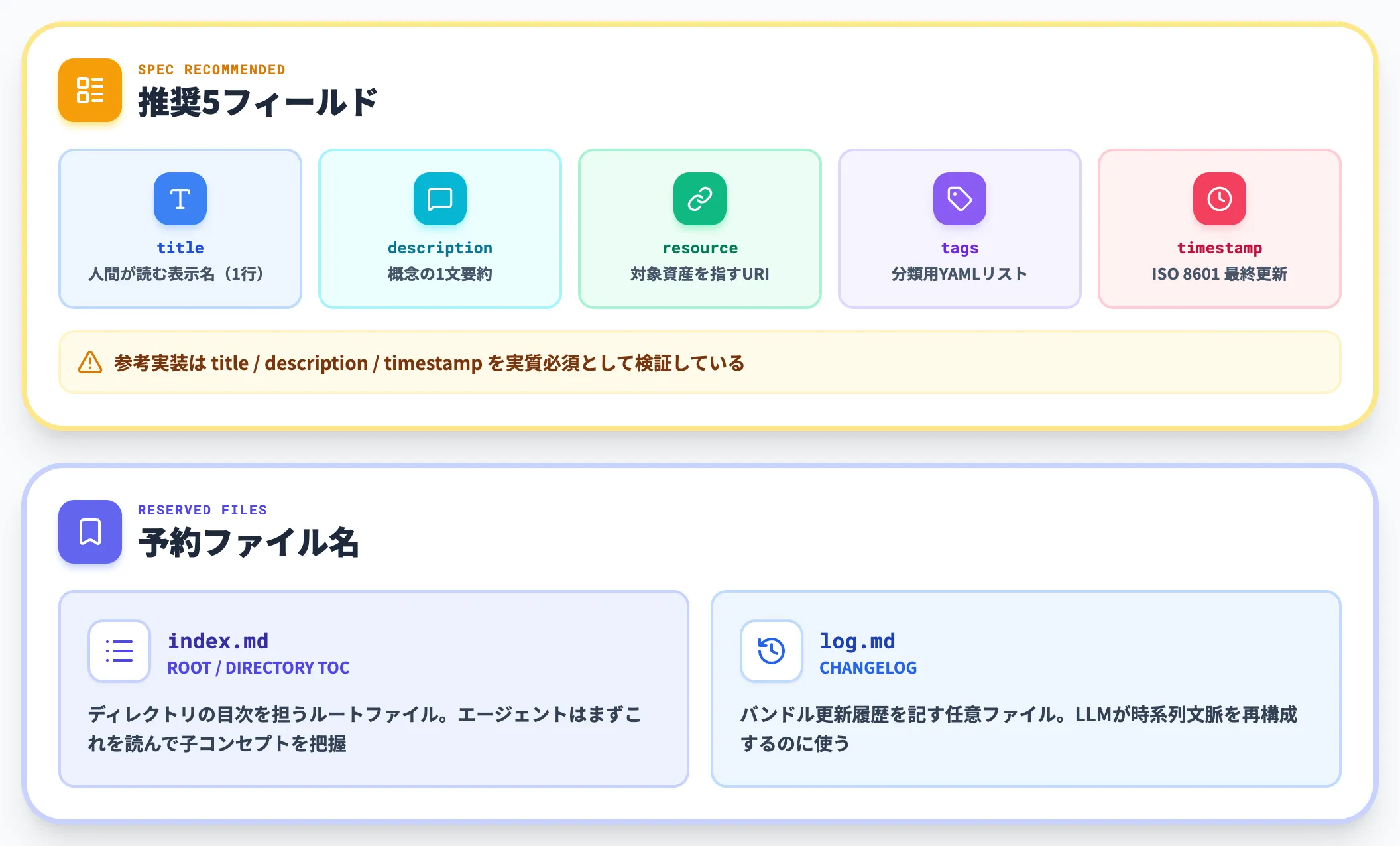
仕様で必須としているのは type だけですが、SPEC.mdは推奨5フィールドを明示しています。
| フィールド | 内容 |
|---|---|
| title | 人間が読む表示名(1行) |
| description | 概念の1文要約 |
| resource | 対象資産を指すURI(BigQueryコンソールのURL等) |
| tags | 分類用のYAMLリスト |
| timestamp | ISO 8601形式の最終更新日時 |
このうち title ・ description ・ timestamp はGoogleが公開した参考実装が実質的に必須要求しており、後述の限界セクションで詳しく触れます。
予約ファイル名は2つで、両方ともディレクトリ単位の運用情報を担います。
-
index.md
ディレクトリの「目次」を担うルートファイル。バンドルをスキャンするエージェントはまずこのファイルを読み、子コンセプトの概要を把握する。
-
log.md
バンドルの更新履歴を記す任意ファイル。Karpathy LLM Wikiにおける「変更ログ」と同じ役割で、LLMが時系列の文脈を再構成するのに使う。
このルールに従えば、消費者側のエージェントは初見のバンドルでも index.md → 子ディレクトリ → 個別コンセプトという順序で安全に走査できます。
OKFを支える3つの設計原則
OKFが「単なるMarkdownの命名ルール」で終わらず、フォーマット仕様として成立しているのは、明確に言語化された3つの設計原則があるからです。
Google Cloud公式ブログとSPEC.mdの両方で明示されており、この3原則を押さえると「OKFがやらないこと」も同時に理解できます。

Minimally opinionated——最小限の規約だけを置く
1つ目の原則は「最小限の意見しか持たない」です。
仕様で必須にするのはtypeフィールドだけで、それ以外のフィールド名・値・本文の構造・章立て・テーブル形式はプロデューサーに完全に委ねる設計になっています。これは「最初から完璧な共通モデルを定義する」OpenMetadataやDataHubのアプローチとは正反対の発想です。
なぜ最小化したかというと、最初から細かく規定すると自社の独自要件を表現できなくなるという現実があるからです。BigQueryユーザーはBigQuery固有のメタデータ(partition情報・clustering列)を載せたいし、Snowflakeユーザーは別の項目を載せたい。仕様が緩いほど、自社の知識を素直に書ける構造になります。
Producer/Consumer independence——書き手と読み手を切り離す
2つ目の原則は「プロデューサーとコンシューマーの独立性」です。
OKFバンドルを生成する側(プロデューサー)と、それを読んで利用する側(コンシューマー)が、お互いを知らなくても動くように設計されています。プロデューサーはGoogle Cloudのenrichment agentでもいいし、自社内製のスクリプトでもいい。コンシューマーはClaude・ChatGPT・Geminiでもいいし、自社のRAGパイプラインでもいい。
この独立性を担保するため、SPEC.mdは消費者側に「未知のtype値・追加キー・壊れたリンク・オプションフィールドの欠落を理由に拒否してはならない」と明示しています。コンシューマーは寛容に振る舞い、知らないフィールドは無視するだけで、エラーで止まらない設計が義務付けられています。
Format, not platform——プラットフォームではなくフォーマット
3つ目の原則は「プラットフォームではなくフォーマット」です。
OKFは特定のクラウド・データベース・LLMベンダーに依存しません。Google Cloudが主導していますが、仕様自体はAWS・Azure・Snowflake・Databricksなど別ベンダー環境でもそのまま使えます。実体はテキストファイルなので、Gitで管理し、Slack・メール・USBメモリで運ぶことすらできます。
これは裏を返すと「OKFを実装した瞬間に何かが便利になる」わけではないことを意味します。フォーマットを採用するだけでは、データカタログとしての検索・ACL・系統管理は一切提供されません。仕様の上に何を載せるかは各組織・各ツールに完全に委ねられています。
3原則がもたらす実務的な意味
3原則をまとめると、OKFは「最低限の共通項だけを定義した持ち運び容器」というポジショニングを意識的に取っています。
OpenMetadata・DataHubのような「リッチなメタデータモデル+検索UI+API」型の製品とは設計思想がそもそも違います。比較するレイヤーが違うため「OKFはOpenMetadataの代わりになるか」という問いは少し的外れで、「OpenMetadataから知識を取り出して別ベンダーに持って行くときの中間言語として使えるか」という問いの方が実態に近くなります。
Karpathy「LLM Wiki」とOKFの関係
OKFの思想的なルーツは、Andrej Karpathy氏が公開した「LLM Wiki」のGitHub Gistに直接つながります。
ただし「LLM Wiki」と一口に言っても、CLAUDE.md・AGENTS.md・Anthropic Agent Skills・OpenAI Codex Agent Skills・GitHub Copilot Agent Skillsなど、似たような文脈ファイルが乱立しているのが2026年の現状です。
ここでは、OKFがこれらとどう違うかを整理します。
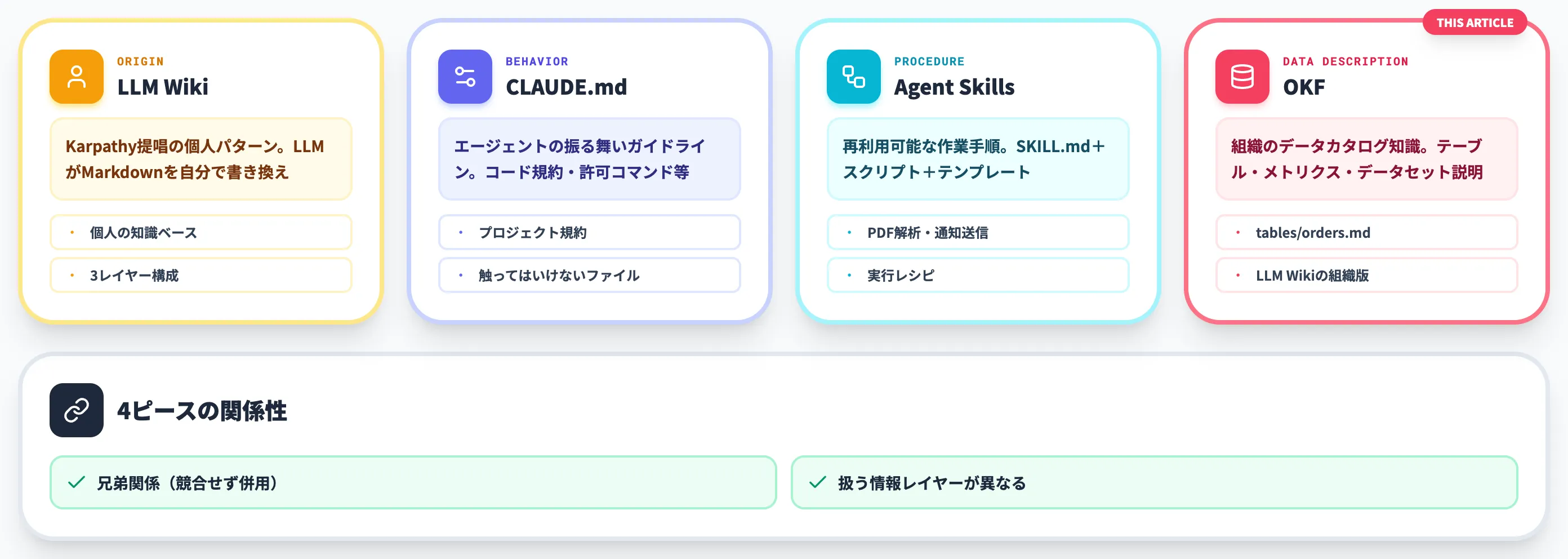
Karpathy LLM Wikiの3レイヤー構成

Karpathy氏が示したのは、ベクトルDB・RAGパイプラインを使わずに、LLM自身がMarkdown知識ベースを書き換えながら維持するというパターンです。
Gist本文では3レイヤー構成で語られており、生データを置く raw sources、LLMがコンセプトごとに書き貯める the wiki、書き方のルールを与える the schema(CLAUDE.md/AGENTS.md相当)の3層で運用します。新しい情報が入るたびにLLMがthe wiki配下のMarkdownを更新し、関連ファイル間にリンクを張ります。「探す」のではなく「読み込み済みの構造化された知識を直接参照する」スタイルで、Karpathy氏自身は個人の研究ノートやAI論文の要約管理に使っている例を示しました。
公開後、コミュニティでは「RAGの代替か」「補完か」という議論が広がり、GitHubにも多数の派生実装が並ぶ反響となりました。OKFはこの流れを正面から受け止め、個人パターンを組織向けに標準化した最初のメジャーフォーマット提案になります。
CLAUDE.md・AGENTS.mdとの違い

CLAUDE.md・AGENTS.mdは、Claude Code・各種AIエージェントがプロジェクトに入る前に読む「エージェント向けの指示書」です。コード規約・許可されたコマンド・プロジェクトの目的・触ってはいけないファイル、といった「振る舞いのガイドライン」を書きます。
OKFはこれとは別レイヤーで、エージェントが業務質問に答えるために参照する「データの記述」を担います。役割を整理すると以下のとおりです。
| ファイル種別 | 主な役割 | 書く内容 |
|---|---|---|
| CLAUDE.md / AGENTS.md | エージェントの振る舞い設定 | コード規約・許可コマンド・プロジェクトの目的・前提知識 |
| OKFバンドル | 組織データの記述 | テーブル定義・メトリクス計算式・ダッシュボード説明 |
CLAUDE.mdが「このプロジェクトをどう扱うべきか」を伝えるのに対して、OKFは「自社にはこういうデータがあり、こう繋がっている」を伝えます。両方を併用して、CLAUDE.mdの中で「データの詳細は okf/sales/ を参照」と誘導するのが自然な使い方です。
Agent Skillsとの違い

2025年12月にAnthropicがオープン標準として公開したAgent Skills(SKILL.md規約)、OpenAI Codex Agent Skills、GitHub Copilot Agent Skillsは、いずれもエージェントの「再利用可能な手順・能力」を記述する仕様です。
Agent Skillsの典型例は、「PDFを解析してテーブルを抽出する」「Slackチャンネルに通知を投げる」「マーケティング素材を生成する」といった実行可能な作業のレシピで、SKILL.mdに加えて補助スクリプト・テンプレート・サンプルデータを同梱できます。
OKFとAgent Skillsの違いを整理すると以下のようになります。
| 観点 | OKF | Agent Skills |
|---|---|---|
| 載せるもの | データの説明(テーブル・メトリクス・データセット) | 作業手順(スクリプト・テンプレ・実行レシピ) |
| 主語 | 「このordersテーブルは何か」 | 「PDFをどう処理するか」 |
| 実行可能性 | 静的な知識(schema・説明) | スクリプト同梱・呼び出し前提 |
| 主な読み手 | エージェント+人間(カタログ参照) | エージェントだけ(実行手順として) |
| 典型的ファイル | tables/orders.md |
skills/pdf-extract/SKILL.md |
両者は競合する仕様ではなく、棲み分けが明確な兄弟関係です。実務では「データの定義はOKF、それを処理する手順はAgent Skills」という併用パターンが自然になります。Agent SkillsのSKILL.mdから okf/sales/ 配下のコンセプトを参照する、といった連携も技術的には可能です。
「LLM Wiki」パターンの組織版としてのOKF
ここまでを整理すると、OKFの立ち位置は次のように説明できます。
- Karpathy LLM Wikiは個人の知識ベースとして広がった
- CLAUDE.md・AGENTS.mdはエージェントの振る舞い設定を担う
- Agent Skillsは再利用可能な作業手順を記述する
- OKFはこれらと並ぶレイヤーで、組織のデータカタログ知識を持ち運べる形にする
つまりOKFは「LLM Wikiの組織版」であると同時に、CLAUDE.md・Skillsとは扱う情報が異なる、ということになります。AI総研の支援現場でも、エージェント基盤を組み始めた企業から「CLAUDE.mdは書いたが、データの説明をどこに置くか」という相談が増えており、OKFはこの空白を埋めるピースになる可能性があります。

公開された参考実装と3つのサンプルバンドル
仕様だけが公開されても採用は進まないため、Googleは動く参考実装と3つのサンプルバンドルを同時公開しました。仕様を読まなくても、リポジトリをcloneして手を動かせばOKFの世界観が掴める構成になっています。
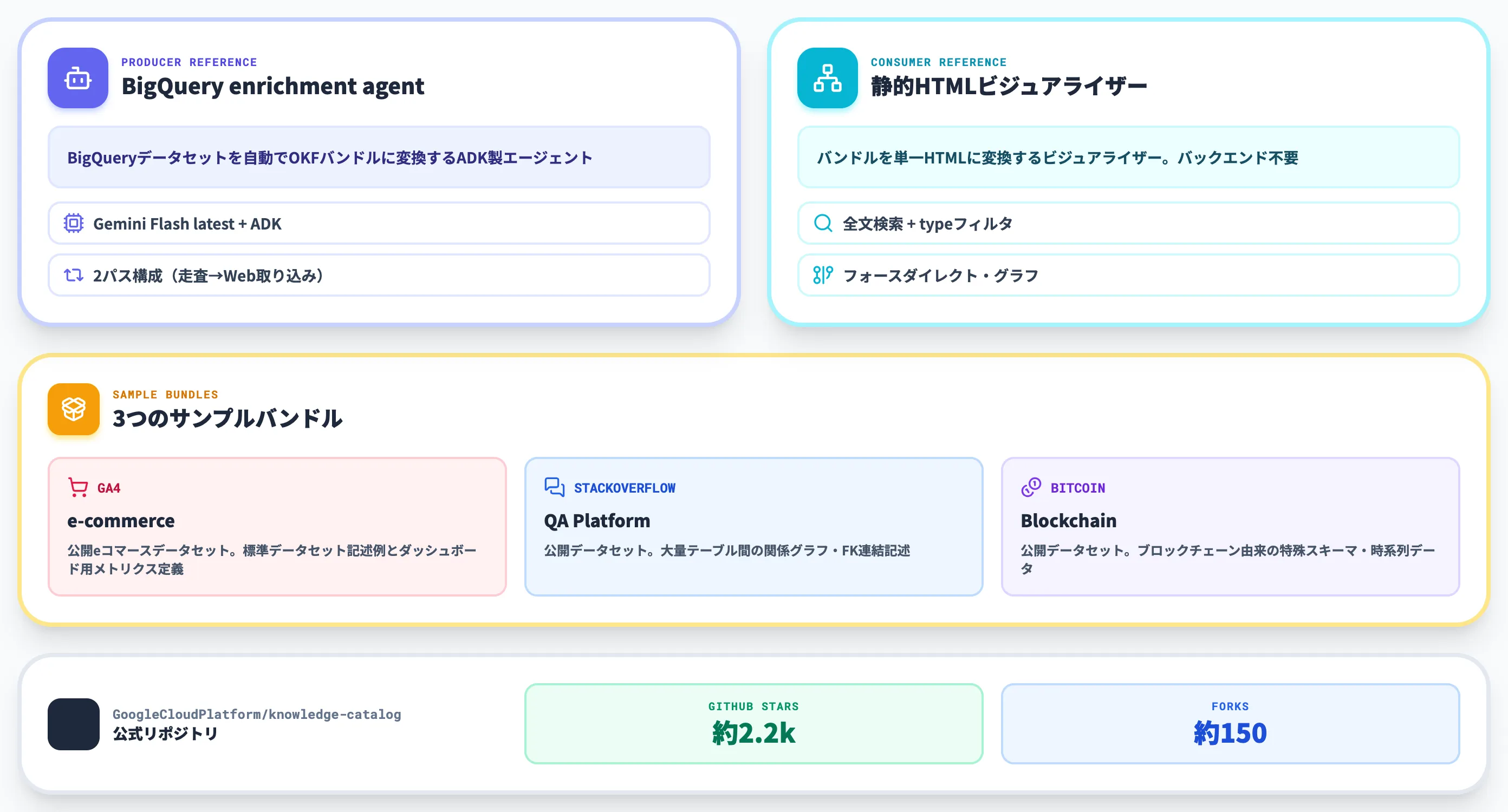
GitHubのGoogleCloudPlatform/knowledge-catalogリポジトリは2026年6月時点でスター約2.2k・フォーク約150と、発表直後にしては勢いのある立ち上がりを見せています。Pythonが約50%・TypeScriptが約30%・HTMLが約20%の構成で、参考実装はPython、ビジュアライザーはTypeScript+HTMLで書かれています。
BigQuery enrichment agent(プロデューサー側)
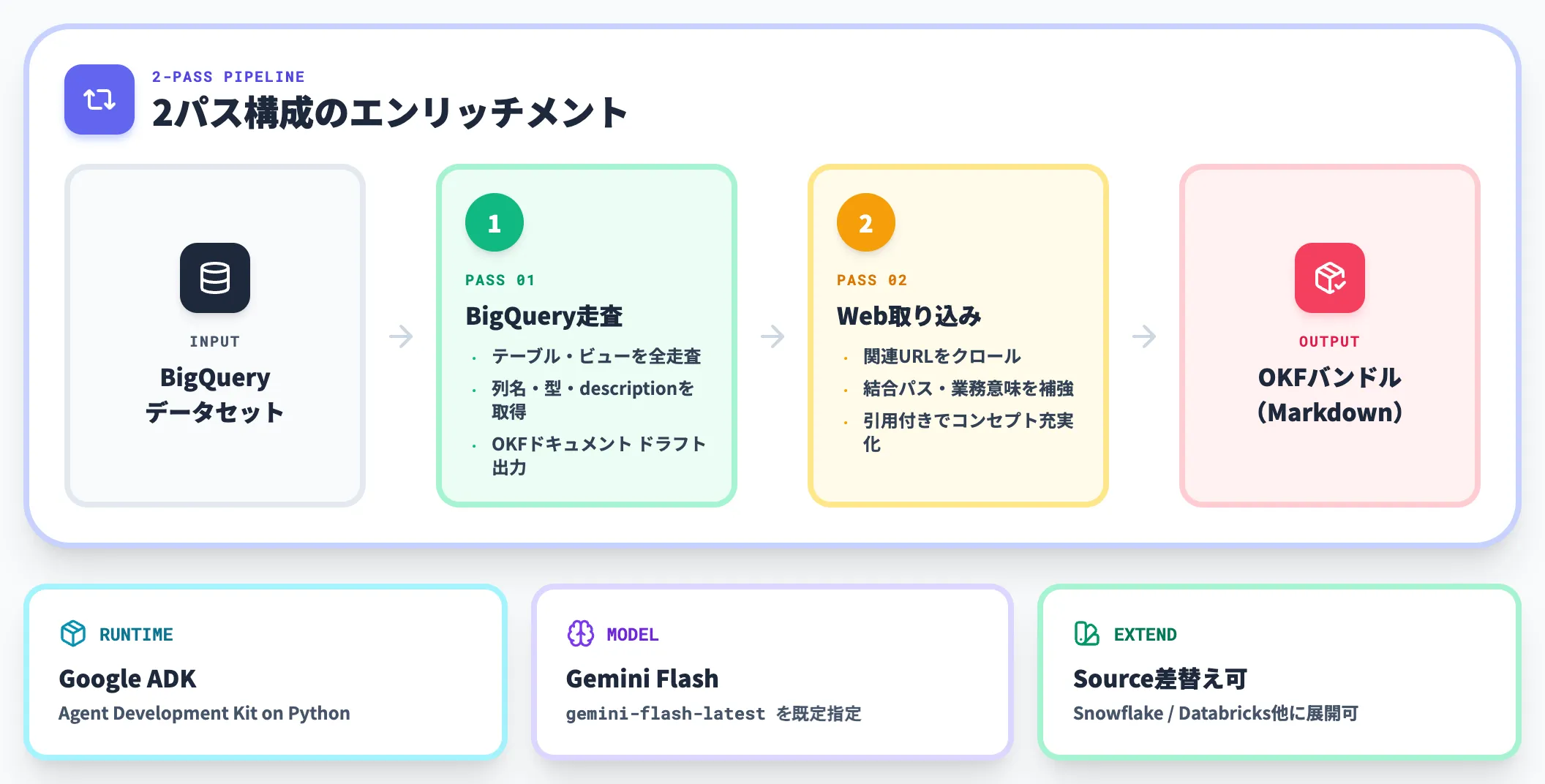
1つ目の参考実装は、BigQueryデータセットを自動でOKFバンドルに変換するエンリッチメントエージェントです。okf/src/enrichment_agent/ 配下にPythonで実装されています。
実装はGoogle Agent Development Kit(ADK)とGeminiモデルをベースにしており、デフォルトモデルは gemini-flash-latest が指定されています。エージェントの動作は2パス構成になっています。
-
第1パス: BigQuery走査パス
指定されたBigQueryデータセット配下の全テーブル・ビューを走査し、BigQueryクライアントのテーブルメタデータAPI(list_tables()/get_table())から列名・型・既存descriptionを取得。各テーブルにつき1つのOKFコンセプトドキュメント(Markdown+frontmatter)をドラフト出力する。
-
第2パス: Web取り込みパス
第1パスで生成したドキュメントを起点に、関連する公式ドキュメント・社内Wiki等のURLをクロール。スキーマの背景・結合パス・業務的な意味づけを引用付きで追記し、コンセプトを充実させる。
このエージェント自体がOKFのプロデューサー側のリファレンスになっており、「自社でも似たような変換パイプラインを書けばいい」という参考実装になっています。BigQueryから他のDB(Snowflake・Databricks等)への置き換えも、Sourceインターフェース1つを実装すれば可能な設計です。
静的HTMLビジュアライザー(コンシューマー側)
2つ目の参考実装は、バンドルを単一のHTMLファイルに変換するビジュアライザーです。
visualize サブコマンドを実行すると、バンドル内の全コンセプトとリンクを埋め込んだ1枚のHTMLファイルが生成されます。バックエンド不要・インストール不要で、ファイルをブラウザで開くだけでフォースダイレクトのグラフが表示されます。
主な機能は以下のとおりです。
- type別の色分け(参考実装の現行コードでは BigQuery Dataset 紫・BigQuery Table 青・Reference 緑・未定義type グレーが固定色として割り当てられている)
- 全文検索とtypeフィルタ
- バックリンク表示(このコンセプトを参照している他コンセプト一覧)
- 複数のレイアウト(フォースダイレクト・階層・円形等)
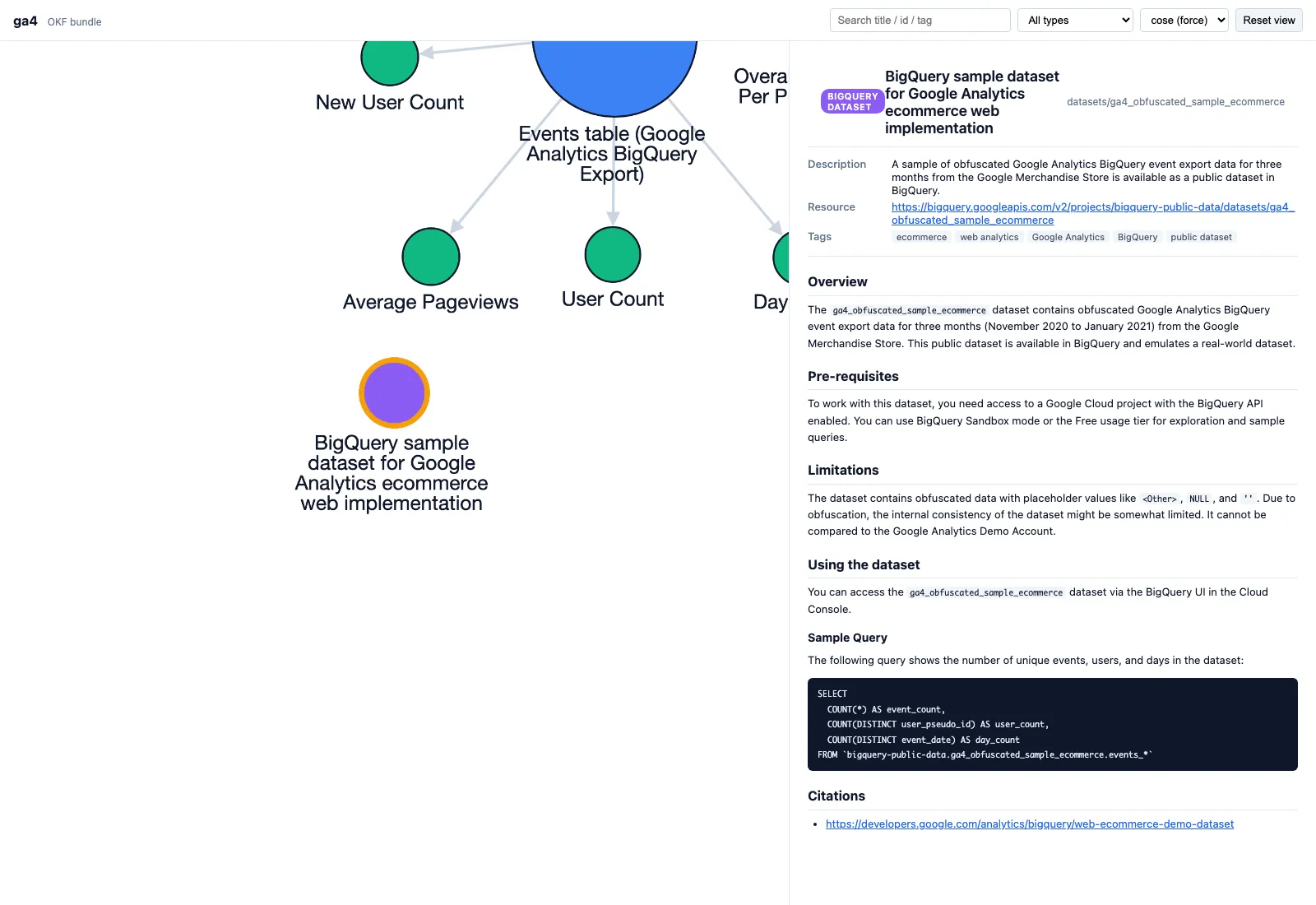
GA4バンドルを静的HTMLビジュアライザーで可視化した例(出典:GitHub knowledge-catalog viz.html)
GA4サンプルバンドルをビジュアライザーで開くと、画像のように Events table (Google Analytics BigQuery Export) を中心に New User Count ・ User Count ・ Average Pageviews ・ Day... などのメトリクス/コンセプトがノードで配置され、ノード間のリンクが関係グラフとして描画されます。右パネルではノードをクリックするとそのコンセプトのMarkdown本文・citations・linkedConceptsが展開される構造です。
このビジュアライザーは「OKFバンドルそのものが自己完結したドキュメントセットになる」ことを実証する役割を担っており、消費者側の実装イメージを掴むのに最も適した参考材料です。
3つのサンプルバンドル
実装と同時に、3つのドメインのサンプルバンドルが公開されています。
| サンプルバンドル | 内容 | 確認できる論点 |
|---|---|---|
| GA4 e-commerce | Google Analytics 4の公開eコマースデータセット | 標準データセットの記述例・ダッシュボード用メトリクス定義 |
| Stack Overflow | Stack Overflow公開データセット | 大量テーブル間の関係グラフ・FK連結記述 |
| Bitcoin | Bitcoin公開データセット | ブロックチェーン由来の特殊スキーマ・時系列データの扱い |
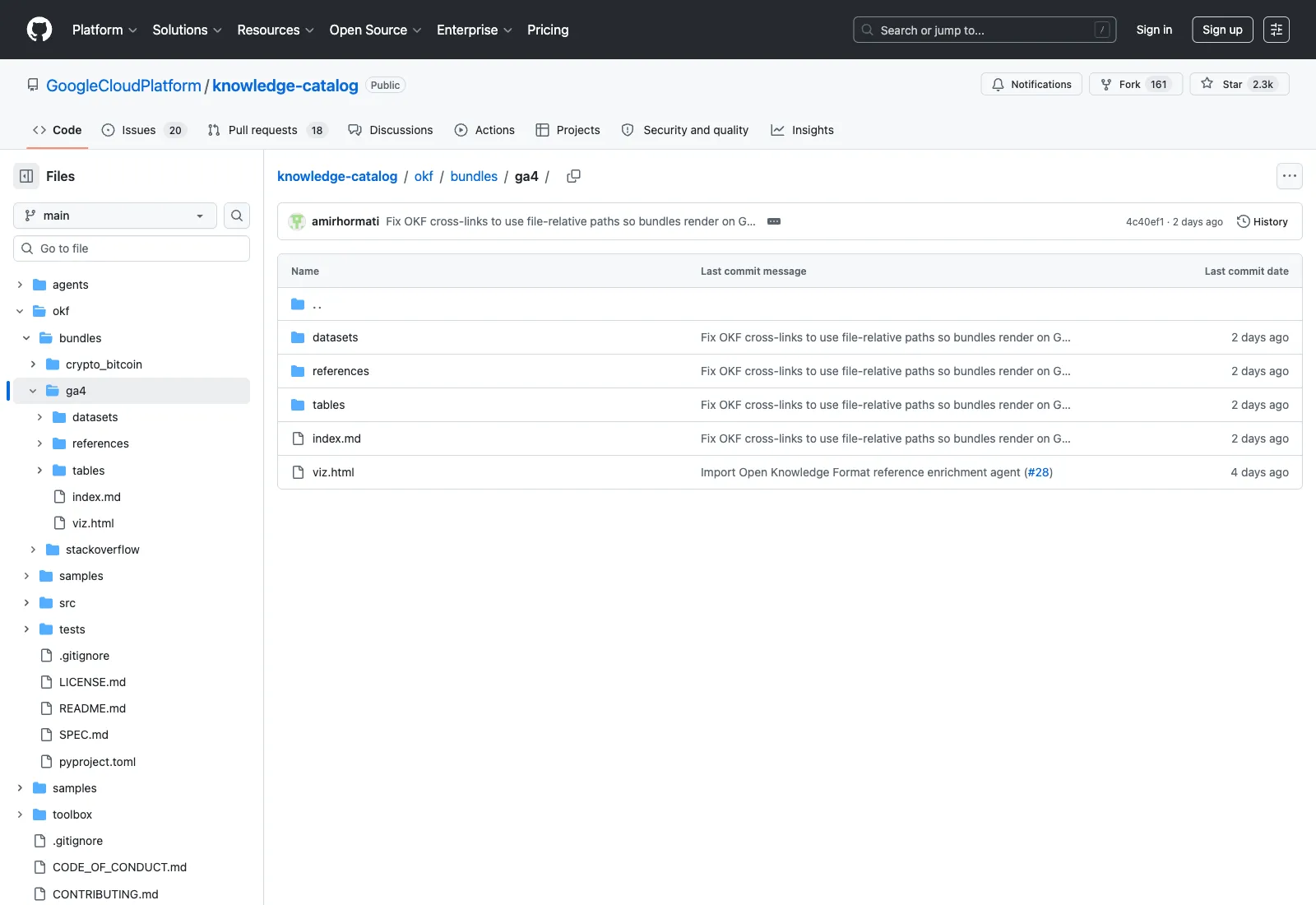
GA4 e-commerceサンプルバンドルの実構造(出典:GitHub knowledge-catalog/okf/bundles/ga4)

GA4バンドルを開くと、画像のとおり datasets/ ・ references/ ・ tables/ の3サブディレクトリと、ルートの index.md ・ ビジュアライザー用の viz.html で構成されています。datasets/ にはデータセット定義、tables/ にはテーブル定義、references/ には外部資料へのリンクが入り、index.md がバンドルの目次として機能します。
これらは「OKFをどう書くか」のチュートリアル教材として機能します。たとえばStack Overflowバンドルを見ると、users ・ posts ・ comments ・ votes などのテーブルがリンクで繋がり、各テーブルのfrontmatterにtype・title・description・resource・tagsが揃っている形が確認できます。
自社で書き始めるときは、近いドメインのサンプルを参考にして、frontmatterの埋め方とリンクの貼り方を真似るのが現実的です。
Knowledge Catalogリポジトリ全体との関係
少しややこしいのは、OKFの参考実装がGoogle Cloudの「Knowledge Catalog」リポジトリの一部として公開されている点です。
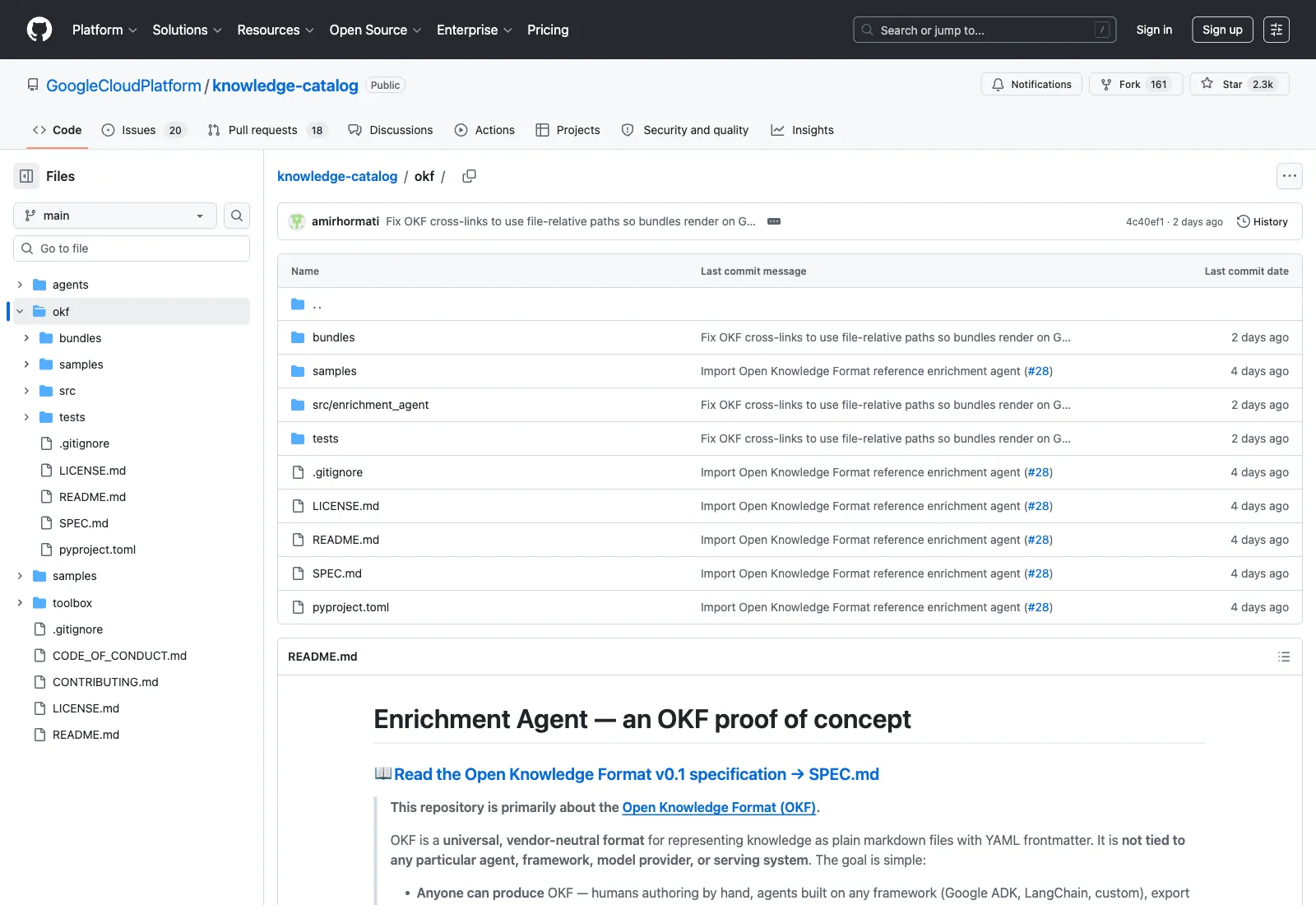
OKF公式リポジトリ(okf/サブディレクトリ)のディレクトリ構造(出典:GitHub knowledge-catalog/okf)
リポジトリ全体は agents/ ・ okf/ ・ samples/ ・ toolbox/ の4ディレクトリで構成され、OKFは okf/ サブディレクトリにスコープされています。Knowledge Catalog全体は「AI-powered data catalog and metadata management platform」と説明されていますが、リポジトリ冒頭には**"This repository and its contents are not an official Google product"**という免責が明記されています。
つまりOKFは「Google Cloudの新サービスの一部」ではなく、Google Cloudの技術者が主導しているオープンソースの仕様として位置づけられています。この点はH2#8の限界セクションでも改めて触れます。
なお、Google Cloud側のKnowledge Catalog自体はOKFバンドルを取り込んでエージェントに提供できるよう更新されており、Google Cloud利用者にとっては「Knowledge CatalogでOKFバンドルを使う」という選択肢も並行して存在します。OKF仕様そのものはこの製品から独立して使えるため、Google Cloudを使わない組織でも仕様だけ採用できる構造になっています。
OKFと隣接技術の位置関係
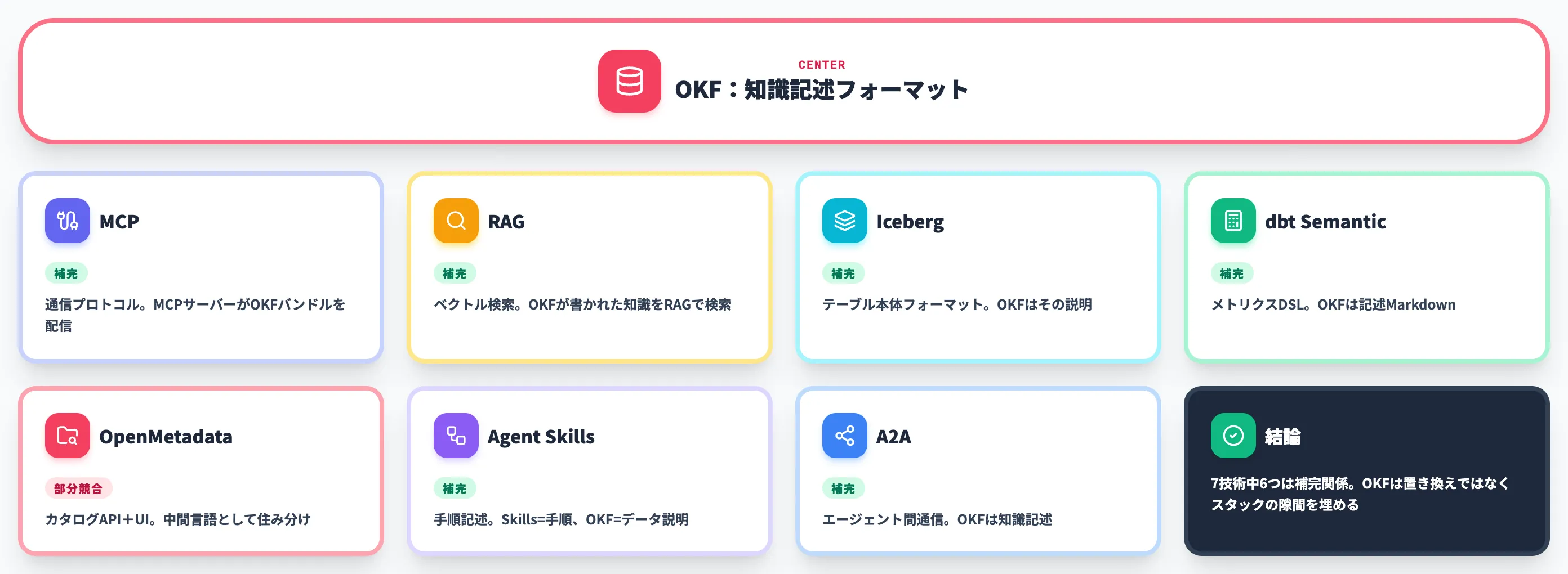
「OKFは○○の代わりになる?」という質問が発表直後から多く出ています。MCP・RAG・Iceberg・dbt Semantic Layer・OpenMetadata——どれもAIエージェント周辺で語られる技術で、OKFと混同しやすいのは事実です。
ここでは、OKFがこれら隣接技術とどこで補完・どこで競合するかを整理します。
隣接技術との位置関係を一覧で
以下の表で、OKFと主要な隣接技術の役割を並べました。
| 技術 | カバーするレイヤー | OKFとの関係 |
|---|---|---|
| MCP(Model Context Protocol) | エージェント⇔ツール/データソース間の通信プロトコル | 補完。MCPサーバーがOKFバンドルを配信する使い方が想定される |
| RAG(Retrieval-Augmented Generation) | ベクトル検索+外部知識のリトリーバル機構 | 補完。OKFが書かれた知識をRAGで検索する併用が現実的 |
| Apache Iceberg | データレイクテーブルの物理フォーマット仕様 | 補完。Iceberg=データ本体、OKF=データの説明 |
| dbt Semantic Layer / Cube / AtScale | メトリクスのSQL生成・統合配信 | 補完。Semantic Layer=メトリクスDSL、OKF=記述Markdown |
| OpenMetadata / DataHub / Amundsen | メタデータカタログのAPI+検索UI | 部分的に競合。OKFはカタログを置き換えず、カタログ間の中間言語として機能 |
| Anthropic Agent Skills | エージェントの再利用可能な作業手順 | 補完。Skills=手順、OKF=データの説明 |
| Agent2Agent(A2A) | エージェント間の通信プロトコル | 補完。OKFが扱うレイヤーは知識記述で、エージェント間通信ではない |
表で並べると、OKFと多くの技術が競合ではなく補完の関係にあることが見えてきます。唯一OpenMetadata等の既存データカタログとは「組織知識のメタデータをどう扱うか」で接点がありますが、これも「置き換える」というよりは「カタログから抜き出して別ベンダーへ持ち運ぶときの中間言語」として住み分ける形になります。
MCPとの関係——「プロトコル」と「フォーマット」の分業

MCPはAnthropicが2024年に発表し、2025年12月にLinux Foundation配下のAgentic AI Foundationへ寄贈されたオープンプロトコルです。AIエージェントが外部のツール・データソースに統一的にアクセスするための通信規約を定めています。
OKFとMCPは役割が違うレイヤーを担当しています。
- MCP: エージェントが「どう接続してどう呼び出すか」のプロトコル
- OKF: エージェントが受け取る/参照する「知識の中身」をどう書くか
典型的な組み合わせは、OKFバンドルをMCPサーバー経由でエージェントに配信する形です。MCPサーバーがバンドル内のMarkdownを返し、エージェント側はOKFのスキーマ前提で読み解く、という分業が成立します。
Microsoft Foundry IQが「MCPサーバーとしてナレッジベースを公開する」設計を採用しているのと同じ方向で、OKFはMCPの上に乗るペイロード仕様としても機能します。
RAGとの関係——「検索」と「記述」の分業
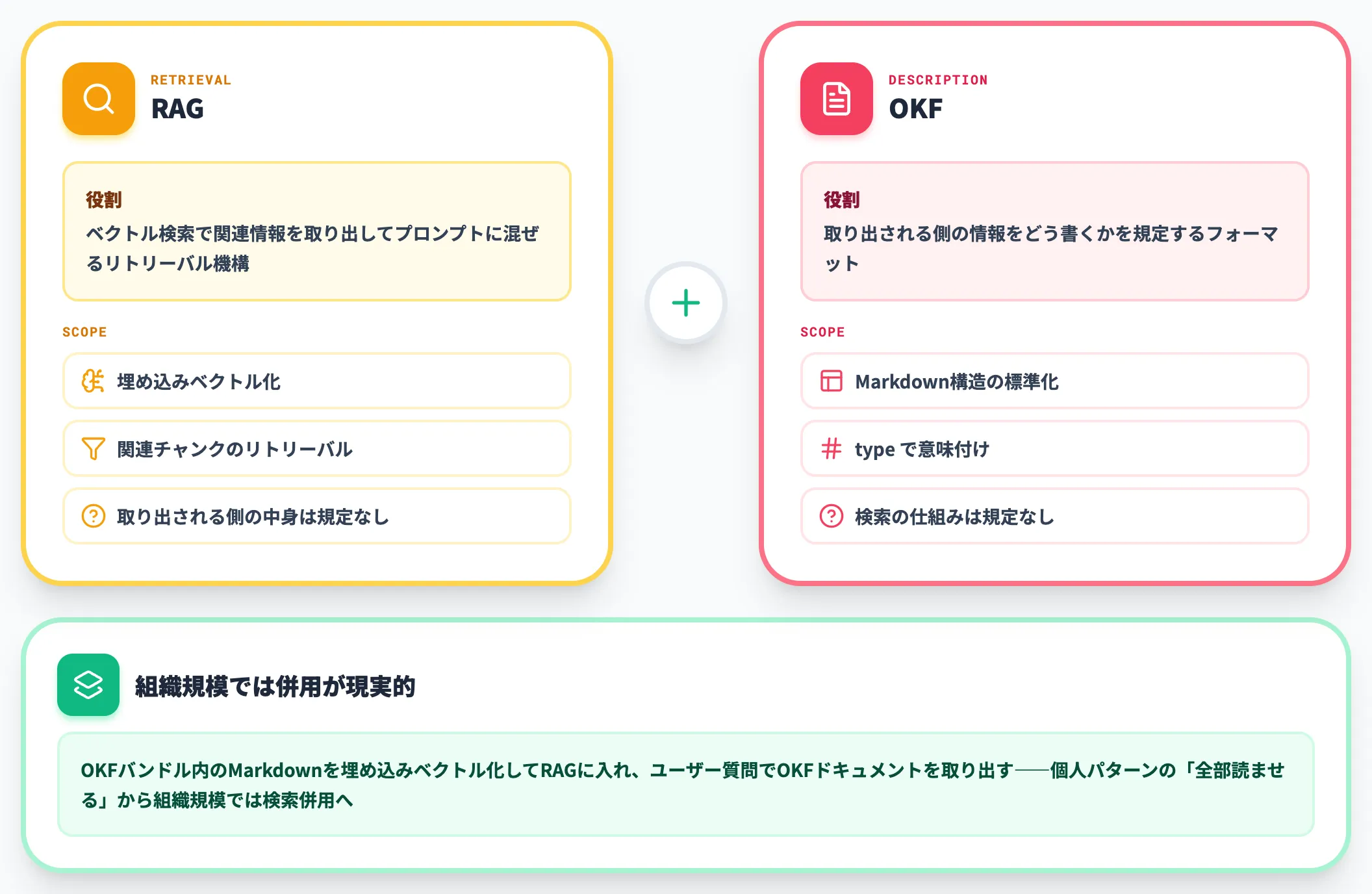
RAGは「ベクトル検索などで関連情報を取り出してプロンプトに混ぜる」リトリーバルパターンです。OKFは「取り出される側の情報をどう書くか」を規定するフォーマットなので、レイヤーが直交します。
実務では、OKFバンドル内のMarkdownを埋め込んでベクトルDBに入れ、ユーザー質問に対してOKFドキュメントを取り出す、という併用が自然です。Karpathy LLM Wikiが「RAGなしでLLMにそのまま読ませる」設計だったのに対し、組織規模のバンドルになるとRAGとの併用が現実的になります。
Apache Iceberg・dbt Semantic Layerとの関係——データ本体・メトリクスDSLとの分業
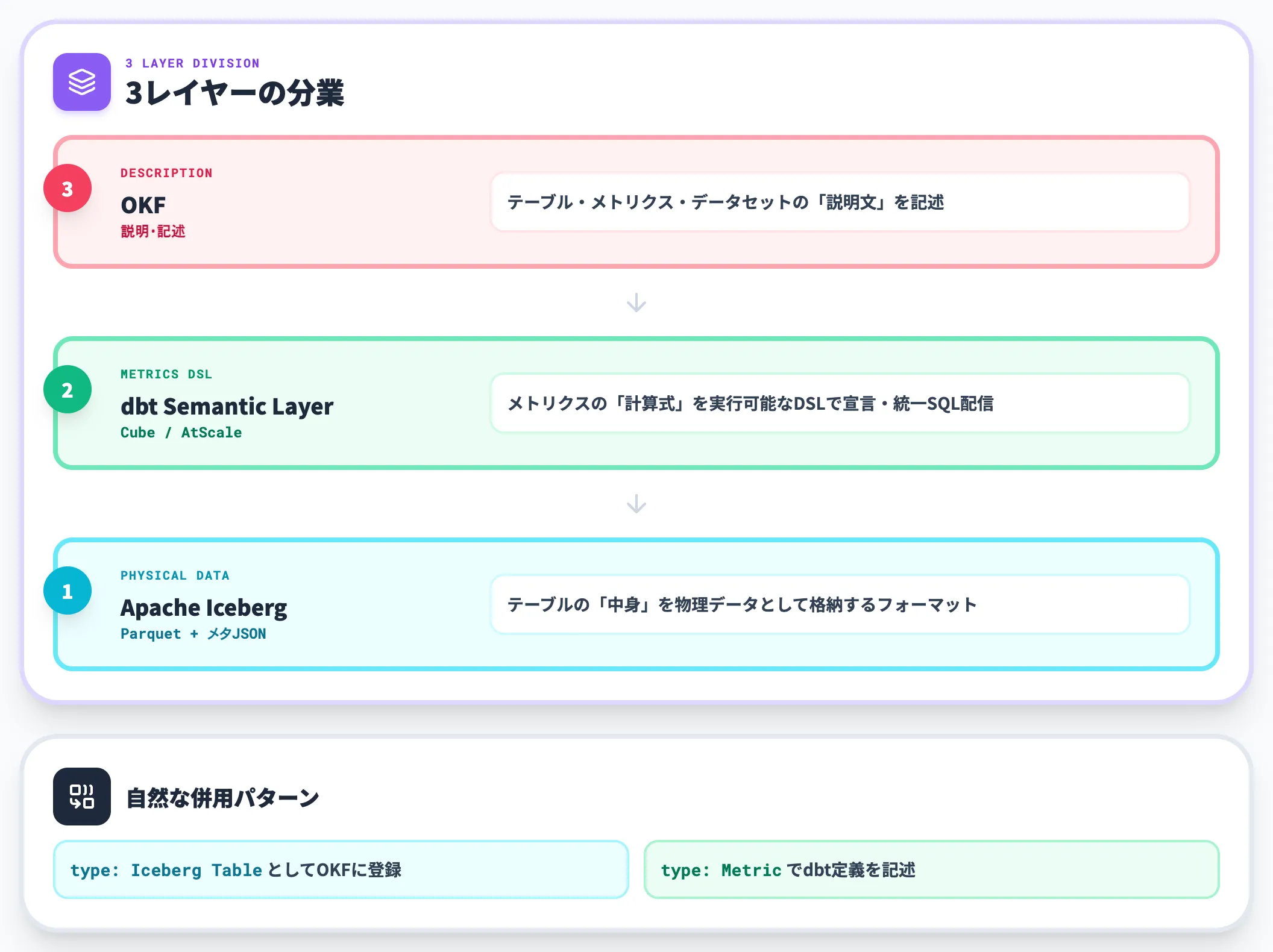
Apache Icebergはデータレイク上のテーブルフォーマット仕様で、Parquetファイル群+メタデータJSONの組み合わせで「テーブルの実体」を定義します。
dbt Semantic Layer・Cube・AtScaleは、メトリクスを宣言的に書いて統一的なSQLとして配信する仕組みです。AtScaleは2025年7月時点でMCP統合を公開しており、2026年現在はMCPサーバー機能を提供しています。Cubeは専用のAI APIエンドポイントを公開しています。
OKFはこれらと競合ではなく補完の関係にあります。
- Iceberg: テーブルの中身(物理データ)の表現
- dbt Semantic Layer: メトリクスの計算式(実行可能なDSL)
- OKF: テーブル・メトリクス・データセットの説明文
Icebergテーブルを type: Iceberg Table としてOKFバンドルに登録し、dbt Semantic Layerで定義したメトリクスを type: Metric として記述する、といった併用が自然です。
OKFでできること/できないこと

ここまでの整理を踏まえ、OKFの境界を明示します。「OKFがやること」と「OKFがやらないこと」を切り分ければ、誤解の多くが解消されます。
OKFがやること(仕様で標準化される範囲)
- ディレクトリレイアウトとMarkdown+YAML frontmatterの書式
- typeフィールドという最低限の構造化メタデータ
- Markdownリンクによるコンセプト間の関係表現
- 予約ファイル名(index.md・log.md)による走査順序の定義
OKFがやらないこと(仕様外)
- type値の中央レジストリ(「BigQuery Table」 vs 「table」 vs 「Snowflake Table」の表記揺れは放置)
- 固定taxonomy・分類体系(taxonomyを揃えたい組織は別途レイヤーを上に乗せる)
- コンテキスト配信プロトコル(→ MCPの領域)
- ベクトル検索・埋め込み(→ RAGの領域)
- カタログ運用API・検索UI・ACL(→ OpenMetadata・DataHubの領域)
- データ本体のテーブルフォーマット(→ Icebergの領域)
- メトリクスの実行可能な計算式(→ dbt Semantic Layerの領域)
この境界を見ると、「OKFはRAGの代替か」「MCPの競合か」「メタデータカタログを置き換えるか」のいずれもNoになることが明確になります。OKFは既存スタックを置き換える仕様ではなく、それらの間に「持ち運び可能な知識記述」というピースを足す仕様です。
OKF v0.1 Draftの限界と注意点
OKFは魅力的な設計ですが、2026年6月時点はv0.1 Draftの出発点であり、本番運用を即座に始められる成熟度には達していません。
導入を検討する前に押さえておくべき限界を、公式に確認できる論点と、第三者が指摘している批判視点の2階層で整理します。

公式に確認できる限界(type値レジストリ・conformance)
SPEC.mdで直接確認できる仕様自身の制約は以下の2点です。
-
type値の中央レジストリが存在しない
プロデューサーはBigQuery Table・bigquery_table・tableのどれを使ってもよく、消費者側に値を揃える責任が委ねられている。複数組織のバンドルを横断するエージェントを書く場合、type値の正規化マップを自前で用意する必要がある。
-
conformance(適合性)の要求が緩い
SPEC.mdは消費者に「未知のtype値・追加キー・壊れたリンク・オプションフィールドの欠落を理由に拒否してはならない」と義務付けている。これはプロデューサー側の自由度を担保する設計だが、「OKFに準拠している=品質が担保されている」とは言えないことを意味する。
これらは仕様の欠陥ではなく、意図的に絞り込んだスコープです。Google CloudのブログでもSPEC.mdでも「v0.1は出発点であり、より多くのプロデューサーとコンシューマーが出現するにつれてフォーマットは進化する」と明示しています。
実務上残る運用論点
SPECで明示されていない、もしくは最小限の言及にとどまり、運用設計が各組織に委ねられている論点もあります。複数ドキュメント間の内容が矛盾するときの解決ルールや、ファセット検索のような高度なクエリ要件はSPECで規定されておらず、コミュニティ議論と各組織の自前ルールに委ねられている段階です。
なお、バージョニングや削除・廃止(deprecated)の扱いはSPEC.mdとlog.mdの慣例として将来版の考え方が示されていますが、運用ルールはまだ最小限で、本格運用には自前のガイドラインを策定する必要があります。加えて、リポジトリ冒頭で示されている "Not an official Google product" の位置づけ(前述)から、SLA・サポート契約の対象外であり、2026年6月時点でリリースもまだ発行されていません。組織として導入を検討する際は、「実験的に試す」「小規模ドメインから始める」スタンスで入るのが現実的で、基幹システムの正本としてOKFバンドルに依存する判断はまだ早い段階です。
Marc Bara氏の第三者批評

OKFには発表直後から第三者の批評も出ています。代表的なのが、Medium上でMarc Bara氏が指摘した「Google's New Format for Agent Context: A Standard, or Just a Folder?」という記事です。
Marc Bara氏の主張のうち、公式コードで実際に確認できる論点は次の1点です。
- SPEC.mdは「type 1フィールドのみ必須」と明記している
- 一方、Googleの参考実装
okf/src/enrichment_agent/bundle/document.pyのvalidate()メソッドは、REQUIRED_FRONTMATTER_KEYS = ("type", "title", "description", "timestamp")という4フィールドを必須として検証している
これは「仕様と参照実装に乖離がある」と読める一方、document.pyのvalidate()はプロデューサー側(enrichment agent自身が生成するドキュメント)の自主的な品質チェックであって、コンシューマー側に4フィールド必須を強制するものではありません。parse() メソッド自体は type なしでもエラーなく読み込みます。
つまり「参考実装が仕様より厳しい品質基準を自分に課している」のが実態で、これは仕様違反ではないものの、「conformanceの定義が現場の感覚と一致しない」という第三者批評の論点としては有効です。
Marc Bara氏は他にも「容器は標準化されたが、意味(セマンティクス)は各プロデューサーに委ねられている」と指摘しており、これは前述のtype値レジストリ未整備とほぼ同じ問題提起です。
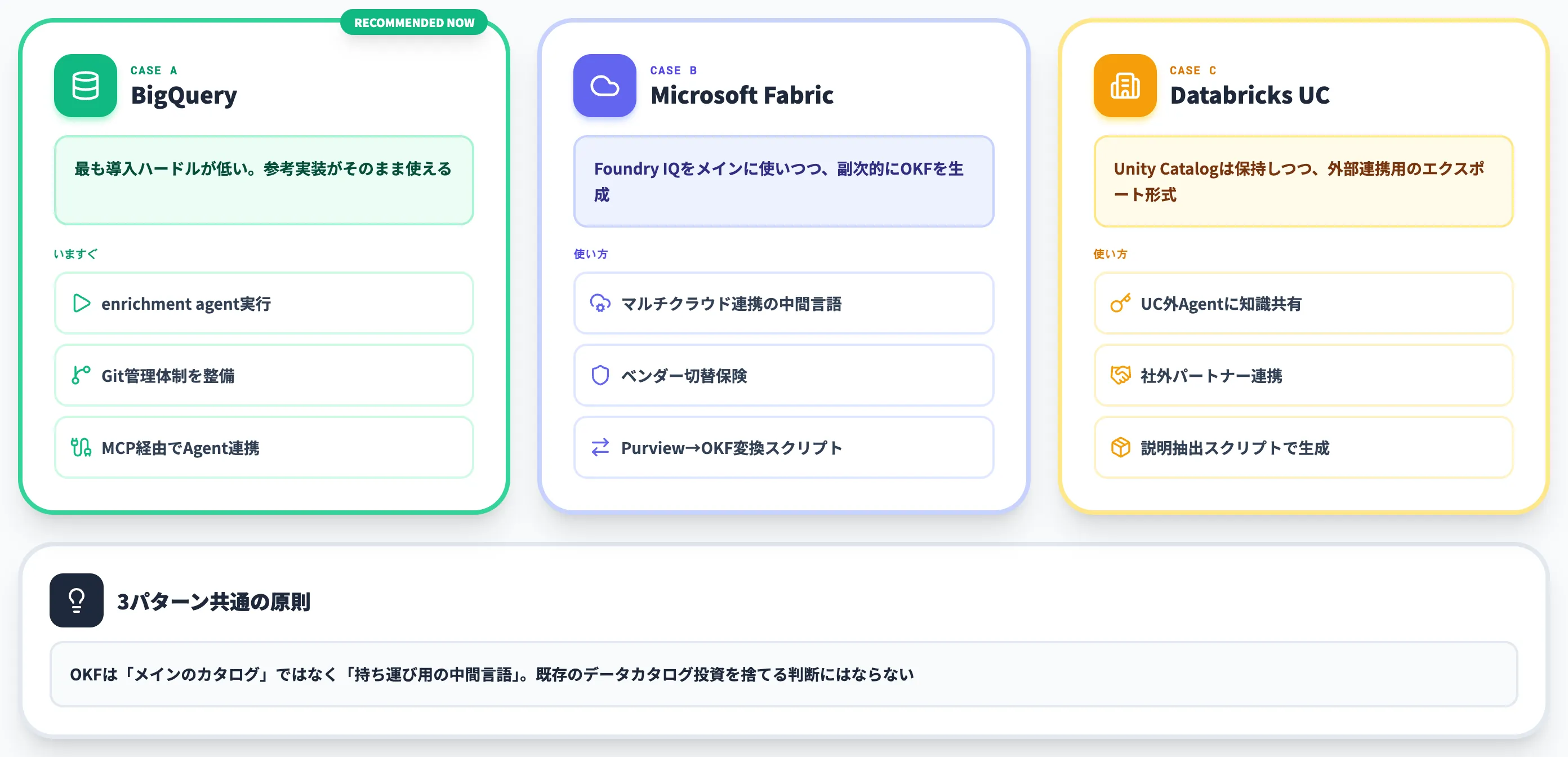
OKFを導入する場合の判断軸(BigQuery/Microsoft Fabric/Databricks別)
OKFは仕様としてはベンダー中立ですが、現実の導入判断は自社が既にどのデータ基盤を使っているかで大きく変わります。
ここではAI総研の支援現場で見えてきた傾向を踏まえ、3つの典型ケース別に「今やるべきこと」を整理します。
BigQuery導入企業——いま試すべきケース
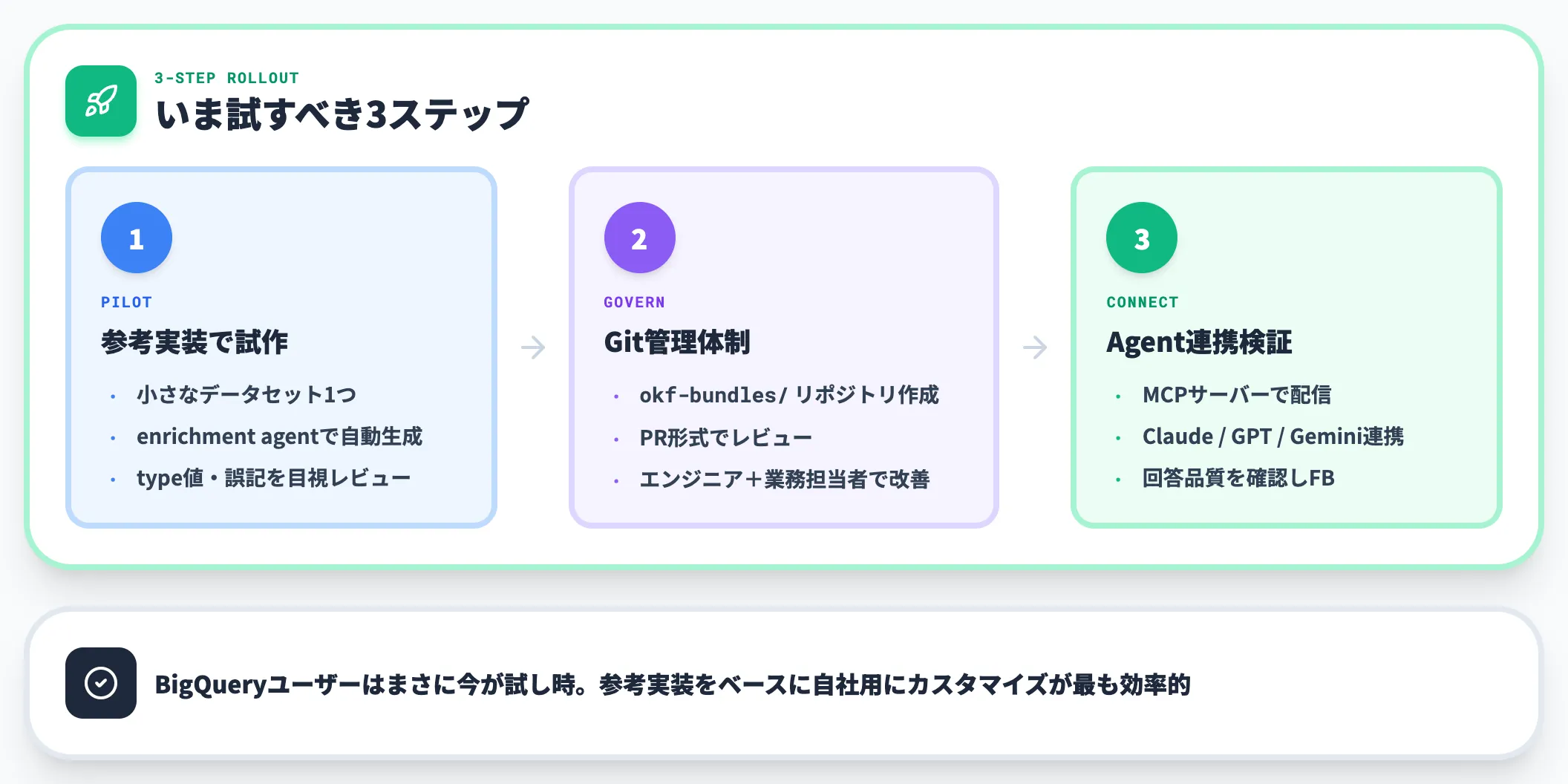
すでにBigQueryを主要データウェアハウスとして使っている企業にとって、OKFは最も導入ハードルが低い選択肢です。
理由は明確で、Googleが提供する参考実装(enrichment agent)がBigQueryのスキーマを起点に自動でOKFバンドルを生成するように設計されているからです。手順は3ステップに集約されます。
-
小さなデータセットで参考実装を回す
営業や財務など、社内で「説明が散在している」と感じるデータセット1つを選び、enrichment agentで自動生成。生成されたMarkdownを目視レビューしてtype値の表記揺れや誤記を確認する。
-
生成バンドルをGitリポジトリに置く
社内Gitにokf-bundles/リポジトリを作成し、生成されたMarkdownをコミット。エンジニアと業務担当者がPR形式で記述を改善できる体制を整える。
-
MCP経由でClaude・ChatGPT・Geminiに食わせる
バンドルをMCPサーバーで配信し、対象エージェントに「自社のordersテーブルの定義をOKFバンドルから読んで回答せよ」と指示。回答品質を確認してフィードバックをバンドルに戻す。
このサイクルが回せれば、「カタログとしての中間言語」を組織内で小さく試す検証が進められます。BigQueryユーザーはまさに今が試し時で、参考実装をベースに自社用にカスタマイズするのが最も効率的です。
Microsoft Fabric導入企業——持ち出し用として併用
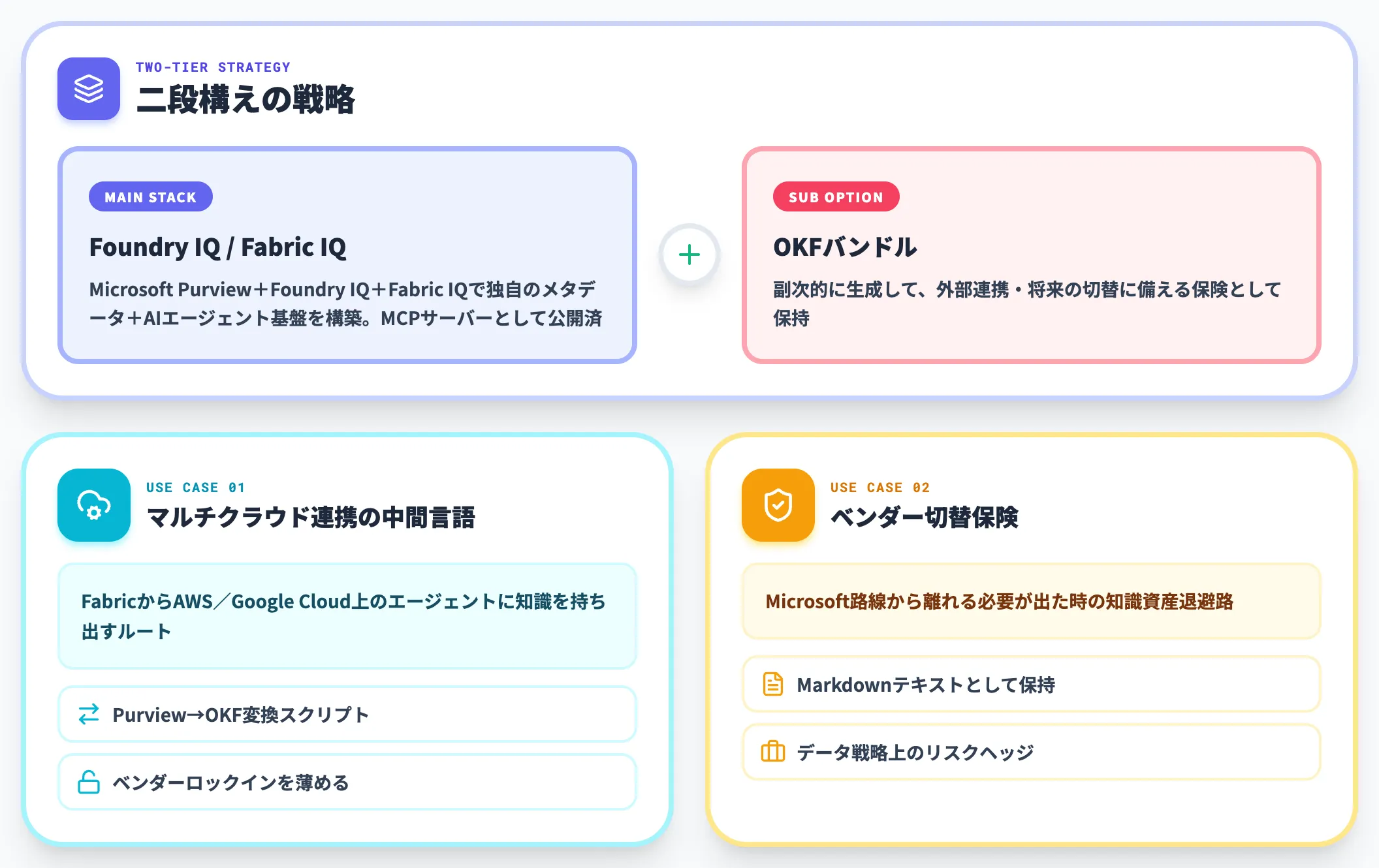
Microsoft Fabricを主要データ基盤として採用している企業の場合、OKFの位置づけは少し異なります。
Microsoftは独自にMicrosoft Purview+Foundry IQ+Fabric IQという独自のメタデータ+AIエージェント基盤を構築しており、Foundry IQはMCPサーバーとしてClaude・ChatGPT・LangChain等から接続可能になっています。2026年6月時点でMicrosoftによるOKF採用表明は確認できないため、Foundry IQ/Fabric IQ/MCPを軸にしたMicrosoft側の知識連携と併用前提で見るのが安全です。
ただし、ユーザー側がOKFを使う意義は別の角度で残ります。
-
マルチクラウド連携の中間言語
Fabricの知識をAWS・Google Cloud上のエージェントに持ち出したい場合、Purview→OKFバンドル変換スクリプトを自前で用意すれば、ベンダーロックインを薄められる。
-
将来のベンダー切替に備えた保険
万一Microsoft路線から離れる必要が出たときに、知識資産を「Markdownのテキストファイル」として持ち出せる状態にしておくのは、データ戦略上のリスクヘッジになる。
Fabric導入企業は、Foundry IQをメインで使いつつ、副次的にOKFバンドルを生成しておく二段構えが現実的です。
Databricks Unity Catalog導入企業——中間言語として併用
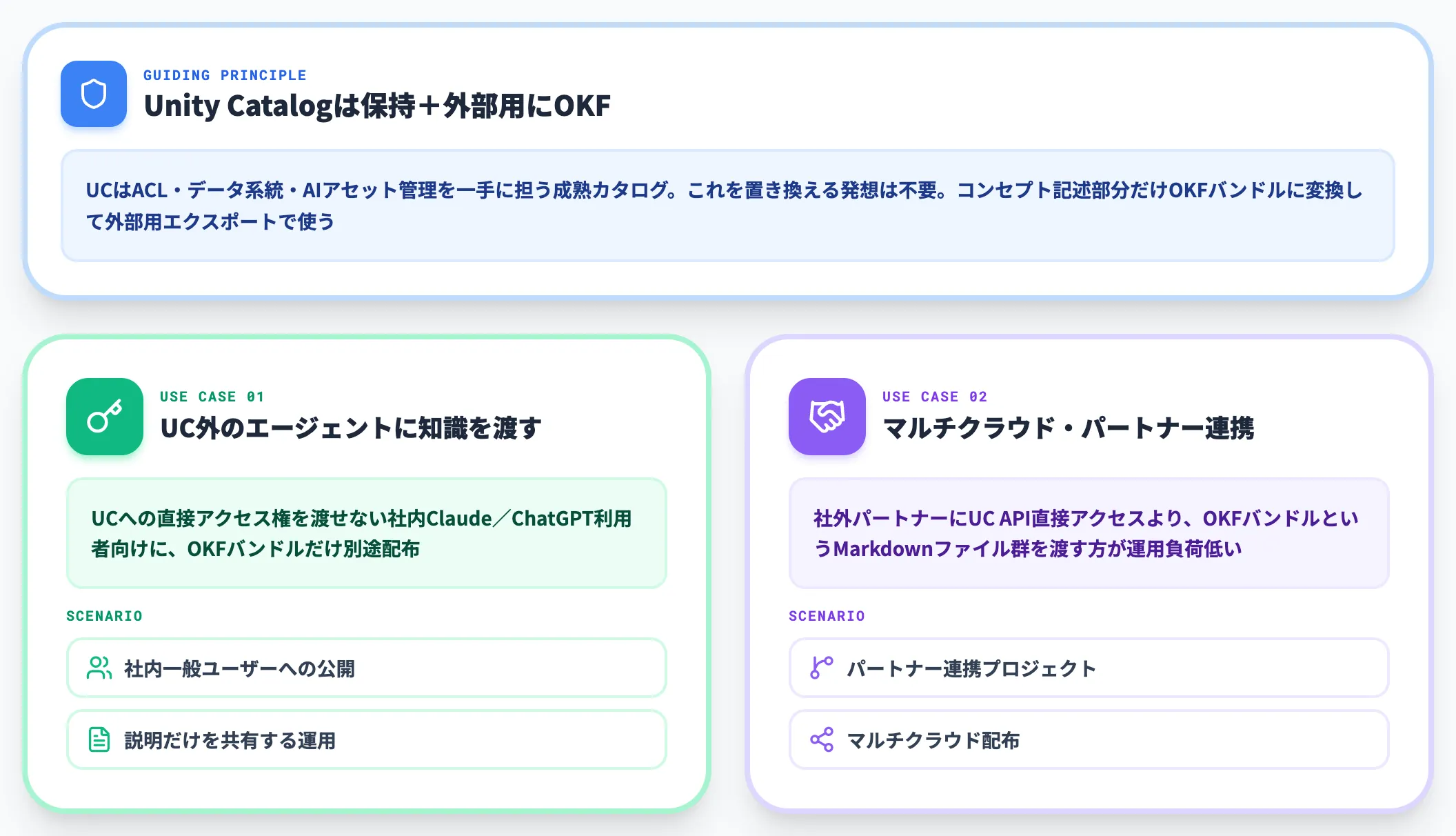
Databricks Unity Catalogをガバナンス層として採用している企業も、Fabric導入企業と似た判断軸になります。
Unity CatalogはACL・データ系統・AIアセット管理を一手に担う成熟したカタログで、これをOKFで置き換える発想は不要です。代わりに、Unity Catalogからコンセプト記述部分を抜き出してOKFバンドルに変換する用途が現実的です。
具体的なユースケースは2つあります。
-
Unity Catalog外のエージェントに知識を渡す
社内のClaude・ChatGPT利用者にUnity Catalogへの直接アクセス権を渡せない場合、OKFバンドルを別途配布することで「説明だけは共有する」運用が可能になる。
-
マルチクラウド/パートナー連携
社外パートナーに自社データの説明を渡す際、Unity Catalog APIへの直接アクセスを許可するよりも、OKFバンドルというMarkdownファイル群を渡す方が運用負荷が低い。
Databricks導入企業は、Unity Catalog本体は保持しつつ、外部連携用のエクスポートフォーマットとしてOKFを試すのが妥当な判断です。
以下の表は、3パターンの優先アクションを1枚にまとめたものです。
| 主要データ基盤 | いますぐやること | 中期で考えること |
|---|---|---|
| BigQuery | 参考実装のenrichment agentを1ドメインで実行し、生成バンドルをGitで管理 | type値の社内ガイドライン策定、MCP経由でのエージェント連携拡大 |
| Microsoft Fabric | Foundry IQ/Fabric IQをメイン採用しつつ、Purview→OKF変換スクリプトを試作 | マルチクラウド連携時の中間言語としてOKFバンドルを整備 |
| Databricks Unity Catalog | Unity Catalogをそのままメインに据え、説明抽出スクリプトで小規模OKFバンドル生成 | 外部パートナー連携・社内Claude/ChatGPT利用時のエクスポート形式として標準化 |
3パターンに共通するのは、OKFを「メインのカタログ」として使うのではなく、「持ち運び用の中間言語」として位置づける点です。既存のデータカタログ投資を捨てる判断にはならず、ベンダーロックインを薄めるための補完投資として考えるのが現実的です。
「いま着手すべきか待つべきか」の判断
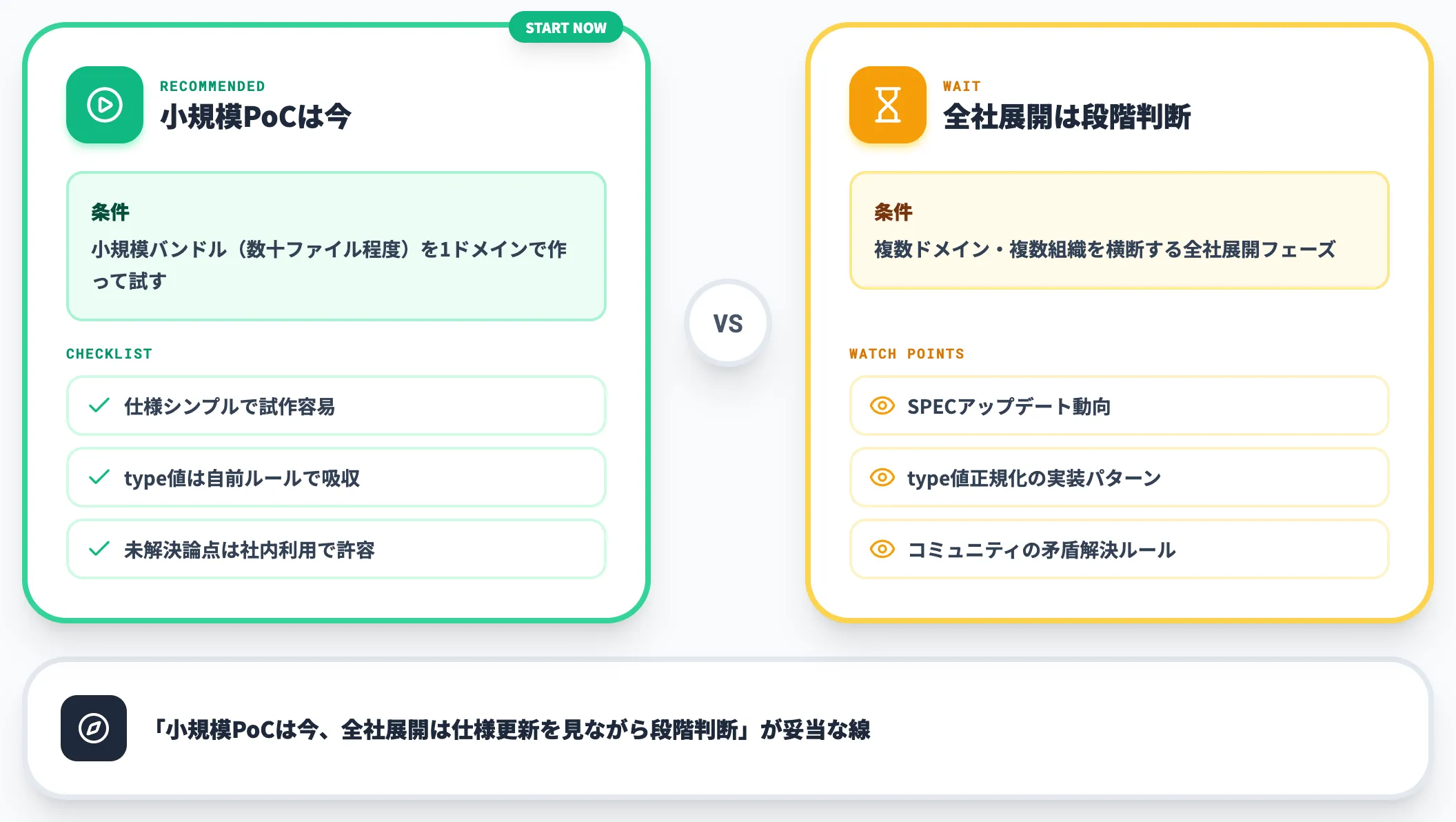
v0.1 Draft段階でも今着手すべきか、それとも仕様が成熟するのを待つべきか——これはAI総研の支援現場でもよく聞かれる論点です。
結論としては、「小規模PoCで検証するなら今、全社展開は仕様更新とコミュニティ動向を見ながら段階判断」が妥当な線です。
仕様自体はシンプルで、小規模バンドル(数十ファイル程度)を1ドメインで作って試す分にはv0.1 Draftで十分です。type値レジストリ未整備などの未解決論点は、社内利用なら自前ルールで吸収できます。一方、複数ドメイン・複数組織を横断する全社展開は、type値正規化・矛盾解決などの運用論点について公式SPECのアップデートとコミュニティの実装パターンを見ながら、段階的に判断するのが安全です。

データ基盤からAIエージェント運用まで一気通貫で進めるなら
OKFのような知識フォーマットを整備しても、それを業務で実際に動かすには、データ統合・エージェント実行・ガバナンスを一体で担う基盤が必要です。「Markdown形式でデータの説明を整えたが、結局どのエージェントに食わせるか・どこで実行するか・どうログを管理するか」で詰まる組織は少なくありません。
ここで効いてくるのが、自社のAzureテナント内で動くエンタープライズAIエージェント基盤 AI Agent Hub です。Microsoft Fabric OneLakeをデータ基盤に据え、整備された知識資産をエージェントの業務実行へ直結させる3層アーキテクチャを採っています。
-
データの説明をそのまま業務アクションに直結
SAP・Salesforceなど基幹システムのデータをFabric OneLakeにZero ETLで仮想統合。Teamsチャットから自然言語で問い合わせれば、AIエージェントが取得結果を報告・申請・承認の各業務に変換します。
-
構築基盤が違っても管理は1つのダッシュボードに集約
Microsoft FoundryでもCopilot StudioでもN8nでも、どこで構築したAgentも同じ管理画面で実行ログ・権限・セキュリティチェックを統合管理。シャドーAIの乱立を防ぎます。
-
データは100%自社テナント内で完結
Azure Managed Applicationsとして顧客テナント内に構築し、AIの学習対象から完全除外。OKFが目指す「ベンダーロックインから切り離された知識資産」の方針と同じ設計思想で、データの所在を自社に保ち続けられます。
AI総合研究所の専任チームが、データ基盤設計からAIエージェント運用までを伴走支援します。AI Agent Hubのサービスページで、自社のデータ知識を業務実装に乗せる具体的な活用ケースをご確認ください。
データ基盤からAIエージェント運用まで統合

Fabric × AIエージェントで分析の先のアクションへ
Microsoft Fabric OneLakeにZero ETLで仮想統合したデータをAIエージェントが業務フローに直接活用。OKFのような知識記述を整えるだけでなく、業務実装・実行ログ・権限管理までを1つのダッシュボードで一元化できる構成です。
Open Knowledge Format(OKF)まとめ
本記事では、2026年6月にGoogle Cloudが公開したOpen Knowledge Format(OKF)について、仕様の構造・3つの設計原則・Karpathy LLM Wikiとの関係・公開された参考実装・MCP/RAG/Iceberg/dbt Semantic Layer/OpenMetadataなど隣接技術との位置関係・v0.1 Draftの限界・BigQuery/Microsoft Fabric/Databricks別の導入判断軸まで、Google Cloudの一次情報とGitHub上の参考実装コードを踏まえて解説しました。要点を改めて整理します。
-
OKFはGoogle Cloudが2026年6月にApache 2.0で公開したベンダー中立な知識フォーマット仕様(GitHub初期公開12日/ブログ発表13日)で、Markdownファイル+YAML frontmatter+ディレクトリだけで成立する最小スタックの設計
-
必須はtypeフィールド1つだけ、推奨はtitle/description/resource/tags/timestampの5つという極端なまでに緩い規約で、Notion・Obsidian・MkDocs・Gitに馴染む書式
-
Karpathy LLM Wikiパターンの組織版にあたり、CLAUDE.md/AGENTS.md(振る舞い設定)・Anthropic Agent Skills/OpenAI Codex Agent Skills(作業手順)とは扱う情報レイヤーが異なる
-
隣接技術との関係は補完が中心で、MCPは配信プロトコル、RAGは検索機構、Icebergはテーブル本体、dbt Semantic Layerはメトリクス計算式と棲み分け、OpenMetadata等のカタログ製品とも「置き換え」ではなく「中間言語」のポジションを取る
-
v0.1 Draftはtype値レジストリ未整備・"Not an official Google product"の位置づけで、参考実装も実質4フィールド要求と仕様との差分があるなど、本番運用には早すぎる段階
-
日本企業の判断軸はBigQuery導入企業ならいま参考実装で試すべき、Fabric/Databricks導入企業は既存カタログを保持しつつ中間言語として併用するのが現実的
データプラットフォーム責任者にとってOKFは、「今すぐ移行すべきか」ではなく、「自社のデータカタログ知識をベンダーロックインから切り離す中間言語を持つかどうか」という問いを突きつける動きです。まずは1ドメイン(営業データなど)を小さなバンドルにして、MCP経由でClaude・ChatGPT・Geminiに食わせる検証から始めるのが、最も実用的な第一歩になります。
AIエージェントが組織のデータを直接読みに来る時代に、知識を誰のクラウドにも縛られないMarkdown資産として持っておくか、特定ベンダーのカタログに閉じ込めたままにするか——その判断軸を持つことが、2026年以降のデータ戦略の分かれ目になりそうです。










