この記事のポイント
 AIによる分析は2026年に汎用LLM側のデータ分析機能とデータ基盤側のAIエージェント両方が成熟し、現場担当者が自然言語で扱える日常業務になった
AIによる分析は2026年に汎用LLM側のデータ分析機能とデータ基盤側のAIエージェント両方が成熟し、現場担当者が自然言語で扱える日常業務になった- 主要ツールは「BI連携型」「対話型」「業務特化型」「データ基盤型」の4類型に整理でき、手元データの規模と業務文脈で選び分けるのが現実的
- ChatGPT Plus月20ドル・Claude Pro月17ドルなら個人〜部門での試験運用、Power BI Copilotや Fabric Capacityは月数万〜数十万円から組織展開という単価感
- 失敗パターンの多くはデータ品質と分析スコープの設計に集中しており、ツール選定より前段のPoC設計で勝負が決まる
- 「Excelで限界」「BIは見るだけ」を起点に始めるなら対話型から、データ基盤を整える段階ならFabric・Databricks・Snowflake側に寄せるのが妥当

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
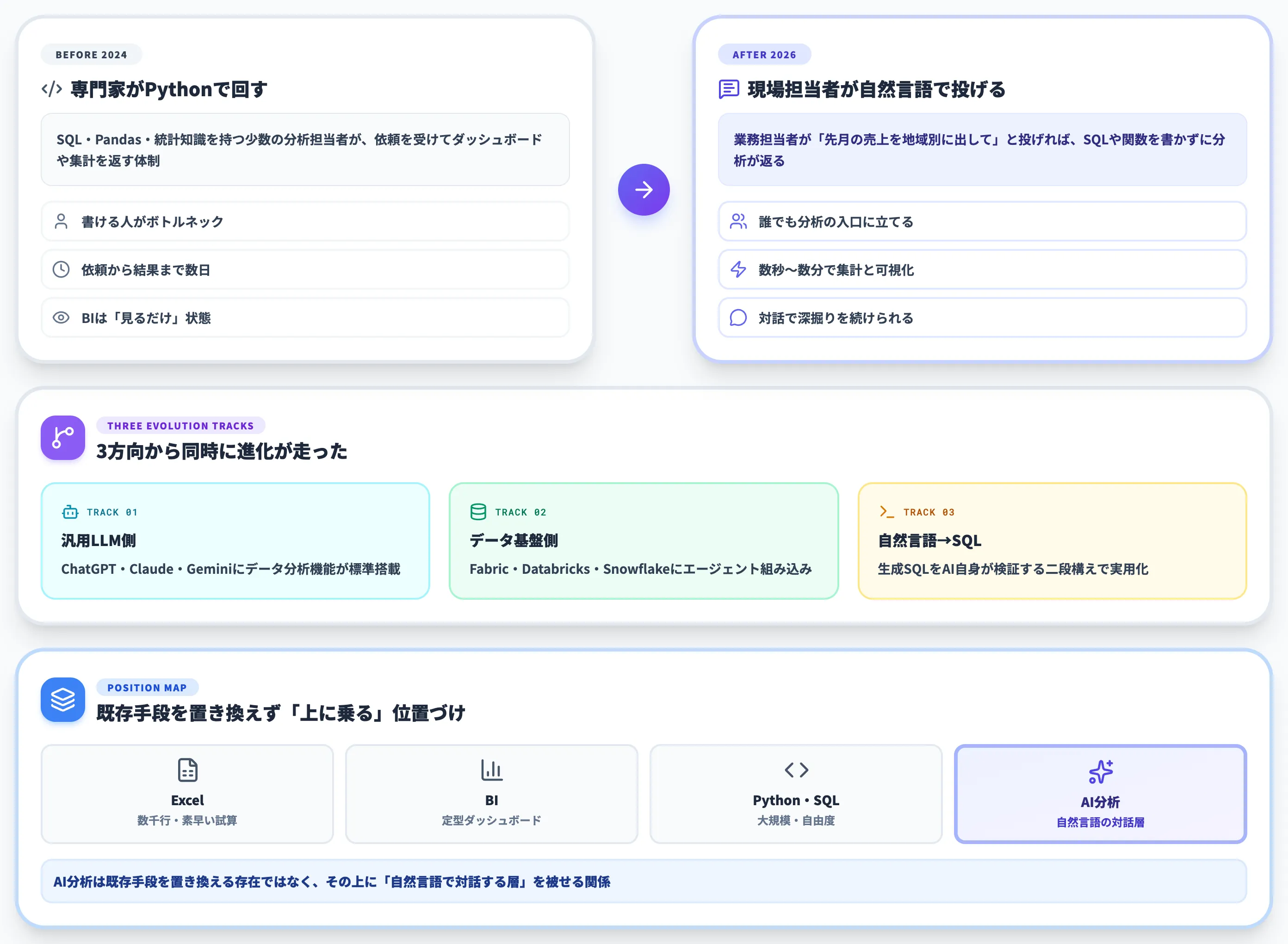
AIを使ったデータ分析は、2026年にかけて「専門家がPythonで回す高度業務」から「現場担当者が自然言語で投げかける日常業務」へ大きく軸が動きました。
背景には、ChatGPTやClaudeの汎用LLMにデータ分析機能が標準搭載されたことと、Microsoft Fabric・Databricks・Snowflakeといったデータ基盤側にAIエージェントが組み込まれたこと、両方の進化があります。
本記事では、5ステップの実務フロー、できることの整理、ツールの4類型、主要9ツールの実力、料金構造とコスト試算、業界別の活用事例、導入前に確認すべき5つのこと、ケース別のツール選定指針までを、2026年6月時点の最新情報で実務目線で解説します。
目次
「機械学習を使った分析」と「生成AIを使った分析」を切り分ける
2. 対象データを棚卸ししてAI-ready dataに整える
ChatGPT Advanced Data Analysis——汎用LLM側のリファレンス実装
Claude——Files APIで定着したデータ分析ワークフロー
Microsoft Copilot——Excel・Teams連携の業務文脈
Microsoft Fabric Copilot——データ基盤側のリファレンス
Databricks AI/BI Genie——Lakehouseと自律エージェント
Snowflake Cortex Analyst——セマンティックモデル前提のNL→SQL
Gemini in BigQuery——Google Cloud内のNL分析
AIを使ったデータ分析の全体像と従来手法との立ち位置
AIによるデータ分析とは、機械学習や生成AI(LLM)を分析パイプラインの中に組み込み、データの収集・前処理・集計・予測・可視化・解釈までの一部または全部を自動化する取り組みを指します。
ここ1〜2年で大きく変わったのは、「分析する側がPythonを書ける専門家である」という前提が崩れたことです。
ChatGPT・Claude・Gemini といった汎用LLMにデータ分析機能が標準で組み込まれ、Microsoft FabricやDatabricksなどのデータ基盤側にもAIエージェントが入りました。結果として、業務担当者が自然言語で「先月の売上を地域別に出してグラフにして」と投げれば、SQLや関数を書かずに分析が返ってくる状態が現実になっています。

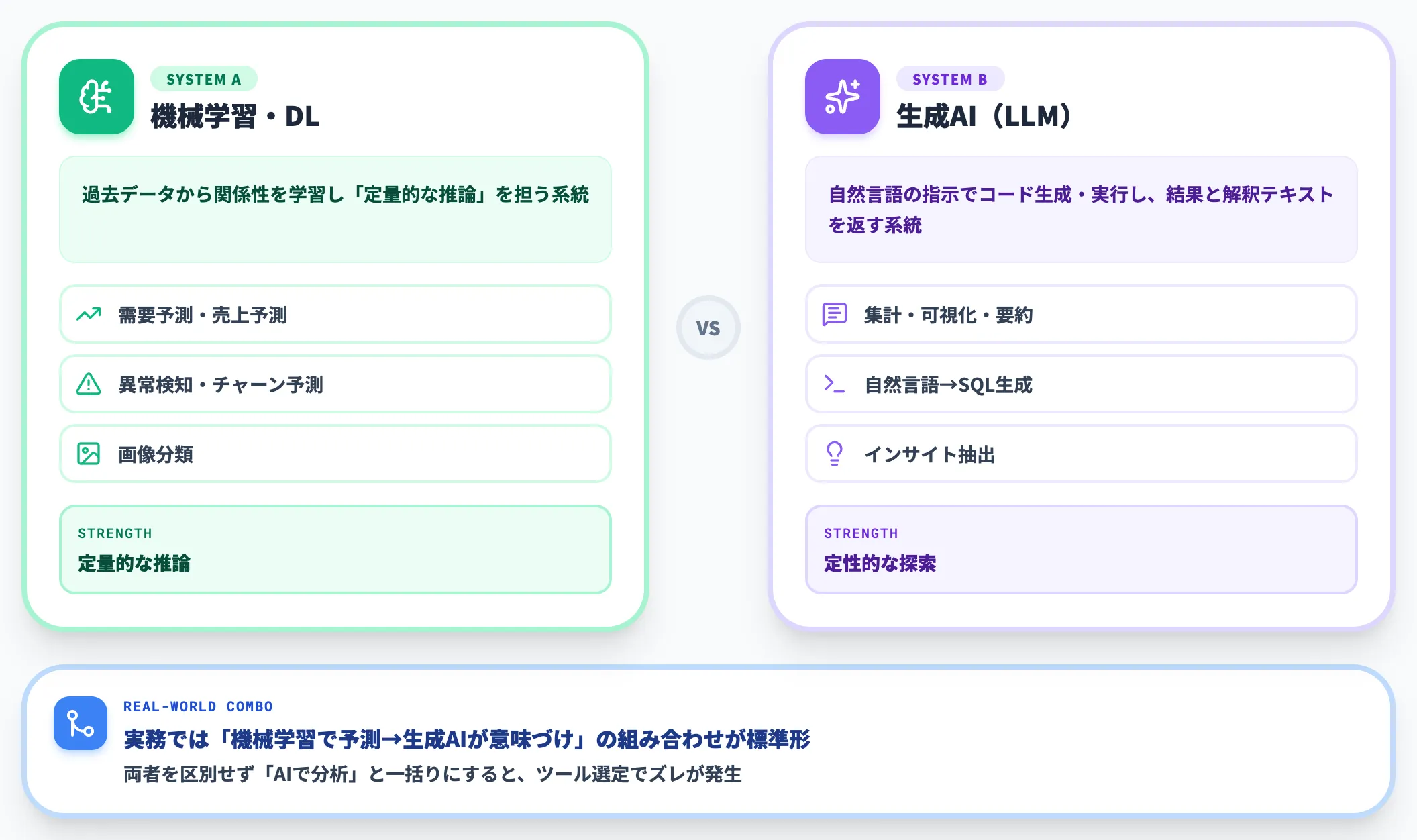
「機械学習を使った分析」と「生成AIを使った分析」を切り分ける
「AIを使ったデータ分析」と一口に言っても、内部で動いている技術は2系統あり、用途と限界が大きく違います。
-
機械学習・ディープラーニングを使った分析
過去データから関係性を学習し、需要予測・異常検知・チャーン予測・画像分類といった「定量的な推論」を担う系統です。機械学習やディープラーニングの手法を組み込んだAI予測モデルが代表例です。
-
生成AI(LLM)を使った分析
ChatGPTのCode InterpreterやClaudeのデータ分析モードのように、自然言語のリクエストを受けてその場でコードを生成・実行し、結果と解釈テキストを返す系統です。集計・可視化・要約・SQL生成・インサイト抽出など「定性的な探索」が強みです。
実務では片方だけ使うことは稀で、「機械学習で予測モデルを作り、生成AIが結果の意味づけと現場への翻訳を担う」のような組み合わせが標準形になりつつあります。
両者を区別せず「AIで分析」と一括りにすると、ツール選定でズレが出やすいので注意が必要です。
従来のBI・Excel・Pythonとの位置関係
Tableauの解説によれば、その位置づけは「人間ではさばききれない情報を、ミスなく短時間で処理できる仕組み」とされます。
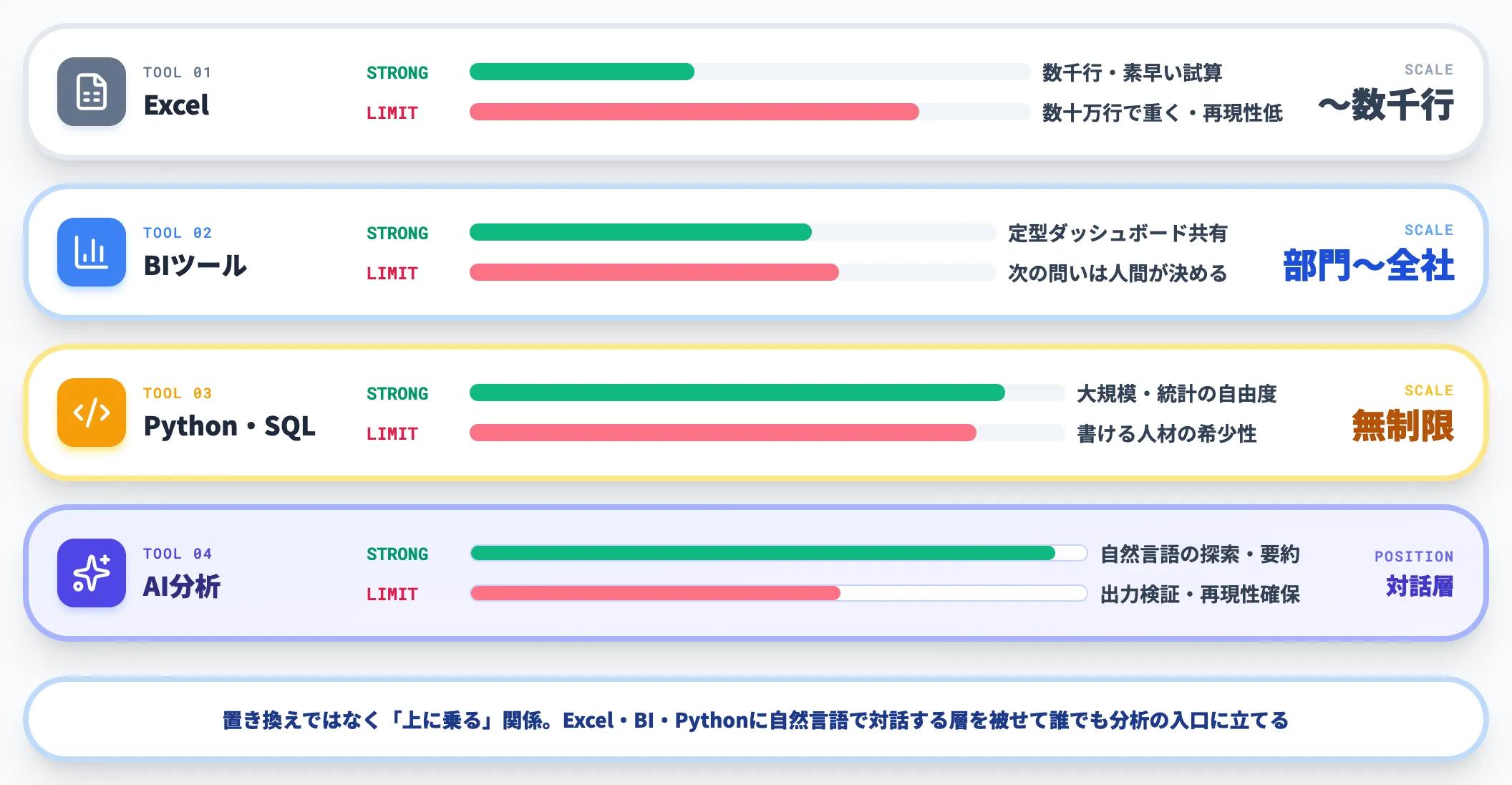
以下の表で、Excel・BIツール・Python・AIデータ分析の役割を整理しました。各手段は対立関係ではなく、扱うデータ規模と業務文脈で使い分ける関係にあります。
| 手段 | 強み | 限界 |
|---|---|---|
| Excel | 数千行までの集計・素早い試算 | 数十万行で重くなり、再現性が低い |
| BIツール(Power BI・Tableau等) | 定型ダッシュボードの可視化・社内共有 | 「次に何を見るべきか」は人間が決める必要があった |
| Python・SQL | 大規模データの加工・統計分析の自由度 | 書ける人材の希少性、書ける人がボトルネック |
| AIによる分析 | 自然言語での探索、コードの自動生成、要約と次の問いの提案 | 出力の精度検証、ハルシネーション、再現性確保が必要 |
つまりこれは、ExcelやBI・Pythonを置き換える存在ではなく、これらの上に「自然言語で対話する層」を被せて誰でも分析の入口に立てるようにする位置づけです。
「BIで作ったダッシュボードを見るだけ」「Pythonを書ける人がいないから諦めていた」という壁を、対話インターフェイスで崩しに行く動きと捉えると整理しやすくなります。
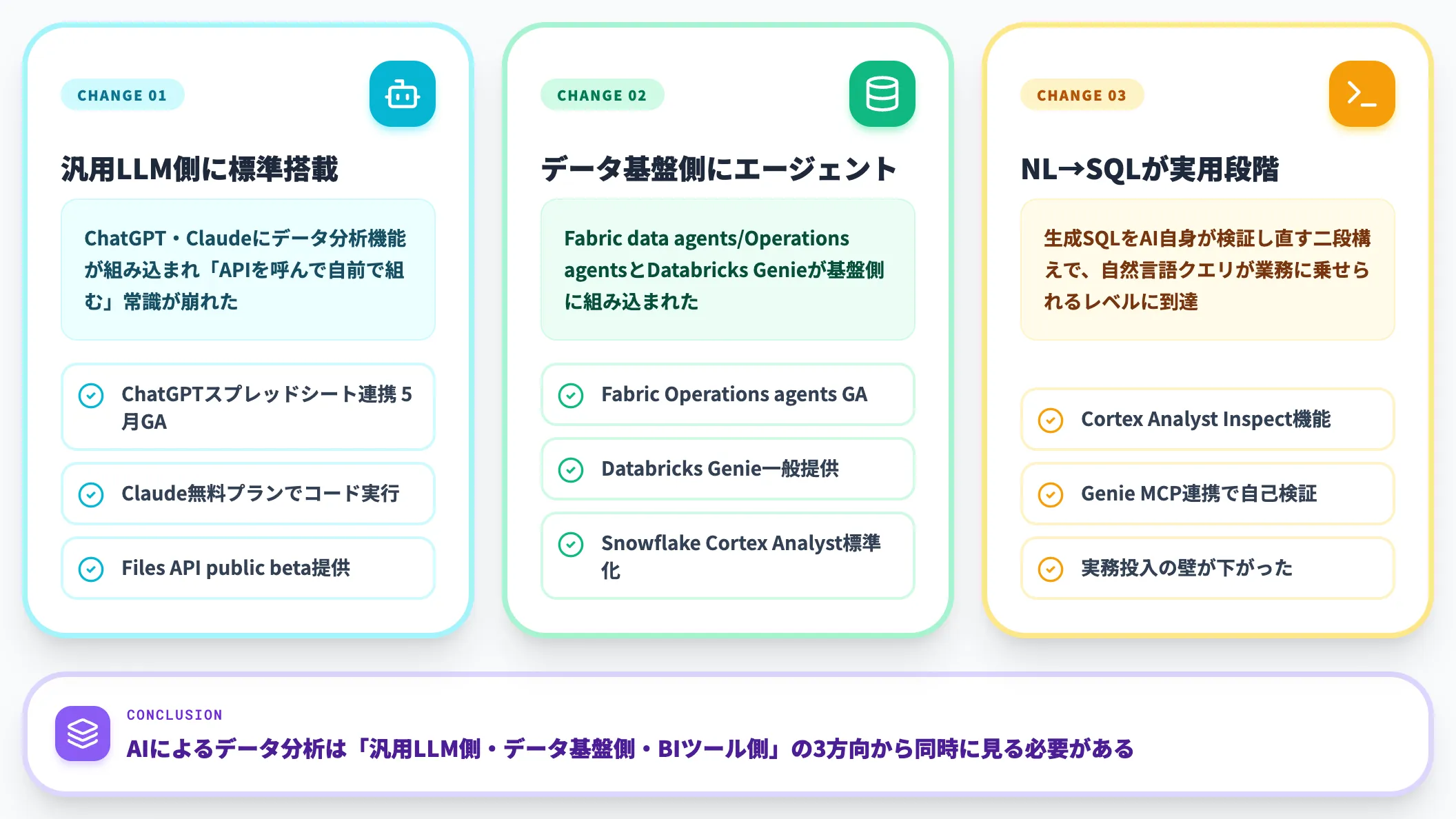
2026年に押さえておきたい3つの変化
直近1年で、この領域の前提が大きく変わりました。本記事を読むうえで押さえておきたい変化が3つあります。
-
汎用LLM側にデータ分析機能が標準搭載された
ChatGPTのスプレッドシート連携(Excel・Google Sheets)が2026年5月にGAへ到達し、ClaudeはClaude.aiの無料プランからコード実行が触れるようになり、APIのFiles APIもpublic betaで提供されています。
「AIにデータ分析させる=APIを呼んで自前で組む」という旧来の常識は崩れています。
-
データ基盤側にもAIエージェントが組み込まれた
Microsoft Build 2026でFabric data agentsとOperations agentsが発表され(Operations agentsはGA、data agentsのMicrosoft 365 Copilot・Copilot Studio連携はPreview)、DatabricksはGenieを一般提供しています。
Genie Codeのスケジュール実行はData + AI Summit 2026で発表され近日提供予定です。SnowflakeもCortex Analystで自然言語→SQLが標準機能化しました。
-
自然言語→SQLが「動く」レベルに到達した
2025年までは精度が不安定で実務に乗せにくかったtext-to-SQLが、Cortex AnalystのInspect機能やGenieのMCP連携で「生成したSQLをAI自身が検証し直す」二段構えになりました。実務に乗せる前段の壁が下がっています。
これらの変化を踏まえると、「AIを使ったデータ分析」を語るとき、汎用LLM側・データ基盤側・BIツール側の3方向から見る必要があります。
このあとのセクションでは、まず実務に組み込むときの進め方を5ステップで整理し、続いてできることを5カテゴリ、ツールの4類型と主要9種、料金、事例、導入前に確認すべきこと、選定指針の順で深掘りします。
AI×データ分析の進め方|5ステップで業務に組み込む
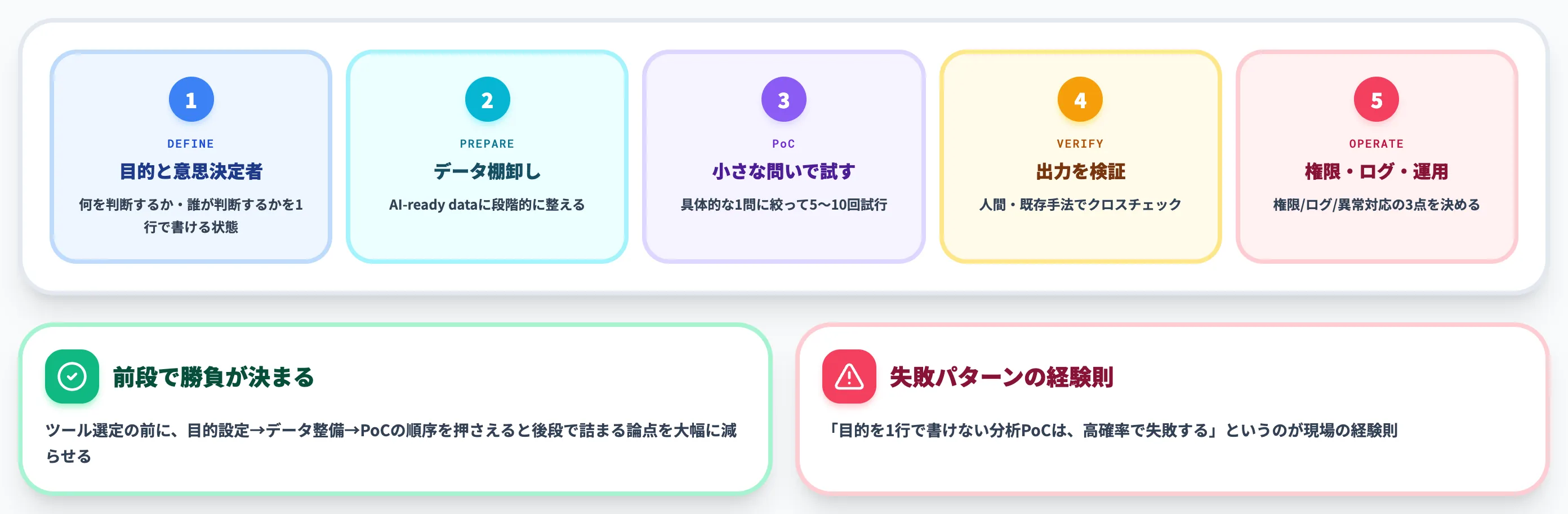
AI×データ分析を業務に組み込むときの実務フローは、5ステップに集約できます。
ツール選定の前に、目的の設定からデータ整備、PoC、検証、運用統制までの順序を押さえると、後段で詰まる論点を大幅に減らせます。
1. 分析の目的と意思決定者を決める
最初に決めるべきは、「この分析で何を判断するか」と「判断する人は誰か」です。
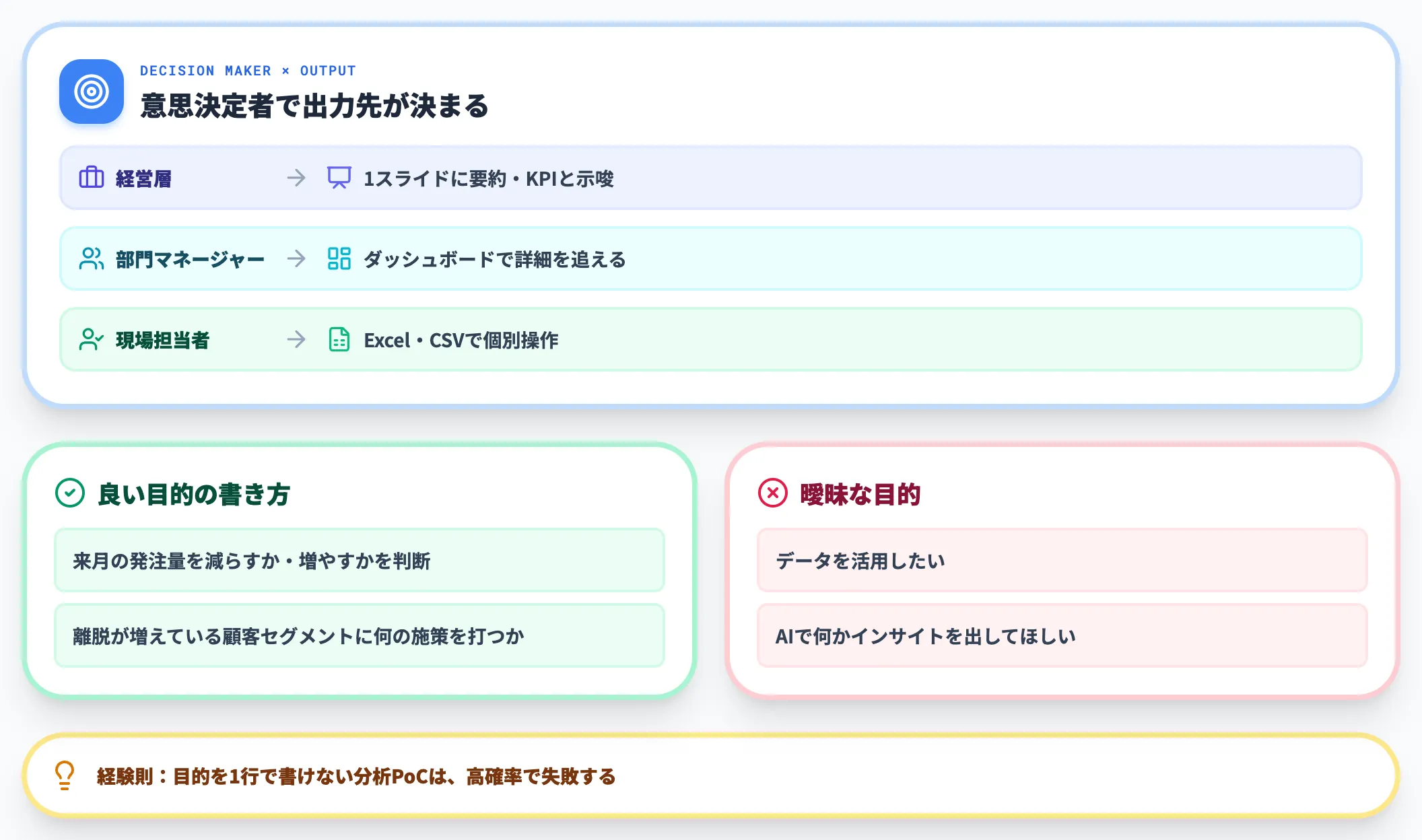
「データを活用したい」だけでは、ツールも問いもデータも絞れません。「来月の発注量を減らすか・増やすか」「離脱が増えている顧客セグメントに何の施策を打つか」のように、意思決定の対象まで具体的に書き出すと、その後の工程がぶれません。
加えて、結果を見て動く意思決定者(経営層/部門長/現場マネージャー)を明示すると、出力フォーマットや粒度の議論も短くなります。経営層向けなら1スライド、部門マネージャー向けならダッシュボード、現場担当者向けならExcel、というように出力先が固まります。
実務的には、「目的を1行で書けない分析PoCは、高確率で失敗する」が現場の経験則です。1行で書けないなら、まだ目的が曖昧か、スコープが広すぎる状態と判断していい段階です。
2. 対象データを棚卸ししてAI-ready dataに整える
目的が固まったら、必要なデータを棚卸しします。社内のどのシステムにあるか、フォーマットは何か、欠損や重複はどの程度かを把握する工程です。
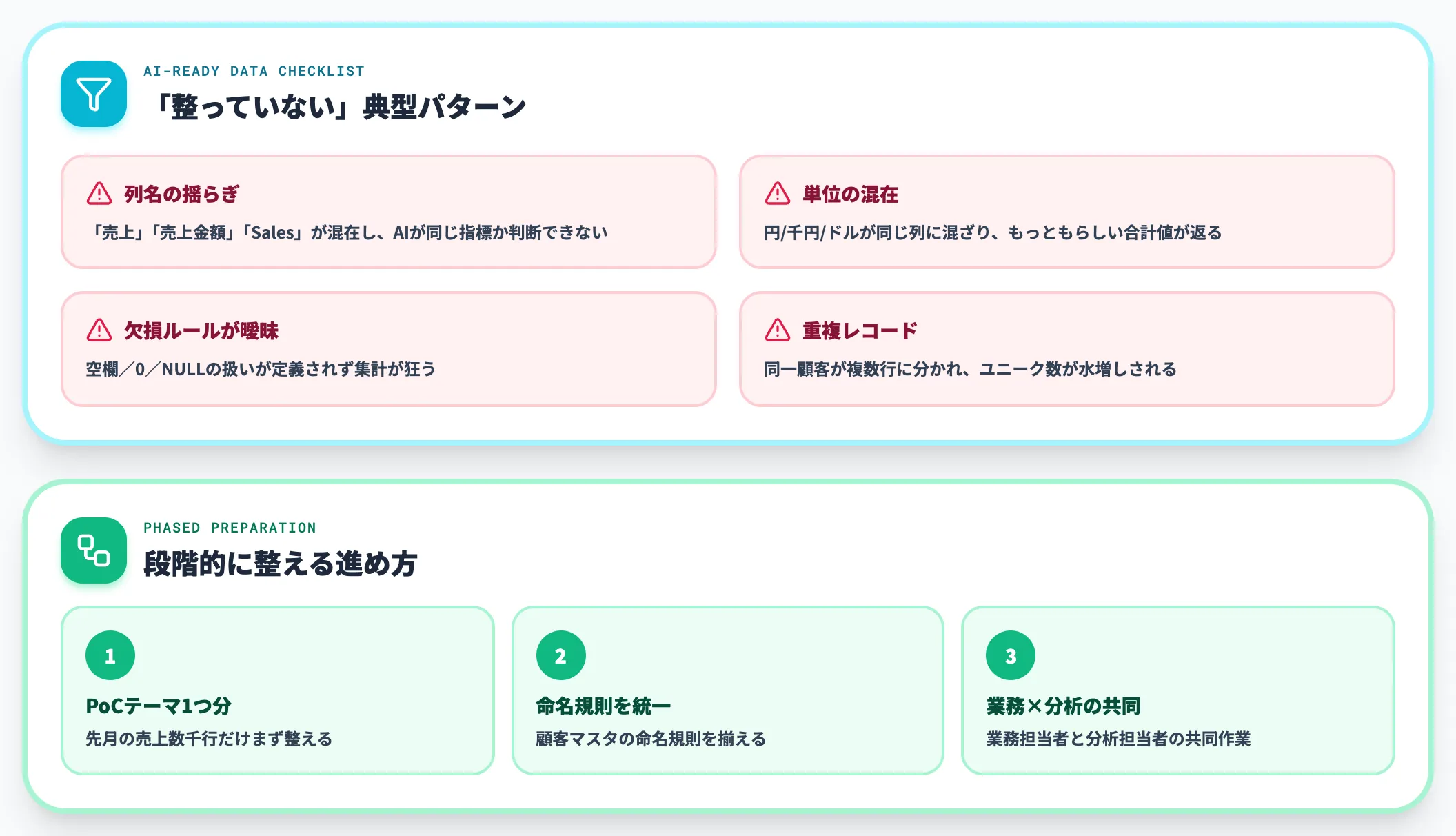
ここで重要なのは、AIに渡せる状態(AI-ready data)に整えることです。列名が揺れている、単位が混在している、欠損ルールが曖昧——このままAIに渡すと、もっともらしいが間違った出力が返ります。AI-ready dataの要件と整備手順はAI-ready dataの解説記事で詳しく整理しています。
AI-ready dataは「いきなり完璧に整える」ではなく、PoCで扱う最初の1テーマ分から段階的に整えるのが現実的です。「先月の売上データ数千行だけまず整える」「顧客マスタの命名規則を統一する」のような最小限のスコープから始めると、整備にかかるコストが見える化されます。
整備の主担当は、現場の業務担当者と分析担当者の共同作業が向きます。業務文脈を知らない人だけで進めると、整えたデータが意思決定に使えない、というすれ違いが起きやすくなります。
3. 小さな問いでPoCを回す
ステップ1で決めた目的を、AIに投げる1つの具体的な問いに落とし込みます。

最初のPoCは「とにかくデータを全部AIに渡して何かインサイトを出して」ではなく、「先月の売上を地域別に出し、前年同月比で異常な動きをしている地域を3つ抽出する」のような粒度に絞ります。
ChatGPT・Claudeの対話型なら数分で結果が返るので、1日に5〜10回試行できます。Snowflake Cortex Analyst・Databricks Genieのようなデータ基盤側ならセマンティックモデルの定義段階に時間がかかるため、最初の1〜2問でツールの当たり外れを判断するのが現実的です。
PoCの目的は「正しい答えを出す」ことではなく「AIが業務に使えるレベルで動くかを見極める」ことです。出力が想定外でも、その理由(プロンプトが曖昧/データが整っていない/ツールが向いていない)まで切り分けると次のステップに進めます。
4. AIの出力を人間・既存手法で検証する
AIの出力は、必ず人間または既存手法でクロスチェックします。
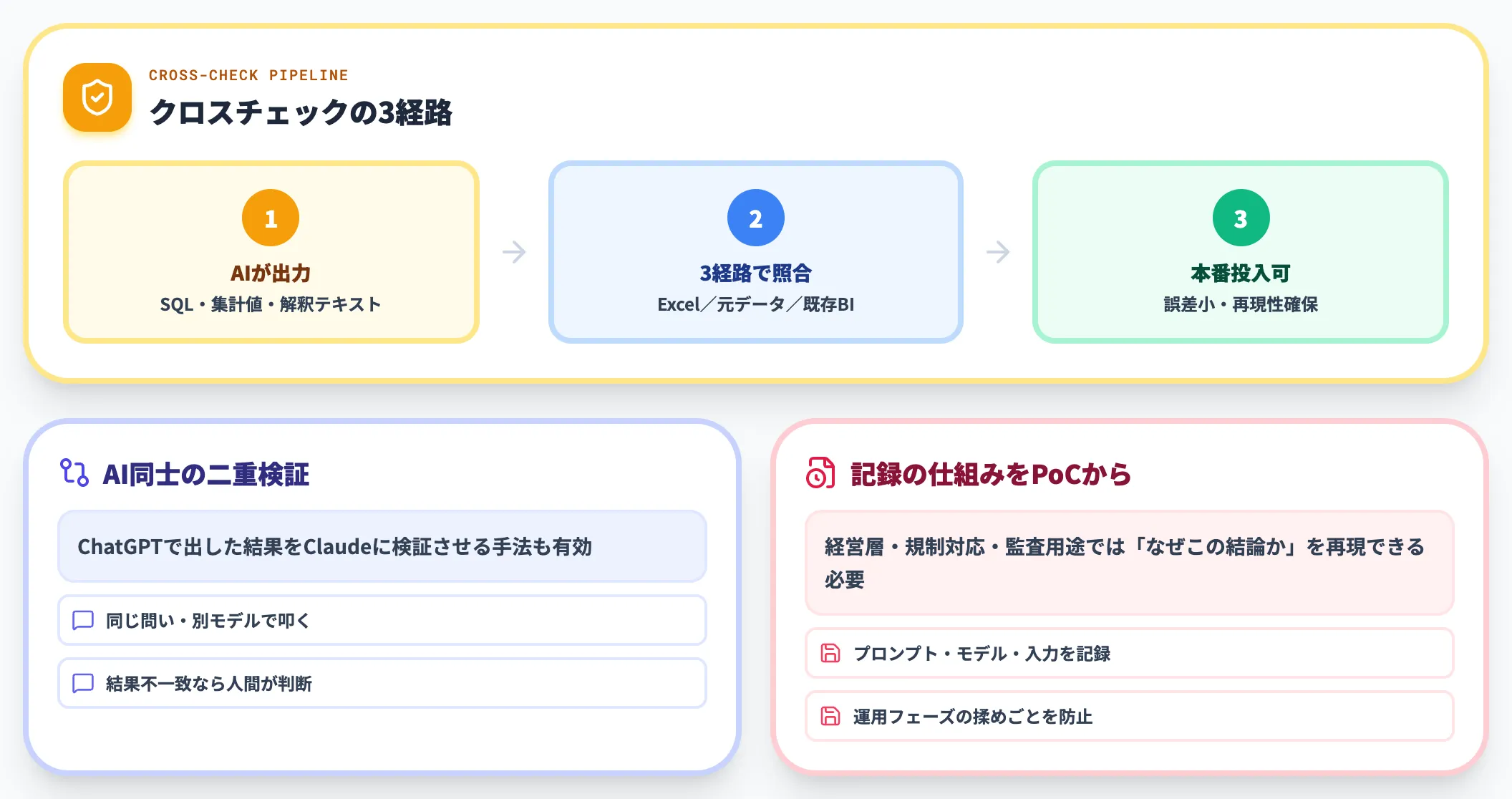
具体的には、AIが生成したSQLや集計値を、Excel・元データの直接確認・既存のBIレポートで照合します。同じ問いを別のAI(ChatGPTで出した結果をClaudeに検証させる)で叩く方法も有効です。
特に経営層・規制対応・監査用途で使う場合、「なぜこの結論に至ったか」を後から再現できる必要があります。プロンプト・モデル・入力データを記録する仕組みを、PoC段階から組み込んでおくと運用フェーズでの揉めごとを防げます。
検証で誤差が大きすぎる、再現性が低いと判断されたら、ステップ2・3に戻ってデータ整備・問いの粒度を見直します。AIの出力をそのまま信用して本番投入するのは早すぎる判断です。
5. 権限・ログ・運用ルールを決めて業務に定着させる
最後に、運用ルールを決めて業務に組み込みます。

決めるべきは、誰がAIにアクセスできるか(権限)、入力・出力をどう記録するか(ログ)、異常時にどう対応するか(運用フロー)の3点です。
権限は、機密データを扱う場合は特に重要で、エンタープライズ契約・データ学習除外設定・社内のアクセス権限管理を組み合わせます。ログは、AIの出力ごとにプロンプト・モデル・タイムスタンプを残せる仕組み(プロンプト管理ツール、Snowflake Cortex AnalystのSQL履歴等)を用意します。
定着段階で見落とされがちなのが、業務担当者への教育です。AIを使う側がプロンプトの書き方・出力の読み方を理解していないと、せっかくの仕組みが「シャドーIT」化します。導入時に20〜30分の研修を業務担当者・分析担当者・意思決定者の3者に分けて実施するだけで、定着率は大きく変わります。
ここまでが実務に組み込む5ステップの全体像です。次のセクションから、各ステップで押さえるべき機能・ツール・料金・事例を順に整理します。
AIによる分析でできること|5つの機能カテゴリで整理

AIによる分析でできることは、機能ベースで以下の5カテゴリに整理できます。
ツール名だけ並べても全体像が見えにくいため、まずこの5カテゴリで「何をやってくれるか」を押さえると、各ツールの強み比較がしやすくなります。
自然言語クエリ(NL→SQL/NL→可視化)
自然言語で「先月の売上を地域別に出して」「先週と先々週の比較を棒グラフで」と問いかけると、その場でSQL・集計・グラフが生成されます。
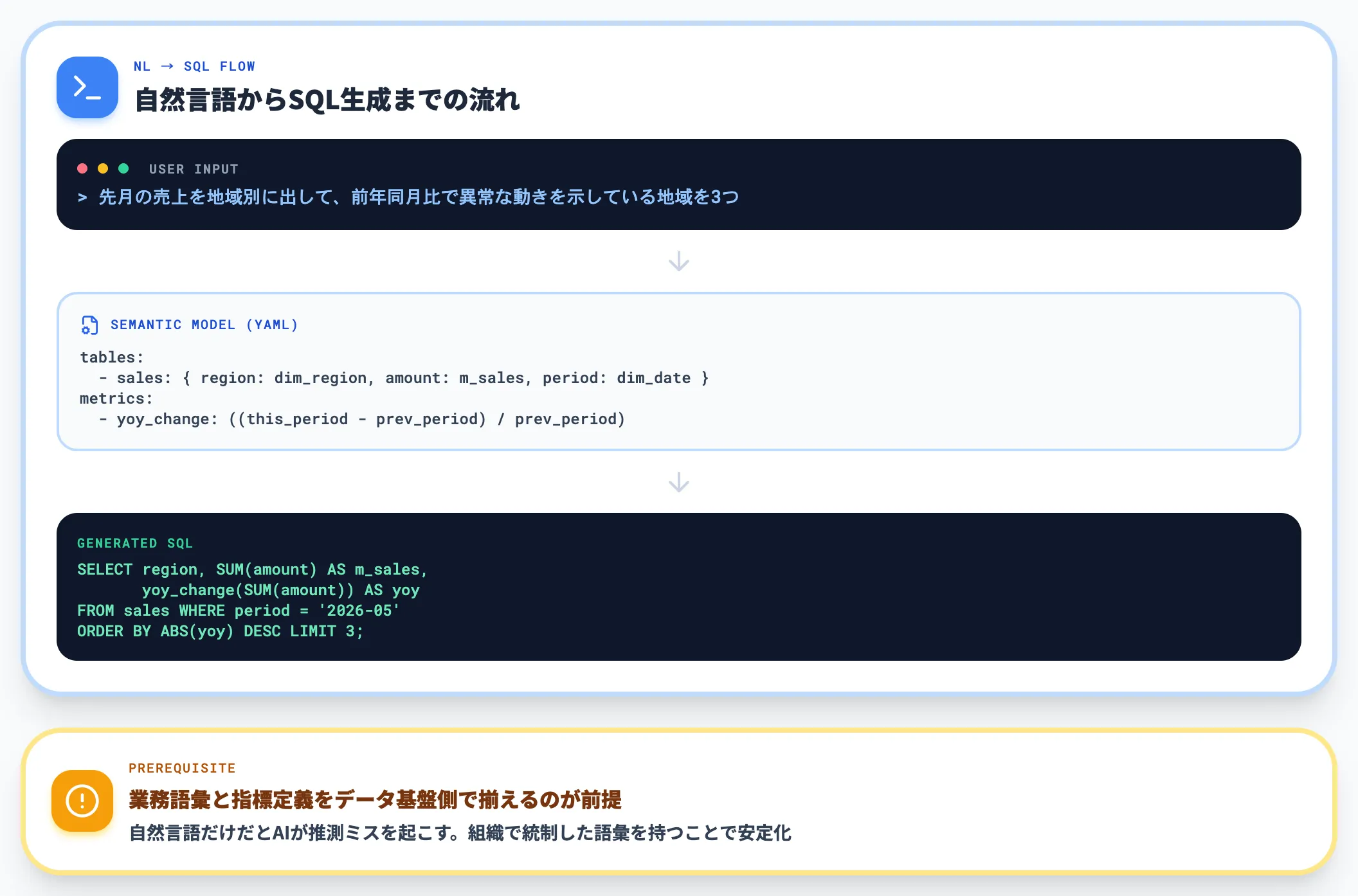
Snowflake Cortex Analyst、Databricks AI/BI Genie、BigQueryのGeminiアシスタントなどが代表例で、業務担当者がSQLを書かずにデータベースを叩ける状態を作ります。
Cortex Analystの場合、Snowflakeが定義した「セマンティックモデル」を介して問い合わせるため、データの意味解釈をAI任せにせず、組織で統制した語彙でクエリを生成できる構造になっています。
ここから読み取れるのは、「自然言語で投げる」だけだとAIが推測ミスをするため、業務語彙・指標定義をデータ基盤側で揃えておくことが、自然言語クエリを実務に乗せる前提条件になるという点です。
自動可視化とダッシュボード生成
データを渡しただけで、AIが「このデータならこういうグラフが向く」「複数の指標は1つのダッシュボードに束ねた方が見やすい」と判断し、可視化を自動生成する機能です。
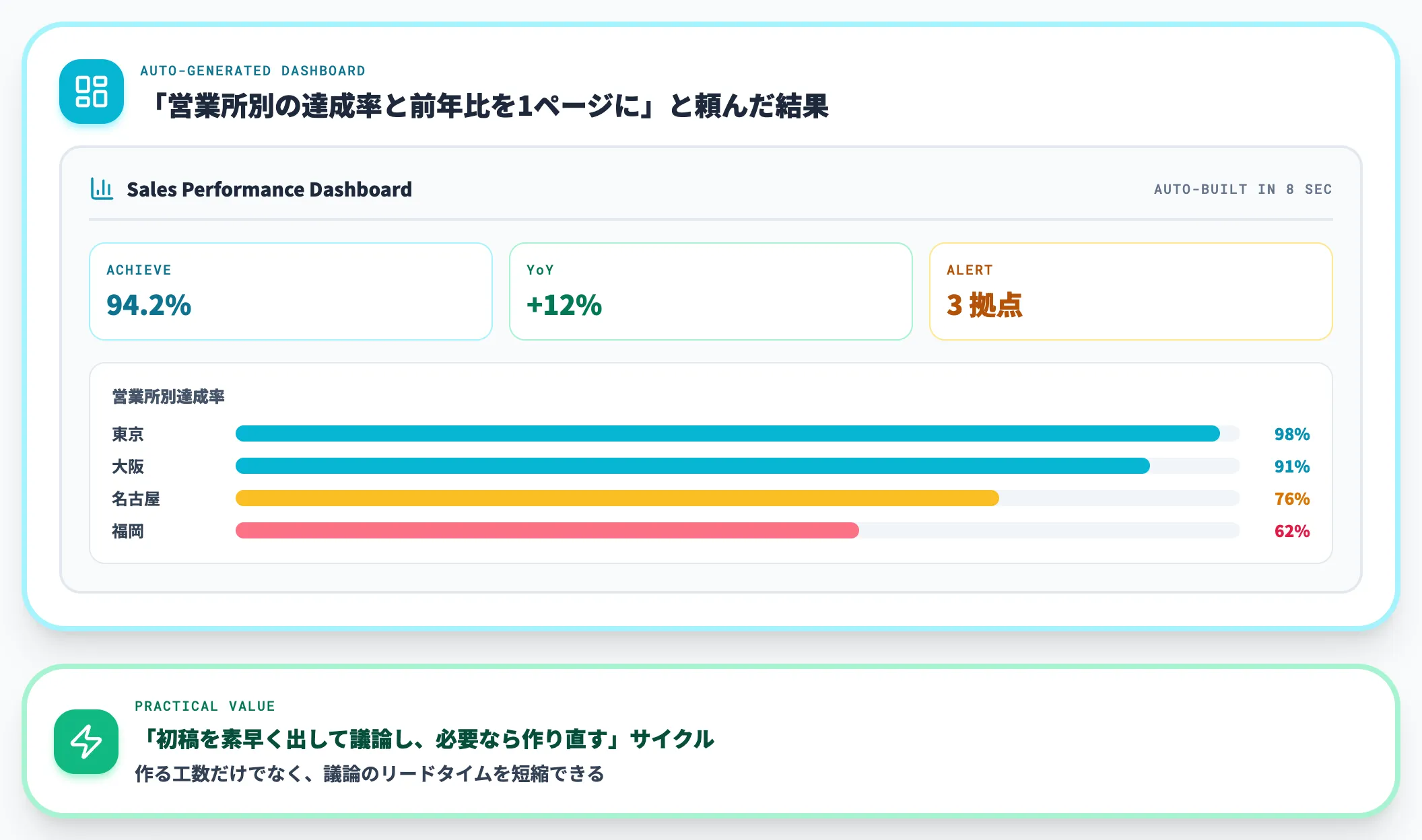
Power BI Copilotは、自然言語で「営業所別の達成率と前年比を1ページにまとめて」と指示すれば、レポート全体をその場で組み立てます。Tableau Agentも2026年2月から追加されたDashboard Narratives(Beta)で、既存ダッシュボードをAIが解析して概要文・インサイトを自動生成するようになりました。
実務的な価値は「ダッシュボードを作る工数」だけでなく、「初稿を素早く出してチームで議論し、必要なら作り直す」というサイクルが回しやすくなる点にあります。
予測(需要予測・売上予測・解約予測)
過去データから未来の値を予測する用途で、需要予測・売上予測・解約予測・故障予測などが代表例です。

汎用LLMでもCSVをアップロードして「来月の予測を立てて」と頼めば回帰モデルを書いて動かしてくれますが、本格運用では需要予測AIやAI予測の専用サービスを使うほうが安定します。
Sony Network Communicationsの「Prediction One」は、売上・受注確度・出荷数・故障予測などを学習データから回帰・分類モデルとして自動生成する仕組みで、データサイエンティスト不在の現場でも使える設計になっています。
予測系は精度の検証が必須なので、PoC段階で「Excel・Pythonでの手作業予測と、AIの予測がどれだけ近いか」を比較してから本番運用に乗せるのが現実的です。
異常検知・分類・パターン抽出
過去パターンから逸脱したデータを自動で検出する用途です。製造業の設備異常、金融の不正取引、ITシステムのログ異常などで広く使われています。
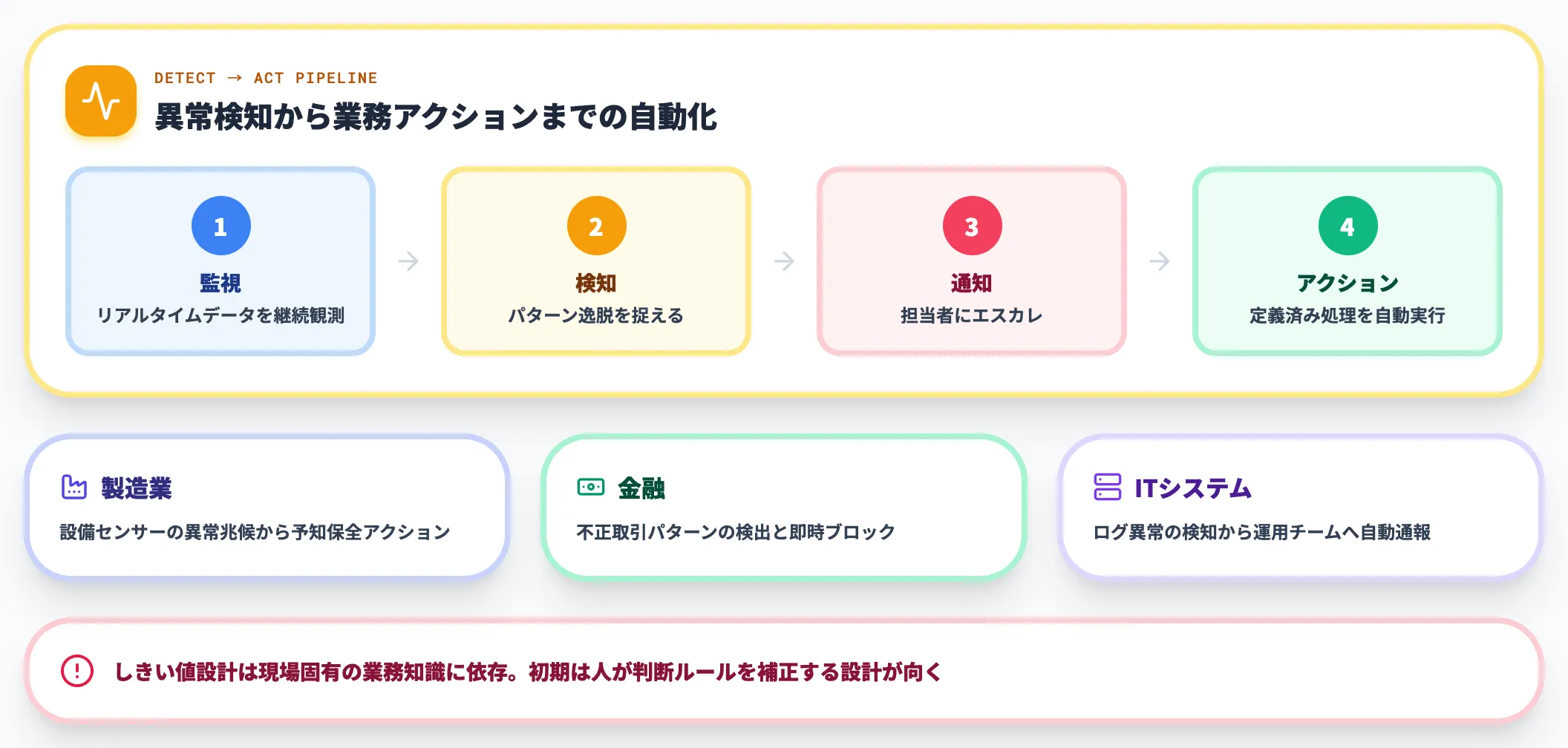
Microsoft FabricのOperations agentsは、リアルタイムデータを継続監視し、パターンや異常を検知して定義済みのアクションを実行できる設計です。「異常を見つける」だけでなく「次の業務アクションまで自動で走らせる」段階に来ています。
異常検知系では、「正常データに対してどれだけ偏っているか」のしきい値設計が現場固有の業務知識に依存するため、最初からAIに全任せにせず、初期は人が判断ルールを補正する運用設計が向いています。
要約とインサイト生成(非構造化データ含む)
自由記述アンケート・顧客レビュー・コールセンター応対ログ・社内Slackなど、構造化されていないテキストデータを要約し、傾向や論点を抽出する用途です。
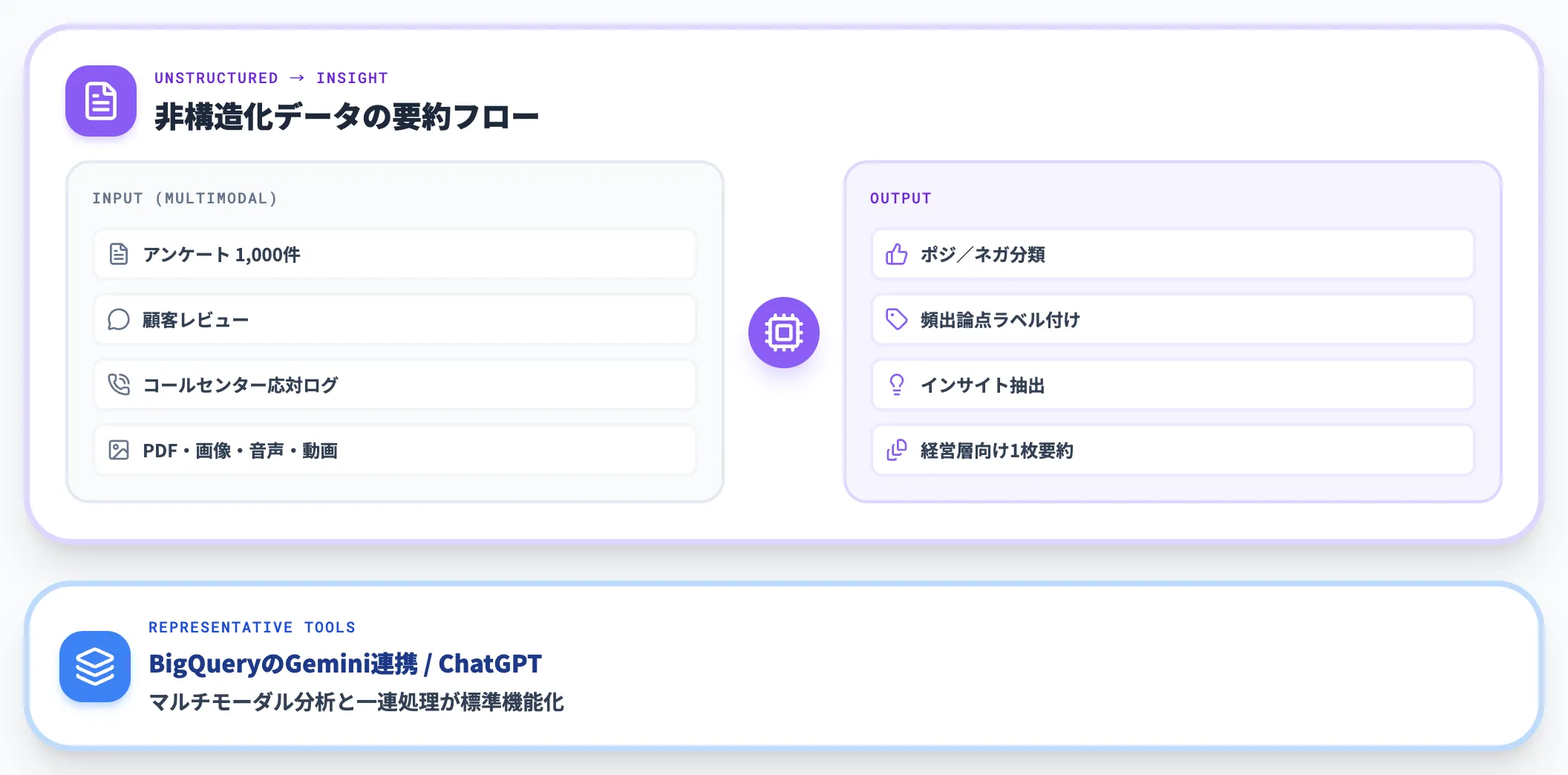
BigQueryのGemini連携は、PDF・画像・音声・動画をそのまま入力としてマルチモーダル分析でき、要約・ラベル付け・インサイト抽出までを一連の処理として実行します。
汎用LLMでも、ChatGPTでアンケート1,000件のテキストをまとめてポジ/ネガ分類し、頻出論点を抽出するような業務はすぐに始められます。
ここまでの5カテゴリは、ツールごとに「全部こなせる」のではなく、強い領域が分かれています。次のセクションで、その違いを4類型として整理します。
AI分析ツールの4類型と代表製品マップ
AI分析ツールは、データへの接し方と業務での位置づけで4類型に整理できます。
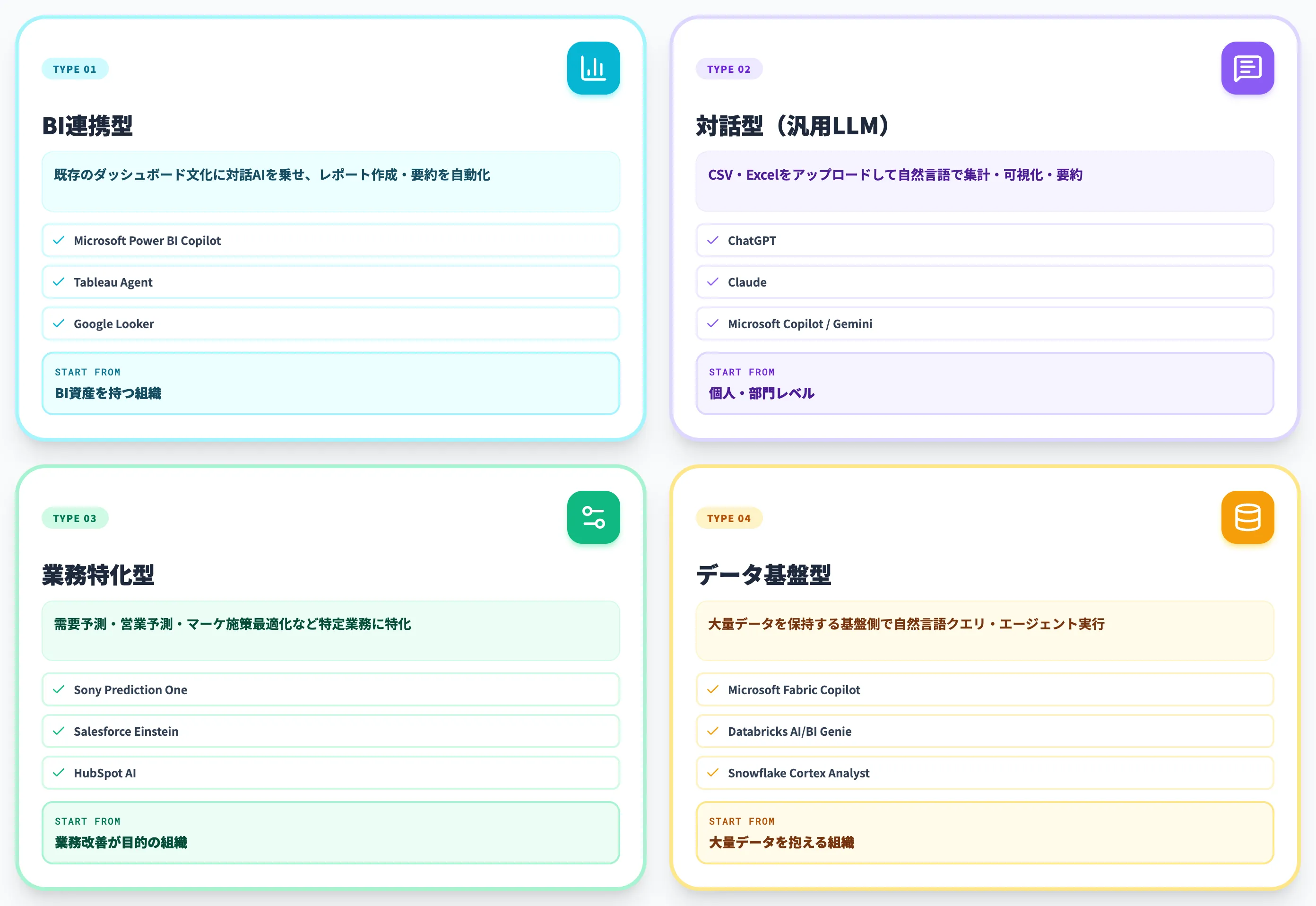
以下の表で、4類型ごとの代表製品とユースケースを整理しました。読者の手元データの規模と業務文脈で、どの類型を起点にするかが変わります。
| 類型 | 代表製品 | ユースケース |
|---|---|---|
| BI連携型 | Microsoft Power BI Copilot、Tableau Agent、Google Looker | 既存のダッシュボード文化に対話AIを乗せ、レポート作成・要約を自動化 |
| 対話型(汎用LLM) | ChatGPT、Claude、Microsoft Copilot、Gemini | CSV・Excelをアップロードして自然言語で集計・可視化・要約 |
| 業務特化型 | Sony Prediction One、Salesforce Einstein、HubSpot AI | 需要予測・営業予測・マーケ施策最適化など、特定業務に特化したAI |
| データ基盤型 | Microsoft Fabric Copilot、Databricks AI/BI Genie、Snowflake Cortex Analyst | 大量データを保持する基盤側で自然言語クエリ・エージェント実行 |
類型ごとに、どんな読者・組織が起点にすべきかをもう少し具体的に整理します。
BI連携型——既存BI資産を持つ組織の起点
Power BI・Tableau・Lookerなどで既にダッシュボード文化がある組織は、BI連携型から入るのが自然です。
ダッシュボードを作る人と見る人が分かれる構造を、対話AIで橋渡しできるのが強みです。BIツールを使えない経営層・現場担当者でも、「このダッシュボードを要約して」「先月との差分の理由を教えて」と聞けるようになります。
Power BI CopilotはMicrosoft 365との統合が強く、Tableau Agentは2026年2月からDashboard Narratives(Beta)で要約自動生成が追加されました。
対話型——個人・部門レベルで始めたい組織の起点
「データはあるがどう触ればいいかわからない」「Excelで限界を感じている」段階の組織は、対話型から入るのが現実的です。
ChatGPTやClaudeにCSVをアップロードするだけで、その場で集計・可視化・解釈テキストが返ってきます。月額20ドル前後の個人プランから始められるため、PoCコストが圧倒的に低いのが特徴です。
ただし機密データを扱う場合は、エンタープライズ契約・データ学習除外の設定を必ず確認してから本番投入する必要があります。
業務特化型——「分析」より「業務改善」が目的の組織の起点
需要予測・営業予測・マーケ施策・人事評価など、業務領域がはっきりしている場合は業務特化型が向きます。
Sony Network Communicationsの「Prediction One」は、売上や顧客属性のデータを学習させると、有望顧客の絞り込み、出荷数予測、故障予測といった分析モデルを自動生成します。データサイエンティストがいなくても回せる設計です。
業務特化型は「汎用LLMでも作れるが精度・運用ループが弱い」領域を、定型化して提供している立ち位置です。
データ基盤型——大量データを抱える組織の起点
Snowflake・Databricks・Microsoft Fabricといったクラウド型データ基盤を既に運用している、もしくはこれから整える組織は、データ基盤型から入るのが筋です。
データを基盤から動かさず、その場で自然言語クエリ・エージェント実行・予測モデル構築まで完結できます。データガバナンスと整合性を保ったまま分析を回せる点が、対話型LLMとの最大の違いです。
Microsoft FabricデータエージェントはFabric内に作成したデータエージェントをMicrosoft 365 CopilotのAgent Store経由でTeamsから直接呼び出せるようになり、データ基盤と業務アプリのつなぎ目が大幅に短くなりました。
ここまでで類型ごとの起点が見えたところで、次は主要ツール9種の実力を具体的に比較します。
主要9ツールの実力と最新機能
ここからは、4類型に該当する主要ツール9種について、2026年6月時点の能力境界と最新機能を整理します。

以下の表で、9ツールの強み・対応データ規模・最新機能のハイライトをまとめました。導入検討の比較用として、まず横断で眺めてから個別を読むと整理しやすくなります。
| ツール | 類型 | 強み | 対応データ規模 | 2026年の主な動き |
|---|---|---|---|---|
| ChatGPT(Advanced Data Analysis) | 対話型 | 多形式ファイルの集計・可視化 | CSV・スプレッドシート 約50MB/ドキュメント 数百MB | スプレッドシート連携が5月にGA、GPT-5.5 Thinking投入 |
| Claude(Files API・コード実行) | 対話型 | 大規模CSV・複数ファイルの自然言語探索 | 1ファイル500MB級 | Files API(Claude APIのbeta)、Claude.ai無料プランからコード実行可能 |
| Microsoft Copilot(Excel・M365) | 対話型 | Excel・Teams・SharePointの業務文脈 | Excel限界(数百万行) | M365 Copilot Chatでデータエージェント呼び出し |
| Gemini in BigQuery | データ基盤型 | BigQuery直結のNL→SQL・マルチモーダル | BigQueryスケール(PB級) | データキャンバスでノーコード探索 |
| Microsoft Fabric Copilot | データ基盤型 | OneLake全体への対話・エージェント実行 | Fabric全域(PB級) | Operations agentsがGA、data agentsのM365/Copilot Studio連携はPreview |
| Databricks AI/BI Genie | データ基盤型 | Lakehouseでの自然言語クエリ・自律実行 | Lakehouseスケール(PB級) | Genie Codeスケジュール実行は近日提供、Managed MCP(Beta)対応 |
| Snowflake Cortex Analyst | データ基盤型 | セマンティックモデル経由の高精度NL→SQL | Snowflakeスケール(PB級) | Cortex Agents経由のAI Credits課金、Inspect機能でSQL自己検証 |
| Power BI Copilot | BI連携型 | 既存BI資産からのレポート自動生成 | Power BIモデル限界 | セマンティックモデル修正、スクリーンショット→レポート |
| Tableau Agent | BI連携型 | ダッシュボード要約・可視化提案 | Tableauデータソース | Dashboard Narratives Beta、Einstein Request credits消費終了 |
表だけでは強みの差が見えにくいので、ここから対話型・データ基盤型・BI連携型の代表的なツールについて、能力境界と実務での使いどころを掘り下げます。
ChatGPT Advanced Data Analysis——汎用LLM側のリファレンス実装
ChatGPTのAdvanced Data Analysis(旧Code Interpreter)は、CSV・Excel・PDF・画像などをアップロードしてその場でPythonを走らせ、集計・可視化・要約まで実行する機能です。
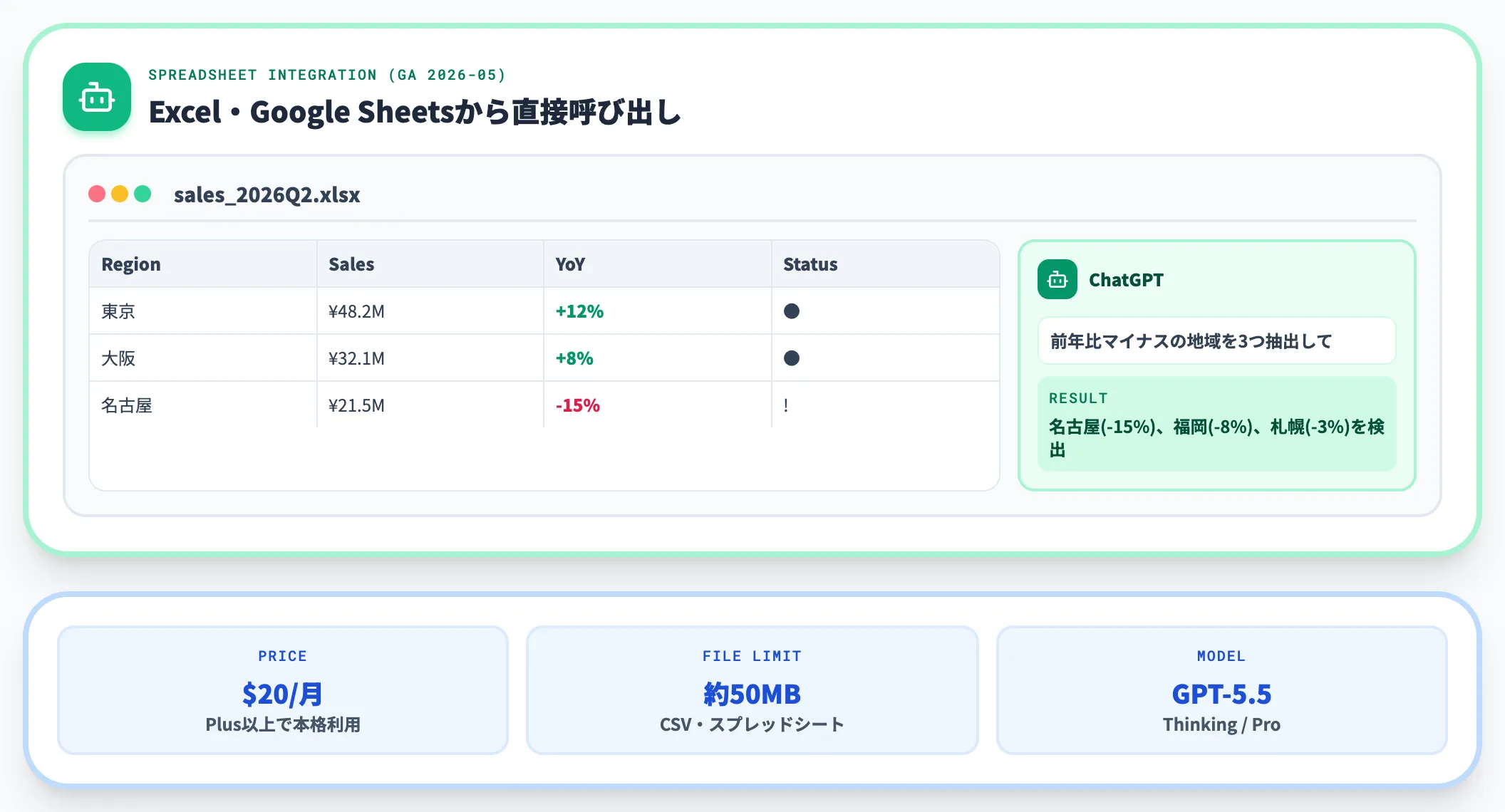
2026年4月にOpenAIが発表したGPT-5.5 Thinking/Proでデータ分析能力が大幅に強化され、Excel連携は3月5日にβ提供開始、Google Sheets連携は4月22日にβ提供開始を経て、5月5日に両方GAへ到達しました。Excel・Google Sheetsのサイドバーから直接ChatGPTを呼び出して分析できます。
Plus(月20ドル)以上のプランで本格利用でき、無料プランも1日3ファイルまで、CSV・スプレッドシートは約50MB上限で触れます。個人〜部門での試験運用にはまず最初に試すべきツールです。
機密データを扱う場合は、データ学習除外(オプトアウト)を有効化したうえで、Enterpriseプランの利用が前提になります。
Claude——Files APIで定着したデータ分析ワークフロー
AnthropicClaudeは、2025年5月22日にFiles APIとCode execution toolをpublic betaで公開して以降、企業のデータ分析ワークフローへの組み込みが進んでいます。
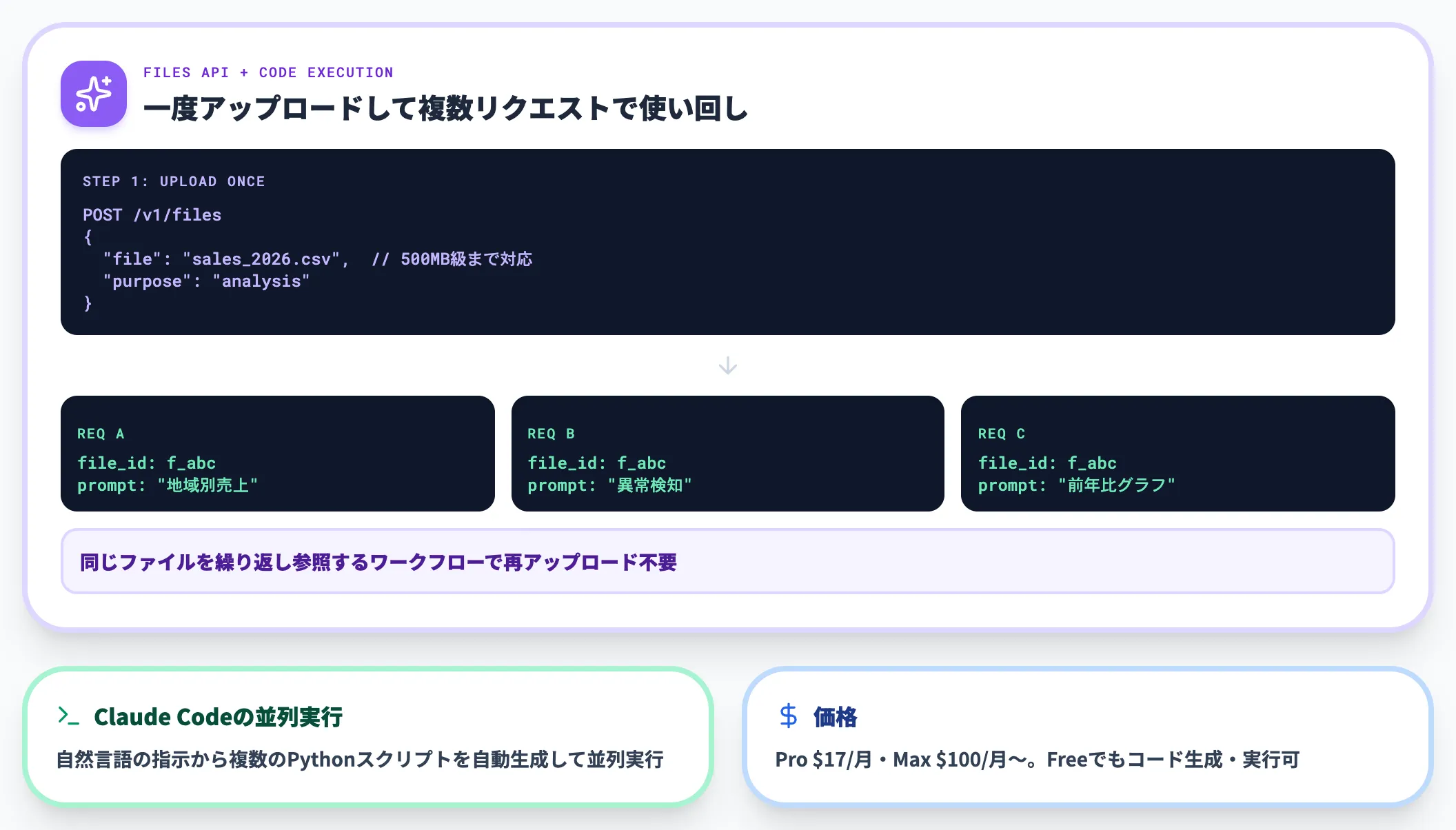
特徴は、CSV・Excel・PDFを一度アップロードすれば複数のAPIリクエストで使い回せる設計で、再アップロードを避けられるため同じファイルを繰り返し参照するワークフローに向きます。
Claude Codeを使えば、自然言語の指示から複数のPythonスクリプトを自動生成して並列実行し、大規模CSVや複数ファイルを横断するデータ探索を回す運用パターンが実務で広がっています。
料金はPro月17ドル・Max月100ドル〜で、Freeプランでもコード生成と実行が含まれる構成です。「無料プランからデータ分析を試したい」場合の最有力候補になります。
Microsoft Copilot——Excel・Teams連携の業務文脈
Microsoft 365 Copilotは、ExcelやTeams・SharePointと一体で動くため、業務担当者の作業文脈に最も近いところでAI分析が走るのが強みです。

Excelに対しては、自然言語で「営業所別の達成率と前年比を計算して、達成率が低い順に並べて」と指示すると、関数・ピボット・並び替えまでをまとめて実行します。
M365 Copilot Chatでは、Fabric側で構築したデータエージェントをそのまま呼び出せるため、データ基盤と日常業務のシームレスな接続が実現しつつあります。詳細はMicrosoft Copilotの解説記事に整理しています。
Microsoft Fabric Copilot——データ基盤側のリファレンス
Microsoft Fabricは、OneLakeに集約したデータに対して、Power BIレポート・データパイプライン・ML・リアルタイム分析を一体で回せる統合プラットフォームです。
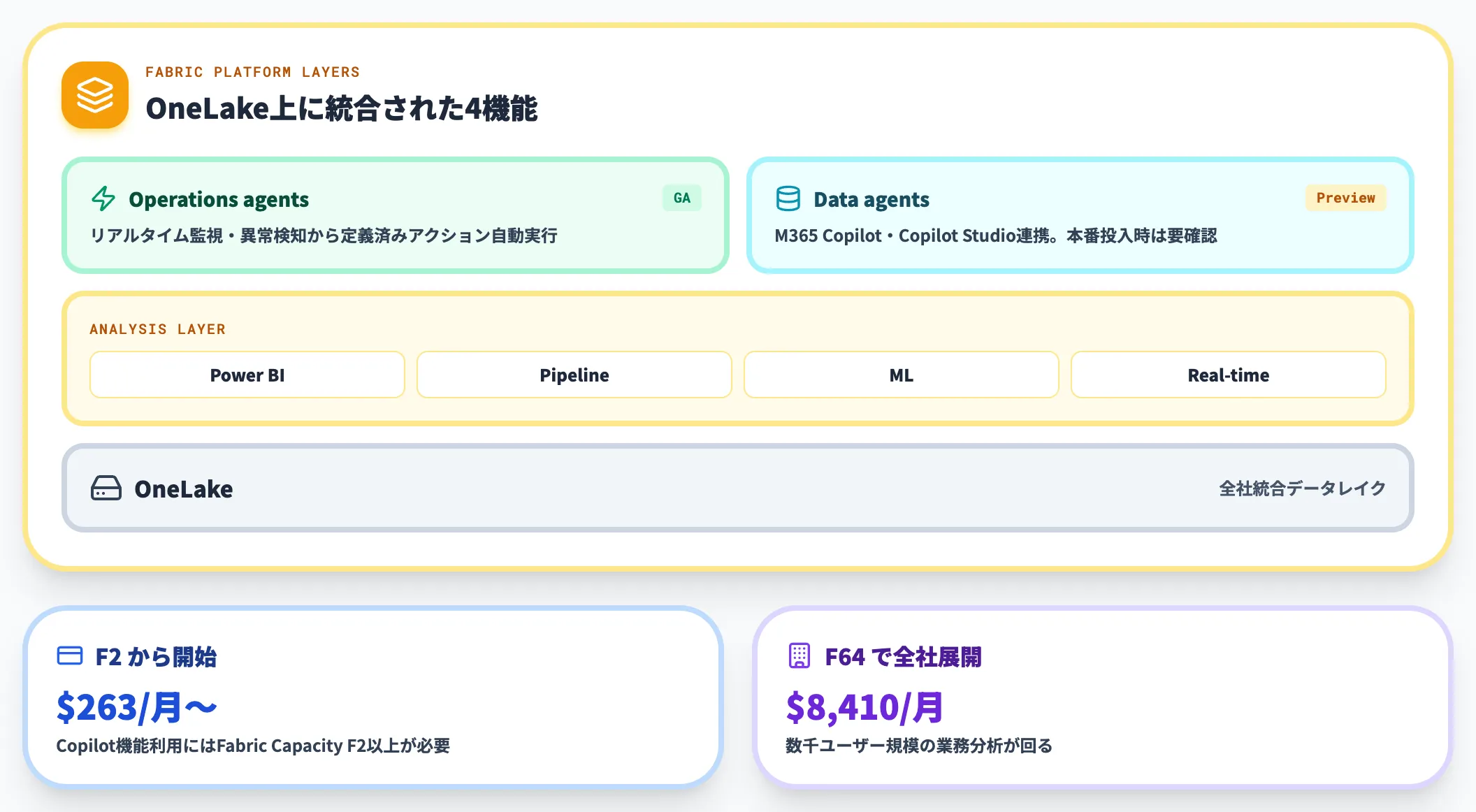
2026年はOperations agentsがGAへ到達したことが大きな転換点で、リアルタイムデータを継続監視し、異常検知から定義済みアクションの自動実行までを担います。
一方、Fabric data agentsのMicrosoft 365 Copilot連携とCopilot Studio連携はPreview段階で、本番投入時は対応状況の確認が必要です。Fabric IQが横串でエージェントエコシステムに広がっており、Copilot StudioのConnected agentsを通じて複数エージェント連携にも広がっています。
Copilot機能を使うには有料のFabric Capacity F2以上(約263ドル/月から)が必要で、F64クラス(約8,410ドル/月)になると数千ユーザー規模の業務分析が回ります。
Databricks AI/BI Genie——Lakehouseと自律エージェント
DatabricksのAI/BI Genieは、Lakehouseに保管したデータに対して、自然言語クエリと自動可視化を提供する機能です。
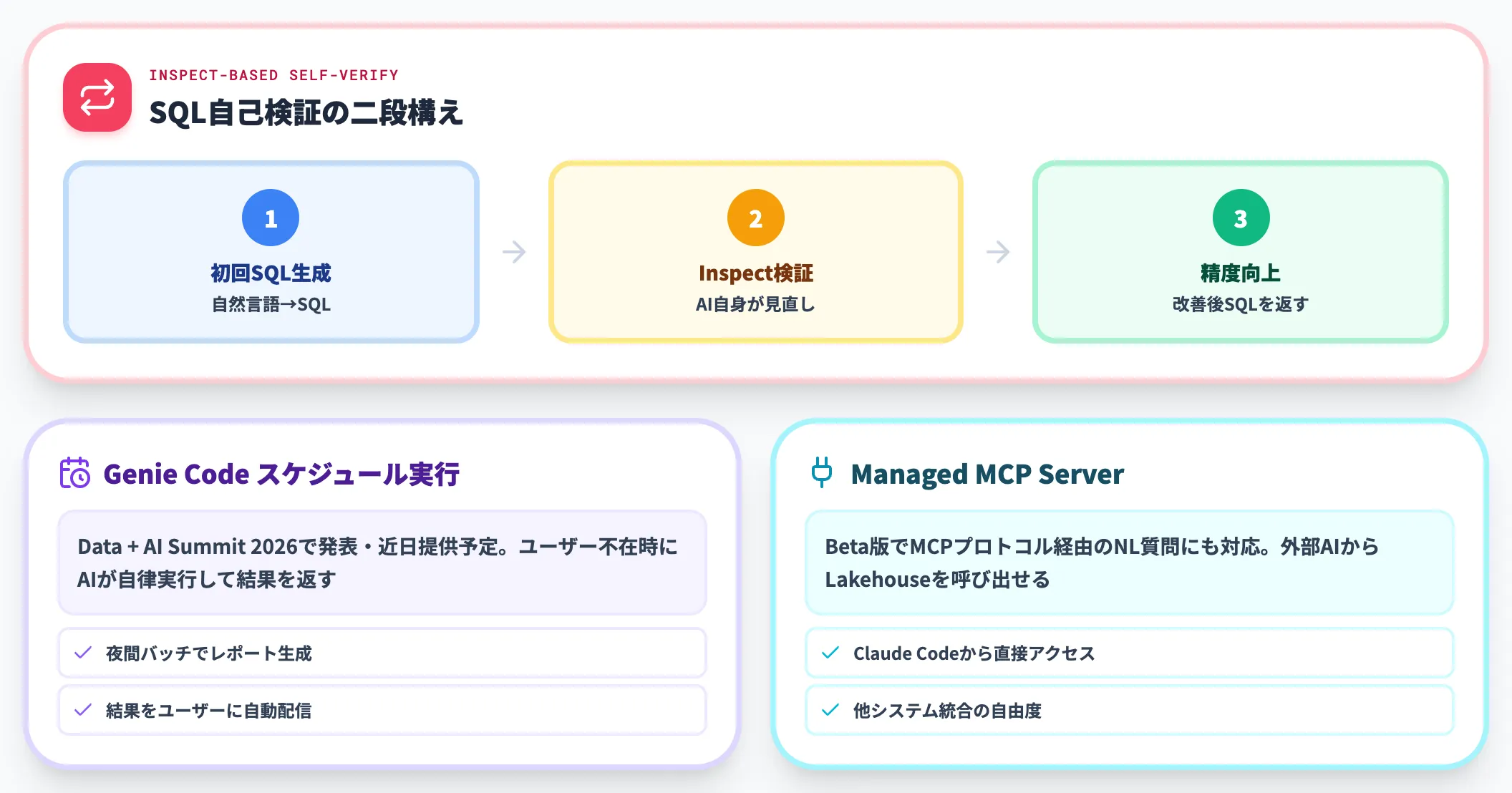
2026年は、Genie Codeのスケジュール実行がData + AI Summit 2026で発表され近日提供予定です。AIエージェントがユーザー不在時に自律実行して結果をユーザーに返す運用が描けるようになります。さらにManaged MCP Server(Beta)でMCPプロトコル経由のNL質問にも対応しています。
Inspect機能(Beta)は、Genieが最初に生成したSQLをAI自身が検証し直し、精度を改善する二段構えで、自然言語クエリの精度限界をカバーする設計です。
Snowflake Cortex Analyst——セマンティックモデル前提のNL→SQL
Snowflake Cortex Analystは、Snowflake内の構造化データに対して、自然言語からSQLを生成して回答する機能です。
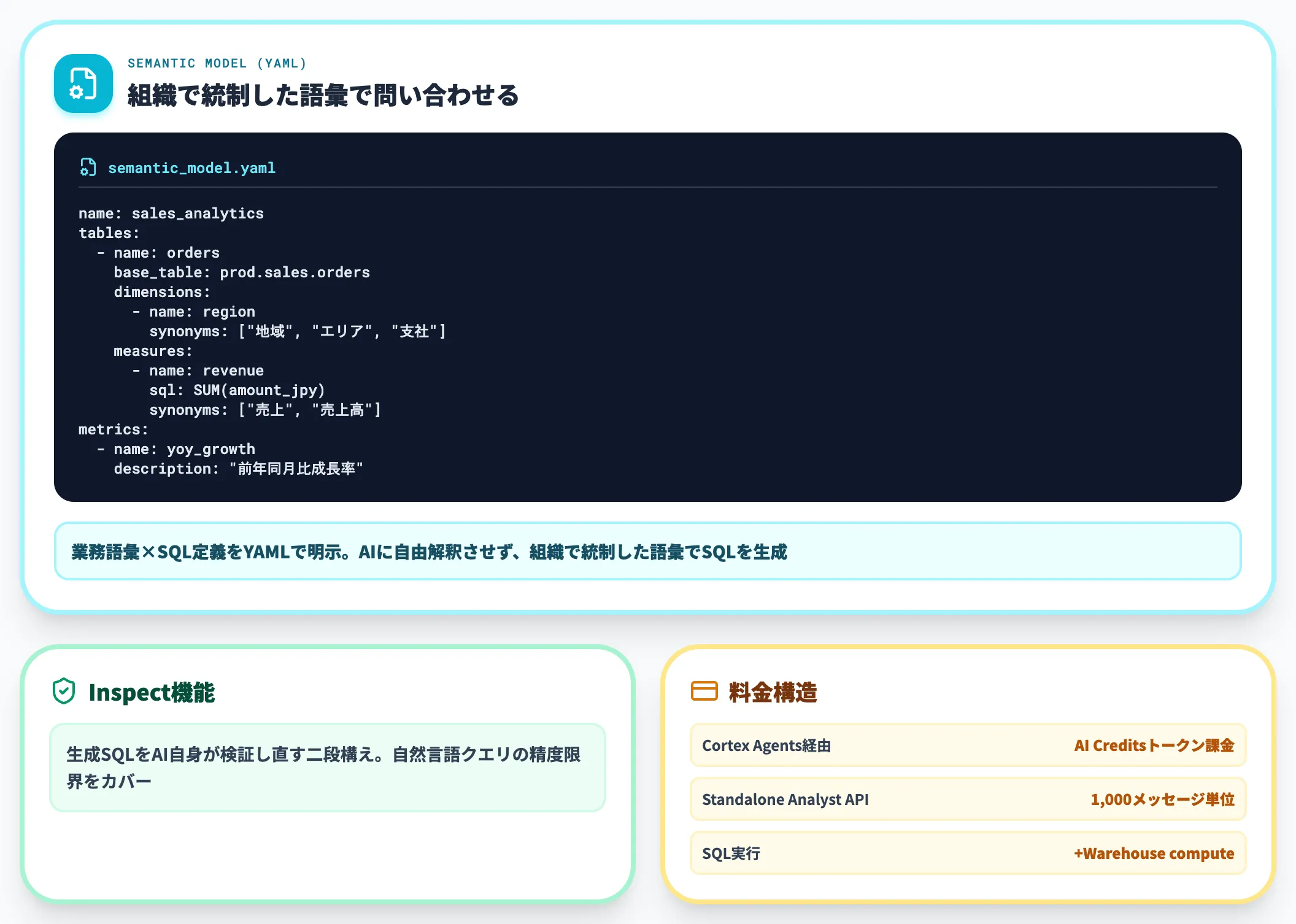
特徴は、組織で定義した「セマンティックモデル(YAML)」を介して問い合わせるため、業務語彙と指標定義をデータ基盤側で統制したうえでクエリを回せる点にあります。AIに自由解釈させず、意味の揺らぎを抑えたい組織向けの設計です。
料金は公式pricingに従い、Cortex Agents経由ならAI Creditsのトークン課金、Standalone Analyst APIなら1,000メッセージ単位での課金で、生成したSQLの実行には別途Warehouse computeが発生する構成です。詳細はSnowflakeの解説記事を参照ください。
Power BI Copilot——既存BI資産を活かす
Power BI Copilotは、既存のPower BIレポート・セマンティックモデルに対して、対話AIでレポート生成・要約・モデル修正ができる機能です。
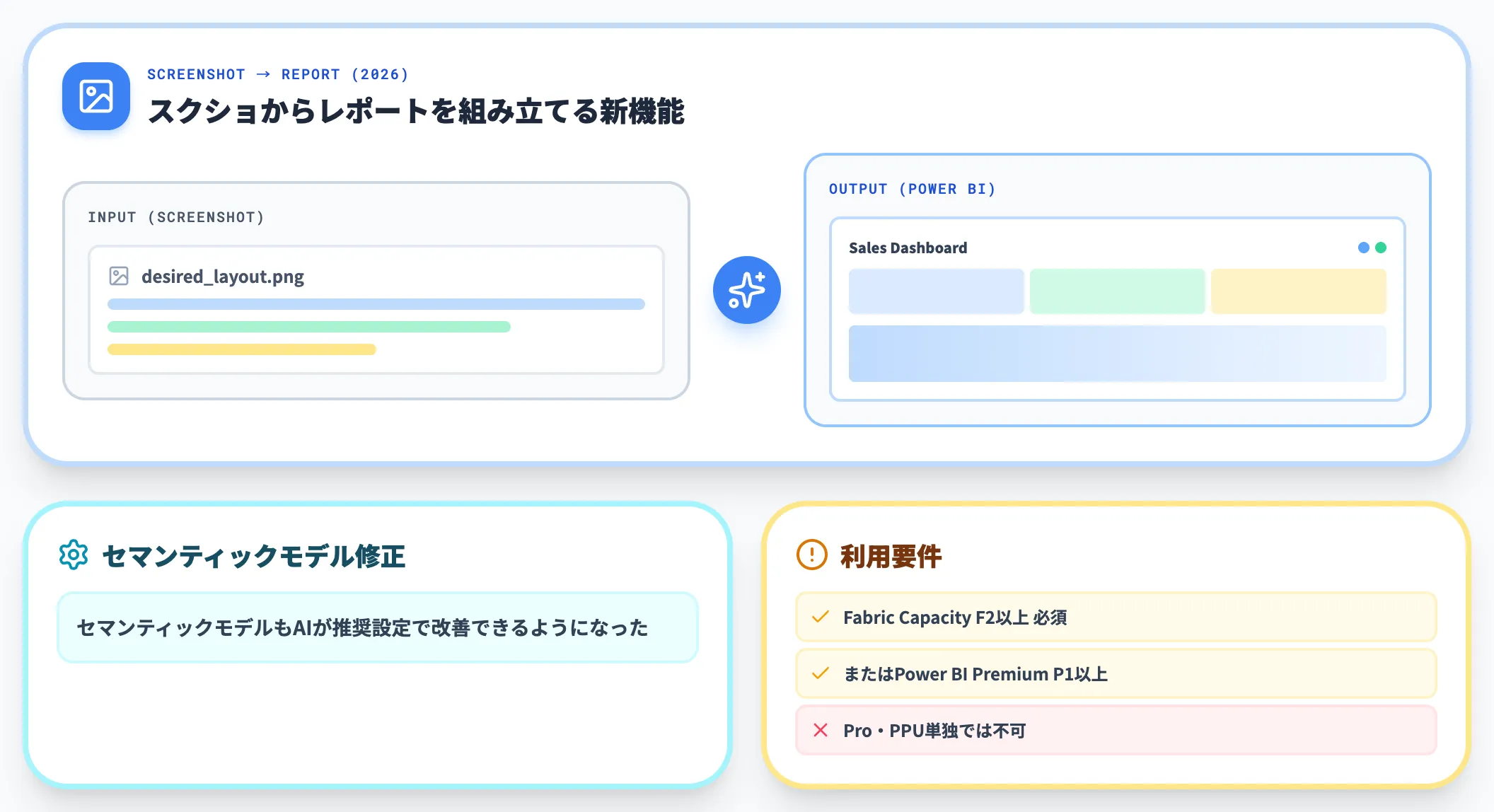
2026年の動きとして、自然言語だけでなく「欲しいレポートのスクリーンショット」を渡すとそれに沿ったレポートを組み立てる機能が追加され、セマンティックモデルもAIが推奨設定で改善できるようになりました。
利用要件として、Fabric Capacity F2以上、もしくはPower BI Premium P1以上が必要です。Power BI Pro・PPU単独では使えない点に注意してください。
Tableau Agent——ダッシュボード要約と提案
Salesforce TableauのTableau Agent(旧Einstein Copilot for Tableau)は、Tableau Cloud Web Authoring上で可視化作成や計算式生成を支援するAIアシスタントです。
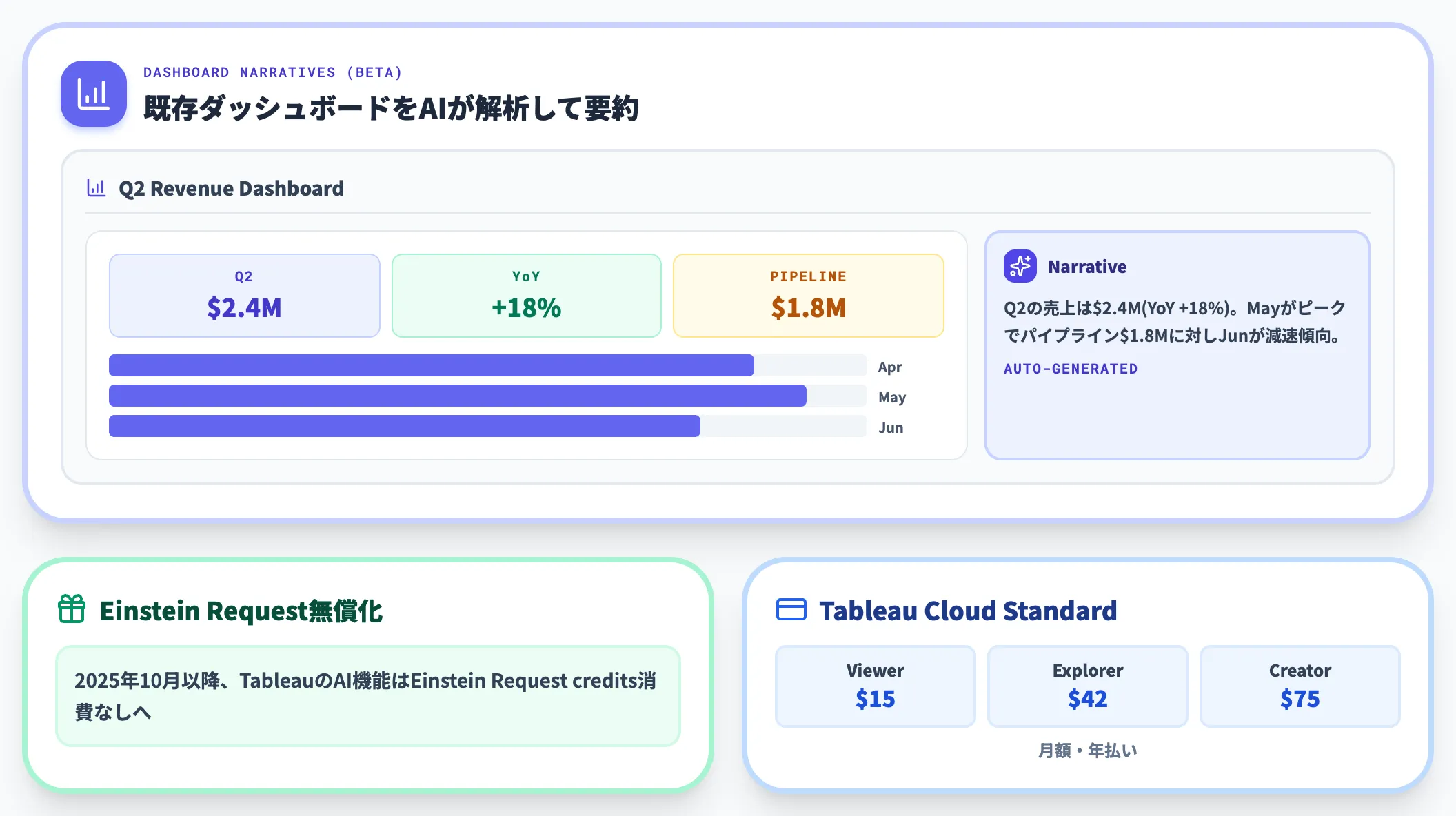
2026年2月からDashboard Narratives(Beta)が追加され、既存ダッシュボードをAIが解析して概要文・インサイト要約を自動生成するようになりました。さらに2025年10月以降、TableauのAI機能はEinstein Request creditsを消費しない無償化が進んでいます。
Tableau Cloud StandardはViewer 15ドル・Explorer 42ドル・Creator 75ドル/月(年払い)、Tableau+(Tableau Agent含む)は個別見積です。
Gemini in BigQuery——Google Cloud内のNL分析
Gemini in BigQueryは、BigQueryに格納したデータに対して、自然言語でSQL・Python生成、データキャンバスでのノーコード探索、マルチモーダル分析(PDF・画像・音声・動画)を提供します。
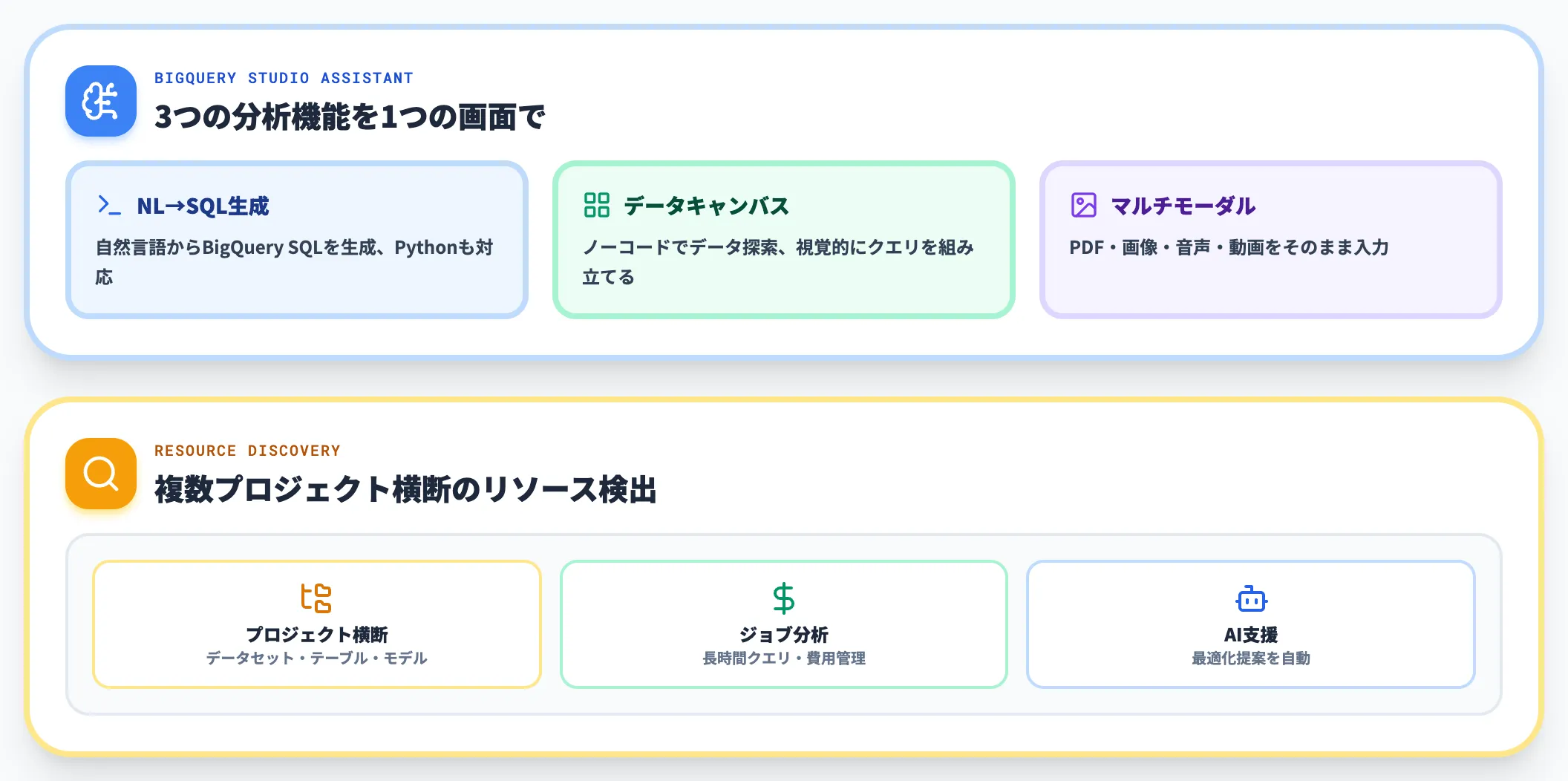
BigQuery Studioのアシスタントは、リソース検出機能で複数プロジェクトをまたいだデータセット・テーブル・モデルの検索ができるようになり、長時間クエリのジョブ分析・費用管理もAIが支援する設計に進化しています。
BigQueryの解説記事にデータウェアハウスとしての位置づけを整理しているので、料金感や他DWHとの比較はそちらを参照ください。
ここまで主要9ツールを見てきましたが、選定の前にもう一段押さえるべきは料金の構造です。次のセクションで整理します。

料金構造とコスト試算の3層整理
AI分析ツールの料金は、課金単位がツールごとに分かれており、月額サブスク・API従量・クレジット課金・容量課金が混在しています。
このセクションでは、コスト構造を3層に分けて整理し、典型的な利用規模ごとの試算を提示します。
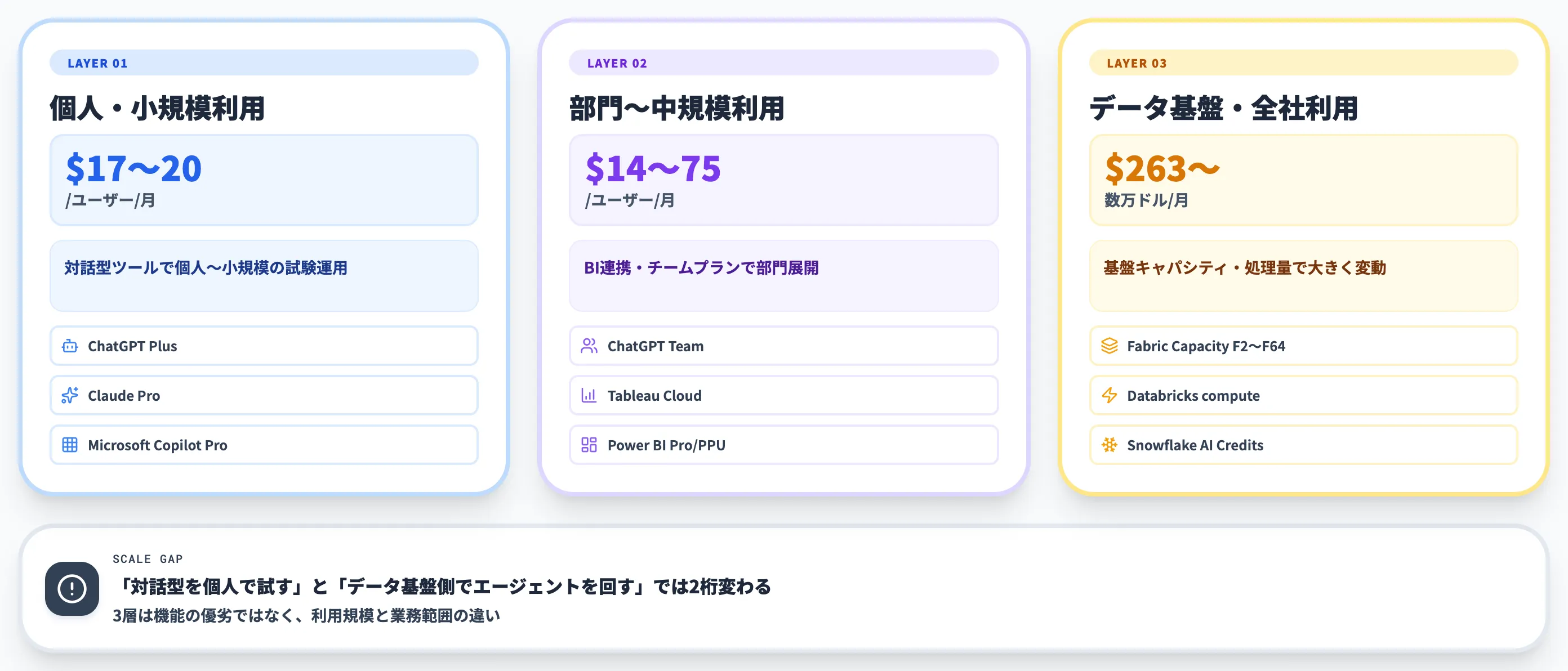
料金体系の3層構造
料金は、3層に分けて見ると把握しやすくなります。以下の表で、3層ごとの代表ツールと月額レンジを整理しました。
| 層 | 代表ツール | 月額レンジ |
|---|---|---|
| 個人・小規模利用 | ChatGPT Plus、Claude Pro、Microsoft Copilot Pro | 17〜20ドル/月 |
| 部門〜中規模利用 | ChatGPT Team、Tableau Cloud、Power BI Pro/PPU | 14〜75ドル/ユーザー/月 |
| データ基盤・全社利用 | Fabric Capacity、Databricks、Snowflake | 263ドル/月〜数万ドル/月 |
注意したいのは、この3層は機能の優劣ではなく、利用規模と業務範囲の違いを示している点です。「対話型を個人で試す」段階と「データ基盤側でエージェントを回す」段階では、必要なコストが2桁変わります。
個人・部門レベルの試算——月額20ドル前後で始められる
最も低コストなのは対話型ツール(ChatGPT・Claude・Copilot)で、個人プランなら月17〜20ドル、業務利用でも1ユーザーあたり月20〜30ドルから始められます。
例えば、ChatGPT Plus(月20ドル、年240ドル)で1人がCSV分析を回すなら、年間コストは3〜4万円程度です。BIツールのライセンスと比べても明らかに安く、PoCのコストを抑える観点では最有力です。
ただし、Excelで扱える数百万行を超えるデータや、組織横断でデータガバナンスを効かせたい場合、対話型単体では運用に乗りません。
データ基盤利用の試算——月額数十万円〜数千万円の幅
データ基盤型は、利用するキャパシティと処理量によって月額が大きく変動します。
Microsoft FabricのCapacityは、F2(約263ドル/月)から始まり、F4(中小企業の最小構成)で月6〜10万円、F64クラス(数千ユーザー利用)で約8,410ドル/月という幅広いレンジです。Snowflake Cortex AIは、AI Credits(トークン課金)・メッセージ単位課金・Warehouse computeの組み合わせで決まり、利用するLLMと処理量で月額が大きく変動します。
Databricksも同様にコンピュートとAI/BI機能の組み合わせで月額が決まり、Lakehouseの規模次第で数万ドルから数十万ドル/月のレンジになります。
ここから読み取れるのは、「データ基盤型」を選ぶ判断は、AI機能だけでなく、Lakehouse・データウェアハウス・データガバナンス全体への投資としての判断であるという点です。AI機能単体を見て選ぶと、コストインパクトを見誤ります。
BI連携型の単価感——既存BIライセンスの上乗せが軸
Power BI Copilotは、Power BI Pro(月14ドル)またはPPU(月24ドル)に加えて、Fabric Capacity F2以上(約263ドル/月)が必要です。
Tableau Cloudは、Viewer 15ドル・Explorer 42ドル・Creator 75ドル/月(年払い・Standard版)から始まり、Tableau+(Tableau Agentを含むエージェント型分析バンドル)は個別見積です。
BI連携型は「既にPower BIやTableauを業務で使っているか」が単価判断の起点になります。既存BIライセンスを持たない組織が新規でBI連携型を選ぶと、AIだけでなくBI全体のライセンス投資が必要になるため、対話型・データ基盤型と比べてコスト負担が重くなります。
隠れコストの読み解き——AI機能ライセンスだけ見るのは危険
本当のコストは、表面上のライセンス料だけでは見えません。実務でかかる「隠れコスト」を4項目で整理しておきます。

-
初期セットアップとデータ接続
データ基盤への接続、認証設定、データソース統合の構築工数
-
既存データの取り込み・前処理
データクレンジング、命名規則統一、メタデータ整備
-
担当者への教育・活用ガイド整備
プロンプト設計の研修、業務別の利用ガイド整備
-
運用ループのチューニング
出力品質のレビュー、誤検知対応、定期的なモデル再学習
これらは目に見えるライセンスコストと同等以上に大きくなることが多く、PoCの予算で見落としやすい部分です。後段の「AI分析を導入する前に確認すべき5つのこと」セクションでも繰り返し触れます。
業界別の活用事例|小売・製造・金融・コールセンター・人事
AIによる分析は、汎用LLMの普及で「自分の業界での具体例」が見えにくいまま導入検討が進みがちです。
このセクションでは、5業界の代表的な活用事例を、出典付きで整理します。「自社の業界でも応用できるか」の参考にしてください。
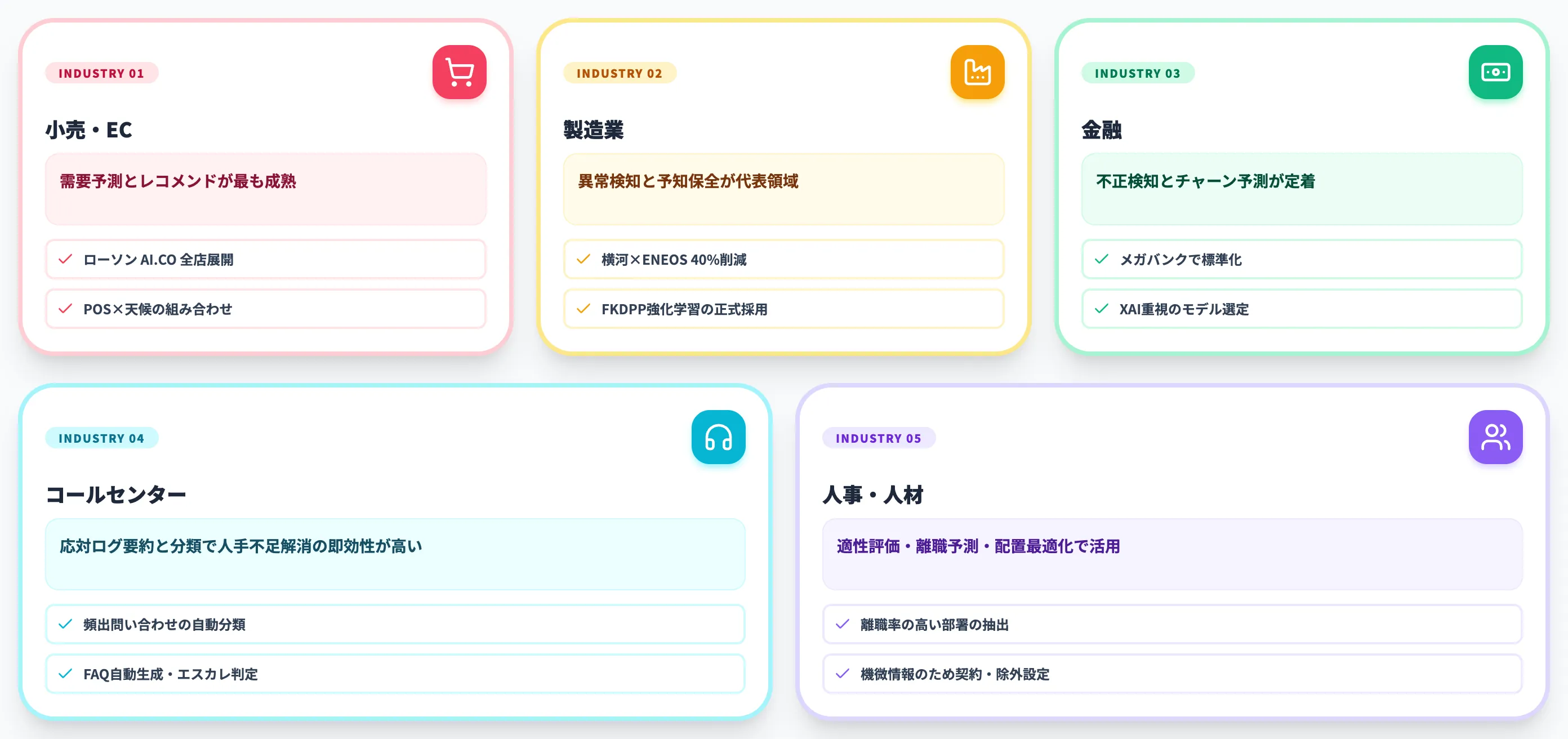
小売・EC——需要予測とレコメンド
小売・ECでは、POSデータ・会員データ・天候データなどを組み合わせた需要予測と、購買履歴に基づくレコメンドエンジンが最も成熟した適用先です。
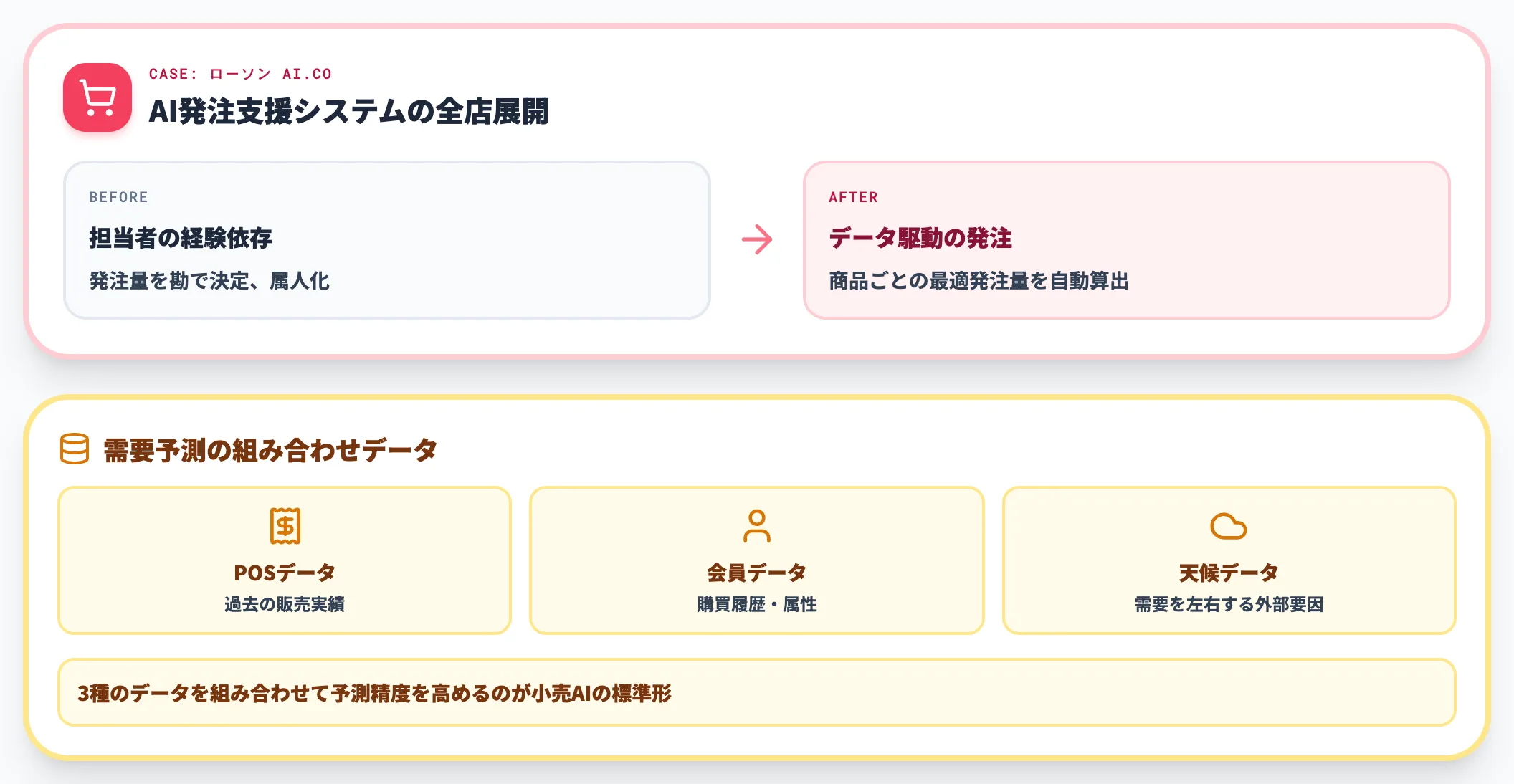
ローソンは、AIによる発注支援システム「AI.CO」を全店展開し、商品ごとの最適発注量を自動算出する仕組みを構築しています。担当者の経験に依存していた発注業務を、データ駆動の運用に切り替えた代表例です。
需要予測AIの各種アルゴリズム・導入事例については別記事でも整理しているので、詳細はそちらを参照ください。
製造業——異常検知と予知保全
製造業では、設備稼働データ・センサーデータをAIで継続監視し、異常の兆候を捉える「予知保全」が代表的な活用領域です。
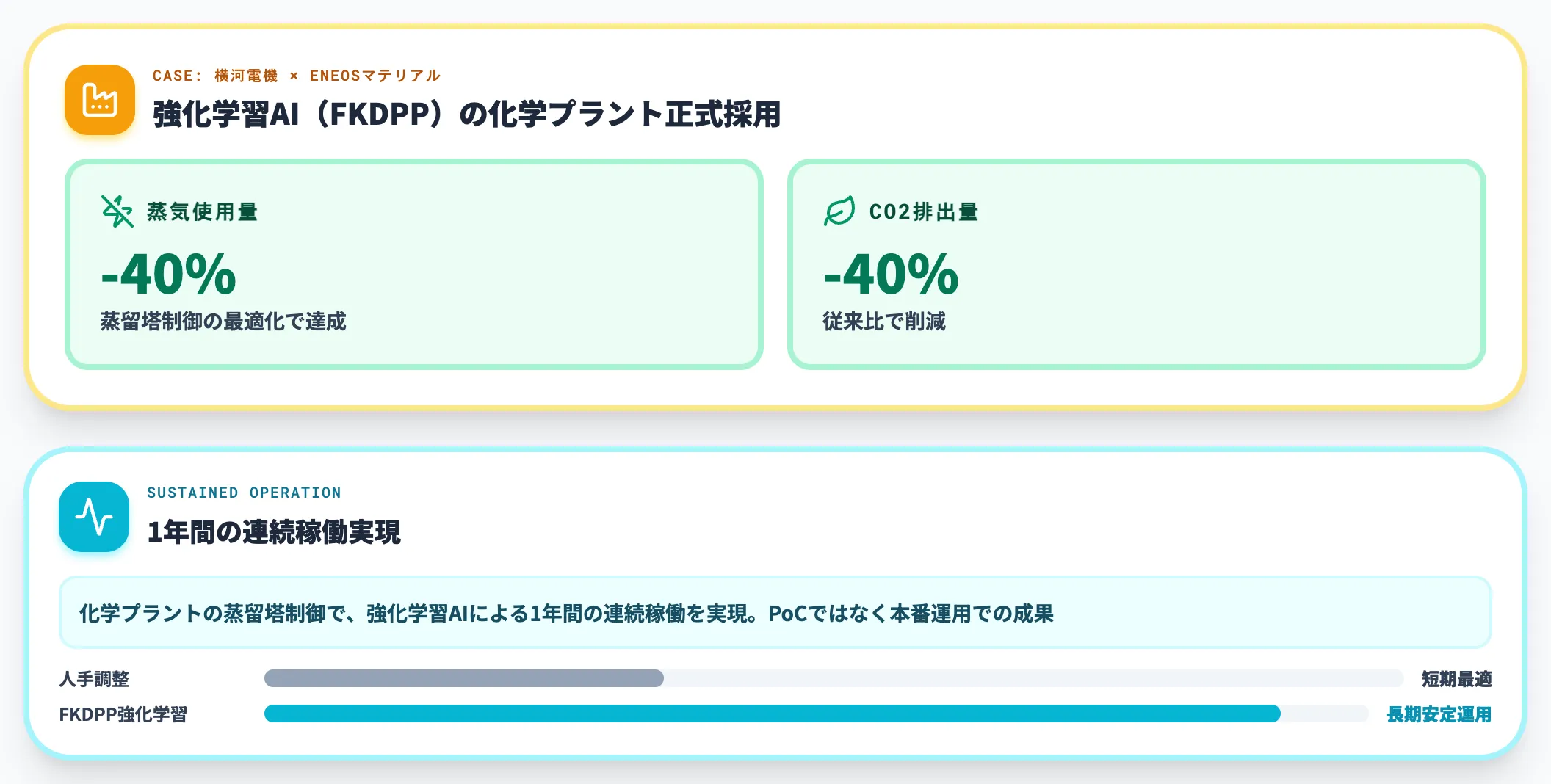
横河電機とENEOSマテリアルは、強化学習AI(FKDPP)の正式採用を発表し、化学プラントの蒸留塔制御で1年間の連続稼働を実現、蒸気使用量とCO2排出量を従来比約40%削減しました。
製造業AIの全体像と適用領域は製造業のAI活用事例20選に整理しています。
金融——不正検知とチャーン予測
金融業では、不正取引検知・クレジットスコアリング・解約予測(チャーン予測)にAIが広く使われています。
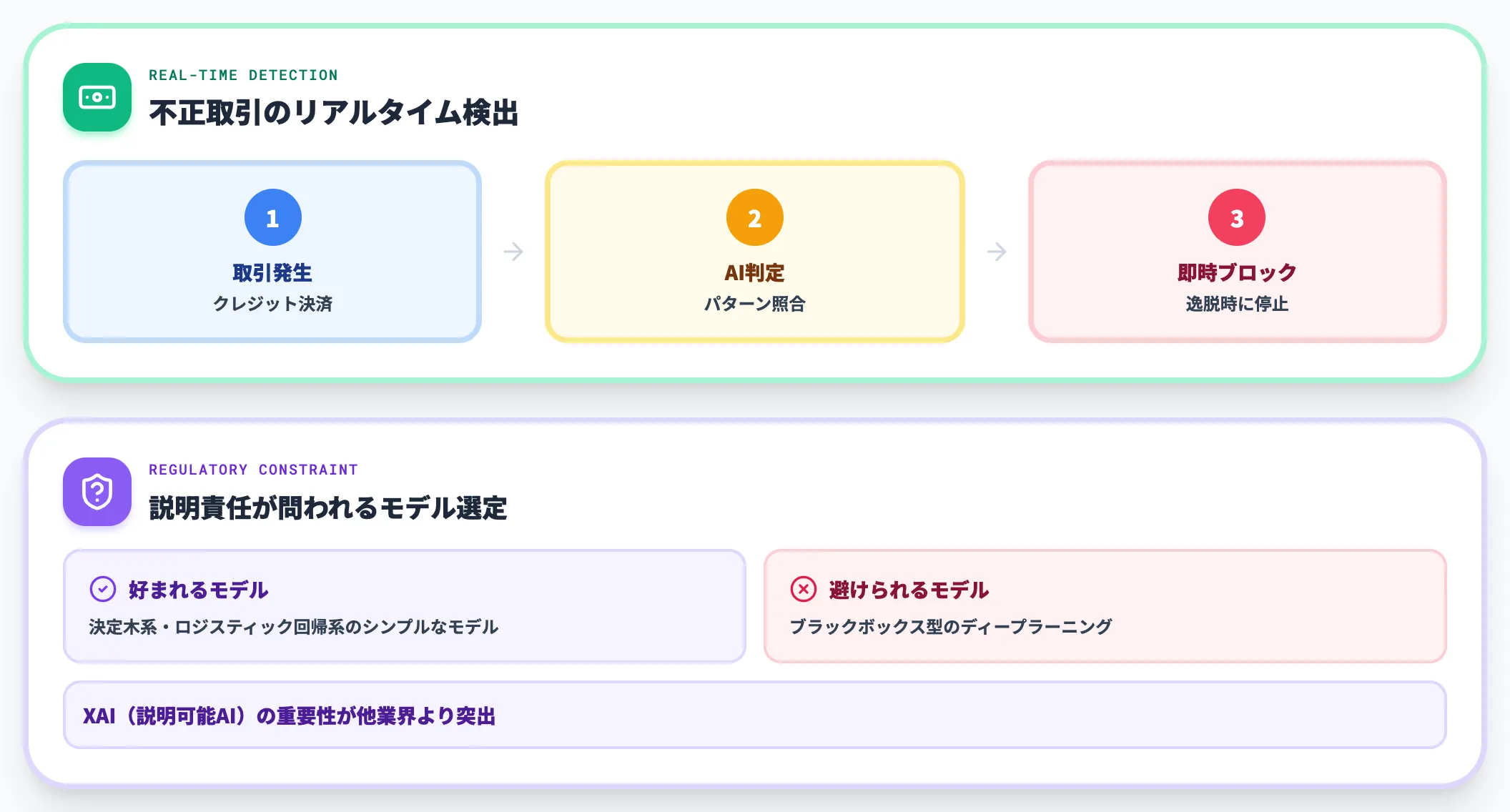
不正取引検知では、過去の取引パターンから逸脱した取引をリアルタイムで検出する仕組みが、メガバンク・カード会社で標準化されています。チャーン予測は、解約の予兆を捉えて事前にリテンション施策を打つ用途で、サブスクリプション事業を中心に普及しました。
金融分野は規制要件が厳しく、AIによる判断の説明責任(XAI)が問われるため、ブラックボックス型のディープラーニングよりも、決定木系・ロジスティック回帰系のシンプルなモデルが好まれる傾向があります。
コールセンター・カスタマーサポート
コールセンターは、AIによるデータ分析の効果が最も早く現れる領域の1つです。
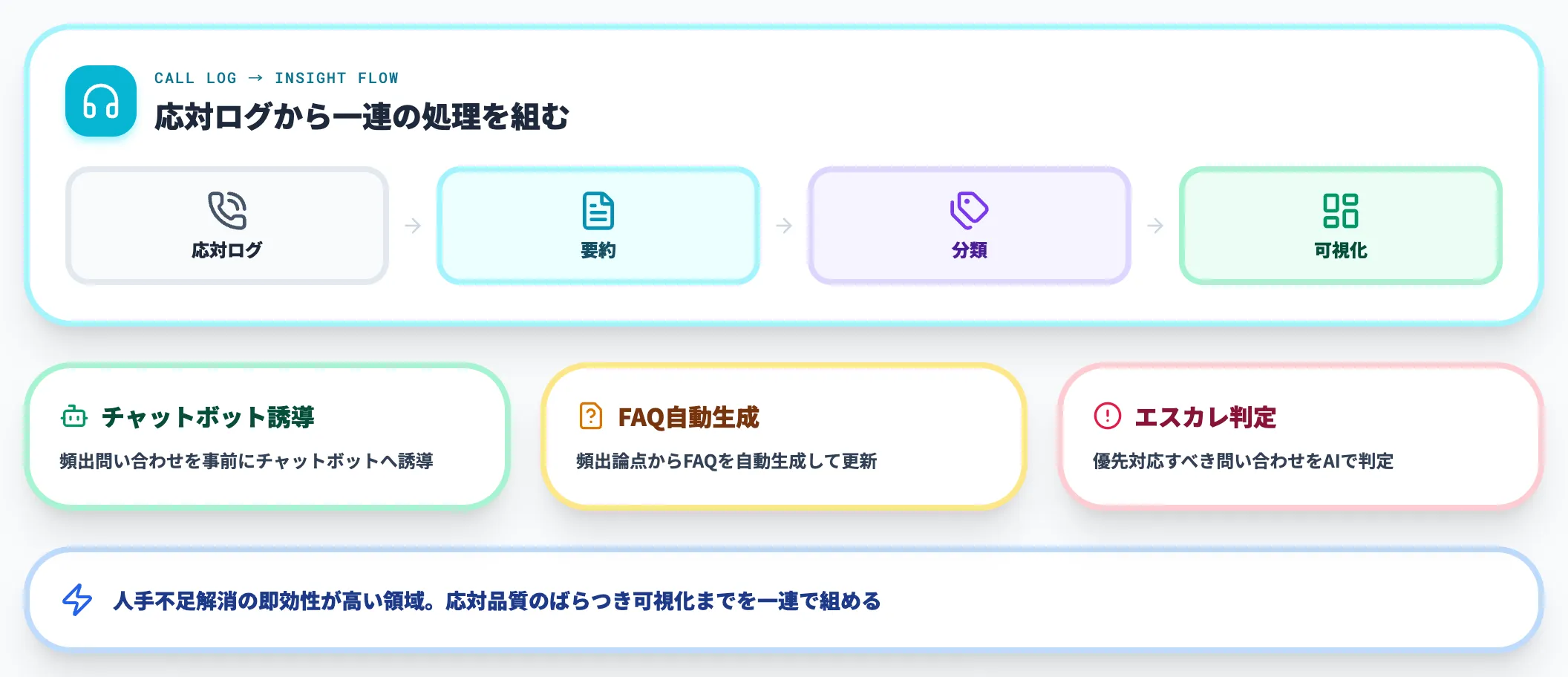
応対ログを生成AIで要約・分類すれば、頻出問い合わせのトピック分布や、応対品質のばらつきを即座に可視化できます。チャットボットへの誘導、FAQ自動生成、エスカレーション判定なども一連で組めるため、人手不足解消の即効性が高い領域です。
ChatGPTとExcel連携やスプレッドシート連携については、それぞれの記事で具体的な手順を解説しています。
人事・人材——適性評価と離職予測
人事領域では、応募者の適性評価、社員の離職リスク予測、評価データの分析、配置最適化などにAIが使われています。
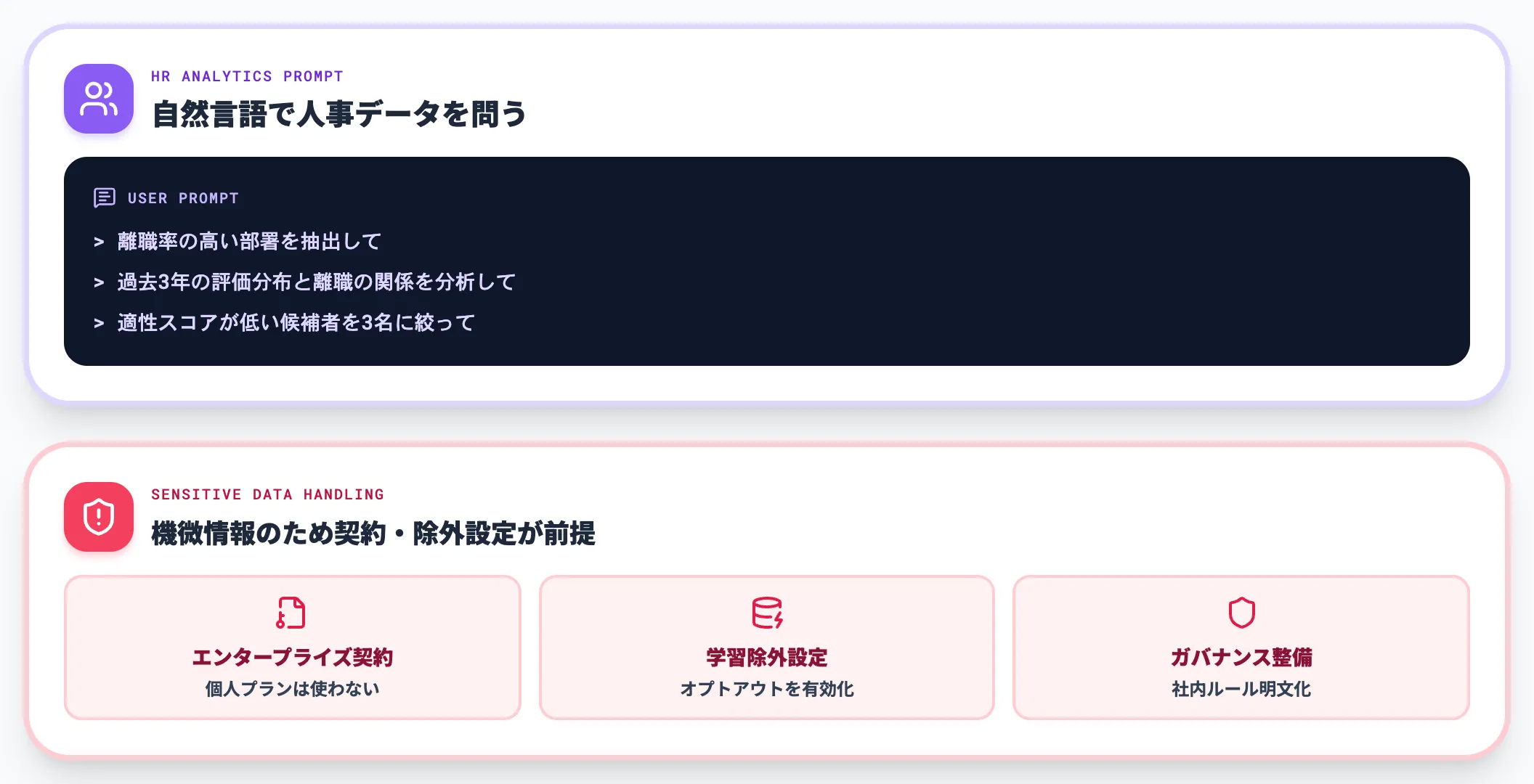
ChatGPTをデータ分析へ活用する方法で扱っているような、自然言語での集計・可視化は、人事領域でも有効です。「離職率の高い部署を抽出して」「過去3年の評価分布と離職の関係を分析して」のような問いをそのまま投げられます。
ただし人事データは個人情報・機微情報を含むため、エンタープライズ契約での運用、データ学習除外設定、社内のデータガバナンス整備が前提になります。
ここまで業界別の活用事例を見てきましたが、いざ自社で始めるとPoCの段階で詰まる論点が複数あります。次のセクションで、導入前に確認すべき5つのことを整理します。
AI分析を導入する前に確認すべき5つのこと
AI分析は、ツールがすぐ使えるぶん、導入前に論点を確認しておかないと本番運用に乗らないまま終わります。
since2020.jpの解説記事などでも整理されているように、現場で詰まる論点はパターン化できます。AI総研が支援している現場でも繰り返し議論になるのは、以下の5つです。
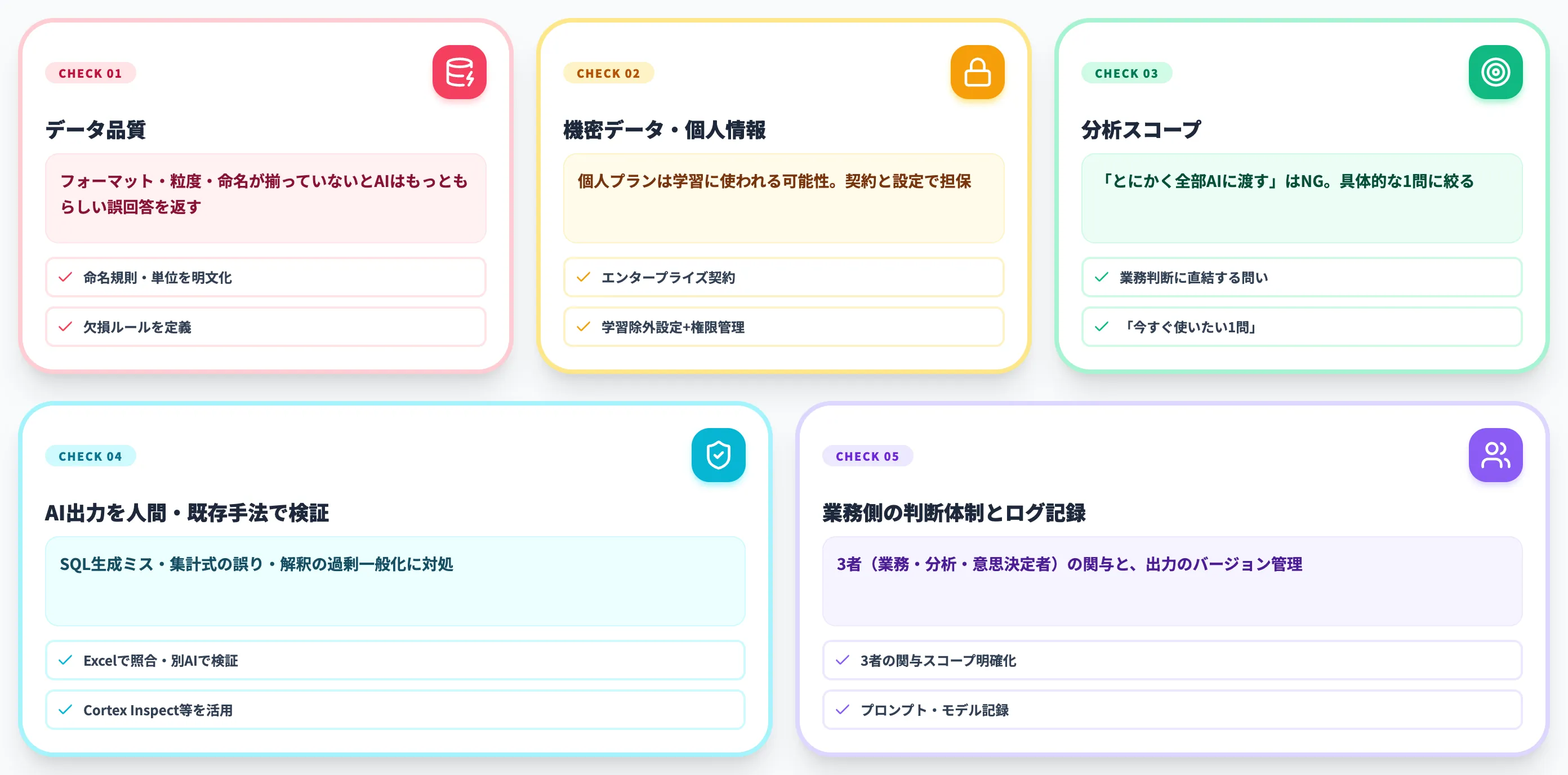
1. データ品質が確保されているか
最も多いのが、データのフォーマット・粒度・命名が揃っていないまま、AIに「分析して」と投げてしまうパターンです。
AIは入力データをそのまま信用するため、列名の揺らぎ・単位の混在・欠損値の扱い・重複が残っていると、もっともらしいが間違った結果を返します。出力テキストはきれいなので、現場で気付かれずに意思決定に乗ってしまう危険があります。
実務的には、PoC着手前に「対象データの命名規則・単位・欠損ルールを明文化したシート」を作り、それに沿ってデータを整えてから分析に投入することが、最も投資対効果の高い前処理になります。
2. 機密データ・個人情報の取扱いが契約と設定で担保されているか
意外と見落とされがちなのが、機密データ・個人情報をAIにそのまま渡してしまうリスクです。
ChatGPT・Claudeの個人プランは、デフォルトで入力データを学習に利用する設定になっているケースがあり、業務の機密データを投げると外部のモデル学習に組み込まれる可能性があります。営業データや顧客リスト、人事評価データなどをそのままアップロードして本番運用に乗せると、後から契約・設定のミスとして問題化します。
導入前に確認すべきは、(1) エンタープライズ契約・ビジネスプランへの切り替え、(2) データ学習除外(オプトアウト)設定の有効化、(3) 社内のアクセス権限管理、(4) アップロード可能なデータ種別の社内ルール化、の4点です。データ基盤型(Microsoft Fabric・Databricks・Snowflake)はデータが基盤側の権限・ガバナンスと連携しやすい設計で、機密データを扱う場面では検討に上がりやすくなります。ただしMicrosoft Fabric data agentのMicrosoft 365 Copilot連携・Copilot Studio連携では応答処理がFabricのコンプライアンス境界・地理的リージョン外で扱われる可能性があるため、本番投入時は処理境界・リージョン・ライセンス条件を公式ドキュメントで確認してください。
実務的には、PoCの最初の段階で「何のデータをAIに渡していいか」を法務・情報セキュリティ部門と握っておくと、本番投入時に手戻りが発生しません。
3. 分析スコープが具体的に絞られているか
「とにかくデータを全部AIに渡して何かインサイトをもらおう」というスコープ設計は、十中八九うまくいきません。
AIは指示の範囲で出力を返すため、問いが広いと一般論しか返ってきません。「先月の売上を地域別に出し、前年同月比で異常な動きをしている地域を3つ抽出する」のように、問いの粒度を具体的にすることで初めて、AIの強みが業務判断に効きます。
実務的には、PoCの最初の問いを「業務担当者が今すぐ意思決定に使いたい1問」に絞り込むことが、スコープ設計の出発点になります。
4. AI出力を人間・既存手法で検証するプロセスがあるか
生成AIは、自信ありげに事実誤認の出力を返すことがあります。データ分析の文脈でも、SQL生成ミス、集計式の誤り、解釈テキストの過剰一般化など、複数の形で発生します。
Cortex AnalystのInspect機能やGenieのSQL検証ステップは、まさにこの問題への対処として組み込まれています。出力されたSQL・集計値を別の経路(Excel・元データ直接確認)でクロスチェックする運用は、PoC段階から必須です。
「AIが出した結果を、AI抜きで再検証できる仕組み」を運用に組み込めないなら、本番投入は早すぎる判断です。
5. 業務側の判断体制とログ記録の仕組みが整っているか
PoC段階で見落とされがちなのが、AI出力を受け取って業務判断する側の体制と、後から再現するためのログ記録の仕組みです。
AIが分析結果を返しても、それを読んで判断する人がいない、判断ルールが定義されていない、判断結果を業務システムに反映するフローがない、という状態では「分析しただけ」で終わります。業務担当者(現場)・分析担当者(IT)・意思決定者(経営層)の3者の関与スコープを、PoCの計画段階で明確にしておくのが現実的です。
加えて、AIの出力は同じ問いでも実行のたびに微妙に揺らぐ確率的性質があります。経営層・規制対応・監査用途で使う場合は、「なぜこの結論に至ったか」を後から再現・説明できる必要があります。プロンプト・モデル・入力データを記録し、出力もバージョン管理する仕組みを、PoC段階から組み込んでおくと運用フェーズでの揉めごとを防げます。
技術PoCと業務PoCを切り分けず、判断体制とログ記録の両方を回すことが本番運用への近道です。
これら5つの確認事項は、AI総研の支援現場でも繰り返し議論になる論点です。ツールを選ぶ前に、これらの観点を導入計画に明文化しておくと、後の手戻りが大幅に減ります。
ケース別のツール選定指針
ここまでで「進め方」「できること」「ツール」「料金」「事例」「導入前確認」を見てきました。最後に、組織の状況別に第一候補となるツールを整理します。
ツール選定は単一の答えではなく、組織の手元データの規模・既存資産・分析リテラシーの組み合わせで決まります。
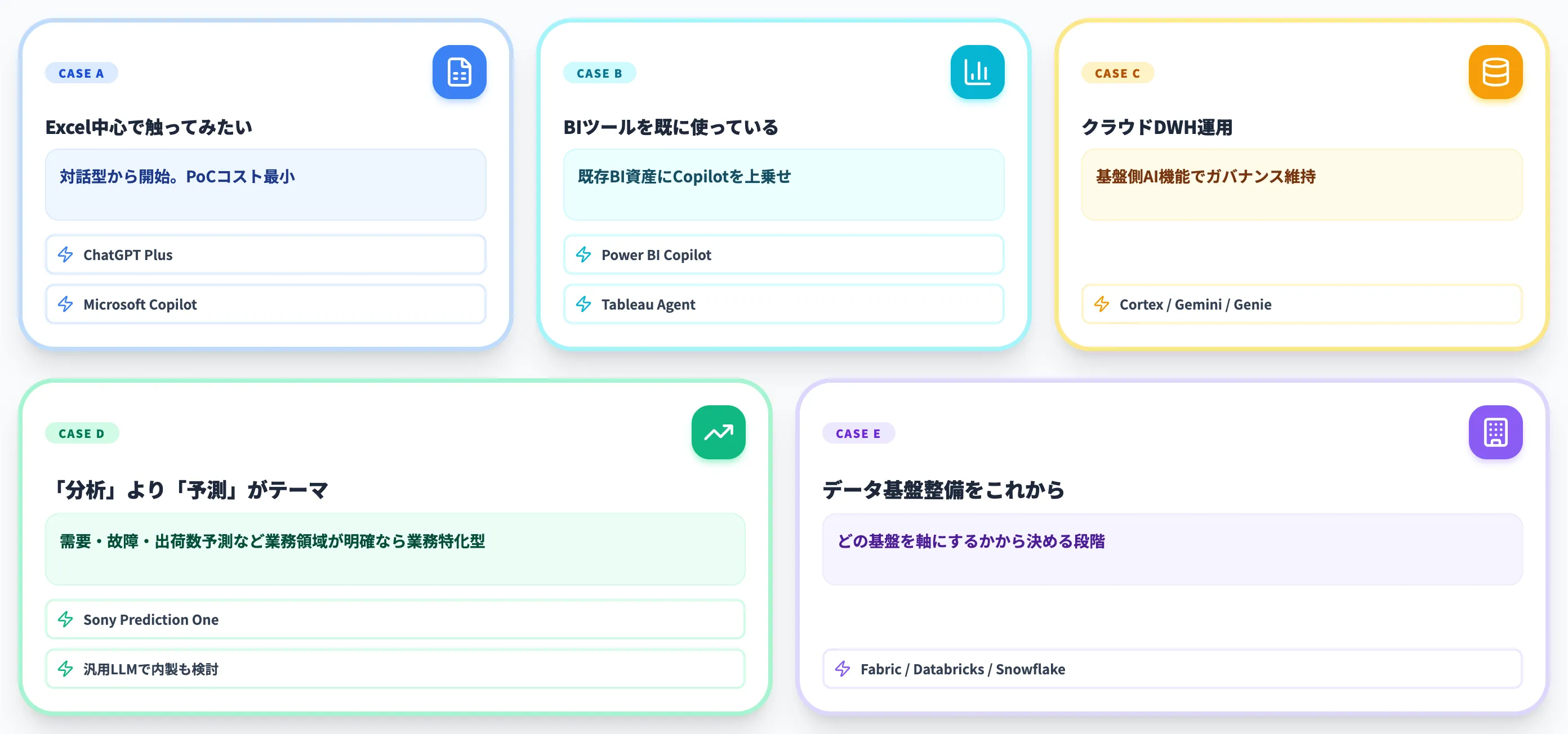
ケースA: Excel中心の業務、まず触ってみたい
Excelで業務を回している段階で、「データはあるが分析の入口が見えない」状態なら、対話型のChatGPT Plus or Microsoft Copilotから始めるのが現実的です。
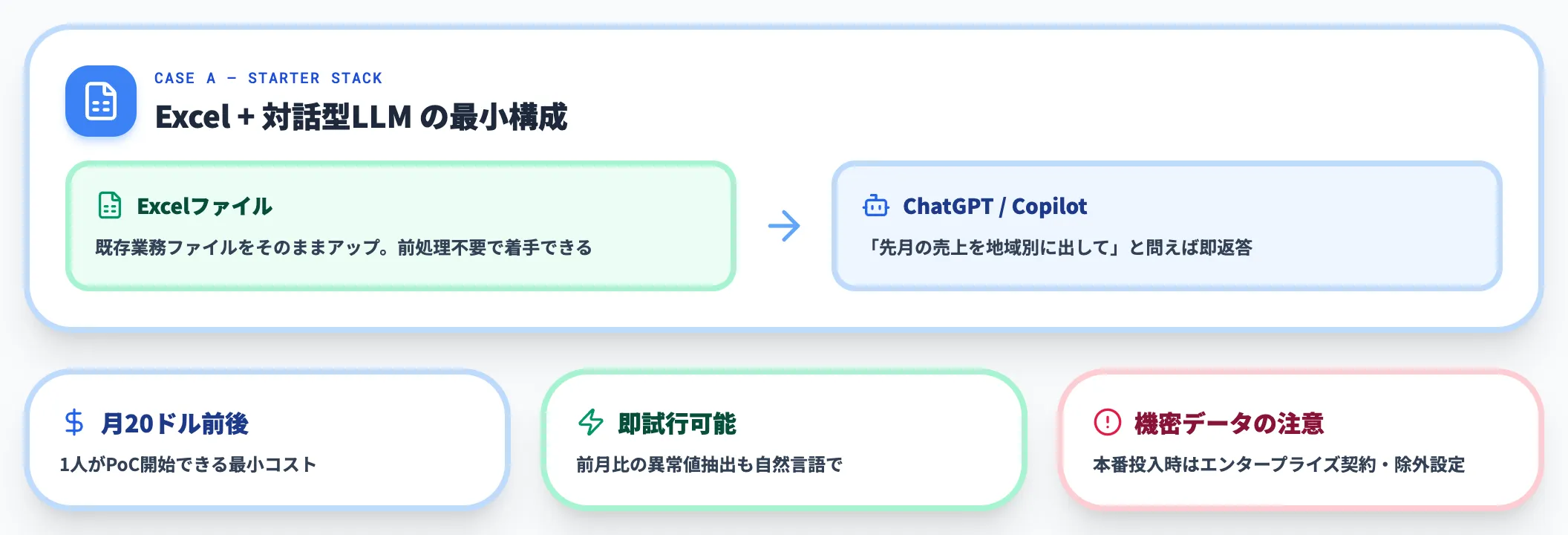
Excelファイルをそのままアップロードして「先月の売上を地域別に出して」「前月比の異常値を抽出して」と問えば、その場で分析結果が返ってきます。月20ドル前後で1人が始められるため、PoCコストが最小です。
機密データを扱う段階では、エンタープライズ契約への移行とデータ学習除外設定が前提になります。
ケースB: BIツールを既に使っている
Power BI・Tableau・Lookerなどで既にダッシュボード文化がある組織は、Power BI Copilot or Tableau Agentから入るのが筋です。

既存BI資産を活かしたまま、レポート作成・要約・自然言語クエリを上乗せできます。Power BI CopilotはMicrosoft 365との統合が強く、Tableau AgentはSalesforce CRMとの連携が強みです。
Power BI Copilotの利用には、Fabric Capacity F2以上が必要な点を忘れずに見積もりに入れてください。
ケースC: クラウドデータウェアハウスを運用している
Snowflake・BigQuery・Databricksを既に運用しているなら、Cortex Analyst・Gemini in BigQuery・AI/BI Genieのどれかに寄せるのが自然です。
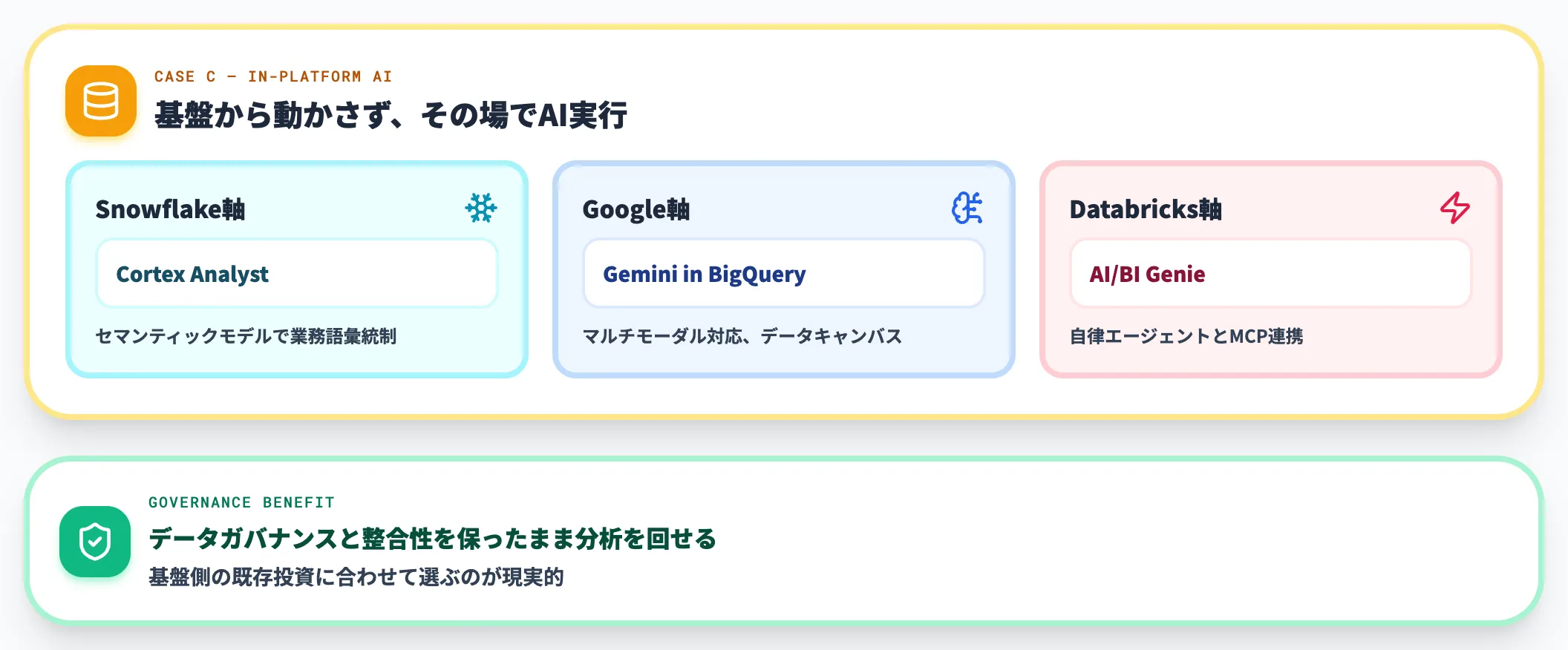
データを基盤から動かさず、その場で自然言語クエリ・エージェント実行ができるため、データガバナンスと整合性を保ったまま分析を回せます。
Cortex Analystはセマンティックモデルでの統制が強く、Gemini in BigQueryはマルチモーダル対応、Genieは自律エージェントとMCP連携が強みです。基盤側の既存投資に合わせて選ぶのが現実的です。
ケースD: 製造業・流通業など「分析」より「予測」がテーマ
需要予測・故障予測・出荷数予測など、業務領域が明確な予測タスクが中心なら、Sony Network Communicationsの「Prediction One」のような業務特化型を検討する価値があります。
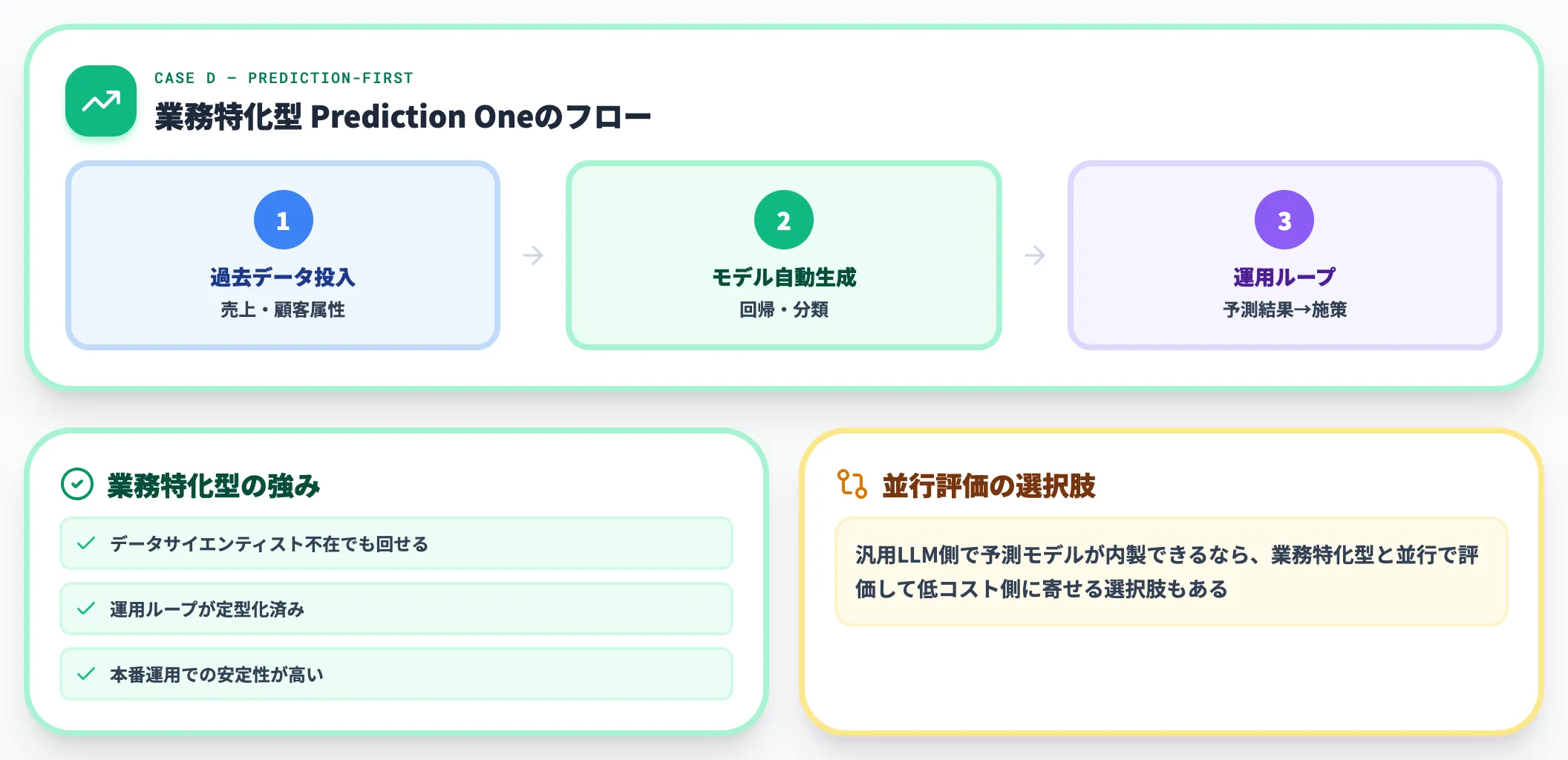
データサイエンティスト不在でも、過去データを与えれば予測モデルを自動生成できる設計で、汎用LLMで作る予測モデルよりも安定運用に向きます。
ただし、汎用LLM側で予測モデルが内製できるなら、業務特化型と並行で評価して低コスト側に寄せる選択肢もあります。
ケースE: 全社的なデータ基盤整備をこれから始める
「これからデータ基盤を整える」段階の組織は、Microsoft Fabric or Databricks or Snowflakeのどれを軸にするかから決める必要があります。

3つの基盤の特徴は、Microsoft Fabric、Databricks、Snowflakeの各記事で解説しています。
実務的な使い分けとしては、Microsoft 365との統合を最優先するならFabric、Pythonデータサイエンスを多用するならDatabricks、データウェアハウスのガバナンス重視ならSnowflakeが第一候補に挙がります。
ここから読み取れるのは、「AIを使ったデータ分析」のツール選定は、AI機能だけで決まらず、組織のデータ基盤戦略の延長線上で決まるという点です。AI機能単体でのベンチマーク比較は、参考にとどめるのが安全です。

AI分析を業務に定着させる
ここまで、AI分析の全体像、進め方5ステップ、できること、ツール類型と主要9種、料金、業界別事例、導入前に確認すべき5つのこと、ケース別の選定指針を整理してきました。
実務で見てきた範囲では、ツール選定よりも前段の「業務側の体制設計」と「PoCの設計」で勝負が決まるケースが大半です。技術PoCだけが先行しても、業務側がAIの出力を受け止める準備ができていないと、本番投入には到底届きません。
AI総合研究所では、AI活用のPoCから全社展開までの設計、部門別ユースケース、運用統制やセキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。データ分析へのAI導入計画を組み立てる際の出発点として活用ください。
AI分析を業務に定着させる

生成AIの業務活用を体系的に学べるガイド
AI分析を試行で終わらせず業務に組み込むには、PoCの設計・部門別ユースケース・運用統制までを一通り押さえる必要があります。AI総合研究所では、生成AIを業務に定着させるための実践手順を220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。
まとめ
本記事では、AIを使ったデータ分析の進め方を、全体像・5ステップの実務フロー・できること・ツール類型・主要9ツール・料金・業界事例・導入前に確認すべき5つのこと・ケース別選定指針まで2026年6月時点の最新情報で解説しました。要点を改めて整理します。
-
AIによる分析は2026年に「専門家がPythonで回す高度業務」から「現場担当者が自然言語で投げる日常業務」へ大きく軸が動いた。汎用LLMとデータ基盤の両側からの進化が同時に進んだことが背景にある
-
できることは「自然言語クエリ」「自動可視化」「予測」「異常検知」「要約とインサイト生成」の5カテゴリに整理できる。ツールごとに強い領域が分かれており、すべてを1ツールで賄うのは非現実的
-
主要ツールは「BI連携型」「対話型」「業務特化型」「データ基盤型」の4類型に分類でき、組織の手元データ規模と業務文脈で起点ツールを選ぶ。対話型は月20ドル前後で始められ、データ基盤型は月263ドル〜数千ドルのレンジになる
-
業界別の活用事例は、小売の需要予測、製造業の予知保全、金融の不正検知とチャーン予測、コールセンターの応対分析、人事の離職予測など、領域は広がっている。出典付きの公式導入事例を参考に、自社の業界での応用余地を見極める価値がある
-
PoCで詰まる典型論点は「データ品質」「分析スコープ」「ハルシネーション」「業務側体制」「再現性と説明責任」の5つ。ツール選定より前段のPoC設計で勝負が決まるため、技術PoCと業務PoCを切り分けず両方回すことが本番運用への近道
AIによる分析は、もはや「いつ始めるか」を議論する段階ではなく、「どう業務に定着させるか」を設計する段階に入りました。
まずはケース別の選定指針に沿って手元の業務に最も合うツールを1つ選び、データ品質と分析スコープを整えた最小限のPoCから着手するのが、最も投資対効果の高い第一歩になります。










