この記事のポイント
 モデル選択の自由度:Claude/OpenAI/Google/ローカルなど75以上のプロバイダーを1つのCLIで切り替え可能
モデル選択の自由度:Claude/OpenAI/Google/ローカルなど75以上のプロバイダーを1つのCLIで切り替え可能- 3経路の料金設計:BYO Key(各社APIキー)/Zen(従量課金・GPT/Claude/Gemini網羅)/Go($10月額・オープンモデル特化)から選択
- Anthropicが第三者ツールのClaude Pro/Max資格情報ルーティングを不許可とし、OpenCodeでClaudeを使うにはAPI直契約・Zen・互換ゲートウェイへの切替が必須
- GitHub Copilotサブスク認証を公式サポート(2026年1月):Copilot Pro/Pro+/Business/Enterpriseの契約内で追加AIライセンスなしにOpenCodeを稼働可能
- 速度・純度はClaude Code、コスト・自由度・モデル選択の広さはOpenCodeが有利で、実務は両方運用が現実解

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OpenCode(オープンコード)は、ターミナル・IDE・デスクトップから使えるMITライセンスのオープンソースAIコーディングエージェントです。
Claude・OpenAI・Google・ローカルモデルなど75以上のプロバイダーを1つのCLIで切り替えられる自由度が特徴で、AnthropicがClaude Pro/Max資格情報の第三者ツール流用を不許可としている現在、商用サブスクの外側にある選択肢として存在感が急拡大しています。
本記事では、OpenCodeが商用サブスクの代替候補として選ばれる背景・機能・料金体系・Claude CodeやCodexとの使い分け・実務での運用パターンを、2026年7月時点の最新情報で解説します。
目次
OpenCodeとは?ターミナルで動くオープンソースAIコーディングエージェント
Anthropic OAuth禁止で崩れた「サブスク持ち込み」ルート
GitHub Copilot認証を公式サポート——追加AIライセンス不要で利用可能に
Plan/Buildの2エージェント切替と読み取り専用モード
subagentによる調査・実装の分担(General / Explore / Scout)
インストール方法(macOS / Linux / Windows)
OpenCodeとClaude Code、Codexの使い分け
Claude CodeやCodex CLIを併用すべきケース
OpenCodeを実務で使う: 個人・小規模チーム・全社標準化の分岐
個人開発者: GitHub Copilot流用またはGoが第一候補
OpenCodeとは?ターミナルで動くオープンソースAIコーディングエージェント
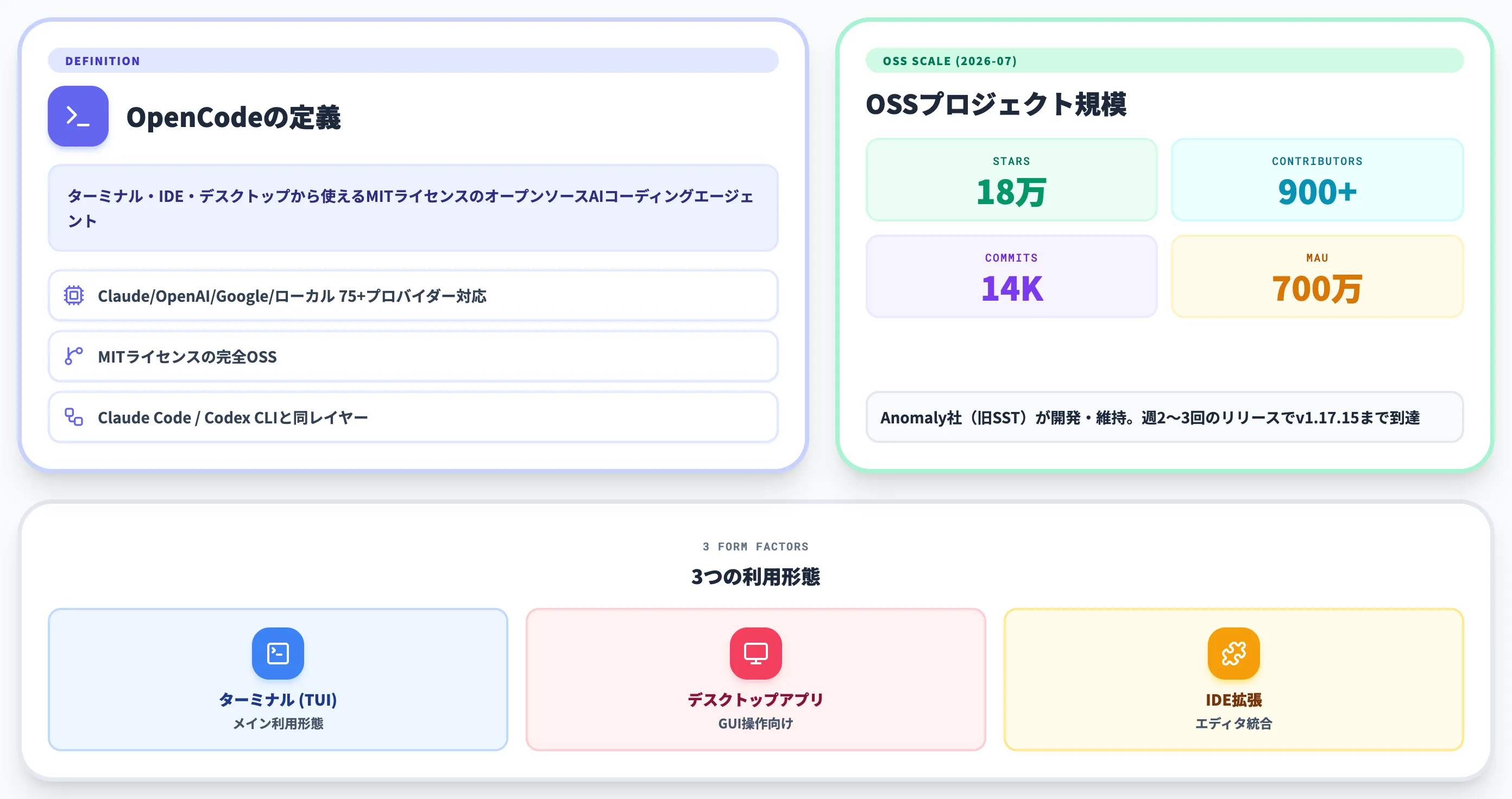
OpenCode(オープンコード)とは、ターミナル・デスクトップ・IDE拡張の3形態で使える、MITライセンスのオープンソースAIコーディングエージェントです。
自然言語でコードベースを読み取り、変更を提案し、ファイル編集まで実行するClaude CodeやCodex CLIと同レイヤーのCLIコーディングエージェントです。
2026年7月現在、OpenCodeはGitHubリポジトリ18万スター・約1万4000コミット規模まで拡大し、第三者メディアでも月間700万人規模の利用が報じられるOSSプロジェクトに育っています。
Claude・OpenAI・Google・ローカルモデルなど75以上のLLMプロバイダーを1つのCLIから切り替えられる自由度が、商用サブスク型が主流の同ジャンルで独自の位置を築いた要因です。
OSS AIコーディングエージェントの中での位置づけ
OpenCodeは、CLIコーディングエージェントというカテゴリで商用サブスク型とOSS型の中間に位置づけられます。
商用ツールの体験に近い機能セットを持ちながら、モデル選択やライセンスの自由度でOSSの強みも活かせる構成です。
-
Claude Code / Codex CLI(商用サブスク型)
Anthropic・OpenAI公式が提供。モデル・実行環境・料金がベンダー統合済みで即使える
-
OpenCode(OSS型)
MIT License。75以上のLLMプロバイダーを差し替え可能で、BYO Key・Zen・GitHub Copilot認証の3経路から選択
-
Aider・Cline等(OSS型・軽量用途)
OpenCodeより機能セットは絞られるが、特定エディタ統合や単機能特化など軽量用途向け
ここでのポイントは、OpenCodeがモデル選択の自由度と機能セットの充実の両方を持つ、という点です。
商用サブスクからの移行背景・料金・使い分けは、後段の各セクションで詳しく整理します。

OpenCodeが商用サブスクの代替候補として選ばれる背景
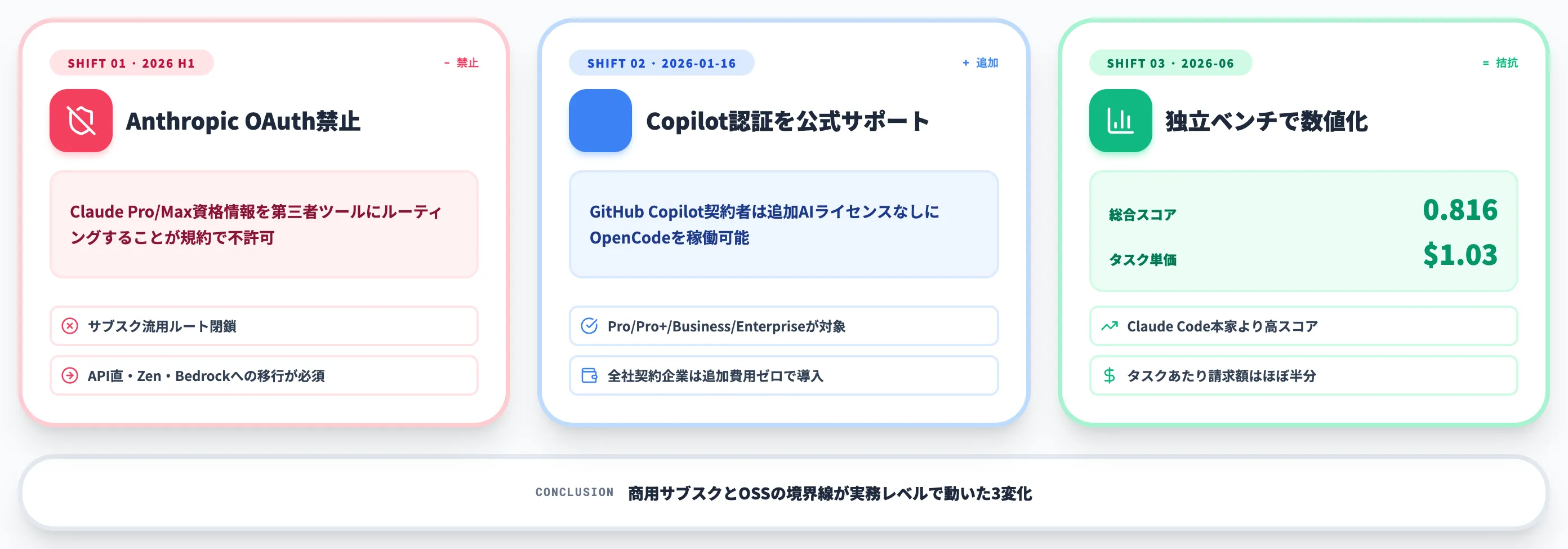
OpenCodeが2026年に入って急速に検討候補として挙がるようになった背景には、3つの具体的な変化があります。
Anthropicによる第三者ツール向けOAuth利用の禁止、GitHub Copilotログインの公式サポート開始、そして独立ベンチマークでの数値的評価の3点です。
いずれも「OpenCodeが優れているから」という抽象論ではなく、商用サブスクとOSSの境界線が実務レベルで動いたことに起因しています。
Anthropic OAuth禁止で崩れた「サブスク持ち込み」ルート
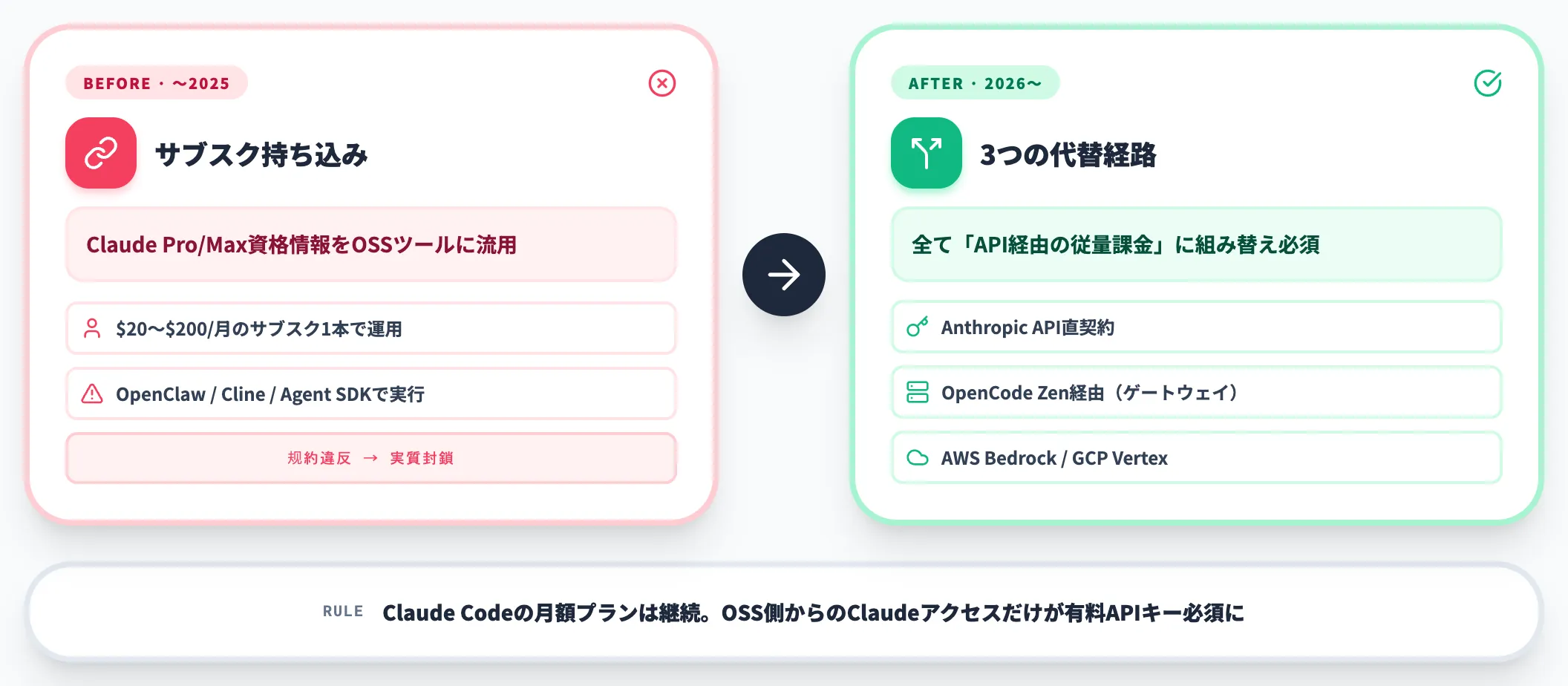
Claude Codeの利用規約では、Claude Pro/Max/Freeサブスクリプションの資格情報を第三者開発者がルーティングして自社製品に組み込むことは許可されていないことが明示されています。
2026年前半にかけて、この方針は段階的に強化されたと第三者メディアで報じられており、OpenCode・OpenClaw・Cline・Anthropic自社のAgent SDKに至るまで、Claudeサブスクを流用して動かしていたコーディングエージェントは、Anthropic APIの従量課金アカウントか、後述するOpenCode Zenのようなゲートウェイ経由での契約に切り替える必要が生じました。
Anthropicの利用規約側もこの方針と整合的な内容になっています。
Claude Codeのサブスクリプション料金プランは変わらず月額$20〜$200で提供されている一方、OSSツール側からのClaudeアクセスはすべて「有料APIキーを別途持ち込む」形式に組み替えざるを得なくなった、というのが実態です。
GitHub Copilot認証を公式サポート——追加AIライセンス不要で利用可能に
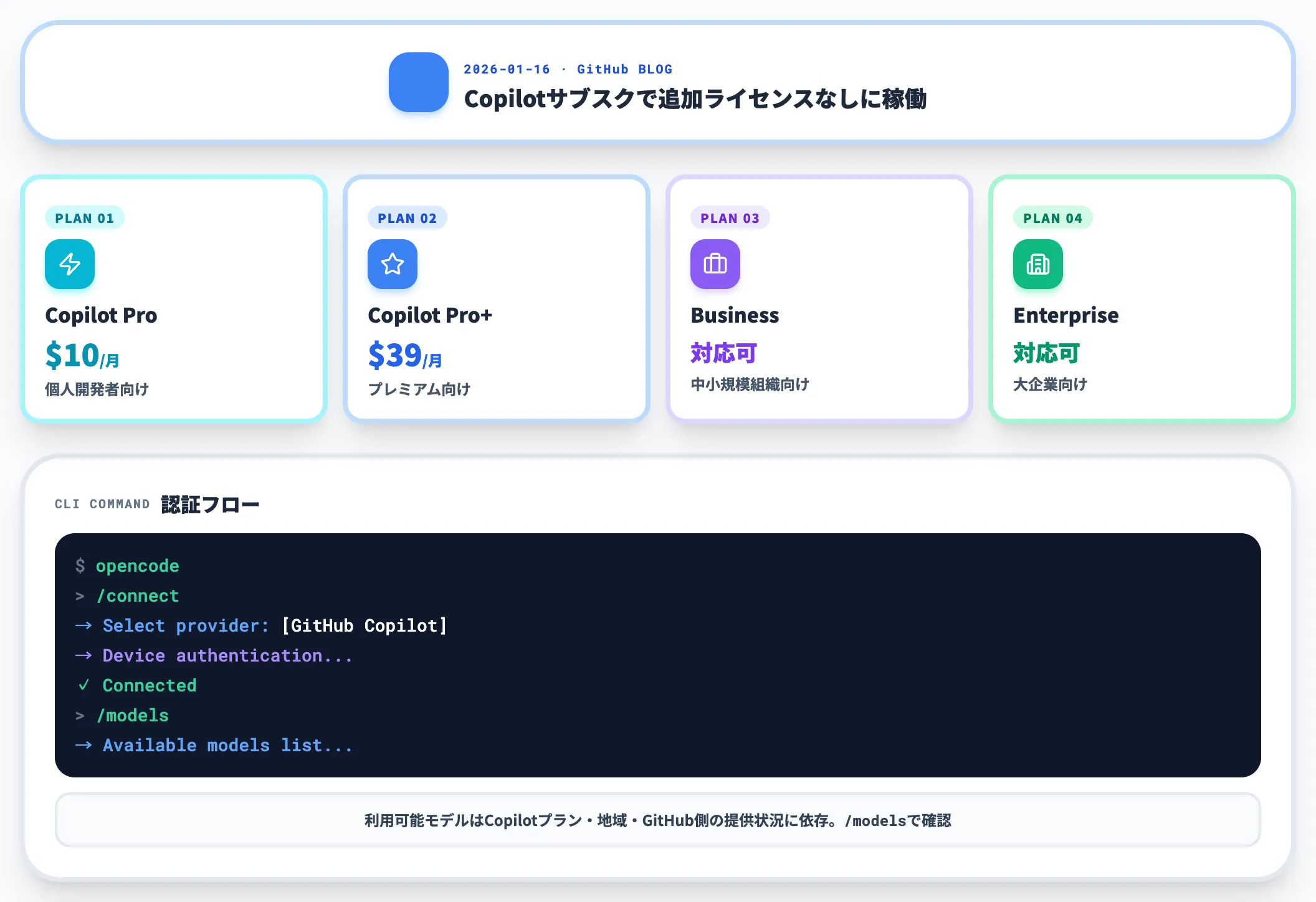
Claude側の締め付けと対照的に、GitHubは2026年1月16日にOpenCodeでのGitHub Copilotサブスクリプション認証を公式サポートするとGitHub Blogで発表しました。
Copilot Pro($10/月)・Pro+($39/月)・Business・Enterpriseの契約者は、OpenCode上で「/connect」コマンドからGitHub Copilotを選び、GitHubのデバイス認証を通すだけで、追加のAIライセンス料なしにOpenCodeを稼働できます。
この提携は、単純な料金メリット以上の意味を持っています。
利用可能なモデルはCopilotプラン・地域・GitHub側の提供状況に依存するため、実際に呼び出せるモデルは「/connect」後に「/models」で確認するのが確実です。
既にCopilotを全社契約している企業にとって、OpenCodeを追加ライセンス費ゼロで導入できる選択肢に変わったのが2026年上半期の大きな変化です。
独立ベンチマークでのスコアとタスク単価が競合と拮抗

3つ目の変化は、性能指標が具体的な数字として出揃ってきたことです。
以下の表で、2026年6月時点の独立ベンチマーク(コーディングタスク総合スコアと平均タスク単価)における主要CLIツールの立ち位置を整理しました。
| ツール | 使用モデル | 総合スコア | タスクあたりコスト |
|---|---|---|---|
| OpenCode | Claude Sonnet 4.6 | 0.816 | $1.03 |
| Grok CLI | Claude Sonnet 4.6 | 0.803 | $2.03 |
| Claude Code | Claude Sonnet 4.6 | 0.789 | $1.83 |
| Cursor | Claude Opus 4.6(Cursor内蔵) | 0.751 | $27.90 |
出典: AIMultiple「AI Coding Benchmark」
この表が示すのは、同じClaude Sonnet 4.6を使わせた場合、OpenCodeがClaude Code本家よりわずかに高いスコアを出し、タスクあたりの請求額もほぼ半分に収まっている、という結果です。
CLIツール群が$1〜$3の帯に収まる中で、Cursorだけが$27.90と桁違いに高いのは、Cursor側のクレジット消費モデルが「1タスクで複数モデル呼び出しを繰り返す」構造になっているためです。
つまりClaude Codeが速度と純度、OpenCodeがコスト効率と広いモデル選択という役割分担が数字で見えつつある、というのが2026年半ばの状況です。
OpenCodeの主要機能

OpenCodeの機能セットは、他のCLIコーディングエージェントに揃えたコア機能に加え、Plan/Buildエージェントの明示的な分離とAGENTS.mdによるプロジェクト固有ルールの明文化という2つの独自性で構成されています。
本セクションでは、実務で影響の大きい5つの機能領域に絞って、それぞれの役割と設計思想を整理します。
Plan/Buildの2エージェント切替と読み取り専用モード
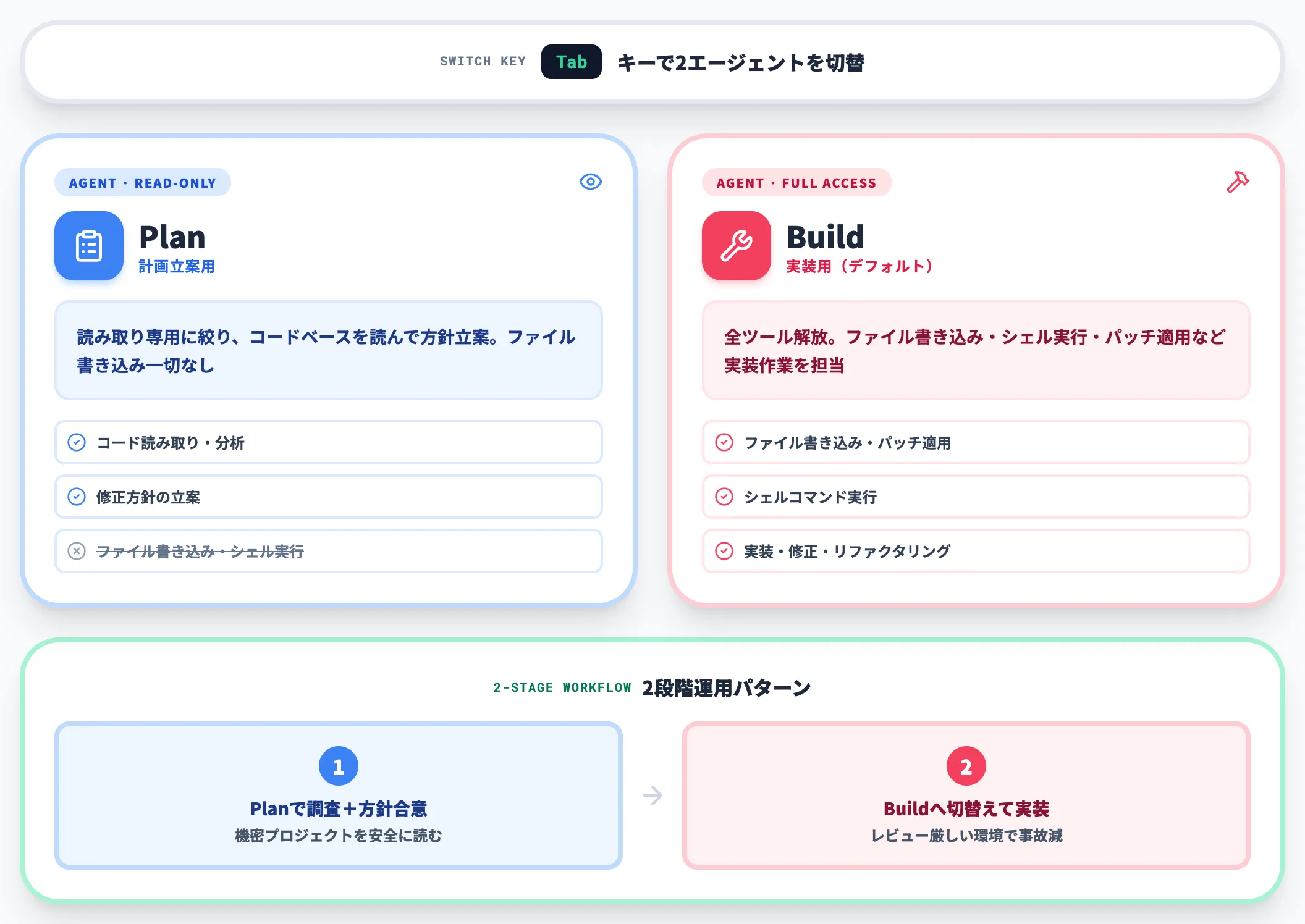
OpenCodeにはプライマリエージェントが2種類あり、「Tab」キーで切り替えられます。
-
Buildエージェント
デフォルトのメインエージェント。ファイル書き込み・シェル実行・パッチ適用など全ツールを解放しており、実装・修正・リファクタリングを担当する
-
Planエージェント
初期状態で読み取り専用に絞られた計画立案用エージェント。コードベースを読み、修正方針を立案するが、ファイルには一切書き込まない
「まず「Plan」で調査と方針を固め、合意できたら「Build」に切り替えて実装」という2段階運用は、機密プロジェクトやレビューが厳しい環境で事故を減らす基本パターンとして機能します。
一般提供のCLIツールで、この読み取り専用モードが標準搭載されているものは多くなく、権限設計を重視する企業導入時に扱いやすい特性です。
subagentによる調査・実装の分担(General / Explore / Scout)
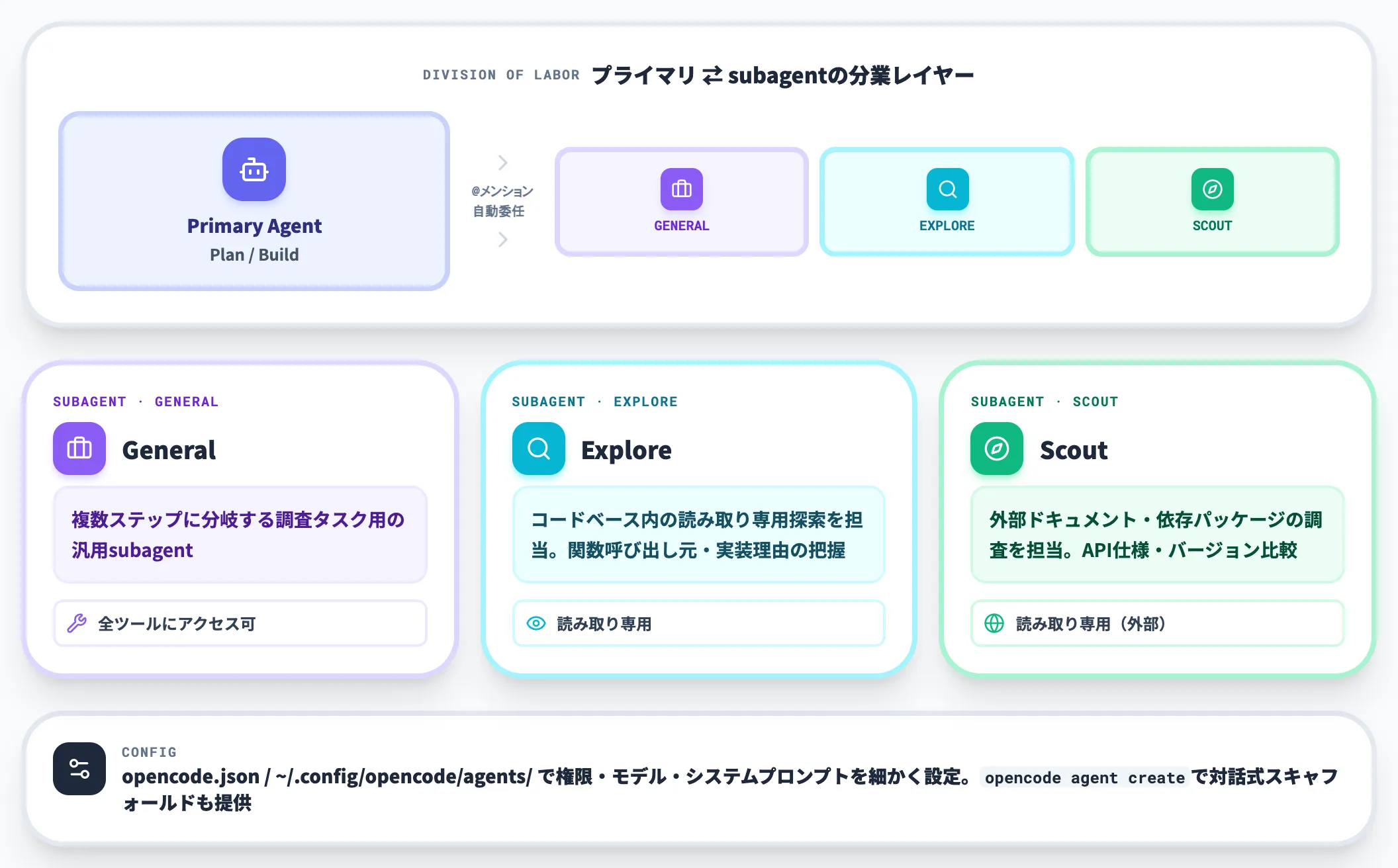
プライマリエージェントから自動的に呼び出される、あるいは「@」メンションで指名できるsubagentも3種類が標準提供されています。
-
General
複数ステップに分岐する調査タスク用の汎用subagent。全ツールにアクセスできる
-
Explore
コードベース内の読み取り専用探索を担当。「この関数を呼び出しているすべての場所」「なぜこの実装になっているか」といった探索型のクエリに強い
-
Scout
外部ドキュメント・依存パッケージの調査を担当する読み取り専用subagent。ライブラリのAPI仕様確認やバージョン比較で使う
設計思想としてはClaude CodeのSubagentsと同じ発想で、メインエージェントのコンテキストを重い調査で汚さないための分業レイヤーです。
subagentは「opencode.json」または「~/.config/opencode/agents/」配下のMarkdownファイルで、権限(ask/allow/deny)・モデル指定・システムプロンプト・温度パラメータ・最大反復回数まで細かく設定できます。
「opencode agent create」コマンドで対話形式のスキャフォールドも提供されており、社内標準のsubagent構成をリポジトリに含めて配布する運用が現実的に組めます。
AGENTS.mdによるプロジェクト固有ルールの明文化
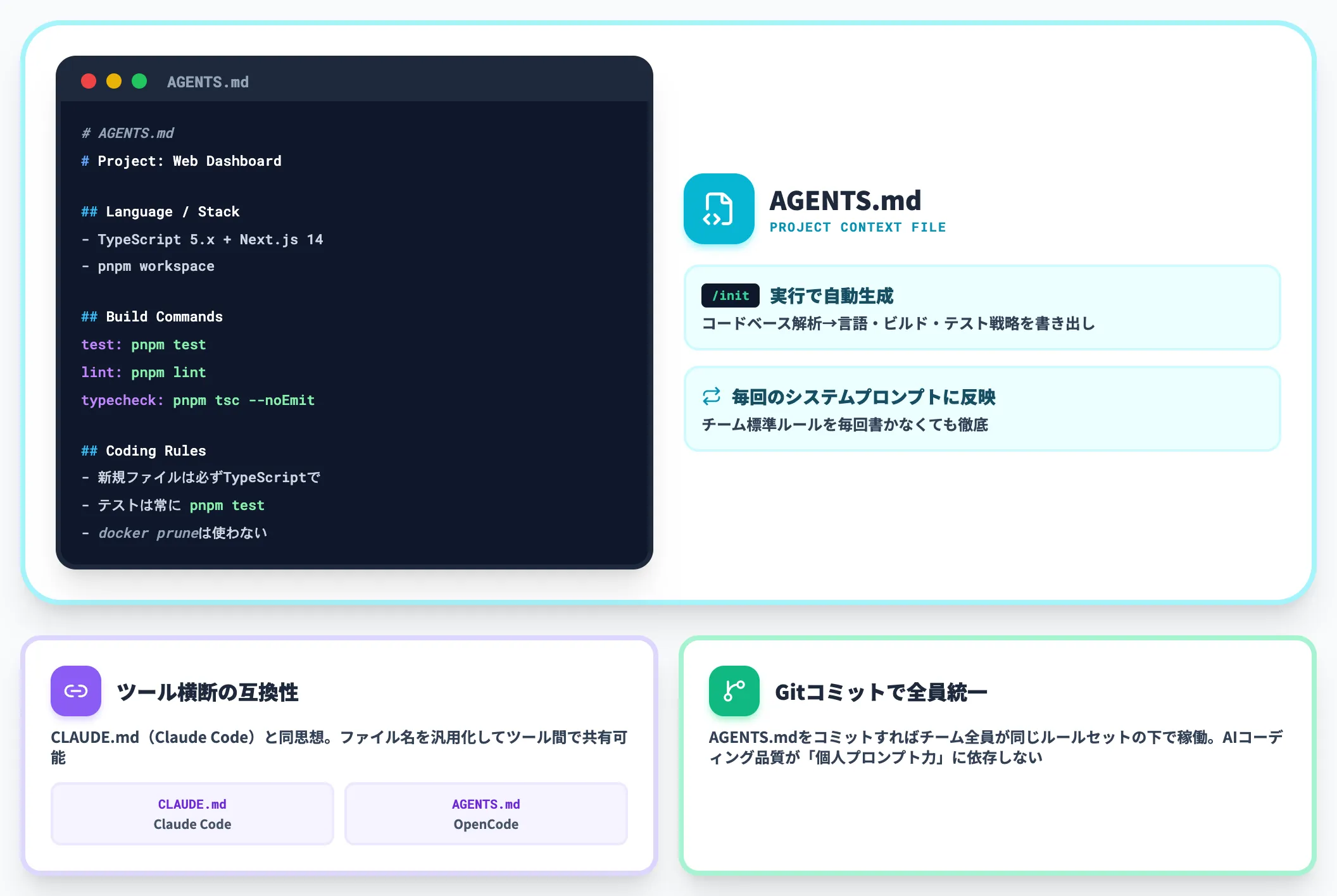
「AGENTS.md」は、プロジェクトルートに置くOpenCode用のコンテキストファイルです。
「/init」コマンドを実行するとOpenCodeがコードベースを解析し、使用言語・ビルドコマンド・テスト戦略・ディレクトリ構成・コーディング規約を「AGENTS.md」に自動書き出しします。
以降のセッションでは、この「AGENTS.md」が毎回のシステムプロンプトに反映されるため、「テストは常に『pnpm test』で回して」「新規ファイルは必ずTypeScriptで」といったチーム標準のルールを、プロンプトで毎回書かなくても徹底できます。
このファイルはClaude Codeが提唱した「CLAUDE.md」とほぼ同じ思想で、ファイル名を汎用化することでツール間の互換性を高める狙いがあります。
「AGENTS.md」をGitでコミットしておけば、全メンバーがまったく同じルールセットの下でOpenCodeを動かせるため、AIコーディングの品質が「個人のプロンプト力」に依存しなくなります。
LSP統合とMCPサーバー連携
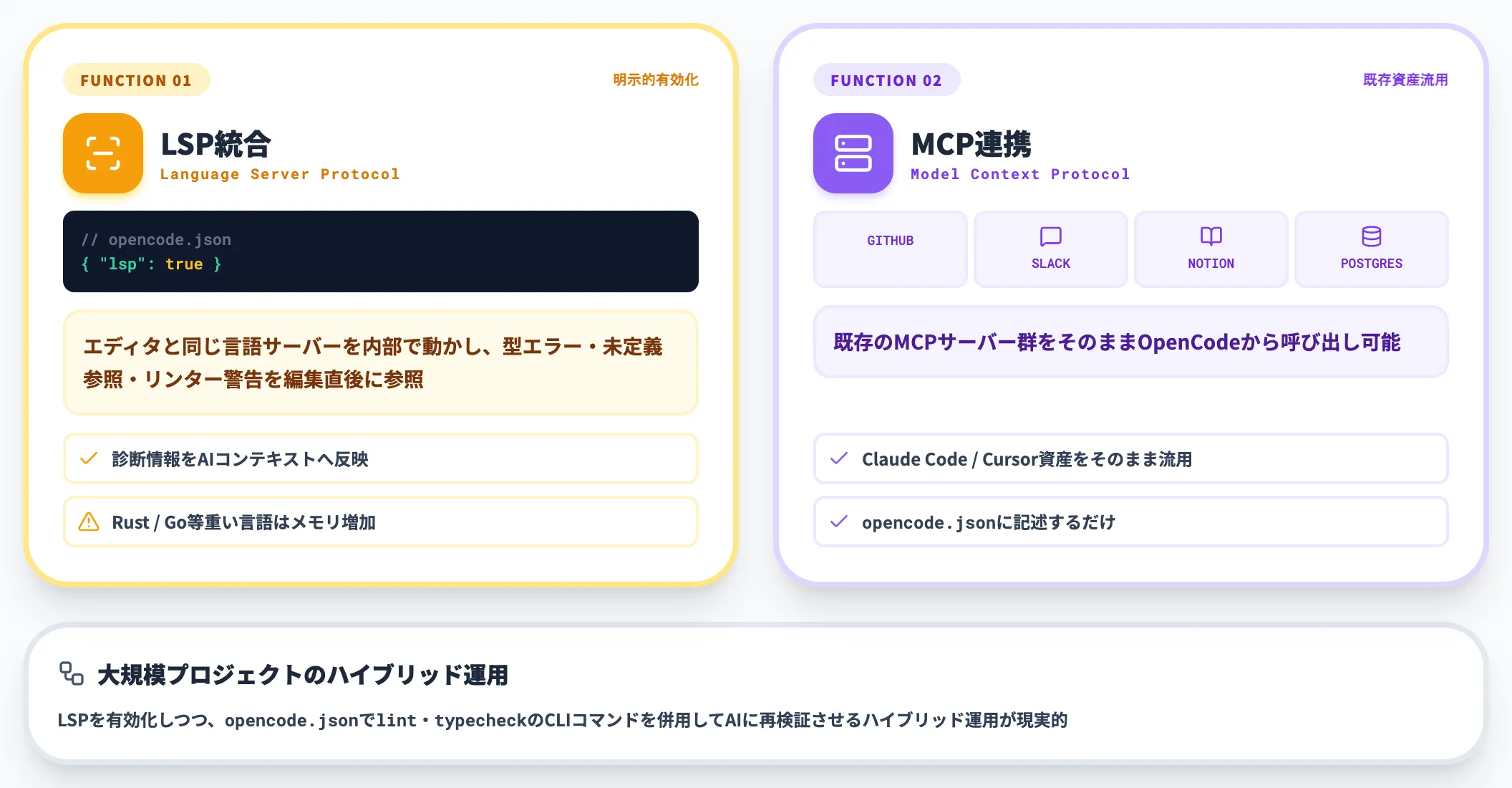
OpenCodeはLanguage Server Protocol(LSP)に対応しており、「opencode.json」で「lsp: true」のように明示的に有効化することで、エディタと同じ言語サーバーを内部で動かせます。
有効化後は、型エラー・未定義参照・リンター警告をAIが編集直後にコンテキストとして参照でき、Claude CodeのLSP対応と同様の補助情報として機能します。
公式docsでは「LSPは診断の補助として役立つ場合があるが、常に有利になるとは限らない」と明記されており、Rust・Go等の重い言語サーバーではセッションのメモリ消費と応答遅延が増えるトレードオフがあります。
大規模プロジェクトでは、LSPを有効化しつつ、「opencode.json」で「lint」・「typecheck」のCLIコマンドを併用してAIに再検証させるハイブリッド運用が現実的です。
さらにMCP(Model Context Protocol)にも対応しており、GitHub操作・Slack投稿・Notion検索・Postgres問い合わせなど、既存のMCPサーバー群をそのままOpenCodeから呼び出せます。
MCPサーバーの設定は「opencode.json」に記述するだけで、Claude CodeやCursor向けに整備した既存のMCPインフラを、そのままOpenCodeでも共有できる点は運用上の大きな利点です。
マルチセッション並列実行とセッション共有
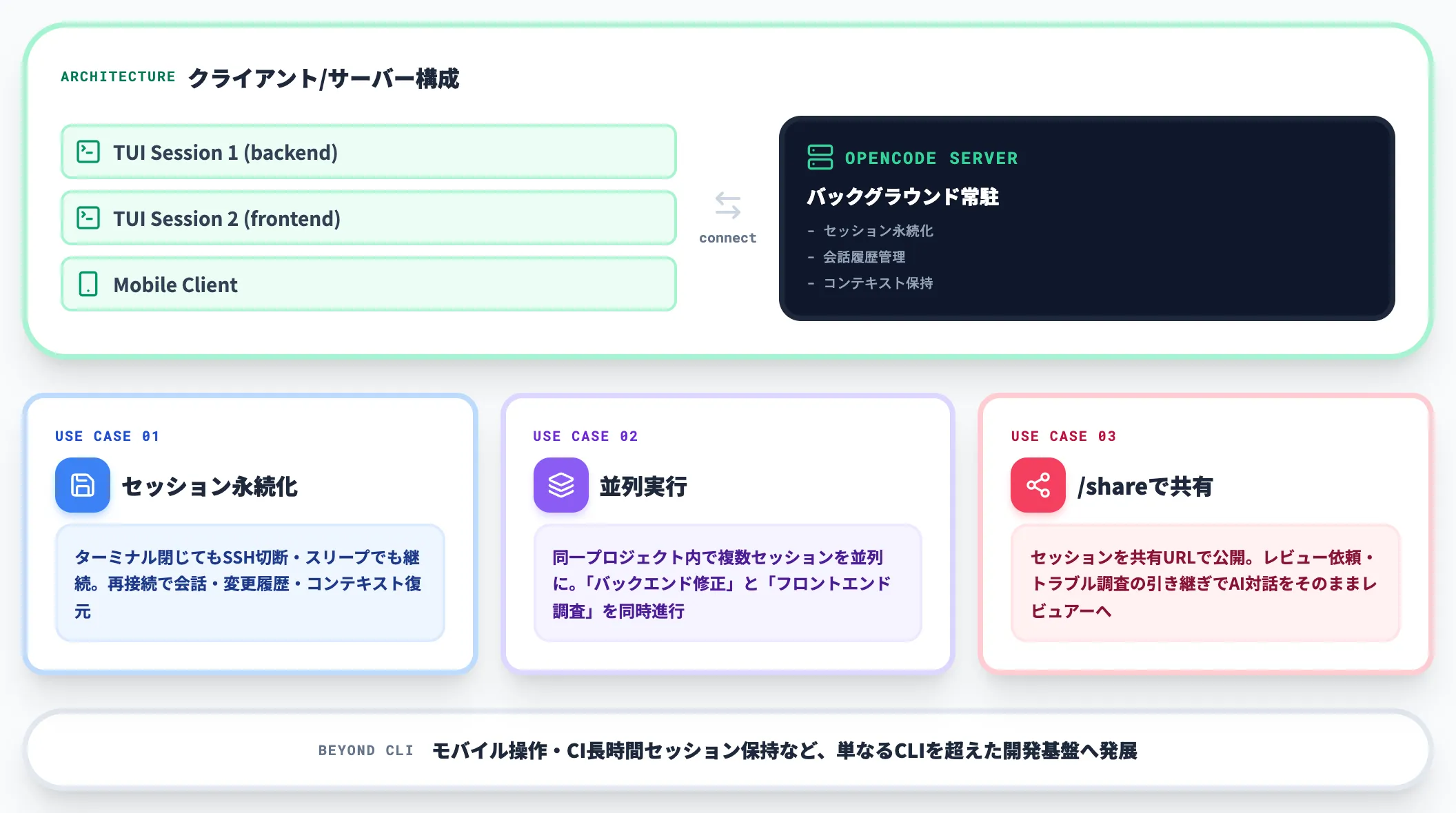
OpenCodeはバックグラウンドで常駐サーバーを起動し、TUIクライアントがそこに接続するクライアント/サーバー構成を採用しています。
この構成により、以下の3つが可能になります。
-
セッションの永続化
ターミナルを閉じても、SSH接続が切れても、マシンがスリープしても、OpenCodeサーバー側のセッションは継続する。再接続すると会話・変更履歴・コンテキストが復元される
-
マルチセッション並列実行
同一プロジェクト内で複数のセッションを並列に走らせられる。「1つのウィンドウでバックエンド修正、別のウィンドウでフロントエンド調査」を同時に進める運用が可能
-
「/share」によるセッション共有リンク発行
特定のセッションを共有URLで公開できる。レビュー依頼・トラブル調査の引き継ぎで、AIとの対話履歴をそのままレビュアーに渡せる
この設計は、モバイルアプリからリモートでOpenCodeを操作したり、CIパイプラインで長時間セッションを保持したりするユースケースへの布石にもなっており、単なるCLIツールを超えた開発基盤としての性格を帯びています。
OpenCodeの料金体系 — 3つのアクセス経路

OpenCodeの料金構造は、他のCLIコーディングエージェントとは根本的に異なります。
OpenCodeというツール本体は完全無料で、コストが発生するのはあくまでモデル呼び出しの部分だけです。
以下の表で、実務で選ばれる3つのアクセス経路と、その特徴を整理しました。
| アクセス経路 | 月額固定費 | 従量課金 | 主な対応モデル | 向く用途 |
|---|---|---|---|---|
| BYO Key(各社API直契約) | なし | 各社API単価 | Claude / GPT / Gemini / Bedrock 各社 | 既にAPI契約済み、コスト予測を各社に分散したい |
| OpenCode Zen | なし(最低$20チャージ) | 各モデル従量 | GPT・Claude・Gemini・Grok等50モデル超 | 複数モデルを1契約で試す、社内で単一ゲートウェイに集約したい |
| OpenCode Go | $5(初月)→ $10 | ドル建ての上限内で使い放題 | GLM・Kimi・DeepSeek・Qwen・MiniMax等13モデル | オープンモデル中心で低コスト運用、個人開発者・PoC用途 |
3経路は排他ではなく、「/models」コマンドから切り替えられるため、1つのOpenCodeインスタンスで併用することも可能です。
以下の各節で、それぞれの経路の設計と実務での判断ポイントを見ていきます。
本体無料+BYO Key(既存APIキーの持ち込み)
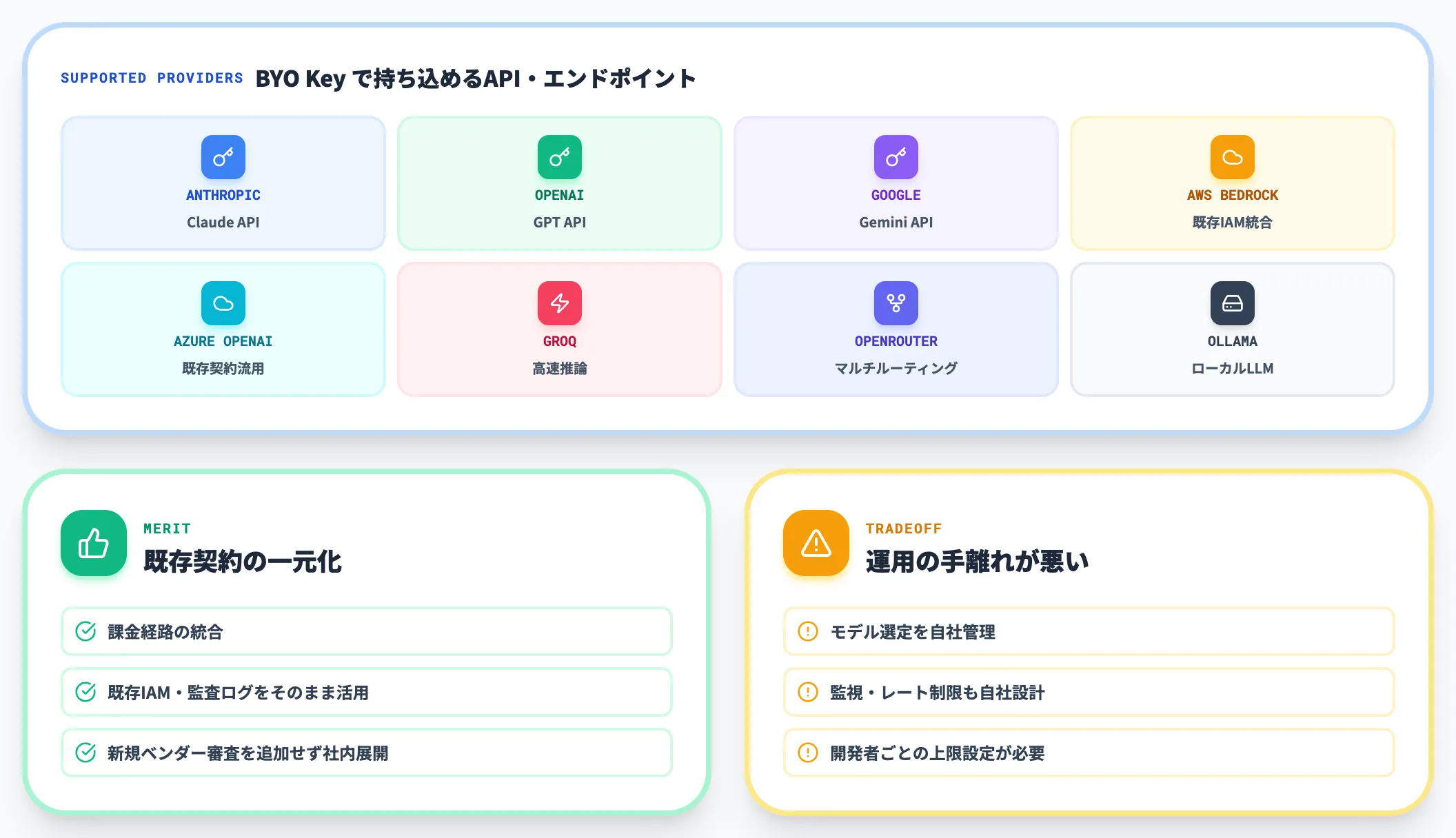
もっとも柔軟な経路が、既存のAPI契約をOpenCodeにそのまま持ち込むBYO(Bring Your Own)Keyパターンです。
Anthropic API、OpenAI API、Google AI、Amazon Bedrock、Azure OpenAI、Groq、OpenRouter、そしてOllamaのようなローカルLLMサーバーまで、「opencode.json」または環境変数にAPIキーを入れるだけで利用開始できます。
この経路のメリットは、課金経路の一元化とセキュリティ設計の維持です。
既に会社としてAWS BedrockでClaude Sonnetを稼働させている場合、そのIAMロールと監査ログの仕組みをそのまま活用できるため、新規ベンダー審査を追加せずにOpenCodeを社内展開できます。
反面、モデル選定・監視・レート制限をすべて自社で管理する必要があります。
「新モデルが出たら追加する」「利用超過したときのフォールバック先を決める」「開発者ごとの上限を設定する」といった運用は、次のZen/Goのようなゲートウェイ型サービスと比べて手離れが悪くなります。
OpenCode Zen(従量課金ゲートウェイ)
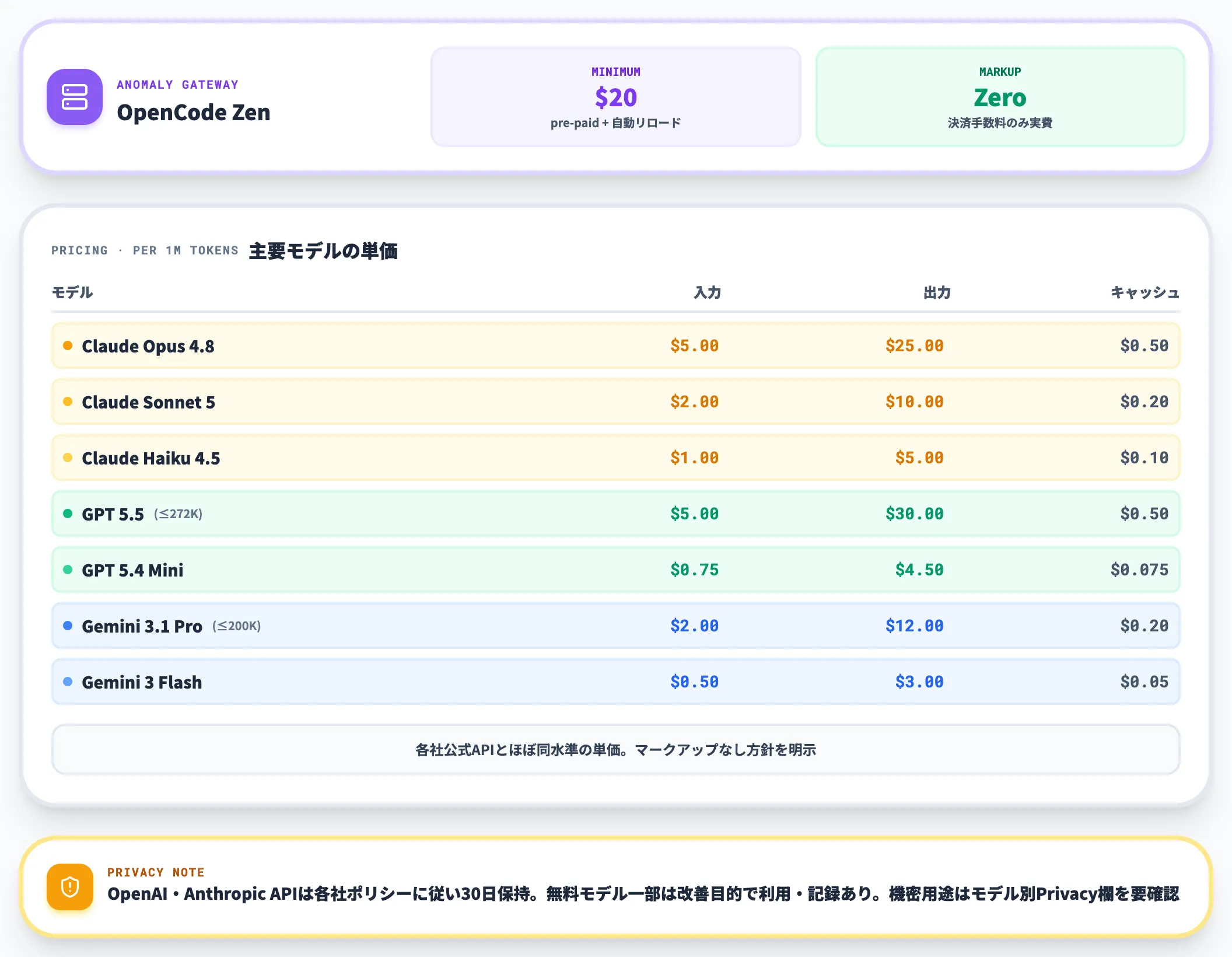
OpenCode Zenは、Anomaly社が運営するAIモデルゲートウェイで、GPT・Claude・Gemini・Grok・DeepSeek・Kimi等の50モデル超を1つのAPIキーで呼び出せるサービスです。
以下の表で、Zenが提供する主要モデルの料金(100万トークンあたり)を整理しました。
| モデル | 入力単価 | 出力単価 | キャッシュ読み取り |
|---|---|---|---|
| Claude Opus 4.8 | $5.00 | $25.00 | $0.50 |
| Claude Sonnet 5 | $2.00 | $10.00 | $0.20 |
| Claude Haiku 4.5 | $1.00 | $5.00 | $0.10 |
| GPT 5.5(≤272K) | $5.00 | $30.00 | $0.50 |
| GPT 5.4 Mini | $0.75 | $4.50 | $0.075 |
| Gemini 3.1 Pro(≤200K) | $2.00 | $12.00 | $0.20 |
| Gemini 3 Flash | $0.50 | $3.00 | $0.05 |
この単価表が示すのは、Zen経由の価格は各社公式APIとほぼ同水準で、マークアップがないという点です。Anomaly社は「zero markup」を明示しており、クレジットカード決済手数料(4.4% + $0.30)だけを実費で乗せる仕組みになっています。
課金は最低$20のpre-paidチャージから始まり、残高が$5を下回ると自動で$20をリロードするオプションが用意されています。月間の支出上限も設定でき、社内のコスト管理を1つのZenアカウントに集約できます。
「Claudeのサブスクをやめてゲートウェイに一本化したい」「複数モデルを条件付きで切り替えて使いたい」「チームメンバーごとの利用量を可視化したい」——こうしたニーズがある場合、Zenは有力な選択肢です。
プライバシー面では、Zenは多くの提供元でゼロ保持方針を掲げていますが、無料モデルの一部は改善目的での利用・記録があり、OpenAI・Anthropic APIは各社ポリシーに従って30日保持されると公式docsに明記されています。機密用途で使う場合は、モデル別のPrivacy欄を確認してから採用可否を判断します。
OpenCode Go($10/月のオープンモデル定額)
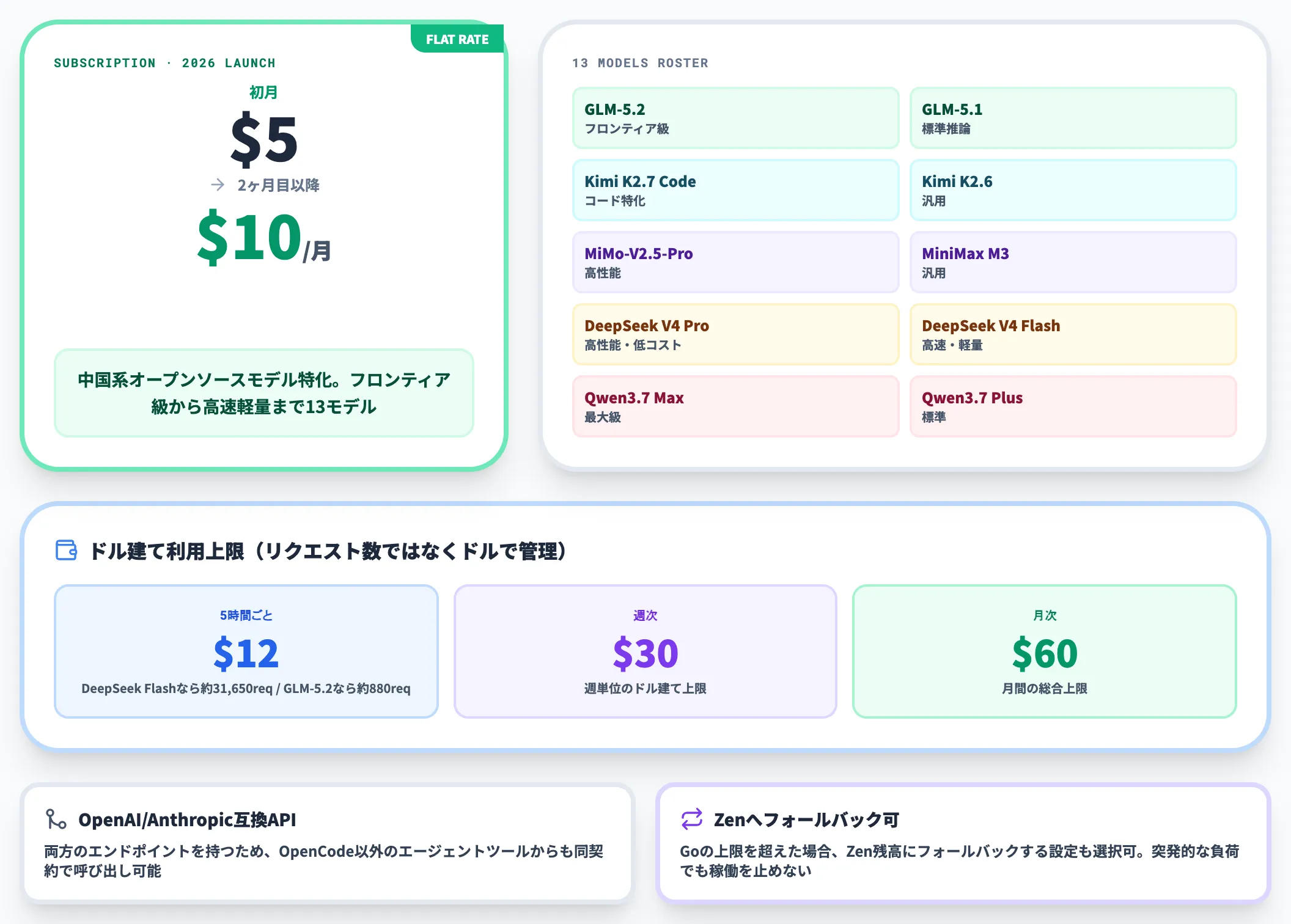
OpenCode Goは、2026年に登場した定額サブスクリプションプランで、初月$5・2ヶ月目以降$10/月で稼働します。
Zenが「あらゆる主要モデルを従量で提供する」プランなのに対し、Goは中国系オープンソースモデル(GLM-5.2、GLM-5.1、Kimi K2.7 Code、Kimi K2.6、MiMo-V2.5-Pro、MiniMax M3、DeepSeek V4 Pro/Flash、Qwen3.7 Max/Plus等13モデル)に絞り、コスト面で振り切った設計です。
以下の表で、Goのドル建て利用上限とモデル別の目安リクエスト数を整理しました。
| 制限単位 | 上限(ドル建て) | 目安リクエスト数 |
|---|---|---|
| 5時間ごと | $12 | DeepSeek V4 Flashで約31,650リクエスト/GLM-5.2で約880リクエスト |
| 週次 | $30 | — |
| 月次 | $60 | — |
この表が示すのは、リクエスト数ではなくドル建てで上限を管理する設計です。同じ$12の枠を、DeepSeek V4 Flashなら数万リクエスト消費できるが、フロンティア級のGLM-5.2なら1,000弱で使い切る、という粒度で運用します。
Goで発行されるAPIキーはOpenAI互換とAnthropic互換の両方のエンドポイントを持ち、OpenCodeだけでなく他のエージェントツールからも同じ契約で呼び出せます。
提供モデルは米国・EU・シンガポールに分散ホストされ、いずれもゼロ保持ポリシーで運用されています。
「Claudeサブスクを解約してオープンモデルで試作したい」「個人開発でClaude Codeの$100/月は重い」——こうしたケースで、月$10で13モデルを試せるGoは費用対効果の高い選択肢です。
Goの制限を超えた場合、Zenの残高にフォールバックする設定も選べるため、突発的な負荷でも稼働を止めない運用が組めます。
OpenCodeのインストールと初期セットアップ

OpenCodeの導入は、単一のコマンドで完了する軽量な設計になっています。
macOS・Linux・Windowsのいずれでも同じ手順で使えるため、社内標準ツールとして配布する際のセットアップコストも小さく抑えられます。
インストール方法(macOS / Linux / Windows)

インストール手段は複数用意されており、環境に応じて選べます。
-
curl一発(macOS / Linux 推奨)
「curl -fsSL https://opencode.ai/install | bash」の1行で導入完了。数十秒で終わり、依存ライブラリのバージョン差異にも巻き込まれにくい
-
npm(Node.js 18+)
「npm install -g opencode-ai」 でインストール可能。Node.js環境が既に整備されているチームで扱いやすい
-
Homebrew(macOS)
「brew install anomalyco/tap/opencode」を推奨。公式ダウンロードページで案内されている最新のtap経由なら、リリース追従が速い
-
Windows
「npm install -g opencode-ai」 で稼働可能。WSL2上で稼働させる方が挙動が安定するため、業務利用ではWSL経由が実用的
インストール後、「opencode --version」でv1.17系が表示されれば導入完了です。
「PATH」が通っていない場合、Homebrewは「/opt/homebrew/bin/opencode」、npmは「$(npm config get prefix)/bin/opencode」にバイナリが置かれているので、「~/.zshrc」等でパスを追加します。
/connectで認証を通す
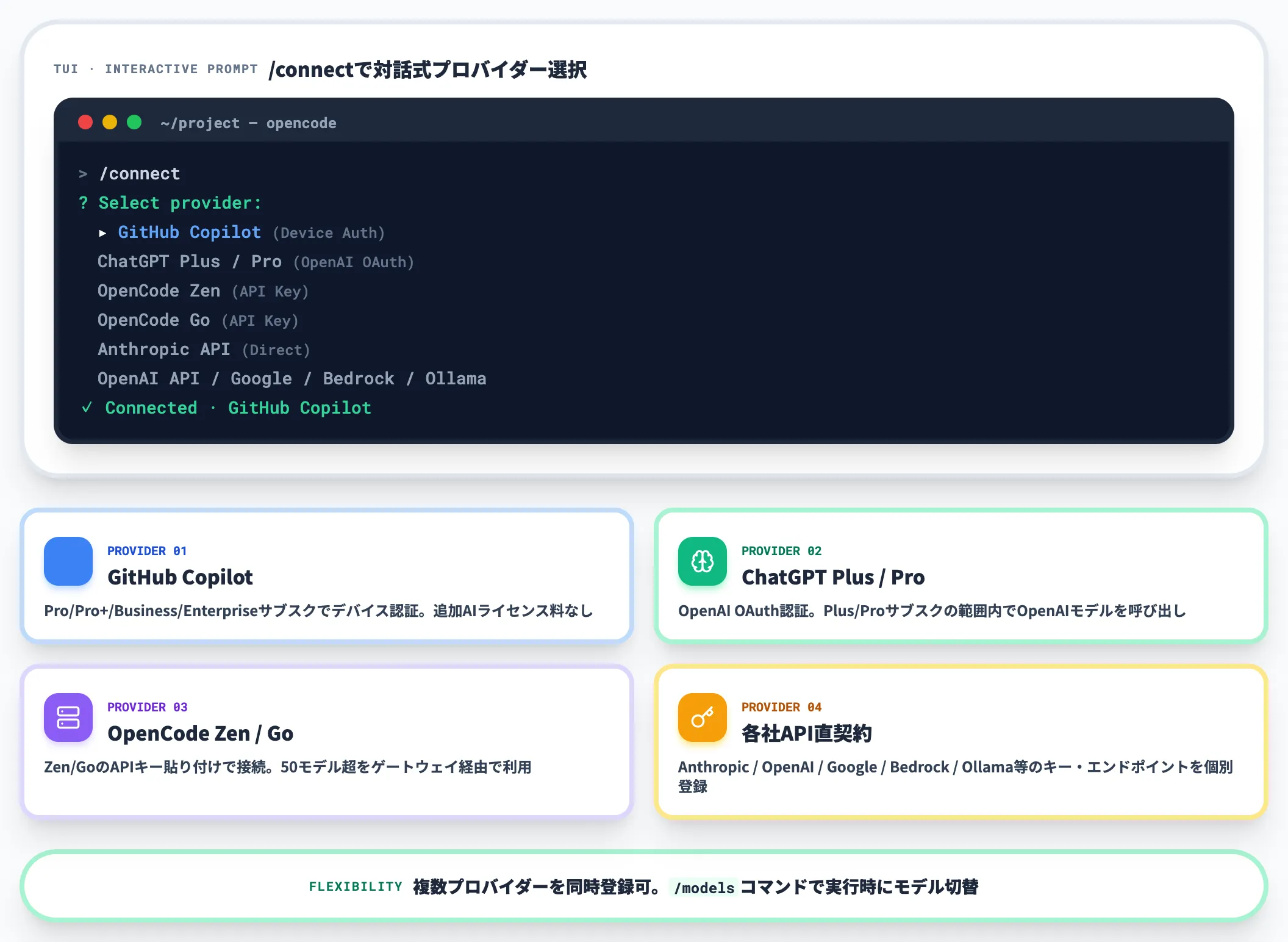
OpenCodeを起動後、まず実行するのが「/connect」コマンドです。
対話式でプロバイダー選択画面が表示され、以下のいずれかを選びます。
-
GitHub Copilot
Copilot Pro/Pro+/Business/EnterpriseのサブスクでGitHubデバイス認証を通す。追加のAIライセンス料はなく、Copilotプランで提供中のモデルにアクセスできる(具体的なモデル一覧はサインイン後に「/models」で確認)
-
ChatGPT Plus / Pro
OpenAIのOAuth認証を通し、Plus/Proサブスクの範囲内でOpenAIモデルを呼び出す
-
OpenCode Zen / Go
Zen/GoのAPIキーを貼り付けて接続
-
各社API直契約
Anthropic・OpenAI・Google・Bedrock・Ollama等のAPIキー・エンドポイントを個別に登録
認証は複数プロバイダーを同時登録でき、「/models」コマンドで実行時にモデルを切り替えられます。
「基本はGitHub Copilotで無料枠を使い、大規模リファクタリング時だけClaude Opusに切り替える」という運用も1つの認証設定で回せます。
/initとAGENTS.mdでプロジェクト初期化
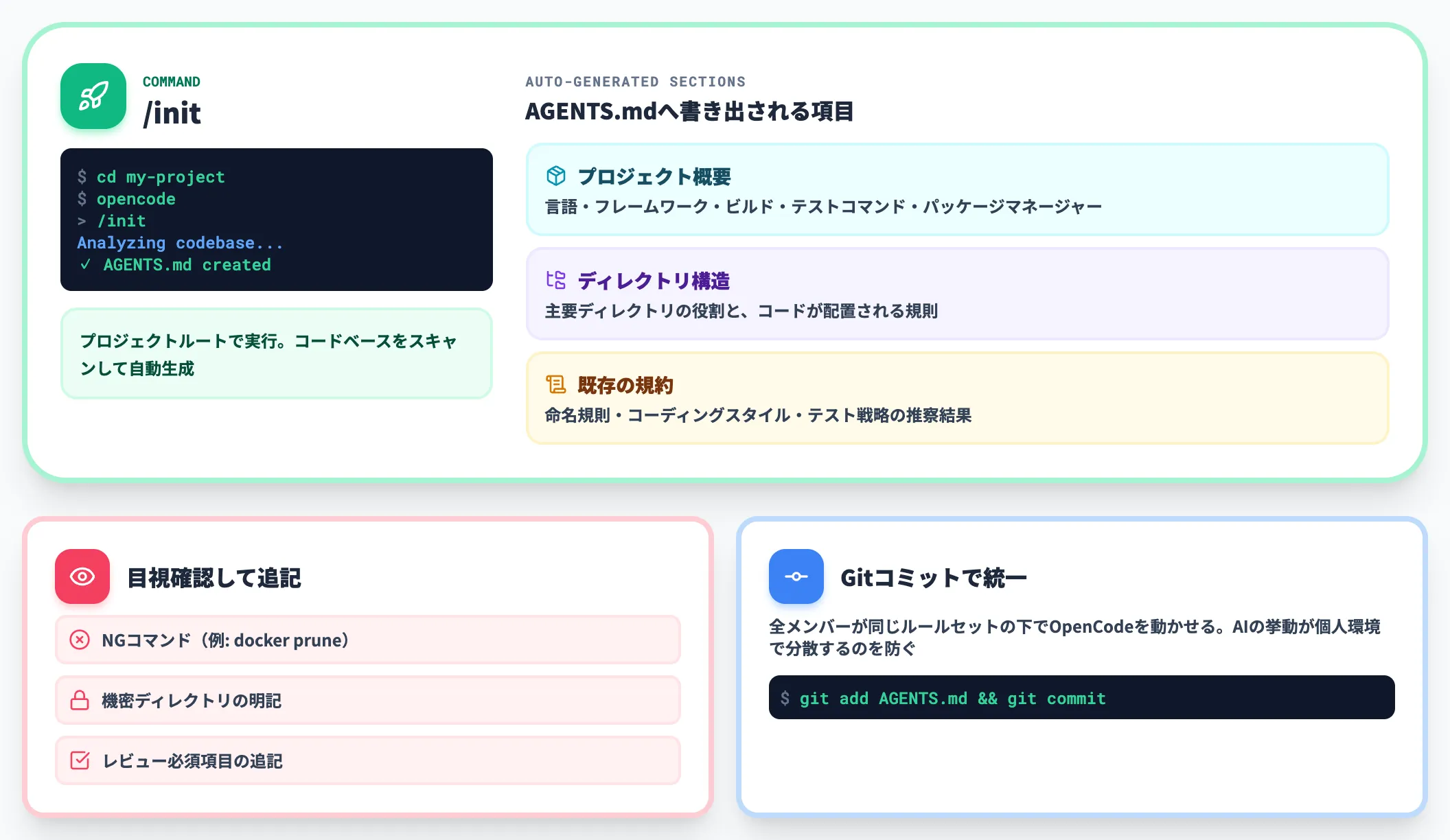
インストールと認証が済んだら、対象プロジェクトのルートで「opencode」を起動し、「/init」コマンドを実行します。
OpenCodeが自動でコードベースをスキャンし、以下の項目を「AGENTS.md」にまとめます。
-
プロジェクト概要
言語・フレームワーク・ビルドコマンド・テストコマンド・パッケージマネージャー
-
ディレクトリ構造
主要ディレクトリの役割と、コードが配置される規則
-
既存の規約
命名規則・コーディングスタイル・テスト戦略の推察結果
生成された「AGENTS.md」は、必ず一度目視で確認し、チーム固有のルール(NGコマンド・機密ディレクトリ・レビュー必須項目)を追記します。
このファイルをGitにコミットしておくと、全メンバーが同じルールセットの下でOpenCodeを動かせるため、AIの挙動が個人環境で分散するのを防げます。
初期化が終わったら、「opencode」を起動し、「this project」『このプロジェクトについて要約して』のように日本語で指示できるかを確認します。
問題なく動けば、その環境がOpenCodeの実運用ラインに乗ったことになります。

OpenCodeとClaude Code、Codexの使い分け
CLIコーディングエージェントの三大候補は、Claude Code・OpenCode・Codex CLIの3つに絞り込まれつつあります。
各ツールの提供元・課金構造・強みが明確に分かれてきたため、「どれか1つ選ぶ」より「どのケースでどれを主に使うか」を設計する段階に入っています。
3ツール比較表
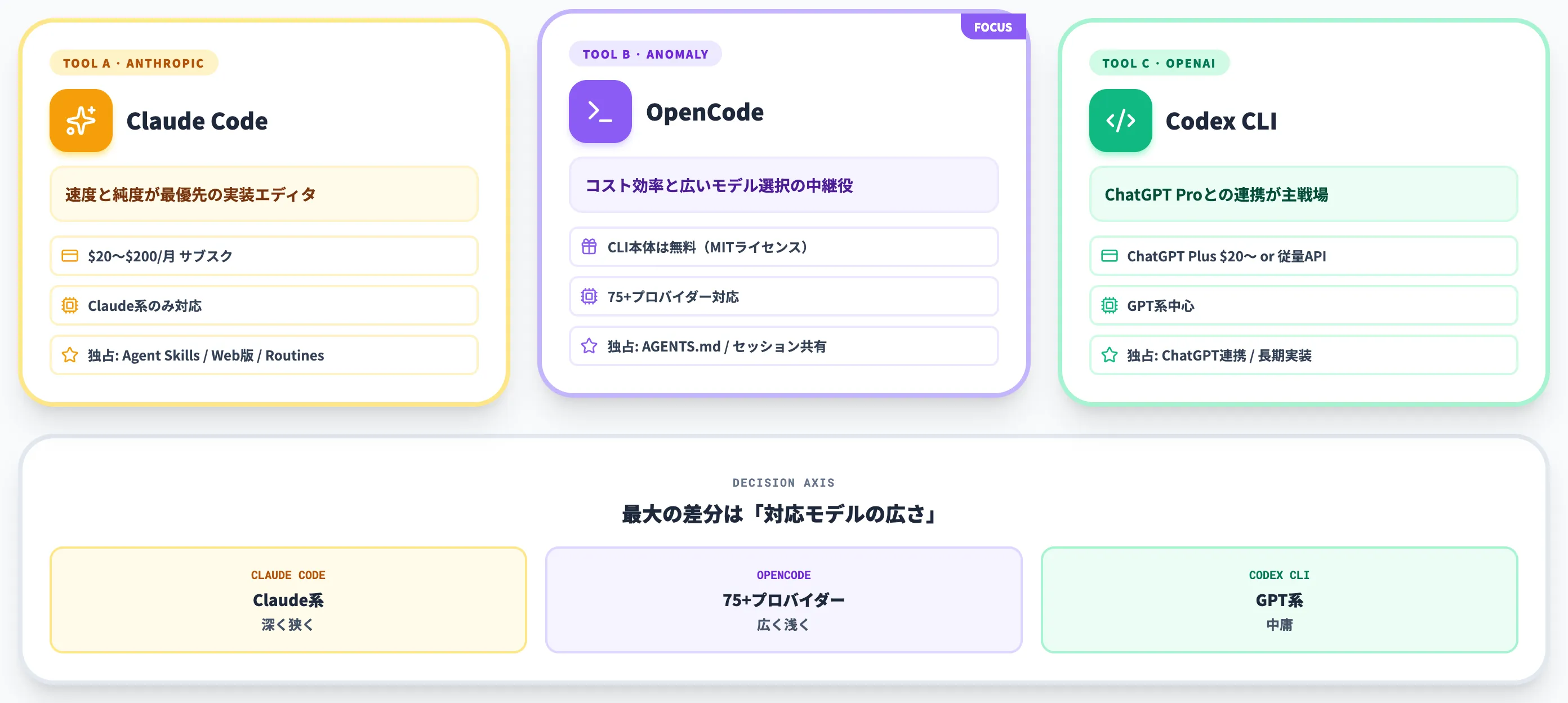
以下の表で、Claude Code・OpenCode・Codex CLIの主要スペックを整理しました。
| 項目 | Claude Code | OpenCode | Codex CLI |
|---|---|---|---|
| 提供元 | Anthropic | Anomaly(旧SST) | OpenAI |
| CLI本体のライセンス | 商用 | MIT(オープンソース) | オープンソース(Rust実装) |
| モデル・サービス利用 | Claude API/Pro/Max/Enterprise | 各社API・Zen・Go・Copilot等を持ち込み | ChatGPTプラン or OpenAI API |
| 対応モデル | Claude系のみ | Claude / OpenAI / Google / ローカル等75+ | GPT系中心 |
| CLI利用料 | $20〜$200/月(サブスク) | 無料(モデル代のみ) | ChatGPT Plus $20〜 or 従量API |
| サブエージェント | Subagents標準搭載 | General/Explore/Scout標準搭載 | 部分対応 |
| MCP対応 | 標準 | 標準 | 標準 |
| LSP | 標準対応 | 有効化して利用 | 標準対応 |
| 独占機能 | Agent Skills / Web版 / Routines | AGENTS.md / セッション共有 | ChatGPT連携・長期エンジニアリング |
この表の最大の差分は「対応モデル」の柱です。
Claude CodeがClaude系に限定され、Codex CLIがGPT系中心である一方、OpenCodeは全モデルを1つのCLIで扱えるため、モデル選択の広さが競争軸として際立ちます。
OpenCodeが第一候補になるケース
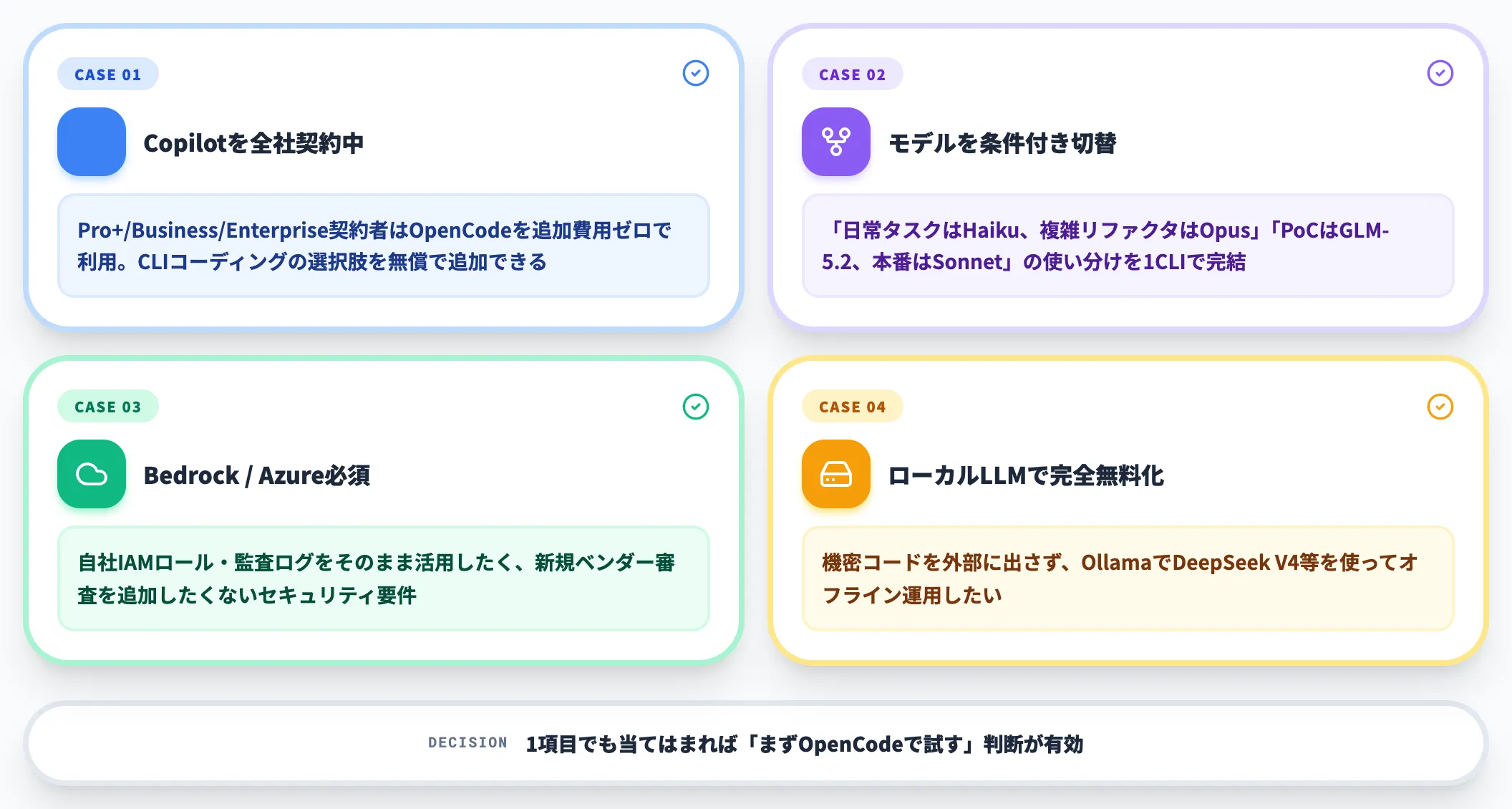
以下のいずれかに当てはまる場合、OpenCodeが有力な第一候補になります。
-
既にGitHub Copilotを全社契約している
Pro+/Business/Enterprise契約者はOpenCodeを追加費用ゼロで利用でき、CLIコーディングの選択肢を無償で追加できる
-
モデルを条件付きで切り替えたい
「日常タスクはHaiku、複雑なリファクタリングはOpus」「PoCはGLM-5.2、本番はClaude Sonnet」のような使い分けを1つのCLIで完結させたい
-
セキュリティ要件でBedrock / Azure OpenAI経由が必須
自社IAMロール・監査ログの仕組みをそのまま活用したく、新規ベンダー審査を追加したくない
-
オープンモデル・ローカルLLMで完全無料化したい
機密コードを外部に出さず、Ollamaで動かすDeepSeek V4等を使ってオフライン運用したい
Claude CodeやCodex CLIを併用すべきケース
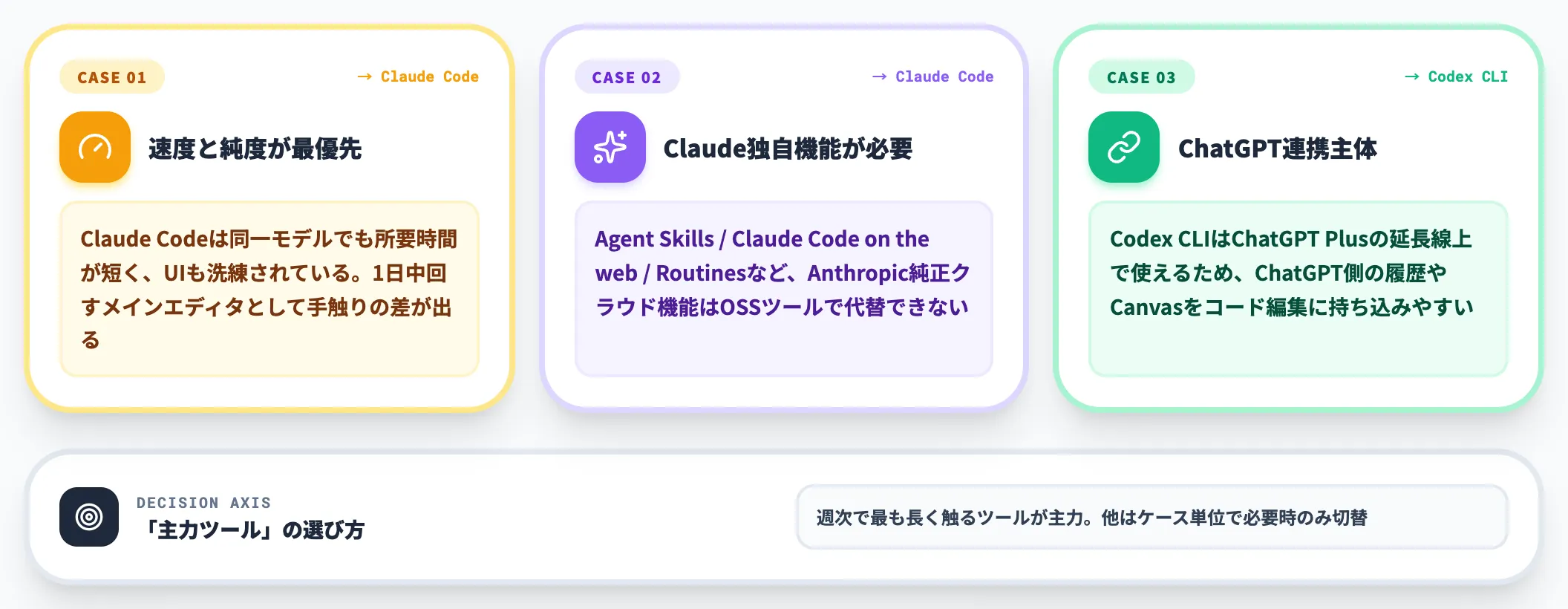
一方、以下のケースではClaude CodeまたはCodex CLIを主力に据える方が現実的です。
-
速度と純度が最優先
Claude Codeは同一モデルでもOpenCodeより所要時間が短く、UIも洗練されている。個人開発者が1日中回すメインエディタとしては手触りの差が出る
-
Claude独自機能(Agent Skills・Web版・Routines)を使いたい
Anthropic純正のClaude Code Agent SkillsやClaude Code on the webのクラウド機能は、OSSツールでは代替できない
-
ChatGPT ProからのDeep Coding連携
Codex CLIはChatGPT Plusの延長線上で使えるため、ChatGPT側の履歴やCanvasをコード編集に持ち込みやすい
実運用は「両方使う」が現実解
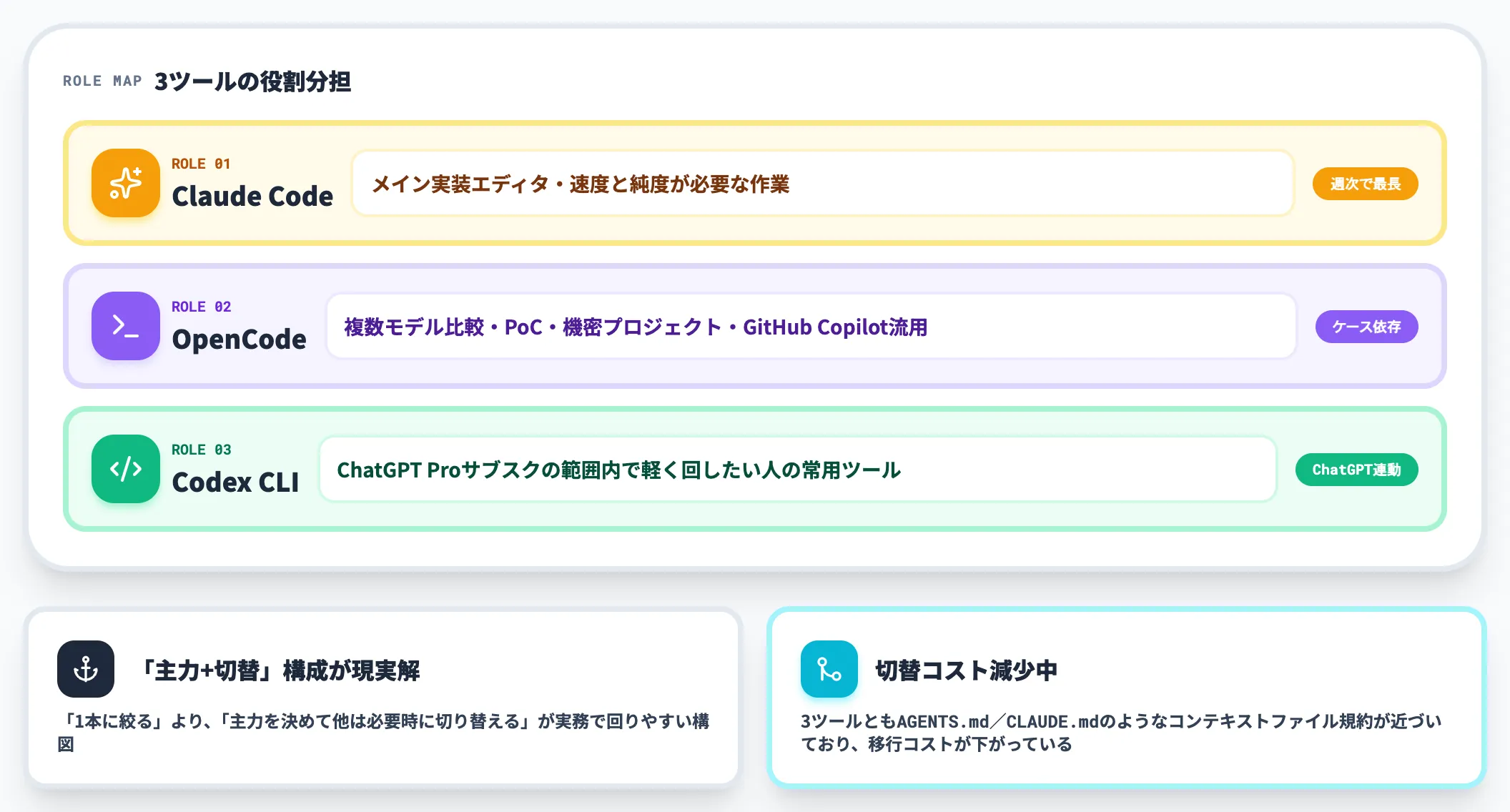
各種比較記事とベンチマークが示しているのは、優劣ではなく役割分担という結論です。
- Claude Code: メインの実装エディタ、速度と純度が必要な作業(週次で最も長く触る)
- OpenCode: 複数モデル比較・PoC・機密プロジェクト・GitHub Copilot流用シーン
- Codex CLI: ChatGPT Proサブスクの範囲内で軽く回したい人の常用ツール
「1本に絞る」より、「主力を決めて、他は必要時に切り替える」構成が実務では回りやすい構図です。
3ツールとも「AGENTS.md」/「CLAUDE.md」のようなプロジェクト固有コンテキストファイルの規約が近づいており、切り替えコストも下がりつつあります。
【関連記事】
Claude CodeとCodexを徹底比較!料金や性能・サブエージェントの違いと選び方を解説
OpenCode導入で押さえたい3つの注意点
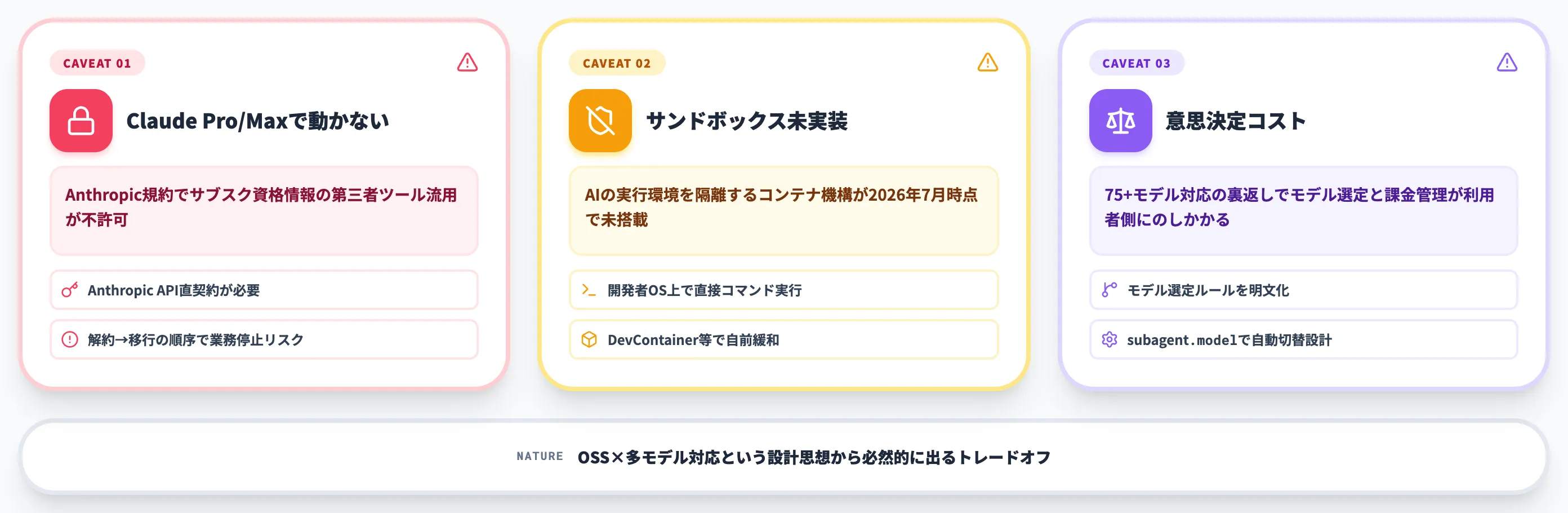
OpenCodeを導入検討する際、事前に把握しておかないと運用開始後に手戻りを起こしやすい制約が3つあります。
いずれも「ツールの欠陥」ではなく、オープンソース・多モデル対応という設計思想から必然的に出てくるトレードオフです。
Claude Pro/Maxサブスクではもう動かせない
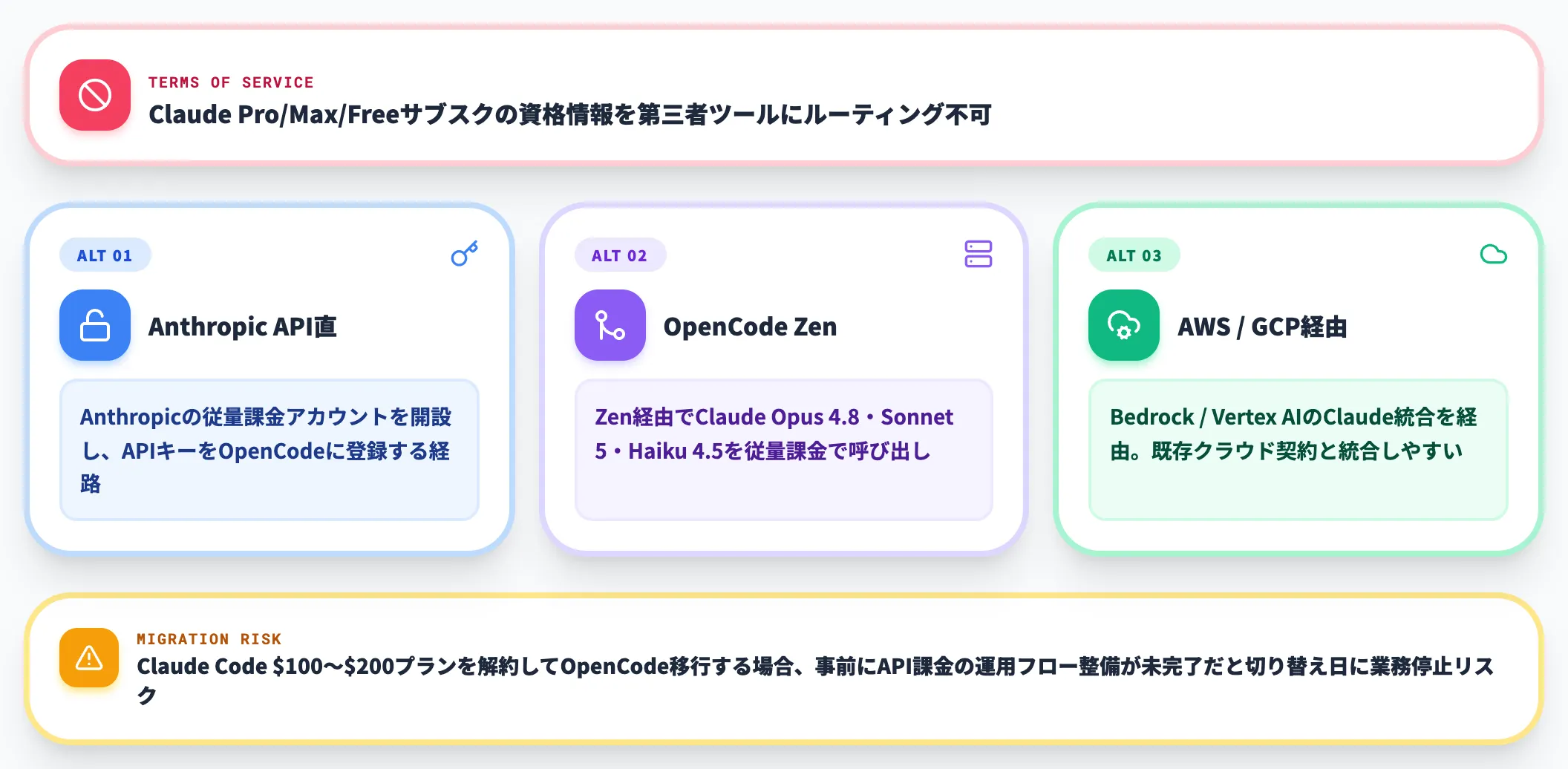
前述の通り、Claude Codeの利用規約ではClaude Pro/Max/Freeサブスクリプションの資格情報を第三者ツールにルーティングすることが許可されていません。
現在OpenCodeでClaudeモデルを利用する場合、以下のいずれかが必要です。
-
Anthropic API直契約
Anthropicの従量課金アカウントを開設し、APIキーをOpenCodeに登録
-
OpenCode Zen
Zen経由でClaude Opus 4.8・Sonnet 5・Haiku 4.5を従量課金で呼び出す
-
AWS Bedrock / GCP Vertex AI
クラウド事業者のClaude統合を経由(既存のクラウド契約と統合しやすい)
過去にOpenClaw等のOSSツールでClaude Proサブスクを流用していたユーザーは、契約体系の切り替えが完了しないとOpenCodeが起動できない状態になっています。
Claude Codeの月額$100〜$200プランを解約してOpenCodeに移行しようとしている場合、事前にAPI課金の運用フローを整えておかないと、切り替え日に業務が止まるリスクがあります。
サンドボックス機能は未実装——権限設計は自前で
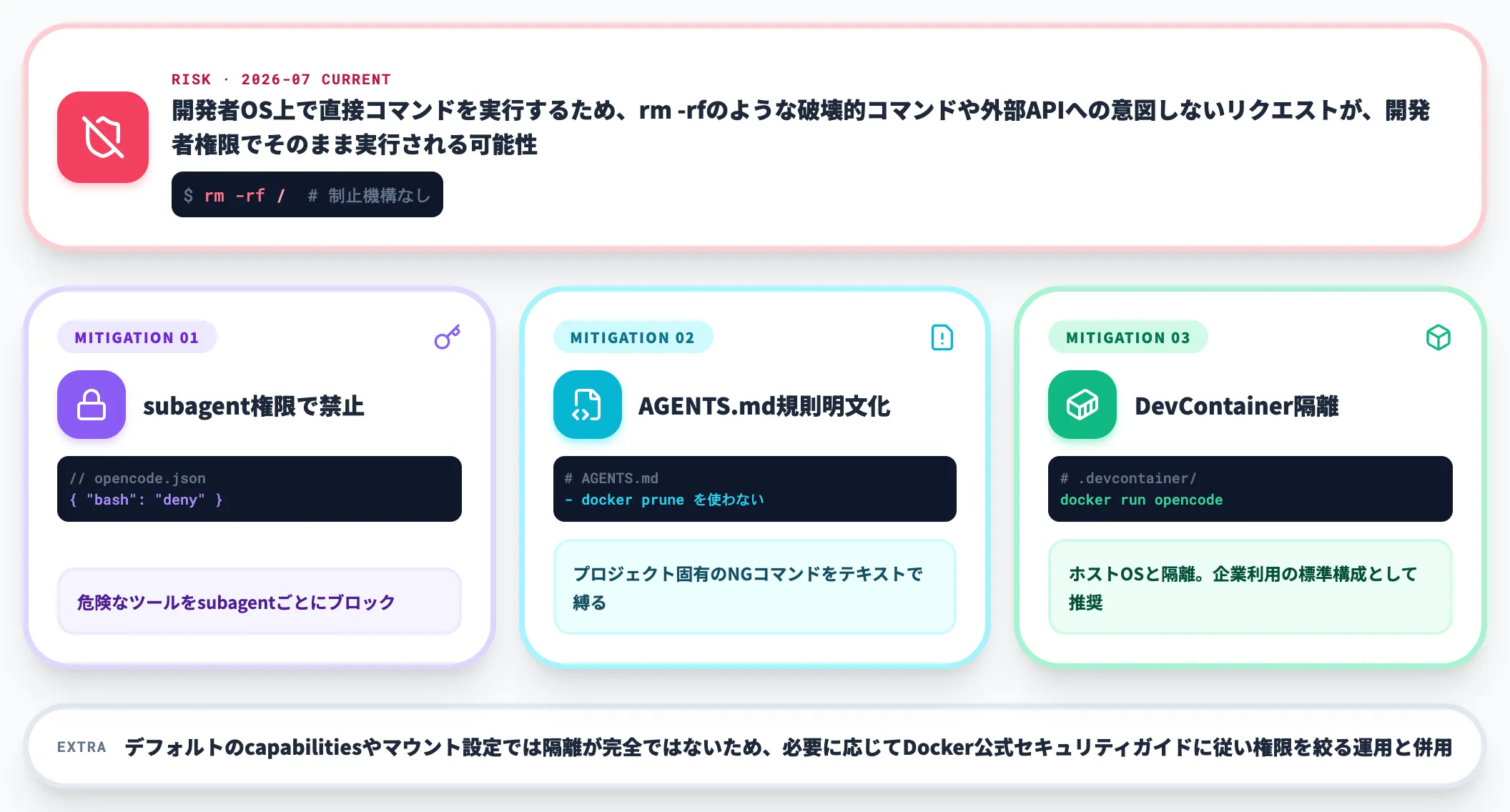
OpenCodeには、AnthropicのClaude Code Securityや、Anthropic DevContainerのような、AIの実行環境をコンテナ隔離するサンドボックス機構が2026年7月時点で未実装です。
OpenCodeは開発者のOS上で直接コマンドを実行するため、「rm -rf」のような破壊的コマンドや、外部APIへの意図しないリクエストが、開発者の権限でそのまま実行される可能性があります。
この制約に対応する実務上の緩和策として、以下の3つが挙げられます。
-
subagentの権限設定
「opencode.json」でsubagentごとに「bash: deny」のように危険なツールをブロック
-
AGENTS.mdでのNGコマンド明文化
「AGENTS.md」に「本プロジェクトでは『docker prune』を使わない」等のルールを明記し、AIの挙動を抑える
-
DevContainer / Docker内でOpenCodeを稼働
Anthropic純正の代替として、Dev Container内で「opencode」を起動し、ホストOSと隔離する
企業利用でセキュリティ要件が厳しい場合、Docker内での稼働を標準構成にすることで、ホストOSへ直接影響するリスクを大きく下げられます。デフォルトのcapabilitiesやマウント設定では隔離が完全ではないため、必要に応じてDocker公式のセキュリティガイドに従って権限を絞る運用と併用します。
モデル選定と課金の管理負荷が個人利用でも発生する

OpenCodeの最大の強みである「75以上のプロバイダー対応」は、裏を返すとモデル選定と課金管理の意思決定を利用者側に押し付ける構造でもあります。
Claude Codeなら「Claude Opus/Sonnet/Haikuからどれか選ぶ」だけで済むところ、OpenCodeでは以下の項目を毎回考える必要があります。
- タスクの複雑度に対して、Sonnet 4.6で足りるか、Opus 4.8が必要か
- Zenの従量課金にするか、Goの定額にするか、BYO Keyで既存契約を活かすか
- コンテキスト長(GPT-5.5の272Kと10K以上の差など)をどう使い分けるか
- モデル別のプライバシー条件(Zen/Goともモデル単位で保持・利用条件が異なる)を要件に照らして選ぶか
個人開発者にとっても、この意思決定は毎日発生します。
「日常タスクはGPT-5.4 Mini、詰まった箇所だけOpus 4.8」というように、明示的なルールを作らないと、料金体系のメリットが逆に「毎回判断コスト」に転化します。
支援経験からは、OpenCodeを社内標準化する場合、モデル選定ルールを「AGENTS.md」か社内Wikiに明文化し、subagentの「model」パラメータで自動切替まで作り込んでおくのが安定運用のパターンです。
OpenCodeを実務で使う: 個人・小規模チーム・全社標準化の分岐
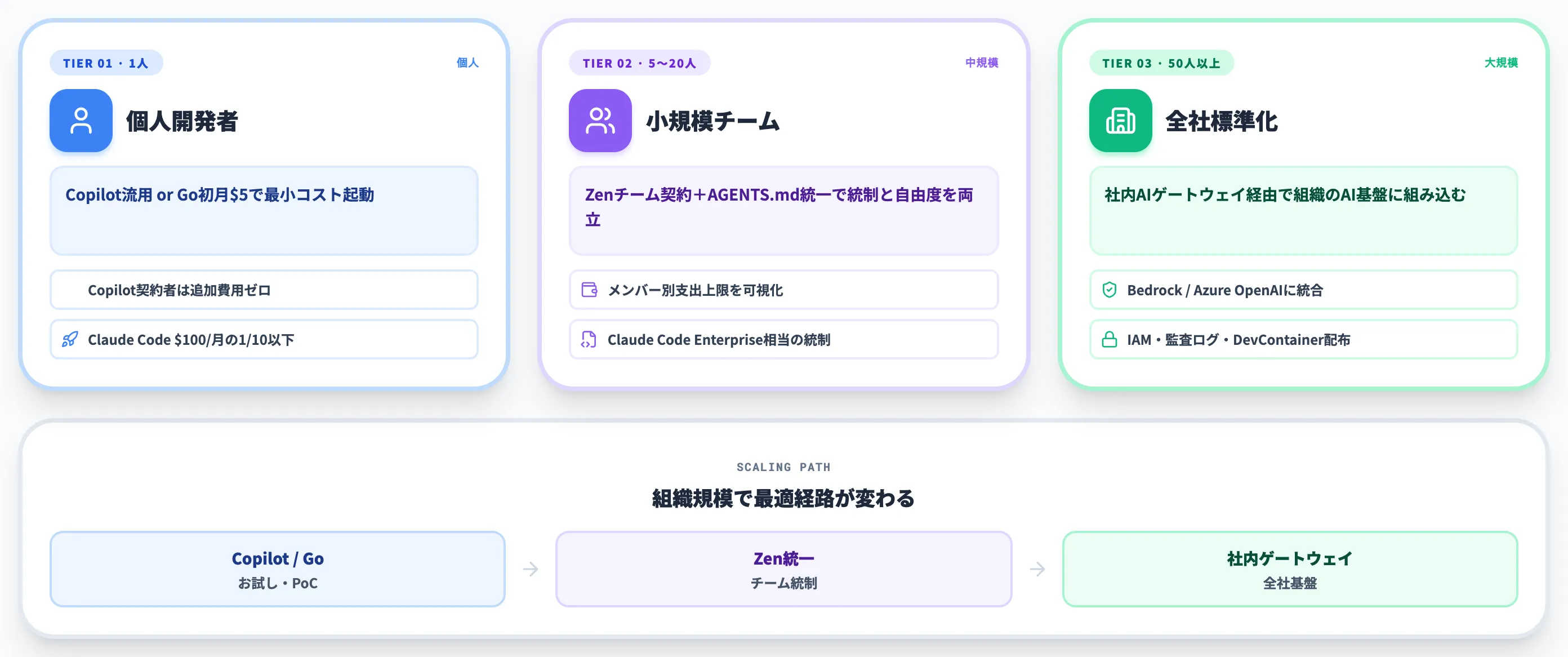
OpenCodeの導入方法は、組織規模と目的で最適解が変わります。
「個人開発者が試す」「5〜20名の小規模チームで採用する」「全社標準として展開する」の3層で、それぞれ推奨経路が異なるため、実務での判断軸を整理します。
個人開発者: GitHub Copilot流用またはGoが第一候補
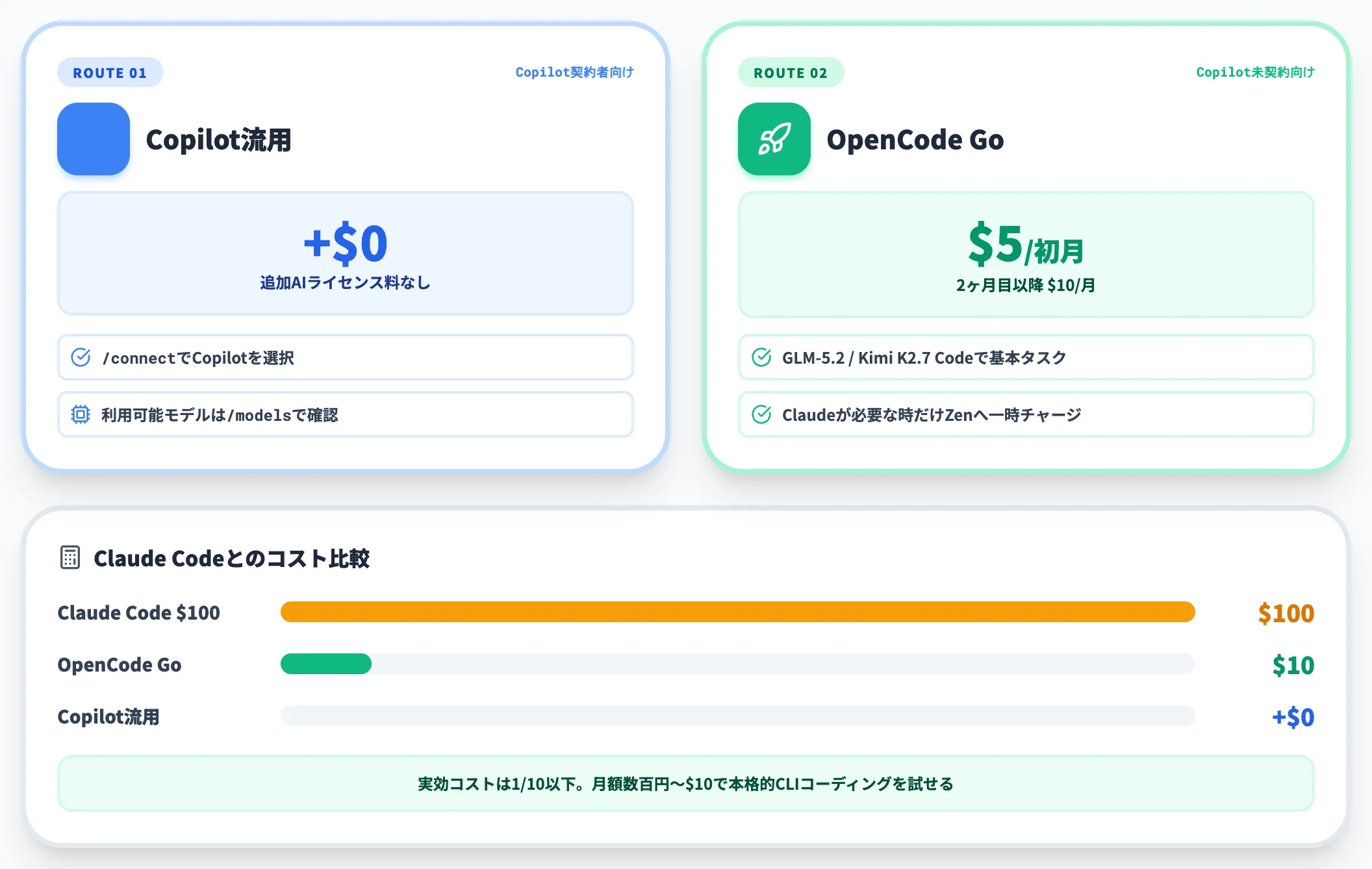
個人開発者が最初にOpenCodeを試す場合、料金面で最もローリスクなのは以下の2ルートです。
-
既にGitHub Copilotを契約している
「/connect」でGitHub Copilotを選択し、追加のAIライセンス料なしにOpenCodeを稼働できる。利用できるモデルはCopilotプラン・地域・GitHub側の提供状況に依存するため、「/models」で確認
-
Copilot未契約でとにかく安く始めたい
OpenCode Goの初月$5を試し、GLM-5.2やKimi K2.7 Codeで基本タスクを回す。Claudeが必要な時だけZenに一時的にチャージ
この2ルートは、Claude Codeの$100/月プランと比べて実効コストが1/10以下に収まります。
「まず動かして品質を確認する」段階の個人開発者にとって、月額数百円〜$10で本格的なCLIコーディングを試せる環境が整っている、というのが2026年7月時点のリアルです。
小規模チーム(5〜20名): Zen+AGENTS.md統一が現実解
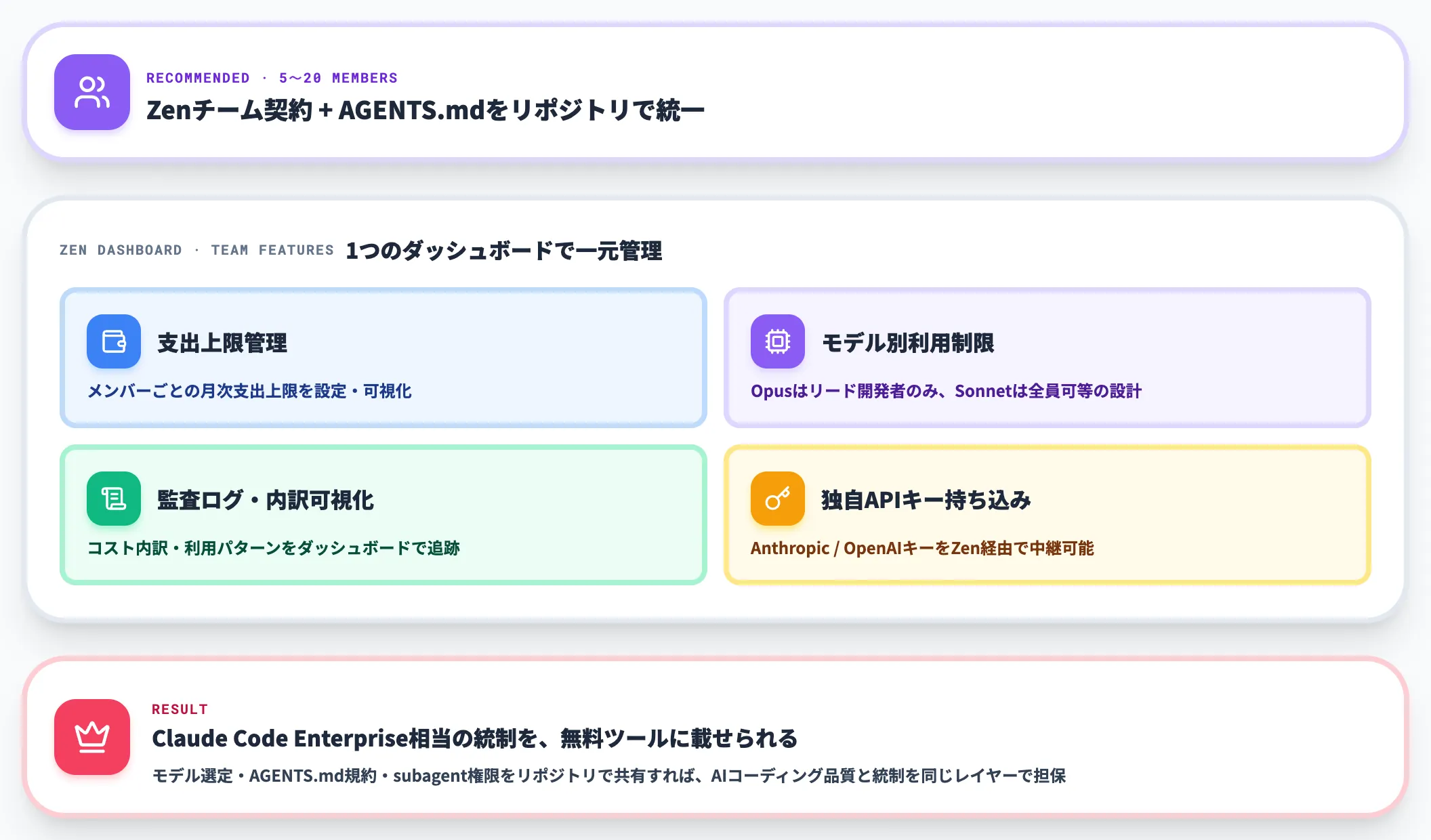
5〜20名程度のチームで導入する場合、推奨するのはOpenCode Zenをチームアカウントで契約し、「AGENTS.md」をリポジトリで統一する構成です。
Zenのチーム機能では、以下を1つのダッシュボードで管理できます。
- メンバーごとの月次支出上限
- モデル別の利用制限(Opusはリード開発者のみ、Sonnetは全員可)
- 監査ログとコスト内訳の可視化
- 独自APIキー(Anthropic / OpenAI)の持ち込み(Zenは中継役に)
この構成の利点は、Claude Code Enterprise相当の統制を、OpenCodeという無料ツールに載せられる点です。
チームで利用するモデル選定・「AGENTS.md」のプロジェクト規約・subagentの権限設定をリポジトリで共有すれば、AIコーディングの品質と統制を同じレイヤーで担保できます。
全社標準化: 社内AIゲートウェイ経由の展開
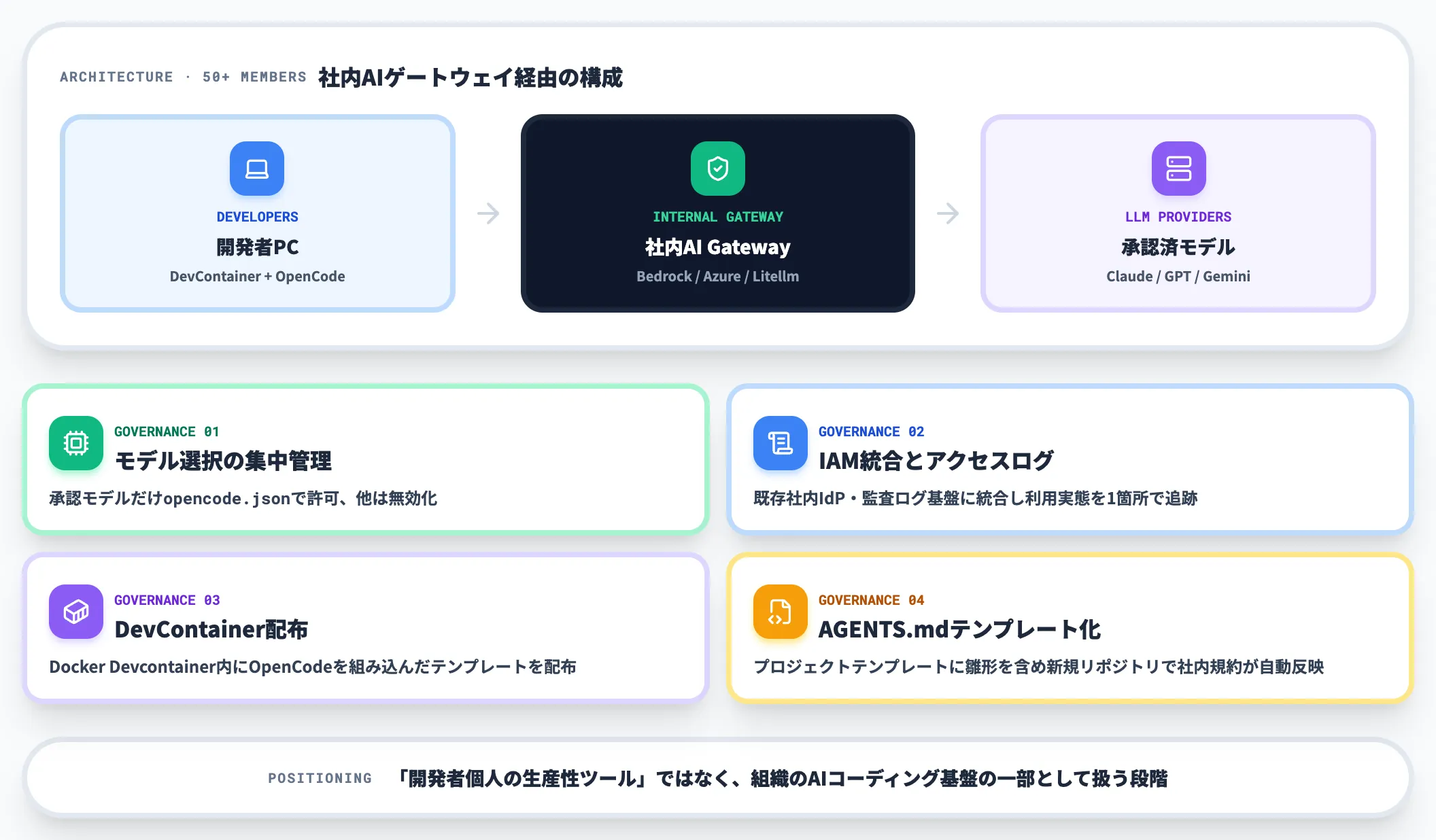
全社(50名〜)で標準化する場合、Zen直接契約ではなく社内AIゲートウェイ経由でOpenCodeを稼働させる構成を推奨します。
具体的には、AWS Bedrock・Azure OpenAI・自社Litellm・OpenRouter Enterprise等の社内単一APIエンドポイントにOpenCodeを向け、以下の統制を効かせます。
-
モデル選択の集中管理
社内で承認したモデルだけを「opencode.json」で許可し、他プロバイダーは無効化
-
IAM統合とアクセスログ
既存の社内IdP・監査ログ基盤に統合し、AIコーディングの利用実態を1箇所で追跡
-
DevContainer + OpenCode配布
Docker Devcontainer内にOpenCodeを組み込んだテンプレートを配布し、開発者ごとの環境差異を吸収
-
「AGENTS.md」テンプレート化
プロジェクトテンプレートに「AGENTS.md」の雛形を含め、新規リポジトリ作成時から社内規約が反映されるようにする
この段階では、OpenCodeは「開発者個人の生産性ツール」ではなく、組織のAIコーディング基盤の一部として扱います。
導入判断の際は、既存のCopilot Business/Enterprise契約と、OpenCodeを組み合わせた費用対効果の試算(Copilot利用者はOpenCodeの追加コスト実質ゼロ、非Copilot利用者はZenで従量課金)が意思決定の中心になります。

開発者のAIコーディングから組織のバックオフィス自動化へ
OpenCodeでCLIコーディング環境を整えると、実装・レビュー・テスト生成のサイクルは速くなります。次に問題になるのは開発チームの外側——経理・請求書処理・営業バックオフィス・情シスなど、組織全体の業務をAIに任せていく段階です。
CLIコーディングは開発者向けのツール、バックオフィス業務の自動化は別レイヤーの話であり、両者は同じ製品で解けるわけではありません。組織側では、Teamsから呼び出す業務Agentと、権限・実行ログ・監査を一元管理する基盤を別途持つ設計が現実的になります。
AI総合研究所のAI Agent Hubは、自社Azureテナント内で動くエンタープライズAIエージェント基盤です。Teamsから呼び出す9種の業務Agent(経費申請・請求書受領・AI-OCR・自動入力等)と管理ダッシュボードで、バックオフィス側の自動化を担う位置づけになります。開発チームのAIコーディング効率化と並走させて、組織側の業務レイヤーもAIに寄せていきたい場合の選択肢の1つです。
AI総合研究所の専任チームが、Microsoft MVP・Solution Partner認定の実績をもとに、バックオフィス業務エージェント基盤の設計から運用まで伴走支援します。AI Agent Hubのサービスページで、組織側の業務Agent運用の全体像をご確認ください。
組織のバックオフィス業務をAI Agentへ

Teamsから9種の業務Agentで自動化
Teamsから呼び出す9種の業務Agent(経費申請・請求書受領・AI-OCR・自動入力等)と管理ダッシュボードで、バックオフィス業務の自動化を自社Azureテナント内で運用できるエンタープライズAIエージェント基盤です。
まとめ
本記事では、OpenCodeの位置づけ・機能・料金体系・競合比較・実務での使い分けを整理しました。
- OpenCodeとは: MITライセンスのオープンソースAIコーディングエージェント。Anomaly社(旧SST)が運営し、GitHub 18万スター・900+コントリビューター規模のOSSプロジェクト
- 選ばれる背景: AnthropicによるClaude Pro/Max資格情報の第三者ツール流用禁止方針、GitHub Copilot認証の公式化(2026年1月)、独立ベンチでClaude Code超えの数値(総合0.816・タスク単価$1.03)が揃った
- 主要機能: Plan/Buildエージェント切替、General/Explore/Scoutのsubagent、AGENTS.md統一、有効化して使うLSP補助、MCP対応、マルチセッション並列
- 料金体系: 本体無料+BYO Key/Zen(従量課金・50モデル超)/Go($10月額・オープンモデル13種)の3経路
- 競合との使い分け: Claude Codeは速度と純度、Codex CLIはChatGPT連携、OpenCodeはコスト効率と広いモデル選択——実務では併用が現実解
- 注意点: Claude Pro/Maxサブスクは不可(API直・Zen経由が必須)/サンドボックス未実装(DevContainer等で緩和)/モデル選定と課金管理の意思決定コスト
- 実務での分岐: 個人はCopilot流用またはGo、小規模チームはZen+AGENTS.md統一、全社は社内AIゲートウェイ経由
2026年に入って、CLIコーディングエージェントは「商用サブスクかOSSか」ではなく「どの契約経路をどう束ねるか」の議論に軸足が移りました。
既にGitHub CopilotやClaude Codeを導入している組織にとって、OpenCodeは「置き換え」ではなく「追加の選択肢」として、モデル選定と契約設計の自由度を広げる存在になっています。
自社の契約状況・セキュリティ要件・開発者の使い方に合わせて、3経路のどれを主軸にするかを設計し、CLIコーディングと業務エージェント基盤を一貫した統制ラインで運用することが、これからのAI活用の実務的な出発点になります。









