この記事のポイント
 社内で売上・CV・KPIの定義がツールごとに揺れているなら、セマンティックレイヤーで意味の単一ソースを確立すべき
社内で売上・CV・KPIの定義がツールごとに揺れているなら、セマンティックレイヤーで意味の単一ソースを確立すべき- コードファースト派はdbt Semantic Layer、API組込み志向はCube、エンタープライズ基幹系はAtScale、既存基盤との相性で選ぶ
- Copilot・ChatGPT・Claudeなど自然言語BIの業務実装が進み、LLMに正しい数字を返させる土台として意味層が再評価されている
- オントロジー/ナレッジグラフとは抽象度が異なり、役割は補完的。両方設計する必要はあるが代替関係ではない
- dbt Starter $100/月〜、Cube Core OSS無料、AtScale $2,500/月〜、Fabric/Databricks標準で完結する例も

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
セマンティックレイヤー(意味層)とは、データウェアハウスやデータレイクといった物理データと、BI・AIツールの間に挟まる「意味の定義層」です。
2026年は生成AI・Copilotの業務適用が進むなかで、「LLMに正しい数字を返させるための土台」として注目が高まっています。
本記事では、セマンティックレイヤーの基本構造(メトリクス・ディメンション・メジャー・APIインターフェース)、オントロジー/データカタログとの違い、主要ツール6種の比較、生成AI・AIエージェントとの統合パターン、導入ステップと失敗パターン、2026年時点の料金相場までを一気通貫で整理します。
BI・生成AI・データエンジニアリングの境界領域で、「次の一手」を探している実務者のための導入ガイドです。
目次
なぜセマンティックレイヤーが生成AI時代に再評価されているのか
Microsoft Fabric Semantic Model
Databricks Unity Catalog metric views(business semantics)
Copilot in Power BI × Semantic Model
MCP(Model Context Protocol)経由での連携
Cube MCP × Claude/ChatGPT/Cursor
dbt Semantic Layer × GraphQL/JDBC/MCP
セマンティックレイヤーとは?

セマンティックレイヤー(Semantic Layer/意味層)とは、データウェアハウス・データレイクといった物理データ層と、BI/AIツールなどの消費層の間に挟まる、「データに意味を与える中間レイヤー」です。
IBMの定義では、セマンティックレイヤーは「データベースやデータウェアハウスの複雑なスキーマと、BI・分析ツールを結ぶ抽象化層」とされています。データの「構造(カラム名・テーブル名)」ではなく「意味(売上・顧客LTV・解約率)」に焦点を当て、業務で使われる言葉とデータ項目を橋渡しする役割を担います。
2026年は、生成AI・Copilot・AIエージェントが数値を扱う機会が急増したため、「どのテーブルのどのカラムが売上なのか」をAIに正しく伝える基盤として、意味層の重要性への注目が高まっています。

意味層が解決する典型的な問題

セマンティックレイヤーが解決しようとしているのは、次のような「定義の分散問題」です。
- 営業の売上と経理の売上で数字が違う(定義が部門ごとにバラバラ)
- Power BIで定義した指標と、Tableauで定義した指標が微妙に違う
- SQLを書くたびにアナリストがKPIを再定義しているため、月次で数字が動く
- Copilotに「先月のARRは?」と聞くと毎回違う計算をする
従来は各ツール内にメトリクスを定義してきましたが、ツール間で定義が同期しないのが構造的な問題でした。セマンティックレイヤーは、この「メトリクスの単一ソース(Single Source of Truth)」を確立するための仕組みです。
Headless BIとセマンティックレイヤー
「Headless BI」という言葉でも、ほぼ同じ概念が語られます。Headless BIは、BIのUI層と意味層・データ層を分離し、意味層をAPIとしてあらゆるツールから呼び出せるようにするアーキテクチャです。
dbt Labs・Cube.devが提唱しており、2026年のモダンデータスタックでは有力な設計アプローチの一つとして注目されています。
セマンティックレイヤーの基本構造
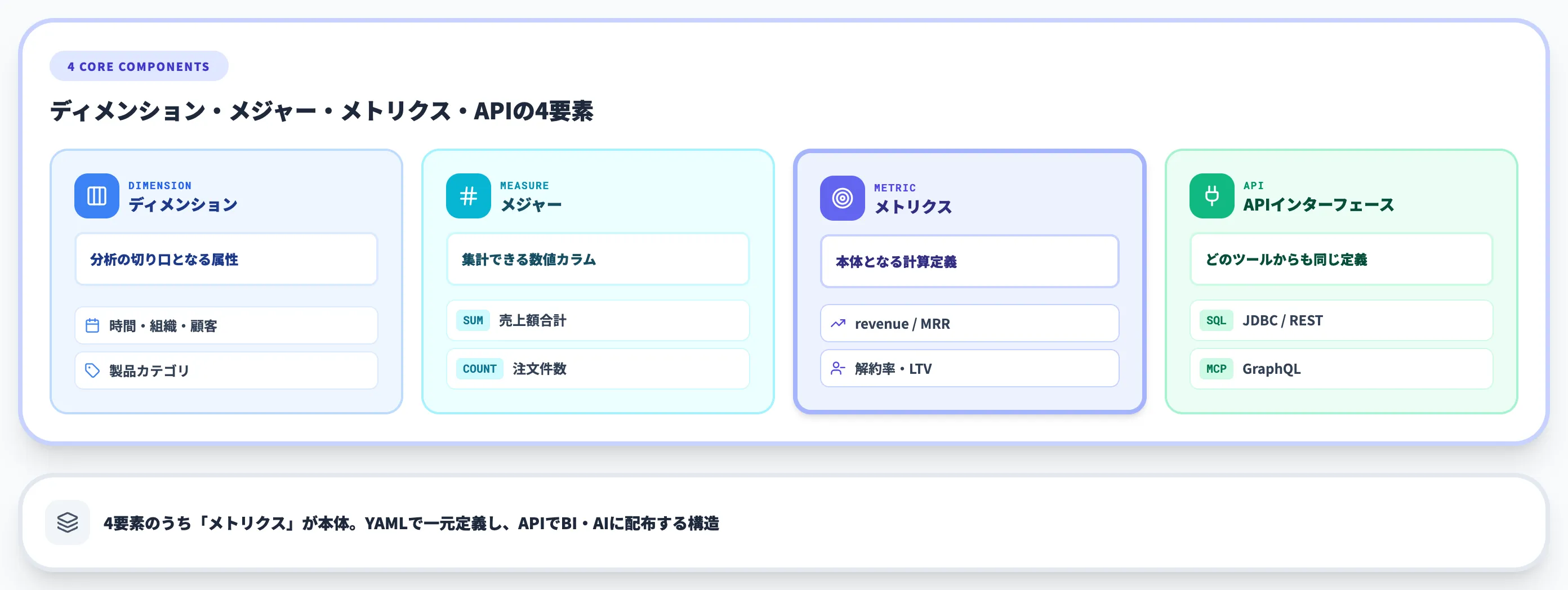
セマンティックレイヤーを構成する要素は、ツールによって呼び方が多少異なりますが、概念としては4つに集約できます。
ここでは代表的な構成要素と、データの流れを整理します。
ディメンション(Dimension)
ディメンションは、分析の切り口を表す要素です。時間(年・月・日)、地域、顧客セグメント、製品カテゴリなどが典型例です。
BIツールでの「スライス・アンド・ダイス」の軸になります。
- 時間軸:年・四半期・月・週・日
- 組織軸:事業部・部署・チーム
- 顧客軸:業種・規模・地域
- 製品軸:カテゴリ・ブランド・モデル
メジャー(Measure)
メジャーは、数値化できる指標です。売上・件数・金額・コストなど、集計対象になる数値カラムがベースになります。
SQLで言う SUM()・COUNT()・AVG() の対象になるものです。
メトリクス(Metric)
メトリクスは、ビジネス上の意味を持った計算定義です。
メジャーとディメンション、計算式、フィルタ条件を組み合わせて、「売上」「MRR」「解約率」といったKPIとして定義されます。
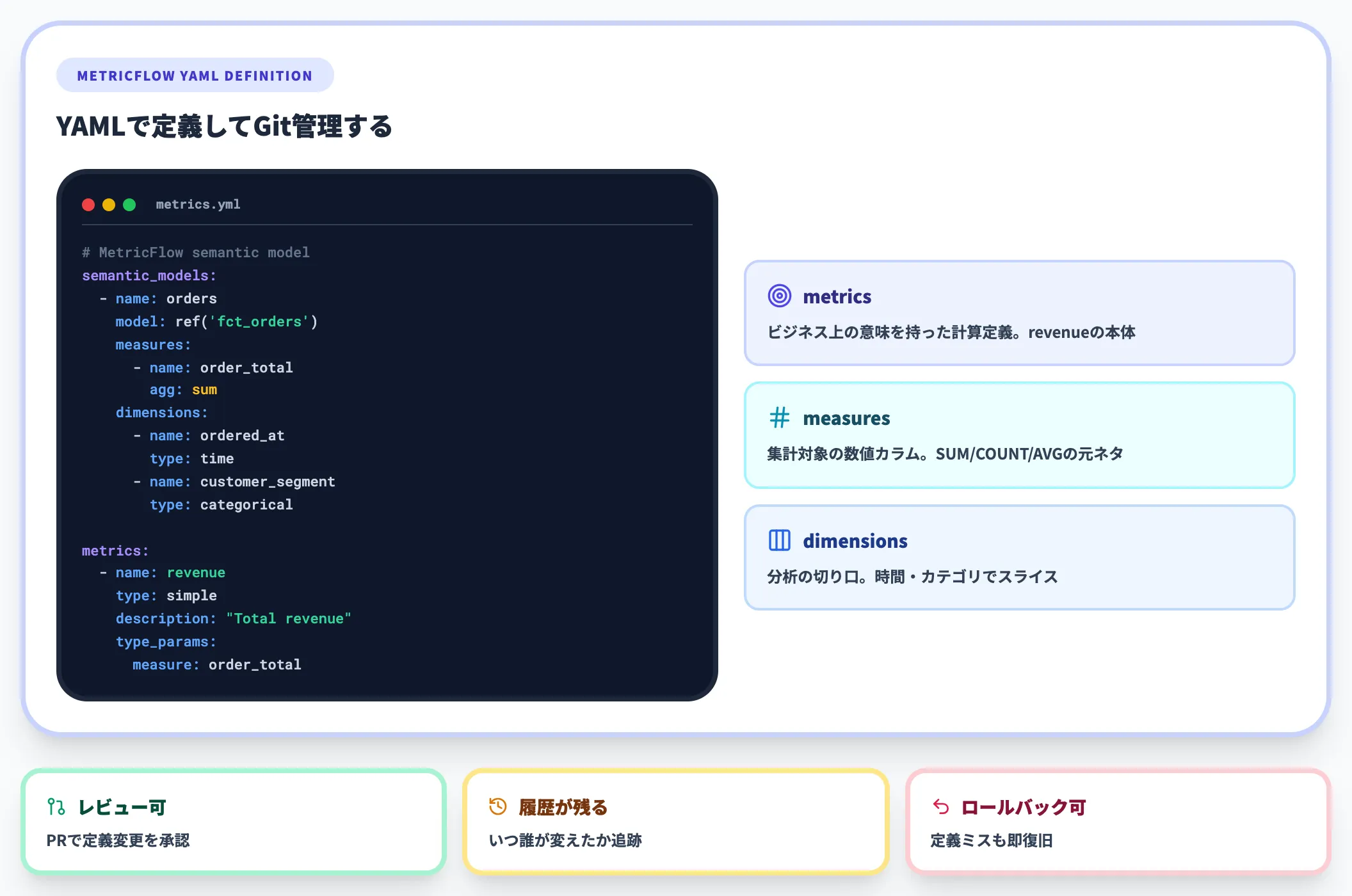
セマンティックレイヤーの本体は、このメトリクスをコード(YAML等)で一元定義し、バージョン管理できるようにする部分です。
dbt Labsの公式ドキュメントでは、MetricFlowを使ってYAMLでメトリクスを定義する方式が採用されています。
# dbt MetricFlow のメトリクス定義例
semantic_models:
- name: orders
model: ref('fct_orders')
measures:
- name: order_total
agg: sum
dimensions:
- name: ordered_at
type: time
- name: customer_segment
type: categorical
metrics:
- name: revenue
type: simple
description: "Total revenue from all orders"
type_params:
measure: order_total
このように定義することで、「revenue」という1つのメトリクスが、SQL・Python・BI・Copilotのどこから参照しても同じ計算結果を返すようになります。
データ基盤のメトリクス設計に関わる中でも、この「YAMLで定義してGit管理する」アプローチは、Excelやノーコードで定義を管理するやり方と比べ、レビュー・変更履歴・ロールバックの観点で明確に優れていると感じる場面が多いです。
APIインターフェース層
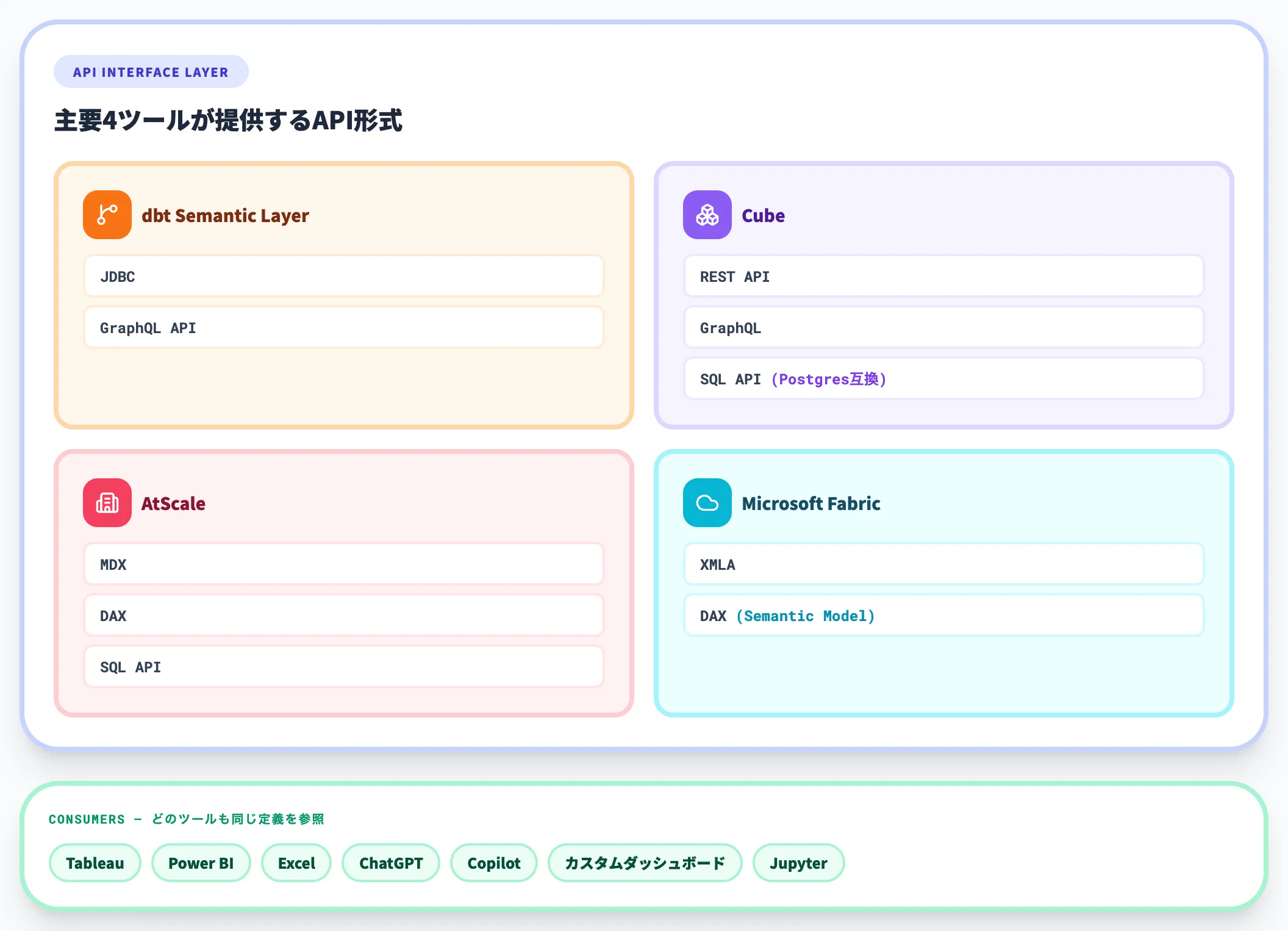
セマンティックレイヤーは、どのツールからも同じ定義にアクセスできるように、REST APIやGraphQL API、SQL APIを提供します。
- dbt Semantic Layer:JDBC/GraphQL API
- Cube:REST/GraphQL/SQL API(Postgres互換)
- AtScale:MDX/DAX/SQL API
- Microsoft Fabric:XMLA/DAX(Semantic Model)
APIを経由することで、Tableau・Power BI・Excel・ChatGPT・Copilot・カスタムダッシュボードなど、あらゆるツールが同じメトリクス定義を参照できるようになります。
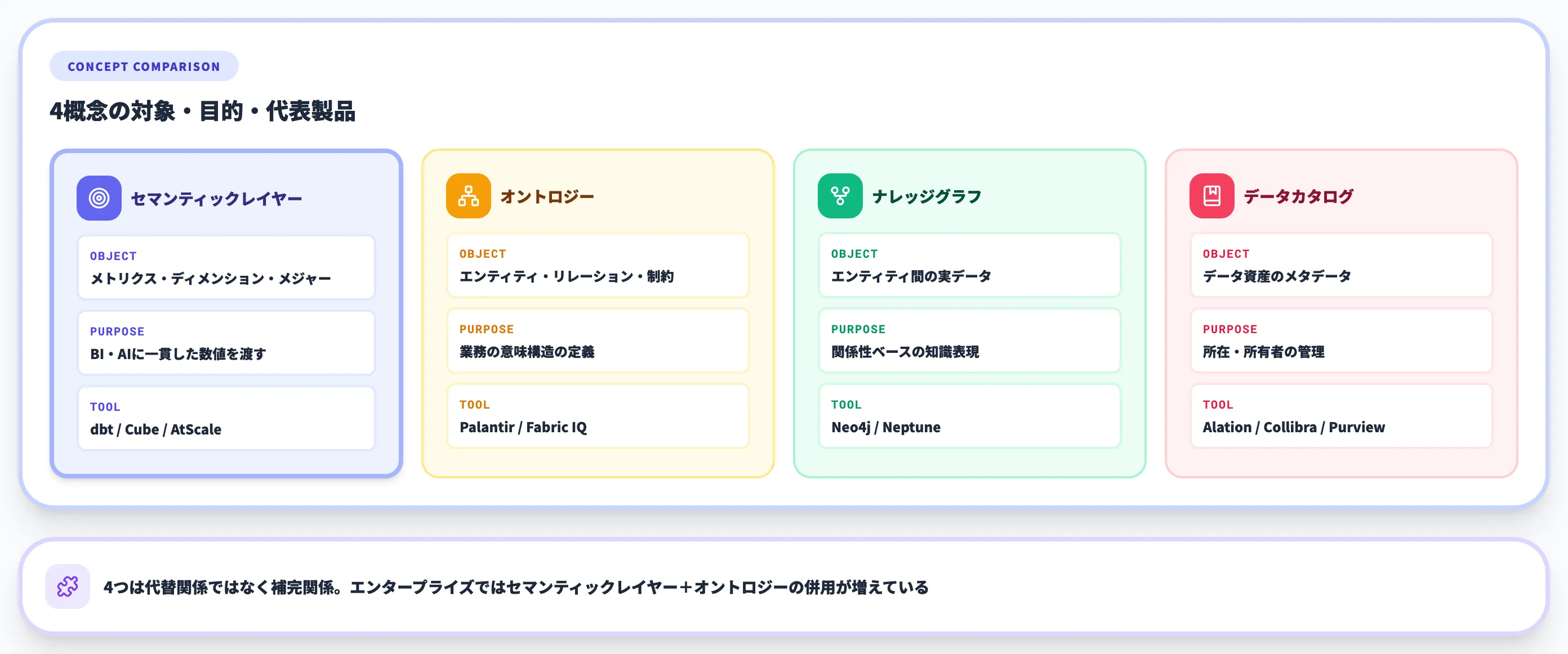
セマンティックレイヤーとオントロジー・データカタログの違い
セマンティックレイヤーは、ナレッジグラフ/オントロジー・データカタログといった隣接概念としばしば混同されます。しかし、それぞれは抽象度と対象が異なります。
4つの概念を整理する
以下の比較表で、セマンティックレイヤー・オントロジー・ナレッジグラフ・データカタログの違いを整理します。
| 概念 | 主な対象 | 主な目的 | 代表製品 |
|---|---|---|---|
| セマンティックレイヤー | メトリクス・ディメンション・メジャー | BI・AIに一貫した数値を渡す | dbt/Cube/AtScale |
| オントロジー | エンティティ・リレーション・制約 | 業務の意味構造の定義 | Palantir/Fabric IQ |
| ナレッジグラフ | エンティティ間の実データ | 関係性ベースの知識表現 | Neo4j/Neptune |
| データカタログ | データ資産のメタデータ | データの所在・所有者の管理 | Alation/Collibra/Microsoft Purview |
この整理から重要な点は、セマンティックレイヤーは「数値指標の一貫性」に特化しており、オントロジー/ナレッジグラフとは抽象度が異なるということです。両者は代替関係ではなく補完関係で、エンタープライズでは両方整備するケースが増えています。
オントロジーとの相補関係
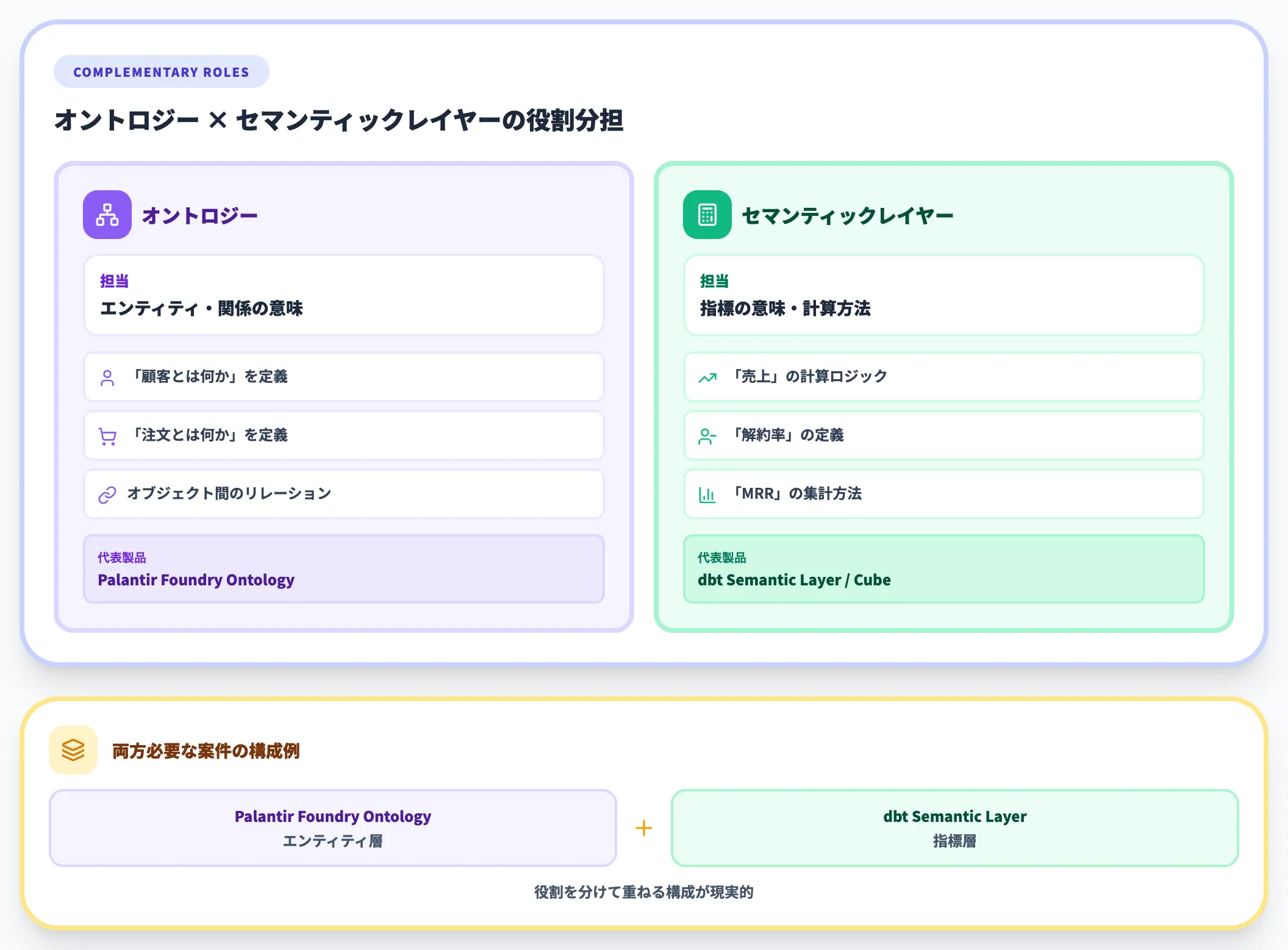
オントロジーは「顧客とは何か、注文とは何か」といったエンティティ・関係の意味を定義します。一方、セマンティックレイヤーは「売上・解約率・MRRはどう計算するか」という指標の意味を定義します。
具体例で言えば、Palantir Foundry Ontologyは主にオブジェクト中心の意味モデルを担い、その上で指標を定義する層としてメトリクスが必要になります。
逆にdbt Semantic Layerは指標に特化しており、エンティティの関係性を表現する用途には向きません。
両方必要な案件では、Palantir Foundry Ontology+dbt Semantic Layerのように役割を分けて重ねる構成が取られます。
データカタログとの違い
データカタログ(Alation・Collibra・Microsoft Purview)は、「どこにどんなデータがあるか」のメタデータ管理が主目的です。
セマンティックレイヤーは「そのデータをどう意味付けて集計するか」の実行定義を担うため、カタログの下流に位置づけられます。
実務では、カタログで発見したデータをセマンティックレイヤーで集計定義し、BIやAIに提供する、という流れが理想形です。どちらか一方だけ導入するとガバナンスが片肺運転になるため、企業データ基盤としてはセット設計が望ましい構成になります。
なぜセマンティックレイヤーが生成AI時代に再評価されているのか
セマンティックレイヤー自体は、2000年代のBIツール(MicroStrategy・Cognos等)にも存在した古典的な概念です。
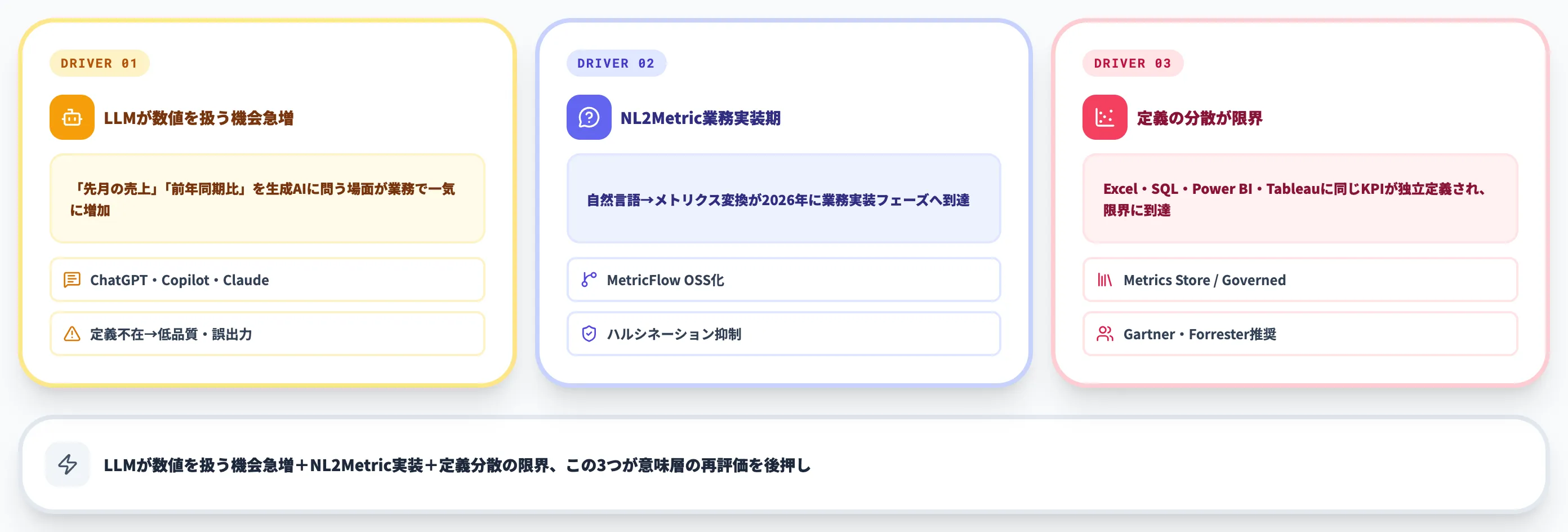
にもかかわらず2026年現在、改めて注目されている背景には、生成AI/LLMの業務適用による3つの構造変化があります。
LLMが数値を扱う機会が急増
ChatGPT・Copilot・Claudeといった生成AIが、業務で「先月の売上は?」「前年同期比は?」といった数値ベースの問い合わせを受ける場面が一気に増えました。
Microsoft Learnでも、Copilot for Power BIでセマンティックモデルを適切に準備しないと「低品質で不正確、誤解を招く出力を生成する」と警告されています。
LLM単体は「自然言語→SQL」の生成はできますが、「どのカラムが売上か」「どのフィルタを適用するか」を正確に判断するには意味層の定義が不可欠です。
生成AIの業務適用を支援する場面でも、「PoCは動いたが社内公開で止まる」原因の多くが、この「数字の一貫性が担保できない」問題に帰着するケースが目立ちます。
自然言語BI(NL2Metric)の業務実装が進展
自然言語からメトリクスを引くインターフェースは、2026年に業務実装フェーズに入りました。dbt Labsはオープンソース化したMetricFlowで「LLMエージェントがメトリクスを安全に呼び出す」ユースケースを前面に打ち出しています(Open source MetricFlowアナウンス)。
セマンティックレイヤーがあると、LLMは「revenueメトリクスを時間ディメンション=先月で集計してくれ」という意図を、正しい定義のまま実行できます。
意味層がないと、LLMがSQLを毎回書き直すため、ハルシネーション(計算の取り違え)が起きやすくなります。
メトリクス定義の分散が限界に
多くの企業で、Excel・SQL・Power BI・Tableau・Lookerに同じKPIが独立定義されており、定義の分散が限界に達しています。
ガートナー・Forrester系レポートでも「Metrics Store」「Governed Metrics」という形で、意味層の集中管理が推奨されるようになりました。
セマンティックレイヤーのエンタープライズ活用シナリオ
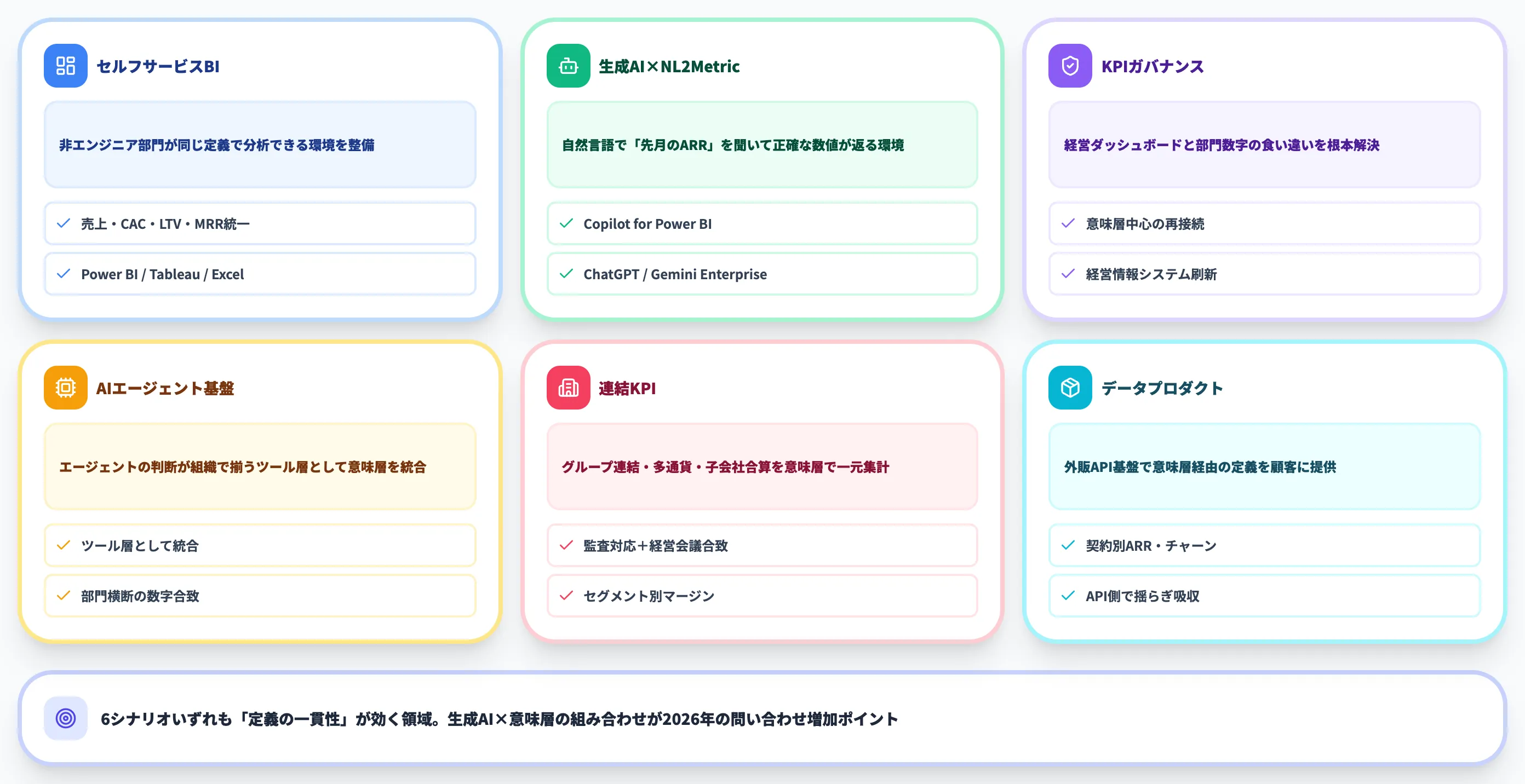
具体的に、どのような業務領域で意味層を導入すると価値が出るのかを、代表的な6シナリオで整理します。
セルフサービスBIの標準化
営業・マーケティング・経営企画といった非エンジニア部門が、同じ指標定義で分析できるようになります。
「売上」「CAC」「LTV」「MRR」といった主要KPIを意味層に集約することで、Power BI・Tableau・Excelで同じ数字が出せるようになります。
生成AIダッシュボードとNL2Metric
Copilot for Power BI・ChatGPT Enterprise・Gemini Enterpriseなどに対して、自然言語で「先月のARR推移は?」と聞くだけで正確な数値が返る環境を整備できます。
意味層導入の投資対効果が見えやすい領域で、2026年に入って問い合わせが増えているシナリオです。
KPIガバナンスと経営ダッシュボード統合
経営ダッシュボードの数字と、部門独自の数字が食い違う問題を根本解決できます。
経営情報システムを刷新する際、意味層をコアに置いて各ツールを再接続するアプローチが検討されるようになっています。
生成AIエージェントの判断基盤
AIエージェントで業務効率化を進める際、エージェントが扱う数値が部門ごとにバラバラだと運用が成立しません。
意味層をエージェントのツール層として統合することで、エージェントの判断が組織で揃います。
財務・経営管理の連結KPI
グループ連結や多通貨決算、子会社合算といった経営管理系の集計は、ExcelやDWHに散在しがちです。
意味層で連結KPI(連結売上・連結営業利益・セグメント別マージン等)を定義しておくと、監査対応と経営会議資料の数字が一致する状態を作れます。
データプロダクト/外販API基盤
自社のデータを顧客向けにAPI提供するデータプロダクト事業でも、意味層が効きます。契約顧客ごとの「ARR」「チャーン」「支払残高」などを、CubeなどのAPI・ファーストな意味層経由で公開することで、定義の揺らぎをAPI側で吸収できます。

主要なセマンティックレイヤーツール比較
2026年時点で、エンタープライズが検討する主要ツールは以下6種です。
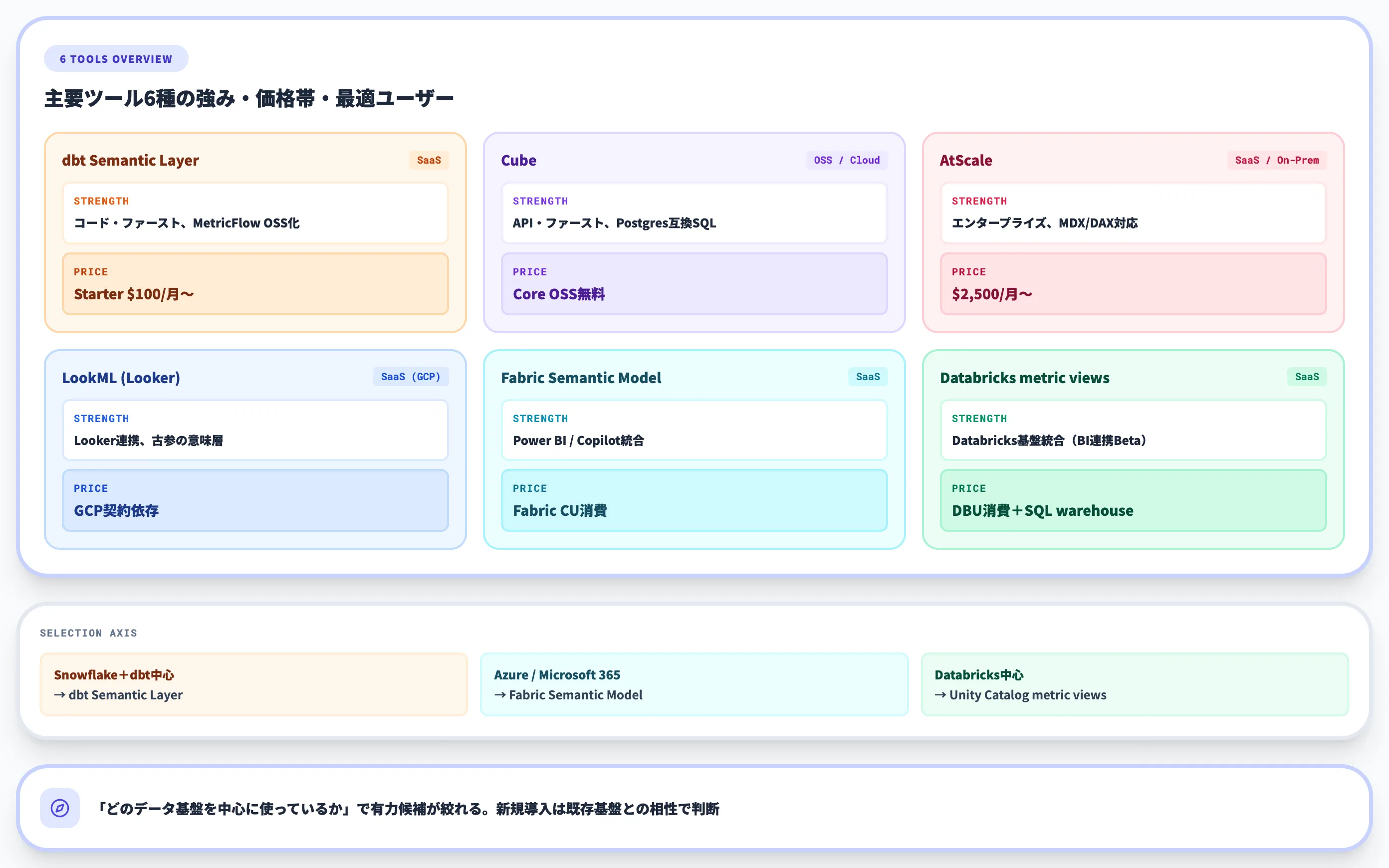
| ツール | 提供形態 | 強み | 価格帯 |
|---|---|---|---|
| dbt Semantic Layer | SaaS(dbt Cloud) | コード・ファースト、MetricFlow | Starter $100/月〜 |
| Cube | OSS/Cloud | API・ファースト、Postgres互換SQL | Core OSS無料、Cloud別途 |
| AtScale | SaaS/オンプレ | エンタープライズ・MDX/DAX対応 | $2,500/月〜(consumption-based) |
| LookML(Looker) | SaaS(GCP) | Looker連携、古参の意味層 | Google Cloud契約に依存 |
| Microsoft Fabric Semantic Model | SaaS | Power BI/Copilot統合 | Fabric CU消費 |
| Databricks Unity Catalog metric views | SaaS | Databricks基盤統合、BI連携はBeta | 既存Databricks上で構成(SQL warehouse/compute課金別途) |
この比較から実務で押さえるべき選定軸は、「どのデータ基盤を中心に使っているか」が有力な決定要因になるという点です。
Snowflakeならdbt、Azure/FabricならFabric Semantic Model、DatabricksならUnity Catalog metric views、と、既存基盤を軸に選ぶのが素直な出発点になります。
dbt Semantic Layer
dbt Labsが提供するセマンティックレイヤー。MetricFlow(2023年にTransform社を買収して取り込んだ技術)がエンジンです。
YAMLでメトリクスを定義し、Git管理・CIレビューが可能な「コード・ファースト」の思想が特徴で、エンジニアリングチーム主導でガバナンスを担保したい場合に向きます。
2025年12月(Coalesce 2025)にMetricFlowがApache 2.0ライセンスでオープンソース化され、ベンダーロックインへの懸念が大きく緩和されました。dbt Starter・Enterprise以上のプランで利用可能です。
Cube
Cubeは、オープンソース版(Cube Core)とクラウド版(Cube Cloud)を提供するAPI・ファーストのセマンティックレイヤーです。
REST/GraphQL/SQL(Postgres互換)に対応し、アプリケーション組み込みに強みがあります。
2026年はAgentic Analytics Platformとしての位置づけを前面に押し出しており、LLMエージェントからの呼び出しを意識した設計になっています。事前集計キャッシュで高速化できるのも特徴です。
AtScale
AtScaleは、MDX/DAXに対応したエンタープライズ向けセマンティックレイヤー。Excelピボットテーブルや旧来型OLAPツールとの互換性が強く、大企業の基幹系分析で採用事例が公開されています。
AtScaleの公式ブログでは、consumption-basedプライシングを採用しており、$2,500/月から始められるとされていますが、エンタープライズソフトウェア扱いのため、小規模チームにはオーバースペックになりやすい点は留意が必要です。
LookML(Looker)
LookMLは、Lookerの定義言語です。Google Cloudに買収されて以降、GCP環境との統合が進んでおり、Lookerは現在もオープンなセマンティックレイヤーを訴求しています。価格は個別見積となっており、既にLookerを導入している企業にとっては有力な継続選択肢です。新規にゼロから導入する場合は、dbt/Cube/Fabric/Databricksなどと並べて既存データ基盤との相性で選定するのが実務的な進め方になります。
Microsoft Fabric Semantic Model
Microsoft Fabricのセマンティックモデルは、Power BIのセマンティックモデルを基盤とし、DAXでメトリクスを定義する形式です。Copilot for Power BI/Copilot in Fabricとのネイティブ統合が最大の強みで、Azure中心の企業では有力候補になります。
2026年4月にはFabric IQ Ontologyがプレビュー開始され、セマンティックモデル・データエージェント・オントロジーなどが別アイテムとして提供される形で、Fabric内の意味定義層が厚くなっています。
Databricks Unity Catalog metric views(business semantics)
Databricks Unity Catalogでは、2026年時点の公式名称としてUnity Catalog business semanticsと呼ばれる領域が整備され、その中核機能としてmetric viewsが提供されています。
Databricksを基盤にしている企業にとっては、別製品を追加せずにメトリクス定義を集中化できる利点があります。
一方、外部BIツール連携(Power BI・Tableau等)は公式ドキュメントでBeta扱いで、Power BIコネクタのBI compatibility modeは削除済みといった注意事項もあります。
metric viewsの作成・利用にはSQL warehouseまたは適切なcomputeが必要で、Databricks自体の従量課金(DBU消費)が別途発生する点も押さえておく必要があります。
Copilot・生成AIとの統合パターン

セマンティックレイヤーの価値は、生成AI・Copilot・エージェントと接続して初めて最大化されます。ここでは2026年時点の代表的な統合パターンを整理します。
NL2Metric(自然言語→メトリクス)
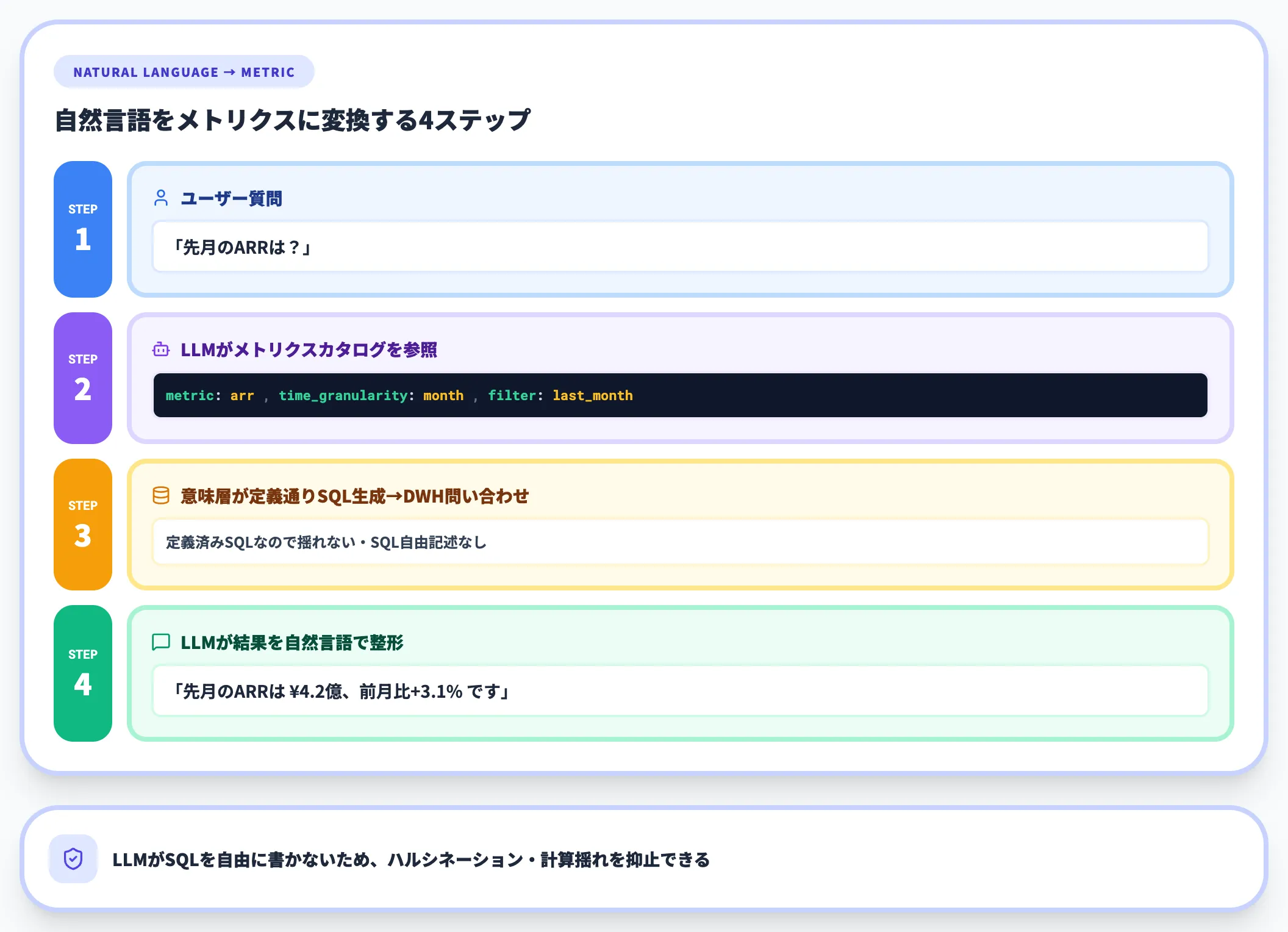
最も基本的なパターンは、自然言語の質問をセマンティックレイヤーのメトリクス定義にマッピングする方式です。
- ユーザー:「先月のARRは?」
- LLM:意味層のメトリクスカタログを参照し、arr メトリクスに time_granularity=month, filter=last_month を適用
- 意味層:定義通りにSQLを生成し、DWHに問い合わせ
- LLM:結果を自然言語に整形して返す
この方式のメリットは、LLMがSQLを自由に書かないため、計算の揺れやハルシネーションが発生しづらい点です。dbt Semantic Layer・Cube・Fabric Semantic Modelはいずれもこのパターンをサポートしています。
Copilot in Power BI × Semantic Model
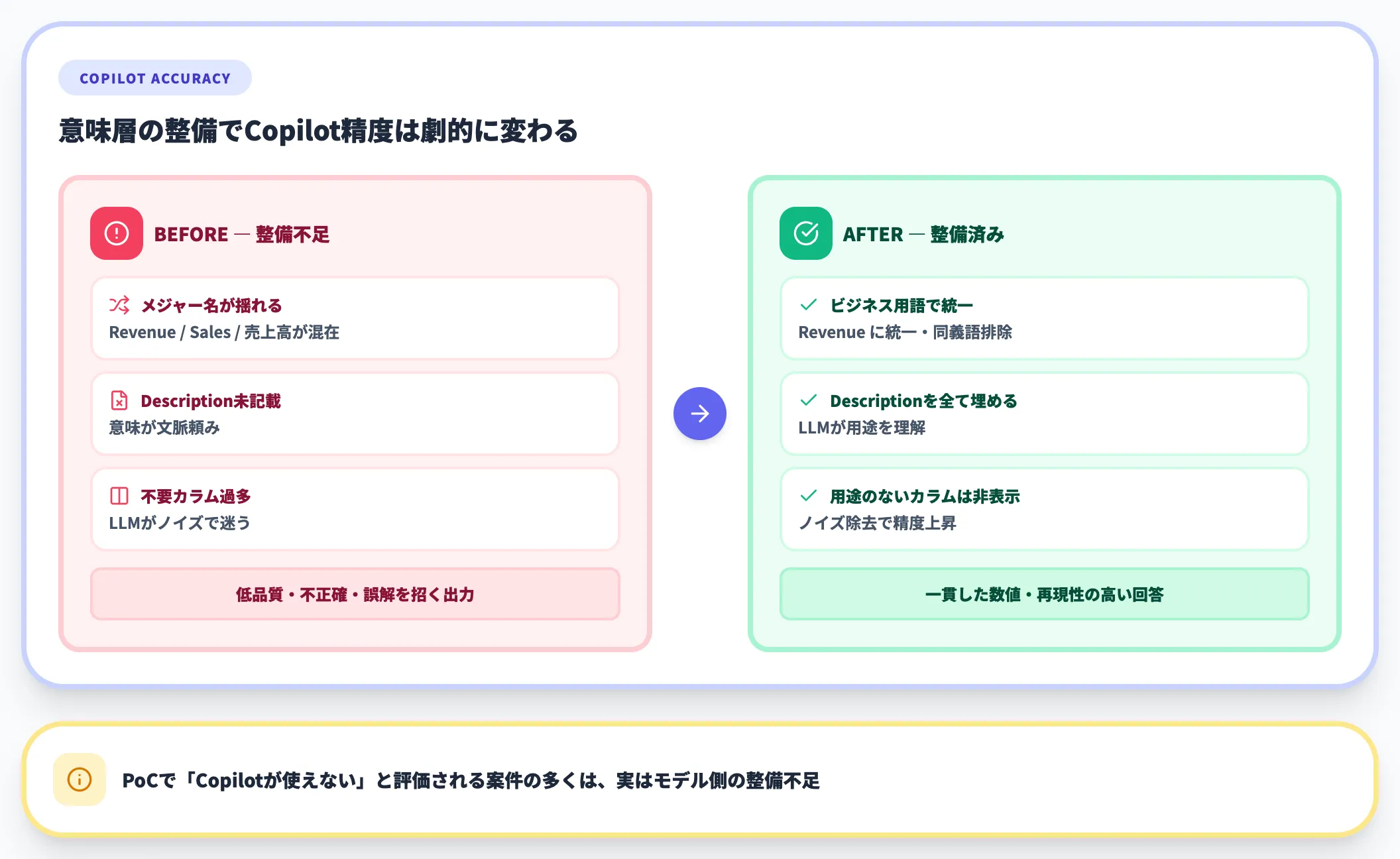
Power BI Copilotは、既存のセマンティックモデル(Power BIデータセット)を参照し、自然言語で質問・レポート生成を行います。Microsoft Learnでは、モデルの準備不足(メジャー名の揺れ・説明の未記載・不要なカラム過多)がCopilotの精度低下の主因と明記されています。
Copilotの精度を上げるには、メジャー名をビジネス用語で統一する、Descriptionを埋める、用途のないカラムを非表示にする、といった意味層側の整備が必須です。
PoCで「Copilotが使えない」と評価される案件の多くが、実はモデル側の整備不足であるケースは実務でも頻繁に遭遇します。
MCP(Model Context Protocol)経由での連携
2025年後半以降、Model Context Protocol(MCP)を経由してセマンティックレイヤーを各種LLMから呼び出す構成も増えています。
Cube・dbt Labsの両社はMCPサーバーを提供しており、Claude・ChatGPT・Cursorなどから統一的にメトリクスを呼び出せます。
エージェントのツールとしての意味層
AIエージェントがツールとして意味層を使うパターンも定着しつつあります。エージェントが「売上分析→異常値検知→経営会議用のスライド生成」といったワークフローを自律的に実行する際、途中の数値はすべて意味層の定義を経由することで、数字の一貫性が保たれます。
AIエージェント×セマンティックレイヤーの統合パターン
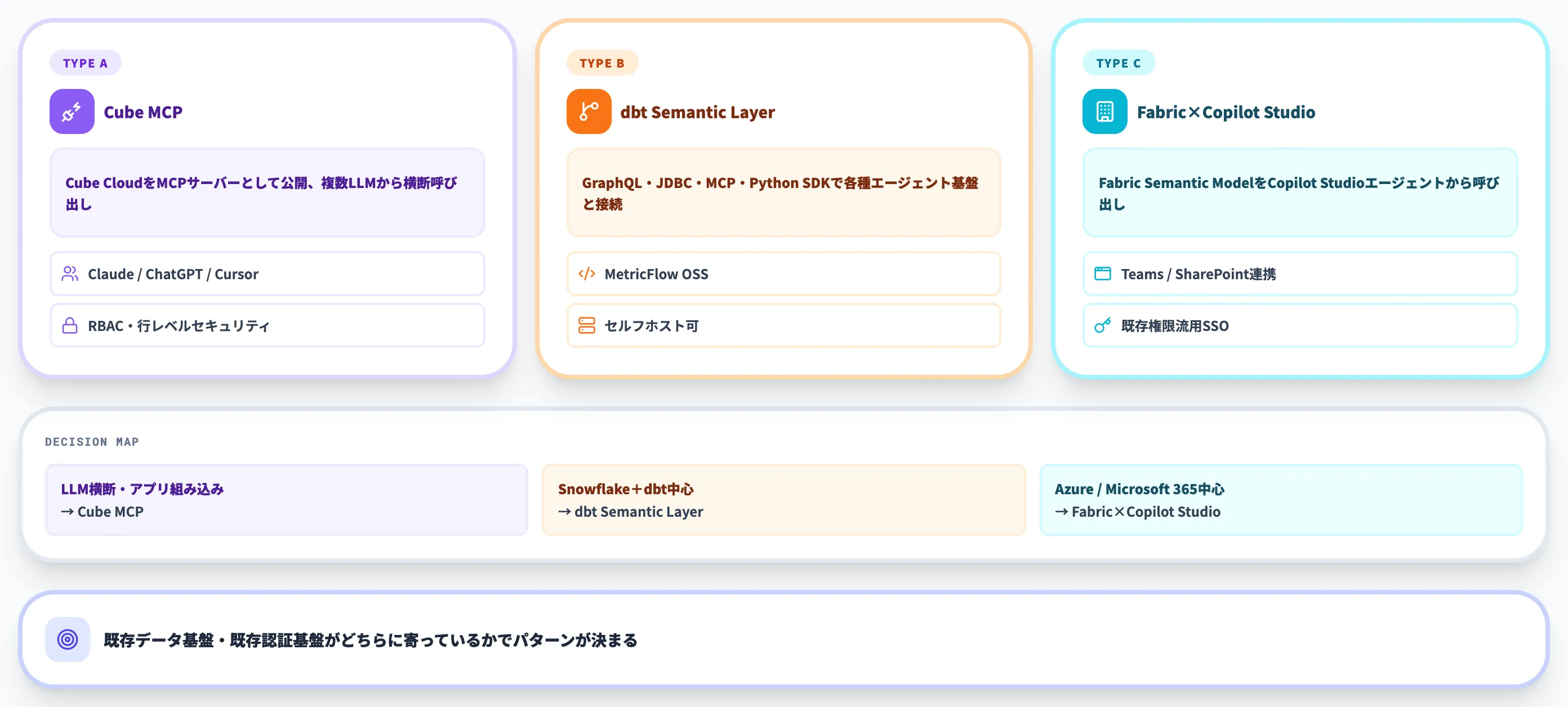
2026年は、AIエージェントが意味層をツールとして呼び出すアーキテクチャが各ベンダーから揃い始めました。ここでは代表的な3パターンの統合アプローチを比較します。
Cube MCP × Claude/ChatGPT/Cursor
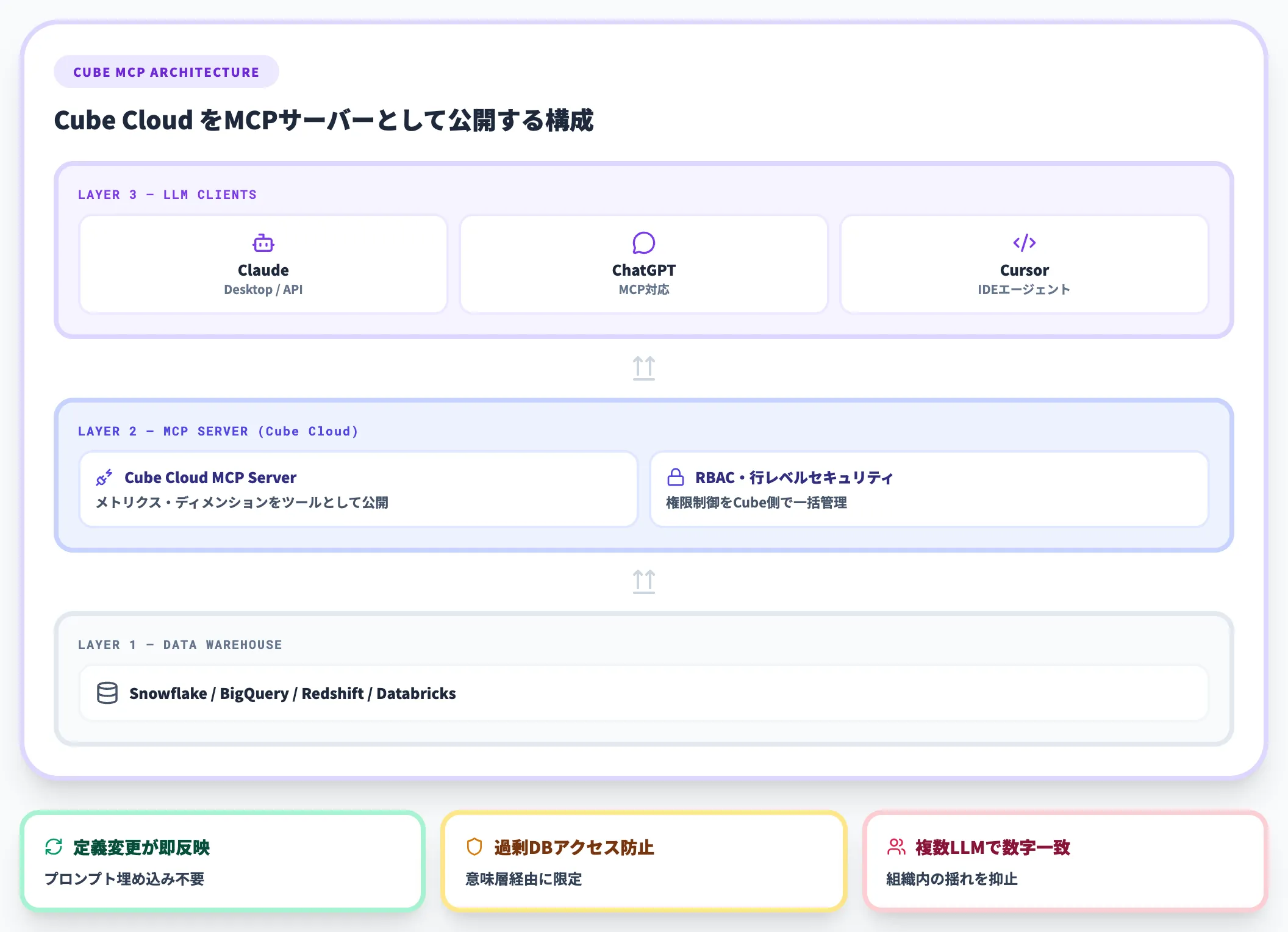
Cube公式は、Cube Cloud上のセマンティックレイヤーをMCPサーバーとして公開する構成を提供しています。
Claude Desktop・ChatGPT・CursorなどのMCP対応クライアントからCubeのメトリクス・ディメンションにアクセスでき、エージェントはメトリクスカタログを「ツール」として呼び出します。
このアプローチの利点は複数あります。
- エージェント側のプロンプトにメトリクス定義を埋め込む必要がなくなり、定義変更がMCP経由で即座に反映される点です。
- 権限制御をCube側のRBAC・行レベルセキュリティで集中管理できる点で、エージェントに過剰なDBアクセスを与えずに済みます。
- Claude・ChatGPT・Cursorなど複数のLLMから同じ定義にアクセスできるため、組織内でLLMが混在していても数字が揺れない点です。
dbt Semantic Layer × GraphQL/JDBC/MCP
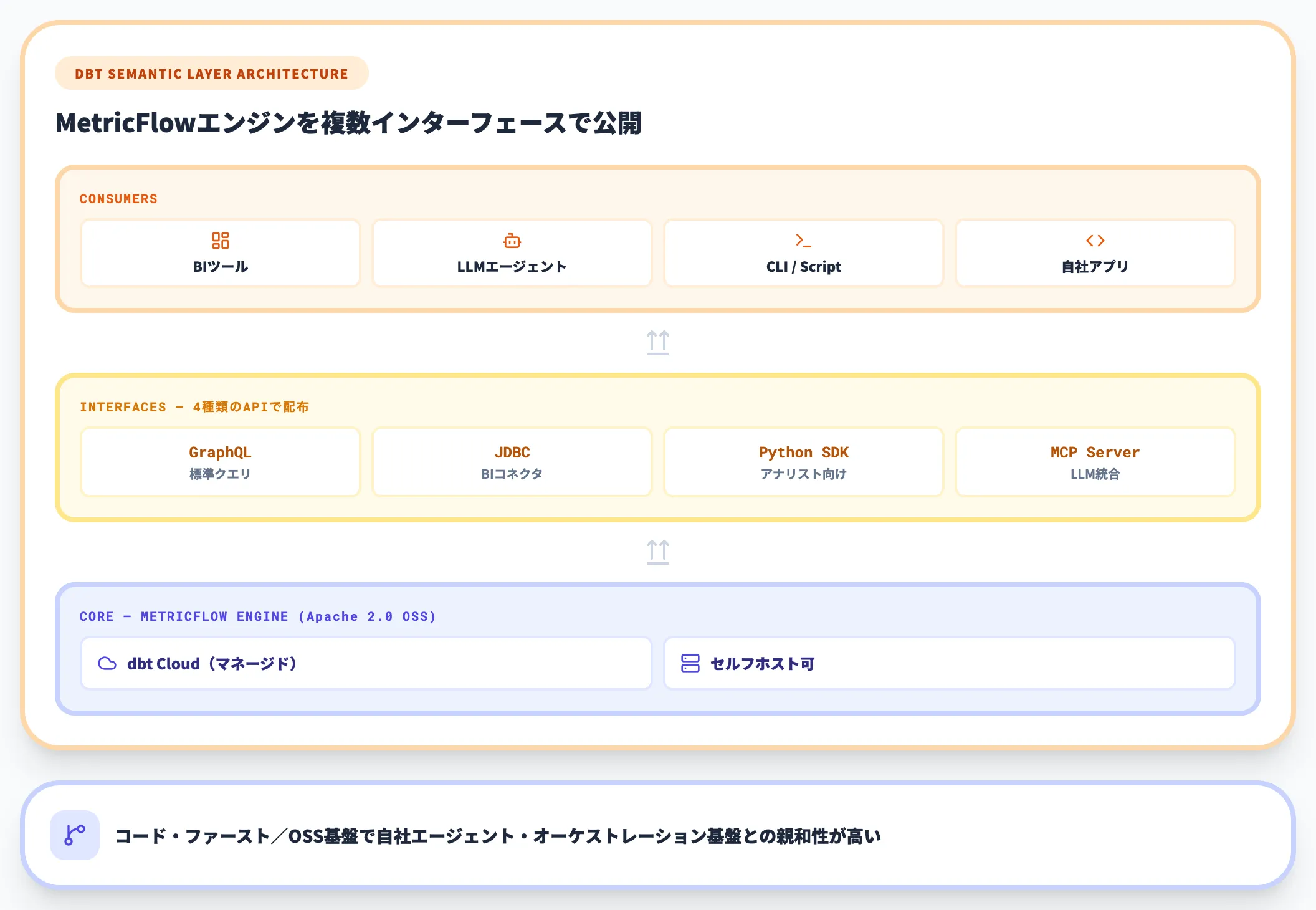
dbt Semantic Layerは、GraphQL/JDBC/Python SDKとdbt MCP Serverを提供しており、これらのインターフェースを経由して各種エージェント基盤から利用できます。
dbtはOSS化したMetricFlowとあわせて「LLMエージェントからガバナンスされたメトリクスを呼ぶ」ユースケースを前面に打ち出しており、コード・ファーストの開発体制と親和性が高い構成です。
MetricFlow自体がApache 2.0でOSS化されたため、自社サーバーでMetricFlowエンジンを動かし、そこに自社製エージェントや各種オーケストレーションフレームワークを接続するセルフホスト構成も現実的な選択肢になります。
Microsoft Fabric Semantic Model × Copilot Studio Agent
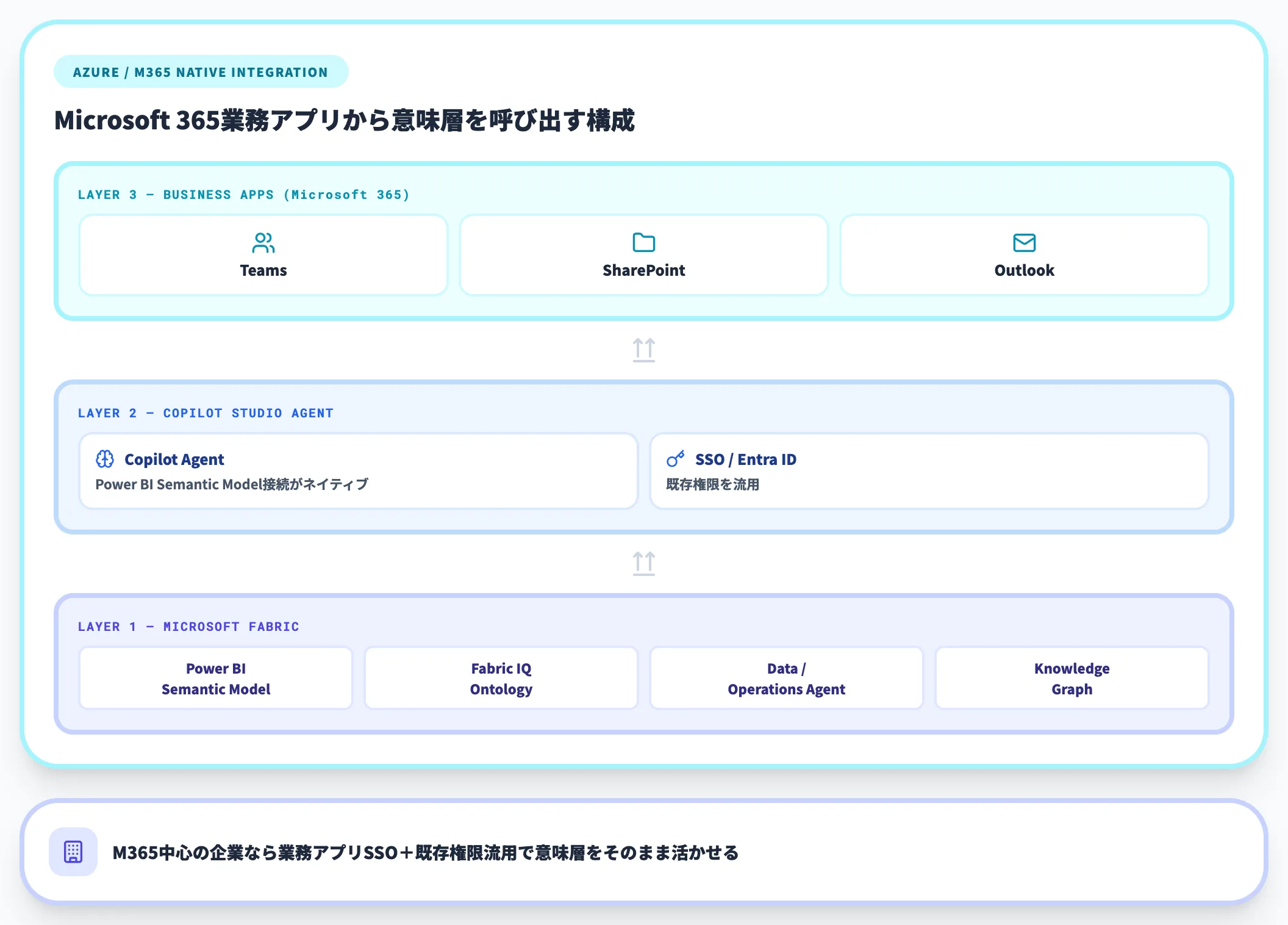
Azure/Microsoft 365中心の環境では、Fabric Semantic ModelをCopilot Studioのエージェントから呼び出す構成が素直です。
Copilot Studioは業務アプリ(Teams・SharePoint・Outlook)との統合が最初から組み込まれており、Power BI Semantic Modelへの接続もネイティブに用意されています。
Fabric側でOntology/Graph/Data agent/Operations agent/Power BI Semantic Modelが別々のアイテムとして提供される構成になっており、ナレッジグラフとセマンティックレイヤーを重ねた設計が可能です。
Microsoft 365中心の企業では、業務アプリ側からのシングルサインオン+既存権限を流用できるのが実装上の大きな利点になります。
3パターンの使い分け
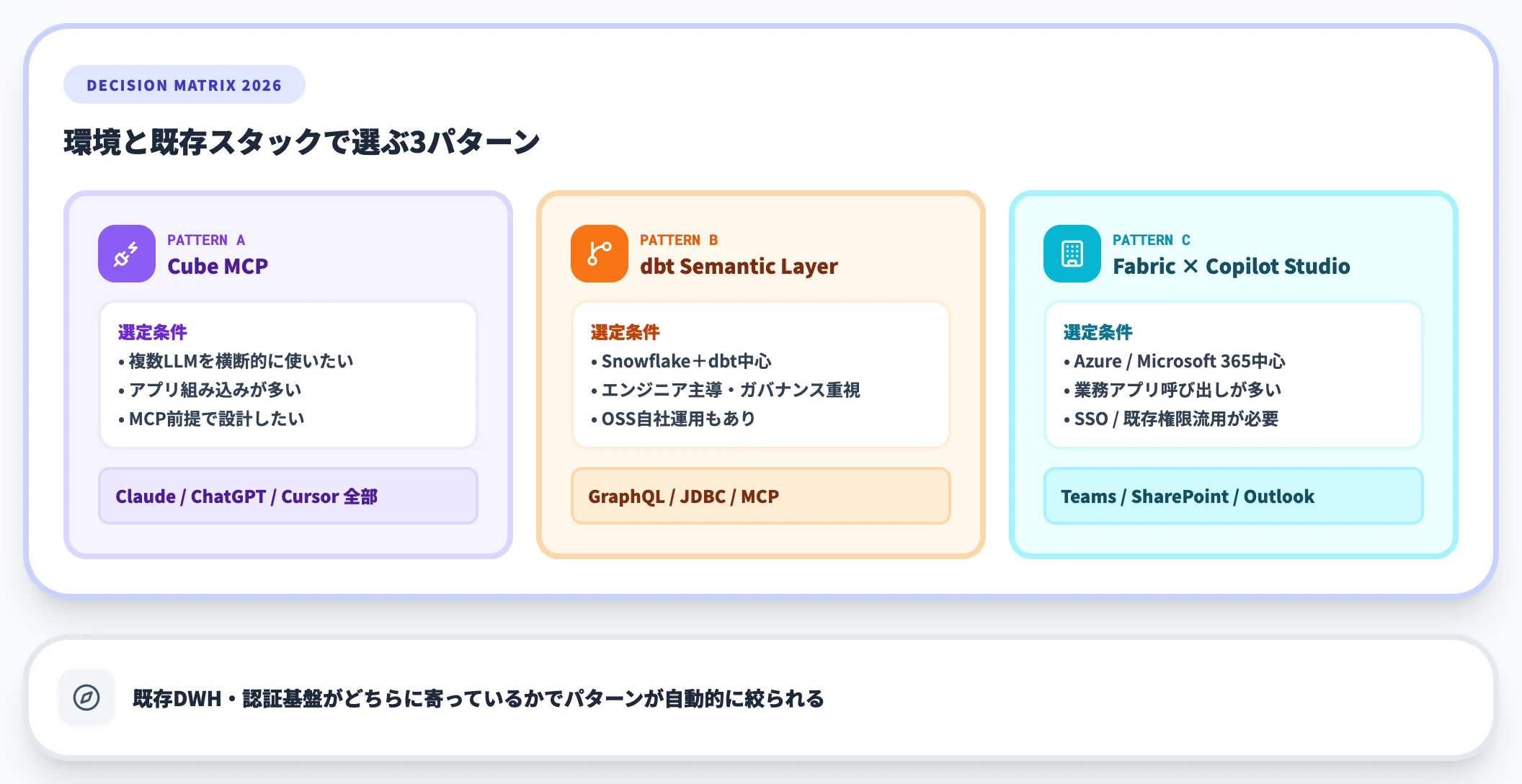
導入環境や既存スタックで以下のように使い分けるのが2026年時点の現実的な整理です。
- Claude・ChatGPT・Cursorを横断的に使いたい/アプリ組み込みが多い
→ Cube MCP - Snowflake+dbt中心/エンジニアリング主導でガバナンス重視
→ dbt Semantic Layer(GraphQL/JDBC/MCP経由) - Azure/Microsoft 365中心/業務アプリからの呼び出しが多い
→ Fabric Semantic Model × Copilot Studio
セマンティックレイヤー導入のステップと失敗パターン
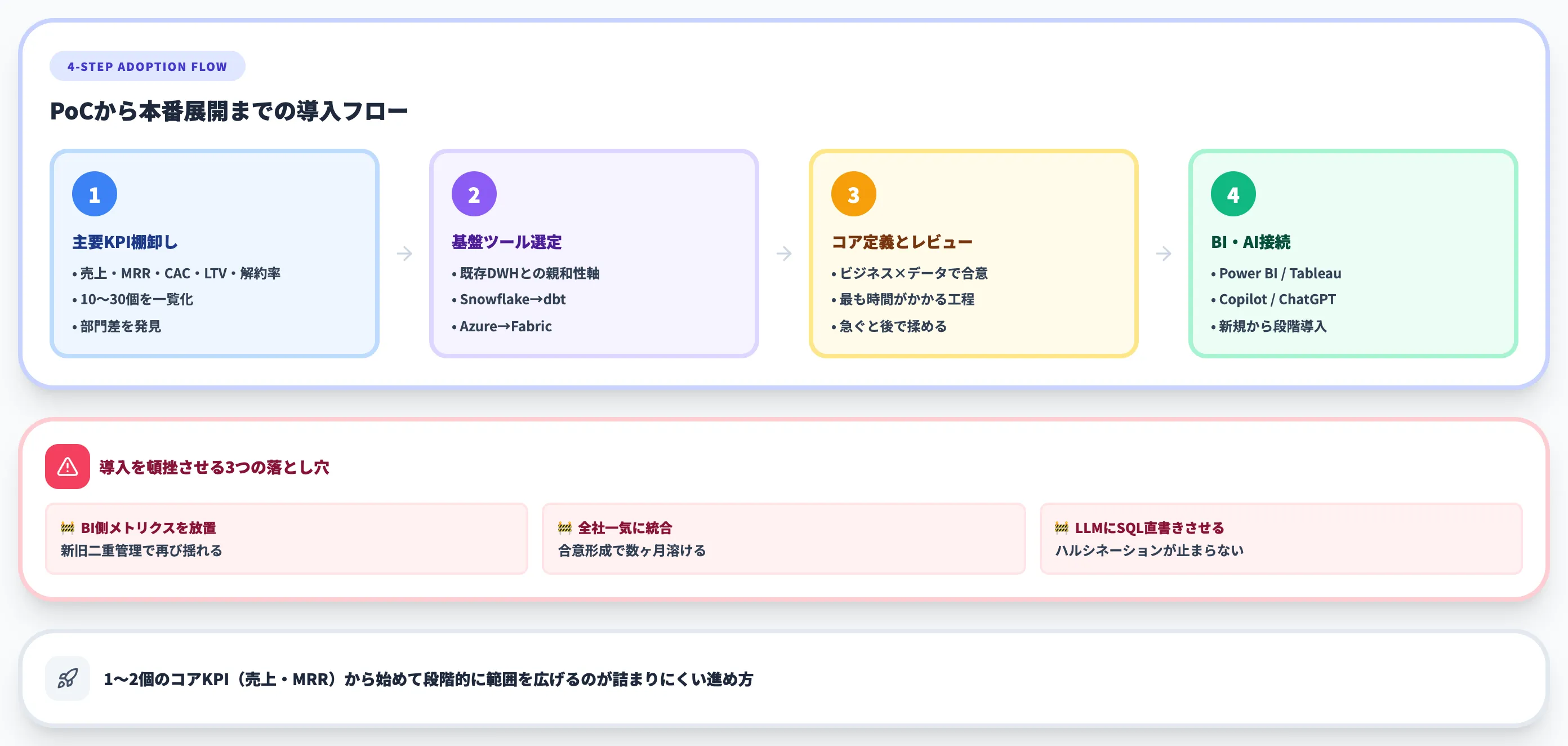
意味層は「入れるだけで効く」ものではなく、設計と運用が必要です。
ここでは4ステップの導入フローと、詰まる論点、よくある失敗パターンを整理します。
Step 1:主要KPIの棚卸し
最初に、社内で使われている主要KPI(10〜30個)を棚卸しします。売上・粗利・MRR・CAC・LTV・解約率などを、「どのツールでどう計算されているか」を一覧化します。
この段階で、部門ごとに定義が違うKPIが必ず見つかります。これが意味層で統一すべき対象です。
Step 2:基盤ツールの選定
Snowflakeならdbt Semantic Layer、Azure/FabricならFabric Semantic Model、DatabricksならUnity Catalog metric views、という具合に、既存DWHとの親和性で選びます。マルチクラウドならCubeが有力候補になります。
Step 3:コアメトリクスの定義とレビュー
棚卸ししたKPIをメトリクスとして定義し、ビジネスサイドとデータサイドでレビューします。定義を決める合意形成が最も時間のかかるフェーズで、ここを急ぐと後で揉めます。
Step 4:BIツール・AIへの接続
定義したメトリクスを、Power BI・Tableau・Copilot・ChatGPT Enterpriseなどに順次接続します。既存ダッシュボードを一度に置き換えるのではなく、新規ダッシュボードから意味層を使う進め方が安全です。
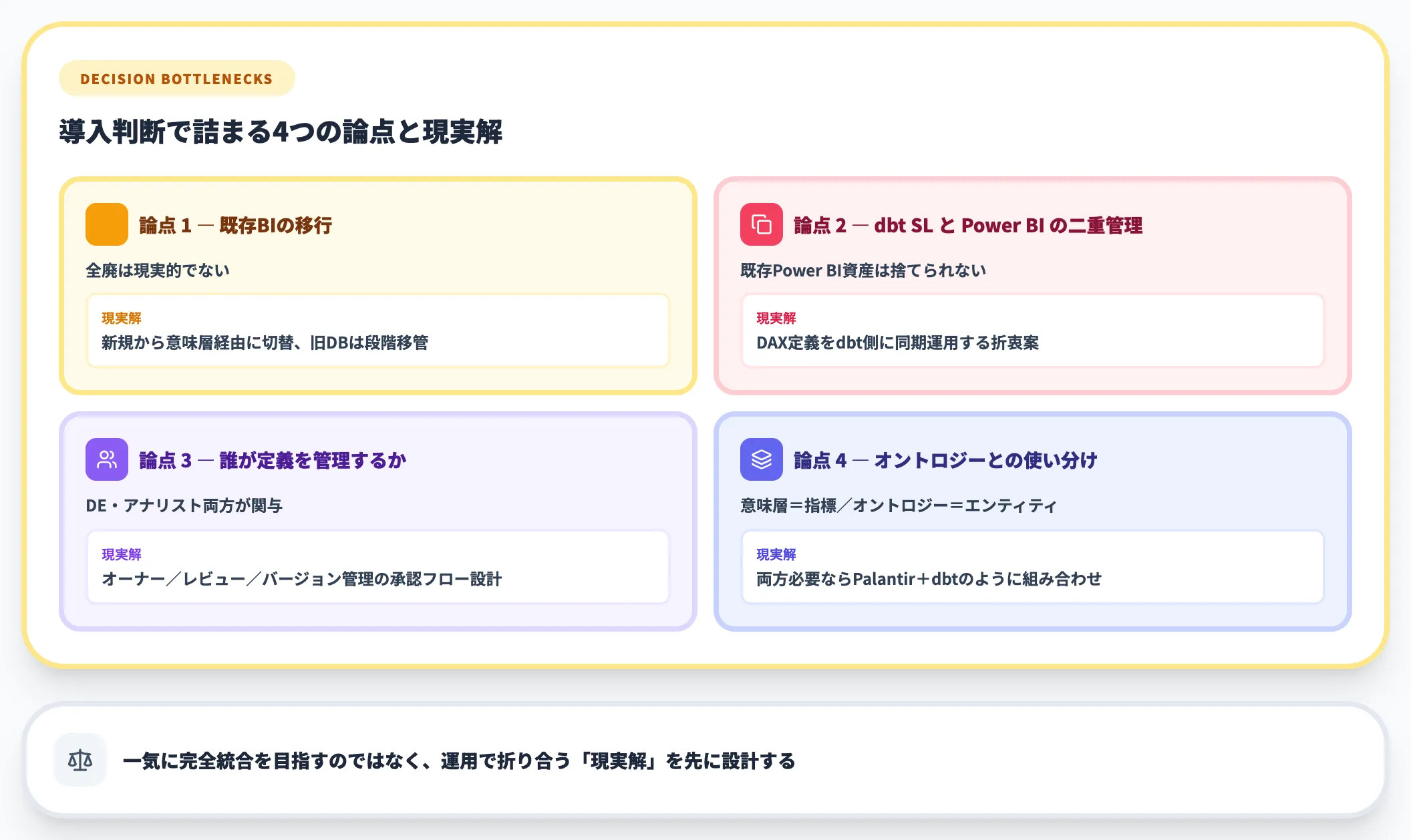
導入判断で詰まる論点
実務で選定・導入に迷う代表的な論点は以下です。
- 既存BIダッシュボードの移行
全廃は現実的でない。新規分から意味層経由に切り替え、古いダッシュボードは徐々に移管する段階移行が基本
- dbt Semantic LayerとBIツール内蔵の意味層(Power BI等)の二重管理
一元化は理想だが、既存Power BIの資産は捨てられない。DAX定義の内容をdbt側にも同期する運用で折衷案を取るケースが多い
- 誰が定義を管理するか
データエンジニアとビジネスアナリストの両方が関与するため、承認フロー(オーナー・レビュー・バージョン管理)の設計が必須
- 意味層とオントロジー/ナレッジグラフの使い分け
意味層はメトリクス、オントロジーはエンティティ。両方必要な案件では、Palantir Foundry Ontology+dbt Semantic Layerのような組み合わせになる
よくある失敗パターン3つ
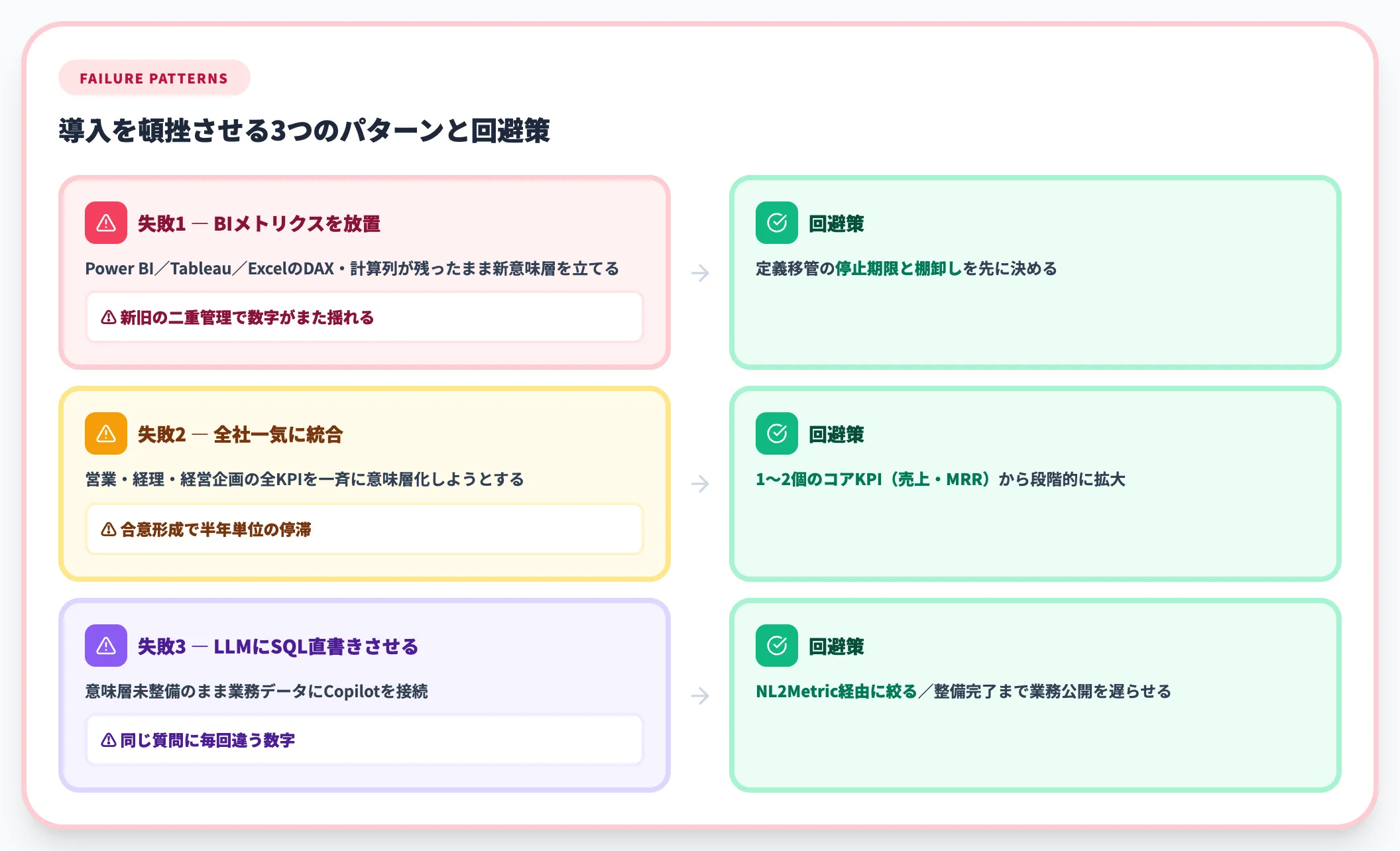
SIerとして意味層の設計支援に関わる中で、導入が頓挫・停滞する案件には共通パターンがあります。
- BIに埋もれた既存メトリクスを放置してdbt側にだけ定義する
Power BI・Tableau・ExcelのDAX/計算列が生き残ったまま新しい意味層を立てると、新旧の二重管理になり、数字がまた揺れる。定義移管の停止期限と棚卸しを先に決めるのが現実解
- 全社統合を一気に進めようとして合意形成に数ヶ月溶ける
営業・経理・経営企画の全KPIを一斉に意味層化しようとすると、定義のすり合わせで半年単位の停滞が起きる。1〜2個のコアKPI(売上・MRR等)から始めて段階的に範囲を広げるのが、PoCから本番移行で最も詰まりにくい進め方
- LLMにSQL直書きさせてハルシネーションが止まらない
「Copilotが数字を返してくれる」と期待してセマンティックレイヤー未整備のままLLMを業務データに接続すると、同じ質問に毎回違う数字が返る状態になる。NL2Metric経由に絞る、または意味層の整備完了まで業務公開を遅らせる判断が必要

セマンティックレイヤーにまつわる料金と選び方

最後に、主要ツールの料金と、ケース別の選び方を整理します。
主要ツールの料金(2026年4月時点)
以下の表に、主要セマンティックレイヤーツールの料金体系をまとめます。表のあと、読み解きを説明します。
| ツール | 最小価格 | 拡張時 | 備考 |
|---|---|---|---|
| Cube Core | OSS無料 | 自社運用コスト | セルフホスト可能 |
| Cube Cloud | Starter有償 | Premium/Enterprise | 事前集計キャッシュ・監査対応 |
| dbt Semantic Layer | dbt Starter $100/月〜 | Enterprise相談 | Queried Metrics課金 |
| AtScale | $2,500/月〜 | 消費ベース | エンタープライズ向け |
| LookML(Looker) | Google Cloud契約 | ユーザー/プラットフォーム課金 | GCP前提 |
| Microsoft Fabric | F SKU従量(F2〜) | 構成により異なる(Copilot運用の一部例でF64利用) | Japan Eastリージョン対応 |
| Databricks | Databricks DBU消費 | ワークロード単位 | Unity Catalog metric views利用時はSQL warehouse/compute課金 |
この料金体系の読み解きとしては、無料のCube CoreやdbtのOSS版MetricFlowで検証し、本番でdbt Semantic LayerかCube Cloudに移行するのが段階的な導入パスの一例として取られます。
既にFabric/Databricksを利用している企業は、標準機能で意味層を構築できるため追加コストは不要になるケースが多いです。
ケース別の選び方
AI総研の支援経験から見たケース別の推奨は以下です。
- モダンデータスタック(Snowflake+dbt)
dbt Semantic Layerが有力候補。MetricFlowはOSS化済みで、ベンダーロックインの懸念は以前より軽い
- Azure/Microsoft 365中心
Fabric Semantic Model+Copilot for Power BIで完結できる。Fabric IQ Ontologyとの組み合わせでエンティティ層も重ねられる
- Databricks中心
Unity Catalog metric views(business semantics)で統合。別製品を追加せずに意味層を構成できるが、実行にはSQL warehouse/computeコストが別途発生し、外部BI連携は2026年時点でBeta段階という前提で選定する
- マルチクラウド/アプリ組み込み/MCP前提
Cube(OSS+Cloud)が有力候補。MCPサーバー提供でClaude・ChatGPT・Cursorから横断呼び出しできる
- 大企業の基幹系・MDX/DAX資産が厚い
AtScaleが候補に入る。Excel/旧OLAP資産との互換性と運用監査要件がハマる場合に選ぶ
- 既にLookerユーザー
LookMLが有力な継続選択肢。拡張時はdbt連携を含め他ツールとの並存も検討する

Copilotが返す数字が揺れる段階に来たら
社内のCopilot/ChatGPT/Claudeに「先月のARRは?」と聞いて毎回違う数字が返ってくる——この状態は、意味層(セマンティックレイヤー)の整備が業務に追いついていないサインです。
PoCまでは動いたのに社内展開で止まる生成AI案件の多くが、この「数字の単一ソースが無い」問題に行き着きます。
AI Agent Hubでは、dbt Semantic Layer・Cube・Microsoft Fabric Semantic Modelといった意味層基盤の選定から、NL2Metric運用の設計、AIエージェントの権限管理・実行ログ・監査までを一画面で統制します。自社テナント内で完結するため、KPI定義や顧客データを外に出さずに、Copilot・社内AIチャット・エージェントに正確な数字を返させる環境を構築できます。
メトリクス棚卸し・定義合意・BI/AI接続といった導入フェーズもSIerとして伴走しており、意味層の導入から業務アプリへの組み込みまでワンストップで進められます。
AI総合研究所は、意味層を軸に生成AIと既存データ基盤を接続する企業向けの設計・実装を支援しています。「Copilotは入れたが社内指標が揺れて使えない」「dbt・Fabric・Cubeのどれを選ぶか判断がつかない」といった段階の企業に向けて、下記の資料で意味層×AIエージェントの全体設計を公開しています。
意味層でCopilotの数字を揃える

メトリクス設計から業務運用まで支援
Copilot・ChatGPT Enterprise・Claude Enterpriseが社内データに問う時代、意味層の整備なしではLLMが返す数字が揺れ続けます。AI Agent Hubなら、dbt Semantic Layer・Cube・Fabric Semantic Modelなどメトリクス基盤の選定から、NL2Metric運用、AIエージェントの権限管理・実行ログまで一画面で統制できます。自社テナント内で完結する設計で、KPI定義を外に出さずにCopilotとAIエージェントに正確な数字を返させられます。
まとめ
セマンティックレイヤー(意味層)は、データ基盤と消費ツールの間に挟まる「意味の定義層」であり、生成AI・Copilot・AIエージェント時代の数値の単一ソースとして再評価されています。
本記事のポイントを整理します。
- 意味層はメトリクス・ディメンション・メジャー・APIインターフェースで構成される
- オントロジー/ナレッジグラフとは抽象度が異なる(指標の意味 vs 実体の意味)
- 主要ツールはdbt Semantic Layer・Cube・AtScale・LookML・Fabric・Databricksの6種
- Copilot・ChatGPT・Claude・AIエージェントとの統合で真価を発揮
- 無料のCube CoreやOSS版MetricFlowで検証し、本番はdbt($100/月〜)または既存DWHの統合機能で十分なケースが多い
社内のKPIが部門ごとに揺れており、Copilot/ChatGPTに数字を聞いても毎回違う答えが返ってくる状態なら、意味層の導入時期に来ています。
1〜2個のコアKPI(たとえば売上とMRR)から始めて、段階的に範囲を広げる進め方が最もリスクが低く、効果も早く見えます。










