この記事のポイント
 マルチクラウド前提でAIエージェントにデータを使わせたいなら、Cross-Cloud Lakehouseを軸にAgentic Data Cloudが第一候補
マルチクラウド前提でAIエージェントにデータを使わせたいなら、Cross-Cloud Lakehouseを軸にAgentic Data Cloudが第一候補- Knowledge Catalogでビジネス意味を一元化することが、エージェントの誤判断(ハルシネーション)を抑える前提条件
- Data Agent KitはVS Code・Claude Code・Gemini CLI・Codexから呼び出せるため、開発フローを変えずに導入できる
- Microsoft Fabric比の差別化はCross-Cloud Lakehouse(AWS/Azure上Iceberg直接分析)とIceberg標準化
- Preview機能が多数含まれるため、本番投入は対象機能のGA/Preview状況を四半期ごとに棚卸しして判断するのが安全

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Agentic Data Cloudは、Googleが2026年4月のCloud Next 2026で発表した、AIエージェントを前提に再設計したデータ基盤の総称です。
BigQueryやAlloyDB、Spanner、Lookerといった既存サービスを「人間がクエリする場所」から「エージェントが行動する基盤」へと進化させ、Cross-Cloud Lakehouse(Preview)によってAWS・AzureのIcebergデータもBigQueryから分析できる構成にも対応します。
本記事では、3本柱(Knowledge Catalog/Cross-Cloud Lakehouse/Data Agent Kit)の仕組み、Data Engineering Agentなど主要エージェントの役割、Microsoft Fabric・Snowflake・Databricksとの違い、料金体系、Vodafone・Virgin Voyages・American Expressの導入事例までを2026年最新情報で体系的に整理します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
目次
Agentic Data Cloudが目指す「System of Action」
【Cross-Cloud Lakehouse】AWS/Azureを跨ぐデータ層
【Data Agent Kit】エージェント開発の共通ツール群
Agentic Data Cloudを支えるデータエージェント
Database Observability Agent(Preview)
Agentic Data Cloud vs 主要データ基盤の比較
Virgin Voyages:1,000以上の特化エージェント
American Express:オンプレDWHのBigQuery移行
Agentic Data Cloudとは?
Agentic Data Cloud(エージェンティック データ クラウド)は、Googleが2026年4月のCloud Next 2026で発表した、AIエージェントを主役に据えて再設計したデータ基盤の総称です。
BigQuery・AlloyDB・Spanner・Cloud SQL・Lookerといった既存のデータサービスを、共通のコンテキスト層・クロスクラウド層・エージェントツール層で束ね、「人間がクエリする場所」から「エージェントが業務を実行する基盤」へと進化させることを狙っています。
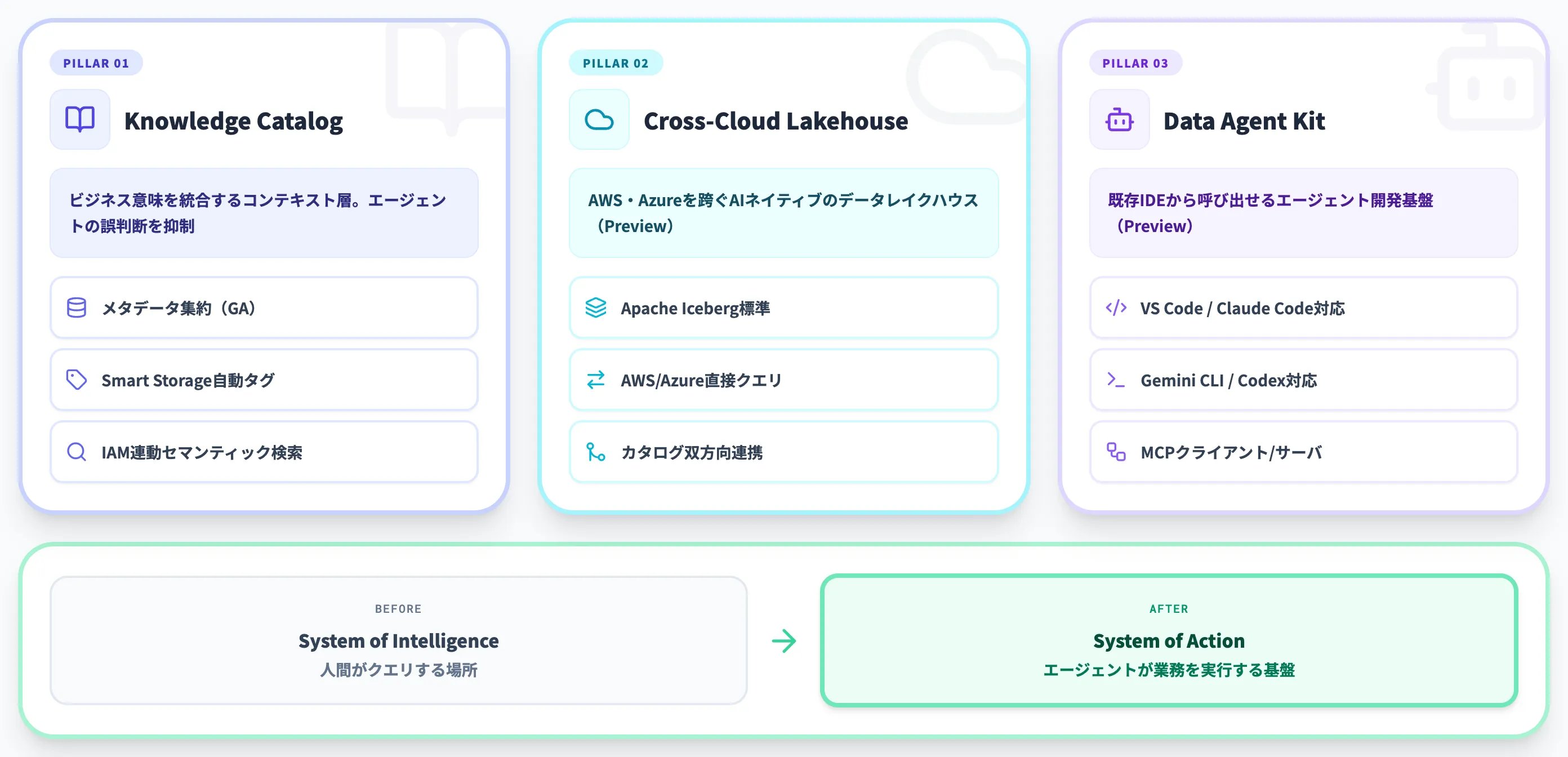
Agentic Data Cloudは、単独の新製品ではなく、以下3つの基盤をまとめたアーキテクチャ概念です。
- Knowledge Catalog(ビジネス意味を統合するコンテキスト層)
- Cross-Cloud Lakehouse(AWS/Azureを跨ぐAIネイティブのデータレイクハウス)
- Data Agent Kit(Preview/VS Code・Claude Code・Gemini CLIなどから呼び出せるエージェント開発基盤)
エージェントが業務を担うようになると、「どのデータが信頼できるのか」「クラウドを跨いだ問い合わせができるのか」「エージェントが安全に書き戻せるのか」が新しい論点になります。
Agentic Data Cloudは、こうしたエージェント時代特有の要件に応える再構成と位置づけられます。

Agentic Data Cloudが目指す「System of Action」

従来のデータ基盤は、人間のアナリストやBIユーザーが「質問する場所」として設計されてきました。
一方、AIエージェントは24時間自律的にデータへアクセスし、判断し、外部システムに書き戻す「行動する利用者」です。
GoogleはAgentic Data Cloudを、思考と実行のギャップを埋める基盤と位置づけています。
具体的には、エージェントが業務文脈を理解するための意味モデル、クラウドを跨ぐデータアクセス、開発者が使い慣れたIDEからエージェントを設計できるツール群を一体で提供することで、「データを眺めるだけ」のシステムを「データに基づいて動くシステム」に転換する設計です。
Google Cloud公式ブログ「BigQuery for the agentic era」では、Geminiで処理されるBigQueryデータが30倍、AI関数による非構造化データ処理が25倍、MCPを使ったエージェント構築ツール利用が20倍に急増したと報告されており、エージェント時代に向けたシフトが急速に進んでいることがわかります。
既存のGoogle Cloudサービスとの関係
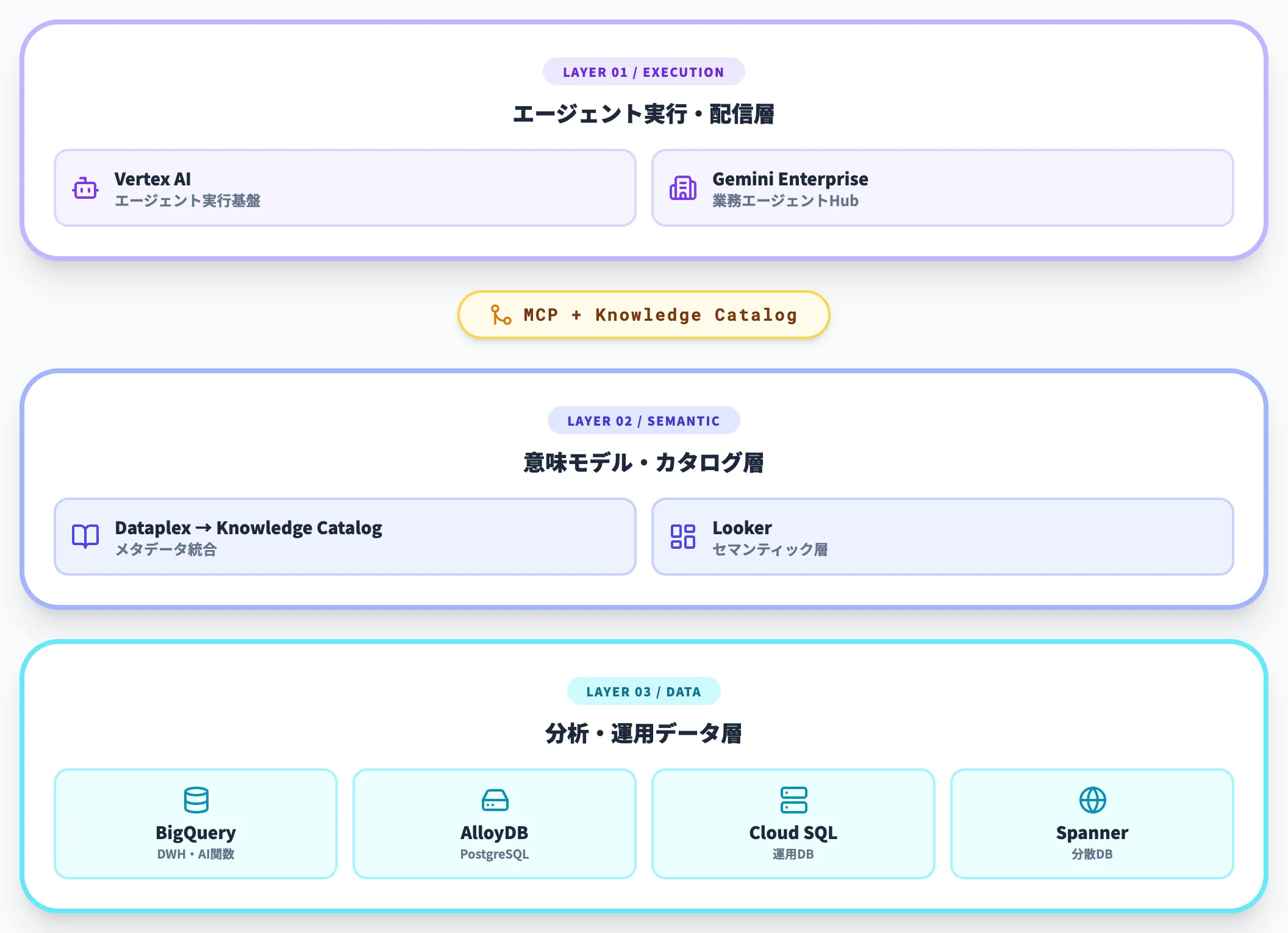
Agentic Data Cloudは、まったく新しいサービスを並べ直したものではなく、既存サービスを「エージェント前提」に組み替えた包括概念です。以下の表で、中核となるサービスの役割を整理しました。
| サービス | 役割 |
|---|---|
| BigQuery | 分析・データウェアハウス層を担い、AI関数とMCPサーバを内蔵 |
| AlloyDB/Cloud SQL/Spanner | 運用系データベース層。エージェントから直接呼び出せるよう拡張 |
| Looker | セマンティック層(ビジネス用語と数式の定義)をエージェントに提供 |
| Dataplex | Knowledge Catalogへ進化し、メタデータ・ビジネス意味の統合層を担う |
| Vertex AI/Gemini Enterprise | エージェントの実行・配信層として連携 |
表が示すように、各層が別々に独立しているのではなく、MCP(Model Context Protocol)と共通カタログで束ねられている点がポイントです。
これによりエージェントは「どこにあるどのデータをどんな意味で使うか」を一貫して扱えるようになります。
なぜAgentic Data Cloudが求められるのか
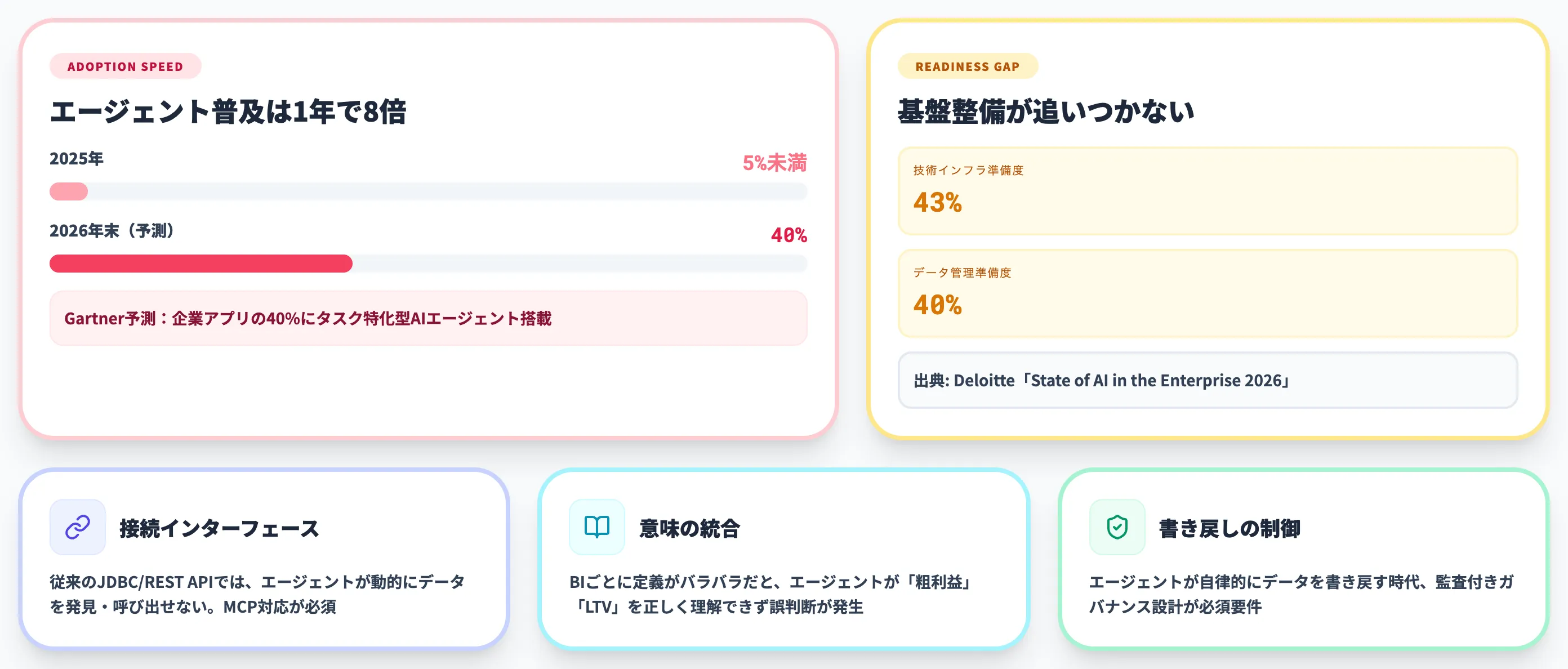
エージェントAIは2026年に入って一気に企業導入が広がりましたが、現場では「期待した行動を取ってくれない」「ハルシネーションが業務影響につながる」といった課題が顕在化しています。
その多くはモデルの性能ではなく、データ基盤側の不備に原因があります。
エージェント普及スピードに対するデータ基盤の遅れ
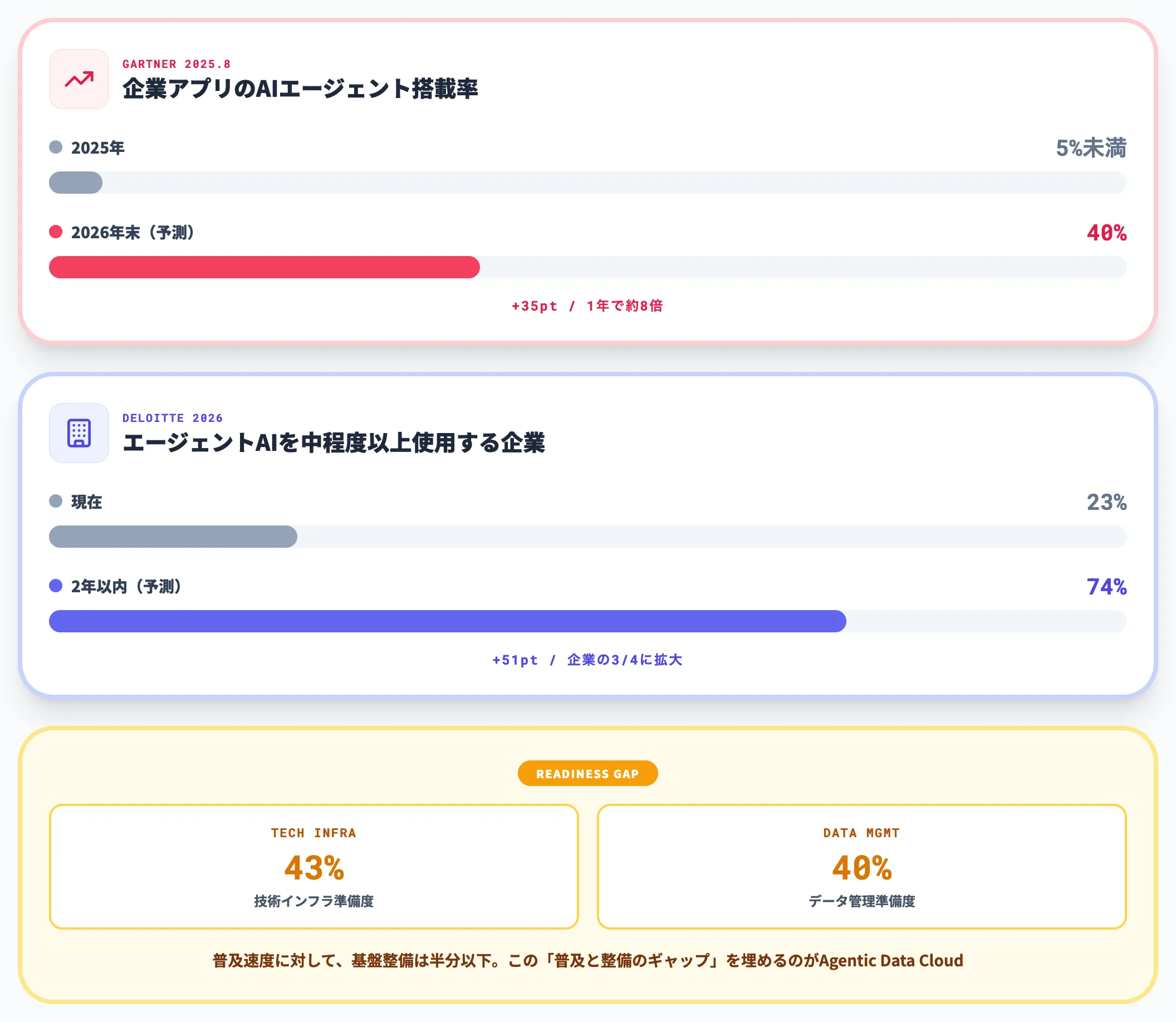
Gartnerは2025年8月の予測で、2026年末までに企業アプリケーションの40%にタスク特化型AIエージェントが搭載されると発表しました。
2025年時点では5%未満だったことを考えると、わずか1年で8倍の普及速度です。
また、Deloitteの「State of AI in the Enterprise 2026」でも、現在23%の企業がエージェントAIを中程度以上使用しており、2年以内に74%まで拡大する見込みとされています。
一方で、同調査では技術インフラの準備度が43%、データ管理の準備度が40%にとどまっており、エージェントの普及スピードに基盤整備が追いついていないことが浮き彫りになっています。
Agentic Data Cloudは、この「普及と整備のギャップ」を埋める標準アーキテクチャとして提示されたと位置づけられます。
従来のデータスタックがエージェントに合わない3つの理由

エージェント時代に既存のデータ基盤がうまく機能しない理由は、大きく3つに分けられます。
以下の表で、人間中心のデータスタックとエージェント中心のデータスタックの違いを整理しました。
| 観点 | 従来のデータスタック | エージェント前提のデータスタック |
|---|---|---|
| 主な利用者 | アナリスト・BIユーザー | 自律的に動くAIエージェント |
| アクセス方法 | 事前に設計したダッシュボード/レポート | 実行時に動的に必要データを発見 |
| 接続インターフェース | JDBC・ODBC・REST API | MCP・関数呼び出し・対話型API |
| 意味の取り扱い | LookerやBIツール内のローカル定義 | 全社共通のセマンティクスとビジネス意味 |
| クラウド範囲 | 単一クラウド前提のサイロ | AWS/Azure/GCP横断のフェデレーション |
| 書き戻し | 主に読み取り、書き込みは別経路 | 監査付きで安全に書き戻し可能 |
表が示すように、エージェントは「事前定義された問い」に答えるのではなく、「実行時に必要なデータを動的に取りに行く」ため、共通のメタデータ層と動的接続インターフェース、そして書き戻しの制御が必要になります。
Agentic Data Cloudの3本柱は、この3つに対応する設計です。
コンテキストギャップが生む業務リスク
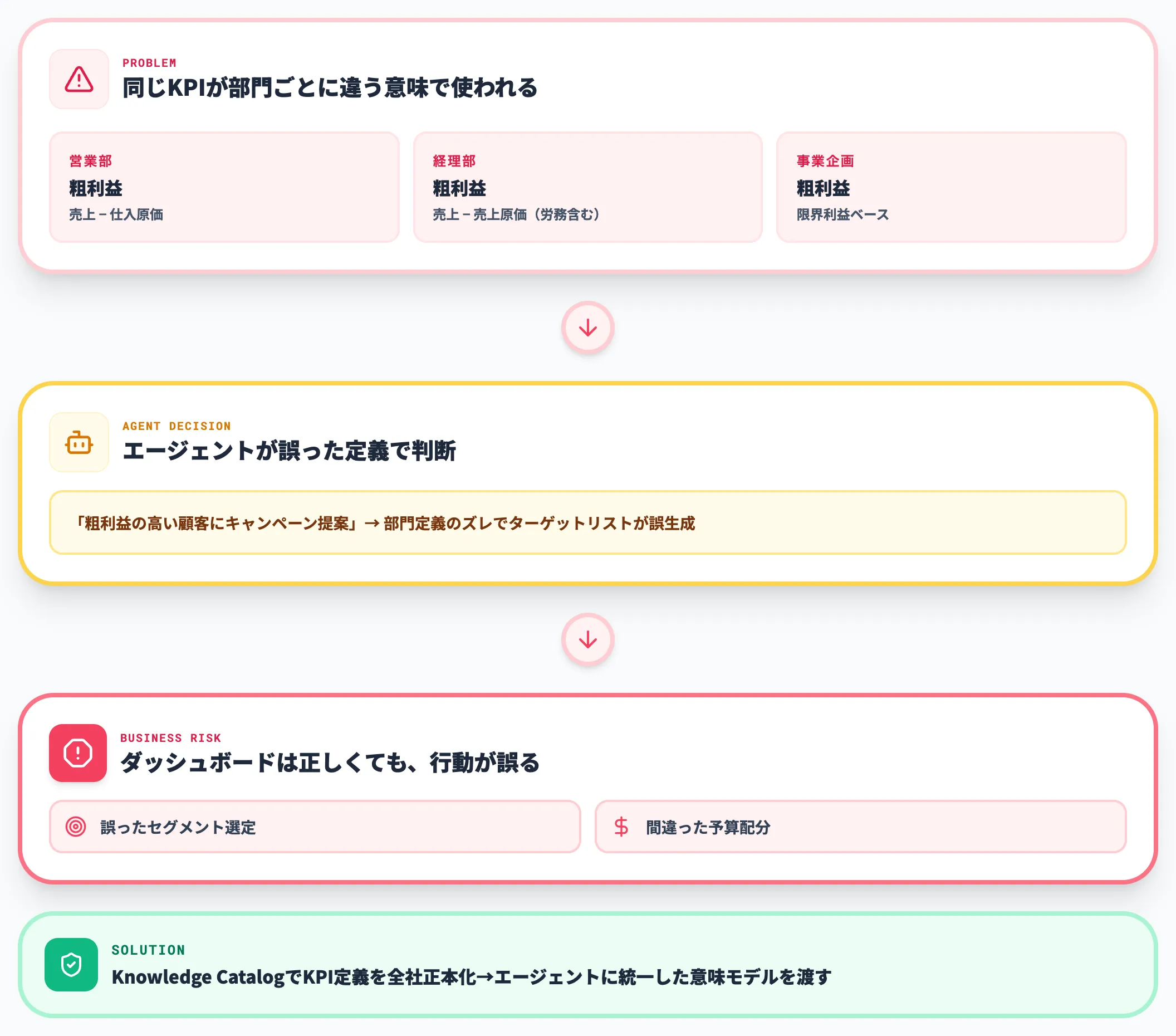
エージェントが「粗利益」「アクティブユーザー」「LTV」といった業務用語を、企業ごとの正しい定義で理解していないと、ダッシュボードでは正しく見える数値でも、エージェントが下した判断は誤ったまま行動につながります。
米国のアナリストKevin Petrie氏(BARC U.S.)はTechTargetの取材で、ハイブリッド/マルチクラウド環境にデータを置く企業がAI採用企業の約半数を占め、フェデレーションされたアクセスが価値を発揮すると指摘しています(出典: TechTarget)。
実務では、まず自社の主要KPIの定義書がエージェントから呼び出せる形で整備されているかを点検することが、Agentic Data Cloud導入の前段で必須となります。
これは特定ベンダーを選ぶ前にやるべき準備作業であり、AI Agent HubのようなエージェントHubを導入する場合も同じ前提が効いてきます。
Agentic Data Cloudの3本柱
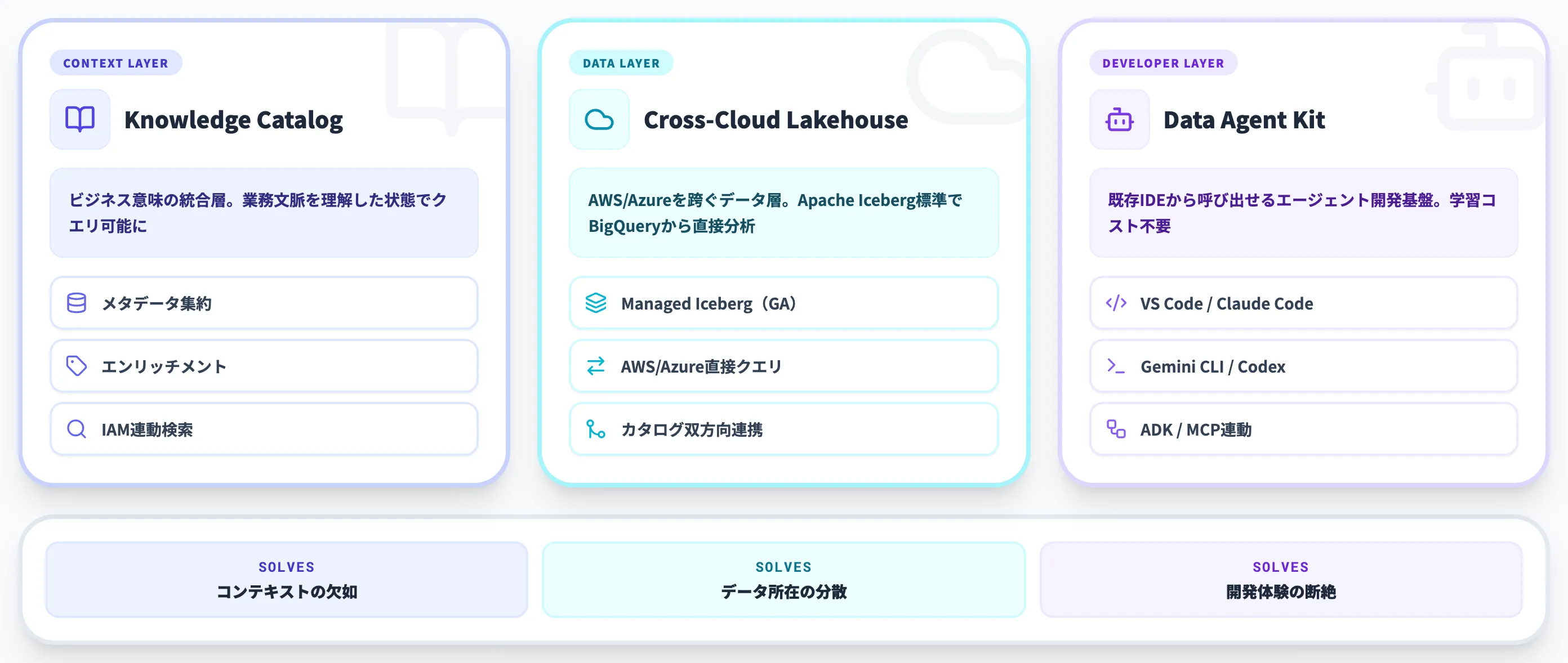
GoogleはAgentic Data Cloudを単一製品としてではなく、3領域を統合するアーキテクチャとして設計しています。これにより、企業は段階的にデータ基盤を整備しながら、AIエージェント活用へ移行しやすくなります。

Agentic Data Cloudを構成する3本柱(出典:Google Cloud Blog)
ここからは、Agentic Data Cloudを構成する3本柱を順に解説します。それぞれが「コンテキスト」「データ所在」「開発体験」という別の問題に対応しているため、目的に応じてどれを最初に整備するかを選ぶことになります。
【Knowledge Catalog】ビジネス意味の統合層

Knowledge Catalogは、従来のDataplexを発展させた、エージェント向けの動的コンテキストエンジンです。
テーブルの定義・ビジネス用語・KPIの計算ロジック・データ品質情報を一元化し、エージェントが業務文脈を理解した状態でクエリできるようにします。
Knowledge Catalogは以下3つの柱で構成されます。
- 集約
BigQuery・AlloyDB・Spanner・Cloud SQLのネイティブメタデータをGAで統合(Firestore・LookerはPreview)、Atlan・Collibra・Datahub等のサードパーティカタログともAPI連携
- エンリッチメント
Smart Storage(Preview)でGoogle Cloud Storage上のファイルにGeminiが自動でタグとメタデータを付与
- 検索
Google検索由来のセマンティック検索エンジンで、IAM権限を尊重したサブ秒の検索を提供
特に注目されるのが、Palantir・Salesforce Data360・SAP・ServiceNow・Workday(いずれもPreview)といったエンタープライズSaaSとのカタログ連携です。
これにより、業務システム側に閉じていたメタデータをエージェントが横断的に参照できるようになり、「カタログ整備のために全データを移行する」発想を取らずに済みます。
【Cross-Cloud Lakehouse】AWS/Azureを跨ぐデータ層
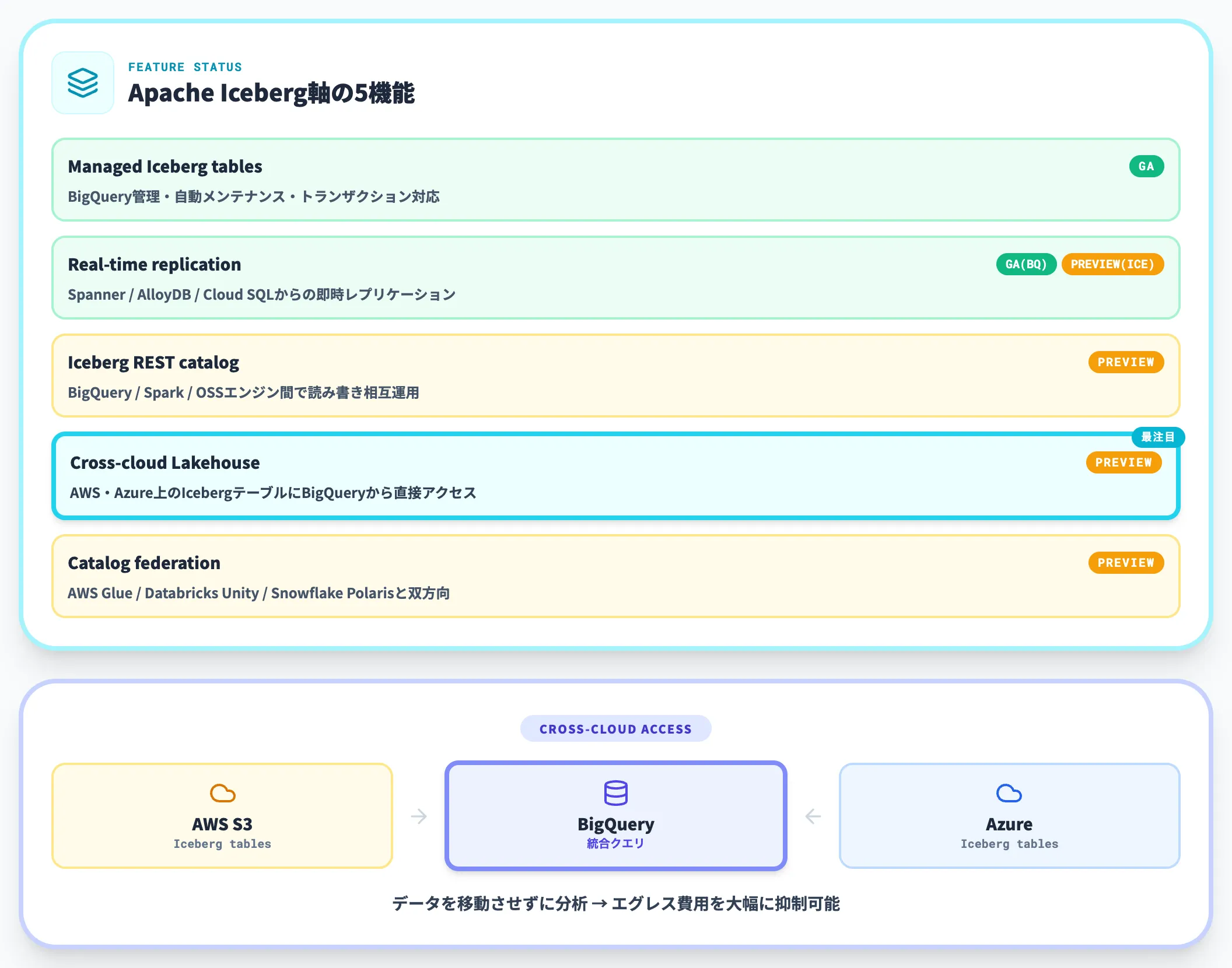
Cross-Cloud Lakehouseは、Apache Iceberg(オープンなテーブル形式)を軸に、AWS・Azure上のデータをBigQueryから直接クエリできるレイクハウス基盤です。
データを大規模に移動させずに分析できるため、クラウドを跨ぐたびに発生していたエグレス費用を大幅に抑えやすい点が特徴です(ただしCross-Cloud Interconnectの物理接続・VLANアタッチメント・データ転送料は課金対象です)。
公式のApache Iceberg Lakehouse紹介ページとBigQuery新機能ブログに基づき、主要機能をまとめます。
| 機能 | 提供状況 | 内容 |
|---|---|---|
| Managed Iceberg tables | GA | BigQuery管理のIcebergテーブル。自動メンテナンス・トランザクション対応 |
| Iceberg REST catalog | Preview | BigQuery・Spark・OSSエンジン間で読み書き相互運用 |
| Cross-cloud Lakehouse | Preview | AWS・Azure上のIcebergテーブルにBigQueryから直接アクセス |
| Catalog federation | Preview | AWS Glue・Databricks Unity Catalog・Snowflake Polarisと双方向連携 |
| Real-time replication | GA(BigQuery)/Preview(Iceberg) | Spanner・AlloyDB・Cloud SQLからの即時レプリケーション |
表のうち実務上の意味が大きいのは「Cross-cloud Lakehouse」と「Catalog federation」です。
AWS S3に置いたままのIcebergデータをBigQueryからクエリでき、Databricks Unity CatalogやSnowflake Polarisとも双方向にやり取りできるため、これまで「BigQueryに移行しないと活用できなかったデータ」を、移行コストなしでエージェントの行動材料にできます。
【Data Agent Kit】エージェント開発の共通ツール群
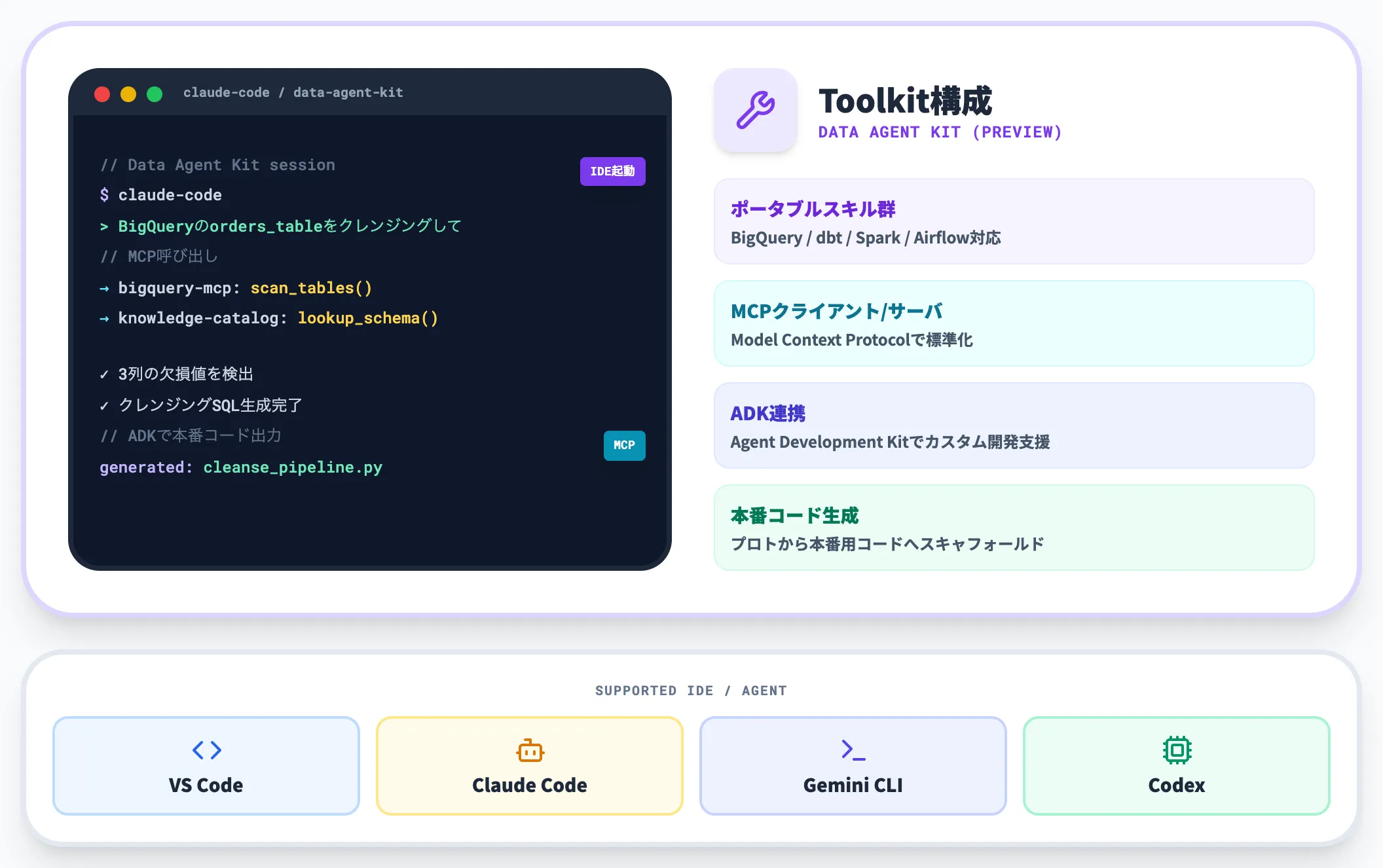
Data Agent Kitは、データに関わる業務エージェントを構築するためのツールキットで、VS Code・Gemini CLI・Codex・Claude Codeといった既存のIDEや開発エージェントから直接呼び出せます。
2026年4月時点ではPreview提供であり、新しい開発UIを覚えることなく、現在の開発フローにエージェント機能を取り込めるのが特徴です。
Data Agent Kitは以下のような付属コンポーネントを持ちます。
- ポータブルなスキル・ツール群(BigQuery/dbt/Spark/Airflowなど主要OSS基盤に対応)
- MCP(Model Context Protocol)クライアント/サーバ実装
- ADK(Agent Development Kit)と連動したカスタムエージェント開発支援
- 本番環境向けコードを生成するスキャフォールド機能
すでにClaude CodeやCodexを開発エージェントとして使っているチームであれば、Data Agent Kitの導入はIDE拡張のセットアップに近い感覚で進められます。
プロトタイピングを「データチームの一部メンバー」だけで完結させやすい点が、Microsoft FabricのData Agent Studioや、Databricksのノートブックワークフローとの大きな違いです。
Agentic Data Cloudを支えるデータエージェント
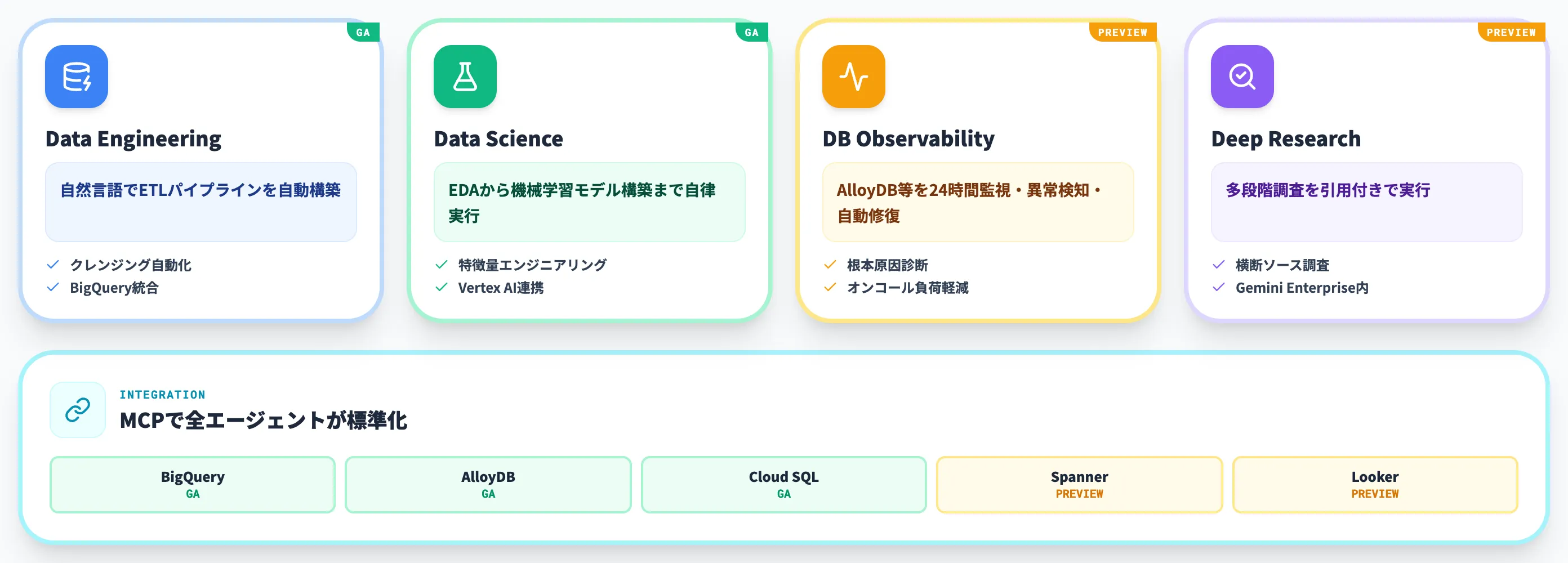
3本柱の上で実際に動く「データエージェント」も、Cloud Next 2026で複数発表されています。
それぞれが担当する役割と提供状況を押さえておくと、自社の業務に当てはめやすくなります。
Data Engineering Agent(GA)
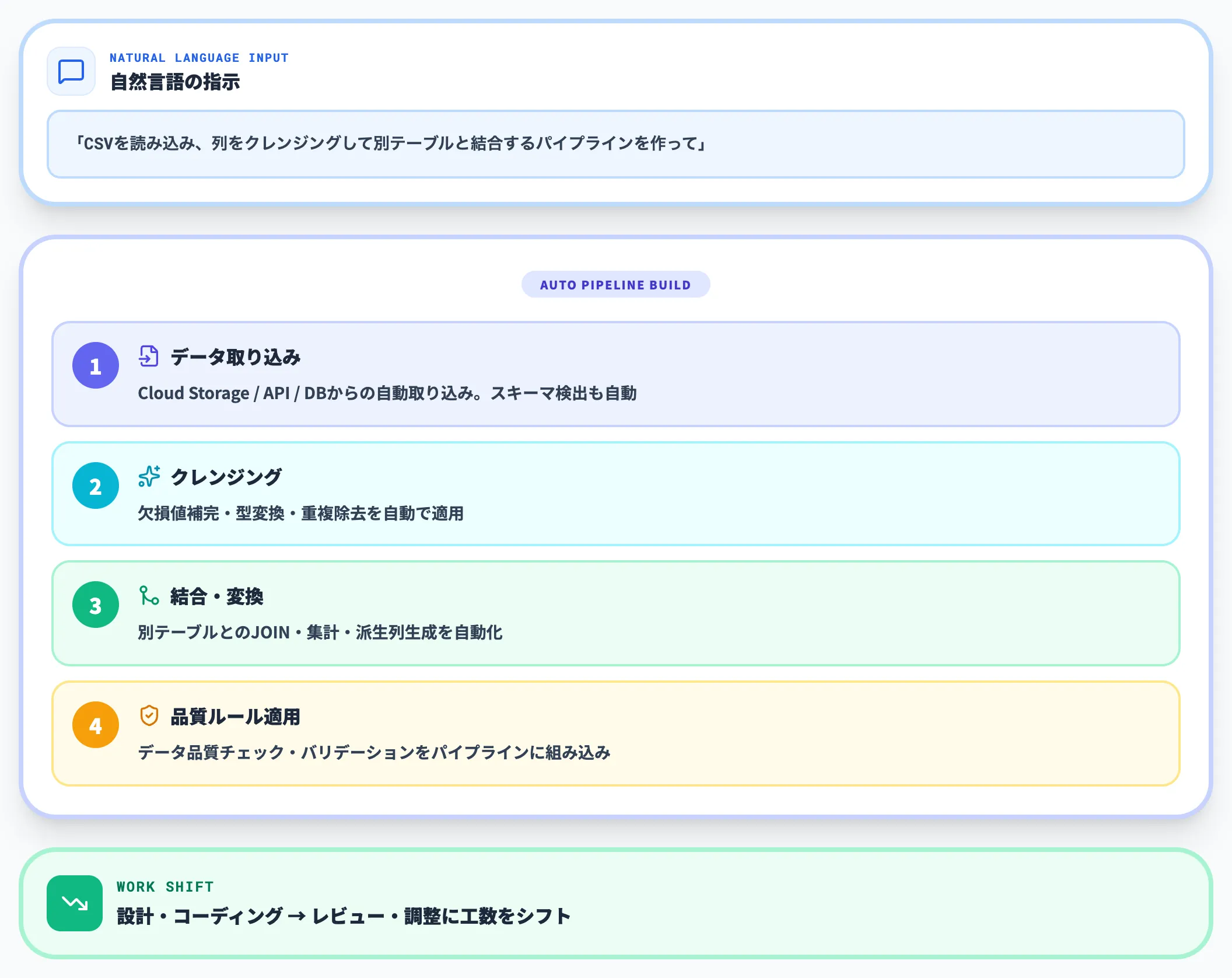
Data Agent Kitの中でもData Engineering Agentは、技術メタデータ・業務メタデータ・ログ情報を活用しながら、自然言語指示からデータパイプライン生成、運用改善、バルク処理自動化までを担う実務特化型エージェントです。
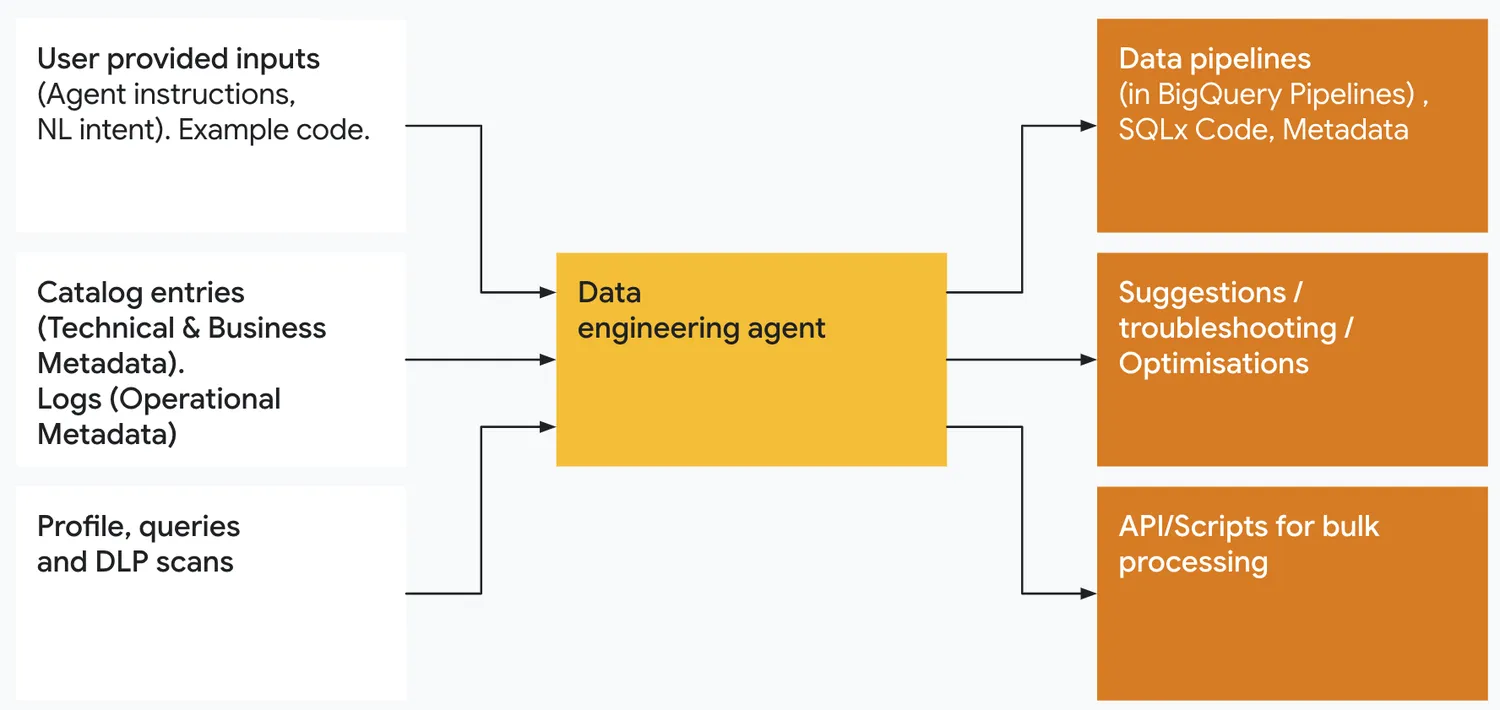
Data Engineering Agentがパイプライン生成・最適化・トラブルシューティングを自動化する構造(出典:Google Cloud Blog)
Data Engineering AgentはBigQuery上で動作し、自然言語で「CSVを読み込み、列をクレンジングして別テーブルと結合するパイプラインを作って」と指示するだけで、ETLパイプラインを自動構築します。
Cloud Storage等のデータソースからの取り込み、データ品質ルールの適用までを一気通貫で実行します。
GAでの提供開始により、本番運用に投入できる段階に入っています。ただし生成されたパイプラインのレビューは必要で、データチームの工数が「設計・コーディング」から「レビュー・調整」に置き換わるイメージで導入を計画するのが現実的です。
Data Science Agent(GA)

Data Science Agentは、BigQueryとVertex AIで提供されるGemini搭載のデータサイエンス向けエージェントです。
探索的データ分析(EDA)、データクレンジング、特徴量エンジニアリング、機械学習モデルの構築までを自律的に実行します。
実務では、データサイエンティストが「分析の最初の一歩」として使うパターンが効果的です。
たとえば過去データから売上予測モデルを試作する、顧客セグメンテーションを試行する、といったプロトタイピングを大幅に短縮できます。一方で、本番展開する際の評価指標の設計や倫理レビューは、引き続き人間が責任を持つ必要があります。
Database Observability Agent(Preview)
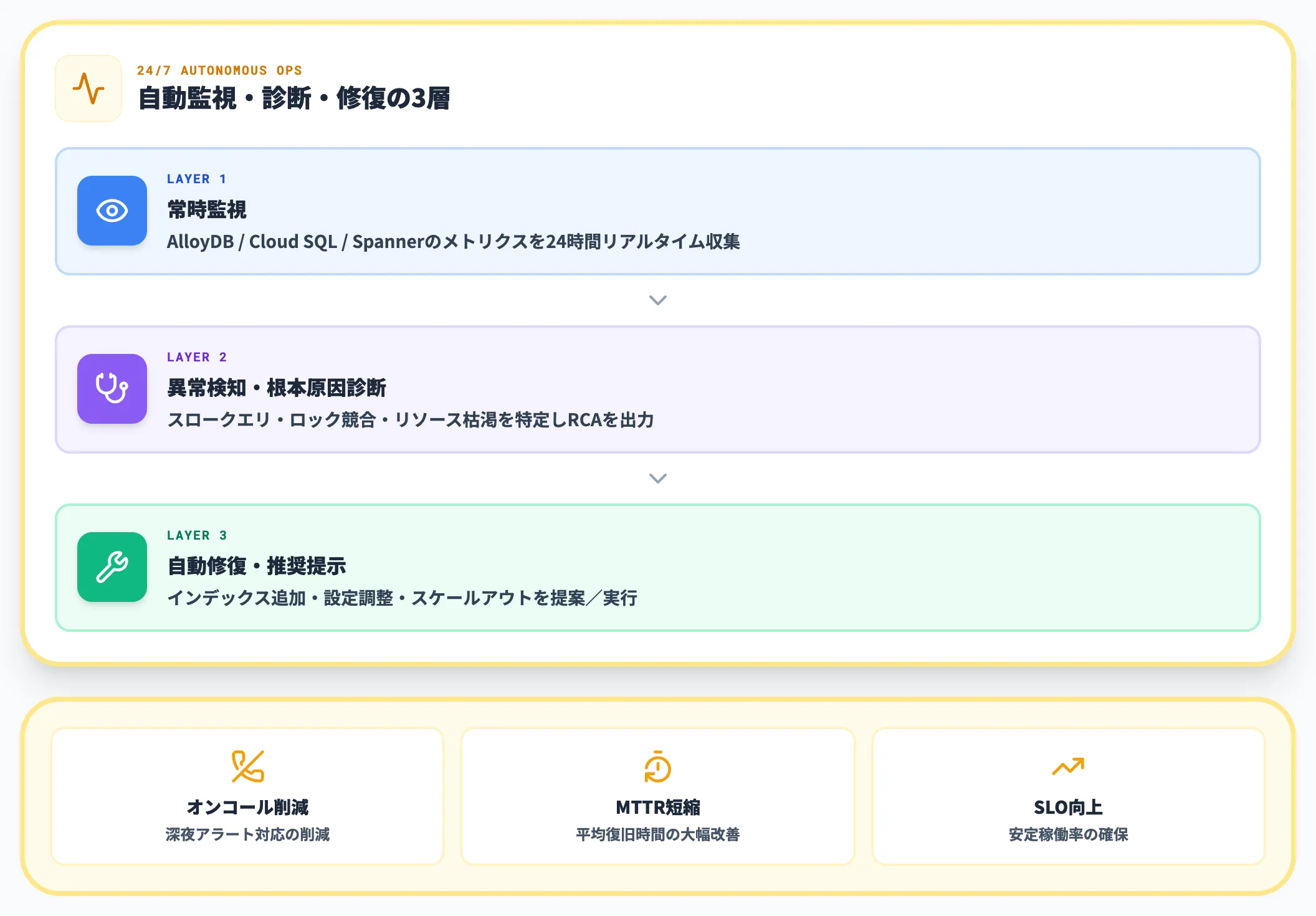
Database Observability Agentは、AlloyDB・Cloud SQL・Spannerといった運用データベースを24時間監視するエージェントです。
パフォーマンスの異常を検知し、根本原因を診断、状況に応じて修復アクションを実行します。
オンコール担当者が深夜に呼び出される頻度を下げる効果が期待されますが、現時点ではPreview段階のため、ステージング環境や非クリティカルなデータベースから試すのが安全です。
Deep Research Agent(Preview)
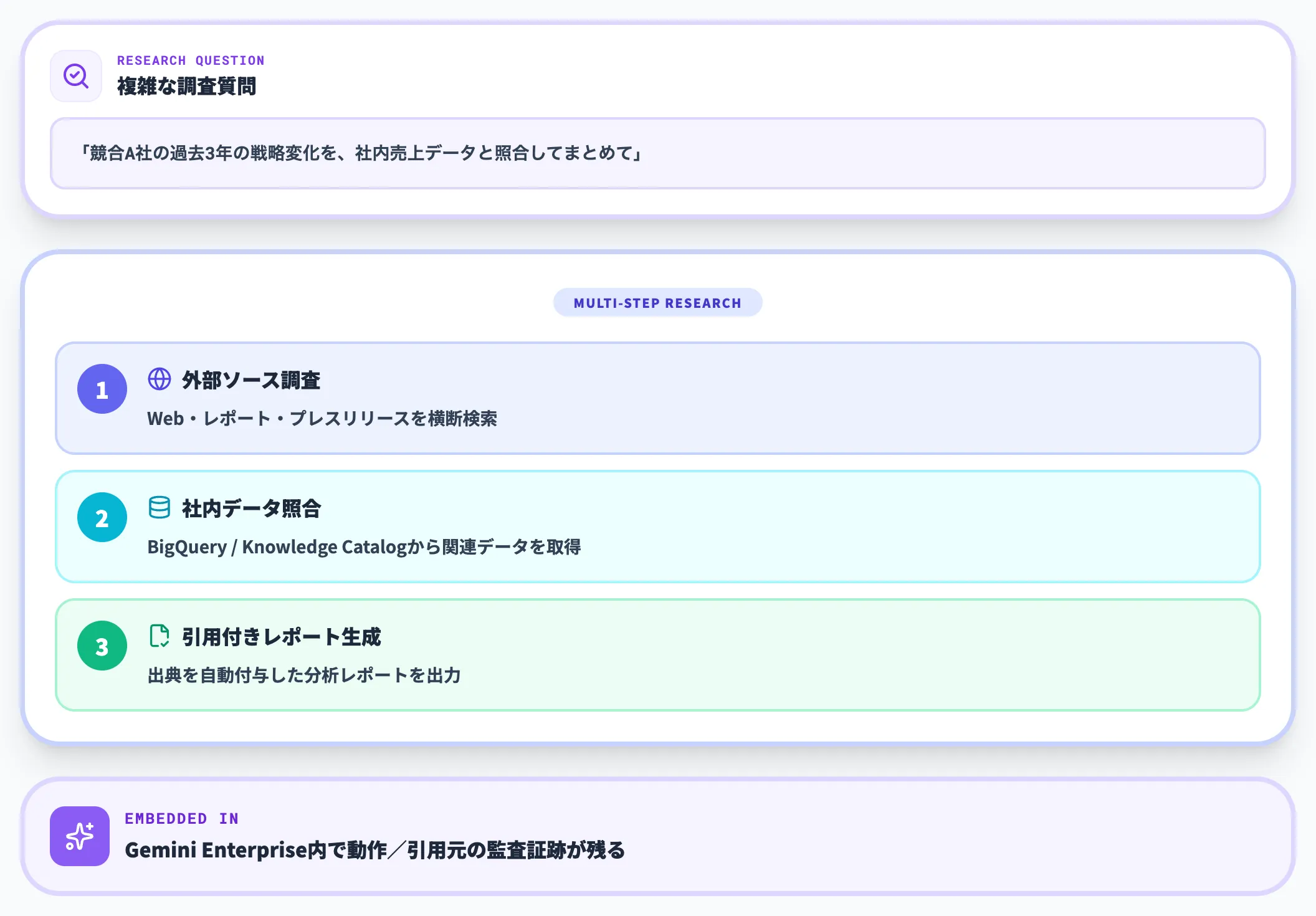
Deep Research Agentは、Knowledge Catalogをコンテキストとして活用し、BigQuery・社内ドキュメント・Web資産を横断した複数ステップの調査を引用付きで返すエージェントです。
Gemini Enterprise内で利用でき、非定型の意思決定支援に向きます。
経営層向けの市場分析レポート、競合動向の継続調査、新規事業のフィージビリティ調査などが代表的なユースケースです。
MCP統合:エージェントから安全にデータを呼び出す
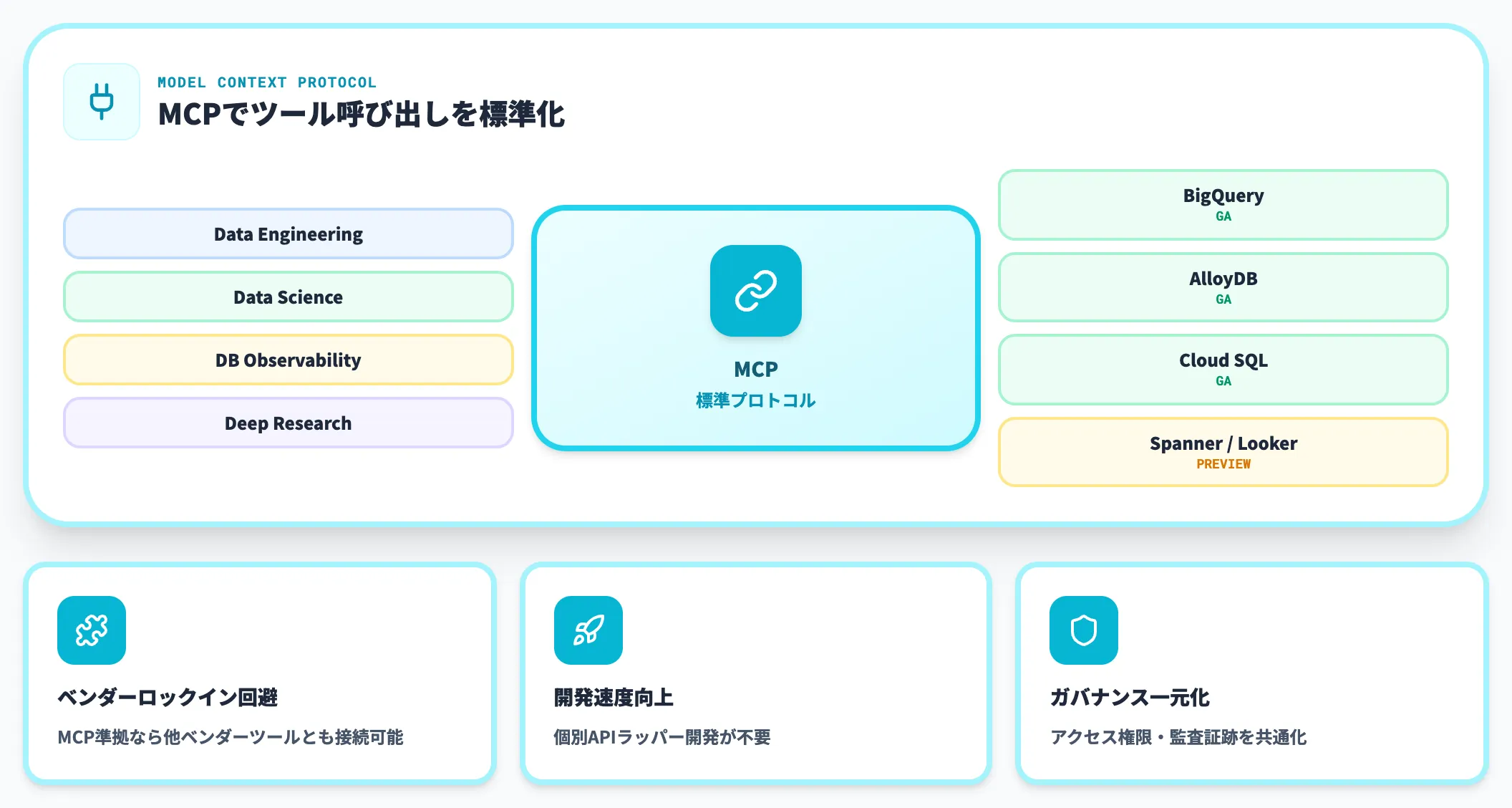
Model Context Protocol(MCP)は、Anthropicが2024年に提唱したAIエージェント向けの標準プロトコルで、Agentic Data CloudはGoogleの主要データサービスをMCP経由で開放しています。提供状況は以下の通りです。
| サービス | MCP対応状況 |
|---|---|
| BigQuery | GA |
| AlloyDB | GA |
| Cloud SQL | GA |
| Spanner | Preview |
| Looker(Looker MCP) | Preview |
MCPに対応していることで、Claude CodeやGemini CLIなど、複数のエージェントから同じインターフェースでデータベースを呼び出せます。
MCP自体の仕組みや活用パターンを詳しく知りたい場合は、MCP(Model Context Protocol)とは?も参考になります。
Agentic Data Cloud vs 主要データ基盤の比較

エージェント時代のデータ基盤として比較されるのが、Microsoft Fabric・Snowflake AI Data Cloud・Databricks Data Intelligence Platformの3社です。
ここでは、位置づけと選定基準を整理します。
主要4プラットフォームの比較表

各社のエージェント対応状況を、データレイヤー・セマンティック層・エージェント基盤・クロスクラウド対応の観点でまとめました。
| 観点 | Google Agentic Data Cloud | Microsoft Fabric | Snowflake AI Data Cloud | Databricks Data Intelligence Platform |
|---|---|---|---|---|
| データレイヤー | BigQuery + Apache Iceberg | OneLake(Delta Lake) | Snowflake独自+Iceberg連携 | Delta Lake / Unity Catalog |
| セマンティック層 | Knowledge Catalog(旧Dataplex)+ Looker | Fabric IQ オントロジー + Power BI | Cortex Semantic Views | Unity Catalog Metric Views |
| エージェント基盤 | Data Agent Kit(Preview)+ MCP(BigQuery/AlloyDB/Cloud SQLはGA、Spanner/LookerはPreview) | Fabric Data Agent | Cortex Agents | Mosaic AI Agent Framework |
| クロスクラウド対応 | Cross-Cloud Lakehouse(Preview)でAWS/Azureのデータを分析可能、双方向フェデレーションは対象カタログ限定 | Azure中心、AWS連携は限定 | マルチクラウド(同社内) | マルチクラウド対応 |
| 開発IDE統合 | VS Code・Claude Code・Gemini CLI・Codex | VS Code・Fabric Studio | Snowsight・SnowCLI | Databricks Notebook・VS Code |
| 主な強み | クロスクラウド/Iceberg標準/開発IDE統合 | M365統合/Power BI/Copilot連携 | SQL第一主義/シンプル運用 | OSS基盤/MLOps成熟度 |
表が示す最大の差別化ポイントは、Cross-Cloud Lakehouse(Preview)によってAWS・Azure上のIcebergデータをBigQueryから分析できる点にあります。
ただし、AWS Glue・Databricks Unity Catalog・Snowflake Polarisとの双方向フェデレーションは対象カタログに限定されたPreview提供のため、全データを無制限に双方向で扱えるわけではありません。
Microsoft FabricはAzure中心、Snowflake/Databricksはそれぞれ自社プラットフォームに寄せる設計のため、すでにAWSやAzureに大量のデータを抱える企業ほど、Cross-Cloud Lakehouseのメリットが大きくなります。
【関連記事】
AIエージェント×データ基盤とは?設計と構築手順を解説
ケース別の選定基準

実務での選定は「すでに何を使っているか」「クラウド戦略がどこに寄っているか」で大きく変わります。代表的なケースを整理します。
- M365・Power BI中心の組織:Microsoft Fabricが第一候補。Copilot連携が業務効率に直結する
- すでにBigQueryを基幹DWHとして使用:Agentic Data Cloudで一貫性を持って拡張するのが自然
- マルチクラウド/オンプレ併用が前提:Agentic Data CloudのCross-Cloud Lakehouseが優位
- SQL中心でデータエンジニアが少ない組織:Snowflake Cortex Agentsで小さく始めるのが楽
- 機械学習基盤を含めて統合したい組織:Databricks Mosaic AIの成熟度が活きる
支援経験から言うと、選定の決め手は「データの所在」と「既存のBI/分析資産」になることが多く、AI機能の差は半年〜1年で互いに追随する傾向があります。
長期的な投資効率を考えると、Apache Iceberg等のオープン規格に乗っているプラットフォームを軸にするほうがロックインを避けやすい設計です。
Microsoft Fabricとの違いを深掘り

最も比較されやすいMicrosoft Fabricとの違いを、もう一段詳しく整理します。
Microsoft Fabricは、OneLakeを中核にAzure・M365との統合を強みとし、Power BI/Copilot/Teamsからエージェントを呼び出す体験に長けています。
一方、Agentic Data CloudはApache Icebergを軸にAWS・Azureも巻き取るオープンな設計で、開発側はClaude CodeやCodexなど好みのIDEからエージェントを開発できます。
つまり、「Microsoft環境を中心に業務全体をAI化したい」ならFabric、「マルチクラウド前提でデータ層をエージェントに開放したい」ならAgentic Data Cloud、というのが基本的な棲み分けです。Microsoft Fabricの詳細については、Microsoft Fabricとは?も併せて確認してください。

Agentic Data Cloudの料金体系
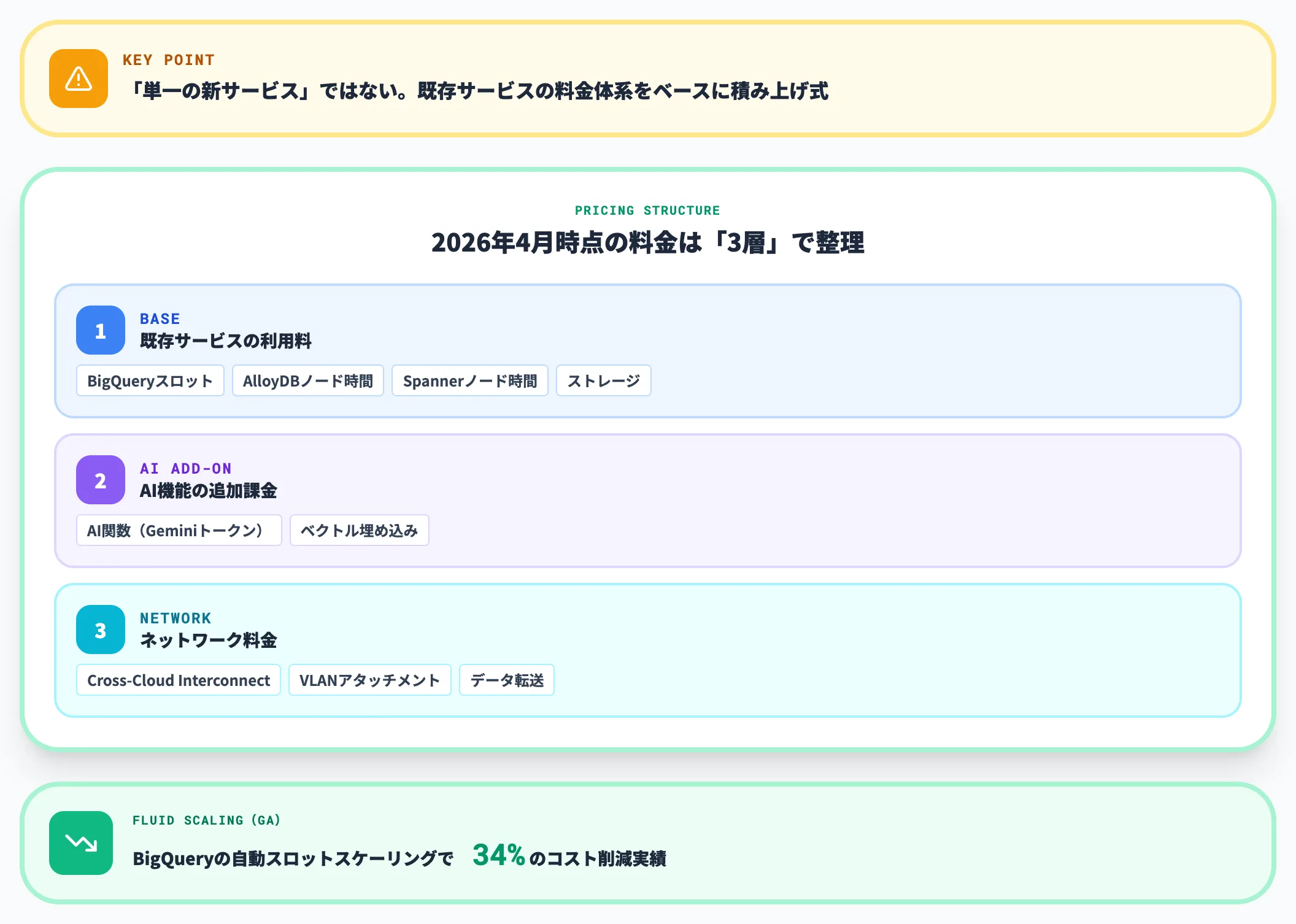
Agentic Data Cloudは「単一の新サービス」ではないため、専用の料金プランは存在しません。
BigQuery・AlloyDB・Spanner・Looker・Dataplex(Knowledge Catalog)といった既存サービスの料金体系をベースに、機能ごとにBigQueryのCompute/Storage/Omni/ML/BI Engine/Streaming、Knowledge Catalogの処理・メタデータ保存、ネットワーク等の課金を個別に確認する必要があります。
料金の基本構成
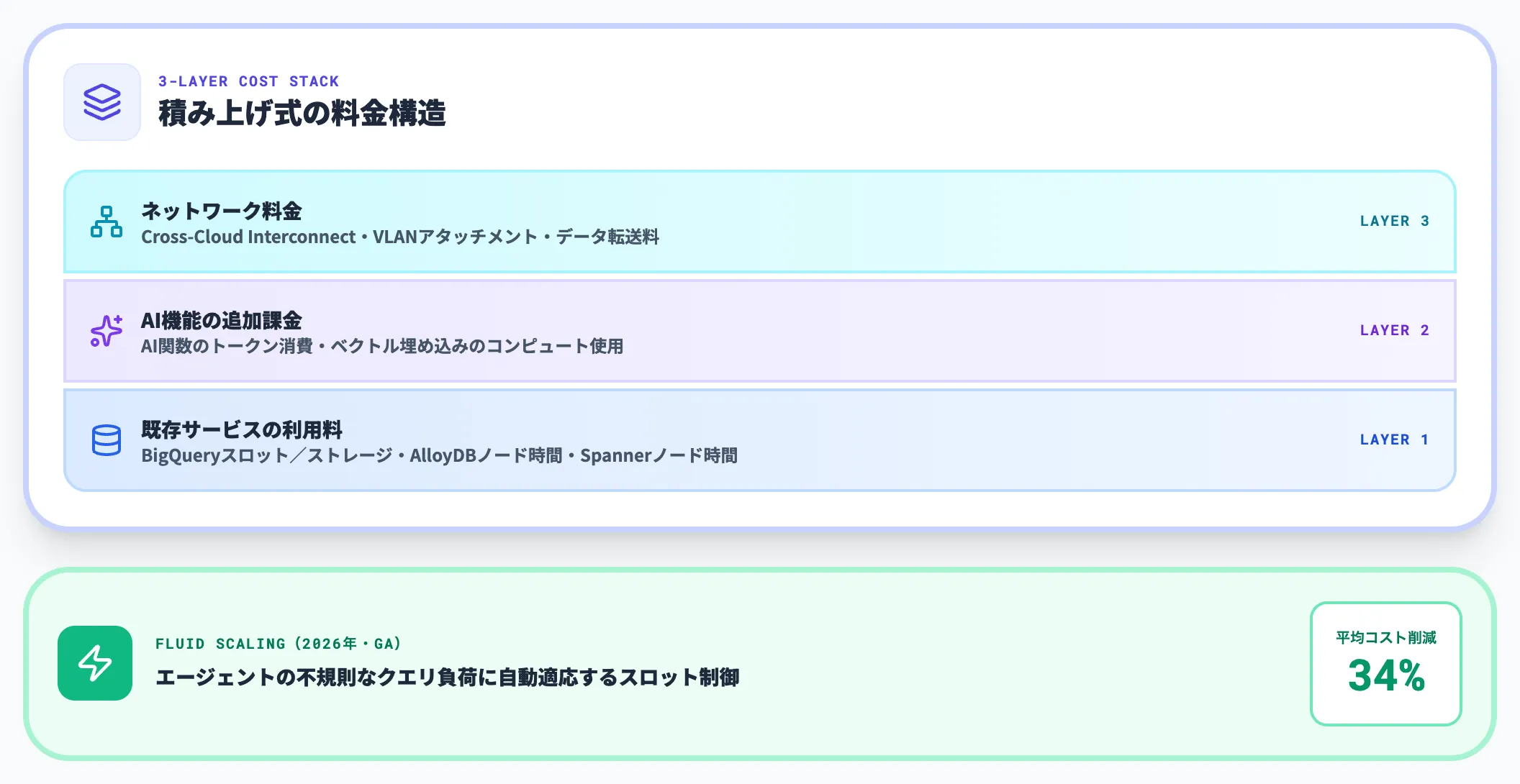
2026年4月時点の料金構造は、以下の3層で考えると整理しやすいです。
- 既存サービスの利用料(BigQueryスロット/ストレージ、AlloyDBノード時間、Spannerノード時間など)
- AI機能の追加課金(AI関数のトークン消費、ベクトル埋め込みのコンピュート使用)
- ネットワーク料金(Cross-Cloud Interconnectの物理接続費・VLANアタッチメント・データ転送料が課金対象)
特にBigQueryでは、2026年版で導入された「Fluid scaling(GA)」により、ワークロードの変動に応じて自動でスロットがスケールし、平均34%のコスト削減が報告されています(出典: BigQuery新機能ブログ)。エージェントが起こす不規則なクエリ負荷とも相性が良い課金モデルです。
主要サービスの価格例
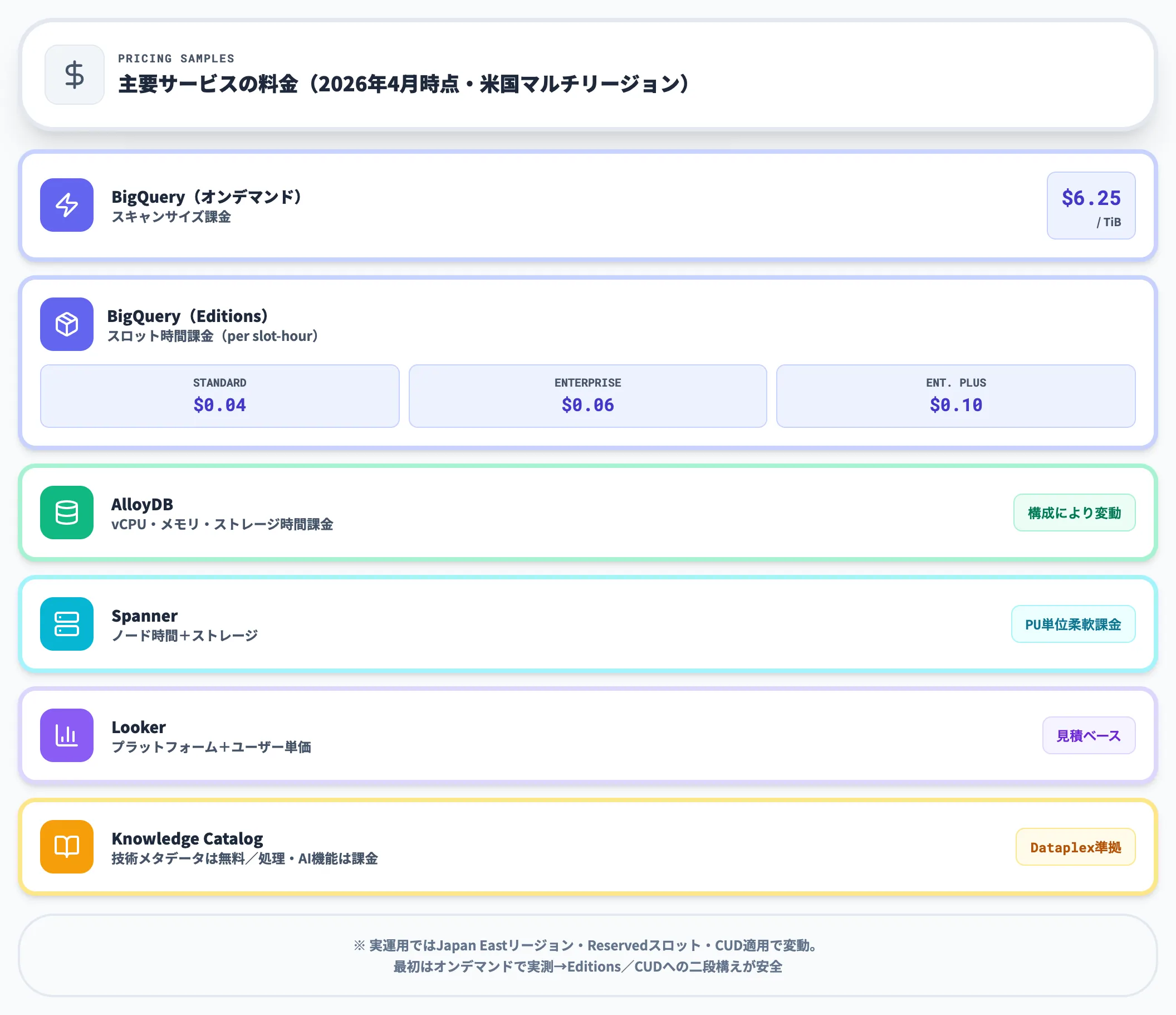
各構成サービスの代表的な料金を、2026年4月時点でまとめます。詳細は各Google Cloud公式の価格ページを必ず確認してください。
| サービス | 課金モデル | 価格例(2026年4月時点) |
|---|---|---|
| BigQuery(オンデマンド) | スキャンサイズ課金 | 6.25ドル/TiB(米国マルチリージョン) |
| BigQuery(Editions) | スロット時間課金 | Standard 0.04ドル/Enterprise 0.06ドル/Enterprise Plus 0.10ドル(per slot-hour) |
| AlloyDB | vCPU・メモリ・ストレージ時間課金 | 構成により変動。1 vCPUあたり時間単価+ストレージGB単価 |
| Spanner | ノード時間+ストレージ | プロセシングユニット単位の柔軟課金あり |
| Looker | プラットフォーム料金+ユーザー単価 | エディションに応じて見積ベース |
| Knowledge Catalog | 既存Dataplex Universal Catalog課金を踏襲 | API呼び出しや自動取り込みのGoogle Cloud技術メタデータは無料。処理・メタデータ保存・AI/高度機能は課金対象になり得る |
表の数字は米国マルチリージョンの参考値です。実際の運用ではJapan East(東京)などのリージョン選定、Reservedスロットの有無、コミットメント割引(CUD)の適用で大きく変わります。
エージェント前提のワークロードは「分析の山が読みにくい」ため、最初はオンデマンドで実測し、数か月後にEditionsまたはCUDへ切り替える二段構えが安全です。
料金面で注意すべき4つのポイント
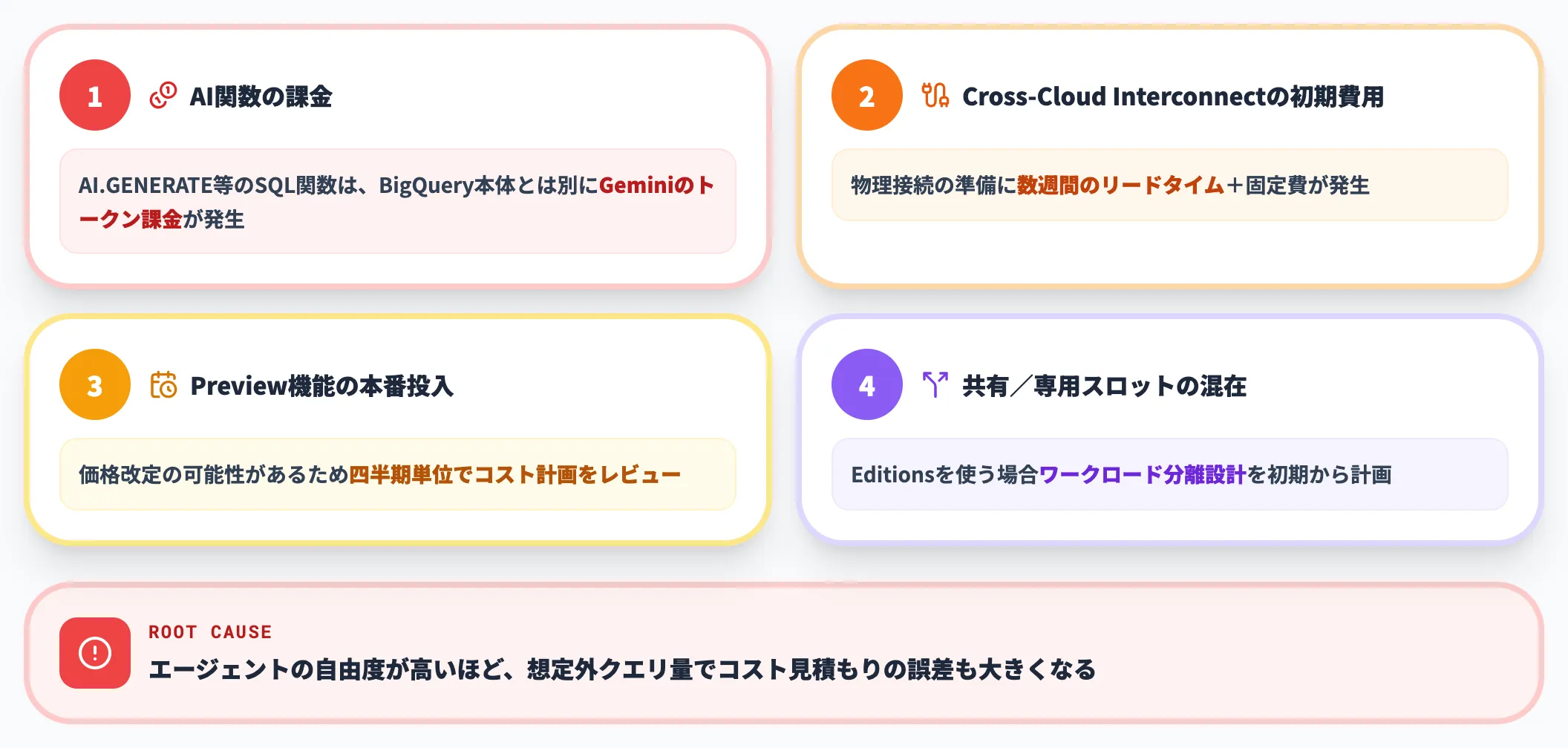
Agentic Data Cloudを設計するときに、料金面で見落としやすいのは以下の4点です。
- AI関数の課金:AI.GENERATE等のSQL関数はGeminiのトークン課金が別途発生する
- Cross-Cloud Interconnectの初期費用:物理接続の準備にリードタイム(数週間)と固定費が発生する
- Preview機能の本番投入:価格改定の可能性があるためコスト計画は四半期単位でレビュー
- 共有スロットと専用スロットの混在:Editionsを使う場合、ワークロード分離設計を初期から計画する
これらは料金そのものというより、エージェントが想定外のクエリ量を生むリスクへの備えです。エージェントの自由度が高いほど、コスト見積もりの誤差も大きくなる点に注意してください。
Agentic Data Cloudの活用事例
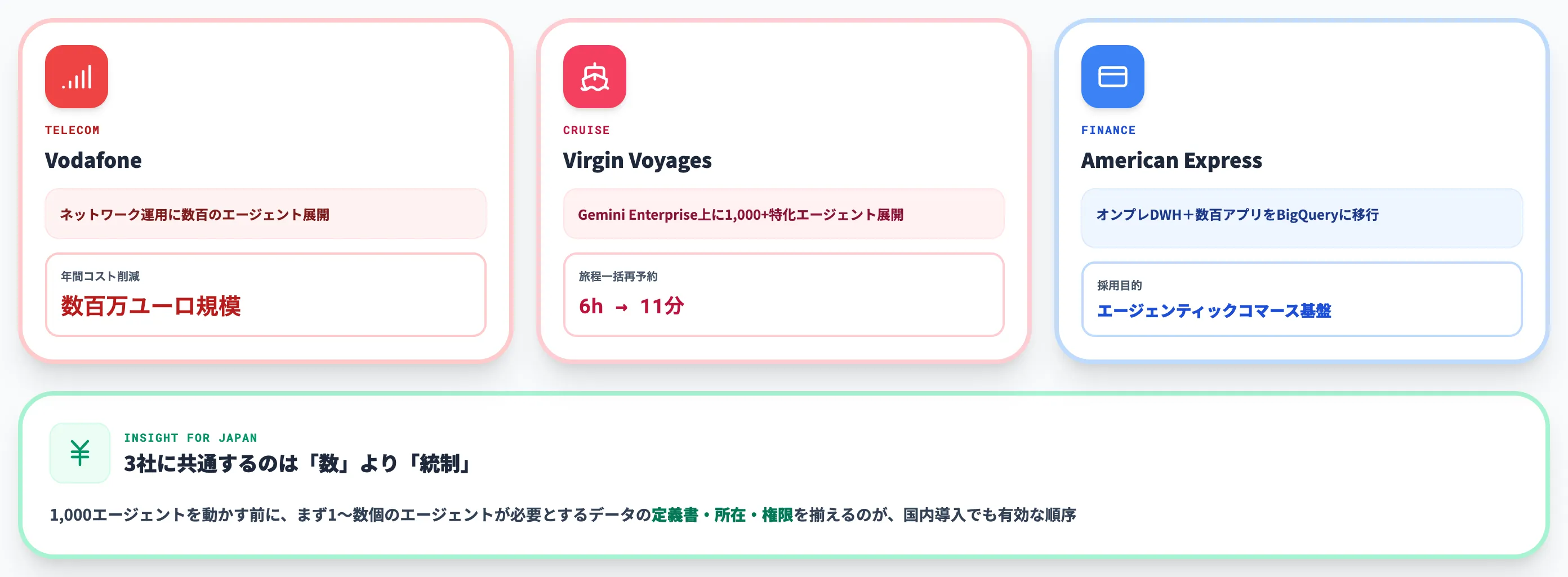
公式発表で紹介された大手企業の事例を、ユースケース別に整理します。いずれも数値効果が明示されており、自社の検討材料として参考になります。
Vodafone:ネットワーク運用に数百のエージェント

VodafoneはAgentic Data Cloudを活用し、大規模なAIエージェント群を通じて顧客維持・サービス品質向上を推進しています。

VodafoneによるAgentic Data Cloud活用事例(出典:Vodafone Business)
Vodafoneは、ネットワーク運用部門に数百のAIエージェントを展開し、年間で数百万ユーロ規模のコスト削減を見込んでいると発表しています(出典: Google Cloud Blog)。
エージェントは故障対応や性能最適化を担当し、オンコール担当者の負荷を下げる効果が期待されています。
Vodafoneは以前からネットワーク運用へのエージェントAI適用に積極的で、Agentic Data Cloudの登場により、運用データを横断的に活用したエージェント運用に拡張しています。
Virgin Voyages:1,000以上の特化エージェント
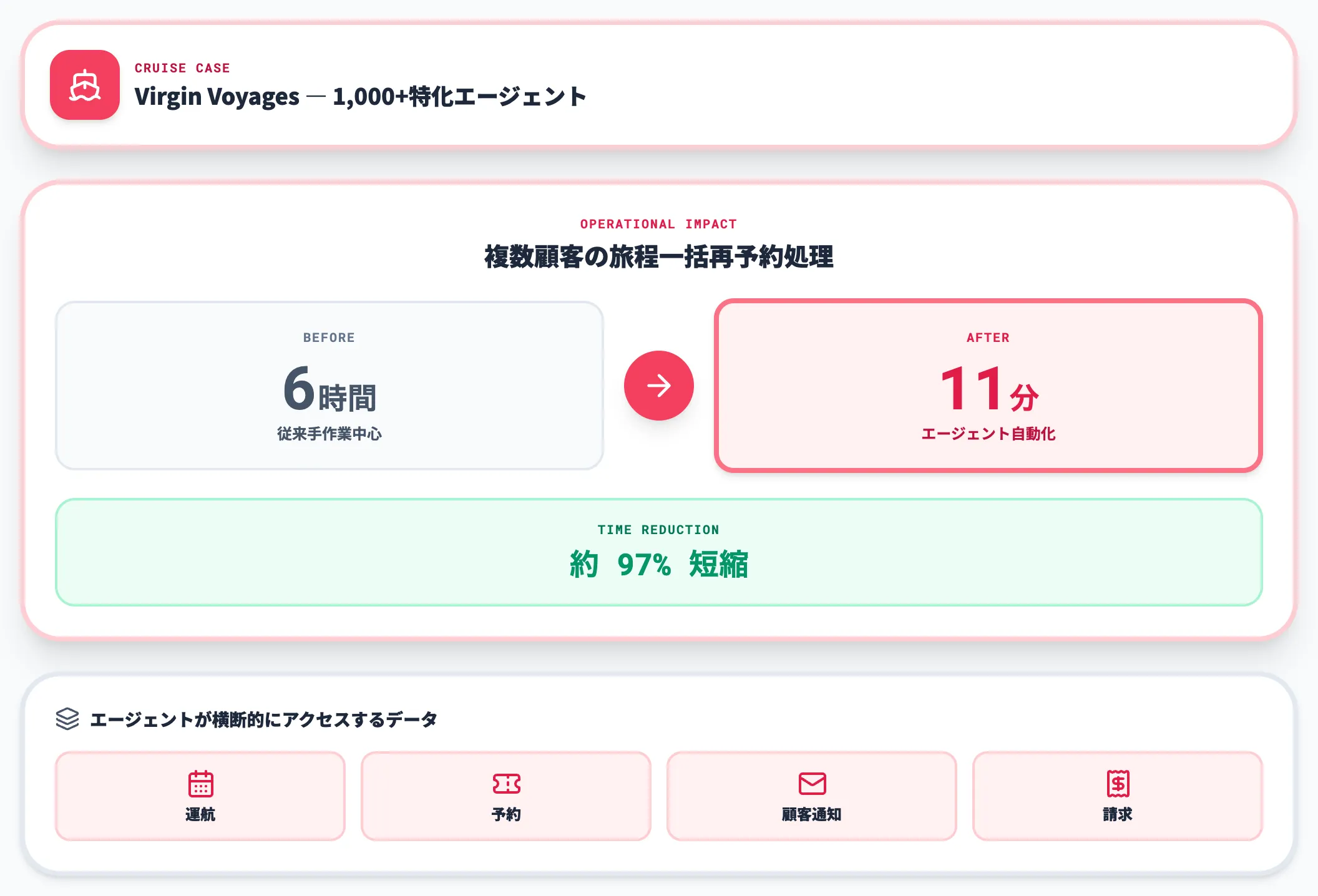
クルーズ会社のVirgin Voyagesは、Google Cloudと戦略的提携を結び、1,000以上の特化型AIエージェントをGemini Enterprise上に展開しています。代表的な事例として、複数顧客の旅程一括再予約処理を6時間から11分へ短縮した実績が報告されています(出典: Google Cloud Blog: What's New in the Agentic Data Cloud)。
なお、Virgin Voyages公式リリースでは「50以上のAIエージェント」やEmail Ellieなどの具体事例が紹介されています(出典: Virgin Voyages公式プレスリリース)。
クルーズ業務は「時刻変更が他の予約に連鎖する」典型的な複合業務で、エージェントが運航・予約・顧客通知・請求の各データに横断的にアクセスできる基盤が前提となります。
Agentic Data Cloudのコンセプトをそのまま体現する事例です。
American Express:オンプレDWHのBigQuery移行
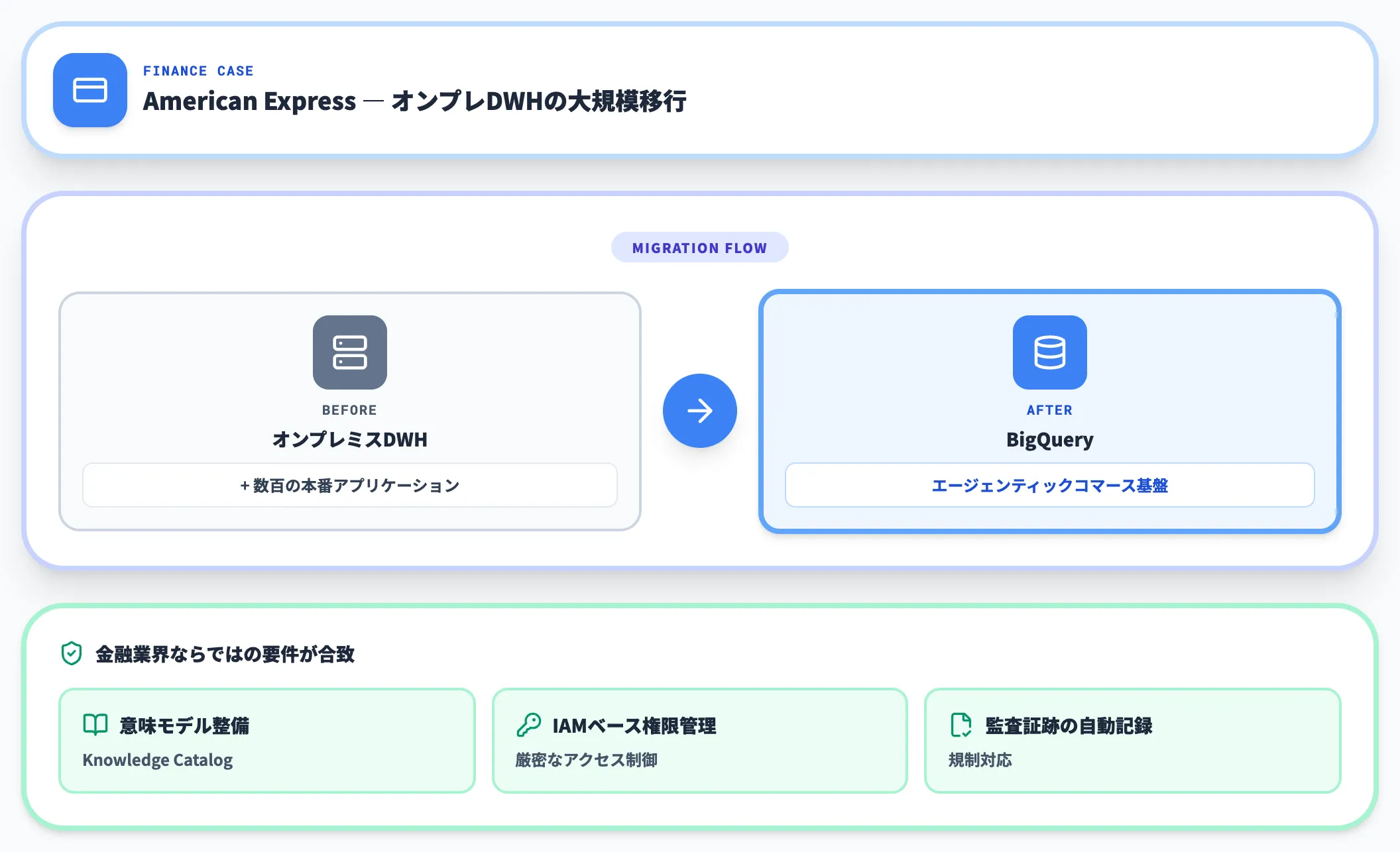
American Expressは、自社のオンプレミス データ ウェアハウスと数百の本番アプリケーションをBigQueryに移行する計画を発表しました。「信頼できるエージェンティック コマース(AIエージェントによる商取引)の基盤」として、Agentic Data Cloudを採用すると説明されています(出典: Google Cloud Blog)。
金融業界は規制とガバナンスの要件が厳しく、エージェント運用には監査証跡や権限管理が不可欠です。Knowledge Catalogによる意味モデルの整備と、IAMベースのアクセス制御がそのまま活かせる構成と言えます。
国内企業がまず参考にすべきポイント
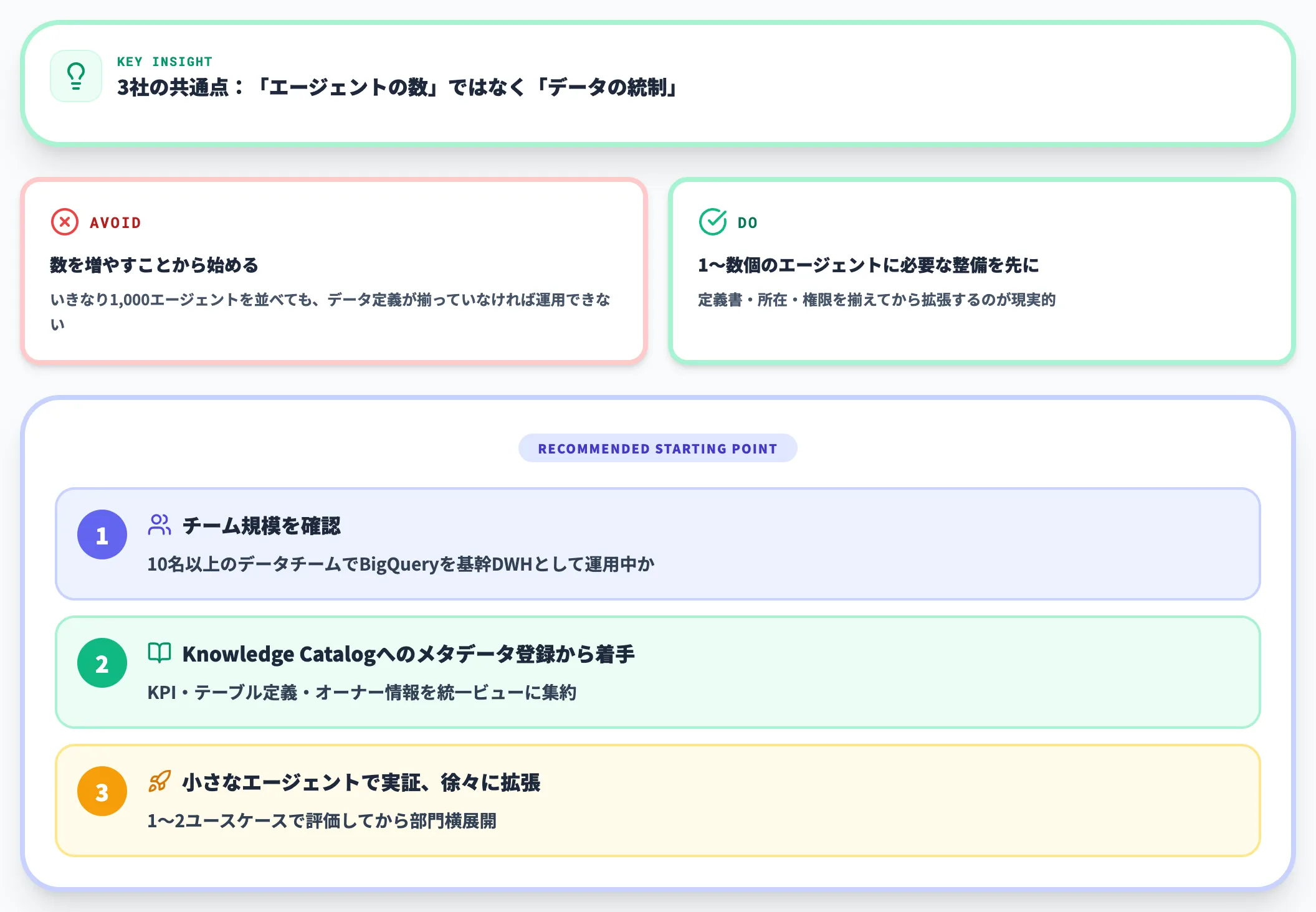
これら3社の共通点は、「エージェントの数」ではなく「エージェントが触るデータの統制」を先に整備していることです。
1,000のエージェントを動かす前に、まずは1〜数個のエージェントが必要とするデータの定義書・所在・権限を揃えるのが、国内導入でも有効な順序になります。
10名以上のデータチームでBigQueryを基幹DWHとして運用している組織であれば、まずKnowledge Catalogへのメタデータ登録から始めるのが現実的です。

Agentic Data Cloud導入で詰まる論点
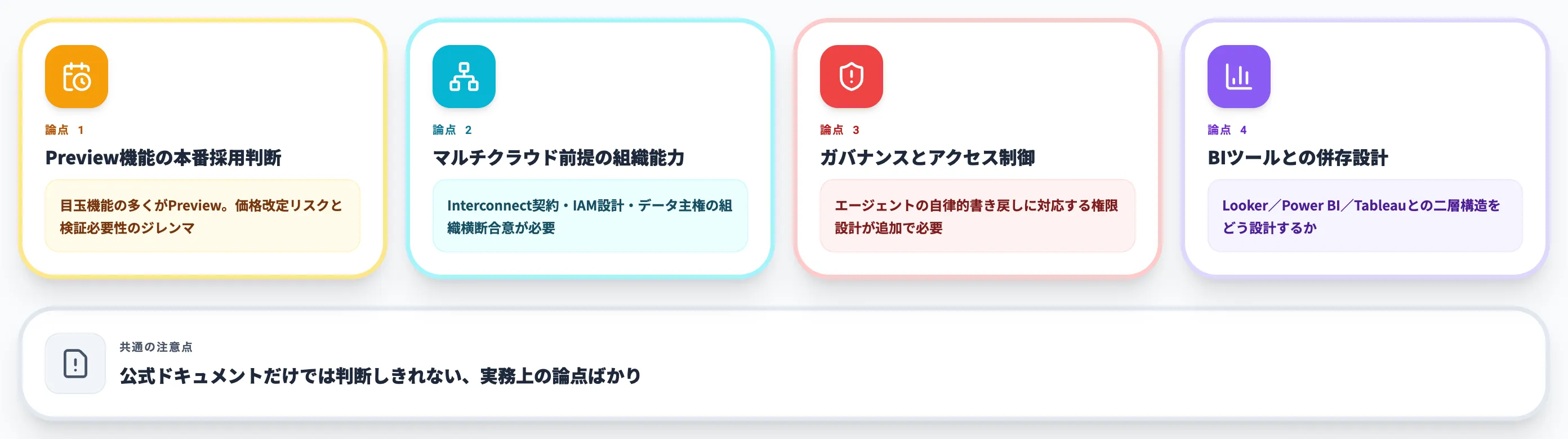
ここでは、実装系記事よりも「導入判断で迷う論点」に焦点を当てて、押さえておきたい4つの論点を整理します。いずれも公式ドキュメントだけでは判断しきれない、実務上の論点です。
Preview機能の本番採用判断

Agentic Data Cloudの新機能群は、2026年4月時点ではPreview段階のものが多く含まれます。Knowledge CatalogのSmart Storage、Spanner MCP、Cross-Cloud Lakehouse、双方向フェデレーションなど、目玉機能の多くがPreviewです。
Previewは仕様変更や価格改定の可能性があるため、本番ワークロードに直接乗せるのは原則として避けます。
一方、「Preview段階で検証を始めないとGA時点で他社に遅れる」というジレンマもあります。実務では、Preview機能をPoC(概念実証)と内部ツールに限定し、四半期ごとに提供状況を見直して本番化を判断する運用が現実的です。
マルチクラウド前提の組織能力
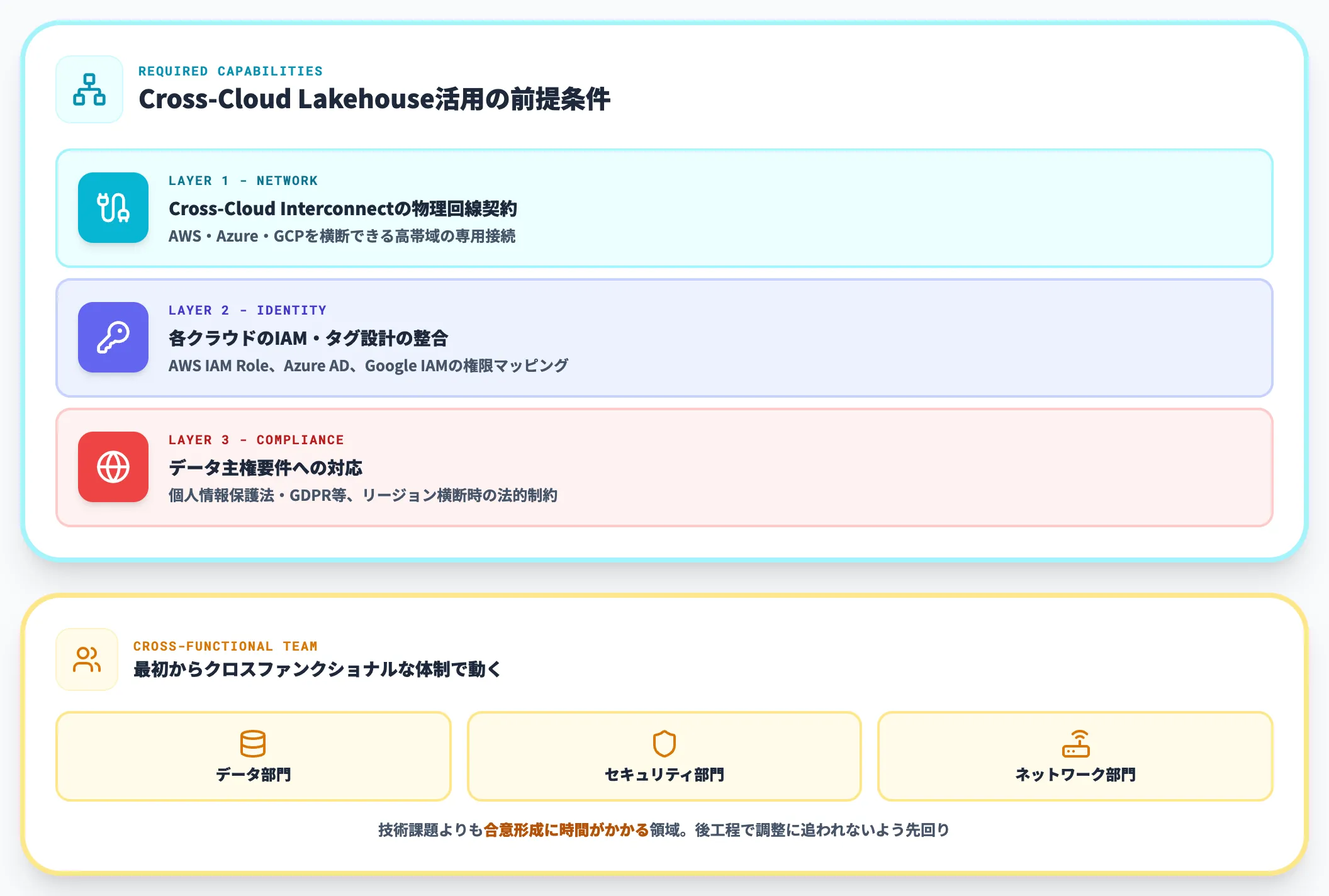
Cross-Cloud Lakehouseの恩恵を享受するには、AWS・Azure・GCPを横断できるネットワーク構成と権限設計が前提となります。具体的には、Cross-Cloud Interconnectの物理回線契約、各クラウドのIAM・タグ設計の整合、データ主権要件への対応などが必要です。
これらは技術的な難しさよりも組織横断の合意形成に時間がかかる領域です。
データ部門だけで進めると、後工程でセキュリティ部門・ネットワーク部門との調整に時間がかかるため、最初からクロスファンクショナルな体制で動くことを推奨します。
ガバナンスとアクセス制御

エージェントが自律的にデータへ書き戻すようになると、従来の人間ユーザー向けの権限設計では事故が起こりやすくなります。エージェントごとのサービスアカウント設計、書き戻し先テーブルの限定、監査ログの保管期間といった追加の設計が必要です。
Knowledge Catalogのアクセス制御連動検索(IAM aware search)は、こうした要件を満たす土台になりますが、設定そのものは利用側が責任を持って設計する必要があります。
エージェントに対して「読み取り専用」「特定スキーマのみ書き込み可」のロールを明示的に分けるのが基本パターンです。
Looker・Power BI・Tableauとの併存設計
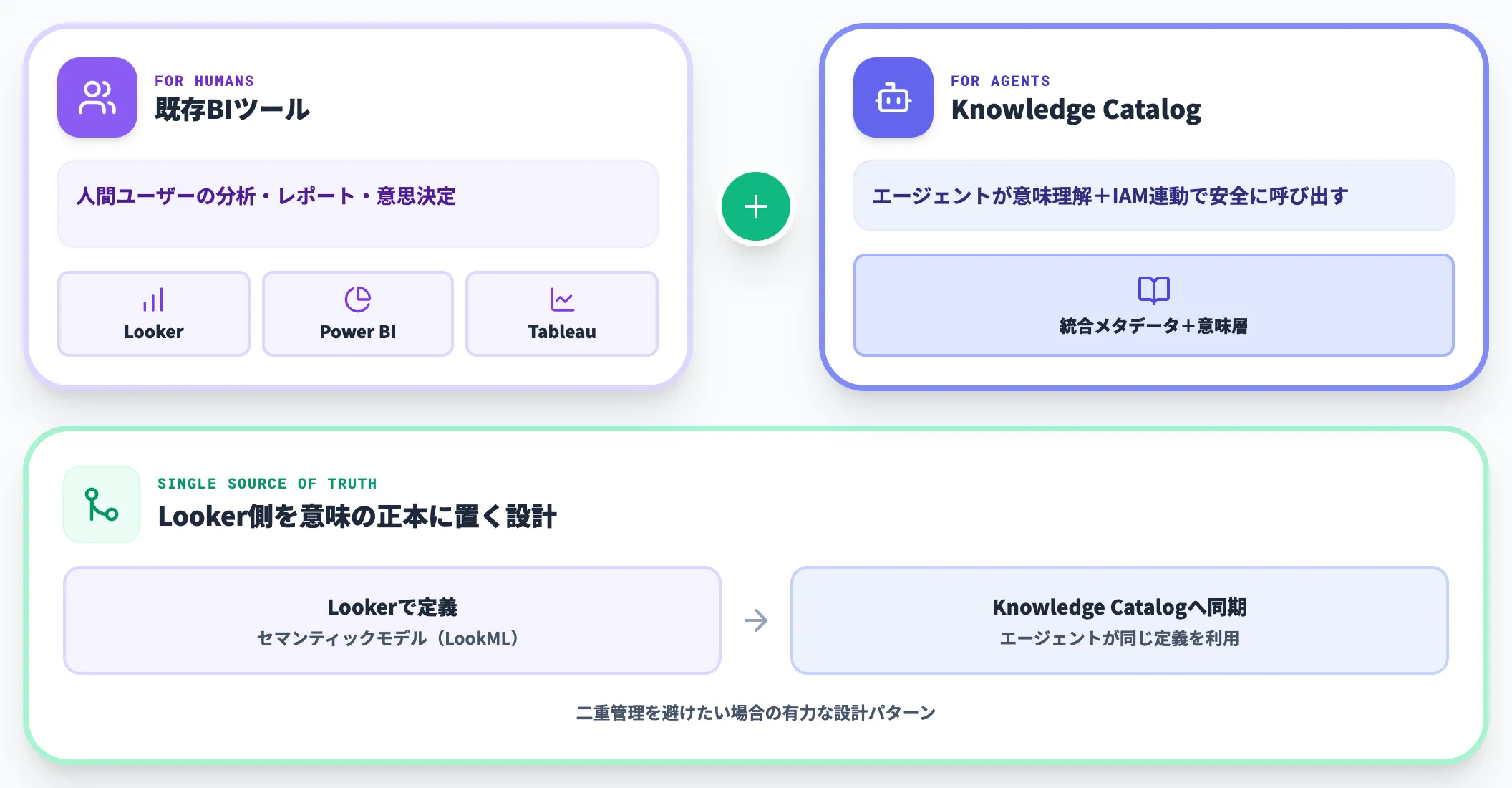
既存のBIツール資産(特にLookerやPower BI、Tableau)は、人間ユーザー向けには引き続き重要です。エージェント向けにはKnowledge Catalogを使い、人間向けには従来のBIをそのまま運用する「二層構造」がしばらく続くと予想されます。
Looker側で定義したセマンティックモデルをKnowledge Catalogに同期する仕組みも提供されているため、二重管理を避けたい場合はLookerを意味の正本(Single Source of Truth)に置く設計が有力です。
Agentic Data Cloudの導入ステップ

最後に、実務での導入手順を、3フェーズに分けて整理します。いきなり全機能を使うのではなく、段階的にスコープを広げる進め方が安全です。
フェーズ1:パイロット(4〜8週)
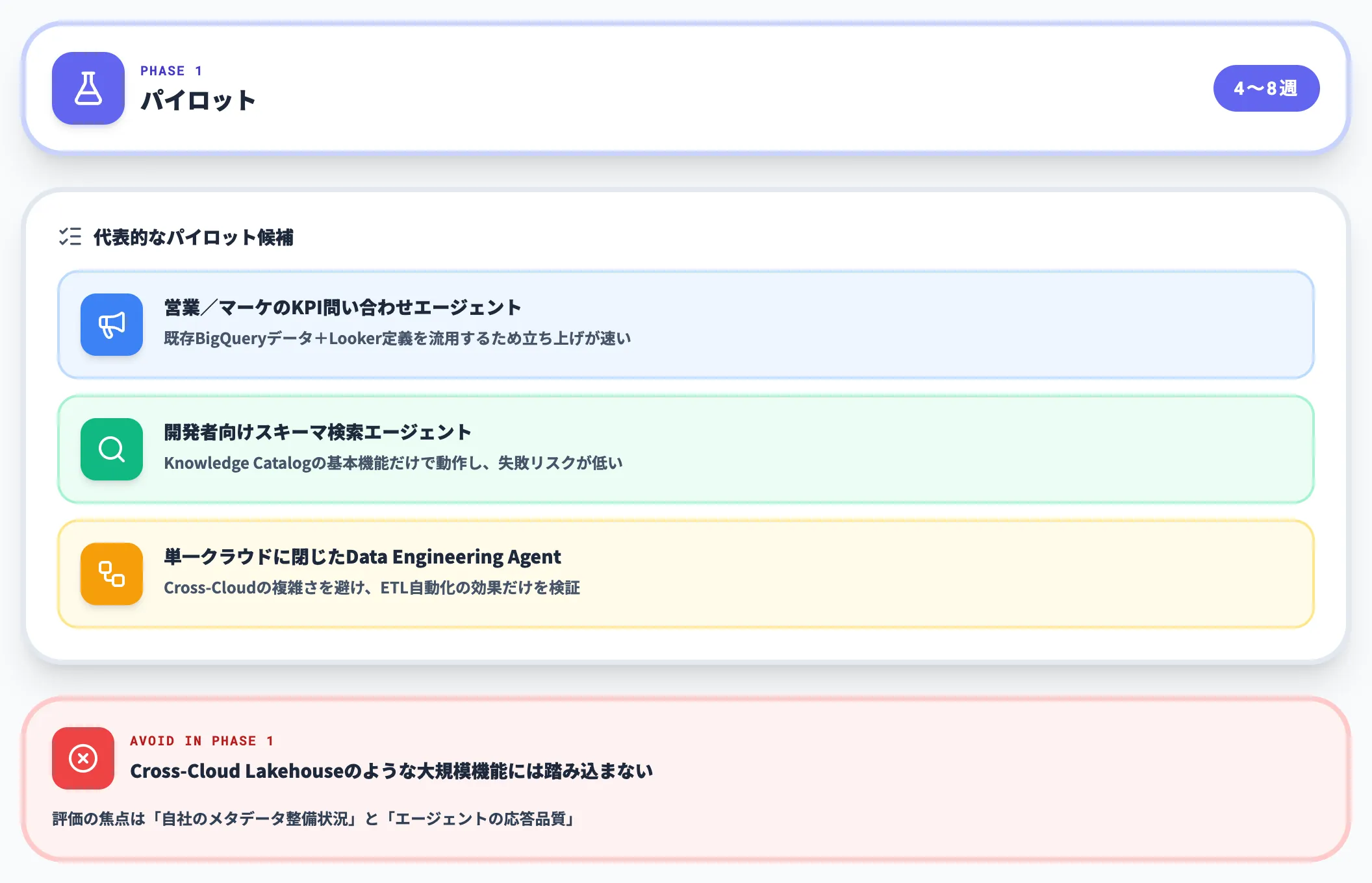
最初のフェーズでは、1〜2のユースケースに絞ってKnowledge CatalogとMCPの動作を検証します。代表的なパイロット候補は以下です。
- 営業/マーケのKPI問い合わせエージェント(既存BigQueryデータ+Looker定義を流用)
- 開発者向けスキーマ検索エージェント(Knowledge Catalogの基本機能のみ)
- 1社のクラウドに閉じたデータパイプラインのData Engineering Agent化
このフェーズでは、Cross-Cloud Lakehouseのような大規模機能には踏み込まず、「自社のメタデータ整備状況」と「エージェントの応答品質」を測ることを優先します。
フェーズ2:段階的展開(3〜6か月)

フェーズ1の成果が見えたら、対象部門を増やし、AlloyDB/Spannerなど運用データベースもMCP経由で接続していきます。並行して、Cross-Cloud Lakehouseが必要なユースケースの設計に入ります。
- 第2部門への横展開(営業→カスタマーサポート→開発、など)
- 運用DBとの接続(AlloyDB MCP、Cloud SQL MCPの追加)
- AWS/AzureデータのCross-Cloud Lakehouse接続検証
- Database Observability Agent(Preview)のステージング適用
展開速度よりも、「既存業務との整合性」を優先するのがコツです。エージェントの誤判断は本番事故に直結するため、各ユースケースで成功条件・失敗時の戻し方を明文化したうえで進めます。
フェーズ3:本格運用とエージェント基盤化(6か月〜)
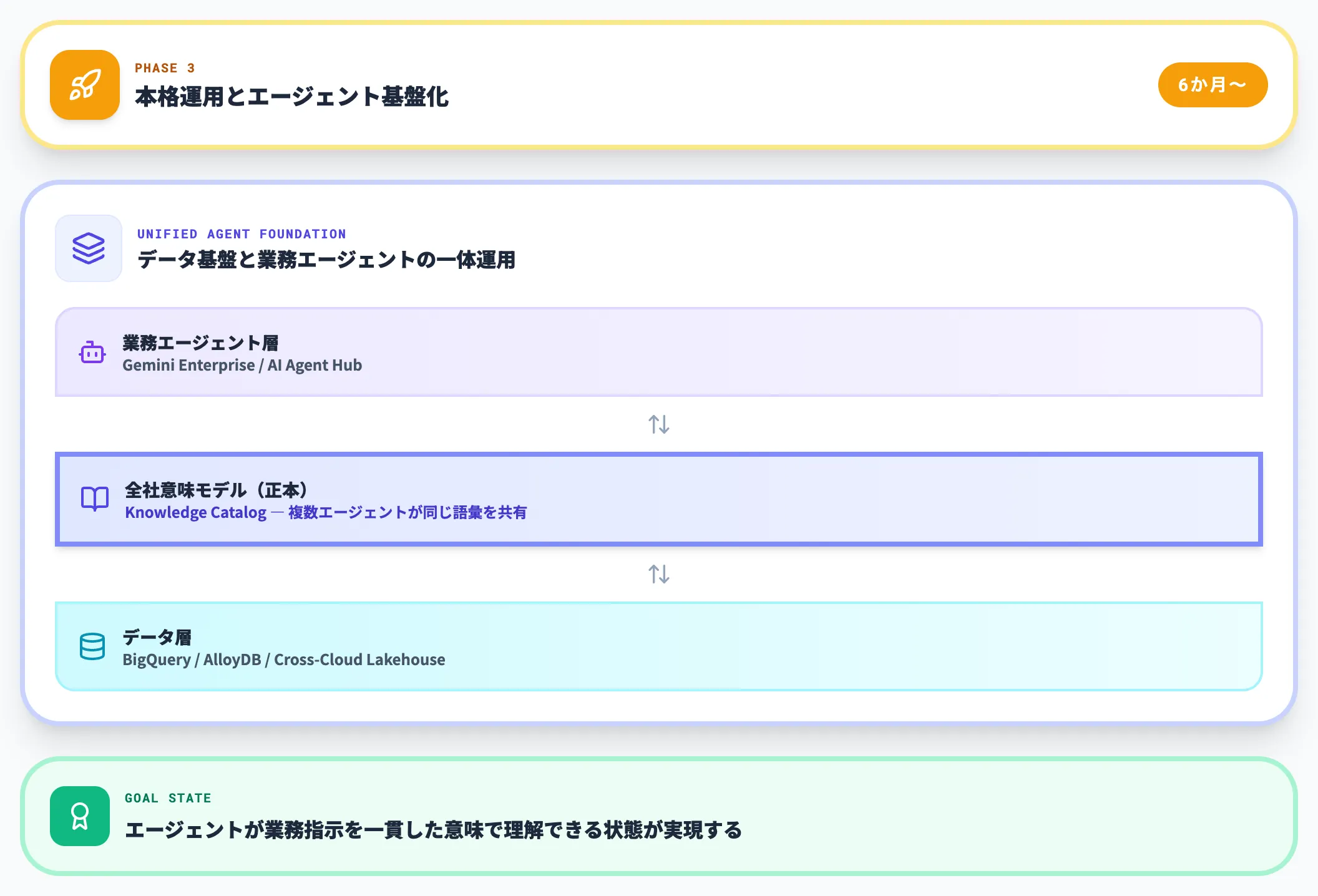
最終フェーズでは、Knowledge Catalogを全社の意味モデルの正本として扱い、複数のエージェントが同じ意味モデルを共有する設計に進みます。同時に、Gemini Enterpriseなど業務側のエージェントHubと統合し、データ基盤と業務エージェントを一体運用する形に移行します。
このフェーズで効いてくるのが、AI Agent Hubのような業務エージェント基盤との連携設計です。データ層で整えた意味モデルを、業務エージェントに同じ語彙で渡すことで、エージェントが業務指示を一貫した意味で理解できる状態が実現します。
point:導入順序の判断軸
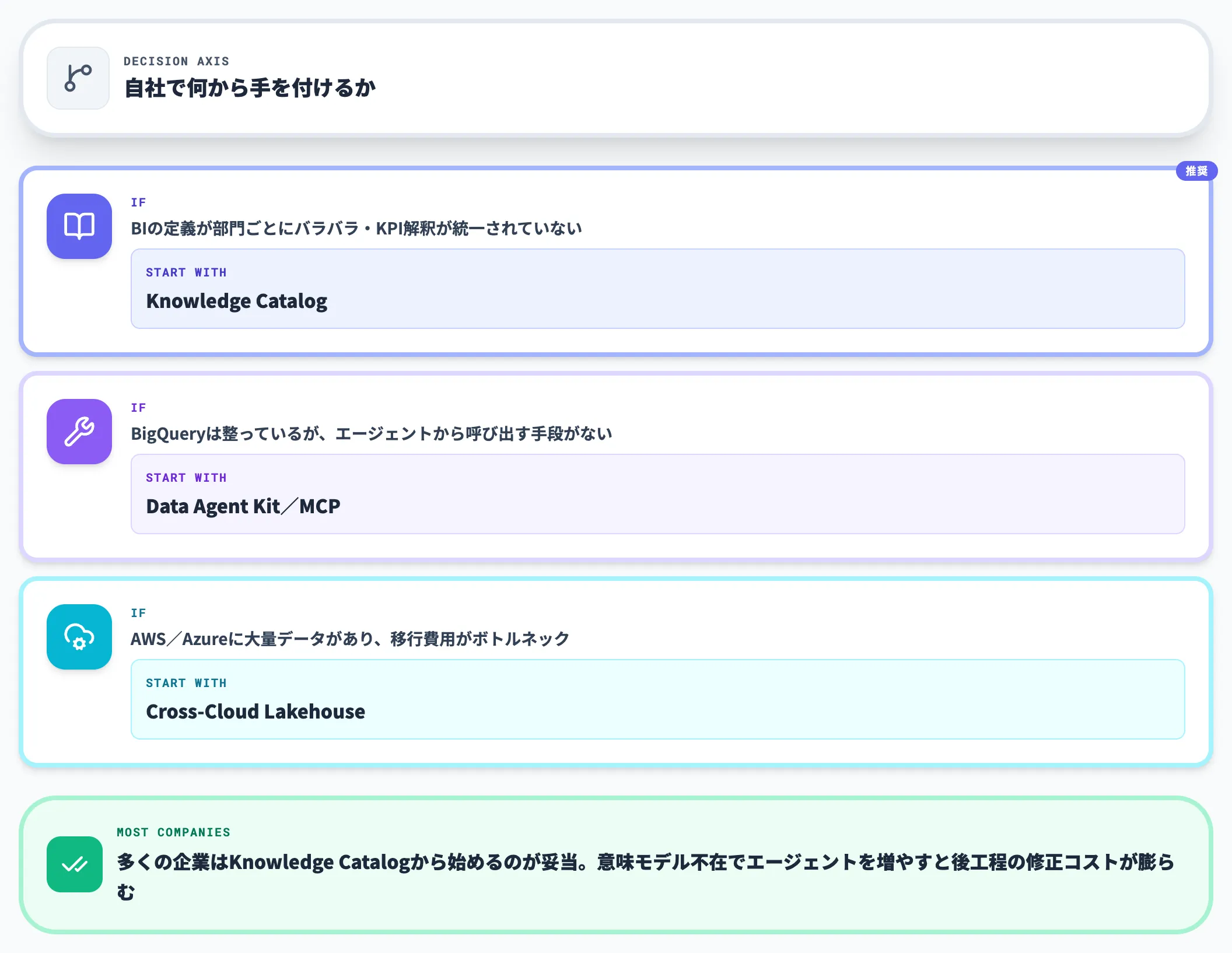
以上のフェーズ設計を踏まえ、自社で何から手を付けるべきかの判断軸を整理します。
- まずKnowledge Catalogから着手すべき組織:BIの定義が部門ごとにバラバラ、KPIの解釈が統一されていない
- まずData Agent Kit/MCPから着手すべき組織:BigQueryは整っているが、開発者がエージェントから呼び出す手段がない
- まずCross-Cloud Lakehouseから着手すべき組織:AWS/Azureに大量データがあり、移行費用がボトルネック
多くの企業はKnowledge Catalogから始めるのが妥当です。意味モデルが揃っていない状態でエージェントを増やすほど、後からの修正コストが大きくなるためです。
Agentic Data Cloudの整備を業務エージェント運用につなぐ
Agentic Data Cloudでデータ基盤を整えた次に問われるのは、その上で業務エージェントをどう動かし続けるかです。Knowledge CatalogとCross-Cloud Lakehouseを整備しても、現場社員が日常業務から自然にAIエージェントを呼び出せる仕組みがなければ、エージェント投資のROIは蓄積しません。データ層と業務層を橋渡しする、業務エージェント運用基盤の設計が鍵になります。
ここで効いてくるのが、AI総合研究所のAI Agent Hubです。Google Cloud(BigQuery)・Microsoft Fabric・AWS S3など複数のデータ基盤と接続可能なエンタープライズ向けAIエージェント内製化プラットフォームとして、Agentic Data Cloudで整備したデータをそのまま業務アクションにつなぐ経路を提供します。
- マルチクラウドのデータ基盤を業務実装まで接続
BigQueryやCross-Cloud Lakehouseで統合したデータを、SAP Concur・freee会計・Dynamics 365などの業務システム連携まで含めた形でAIエージェントに接続する設計を支援します。既存のクラウド戦略を活かしたまま、業務フローへの定着を進められます。
- どこで構築したAgentも1つのダッシュボードで管理
Vertex AI・Copilot Studio・n8nなど開発基盤が分かれていても、実行ログ・アクセス権限・セキュリティスキャンを横断管理。Agent普及に伴うシャドーAIの乱立を構造的に防ぎます。
- データは100%自社テナント内で完結
Azure Managed Applicationsとして顧客テナント内に構築されるため、エージェントが扱うデータや実行履歴が外部に出ることはありません。金融・製造など規制要件が厳しい業界でも、Agentic Data Cloudのガバナンス思想と整合する形で運用できます。
AI総合研究所の専任チームが、Microsoft MVP / Solution Partner認定と600社以上の相談実績をもとに、データ基盤と業務エージェントの橋渡しを伴走支援します。まずは無料の資料で、自社のマルチクラウド環境でAI Agent Hubをどう活用できるかご確認ください。
データ基盤と業務エージェントを一気通貫で

BigQueryのデータを業務アクションに直結
Agentic Data CloudでBigQueryやAlloyDBをエージェント前提で活用するには、データ基盤と業務エージェントを橋渡しする運用設計が欠かせません。AI Agent Hubのサービスページでは、Microsoft Fabric・Google Cloudなど複数のデータ基盤と連携する業務エージェント基盤の全体像と導入ステップを整理しています。
まとめ
Agentic Data Cloudは、Googleが2026年4月のCloud Next 2026で発表した、AIエージェントを前提としたデータ基盤の総称です。Knowledge Catalogによる意味モデル統合、Cross-Cloud LakehouseによるAWS/Azure横断、Data Agent KitによるIDE統合という3本柱で、人間中心のデータスタックをエージェント中心に組み替える設計となっています。
Microsoft Fabricと比較すると、Apache Icebergを軸にしたオープンな設計と、Cross-Cloud Lakehouse(Preview)によってAWS/AzureのIcebergデータをBigQueryから分析できる点が最大の差別化ポイントです。ただし、双方向フェデレーションは対象カタログに限定されたPreview提供のため、本番投入は段階的に進める必要があります。
実務的にはまずKnowledge Catalogから始め、ビジネス用語とKPIの意味を一元化することがエージェント時代の前提条件になります。そのうえで、Data Engineering AgentやMCP連携を通じて開発フローに組み込み、最終的にCross-Cloud LakehouseやAI Agent Hubと連携した業務エージェント運用へと進むのが、現実的な導入順序と言えるでしょう。










