この記事のポイント
 Stable DiffusionのWebUIならForgeが第一候補、AUTOMATIC1111より高速・安定でVRAM消費も少なく低スペックGPUも可
Stable DiffusionのWebUIならForgeが第一候補、AUTOMATIC1111より高速・安定でVRAM消費も少なく低スペックGPUも可- 自社で画像生成を内製化するなら、Azure仮想マシンでの環境構築が最適。GPU付きVMを使えば高スペックPCを購入せずに無制限で画像生成が可能になる
- インストール時はNVIDIAドライバとCUDAツールキットのバージョン整合性が最重要、公式docsのバージョン指定に厳密に従う
- モデル選定は用途別にCheckpointを使い分け、リアル系はSD 3.5 Large・イラスト系はアニメ特化モデル、Civitaiで評価高いものから試す
- LoRAを活用すれば少ない計算資源でモデルの画風調整が可能。プロンプトエンジニアリングと組み合わせることで、商用レベルの出力品質を安定的に実現できる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「Stable Diffusionをローカル環境で自由に使いたいけど、セットアップが難しそう」「もっと高速で安定したWebUIはないの?」
そんな方に最適なのが、人気のGUIツール「Stable Diffusion WebUI」をさらに進化させた『Stable Diffusion WebUI Forge』です。従来のWebUIよりも高速かつ安定しており、多くの開発者に支持されています。
本記事では、この『Stable Diffusion WebUI Forge』について、そのインストールから使い方までを徹底的に解説します。
Azure仮想マシンを使った環境構築の全手順、高品質な画像を生成するためのモデル導入方法、プロンプトの基本、そしてよくあるエラーの解決策まで、詳しくご紹介します。
✅Microsoft 365 Copilotの最新エージェント機能「Copilot Cowork」については、以下の記事をご覧ください。
Copilot Coworkとは?機能や料金、Claude Coworkとの違いを解説
目次
2. ローカル環境(自身のPC)またはクラウド環境で利用する方法:
Stable Diffusionの料金と使い方【Webサービス編】
1. Dream Studio (Stability AI公式)
3. Hugging Face (Stable Diffusion Demo)
5. Leonardo.Ai (旧 Leonaldo AI 表記箇所あり)
Stable Diffusionの料金と環境構築【ローカル・クラウド編】
【無料・有料|Google Colaboratory (Colab)】
【具体的な導入手順】Stable Diffusion WebUI Forgeでローカル環境を構築する
Stable Diffusion WebUI Forgeとは
個人での画像生成から企業でのクリエイティブ制作まで、幅広い用途に対応できる柔軟性を持ち、特にAzure仮想マシンとの組み合わせにより、高性能な画像生成環境を構築することができます。
Stable Diffusion WebUI Forgeのインストール方法
Stable Diffusion WebUI Forgeの使い方
Stable Diffusionとは
「Stable Diffusion」は、2022年に英Stability AI社が公開した、無料で利用できる画像生成AIです。 テキスト(プロンプト)を入力するだけで、写真のようにリアルな画像からイラスト風の作品まで、多種多様な画像を生成できるのが特徴です。
技術的には「拡散モデル(Diffusion Model)」と呼ばれる深層学習モデルの一種で、特に「潜在拡散モデル(Latent Diffusion Model)」という仕組みを採用しています。 これは、ノイズだけの画像から少しずつノイズを除去してクリアな画像を復元する技術であり、比較的低い計算コストで高品質な画像を高速に生成することを可能にしました。
例えば、「カフェでリモートワークを行う26歳 成人男性 独身」という言葉をAIに与えるだけで、下記のような高精度かつリアルな画像が生成できます。
このようにして入力する文章は「プロンプト」と呼ばれます。このプロンプトを上手く組みわせることで、ユーザーが望む画像を簡単に出力できる仕組みとなっています。

Stable Diffusionを使って作り出した画像

最大の特徴:オープンソースであること
Stable Diffusionが他の画像生成AIと一線を画す最大の特徴は、モデルがオープンソースとして無償で公開されている点にあります。
MidjourneyやDALL-Eといった多くの画像生成AIが、企業が管理するクラウド上でしか利用できないクローズドなサービスであるのに対し、Stable Diffusionは誰でもモデルのプログラムを自身のPC(ローカル環境)にダウンロードし、自由にカスタマイズして利用することが可能です。
このオープンな性質により、世界中の開発者やクリエイターが独自の追加学習モデル(CheckpointやLoRA)を開発・共有する巨大なエコシステムが生まれました。 これにより、特定のキャラクターや画風を再現したり、新たな機能を追加したりといった、無限の拡張性を実現しています。
もちろん、高性能なPCがない場合でも、様々な企業が提供するWebサービスを通じて、Webブラウザから手軽にStable Diffusionを体験することもできます。
Stable Diffusionの主な利用方法
Stable Diffusionを利用するには、大きく分けて以下の2つの方法があり、それぞれ料金体系や準備の手間が異なります。
1. Webサービスを利用する方法
- 概要:
ブラウザ上で手軽に利用開始でき、専門知識や高性能なPCは不要です。
- 料金傾向:
無料で試せるサービスが多いですが、生成枚数制限や機能制限があり、本格利用には有料プラン(月額制やクレジット購入制)が必要になることが一般的です。
- 主なサービス例:
Dream Studio, Mage.space, Hugging Face Demoなど。
2. ローカル環境(自身のPC)またはクラウド環境で利用する方法:
-
概要:
より高度なカスタマイズや無制限の画像生成が可能ですが、PCスペック(特にGPU)やある程度の知識が必要です。
-
料金傾向:
ローカル環境: Stable Diffusionのソフトウェア自体は無料ですが、高性能PCの初期投資や電気代がかかります。
クラウド環境: Google Colaboratoryのような無料枠のあるサービスから、時間単位で高性能GPUをレンタルできる有料サービスまで様々です。
-
代表的なツール:
Stable Diffusion Web UI (AUTOMATIC1111版など)
以下の図は、これらの始め方の選択肢を示しています。
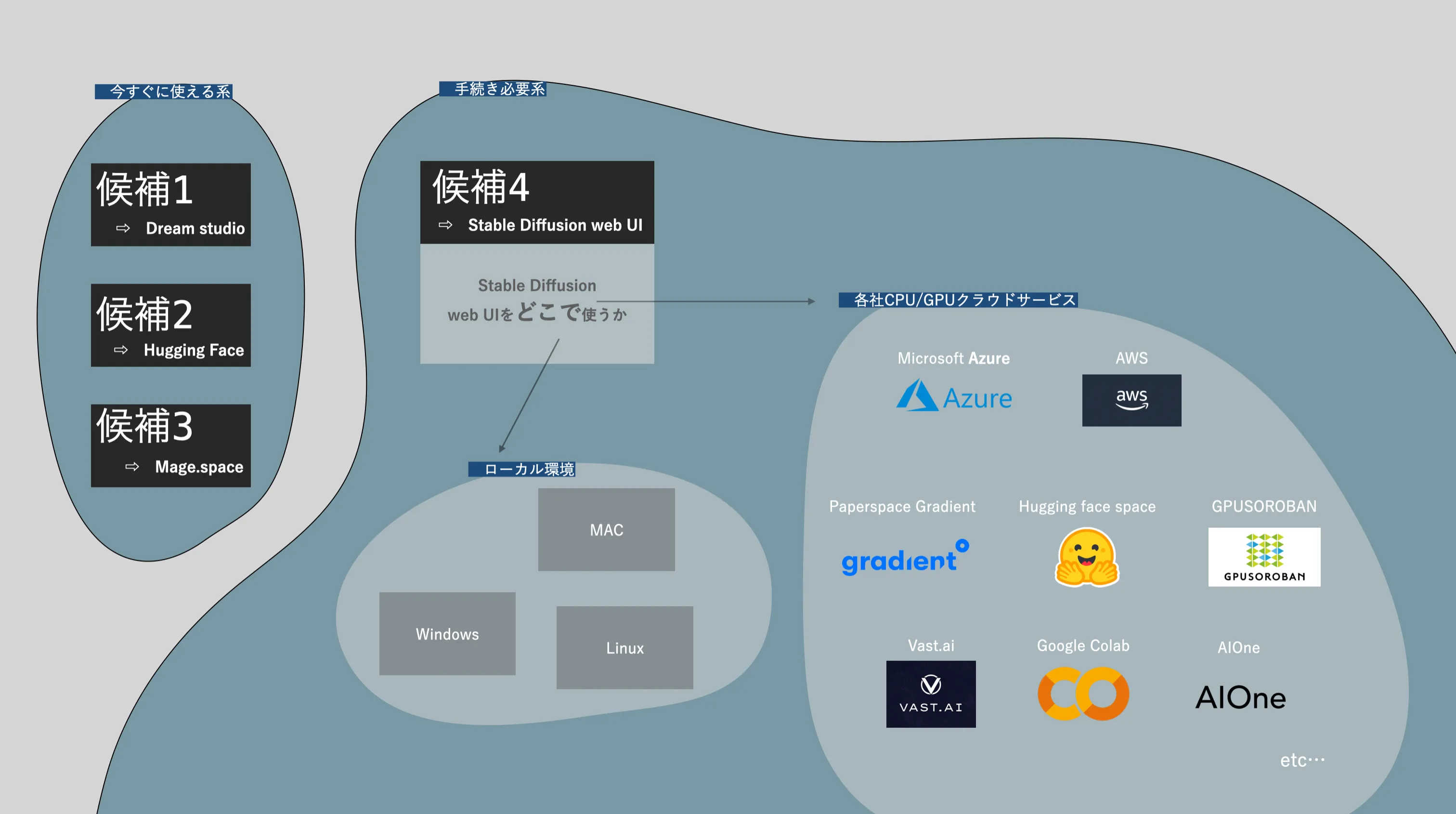
Stable Diffusionの始め方マップ
これらの中から、予算や用途、技術スキルに応じてどの利用方法が最適かを検討していくことをおすすめします。
以降では、それぞれの方法について、より詳しく料金や使い方を見ていきましょう。
Stable Diffusionの料金と使い方【Webサービス編】
企業が提供するStable Diffusionのサービスは多岐にわたります。ここでは主要なサービスを取り上げ、料金と基本的な使い方を解説します。
多くのサービスで無料利用枠が提供されているため、まずは試してみるのがおすすめです。
1. Dream Studio (Stability AI公式)
DreamStudioのトップページ (参考:Dream Studio)
「Dream Studio」は、Stable Diffusionの開発元であるStability AI社が公式に提供するWebサービスです。商用利用も可能で、テーマや画像サイズ、出力する際の重みづけなど、画像生成時に詳細な設定が可能です。
- 料金:
アカウント登録時に無料クレジット(執筆時点では25クレジット、画像約125枚分に相当)が付与されます。これを超えて利用する場合は、追加でクレジットを購入(例: 10ドルで約500クレジット)する従量課金制です。
- 特徴:
公式サービスとしての信頼性、比較的詳細な設定項目。
Dream Studioの使い方
- まず、Dream Studioにアクセスします。初めての人は「サインアップ」、既に登録済みの人は「ログイン」を選択してください。
- 左上のプロンプトの欄に、英語で好きな文章を入力し、左下の「Dream」を選択すれば、画像が生成されます。
DreamStudio 操作画面
3. 画面一番右上のアイコンの横に、「クレジット数」の表示があります。この数値が0になると画像が生成できなくなり、追加料金が必要となります。
また、プロンプト入力欄の下部にある「Negative prompt」という項目で、「生成して欲しくない要素」を指定することができます。試しに「personal computer,mac,windows」というワードを入力し、生成された画像からパソコンを消してみましょう。

DreamStudio 出力例.1
- すると、このようにパソコンが消された画像が出力されました。
そして、「Setting」の項目で生成する画像の細かい調整ができます。いくつかの項目を抜粋して概要を確認します。
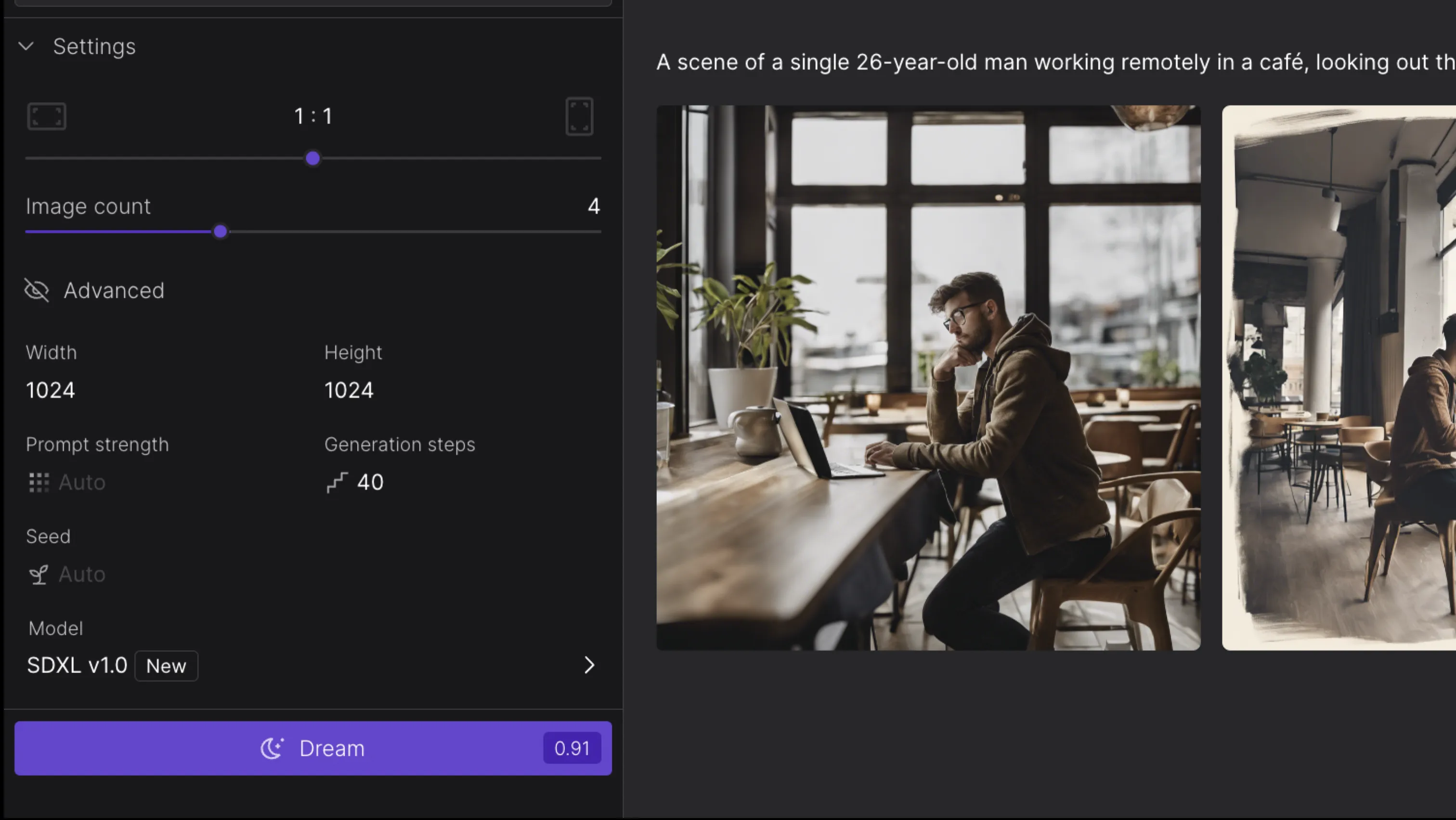
DreamStudioのSetting機能
Dream Studioの詳細設定
- アスペクト比の変更:
一番上にある「1:1」などを操作することで、生成する画像のアスペクト比を変更できます。比率を変えると、クレジット消費数が多くなる場合があります。
- 生成する枚数の変更:
「Image count」の数値を上げれば上げるほど、一度に生成される画像の枚数は増えます。クレジット消費も増えるので注意しましょう。
- Prompt strength:
この数値を高くすればするほど、プロンプトに忠実に画像を生成しようとします。文章量が多い場合は、クオリティーが下がる場合があるので、基本的には「Auto」または中程度の値がおすすめです。
- Generation steps:
画像のサンプリングステップ数を設定できます。簡単に言えば「画像生成までに何回計算を繰り返すか」という数値です。数が高いほど細部まで描画されクオリティが上がりますが、生成時間とクレジット消費量が増加します。
Dream Studioは、「一通りStable Diffusionの機能を体験してみたい」「公式サービスで安心して使いたい」という方におすすめです。
2. Mage.space
Mage.spaceの操作画面 (参考:Mage.space)
Ollano社が運営する「Mage.space」も、無料でStable Diffusionの各種機能を利用でき、商用利用可能なサービスです。
- 料金:
基本無料(枚数制限なし、一部モデル制限あり)。有料プラン(月額15ドル~)では、より多くのモデル利用、高速生成、プライベートモードなどが提供されます。
無料版では登録なしでも利用できますが、一定回数を超えると無料アカウント作成を求められることがあります。
- 特徴:
クレジット制ではない無料利用、直感的なインターフェース、他のユーザーの作品やプロンプトを閲覧可能。
Mage.spaceの使い方
Mage Spaceにアクセスすると、上記の操作画面に遷移します。
さっそくプロンプトを入力してみます。
|プロンプト
「A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage.
She wears a black leather jacket, a long red dress, and black boots, and carries a black purse.
She wears sunglasses and red lipstick. She walks confidently and casually.
The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.」
Mage.space プロンプトの入力
すると、このような結果になりました。
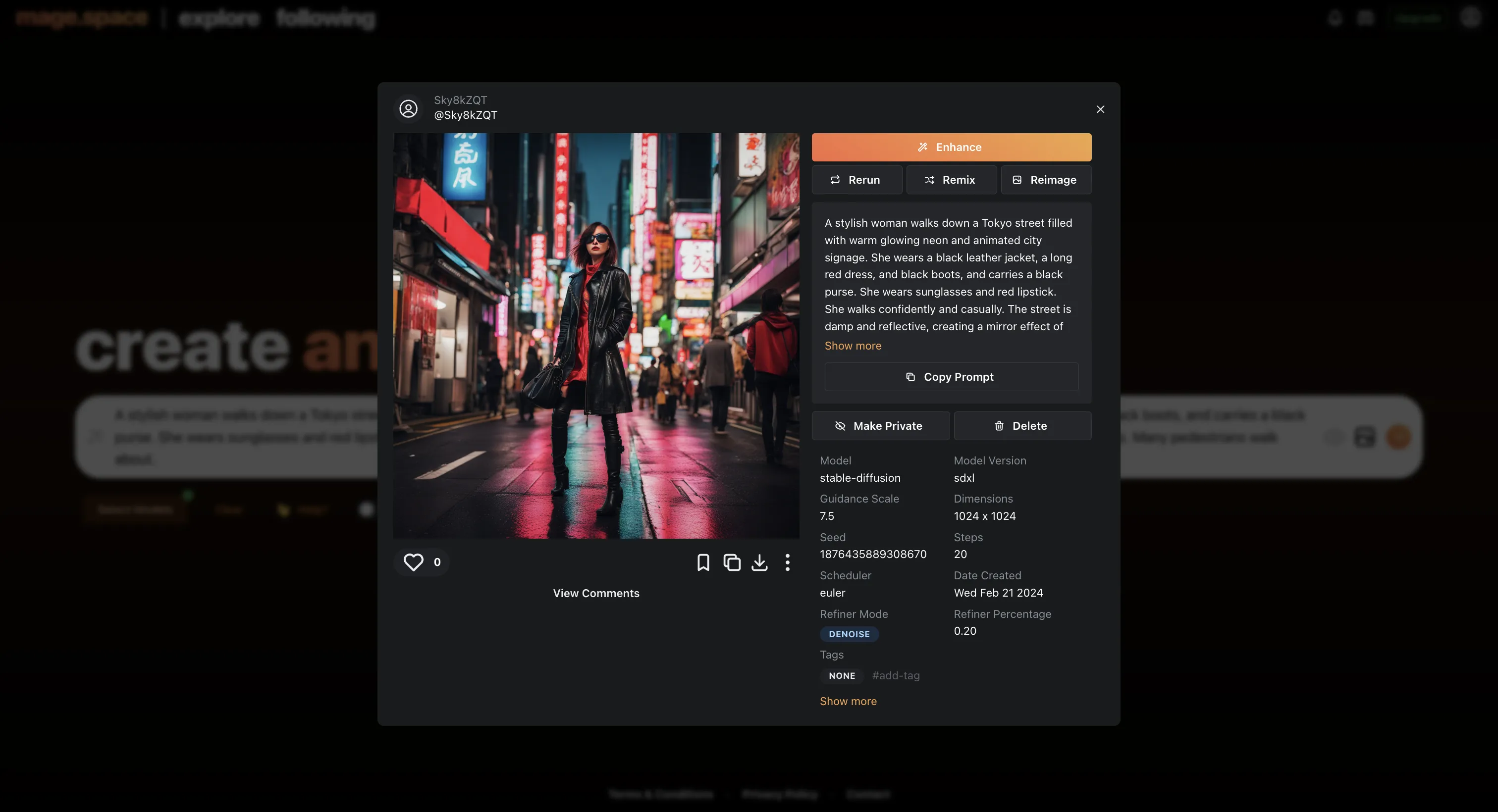
Mage.space 出力例.1
生成した画像を保存するには、「Enhance」ボタンを選択します。すると、「Upscale + Face Fix」のボタンが出るので、そちらを選択します(一部有料機能の場合あり)。
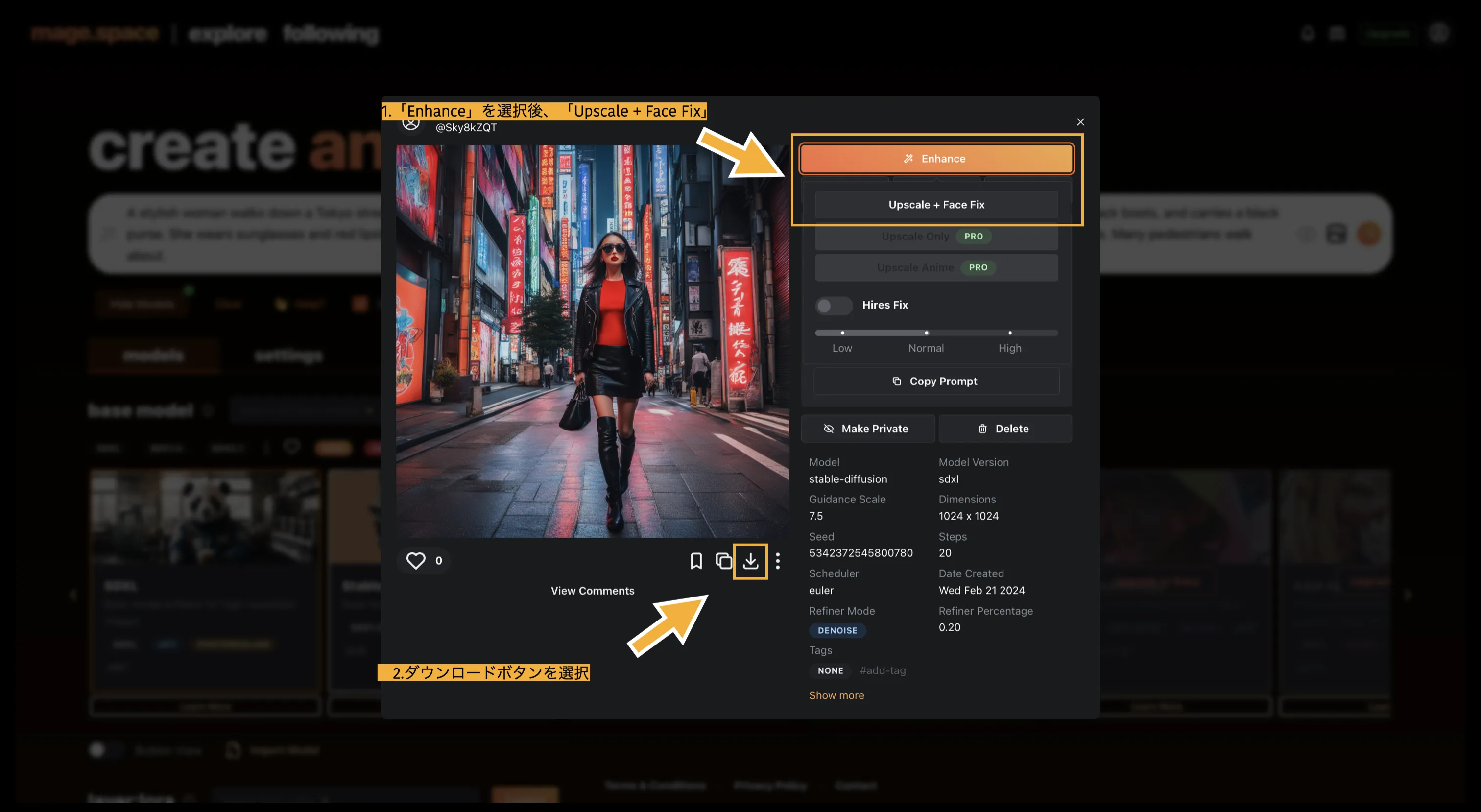
Mage.space 画像の保存方法
画像の下にあるダウンロードボタンをクリックして、ダウンロード完了です。こちらで生成した画像は商用利用できます(利用規約を確認してください)。
「Enhance」ボタンの下に、「Return」「Remix」「ReImage」など、3つの選択肢があり、これらを操作することで出力された画像をさらに加工することができます。
例えば、「Remix」を押してから、プロンプト入力画面で「Cat」と入力すると、女性が猫に置き換わります。
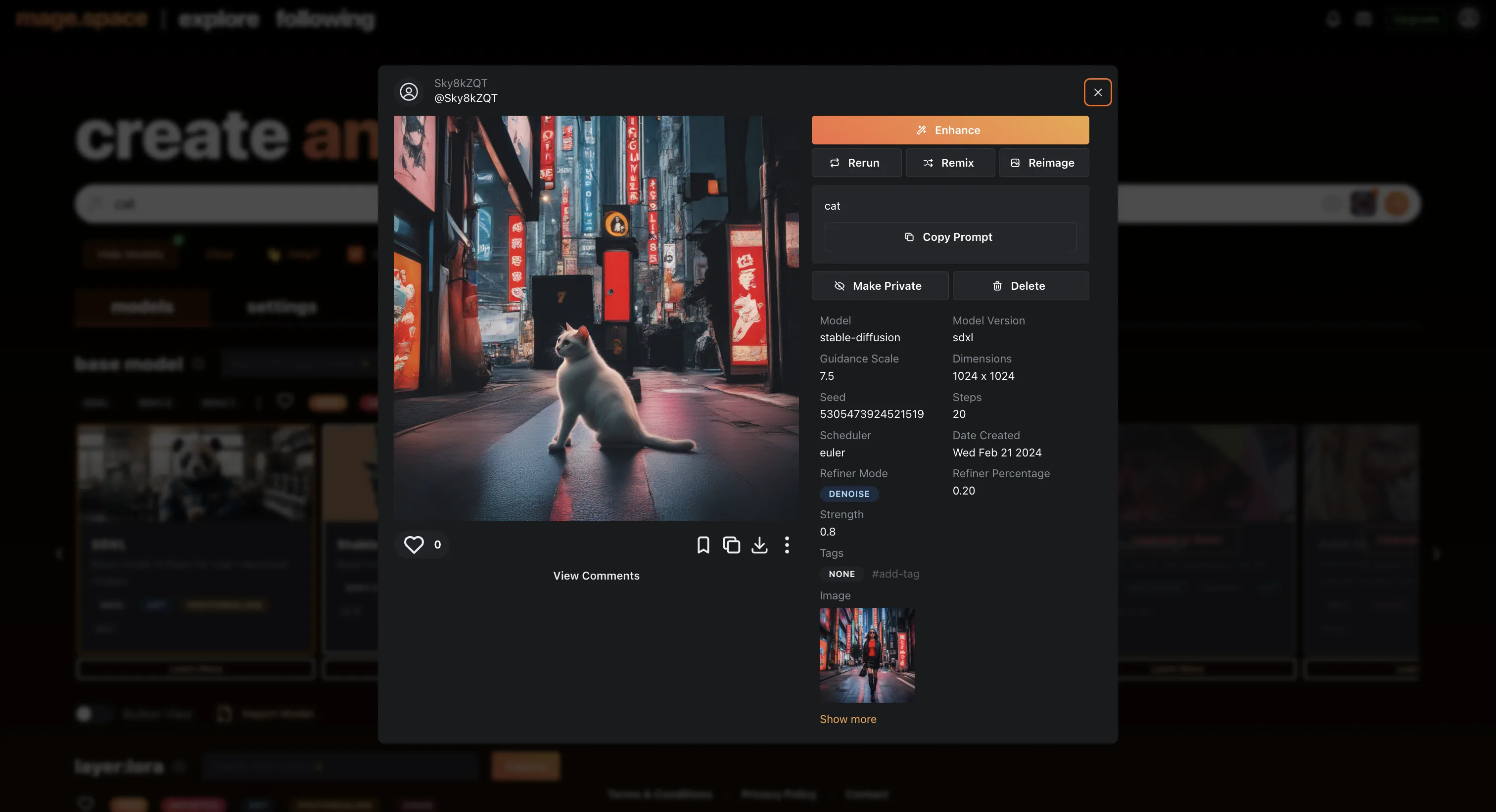
Mage.space Remix機能
また、Mage.spaceは「画像生成に利用するモデル」を変更することもできます。ここでのモデルの変更とは、簡単に言えば、画像のテイストを変えるというニュアンスです。各モデルごとに学習データが異なるため、同じプロンプトでも異なる出力結果が得られます。
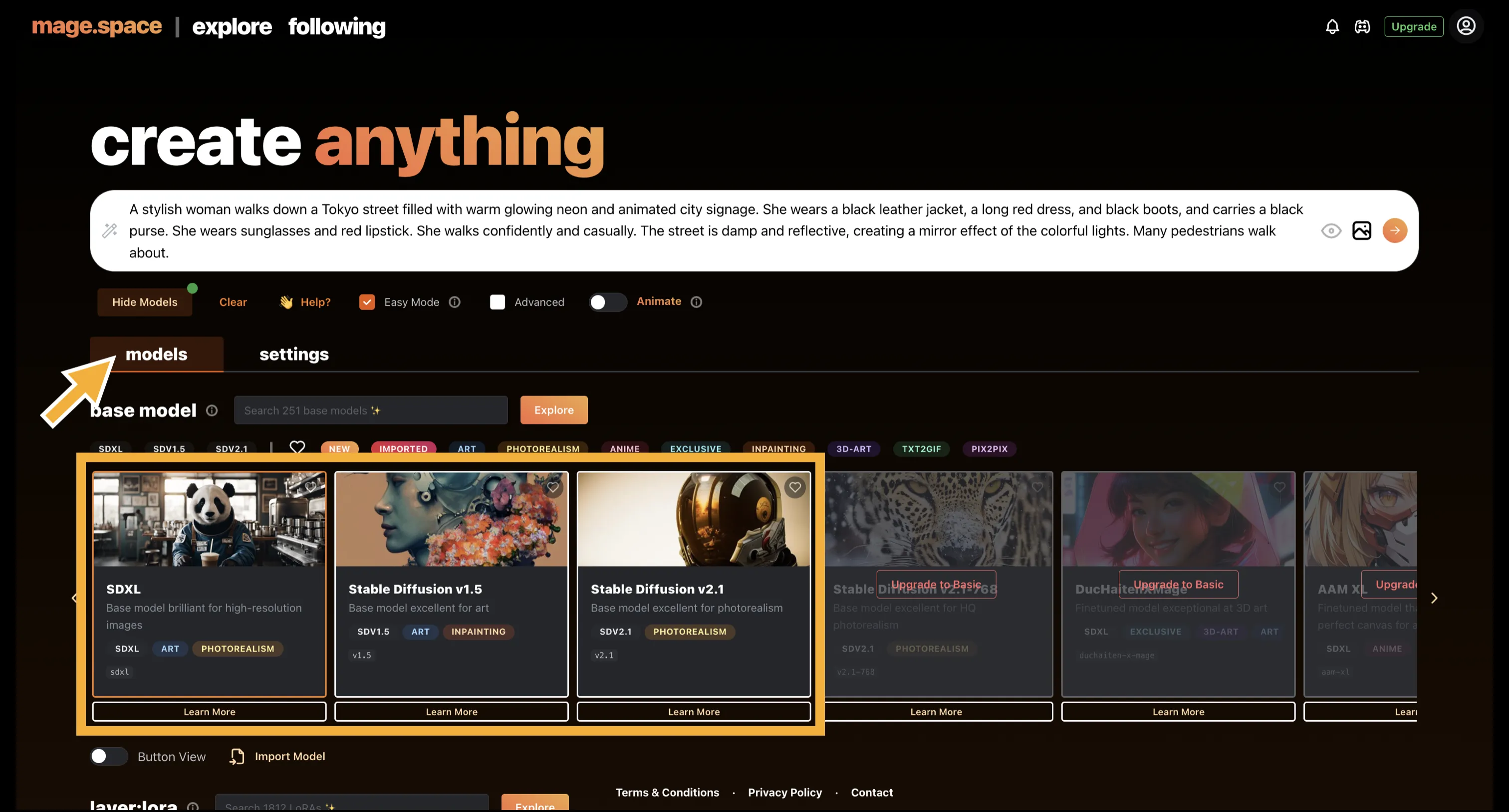
Mage.space 各モデル
無料で使用することができるのは数種類ですが、有料版では、「特定のアニメ調で出力することが得意なモデル」や「特定の人間の顔を出力することが得意なモデル」など、より多くのモデルを使用できます。
3種類のモデルに対して、同じプロンプトを与えた結果が以下になります。

Mage.space モデルごとの出力事例
Stable diffusion v1.5は旧型で、Stable diffusion v2.1は新型のモデルであり、一般的に精度が向上しています。
Mage.spaceは、「無料で多くの画像を試したい」「様々なモデルを手軽に切り替えてみたい」という方に向いています。
3. Hugging Face (Stable Diffusion Demo)
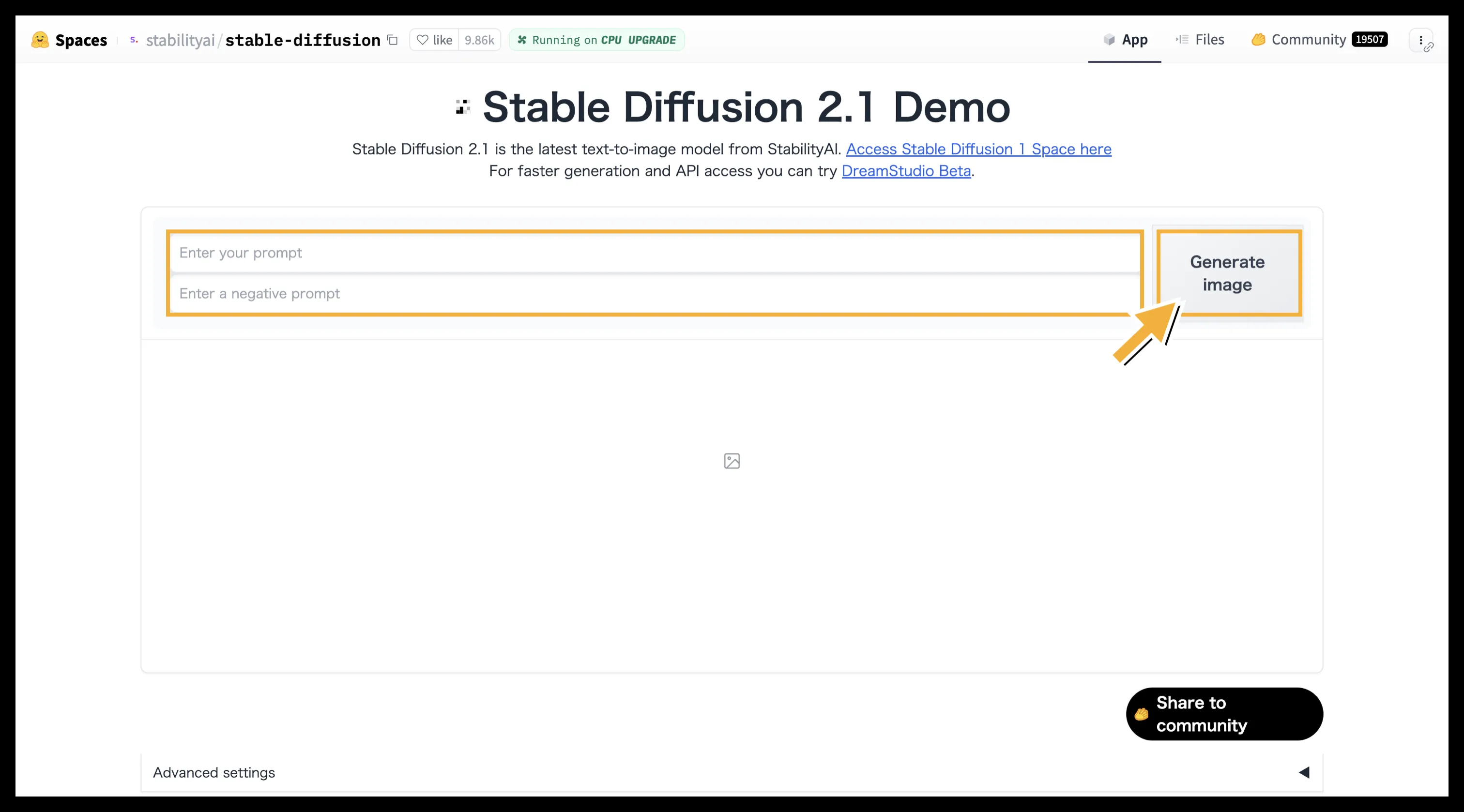
Hugging Face Stable Diffusion 2.1 Demo 操作画面 (参考:Hugging Face)
AIモデルやデータセットの共有プラットフォームである「Hugging Face」でも、Stable Diffusionのデモ版が多数公開されています。Stability AI公式のデモなどがあります。
- 料金: 多くは無料・登録不要で利用可能。
- 特徴: 手軽に最新モデルのデモを試せる場合がある。ただし、機能は限定的で、生成速度や画像の品質は専用サービスに劣ることがあります。
Hugging Face (Stable Diffusion Demo) の使い方
- デモページ(例: Stable Diffusion 2.1 Demo)にアクセスします。
- 「Enter your prompt」と記載している部分に作りたい画像の元となる文章(プロンプト)を英語で入力します。
- 必要であれば、その下にある「Negative prompt」も入力します。
- 右横の 「Generate image」を選択すると、画像が生成されます。
4. Stable Diffusion Online

Stable Diffusion Online (参考:Stable Diffusion online)
Stable Diffusion Onlineは、無料でStable Diffusionを利用できるWebサービスです。
- 料金: アカウント登録時に「クレジット」が付与され、これを消費して画像を生成。クレジットは1日おきに更新されますが、上限を超えて生成したい場合は別途課金が必要です。
- 特徴: 入門者向けでシンプルな操作性。ローカル環境での利用に比べて細かな設定はできず、カスタマイズ性は低いです。
Stable Diffusion Onlineは、「ひとまずStable Diffusionを使ってみたい」という初心者の方におすすめです。
5. Leonardo.Ai (旧 Leonaldo AI 表記箇所あり)
Leonardo.Aiのトップページ (参考:Leonardo.Ai)
「Leonardo.Ai」は、Stable Diffusionをベースとしつつ、独自の学習モデルや多彩な画像編集機能を搭載した高機能な画像生成プラットフォームです。
- 料金: 登録時に無料トークンが付与され(毎日リセット)、その範囲内で画像生成が可能。より多くのトークンや高度な機能(画像の非公開化、新機能への優先アクセスなど)は有料プラン(月額10ドル~、年間契約で割引あり)で提供されます。
- 特徴: 独自の高品質モデル、多彩な編集ツール、コミュニティ機能。
| プラン名 | 料金(月額目安) | 使用可能トークン数(月目安) | 画像を非公開にする機能 | 新機能への優先的なアクセス権 | 同時実行ジョブ数 |
|---|---|---|---|---|---|
| Free プラン | 無料 | 1日あたり約150トークン | × | × | 1 |
| Apprentice | 約$12 | 約8,500トークン | ○ | ○ | 5 |
| Artisan | 約$30 | 約25,000トークン | ○ | ○ | 10 |
| Maestro | 約$60 | 約60,000トークン | ○ | ○ | 20 |
| (料金やプラン内容は変動する可能性があるため、必ず公式サイトで最新情報をご確認ください) |
Leonardo.Aiは、高品質な画像を求めるクリエイターや、ゲームアセット制作など特定の用途で活用したい方におすすめです。
Stable Diffusionの料金と環境構築【ローカル・クラウド編】
Webサービスの手軽さも魅力ですが、より自由度の高い画像生成や、枚数制限を気にせずに利用したい場合は、自身のPC(ローカル環境)やクラウド上の仮想マシンにStable Diffusionをセットアップする方法があります。
この場合、Stable Diffusionのソフトウェア自体は無料ですが、実行環境を用意するためのコストがかかります。特に高性能なGPU(グラフィックボード)が重要となり、これが初期投資の大部分を占めることがあります。
ローカル環境でStable Diffusionを動かす際によく使われるのが「Stable Diffusion Web UI」(AUTOMATIC1111版が有名)というGUIツールです。
これを利用すると、ブラウザ経由で比較的簡単に操作でき、無料かつ無制限で画像を生成できます。また、拡張機能によるカスタマイズ性も非常に高いのが特徴です。ただし、導入にはある程度のPC知識や環境設定の手間が必要です。
以下は、Stable Diffusionを快適に動作させるための推奨PCスペックの目安です。
| 種別 | 推奨スペック |
|---|---|
| PCの形態 | デスクトップ型 |
| OSの種類 | Windows(64bit) (Linux, macOSも可) |
| CPUの性能 | 最新モデルのCore i5~Core i7、Ryzen 5~7相当 |
| GPUの性能 | NVIDIA RTX 30シリーズやRTX 40シリーズのVRAMが12GB以上 |
| メモリ容量 | 16GB~32GB以上 |
| ストレージ容量 | 512GB以上 (SSD推奨) |
これらのスペックを満たすPCを既に持っている場合は追加コストは少ないですが、新規に購入する場合は数十万円の費用がかかることもあります。
自分のPCスペックが足りない場合や、初期投資を抑えたい場合は、クラウドサービスを利用して、必要な時だけ高性能な計算リソースをレンタルする方法も有効です。
以下では、そのようなクラウドサービスについて紹介していきます。
【無料・有料|Google Colaboratory (Colab)】
Googleが提供するクラウドサービスで、ブラウザからPythonコードを記述、実行できます。
無料版でもGPUを利用できますが、利用時間や割り当てられるGPUの種類に制限があります。長時間の利用や高性能なGPUを確実に使いたい場合は、有料版の「Colab Pro」や「Colab Pro+」へのアップグレードが必要です。
➡️Google Colab
【無料・有料|Paperspace Gradient】
Paperspaceは、AIと機械学習の開発に特化したクラウドコンピューティングプラットフォームです。Gradientはその中の一サービスで、ディープラーニングモデルのトレーニングと開発を容易にするためのツールとインフラを提供します。
また、Jupyterベースのノートブックインターフェースを通じてアクセスでき、高性能なGPUリソースをレンタルできます。無料枠もありますが、本格的な利用には有料プランが必要です。設定が少し複雑で、初心者の方にはハードルが高いかと思われます。
【有料|Vast.ai】
Vast.aiは、個人や企業がGPUリソースを共有し、レンタルすることができるマーケットプレイスを提供しています。「RTX4090」などのハイスペックなGPUを搭載した仮想PCがオンラインで1時間あたり数十円から提供されており、利用者はニーズに応じてGPUの種類や性能を選択し、時間単位でレンタルすることができます。
比較的安価に高性能GPUをレンタルできるというメリットがある一方、個人間のレンタルサービスである為にセキュリティリスクが無いとは言い切れません。
個人間でのレンタルということは、「GPUを使用するにあたっての処理が、ホスト側に筒抜けになる」ということになります。そのため、レンタル時には機密情報の取り扱いに注意しましょう。
【有料|GPUSOROBAN】
GPUSOROBANは、1時間50円から「RTX A4000級」のサーバーが利用できる日本のサービスです。通信料・ストレージの100GB分が無料で利用可能なため、ディスク容量と費用、ネットワーク費用などの従量課金について心配する必要がなく、予算が組みやすい点が特徴です。
【有料|さくらのクラウド】
さくらのクラウドは、日本の大手クラウド事業者であるさくらインターネットが提供するサービスです。2023年度にデジタル庁が募集した「ガバメントクラウド整備のためのクラウドサービス」に認定された実績があり(※最新の認定状況は公式サイトでご確認ください)、政府共通のクラウドサービスの利用環境として使用されていることから、セキュリティ面で信頼できるサービスと言えます。
初期費用をかけることなく、高性能なGPUをを1日単位で利用できることが特徴です。
各種クラウドサービスの整理
無料で手軽に始めたい場合は、Google Colabの無料枠がおすすめです。操作方法も比較的簡単で初心者でも扱いやすいでしょう。
より高性能なGPU機能が必要な場合や長時間の利用を考える場合は、Google Colabの有料版や、Vast.ai、GPUSOROBAN、さくらのクラウドなど、予算や必要なスペックに応じて多様な選択肢があります。それぞれの選択肢で料金計算が変わってくるので、それぞれの特徴から使用するサービスの判断をしましょう。
また、商用利用で機密情報を扱う場合は、さくらのクラウドなどセキュリティに信頼がおけるサービスを使用することを推奨します。

【具体的な導入手順】Stable Diffusion WebUI Forgeでローカル環境を構築する
前の章では、Stable Diffusionをローカル環境で利用するメリットや、必要なPCスペックの概要についてご紹介しました。
この章では、その中でも特に推奨される最新ツール**『Stable Diffusion WebUI Forge』を使い、実際にあなたの環境にStable Diffusionを導入するための全手順**を、ステップバイステップで詳しく解説していきます。
このガイドを読み進めることで、以下の内容がすべてわかります。
- Stable Diffusion WebUI Forgeの具体的なインストール手順
- 高品質な画像を生成するための「モデル」の導入方法
- プロンプトの基本と、思い通りの画像を生成する使い方
- よくあるエラーと、その解決方法
本ガイドでは専門的な環境であるAzure仮想マシンを例に解説を進めますが、モデルのダウンロードや基本的な使い方、プロンプトの考え方などは、WindowsのPCに導入した場合でも全く同じです。
少し手順が多く感じるかもしれませんが、一つ一つ進めれば誰でも最強の画像生成環境を手にすることができます。さっ-そく始めていきましょう。
Stable Diffusion WebUI Forgeとは
Stable Diffusion WebUI Forgeは、人気の画像生成AI「Stable Diffusion」をより使いやすく進化させたオープンソースのGUIツールです。従来のWebUIから派生し、より高速な処理と安定した画像生成を実現します。
コミュニティによって活発に開発が進められ、LoRAやモデルの管理機能など、多彩な機能を備えています。
個人での画像生成から企業でのクリエイティブ制作まで、幅広い用途に対応できる柔軟性を持ち、特にAzure仮想マシンとの組み合わせにより、高性能な画像生成環境を構築することができます。
Stable Diffusion WebUI Forgeのインストール方法
AIを活用した画像生成環境を構築するため、Azureの仮想マシンを使用してStable Diffusion WebUI Forgeを導入します。環境のセットアップから初回起動まで、具体的な手順に沿って説明していきます。
Homebrewのインストール、必要なツールの準備、NVIDIAドライバの設定など、確実な導入のためのステップを順を追って解説します。
導入環境
まず、今回Stable Diffusionを立ち上げるにあたっては、Azureの仮想マシン(Azure VM)を使用します。
Azureの仮想マシンについては、こちらの解説記事をご覧下さい。
【ステップ1】仮想マシンへの接続
まずは、下記のコマンドを実行し、Azureにログインして下さい。
az login
使用するアカウントのサブスクリプション一覧と下記のような表示が出てきます。準備した仮想マシンのあるサブスクリプションの番号を入力して下さい。
 サブスクリプションの選択
サブスクリプションの選択
SSHを使用して仮想マシンに接続します。以下の接続コマンドをターミナルで実行して下さい。
ssh -i {秘密鍵のパス} azureuser@{パブリックIPアドレス}
パブリックIPアドレスは、以下のコマンドまたはAzureポータルで確認できます。
terraform output public_ip_address
コマンドでのパブリックIPアドレスの確認
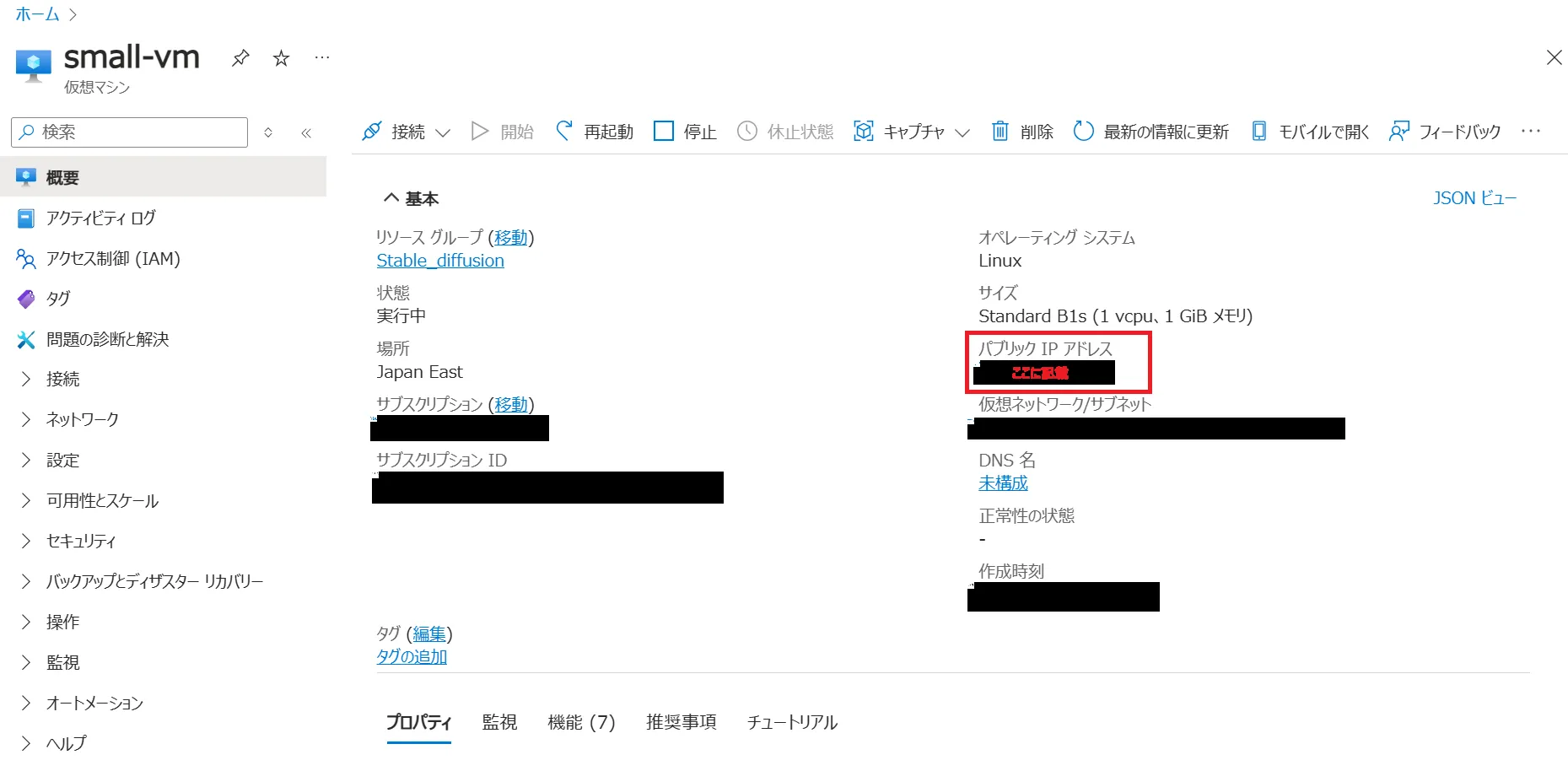 AzureポータルでのパブリックIPアドレスの確認
AzureポータルでのパブリックIPアドレスの確認
初めてSSH接続を行う場合には、以下の画像のような警告が表示されるかもしれませんが、「yes」と入力し、確定して大丈夫です。
 SSH接続を初めて行う際に表示される警告
SSH接続を初めて行う際に表示される警告
すると、以下のような1行目の文章とともに、システムの情報などが表示されます。
 SSH接続の成功
SSH接続の成功
これで、SSHを使用して仮想マシンに接続することが出来ました。
【ステップ2】立ち上げの為のセットアップ
仮想マシンに接続した後は、以下のように緑色の表示が出てきます。
ここにコマンドを入力することで、仮想マシンでそのコマンドを実行することが出来ます。
 仮想マシンの操作
仮想マシンの操作
【ステップ2-1】Homebrewのインストール
必要な依存関係をインストールします。以下のコマンドを順に実行して下さい。
sudo apt-get update
sudo apt-get install -y build-essential procps curl file git
 1つ目のコマンドの実行結果
1つ目のコマンドの実行結果
 2つ目のコマンドの実行結果の一部
2つ目のコマンドの実行結果の一部
次に、Homebrewをインストールします。以下のコマンドを使用して、インストールスクリプトを実行します。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
なお、実行時には下記のようにパスワードを求められます。
 実行時のパスワード入力
実行時のパスワード入力
パスワードを忘れてしまった場合は、以下のコマンドで設定することが出来ます。
sudo passwd azureuser
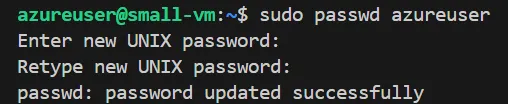 パスワードの設定
パスワードの設定
パスワード設定後、インストールスクリプトを実行し直しました。インストール時には、途中で下記のような表示が出てくるので、「Enter」を押して下さい。
 Homebrewインストール時の操作
Homebrewインストール時の操作
インストールが進むと、'Linuxbrew'のディレクトリが作成されます。
エラー無くHomebrewが正常にインストールされたら、以下のコマンドを順に実行して、シェル環境にHomebrewのパスを追加します。
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> ~/.profile
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
 Homebrewインストール確認
Homebrewインストール確認
パスを追加しても特に何か表示されるわけではありません。
正常にインストールされたか確認するために、以下のコマンドを実行してバージョンを表示します。
brew --version
 Homebrewバージョン表示
Homebrewバージョン表示
【ステップ2-2】必要なツールのインストール
以下のコマンドを使用して、必要なツールをインストールして下さい。
brew install cmake protobuf rust python@3.10 git wget
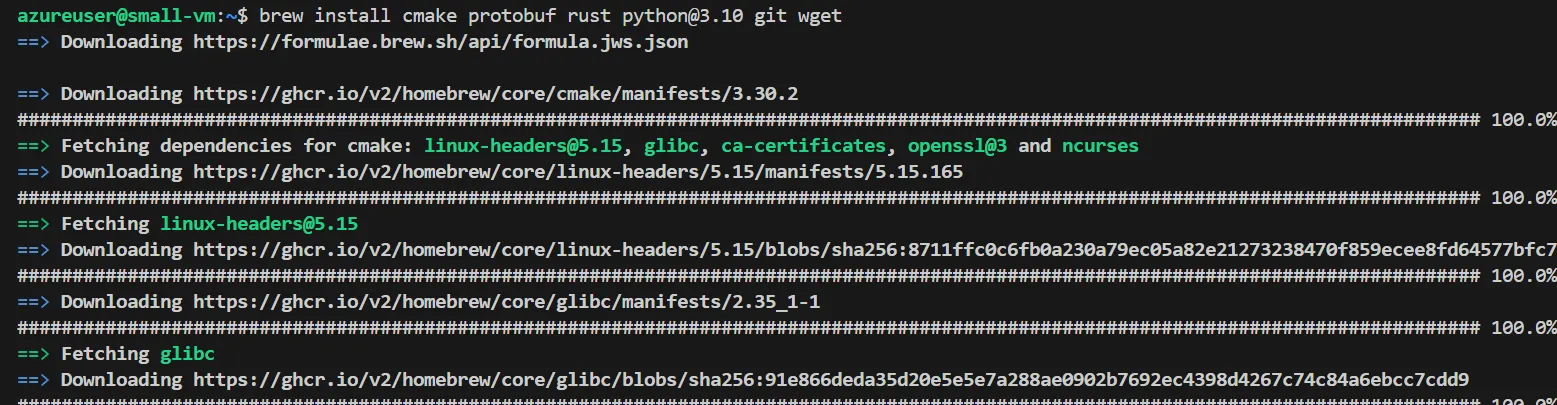 必要なツールのインストール
必要なツールのインストール
インストールの完了には少々時間がかかります。
【ステップ1】NVIDIAドライバとCUDAツールキットのインストール
NVIDIAドライバはシステムのハードウェアに深く関わるものなので、homebrewではなく、aptを使ってインストールします。
まずは、以下のコマンドを実行し、あなたの環境で使用可能なドライバのバージョンを表示して下さい。
ubuntu-drivers devices
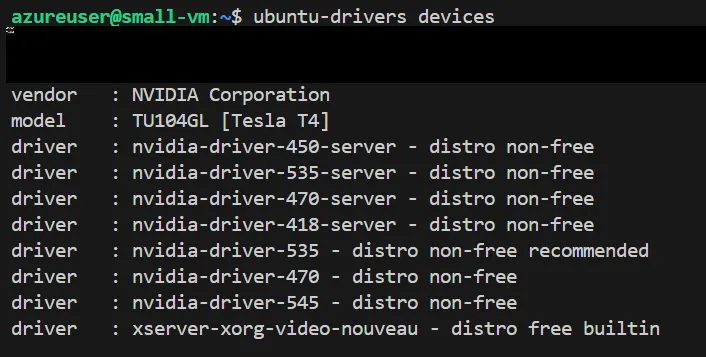 使用可能NVIDIAドライバ一覧
使用可能NVIDIAドライバ一覧
使用するバージョンを選び、以下の順でコードを実行し、NVIDIAドライバをインストールできます。なお、最後のコードによって、一旦再起動するので、接続し直してください。
sudo apt-get update
sudo apt-get install -y nvidia-driver-<バージョン番号>
sudo reboot
今回、筆者は「535」のバージョンを選びました。
NVIDIAドライバが正しくインストールされているかを確認するには、以下のコードを実行します。
nvidia-smi
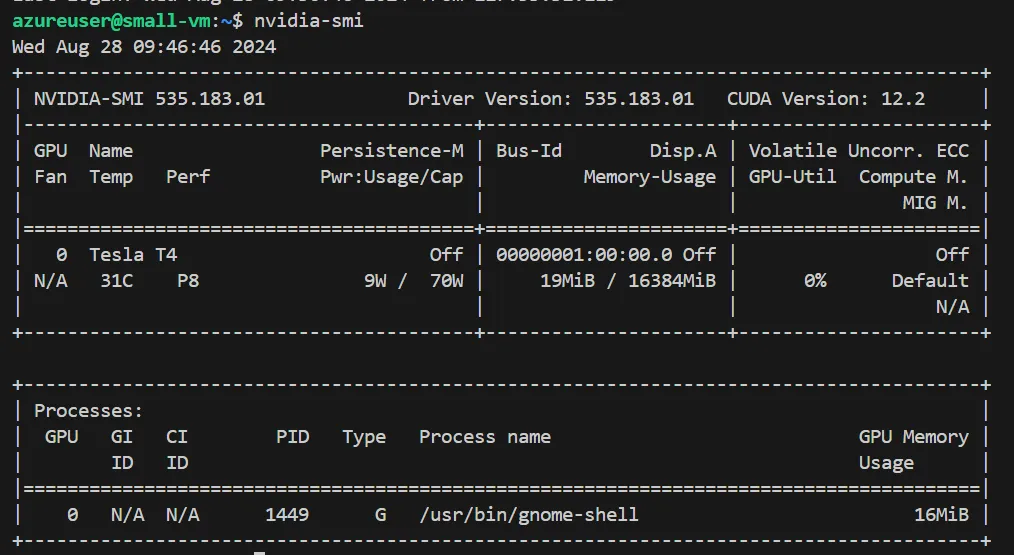 NVIDIAドライバのインストール確認
NVIDIAドライバのインストール確認
次に、必要なCUDAツールキットをインストールします
sudo apt-get update
sudo apt-get install -y nvidia-cuda-toolkit
CUDAが正しくインストールされているかは、以下のコマンドを実行して確かめることが出来ます。
nvcc --version
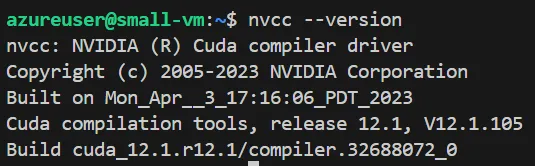 CUDAのインストール確認
CUDAのインストール確認
次に以下を順に実行し、環境変数を設定します。
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
【ステップ3】Stable Diffusion WebUI Forgeの立ち上げ
Stable Diffusion WebUI Forgeのリポジトリをクローンします。下記のコマンドを実行して下さい。
git clone https://github.com/lllyasviel/stable-diffusion-webui-forge.git
 リポジトリのクローン
リポジトリのクローン
クローンが完了したら、「stable-diffusion-webui-forge」という名前のフォルダが作成されているか確認するために、以下のコマンドを実行します。
ls
 クローンの確認
クローンの確認
ここで、forgeへのアクセス方法としては、リモートデスクトップで直接アクセスするか、forgeを公開して様々なデバイスからアクセスするかの2通りあります。
forgeを公開して様々なデバイスからアクセスする方は、まず、「stable-diffusion-webui-forge」ディレクトリで以下のコマンドを実行して下さい。
nano webui.sh
するとエディターが起動します。
矢印キーを使って一番下へと移動し、下記画像のように「--listen」と追加して下さい。
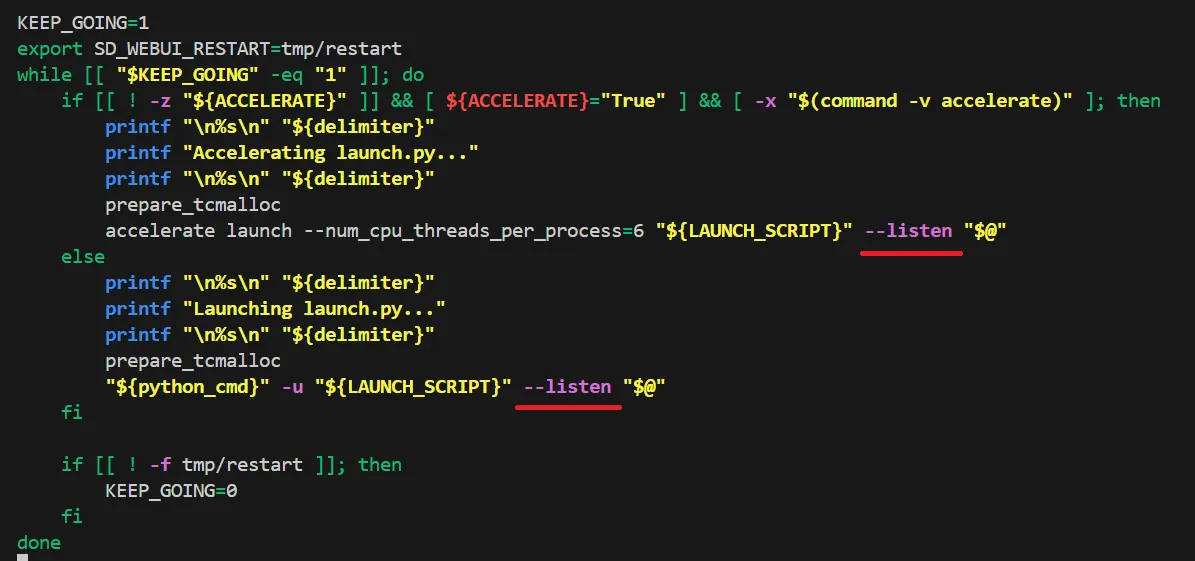 listenの追加
listenの追加
そうしたら、「Ctrl + O」 > 「Enter」 > 「Ctrl + X」の順で押して下さい。
なお、「webui-user.sh」を編集することで、ご自身の環境に合わせてカスタマイズする事が出来ます。
【ステップ4】Stable diffusionの起動
「stable-diffusion-webui-forge」ディレクトリで下記のコマンドを実行して下さい。
./webui.sh
初回起動時にはかなり時間がかかります。
 初回起動時のインストール
初回起動時のインストール
すると、forgeの立ち上げが成功し、下記のように出力の最後の方に、forgeアクセスの為のURLが表示されます。
 forgeの立ち上げ成功
forgeの立ち上げ成功
ここで注意点として、今回は仮想マシンでforgeを立ち上げようとしているので、このURLにアクセスしても接続できません。
- リモートデスクトップを使用する場合
ここで表示されるURLをリモートデスクトップの検索バーに貼り付けることで、forgeへとアクセス出来ます。
- **forgeを公開して様々なデバイスからアクセスする方
表示されたURLが「http://〇:△」のような形になっていると思います。
〇部分をVMのパブリックIPアドレスに変更し、それを検索バーに入力することで、forgeへとアクセスすることが出来ます。
「http:// {パブリックIPアドレス}:△」
Mbr>forgeにアクセスすると、以下のような画面が表示されます。これでforgeの導入を一通り終える事が出来ました。
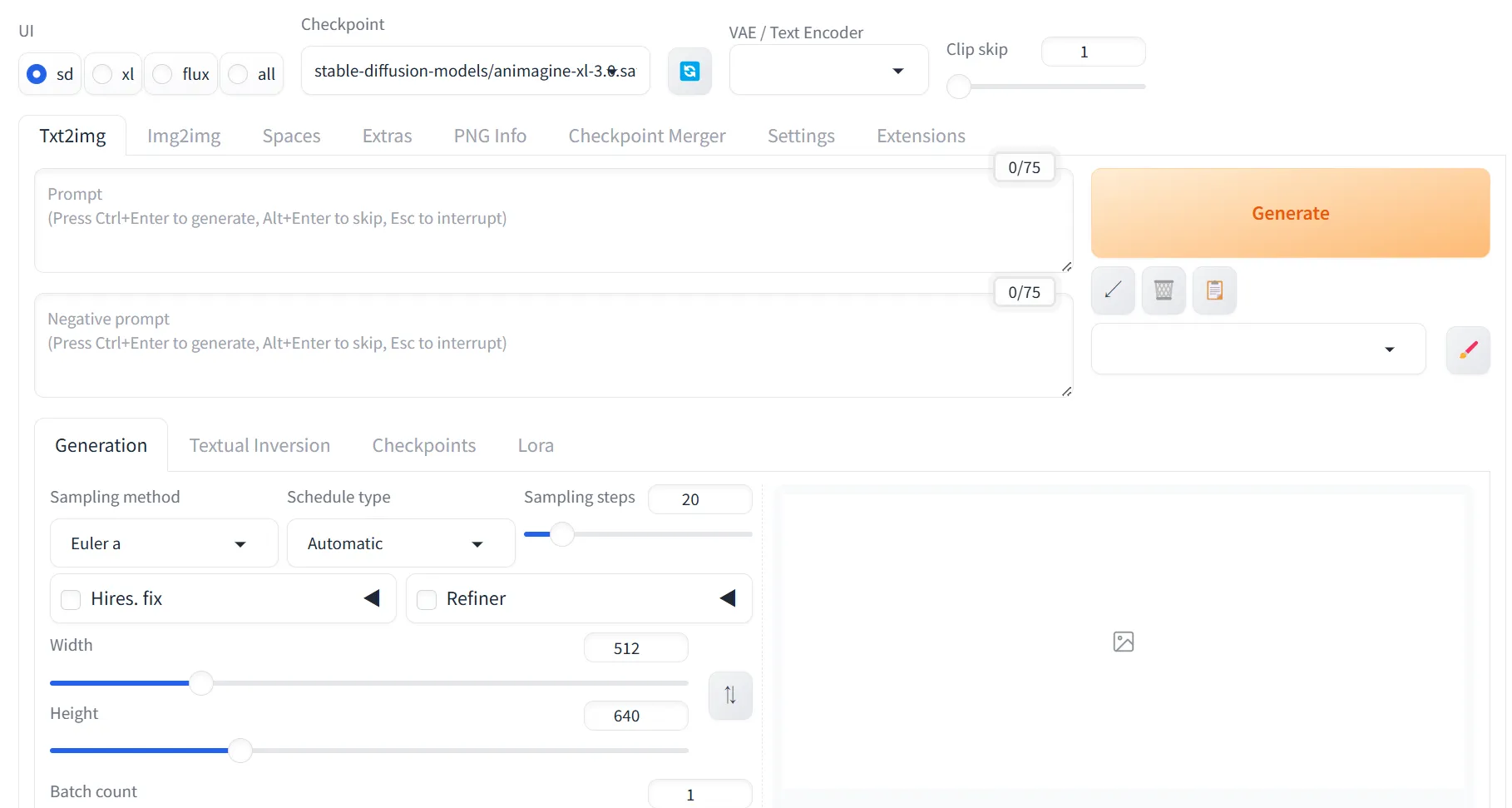 forge起動画面
forge起動画面
Stable Diffusion WebUI Forgeの使い方
Stable Diffusion WebUI Forgeを効果的に活用するためには、適切なモデルの準備と基本的な操作方法の理解が重要です。
ここでは、モデルの導入から実際の画像生成まで、実践的な使い方を解説します。
モデルのダウンロード
まずは、モデルを用意する必要があります。モデルは、「stable-diffusion-webui-forge > models > Stable-diffusion」内に保存することになります。
使用したいモデルを探してください。今回は例として、「realisticVisionV51_v51VAE」を使用したいと思います。こちらにアクセスすると、下記のような画面が出てきます。
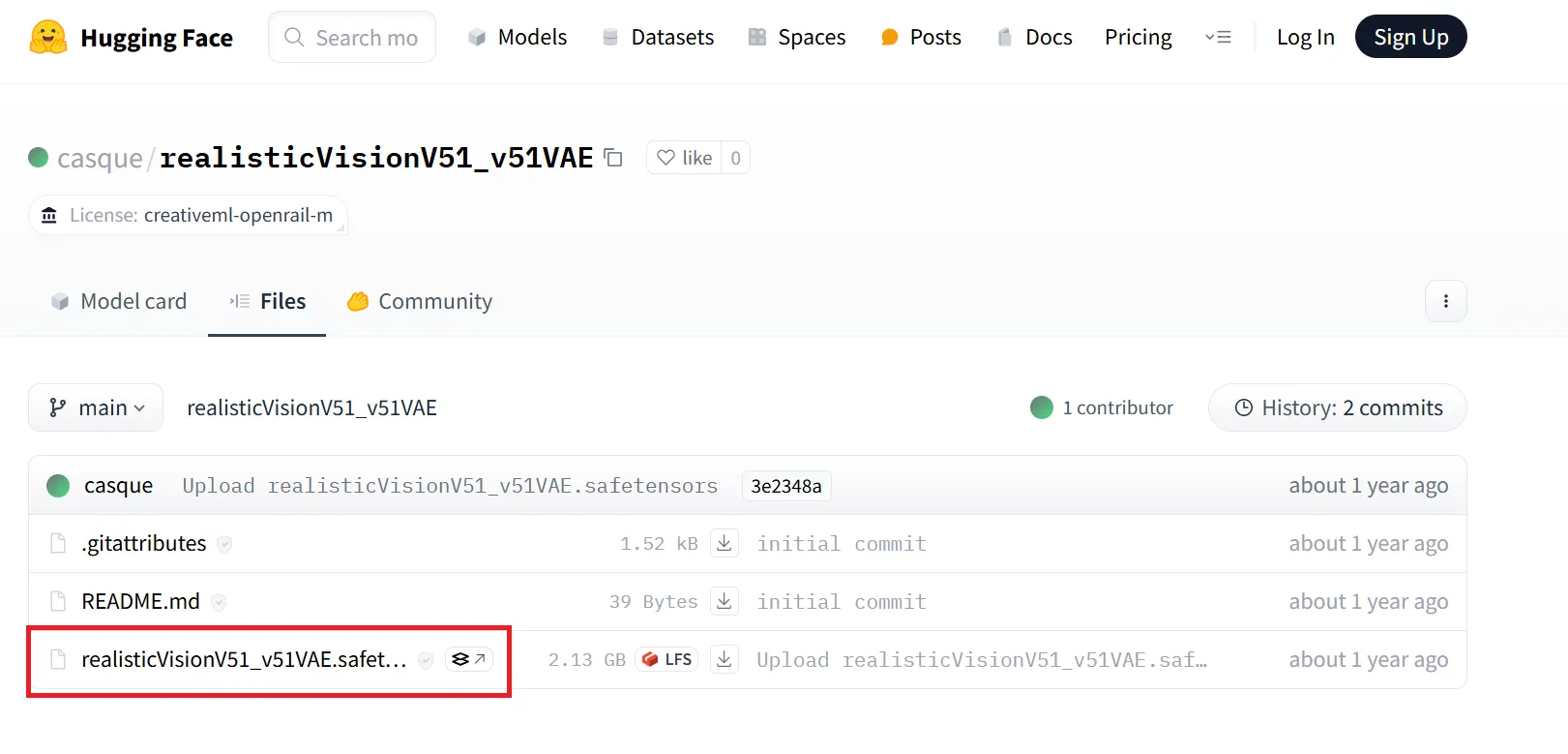 モデルのダウンロード手順その1
モデルのダウンロード手順その1
赤枠部分をクリックし、モデルがダウンロード出来るページへと移動します。
すると、以下のような画面が出てくるので、「Copy download link」をクリックし、リンクをコピーします。
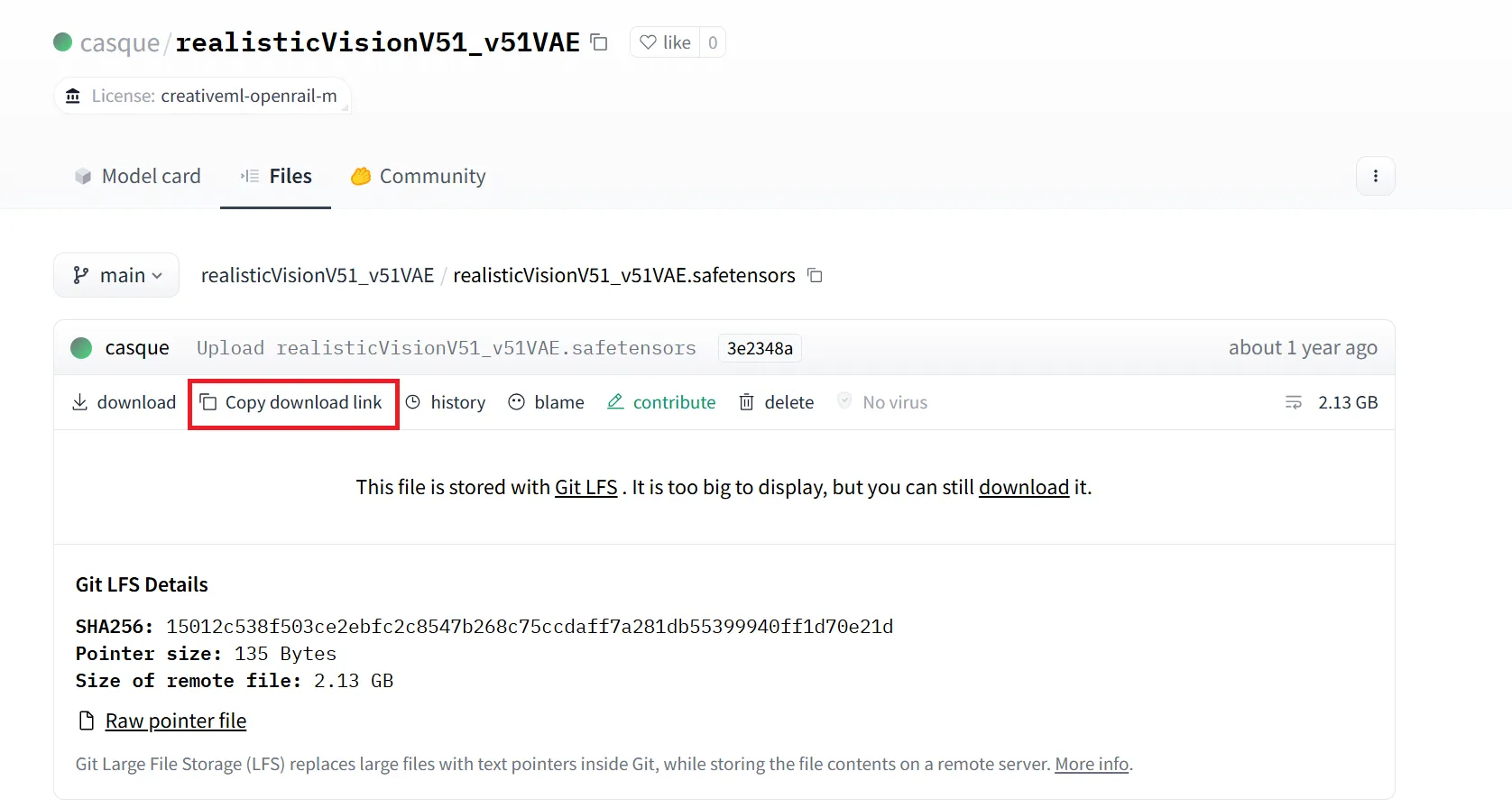 モデルのダウンロード手順その2
モデルのダウンロード手順その2
次に、stable-diffusion-webui-forge > models > Stable-diffusion へと移動し、下記のコマンドを実行することで、モデルをダウンロードする事が出来ます。
wget {コピーしたリンク}
今回の場合は、以下の画像のようになります。
 モデルのダウンロード手順その3
モデルのダウンロード手順その3
使用したいモデルのリンクをコピーし、先ほどと同じように作業すれば、お好きなモデルで色々と試すことが出来ます。
動作テスト
まずは、本当に動くのかを試すために、簡単なプロンプトで画像を生成してもらいます。
上のCheckpointでモデルを選択し、その下のPromptにプロンプトを入力します。
Prompt:モデルに生成してほしい内容やスタイルを具体的に指示するもの
Negative prompt:モデルに生成してほしくない要素や避けたいスタイルを指示するもの
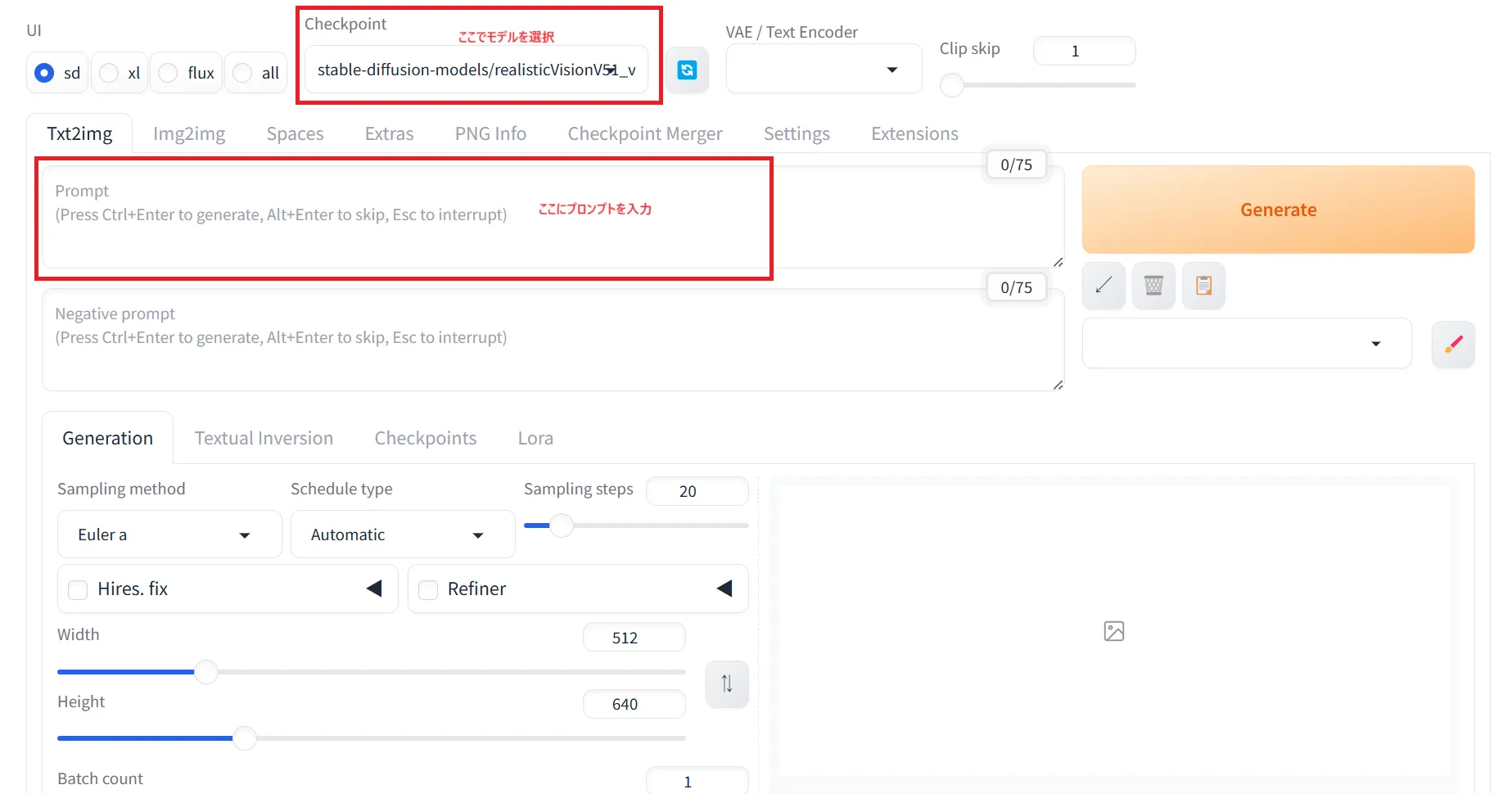 forgeの簡単なテスト
forgeの簡単なテスト
テストとしてまずは、「金髪の1人の女の子」というプロンプトを試してみました。
1girl, blond hair
出力された画像は、以下の通りです。
 テスト結果その1
テスト結果その1
次に、先ほどのプロンプトに「夜の賑やかな東京の通りに立っている」という条件を追加してみました。
1girl, blond hair, standing on a busy Tokyo street at night
出力された画像は、以下の通りです。
 テスト結果その2
テスト結果その2
これらの出力は、stable-diffusion-webui-forge内の「outputs」フォルダに保存されていきます。これら仮想マシンに保存された出力をローカルに持ってくる場合は、ローカルで以下のコマンドを実行して下さい。
scp -i /path/to/your/private_key -r azureuser@<VM_IP_ADDRESS>:/path/to/remote/directory /path/to/local/destination
-
-i /path/to/your/private_key: 使用するSSHキーを指定します。
-
azureuser@<VM_IP_ADDRESS>:/path/to/remote/file: 仮想マシン内のファイルのパスを指定します。(ここを変えることで、どの範囲の出力を保存するか選べます)
-
/path/to/local/destination: ローカルPCの保存先を指定します。
LoRAの活用
更に使いこなしたい方に向けて、LoRAという手法があります。LoRAは、より少ない計算資源でモデルを適応させることが出来る技術です.
-
checkpoint
モデルのトレーニングの途中で保存されたモデルの状態を表します。これには、モデルのすべてのパラメータ(重みなど)が含まれています。
-
LoRA
Stable Diffusionなどの画像生成モデルに対して、モデルの一部だけを効率的に調整するための手法です。
LoRAは、モデル全体を再トレーニングする代わりに、特定のパラメータ(例えば、特定の層)に対して低ランクの更新を適用します。
LoRAに関しては、以下の記事で詳しく解説しています
▶︎AIのLoRAとは?その仕組みや作り方、StableDiffusionでの導入方法を解説
Stable Diffusion WebUI Forge導入時のトラブルシューティング
Stable Diffusion WebUI Forgeの導入時には、いくつかの一般的な問題に遭遇することがあります。
ここでは、よくある問題とその解決方法について、具体的な対処法を紹介します。
「insightfaceがインストールされていない」という警告が表示される
「webui.sh」実行時に、「自動でinsightfaceがダウンロード出来ませんでした」という旨のエラーが発生する事があります。
その場合はVMに接続し直して、以下のコマンドを実行してからもう一度「webui.sh」を実行してみると上手く行く可能性があります。
cd stable-diffusion-webui-forge
cd venv
pip install insightface
VMのストレージが足りない
そもそもforgeを起動するためのストレージが足りない場合や、様々なモデルを試したい場合にストレージが足りないことがあります。ストレージが足りない場合は、VMのストレージサイズを大きくする必要があります。
筆者はモデルを追加する際に、OSディスクのストレージは足りないものの、データディスクのストレージに空きがあったので、モデル自体のインストールはデータディスクで行い、Stable diffusionが参照するモデルのファイルをデータディスクのファイルになるようにシンボリックリンクを作成する事で問題を解決しました。
下記の記事で、Azure仮想マシンのディスク拡張・変更方法に関して詳しく解説しています。
Azure仮想マシンのディスク拡張・変更方法をわかりやすく解説!
〇〇が認識できていない
正しくインストールしたのにも関わらず、ツールや環境が認識されずにforgeが起動できない場合は、パスの設定が誤っているか可能性が高いです。
正しいパスを設定したり、シンボリックリンクを作成してリンク先のファイルへアクセスするように設定すると上手く行く可能性があります。

Stable Diffusionの出力精度を上げるポイント
前提として、Stable Diffusionはインターネット上の大量の画像データを学習しており、画像の生成はプロンプトを元にそのデータベースから行われます。人間でいうところの記憶のようなものです。
この時、プロンプトが与える情報の方向性(ベクトル)に対して、最も一致度が高いのはどのような画像かという観点で出力されるようになっています。
情報の方向性(ベクトル)について、「Mage.space」を使って確認していきましょう。
例えば、若者向けサービスの広告用に「男性の画像」が欲しいとします。
試しに「man」という「情報の方向性」を入力すれば、以下のように出力されます。

男性の画像.1
出力されたのは、マンガ風のタッチで描かれた白髪の白人男性です。
これでは若者向けの広告としては使えそうにありません。何故このような出力結果になったのかは、2つの理由が考えられます。
- 学習の偏り
Stable DiffusionなどのAIモデルは、開発された地域や開発者がアクセスできるデータに基づいて学習されます。
したがって、モデルが学習するデータが海外、特に開発者の国や地域のデータに偏っている場合、その影響がモデルの出力に反映される可能性があります。
- 情報の方向性の曖昧さ
「man」という言葉には、「右を向いている男性」や「男性の全身雑」など、複数の可能性が同時に含まれています。
そのため、「man」という抽象的な情報の方向性だけでは、狙ったポージングや表情、服装などの具体的な画像を出力させることが難しいです。
つまり、コンピューターにとっては、一つの言葉が、人間の思い描く一つのイメージや物体に対応することはありません。
AIにとって、言葉や文章は一定のベクトルとして理解されます。
つまり、「man」という情報は、多くの異なる意味を持つ可能性があり、その結果としてその意味が不明瞭になります。
次に、「Photo of a young Japanese man standing on the side of the road.(若い日本人男性が道端に立っている写真)」と入力してみます。

男性の画像.2
さきほどより良くなりましたね。
このように、「シンプルに一人の男性の画像を生成する場合」にも、情報の方向性を明確に定義する必要があります。
しかし、なんとなく自信がなさそうで、広告に使うにはまだ十分ではありません。
ここで発想を転換してみましょう。
「Street snapshot of a 20-year-old Japanese male(20歳の日本人男性のストリートスナップ)」と入力してみます。

先ほどに比べ、おしゃれでイケてる風の男性画像が生成されました。ここでは、プロンプトの内、何が有効に機能したのでしょうか?
それは「ストリートスナップ」という文言です。
「ストリートスナップ」は、ファッション性を目立たせるために、大半の写真が、全身像で、ファッショナブルなことが特徴です。
また、構図や背景が一定のリテラシーの元で構成されています。
つまり、「ストリートスナップ」という情報の方向性は、再現性が高いのです。
ここでの再現性は、「どのストリートスナップ」をみても、画像の見た目は似ているという意味です。
このように、画像の出力方法の仕組みを何となくでも理解しておけば、望んだ画像を入手しやすくなります。
Stable Diffusionの商用利用と注意点
Stable Diffusionは基本的に商用利用が可能ですが、使用するモデルやライセンス、利用方法によって条件が異なるため、いくつかの重要な注意点があります。
Webサービスの場合の商用利用と注意点
企業が提供するWebサービスを利用する場合、基本的に各サービスの利用規約に従います。
多くのサービスでは商用利用が認められていますが、無料プランでは制限があったり、有料プランでのみ許可されたりする場合があります。必ず各サービスの利用規約を確認しましょう。
例外として注意が必要なのは、「画像から画像を生成する場合(image to image)」です。AIに入力する元画像(素材)が他者の著作物である場合、それを元に生成した画像を商用利用すると著作権侵害にあたる可能性があります。例えば、「DreamStudio」や「Mage.space」はimage to image機能がありますが、使用する画像の著作権には十分注意が必要です。
ローカル環境の場合の商用利用と注意点
自身のPCやクラウド環境でStable Diffusionを利用する場合(特にStable Diffusion Web UIなどを使用する場合)は、以下の点に注意が必要です。
技術的な側面
Stable Diffusionの性能を最大限に引き出すには、適切なハードウェア(特に高性能GPU)とソフトウェアの設定が求められます。スペックの足りないPCで無理に動かそうとしても、動作が非常に遅かったり、エラーが発生したりすることがあります。
商用利用の側面(モデルのライセンス)
Stable Diffusionの基本的なオープンソースモデル(例: SD 1.5, SDXLなど)自体は比較的自由に商用利用できるライセンスが付与されていることが多いです。
しかし、ローカル環境では、他のユーザーが作成・公開している追加学習モデル(チェックポイント、LoRA、Textual Inversionなど)を組み合わせて使用することが一般的です。
これらの追加モデルの中には、商用利用が認められていないものが存在することに十分注意してください。モデルをダウンロードする際には、CivitaiやHugging Faceなどの配布サイトで、各モデルに付与されているライセンス(例: 「creativeml-openrail-m」, 「fair-use」, 「personal-use-only」など)を必ず確認し、商用利用の可否を判断する必要があります。
生成する画像の内容に関する一般的な注意点
Webサービス利用、ローカル環境利用を問わず、生成する画像の内容については以下の点に注意が必要です。
- 著作権: 実在するキャラクター、ブランドロゴ、芸術作品など、他者の著作物を模倣した画像を無断で商用利用することは著作権侵害のリスクがあります。
- 肖像権・パブリシティ権: 実在の人物、特に有名人の画像を無許可で生成し、商用利用することは肖像権やパブリシティ権の侵害にあたる可能性があります。
- 倫理的配慮: 誤情報、名誉毀損、差別的内容など、他者に危害を加えたり、社会的に問題のある画像の生成・利用は避けるべきです。
トラブルを避けるためには、利用規約やライセンスを事前にしっかりと確認し、著作権法や関連法規を遵守することが重要です。不明な場合は専門家に相談することも検討しましょう。
AI画像生成の技術理解を組織のAI活用に広げるなら
Stable Diffusionの仕組みや環境構築を理解したことで、AIが実務でどこまで使えるかの解像度が高まったはずです。次のステップは、こうしたAIへの理解を画像生成に限定せず、組織全体の業務プロセスに展開していく段階設計です。
AI総合研究所では、Microsoft環境でのAI業務自動化を段階的に進めるための実践ガイド(220ページ)を無料で提供しています。部門別のBefore/After付きユースケースから、PoC→パイロット→全社展開のロードマップまで、導入に必要なステップを網羅しています。
AI総合研究所が、AI技術の理解を組織の業務改善に転換する道筋を設計段階からサポートします。
Stable Diffusionの理解を組織AI活用へ

段階的なAI導入の実践ガイド(220p)
Stable Diffusionでの画像生成を理解した次の段階は、AIを画像生成に限らず組織全体の業務プロセスに展開することです。Copilot Chat→M365 Copilot→Copilot Studioの段階設計と部門別Before/Afterを220ページにまとめた実践ガイドで、導入の全体像をご確認ください。
まとめ
この記事では、画像生成AI「Stable Diffusion」の概要から、主な利用方法(Webサービス、ローカル/クラウド環境)、それぞれの料金体系、主要なWebサービスの使い方、ローカル環境で利用する際の推奨スペックとクラウドサービスの選択肢、さらには出力精度を上げるためのプロンプトのコツ、そして商用利用する際の重要な注意点まで、幅広く解説してきました。
記事のポイントをまとめると、以下の通りです。
- Stable Diffusionとは: テキストから高品質な画像を生成できるオープンソースのAI技術で、Webサービスやローカル環境で利用可能です。
- 主な利用方法と料金:
- Webサービス: 手軽に始められ、無料枠も多いですが、本格利用は有料プランが中心。本記事ではDream Studio, Mage.spaceなどの使い方と料金を紹介しました。
- ローカル/クラウド環境: 自由度が高いですが、PCスペックや知識が必要。ソフトウェアは無料でも環境コストがかかります。Stable Diffusion Web UIが代表的なツールです。
- 出力精度向上のコツ: プロンプトの具体性、効果的なキーワードの選択、情報の方向性の理解が重要です。
- 商用利用と注意点: 基本的に可能ですが、利用するサービスやモデルのライセンス、生成する画像の内容(著作権、肖像権など)には十分な確認と配慮が必要です。
Stable Diffusionは、あなたの創造性を刺激し、アート制作からビジネス活用まで、新たな可能性を切り開く非常に強力なツールです。この記事が、あなたがStable Diffusionをより安全かつ効果的に利用するための一助となれば幸いです。
個々のサービス内容や料金プラン、各種モデルのライセンスは変更されることがありますので、利用前には必ず公式サイト等で最新の情報を確認するようにしてください。










