この記事のポイント
 社内RAGが固有名詞や関係性で外す段階に入っているなら、ナレッジグラフを意味層として挟むGraphRAG構成が第一候補
社内RAGが固有名詞や関係性で外す段階に入っているなら、ナレッジグラフを意味層として挟むGraphRAG構成が第一候補- PoCはNeo4j AuraDB Free+MS GraphRAG(OSS)でDBコストゼロ、本番はAuraDB Professional($65/GB/月)
- 単なるグラフDB導入ではなく、オントロジー(コアエンティティ5〜15種)の設計を含めて初めて価値が出る
- カスタマー360・サプライチェーン・不正検知・サイバーセキュリティなど関係性の複雑度が高い領域からPoCを始めるとROIが説明しやすい
- 2026年はNeo4j Aura Agent・MS Agent Framework・Palantir AIP Studioが代表選択肢、既存基盤の親和性で選ぶ

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ナレッジグラフ(Knowledge Graph)とは、企業や世界の知識を「エンティティ(モノ・人・概念)」と「リレーション(関係)」のネットワークとして表現し、意味のある検索と推論を可能にするデータ構造です。
Googleの検索結果パネルに始まり、いまではMicrosoft GraphRAG・Neo4j・Palantir Foundry Ontologyといったエンタープライズ基盤でも活用される概念に拡張しており、生成AIとAIエージェントの実用化に伴って2026年は企業現場でも注目が高まっています。
本記事では、ナレッジグラフの基本構造、オントロジー/グラフDBとの違い、GraphRAGとの統合、主要プラットフォームの比較、エンタープライズでの7つの活用シナリオ、構築ステップと失敗パターン、料金相場までを、2026年時点の公式一次情報で整理します。
生成AI時代の「意味ある検索」と「エージェントの判断基盤」を設計するための実務ガイドとして活用してください。
目次
ナレッジグラフの代表例:Google Knowledge Graph
トリプル(Subject-Predicate-Object)
なぜAIエージェント時代にナレッジグラフが再評価されているのか
Microsoft Agent Framework × Neo4j の実装例
Microsoft Agent Framework × Neo4j GraphRAG
ナレッジグラフとは?
ナレッジグラフ(Knowledge Graph)とは、実世界のエンティティ(モノ・人・場所・概念など)と、それらをつなぐリレーション(関係)を、ノード(点)とエッジ(線)のネットワーク構造で表現した知識データベースです。
従来のリレーショナルデータベースが「テーブルに行を積む」発想だったのに対し、ナレッジグラフは「関係そのものをデータとして持つ」発想に基づいて設計されます。
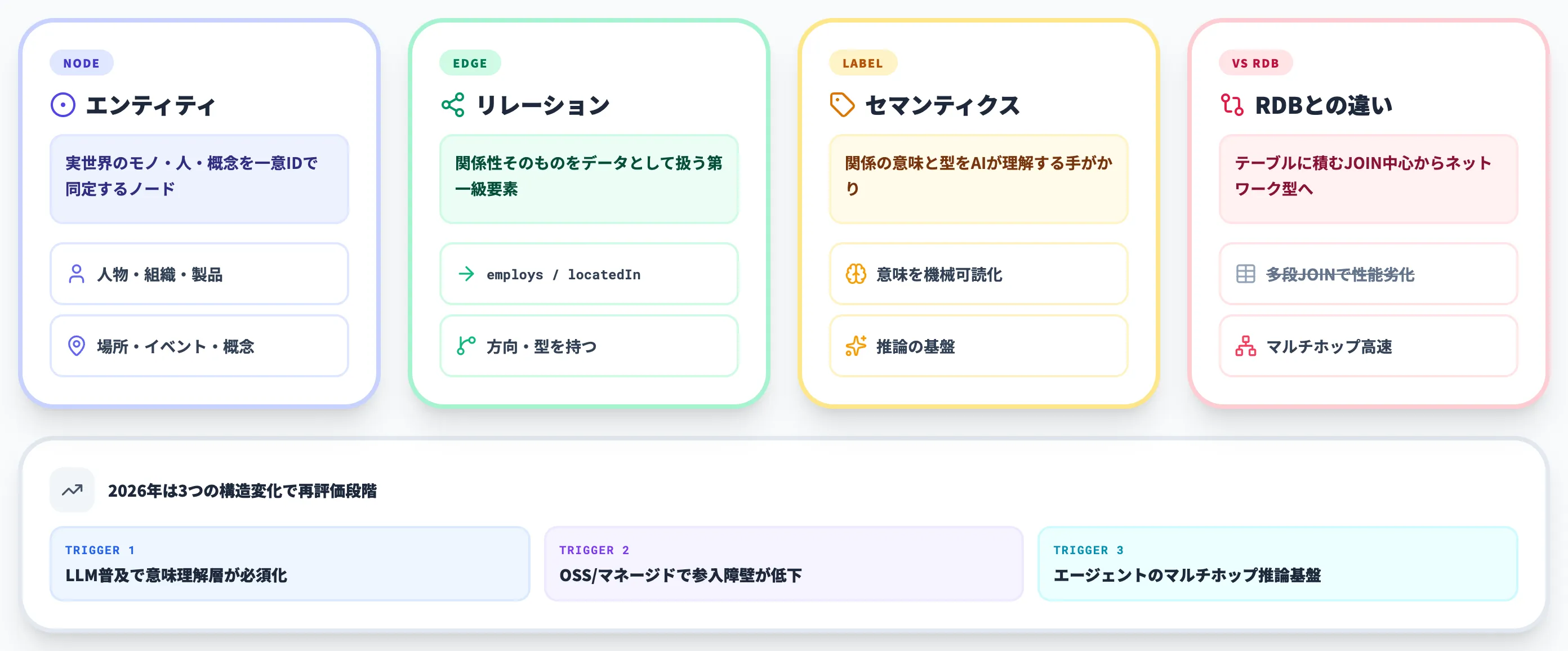
IBMの整理では「実世界のエンティティとそれらの関係を表現するセマンティックネットワーク」と定義されており、通常はグラフデータベース上に保存され、ノード/エッジ/ラベルの3要素で構成されます。
最大の特徴は、情報を単独のレコードとして保存するのではなく、情報同士のつながり(関係性)を第一級の要素として扱う点です。
従来のRDBが「顧客と注文はJOINで繋ぐ」構造だったのに対し、ナレッジグラフでは「顧客 ── 注文した ── 商品」という関係そのものがデータとして存在します。
この違いが、検索・推論・AIエージェントの判断基盤として再評価されている理由です。

ナレッジグラフの位置づけ
ナレッジグラフは、データ工学・情報検索・セマンティックWeb・AIの交差点にある技術領域です。2010年代は研究領域や一部大企業の検索基盤にとどまっていましたが、2026年時点では3つの構造変化によって実務での検討が進んでいます。
- 大規模言語モデル(LLM)の普及により、曖昧な意味理解を担うバックエンドとしての役割が明確化
- Microsoft GraphRAG や Neo4j GraphRAG のようなオープンソース実装/マネージドサービスの登場で、参入障壁が大幅に低下
- エージェント型AIの本格稼働に伴い、マルチホップ推論の土台として構造化知識が必須化
言い換えると、ナレッジグラフは「AIエージェント時代のデータ基盤として有力な選択肢」に位置づけられつつあります。
ナレッジグラフの代表例:Google Knowledge Graph
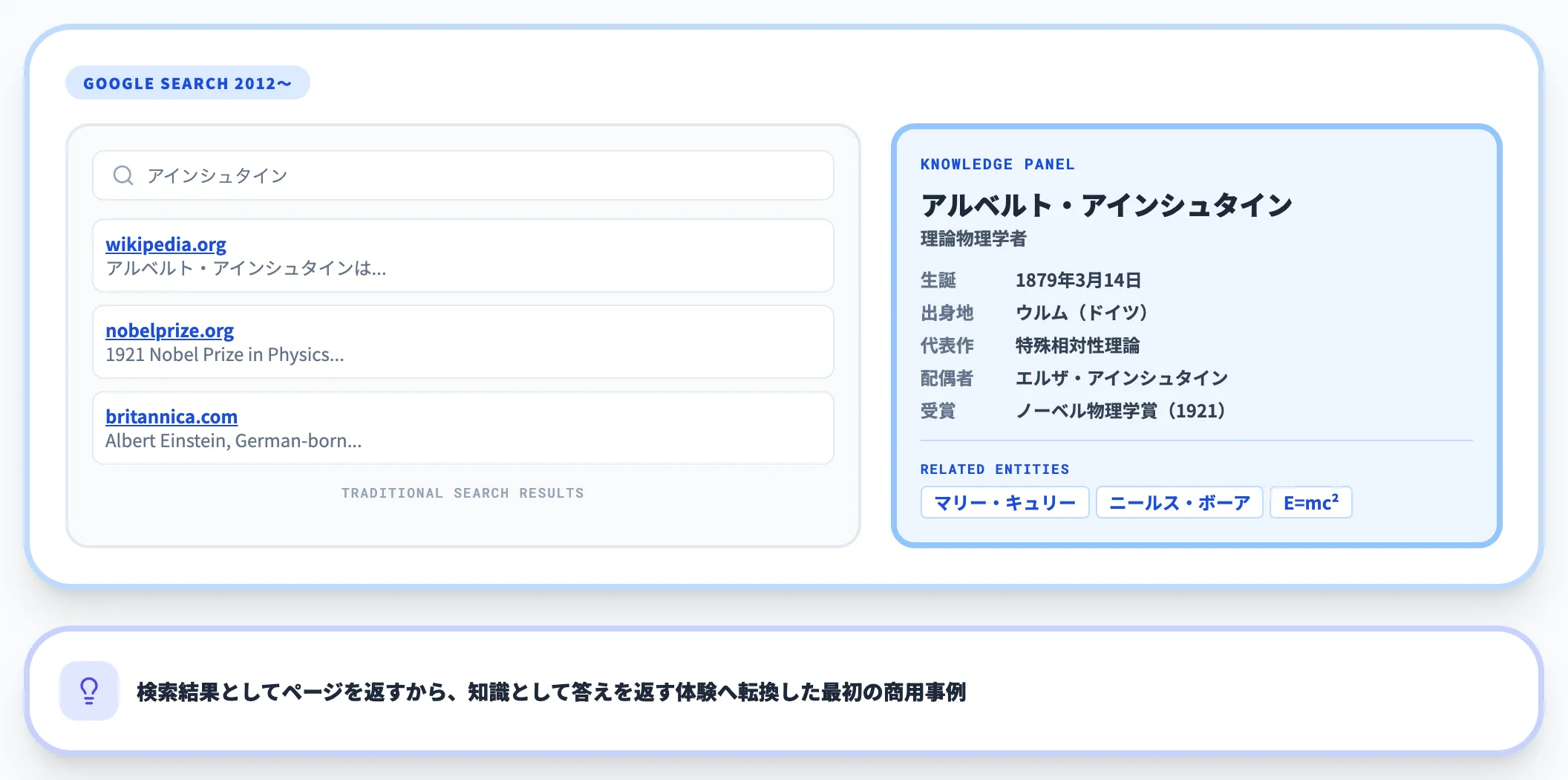
実装例として最も有名なのは、Googleが2012年に導入したKnowledge Graphです。Wikipedia・Freebase・CIA World Factbookといった複数ソースから実世界のエンティティを統合し、検索結果ページの右側に表示される「ナレッジパネル」として提供されています。
この仕組みは、ユーザーが「アインシュタイン」と検索したとき、アインシュタイン本人・代表作・出身地・家族関係などを、関連エンティティとして一画面に示す体験を実現しています。
「検索結果としてページを返す」から「知識として答えを返す」への転換を、最初に商用化した事例と言えます。
ナレッジグラフの基本構造
ナレッジグラフは、一見複雑そうに見えても、3つの基本要素の組み合わせで成り立っています。
ここではエンティティ・リレーション・属性(プロパティ)、そしてこれらを表現する最小単位「トリプル」の考え方を整理します。

エンティティ(ノード)
エンティティは、ナレッジグラフのノード(点)にあたる要素で、現実世界の「モノ」や「概念」を指します。具体例を挙げると以下の通りです。
| 分類 | 具体例 |
|---|---|
| 人物 | 山田太郎、Tim Cook等 |
| 組織 | Microsoft、東京大学等 |
| 製品・サービス | Azure OpenAI Service、iPhone 17等 |
| 場所 | 東京駅、カリフォルニア州等 |
| 概念 | 機械学習、量子コンピューティング等 |
| イベント | 2026年東京マラソン等 |
エンティティには、一意に識別するためのID(URIやエンティティID)が付与されます。
同じ名前でも異なるエンティティ(例:「Apple」という会社と果物)を区別するため、IDによる厳密な同定が不可欠です。
リレーション(エッジ)
リレーションは、エンティティ同士をつなぐエッジ(線)で、「どのような関係にあるか」を表現します。
リレーションには方向と意味があり、代表的なものは以下の通りです。
| リレーション | 意味 | 例 |
|---|---|---|
| employs | 雇用している | Microsoft → Satya Nadella |
| locatedIn | 所在している | 東京駅 → 東京都千代田区 |
| partOf | の一部である | iPhone 17 → Apple製品ライン |
| authoredBy | によって書かれた | 論文A → 著者B |
リレーションは単なる「線」ではなく、それ自体が型(種類)を持ち、AIエージェントが「この関係は何を意味するか」を理解するための手がかりになります。
リレーションの設計品質が、後工程のクエリ精度・推論精度を左右する最重要ポイントです。
属性(プロパティ)
ノードやエッジに付随する詳細情報が属性(プロパティ)です。人物ノードであれば「生年月日」「役職」「メールアドレス」、リレーションであれば「開始日」「有効期限」などが保持されます。
プロパティの持ち方によって、ナレッジグラフは大きく2系統のモデルに分かれます。

-
プロパティグラフモデル
ノードとエッジの両方に属性を持てるモデル。Neo4j・Amazon Neptune Property Graphが採用。実装エコシステムが豊富で、開発速度を重視する案件で有利
-
RDFモデル
ノード・リレーション・リテラル値を「主語-述語-目的語」のトリプルで表現するW3C標準。推論エンジン・公共セクターでの採用が中心
トリプル(Subject-Predicate-Object)
ナレッジグラフの最小表現単位が「トリプル」と呼ばれる3つ組です。主語(Subject)──述語(Predicate)──目的語(Object)の形で、1つの事実を表現します。
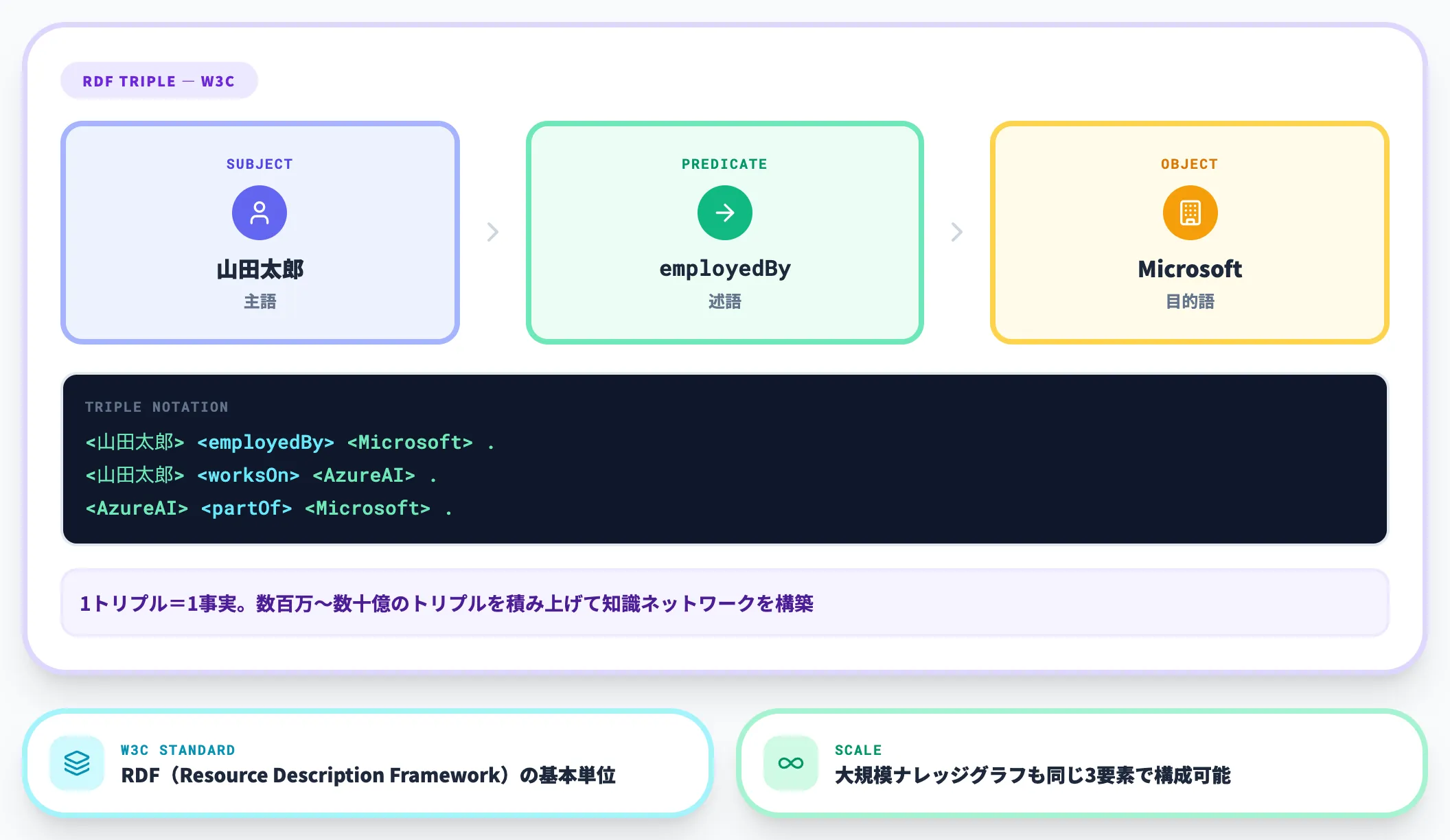
例えば「山田太郎はMicrosoftに勤めている」という事実は、以下のトリプルで表現できます。
<山田太郎> <employedBy> <Microsoft>
この3つ組を大量に積み上げることで、複雑な知識ネットワークが構築されます。
W3Cが勧告するRDF(Resource Description Framework)はトリプルを基本とする表現規格で、ナレッジグラフの主要な表現形式の一つとして用いられています。
ナレッジグラフとオントロジー・グラフDBの違い
ナレッジグラフは、しばしば「オントロジー」「グラフDB」「セマンティックWeb」といった隣接概念と混同されます。
しかし、それぞれは役割・抽象度が異なります。用語の混乱が設計判断のブレにつながりやすいため、ここで整理しておきましょう。
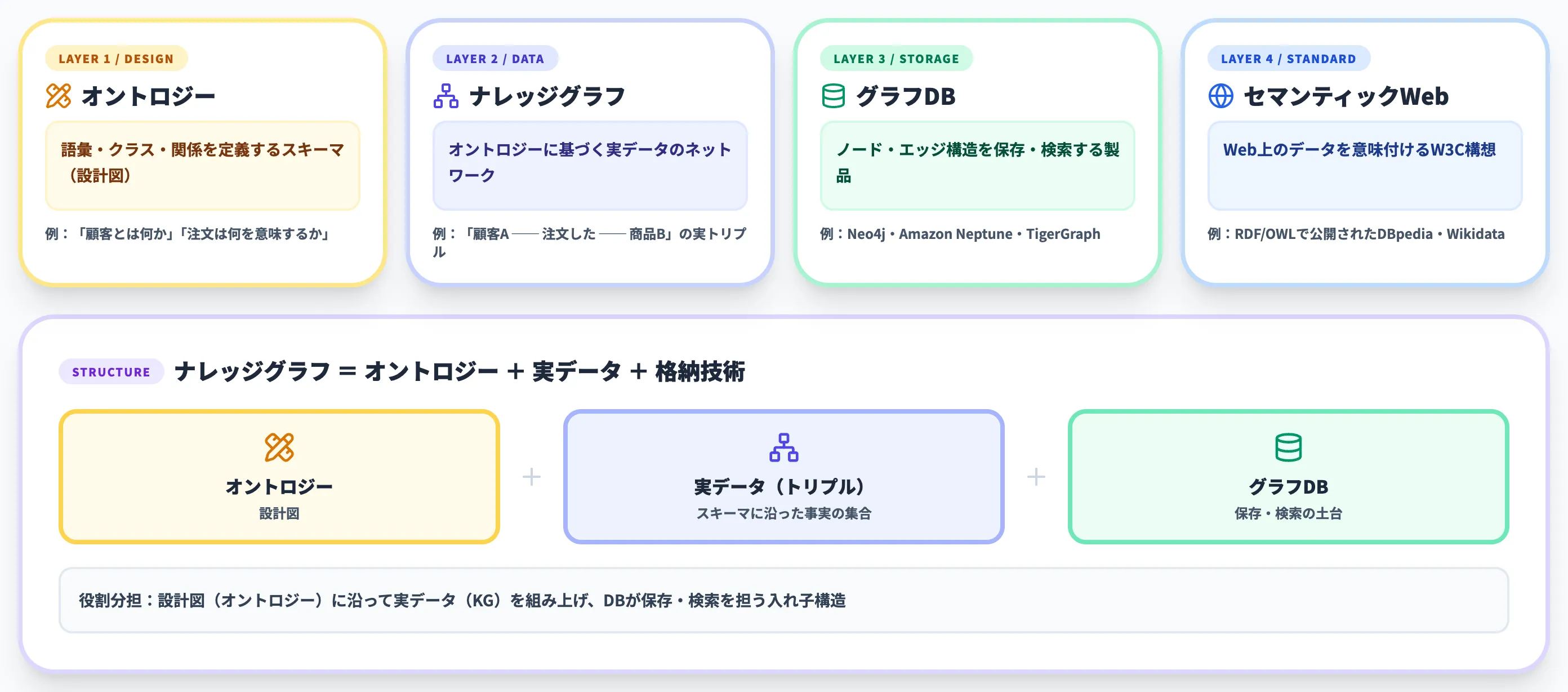
4つの概念の関係整理
以下の表で、ナレッジグラフと周辺概念の違いをまとめます。
| 概念 | 役割 | 具体例 |
|---|---|---|
| オントロジー | 語彙・クラス・関係の定義(スキーマ・設計図) | 「顧客とは何か」「注文は顧客が商品に対して行う行為である」を定義 |
| ナレッジグラフ | オントロジーに基づく実データのネットワーク(実装・事実の集まり) | 「顧客A ── 注文した ── 商品B」という実トリプル |
| グラフDB | ノード・エッジ構造を効率的に保存・クエリできるデータベース製品 | Neo4j、Amazon Neptune、TigerGraph |
| セマンティックWeb | Web上のデータに意味付けして機械可読にするW3Cの構想 | RDF/OWLで公開されたDBpedia、Wikidata |
この整理から重要なのは、ナレッジグラフ=オントロジー+実データ+格納技術という入れ子構造になっている点です。
オントロジーはスキーマ(設計図)であり、ナレッジグラフはそのスキーマに従って投入された実データの集合、グラフDBはそれを保存・検索する土台、という役割分担になります。
オントロジーとナレッジグラフの関係
先行して公開したオントロジーとは?の記事でも触れていますが、両者の関係は建築になぞらえると理解しやすくなります。
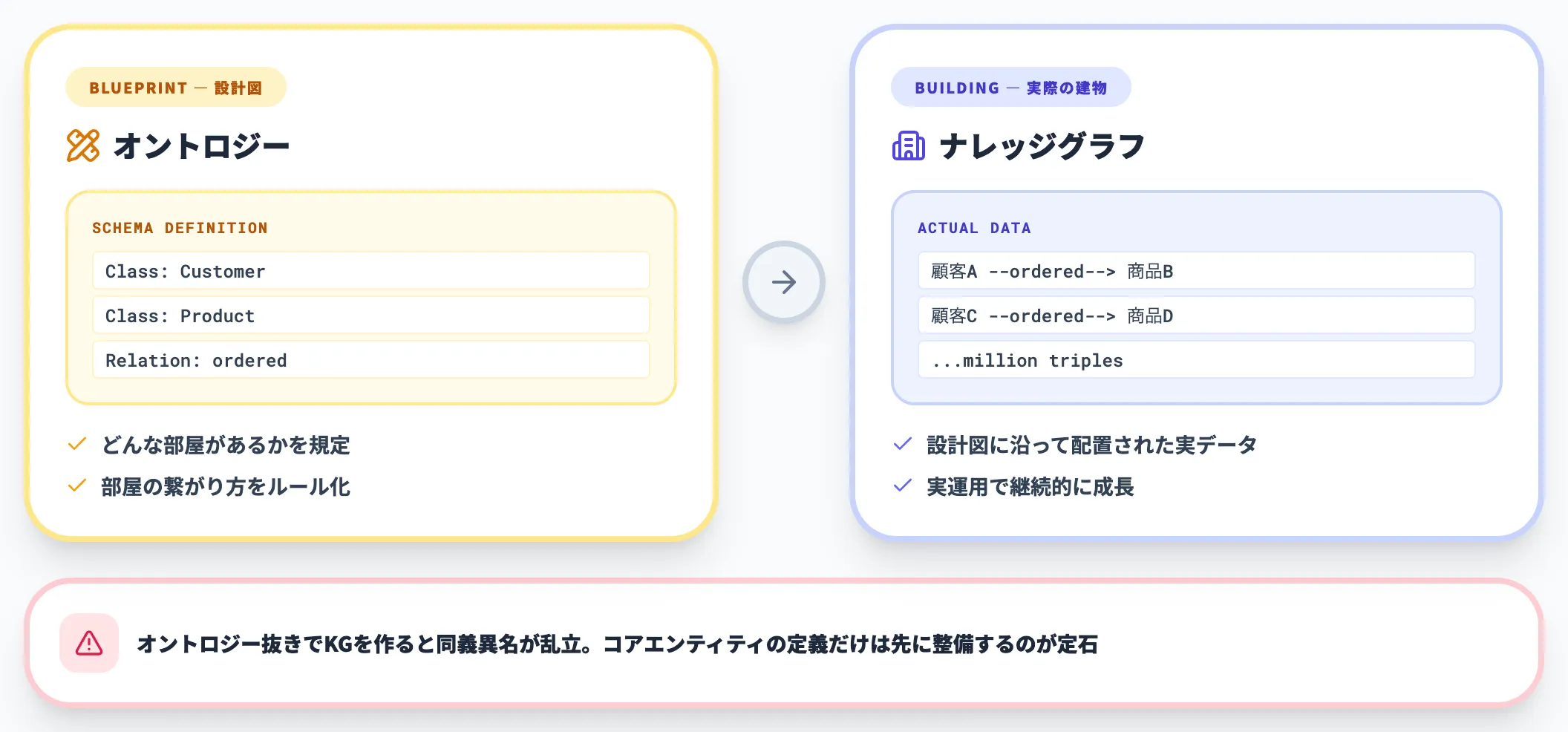
- オントロジー 建築の設計図(どんな部屋があって、どう繋がっているかのルール)
- ナレッジグラフ 実際に建った建物(設計図に従って配置されたデータ)
実務的には、オントロジーをまったく定義せずにナレッジグラフを作ることもできます。
しかし、その場合は「エンティティの型や関係の意味が揺れる」「部門ごとに同義異名が乱立する」といった問題が発生しやすくなります。
エンタープライズでの本格利用では、最低限のオントロジー(コアエンティティ・コアリレーションの定義)をセットで整備するのが定石です。
リレーショナルDB・ドキュメントDBとの違い
グラフ系以外のDBと比較した場合、最大の違いは関係性の表現力です。
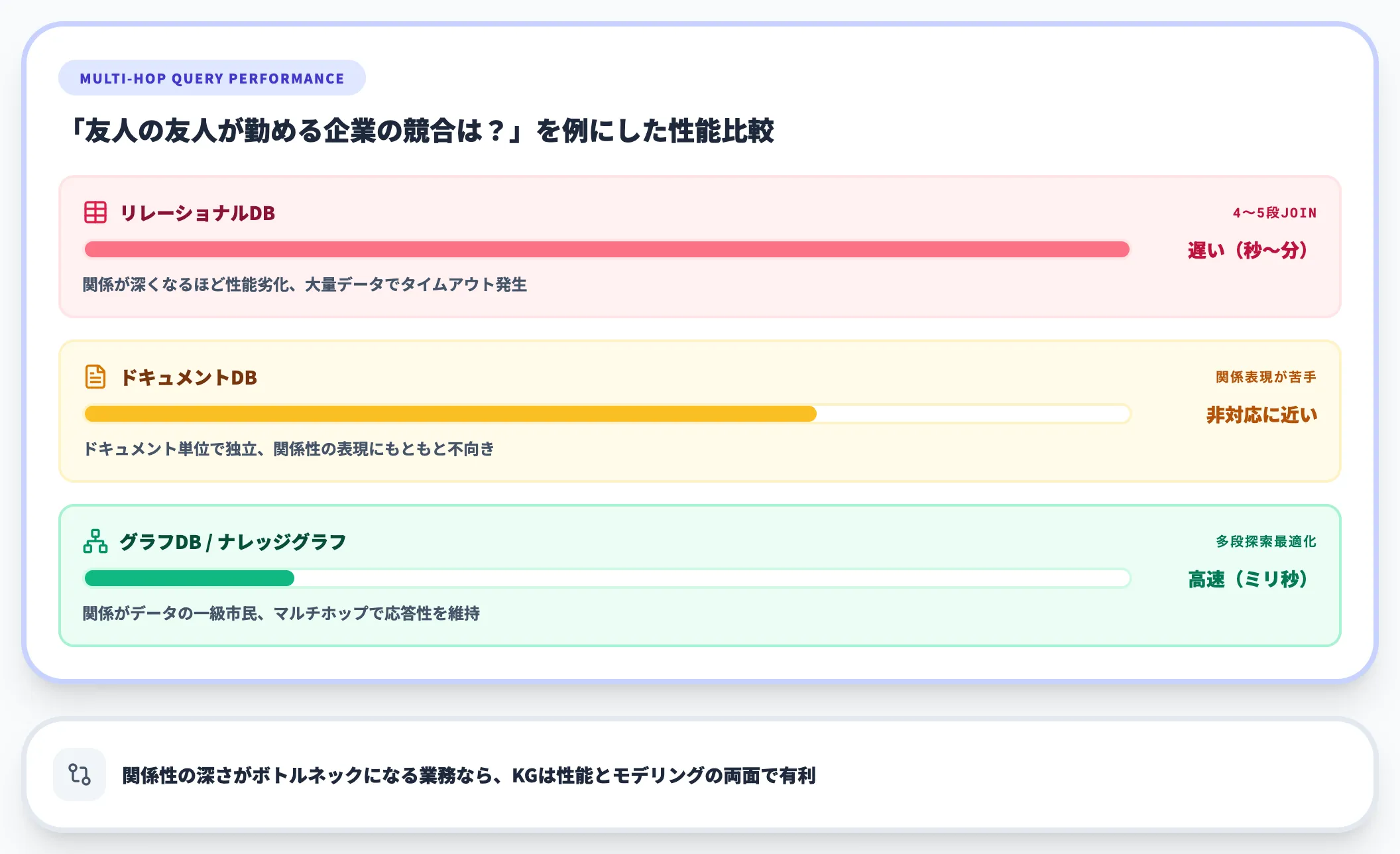
- リレーショナルDB(MySQL・PostgreSQL等) JOINで関係を都度計算する方式。関係が深い(多段JOIN)ほど性能が劣化
- ドキュメントDB(MongoDB等) ドキュメント単位で独立し、関係性の表現は苦手
- グラフDB/ナレッジグラフ 関係がデータの一級市民。多段の関係探索(マルチホップクエリ)が高速
特にマルチホップクエリ(例:「友人の友人が勤める企業の競合は?」)は、リレーショナルDBではJOINが4〜5段必要になり性能的に厳しい一方、ナレッジグラフは多段探索に最適化されたデータモデルで応答性を維持しやすい構造です。
関係性の深さがボトルネックになっている業務は、ナレッジグラフの得意領域といえます。
なぜAIエージェント時代にナレッジグラフが再評価されているのか
ナレッジグラフ自体は1990年代から研究されてきた概念です。にもかかわらず2026年に世界中の企業が改めて注目している背景には、生成AIとAIエージェントの本格稼働による3つの構造変化があります。
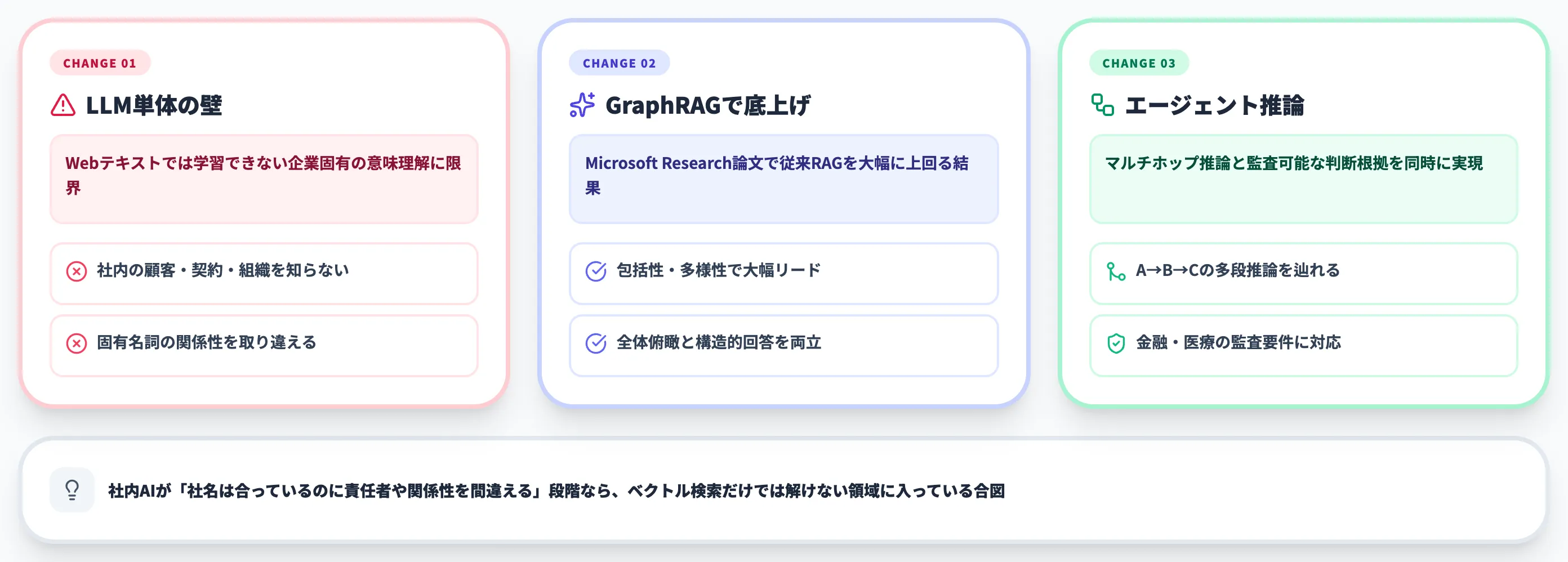
LLM単体では解けない企業知識の壁
大規模言語モデル(LLM)は、Web上のテキストを大量に学習しているため、一般的な知識や言語理解では高い性能を発揮します。
しかし、次のような「企業固有の知識」は学習していません。
- 社内の顧客・商品・契約の個別エンティティ
- 自社の組織構造・承認ルール・商流
- プロジェクト間の依存関係、人事・スキルの紐づけ
- 2026年時点の最新の社内状況
そのため、社内でRAG(検索拡張生成)を構築しても、チャンク同士の文脈がつながらず曖昧な回答になる、固有名詞の関係性を取り違える、といった失敗が頻発します。
ナレッジグラフは、この「企業固有の意味」を構造化して扱えるため、LLMの弱点を補完する役割を担います。
もし社内AIの回答が「社名は合っているのに、関係性や責任者を間違える」状態に陥っているなら、単なるベクトル検索では解けない段階に入っている合図です。
GraphRAGによるRAG精度の底上げ
2024年にMicrosoft Researchが発表したGraphRAG論文は、従来のベクトルRAGにナレッジグラフを組み合わせたアプローチです。

「100万トークン規模のプライベートなテキストコーパスに対するグローバルな意味理解タスク」で、包括性(Comprehensiveness)と多様性(Diversity)の双方で、ベースラインRAGを大幅に上回ることを報告しています。
ポイントは、単にドキュメント断片を引くのではなく、エンティティ・リレーションを抽出してグラフを構築し、コミュニティ検出(Leiden algorithm)でグラフをクラスタに分割、クラスタ単位の要約を作ることで全体像の理解が可能になる点です。
従来のRAGが「切り出されたテキスト片」しか見られなかったのに対し、GraphRAGは「関係性を踏まえた構造的回答」を返せます。
AIエージェントのマルチホップ推論
AIエージェントの自律的な判断には、「Aが起きたとき、Bに影響があるため、Cを実行する」といった多段の論理推論が求められます。LLM単体ではハルシネーションが発生しやすい領域ですが、ナレッジグラフがあれば事実関係を検証可能な形で辿れるため、エージェントの判断精度と説明責任が向上します。
Palantir・Microsoft・Neo4jといった主要ベンダーが、エージェント基盤としてナレッジグラフを前面に押し出しているのもこの背景です。
特に「エージェントが何を根拠に結論を出したのか」を監査できる点は、金融・医療・公共セクターでは必須要件になります。
ナレッジグラフのエンタープライズ活用シナリオ
ナレッジグラフは2026年現在、以下のシナリオで実績が積み上がっています。
特に関係性の複雑度が高く、従来のBIやベクトル検索では捕捉しきれない領域で効果を発揮します。

カスタマー360(Customer 360)
顧客・契約・問い合わせ・製品・関連企業をグラフでつなぎ、「この顧客に影響する他部門の動き」「関連企業の取引状況」を一画面で可視化する用途です。
Stardogのユースケースでは、従来のCRMでは分断されていた「親会社・子会社・サブコントラクター」の相関関係を統合的に追跡し、解約予兆の早期検知に活用されている事例が紹介されています。
サプライチェーンと製造業
製造業では、部品・サプライヤー・設備・製品のネットワーク関係をナレッジグラフで管理することで、サプライヤー起因のリスク波及を可視化できます。
Cogniteの産業ナレッジグラフは、設備のセンサーデータ・設計情報・保守履歴をグラフ化し、故障予兆の早期検知や現場エンジニアの意思決定支援に利用されています。
不正検知・金融コンプライアンス
金融機関では、口座・取引・IPアドレス・デバイス・住所などをつないだグラフで、マネーロンダリングやアカウント乗っ取りの検出に活用されます。
リレーショナルDBではJOINが深くなって検出に時間がかかる「4段先の関連口座」も、グラフDBの多段探索で処理しやすくなります。
Neo4jやTigerGraphは、金融不正・AML領域の事例を公開しています。
サイバーセキュリティ
ログ・脆弱性・資産・ID・アラート・脅威インジケータを相互接続し、攻撃経路の追跡と横展開(ラテラルムーブメント)の検知に使う用途です。
インフラを相互接続されたグラフとして表現することで、コンテキスト豊富な分析と誤検知の削減が可能になります。
SOC(Security Operation Center)の運用効率化を目的としたナレッジグラフ導入は、2026年以降の主要トレンドの一つです。
医薬・ライフサイエンス研究
論文・化合物・ターゲット・臨床データ・遺伝子をつないだグラフで、創薬候補の絞り込みや既存薬の新規適応症発見に活用されています。
各研究所が異なる用語・フォーマットを使う課題を、共通オントロジーとナレッジグラフで解消するアプローチが主流です。AstraZenecaやBayerといった大手製薬企業の論文・事例公開も相次いでいます。
人材・スキルマッチング
LinkedInのEconomic Graphは、プロフェッショナル・企業・教育機関・スキルの関係を大規模に表現したナレッジグラフの代表例です。
労働市場のトレンド分析、人材マッチング、スキルベースの学習パス提案などに利用されています。社内でも、従業員・スキル・プロジェクト・案件履歴を結んだ人材グラフを構築することで、適任者の自動推薦や離職リスクの早期検知に活用できます。
知識ベースQ&A/社内検索
社内ドキュメント・チケット・Wiki・Slack履歴を統合したナレッジグラフは、社内版Google Knowledge Graphとして機能します。「この案件の責任者は誰?」「過去の類似トラブルは?」といった曖昧な質問にも、グラフ構造を辿って回答できるようになります。
Gleanのレポートでも、エンタープライズAIの必須コンテキスト基盤としてナレッジグラフの重要性が強調されています。
ここで紹介した7つのシナリオに共通するのは、「データとデータの関係を辿れないと答えが出ない業務」という点です。
関係性の深さがボトルネックになっている業務ほど、ナレッジグラフのROIが出やすくなります。逆に、単発のFAQ検索や定型的な帳票処理しか求められない業務では、従来のベクトルRAGやRDBで十分です。

主要ナレッジグラフプラットフォーム比較
2026年時点で、エンタープライズが選択できる主要なナレッジグラフプラットフォームは以下の通りです。
以下の比較表で特徴を整理したあと、それぞれの向き不向きを解説します。
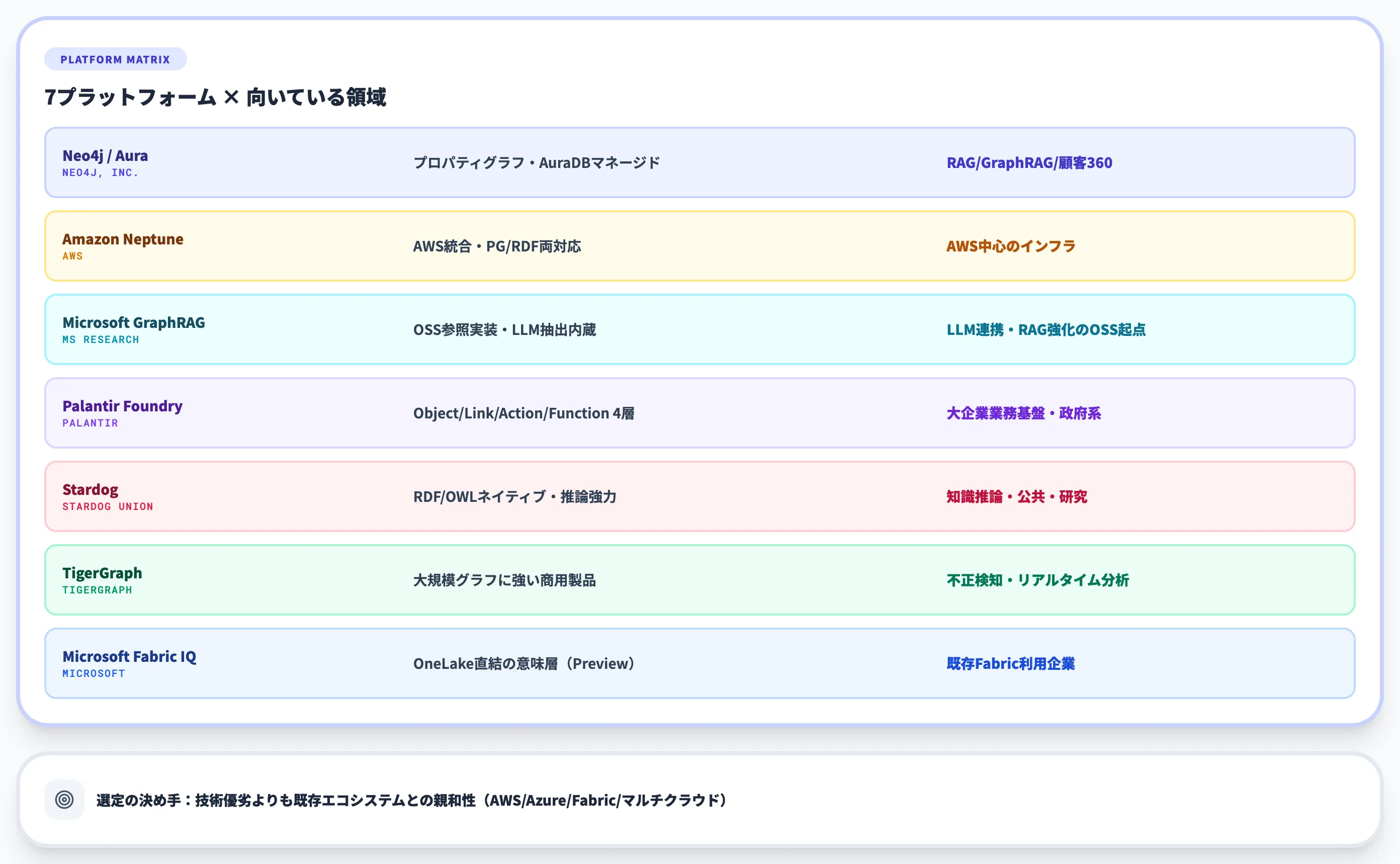
| プラットフォーム | ベンダー | 特徴 | 向いている領域 |
|---|---|---|---|
| Neo4j | Neo4j, Inc. | プロパティグラフ系の有力な選択肢。AuraDBはマネージド提供 | RAG/GraphRAG/カスタマー360 |
| Amazon Neptune | AWS | AWS統合・プロパティグラフとRDF両対応 | AWS中心のインフラ環境 |
| Microsoft GraphRAG | Microsoft Research | GraphRAGのオープンソース参照実装 | LLM連携・RAG強化のOSS起点 |
| Palantir Foundry Ontology | Palantir Technologies | Object/Link/Action/Functionの4層構造。AIP Agent Studio連携 | 大企業の業務基盤・政府系 |
| Stardog | Stardog Union | RDF/OWLネイティブ・推論エンジン強力 | 知識推論・公共・研究 |
| TigerGraph | TigerGraph, Inc. | 大規模グラフに強い商用製品 | 不正検知・リアルタイム分析 |
| Microsoft Fabric IQ Ontology | Microsoft | OneLake直結の意味層 | 既存Fabric利用企業 |
この比較から実務で押さえるべきポイントは、「既存の業務基盤との親和性」が選定の最大要因になるという点です。
AWS中心ならNeptune、Azure/Fabric中心ならFabric IQ、オンプレ/マルチクラウドならNeo4j、というように、技術的優劣よりもエコシステム統合が決め手になります。
Neo4j/Neo4j Aura
Neo4jは、プロパティグラフモデルで広く利用されているグラフDBです。Cypherクエリ言語、豊富なドライバ、Neo4j GraphRAG PythonパッケージによるLLM連携が整備されており、2026年の新規案件で有力候補として挙げられるケースが増えています。
クラウドマネージド版のAuraDBはAWS・Azure・GCPマーケットプレイスから利用でき、無料枠のAuraDB Freeも提供されています。
2026年2月には、後述するNeo4j Aura Agent(ノーコードでエージェントを構築・デプロイできるマネージドサービス)がGAに到達し、単なるDBからエージェント実行基盤へと拡張が進んでいます。
Microsoft GraphRAG
Microsoft GraphRAGは、LLMを使ってドキュメントからエンティティ・リレーションを抽出し、ナレッジグラフを自動構築するオープンソース実装です。
Neo4j公式が発表したMS GraphRAG統合ガイドでは、「Microsoft GraphRAGでグラフ構築 → parquet経由でNeo4jに格納 → LangChain/LlamaIndexからエージェント統合」という組み合わせが、統合パターンの一例として紹介されています。
Palantir Foundry Ontology
PalantirのFoundry Ontologyは、Object / Link / Action / Functionの4層構造でナレッジグラフを拡張したエンタープライズ基盤です。
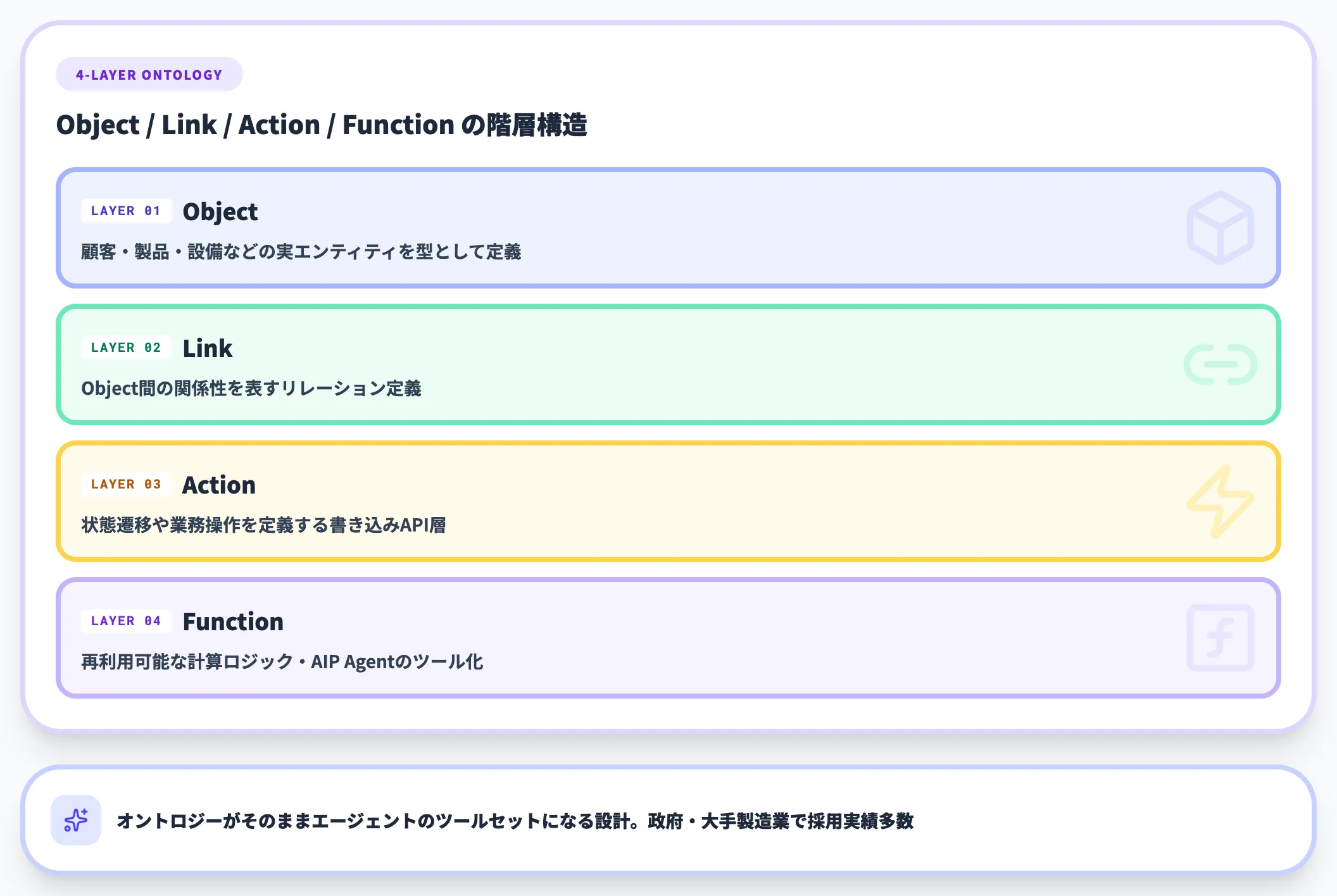
AIP Agent Studioと統合されており、オントロジーをエージェントのツールとしてそのまま渡せる強みがあります。大規模政府案件・軍事・大手製造業で多数の実績があり、伴走型導入を前提とする企業に向きます。
Microsoft Fabric IQ Ontology
2026年にプレビュー提供されたFabric IQ Ontologyは、OneLake上のデータに直接バインドできるエンタープライズ語彙・意味層です。
Fabric IQではOntology/Graph/Data agent/Operations agent/Power BI semantic modelsが別アイテムとして提供されており、Ontologyは意味層、Graph(プレビュー)はノード・エッジ・トラバーサルの実行基盤という役割分担になっています。
したがってナレッジグラフ基盤として用いるなら、Ontology + Graph の組み合わせで設計するのが前提です。既存のFabric環境から段階的に意味層を整備したい企業に向きます。
GraphRAG:ベクトルRAGからの進化
2026年のナレッジグラフ活用で最も注目されているのがGraphRAG(Graph Retrieval-Augmented Generation)です。
従来のベクトルRAGとの違い、Local Search/Global Searchの使い分け、そしてペイしない場面を整理します。
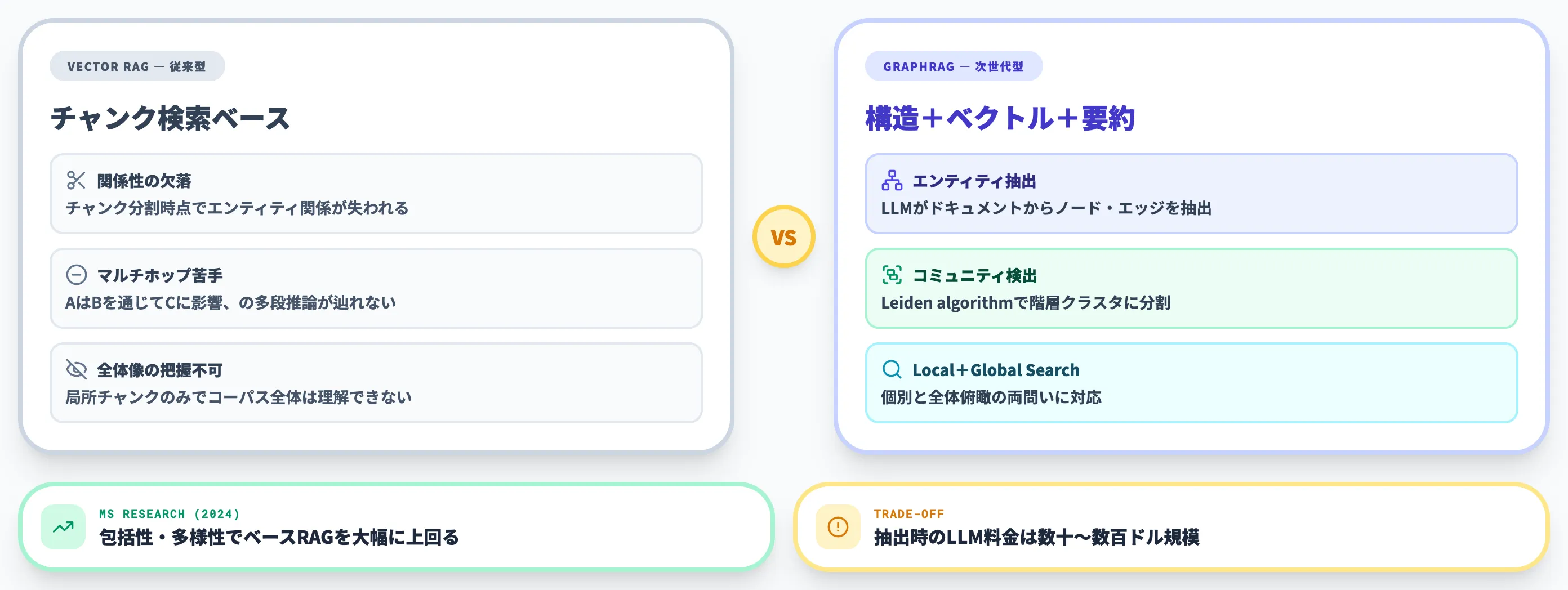
従来のベクトルRAGの限界
一般的なRAGは、ドキュメントをチャンクに分割し、ベクトル検索で類似度の高い断片を取ってきてLLMに渡す方式です。
立ち上がりが早く、シンプルで扱いやすい反面、以下の弱点があります。
-
関係性の欠落
チャンクを切り出した時点で、エンティティ間の関係情報が失われる
-
マルチホップが苦手
「AはBを通じてCに影響する」のような多段の論理が辿れない
-
全体像の把握不可
局所的なチャンクしか見えず、データセット全体の構造は理解できない
GraphRAGの仕組み
Microsoft Researchが提唱するGraphRAGは、以下の4ステップで動作します。

-
グラフ構築
LLMを使ってドキュメントからエンティティ・リレーションを抽出し、ナレッジグラフを構築
-
コミュニティ検出
Leiden algorithmでグラフを階層的クラスタに分割
-
コミュニティ要約
各クラスタの要約をLLMで生成し、階層的に保持
-
検索戦略の使い分け
質問をLocal Search(ローカルコンテキスト)/Global Search(全体俯瞰)で処理し、グラフ+ベクトル+要約を統合
Local Search vs Global Search
GraphRAGの核心は、2種類の検索戦略を使い分けられる点です。
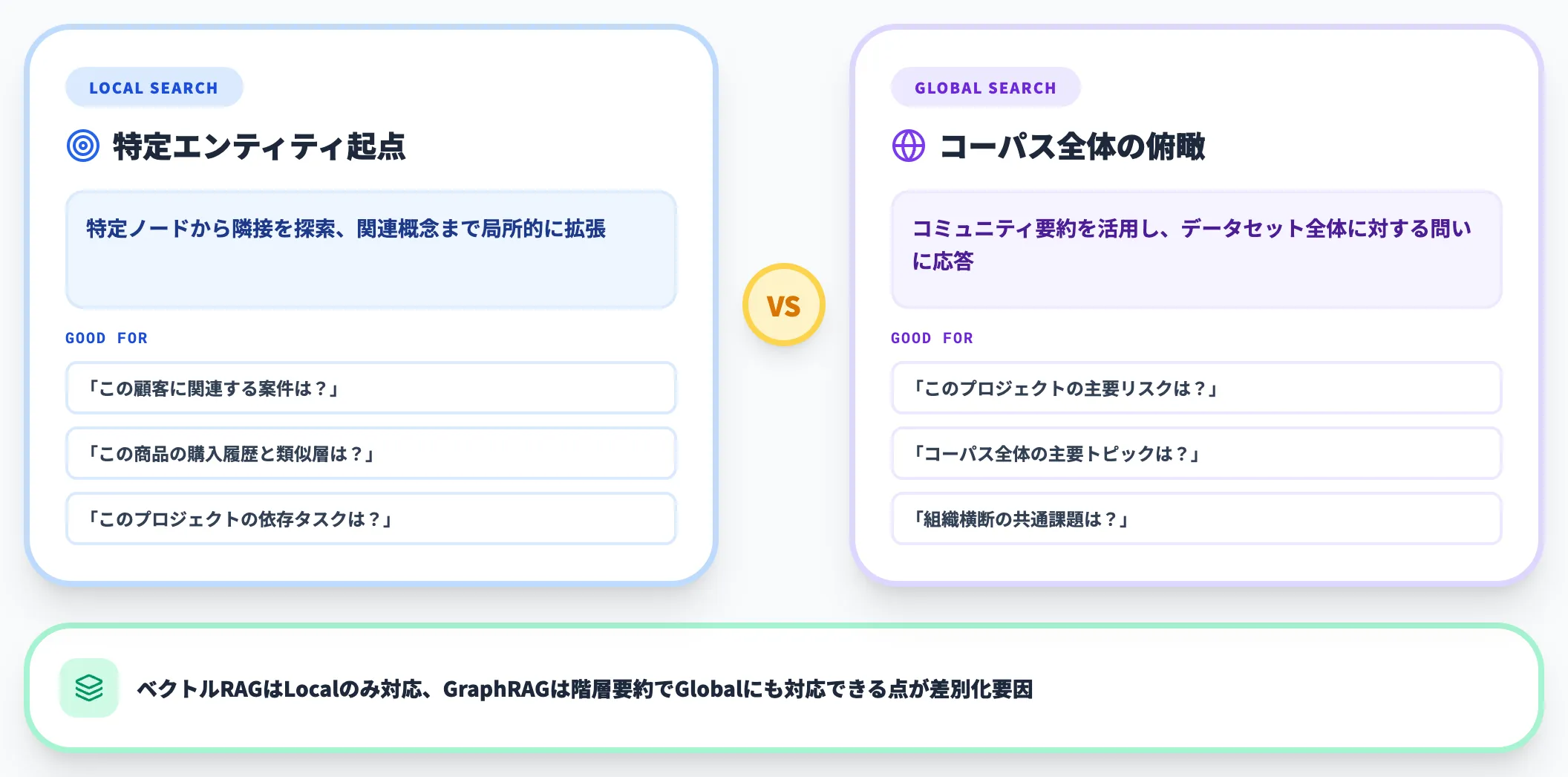
- Local Search 特定のエンティティを起点に、隣接ノードと関連概念へ拡張して回答する検索方式。「この顧客に関連する案件は?」といった局所的な問いに強い
- Global Search コーパス全体のコミュニティ要約を活用し、データセット全体に関する総合的な質問に答える検索方式。「このプロジェクトの主要リスクは?」といった全体俯瞰型の問いに強い
従来のベクトルRAGがLocal Search相当の限定的な検索しかできなかったのに対し、GraphRAGは階層的コミュニティ要約によってGlobal Searchにも対応できます。
これが、センスメイキング型タスクでベクトルRAGを大幅に上回る理由です。
GraphRAGが有効な場面 / ペイしない場面
GraphRAGは万能ではありません。構築コストに見合うかの判断軸を、明確にしておきましょう。
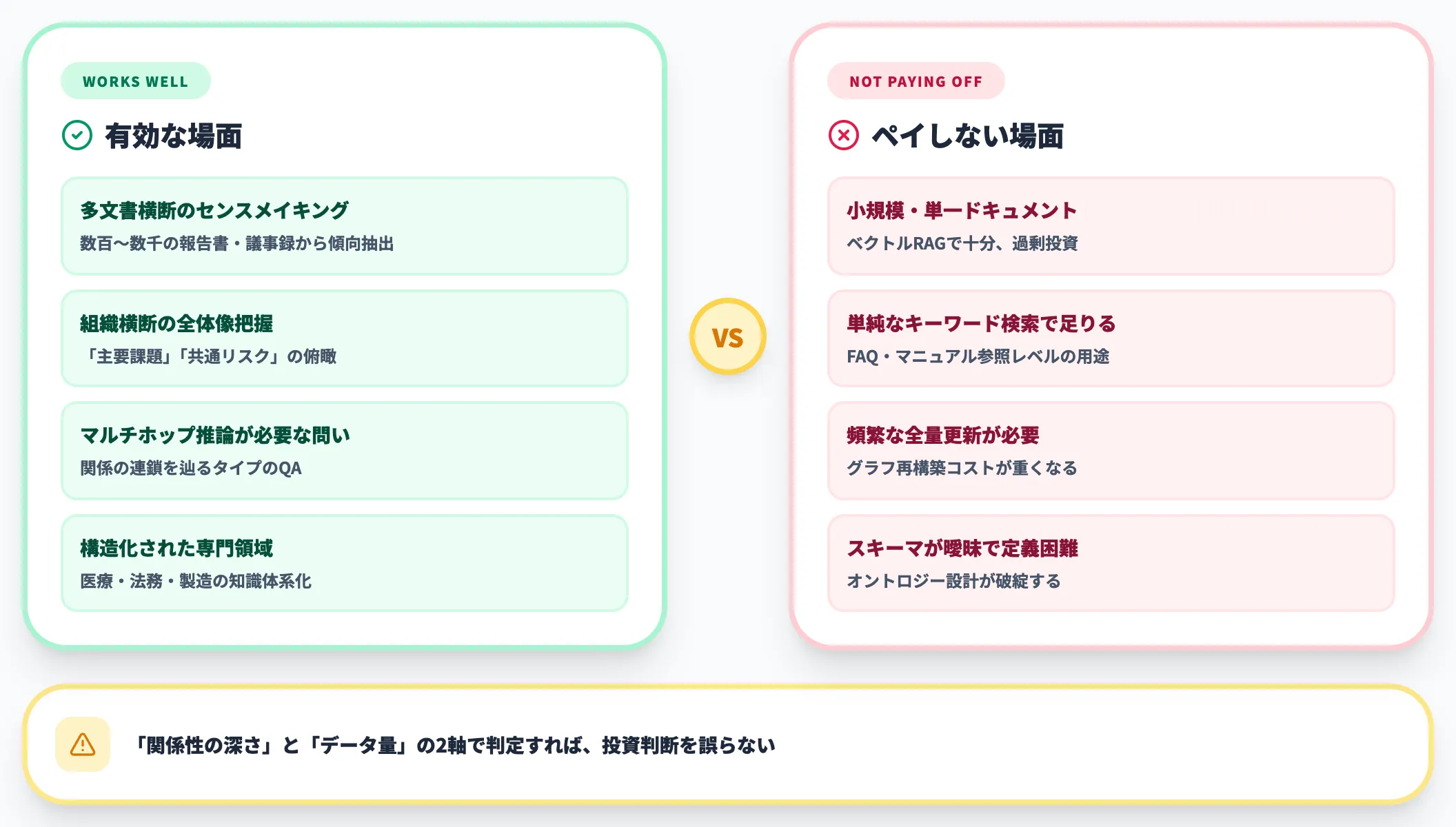
- GraphRAGが有効 複雑なセンスメイキング、マルチホップ質問、全体俯瞰、関係性ベースの推論が必要な業務
- ベクトルRAGで十分 単純なFAQ、ドキュメント検索、1ショットの類似文書検索で事足りる用途
ナレッジグラフ構築時のLLM抽出コスト(100〜1000万トークンの読み込み)は、数十〜数百ドル規模で発生します。
そのため、年に数回しか利用しない業務ではペイしません。一方、日次・時次でクエリが発生するカスタマー360やセキュリティ領域では、初期コストを回収しやすい構造です。
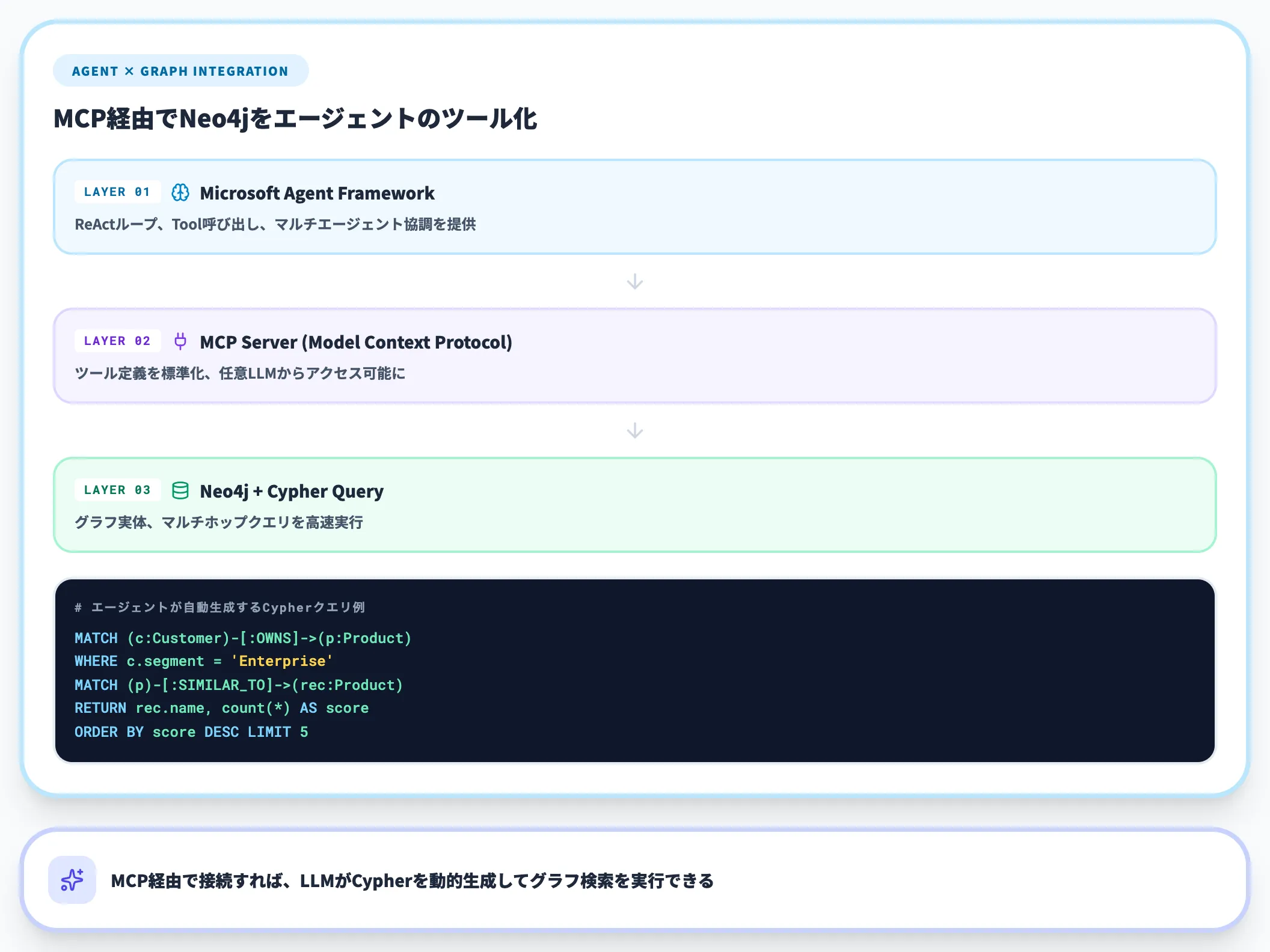
Microsoft Agent Framework × Neo4j の実装例
Microsoft Learnに公開されたNeo4j GraphRAG Context Providerを使うと、Agent FrameworkからNeo4jナレッジグラフをコンテキストソースとして扱う実装を、数十行で構築できます。Pythonでの最小例は以下の通りです。
from agent_framework import Agent
from agent_framework.foundry import FoundryChatClient
from agent_framework_neo4j import (
Neo4jContextProvider, Neo4jSettings, AzureAISettings, AzureAIEmbedder,
)
from azure.identity.aio import AzureCliCredential
neo4j_settings = Neo4jSettings()
azure_settings = AzureAISettings()
neo4j_provider = Neo4jContextProvider(
uri=neo4j_settings.uri,
username=neo4j_settings.username,
password=neo4j_settings.get_password(),
index_name=neo4j_settings.vector_index_name,
index_type="vector", # vector / fulltext / hybrid
embedder=AzureAIEmbedder(...),
top_k=5,
retrieval_query="""
MATCH (node)-[:FROM_DOCUMENT]->(doc:Document)
OPTIONAL MATCH (doc)<-[:FILED]-(company:Company)
RETURN node.text AS text, score,
doc.title AS title, company.name AS company
ORDER BY score DESC
""",
)
async with (
neo4j_provider,
AzureCliCredential() as credential,
Agent(
client=FoundryChatClient(credential=credential, ...),
instructions="You are a financial analyst assistant.",
context_providers=[neo4j_provider],
) as agent,
):
session = agent.create_session()
response = await agent.run("What risks does Acme Corp face?", session=session)
このアプローチの利点は3つあります。
- 検索モードの柔軟性 vector(セマンティック類似)/fulltext(BM25キーワード)/hybrid(両者の組み合わせ)を切り替え可能
- Cypherで関係性を自由に辿れる
retrieval_queryに書いたCypherで、関連エンティティまで一括取得できる - 既存ベクトル検索からの段階移行 最初はベクトルRAGで運用し、精度の壁に当たった段階でグラフ要素を足していく進め方が現実的
AIエージェント×ナレッジグラフの統合パターン
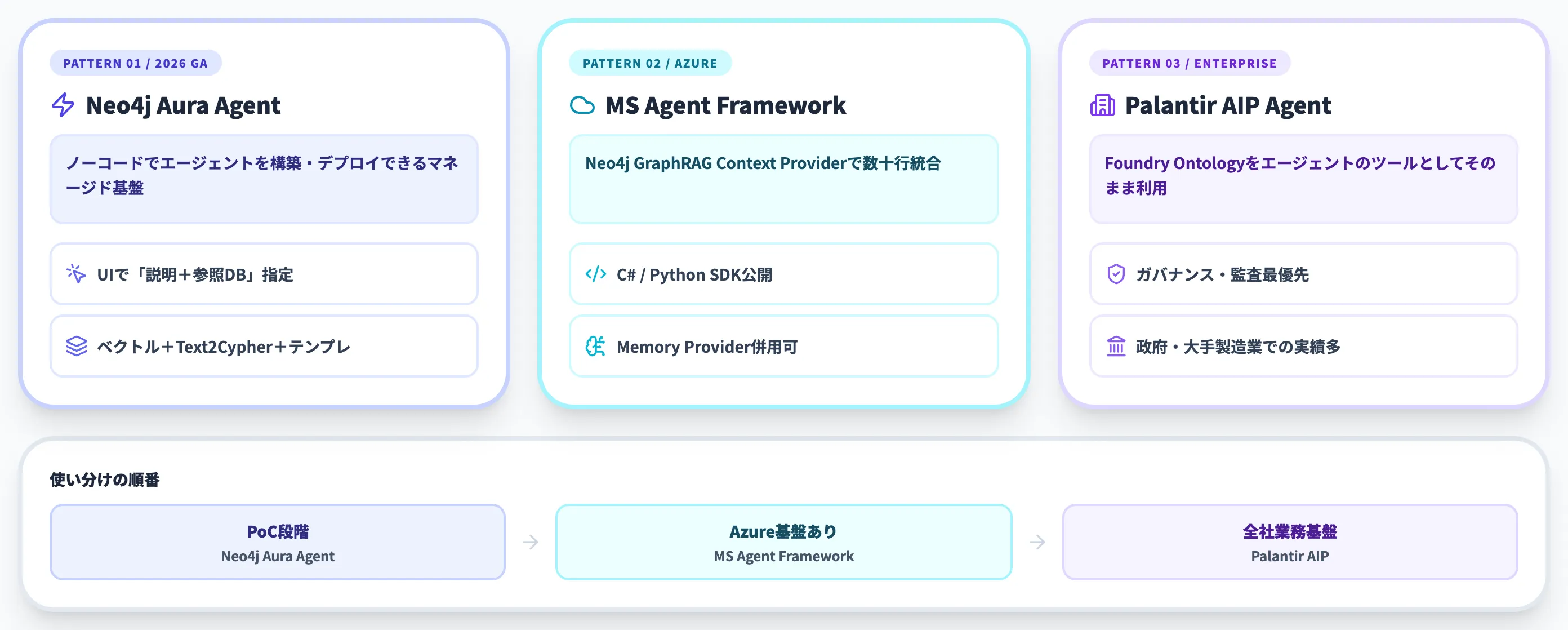
2026年は、ナレッジグラフをAIエージェントの「判断基盤」として組み込む構成が広がりを見せています。
ここでは代表的な3パターンを、成熟度の違いも踏まえて整理します。
Neo4j Aura Agent
Neo4j Aura Agentは、2026年2月にGAした、ナレッジグラフとAIエージェントを統合したマネージド基盤です。UI上で「タイトル・説明・システムプロンプト・参照するグラフDB」を指定するだけで初期エージェントを自動生成でき、以下の3種類の検索手法を組み合わせて動作します。
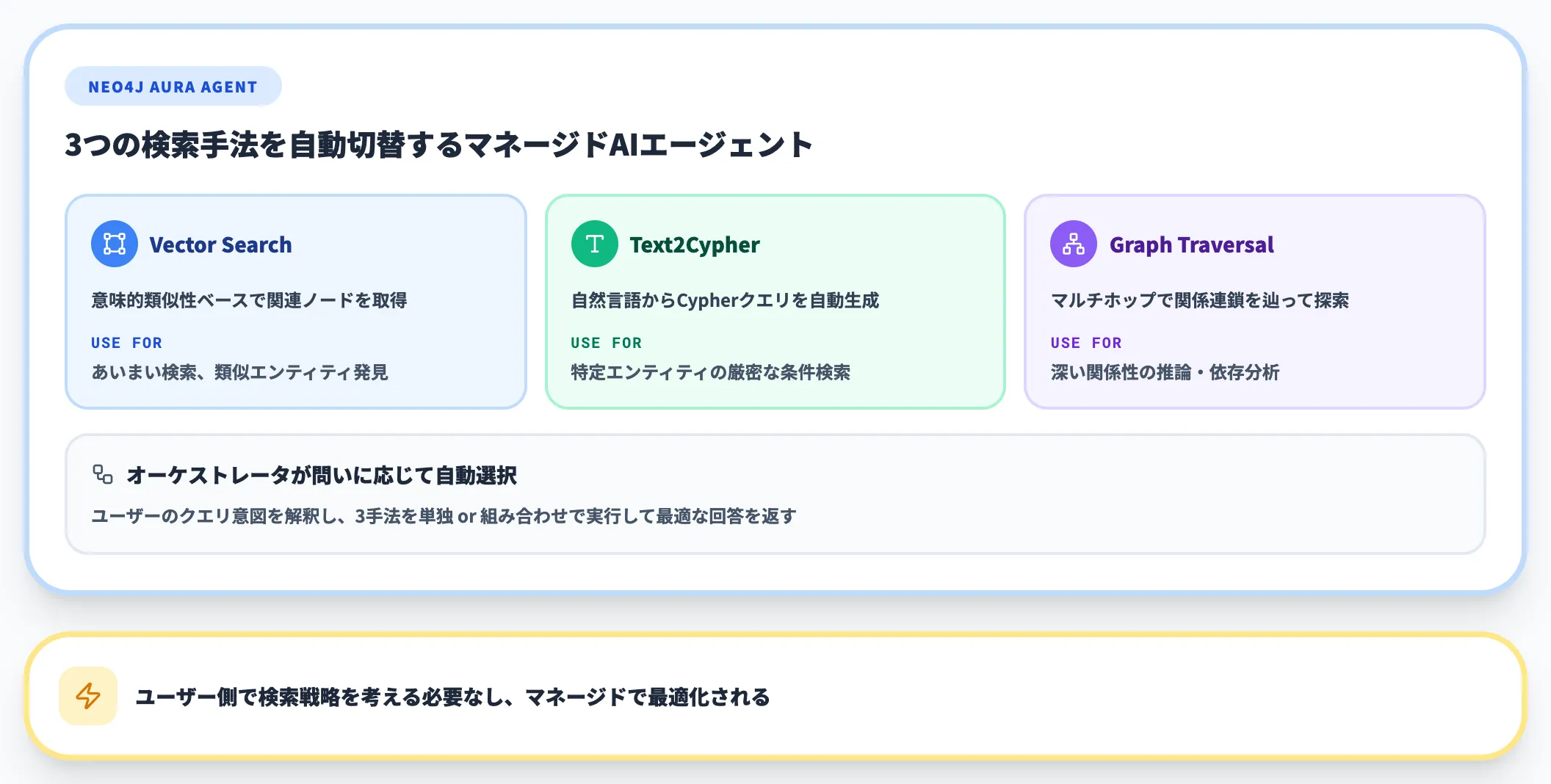
- ベクトル類似度検索 関連エンティティをマッチングし、グラフ走査で文脈を補強
- Text2Cypher グラフスキーマに基づき、自然言語からCypherクエリを動的生成
- Cypherテンプレート 事前パラメータ化された安全なクエリを実行
ノーコードでエージェントを構築したい企業や、すでにNeo4jを使っている企業にとっては、MCP統合・APIキー認証・本番デプロイまで一気通貫で動かせる点が強みです。
Microsoft Agent Framework × Neo4j GraphRAG
Azure基盤で生成AIを運用している企業向けには、前節で触れたMicrosoft Agent FrameworkのNeo4j GraphRAG Context Providerが選択肢になります。Agent Frameworkは現行ドキュメントでprereleaseパッケージ指定が見られる段階ですが、Azure AI Foundry・Azure OpenAIと連携するC#/Python SDKが公開されています。Neo4j側にAuraDB、Foundry側にGPT-4o系モデル+埋め込みモデルを置く組み合わせが、公式ドキュメントのサンプルで示されています。
加えて、Neo4jはMemory Provider(会話履歴からナレッジグラフを自動構築する永続メモリ)も公開しており、「既存グラフに問い合わせるGraphRAG」と「会話から育てるメモリ」を同じAgent Framework上で共存させられます。エージェントに「知識を蓄積する機能」を持たせたいケースで有効です。
Palantir Foundry + AIP Agent Studio
大規模エンタープライズ案件では、Palantir AIPのAgent Studioが代表的な選択肢です。
Foundry Ontologyで定義されたエンティティ・アクション・関数を、エージェントが直接ツールとして呼び出せる構造になっており、「オントロジーがそのままエージェントのツールセットになる」という設計思想が特徴です。
政府機関や大手製造業で採用事例が多く、ガバナンス・監査性を重視する業界に向きます。
3パターンの使い分け
3つの統合パターンは、それぞれ向く領域が異なります。
- Neo4j Aura Agent ノーコードで立ち上げたい/Neo4jを既に使っている/マルチクラウドで運用したい
- Microsoft Agent Framework × Neo4j Azure・Fabric基盤/Copilotと連携したい/C#/Python開発文化がある
- Palantir AIP Agent Studio ガバナンス・監査性が最優先/大規模業務基盤/伴走型導入の予算がある
現時点でPoC段階ならNeo4j Aura Agent、Azure中心の基盤を持っているならMicrosoft Agent Framework、全社業務基盤として統合するならPalantir、という順で検討するのが実務的な使い分けです。
ナレッジグラフ構築のステップと失敗パターン
ナレッジグラフは「グラフDBを買えば動く」ものではなく、設計と運用の両輪が必要です。
ここでは5ステップの導入フロー、実務で詰まる論点、そして現場でよく見る失敗パターンを整理します。
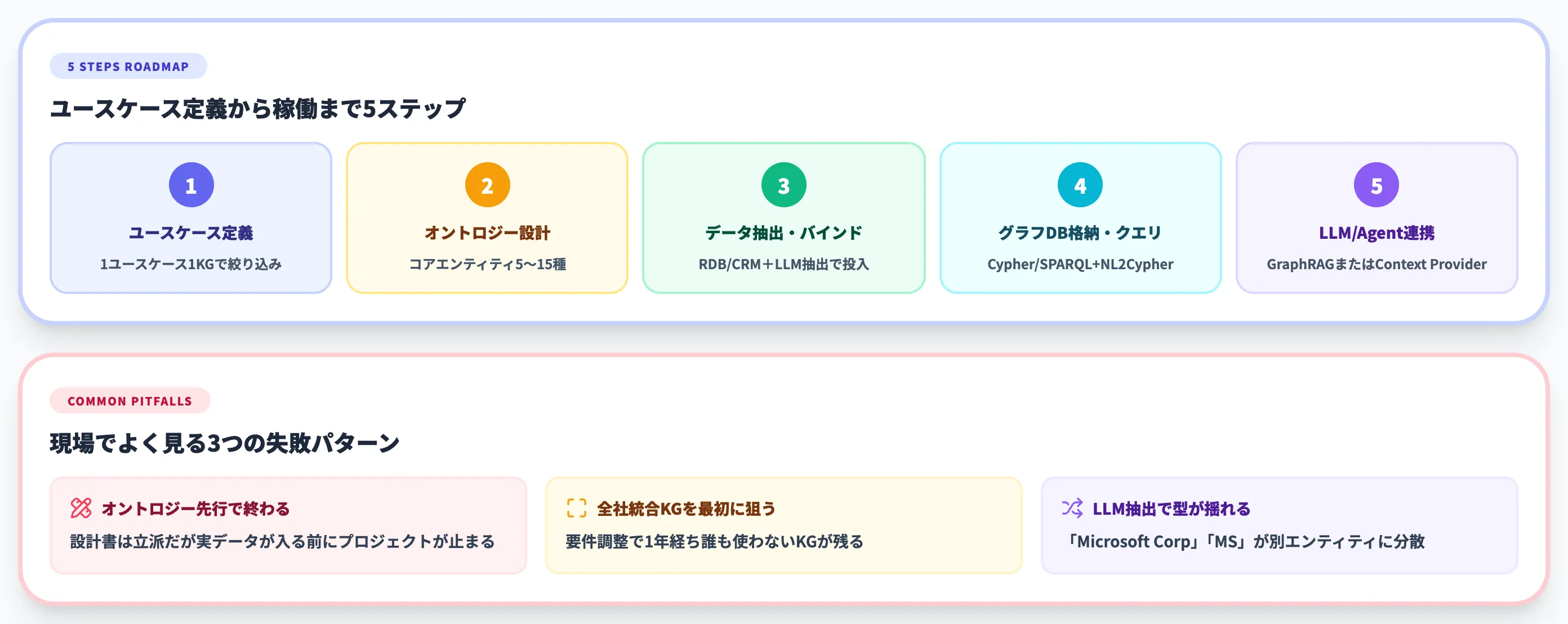
1.対象ドメインとユースケースの定義
最初にやるべきは、「どの業務で・どんな質問に答えるか」を絞り込むことです。全社一斉導入は失敗率が高く、1ユースケース1ナレッジグラフで始めるのが鉄則です。
- カスタマー360なら「解約予兆検知」にターゲットを絞る
- サプライチェーンなら「サプライヤー依存度の可視化」に絞る
- 社内QAなら「過去の類似トラブル検索」に絞る
2.オントロジー(コアスキーマ)の設計
対象ドメインのエンティティ・リレーション・主要属性を定義します。オントロジー設計の詳細は前回記事を参照してください。
ここで手を抜くと、後工程で「同じ顧客が3つの違う名前で入っている」といった問題が噴出します。
コアエンティティは5〜15種、コアリレーションは10〜30種を目安に、最小限から始めて育てるのが現場で通用するやり方です。
3.データソースからの抽出とバインド
既存の構造化データ(RDB・CRM・ERP)からはSQLやETLでトリプルを生成し、非構造化データ(PDF・メール・議事録)からはLLMやNER(固有表現抽出)で抽出します。2026年はLLMによる抽出精度が実用レベルに達しており、Microsoft GraphRAGやLlamaIndexのPropertyGraphIndexが実装の中心になっています。
4.グラフDBへの格納とクエリ層の整備
Neo4j・Neptune・TigerGraphなどにトリプルを投入し、Cypher/SPARQL/Gremlinといったクエリ言語でアクセスできるようにします。自然言語からCypherを生成するNL2Cypher(LangChainのGraphCypherQAChain等)を組み合わせると、業務ユーザーもアクセス可能になります。
5.LLM/AIエージェントとの連携
GraphRAGパターンでLLMに接続するか、Agent Frameworkのコンテキストプロバイダとして登録します。エージェントがCypherクエリを発行しながら推論する構成は、2026年の有力な設計パターンの一つです。
導入判断で詰まる論点
実務で選定・導入に迷う代表的な論点は以下です。
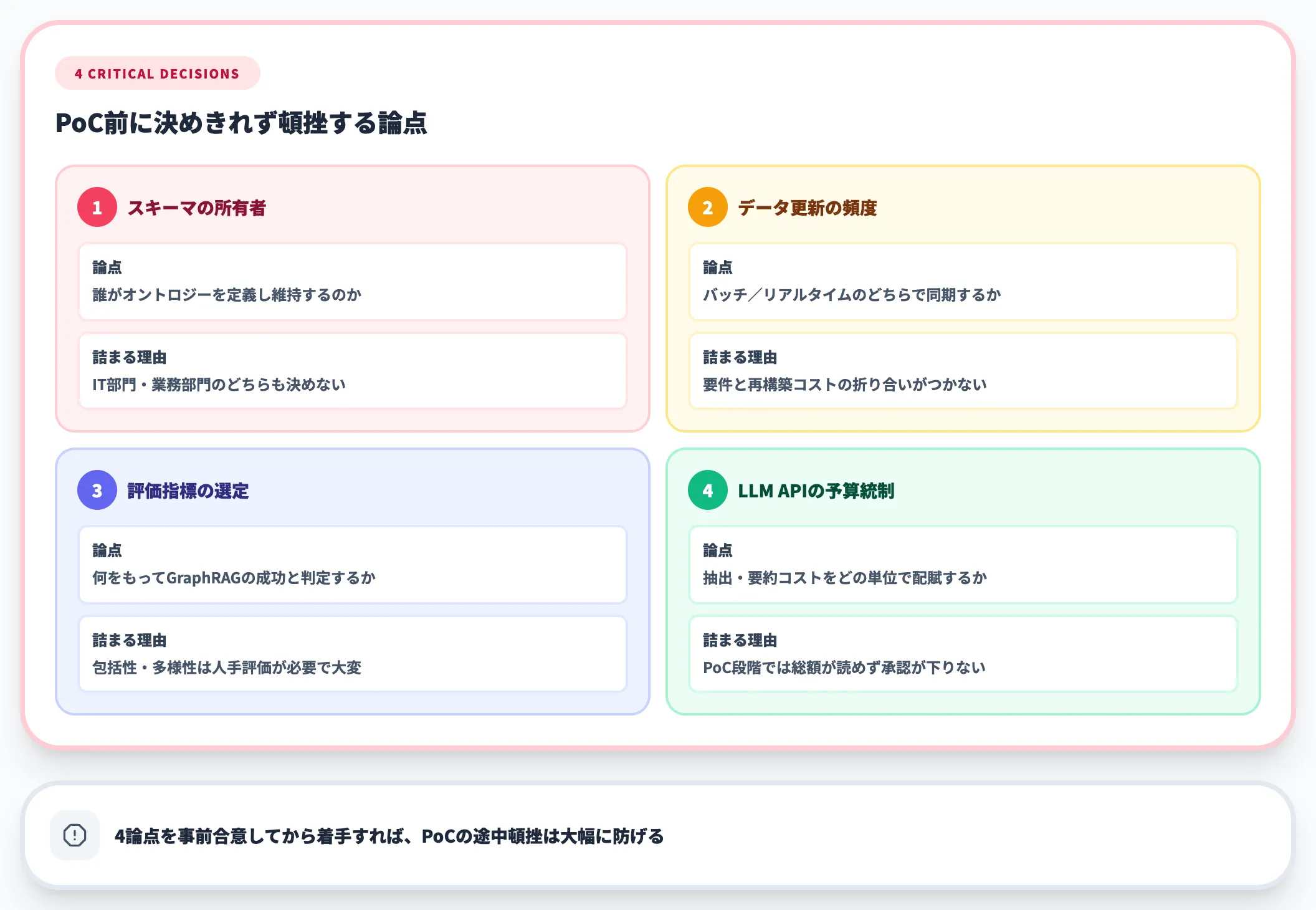
-
RDF vs プロパティグラフ
標準化と推論を重視するならRDF(Stardog等)、開発速度と実装エコシステムならプロパティグラフ(Neo4j)。大半のエンタープライズ案件ではプロパティグラフで十分
-
自前構築 vs プラットフォーム採用
ライセンス費は回避できるが、推論エンジン・可視化・運用ツールをすべて自前実装するコストは甚大。運用・監査・SLA要件が重い案件では商用プラットフォームの採用を検討 -
既存RAGの置き換え範囲
ベクトルRAGを全廃する必要はない。**ハイブリッド検索(ベクトル+グラフ)**で段階移行するのが安全 -
オントロジーの粒度
細かすぎると設計が終わらず、粗すぎると意味が揺れる。コアエンティティ5〜15種、コアリレーション10〜30種を目安に最小限で始める
よくある失敗パターン
最後に、エンタープライズでの導入支援でよく見る失敗を3つ挙げます。着手前にチェックしておくと、後戻りコストを大きく減らせます。

-
オントロジー先行で終わる
設計書は立派だが、実データが入る前にプロジェクトが止まる。最小のコアスキーマで実データを投入し、運用しながら拡張する。「完璧な設計を先に」は失敗への王道
-
全社統合KGを最初から狙う
全部門・全データの統合を目指した結果、要件調整で1年経ち、誰も使わない。1ユースケース1KGで価値を出してから統合する
-
LLM抽出で型が揺れる
LLMでの自動抽出に頼りきった結果、「株式会社Microsoft」「Microsoft Corp」「MS」が同一エンティティに寄せられず分散。
抽出後のEntity Resolution(名寄せ)層を必ず挟み、コアエンティティにはAlias Dictionary(別名辞書)を用意する
ナレッジグラフ構築にまつわる料金相場と市場動向
最後に、2026年時点の主要プラットフォームの料金相場と、市場全体の成長見通しを整理します。

主要プラットフォームの料金(2026年4月時点)
以下の表に、代表的な商用プラットフォームの公開価格帯をまとめます。表のあと、料金体系の読み解きを説明します。
| プラットフォーム | 最小価格 | スケール時 | 備考 |
|---|---|---|---|
| Neo4j AuraDB Free | 無料 | ノード・リレーション数に上限あり | 検証用途・学習用途に十分 |
| Neo4j AuraDB Professional | $65/GB/月〜 | 1GB最小クラスタから従量課金 | 7日バックアップ、ベストエフォート支援 |
| Neo4j AuraDB Business Critical | $146/GB/月〜 | 2GB最小クラスタから従量課金 | 99.95% SLA、RBAC・SSO・IPフィルタ、PITR |
| Neo4j AuraDB Virtual Dedicated Cloud | 要見積 | 専用VPC/カスタム設計 | 大企業・規制業種向け |
| Amazon Neptune | db.r5.large $0.348/時〜 | インスタンス時間+ストレージ+I/O+バックアップの合算 | 公式料金例で月$296.61(db.r5.largeの例) |
| Microsoft Fabric IQ Ontology | 要試算 | Fabric CU消費 | 2026年プレビュー提供、既存Fabric利用料に加算 |
| Palantir Foundry | 要見積 | 数千万円〜/年規模 | 大企業向け、伴走型導入 |
| Stardog Cloud | 要見積 | エンタープライズ向け | 推論特化・公共セクター採用多 |
| Microsoft GraphRAG(OSS) | 無料 | LLM API料金のみ | 自前ホストなら計算リソース分のみ |
この料金体系の読み解きとしては、検証段階はNeo4j AuraDB Free+OSSのGraphRAGで、DBライセンス費ゼロから立ち上げられます。
ただしGraphRAGはエンティティ抽出・コミュニティ要約でLLM APIまたは自前計算資源のコストが別途発生するため、完全な「ゼロ円運用」にはなりません。
本番に入る段階でAuraDB Professional($65/GB/月〜)に切り替え、SLAや監査要件が厳しくなったタイミングでBusiness Critical($146/GB/月〜)や専用プラットフォームに昇格させる流れが一般的です。
GraphRAG構築時の隠れコスト
料金表には表れませんが、GraphRAGのグラフ構築時にかかるLLM API料金は無視できないコストです。
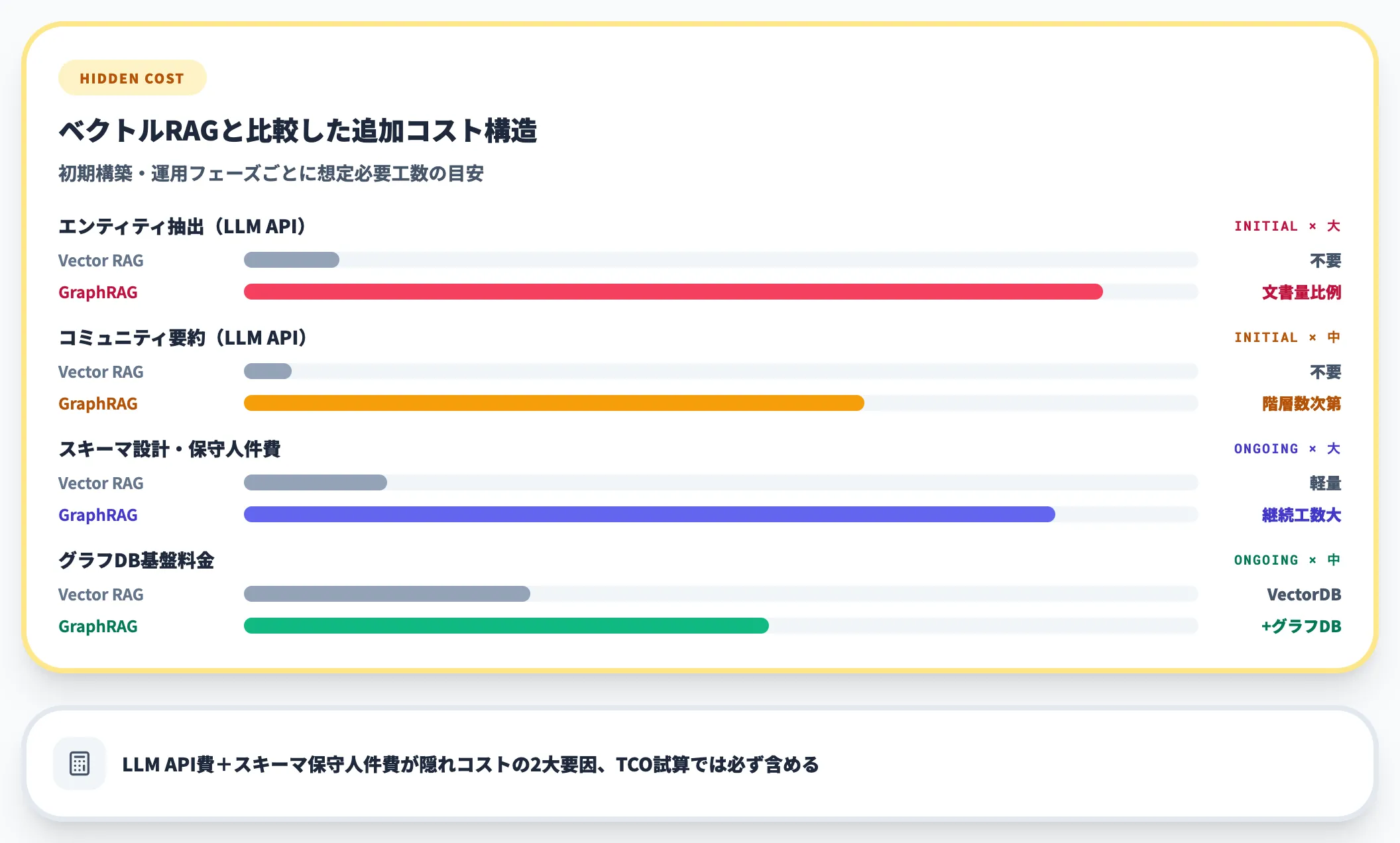
1000ページ級のドキュメントからエンティティ・リレーションを抽出し、コミュニティ要約を生成する場合、数十〜数百ドル規模のAPI料金が発生します。
小規模検証ならGPT-4o-mini等の低価格モデルで代替できますが、精度が求められる本番環境ではGPT-4oクラスが無難です。
市場規模の見通し
Precedence Researchによると、グラフデータベース市場は以下のように推移する見込みです。
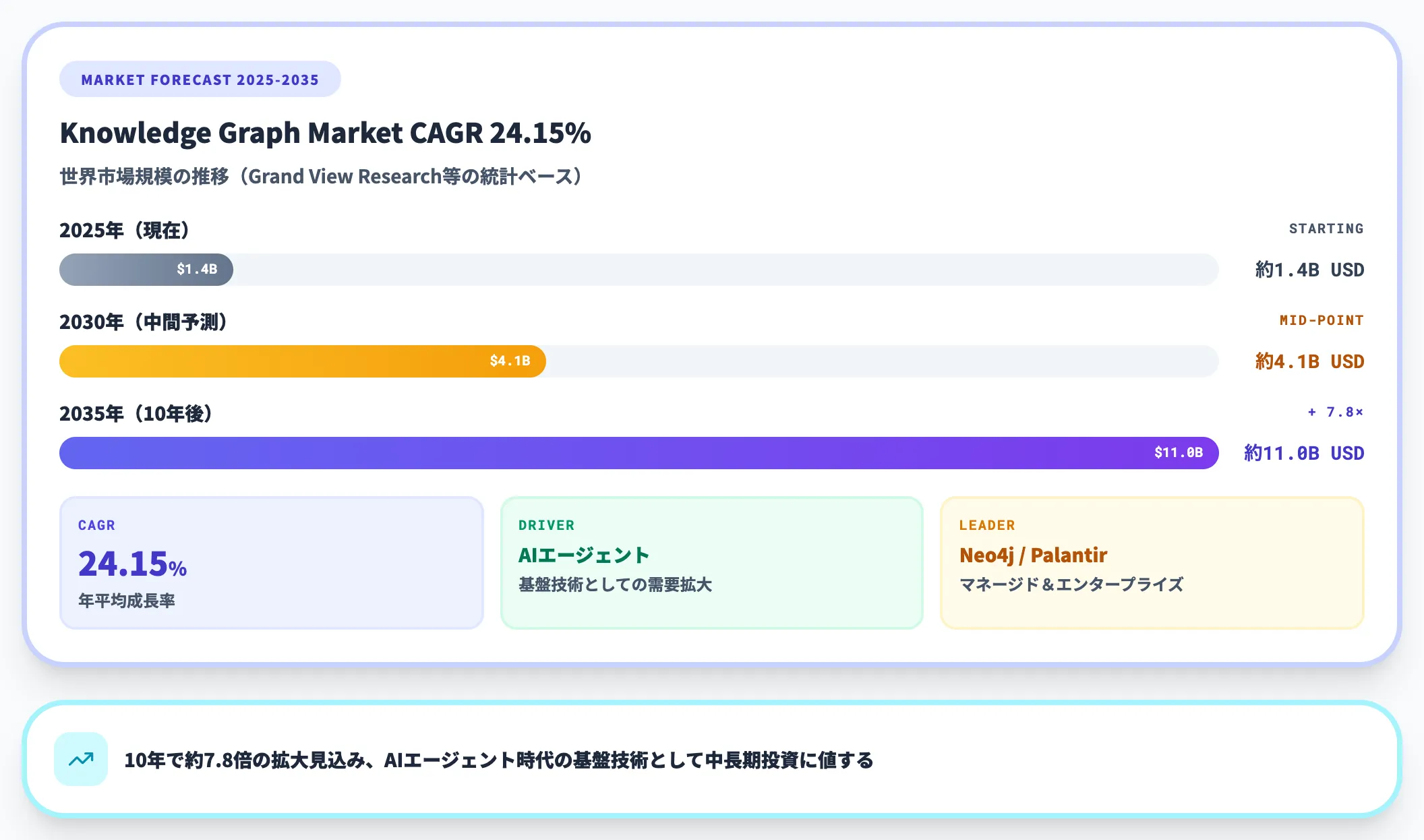
- 2025年:約29億ドル
- 2026年:約36億ドル
- 2035年:約252億ドル(CAGR 24.15%)
この成長を牽引しているのが、本記事で取り上げたGraphRAG・AIエージェント基盤・不正検知・サイバーセキュリティといった用途です。グラフ技術は「一部の専門領域の技術」から「AI時代のデータ基盤における有力な選択肢」へと位置づけが広がりつつあります。
ケース別の選び方
支援経験から見たケース別の推奨は以下です。

- PoC・検証段階 Neo4j AuraDB Free+Microsoft GraphRAG(OSS)で始める。DBライセンス費ゼロで立ち上げられる(LLM API料金または自前計算資源のコストは別途発生)
- 数十人規模でRAG精度改善が目的 Neo4j AuraDB Professional+LangChain/LlamaIndex/Aura Agent
- Azure/Fabric中心の基盤 Microsoft Agent Framework × Neo4j GraphRAG Context Providerで段階導入
- 大企業の業務基盤として全社展開 Palantir Foundry(予算が取れるなら)か Microsoft Fabric IQ Ontology(Azure中心なら)
- 研究・知識推論が主目的 Stardogが有力候補
- AWS中心のインフラ Amazon Neptuneで統合

RAGが固有名詞や関係性で外す段階に来たら
ナレッジグラフは、エンティティと関係を構造的に扱うことで、ベクトルRAGの「チャンクで文脈を失う」「固有名詞の関係性を取り違える」弱点を埋める意味層として機能します。
2026年にNeo4j Aura Agent・Microsoft Agent Framework・Palantir AIP Agent Studioが出揃い、オントロジー×エージェントの統合難易度は大きく下がったタイミングです。
ここから実装に踏み込む場合、1ユースケースのPoCを切り出し、Neo4j AuraDB Free+Microsoft GraphRAGでDBライセンス費ゼロから立ち上げ(GraphRAG側のLLM API料金は別途発生)、本番移行時に自社テナント内のエージェント実行基盤と統合するのが最短ルートです。
AI Agent Hubは、自社Azureテナント内でAIエージェントを運用する基盤として、既存のCRM・ERP・SharePointデータとナレッジグラフを接続し、GraphRAGの実装から実行ログ・権限管理・セキュリティスキャンまで一画面で統制できます。データは100%自社テナント内に保持されるため、顧客・契約情報が外部に出ない設計で意味検索とマルチホップ推論を業務に組み込めます。
AI総合研究所の専任チームが、Microsoft MVP/Solution Partner認定の実績をもとに、オントロジー設計・プラットフォーム選定・GraphRAG実装・既存データ基盤との接続までを伴走支援します。
まずは無料の資料で、ナレッジグラフをAIエージェントの判断基盤に組み込む進め方をご確認ください。
RAG精度をナレッジグラフで底上げ

オントロジー設計から業務実装まで支援
ベクトルRAGが固有名詞や関係性で外す段階に来たら、ナレッジグラフを意味層として挟むタイミングです。AI Agent Hubなら、Neo4j・Microsoft GraphRAGを軸にオントロジー設計からGraphRAG実装、AIエージェントの権限管理・実行ログまで一画面で統制できます。自社テナント内で完結する設計で、顧客・契約データを外に出さずに意味検索とマルチホップ推論を業務に組み込めます。
まとめ
ナレッジグラフは、エンティティとリレーションを第一級の要素として扱うことで、LLM単体では解けない企業固有の意味理解を可能にする技術です。2026年は生成AI・AIエージェントの実用化に伴って再評価が進み、Microsoft・Palantir・Neo4jといった主要ベンダーが積極的に投資している領域でもあります。
本記事で解説した主要ポイントを再度整理します。
- ナレッジグラフはノード・エッジ・トリプルで知識を表現し、関係性を第一級の要素として扱う
- オントロジー(設計図)・ナレッジグラフ(実データ)・グラフDB(格納技術)は役割が異なる
- GraphRAGはLocal SearchとGlobal Searchを使い分け、複雑な意味理解タスクで従来RAGを大幅に上回る
- 2026年のAIエージェント統合はNeo4j Aura Agent/Microsoft Agent Framework/Palantir AIP Agent Studioが代表例
- Neo4j AuraDB Free+Microsoft GraphRAG(OSS)ならDBライセンス費ゼロからPoCを始められる(LLM API料金は別途発生)
- 本番はAuraDB Professional $65/GB/月が目安、監査要件が厳しければBusiness Critical $146/GB/月に昇格
- グラフDB市場はCAGR 24.15%で成長し、2035年に約252億ドル規模の見込み
社内のRAGが「固有名詞や関係性で外す段階」に入っていると感じるなら、ナレッジグラフを意味層として挟む時期に来ています。
まずはPoCレベルで1ユースケースを切り出し、Neo4j AuraDB Freeで検証を始めるのが、2026年時点で最もリスクの低い進め方です。










