この記事のポイント
 社内のデータ資産がSharePoint・BI・ERP・SaaSに散在し、誰がどこに何を持っているか不明なら、データカタログで横断可視化から始める価値がある
社内のデータ資産がSharePoint・BI・ERP・SaaSに散在し、誰がどこに何を持っているか不明なら、データカタログで横断可視化から始める価値がある- データカタログはオントロジー・ナレッジグラフ・セマンティックレイヤーと役割が異なり、代替ではなく補完関係。4つを整理することで重複投資を避けられる
- 2026年のData Intelligence潮流(Purview/Atlan/Alation)でAIがメタデータを自動キュレーションする段階に
- Purview/Alation/Atlan/Collibraなど主要8製品、既存クラウドと既存BIの組合せで絞れる
- Purviewは$0.0165/アセット/日の従量、Alation/Atlan/Collibra等専業は年契約・要見積、規模と体制で選定

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
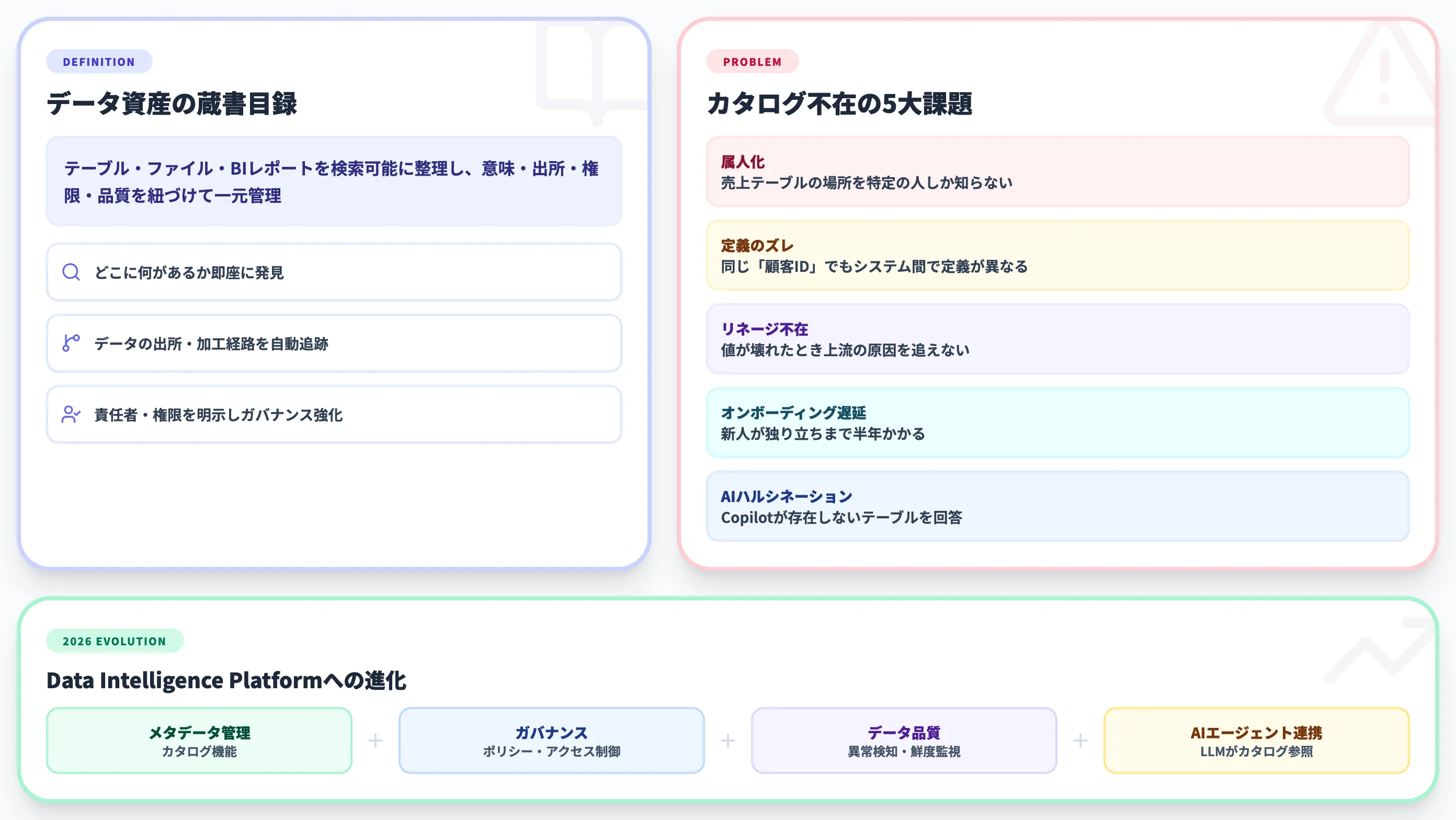
データカタログとは、社内に散在するテーブル・ファイル・BIレポートなどのデータ資産を、検索可能なかたちで整理し、意味・出所・権限・品質情報を紐づけて管理する仕組みです。
2026年は生成AIとAIエージェントが社内データに直接問いかける時代に入り、「LLMが正しいテーブルを見つけられるかどうか」がデータカタログの新しい評価軸になっています。
本記事では、データカタログの基本機能(データディクショナリ/リネージ/用語集/スチュワードシップ/検索)、オントロジー・ナレッジグラフ・セマンティックレイヤーとの違い、主要8製品比較、AIエージェントとの統合パターン、Microsoft Purview・Alation・Collibraなどの料金相場までを一気通貫で整理します。
データ基盤・ガバナンス・AI活用の境界領域で、「次の一手」を探している実務者のための導入ガイドです。
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
Data Intelligence Platformへの進化
データスチュワードシップ(Data Stewardship)
データカタログとオントロジー・ナレッジグラフ・セマンティックレイヤーの違い
なぜAIエージェント時代にデータカタログが再評価されているのか
Open Semantic Interchange(OSI)の始動(2025年9月)
Microsoft Purview Unified Catalog
パターンA:Purview Unified Catalogの検索×M365 Copilotへの統制
パターンB:Collibra AI Governance × Agent Framework
パターンC:Alation Agentic Platform / AI Agent SDK
データカタログとは?
データカタログ(Data Catalog)とは、企業内に散在するデータ資産を検索可能なかたちで整理し、意味・出所・権限・品質情報を紐づけて管理する仕組みです。図書館の蔵書目録に似た役割で、「どの棚に何の本があるか」を一元的に把握できるようにするのがデータカタログの基本です。
IBMの定義では、データカタログは「組織のデータ資産を詳細に記述した在庫一覧であり、ユーザーがすばやく必要なデータを見つけ、理解し、信頼できるようにするもの」とされています。テーブル・カラム・ビュー・ファイル・ダッシュボードなど、物理的なデータだけでなくBIレポートや機械学習モデルまで含めて管理するのが2026年時点の一般的な捉え方です。
データカタログが解決する典型的な問題
データカタログが解決しようとしているのは、次のような「データ資産のブラックボックス化問題」です。
- 分析したい売上データがどのテーブルにあるか誰も知らない(属人化)
- 同じ「顧客ID」でもシステムごとに定義が違う(セマンティックのズレ)
- ある列の値が最近おかしいが、どの上流処理で崩れたか追えない(リネージ不在)
- 新人アナリストが入社してから独り立ちするまで半年かかる(オンボーディング遅延)
- Copilotに「過去3年の売上推移は?」と聞くと、存在しないテーブル名を答える(ハルシネーション)
従来、これらは社内Wiki・Excelの手作りカタログ・アナリスト同士の口伝で補われていましたが、データ基盤の拡大とSaaS化によって追従できなくなったのが構造的な問題です。データカタログは、この「データ資産の一次インデックス」を自動収集・自動更新するための仕組みです。
Data Intelligence Platformへの進化
2026年の主要ベンダー(Microsoft/Alation/Atlan/Collibra/Databricks)は、従来の「カタログ」という用語を超えて、Data Intelligence Platformという概念を前面に出しはじめています。これは、メタデータ管理(カタログ機能)・データガバナンス・データ品質・アクセス制御・AIエージェント連携を1つの基盤で統合する考え方です。
SIerとしてデータ基盤の設計に関わる中で、2024〜2025年までは「カタログ」と「ガバナンス」と「品質」を別プロダクトで組み合わせるのが主流でしたが、2026年に入ってからは「AIが社内データに直接問う」前提で、これらを1つのプラットフォームに寄せる動きが明確です。

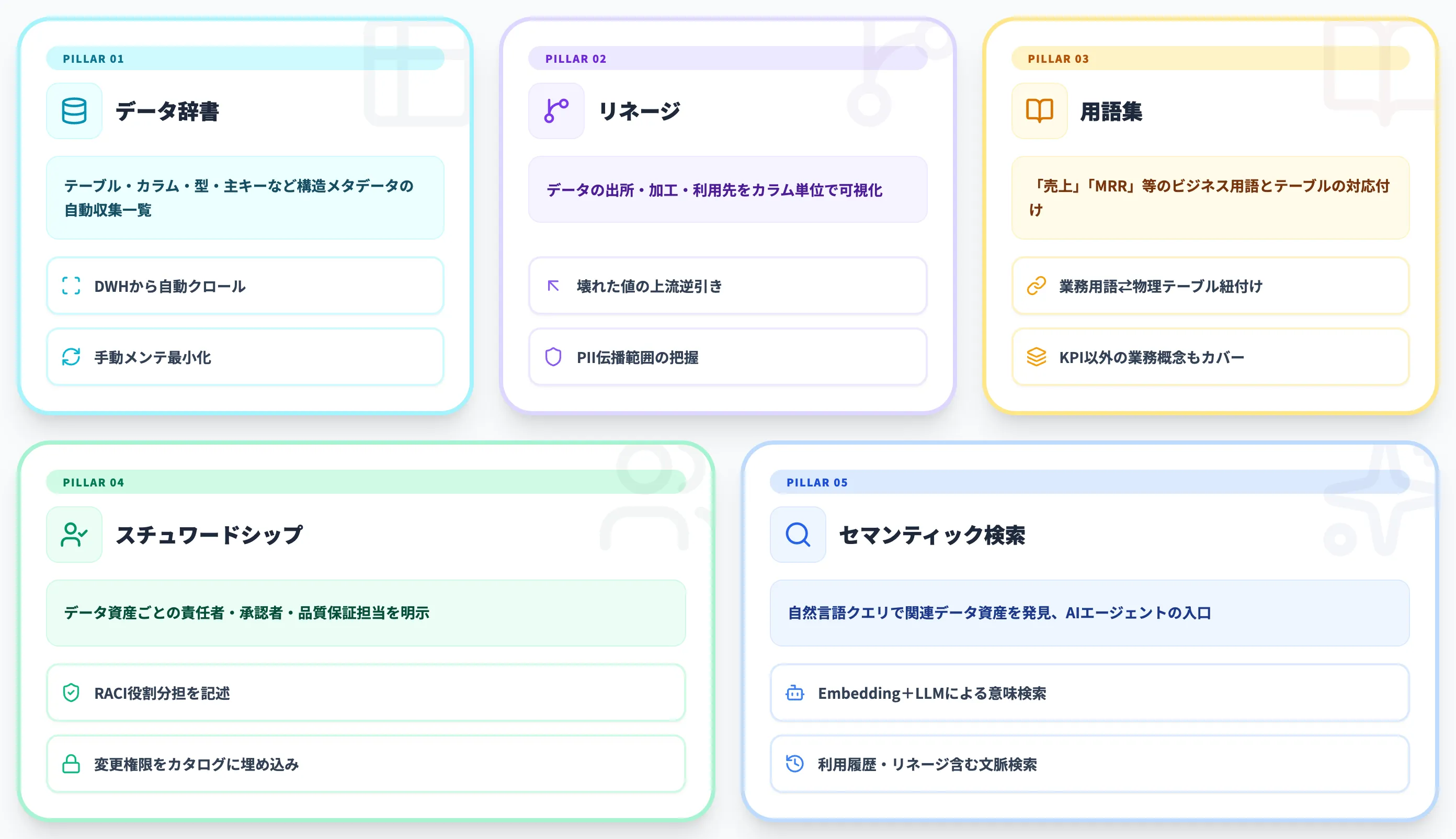
データカタログの基本機能
データカタログを構成する機能は、ベンダーによって呼び方が多少異なりますが、概念としては5つの柱に整理できます。
ここでは代表的な構成要素と、それぞれが解決する課題を整理します。
データディクショナリ(Data Dictionary)
データディクショナリは、テーブル・カラム・スキーマのメタデータ一覧です。テーブル名・カラム名・データ型・NULL可否・主キー・外部キー・作成日・最終更新日などの「構造メタデータ」を自動収集して一覧化します。
PostgreSQL・Snowflake・BigQueryといったDWHから自動クロールする機能が標準化しており、手動メンテナンスは最小限で済むのが2026年時点の標準です。
データリネージ(Data Lineage)
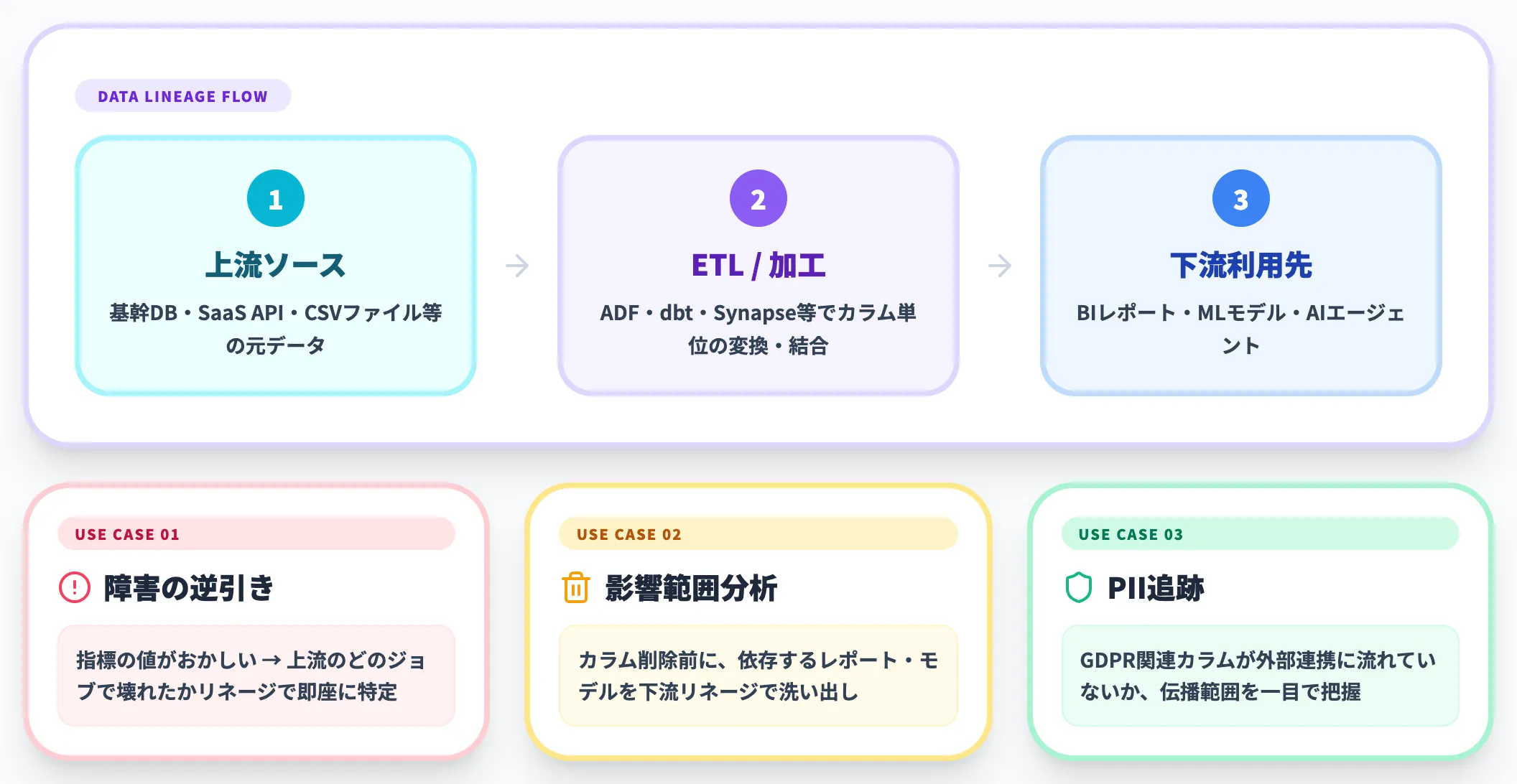
データリネージは、あるデータが「どこから来て、どこで加工され、どこに使われているか」の流れを可視化する機能です。ETLジョブ・SQLクエリ・BIレポートをパースして、カラム単位の依存関係をグラフで表示します。
実務的には、次のような場面で威力を発揮します。
- ある指標の値がおかしい → 上流のどのジョブで壊れたかをリネージで逆引き
- カラムを削除したい → そのカラムに依存するレポート・モデルを下流リネージで洗い出し
- GDPR/個人情報関連カラムが外部連携していないか → 下流リネージでPIIの伝播範囲を把握
Microsoft Learnによると、Microsoft Purview Unified Catalogは、Azure Data Factory・Synapse・Fabric・Power BIと連携してカラム単位のリネージを自動生成します。
ビジネス用語集(Business Glossary)
ビジネス用語集は、「売上」「MRR」「解約率」「アクティブユーザー」などのビジネス用語の定義と、実際のテーブル・カラムの対応付けを行う機能です。データディクショナリが「技術メタデータ」なら、ビジネス用語集は「業務メタデータ」にあたります。
セマンティックレイヤーと役割が近い部分ですが、データカタログのビジネス用語集はより広く「KPI以外の業務用語(部門/地域/セグメント等の意味)」までカバーするのが一般的です。
データスチュワードシップ(Data Stewardship)
データスチュワードシップは、各データ資産の責任者・承認者・品質保証担当を明示する機能です。テーブル単位で「このデータはマーケティング部のAさんが管轄」「このカラムは人事部のBさんしか変更できない」といった責任分担をカタログに埋め込みます。
2026年時点ではRACI(Responsible/Accountable/Consulted/Informed)の役割分担を記述できる製品も増えており、ガバナンス視点での重要度が高まっています。
セマンティック検索・ディスカバリ
セマンティック検索は、「今月の北米売上が入っているテーブルは?」のような自然言語クエリから、関連するデータ資産を探し出す機能です。従来のキーワード検索から、埋め込みベクトル(Embedding)+LLMによる意味検索へと進化しています。
Alation Agentic Data Intelligence Platformは、カタログ内のメタデータ・ビジネス用語・利用履歴を統合した上で、自然言語検索・推薦を返す設計になっています。2026年のベンダー各社は、このNL検索を「AIエージェントのエントリポイント」として位置づけつつあります。
データカタログとオントロジー・ナレッジグラフ・セマンティックレイヤーの違い
データカタログを初めて導入する際に、オントロジー/ナレッジグラフ/セマンティックレイヤーとの違いが分からないという質問を現場で頻繁に受けます。2026年時点では、この4つが混在して語られるため、まず「それぞれの守備範囲」を整理しておきます。

| 概念 | 主な目的 | 典型的な成果物 | 主な利用者 |
|---|---|---|---|
| データカタログ | データ資産の在庫管理・検索 | テーブル一覧/リネージ/用語集/責任者 | データエンジニア/アナリスト/ガバナンス担当 |
| オントロジー | 業務概念・関係の形式定義 | クラス階層/プロパティ/公理 | アーキテクト/ドメイン専門家 |
| ナレッジグラフ | エンティティと関係のグラフ実装 | ノード/エッジ/トリプル | AIエンジニア/業務アプリ開発者 |
| セマンティックレイヤー | メトリクス・ディメンションの単一定義 | MetricFlow YAML/Cube定義/LookML | BIエンジニア/アナリスト |
この表から読み取れるのは、データカタログが「何というデータがどこにあるか」のインデックスなのに対し、オントロジーは「業務概念をどう定義するか」のモデル、ナレッジグラフは「エンティティ同士の関係をどう実装するか」の物理層、セマンティックレイヤーは「数値指標をどう統一計算するか」の計算層という位置づけになっている点です。
4概念の関係性

4つは代替関係ではなく補完関係です。多くのエンタープライズでは、次のような組み合わせで運用されます。
- オントロジーで業務概念を設計し
- ナレッジグラフに物理的なエンティティ関係を実装し
- セマンティックレイヤーでKPIを単一定義し
- データカタログでデータ資産・責任者・リネージを横断管理する
SIerとして意味層とガバナンスを同時に設計する場面では、「オントロジーとナレッジグラフでモデル側を固め、セマンティックレイヤーで計算を固め、データカタログで在庫と出典を固める」という四層構成で議論することが多いです。
データカタログとデータガバナンスの違い
もう1つ混同されやすいのが「データガバナンス」という用語です。データガバナンスはポリシー・プロセス・組織体制を含む概念で、データカタログはその技術基盤の1つにあたります。
2026年のMicrosoft Purviewは、従来「Purview Data Catalog」と「Purview Data Governance」が別機能だったものを、Purview Unified Catalogとして統合しました。これにより、カタログ機能とガバナンス機能(ポリシー/アクセス制御/データマップ)を1つの製品で扱えるようになっています。
なぜAIエージェント時代にデータカタログが再評価されているのか
データカタログは2000年代から存在する概念ですが、2025〜2026年にかけて再評価されている理由は、生成AIとAIエージェントがデータに直接問う時代になったことに尽きます。
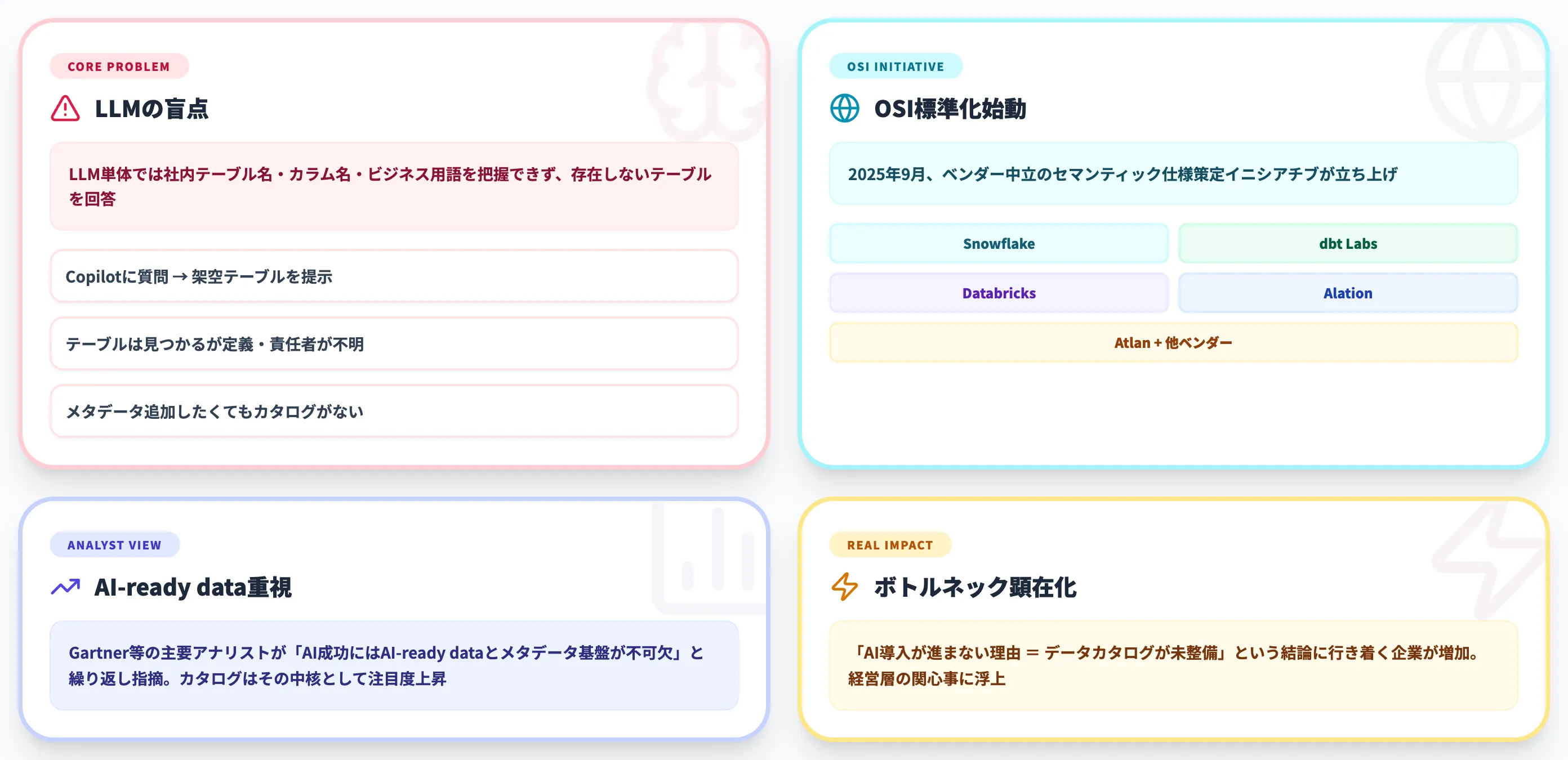
LLMは「存在するテーブル」を知らない
Copilot・ChatGPT・Claudeなどの生成AIが社内データに答える際、最大の障害は「どこに何のデータがあるか」を知らないことです。LLM単体では、社内システムに存在するテーブル名・カラム名・ビジネス用語を把握しておらず、存在しないテーブルを答えたり、別のテーブルを誤って参照したりします。
Microsoft Fabric Data Agentのように、AIエージェントが社内データに答える製品はすべて、背後にデータカタログ相当の「メタデータ検索レイヤー」を必要とします。つまり、カタログはAIエージェントの「世界地図」にあたる位置づけに変化しています。
Open Semantic Interchange(OSI)の始動(2025年9月)
2025年9月、Snowflake・dbt Labs・Databricks・Alation・Atlanなど主要ベンダーが参加するOpen Semantic Interchange(OSI)というベンダー中立のセマンティック仕様策定イニシアチブが立ち上がりました。データカタログ間・セマンティックレイヤー間でのメタデータ可搬性を目指し、ワーキンググループによる仕様策定が進行中です。
これが意味するのは、ベンダーロックインを前提とせずに、AIエージェントが複数のカタログ・レイヤーを横断して意味メタデータを扱える方向に業界が動き始めたことです。今後OSI準拠の連携実装が広がれば、カタログ投資の評価軸も変わっていく可能性があります。
アナリスト各社の見立て
主要アナリストファームは、AIの成功にはAI-ready dataとメタデータ基盤の整備が不可欠であることを指摘しています。Gartnerも公開資料で、AI-ready dataの不足がAIプロジェクトのリスクになると繰り返し言及しており、データカタログはそのメタデータ基盤を支える中核として注目度が高まっています。
2026年の実務インパクト
SIerとして生成AIの業務適用を支援する場面でも、データカタログの整備が追いついていない企業では、次のような現象が頻発します。
- AIチャットに業務質問をすると「関連テーブルが見つかりません」と返す
- テーブルは見つかるが、そのテーブルの定義・責任者が不明で回答の信頼性を担保できない
- 精度改善のためにメタデータを追加しようとすると、そもそもカタログがなく着手できない
結果として、「AI導入が進まない理由=データカタログが未整備」という結論に行き着くケースが増えており、AI活用のボトルネックとしてのデータカタログが、経営層の関心事になりはじめています。
データカタログのエンタープライズ活用シナリオ
データカタログは単独で導入されるよりも、他の課題(AI/ガバナンス/データ民主化)と組み合わせて導入されるケースが大半です。2026年時点で投資対効果が見えやすい6つのシナリオを整理します。
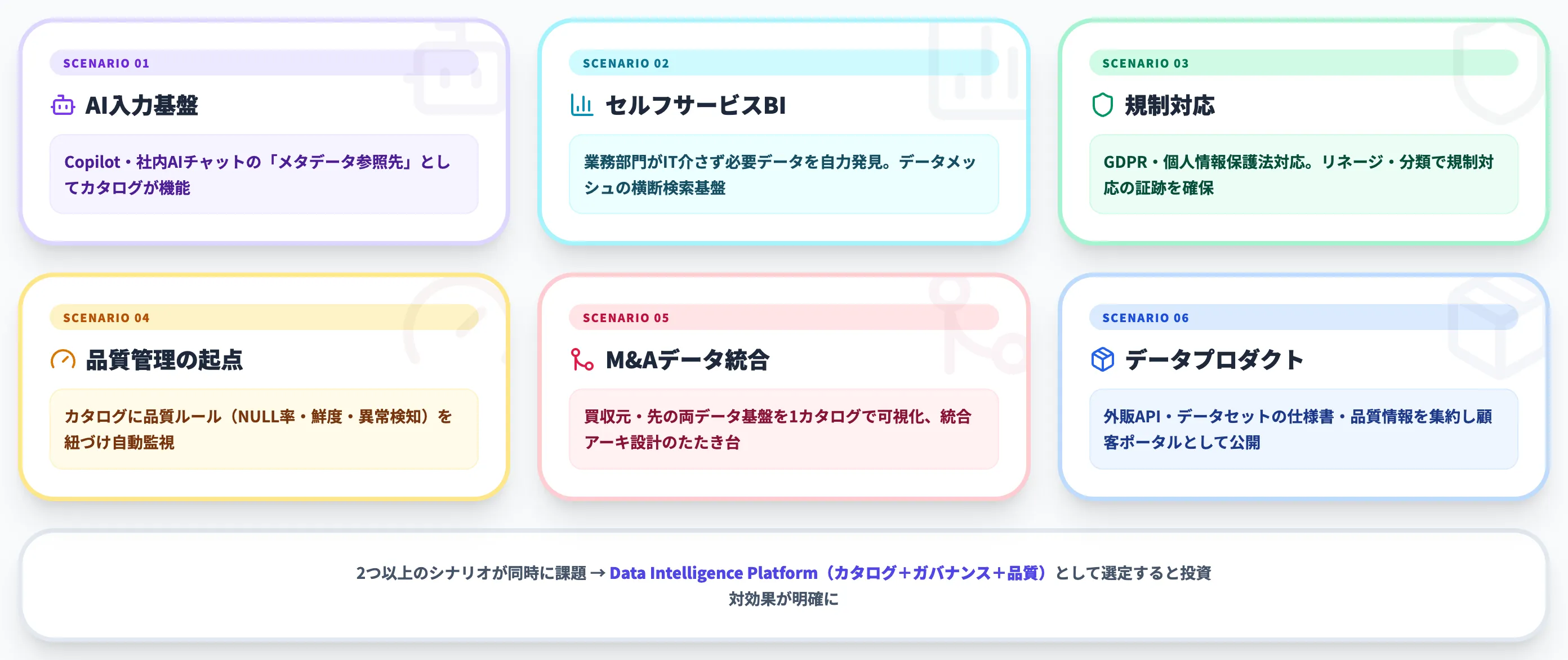
シナリオ1:AIエージェントの入力基盤
Copilot for Fabric・Microsoft 365 Copilot・社内AIチャットなどが、社内データに答える際の「メタデータ参照先」としてデータカタログを使います。AIエージェントはまずカタログで関連テーブルを特定し、そのテーブルのリネージ・品質・責任者を確認した上でクエリを実行します。
シナリオ2:セルフサービスBI・データメッシュ
データアナリストや業務部門が、IT部門を介さずに必要なデータを自分で見つけるためのインデックスとして使います。データメッシュの「プロダクトとしてのデータ」という考え方と組み合わせると、ドメインごとのデータプロダクトを横断検索できる基盤として機能します。
シナリオ3:コンプライアンス・規制対応
GDPR・個人情報保護法・業界規制などで、「どのデータに個人情報が含まれているか」「外部委託先にどのカラムを渡しているか」を追跡する必要があります。データカタログのリネージ・分類機能は、この規制対応の証跡として使えます。
シナリオ4:データ品質管理の起点
データカタログは「何が存在するか」を管理しますが、近年は**データ品質監視(Data Observability)**と統合する製品が増えています。Atlan・Monte Carlo・Databricksなどは、カタログに紐づけた品質ルール(NULL率・鮮度・異常検知)を自動実行し、問題時にカタログ上で警告を表示します。
シナリオ5:M&A・事業統合時のデータ統合
M&Aや事業統合時に、双方のデータ資産を把握するためにカタログを導入するケースが増えています。買収元・買収先のデータ基盤を1つのカタログで可視化し、統合後のデータアーキテクチャ設計のたたき台として使います。
シナリオ6:データプロダクト・外販API基盤
自社データを外販する企業では、外販するデータセットの仕様書・リネージ・品質情報をデータカタログに集約し、顧客向けのポータルとして公開するケースもあります。データプロダクト管理のフロントエンドとしての活用です。
SIerとしてデータ基盤の再設計に関わる中で、これら6シナリオのうち2つ以上が同時に課題になっている企業では、データカタログ単品の導入ではなく、Data Intelligence Platform(カタログ+ガバナンス+品質)として選定するほうが投資対効果が見えやすいと感じる場面が多いです。

主要データカタログ製品比較
2026年4月時点で、エンタープライズ向けのデータカタログは主に以下の製品群から選ばれます。
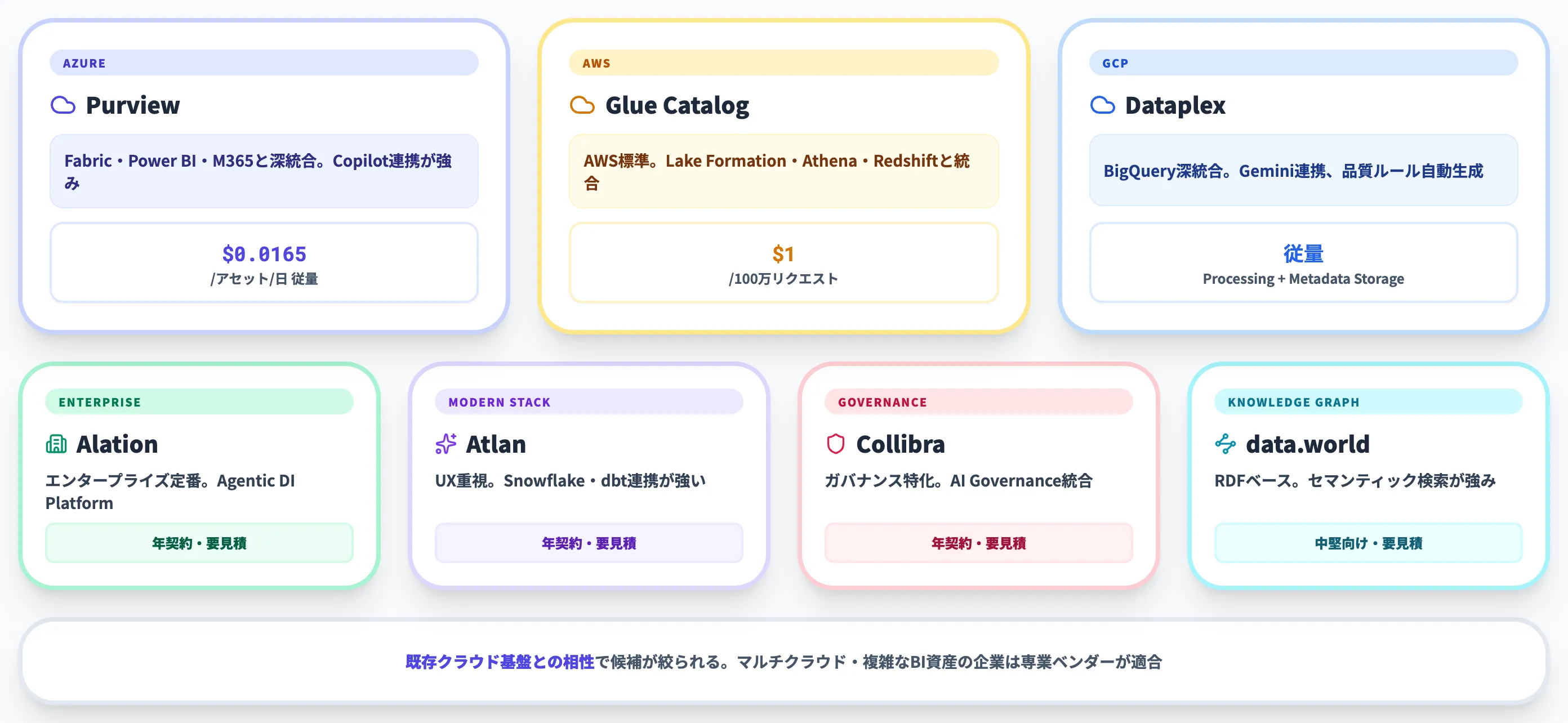
| 製品 | 提供形態 | 強み | 価格帯 |
|---|---|---|---|
| Microsoft Purview Unified Catalog | SaaS(Azure) | Fabric/Power BI/M365と深く統合、Copilot連携 | $0.0165/アセット/日 従量 |
| Alation | SaaS/オンプレ | エンタープライズ定番、Agentic Data Intelligence Platform | 年契約、要見積 |
| Atlan | SaaS | モダンデータスタック最適、UX重視 | 年契約、要見積 |
| Collibra | SaaS | データガバナンス特化、AI Governance機能 | 年契約、要見積 |
| Informatica CLAIRE | SaaS/オンプレ | AI駆動(CLAIRE GPT)、IDMC統合 | 大企業向け、要見積 |
| AWS Glue Data Catalog | SaaS(AWS) | AWS標準、Lake Formation連携 | $1/100万リクエスト |
| Google Dataplex | SaaS(GCP) | BigQuery深統合、Catalog+Quality統合 | 従量(Processing・Metadata Storage) |
| data.world | SaaS | ナレッジグラフベース、セマンティック検索 | 中堅企業向け、要見積 |
この比較から分かるのは、既存のクラウド基盤との相性で有力候補が大きく絞られる点です。Azure中心ならPurview Unified Catalog、AWS中心ならGlue Data Catalog+外部カタログ、GCP中心ならDataplexというのが自然な選択になります。一方、マルチクラウド・既存BI資産が複雑な企業は、Alation/Atlan/Collibraなどクラウド非依存の専業ベンダーが適します。
Microsoft Purview Unified Catalog
Microsoft Purview Unified Catalogは、従来のPurview Data CatalogとPurview Data Governanceを統合した新世代製品です。2024年後半に名称刷新が告知され、2025年1月から地域別にGA・課金開始が順次進行しています。Fabric・Power BI・Azure Data Factoryに深く組み込まれており、Fabric Data Agentなどからカタログメタデータを参照する設計になっています。
Azure中心の企業では「追加でカタログ製品を買わなくてもよい」ケースが多く、2026年現在、AI Agent向けのメタデータ基盤として採用が増えています。
Alation
Alationは、エンタープライズ定番のデータカタログ製品です。2025年3月にAlation Agentic PlatformとAI Agent SDKを発表し、カタログ内のメタデータを自然言語で問い合わせるエージェント機能を提供しています。現行はAgentic Data Intelligence Platformとして位置づけられ、金融・製薬・大企業での導入実績が厚いのが特徴です。
Atlan
Atlanは、2018年創業の比較的新しいカタログベンダーで、モダンデータスタック(Snowflake・dbt・Fireboltなど)との連携のUXに強みがあります。2023年に初のAIドキュメンテーション・エージェントを投入しており、現在はAtlan Context Agentsとして、カタログとコラボレーションツール(Slack・Teams)を接続する設計を打ち出しています。
Collibra
Collibraは、データガバナンス特化のベンダーで、規制業種(金融・医療)での採用が多い製品です。2026年はCollibra AI GovernanceというAIモデル・エージェントのガバナンス機能を強化しており、AIカタログとデータカタログの統合アプローチを示しています。
Informatica CLAIRE
Informatica IDMCは、データカタログ・データ品質・マスタデータ管理を統合したプラットフォームで、CLAIRE GPTという生成AI機能を搭載しています。大企業向けで、既存のInformatica基盤と親和性が高いのが特徴です。
AWS Glue Data Catalog
AWS Glue Data Catalogは、AWS標準のメタデータストアで、単体というよりはAWSデータ基盤の一部として使われます。Lake Formation・Athena・Redshift Spectrumと統合されるため、AWS中心の企業では追加コスト最小で導入できます。ただし、ビジネス用語集・スチュワードシップ機能は専業カタログに比べて限定的です。
Google Dataplex
Google Dataplexは、BigQueryと深く統合されたカタログ+データ品質プラットフォームです。
2024年以降はGemini統合でNL検索・データ品質ルール生成が強化され、GCP中心の企業の第一候補になっています。料金はDataplex独自の従量課金(Processing・Metadata Storage)で、Gemini連携機能はBigQuery側やCode Assist側で別途課金される点に注意が必要です。
data.world
data.worldは、ナレッジグラフをバックボーンとして設計されたカタログで、RDFベースのセマンティック検索が強みです。メタデータを意味ネットワークとして扱いたい組織(研究機関・医療・メディア)で採用されています。
AIによるデータカタログ機能強化パターン
2026年のデータカタログ製品は、生成AIを前提に再設計されているのが大きな特徴です。AIが関与する領域を4つのパターンに整理します。

パターン1:AIによるメタデータ自動キュレーション
手動で書いていたテーブル説明・カラム説明・用語集を、LLMがサンプルデータ・スキーマ・SQLクエリから自動生成します。Alation Agentic Data Intelligence Platform・Atlan Context Agents・Informatica CLAIRE GPTなど、主要ベンダーがほぼ全て実装しています。
結果として、カタログの「記述カバー率」が大幅に改善するケースが各ベンダーから報告されています。記述の品質は人間が最終確認する前提ですが、初期投入コストが大幅に下がったのが2026年の実務的変化です。
パターン2:タグ・分類の自動付与
個人情報・機密情報・PCI-DSS対象カラムなどの分類を、LLMがカラム名・サンプルデータから推論して付与します。Microsoft Purviewは200以上の組み込み分類子を持ち、カスタム分類の追加にも対応しています。
パターン3:自然言語検索・推薦
「今月の北米売上が入ったテーブルは?」のような自然言語クエリに、関連するデータ資産を返します。2026年のトレンドは、単なるキーワード検索から利用履歴・リネージ・組織情報を含めた文脈検索への進化で、Alation・Atlan・data.worldが先行しています。
パターン4:データ品質異常の自然言語説明
NULL率急増・鮮度低下などの品質異常を、LLMが「上流のETLジョブXが失敗したため、テーブルYのZ列が欠損しています」のような形で自然言語で説明します。Monte Carlo・Atlan・Databricksなどで実装が進んでいます。
AIエージェント×データカタログの統合パターン
2026年はデータカタログがAIエージェントの知識基盤として位置づけられる年です。主要ベンダーの統合パターンを3つ整理します。
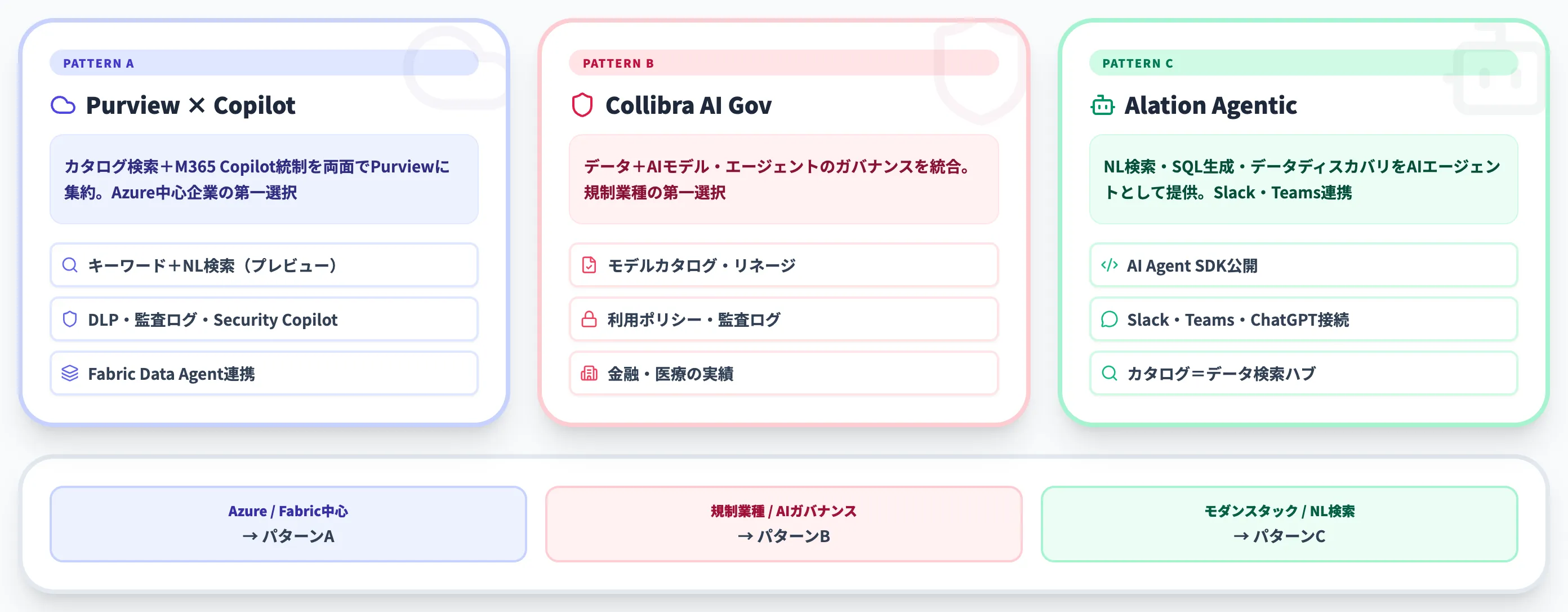
パターンA:Purview Unified Catalogの検索×M365 Copilotへの統制

Microsoft Purview Unified Catalogでは、データ資産の検索はキーワード・フィルタベースで提供されています。一方、データ製品(Data Product)レベルでは自然言語検索のプレビュー機能が導入されつつあります。カタログ利用者がデータ資産を探す際は、登録アセットとリネージから関連するデータ資産を返す設計です。
一方、Microsoft 365 Copilotが社内データに回答する局面では、Security Copilot in Purviewを含むPurviewのセキュリティ・コンプライアンス機能によって、機密情報の保護・データ損失防止(DLP)・監査ログを統制する構成になります。Azure/Microsoft 365中心の企業では、カタログ側の検索(データ製品レベルでは自然言語検索プレビューも利用可能)と、M365 Copilot側の統制を両面でPurviewに寄せられる点が2026年時点の実務的な強みです。
パターンB:Collibra AI Governance × Agent Framework
Collibra AI Governanceは、データカタログに加えてAIモデル・AIエージェントのガバナンス(モデルカタログ・モデルリネージ・利用ポリシー)を統合しています。金融・医療など規制業種では、AIエージェントが参照したデータと、エージェントの実行ログの両方を監査する必要があり、Collibraはこの両面をカバーします。
パターンC:Alation Agentic Platform / AI Agent SDK
Alation Agentic PlatformとAI Agent SDKは、カタログ内のメタデータ・ビジネス用語・利用履歴を統合した上で、自然言語検索・SQL生成・データディスカバリをAIエージェントとして提供します。Slack・Teams・ChatGPTなどの外部インタフェースとの連携経路が想定されており、カタログをAIエージェントの「データ検索ハブ」として位置づける設計です。
3パターンの使い分け
どのパターンを選ぶかは、既存の基盤と業務要件で決まります。
- Microsoft中心/Fabric活用: パターンA(Purview Unified Catalogの検索・データ製品NL検索プレビュー+M365 Copilotの統制)
- 規制業種/AIガバナンス重視: パターンB(Collibra AI Governance)
- モダンデータスタック中心/NL検索重視: パターンC(Alation Agentic Platform / AI Agent SDK)
SIerとしてAIエージェントの業務実装を支援する場面では、「AIエージェントの入口」をどこに置くかの議論から入ると、カタログ選定がスムーズに進むことが多いです。TeamsならPurview、SlackならAlation/Atlan、専用ポータルならCollibra、というように、エージェントのUX起点で逆算すると結論が出やすくなります。
データカタログ構築のステップと失敗パターン
データカタログは、製品を入れれば動くものではありません。メタデータ収集・用語集設計・責任者割当・運用ルールの4つを段階的に積み上げる必要があります。
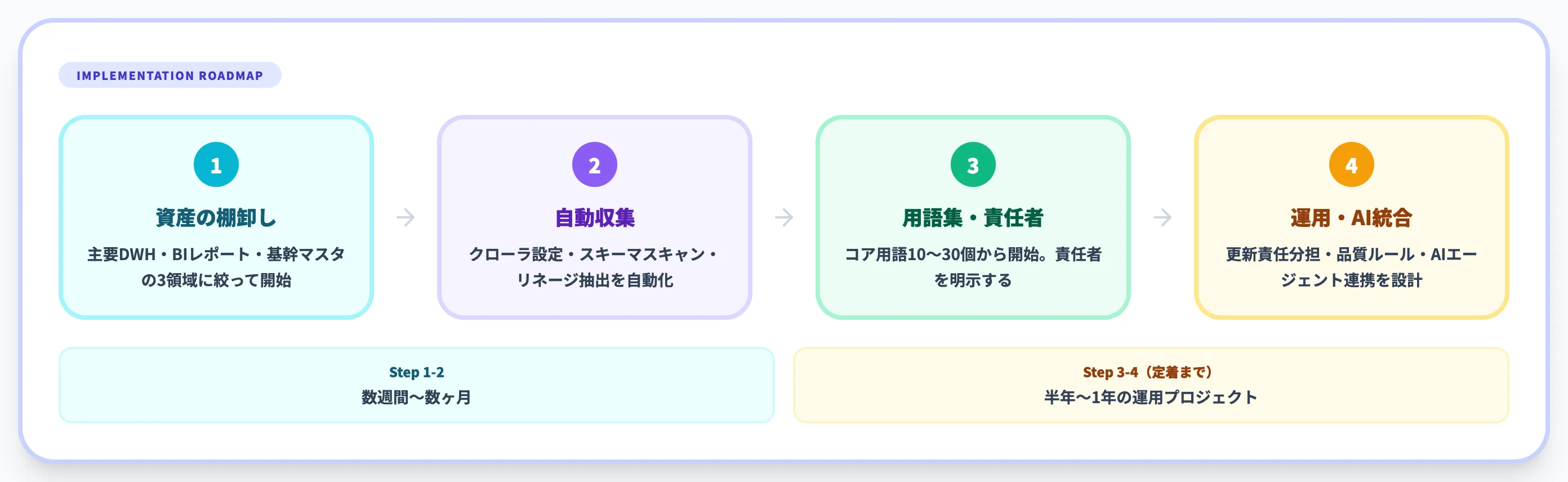
構築の4ステップ
カタログ導入の基本フローは次のように整理できます。
- 対象資産の棚卸し: 最初からすべてを対象にせず、まず重要DWH・主要BIレポート・基幹マスタの3領域に絞る
- メタデータの自動収集: クローラ設定・スキーマスキャン・リネージ抽出を自動化する
- ビジネス用語集・スチュワードシップの整備: 最初は10〜30個のコア用語から。責任者を明示する
- 運用ルールとAI統合: カタログ更新の責任分担、品質ルール、AIエージェント連携を設計する
1〜2だけなら数週間〜数ヶ月で立ち上がりますが、3〜4が定着するまでは半年〜1年単位の運用プロジェクトとして捉えるのが現実的です。
導入判断で詰まる論点
カタログの導入を検討する際、実務で頻繁にぶつかる論点が4つあります。
- どこまでを対象にするか: 全社一気に棚卸しするか、事業部単位から始めるか
- ビジネス用語の粒度: 営業の「受注」と経理の「売上計上」を1つの用語でまとめるか分けるか
- スチュワードの権限範囲: カタログ更新権限を誰に持たせるか、承認フローをどう設計するか
- 既存ツールとの住み分け: 既存のBIメタデータ・既存のガバナンスツールとどう併存させるか
これらは、製品を入れてから議論するより、RFP段階で決めておくほうが導入スピードが上がります。
よくある失敗パターン3つ

SIerとしてデータカタログ導入を支援する中で、次の3つの失敗パターンをよく見ます。
- 全社一気に棚卸ししようとして半年以上動かない: 対象を絞らないまま「とりあえずクロール」すると、数十万アセットが入り、意味のある検索ができなくなる。最初は主要DWH+主要BIの2領域に絞るべき
- 技術メタデータだけ充実してビジネス用語集が空になる: クロールで自動取得できるデータディクショナリは充実するが、手動整備が必要なビジネス用語集・責任者が空のまま放置される。用語集は「使う部門が育てる」前提の運用設計が必要
- AIエージェント連携を後付けしようとしてベンダーロックインに気づく: 構築後にAIエージェントを繋ごうとしたら、使いたいエージェント基盤と選定したカタログが連携できず、移行コストが発生する。最初からAIエージェント統合パターンを前提に選定すべき

データカタログの料金と選び方
データカタログの料金体系は、**従量課金(アセット数/リクエスト数)と年間固定費(ユーザー数/導入規模)**に大別されます。2026年4月時点の公開料金を整理します。

| 製品 | 料金体系 | 概算 | 備考 |
|---|---|---|---|
| Microsoft Purview Unified Catalog | 従量(アセット/日) | $0.0165/アセット/日 | 30日換算で約$0.50/アセット/月。DGPU別途(Basic $15/Standard $60/Advanced $240 per 60分) |
| Alation | 年契約 | 要見積 | エンタープライズ向け |
| Atlan | 年契約 | 要見積 | 中堅〜大企業、UX重視 |
| Collibra | 年契約 | 要見積 | ガバナンス重視、規制業種 |
| Informatica IDMC | 年契約 | 要見積 | 大企業向け |
| AWS Glue Data Catalog | 従量 | $1/100万リクエスト + ストレージ | AWS環境の標準機能 |
| Google Dataplex | 従量 | Processing・Metadata Storage従量 | 公式。Gemini機能はBQ/Code Assist側課金 |
| data.world | 年契約 | 要見積 | 中堅向け |
この料金表から読み取れるのは、クラウド標準機能(Purview/Glue/Dataplex)は初期費用が低く始めやすい一方、専業ベンダー(Alation/Atlan/Collibra)は年契約ベースで要見積が中心になっている点です。Microsoft Purviewは従量課金なので、数百〜数千アセット規模なら月額数百ドルから始められますが、数万アセットを超えると月額数千〜数万ドル規模に増加するため、アセット数の見積もりが重要です。
Microsoft Purview Unified Catalogの料金詳細
Purview Unified Catalogは、公式価格表によると、次の2軸で課金されます。
- Data Map消費: ユニーク管理対象アセットあたり$0.0165/日(約$0.50/月)
- Data Governance Processing Unit(DGPU): スキャン・分類・リネージ処理時間で課金。Basic $15/Standard $60/Advanced $240 per 60分
Data Map消費だけで試算すると、1,000アセットで月約$495、1万アセットで月約$4,950、10万アセットで月約$49,500です。これにDGPU(スキャン・分類処理)のコストが加算されるため、実運用ではアセット数だけでなくスキャン頻度の設計が総額を左右します。
ケース別の選び方
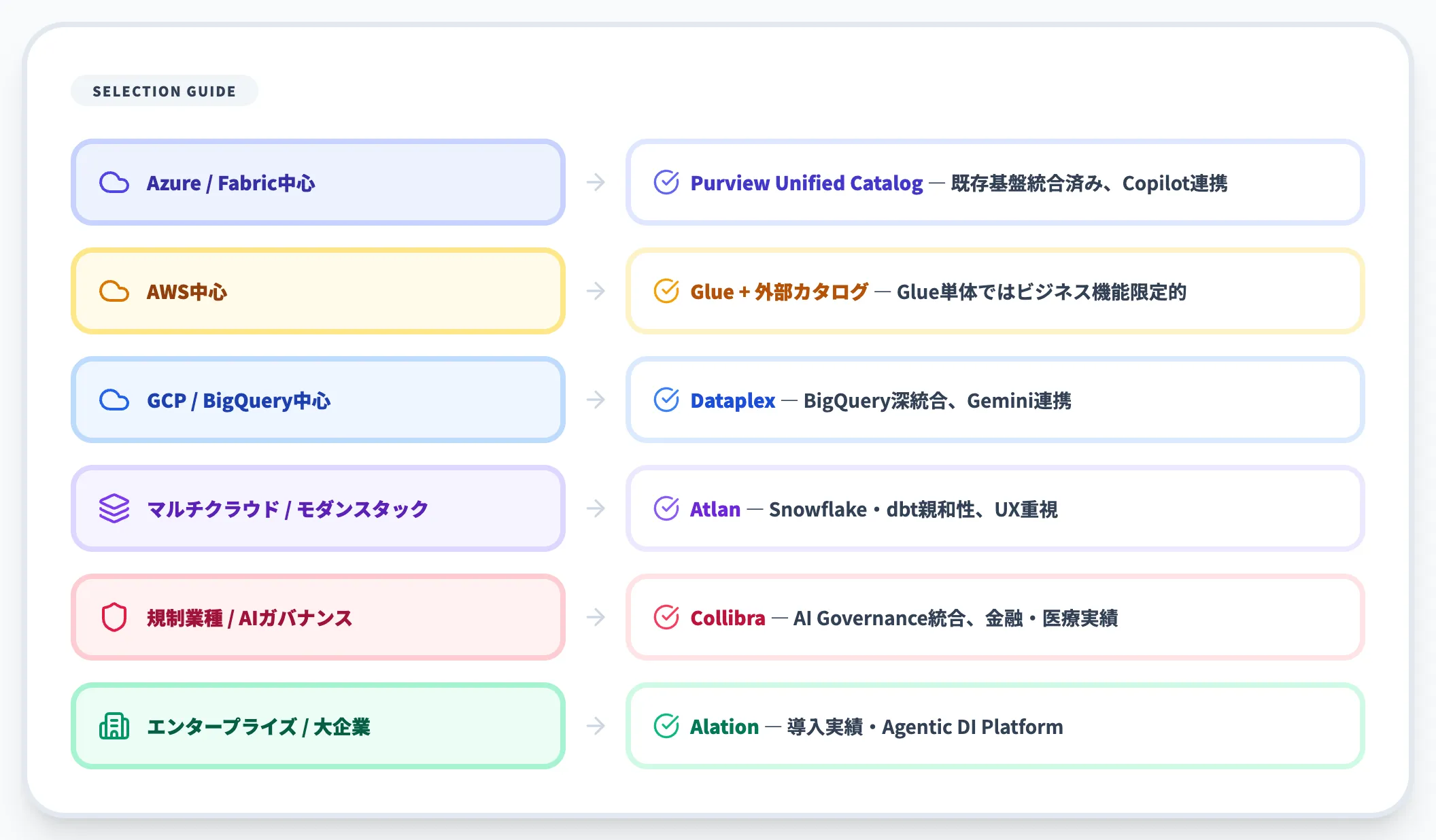
2026年4月時点でのケース別推奨を整理します。
- Azure/Fabric中心: Microsoft Purview Unified Catalog(既存基盤と統合済み、Copilot連携が強い)
- AWS中心: AWS Glue Data Catalog+外部カタログ(Glue単体ではビジネス機能が限定的)
- GCP/BigQuery中心: Google Dataplex(BigQueryと深統合、Gemini連携)
- マルチクラウド/モダンデータスタック: Atlan(Snowflake・dbt・Fireboltと親和性、UX重視)
- エンタープライズ・大企業: Alation(実績・導入事例、Agentic Data Intelligence Platform)
- 規制業種(金融・医療)・AIガバナンス強化: Collibra(AI Governance統合)
- ナレッジグラフ志向: data.world(セマンティック検索、RDFベース)
- 既存Informatica資産がある: Informatica IDMC(既存連携最大化)
SIerとしてデータ基盤の選定に関わる中で、「AIエージェントの入口をどこに置くか」→「既存クラウドとの親和性」→「ガバナンス要件」の順で議論すると、2〜3製品に絞れるケースが多いです。PoC段階では、デモ環境や製品ツアーが用意されている製品(Atlan/data.world等)から触ってみるのが現実的です。
AIがテーブルを見つけられない段階に来たら
データカタログを整備しないまま生成AI・AIエージェントを業務導入すると、ほぼ必ず「AIが存在するテーブルを見つけられない」「見つけても出典を示せない」「責任者が不明で回答を信頼できない」という壁にぶつかります。2026年はPurview Unified Catalog・Alation Agentic Platform・Atlan Context Agentsなど主要ベンダーが相次いでAIエージェント統合機能を投入しており、カタログ整備とAIエージェント設計を一体で進める段階に来ています。
AI Agent Hubは、Microsoft Purview・Alation・AtlanといったデータカタログとAIエージェントを組み合わせ、メタデータ検索・リネージ参照・アクセス権限・実行ログを1つの基盤に統合するエンタープライズAI運用プラットフォームです。社員がTeamsから「先月の売上が確認できるダッシュボードは?」と問うと、カタログに登録された資産と責任者を参照して回答し、誰がどのデータにアクセスしたかがダッシュボードに残ります。自社テナント内で動作するため、メタデータやアクセスログを外部に出さずにAIエージェントを運用できます。
AI総合研究所の専任チームが、カタログ選定からAIエージェントの業務実装・運用設計までを一貫して伴走支援します。まずは無料の資料で、自社のデータ資産をAIエージェントに安全に使わせる設計をご確認ください。
AIに正しいテーブルを引かせる

メタデータ整備からAgent運用まで支援
Copilot・社内AIチャット・AIエージェントが社内データに問う時代、データカタログが整っていないとAIは存在するテーブルを見つけられず、見つけても出典を示せません。AI Agent Hubなら、Microsoft Purview・Alation・AtlanなどのデータカタログとAIエージェントを連携させ、NL検索・リネージ参照・アクセス権限・実行ログを一画面で統制できます。自社テナント内で完結する設計で、メタデータを外に出さずにAIエージェントが正しいデータにたどり着ける環境を構築できます。
まとめ
データカタログとは、社内に散在するデータ資産を検索可能なかたちで整理し、意味・出所・権限・品質情報を紐づけて管理する仕組みです。データディクショナリ・リネージ・ビジネス用語集・スチュワードシップ・セマンティック検索の5つの基本機能で構成され、オントロジー・ナレッジグラフ・セマンティックレイヤーとは役割が異なり、補完関係で運用されるのが一般的です。
2025年9月のOpen Semantic Interchange(OSI)イニシアチブ始動とData Intelligence Platform潮流により、データカタログがAIエージェントの知識基盤として再評価される段階に入りました。Microsoft Purview Unified Catalog・Alation Agentic Platform/AI Agent SDK・Atlan Context Agents・Collibra AI Governanceなど、主要ベンダーがAIエージェント統合機能を相次いでリリースしています。
選定は、既存クラウド(Azure/AWS/GCP)との親和性・AIエージェント統合パターン・ガバナンス要件の3軸で絞るのが現実的です。Azure中心ならMicrosoft Purview、AWS中心ならGlue+外部カタログ、GCP中心ならDataplex、マルチクラウドならAtlan、規制業種ならCollibra、大企業定番ならAlationが有力候補になります。社内データにAIエージェントが問う時代が本格化する2026〜2027年、データカタログは「持っていると便利」から「AIエージェント成立の前提条件」へと位置づけが変わっていきます。










