この記事のポイント
 知識蒸留は教師の確率分布まで生徒に伝えるため、同サイズのスクラッチ学習より精度を引き上げやすい
知識蒸留は教師の確率分布まで生徒に伝えるため、同サイズのスクラッチ学習より精度を引き上げやすい- DeepSeek R1の蒸留群はMITで公開され、Qwen-32BベースでもAIME 2024 72.6%とOpenAI o1-miniを上回る
- 蒸留はFT・量子化と排他ではなく、用途別に組み合わせて推論コストを最大1/10程度まで圧縮できる
- OpenAIは競合モデル開発への出力利用を、Anthropicは無断のmodel distillationを制限。外部モデル化の用途ではオープンウェイト系を選ぶのが現実解
- 多くの企業はゼロから蒸留せず、既存の蒸留モデル+少量FTで十分に投資回収できる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
知識蒸留(Knowledge Distillation)は、巨大な教師モデルが持つ判断の傾向まで小型の生徒モデルへ移し、軽さと精度の両立を狙う機械学習の手法です。
2015年にGeoffrey Hintonらが提案して以来、画像認識やBERT世代を経て、いまはDeepSeek R1の蒸留モデル群やSakana AIのTAIDなど、LLMの実用化を支える中核技術として再注目されています。
一方で2025年以降、OpenAIでは競合AIモデル開発への出力利用が(プラットフォーム内蒸留などの例外を除いて)制限され、Anthropicでは事前承認のないmodel distillationが明示禁止されるなど、自社で「どこまで蒸留してよいか」を判断する必要性も高まりました。
本記事では、知識蒸留の仕組みと手法、ファインチューニング・量子化との違い、実務的な効果と制約、代表的な蒸留モデル、PyTorchによる実装例、ライセンス上の論点、そして企業が導入判断する際の軸を、2026年6月時点の最新情報で体系的に解説します。
目次
On-Policy Distillation——2026年に広がる新潮流
代表的な蒸留モデル——DeepSeek R1・Sakana TAID・OpenAI Distillation API
Sakana AI TAIDとTinySwallow-1.5B
蒸留損失関数(KL Divergence + CE Loss)
知識蒸留とは?大規模モデルの能力を小型モデルに移す技術
知識蒸留(Knowledge Distillation)は、高性能な「教師モデル」が持つ判断の傾向ごと、より小さな「生徒モデル」に転移させる機械学習の手法です。
通称として「AIの蒸留」「モデル蒸留」「蒸留」「蒸留モデル」など複数の呼び方があり、文脈によって使い分けられますが、技術的な正式名称はあくまで知識蒸留です。
本セクションでは、知識蒸留の基本的な仕組みと、いま改めて注目される背景を整理します。


知識蒸留の基本的な仕組み
知識蒸留の中心にあるのは、**「教師モデルが出力する確率分布(ソフトターゲット)を生徒モデルに学習させる」**というアイデアです。
通常の教師あり学習では、生徒モデルに対して「正解クラスは1、それ以外は0」というハードラベルしか渡しません。知識蒸留では、それに加えて教師モデルが出力した「クラスAは0.7、クラスBは0.2、クラスCは0.1」のような滑らかな確率分布を学習対象に追加します。
このソフトターゲットには、「Aが本命だが、AとBは似たクラスでCとは離れている」といったクラス間の関係性まで埋め込まれています。
ハードラベルだけでは伝わらない教師の判断ニュアンスを生徒に渡せるため、同じサイズのモデルをスクラッチで学習させるよりも精度を引き上げやすいのが、知識蒸留の最大の強みです。
ソフトターゲットを使った学習の流れを、Sakana AIが解説図でシンプルに整理しています。
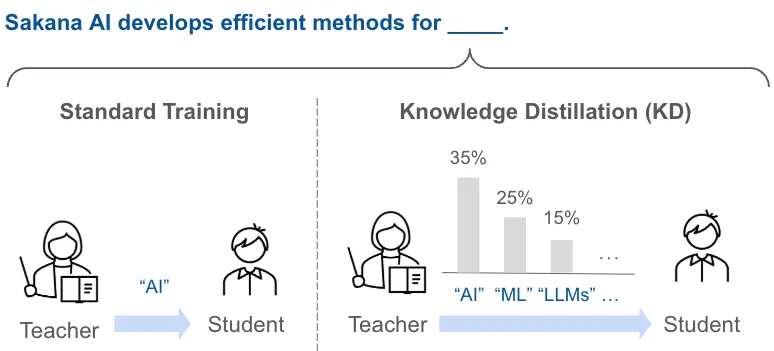
Standard TrainingとKnowledge Distillationの違い(出典:Sakana AI)
ソフトターゲットと温度パラメータの役割
ソフトターゲットを意図的に「より滑らかな分布」に変換するために使われるのが、温度パラメータTです。

通常のSoftmaxでは確率分布が鋭く偏りますが、ロジットを温度Tで割ってからSoftmaxを取ると、確率分布全体がなだらかになります。
| 温度Tの値 | 確率分布の傾向 | 期待される効果 |
|---|---|---|
| T = 1 | 通常のSoftmax。最大確率クラスに大きく寄る | 教師の自信が高いクラスのみ強調される |
| T = 2〜10 | 全クラスに確率が広がる中間的な分布 | クラス間の類似度情報を生徒が学びやすい |
| T → ∞ | 全クラスがほぼ均等な確率になる | 情報が薄まり、学習効果が落ちる |
Hinton et al.(2015)の原論文は、高い温度のSoftmaxで確率分布を滑らかにする効果と、損失をTの二乗で補正する必要性を示しました。実験ではT=2.5〜4、T=20、T=[1,2,5,10]などタスクや教師サイズに応じて幅広く採られています。
実務でも2〜10程度を含めて小さな探索で最適値を決めるのが現実的で、後述する実装セクションのようにグリッドサーチに乗せるのが定石です。
知識蒸留が注目される背景
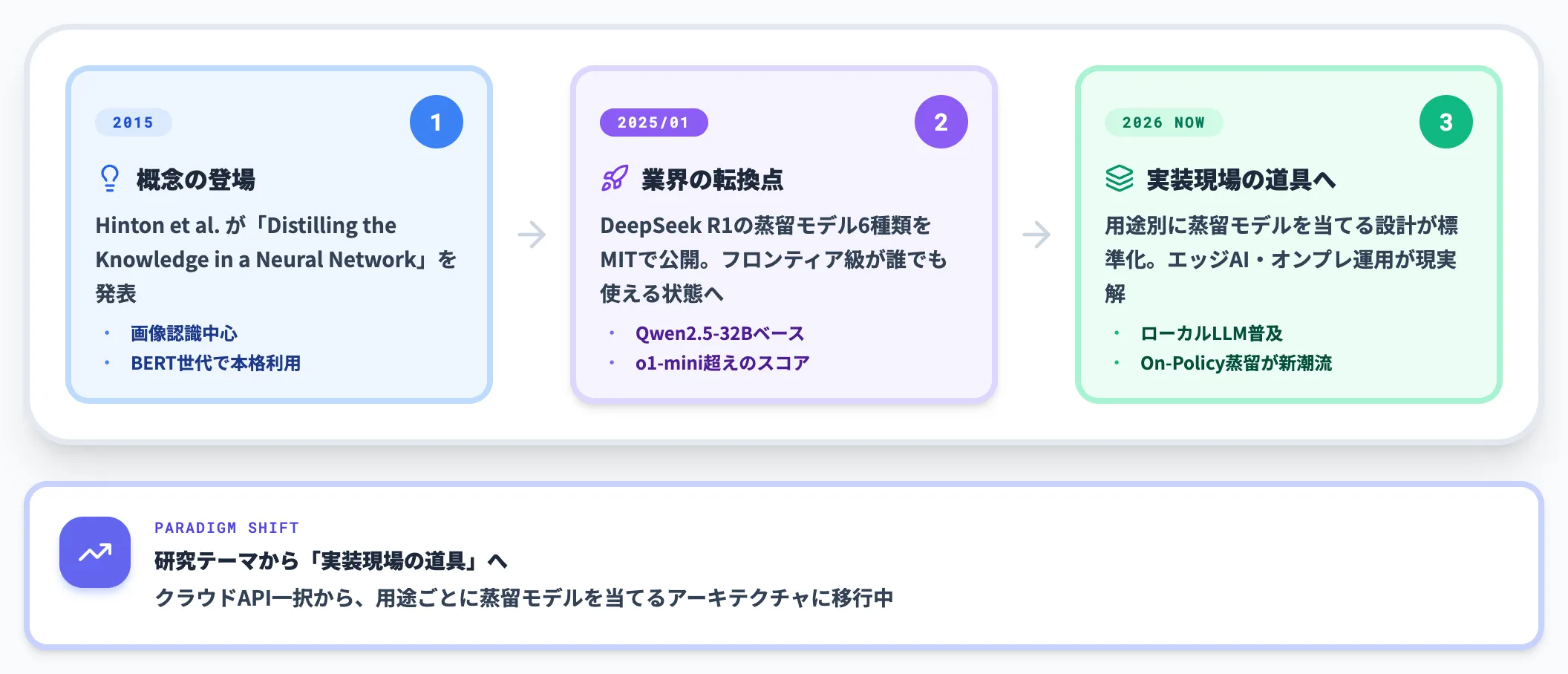
知識蒸留のアイデア自体は2015年にGeoffrey Hintonらが論文「Distilling the Knowledge in a Neural Network」で導入したもので、決して新しい技術ではありません。
それでも2025年以降、再び大きく注目されているのは、大規模言語モデル(LLM)の世代交代に伴って「教師として使えるモデル」が一段とパワフルになり、同時に「生徒モデルをそのまま業務にデプロイしたい」というニーズが急速に増えているためです。
特に2025年1月のDeepSeek R1の登場以降、フロンティアモデル級の推論能力を持つ「蒸留モデル」を、誰でもMITライセンスでダウンロードできる状態が生まれました。
ローカルLLM・エッジAI・社内オンプレ運用といった選択肢が現実的になり、「クラウドAPI一択」から「用途ごとに蒸留モデルを当てる」設計が普通になりつつあります。
つまり知識蒸留は、研究テーマから「実装現場の道具」へと位置づけが変わったタイミングです。
知識蒸留の主要な手法とアプローチの進化
知識蒸留は手法ごとに教師と生徒の動かし方が大きく違い、それぞれ得意領域が異なります。
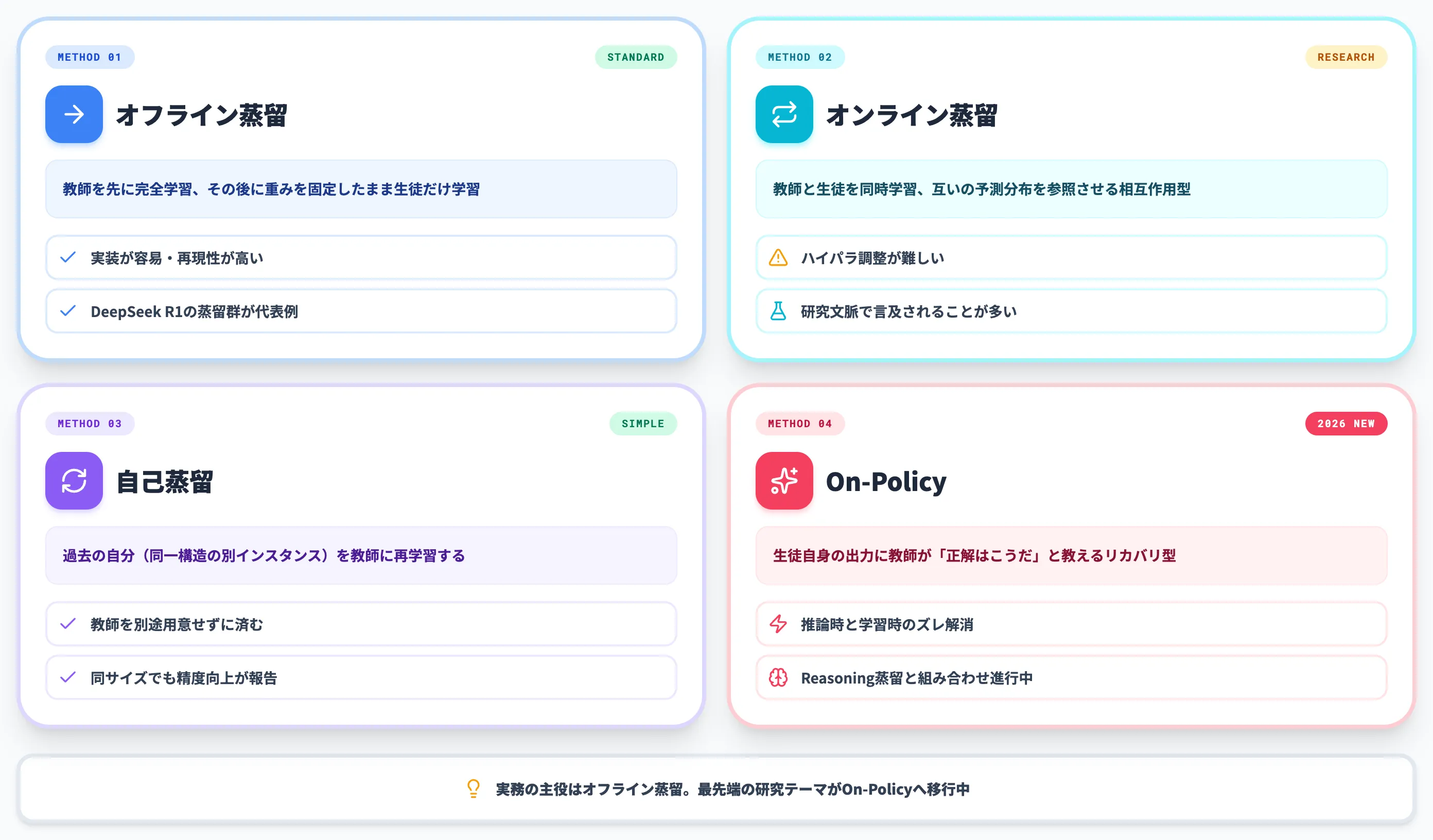
本セクションでは、伝統的な3手法と、2026年に研究と実装の両面で広がっているOn-Policy Distillationまでを整理します。
オフライン蒸留——最も標準的なアプローチ
オフライン蒸留(Offline Distillation)は、先に教師モデルを完全に学習させ、その後で重みを固定したまま生徒モデルだけを学習させる手法です。
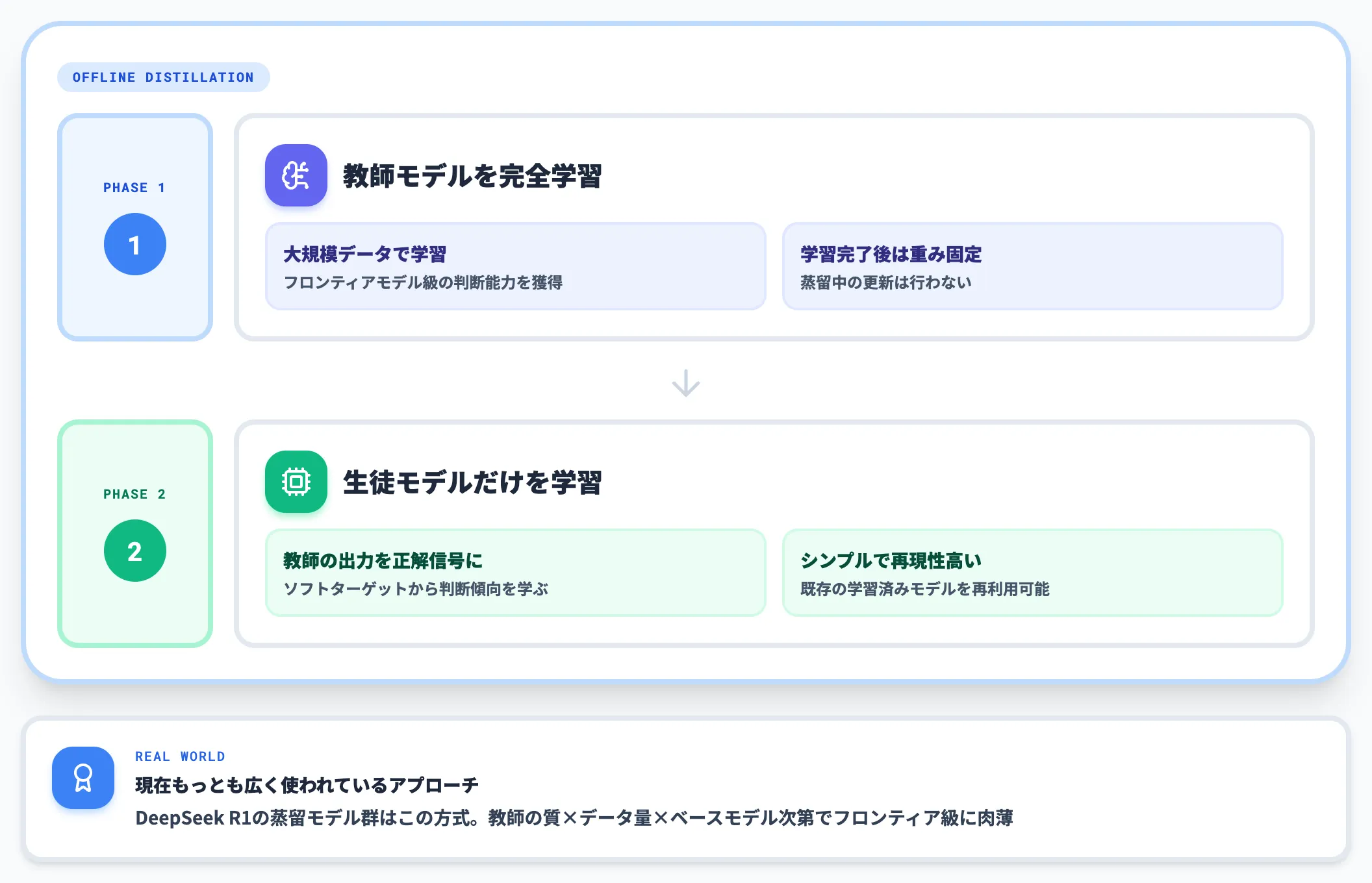
教師モデルが安定しているため学習プロセスがシンプルで、再現性も高いのが特徴です。実装が比較的容易で、既存の学習済みモデルを教師として再利用できる柔軟さもあります。
一方で、教師モデルの欠点や偏りもそのまま生徒に伝わってしまうため、教師選びが結果を大きく左右します。
DeepSeek R1の蒸留モデル群もこのオフライン蒸留に分類され、現在もっとも広く使われているアプローチです。
オンライン蒸留——教師と生徒を同時に学習させる
オンライン蒸留(Online Distillation)は、教師モデルと生徒モデルを同時に学習させながら、互いの予測分布を参照させる手法です。

学習途上の教師モデルが、まだ精度を上げきっていない生徒に対して「いま分かっている範囲の判断傾向」を渡し、生徒の学習が進んでくると教師側も生徒の情報を取り込んで改善する、という相互作用が起こります。
ただし学習プロセスが複雑で、ハイパーパラメータ調整の難易度が高く、計算コストもオフライン蒸留より重くなる傾向があります。
実務での採用例はまだ限定的で、研究文脈で言及されることが多い手法という位置づけです。
自己蒸留——一つのモデルが自分自身を教師にする
自己蒸留(Self-Distillation)は、1つのモデルが過去の自分自身(または同一構造の別インスタンス)を教師として再学習する手法です。
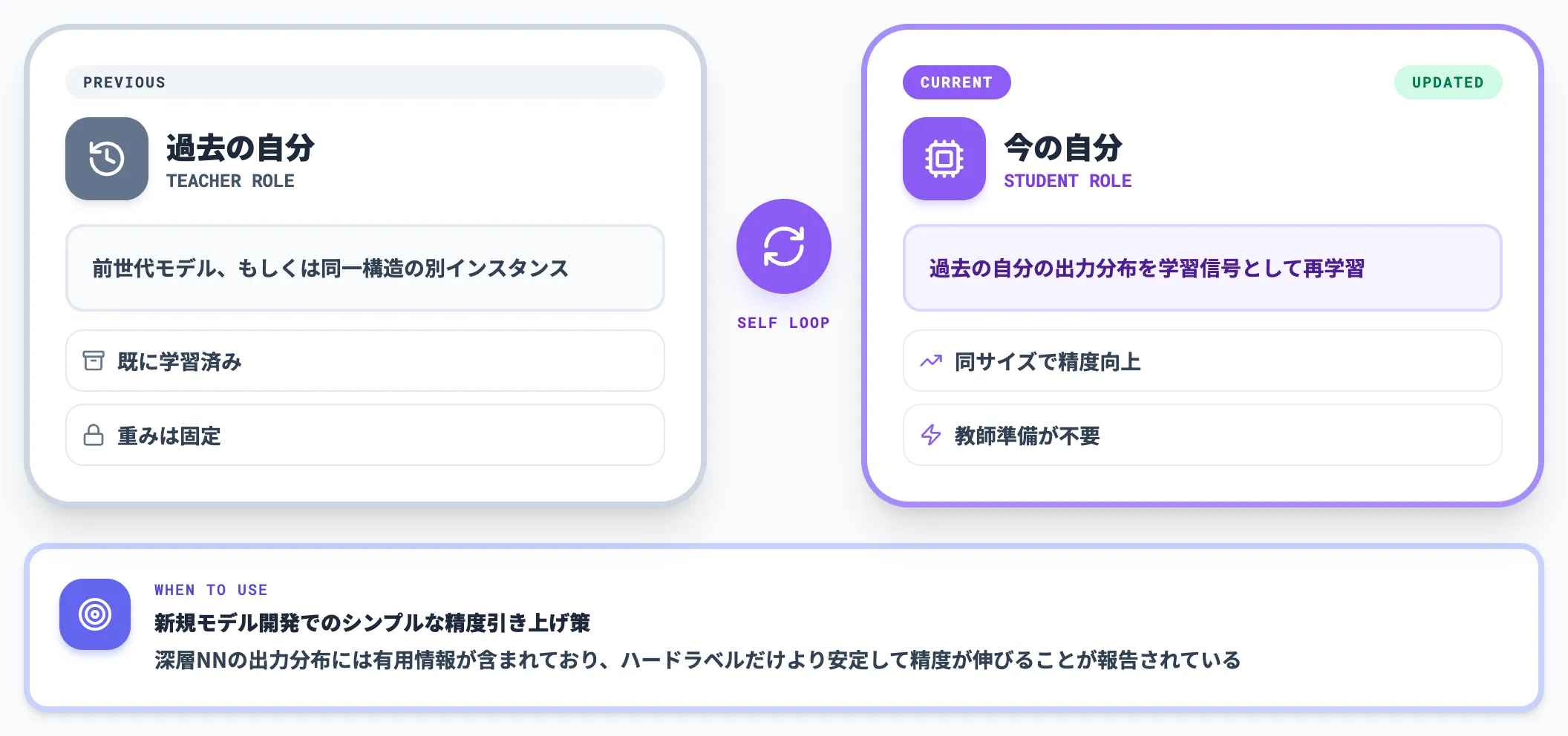
「同じサイズのモデルを学習し直すだけで精度が上がるのか」と疑問を持たれがちですが、深層ニューラルネットワークでは出力の確率分布に有用な情報が含まれており、ハードラベルだけで学習するより安定して精度が伸びることが報告されています。
教師モデルを別に用意する必要がないため、新規モデルを開発する際のシンプルな精度引き上げ策として使われます。
On-Policy Distillation——2026年に広がる新潮流
従来のオフライン蒸留には、**「生徒モデルが学習時に自分の誤った出力に出会わない」**という構造的な弱点があります。

教師が生成した正解寄りのデータだけで学習するため、推論時に生徒が間違った出力をしてしまったときの「リカバリ能力」を獲得できない、というミスマッチです。
これに対する対応として、2026年に注目度が急速に上がっているのがOn-Policy Distillationです。生徒モデル自身が生成した出力に対して、教師モデルが「正解はこうだ」と教える形に変えることで、推論時の挙動と学習時の挙動を揃えます。
Hugging Faceの研究まとめでもサーベイ論文が公開されており、Awesome-LLM-On-Policy-Distillationのようなコミュニティリポジトリも立ち上がっています。

テンセント研究チームによるOn-Policy Distillationのサーベイ論文(出典:Hugging Face Papers 2604.00626)
同サーベイ論文は2026年初頭にHugging Face Papersで公開され、On-Policy蒸留の体系的整理として参照される機会が増えています。
推論モデルの蒸留(Chain-of-Thought蒸留)と組み合わせる動きも進んでおり、フロンティアモデルの推論能力を小型モデルに渡す実用研究の中心テーマになりつつあります。
知識蒸留と他のモデル軽量化技術との違い
実務で「モデルを軽くしたい」という要件に直面したとき、選択肢は知識蒸留だけではありません。ファインチューニング・量子化・プルーニングといった近接技術と何が違うのかを押さえておくと、自社の制約に合った手を選びやすくなります。

以下の表で、4つの技術を「目的」「対象になる変更」「典型的な得意領域」で整理しました。
| 技術 | 主な目的 | 対象になる変更 | 典型的な得意領域 |
|---|---|---|---|
| 知識蒸留 | サイズ圧縮+精度維持 | 別の小型モデルを新規学習 | 大幅な軽量化・別ドメインへの転用 |
| ファインチューニング | タスク適応 | 既存モデルの重みを微調整 | 特定タスクへの精度引き上げ |
| 量子化 | メモリ・推論速度の改善 | 重みのビット精度を下げる | デプロイ直前の高速化・省メモリ化 |
| プルーニング | パラメータ数の削減 | 寄与度の低い重みを削除 | モデルの“不要な部位”の除去 |
4つの技術はトレードオフが異なるだけで排他ではなく、組み合わせて使うのが実務では一般的です。
ファインチューニングとの違い
ファインチューニングは、既存のモデルそのものを特定タスク用に微調整する技術です。

モデルのサイズは変わらず、「同じモデルが特定タスクに強くなる」状態を作ります。
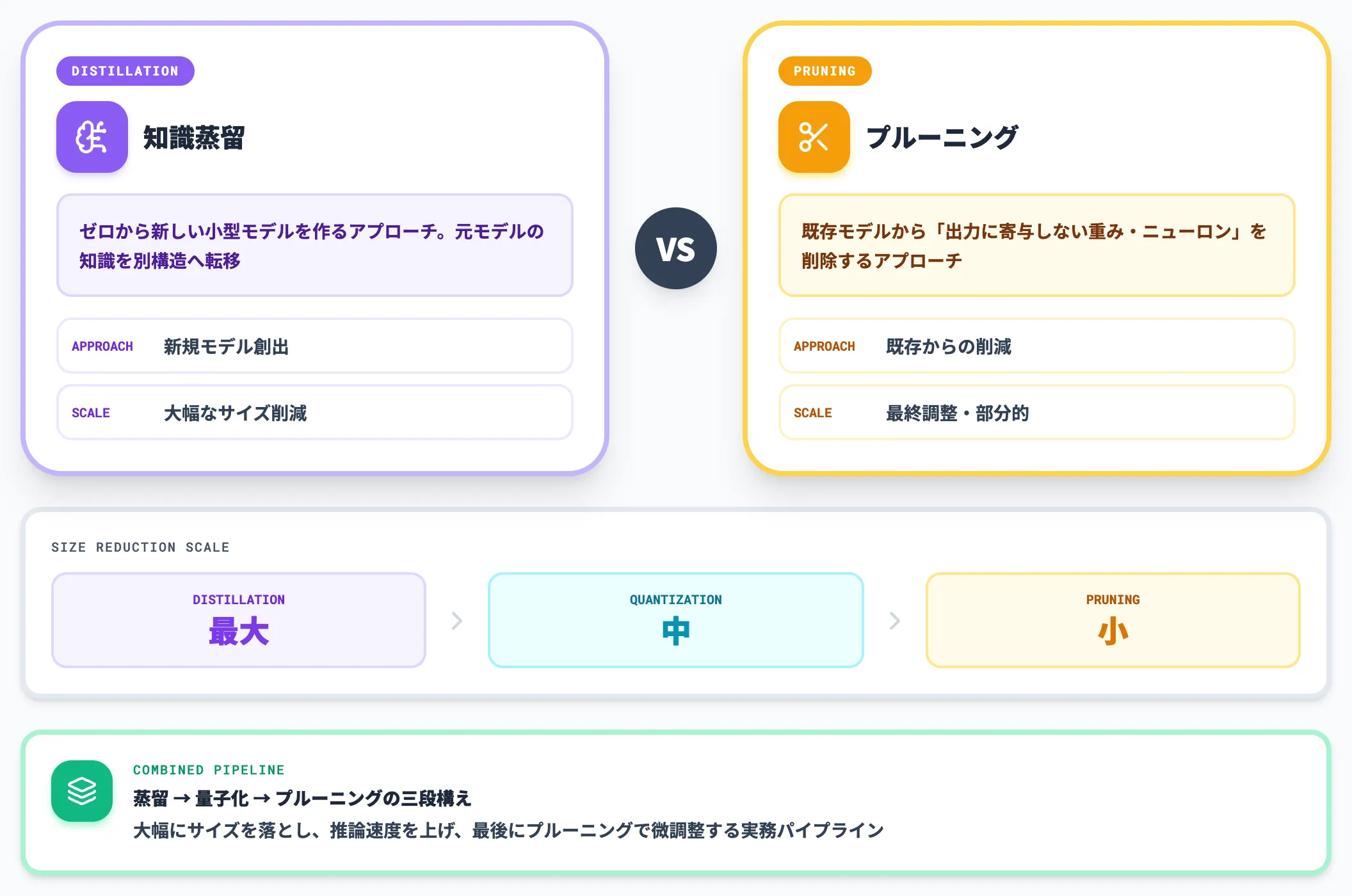
知識蒸留は逆に、モデル構造そのものを変えながら(多くの場合より小さくして)、教師の能力を生徒に再現させる点に主眼があります。
両者は競合関係ではなく、よく組み合わされます。「フロンティアモデルから小型モデルへ蒸留したあと、自社データでファインチューニングして特定タスクに最適化する」という二段構えが定番のパターンです。
量子化との違い
量子化は、モデルの重み(パラメータ)を表現する数値精度を下げる技術です。

FP32(32ビット浮動小数)の重みをINT8やINT4に変換すれば、メモリ使用量を1/4〜1/8に圧縮でき、推論速度も向上します。
知識蒸留が「別のモデルに学習し直す」プロセスを伴うのに対し、量子化は「同じモデルの数値表現を変えるだけ」で済みます。
サイズ削減の効果が大きい順に並べると、知識蒸留 → 量子化 → プルーニング という関係になり、推論コストを最大限まで詰めたい場合は知識蒸留で得た小型モデルをさらに量子化するのが定石です。
スマートフォンGPU上で実用可能なレベルまで圧縮したいなら、両者の併用がほぼ前提条件になります。
プルーニングとの違い
プルーニング(Pruning)は、学習済みモデルの中で「出力にあまり寄与していない重み・ニューロン」を削除する技術です。
数値精度はそのままにパラメータ数だけを減らすため、量子化とは違う種類の軽量化が得られます。
知識蒸留が「ゼロから新しい小型モデルを作る」のに対し、プルーニングは「既存モデルから不要部分だけ削る」アプローチで、サイズ削減幅は知識蒸留より小さくなる傾向があります。
実務的には、知識蒸留で大幅にサイズを落とし、量子化で推論速度を上げ、プルーニングで最後の調整をする、という三段構えがよく取られます。
それぞれの併用パターン
3つの軽量化技術と知識蒸留は、組み合わせて使うことを前提に設計するのが現実的です。
-
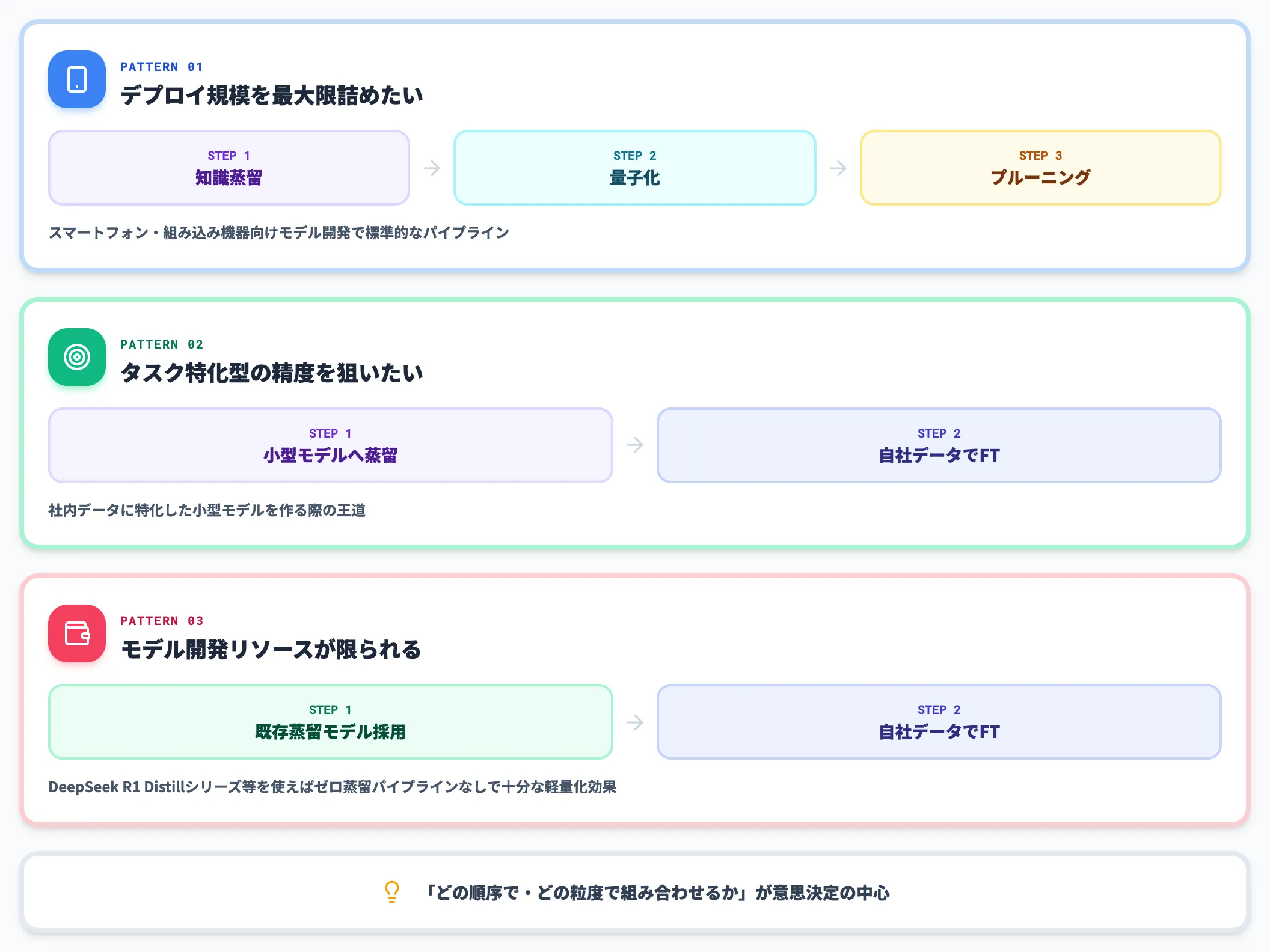
デプロイ規模を最大限詰めたい場合
知識蒸留 → 量子化 → プルーニングを順に適用する。スマートフォン・組み込み機器向けのモデル開発で標準的なパイプライン。
-
タスク特化型の精度を狙う場合
知識蒸留で小型モデルを作る → 自社データでファインチューニング、の順に適用する。社内データに特化した小型モデルを作る際の王道。
-
モデル開発リソースが限られる場合
既存の蒸留モデル(DeepSeek R1 Distillシリーズ等)を採用 → 自社データでファインチューニング、の組み合わせ。ゼロから蒸留を回さなくても、十分な軽量化効果が得られる。
「どの技術を選ぶか」よりも、「どの順序で・どの粒度で組み合わせるか」が現場の意思決定の中心になります。
知識蒸留が実務にもたらす効果と制約
知識蒸留を採用する判断は、最終的にはコスト・速度・精度のバランスで決まります。本セクションでは、得られる定量的な効果と、見落としやすい制約を整理します。
推論コスト削減の具体的なインパクト
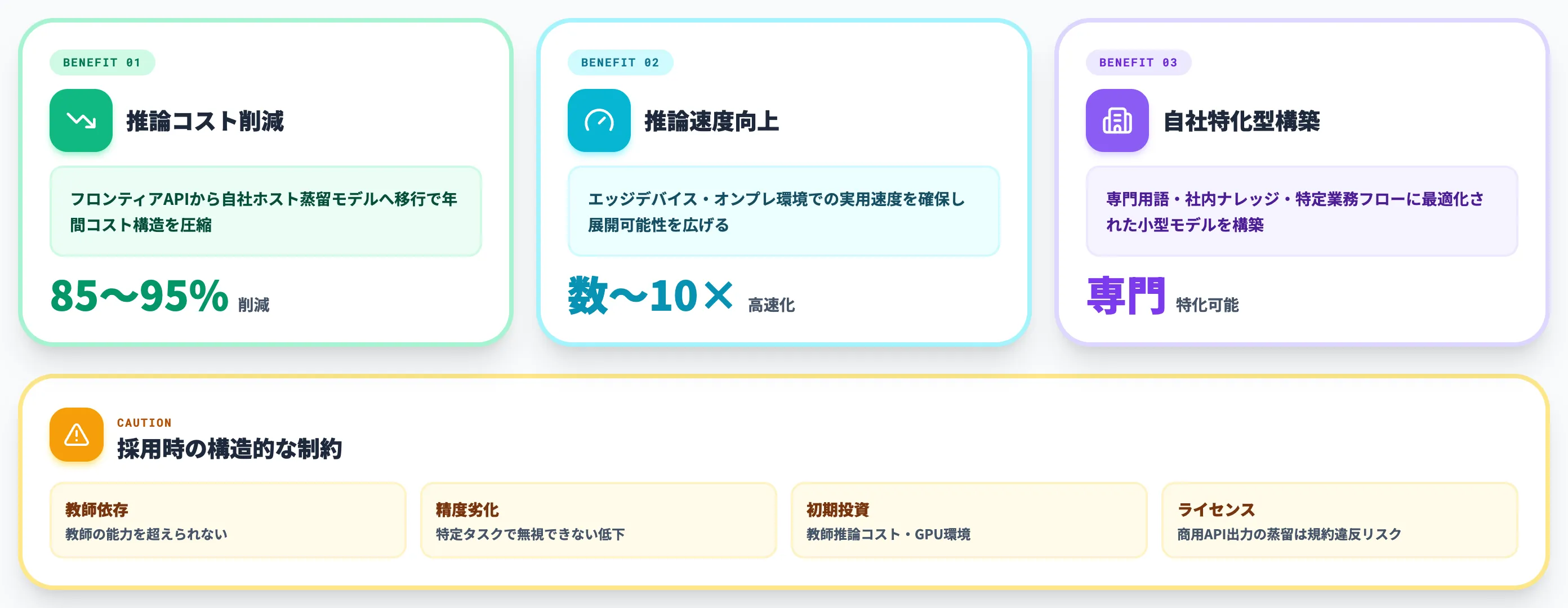
知識蒸留の最も分かりやすい効果は、推論コストの大幅な削減です。
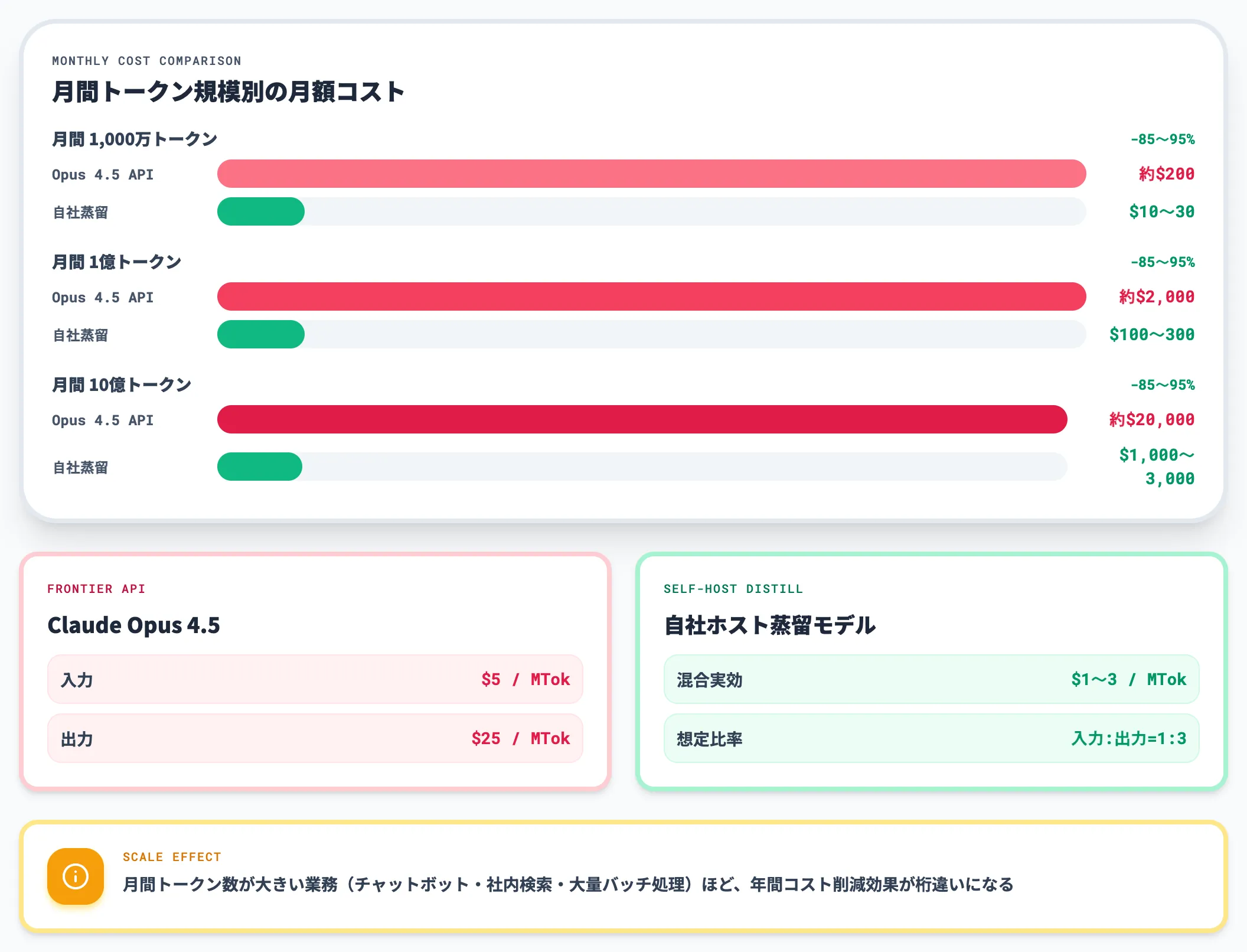
たとえばClaude Opus 4.5クラスのAPI料金はAnthropic公式pricingで100万トークンあたり入力$5・出力$25です。一方、蒸留して得られる中小規模モデルなら、自社GPUでのホスティング込みで100万トークンあたり$1〜$3程度まで落とせるケースが珍しくありません。
入出力比は業務によって変動しますが、ここでは社内検索やチャットボット運用で典型的な「入力:出力=1:3」(混合実効単価が約100万トークンあたり$20)を仮定して月額試算を出します。
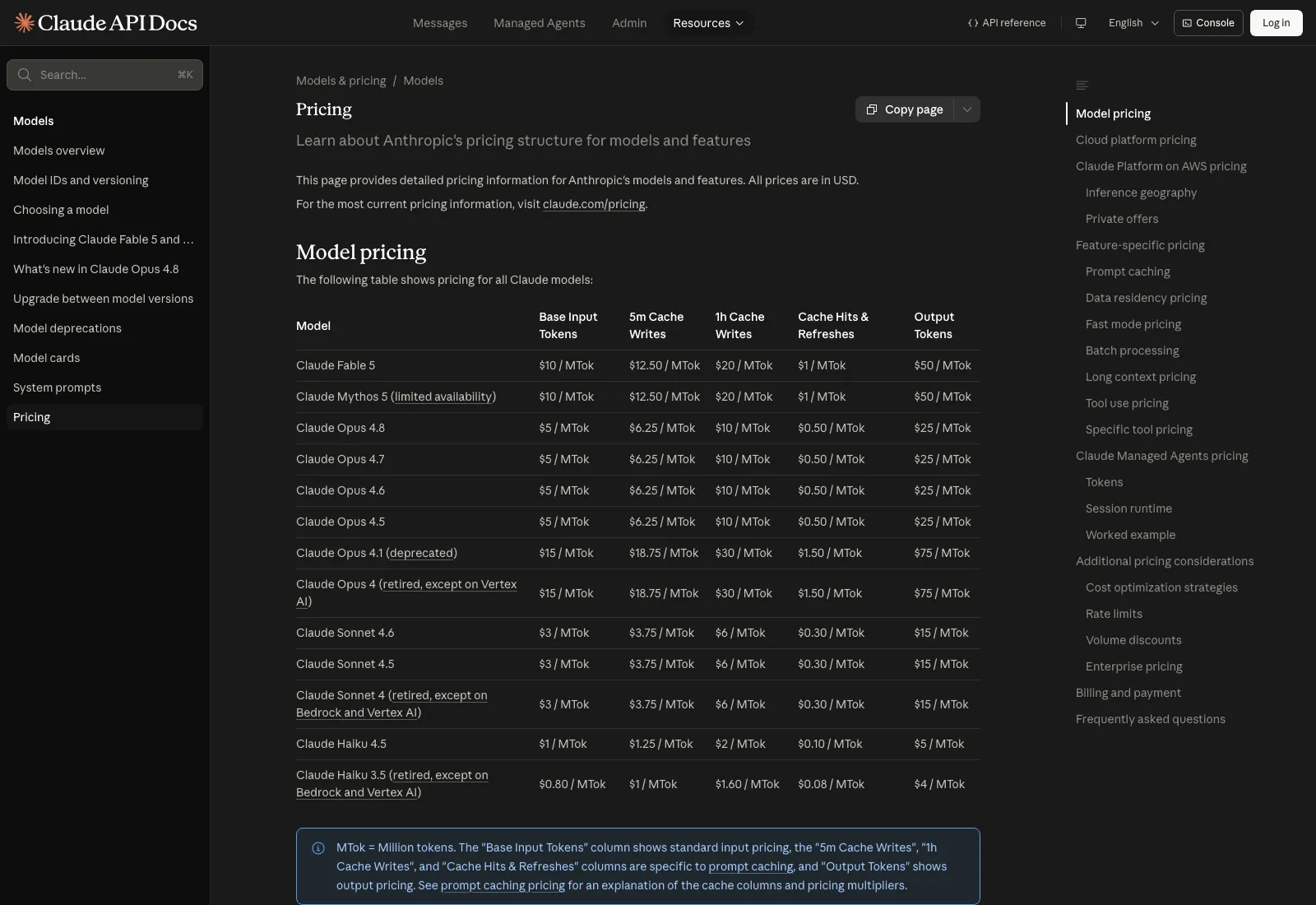
Claude API公式のモデル別単価(出典:Anthropic Pricing)
公式pricingページではClaude Opus 4.5・Sonnet 4.5・Haiku 4.5など各モデルの入力・出力単価が表形式で公開されており、Opus 4.5の行で入力$5・出力$25/MTokを確認できます。
| 想定月間トークン数(入力+出力合算) | フロンティアAPI(Opus 4.5)の月額コスト目安 | 自社ホスト蒸留モデルの月額コスト | 削減効果 |
|---|---|---|---|
| 1,000万トークン | 約$200 | 約$10〜$30 | 約85〜95%削減 |
| 1億トークン | 約$2,000 | 約$100〜$300 | 約85〜95%削減 |
| 10億トークン | 約$20,000 | 約$1,000〜$3,000 | 約85〜95%削減 |
入出力比が出力寄り(1:5やそれ以上)になれば実効単価は上がり、削減効果はさらに大きくなります。逆に分類タスクのように出力が短い用途では差が縮まります。月間トークン数が大きい業務(チャットボット・社内検索・大量バッチ処理など)ほど、年間コスト削減効果が桁違いになる構造は変わりません。
100万トークン単価の差は小さく見えても、トラフィックが大きい運用ではROIの差が極端に出るのが知識蒸留の特徴です。
推論速度の向上とエッジ展開
蒸留モデルはパラメータ数が大幅に小さいため、推論速度が数倍〜10倍以上速くなることが多くあります。
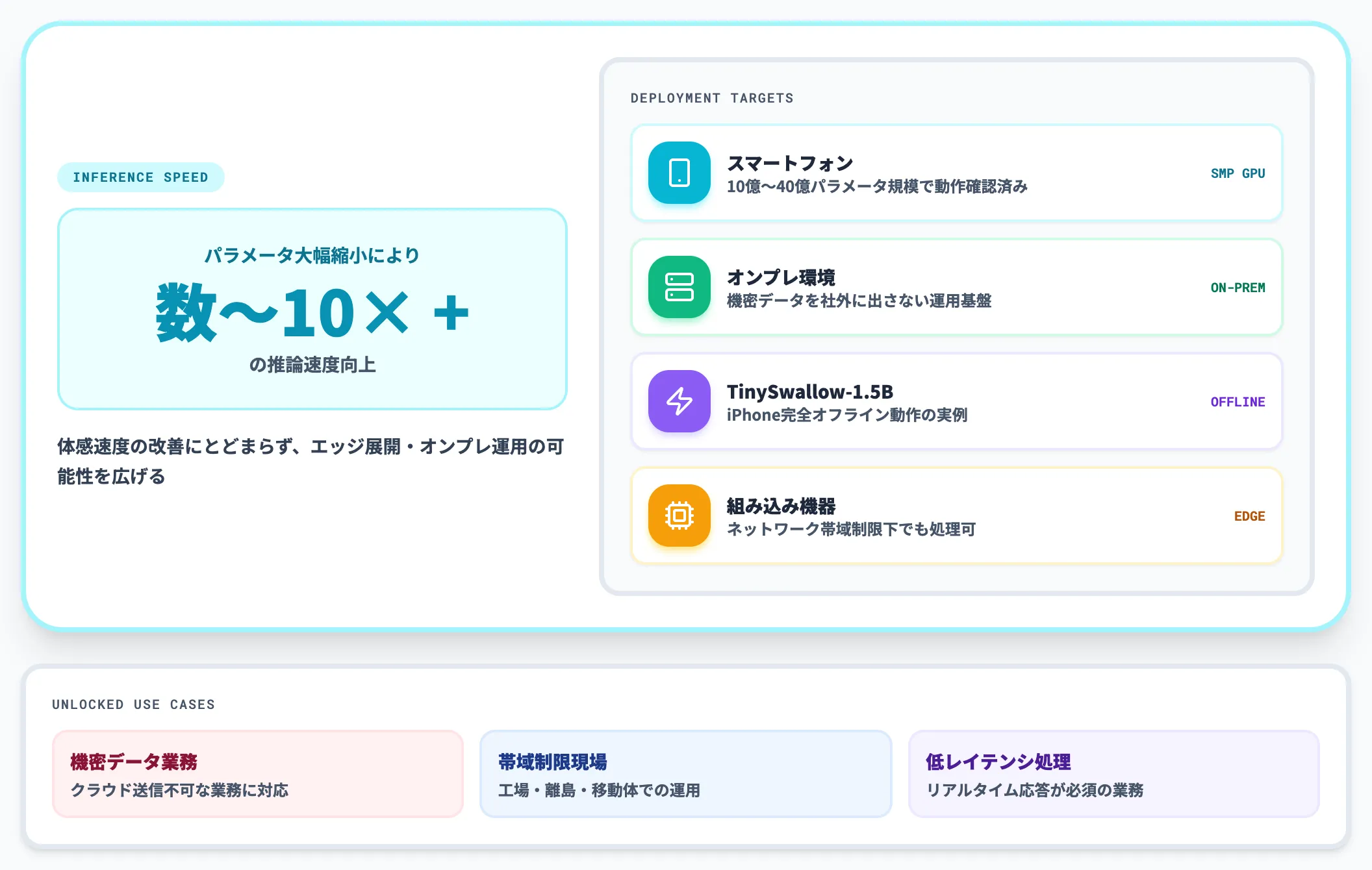
これは単なる体感速度の改善にとどまらず、エッジデバイスやオンプレミス環境への展開可能性を広げます。
エッジAIの文脈では、10億〜40億パラメータ規模の蒸留モデルがスマートフォンGPUで動作することが確認されており、Sakana AIのTinySwallow-1.5BのようにiPhoneで完全オフライン動作する事例も登場しています。
クラウド送信不可な機密データを扱う業務・ネットワーク帯域が制限された現場・低レイテンシが必須のリアルタイム処理など、API型LLMでは届かなかった領域が現実的な選択肢になります。
自社特化型の小型モデル構築
知識蒸留はオフザシェルフの汎用モデルだけでなく、自社業務に特化した小型モデルを作るための土台にもなります。

具体的には、フロンティアモデルを教師にして自社データでオフライン蒸留を行うことで、専門用語・社内ナレッジ・特定業務フローに最適化された小型モデルを構築できます。
このアプローチでは、教師モデルのコストは初期の学習データ生成時にのみ発生し、運用フェーズでは小型モデル単体で完結します。
長期運用するほどコスト構造の有利さが効いてくるため、業務量が多い特定タスク(カスタマーサポート・FAQ応答・契約書チェック等)には適した設計です。
採用時の制約と注意点
一方で、知識蒸留にはいくつかの構造的な制約があります。これらを把握せずに導入すると、期待した効果が得られないリスクが高くなります。

-
教師モデルへの依存
蒸留モデルの上限は教師モデルの能力に縛られる。教師が解けないタスクは、生徒も解けない。教師選定が結果を大きく左右する。
-
精度劣化のリスク
複雑な推論タスク・長文理解・専門領域の知識など、特定タスクでは無視できない精度低下が起こる。ベンチマークでなく自社タスクで実測する必要がある。
-
データ準備とインフラのコスト
特に自社データで蒸留する場合、教師モデルでの大量推論コスト・学習用GPU環境・データクレンジング工数が無視できない初期投資になる。
-
ライセンスと規約上の制約
教師モデルが商用クローズドAPI(OpenAI・Anthropic等)の場合、その出力を使った蒸留は規約違反になる可能性が高い。詳細は後述のライセンスセクションを参照。
これらの制約を踏まえると、「すべての業務に蒸留モデルを当てる」のではなく、コスト効率と精度のバランスが取れるユースケースに絞って採用するのが現実的な使い方になります。
代表的な蒸留モデル——DeepSeek R1・Sakana TAID・OpenAI Distillation API
知識蒸留の実装現場で2026年6月時点に最も参照される事例は、オープンウェイトの蒸留モデル群と蒸留パイプラインのプラットフォーム化の2系統に分けられます。
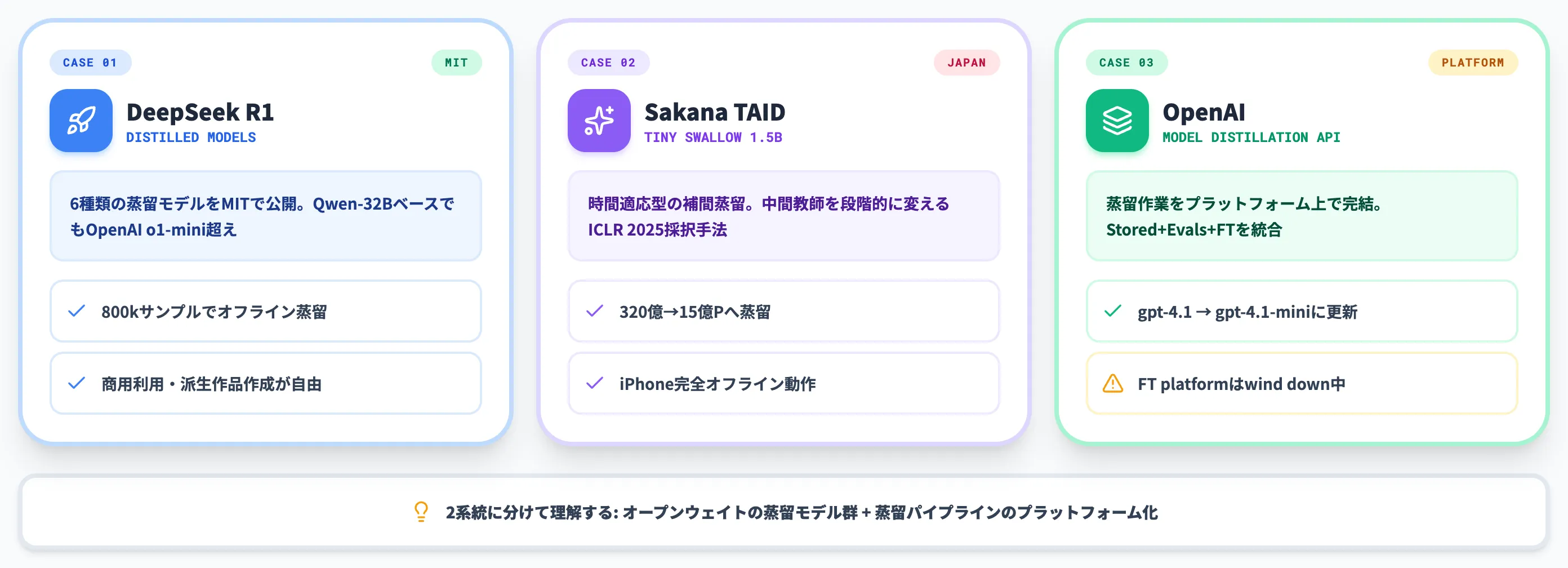
本セクションでは、導入判断で押さえるべき3つの事例を取り上げます。
DeepSeek R1の蒸留モデル群
DeepSeek R1は、2025年1月にDeepSeek社が公開した推論特化型の大規模言語モデルです。

R1本体と同時に、Hugging Faceで6種類の蒸留モデルが公開されたインパクトが非常に大きく、知識蒸留が「LLM時代の実用技術」として再認識される決定打となりました。
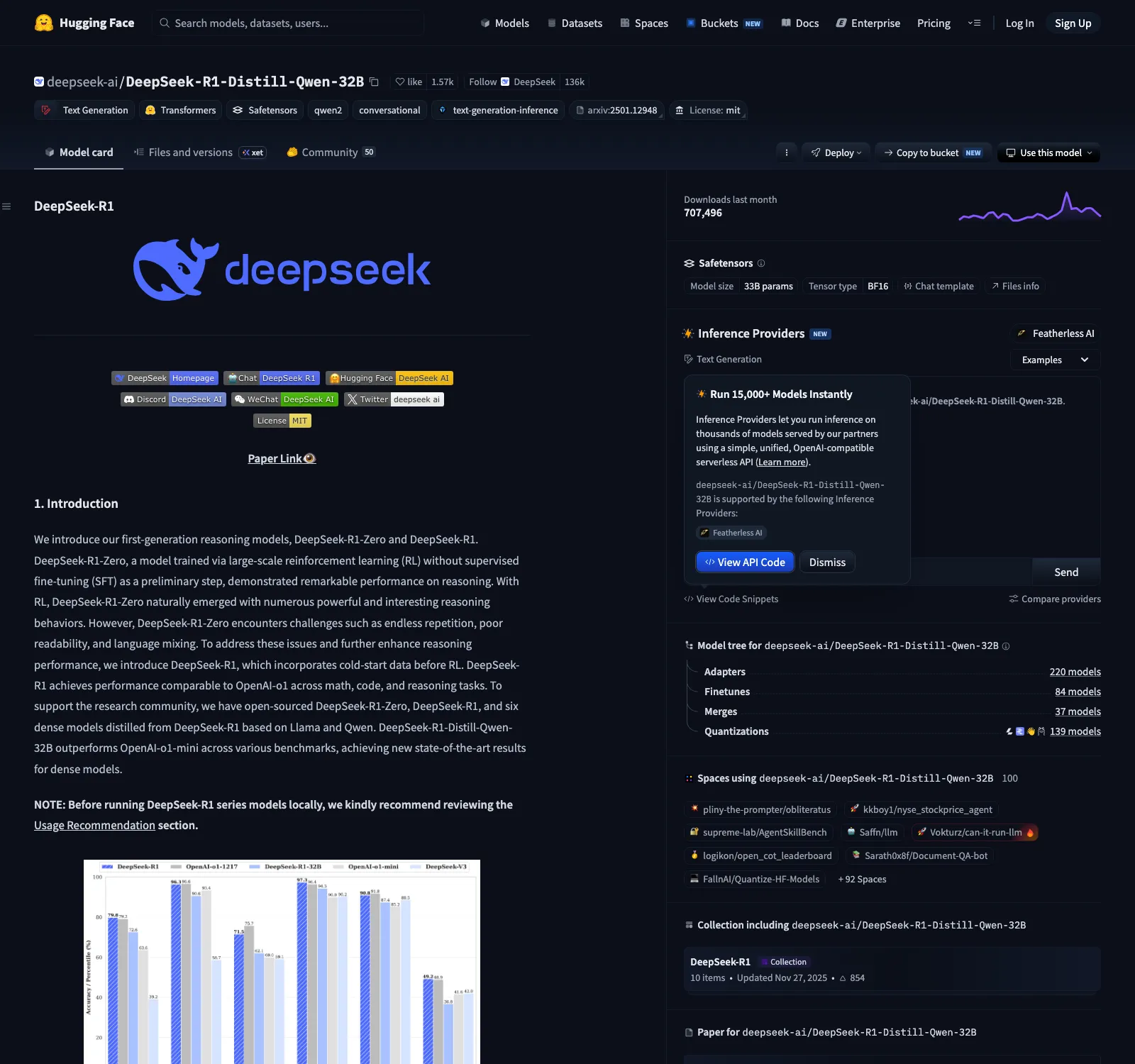
DeepSeek-R1-Distill-Qwen-32BのHugging Faceモデルカード(出典:Hugging Face — deepseek-ai/DeepSeek-R1-Distill-Qwen-32B)
Hugging Faceのモデルカード冒頭では、800kサンプルでオフライン蒸留した経緯とベンチマーク比較が記載されており、企業がモデル選定する際の一次情報源になります。
| モデル | ベースモデル | サンプル数 | AIME 2024 (pass@1) | MATH-500 (pass@1) | GPQA Diamond |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 800,000 | 72.6% | 94.3% | 62.1% |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 800,000 | 69.7% | 93.9% | 59.1% |
| DeepSeek-R1-Distill-Llama-70B | Llama 3.3-70B | 800,000 | 70.0% | 94.5% | 65.2% |
Qwen2.5-32Bベースの蒸留モデルでOpenAI o1-miniを上回るスコアが報告されており、しかもMITライセンスで商用利用・派生作品作成が自由です。
蒸留方式はオフライン蒸留に分類され、R1で生成した80万件の推論トレース(Chain-of-Thought付き)で生徒モデルを教師ありファインチューニング(SFT)する、シンプルなパイプライン構成です。
派手な新手法ではないものの、「教師の質×データ量×ベースモデルの良さ」が揃えばオフライン蒸留だけでフロンティア級モデルに肉薄できることを示した、業界の方向性を変える事例です。
Sakana AI TAIDとTinySwallow-1.5B
日本発の知識蒸留事例として注目されているのが、Sakana AIが2025年1月30日に公開したTAID(Temporally Adaptive Interpolated Distillation)と、その成果モデルTinySwallow-1.5Bです。
TAIDの中核アイデアは、**「学習段階に応じて中間教師を変える時間適応型の補間蒸留」**です(TemporallyはAdaptiveの修飾で、「時間的=学習が進むにつれて」を意味します)。
従来の知識蒸留では、教師モデルが強すぎると生徒モデルが学習を追いきれない問題がありました。TAIDは「中間教師」という概念を導入し、最初は生徒のレベルに近い教師から学ばせ、生徒の成長に合わせて教師を徐々に高度なものへ切り替えていきます。
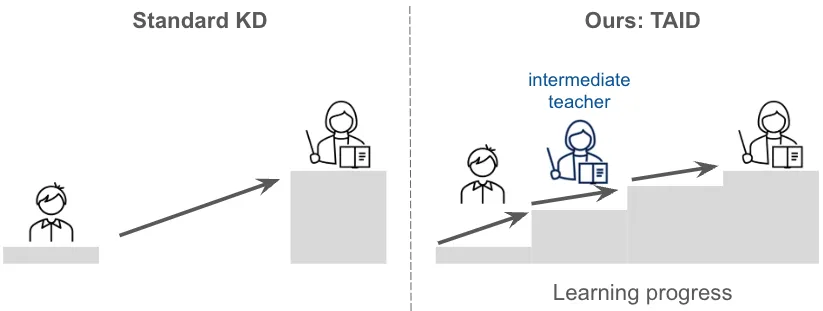
TAIDが導入する中間教師の段階的学習(出典:Sakana AI)
Sakana AIの解説図では、標準的なKDが「いきなり最終教師」だけを与えるのに対し、TAIDは生徒の学習進度に合わせて段階的に教師を強くしていく構造が示されています。
Sakana AI公式発表によれば、TAIDで320億パラメータのLLMから15億パラメータのローカルLLMを蒸留し、同規模帯では最高水準の日本語ベンチマークスコアを達成しています。
TinySwallow-1.5Bはスマートフォン・PC上で完全オフライン動作するレベルまで小型化されており、TAID自体はICLR 2025に採択されています。
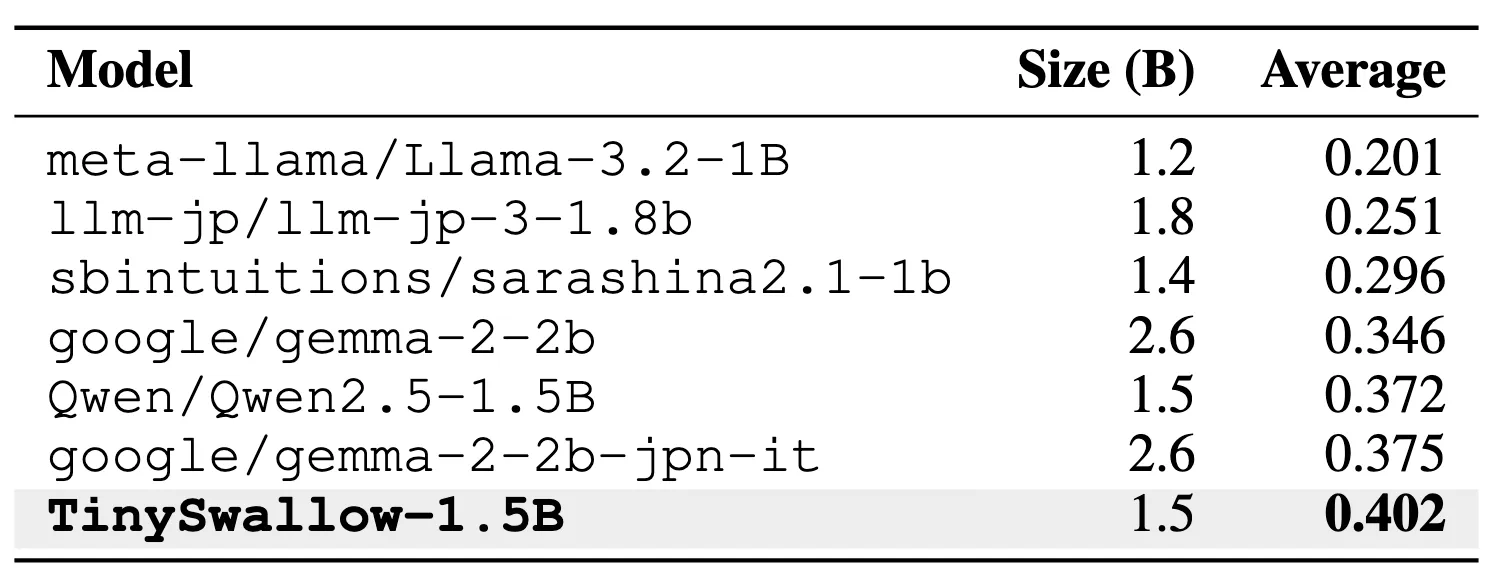
TinySwallow-1.5Bが同規模帯日本語SLMで最高水準スコアを記録(出典:Sakana AI)
TinySwallow-1.5BはLlama-3.2-1B・gemma-2-2b・Qwen2.5-1.5Bなど主要1.5B〜2.6Bクラスを抑え、Average 0.402で1位を取っています。
このアプローチは、「教師と生徒のサイズ差が大きすぎて蒸留がうまくいかない」という古典的な課題への明確な回答であり、日本語など特定言語に最適化したい企業にとっても参考にしやすい設計です。
OpenAI Model Distillation API
研究や自前パイプライン構築の文脈とは別に、蒸留作業そのものを商用プラットフォーム上で完結させる動きも進んでいます。

代表例が2024年10月にOpenAIが発表したModel Distillation APIです。
OpenAIプラットフォーム上で、以下の3つの機能が統合されています。
-
Stored Completions
本番APIで生成された入出力ペアを自動的に保存し、蒸留用データセットとして利用できる。
-
Evals
カスタム評価を作成・実行して、蒸留後の生徒モデルの性能を定量的に測定できる。ただしEvals platformは移行期にあり、OpenAI公式docsでは2026年10月31日に既存ユーザー向けread-only化、11月30日にshutdown予定とされている。新規評価はDatasets等への移行も視野に入れる必要がある。
-
Fine-tuning
保存したStored Completionsをそのままファインチューニングジョブの入力として使える。
2024年10月の発表当時、公式ブログが代表例として挙げたのはo1-previewやGPT-4oの出力をGPT-4o miniに蒸留する構成で、フロンティアモデルで生成した高品質な応答を、より安価で速い小型モデルに移植する流れが想定されていました。
OpenAI Developers公式のSupervised fine-tuningドキュメント(出典:OpenAI Developers)
ただし2026年6月時点では、OpenAI公式Supervised fine-tuning docs上で「fine-tuning platformはwind down中・新規ユーザーは利用不可・既存ユーザーは今後数か月のみジョブ作成可能」と明記されている点に注意が必要です。現行docsで紹介されている蒸留例も gpt-4.1 → gpt-4.1-mini に置き換わっており、GPT-4o系の例は2024年発表当時の構成として扱うのが安全です。
加えて、OpenAIのAPI出力を**「OpenAIと競合するAIモデル」の開発に使うことは、Permitted Exceptionを除き利用規約で制限されているため、Distillation API系の枠組みや自社内で完結する分類・整理用途のようなPermitted Exceptionに収まる範囲で利用する**のが基本姿勢になります(詳細は後述のライセンスセクションで解説します)。

PyTorchによる知識蒸留の実装例
ここでは、画像分類タスクを例にPyTorchで知識蒸留を実装する最小構成を示します。LLMの蒸留も基本原理は同じで、損失関数の組み立て方をそのまま流用できます。
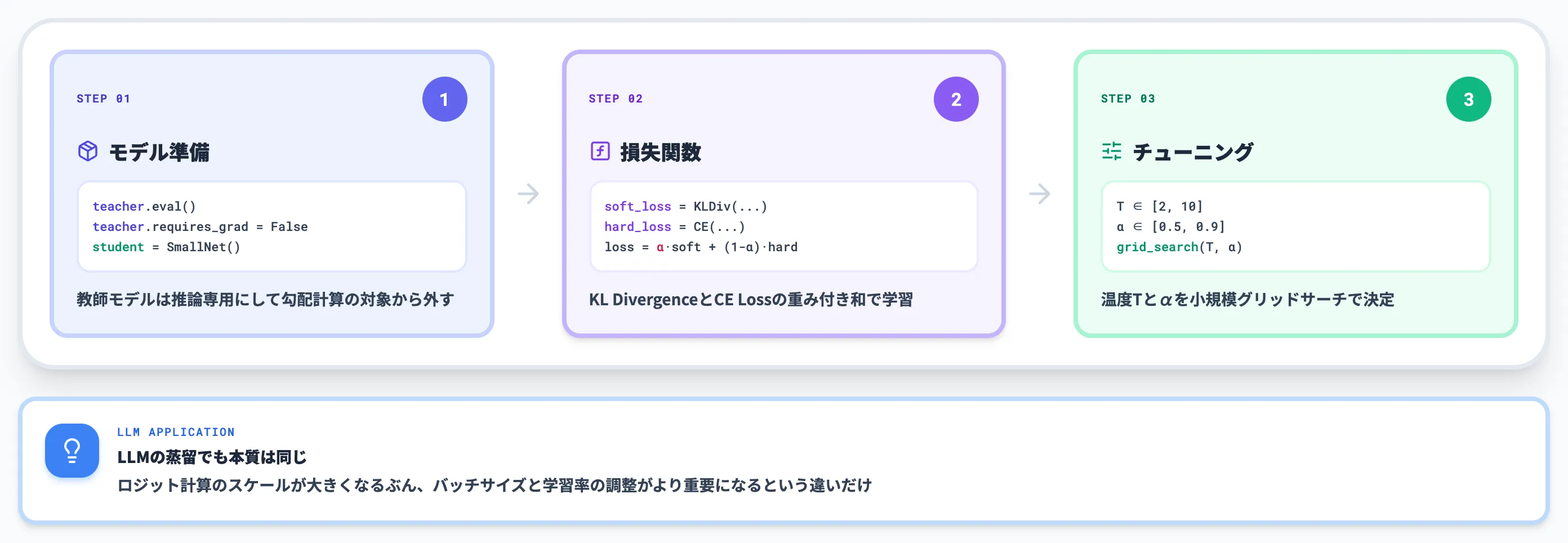
教師モデルと生徒モデルの準備
実装の出発点は、学習済みの教師モデルと、これから学習する生徒モデルを用意することです。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
# 学習済みの教師モデルをロード(重みは固定)
teacher = load_pretrained_teacher()
teacher.eval()
for param in teacher.parameters():
param.requires_grad = False
# より小さな生徒モデルを定義
student = SmallStudentNetwork()
student.train()
教師モデルは推論専用にし、勾配計算の対象から外しておくのがポイントです。生徒モデルだけが更新されるようにすることで、学習効率と再現性が高まります。
蒸留損失関数(KL Divergence + CE Loss)
知識蒸留の核心は損失関数の設計です。教師の確率分布に近づけるソフト損失と、正解ラベルに近づけるハード損失を重み付き和で組み合わせます。
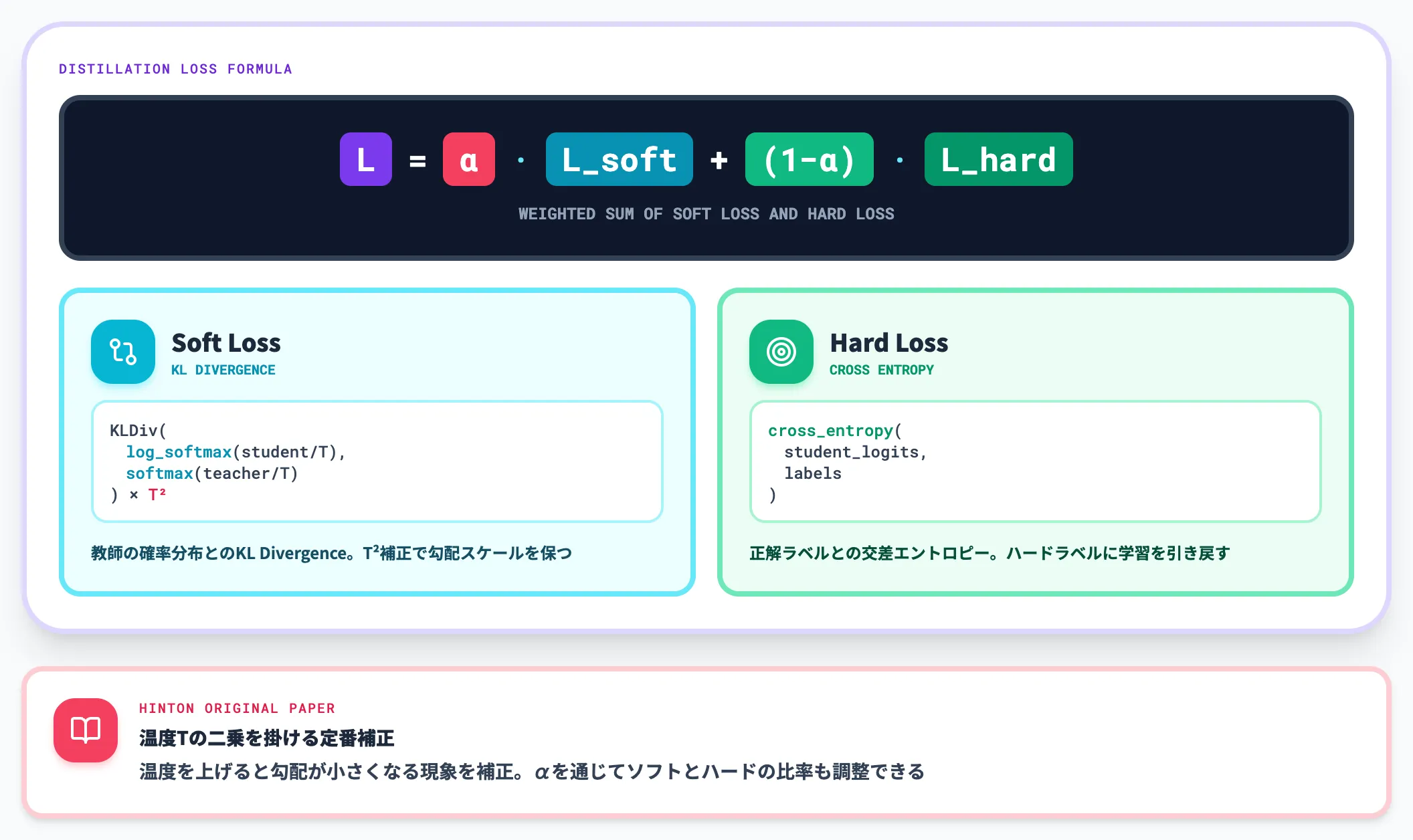
class DistillationLoss(nn.Module):
def __init__(self, temperature=4.0, alpha=0.7):
super().__init__()
self.T = temperature # 温度パラメータ
self.alpha = alpha # ソフト損失とハード損失の重み
def forward(self, student_logits, teacher_logits, labels):
# ソフト損失:教師の確率分布とのKL Divergence
soft_loss = F.kl_div(
F.log_softmax(student_logits / self.T, dim=-1),
F.softmax(teacher_logits / self.T, dim=-1),
reduction='batchmean'
) * (self.T ** 2)
# ハード損失:正解ラベルとの交差エントロピー
hard_loss = F.cross_entropy(student_logits, labels)
return self.alpha * soft_loss + (1 - self.alpha) * hard_loss
このアプローチには複数の利点があります。
第1に、KL Divergenceに温度Tの二乗を掛けることで、温度を上げてもソフト損失の勾配スケールが保たれます。温度を高くするほど勾配が小さくなる現象を補正する、Hintonら原論文で示された定番の補正です。
第2に、αを通じてソフト損失とハード損失の比率を調整できるため、教師に近づけたいタスクと正解ラベルに合わせたいタスクをチューニングで使い分けられます。
温度パラメータとαのチューニング
学習ループ本体は、通常の教師あり学習とほとんど同じ形になります。

loss_fn = DistillationLoss(temperature=4.0, alpha=0.7)
optimizer = torch.optim.AdamW(student.parameters(), lr=1e-4)
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
# 教師の出力は勾配計算なしで取得
with torch.no_grad():
teacher_logits = teacher(batch_x)
# 生徒の出力と損失計算
student_logits = student(batch_x)
loss = loss_fn(student_logits, teacher_logits, batch_y)
# 通常の最適化ステップ
optimizer.zero_grad()
loss.backward()
optimizer.step()
実装で詰まりやすいのは、温度Tとαをそれぞれグリッドサーチでチューニングしないとうまくないことです。
| パラメータ | 一般的な探索範囲 | 影響の方向性 |
|---|---|---|
| 温度 T | 2〜10 | 高くするほど分布が滑らかに。クラス間関係の情報量が増える |
| α(ソフト損失の重み) | 0.5〜0.9 | 高くするほど教師の真似に寄る。正解ラベルからは離れがち |
2〜3パターン程度の小規模グリッドサーチでも目安は掴めるため、最初から最適値を狙うよりも、ベースラインを作って改善を回す姿勢が現実的です。
LLMの蒸留でも本質は同じで、ロジット計算のスケールが大きくなるぶんバッチサイズと学習率の調整がより重要になる、という違いがあるだけです。
知識蒸留のライセンス・利用規約上の論点
知識蒸留が技術として成熟する一方で、2025年から2026年にかけて**「どの教師モデルから蒸留してよいか」**という規約面の論点が一気に表面化しました。
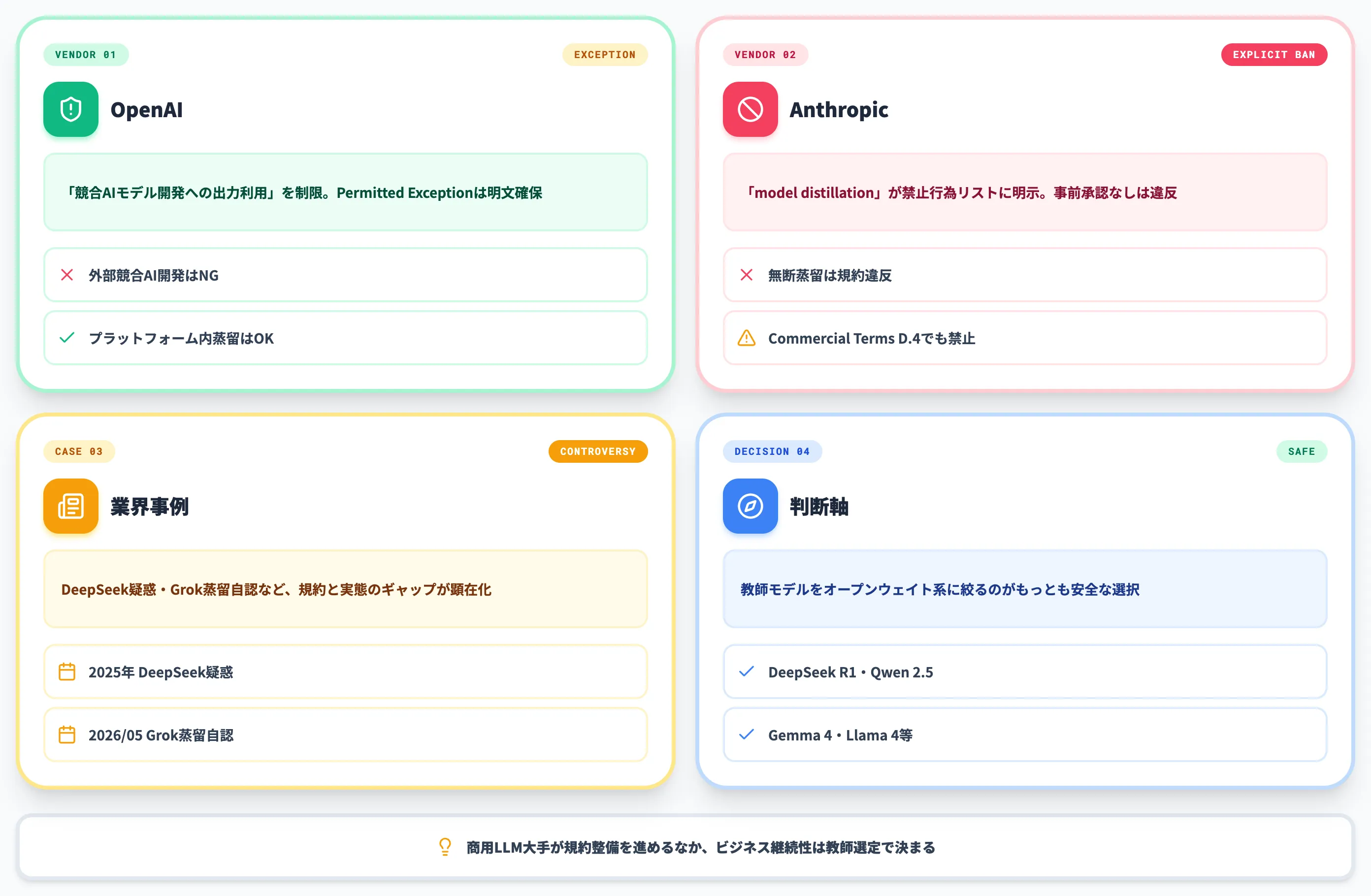
商用LLM大手が利用規約を整備し、規約違反として問題化された事例も複数報じられています。本セクションでは、企業として把握しておくべき主要な条文と判断軸を整理します。
OpenAIの「競合モデル開発禁止」条項
OpenAIのAPI・ビジネス用途は個人向けTermsとは別のServices Agreementが適用され、§3.3 Restrictions (e) として次の条項が定められています。

「except for a Permitted Exception, use Output to develop artificial intelligence models that compete with OpenAI's products and services」(Permitted Exceptionを除いて、OutputをOpenAIの製品・サービスと競合する人工知能モデルの開発に使ってはならない)
ポイントは、無条件の蒸留禁止ではなく**「競合AIモデル開発への出力利用」が制限対象であり、しかも「Permitted Exception(許可された例外)」が明文で確保されている**点です。
この例外として代表的に語られるのが、2024年10月にOpenAIが発表したModel Distillation APIを介して、GPT-4oの出力をGPT-4o miniへ移植するようなOpenAIプラットフォーム内で完結する蒸留でした。ただし2026年6月時点では、同社のSupervised fine-tuning ドキュメントで**fine-tuning platformがwind down中(新規ユーザー利用不可・既存ユーザーは今後数か月のみジョブ作成可能)**と告知されており、現行docsの蒸留例も gpt-4.1 → gpt-4.1-mini に更新されています。
整理すると、ChatGPT-5を含むOpenAI製モデルの出力を「OpenAIと競合するAIモデル」の開発に使う行為は規約違反リスクが高く、OpenAIプラットフォーム内蒸留や第三者配布しない社内分類モデルなどPermitted Exceptionに収まる場合は利用可能な一方、OpenAI公式の蒸留パイプライン自体が新規利用の窓を絞り込んでいる点も合わせて踏まえる必要があります。
Anthropicの「model distillation」明示禁止
Anthropicの利用規約はさらに明示的で、禁止行為のリストに以下が含まれます。
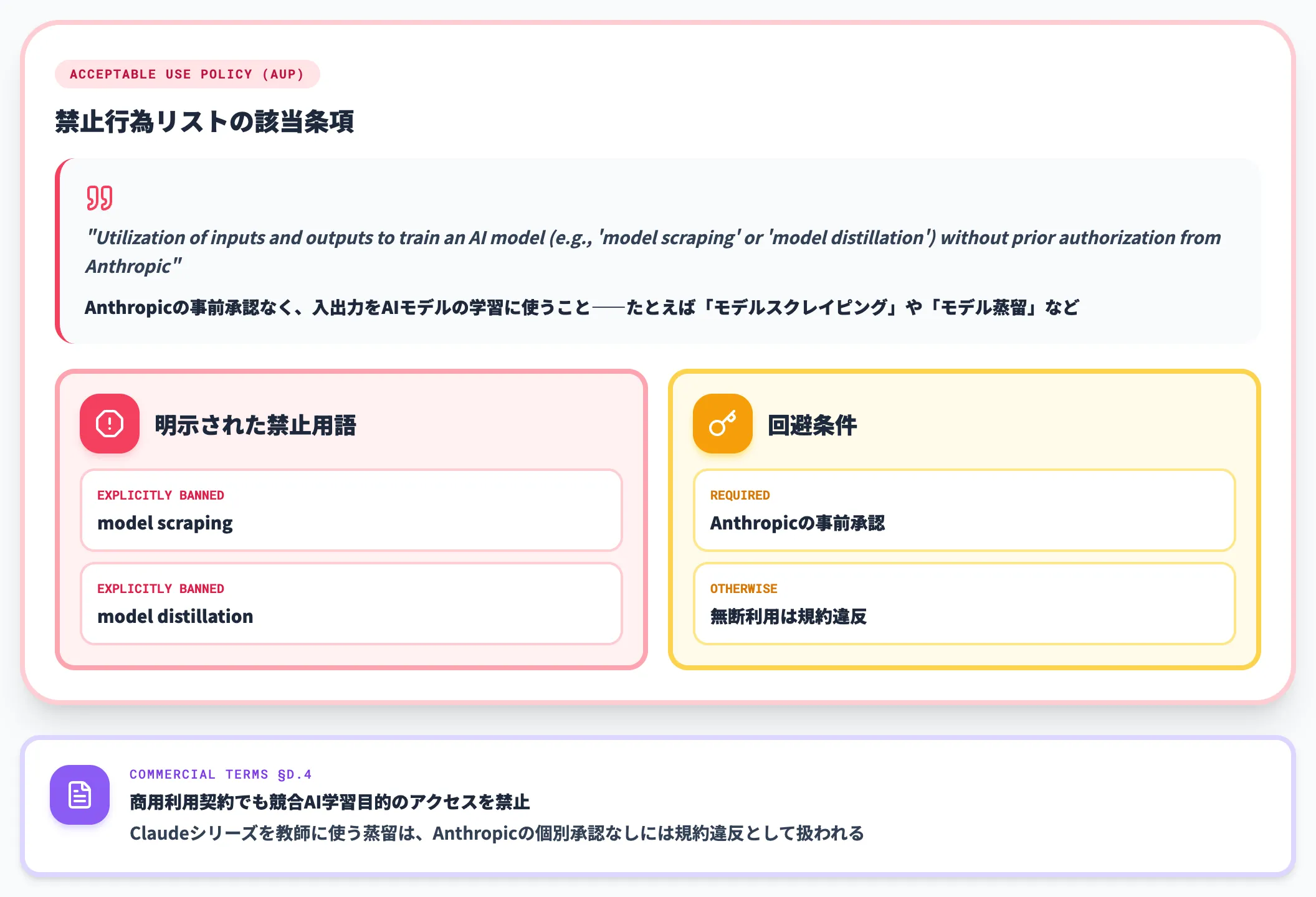
「Utilization of inputs and outputs to train an AI model (e.g., 'model scraping' or 'model distillation') without prior authorization from Anthropic」(Anthropicの事前承認なく、入出力をAIモデルの学習に使うこと——たとえば「モデルスクレイピング」や「モデル蒸留」など)
「model distillation」というワードがそのまま規約文に書かれている点が決定的です。
加えてCommercial TermsのD.4条でも、競合AIモデルの学習目的でのサービスアクセスは明示的に禁止されています。
Claudeシリーズを教師として使う蒸留は、Anthropicの個別承認を得ない限り規約違反として扱われます。
DeepSeek論争とGrokの蒸留自認
実際の業界事例として、2025年から2026年にかけて以下のような出来事が報じられています。
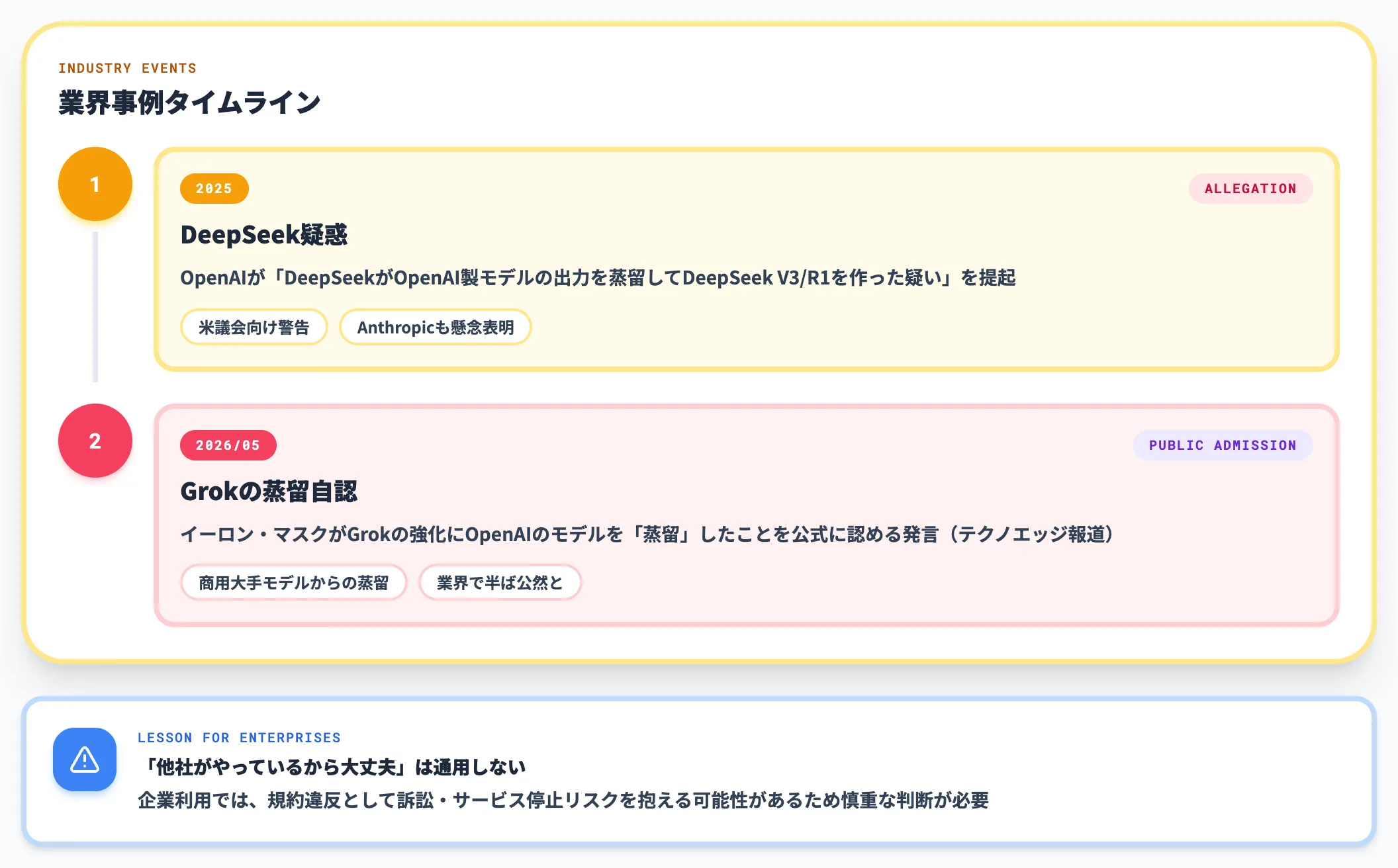
-
DeepSeek疑惑(2025年)
OpenAIが「DeepSeekがOpenAI製モデルの出力を蒸留してDeepSeek V3/R1を作った疑い」を提起し、米議会向けに警告を出した。Anthropicも同様の懸念を表明。
-
Grokの蒸留自認(2026年5月)
イーロン・マスクがGrokの強化にOpenAIのモデルを「蒸留」したことを公式に認める発言があったとテクノエッジが報道。商用大手モデルからの蒸留が業界で半ば公然と行われている実態が浮き彫りに。
これらの事例は、規約上の禁止条項と実際の業界慣行の間に大きなギャップがあることを示しています。
特に企業利用の場合、「他社がやっているから大丈夫」という感覚で蒸留に着手すると、後で規約違反として訴訟・サービス停止リスクを抱える可能性があるため、慎重な判断が必要です。
実務的な判断軸——オープンウェイトに絞る選択
ライセンスリスクを避けつつ知識蒸留を実務に取り入れるには、教師モデルを最初からオープンウェイト系に絞るのがもっとも安全です。
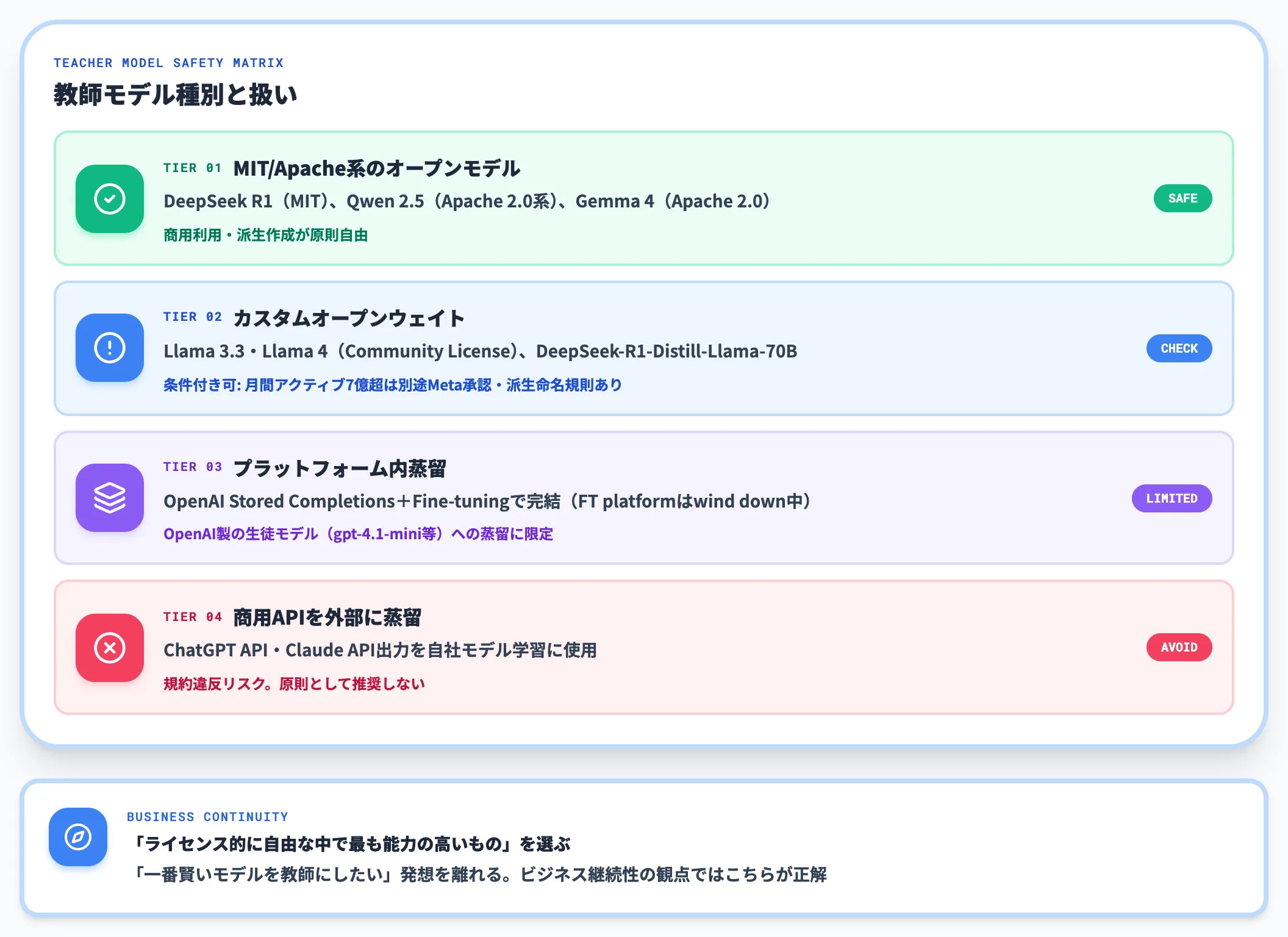
| モデル種別 | 代表例 | 蒸留教師としての扱い |
|---|---|---|
| MIT/Apache系のオープンモデル | DeepSeek R1(MIT)、Qwen 2.5(Apache 2.0系)、Gemma 4(Apache 2.0) | 商用利用・派生作成が原則自由 |
| カスタムオープンウェイト | Llama 3.3(Llama 3.3 Community License)、Llama 4(Llama 4 Community License Agreement)、DeepSeek-R1-Distill-Llama-70B(元のLlamaライセンスを継承) | 商用利用は可能だが、月間アクティブユーザー7億超の組織は別途Meta承認が必要・派生モデルの命名規則あり等の条件付き |
| プラットフォーム内蒸留 | OpenAI Stored Completions+Fine-tuningで完結する場合(2026年6月時点はfine-tuning platformがwind down中・新規ユーザー利用不可) | OpenAI製の生徒モデル(gpt-4.1-mini等)への蒸留に限定。プラットフォーム外への持ち出しはNG。新規導入は現行docsで利用可否を要確認 |
| 商用APIを外部に蒸留 | ChatGPT API・Claude API出力を自社モデル学習に使用 | 規約違反リスク。原則として推奨しない |
実務上は、DeepSeek R1の蒸留モデル、Llama 3.x/4、Qwen3-Coder、Gemma 4など、オープンウェイト系のフロンティアモデルが揃ってきたため、商用APIに頼らなくても十分な能力の教師モデルを選択できます。
ただしオープンウェイトは「MIT/Apache系の自由ライセンス」と「Llama Community Licenseのような条件付きカスタムライセンス」が混在しているため、商用利用前には必ず各モデルのライセンス本文を法務確認することが必要です。
「とにかく一番賢いモデルを教師にしたい」という発想を一度離れ、ライセンス的に自由なモデルの中で最も能力の高いものを選ぶ、というアプローチがビジネス継続性の観点では正解です。
企業が知識蒸留を導入する際の判断ポイント
知識蒸留を実務に取り入れる場合、**「自社で蒸留するか、既存の蒸留モデルを使うか」**という選択がROIを大きく左右します。

AI総合研究所の支援現場でも、ここで判断を誤ると初期投資が回収できないケースが少なくありません。本セクションでは、判断を支える具体的な軸を整理します。
自社で蒸留するか、既存蒸留モデルを使うか
ゼロから蒸留パイプラインを構築する必要があるのは、実は少数のケースに限られます。多くの企業は既存の蒸留モデル+少量の追加学習で十分な効果が得られます。
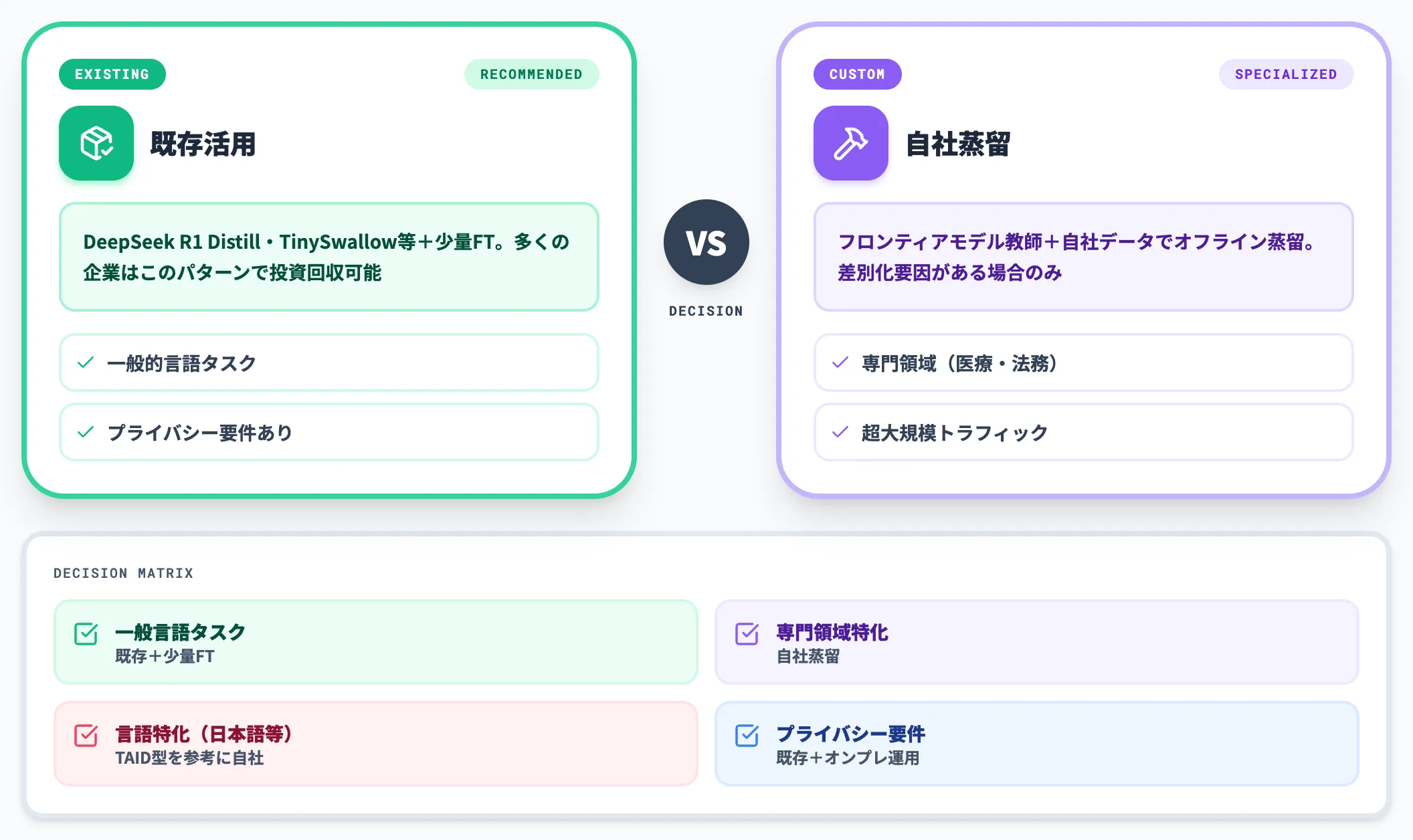
以下の表で、自社蒸留と既存モデル活用の使い分けを整理しました。
| 状況 | 推奨アプローチ | 理由 |
|---|---|---|
| 業務が一般的な言語タスク(要約・分類・FAQ応答等) | 既存蒸留モデル+少量FT | ゼロ蒸留のコストに見合うほどの差別化要因がない |
| 専門領域(医療・法務・特定業界)に強く最適化したい | フロンティアモデル教師+自社データで蒸留 | 既存モデルでは届かない領域知識を埋め込める |
| 言語特化(日本語・低リソース言語) | TAID型の手法を参考に自社で蒸留 | 英語中心の既存モデルでは精度が頭打ち |
| プライバシー要件で外部APIに送れないデータがある | 既存蒸留モデル+オンプレ運用 | 学習データを外に出さずに済む |
| トラフィックが極めて大きく数%の精度差が大きなコストになる | 自社蒸留で精度・コストを微調整 | 規模の経済が初期投資コストを正当化する |
多くの企業は「既存蒸留モデル+少量FT」のパターンで投資対効果を出せるため、まずはそこから検証を始めるのが現実的です。
ファインチューニングだけで足りるケース
「蒸留が必要に見える要件」の中には、実はファインチューニングだけで十分なものも少なくありません。

-
既存モデルのサイズで運用上問題ないが、特定タスクの精度が足りない場合
モデルサイズを変えずに精度を上げたいだけなら、ファインチューニングのほうが工数も少なく、結果も読みやすい。
-
教師モデルとなる十分強力なモデルが見つからない場合
自社用途より精度の高い教師モデルがないなら、蒸留しても上限が上がらない。同サイズのFTのほうが現実的。
-
学習データが少量しか用意できない場合
蒸留は教師モデルでの大量推論を前提とするため、データが少ないとパイプライン自体が成立しにくい。
「蒸留 vs FT」を二者択一で考えるより、**「サイズを変えたいなら蒸留、性能だけ上げたいならFT」**という素朴な軸で振り分けるのが、初期段階の意思決定としては最も外しにくい判断です。
投資判断のチェックリスト
知識蒸留に本格投資する前に、以下のチェックリストで自社の状況を整理することを推奨します。

- 既存の蒸留モデル(DeepSeek R1、Sakana TinySwallow、Llama Distill等)で要件が満たせないか、まず確認したか
- 教師モデルとして使う候補は、ライセンス上自由に使えるオープンウェイトか
- 蒸留後の生徒モデルを評価するための、自社タスクに沿った評価データセットが用意できているか
- 学習用のGPU環境またはエッジAI向け推論環境のインフラ計画が立っているか
- 蒸留後の精度劣化が許容範囲内か、PoCで実測する計画があるか
- 規約・コンプライアンス面で問題ないことを法務確認できているか
このチェックリストを満たさない段階で本格投資を進めると、**「蒸留パイプラインは完成したが、想定した精度が出ない/教師モデルの規約違反が後から発覚する/自社GPUインフラの維持費がAPI利用料を上回る」**といった事故が起こりがちです。
逆にチェックリストを通過する案件であれば、知識蒸留はLLM運用コストを構造的に下げる強力な選択肢になります。

知識蒸留で得た軽量化の発想を、自社業務の自動化に落とし込む
知識蒸留はあくまで「モデルを軽くする」技術であり、それ自体が業務を変えるわけではありません。
軽量化で生まれたコスト余地を、どの業務に・どの規模で・どのモデルで投入するかという設計があってはじめて、ROIが出ます。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、自社専用のAIエージェント基盤としてAI Agent Hubのような選択肢を組み合わせる際の判断軸まで、220ページの「AI業務自動化ガイド」にまとめて無料公開しています。蒸留モデルの導入可否を問わず、自社のAI活用戦略を整理する第一歩として活用ください。
AI軽量化の次は業務適用の設計

PoCから全社展開までの設計を1冊で
知識蒸留で削れるのは推論コストだけです。ROIを出すには、どの業務で・どの規模で・どのモデルを使うかという設計が欠かせません。AI業務自動化ガイド(220ページ)では、PoC段階から全社展開までの進め方、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、知識蒸留(Knowledge Distillation)について、仕組み・主要手法・関連技術との違い・実務効果・代表モデル・PyTorch実装・ライセンス論点・導入判断軸まで、2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
知識蒸留はソフトターゲットと温度パラメータを通じて、教師モデルの判断ニュアンスごと小型の生徒モデルに転移させる技術で、Hinton et al.(2015)以降の長い歴史を持ちつつ、LLM時代に「実装現場の道具」として再注目されている
-
手法はオフライン・オンライン・自己蒸留が伝統的な3分類で、2026年はOn-Policy DistillationやReasoning蒸留など、生徒の自己出力を活用する新潮流が広がっている
-
量子化・プルーニング・ファインチューニングとは排他ではなく、組み合わせて使う前提で考えると、エッジ展開やコスト圧縮の上限が大きく広がる
-
DeepSeek R1の蒸留モデル群はMITライセンスで公開され、Qwen2.5-32BベースでもAIME 2024 72.6%とOpenAI o1-miniを上回るスコアを達成。Sakana AI TAIDやOpenAI Model Distillation APIなど、用途別に参照すべき事例が揃っている
-
OpenAI・Anthropic等の商用APIを外部に蒸留する用途は規約違反リスクが高いため、商用利用はオープンウェイト系(DeepSeek R1、Qwen 2.5、Gemma 4などのMIT/Apache系+条件付きカスタムのLlama)に絞り、各モデルのライセンス本文を法務確認するのが実務的な判断
-
多くの企業はゼロから蒸留する必要はなく、既存蒸留モデル+少量ファインチューニングで投資回収できる。ゼロ蒸留は専門領域特化・言語特化・極めて大規模なトラフィックがある場合に限られる
知識蒸留は「LLMが大きくなりすぎた時代の現実解」として、もはや研究テーマではなく業務インフラの一部です。フロンティアモデルのAPIを呼び続けるか、自社用途に合った蒸留モデルへ移行するかという選択は、2026年以降のAIコスト構造を決める重要な岐路になります。まずは既存の蒸留モデルでPoCを回し、自社タスクでの精度とコストを実測することから始めるのが、最も投資対効果の高い第一歩です。










