この記事のポイント
 大規模SQL分析とAI活用をつなぐクラウドデータウェアハウスとしての中核的な位置づけ
大規模SQL分析とAI活用をつなぐクラウドデータウェアハウスとしての中核的な位置づけ- 変動ワークロードならServerless、安定本番ならProvisionedを検討する判断軸
- Aurora/RDS/DynamoDBとのゼロETL統合でリアルタイム分析基盤を構築できる
- Redshift ML、SageMaker Lakehouse、Amazon Qを含めたAI連携の全体像
- Serverless Reservationsで3年最大45%/1年最大24%のコンピュート費用削減が可能
- DC2インスタンスは2026/04/24にEOL、既存ユーザーはRA3かServerlessへ移行必須
- Python UDF終了予定やデータ連携設計を含めた導入前の注意点

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Amazon Redshiftは、AWSが提供するクラウドデータウェアハウスです。
大規模データに対してSQL分析を行うだけでなく、S3、Aurora/RDS/DynamoDBとのゼロETL統合、SageMaker Lakehouse、Redshift ML、Amazon Q DeveloperによるSQL生成と組み合わせて、AI活用のための分析基盤として育てられます。
2026年に入りServerless Reservationsで最大45%のコンピュート費用削減が可能になった一方、DC2インスタンスは2026年4月24日にEOLを迎えるため、既存ユーザーには移行計画が急務です。
本記事では、Amazon Redshiftの基本概念、主要機能、ServerlessとProvisionedの違い、ゼロETL統合、AI・ML連携、使い方、導入事例、料金、導入時の注意点までを、2026年4月時点のAWS公式情報ベースで整理して解説します。
Amazon Redshiftとは?
Amazon Redshiftの管理ガイドでは、Amazon Redshiftを、フルマネージドでペタバイト規模に対応するクラウドデータウェアハウスとして説明しています。大量の構造化データや半構造化データを、SQLで分析しやすい形にまとめるためのAWSサービスです。

Amazon Redshiftの製品ページでは、SQL分析とAIアプリケーション向けのデータウェアハウスとして位置づけられています。実務的には、業務データを分析・BI・AI活用へ渡すための中核データ基盤と捉えると分かりやすいです。
Amazon Redshiftの役割を整理すると、次の表になります。
| 領域 | Amazon Redshiftが担うこと | 実務上の意味 |
|---|---|---|
| データウェアハウス | 大量データをSQLで集計・分析する | 経営指標や業務KPIを高速に見やすくする |
| データレイク連携 | S3や外部データを分析対象に含める | すべてのデータを毎回移動せずに分析しやすい |
| データ共有 | 組織やアカウントをまたいでデータを扱う | 部門別のデータ分断を減らしやすい |
| AI・ML連携 | Redshift ML、SageMaker、Bedrock、Amazon Qと連携する | 分析結果を予測や生成AI活用へつなげやすい |
| 運用方式 | ServerlessとProvisionedを選べる | 利用量や運用体制に合わせて始めやすい |
Redshiftは、業務アプリケーション用のデータベースそのものを置き換えるサービスではありません。たとえばAmazon RDSはアプリケーションのトランザクション処理向けに使われることが多く、Redshiftは複数データを集めて分析する用途に向きます。
つまり、注文、顧客、問い合わせ、広告、ログなどのデータを統合し、BIやAIエージェントが参照しやすい状態に整える基盤がRedshiftです。AI活用を進める企業では、モデルやエージェントを選ぶ前に、Redshiftのような分析基盤で信頼できるデータをどう整えるかが重要になります。

Amazon Redshiftの主要機能
Amazon Redshiftの主要機能は、単にデータを保存するだけではありません。大規模分析、運用方式の選択、データレイク連携、データ共有、AI連携までをまとめて考える必要があります。

ServerlessとProvisionedを選べる
Amazon Redshiftの管理ガイドでは、RedshiftにServerlessとProvisionedの2つの利用方式があると説明されています。Serverlessは、クラスター管理を意識せずにデータウェアハウスを使いたい場合に向き、Provisionedは、ワークロードが安定していて構成を細かく管理したい場合に向きます。
2つの違いを実務視点で整理すると、次の表になります。
| 方式 | 向いているケース | 注意点 |
|---|---|---|
| Redshift Serverless | 利用量が読みにくい、PoCから始めたい、管理負荷を下げたい | RPU使用量と稼働時間を監視する必要がある |
| Provisioned cluster | 定常的に高負荷な分析、本番運用、予約によるコスト最適化を検討したい | ノード構成、リサイズ、予約の判断が必要 |
初期検証ではServerlessから始め、本番ワークロードが見えてきたらProvisionedや予約の選択肢を検討する流れが現実的です。ただし、どちらが常に安いとは言えません。クエリ頻度、同時実行数、データ量、利用時間で最適解が変わるためです。
S3やデータレイクと組み合わせられる
Redshiftは、データウェアハウス内のデータだけを分析するサービスではありません。Amazon Redshiftの管理ガイドでは、データウェアハウス、業務データベース、データレイク、第三者データセットにまたがるデータを保存・アクセス・分析できると説明されています。
この考え方は、AI活用でも重要です。すべてのデータを1か所に無理にコピーするのではなく、S3、業務データベース、外部データを用途に応じて参照できる状態にすると、分析やAIエージェント向けの文脈づくりが進めやすくなります。
SageMaker LakehouseやAmazon Qとつながる
Amazon Redshiftの製品ページでは、SageMaker Lakehouseとの連携や、Amazon Q DeveloperによるSQL生成も紹介されています。これにより、Redshiftは単独の分析サービスではなく、AWS上のAI・データ基盤の一部として使う位置づけになっています。
たとえば、データ分析者がSQLを書く場面では、Amazon Q DeveloperのSQL生成を補助として使えます。一方、機械学習や生成AIの文脈では、Amazon SageMakerやAmazon Bedrockと組み合わせ、予測、分類、要約、テキスト分析へ広げる構成が考えられます。
Aurora・RDS・DynamoDBとゼロETLで連携できる
業務データをほぼリアルタイムで分析したい場合に重要なのがゼロETL統合です。Zero-ETL integrationsの公式ドキュメントでは、Amazon Aurora(MySQL/PostgreSQL)、Amazon RDS for MySQL、Amazon DynamoDBからRedshiftへ、複雑なETLパイプラインを組まずにスキーマとデータ変更を継続的にレプリケートできると説明されています。
Aurora zero-ETL integration with Amazon Redshiftの製品ページでは、トランザクションデータがAuroraに書き込まれてから数秒以内にRedshift側で参照可能になり、列追加・削除やテーブル追加・削除といったスキーマ変更も自動で取り扱われると案内されています。
実務的な使いどころとしては、注文・決済・問い合わせ・在庫といったトランザクションデータを、ETLジョブの開発・運用なしに分析側へ流したいケースが代表例です。AI総合研究所のSIer目線では、ゼロETLを「ETLが不要になる魔法」ではなく、「ETLの開発工数を下げる代わりに、参照先のスキーマ変更ガバナンスとデータ品質責任が分析側に降りてくる仕組み」と捉えると、設計判断を間違えにくくなります。
Amazon RedshiftでできるAI・ML活用
RedshiftをAI活用の文脈で見ると、重要なのは「AIモデルを直接置く場所」ではなく、AIが使う業務データを整え、SQLやML処理につなげる場所である点です。ここでは、2026年時点で押さえたい連携を整理します。

Redshift MLでSQLから機械学習を使える
Redshift MLのドキュメントでは、SQLユーザーがSQLコマンドを使って機械学習モデルを作成・学習・デプロイできると説明されています。機械学習の専門家でなくても、既存の分析データに対して予測や分類を試しやすいのが特徴です。
Redshift MLの用途を整理すると、次のようになります。
| 用途 | 使い方の例 | 注意点 |
|---|---|---|
| 予測 | 解約予測、需要予測、売上予測 | 学習データの品質と目的変数の定義が重要 |
| 分類 | 顧客セグメント分類、不正疑いの分類 | 誤分類時の業務影響を確認する必要がある |
| テキスト分析 | 要約、感情分析、エンティティ抽出 | 生成AIの出力は検証前提で扱う |
| 外部モデル連携 | 外部で学習したモデルをRedshiftから呼び出す | 推論先の権限、費用、遅延を確認する必要がある |
特にRedshift MLのドキュメントは、Amazon Bedrockモデルを使ったテキスト生成や分析についても案内しています。ただし、生成AIの出力は不正確な情報を含むことがあるため、重要な業務判断では人の確認や評価プロセスを入れる前提で設計する必要があります。
Amazon Q DeveloperでSQL作成を補助できる
Amazon Redshiftの製品ページでは、Amazon Q Developer in SQL generation が一般提供として紹介されています。自然言語からSQL作成を補助できるため、Redshiftを使う分析者やエンジニアの初動を速めやすい機能です。
ただし、SQL生成は便利な一方で、業務定義を自動で正しく理解するわけではありません。たとえば「売上」「アクティブユーザー」「解約」の定義が部門ごとに違う場合、生成されたSQLが技術的に正しくても、経営指標としてはズレる可能性があります。Amazon Qを使う場合でも、テーブル定義、指標定義、権限設計をそろえておくことが前提になります。
AIエージェント向けのデータ基盤にもなる
AIエージェントを実業務に入れる場合、エージェントが参照するデータの出どころが曖昧だと、回答やアクションの品質が安定しません。Redshiftは、営業、サポート、マーケティング、財務などのデータを整理し、AIエージェントが使う業務文脈を作る基盤になり得ます。
【関連記事】
AIエージェント×データ基盤とは?設計と構築手順を解説
AI分析とは?データの活用・その仕組みやできること、プロセスを徹底解説
このとき重要なのは、Redshiftにデータを集めること自体ではなく、AIが参照してよいデータ、参照してはいけないデータ、集計後に渡すべきデータを分けることです。分析基盤とAI実行基盤の間に権限と品質管理を置けるかが、実運用では大きな差になります。
Amazon Redshiftの使い方
Amazon Redshiftは多機能ですが、最初からデータレイク連携や機械学習まで入れる必要はありません。初期導入では、分析したいデータと利用者を絞り、Serverlessで短く試すほうが進めやすいです。

Redshift Serverlessのgetting startedを踏まえると、初期導入は次の流れで考えると整理しやすくなります。
- まず、分析したい対象データと利用者を決めます。売上、問い合わせ、広告、ログなど、業務意思決定に直結するテーマから始めるとPoCの評価がしやすくなります。
- 次に、Redshift Serverlessの名前空間とワークグループを作成し、接続方法、権限、ネットワークを確認します。
- 続いて、サンプルデータや既存データをロードし、SQLで集計結果が出せるかを確認します。
- その後、BIツール、データ連携、S3、業務データベース、SageMakerやBedrockとの連携範囲を決めます。
- 最後に、クエリ性能、RPU使用量、ストレージ、同時実行数、権限設計を見ながら、本番構成に進めるかを判断します。
この流れで重要なのは、PoCの成功条件を「Redshiftが動いたか」ではなく、「意思決定に使える指標が安定して出せたか」に置くことです。データウェアハウスは、作った瞬間ではなく、部門横断で同じ数字を見られるようになった時点で価値が出ます。

Amazon Redshiftの導入事例
Redshiftの導入効果は、クエリ速度だけでなく、データをどれだけ業務判断に使いやすくできたかで評価する必要があります。AWS公式で確認できる事例から、特に分かりやすいものを2つ紹介します。

PayU
PayUのAmazon Redshift事例では、グローバル決済企業のPayUが、Amazon Redshiftを使ってデータ環境を統合したことが紹介されています。同事例では、以前10〜15分かかっていたクエリを1分未満で実行できるようになり、月額コストも2万ドル削減したとされています。
この事例で重要なのは、単なる高速化ではなく、データ利用者が信頼できるレポートへアクセスしやすくなった点です。決済事業のようにデータ量が大きく、部門ごとの意思決定が速さを求められる業務では、Redshiftのような統合分析基盤が効きやすくなります。
GE Aerospace
GE AerospaceのRedshift事例では、同社がODS移行でAmazon Redshiftを採用し、年間50万ドル超のコスト削減を見込み、クエリ性能を約70パーセント改善したと紹介されています。従来1時間半かかっていたクエリが7分で実行できたというコメントも掲載されています。
この事例は、既存の大規模分析基盤を移行するケースの参考になります。単に新規分析環境を作るだけでなく、既存レポートや長い手続き、データレイク移行まで含めて段階的に進める必要があるためです。
どちらの事例にも共通するのは、Redshiftの価値が「速いデータベース」だけでは説明できないことです。業務利用者が同じデータを見られる、レポート提供が安定する、データ量が増えても運用しやすい、といった基盤面の価値まで含めて評価されています。
AIやエージェント活用でも同じです。モデルやチャットUIを先に作るより、業務データが信頼できる形で集計され、参照権限と定義が整っているほうが、実運用に乗せやすくなります。
RedshiftをAI活用のデータ基盤として育てる

分析基盤とAIエージェントをどう接続するかを整理
Amazon Redshiftは分析用データウェアハウスとしてだけでなく、AIエージェントに渡す業務データを整える基盤にもなります。AI Agent HubのLPで、データ基盤から業務実行までつなぐ設計の考え方をご確認ください。
Amazon Redshiftと周辺サービスの違い
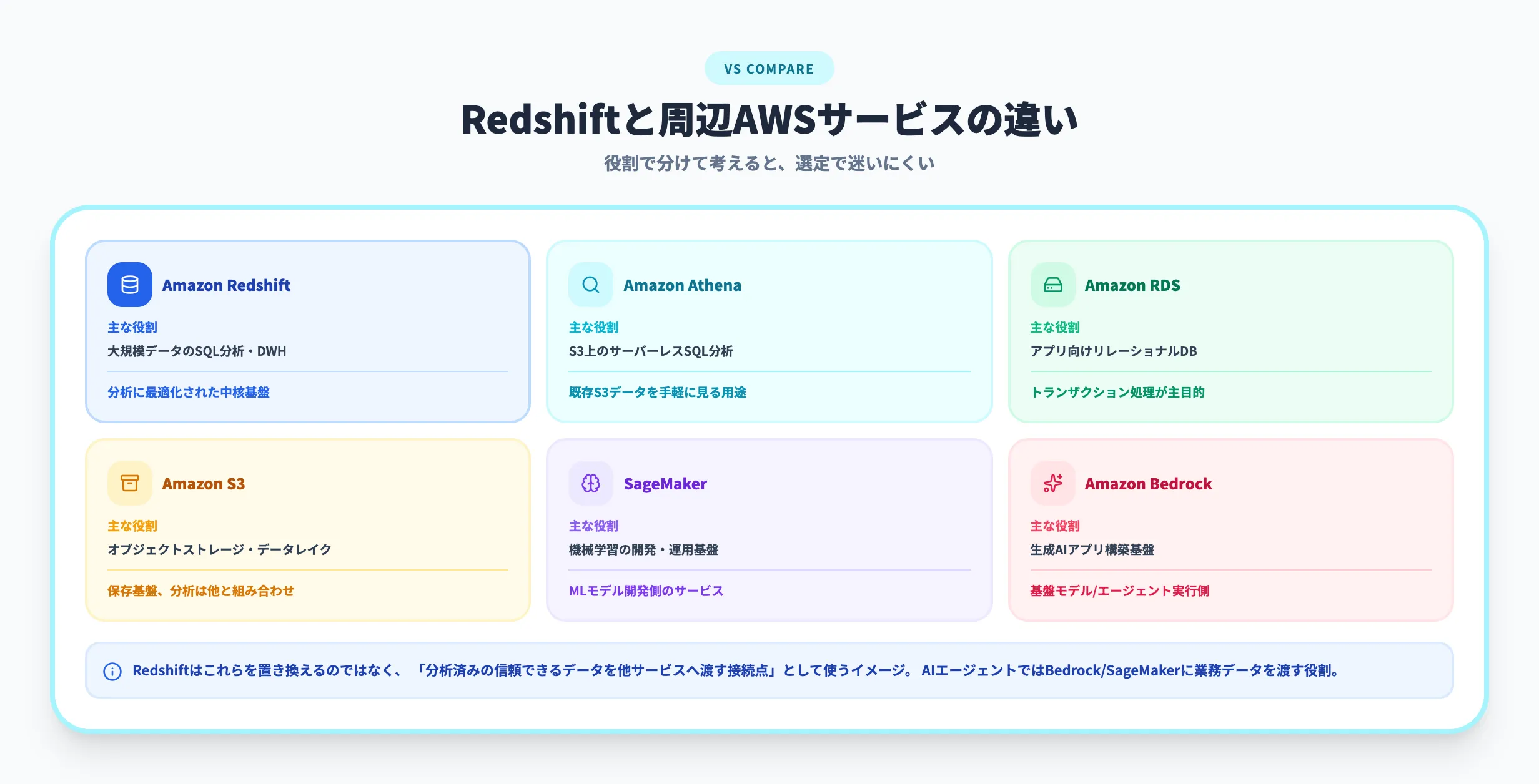
AWSには分析やデータ管理のサービスが多く、Redshift、Athena、RDS、S3、SageMaker、Bedrockの違いで迷いやすいです。ここでは、導入判断で混同しやすいサービスを実務視点で整理します。
| サービス | 主な役割 | Redshiftとの違い |
|---|---|---|
| Amazon Redshift | 大規模データのSQL分析、データウェアハウス | 分析用に最適化された中核基盤 |
| Amazon Athena | S3上のデータをサーバーレスでSQL分析 | 既存のS3データを手軽に見る用途に向く |
| Amazon RDS | アプリケーション向けリレーショナルDB | トランザクション処理が主目的 |
| Amazon S3 | オブジェクトストレージ、データレイク | 保存基盤であり、分析処理は他サービスと組み合わせる |
| Amazon SageMaker | 機械学習の開発・運用基盤 | MLモデル開発側のサービス |
| Amazon Bedrock | 生成AIアプリケーション構築基盤 | 基盤モデルやエージェント実行側のサービス |
選び方としては、定型レポートや部門横断の指標管理を安定させたいならRedshiftが候補になります。S3上のログを必要なときだけ見るならAthena、アプリケーションの本番DBならRDS、機械学習モデルの開発ならSageMaker、生成AIアプリケーションならBedrock、と役割を分けると判断しやすいです。
【関連記事】
Amazon Bedrockとは?主要機能や料金、導入事例を解説
Amazon SageMakerとは?機能や料金、導入事例を解説
Redshiftは、これらを置き換えるというより、分析済みの信頼できるデータを他サービスへ渡す接続点として使うイメージです。特にAIエージェント導入では、Redshiftを業務データの参照元にして、BedrockやSageMaker側で推論・生成・業務実行へつなげる設計が現実的です。
Amazon Redshift導入で詰まりやすい論点
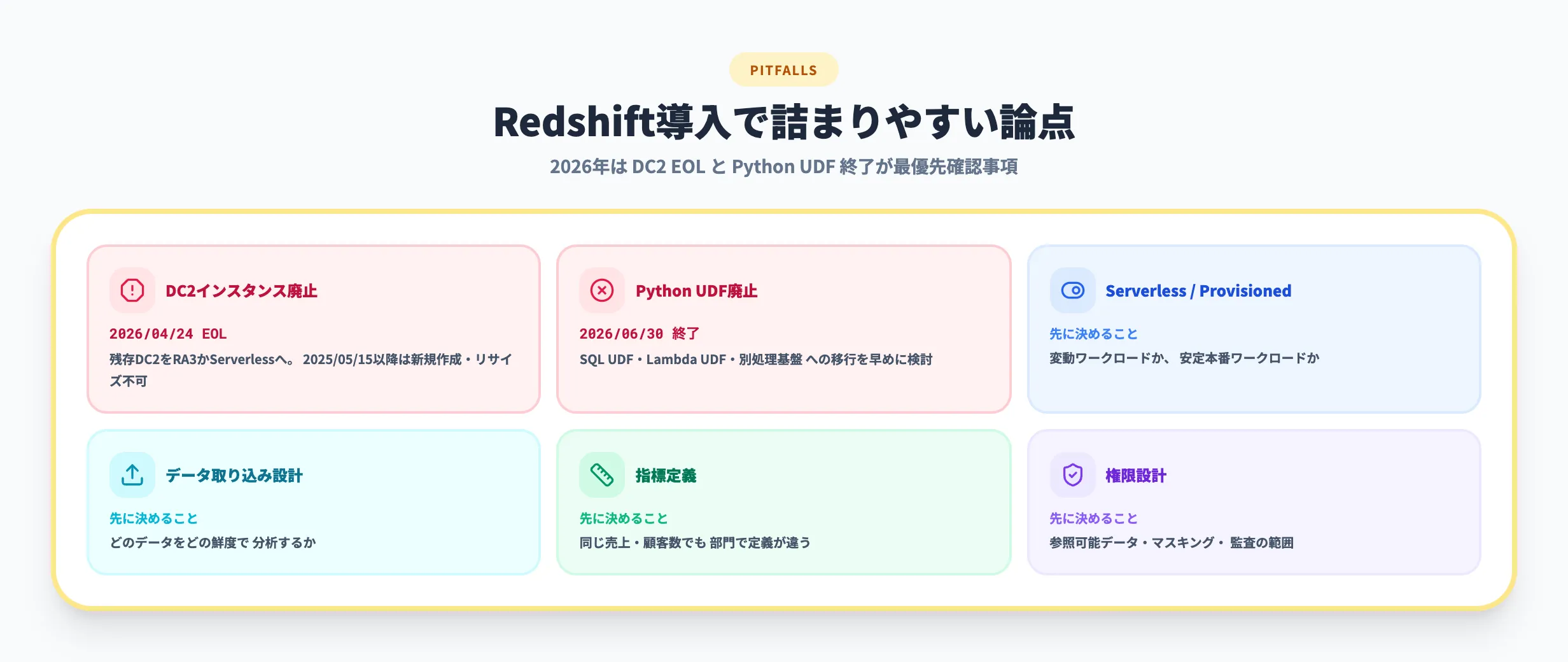
Redshiftはフルマネージドで始めやすい一方、データ基盤として本番運用するには設計上の論点が残ります。導入前に詰まりやすい点を先に整理しておきます。
| 論点 | 詰まりやすい理由 | 先に決めるべきこと |
|---|---|---|
| ServerlessとProvisioned | 料金と運用負荷の見方が違う | 変動ワークロードか、安定本番ワークロードか |
| DC2インスタンス廃止 | 既存DC2クラスターは2026年4月24日にEOL | 残存DC2をRA3かServerlessへ移行する計画 |
| データ取り込み | ETL、ゼロETL、S3連携の選択肢が多い | どのデータをどの鮮度で分析するか |
| 指標定義 | 同じ売上や顧客数でも部門で定義が違う | KPI定義とデータオーナー |
| 権限設計 | AIやBIから参照する範囲が広がる | 参照可能なデータ、マスキング、監査 |
| 生成AI連携 | SQL生成やテキスト分析の出力を過信しやすい | 人の確認、評価、業務影響の範囲 |
| Python UDF | 既存環境で使っている場合に影響がある | 2026年6月30日以降の移行計画 |
2026年に最優先で確認すべきはDC2インスタンスの廃止です。DC2からRA3への移行ベストプラクティス(AWS Big Data Blog)では、Dense Compute(DC2)ノードが2026年4月24日にEOLを迎え、2025年5月15日以降は新規DC2クラスターの作成、リサイズ、ノード追加ができなくなったと説明されています。残存DC2を運用しているチームは、RA3またはRedshift Serverlessへの移行計画を早急に立てる必要があります。RA3とServerlessはストレージとコンピュートが分離されており、データ共有、書き込みの同時実行スケーリング、ゼロETL連携といった新機能の前提にもなります。
続いて注意したいのがPython UDFです。AWS公式ブログでは、Amazon RedshiftのPython UDFが2026年6月30日以降サポート終了となり、実行できなくなる予定が案内されています。既存のRedshift環境でPython UDFを使っている場合は、SQL UDF、Lambda UDF、別の処理基盤への移行を早めに検討したほうが安全です。
また、AI活用まで見据える場合は、Redshiftの導入をDWH構築だけで終わらせないことが重要です。どのデータをAIエージェントへ渡すか、どのデータは人間の確認後に使うか、どの指標を正式な値として扱うかを決めておかないと、後から権限と定義の調整で詰まりやすくなります。
Amazon Redshiftの料金
Amazon Redshiftの料金は、2026年4月時点では、ServerlessのRPU時間、Provisioned clusterのノード時間、ストレージ、バックアップ、データ転送、Redshift MLや周辺サービス費用を分けて見る必要があります。Amazon Redshiftの料金ページでも、利用方式や機能ごとに課金要素が分かれています。

Serverlessの料金
Amazon Redshiftの料金ページでは、Amazon Redshift ServerlessはRPU時間で課金され、60秒の最低料金を前提に秒単位で請求されると説明されています。起動時間には課金されず、非アクティブ時はシャットダウンされ、同ページではServerlessを1時間あたり1.50 USDからと案内しています。
Serverlessの料金で見るべき要素は、次の表のとおりです。
| 要素 | 見るべきポイント | 実務上の注意 |
|---|---|---|
| RPU時間 | クエリ実行時に使った処理能力と時間 | 利用量が増えると費用も増える |
| ストレージ | 保存データ量 | 分析しないデータを持ち続けるとコスト化する |
| Redshift Spectrum | S3上のデータスキャン | Provisionedではスキャン量、ServerlessではRPU時間の見方を分ける |
| Redshift ML | モデル学習・推論の周辺費用 | SageMakerやBedrock側の費用も確認する |
PoCや利用量が読みにくい業務では、Serverlessから始めると運用負荷を抑えやすいです。ただし、使った分だけ課金されるため、クエリの暴走、ダッシュボードの高頻度更新、不要なスキャンは早めに監視したほうが安全です。
Serverlessを長期で使う見通しが立った場合は、Serverless Reservationsの利用が候補になります。AWS What's Newでは、1年予約で最大24%、3年予約で最大45%のコンピュート費用削減が可能と案内されています。Serverless Reservationsはペイヤーアカウントレベルで管理され、複数AWSアカウントで共有できるため、組織横断でServerlessワークロードを抱えているチームほど効果が出やすい仕組みです。
Provisioned clusterの料金
Provisioned clusterでは、利用するノードタイプと稼働時間に応じたオンデマンド料金が基本になります。Amazon Redshiftの料金ページでは、安定した本番ワークロードにはリザーブドインスタンスが適しており、1年または3年契約でオンデマンドより費用を抑えられると説明されています。
Provisionedを選ぶ場合は、次の観点で見積もります。
| 要素 | 見るべきポイント | 実務上の注意 |
|---|---|---|
| ノードタイプ | RA3などの構成 | 性能とストレージの分離を理解する |
| 稼働時間 | 常時稼働か、時間限定か | 常時稼働なら予約も検討対象 |
| Redshift Managed Storage | 実際に保存するデータ量 | RA3ではマネージドストレージが別課金になる |
| バックアップ・スナップショット | 保持期間とリージョン | 長期保管やリージョン間コピーは費用化しやすい |
本番環境でクエリ量が安定している場合は、Provisionedとリザーブドインスタンスを検討する価値があります。一方で、利用量が読みにくい初期段階で長期予約に寄せると、後から構成変更しづらくなるため、まず実測を取るほうが安全です。
料金を見るときの注意点
Redshiftの見積もりでは、表示されている開始価格だけで判断しないほうが安全です。2026年4月時点の公式料金ページでは、無料トライアルとしてRedshift Serverless向けに300 USD分のクレジットを90日間利用できる案内もありますが、本番費用はワークロード次第で変わります。
見落としやすい費用要素は、次の3つです。
- Redshift Spectrumでは、Provisioned clusterの場合はスキャンされたバイト数に対して課金されます。一方、ServerlessでS3上の外部データをクエリする場合はRPU時間の請求に含まれるため、見積もりでは方式ごとに分けて確認する必要があります。
- Redshift MLやBedrock連携では、RedshiftだけでなくSageMakerやBedrock側の学習・推論費用も確認する必要があります。
- リージョン間のデータ共有やスナップショットコピー、VPC経由のデータ転送では、標準のAWSデータ転送料金が関係します。
そのため、東京リージョンなど実際に使うリージョンで見積もる場合は、公式料金ページとAWS Pricing Calculatorで、RPU、ノード、ストレージ、スキャン量、ML連携、データ転送を分けて確認するのが安全です。

RedshiftをAIエージェントのデータ基盤にするなら
Amazon Redshiftは、BIやレポートのためだけに使うなら、データウェアハウスとしての設計で十分です。ただし、AIエージェントや生成AI活用まで見据えるなら、どのデータをエージェントが参照し、どの指標を正式な値として使い、どこで人の確認を入れるかまで設計する必要があります。
特に、営業、サポート、マーケティング、財務のデータを横断してAIに使わせたい場合、データ基盤とAI実行基盤を別々に考えると、権限、品質、監査、業務フローの整合性が崩れやすくなります。AI総合研究所のAI Agent Hub資料では、Redshiftのようなデータ基盤をAIエージェント導入へつなげるための整理軸をまとめています。分析基盤を作って終わらせず、業務実行までつなげたい場合の判断材料としてご確認ください。
RedshiftをAI活用のデータ基盤として育てる
分析基盤とAIエージェントをどう接続するかを整理
Amazon Redshiftは分析用データウェアハウスとしてだけでなく、AIエージェントに渡す業務データを整える基盤にもなります。AI Agent HubのLPで、データ基盤から業務実行までつなぐ設計の考え方をご確認ください。
まとめ
Amazon Redshiftは、AWSのフルマネージドなクラウドデータウェアハウスです。大量データをSQLで分析し、S3、業務データベース、Aurora/RDS/DynamoDBとのゼロETL統合、SageMaker Lakehouse、Bedrock、Amazon Qと組み合わせながら、BIやAI活用のためのデータ基盤を作れます。
導入時は、ServerlessとProvisionedのどちらを選ぶか、どのデータをどの鮮度で取り込むか、指標定義と権限をどう統一するかを先に決めることが重要です。長期利用が見えてきたら、Serverless Reservations(3年で最大45%、1年で最大24%)でコンピュート費用を抑える選択肢も検討対象になります。
2026年に既存環境を持つチームが特に意識すべきは、2026年4月24日に予定されているDC2インスタンスのEOLと、6月30日のPython UDFサポート終了です。残存するDC2クラスターはRA3またはServerlessへ、Python UDFはSQL UDFやLambda UDFへの移行計画を早めに立てることが、後工程の事故を防ぐ近道です。AIエージェント活用まで見据えるなら、Redshiftを単なる分析環境ではなく、AIが参照する信頼済みデータ基盤として、権限設計と指標定義込みで育てる発想が現実的です。







