この記事のポイント
 画像生成AIを無料で始めるなら、Stable Diffusion Onlineが第一候補。登録後すぐに使えて環境構築が不要なため、初心者でも即座に試せる
画像生成AIを無料で始めるなら、Stable Diffusion Onlineが第一候補。登録後すぐに使えて環境構築が不要なため、初心者でも即座に試せる- 本格的に画像生成に取り組むなら、ローカル環境のWebUI Forgeを導入すべき。AUTOMATIC1111より高速かつ安定しており、VRAM効率も優れている
- 2026年現在の最新はSD 3.5シリーズ、高品質重視はLarge、速度はLarge Turbo、低スペックPCはMediumが最適
- LoRAによるカスタマイズはCivitaiから無料でダウンロードして始められるため、独自の画風やキャラクター表現を追求したい場合は積極的に活用すべき
- 商用利用を想定する場合はモデルごとのライセンスが異なるため、利用規約を必ず事前確認し、社内ガイドラインを整備してから運用を開始すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIによる画像生成が急速に普及する2026年、その先駆け的存在である「Stable Diffusion」は、依然として無料で使えるツールとして世界中のユーザーから支持を集めています。
本記事では、ブラウザから即座に試せるオンラインサービスから、スマートフォンアプリ、Google Colabを経由したクラウド活用、さらには自分のパソコンでフル活用するローカル環境の構築まで、Stable Diffusionをゼロから使いこなすための2026年最新情報をお届けします。
「Stable Diffusion Online」「Leonardo AI」「Hugging Face」「Mage.space」など無料で使えるWebサービスの特徴と使い方、プロンプト(命令文)の書き方のコツ、モデルをカスタマイズできる「LoRA」の基本、WebUI(AUTOMATIC1111・Forge・ComfyUI)の選び方、そして2026年現在の最新モデル(Stable Diffusion 3.5シリーズ)の違いも丁寧に解説します。
また、FLUXとの違いやスマホでの利用方法、商用利用の注意点まで網羅しているため、初心者から上級者まで参考にしていただける内容です。
目次
Stable Diffusionとは?無料で使える理由を理解しよう
2026年現在の最新モデル:Stable Diffusion 3.5シリーズ
Stable DiffusionとFLUXシリーズ:2026年時点の位置づけ
Google ColabでStable Diffusionを使う方法
LoRAで表現を広げる:Stable Diffusion無料カスタマイズの第一歩
ローカル環境でのStable Diffusion無料活用:WebUIの選び方
Stable Diffusionとは?無料で使える理由を理解しよう
Stable Diffusionは、英国のスタートアップ企業「Stability AI」が開発し、2022年に公開したオープンソースの画像生成AIです。テキスト(プロンプト)を入力するだけで、写真のようにリアルな画像からアニメ風のイラストまで、さまざまなスタイルの画像を自動生成できます。
Stable Diffusionが無料で使える最大の理由は、オープンソースとして公開されている点にあります。ソースコードとモデルの重みデータが誰でも入手可能なため、世界中の開発者がさまざまなアプリケーションやサービスを構築し、その多くが無料で公開されています。ChatGPTやMidjourneyのような完全なクローズドモデルとは根本的に異なる設計思想であり、「自分のパソコンで動かせる」「無制限に画像生成できる」という特徴が、多くのクリエイターや開発者を引きつけています。

2026年現在の最新モデル:Stable Diffusion 3.5シリーズ
2024年10月にStability AIがリリースしたStable Diffusion 3.5シリーズは、2026年現在も最前線で使われ続けている最新世代のモデルです。従来世代と比べて画質・速度・テキスト描画精度が大幅に向上しており、3D・写真・絵画・線画など幅広いスタイルに対応しています。また、人体描写の崩れが劇的に改善されたことも大きな進化ポイントです。
以下の表で、SD 3.5の3つのバリエーションの特性を整理しました。この表を読んだ上で、次のセクションで各サービスでの実際の活用方法を紹介します。
| モデル名 | パラメータ数 | 生成速度 | 画像品質 | 推奨用途 |
|---|---|---|---|---|
| Stable Diffusion 3.5 Large | 約81億 | 通常速度 | 最高品質 | プロフェッショナル向け・高品質重視 |
| Stable Diffusion 3.5 Large Turbo | 約81億(蒸留版) | 高速(4ステップで生成) | Largeより若干劣る | 高速生成が求められる場面 |
| Stable Diffusion 3.5 Medium | 約25億 | 通常速度 | 中程度の品質 | コンシューマー向け・カスタマイズ重視 |
ここで注目すべきは、Large Turboの存在です。わずか4ステップで画像を生成できるため、アイデア出しや大量のバリエーション検討に最適であり、通常のLargeモデルと合わせて使い分けることで、制作効率を大幅に高めることができます。つまり、用途に応じてモデルを選ぶ習慣が、Stable Diffusion活用の第一歩になるということです。
Stable DiffusionとFLUXシリーズ:2026年時点の位置づけ
2026年の画像生成AI市場では、元Stable Diffusion開発者チームが設立したBlack Forest Labsによる「FLUXシリーズ」がStable Diffusionと並ぶ主要なオープンソースモデルとして定着しています。2025年11月には最新の**FLUX.2**がリリースされ、32Bパラメータのモデルで4Kメガピクセル解像度に対応するなど性能が大幅に向上しました。2026年1月にはコンシューマーGPU向けの軽量版「FLUX.2 Klein」も公開されています。
以下の表で、Stable Diffusion 3.5とFLUXシリーズの特徴の違いを整理しました。どちらが優れているという単純な話ではなく、用途によって使い分けることが重要です。
| 項目 | Stable Diffusion 3.5 | FLUXシリーズ(FLUX.2) |
|---|---|---|
| 開発元 | Stability AI | Black Forest Labs(元SD開発者チーム) |
| 最新モデル | SD 3.5 Large(約81億パラメータ) | FLUX.2(32Bパラメータ、4K解像度対応) |
| 得意な用途 | ワークフロー組み込み・LoRAカスタマイズ | 高精度なテキスト描画・フォトリアル |
| カスタマイズ性 | 非常に高い(LoRA豊富) | FLUX.2で対応LoRAが急速に増加中 |
| ComfyUI対応 | 対応済み | カスタムノードで対応(推奨環境) |
| ライセンス | Stability AI Community License | FLUX.2 KleinはApache 2.0 |
ここで注目すべきは、Stable Diffusionは豊富なLoRAやカスタムモデルの蓄積という点で圧倒的な優位性を持っている点です。FLUX.2のリリースでFLUXシリーズの画像品質はさらに向上しましたが、2026年時点でもCivitaiには膨大な数のSD用LoRAが公開されており、独自スタイルを追求するクリエイターにとって、Stable Diffusionのカスタマイズ資産の厚みは依然として他に類を見ないものです。
Stable Diffusionを無料で使う4つの方法
Stable Diffusionの利用方法は大きく4つに分かれます。それぞれの特徴を理解した上で、自分に合った入り口を選ぶことが重要です。
以下の表で、4つの利用方法の違いを整理しました。この表の内容を踏まえて、次のセクションでは各方法の具体的な使い方を順番に説明していきます。
| 利用方法 | セットアップ | コスト | 制限 | おすすめの人 |
|---|---|---|---|---|
| オンラインサービス | 不要(ブラウザのみ) | 基本無料(一部制限あり) | 生成枚数・機能に制限 | まず試したい初心者・手軽に使いたい人 |
| スマホアプリ | アプリインストールのみ | 基本無料(アプリ内課金あり) | 生成品質・機能に制限 | スマホ派・外出先で使いたい人 |
| Google Colab | Googleアカウントのみ | 無料版は制限あり(Pro推奨) | GPU利用時間に制限 | PCスペック不足だがローカルに近い体験をしたい人 |
| ローカル環境 | PCへのインストール必要 | 完全無料(電気代のみ) | ほぼ無制限 | 本格的に使いたい人・商用利用を検討している人 |
ここで注目すべきは、ローカル環境は一度構築してしまえば制限なし・追加費用なしで使い続けられる点です。初期の導入ハードルは高いものの、長期的に見ればコストパフォーマンスは圧倒的に優れており、それがStable Diffusionを他の画像生成AIサービスと大きく差別化している要因となっています。
Stable Diffusionが無料で使えるサービス
Stable Diffusionが無料で使えるサービスはいくつか提供されていますが、この記事では以下のサービスについて概要と使い方を説明していきます。
- Stable Diffusion Online シンプルで初心者に最適なWebサービス
- Leonardo AI 多機能な独自モデル選択が魅力のプラットフォーム
なお、以下のサービスについては別の記事で取り上げています。ぜひあわせてご覧ください。
- Dreamstudio
- Mage.space
- Hugging Face
Stable Diffusionとは?ローカル環境での使い方や料金体系を解説! | AI総合研究所
Stable Diffusion WebUI Forgeのインストール方法と使い方を徹底解説。Azure仮想マシンでの環境構築から、モデルの導入、プロンプトの基本、トラブルシューティングまで紹介します。
https://www.ai-souken.com/article/pricing-stable-diffusion

また、ローカルでの利用方法については、こちらの記事をご覧ください。
Stable Diffusion Web UI Forgeのインストール方法・使い方をわかりやすく解説
Stable Diffusion Online
Stable Diffusion Onlineは、他のサービスと比べてシンプルな機能に絞られているのが特徴です。拡張機能や詳細な設定はできませんが、初心者でも簡単に画像生成を始められます。
基本的に無料で使用できますが、一定以上の枚数を出力すると制限がかかり、有料プランへの移行が必要となります。スマートフォンのブラウザからもアクセスできるため、PCを持っていない方でも手軽に試せる点が魅力です。
Stable Diffusion Onlineの使い方
- Stable Diffusion Onlineにアクセスし、登録を済ませます。
Stable Diffusion Onlineのトップページ
- トップページ中央には「何を描きたいですか?」と表示されています。
ここに描きたい画像についての文章(プロンプト)を入力し、「生成」ボタンを押すだけで画像が生成されます。
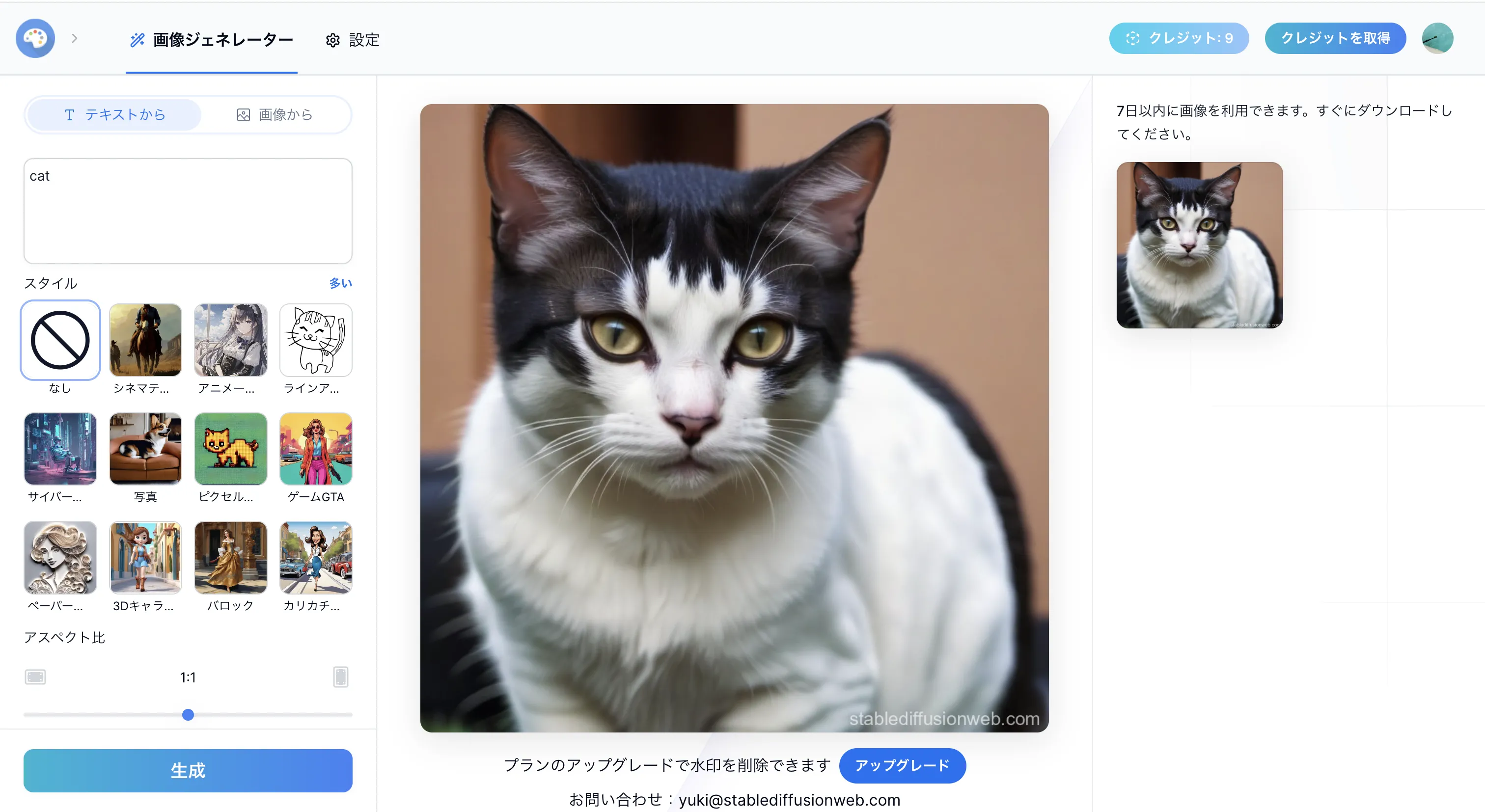
プロンプトを入力し、生成する。
-
一眼レフで撮影されたような猫の画像が出力されました。プロンプト入力欄の下にある「スタイル」を変更すると、様々なバリエーションを楽しめます。
ラインアート風やピクセルアート風にも変更できます。
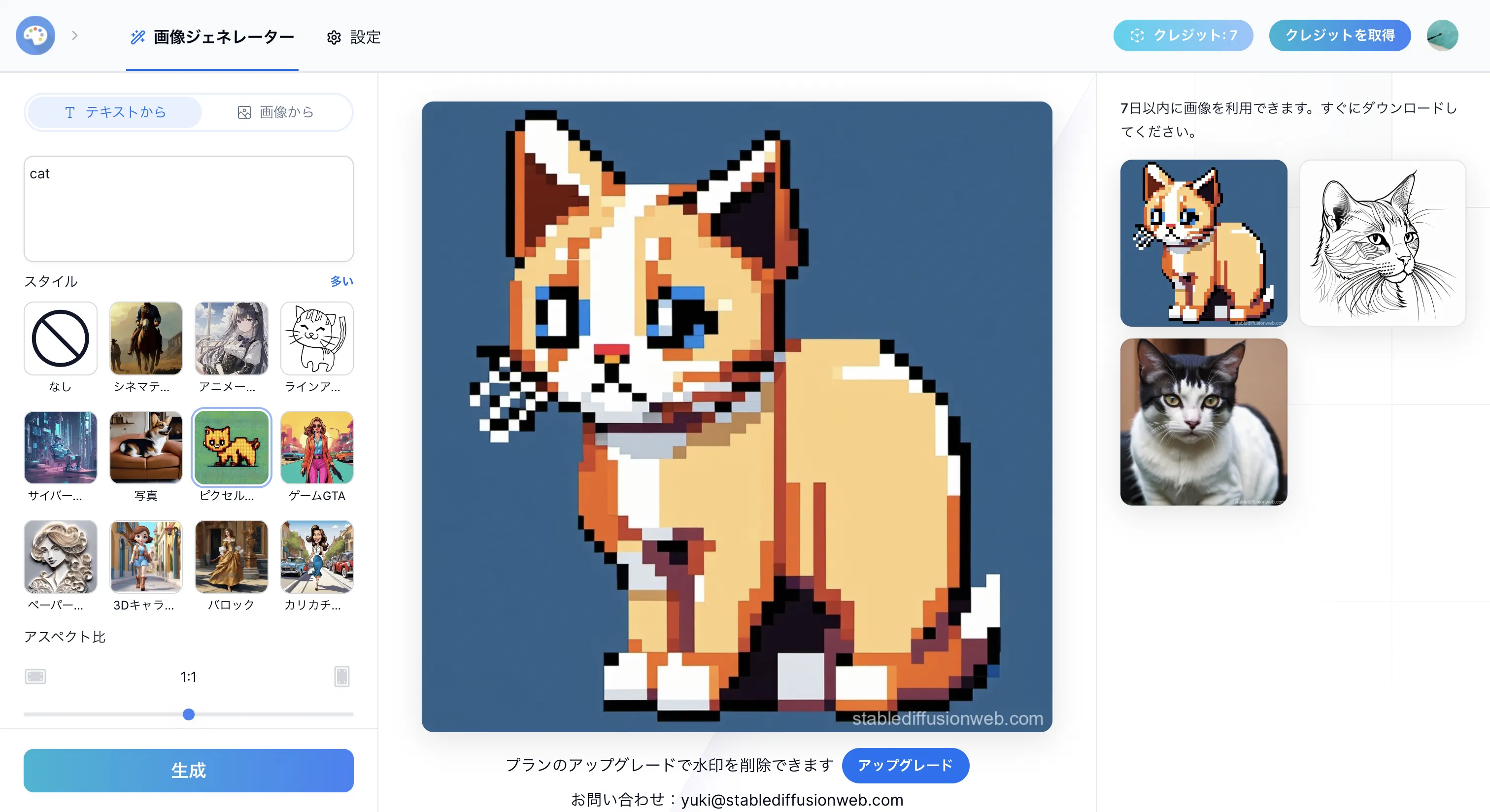
ラインアート風、ピクセルアート風のスタイルに変更してみた例
-
さらに、「画像から」ボタンを選択すると、自分が持っている画像をベースにアレンジを加える機能(Image to Image)も利用できます。画
像をアップロードしてプロンプトを入力すれば、その画像とプロンプトの情報が混ざった結果を出力できます。
例えば、ピクセルアート風の猫を生成した際のプロンプト「cat」と、スタイル「ピクセルアート」を維持しつつ、「19世紀後半から20世紀初頭にかけての古びた白人男性の肖像写真」を加えると、次のような結果になりました。
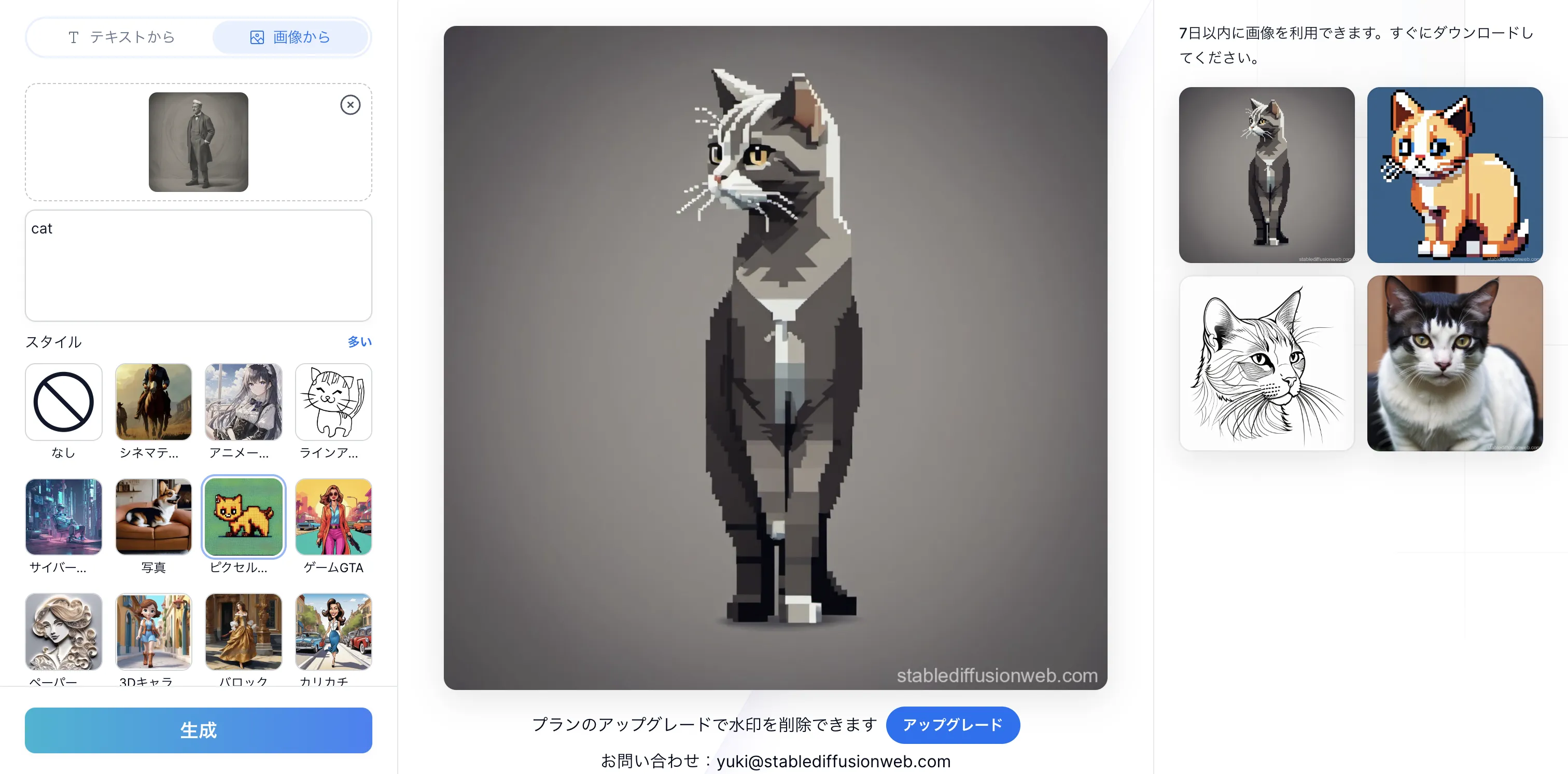
画像から生成した事例
男性肖像写真の特徴(全身像、体が左に向いている、グレー)とピクセル風の猫がうまく組み合わされています。
Leonardo AI
Leonardo AIもStable Diffusion Onlineと同様に、テキスト(プロンプト)から画像を生成できるサービスです。
大きな違いとして、Leonardo AIは、さまざまなモデルが用意されていることです。
アニメ風のイラストに特化したモデルやビンテージな写真に特化したモデルなど、モデルを変えることで出力される画像のテイストが変化します。
ここでは、その一部をご紹介します。
Leonard AIの使い方
まず、「モデルの選択」から説明していきます。
-
Leonardo AIにアクセスし、登録します。
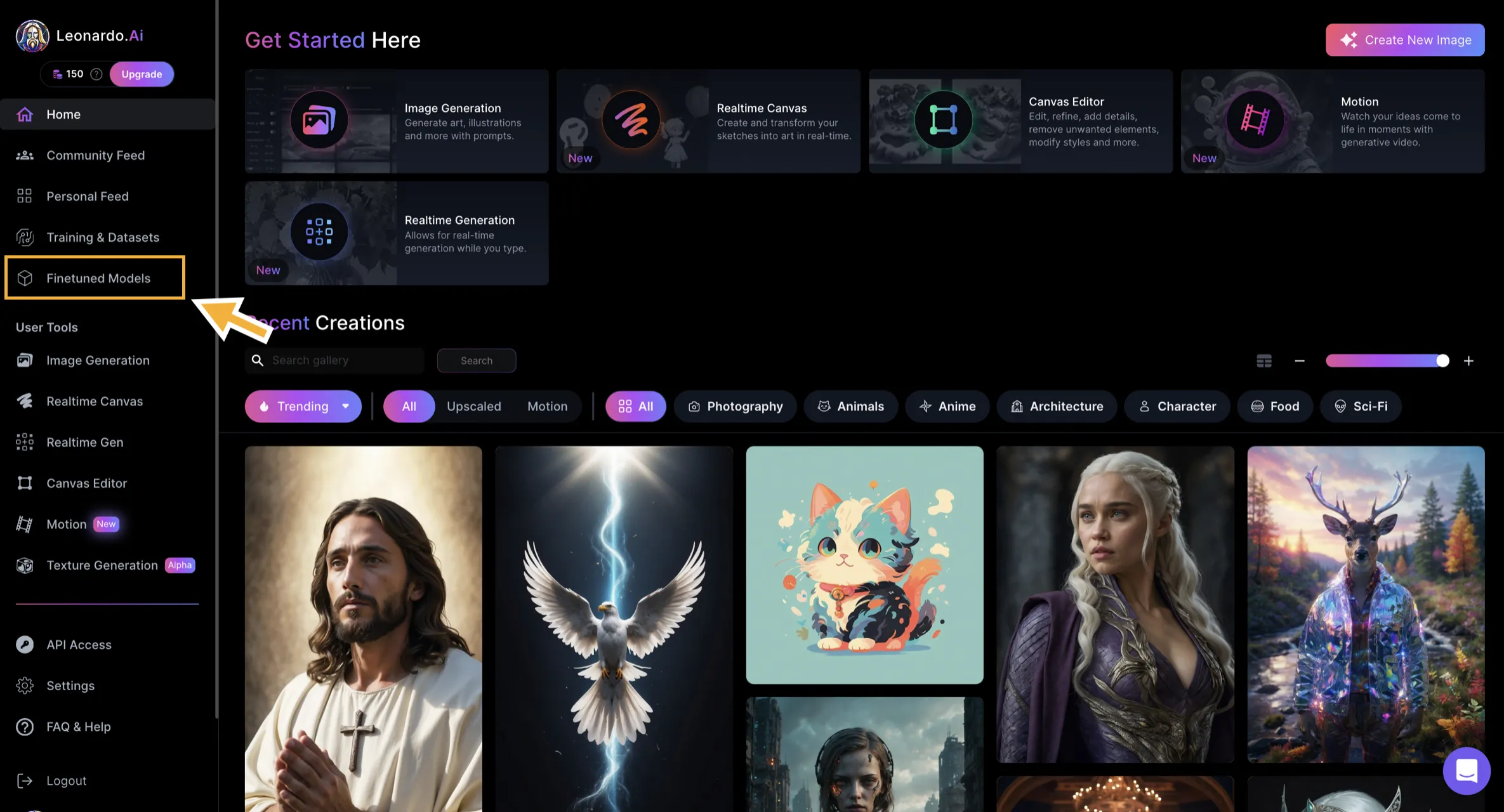
-
ログイン後、画面の右端に「Finetuned Models」とありますが、こちらで使用できるモデルを選択することができます。
Leonardo AIの説明画像
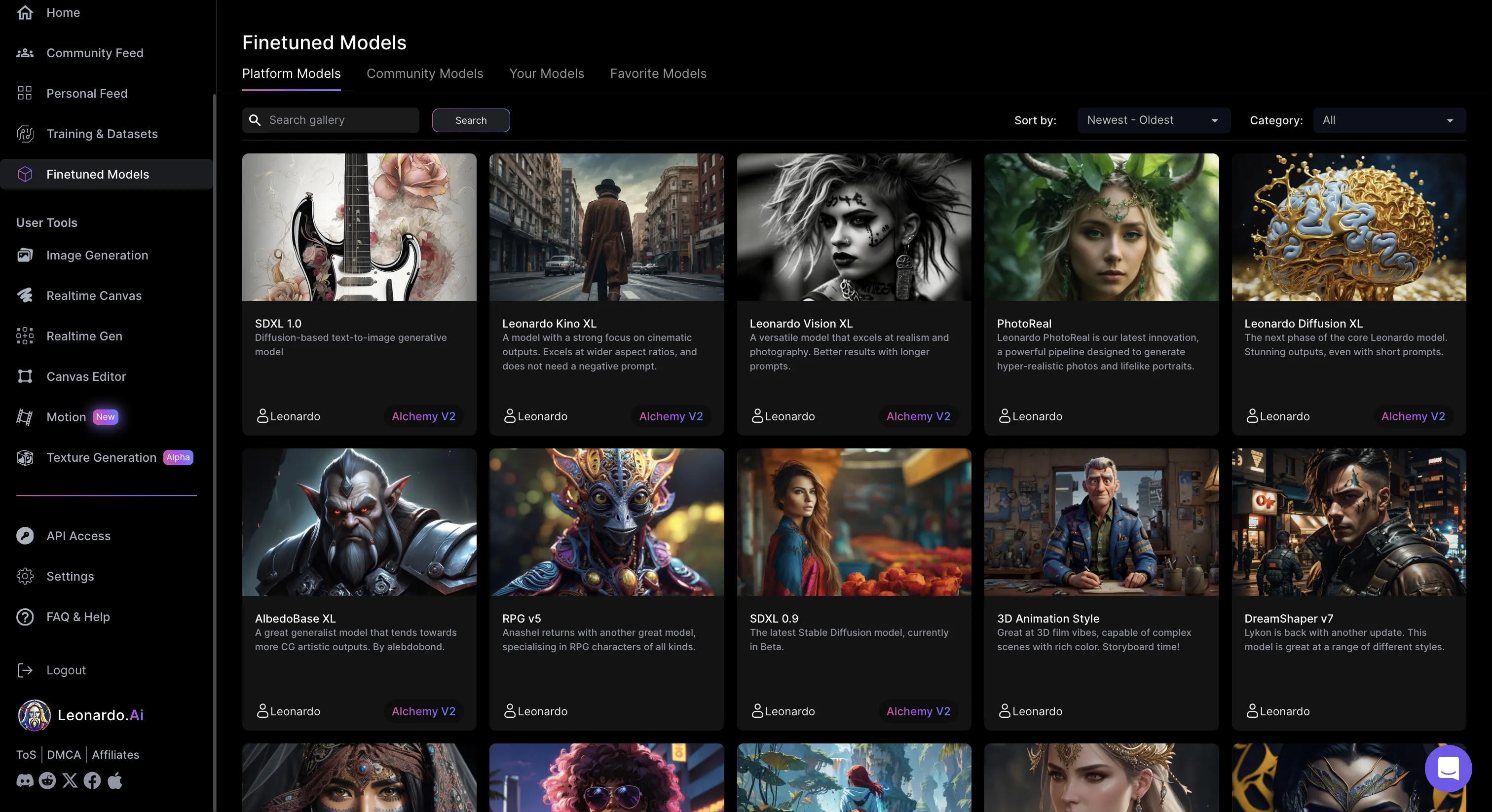
-
さまざまなモデルがあるので、自分が使いたいモデルを選択しましょう。
Leonardo AIの説明画像
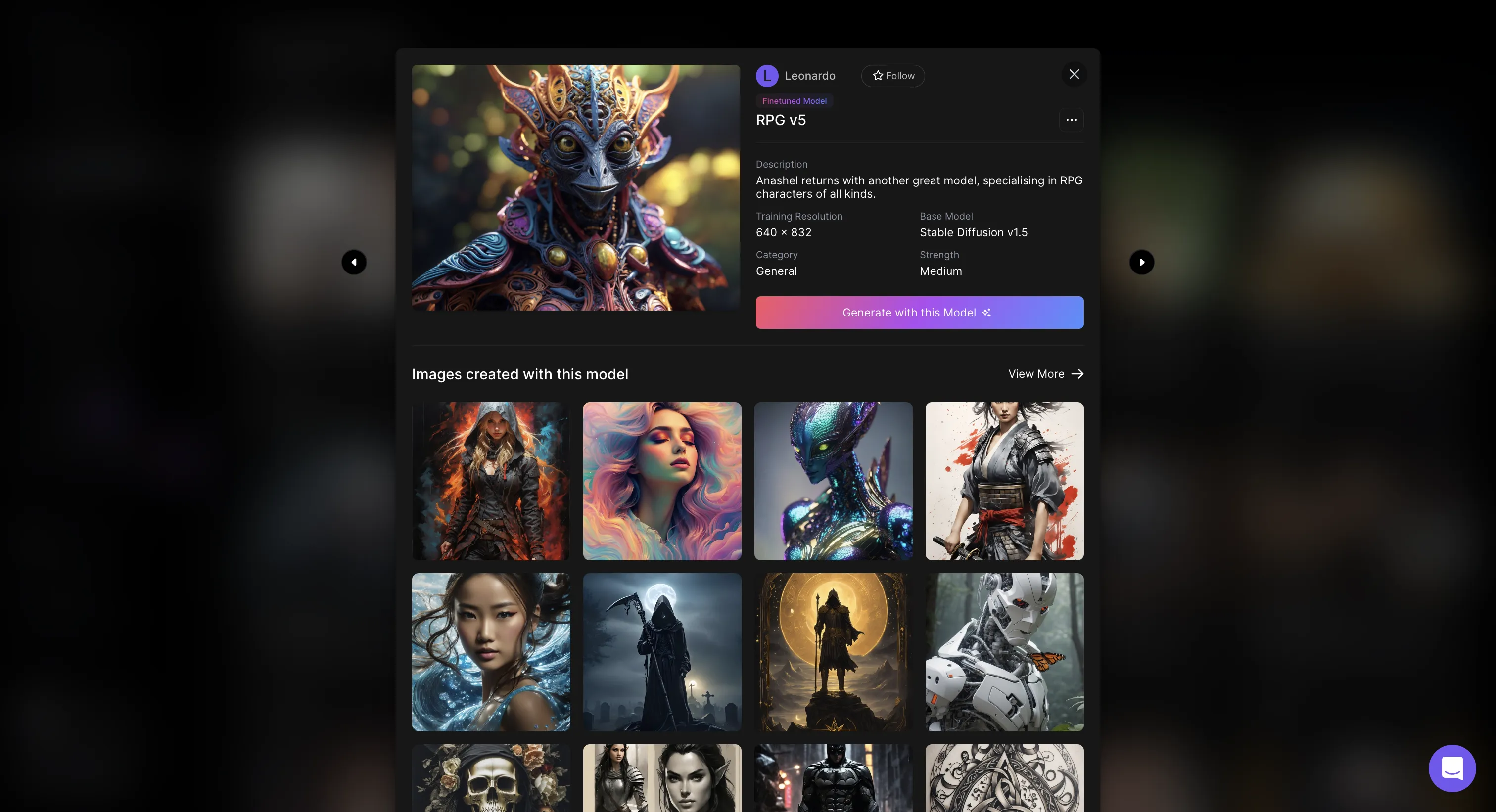
-
「Generate with this Model」を選択すれば、そのモデルを使用できるようになります。
Leonardo AIの説明画像
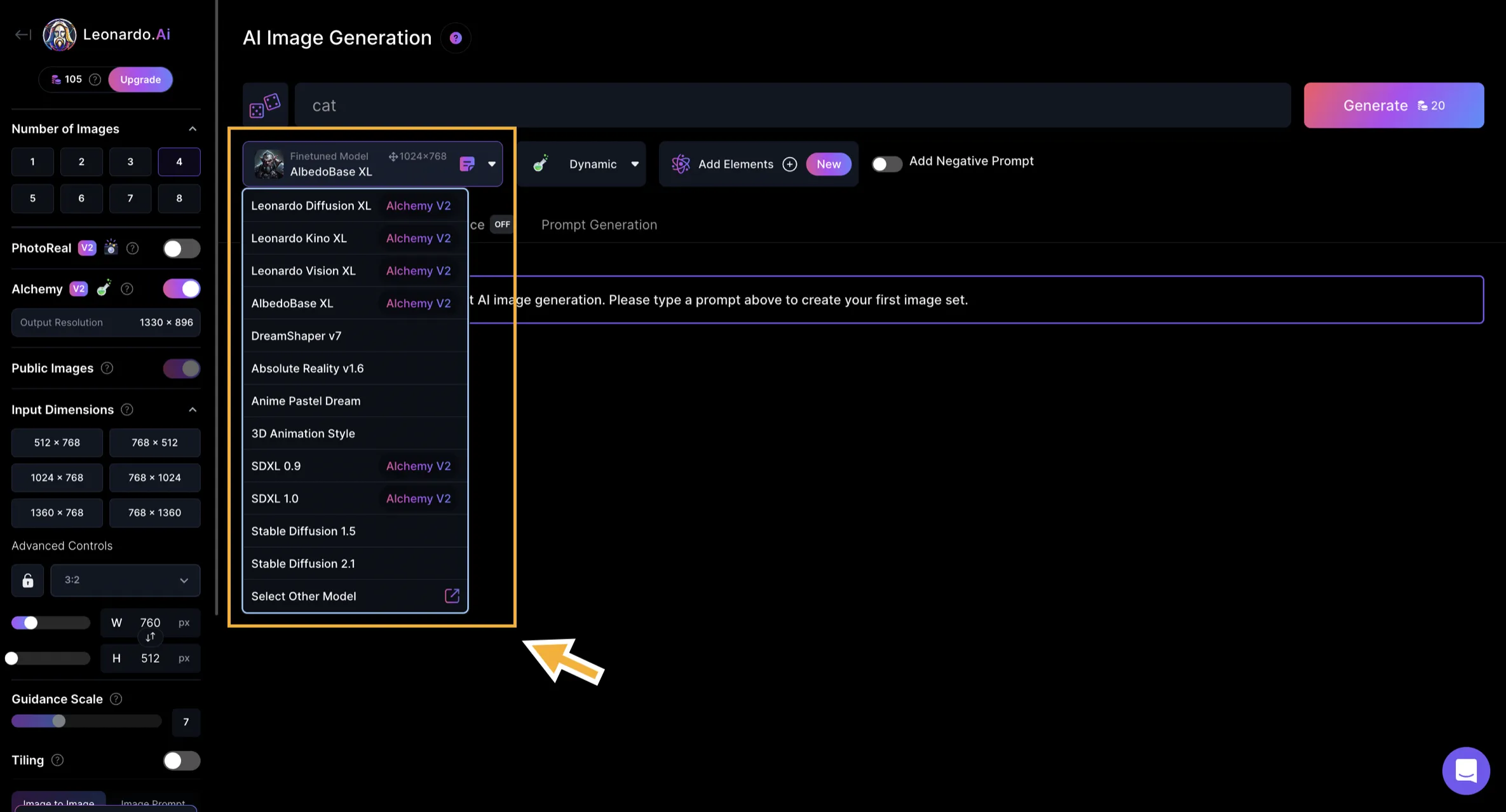
-
モデルを選択後、具体的な操作画面へと遷移します。
この画面上でも、モデルの選択、変更を行うことが可能です。
Leonardo AIの説明画像
画像を生成する
Leonardo AIでは、プロンプトから画像を生成することも、画像から画像を生成すること(Image to Image)もできます。
以下に、操作画面の主要機能を整理しました。
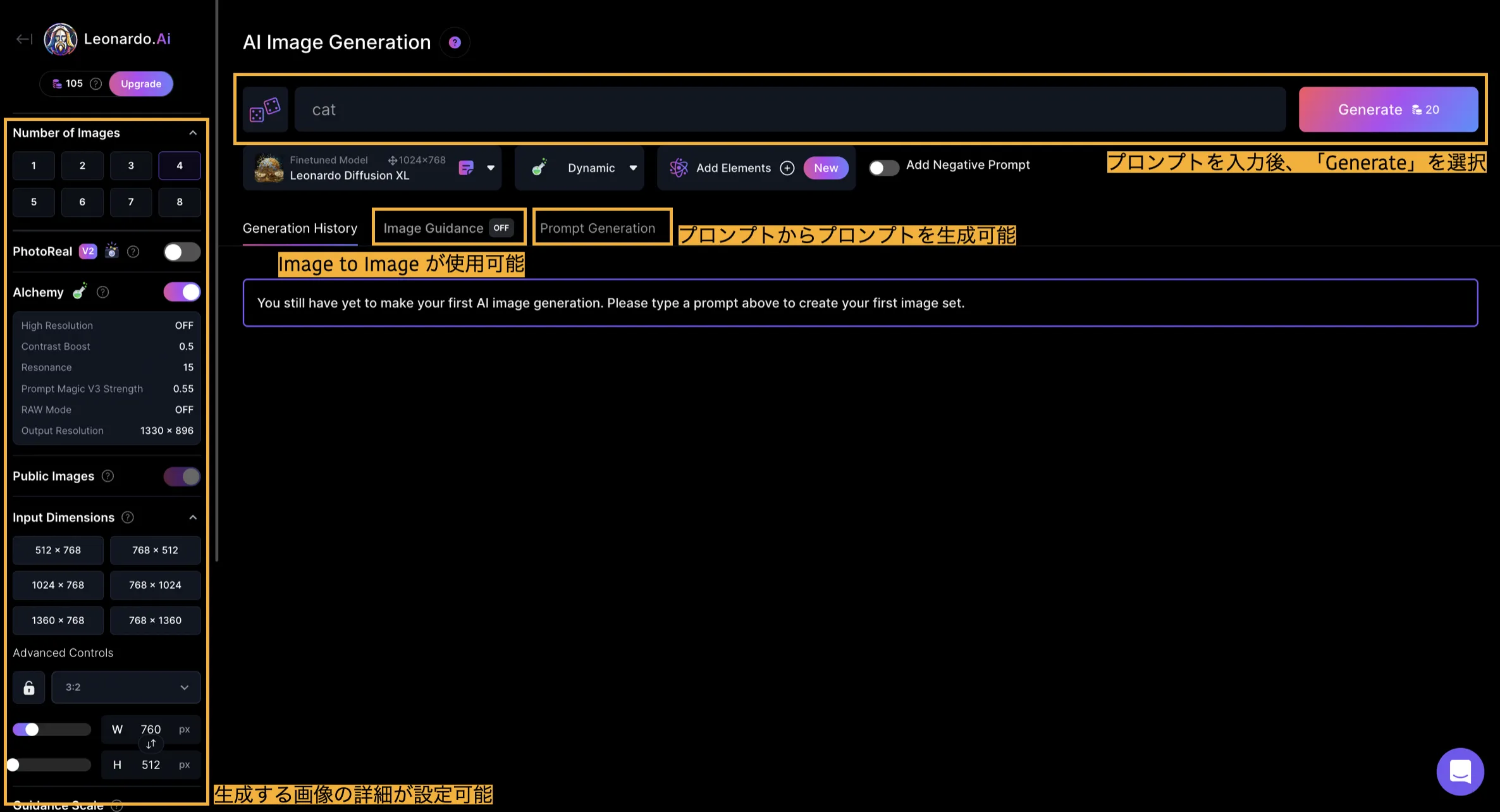
Leonardo AIの説明画像
画像から画像を生成したい場合は、画面中央左側の「Image Guidance」を選択し、画像をアップロードします。
ここでは、魚の画像をアップロードしてみました。
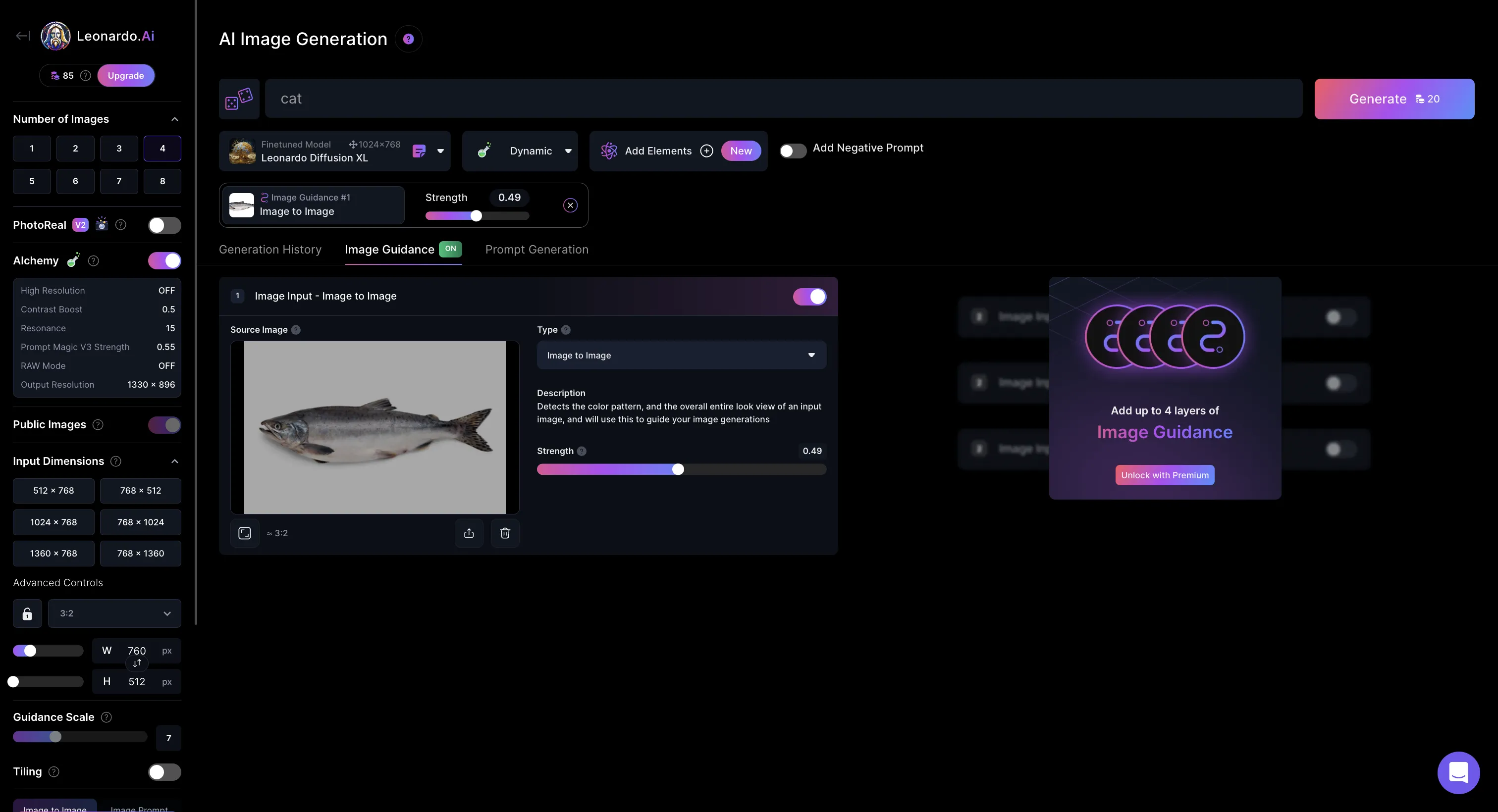
Leonardo AIの説明画像
ただし、画像をアップロードするだけでは別の画像を生成できません。プロンプトを入力し、その内容と画像を組み合わせた画像が生成されます。
今回は、プロンプト入力欄に「cat」と入力して生成してみました。
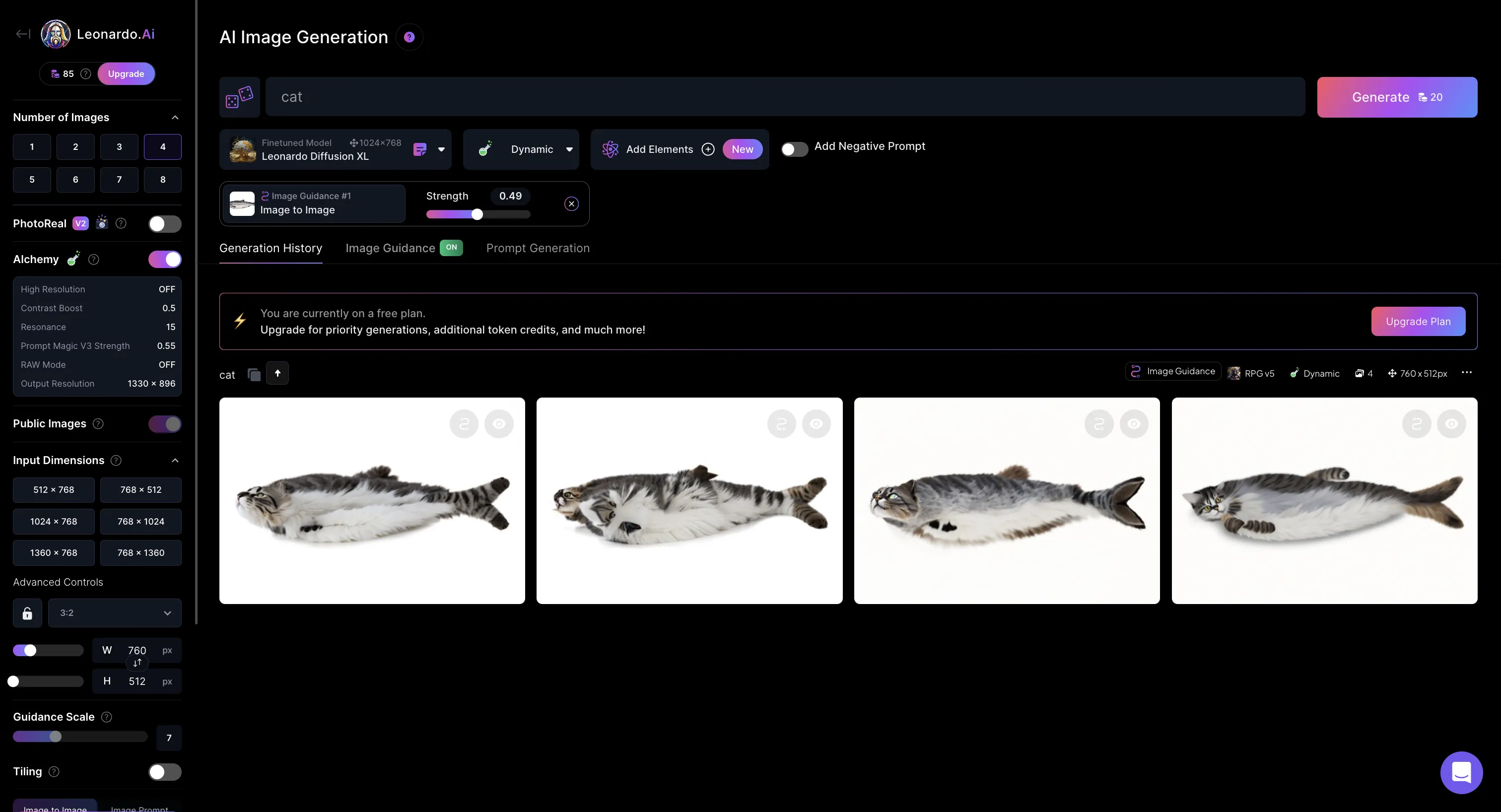
Leonardo AIの説明画像
魚の頭部が猫の頭部に入れ替わりましたが、魚の形は維持されたままです。また、表面も猫の毛並みになっています。
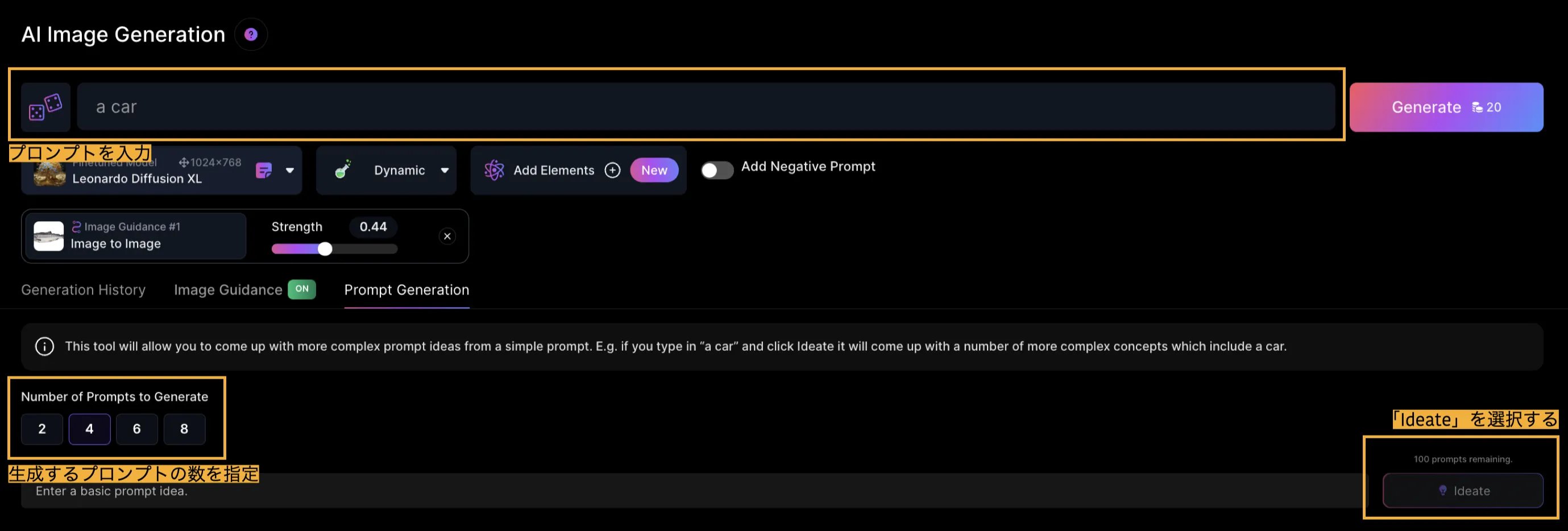
プロンプトからプロンプトを生成する
このツールを使用すると、単純なプロンプトからより複雑なプロンプトのアイデアを発想することができます。
たとえば、「a car」と入力して「Ideate」をクリックすると、「a car」を含むより複雑なコンセプトが多数表示されます。
Dream Studio
DreamStudioは、Stability AI社が開発・運営している画像生成AIツールで、同社の「Stable Diffusion」を基盤としています。
Dream Studioの使い方
- DreamStudio にアクセスします。
DreamStudioのログイン画面
- 右上の「Get started」を選択します。
- メールアドレスとパスワードを入力して新規登録するか、GoogleまたはDiscordのアカウントを使用する事ができます。
- プロンプトの入力
-
画面下部のテキストボックスに、生成したい画像の説明を英語で入力します。今回はドイツのクリスマスマーケットをテーマにやってみましょう。
- 例: A traditional German Christmas market at night, warm glowing lights illuminating wooden stalls, selling handmade ornaments, gingerbread cookies, and mulled wine,a large decorated Christmas tree in the center, joyful people wearing winter clothes, in a cozy and festive atmosphere, high detail, photorealistic, 8k resolution
-
- 例:blurry, low quality, low resolution, bad anatomy, unrealistic proportions, distorted face, watermark, text, logo, overexposed, underexposed, too dark, too bright, noisy, grainy
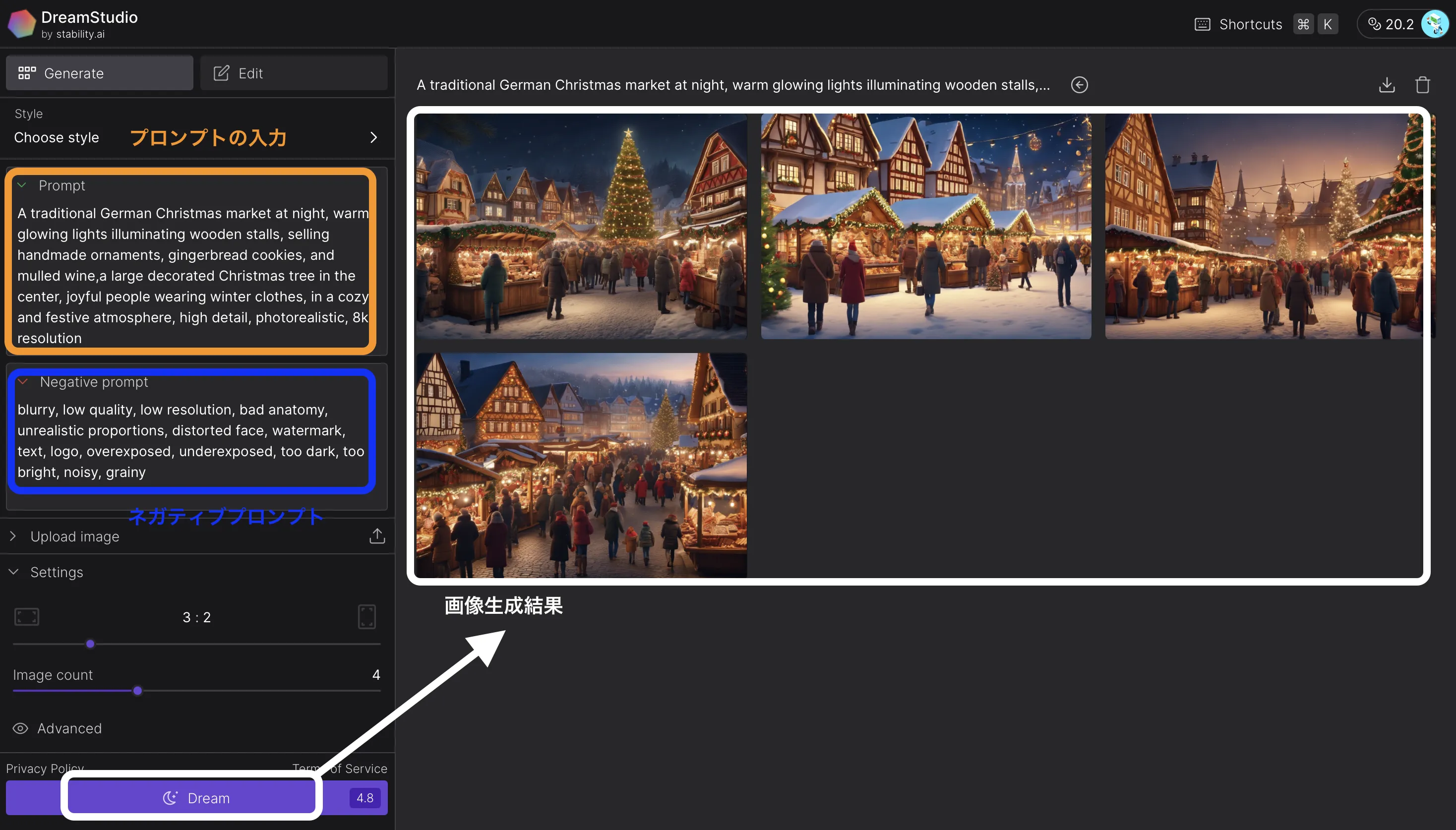
DreamStudioのUI画像
-
画像の生成
- 設定が完了したら、右側の「Dream」ボタンをクリックします。
- 数秒から数十秒で、指定したプロンプトに基づく画像が生成されます。
- 生成された画像は、クリックして拡大表示やダウンロードが可能です。
-
スタイルの調整
DreamStudioでは生成画像のスタイル選択ができる事が特徴です。
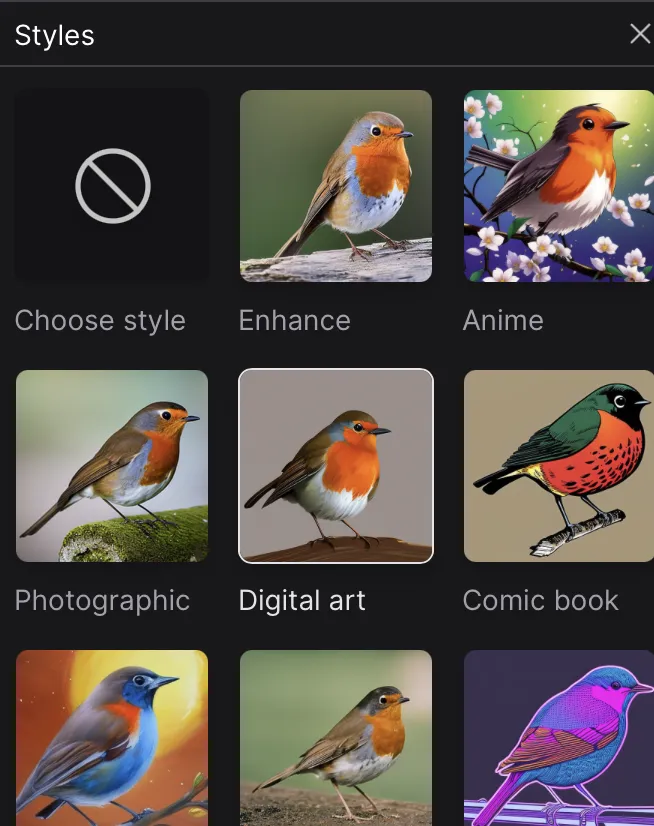
スタイルの調整
アニメ調、写真風、デジタルアート、コミック風など、さまざまなアートスタイルから選ぶ事ができます。
例えば先ほどのクリスマスマーケットの画像を「Craft clay(粘土風)」に変更してみましょう。
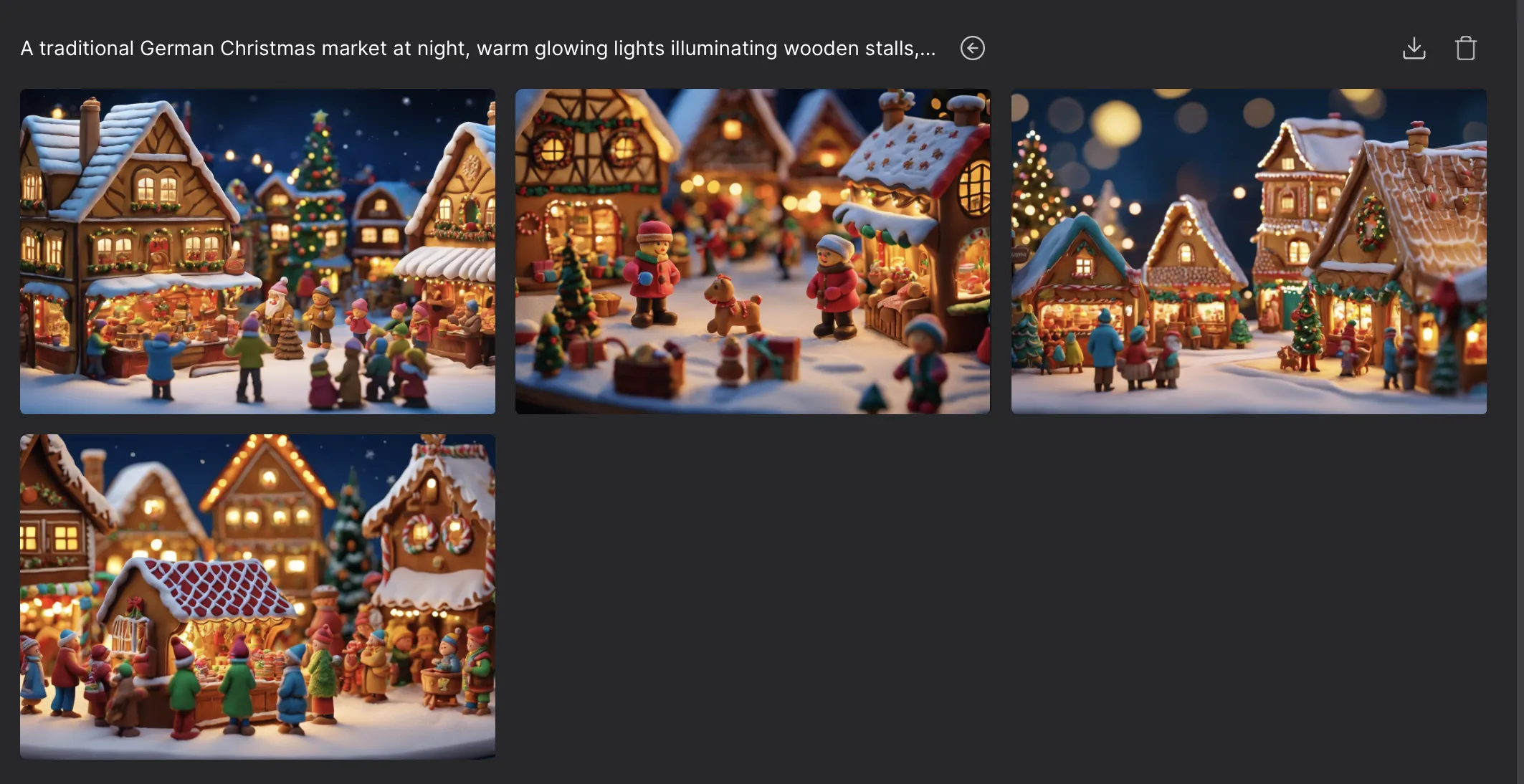
CraftClayを選択した結果
すると、先ほどのリアリスティックな画像から一変、暖かく柔らかみのある画像が生成されました。
このように、同じプロンプトでもスタイル設定によって生成結果が大きく異なります。
DreamStudioを使用する際にはご自身のお気に入りのスタイルを探して見てください。
料金体系
クレジット制
アカウント作成時に25クレジットが無料で付与され、追加クレジットは10ドルで1,000クレジットを購入可能です。
消費クレジット
画像生成ごとにクレジットを消費し、生成する画像のサイズや解像度、生成ステップ数などによって消費クレジット数が変動します。
Mage Space
Mage.spaceは、Ollano社が提供するオンラインの画像生成AIサービスで、Stable Diffusionを搭載しています。
Mage Spaceの使い方
-
Mage.space公式サイトにアクセスします。
-
使用するモデル・スタイルを選択
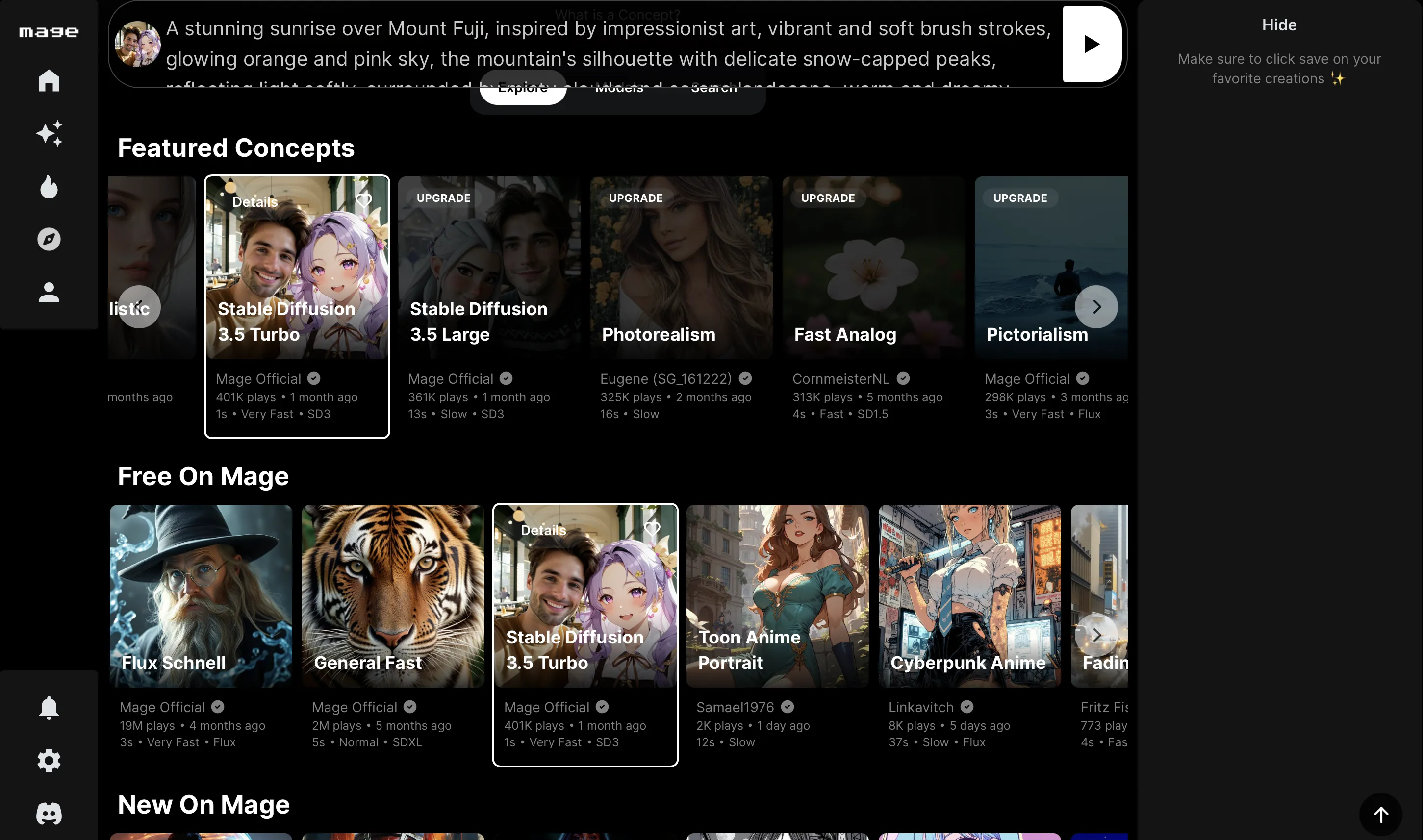
使用するモデル・スタイルを選択
使用するモデルから今回は【Stable Diffusion3.5Turbo】を選択します。
他にもFlux.1やリアル・アニメなどのスタイル設定があるので、ニーズに基づいて選択してみてください。
- プロンプトの入力・生成
今回はオーガニックスーパーの広告を表現してみましょう。
使用したプロンプト:blurry, low quality, pixelated, messy background, harsh lighting, artificial colors, text overlapping, cartoonish
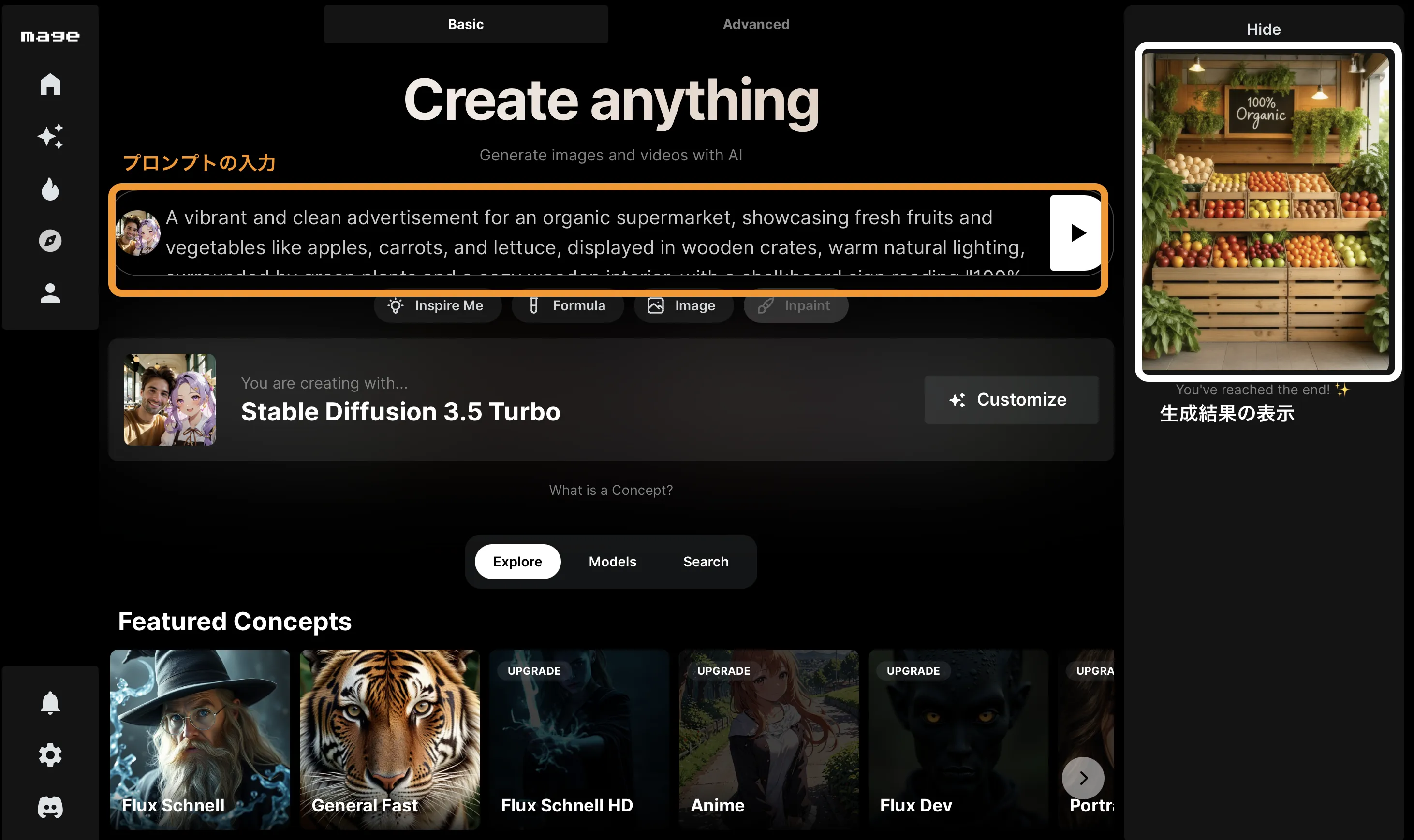
オーガニックスーパーの生成例
利用時の注意点
SD3.5 Turboは、生成速度を重視したモデルで、少ないステップ数(4ステップ)で画像を生成するため、出力される画像の品質や精度が他のモデルと比べて劣る場合が多いです。

各モデルの生成結果比較
今回はMageで利用可能な4つのモデルを同じプロンプトで比較しましたが、FLUXシリーズやGeneral Fastの方が生成精度が高いように感じます。
Mageを利用する際に、無料ユーザーがStable Diffusion 3.5 Largeを使えない点はやや不便ですね。
Huggingface
HuggingfaceでStableDiffusuionを使用する方法
-
Hugging Face公式サイト にアクセスします。
-
Inference APIのテキストボックスにプロンプトを入力
今回はジャングルにいる宇宙飛行士を作成してみましょう。
【使用プロンプト】
Astronaut in a jungle, cold color palette, muted colors, detailed, 8k
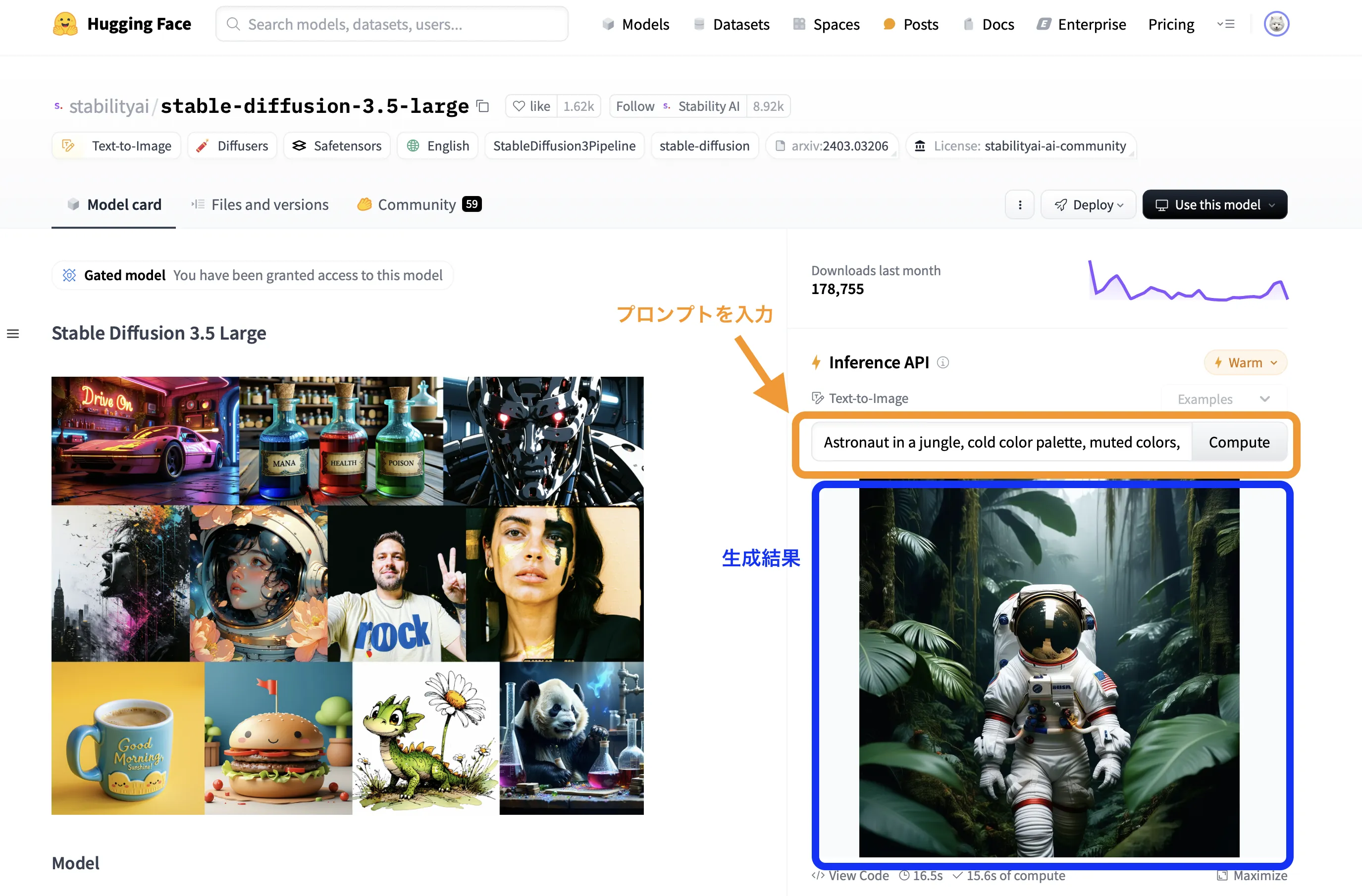
Huggingfaceの生成画面
Hugging Face利用時の注意点
Hugging Faceで「Stable Diffusion」を検索すると、さまざまなモデルが見つかるはずです。
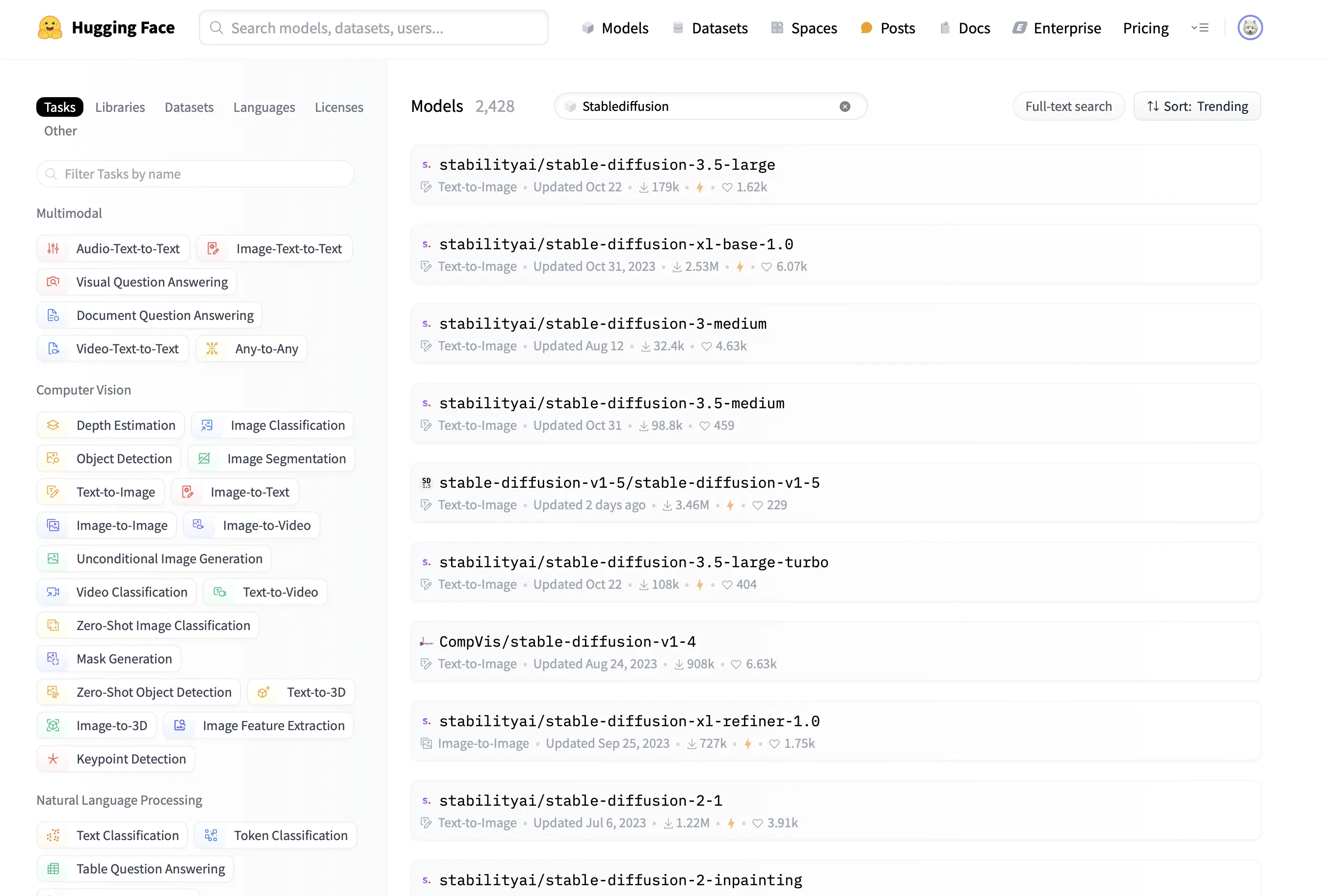
HuggingFace上で使用できるStable Diffusionのモデル例
もちろん用途や目的に応じて選ぶことができますが、stabilityai/stable-diffusion-3.5-largeの使用をおすすめします。
以下の表で、Hugging Face上で使用できる主なモデルのスペックを整理しました。この表を参考に、自分の用途に合ったモデルを選んでみてください。
| 項目 | Stable Diffusion 3.5 Large | Stable Diffusion 3.5 Large Turbo | Stable Diffusion 3 Medium |
|---|---|---|---|
| パラメータ数 | 約80億 | 約80億(蒸留版) | 約26億 |
| 生成速度 | 通常速度 | 高速(4ステップで生成) | 通常速度 |
| 画像品質 | 高品質(最高レベル) | Largeより若干劣る | 中程度の品質 |
| 用途 | プロフェッショナル向け | 高速生成が求められる場合 | カスタマイズ性が高い軽量モデル |
ここで注目すべきは、Hugging Faceは単なるモデル配布サイトではなく、ブラウザ上でそのまま推論(画像生成)を試せるInference APIを提供している点です。ローカル環境を持たないユーザーでも、最新モデルの品質を直接体験できるという点で、モデル比較や学習目的での利用に特に向いています。
スマートフォンでStable Diffusionを使う方法
PCを持っていない方や外出先でも画像生成を楽しみたい方のために、スマートフォンからStable Diffusionを利用する方法を紹介します。スマホ向けの選択肢は大きく2つに分かれます。
ブラウザ経由でWebサービスを使う
最も手軽な方法は、スマートフォンのブラウザからWebサービスにアクセスすることです。前述のStable Diffusion OnlineやLeonardo AIはスマホブラウザにも対応しており、PC版とほぼ同じ操作感で利用できます。特別なアプリのインストールも不要で、iPhoneでもAndroidでも使えるため、まず試してみる入り口として最適です。
ただし、スマホ画面ではUIの一部が見づらくなる場合もあるため、細かい設定を行いたい場合はPC利用を推奨します。
スマホアプリを利用する
Stable Diffusionを搭載したスマートフォン専用アプリも複数存在します。アプリはUIがスマホに最適化されており、直感的に操作できる点が強みです。
以下の表で、代表的なスマホアプリの特徴を整理しました。それぞれ得意な機能が異なるため、目的に合ったものを選ぶことをおすすめします。
| アプリ名 | 対応OS | 特徴 | 無料範囲 |
|---|---|---|---|
| AI Dreamer | iOS | シンプルな操作性・写真風生成に強み | 基本機能無料、一部課金 |
| Stable Diffusion AI | Android | SD本来のモデル設定に近い体験が可能 | 基本機能無料 |
| Clipdrop | iOS / Android | 背景削除・画像拡大など実用機能も充実(現在はJasper.aiが運営) | 基本機能無料 |
ここで注目すべきは、Clipdropの存在です。もともとStability AIが提供していたアプリですが、2024年2月にJasper.aiへ売却され、現在はJasper傘下で運営されています。画像生成だけでなく背景削除・テキスト消去・画像拡大といった実用的な機能も含まれており、日常のコンテンツ制作に即座に役立てられます。
スマホアプリはPC版のローカル環境と比べて機能・カスタマイズ性に制限がありますが、「まず動かしてみたい」「軽作業をスマホで完結させたい」という場面では非常に有効な選択肢です。
Google ColabでStable Diffusionを使う方法
自分のPCにNVIDIA製GPUがない場合や、セットアップを簡略化したい場合の選択肢として、「Google Colab」があります。Google ColabはGoogleが提供するクラウドノートブック環境で、ブラウザ上からGPUを借りてStable Diffusionを動かせます。
2026年時点のGoogle Colab利用状況と注意点
Google Colabは以前、無料でStable Diffusionを動かす代表的な手段でしたが、2026年現在は注意が必要な状況になっています。Googleが無料プランのGPU使用に制限をかけており、特にAUTOMATIC1111やForgeなどのWebUI(Gradioベースのリモートフロントエンド)を無料ティアで動かすことは制限対象となっています。一方で、Hugging FaceのDiffusersライブラリを使ったノートブック内での画像生成は引き続き利用可能です。いずれにしても、継続的に利用するには有料プランへの移行が現実的です。
以下の表で、Google Colabの料金プランを整理しました。自分の利用頻度と予算に合わせてプランを選んでください。
| プラン | 月額費用(目安) | GPU品質 | 制限 |
|---|---|---|---|
| 無料プラン | 0円 | 低速GPU(制限付き) | Stable Diffusionの使用に警告・制限あり |
| Colab Pro | 約1,179円/月 | 高速GPU | 月100コンピューティングユニット |
| Pay As You Go | 1,179円/100単位〜 | 高速GPU | 使った分だけ課金(柔軟な利用が可能) |
ここで注目すべきは、無料プランでの使用はアカウント停止のリスクもある点です。Googleの利用規約上、GPU集中型の用途は無料プランでは推奨されていないため、月に数回程度の試用にとどめるか、Colab Proへ移行することをおすすめします。PCスペックが十分であれば、長期的にはローカル環境の方が経済的で自由度も高いです。

プロンプトの書き方:より良い画像を生成するためのコツ
Stable Diffusionの画像品質を左右する最大の要因が、プロンプトの書き方です。どれだけ高性能なモデルを使っても、プロンプトの精度が低ければ意図した画像は生成できません。初心者のうちから正しいプロンプトの考え方を身につけておくことが、上達への近道です。
ポジティブプロンプトの基本ルール
ポジティブプロンプトとは、「生成したい画像の特徴」をAIに伝えるための命令文です。Stable Diffusionのプロンプトは基本的に英語で入力することが推奨されます。日本語にも対応しているモデルはありますが、英語の方がモデルの学習データが豊富なため、精度の高い画像が得られることが多いからです。
以下の表で、プロンプト作成の主なルールを整理しました。この表の内容を踏まえて実際に試してみると、プロンプトの改善がどのように画像品質に影響するかが体感できます。
| ルール | 内容 | 例 |
|---|---|---|
| カンマ区切り | 単語やフレーズはカンマで区切る | a cat, sitting, window, sunlight |
| 優先順位 | 文頭に書いた単語ほど画像への影響が強い | masterpiece, best quality, a cat... |
| 具体的な描写 | 曖昧な表現より、具体的な描写を心がける | photorealistic, 8k resolution, detailed |
| スタイル指定 | 絵のスタイルを明示すると一貫した画風になる | anime style, oil painting, watercolor |
ここで注目すべきは、「masterpiece」「best quality」という品質指定ワードを冒頭に置く慣習です。これはモデルが品質の高い学習データを優先的に参照するよう誘導する方法であり、多くの上級ユーザーが実践しているテクニックです。つまり、まず品質キーワードから始め、次にスタイル、最後に具体的な被写体・構図を記述するという流れが、一貫した高品質画像を生成するための基本構造ということです。
ネガティブプロンプトで品質を底上げする
Stable Diffusionには、「生成したくない要素」を指定するネガティブプロンプトという機能があります。特に人物画像を生成する際の「指の本数のおかしさ」「顔の崩れ」「テキストの混入」といったStable Diffusionに特有のトラブルを防ぐ上で、ネガティブプロンプトは欠かせないテクニックです。
初心者が最初に押さえておきたい代表的なネガティブプロンプトを以下にまとめました。これらを記事内のサービス(Dream Studio、Mage.spaceなど)のネガティブプロンプト欄に入力するだけで、出力の品質が目に見えて改善されます。
以下の表で、目的別のネガティブプロンプトを整理しました。この表を参考に、生成したい画像の種類に応じて組み合わせてみてください。
| 目的 | 推奨ネガティブプロンプト |
|---|---|
| 全般的な品質向上 | blurry, low quality, low resolution, noisy, grainy, watermark, text, logo |
| 人物画像の品質向上 | bad anatomy, extra fingers, missing fingers, distorted face, deformed hands, unrealistic proportions |
| 構図・照明の改善 | overexposed, underexposed, too dark, too bright, cropped, out of frame |
ここで注目すべきは、ネガティブプロンプトもポジティブプロンプトと同様に、前に書いた単語ほど効果が強くなるという点です。人物の崩れが特に気になる場合は「bad anatomy, extra fingers」を最初に書くなど、自分の画像の課題に応じて順番を調整する習慣をつけることが、品質向上への効果的なアプローチです。
プロンプトをAIに作ってもらう活用術
2026年現在、ChatGPTやClaude、Geminiなどの大規模言語モデルを使ってプロンプトを自動生成する手法が広まっています。「日本語で画像の概要を伝え、英語のSD用プロンプトに変換してもらう」という使い方は、英語に不慣れな方でも高品質なプロンプトを短時間で用意できる実践的なテクニックです。また、Leonardo AIのようにプロンプト補助機能(Ideate)を内蔵したサービスを使えば、単純な単語から複雑なプロンプトのバリエーションを自動で提案してもらえます。
LoRAで表現を広げる:Stable Diffusion無料カスタマイズの第一歩
プロンプトだけで思い通りの画像が生成できない場合、次のステップとして「LoRA(Low-Rank Adaptation)」の活用が効果的です。LoRAとは、Stable Diffusionに追加学習を施すための軽量なファイルで、特定の画風・キャラクター・スタイルを再現するためにモデルをカスタマイズできます。ファイルサイズが数MB〜数百MBと小さく、複数のLoRAを組み合わせることも可能です。
LoRAとは何か:モデルとの違いを理解する
Stable Diffusionの「モデル」(チェックポイント)がAIの全体的な知識や画風の土台であるのに対し、LoRAはその土台の上に「特定の傾向を上乗せする調整ファイル」です。たとえば、リアル系の写真ベースモデルにアニメ調のLoRAを組み合わせると、リアルな質感を残しながらアニメっぽい雰囲気を持つ独自の画風が生まれます。
この組み合わせによる自由度の高さこそが、Stable Diffusionがクリエイターから選ばれ続ける理由の一つです。有料の画像生成サービスではモデルの変更に制限がかかりますが、Stable DiffusionのローカルWebUIではLoRAを無制限に試せる点は、コストパフォーマンスの面でも大きなメリットといえます。
LoRAの入手方法:Civitaiを使いこなす
LoRAを無料で入手できる代表的なプラットフォームが「Civitai(シビタイ)」です。世界中のクリエイターが作成したLoRAやチェックポイントモデルが無料で公開されており、スタイル別・目的別で絞り込んで検索できます。
以下の表で、LoRAの主な入手先と特徴を整理しました。この表を参考に、自分の目的に合った入手先を選んでください。
| プラットフォーム | 特徴 | 主なコンテンツ | 利用条件 |
|---|---|---|---|
| Civitai | 世界最大のSD用モデル配布サイト。UIが直感的で検索しやすい | LoRA、チェックポイント、Embeddings | 無料(一部モデルは要ログイン) |
| Hugging Face | 研究・開発向けのAIモデルハブ。公式モデルも多数 | 公式SD 3.5シリーズ、研究用モデル | 無料(要アカウント登録) |
ここで注目すべきは、Civitaiでは各LoRAにユーザーレビューと生成サンプルが付いている点です。実際にどのような画像が生成できるかを事前に確認してからダウンロードできるため、試行錯誤の時間を大幅に短縮できます。つまり、「どんな画像が出来上がるか」を見てからカスタマイズファイルを選べるという点が、Civitaiを初心者に特におすすめする最大の理由です。
LoRAの基本的な使い方(ローカル環境)
LoRAは主にローカル環境のWebUI(AUTOMATIC1111やStable Diffusion Forge)で使用します。使い方の手順は以下の通りです。
まず、CivitaiなどからダウンロードしたLoRAファイル(拡張子は.safetensorsまたは.pt)を、WebUIの所定のフォルダ(models/Lora/)に配置します。次に、プロンプト欄に以下の形式で記述するだけで、そのLoRAの効果を画像に反映させることができます。
masterpiece, best quality, <lora:LoRAファイル名:0.8>, a beautiful girl, anime style
このアプローチの利点は複数あります。まず、上記のプロンプト内にある数値部分(0.0〜1.0)を調整することで、LoRAの影響度を細かく制御できます。0.8程度が一般的な推奨値ですが、数値を下げると元のモデルの特性が強く残り、上げるとLoRAの画風が前面に出てきます。また、複数のLoRAを同時に適用することも可能なため、「キャラクターLoRA」と「画風LoRA」を組み合わせるなど、独自のスタイルを確立していくことができます。
ローカル環境でのStable Diffusion無料活用:WebUIの選び方
オンラインサービスの制限を超えて、Stable Diffusionを真に無制限・無料で活用したいなら、ローカル環境の構築が最善の選択肢です。自分のパソコンにインストールすることで、1日の生成枚数制限がなくなり、カスタムモデルの導入や高度なパラメータ調整も自由に行えます。電気代以外の費用はかかりません。
3大WebUIの特徴と選び方
ローカル環境でStable Diffusionを使う際には、**WebUI(操作インターフェース)**を選ぶ必要があります。2026年現在、特に広く使われているのが以下の3つです。それぞれ得意な用途と対象ユーザーが異なるため、自分の目的に合ったものを選ぶことが重要です。
以下の表で、3つのWebUIの特性を整理しました。この表の内容を踏まえて、どのWebUIから始めるべきかを判断してください。
| WebUI | 難易度 | 動作速度 | 特徴 | おすすめの人 |
|---|---|---|---|---|
| AUTOMATIC1111 | 初級〜中級 | 標準 | 最も豊富な拡張機能・情報量 | 情報を探しながら学習したい初心者 |
| Stable Diffusion Forge | 初級〜中級 | AUTOMATIC1111比30〜75%高速 | Forgeベースで軽量・高速・省メモリ | メモリが少ないPCを使っている人 |
| ComfyUI | 中級〜上級 | 最速(AUTOMATIC1111比2倍) | ノードベースの視覚的ワークフロー設計 | ワークフローを細かく制御したい上級者 |
ここで注目すべきは、初心者にはStable Diffusion Forgeが特に推奨されるという点です。AUTOMATIC1111と互換性がありながら動作が速く、VRAMが少ないPCでも快適に動かせるため、環境構築のストレスを最小限に抑えられます。つまり、ローカル環境を初めて構築するなら、まずForgeから始めて、操作に慣れたらComfyUIへステップアップするというルートが、挫折リスクを最も低く抑えるアプローチということです。
また、2026年現在ではStability Matrixというオールインワンの管理ツールも普及しています。Stability MatrixはForge・AUTOMATIC1111・ComfyUIのインストールと切り替えを一つのUIから行えるツールで、複数のWebUIを使い分けたい場合に特に便利です。
当サイトではStable Diffusion Forgeのインストール方法を別記事で詳しく解説していますので、ローカル環境の構築を検討している方はぜひご参照ください。
Stable Diffusion Web UI Forgeのインストール方法・使い方をわかりやすく解説
ローカル環境の動作要件(推奨スペック)
ローカル環境でStable Diffusionを快適に動作させるには、ある程度のPCスペックが必要です。特にGPU(グラフィックボード)が最も重要で、VRAMが少ないとモデルの読み込みができなかったり、生成が極端に遅くなったりする場合があります。また、Stable DiffusionはNVIDIA独自の処理技術(CUDA)を利用するため、NVIDIA製のGPUが推奨されます。AMD製GPUでも動作しますが、対応状況や速度は限定的です。
以下の表で、GPU VRAMの容量別に期待できる動作環境を整理しました。この表を参考に、自分のPCのスペックを確認してみてください。
| GPU VRAM容量 | 動作レベル | 対応モデル例 | おすすめ度 |
|---|---|---|---|
| 4GB | 最低限動作可能 | SD 1.5系(小さいモデル限定) | △ |
| 6〜8GB | 実用的な動作ライン | SD 1.5系、SDXL(低解像度設定) | ○ |
| 12GB以上 | 快適に動作 | SD 3.5 Medium、SDXL(高解像度) | ◎ |
| 24GB以上 | 最高品質・大型モデル対応 | SD 3.5 Large、高解像度バッチ処理 | 最適 |
ここで注目すべきは、VRAM 12GB以上のGPUが現実的な快適動作の境界線という点です。VRAM 4〜6GBのGPUでも動作はしますが、使えるモデルが制限され、生成速度も遅くなるため、本格的な利用を想定しているならRTX 3060(VRAM 12GB)以上を目標にするとよいでしょう。なお2026年にはNVIDIA RTX 5070 Tiシリーズが登場しており、同シリーズのGPUでも快適にStable Diffusionを動作させることが報告されています。GPUの他にも以下の要件を確認しておくことをおすすめします。
- メインメモリ(RAM)
16GB以上を推奨。不足するとモデルのロード中にエラーが発生しやすくなる
- ストレージ空き容量
モデルファイルが数GB〜十数GBになるため、20GB以上の空き容量を確保しておく
- Python
バージョン3.10.6の使用が多くのWebUIで推奨されている
- Git
バージョン管理ツールのGitが必要(インストールは無料)

Stable Diffusionの無料サービス利用時のポイント・注意点
Stable Diffusionを無料で利用できるサービスは数多くありますが、それぞれ特徴や制限が異なります。
ここでは、無料で利用する際のポイントと注意点を3つ紹介します。
さまざまなサービスを試して比較しよう
Stable Diffusionを利用した無料アプリケーションは、Web上に数多く存在します。基本的な機能は似ていることが多いですが、細かい仕様や独自の機能を持つものもあります。
例えば、Leonardo AIには独自の機能が搭載されています。
自分に最適なアプリを見つけるには、実際に複数のサービスを試してみることが一番の近道です。Webサービス・スマホアプリ・Google Colab・ローカル環境と、利用形態によっても体験が大きく変わります。最初はWebサービスで感触をつかみ、より深く使いたくなったらローカル環境に挑戦するという段階的なアプローチが、無駄なく上達できる方法です。
ローカル環境の構築にチャレンジ
Webアプリは便利ですが、制限もあります。「1日あたりの画像生成数が決まっている」ことや、「商用利用には有料プランが必要な場合」もあります。
より自由にStable Diffusionを活用したい場合は、自分のパソコン上に環境を構築することをおすすめします。
自前の環境で動かせるというのは、Stable Diffusionが他の画像生成AIと大きく異なる点の一つです。Stability Matrixなどの管理ツールを使えば、以前よりも格段に簡単にローカル環境を構築できるようになっています。
商用利用時の注意点
Stable Diffusionは、オープンソースで提供されているAI画像生成モデルです。このモデルを活用したサービスは複数存在しますが、それぞれ独自の利用規約を設けています。
中には「無料プランでも商用利用が許可されているサービス」がある一方で、「商用目的での使用には有料プランへの移行が必須となる場合」もあります。
Stable Diffusionのモデル本体(SD 3.5シリーズ)は「Stability AI Community License」のもとで提供されており、年間総収益が100万ドル未満の組織・個人であれば商用・非商用を問わず無料で利用できます。ただし、各オンラインサービス(Stable Diffusion Online、Leonardo AIなど)にはそれぞれ独自の利用規約があるため、商用利用を検討している場合は必ず各サービスの規約を確認することが必要です。AIで生成した作品の著作権についても理解しておくことをおすすめします。
Stable Diffusionを活用することで、クリエイティブな表現の幅が大きく広がります。無料で利用できるサービスを賢く使いこなし、独自の環境構築にもチャレンジしながら、画像生成AIの可能性を存分に探求していきましょう。
【関連記事】
Stable Diffusionの商用利用を解説!モデルやライセンス別の確認方法も
DALL-E3とは?使い方や料金、無料で使う方法を紹介!商用利用も解説
AI画像生成の体験を業務でのAI活用に広げる

AI業務自動化ガイド
Stable Diffusionで画像生成を体験したなら、次は業務全体のAI化です。AI総合研究所のAI業務自動化ガイドでは、Microsoft環境でのAI業務自動化から運用設計まで、220ページで実践手法を解説しています。
AI画像生成の体験を業務でのAI活用に広げる
Stable Diffusionのような画像生成AIを無料で試した経験は、生成AIの可能性を実感する貴重な入り口になります。テキストから画像を生成する技術は、マーケティング素材の作成や製品プロトタイプのビジュアライズなど、業務での応用範囲が広がり続けています。
AI総合研究所では、画像生成をはじめとする生成AIの業務活用を体系的にまとめた「AI業務自動化ガイド」を無料で提供しています。個人の体験を組織的な活用へとつなげる実践ノウハウを220ページに凝縮しました。
AI画像生成の体験を業務でのAI活用に広げる
AI業務自動化ガイド
Stable Diffusionで画像生成を体験したなら、次は業務全体のAI化です。AI総合研究所のAI業務自動化ガイドでは、Microsoft環境でのAI業務自動化から運用設計まで、220ページで実践手法を解説しています。
まとめ
この記事では、以下の点について説明しました。
- Stable Diffusionはオープンソースで提供されているため、オンラインサービス・スマホアプリ・Google Colab・ローカル環境の4つの方法で無料利用が可能。
- 2026年現在の最新モデルはSD 3.5シリーズで、Large・Large Turbo・Mediumの3種類から用途に応じて選ぶことが重要。Large Turboは4ステップ生成で高速な点が特徴。
- 2026年の画像生成AI市場ではFLUX.2(2025年11月リリース)も台頭しているが、豊富なLoRAやカスタムモデルの面ではStable Diffusionが依然として優位性を持つ。
- スマートフォンからも利用でき、Clipdrop(現在はJasper.ai運営)など画像生成・編集アプリが充実。ブラウザ経由のWebサービスもスマホに対応している。
- Google Colabは2026年現在、無料プランでのStable Diffusion利用には制限・警告があり、継続利用にはColab Pro(月約1,179円)が現実的。
- Stable Diffusion Onlineは、シンプルな機能で初心者にも扱いやすいため、まず試してみることをおすすめする。
- プロンプトは英語で、品質キーワードを冒頭に置き、具体的に記述するのが高品質な画像生成のコツ。ネガティブプロンプトの活用も忘れずに。AIでプロンプトを生成させる方法も実践的。
- LoRAを活用することで画風や表現の幅を自由にカスタマイズできる。CivitaiやHugging Faceから無料でダウンロードして試せる。
- ローカル環境を構築する際は、初心者にはStable Diffusion Forgeが特におすすめ。Stability Matrixを使えばForge・AUTOMATIC1111・ComfyUIを一元管理できる。快適な動作にはVRAM 12GB以上のGPUを推奨。
- 商用利用や利用規約はサービスによって異なるので、事前に確認が必要である。
画像生成AIの技術は日々進歩しており、今後さらに多様なサービスが登場すると予想されます。最新の情報にアンテナを張り、クリエイティビティを存分に発揮していきましょう。










