この記事のポイント
 Google Cloud中心の分析基盤ではBigQueryが第一候補
Google Cloud中心の分析基盤ではBigQueryが第一候補- Sandboxから始める段階導入の現実解
- GA4・広告・CRMを統合する分析基盤
- Snowflake・Redshift・Synapseとの選定基準
- クエリ設計とガバナンスによるコスト管理

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
BigQueryは、Google Cloudが提供するフルマネージドのデータウェアハウスです。SQLを中心に大規模データを分析でき、サーバーやクラスターの運用を意識せずに使い始められます。
2026年4月時点のBigQueryは、単なるDWHにとどまらず、AI・機械学習・外部データ連携・リアルタイム分析までを同じ基盤で扱えるデータ/AIプラットフォームへ広がっています。本記事では、BigQueryの基本機能、向いているユースケース、始め方、料金、他サービスとの違い、導入時の注意点を公式情報ベースで整理します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
目次
BigQueryとは
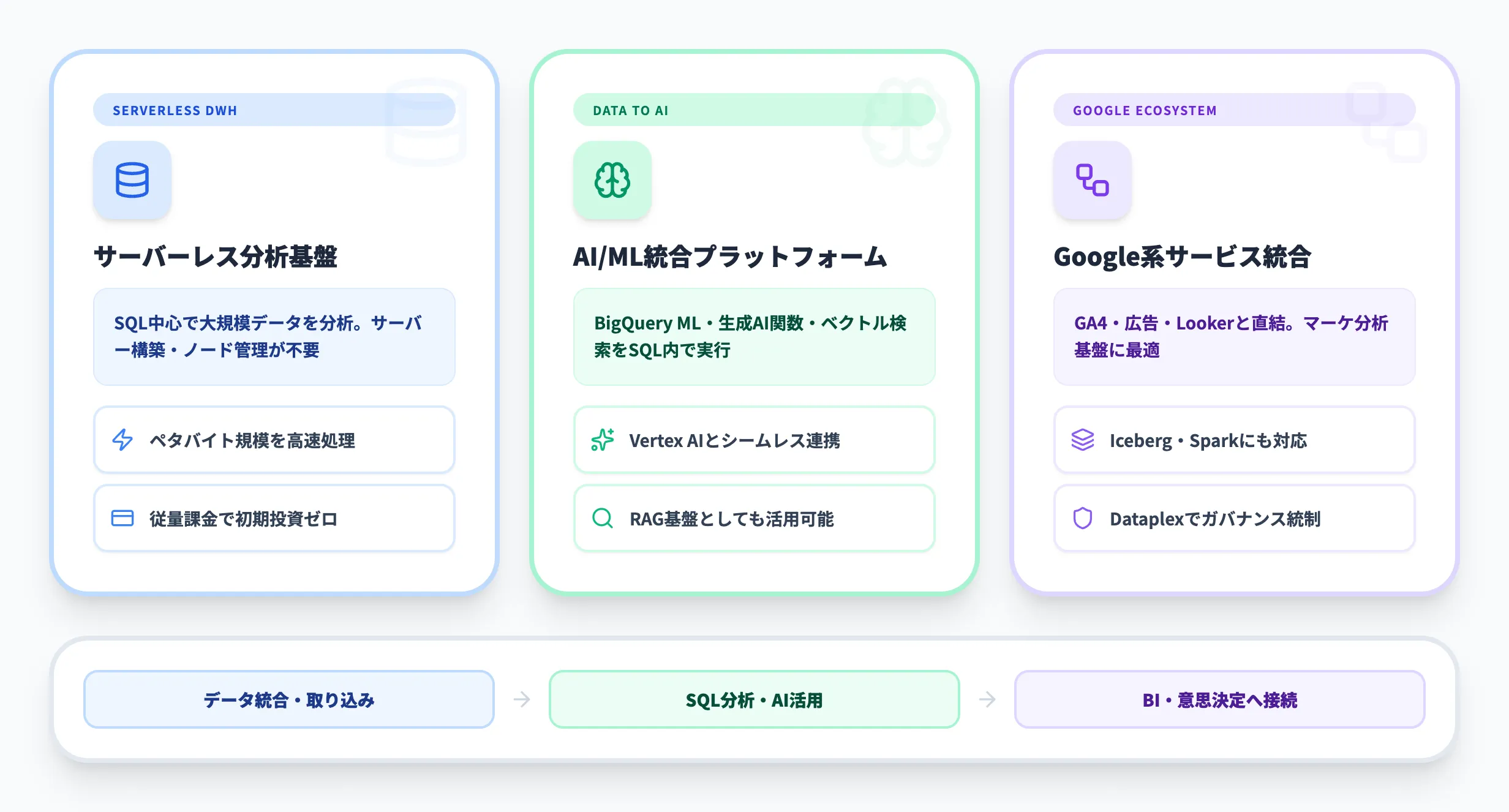
BigQueryは、Google Cloud公式が「data to AI platform」と位置づける分析基盤であり、BigQuery overviewではフルマネージドのデータ分析サービスとして案内されています。もともとはデータウェアハウスとして広く普及しましたが、2026年4月時点ではSQL分析だけでなく、AI、機械学習、外部テーブル、ストリーミング、ガバナンスまでを同じ体験で扱える点が大きな特徴です。
つまりBigQueryを一言で言うと、大規模データをSQL中心で扱いたい企業向けのサーバーレス分析基盤です。利用者はサーバーの構築やノード管理よりも、どのデータをどう整理し、どの意思決定につなげるかに集中できます。
DWHとしてのBigQueryの役割
データウェアハウスの役割は、社内外に散在するデータを1か所に集め、分析しやすい形で管理することです。たとえば、GA4の行動データ、広告配信データ、ECの受注データ、SFAやCRMの顧客データが別々の場所にある状態では、全体最適の判断が遅くなります。
BigQueryはこの分散データをまとめ、SQLで横断分析できるようにする役割を担います。特に、Google系サービスやWebログとの親和性が高いため、マーケティング分析、経営ダッシュボード、プロダクト分析の基盤として採用されやすいサービスです。

BigQueryの位置づけ
現在のBigQueryは、従来型DWHの延長ではありません。Google Cloud公式の製品ページでは、生成AI関数、ベクトル検索、エージェント支援、serverless Spark、Icebergを含むオープン形式対応までが一体で説明されています。つまり「分析の倉庫」ではなく、データを取り込み、加工し、分析し、AIで活用するまでをつなぐプラットフォームとして見るほうが実態に近いです。
この点は、AI活用基盤を同時に考えたい企業にとって重要です。たとえば、分析結果をそのままVertex AIへつなぎたい、あるいは将来的にAIエージェント×データ基盤の形まで発展させたい場合、BigQueryは単なる保管先ではなく、上流から下流までの中核になり得ます。

BigQueryの主な機能
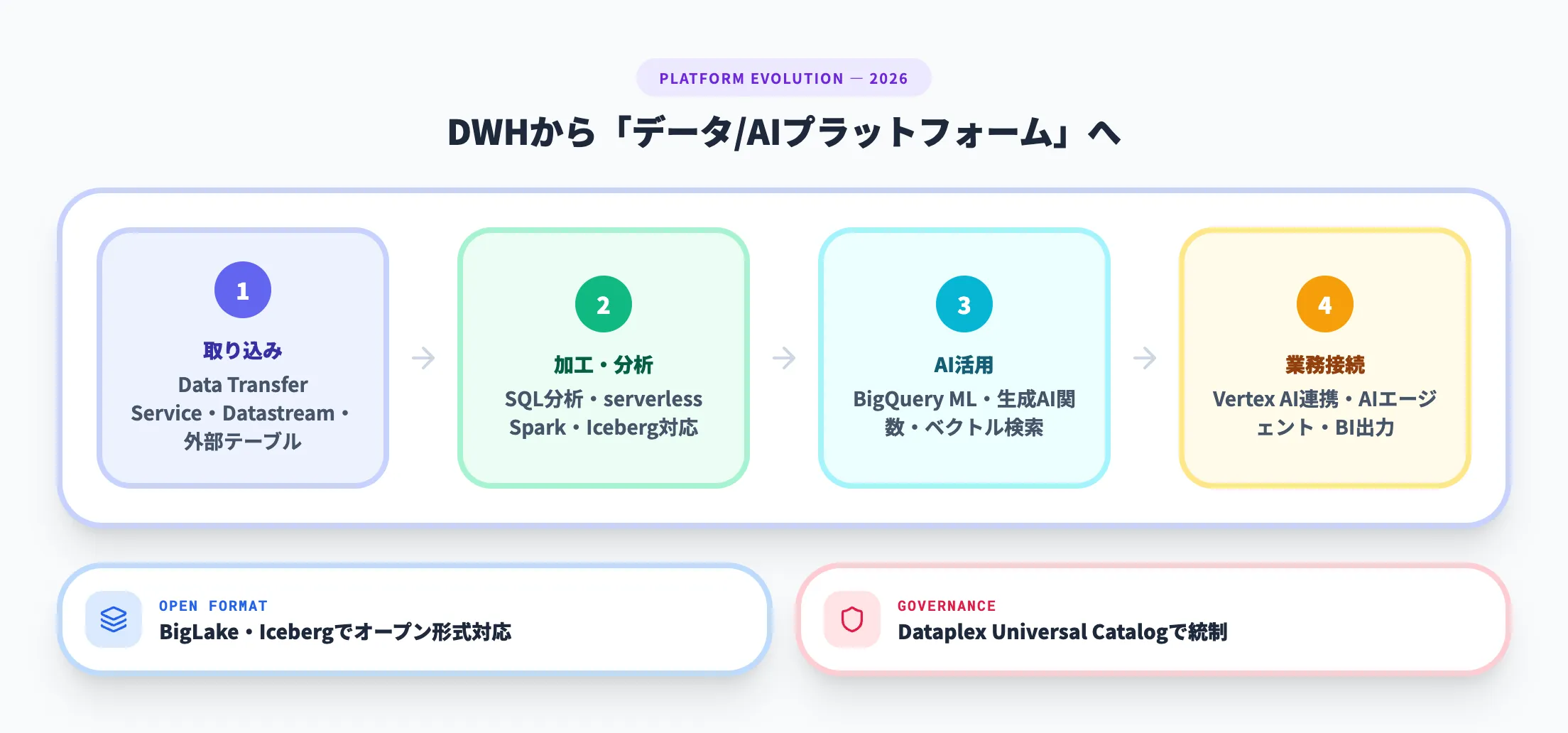
BigQueryを評価するときは、「どのデータを」「どの頻度で」「誰が使うか」の3点で見ると整理しやすくなります。代表的な機能を表でまとめると、次のとおりです。

| 機能 | できること | 向いている場面 |
|---|---|---|
| SQLベースの分析 | 大規模データをSQLで集計・結合・可視化用に整形 | 定型レポート、探索分析、経営ダッシュボード |
| データ連携・取り込み | BigQuery Data Transfer Service、Datastream、外部テーブルでデータを集約 | GA4、広告、SaaS、DBの統合 |
| AI/ML連携 | BigQuery ML、生成AI関数、ベクトル検索、Vertex AI連携 | 需要予測、分類、自然言語分析、RAG基盤 |
| リアルタイム分析 | ストリーミング取り込みやcontinuous queriesで即時集計 | 異常検知、在庫監視、施策の即時評価 |
| オープン形式対応 | BigLake、Iceberg、serverless Sparkで外部データやオープンフォーマットを扱う | Lakehouse志向、マルチワークロード基盤 |
この表から分かるように、BigQueryの強みは「高速SQL」だけではありません。データ統合、分析、AI活用を同じ基盤で段階的に広げやすいことが、2026年時点の大きな優位性です。
BigQueryが向いているユースケース
BigQueryはあらゆる企業に必要なわけではありません。一方で、次のような状態にある組織では導入効果が出やすいです。

GA4・広告・アプリログの統合分析
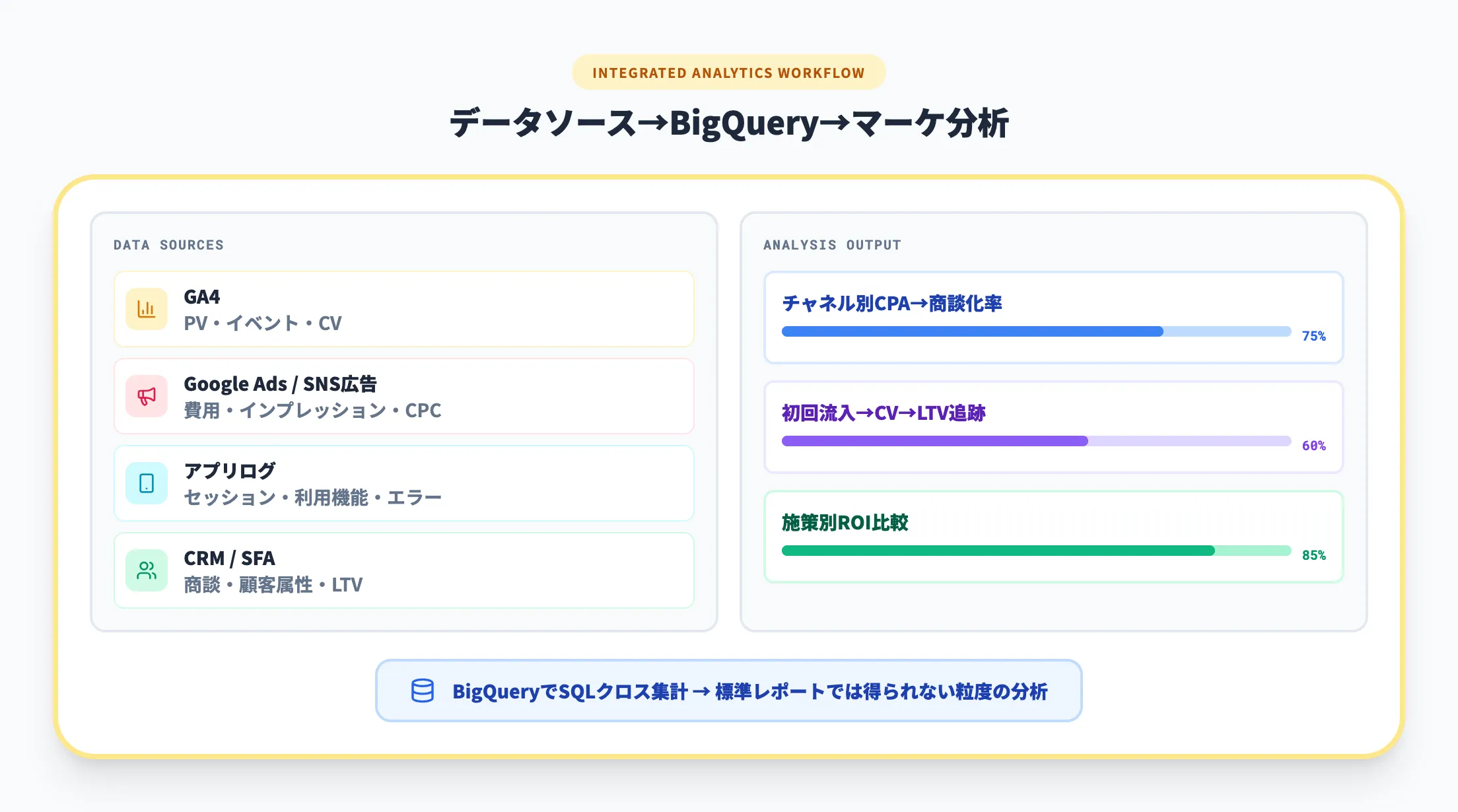
Webサイトやアプリの改善を進める企業では、GA4の標準レポートだけでは物足りなくなる場面が多くあります。ユーザーの行動を広告費、売上、CRMと合わせて分析したい場合、BigQueryにデータを寄せて独自のSQLで集計するほうが実務に合います。
とくに、マーケティングチームが「媒体別のCPA」だけではなく、「初回流入から商談化まで」や「チャネル別LTV」を見たい段階に入っているなら、BigQuery導入の優先度は高いといえます。標準ダッシュボードの延長ではなく、意思決定に必要な粒度でデータを持つためです。
部門横断ダッシュボードとBI基盤
営業、マーケティング、カスタマーサクセス、経理がそれぞれCSVやSaaS画面から数字を取り出している状態は、分析基盤を見直す典型的なサインです。BigQueryにデータを集約すれば、LookerやLooker Studioはもちろん、既存のPower BIから利用する構成も取りやすくなります。
もし毎週の会議で「数字の定義合わせ」から始まっているなら、それはBIツールの問題ではなく、基礎データの集約先が不足している可能性があります。BigQueryは、その土台づくりに向くサービスです。

リアルタイム分析とAI活用
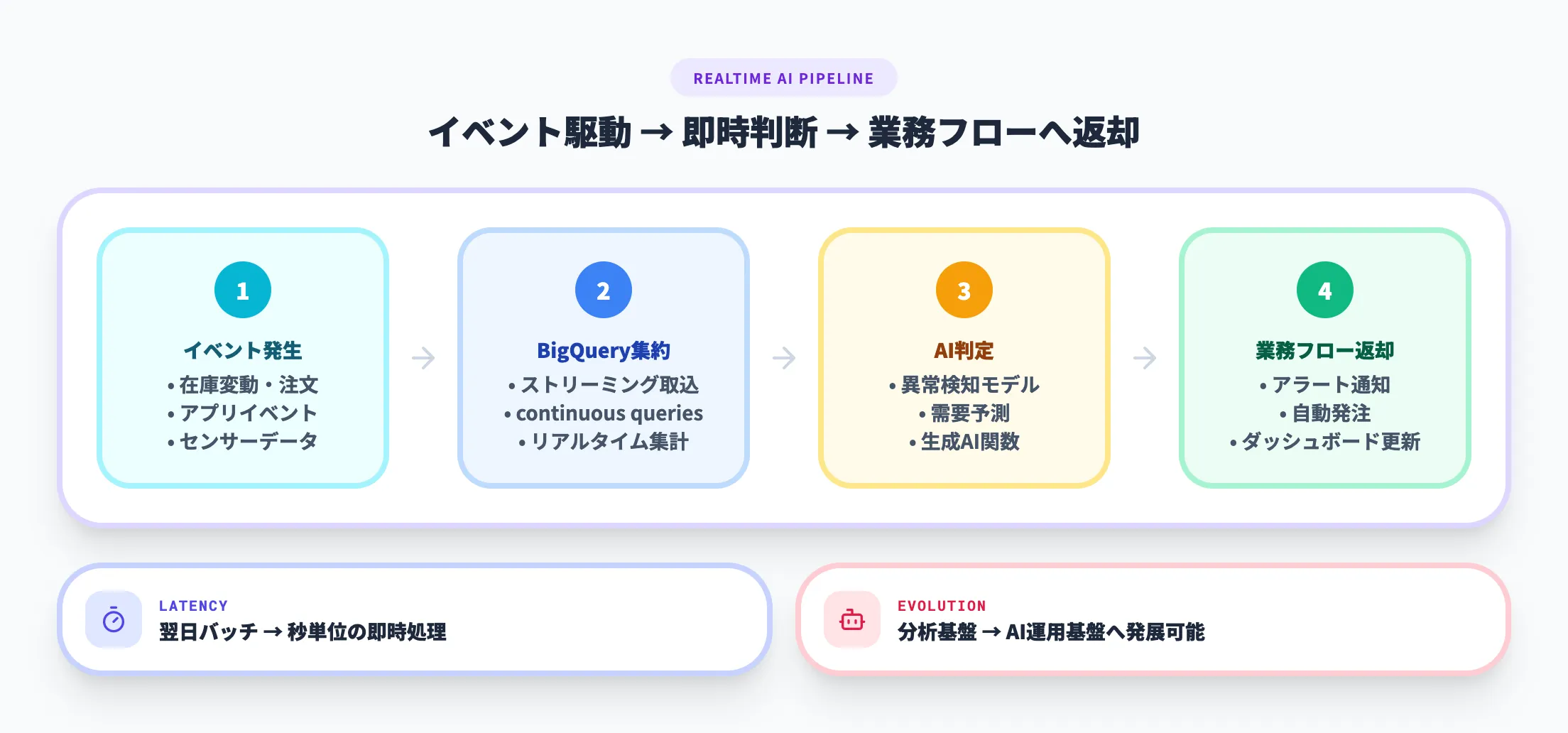
Google Cloud公式の製品ページでは、BigQueryのリアルタイム分析、生成AI関数、エージェント機能が前面に出ています。つまり、BigQueryは「レポートを翌日に見る」ためだけでなく、イベント駆動で即時に判断する用途にも広がっています。
たとえば、在庫や注文、アプリイベントがリアルタイムで流れる環境では、BigQueryで集約したデータをもとに異常検知や予測を行い、その結果を業務フローへ返す構成が有効です。将来的に分析基盤をAI運用基盤へつなげたい企業ほど、BigQueryの価値は高くなります。
BigQueryの始め方
BigQueryは高機能ですが、最初から全社基盤として導入する必要はありません。小さく始めて、効果が見えたところから広げる進め方が現実的です。
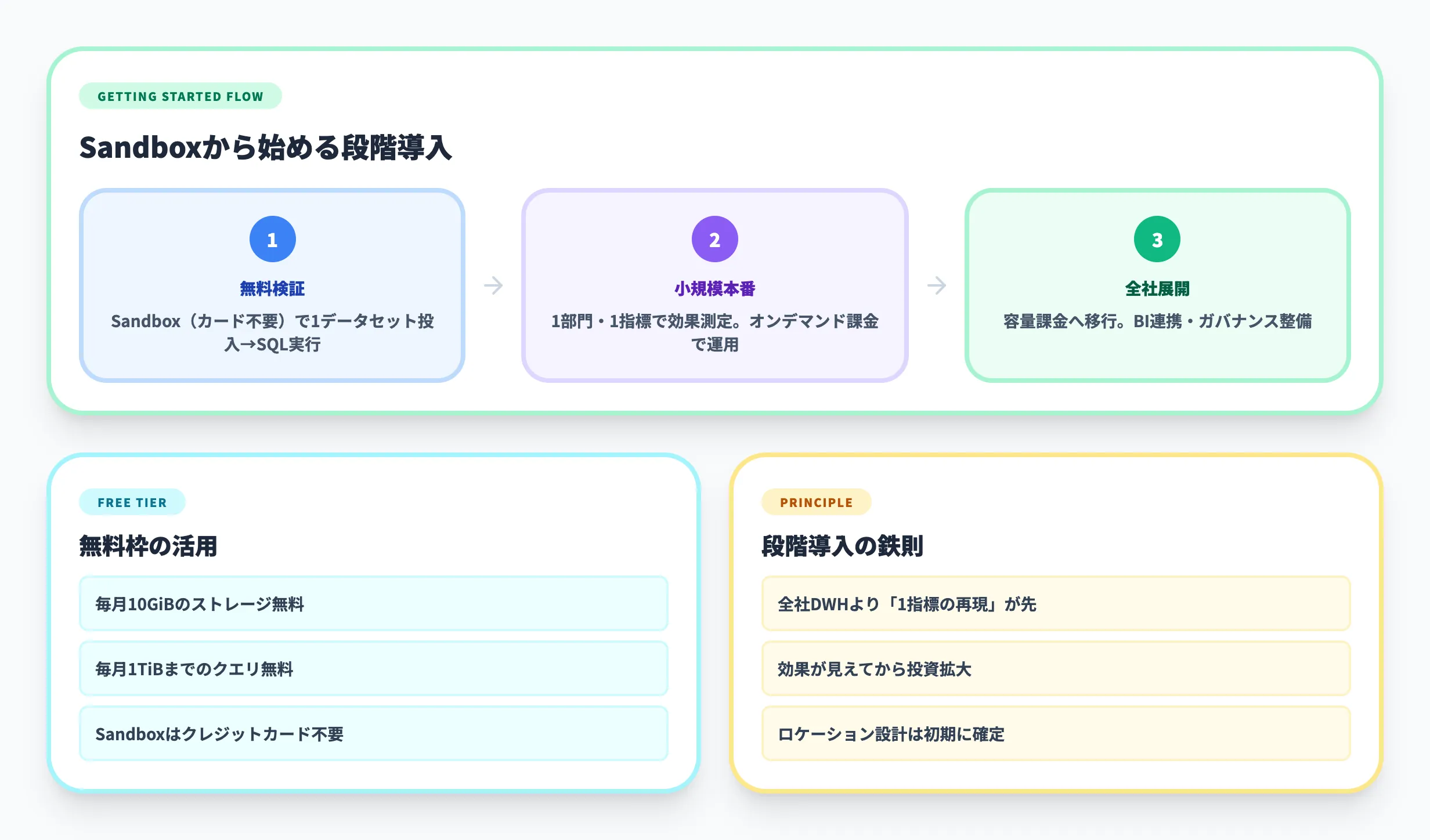
まずはSandboxで試す
Google Cloud公式のBigQueryページでは、毎月10GiBの保存と1TiBまでのクエリが無料枠として案内されています。また、BigQuery sandboxを使えば、クレジットカードなしで検証を始めることも可能です。
このため、最初の検証段階では「本番導入するかどうか」を決める前に、まず1つのデータセットを入れてSQLを回すのが合理的です。いきなり大規模移行を考えるより、分析の再現性と運用コストの感触を早く掴めます。
導入の基本手順
導入の最小ステップは、次の4段階で考えると進めやすいです。
- プロジェクトを用意する
Google Cloudプロジェクトを作成し、BigQueryを有効化します。検証段階ならSandbox、本番化を見据えるなら課金アカウント連携まで先に済ませます。
- データセットのロケーションを決める
後から設計を戻しにくいため、日本向けデータを中心に扱うなら東京リージョンを含め、連携元と監査要件に合わせて早めに決めます。
- 最初のデータを取り込む
CSVの手動投入、小規模のログロード、またはData Transfer Serviceによる定期連携から始めます。最初から全ソースをつなぐ必要はありません。
- 最初の1本の指標を作る
売上、広告効率、継続率など、1つの業務KPIに絞ってSQLを確定させます。必要に応じてパーティションやクラスタリングを後から加えます。
この順番で進めると、BigQueryを「機能が多い基盤」としてではなく、「1つの分析課題を早く再現するための基盤」として使い始めやすくなります。

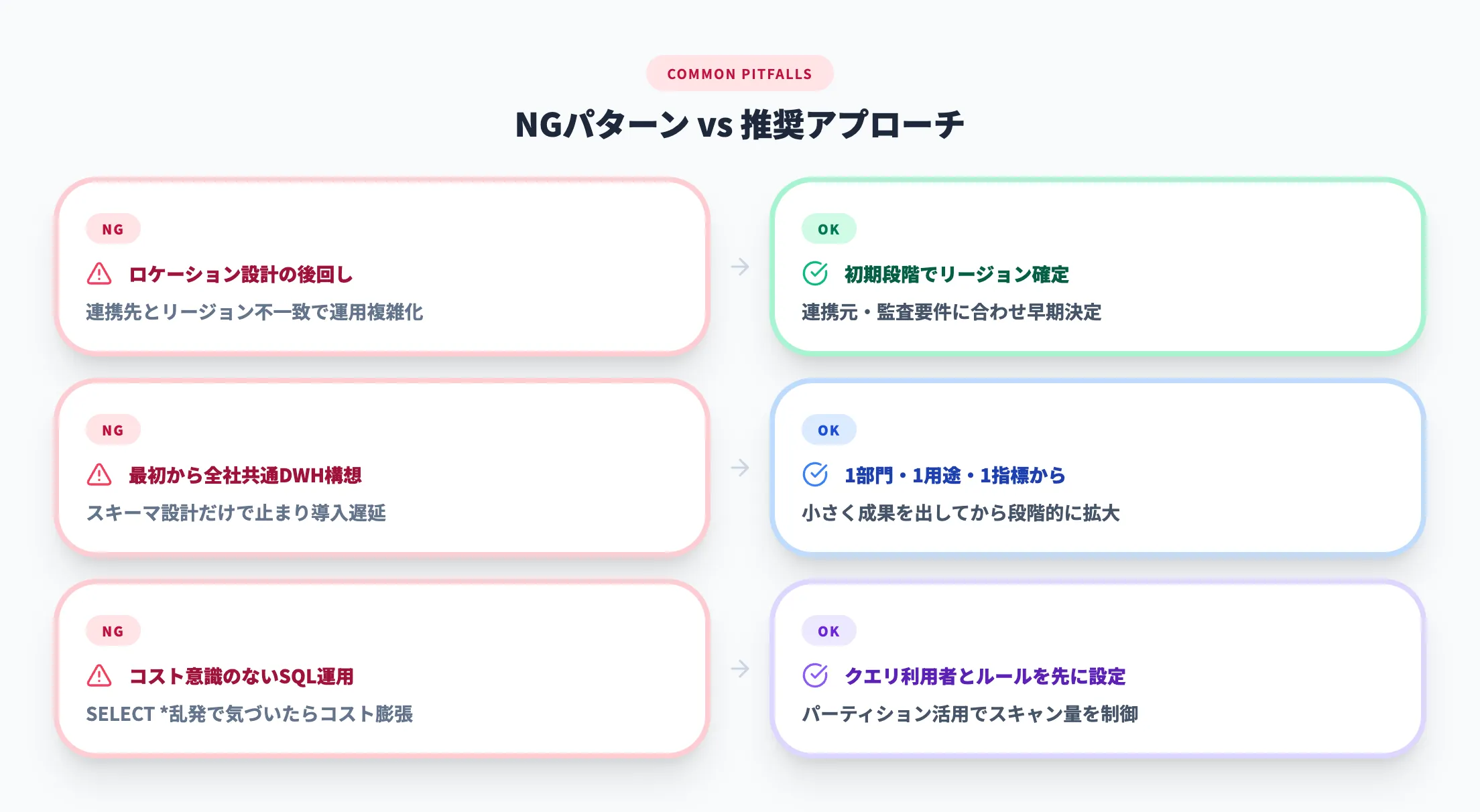
導入初期の詰まりポイント
初期導入でつまずきやすいのは、機能不足ではなく設計の粗さです。
- ロケーションの設計不足
連携先とリージョンが噛み合わないと、運用が複雑になります。特に本番データでは、場所の決定を後回しにしないほうが安全です。
- 分析テーマを広げすぎること
最初から全社共通DWHを目指すと、スキーマ設計だけで止まりやすくなります。最初は1部門、1用途、1指標で十分です。
- コスト意識のないSQL運用
BigQueryは簡単に大規模データを読める反面、雑なクエリでも処理が通るため、気づいたらコストが膨らむことがあります。早い段階で誰がどんなクエリを打つかを決めておくべきです。
言い換えると、BigQuery導入の成否は製品選定よりも、最初に扱うデータ範囲と運用ルールをどこまで狭く定義できるかで決まりやすいです。

BigQueryの導入事例
BigQueryの価値は、単に「速い」ことよりも、運用負荷と分析速度のバランスが改善する点にあります。ここではGoogle公式が公開している事例から、示唆の大きいものを2つ紹介します。
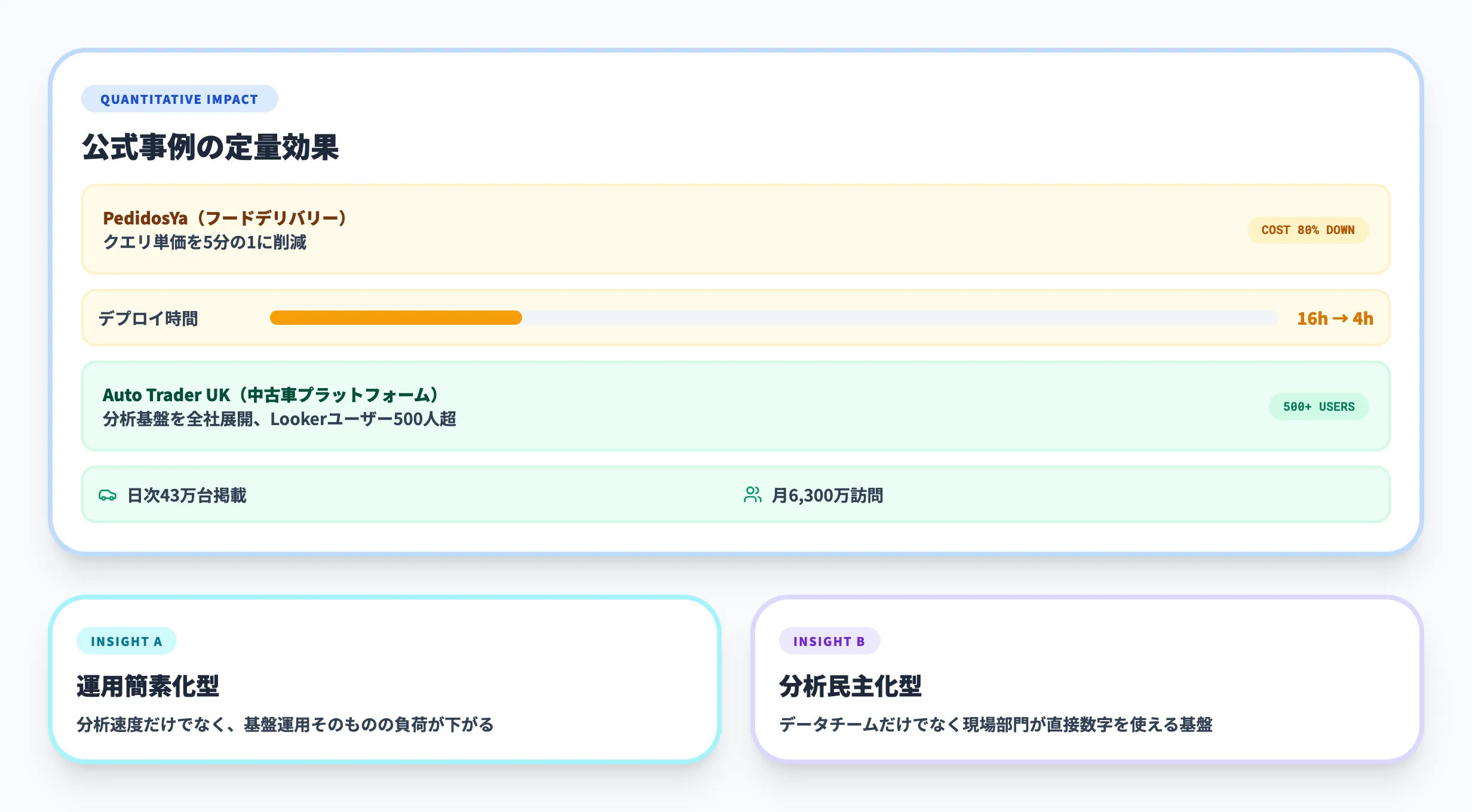
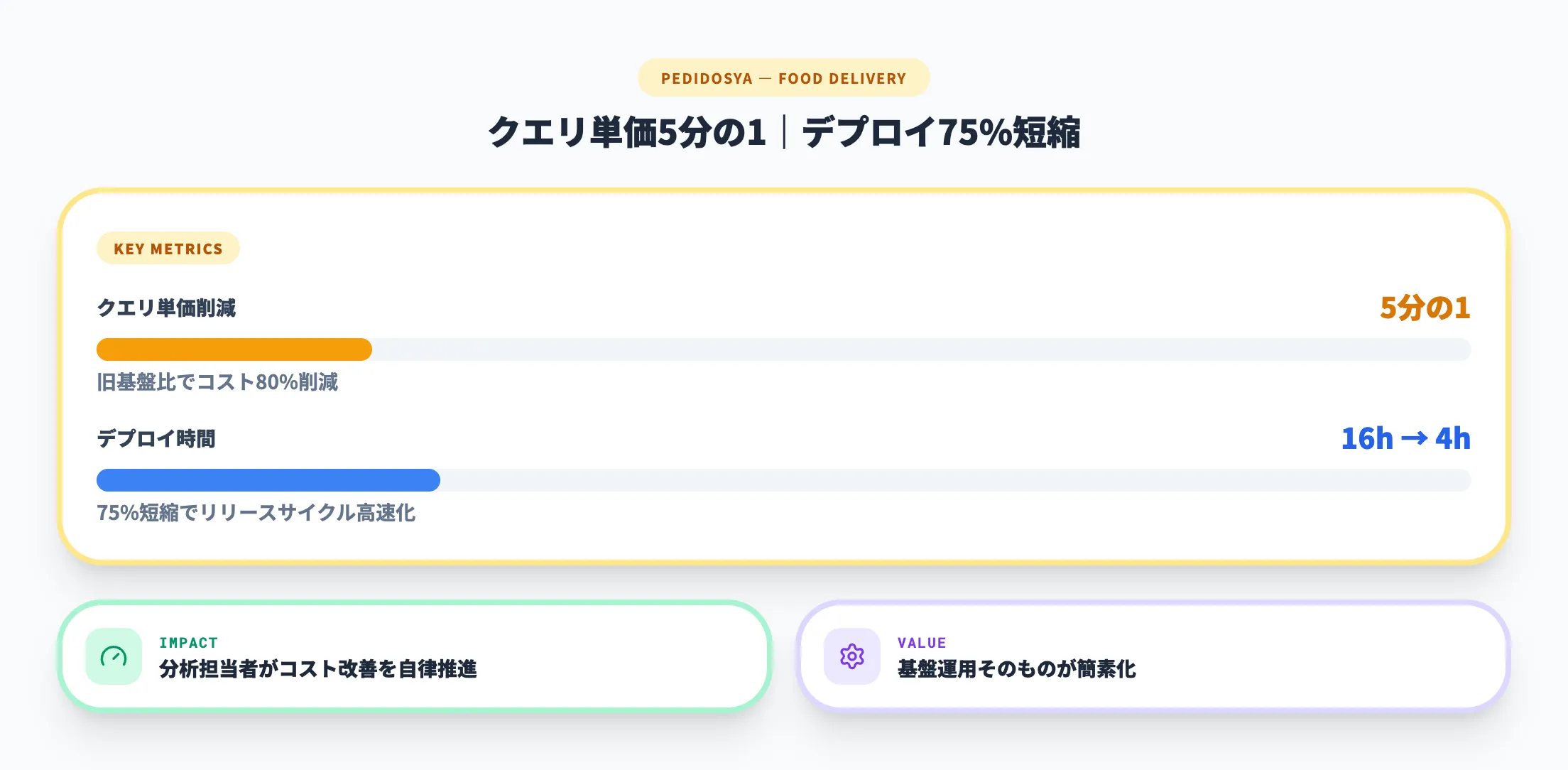
PedidosYa
Google Cloud BlogのPedidosYa事例では、BigQuery導入後に総クエリ単価を5分の1に削減できたと紹介されています。加えて、旧基盤で約16時間かかっていたデプロイ作業を約4時間に短縮した点も重要です。
この事例が示すのは、BigQueryの価値が単なる分析速度ではなく、データ基盤運用そのものの簡素化にあることです。分析担当者がクエリコストを見ながら改善できる体制まで含めて、BigQueryのメリットが出ています。
Auto Trader UK
Google Cloud BlogのAuto Trader UK事例では、同社が1日43万台超の車両掲載と月6,300万回超のクロスプラットフォーム訪問を支える中で、BigQueryをリアルタイム在庫・価格分析の中核に据えたと説明されています。さらに、Lookerのアクティブユーザーが500人を超え、社内の半数以上が分析基盤を活用する状態まで広がっています。
ここで重要なのは、BigQueryがデータチームだけの道具にとどまらず、現場部門が直接数字を使える基盤になっていることです。BigQueryは、分析の民主化が必要な企業ほど効果が出やすいサービスだと分かります。
自社でBigQueryを試すなら、いきなり全社共通基盤を作るより、まずは1つのダッシュボード要件に絞って「分析時間が何時間減るか」「レポート更新が何日早くなるか」を測る進め方が堅実です。その数字が見えれば、次の投資判断がしやすくなります。

BigQueryの分析基盤を業務実装までつなぐ

分析結果を業務導線へ載せる設計を整理
BigQueryでデータを整備しても、実際に成果を出すには業務システム連携や権限設計、実行管理まで含めた設計が必要です。AI Agent HubのLPで、分析基盤を業務実装へつなぐ全体像をご確認ください。
BigQueryと他のデータウェアハウスの違い
BigQueryは有力な選択肢ですが、唯一の正解ではありません。比較するときは「どのクラウドを主軸にしているか」「運用をどこまで自動化したいか」「AIやレイクハウスまで含めるか」で判断すると整理しやすくなります。
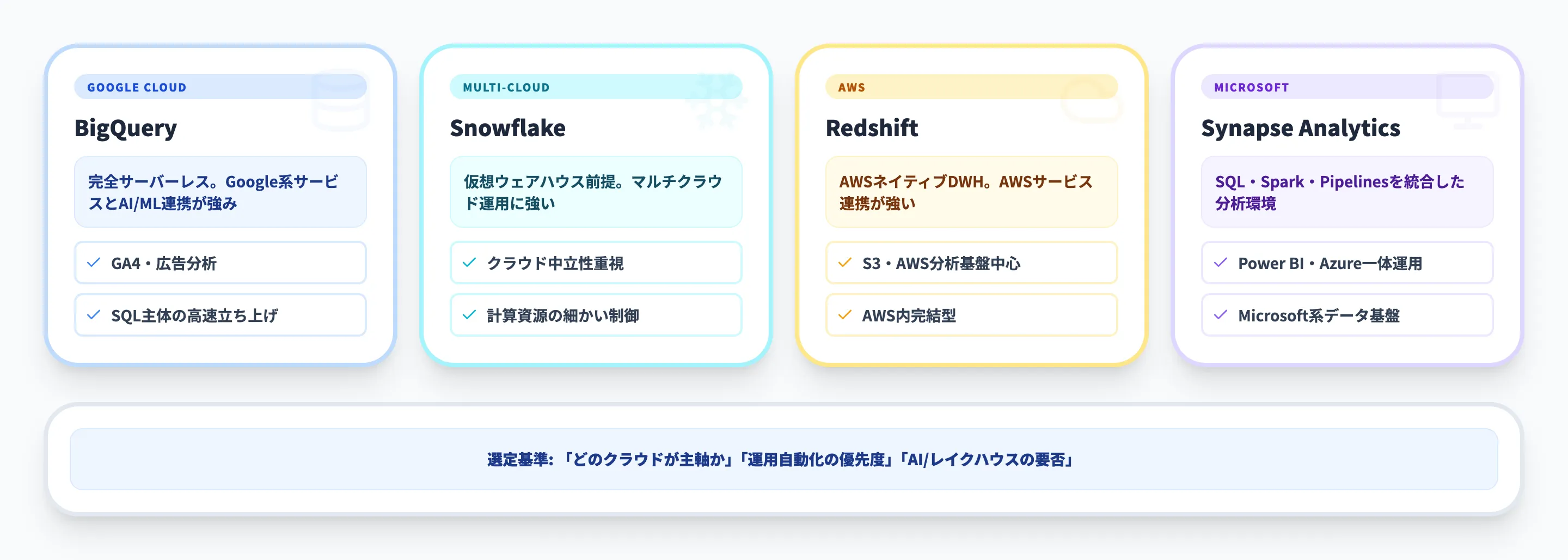
| サービス | 主な特徴 | 向いているケース |
|---|---|---|
| BigQuery | 完全サーバーレス、Google系サービスとの親和性、AI/ML連携が強い | Google Cloud中心、GA4や広告分析、SQL主体の高速立ち上げ |
| Snowflake Warehouses | 仮想ウェアハウス前提、マルチクラウド運用に強い | クラウド中立性を重視、計算資源を細かく制御したい |
| Amazon Redshift | AWSネイティブなクラウドDWH、AWSサービス連携が強い | S3やAWS分析基盤が中心、AWS内で完結したい |
| Azure Synapse Analytics | SQL、Spark、Pipelinesを統合した分析環境 | Microsoft系データ基盤、Power BIやAzureとの一体運用 |
この比較から見えてくるのは、BigQueryが「Google系データとSQL中心の分析を、できるだけ運用負荷を抑えて始めたい」組織に強いという点です。一方で、Microsoft寄りの既存資産が多いならAzure Synapse AnalyticsやMicrosoft Fabric Data Warehouse、オープンなレイクハウス設計を深く使い分けたいならMicrosoft Fabric Lakehouseのような選択肢も比較対象になります。
導入判断で詰まる論点
概念だけでは決めにくいので、判断を3つの論点に絞ると選びやすくなります。
- Google系データが中心かどうか
GA4、Google Ads、Looker Studio、Google Cloudを軸にしているなら、BigQueryを第一候補にするのが自然です。接続性の良さがそのまま導入スピードに効きます。
- 完全サーバーレスを重視するか
インフラ管理や性能チューニングより、分析の立ち上がりを優先したいならBigQueryが向いています。逆に、計算資源を明示的に切り分けて管理したいならSnowflakeの考え方が合うケースもあります。
- Microsoft基盤との一体運用が必要か
Power BIやAzure側の既存統制が強い企業では、SynapseやFabric系のほうが組織実装しやすいことがあります。ただし、Google系のマーケデータ分析が主目的ならBigQueryのほうが短期成果は出しやすいです。
この3点で優先順位を整理すると、「まずBigQueryで始めるべきか」「別基盤を比較対象に残すべきか」を実務ベースで判断しやすくなります。

BigQueryの料金体系
BigQueryの料金は「高いか安いか」ではなく、「どの課金軸で使うか」を理解できているかで印象が変わります。とくに、クエリ量が読めない段階と、定常的なダッシュボード運用の段階では、最適な料金モデルが変わります。
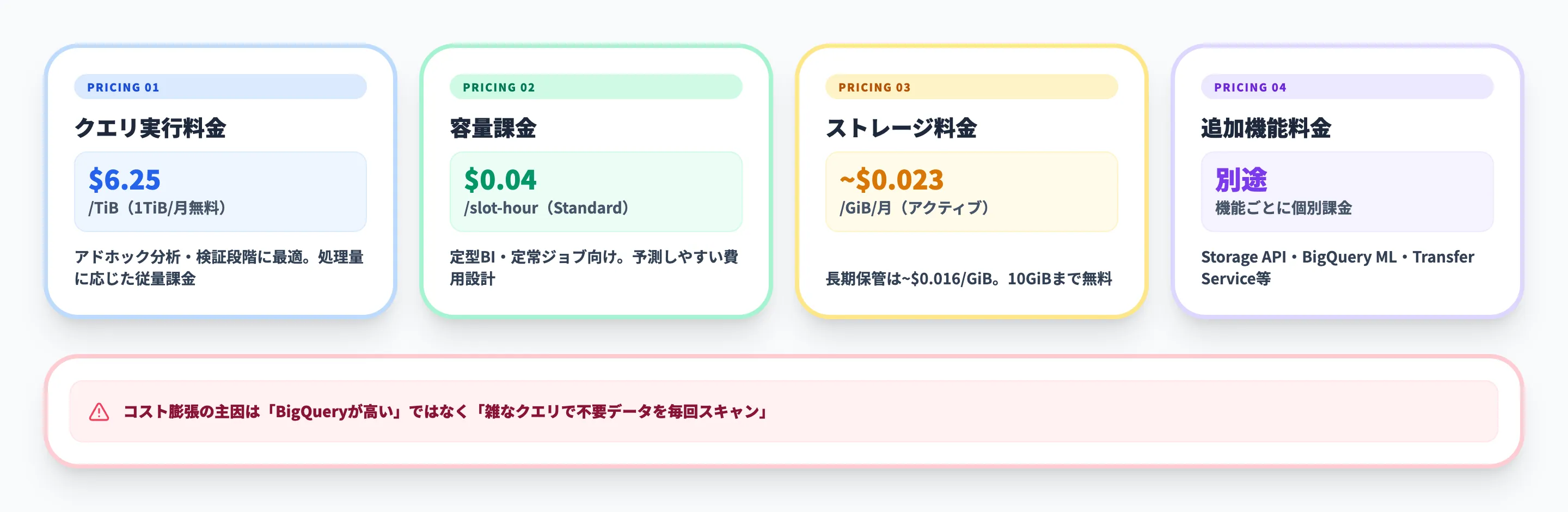
料金を構成する要素
料金を見るときは、次の4つに分けると混乱しにくいです。
- クエリ実行料金
オンデマンド課金では、クエリで処理したデータ量に応じて請求されます。分析用途の小規模検証や、利用量がまだ読めない段階に向きます。
- 容量課金
slot-hour単位でコンピュート能力を確保するモデルです。毎日決まった量のレポートやBIダッシュボードを回す運用で、予測しやすい費用設計に向きます。
- ストレージ料金
保存データ量に応じて課金されます。アクティブ保管と長期保管で単価が異なります。
- 追加機能の料金
Storage Read API、Storage Write API、BigQuery ML、Data Transfer Serviceの一部コネクタなど、機能ごとに追加料金が発生するものがあります。
そのため、BigQueryの料金を読むときは1つの単価だけを見るのではなく、「どの使い方でどの課金軸が立つのか」を先に分解することが重要です。
2026年4月時点の価格例
BigQuery pricingをもとに、代表的な価格を整理すると次のとおりです。2026年4月時点の東京リージョン(asia-northeast1)を含む価格ページ上の代表値で、ストレージの月換算値は公式の時間単価からの概算です。

| 項目 | 価格例 | 補足 |
|---|---|---|
| オンデマンドクエリ | 最初の1TiB/月は無料、その後は6.25ドル/TiB | アドホック分析向け |
| Standard Edition 容量課金 | 0.04ドル/slot-hour | 継続的なBIや定型処理向け |
| アクティブ論理ストレージ | 0.000031507ドル/GiB-hour | 月換算で約0.023ドル/GiB、最初の10GiBは無料 |
| 長期論理ストレージ | 0.000021918ドル/GiB-hour | 月換算で約0.016ドル/GiB、90日以上更新がないデータ向け |
この表から分かるように、BigQueryは「保存コストが極端に高いサービス」ではありません。むしろ、雑なクエリ運用で分析コストが読みにくくなることのほうが問題になりやすいです。
価格を見るときの注記
価格表を見る際は、同じBigQueryでもクエリ課金、容量課金、ストレージ課金、追加API課金が別々に存在する点を分けて理解する必要があります。特に、表中のストレージ月額はBigQuery pricingの時間単価を30日換算した概算値であり、実際の請求額は保存量、利用エディション、追加機能の有無によって変わります。
また、BigQueryは無料枠がある一方で、Storage Read APIやStreaming Writeなどを使うと別の課金軸が追加されます。価格は「単価」だけでなく、「どの運用パターンでその単価が発生するか」までセットで読むべきです。
料金をどう読むべきか
少人数で試行錯誤しながらクエリを回す段階では、まずオンデマンド課金で十分です。月次のクエリ量が安定し、毎朝・毎時の定型ジョブが増えてきたら、容量課金を検討する流れが一般的です。
また、データを長く持つほどストレージ単価は相対的に下がりますが、ストリーミングや読み出しAPI、外部転送が絡むと別のコスト軸が乗ります。料金表は「保存」と「分析」を分けて読むことが重要です。

BigQuery導入で注意したいポイント
BigQueryは導入しやすい一方で、運用設計を曖昧にすると「思ったより使いこなせない」状態にもなりやすいです。特に注意したい論点を整理します。

コストが読みにくくなるケース
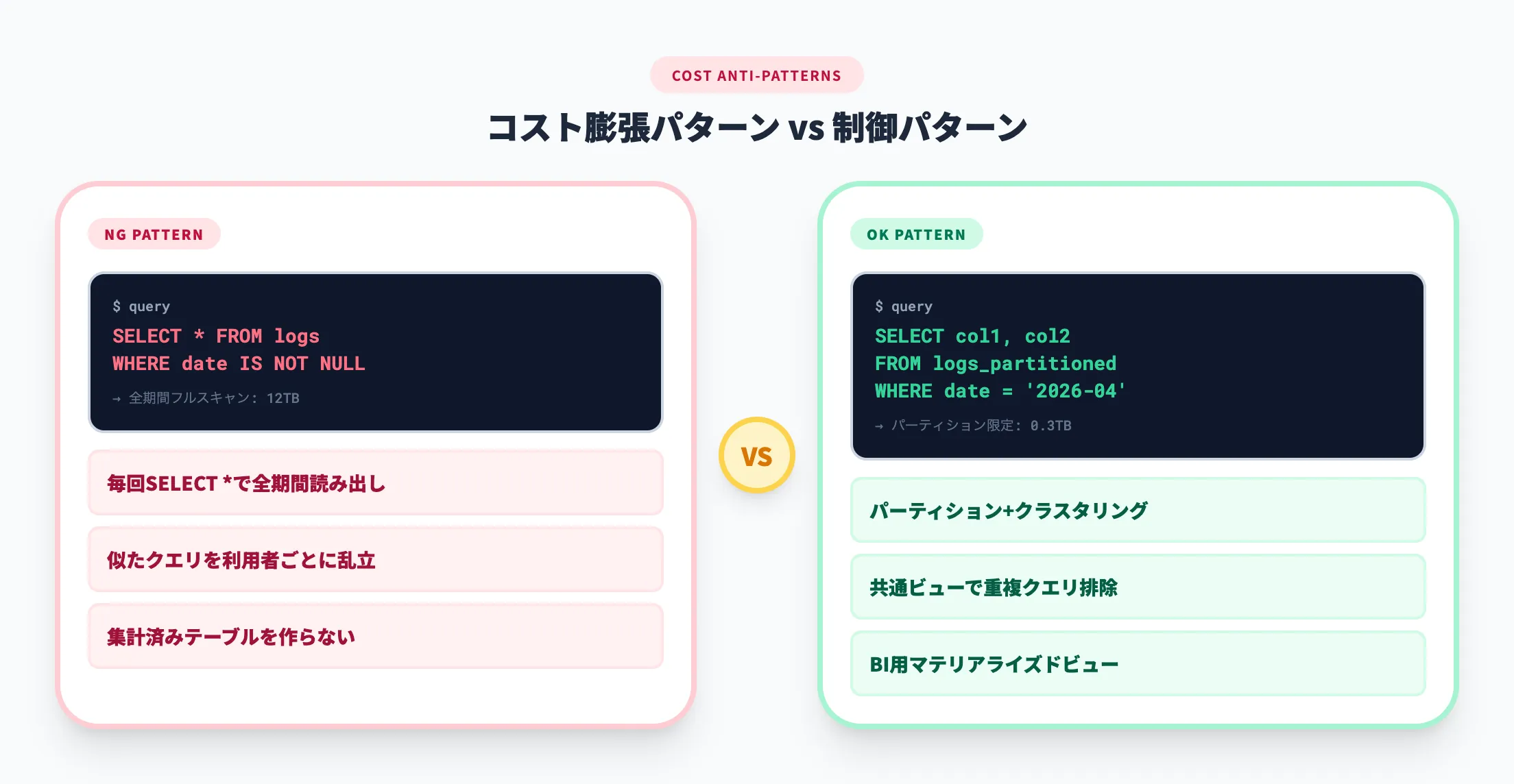
BigQuery pricingでも、パーティションやクラスタリングでスキャン量を減らすことが推奨されています。つまり、コストが膨らみやすいのは「BigQueryが高いから」ではなく、必要以上に大きなデータを毎回読んでいるからです。
具体的には、毎回SELECT *で全期間を読む、利用者ごとに似たクエリを乱立させる、ダッシュボード用の集計済みテーブルを作らない、といった運用が典型です。BigQueryは速く処理できる分、問題に気づくのが遅れやすい点に注意が必要です。
データ設計とガバナンス
Google Cloud公式のBigQueryページでは、Dataplex Universal Catalogを軸にしたガバナンス機能も前面に出ています。部門横断で使うなら、テーブルの意味、更新頻度、責任者、データ品質を最初から決めておかないと、結局「データはあるが信用されない」状態に陥ります。
特に、経営指標や顧客データを扱う場合は、分析しやすさと同じくらい権限設計が重要です。BigQueryは技術的に拡張しやすいぶん、ルールを曖昧にしたまま広げると、あとから運用負荷が増えます。

まず決めるべき最初の一歩
BigQuery導入で最も重要なのは、「まず何を良くするのか」を明確にすることです。おすすめは、1つの業務テーマに絞って、対象データ、更新頻度、KPI、利用者を先に決める進め方です。たとえば「広告と売上を週次でつなぐ」「GA4とCRMをつないで流入別の商談化率を見る」といった粒度なら、効果測定まで持っていきやすくなります。
情報を集めるだけで終わらせず、まずはSandboxか小規模本番で1本の分析ラインを作ってみることが、BigQuery導入では最短の一歩です。
BigQueryの分析基盤を業務アクションまでつなぐなら
BigQueryでデータを統合し、ダッシュボードや予測分析まで進めても、現場の業務を本当に変えるにはその先の設計が必要です。分析結果をどのシステムに返すか、誰がどの指標を起点にアクションするかまで整理しないと、活用はレポート閲覧で止まりやすくなります。
特に、自然言語クエリやML予測を使い始めると、データ基盤だけでなく、業務フローへの組み込み、権限、実行ログの扱いまで含めて設計する必要があります。
AI総合研究所のAI Agent Hub資料では、BigQueryのような既存データ基盤を前提に、業務システム連携、管理ダッシュボード、実行導線の整備をどう進めるかを整理しています。BigQuery活用を業務実装へ広げる判断材料としてご確認ください。
BigQueryの分析基盤を業務実装までつなぐ
分析結果を業務導線へ載せる設計を整理
BigQueryでデータを整備しても、実際に成果を出すには業務システム連携や権限設計、実行管理まで含めた設計が必要です。AI Agent HubのLPで、分析基盤を業務実装へつなぐ全体像をご確認ください。
まとめ
BigQueryは、Google Cloudが提供するサーバーレスのデータウェアハウスであり、2026年4月時点ではAI・機械学習・リアルタイム分析まで含むデータ/AIプラットフォームへ進化しています。
Google系サービスとの接続性、SQL中心での扱いやすさ、運用負荷の低さを重視するなら、BigQueryは非常に有力です。特に、GA4や広告、業務SaaSのデータが分散しており、部門横断で同じ数字を見たい企業には相性がよい選択肢です。
一方で、導入効果を出すには、最初から全社基盤を作ろうとせず、1つの分析テーマから始めることが重要です。BigQueryは「何でもできる」からこそ、最初の用途を絞った企業のほうが早く成果を出せます。







