この記事のポイント
 LLM推論のメモリボトルネックを解消するなら、KVキャッシュ圧縮のTurboQuantが2026年最有力の技術候補
LLM推論のメモリボトルネックを解消するなら、KVキャッシュ圧縮のTurboQuantが2026年最有力の技術候補- GPTQ・AWQは「モデルの重み」、TurboQuantは「推論中のKVキャッシュ」と圧縮対象が異なり、併用が最適解
- 70B級モデルでも4bit重み+3bit KVキャッシュの併用で単一80GB GPUに収まる可能性があり、長文推論の選択肢が広がる
- メモリ半導体株の急落は過剰反応の側面が強く、AI需要拡大がメモリ効率化を上回るとの見方が有力
- 公式コードは未公開だが、llama.cpp・PyTorch向けの非公式実装で先行検証を始められる段階

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Google Researchが2026年3月に発表した「TurboQuant」は、LLM(大規模言語モデル)のKVキャッシュメモリを最大6分の1に圧縮し、NVIDIA H100 GPU上でAttention logits計算を最大8倍高速化する新技術です。
公開ベンチマークで精度低下が観測されず・トレーニング不要という特性から「GoogleのDeepSeekモーメント」とも呼ばれ、メモリ半導体株の下落材料として報じられるなど業界に大きな衝撃を与えました。
本記事では、TurboQuantの技術構成(PolarQuant×QJL)からベンチマーク結果、従来の量子化技術との違い、向き不向き、推論コスト削減効果までを体系的に解説します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
目次
Google TurboQuantとは?KVキャッシュを6倍圧縮する新技術
TurboQuantの技術構成:PolarQuantとQJLの2段階圧縮
TurboQuantのベンチマーク結果:Attention計算で最大8倍の高速化
精度検証:Needle-in-a-Haystack完全スコア
Google TurboQuantとは?KVキャッシュを6倍圧縮する新技術
TurboQuant(ターボクアント)は、Google Researchが2026年3月24日に発表した、大規模言語モデル(LLM)の推論メモリを大幅に圧縮する新技術です。

具体的には、LLMがAI推論中に使うKVキャッシュ(後述)のメモリ消費を最大6分の1に削減し、NVIDIA H100 GPU上でAttention logits計算を最大8倍高速化します。公開ベンチマークでは精度低下が観測されておらず、モデルの再学習も不要という特性を持っています。なお、8倍高速化はAttention計算部分の数値であり、推論全体のエンドツーエンド速度とは異なる点に注意が必要です。
この技術はAI業界に大きなインパクトを与え、発表後にはメモリ半導体関連株が下落し、TurboQuantの発表が材料視されたと報じられました。CloudflareのCEOであるMatthew Prince氏は、TurboQuantを「GoogleのDeepSeekモーメント」と表現し、AIの効率化における歴史的な転換点になりうると評価しています。
本記事では、TurboQuantの技術的な仕組みから実用化の見通し、企業のAI推論基盤への影響までを体系的に解説します。

そもそもKVキャッシュとは何か
TurboQuantを理解するには、まず「KVキャッシュ」が何かを知る必要があります。
LLMがテキストを生成するとき、すでに処理した文脈の情報を保持するために「Key-Value(KV)キャッシュ」と呼ばれる一時メモリを使います。これはLLMが「会話の文脈を覚えておくためのメモ帳」のようなものです。
問題は、このKVキャッシュがコンテキスト長(入力テキストの長さ)に比例して膨張する点にあります。以下の表で、KVキャッシュがGPUメモリをどれだけ消費するかを整理しました。
| モデル(例) | コンテキスト長 | KVキャッシュの消費メモリ(fp16) |
|---|---|---|
| Llama 3.1 8B | 4K トークン | 約0.5 GB |
| Llama 3.1 8B | 128K トークン | 約16 GB |
| Llama 3.1 70B | 128K トークン | 約39 GB |
※ KVキャッシュの容量はレイヤー数・KVヘッド数・ヘッド次元・GQA(Grouped-Query Attention)の有無によってモデルごとに大きく異なります。上記はHugging Face公式ブログの値を基にした参考値です
コンテキスト長が4Kから128Kに伸びるだけで、KVキャッシュの消費メモリは数十倍に膨れ上がります。70Bクラスのモデルで長文を扱おうとすると、モデルの重み自体よりもKVキャッシュの方がGPUメモリを多く消費するケースすら生じます。
TurboQuantは、まさにこのKVキャッシュのメモリ消費問題を根本から解決する技術です。
TurboQuantの基本的な仕組み
TurboQuantのアプローチは、KVキャッシュの各ベクトルデータを16ビットからわずか3ビットに圧縮するというものです。
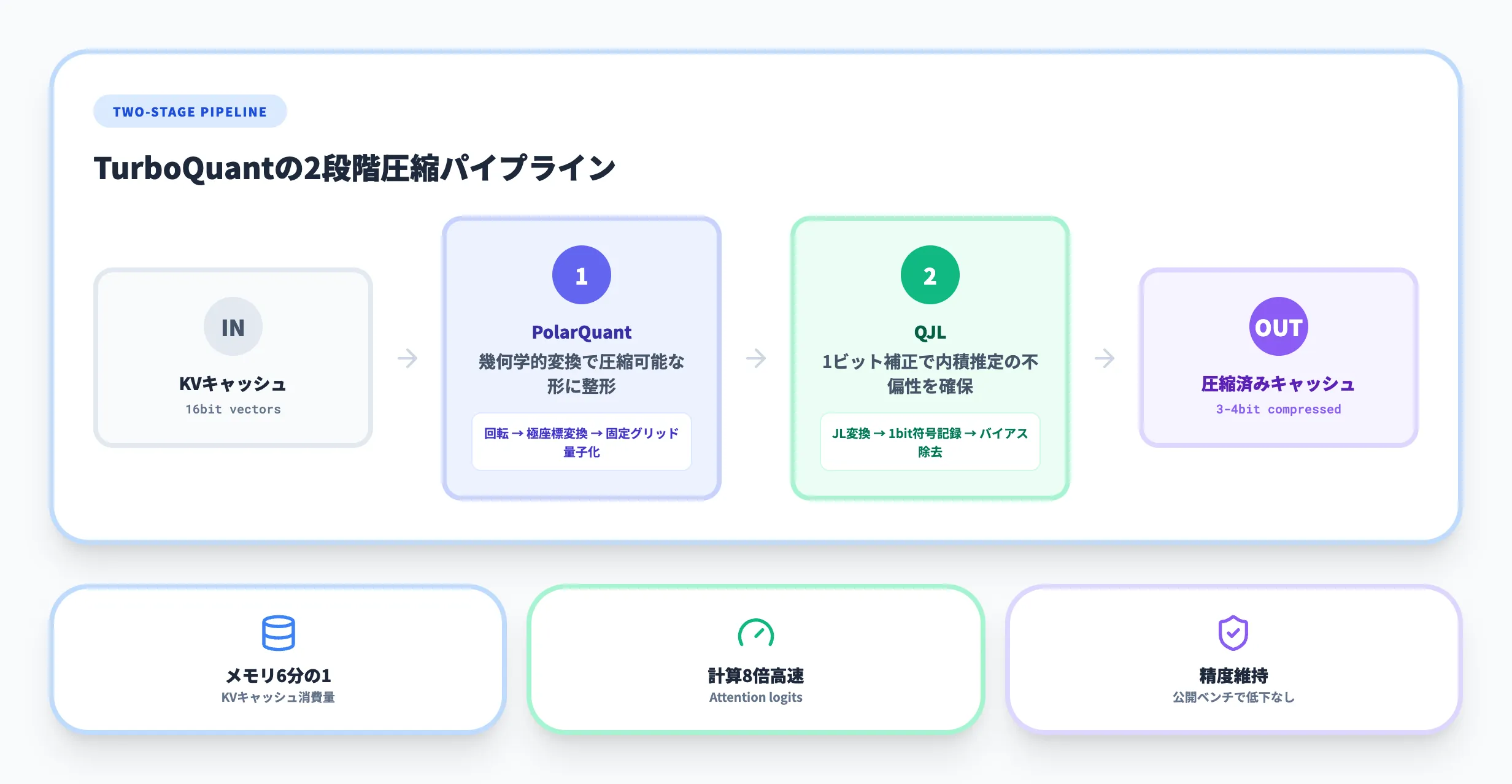
従来の量子化技術との最大の違いは、TurboQuantが2段階の圧縮パイプラインを採用している点にあります。
- PolarQuant(第1段階)
入力ベクトルをランダムに回転させてから極座標系に変換し、データを圧縮しやすい形に整える。従来手法で必要だった「正規化定数」の保存が不要になり、メモリのオーバーヘッドがほぼゼロになる
- QJL(第2段階)
PolarQuantの圧縮で生じた微小な誤差を、Johnson-Lindenstrauss変換を用いた1ビットの補正レイヤーで補正する。これにより、注意スコアの内積推定が不偏(バイアスなし)になることが理論的に示されている
この2段階の組み合わせにより、**トレーニング不要(追加学習なし)かつデータ非依存(どのモデルにも即座に適用可能)**という実用性の高い設計が実現されています。
開発の経緯と論文情報
TurboQuantの原論文は、arXiv:2504.19874として2025年4月に初版が公開され、その後ICLR 2026(2026年4月開催)に採択されました。
著者はAmir Zandieh氏(Google Research)、Majid Daliri氏(ニューヨーク大学)、Majid Hadian氏(Google DeepMind)、Vahab Mirrokni氏(Google Research)の4名です。
なお、第1段階のPolarQuantは独立した論文としてAISTATS 2026でも発表されており、KVキャッシュに限らずベクトル検索や埋め込み圧縮にも応用可能な汎用的な量子化手法として位置づけられています。
TurboQuantが登場した背景:LLM推論のメモリ課題
TurboQuantが大きな注目を集めた理由を理解するには、LLM推論におけるメモリ問題の深刻さを知る必要があります。このセクションでは、技術的な背景と、なぜTurboQuantが「破壊的」と評されるのかを解説します。
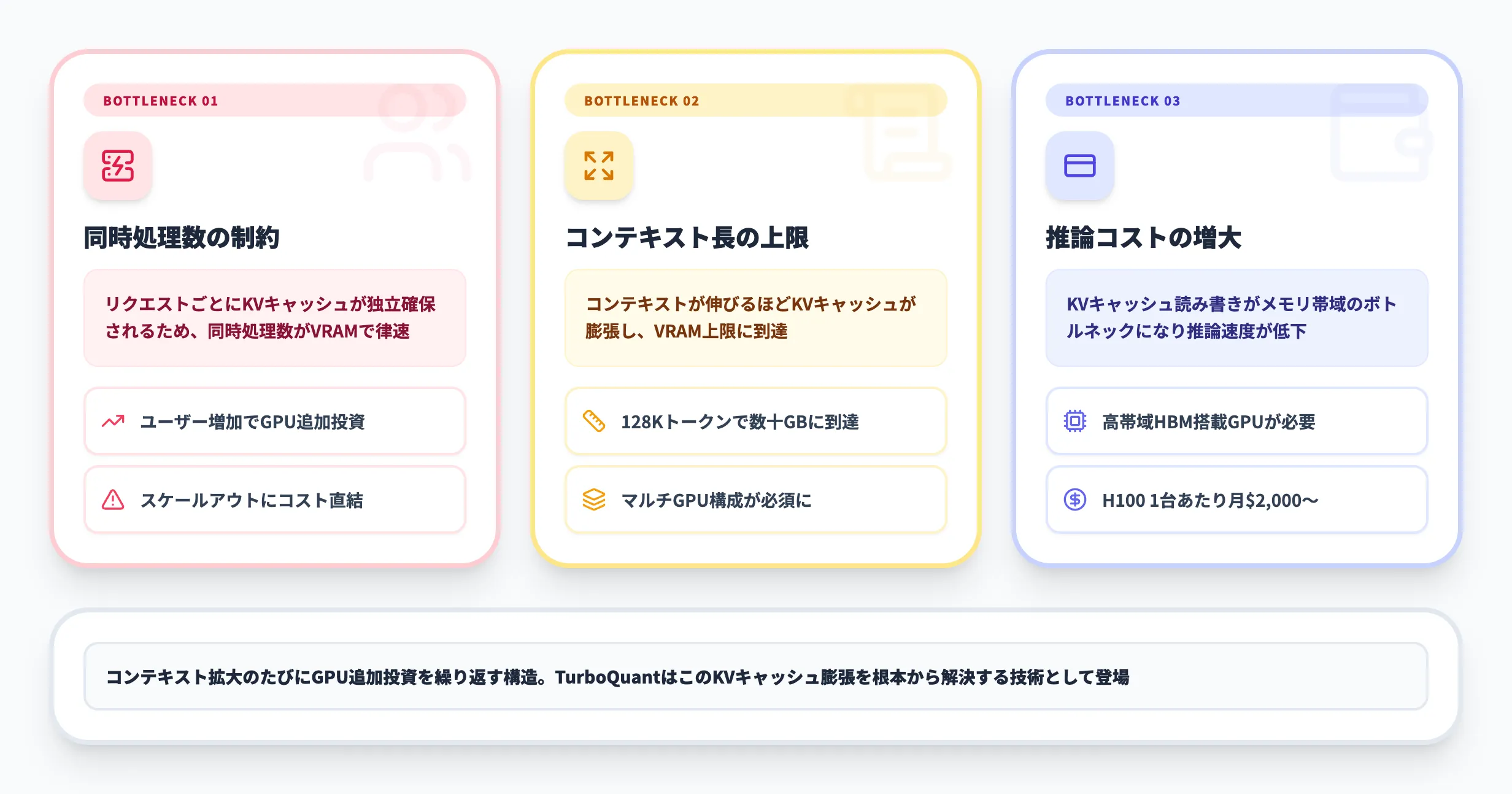
LLM推論におけるKVキャッシュのメモリ消費問題
2026年に入り、LLMのコンテキストウィンドウは急速に拡大しています。100万トークン(約75万語相当)を超えるコンテキストに対応するモデルが登場し、「長文を丸ごと読ませて処理する」ユースケースが現実的になりました。
しかし、コンテキストが長くなるほどKVキャッシュの消費メモリが線形に増大するため、GPUメモリの物理的な限界が推論性能のボトルネックになっています。
この問題は以下のような形で企業のAI運用に影響を及ぼしています。
- 同時処理数の制約
1台のGPUで同時に処理できるリクエスト数が、KVキャッシュのメモリ消費によって制限される。ユーザー数が増えるとGPUの追加投資が必要になる
- コンテキスト長の上限
モデルが対応するコンテキスト長をフルに活用しようとすると、KVキャッシュだけでGPUメモリの大半を占有してしまう。結果として、長文処理にはマルチGPU構成が必須になる
- 推論コストの増大
KVキャッシュの読み書きがメモリ帯域のボトルネックになり、推論速度が低下する。スループット(単位時間あたりの処理量)を維持するために、より高価なGPUやHBM(高帯域メモリ)を搭載したハードウェアが求められる
LLMの推論サーバーを運用していて、コンテキスト長が伸びるたびにGPUメモリの追加投資が必要になっている——その繰り返しに限界を感じているなら、まさにTurboQuantが解決しようとしている課題に直面しています。
「GoogleのDeepSeekモーメント」と呼ばれる理由
TurboQuantの発表は、2026年初頭にDeepSeekが引き起こした「効率化ショック」と重ね合わせて語られることが多く、TechCrunchの報道でも「GoogleのDeepSeekモーメント」として取り上げられました。
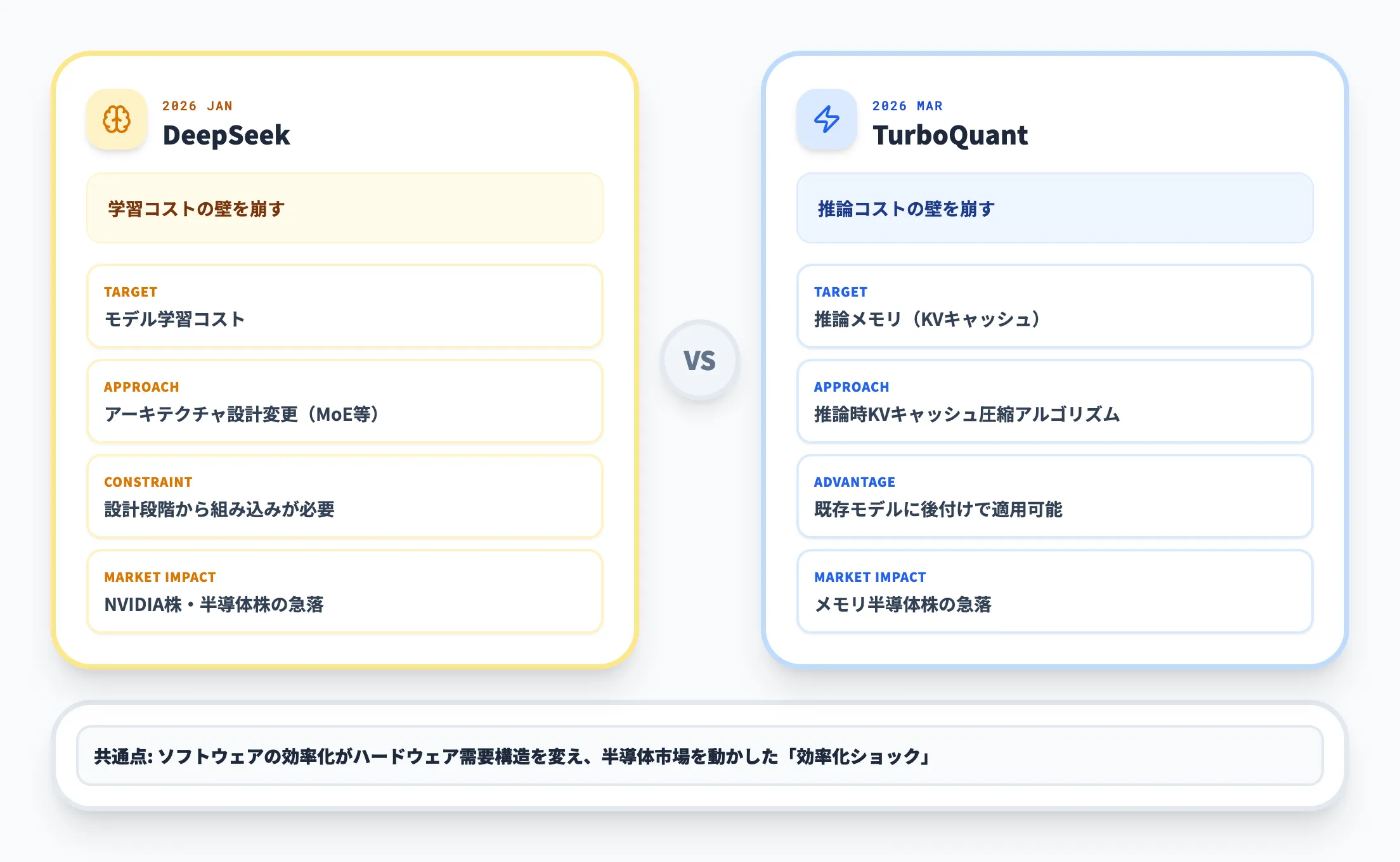
両者の共通点と相違点を以下の表で整理します。
| 比較項目 | DeepSeek | TurboQuant |
|---|---|---|
| 効率化の対象 | モデルの学習(トレーニング)コスト | モデルの推論(インファレンス)メモリ |
| アプローチ | アーキテクチャレベルの設計変更(MoE等) | 推論時のKVキャッシュ圧縮アルゴリズム |
| 既存モデルへの適用 | 不可(最初から設計に組み込む必要あり) | 可能(トレーニング不要で即座に適用) |
| 精度への影響 | 同等性能を低コストで達成 | 公開ベンチマークで精度低下が観測されていない |
| 業界へのインパクト | NVIDIA株・半導体株の急落(2026年1月) | メモリ半導体株の急落(2026年3月) |
DeepSeek V3が「低コストのハードウェアでも高性能なモデルを学習できる」ことを示したのに対し、TurboQuantは「既存のモデルをそのまま、大幅に少ないメモリで推論できる」ことを示しました。
特にTurboQuantの場合、既存のモデルに後付けで適用できる点が実務上の大きな強みです。DeepSeekのアプローチは設計段階から組み込む必要がありますが、TurboQuantはすでに運用中のLLMに対しても適用可能であり、導入のハードルが格段に低いと言えます。
また、インターネット上ではTurboQuantを「リアル版Pied Piper(パイドパイパー)」と呼ぶ声も上がりました。これはドラマ「シリコンバレー」に登場する架空の圧縮技術企業になぞらえた表現です。
【関連記事】
DeepSeek(ディープシーク)とは?株式市場に与えたショックや安全性を徹底解説!
TurboQuantの技術構成:PolarQuantとQJLの2段階圧縮
TurboQuantが公開ベンチマークで精度低下を起こさずにKVキャッシュを3ビットまで圧縮できる仕組みを、技術的な観点から段階的に解説します。数式は使わず、各ステップが「何をしているか」「なぜ必要か」を中心に説明します。
第1段階:PolarQuantによる幾何学的変換
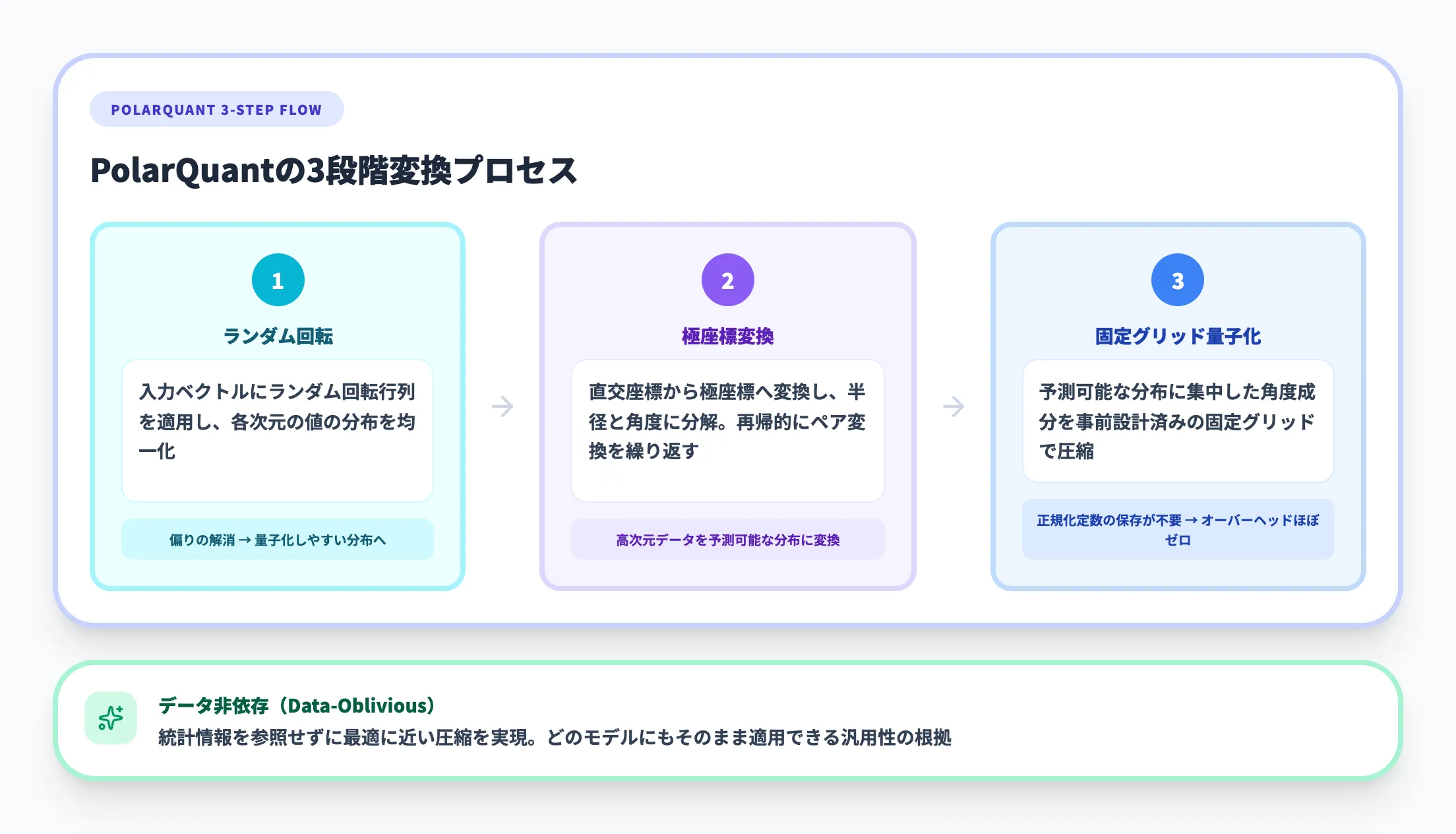
PolarQuantは、高次元のベクトルデータをより圧縮しやすい形に変換する技術です。
通常、LLMのKVキャッシュに格納されるベクトルは数百〜数千次元のデータですが、そのままでは各次元の値の分布がバラバラで、効率よく量子化(低ビット表現に変換)することが困難です。
PolarQuantは以下の3ステップでこの問題を解決します。
- ランダム回転
入力ベクトルに対してランダムな回転行列を適用し、各次元の値の分布を均一化する。これにより、特定の次元に値が偏る問題が解消される
- 極座標変換
回転後のベクトルを直交座標系から極座標系に変換する。2つずつの座標をペアにして「半径」と「角度」に分解し、再帰的に極座標変換を繰り返す
- 固定グリッド量子化
極座標変換後の角度成分は予測可能な分布に集中するため、事前に設計した固定の量子化グリッド上で圧縮できる。従来の手法で必要だった「ブロックごとの正規化定数」を保存する必要がなくなり、メモリオーバーヘッドがほぼゼロになる
PolarQuantのポイントは、データの統計情報を一切参照せずに(データ非依存で)最適に近い圧縮を実現する点にあります。これが「どのモデルにもそのまま適用できる」汎用性の根拠です。
第2段階:QJLによる1ビット誤差補正
PolarQuantだけでもKVキャッシュの大幅な圧縮は可能ですが、注意機構(Attention)の計算では「内積の正確さ」が特に重要です。PolarQuantで生じるわずかな量子化誤差が、長いコンテキストの処理で蓄積すると問題になる可能性があります。
QJL(Quantized Johnson-Lindenstrauss)は、この残差を消し去るために設計された補正アルゴリズムです。
Johnson-Lindenstrauss変換とは、高次元のデータを低次元に射影しても、データ間の距離関係がおおむね保存されるという数学的性質を利用した手法です。QJLはこの変換を応用し、PolarQuantの圧縮で残った誤差ベクトルに対して**わずか1ビットの符号情報(+1または-1)**を記録します。
この1ビットの補正により、TurboQuant全体での注意スコアの内積推定が**不偏推定量(バイアスなし)**になることが論文で理論的に示されています。つまり、圧縮に起因する体系的な偏りが注意計算に蓄積しない設計になっています。ただし、これは注意スコア推定のバイアスに関する理論保証であり、あらゆる下流タスクで精度低下ゼロを数学的に保証するものではありません。
トレーニング不要・データ非依存の設計思想
TurboQuantの設計で最も実用的に重要なのは、トレーニング(追加学習)が一切不要という点です。
従来のKVキャッシュ量子化手法の多くは、モデルごとにキャリブレーション(調整)データを用意し、量子化パラメータを最適化するプロセスが必要でした。この作業はモデルを更新するたびに繰り返す必要があり、運用負荷の原因になっていました。
TurboQuantはデータ非依存(data-oblivious)な設計のため、以下のメリットがあります。
- モデルのバージョンアップ時に再キャリブレーションが不要
- 新しいモデルが公開された時点で即座に適用可能
- バッチごとに異なるリクエスト内容に対しても、同じ圧縮アルゴリズムがそのまま機能する
この「プラグアンドプレイ」で使える設計が、TurboQuantの実用化を加速させている大きな要因です。
TurboQuantのベンチマーク結果:Attention計算で最大8倍の高速化
TurboQuantの性能を、Google Researchの公式ブログおよびICLR 2026論文に掲載されたベンチマークデータに基づいて解説します。
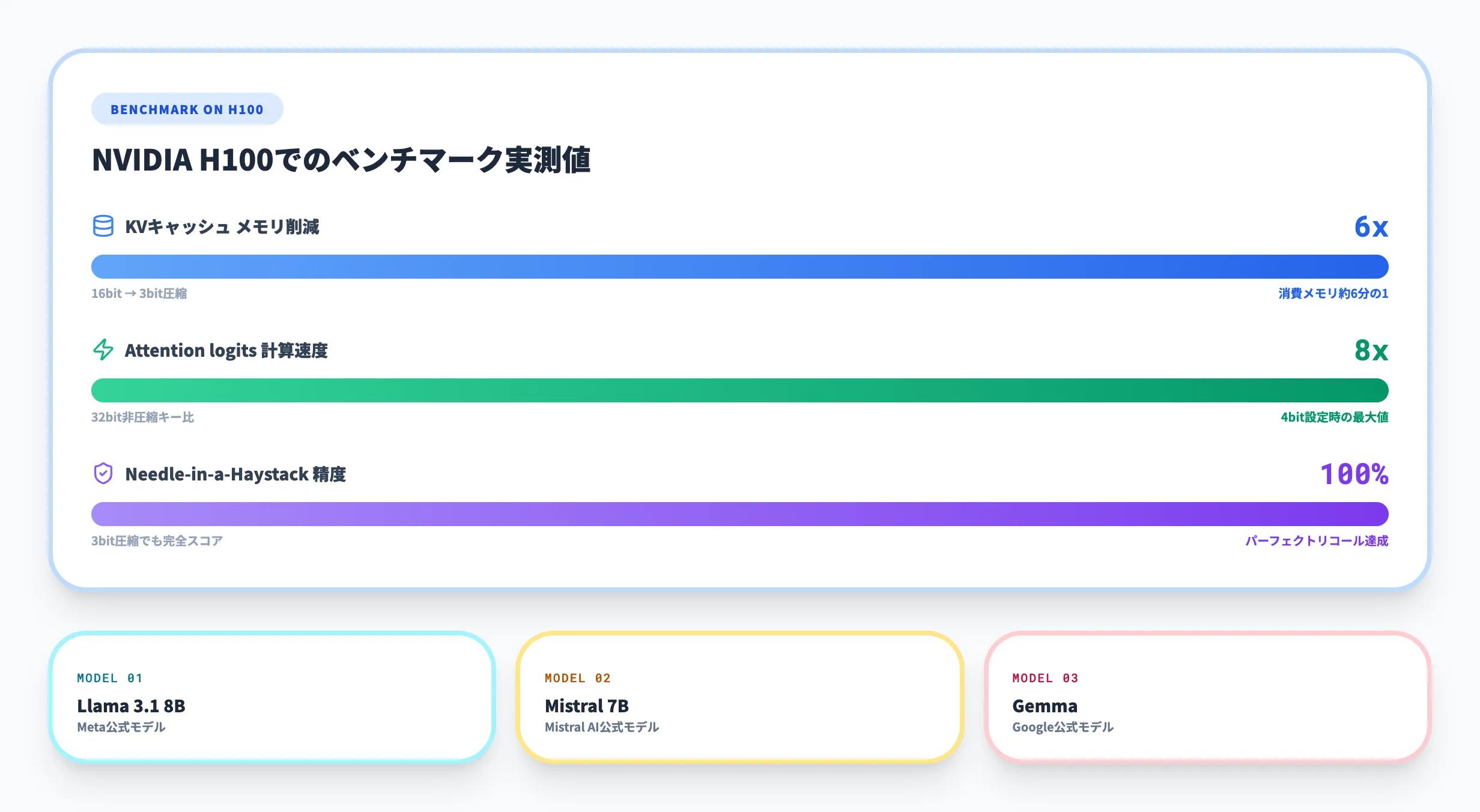
メモリ削減率と推論速度の実測値
以下の表は、NVIDIA H100 GPU上でのTurboQuantの実測パフォーマンスを、非圧縮(16bit/32bit)と比較したものです。
| 指標 | 非圧縮(16bit) | TurboQuant(3bit) | TurboQuant(4bit) |
|---|---|---|---|
| KVキャッシュのメモリ消費 | 基準(1倍) | 約6分の1 | 約4分の1 |
| Attention計算速度(対32bit比) | — | — | 最大8倍 |
| 精度(Needle-in-a-Haystack) | 100% | 100% | 100% |
| 追加学習の必要性 | — | 不要 | 不要 |
4ビット設定ではAttention logits計算の速度が32bit非圧縮キー比で最大8倍に達しています。ただし、これはAttention計算部分のみの数値であり、エンドツーエンドの推論速度全体が8倍になるわけではありません。また、公開ベンチマークでは3ビット圧縮でも精度低下が観測されていません。
ベンチマークはLlama-3.1-8B、Mistral-7B、Gemmaといったオープンソースモデルで実施されており、特定のモデルに依存した最適化ではないことが確認されています。
精度検証:Needle-in-a-Haystack完全スコア
LLMの長文処理能力を測る代表的なテストに「Needle-in-a-Haystack(干し草の中の針)」があります。大量のテキストの中に埋め込まれた特定の情報を正確に取り出せるかを検証するもので、KVキャッシュの圧縮が精度に影響を与えるかどうかの判断材料になります。
Tom's Hardwareの報道によると、TurboQuantは3ビット圧縮の状態でもこのテストで**完全スコア(パーフェクトリコール)**を達成しています。
この結果は、公開ベンチマークの範囲内ではTurboQuantの圧縮が情報の欠落を伴わないことを示しています。特に、RAG(検索拡張生成)やドキュメント要約といった長文コンテキストを必要とするユースケースでは、KVキャッシュの圧縮による品質劣化が最も懸念されるポイントですが、少なくとも論文で検証されたモデル・タスクの範囲ではこの懸念はクリアされています。
【関連記事】
GPUとは?その種類や特徴、活用分野をわかりやすく解説!

【詳細比較】TurboQuantと従来の量子化技術(GPTQ・AWQ)の違い
LLMの効率化に量子化技術を使っている方にとって気になるのは、「TurboQuantは既存のGPTQやAWQを置き換えるのか?」という点でしょう。結論から言えば、TurboQuantはGPTQ・AWQと競合するのではなく、補完する技術です。

圧縮対象の違い:モデル重み vs KVキャッシュ
GPTQ・AWQとTurboQuantでは、そもそも圧縮する対象が異なります。以下の表で整理します。
| 比較項目 | GPTQ | AWQ | TurboQuant |
|---|---|---|---|
| 圧縮対象 | モデルの重み(Weight) | モデルの重み(Weight) | KVキャッシュ(推論時メモリ) |
| 圧縮ビット幅 | 主に4bit | 主に4bit | 3〜4bit |
| 精度への影響 | 1〜2%程度の劣化 | 0.5〜1%程度の劣化 | 公開ベンチで低下なし(注意スコアの不偏性は理論保証) |
| キャリブレーション | 必要(Hessian計算) | 必要(活性化考慮) | 不要(データ非依存) |
| 適用タイミング | オフライン(事前に1回) | オフライン(事前に1回) | オンライン(推論中にリアルタイム) |
| モデル更新時の再作業 | 必要 | 必要 | 不要 |
分かりやすく例えるなら、GPTQ・AWQはLLMの「脳(モデルの重み)」を圧縮する技術であり、TurboQuantはLLMの「メモ帳(推論中のKVキャッシュ)」を圧縮する技術です。圧縮する場所が違うため、そもそも競合関係にはありません。
TurboQuantとGPTQ・AWQの併用が最適解

TurboQuantとGPTQ・AWQは組み合わせて使うことで最大の効果を発揮します。
たとえば、Llama 3.1 70Bクラスのモデルに対してGPTQ/AWQで4bit重み量子化を適用し、さらにTurboQuantで3bit KVキャッシュ圧縮を適用した場合、VRAM消費の構造は以下のように変化します。なお、実際の総VRAM量はモデルアーキテクチャ(レイヤー数・隠れ次元・KVヘッド数)やコンテキスト長に強く依存するため、以下は傾向を示すものです。
| 構成 | 重みのVRAM目安 | KVキャッシュのVRAM傾向 |
|---|---|---|
| 70Bモデル(16bit重み+16bit KVキャッシュ) | 約140 GB(マルチGPU必須) | コンテキスト長に比例して大きく増大 |
| 70Bモデル(4bit重み+16bit KVキャッシュ) | 約34 GB | コンテキスト長に比例して増大 |
| 70Bモデル(4bit重み+3bit KVキャッシュ) | 約34 GB | KVキャッシュ分が約5分の1に圧縮 |
重要なのは、4bit重み+3bit KVキャッシュの組み合わせにより、70B級モデルでも単一のH100 GPU(80GB VRAM)に収まる可能性が出てくる点です。具体的にどの程度のコンテキスト長まで対応できるかはモデルと同時処理数に依存しますが、従来のマルチGPU必須だった構成が単一GPUで実現可能になるインパクトは大きいと言えます。
AI総研の導入支援の経験から言えば、LLMの推論基盤を設計する際に「重み量子化とKVキャッシュ量子化を別レイヤーとして組み合わせる」発想を持つことが、2026年以降のインフラコスト最適化の鍵になります。TurboQuantが実用化されれば、従来は「GPUを追加する」しかなかった長文推論の課題に対して、「ソフトウェアレベルの最適化で対応する」という選択肢が加わります。
推論コスト削減を業務ROIに直結させる

GPU最適化を業務成果につなげる設計
TurboQuantのような推論効率化技術を追うだけでは、経営としてのAI投資対効果は見えにくいままです。PoCから全社展開までの段階設計、部門別ユースケース、インフラコスト削減と業務成果の両立策をまとめたAI業務自動化ガイド(220ページ)を無料で公開中です。
TurboQuantが向いている場面と向かない場面
TurboQuantはあらゆるLLM推論に万能な技術ではありません。このセクションでは、TurboQuantの導入を検討する際に「どのケースで効果が大きいか」「どのケースでは別のアプローチが必要か」を整理します。
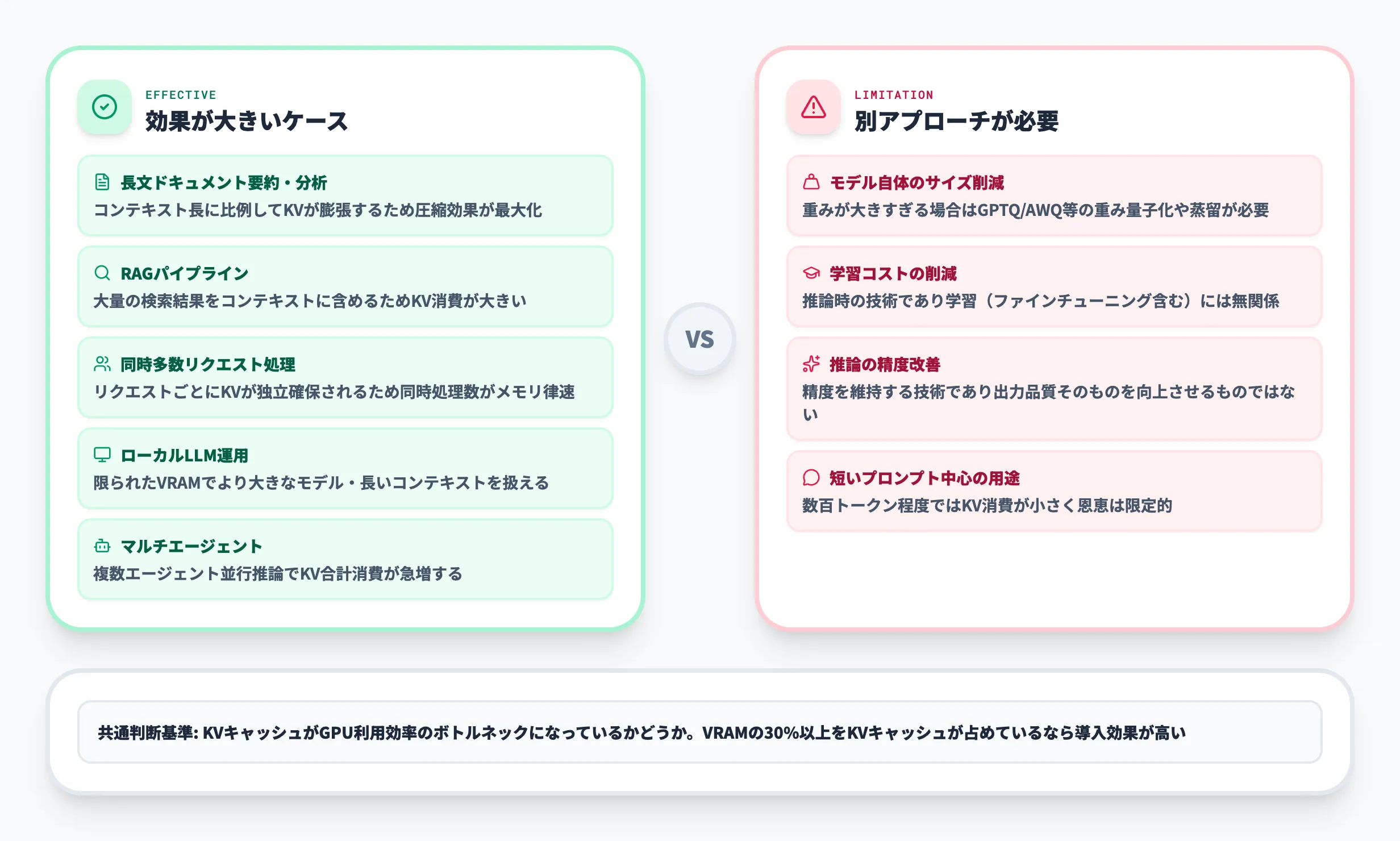
特に有効なユースケース
以下の表に、TurboQuantの導入効果が特に高いユースケースをまとめました。
| ユースケース | TurboQuantが有効な理由 |
|---|---|
| 長文ドキュメントの要約・分析 | コンテキスト長に比例してKVキャッシュが膨張するため、圧縮効果が最大化される |
| RAG(検索拡張生成)パイプライン | 大量の検索結果をコンテキストに含めるため、KVキャッシュ消費が大きくなりやすい |
| 同時多数リクエストの処理 | リクエストごとにKVキャッシュが独立して確保されるため、同時処理数がメモリで律速される |
| ローカルLLMの運用 | 限られたGPUメモリ内でより大きなモデルやより長いコンテキストを扱えるようになる |
| マルチエージェントシステム | 複数のエージェントが並行してLLM推論を行う場合、KVキャッシュの合計消費が急増する |
共通するのは、KVキャッシュのメモリ消費がGPU利用効率のボトルネックになっている場面です。逆に、短いプロンプト(数百トークン程度)しか扱わない用途では、KVキャッシュの消費量がそもそも小さいため、TurboQuantの恩恵は限定的です。
TurboQuantだけでは解決しないケース
TurboQuantはKVキャッシュの圧縮に特化した技術であり、以下のような課題には別のアプローチが必要です。
- モデル自体のサイズ削減
モデルの重みが大きすぎてGPUに載らない場合は、GPTQ・AWQ等の重み量子化や、蒸留(Distillation)による小型モデルの作成が必要
- 学習コストの削減
TurboQuantは推論時の技術であり、モデルの学習(ファインチューニング含む)には影響しない
- 推論の精度改善
TurboQuantは「精度を維持したまま効率化する」技術であり、モデルの出力品質そのものを向上させるものではない
導入判断で詰まる論点
TurboQuantの導入を検討する際に多くの企業が迷うのは、以下のような論点です。
公式実装を待つべきか、非公式実装で先行検証すべきか
2026年3月時点で、Googleの公式実装はまだリリースされていません。公式コードの公開時期はGoogle側から明示されておらず、ICLR 2026(2026年4月)での正式発表が予定されている段階です。一方で、llama.cppやPyTorchベースの非公式実装がすでにコミュニティから公開されています。
AI総研としての推奨は、非公式実装でPoCを進めつつ、本番環境への適用は公式実装または主要フレームワークへの統合を待つというアプローチです。先行検証によって自社のワークロードでの実効性を確認しておけば、公式実装が出た段階で即座に本番適用に移れます。
既存の量子化設定を見直す必要があるか
すでにGPTQ・AWQで重み量子化を運用している場合、TurboQuantの追加適用は既存の設定を変更せずに行えるはずです。重み量子化とKVキャッシュ量子化はレイヤーが異なるため、原理的には干渉しません。ただし、組み合わせ時の精度検証は個別に行う必要があります。
どの程度のコスト削減効果が見込めるか
効果はワークロードに大きく依存します。KVキャッシュがメモリの主要なボトルネックになっているケース(長文処理・高同時接続数)では50%以上のコスト削減も見込めますが、短いプロンプト中心のワークロードでは効果が限定的です。まずは自社の推論サーバーのメモリプロファイリングを行い、KVキャッシュの消費割合を把握するところから始めるのが現実的です。
TurboQuantの実装状況とメモリ半導体市場への影響
TurboQuantは2026年3月の発表から間もない技術であり、実用化と市場への影響はまだ進行中です。このセクションでは、技術の実装状況と、メモリ半導体市場に与えたインパクトの両面から現状を整理します。

公式実装のタイムラインとOSSプロジェクト
2026年3月31日時点での実装状況を以下の表にまとめます。
| プロジェクト | ステータス | 備考 |
|---|---|---|
| Google公式実装 | 未公開 | 公開時期は公式未発表。ICLR 2026(2026年4月)での正式発表が予定されている |
| llama.cpp | 非公式実装が動作検証中 | Apple Silicon対応のMLX版も存在。約4.6倍の圧縮を確認 |
| vLLM | Feature Request段階(Issue #38171) | コミュニティからの統合提案が出ている段階 |
| PyTorch実装(複数) | 動作可能 | tonbistudio/turboquant-pytorch等、複数のOSSプロジェクトが公開済み。PyPIにも登録あり |
| TensorRT-LLM | 未対応 | 統合時期は未定 |
公式実装はまだ出ていないものの、論文とアルゴリズムの設計がシンプルなこともあり、コミュニティによる非公式実装が急速に進んでいます。PyPI(Pythonパッケージ管理)でもturboquant-torchパッケージが公開されており、手元で試すこと自体はすでに可能です。
ICLR 2026(2026年4月)での正式発表が控えていますが、Googleの公式コード公開時期や主要推論フレームワークへの統合スケジュールは、2026年3月時点では公式には発表されていません。
【関連記事】
NVIDIA Dynamoとは?主な特徴や導入手順、料金を解説
メモリ関連株の急落と市場アナリストの見方
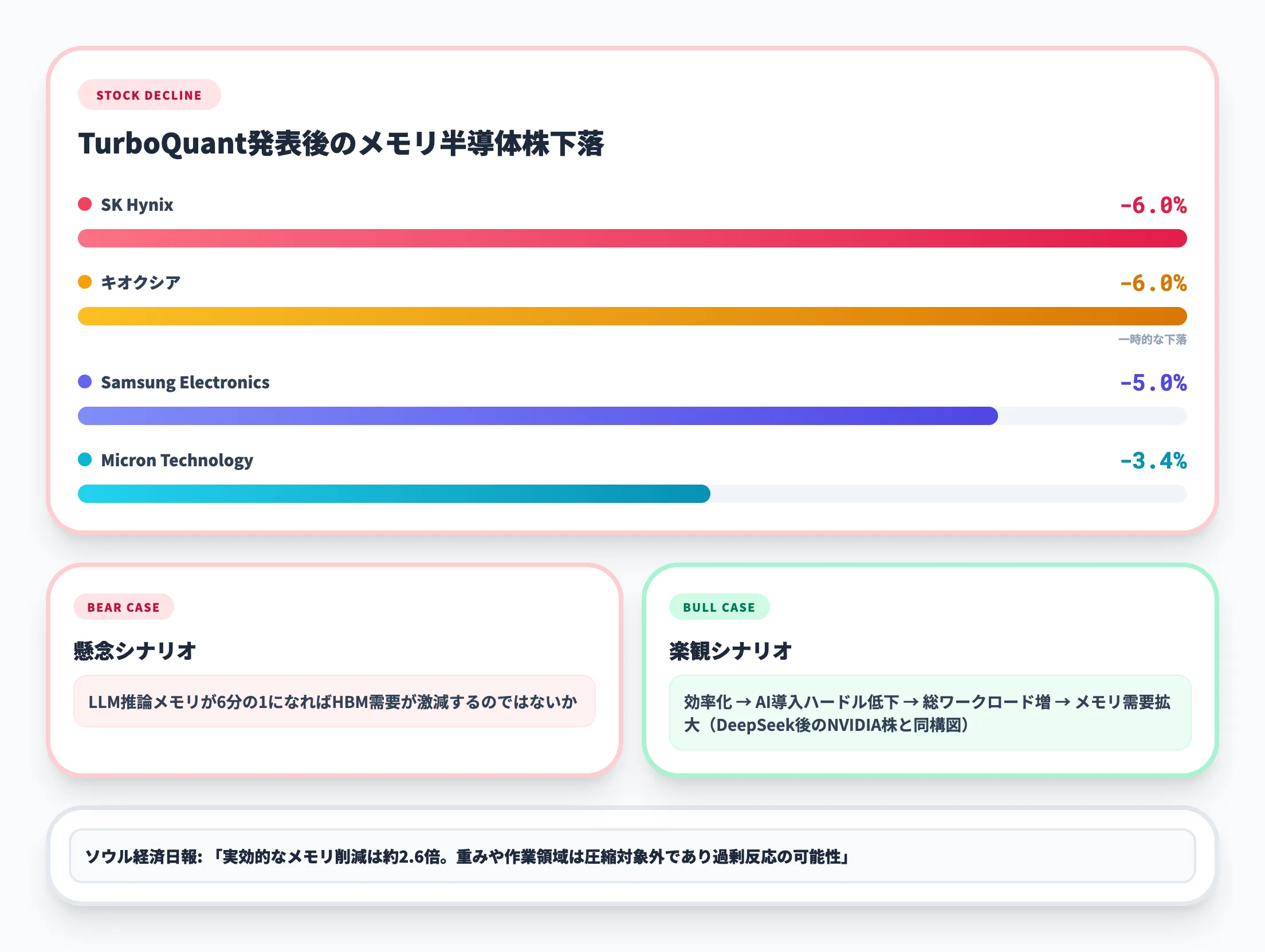
TurboQuantの発表は金融市場にも大きなインパクトを与えました。CNBCの報道によると、発表翌日にメモリ半導体関連株が軒並み急落しています。
| 企業 | 株価下落幅 |
|---|---|
| SK Hynix | 約6% |
| Samsung Electronics | 約5% |
| Micron Technology | 約3.4% |
| キオクシア | 一時6% |
投資家の懸念は明快で、「LLMの推論にメモリの6分の1しか必要なくなるなら、データセンター向けHBM(高帯域メモリ)の需要が激減するのではないか」というものです。GIGAZINEの報道でも、メモリ関連銘柄への影響が広範囲に及んだことが伝えられています。
しかし、この急落は過剰反応である可能性が高いとする見方も出ています。ソウル経済日報の分析では、「実効的なメモリ削減は最大でも約2.6倍に限定される」と指摘されています。理由は、TurboQuantが圧縮するのはKVキャッシュのみであり、モデルの重みや作業領域のメモリは圧縮対象外だからです。
さらに、ソフトウェア効率の向上は「同じハードウェアでより多くの処理ができる」ことを意味するため、AI導入のハードルが下がることでAIワークロード全体の総量が増え、結果的にメモリ需要は増加に向かうという楽観的なシナリオも十分にありえます。これはDeepSeekショック後のNVIDIA株が回復した経緯と同様の構図です。
企業が今から準備すべきこと
TurboQuantの公式実装を待つ間に、以下のアクションを進めておくと、実用化時にスムーズに導入できます。
- 推論サーバーのメモリプロファイリング
自社のLLM推論ワークロードで、KVキャッシュがGPUメモリの何割を占めているかを計測する。この数字がTurboQuant導入時の期待効果の見積もりになる
- 非公式実装での小規模PoC
llama.cppやPyTorch実装を使い、7B〜13Bクラスのモデルで圧縮率と精度を検証する。本番環境のワークロードに近い条件で試すことが重要
- 推論フレームワークのアップデート計画
vLLM・TensorRT-LLM等を使っている場合、TurboQuant対応バージョンへの更新スケジュールを計画に含めておく
まずは自社の推論サーバーでKVキャッシュのメモリ消費比率を計測するところから始めてみてください。その結果、KVキャッシュがVRAMの30%以上を占めているようなら、TurboQuantの導入で明確なコスト削減効果が期待できます。

TurboQuantの推論コスト削減効果
TurboQuantは研究論文が公開されており、コミュニティによる非公式実装(PyPI: turboquant-torch、turboquant-vllm等)で試すことができます。Google公式のコードリリースは2026年3月時点で未定です。ここでは、TurboQuantの導入がLLM推論のインフラコストにどのような影響を与えるかを試算します。
GPU VRAMの節約効果と同時処理数の増加
TurboQuantの最大の実務的価値は、同じGPUでより多くのリクエストを同時処理できるようになる点にあります。以下の表で、TurboQuant適用前後のGPU利用効率を比較します。
| 指標 | TurboQuantなし(16bit KVキャッシュ) | TurboQuantあり(3bit KVキャッシュ) |
|---|---|---|
| KVキャッシュのメモリ消費 | 基準(1倍) | 約6分の1 |
| KVキャッシュが空けたVRAMの活用 | — | 同時処理数の増加、またはコンテキスト長の拡張に充当可能 |
KVキャッシュの消費メモリが6分の1になれば、その分のVRAMを同時処理数の増加やコンテキスト長の拡張に回せます。具体的な改善幅はモデルサイズやワークロードに依存しますが、KVキャッシュがボトルネックになっている環境では同時処理数が数倍に増える効果が見込めます。推論サーバーの台数を削減するか、同じ台数でより多くのユーザーを処理するか、どちらの方向でもインフラコストの最適化につながります。
推論コスト削減のシミュレーション
VentureBeatの試算では、TurboQuantにより推論インフラコストが50%以上削減可能とされています。ただし、この数値はKVキャッシュがボトルネックとなっているワークロードを前提としており、すべてのケースに当てはまるわけではありません。
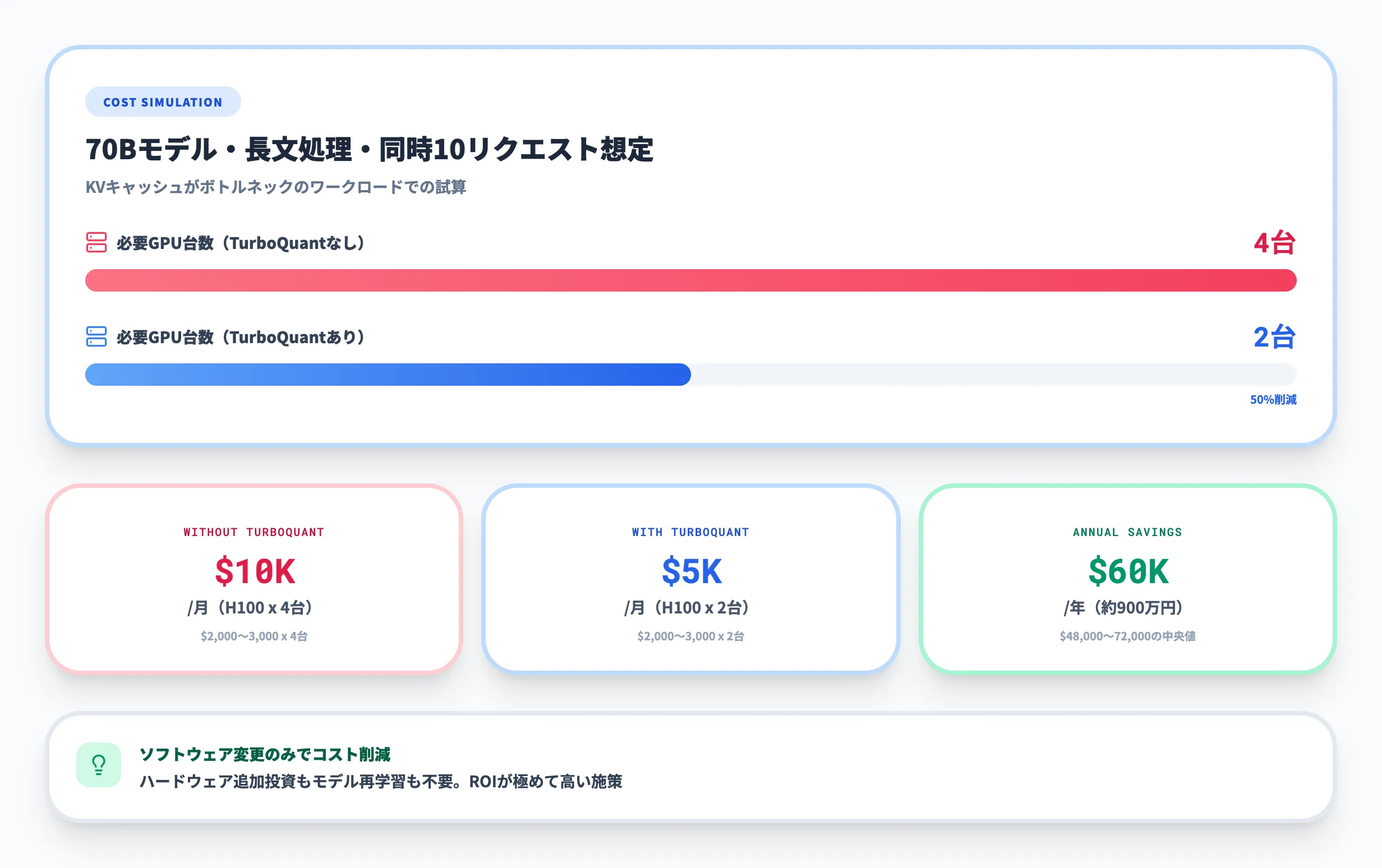
以下に、KVキャッシュがメモリのボトルネックになっている典型的なケースでの試算例を示します。なお、この試算はGPU使用率やワークロード構成に依存する推定値であり、実際の削減額は環境によって異なります。
| 項目 | TurboQuantなし | TurboQuantあり |
|---|---|---|
| 必要なH100 GPU数(70Bモデル・長文処理・同時10リクエスト) | 4台 | 2台 |
| クラウドGPUの月額コスト目安(1台あたり約2,000〜3,000ドル) | 約8,000〜12,000ドル/月 | 約4,000〜6,000ドル/月 |
| 年間の削減額 | — | 約48,000〜72,000ドル(約720〜1,080万円) |
この試算では、2026年3月時点の主要クラウドプロバイダーにおけるH100 GPUインスタンスの価格帯を参考にしています。実際のコスト削減効果は、モデルサイズ・コンテキスト長・同時処理数・GPUの利用率といった変数に依存するため、自社環境でのプロファイリングが欠かせません。
重要なのは、TurboQuantによるコスト削減はソフトウェアの変更のみで実現できるという点です。ハードウェアの追加投資やモデルの再学習は不要であるため、投資対効果(ROI)が極めて高い施策と言えます。
推論コスト削減を業務ROIに直結させる
GPU最適化を業務成果につなげる設計
TurboQuantのような推論効率化技術を追うだけでは、経営としてのAI投資対効果は見えにくいままです。PoCから全社展開までの段階設計、部門別ユースケース、インフラコスト削減と業務成果の両立策をまとめたAI業務自動化ガイド(220ページ)を無料で公開中です。
まとめ
本記事では、Google Researchが発表した新技術TurboQuantについて、技術の仕組みからベンチマーク結果、市場インパクト、推論コスト削減効果までを解説しました。
TurboQuantが企業のAI推論基盤にもたらす価値は、大きく3つにまとめられます。
- メモリ効率の飛躍的改善
KVキャッシュを3ビットに圧縮し、同じGPUでより多くのリクエスト・より長いコンテキストを処理できるようになる。注意スコア推定のバイアスが理論的に抑えられ、公開ベンチマークでも精度低下が観測されていない点が、他の圧縮技術にない強みです
- 既存資産への即時適用
トレーニング不要・データ非依存の設計により、すでに運用中のLLMにそのまま適用できる。GPTQ・AWQとの併用も可能で、既存の重み量子化設定を変更する必要がありません
- 推論コストの構造的削減
ソフトウェアの変更のみで推論インフラコストを大幅に削減できる可能性がある。ハードウェア追加投資が不要なため、ROIが極めて高い施策です
次のステップとしては、まず自社の推論サーバーでKVキャッシュのメモリ消費比率を計測し、TurboQuantの導入効果が見込めるかを判断することをおすすめします。その上で、コミュニティの非公式実装で小規模なPoCを進め、Google公式のコードリリースに備えるのが、現時点での最も現実的な導入ステップです。
TurboQuantは「LLM推論の効率化」という、AI普及のボトルネックを解消する技術です。DeepSeekが学習コストの壁を崩したように、TurboQuantが推論コストの壁を崩す可能性は十分にあります。AI推論基盤の設計を見直すタイミングとして、この技術の動向を継続的にウォッチしておくことを推奨します。










