この記事のポイント
 機密データをクラウドに出せない環境でローカルLLMを試すなら、GUI完結のLM Studioが第一候補
機密データをクラウドに出せない環境でローカルLLMを試すなら、GUI完結のLM Studioが第一候補- OpenAI互換APIとMCP対応により、既存のChatGPT連携アプリやAIエージェントをローカルLLMに置き換え可能
- 2025年7月以降は社内業務利用も無料(外部向けSaaS提供等はApp Terms要確認)、EnterpriseはSSO・モデル/MCP統制が要件のケース
- 0.4.15のTensor Parallelism対応で、マルチGPUによる大規模モデル検証・一部運用の選択肢が増えた(本番運用はvLLM等との比較検証が前提)
- 個人検証・PoCはLM Studio、本番APIはDocker・運用エコ重視ならOllama/vLLM(LM Studioもheadlessで常駐運用可)

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
LM Studio(エルエムスタジオ)は、Windows・macOS・LinuxでローカルLLMをGUIから動かせる無料アプリです。
Hugging Face連携によるモデル検索、内蔵チャットUI、PDF・DOCXのRAG、OpenAI互換APIサーバー、MCPサーバー連携までを1つのアプリで完結できる点が支持されています。
本記事では、LM Studioの基本機能と使い方に加え、2025年7月の商用利用無料化、2026年4月のMCP OAuth対応、5月のTensor Parallelism対応、6月のLocally iOSアプリでのLM Link対応(iPhone⇄Mac連携)など、直近のアップデートを2026年6月時点で整理します。
LM Studio EnterpriseやHubのTeam organizationを含む組織利用のオプション、Ollamaとの使い分け判断軸についても、SIerとしての実務観点で解説します。
目次
LM Studioとは?ローカルLLMをGUIで完結させるデスクトップアプリ
LM Studioの主要機能——モデル管理からRAG・API・モバイル連携まで
モデル管理:Hugging Faceから直接検索・ダウンロード
チャット機能:プリセット・コンテキスト・推論パラメータの調整
RAGドキュメントチャット:PDF・DOCXをドラッグ&ドロップで読み込む
OpenAI互換APIサーバー:ChatGPT前提アプリをローカルに切り替える
LM Link:リモートのLM Studioに接続してモデルを共有する
LM Studioのインストールと使い方——5ステップで初回対話まで
エンタープライズ活用——マルチGPU・Hub Team organization・Enterprise
Tensor Parallelismでマルチ GPUを束ねる(0.4.15〜)
LM Studio HubのTeam organization——チームでプロンプトとモデル設定を共有する
LM Studio Enterprise——SSO・モデル統制・MCPゲーティング
LM Studioとは?ローカルLLMをGUIで完結させるデスクトップアプリ
LM Studio(エルエムスタジオ)は、自分のPC上でオープンソースの大規模言語モデル(LLM)をダウンロード・実行・対話・API公開まで完結できる、無料のクロスプラットフォームGUIアプリです。
開発元はElement Labs(LM Studio)で、Windows・macOS(Apple Silicon含む)・Linuxに対応しています。Hugging Faceなどから取得したオープンモデル(Llama 3/Qwen/Gemma/Phi/DeepSeek/GPT-OSSなど)をワンクリックでロードし、そのままチャットやOpenAI互換API経由で呼び出せます。
LM Studio公式サイトのトップページ。ローカルでLlama / DeepSeek / Qwen / Phiを動かす「Your local AI toolkit」を掲げる
従来、LLMの活用はクラウドAPI前提になりがちでした。LM Studioはモデルのダウンロード・実行・対話・API提供までを手元のPCで完結できる点が核になります。
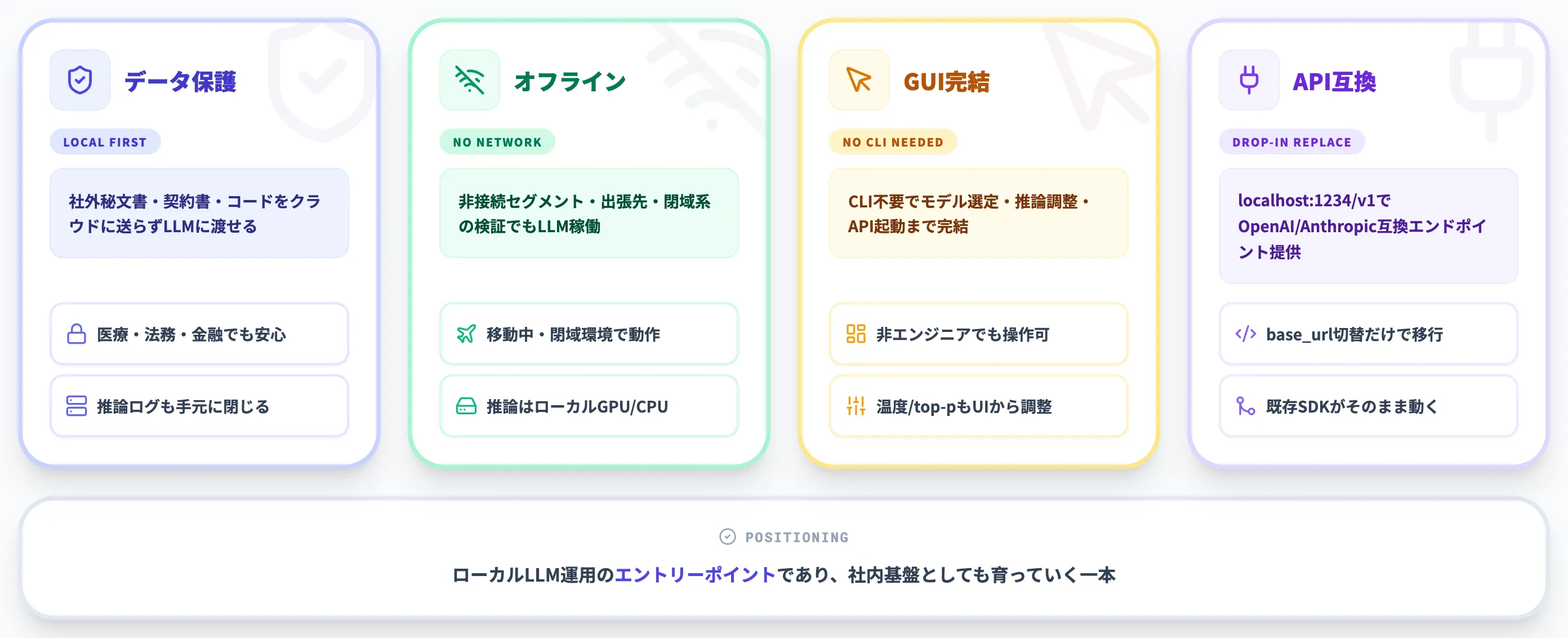
ローカル完結により得られる主なメリットは次のとおりです。「便利そう」で終わらせず、運用観点で効くポイントだけ押さえるのがコツです。
-
データを外に出さない運用
社外秘ドキュメント・契約書・コードレビュー対象を、クラウドに送らないままLLMに渡せます。
-
オフライン利用
ネットワーク非接続のセグメント・出張先・閉域系の検証環境でもLLMを動かせます。
-
GUIで完結する操作性
コマンドライン操作なしでモデル選定・推論パラメータ調整・API起動まで完了します。
もうひとつ押さえておきたいのが、OpenAI互換APIサーバー機能です。LM Studioをサーバーモードで起動すると localhost:1234/v1 でAPIが立ち上がり、OpenAI SDKや既存のChatGPT連携アプリのエンドポイントを切り替えるだけでローカルLLMに置き換えられます。

想定ユーザー像と利用シーン
LM Studioは「ローカルLLMをGUIで触ってみたい人」向けに設計されていますが、ユーザー層は時間とともに広がっています。

- 個人エンジニア・研究者の検証用途
- 機密データを扱う企業のPoC(試作検証)
- 開発チーム内での共通プロンプト基盤
- データを外部に出せない医療・法務・金融の業務利用
当初は個人ユーザーの「触ってみるアプリ」というポジションでしたが、後述するMCP連携・Tensor Parallelism・Enterprise版・HubのTeam organizationの追加により、社内基盤として運用する選択肢にも踏み込んでいます。
2026年で変わった立ち位置
直近6〜12ヶ月の主要な変化を押さえておくと、本記事の読み解きが速くなります。

| 時期 | 変化 | インパクト |
|---|---|---|
| 2025年7月 | 社内業務利用が無料化(外部向けSaaSはApp Terms要確認) | 社内利用に別途ライセンス取得が不要に |
| 2025年(0.3.17) | MCP(Model Context Protocol)対応 | ローカルLLMで社内ツール連携が可能に |
| 2026年2月(0.4.6) | LM Link 追加 | リモートのLM Studioインスタンスへ E2E暗号化接続(Tailscale連携) |
| 2026年4月(0.4.10) | MCP OAuth対応 | 認証付きMCPサーバーとの接続が可能に |
| 2026年4月 | Locally AI買収(4/8発表) | iOS/iPadOS/Mac向けネイティブAIアプリの統合 |
| 2026年5月(0.4.14) | MTP Speculative Decoding安定化 | 対応モデルの生成速度が向上 |
| 2026年5月(0.4.15) | Tensor Parallelismでマルチ GPU対応(CUDA) | マルチGPUで大規模モデルを検証・一部運用する選択肢が増加 |
| 2026年6月(0.4.16) | Locally iOS/iPadOSアプリで LM Link 対応/マルチGPU選択バグ修正 | iPhone/iPadからMacのモデルを呼び出せる構成が完成 |
これらの変化を踏まえると、「LM Studio=個人検証ツール」という以前の整理は古くなっています。商用無料化・MCP対応・マルチGPU・モバイル拡張が組み合わさり、社内PoCから組織内展開まで段階的にスケールできる土台として位置づけ直すのが2026年の見方です。
【関連記事】
ローカルLLMとは?メリットやおすすめモデル、導入方法を解説
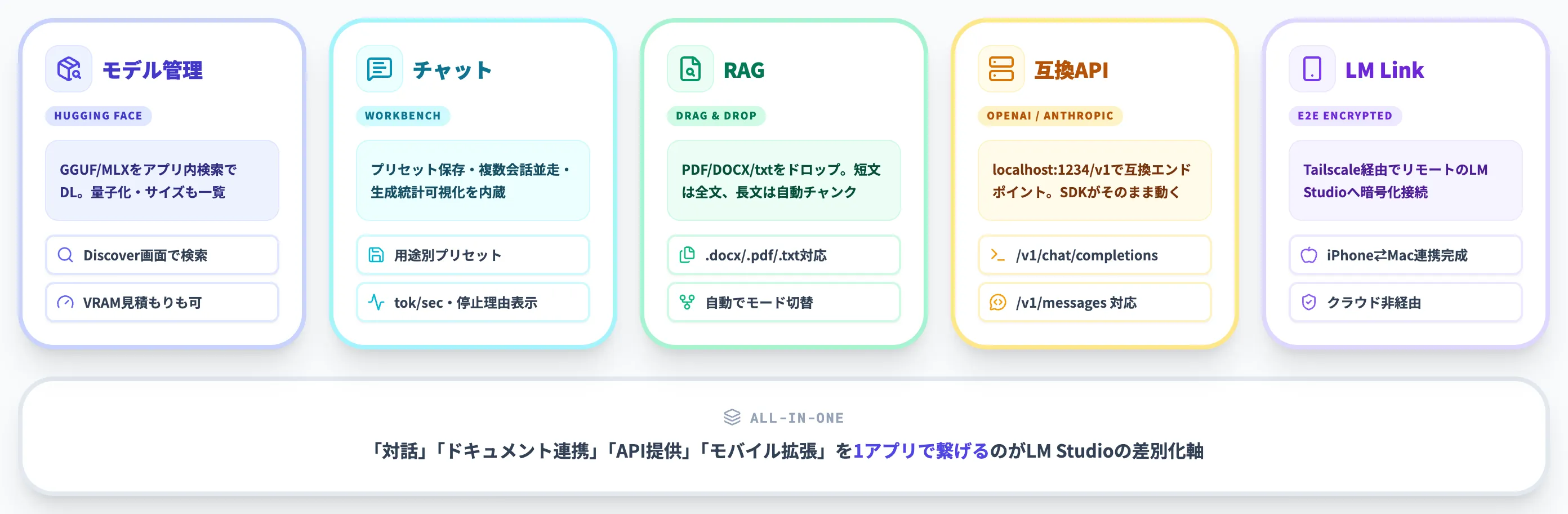
LM Studioの主要機能——モデル管理からRAG・API・モバイル連携まで
ここからは、LM Studioで実際に扱える主要機能を「日常のチャットUI」「ドキュメント連携」「API提供」「モバイル拡張」の4軸で整理します。
LM Studioが他のローカルLLMツール(Ollamaなど)と差別化されているのは、これらの機能をGUI上で繋げて使える点にあります。
LM Studio左サイドバーの主要セクション。チャット/開発者ツール/マイモデル/検索の4つで構成される
サイドバーから見えるとおり、LM Studioは「対話する場所」「API・MCPを管理する場所」「ローカルモデルを管理する場所」「モデルを探す場所」を1つのアプリに収めています。それぞれが何を担当するかを順番に見ていきます。
モデル管理:Hugging Faceから直接検索・ダウンロード
LM StudioはHugging Face上に公開されているGGUF/MLX形式のモデルを、アプリ内検索からそのままダウンロードできます。
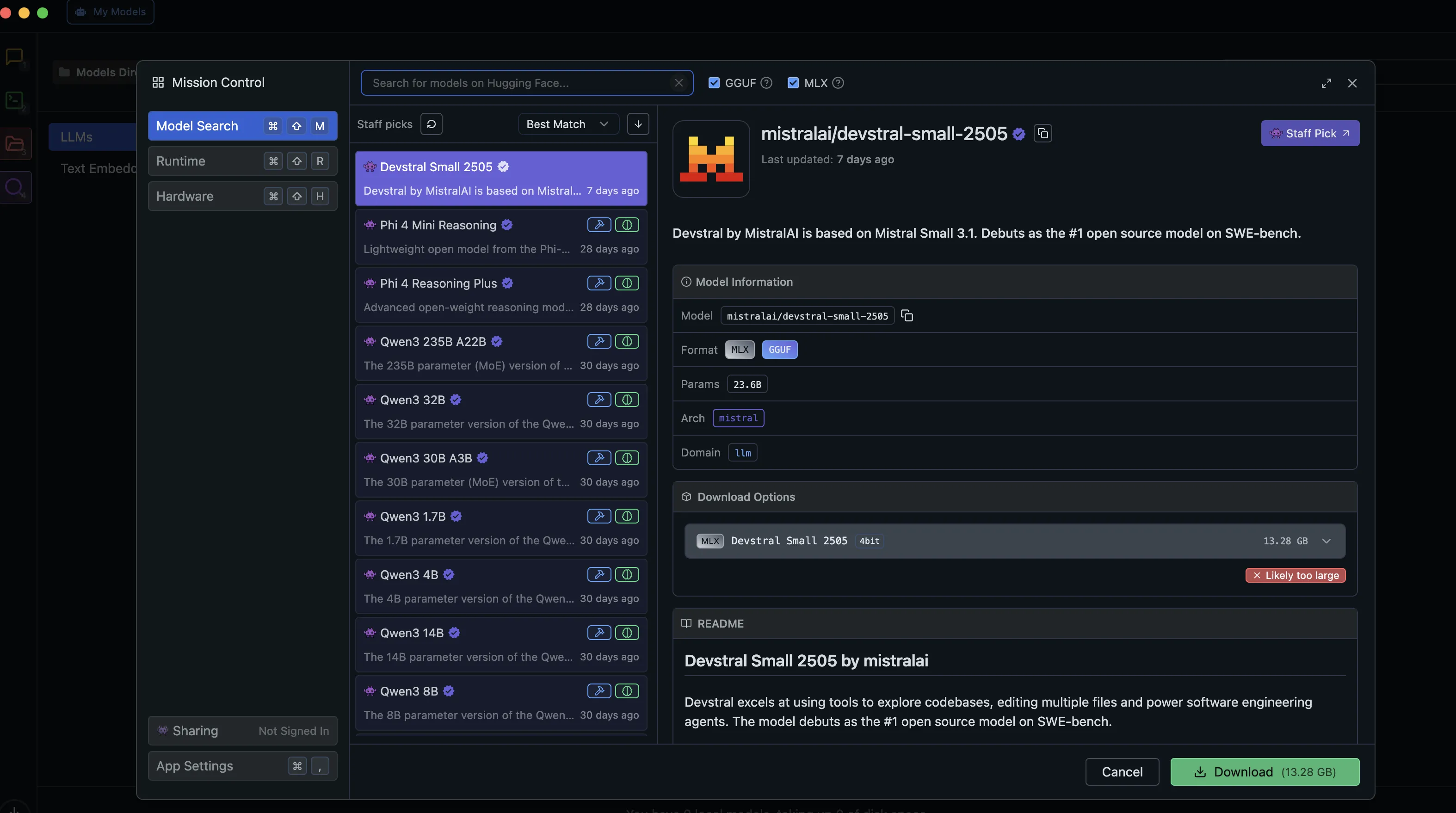
Mission Control内のModel Search。Hugging Faceのモデルカードと量子化バリアントが一覧できる
モデル一覧では、量子化(Q3_K_L/Q4_K_M/Q8など)・パラメータ数・ファイルサイズ・「PCで動くかどうか」の判定(Likely too large等)が同じ画面で確認できる点が便利です。
CLIで操作したい場合は、付属の lms コマンドが用意されています。
- lms ls --variants で多重バリアントのモデル一覧表示
- lms load --estimate-only モデル名 でロード前にGPU・メモリ使用量を見積もり
「PCに乗るかどうかを試す前に見積もれる」のは、検証時間を大きく節約します。GPUが足りないモデルを選んでクラッシュさせる事故が減ります。
チャット機能:プリセット・コンテキスト・推論パラメータの調整
モデルをロードしたあと、内蔵のチャットUIから直接対話を開始できます。
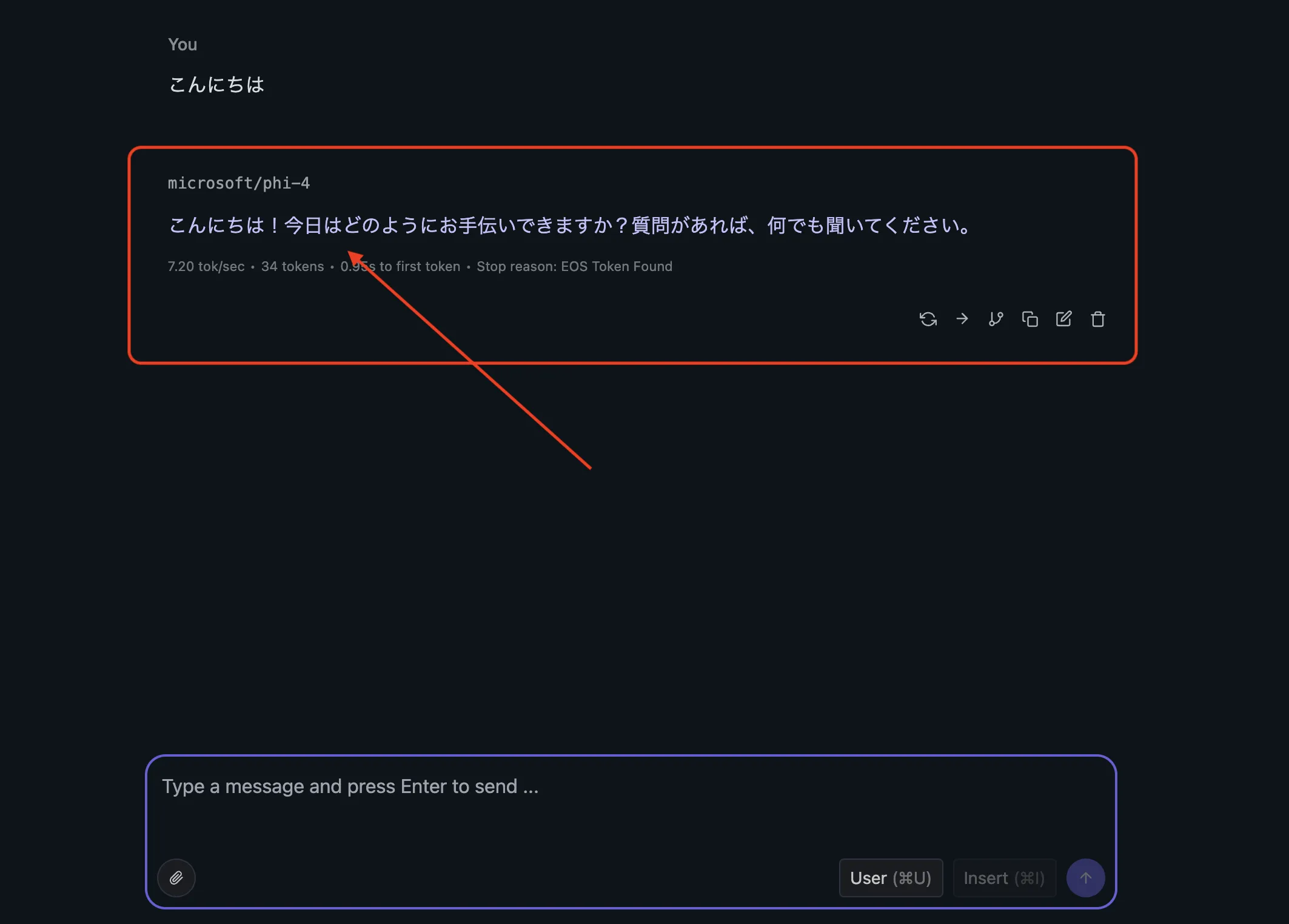
microsoft/phi-4 と日本語で対話している様子。生成速度(tok/sec)・初回トークンまでの時間・停止理由も画面下に表示される
チャット画面では、システムプロンプト・温度(temperature)・top-k/top-p・コンテキスト長などを右ペインから細かく調整できます。
実務的に便利なのは、以下の3点です。
- プリセットの保存: コーディング用・要約用・社内FAQ用などをプリセット化して切り替えられる
- 複数会話の並走: チャットスレッドを複数立ち上げて、別モデルで同じプロンプトを試せる
- 生成統計の可視化: 何tok/secで生成しているか、停止理由(EOS/長さ制限)が見えるため、モデル選定の判断に直結する
「とりあえずチャットできる」を超えて、モデル比較・プロンプト検証のワークベンチとして使えるのがLM Studioの強みです。
RAGドキュメントチャット:PDF・DOCXをドラッグ&ドロップで読み込む
LM Studioは、ローカルドキュメントを参照しながら回答するRAG機能を内蔵しています。
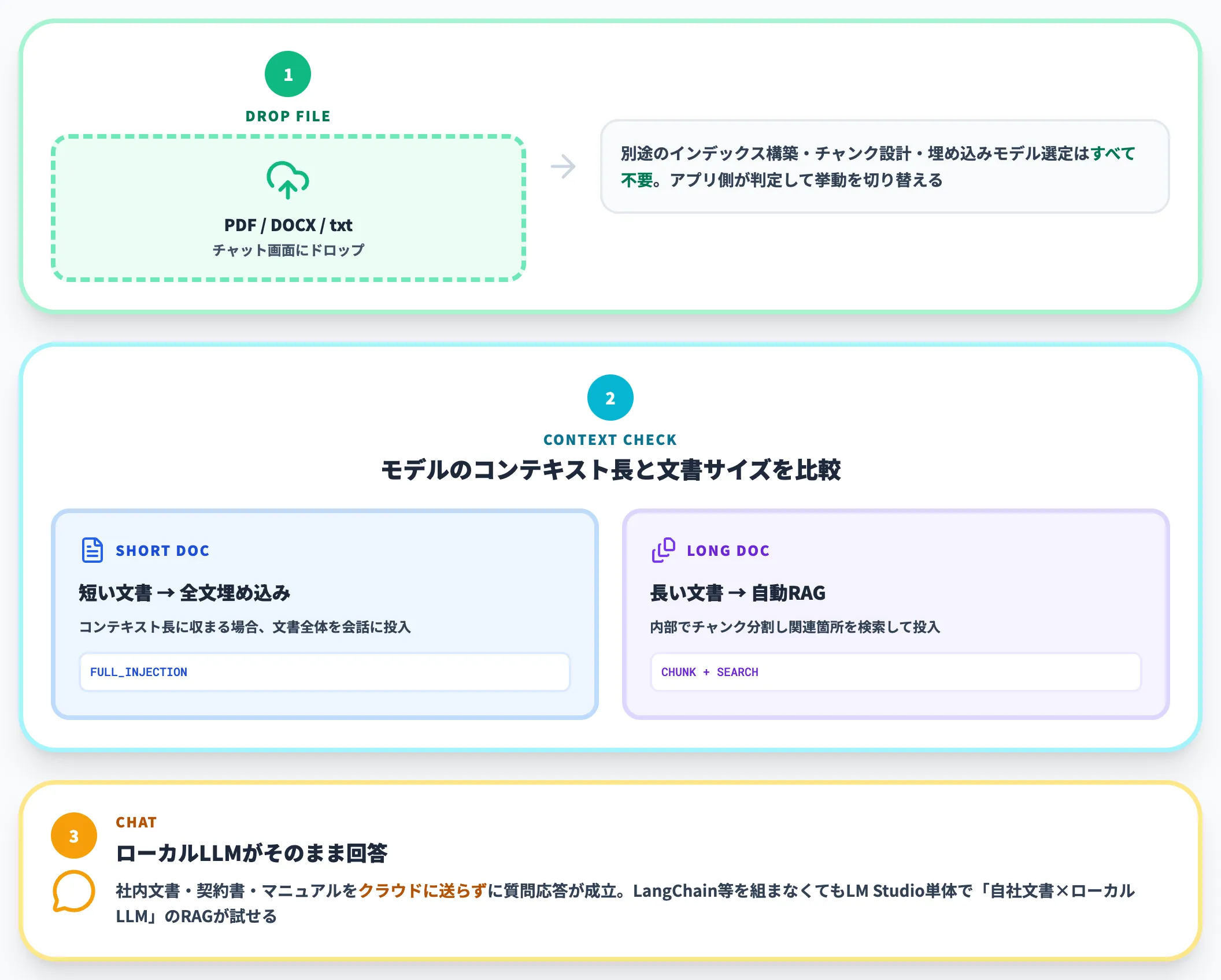
機能のポイントは以下のとおりです。
- 対応形式: .docx/.pdf/.txt(現行公式Docs記載)
- 挙動の自動切り替え: モデルのコンテキスト長に収まる短い文書は全文を会話に埋め込み、長い文書は内部で自動的にチャンク分割+検索(RAG)に切り替える
- ファイル上限: 現行Docsには明示の数値記載がない。旧0.3.0リリースブログでは PDF/.docx の30MB上限への言及があるため、運用時は最新の公式ページで仕様を確認するのが安全
使い方はチャット画面に対象ファイルをドラッグ&ドロップするだけで、別途インデックス構築の作業は不要です。
社内文書をクラウドに置けない領域(医療・法務・金融・行政)では、ローカルで動くRAGは非常に価値があります。LangChain等を組まなくても、まずはLM Studio単体で「自社マニュアル × ローカルLLM」のRAGを試せます。
OpenAI互換APIサーバー:ChatGPT前提アプリをローカルに切り替える
LM Studioをサーバーモードで起動すると、localhost:1234/v1 でOpenAI互換のRESTエンドポイントが立ち上がります。
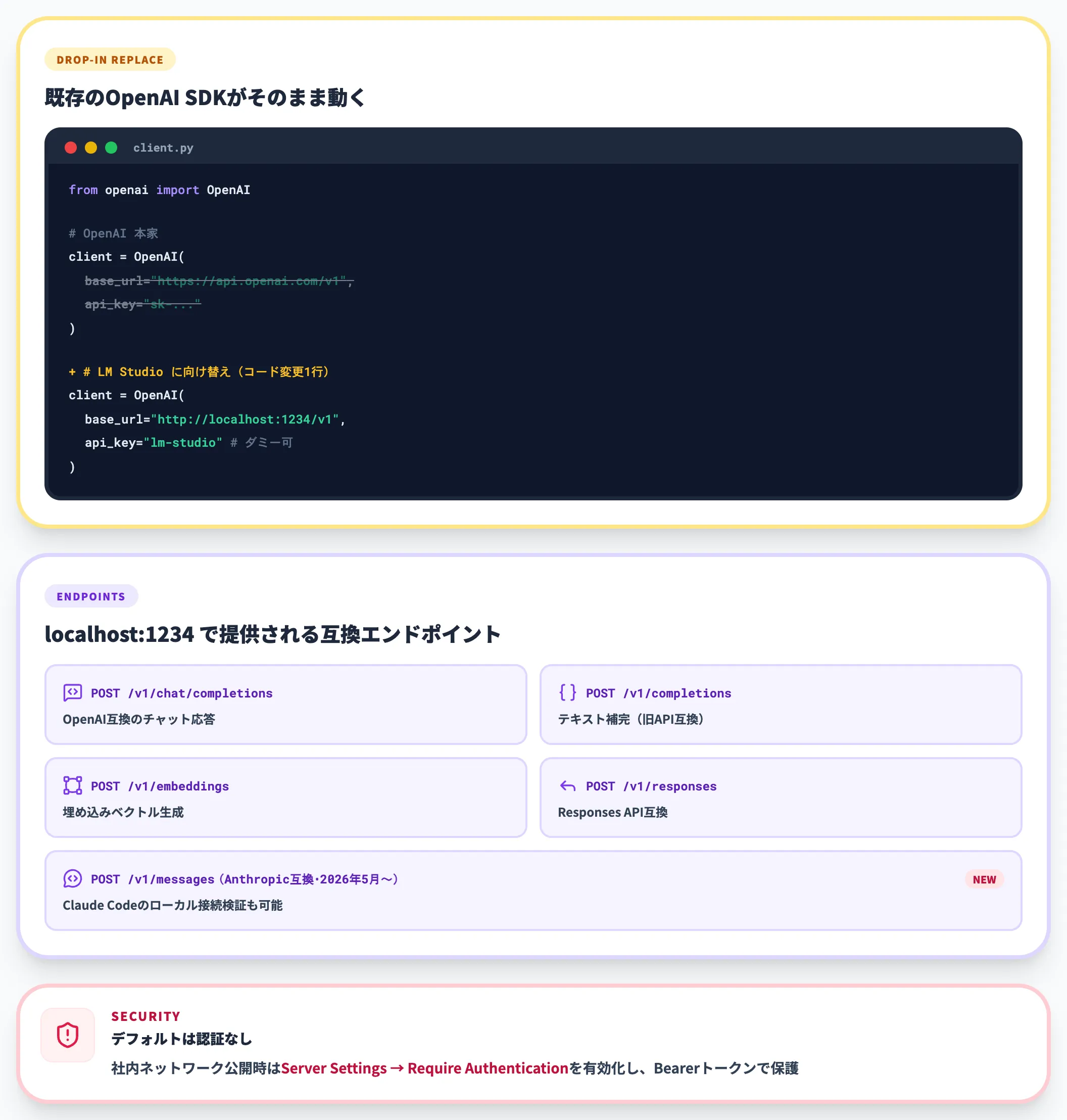
具体的に何が便利かというと、次のような置き換えがコード変更ほぼなしで成立する点です。
- OpenAI SDKの base_url を localhost:1234/v1 に向けるだけで、既存のChatGPT連携アプリがローカルLLMに切り替わる
- /v1/chat/completions・/v1/completions・/v1/embeddings・/v1/responses といったOpenAI互換エンドポイントに加え、0.4.0以降は /api/v1/* 配下のネイティブREST APIも提供
- 2026年5月以降は /v1/messages API(Anthropic互換)でシステムメッセージにも対応し、Claude Codeのローカル接続検証もしやすくなった
OpenAIや Anthropic API で動かしていたエージェントやRAGアプリを、機密データ用途だけローカルLLMに退避させる——という構成が現実的に取れます。/v1/messages 系のAnthropic互換APIは公式Docsを参照してください。
なお社内ネットワークでAPIを公開する場合は、LM Studio APIはデフォルトで認証不要な点に注意してください。Developers Page > Server Settings から「Require Authentication」を有効にしてAPI Tokenを発行し、Authorization: Bearer ヘッダーで保護するのが推奨運用です(認証ドキュメント・0.4.0以降対応)。「Serve on Local Network」を有効化する際は、認証設定とCORS設定も併せて見直しておくと安全です。
LM Link:リモートのLM Studioに接続してモデルを共有する
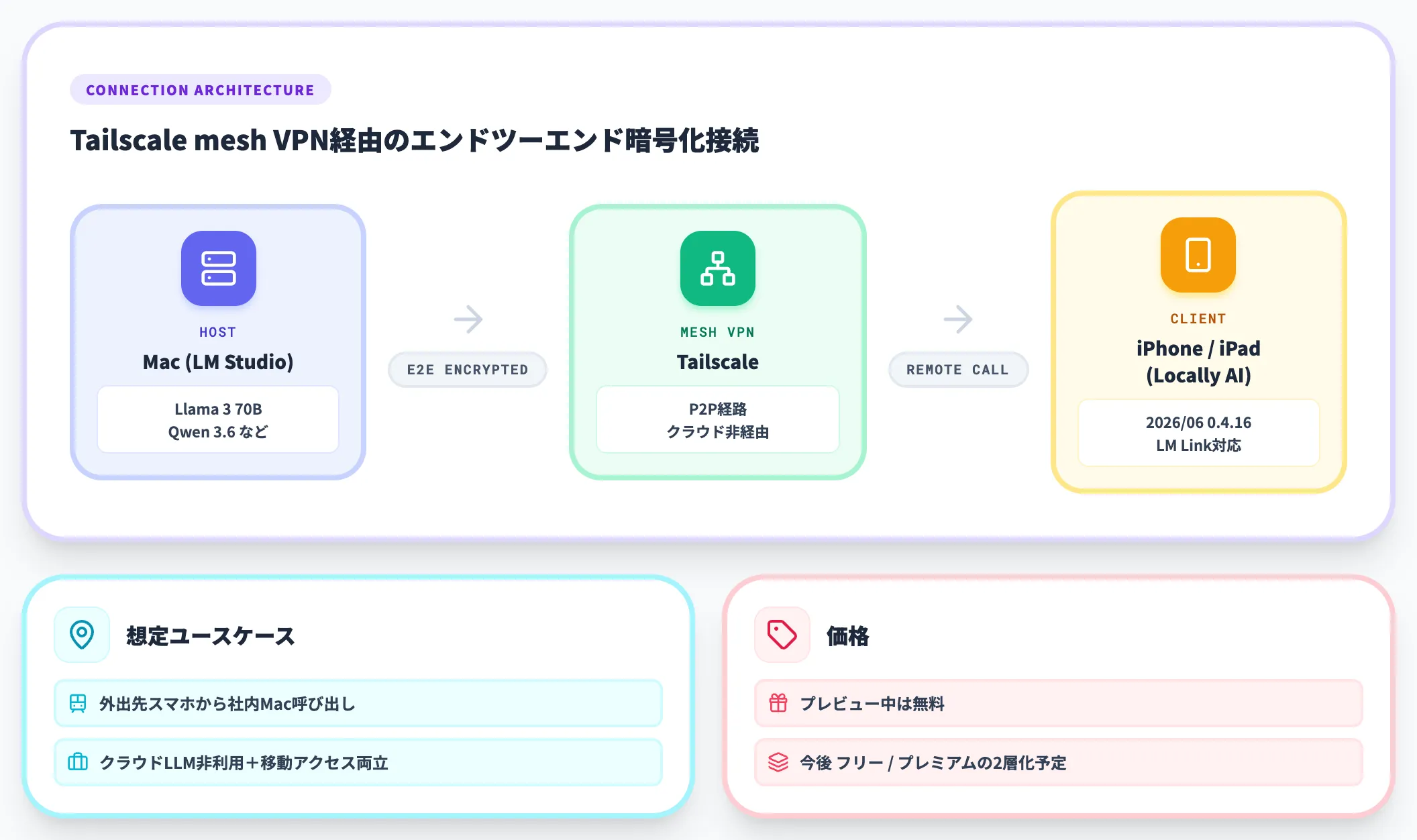
「LM Link」は2026年2月27日リリースのバージョン0.4.6で追加された機能です。別マシンのLM Studioインスタンスにエンドツーエンド暗号化で接続し、リモートのモデルをローカルのように呼び出せます。通信はTailscaleとの連携によるmesh VPNで成立します。
LM Studioは2026年4月8日に、iOS/iPadOS/Mac向けの「Locally AI」アプリを買収しました。Locally AI開発者がLM Studioチームに合流し、複数デバイス間でモデルとエージェントをシームレスに使えるロードマップが示されています。
そして2026年6月4日の0.4.16では、Locally iOS/iPadOSアプリ側でLM Linkに対応しました。これにより、Macで動かしているLM Studio内のモデルをiPhone/iPadから呼び出す構成が揃ったことになります。
接続と通信の構成は次のとおりです。
- 接続: Macの「LM Studio」 ⇄ 別マシンのLM Studio/iPhone・iPadの「Locally AI」
- 通信: カスタムTailscale mesh VPN経由のエンドツーエンド暗号化
- 価格: プレビュー中は無料。今後フリー枠とプレミアム枠の2層構成を予定
外出先のスマホから自宅・社内のMacにあるLlama 3 70BやQwen 3.6を呼び出せる、という使い方が現実的になっています。機密情報を扱う組織にとっては、「クラウドLLMには触らないが、移動中もアクセスはしたい」というニーズへの解として有効です。
LM Studioのインストールと使い方——5ステップで初回対話まで
ここからは実際の導入手順を、推奨スペックの確認から初回対話までの順番で整理します。後段のセクションで紹介するMCP連携やTensor Parallelismも、まずはこの基本セットアップが前提になります。
推奨動作スペック
公式のシステム要件と、モデルサイズ別の実務目安を分けて整理します。動かしたいモデルのサイズで必要メモリが大きく変わるため、実務目安は参考値として読んでください。
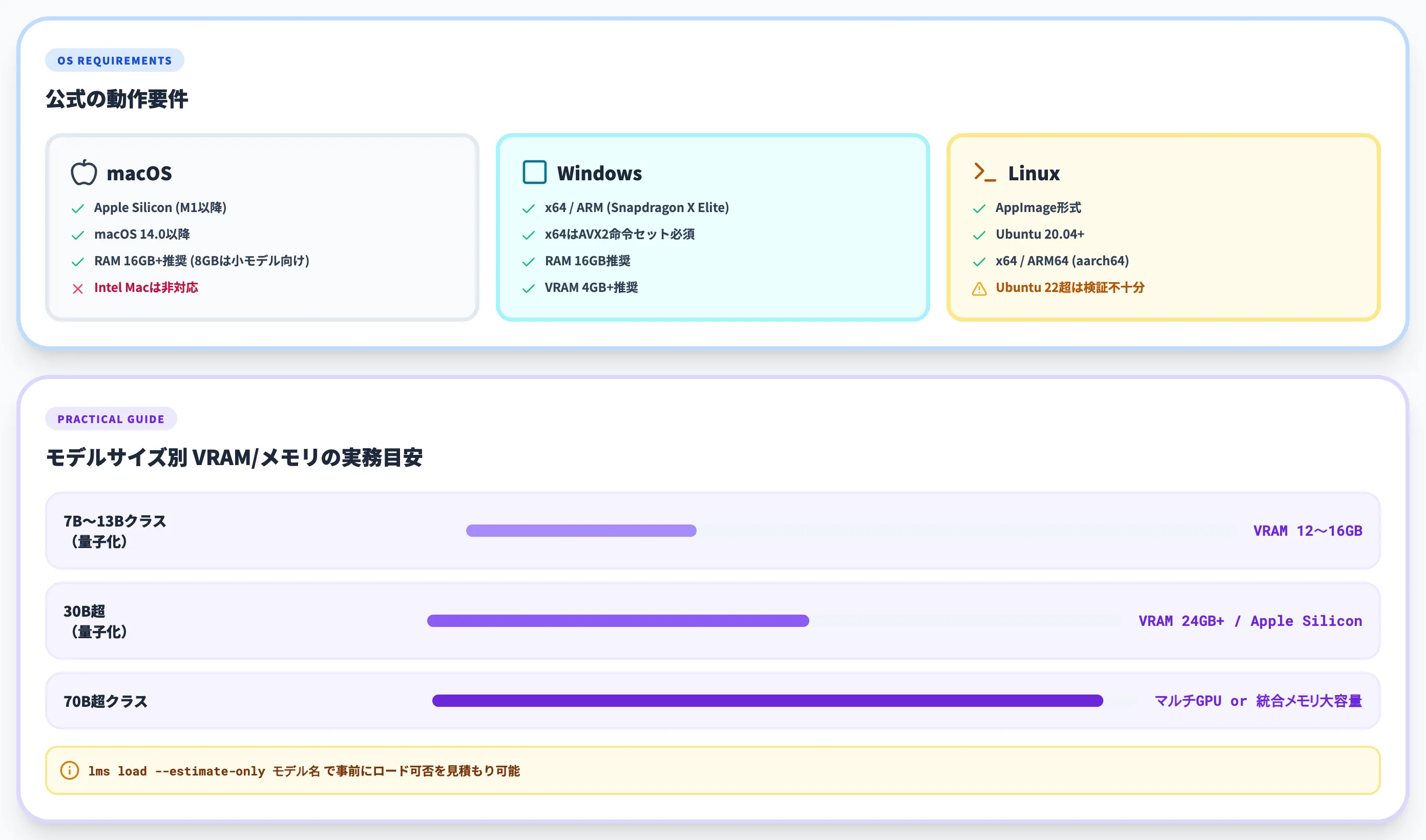
以下の表で、公式の対応要件を整理しました。
| OS | 公式要件 |
|---|---|
| macOS | Apple Silicon(M1以降)かつ macOS 14.0+。RAM 16GB+ 推奨(8GBは小モデル向け)。Intel Macは非対応 |
| Windows | x64/ARM(Snapdragon X Elite)対応。x64は AVX2 命令セット必須。RAM 16GB 推奨、VRAM 4GB+ 推奨 |
| Linux | AppImage形式。Ubuntu 20.04+。x64/ARM64(aarch64)対応。Ubuntu 22より新しいバージョンは十分には検証されていない |
続いて、モデルサイズ別の実務目安を整理しました。公式が明示しているわけではないため、現場感覚の参考値として扱ってください。
| 動かしたいモデル | VRAM/統合メモリの目安 |
|---|---|
| 7B〜13Bクラスの量子化モデル | VRAM 12〜16GB(CPU推論なら時間がかかる) |
| 30B超の量子化モデル | VRAM 24GB以上、もしくはApple Silicon統合メモリ |
| 70B超クラス | 単一GPUでは厳しい。マルチGPU(Tensor Parallelism)かApple Silicon統合メモリの大容量モデルが射程 |
同じモデルでも量子化レベル(Q3/Q4/Q5など)でメモリ消費が大きく変わります。先述のCLIコマンド lms load --estimate-only モデル名 で事前に見積もるのが安全です。
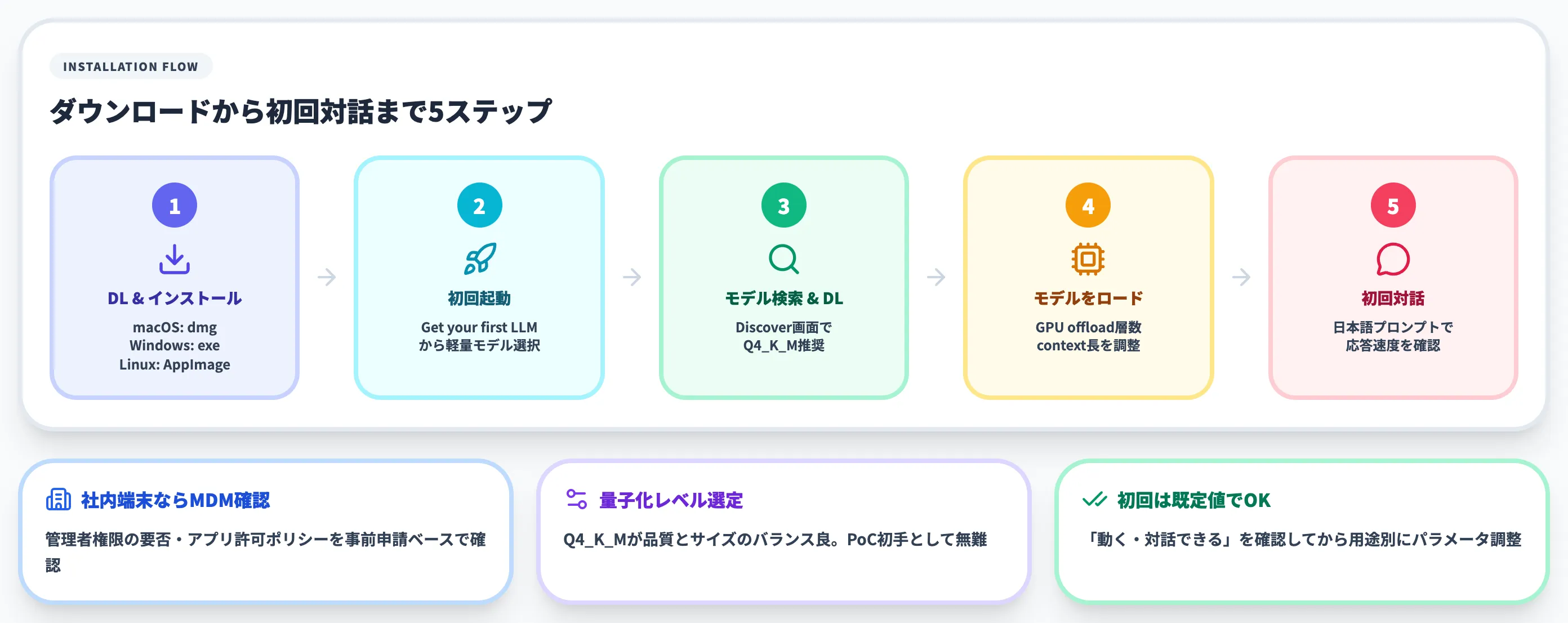
ステップ1:インストーラーをダウンロードしてインストール
LM Studio公式サイトから、自分のOSのインストーラーをダウンロードします。
macOS版のインストール画面。アプリアイコンをApplicationsフォルダにドラッグ&ドロップして完了
macOSはdmgファイルをマウントしてApplicationsへドラッグ、Windowsはexeを実行、Linuxはappimage形式を実行するだけで導入完了します。導入手順自体はシンプルですが、社内端末ではMDM管理・管理者権限の要否・アプリ許可ポリシー(許可リスト方式の場合は事前申請)を必ず確認してください。
ステップ2:初回起動とユースケース選択
インストール後にLM Studioを起動すると、初回ウィザードが起動します。
起動直後の画面。「Get your first LLM」から最初のモデル取得に進む
「Get your first LLM」を押すと、推奨モデルの一覧が表示されます。最初は手元のスペックに収まる軽量モデル(Phi-4・Qwen 3 8B・Llama 3.1 8B等)を選ぶのが安全です。
ステップ3:モデルの検索とダウンロード
サイドバーの検索アイコン(Discover)から、Hugging Faceに公開されているモデルを検索できます。
microsoft/phi-4をダウンロード中の画面。進捗・速度・残り時間が確認できる
Staff Picksタブには公式が推奨するモデルが表示され、「とりあえず外さないモデル」を選ぶ参考になります。
ダウンロード時はバリアント(量子化レベル)の選択が重要です。Q4_K_Mが品質とサイズのバランスが良く、PoCの初手として無難です。
ステップ4:モデルをロードして使う準備
ダウンロード後、画面上部のモデル選択ドロップダウンから対象モデルを選ぶと、ロードが始まります。
microsoft/phi-4を88%ロード中。メモリ使用量(3.62GB / 16GB)・コンテキスト長(4096)・量子化レベル(Q3_K_L)が表示される
ロード時の調整ポイントは以下です。
- GPU offload層数: GPUに乗せる層を調整できる。VRAMギリギリの場合は層数を減らしてCPUへ逃がす
- コンテキスト長: 長文を扱うなら2048→4096→8192へ拡張。ただしメモリを多く消費する
- Flash Attention: 対応モデルなら有効化で推論速度が向上
初回は既定値のままで問題ありません。ロード後の生成速度(tok/sec)を見て、不満があればパラメータを下げる、というアプローチで十分です。
ステップ5:チャット画面で初回の対話を試す
ロード完了後、サイドバーのチャットアイコンから対話を開始できます。「こんにちは」など簡単な日本語プロンプトで応答速度と日本語品質を確認するのが、最初のチェックポイントです。
応答品質に物足りなさを感じた場合は、以下のいずれかが原因です。
- モデル自体の日本語性能不足(→Qwen 3/DeepSeek-V3/Llama 3 Japanese系を試す)
- 量子化レベルが低すぎる(→Q3→Q4→Q5へ上げる)
- プロンプトテンプレートのミスマッチ(→モデル別にテンプレートを切り替える)
初手で完璧を求めず、まずは「動く・対話できる」を確認してから、用途に合わせて段階的に詰めていくのが現実的です。
MCP連携でローカルLLMを社内ツールにつなぐ
2025年に追加されたModel Context Protocol(MCP)対応は、LM Studioを「単なるチャットツール」から「ローカルLLMをエージェント化するハブ」へ引き上げた、最大級のアップデートです。
ここでは仕組み・設定方法・2026年4月のOAuth対応・注意点を順に整理します。
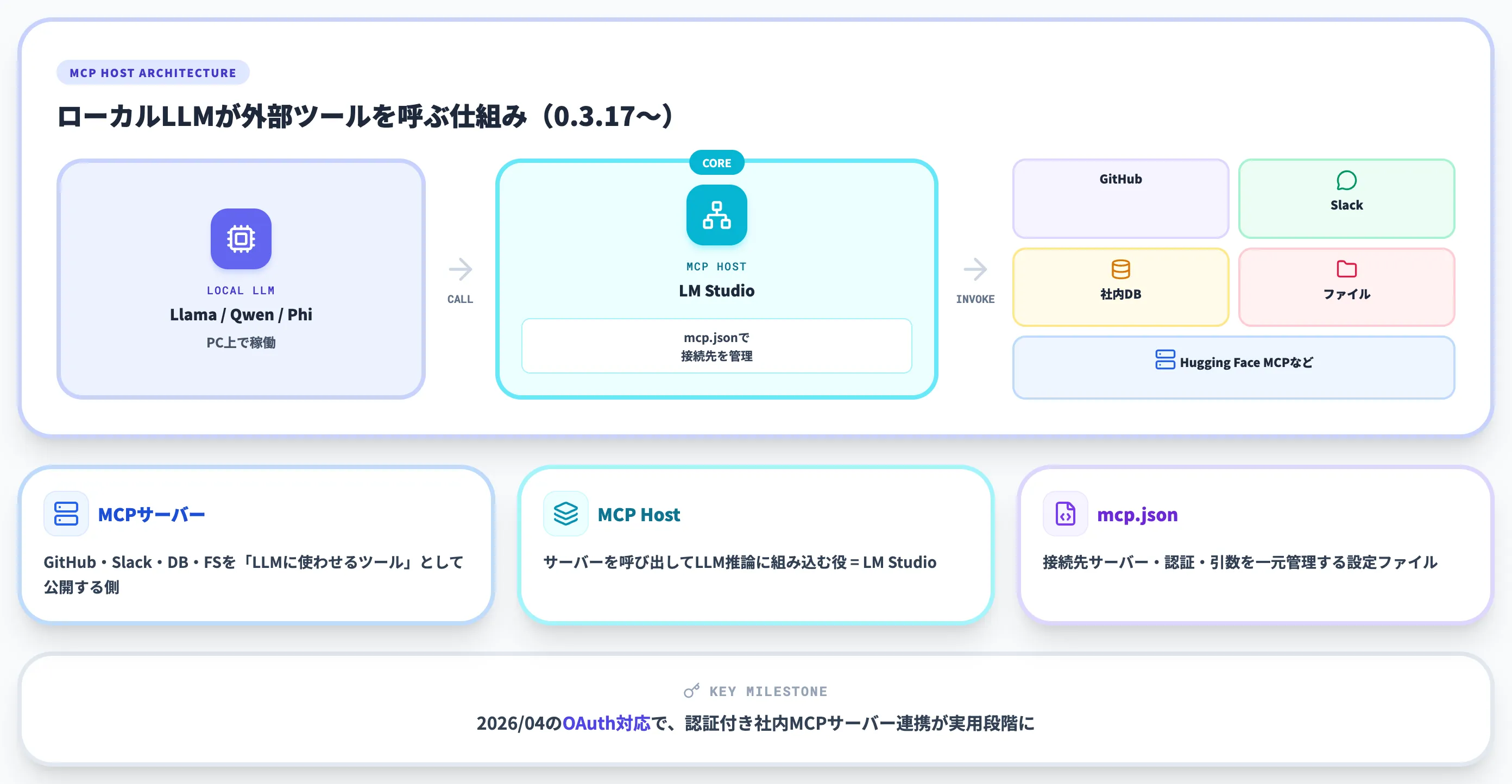
MCP Hostとして動作する仕組み
LM Studio 0.3.17以降は「MCP Host」として動作します。これは、ローカルで動くLLMが外部のMCPサーバー(社内ツール・データベース・API)を呼び出して、関数実行や情報取得ができるという意味です。
仕組みを噛み砕くと以下のとおりです。
- MCPサーバー: GitHub・Slack・社内DB・ファイルシステムなどを「LLMに使わせるツール」として公開するサーバー
- MCP Host: そのサーバーを呼び出してLLMの推論に組み込む役(ここではLM Studio)
- 設定ファイル: 接続先サーバーは mcp.json ファイルで管理
イメージとしては、「ローカルLLMがClaude DesktopやCursorと同じようにMCPサーバーを使える」と捉えると分かりやすいです。
mcp.jsonでサーバーを登録する
設定はLM Studioアプリの「Program」タブ → 「Install > Edit mcp.json」から実施します。記法はCursorの mcp.json と同じで、以下のような形式です。
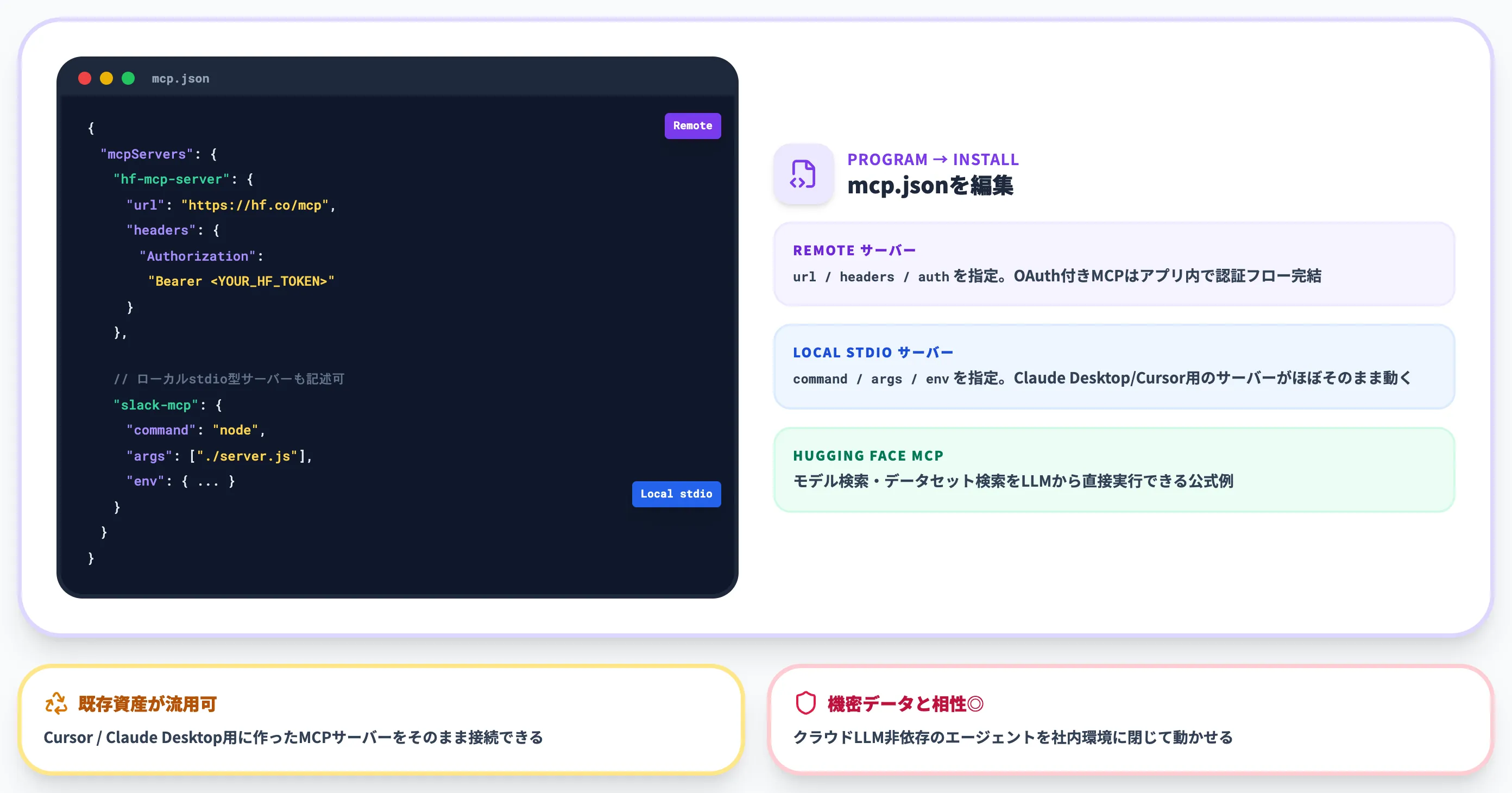
{
"mcpServers": {
"hf-mcp-server": {
"url": "https://hf.co/mcp",
"headers": {
"Authorization": "Bearer <YOUR_HF_TOKEN>"
}
}
}
}
このアプローチの利点は複数あります。
ひとつは、既存のMCPサーバー資産を流用しやすい点です。Claude DesktopやCursor用に作ったMCPサーバーは、transport(リモート/ローカルstdio)と認証方式に応じて、リモートなら url/headers/auth、ローカルstdioなら command/args/env を調整すればLM Studioからも呼び出せます。
もうひとつは、ローカルLLMで完結したエージェント構築が現実的になる点です。クラウドLLMに依存しないエージェントを社内環境に閉じて動かせるため、機密データを扱う業務との相性が良くなります。
公式ドキュメントの例では、Hugging Face MCP Serverが紹介されており、モデル検索やデータセット検索をLLMから直接実行できます。
OAuth対応(2026年4月/0.4.10〜)
2026年4月のバージョン0.4.10でMCPサーバーのOAuth認証に対応しました。これにより、認証付きで運用されている社内MCPサーバー(Slack・GitHub・社内SSO配下のAPI等)にも接続可能になっています。
- 0.4.12(2026年4月17日)でWindows環境のOAuth不具合を修正
- 認証フローはアプリ内で完結し、トークン管理もLM Studio側で行う
「ローカルLLM × 認証付きMCPサーバー」の組み合わせが実用段階に入った、と整理できます。社内システムへの連携を視野に入れる場合、この対応は重要な前提になります。
注意点:信頼できるMCPサーバーだけを入れる
公式ドキュメントは強い注意喚起をしています。
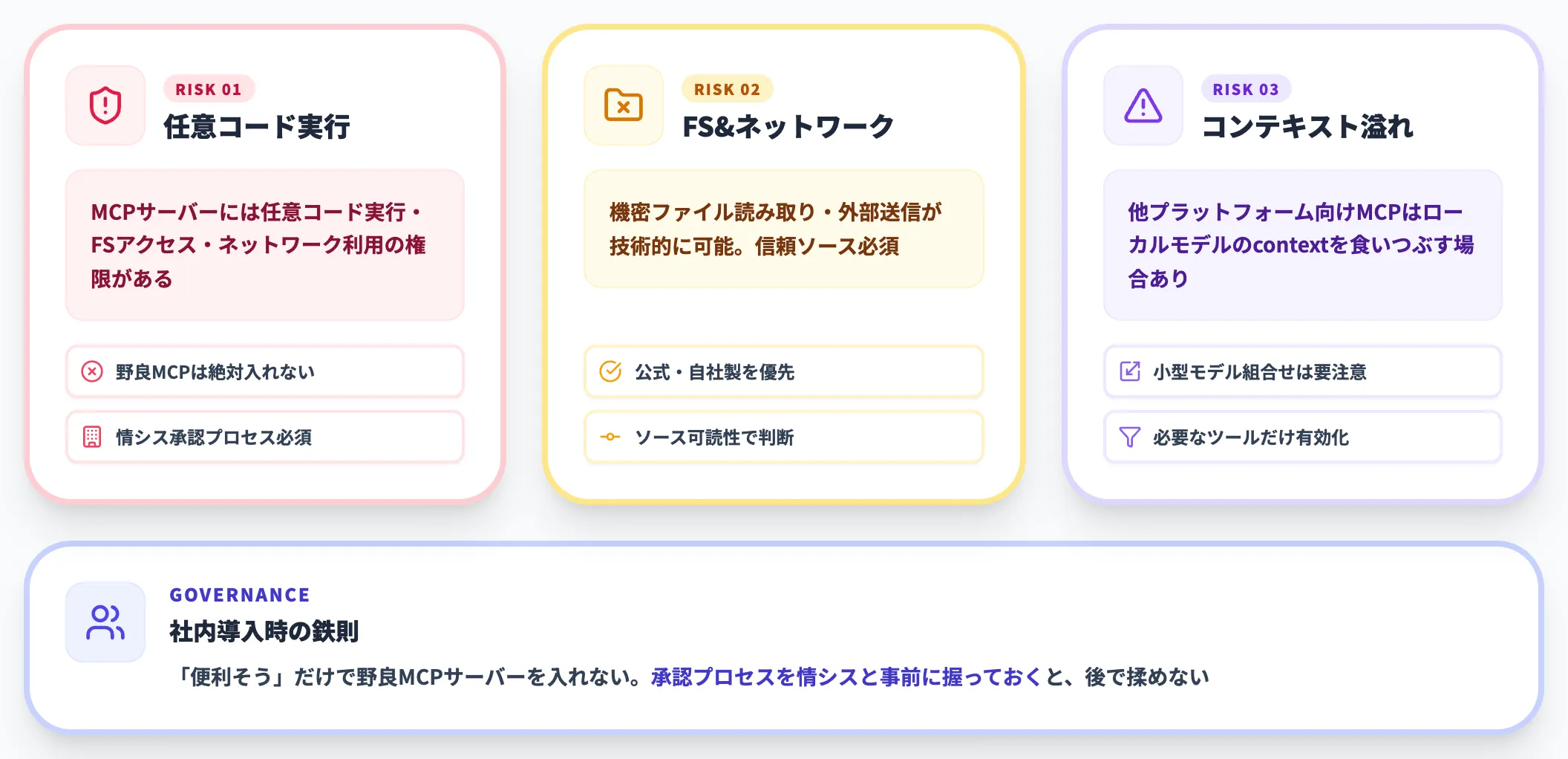
- 任意コード実行・ローカルファイルアクセス・ネットワーク利用が可能な権限を持つMCPサーバーが存在する
- 信頼できないソースのMCPは絶対にインストールしない
- 他プラットフォーム向けに設計されたMCPサーバーは、ローカルモデルのコンテキスト長を消費してオーバーフローを引き起こす場合がある
「便利そう」だけで野良MCPサーバーを入れない、というのは社内導入時のガバナンス上の鉄則です。MCPサーバーの導入承認プロセスを情シスと事前に握っておくと、後で揉めません。
エンタープライズ活用——マルチGPU・Hub Team organization・Enterprise
「個人検証だけのアプリ」だったLM Studioを、組織で本格運用する選択肢が2026年に揃いました。Tensor Parallelism・LM Studio HubのTeam organization・LM Studio Enterpriseの3つを順に見ていきます。

Tensor Parallelismでマルチ GPUを束ねる(0.4.15〜)
2026年5月29日リリースの0.4.15で、Tensor Parallelism(マルチGPU並列推論)に対応しました。これは、1つのモデルを複数GPUに分割して推論する仕組みで、単一GPUのVRAMでは収まらない大規模モデル(70B超など)を扱う選択肢が増えたことを意味します。

主な対応内容は以下のとおりです。
- マルチGPUへのモデルロードに対応(CUDA環境)
- 「Physical Batch Size」高度ロードオプションの追加
- LM Studio Engine Protocol beta 2 を導入
- Claude Codeで発生していたプロンプトキャッシュ問題を修正
これまでマルチGPU推論はvLLMやOllama寄りの領域でしたが、GUIで設定できるマルチGPU推論という選択肢が増えた意味は大きいです。社内のGPUワークステーション(RTX 6000 Ada × 4枚など)でLlama 3 70Bを動かす検証・一部運用の構成が射程に入りました。ただし本番運用に持ち込む場合は、安定性・監視・同時実行性能をvLLM等と比較検証することが前提になります。
なお2026年6月4日リリースの0.4.16では、CUDA 12/ROCm/Vulkan環境の一部で発生していたマルチGPU選択バグの修正も入っています。マルチGPU運用を検討する場合は最新版の利用を推奨します。
LM Studio HubのTeam organization——チームでプロンプトとモデル設定を共有する
LM Studio Hubは、プリセット・プロンプト・モデル構成を共有できる場所です。組織内でプライベートに共有する用途については、2025年7月の公式ブログで「later this month」と予告されており、現行のLM Studio Enterpriseページには「Team organization」を開設する導線が設けられています。最新の機能範囲と価格は公式ページで確認してください。
これまで、社内チームで「同じプロンプトテンプレート」「同じモデル設定」を共有する仕組みは、各自のローカル設定ファイルを手渡しする世界でした。LM Studio Hub上の community presets は公開(public)になる前提のため、社内クローズドな共有を行う場合は Enterprise の Team organization 経由になります。導入時の想定運用は以下のとおりですが、プライベート共有の範囲・正式名称・価格は公式画面または問い合わせで確認してください。
- 部門内で承認済みプロンプトテンプレートを集約
- モデル選定の社内標準を一覧化
- 新規参加メンバーへの引き継ぎを「Hub組織のリンクを共有」で完結
「ローカルLLMの設定はメンバー個人に依存する」という属人化問題を、組織側で巻き取れる構造です。

LM Studio Enterprise——SSO・モデル統制・MCPゲーティング
組織横断でLM Studioを展開する場合は、LM Studio Enterpriseが選択肢になります。エンタープライズ版が個人向け(無料版)と異なる点を整理します。
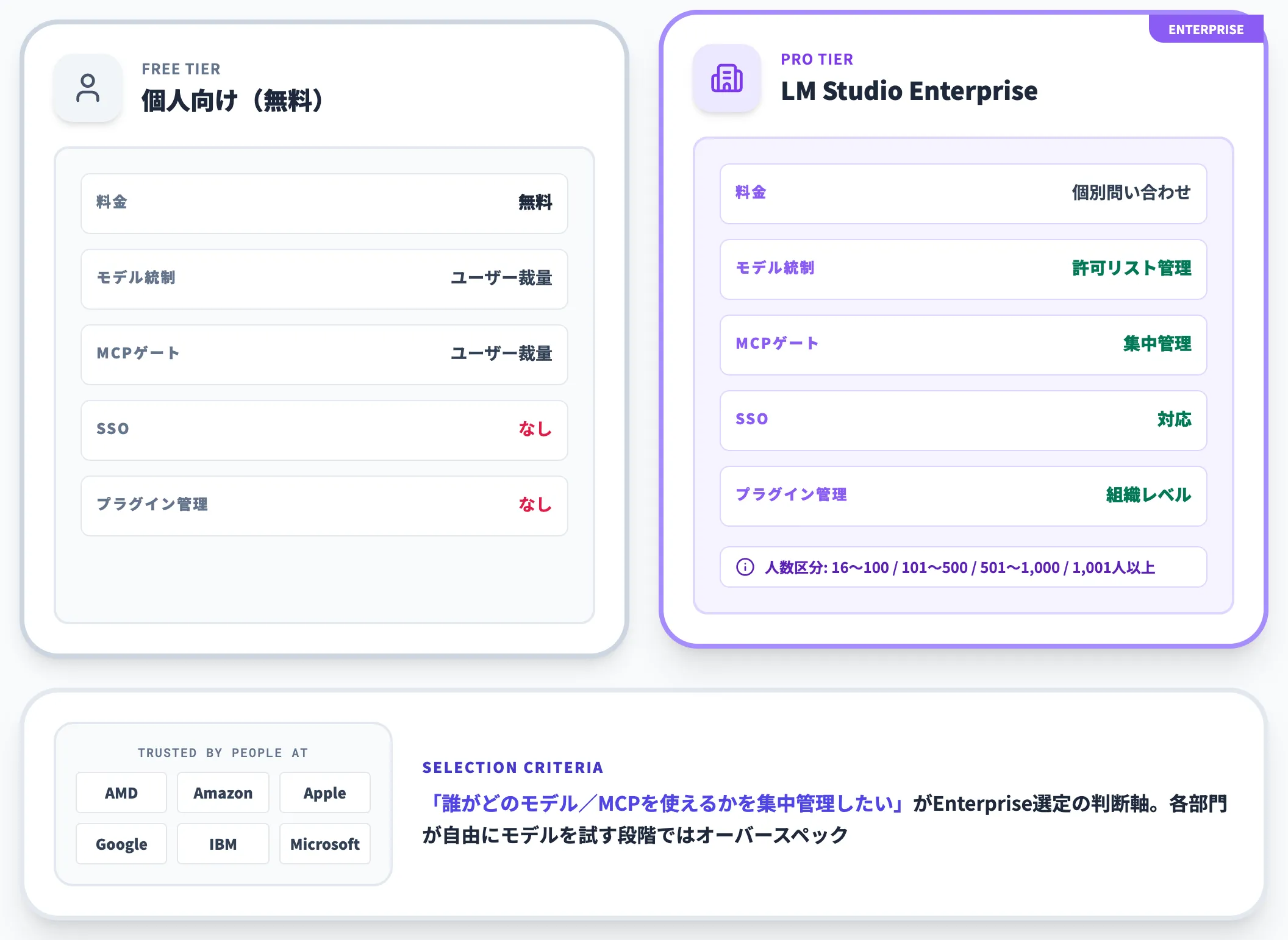
| 項目 | 個人向け(無料) | LM Studio Enterprise |
|---|---|---|
| 料金 | 無料 | 個別問い合わせ |
| 問い合わせ時の人数区分 | 個人〜小規模利用 | 16〜100人/101〜500人/501〜1,000人/1,001人以上の各帯(公式問い合わせフォーム選択肢) |
| モデル統制 | 各ユーザーの裁量 | 管理者がモデルを許可リストで管理 |
| MCPゲーティング | 各ユーザーの裁量 | 管理者がMCPサーバーの利用可否を集中管理 |
| SSO | なし | 対応 |
| プラグイン管理 | なし | プラグインの組織レベル管理 |
| 公式ページの掲載ロゴ例 | - | 「Trusted by people at」として AMD・Amazon・Apple・Google・IBM・Microsoft などのロゴが掲載 |
「組織のローカルAI基盤として、誰がどのモデルを使えるか/どのMCPサーバーに接続できるかを集中管理したい」というニーズが、Enterprise版を選ぶ判断軸です。逆に、各部門が自由にモデルを試したい段階ではオーバースペックになります。
価格は非公開で、想定ユーザー数を伝えて個別見積もりという運用です。導入検討段階ではトライアル相当の構成で評価する流れが一般的です。
ライセンスと商用利用——社内業務利用は2025年7月以降無料
「LM Studioって商用利用できるの?」は最も多い疑問のひとつでした。2025年7月の方針変更を境に、この論点はかなりシンプルになっています。ただし「無料化」の射程は社内利用までであり、外部向けサービスへの組み込みは別ルールが適用される点に注意が必要です。

2025年7月8日に社内業務利用が無料化
LM Studioブログの公式発表により、2025年7月8日以降、LM Studioは個人利用および社内業務利用(personal and / or internal business purposes)が無料となりました。
変更前後を整理すると以下のとおりです。
| 時期 | ライセンス |
|---|---|
| 〜2025年7月7日 | 個人利用は無料。職場・組織利用は別途商用ライセンスの取得が必要 |
| 2025年7月8日〜 | 個人利用および社内業務利用(personal and / or internal business purposes)が無料。フォーム記入・問い合わせ不要 |
つまり、以前あった「企業利用するには事前申請」の手間は完全になくなりました。社内検証から社内本番運用までは、無料で利用できる前提に切り替わっています。
外部向けサービスへの組み込みは別ルール
ここで誤解されやすいのが、「無料化=何にでも組み込んでよい」ではない点です。LM Studio App Termsでは、利用許諾の範囲が「personal and / or internal business purposes」に限定され、以下の用途は明示的に禁止されています。
- SaaS・ASP・service bureau としての提供
- 外部第三者への再配布・サブライセンス・販売・リース
- 改変・派生物の作成・リバースエンジニアリング
つまり、自社の社員がLM Studioを業務で使うのは無料で問題ありませんが、LM Studioを組み込んだサービスを外部顧客に提供する形態(SaaSの基盤として配布する等)はApp Termsで禁止される範囲に入る可能性が高いということです。外部向け商用サービスへの組み込みを検討する場合は、必ずApp Termsの最新版を確認し、必要ならEnterprise版経由でライセンス条件を相談してください。
個人・チーム・Enterpriseの線引き
無料化されたとはいえ、組織展開での選択肢は3段階に整理されます。

- 無料版: 個人・チームの単純利用に十分。フォーム記入・登録一切不要
- LM Studio Hub の Team organization: 組織内でプロンプト・モデル設定を共有する用途。プライベート共有の範囲・価格は公式画面で要確認
- LM Studio Enterprise: SSO・モデル統制・MCPゲーティング・プラグイン管理・プライベート共同利用などの組織統制機能が要件のケース
「ローカルLLM+GUIさえ使えればOK」なら無料版で十分です。Enterpriseが必要になるのは「誰がどのモデル/MCP/プラグインを使えるか」を組織として統制したい段階、あるいはプライベートに共同利用したい段階から、と覚えておくと迷いません。
注意:モデル自体のライセンスは別
ここで混同しがちなのが、LM Studioアプリのライセンスと、LM Studioを通じて動かすモデル本体のライセンスは別物だという点です。
- LM Studio本体 → 社内業務利用は無料/外部向けSaaS・サービス組み込みはApp Terms要確認(2025年7月以降)
- Llama 3 → Metaの利用規約(月間アクティブユーザー数による制限あり)
- Gemma → Googleの利用規約
- Qwen → Alibabaの利用規約
- DeepSeek-V3 → モデルカードに準拠
商用サービスに組み込む場合は、使うモデルのライセンスを必ず確認するのが鉄則です。LM Studioが無料でも、モデル側に制限があれば商用利用に制約がかかります。
LM Studio vs Ollama——使い分けの判断軸
ローカルLLMツールの選択肢としてOllamaとLM Studioはよく比較されます。両者はllama.cppをエンジンに採用しており、GGUF/llama.cpp系では生成速度が近い傾向にありますが、ランタイム版・量子化レベル・GPU backend・MLX有無(LM StudioはApple SiliconでMLXも併用)で実測は環境依存です。設計思想が異なるため、速度より「向く用途」で選ぶのが正解です。
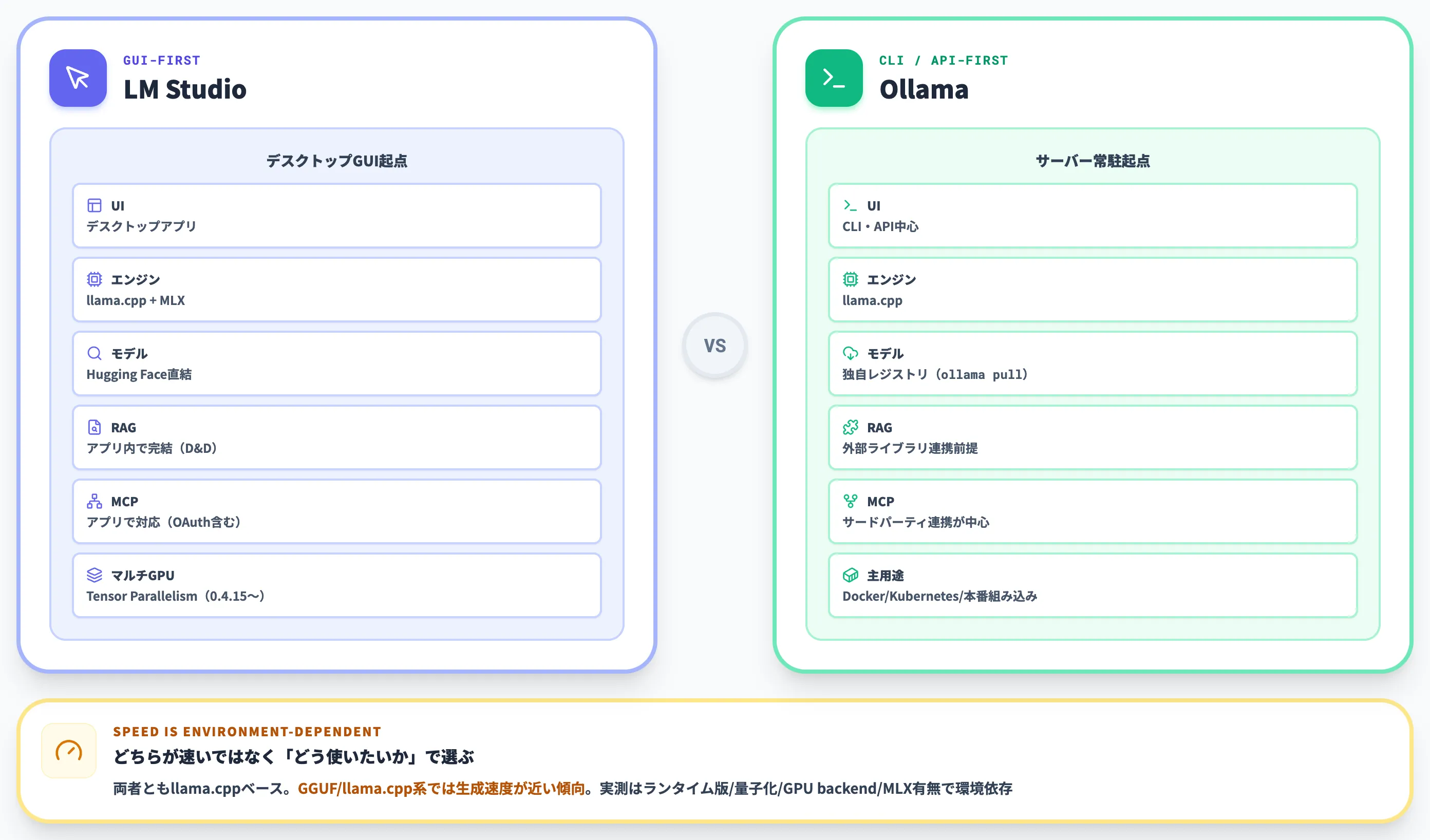
基本性能と設計思想の比較
以下の表で、両者の特性を整理しました。
| 観点 | LM Studio | Ollama |
|---|---|---|
| UI | デスクトップGUI | CLI・API中心 |
| 推論エンジン | llama.cpp + MLX(Apple Silicon併用) | llama.cpp |
| モデル取得元 | Hugging Face直結(Discover画面) | 独自レジストリ(ollama pull コマンド) |
| 起動方式 | デスクトップアプリに加え、llmster/headlessで常駐・Linuxサーバー運用可(0.4.0+) | バックグラウンドサービスとして常駐 |
| APIエンドポイント | localhost:1234/v1 | localhost:11434/v1 |
| マルチGPU | Tensor Parallelism対応(0.4.15〜) | 複数GPU利用は可能なケースあり。Tensor Parallelism相当・同時実行の挙動は実装・設定に依存 |
| RAG | アプリ内で完結(ドラッグ&ドロップ) | 外部ライブラリ連携前提 |
| MCP | アプリで対応(OAuth含む) | サードパーティ連携が中心 |
| 主用途 | 個人検証・PoC・社内RAG | 開発者統合・サーバー常駐・本番組み込み |
同じllama.cppベースなので「どちらが速い」ではなく、「どう使いたいか」で選ぶのが正解です。
ケース別の使い分け(SIerの視点)
AI総合研究所のローカルLLM導入支援の経験から、ケース別の使い分けは次のように整理できます。
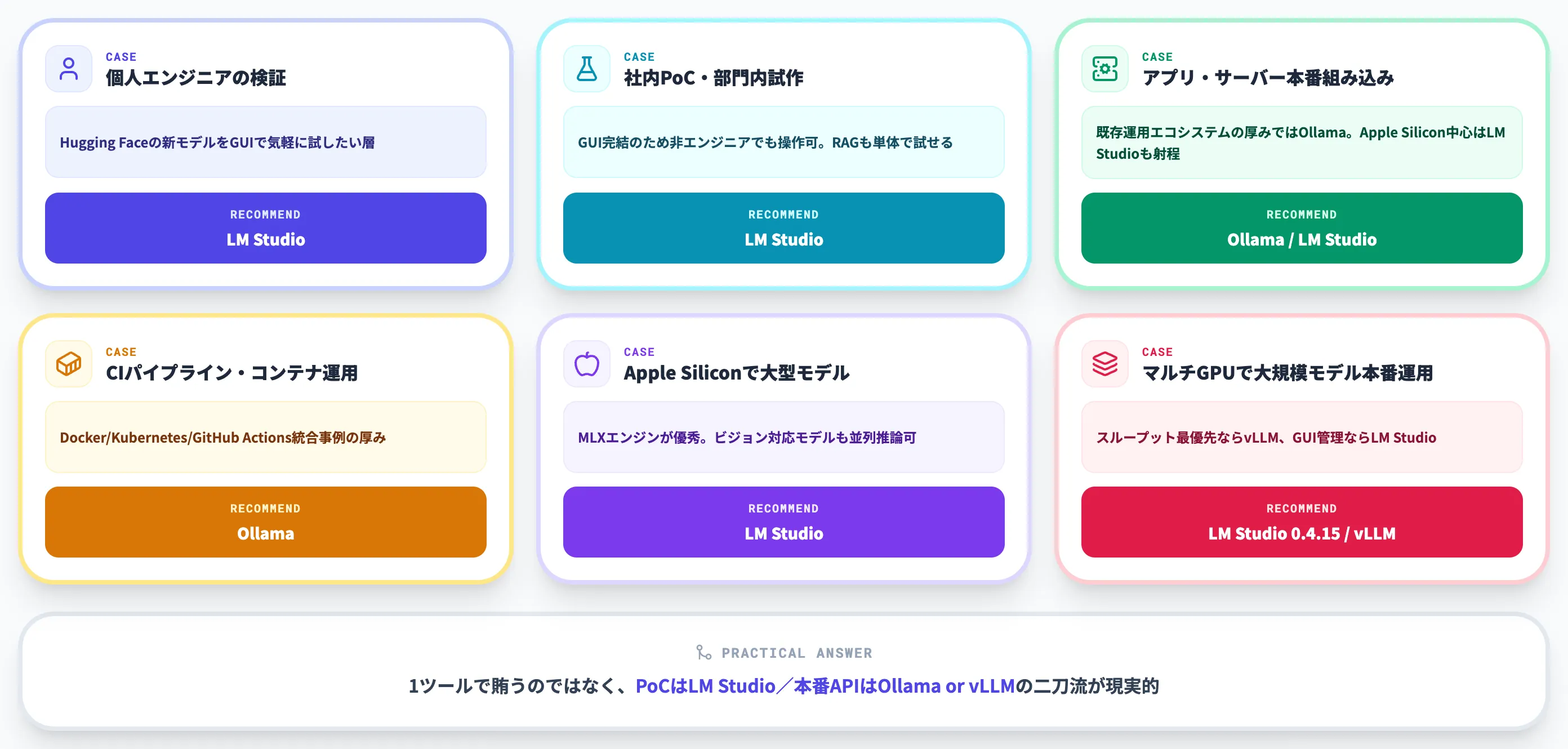
個人エンジニア・研究者の検証
LM Studioが第一候補。Hugging Faceの新モデルをGUIで気軽に試せるため、モデル比較とプロンプト検証のサイクルが速い。
社内PoC・部門内の試作
LM Studioが向く。GUI完結のため、エンジニア以外のメンバー(業務部門の担当者・コンサルタント)も操作できる。RAGがアプリ内で完結する点も、社内文書 × LLMのPoCで効きます。
アプリ・サーバーへの本番組み込み
現状はOllamaが選びやすい。Docker・Kubernetes・既存運用エコシステムへの組み込み事例の厚みで一日の長があります。一方、LM Studioも0.4.0以降は llmster/headless による常駐運用・LinuxサーバーやGPU rigでの起動時自動起動・JIT(オンデマンド)ロードに対応しており、デスクトップ起動を前提としない構成も組めます。Apple Silicon中心の構成や既存LM Studio資産を活かしたい場合は十分選択肢に入ります。
CIパイプライン・コンテナ運用
Ollamaが向く。Docker・Kubernetes・GitHub Actionsとの統合事例が豊富で、ollama serve の挙動が予測しやすい。
Apple Silicon Macで大型モデルを動かしたい
LM StudioのMLXエンジンが優秀。Qwen 3.5/3.6・Gemma 4などのビジョン対応モデルも、MLX engine v1.8.1(0.4.13〜)で並列推論できる。
マルチGPUサーバーで大規模モデルを本番運用
LM Studio 0.4.15のTensor Parallelism、もしくはvLLM。スループット最優先ならvLLM、GUIで管理したいならLM Studioという棲み分け。
「GUIで触る/本番常駐/マルチGPU」の3観点で考えると、組み合わせの最適解が見えてきます。 1ツールで全部を賄うのではなく、PoCはLM Studio、本番APIはOllamaまたはvLLM、という二刀流が現実的な答えになることが多いです。
【関連記事】
ローカルLLMとは?メリットやおすすめモデル、導入方法を解説

ローカルLLMの知見を、社内AIの業務定着につなげる
LM Studioでローカル環境のLLMに触れる体験は、「AIをどこに使うか」「どこに置けるか」「どこに置けないか」を肌で理解する近道です。
一方で、社内のAI活用を本格的に進めるフェーズに入ると、ローカルLLM単体では届かない論点が次々と出てきます。どの業務にAIを組み込むか/部門ごとの優先順位/統制と権限設計/PoCから全社展開へのスケール手順などです。
AI総合研究所では、PoCから全社展開までの設計、部門別ユースケース、AI運用における統制・セキュリティのチェックポイントを220ページにまとめた「AI業務自動化ガイド」を無料で公開しています。LM Studioで掴んだ「AIの仕組み感」を、社内のAI定着の設計図に変える第一歩として活用ください。
ローカルLLMの知見を社内AI定着へ

LM Studioで掴んだ運用感を全社設計に
LM Studioでローカル環境のLLM運用に触れたなら、AIの仕組みとコスト感を肌で理解する基盤ができています。その知見を部門横断のAI業務自動化に展開する設計図として、AI業務自動化ガイド(220ページ)でPoCから全社展開までの進め方・部門別ユースケース・統制ポイントを整理しています。
まとめ
本記事では、LM Studioについて、概要・主要機能・インストール手順・MCP連携・エンタープライズ活用・ライセンス・Ollamaとの使い分けまで、2026年6月時点の情報で整理しました。要点を改めて整理します。
-
LM StudioはWindows・macOS・LinuxでローカルLLMをGUIから動かせる無料アプリで、モデル管理・対話・RAG・OpenAI互換API・MCP連携・モバイル連携までを1つのアプリで完結できる
-
主要機能としてHugging Face直結のモデル検索、.docx/.pdf/.txtのRAG、OpenAI互換APIサーバー、MCPサーバー連携、2026年2月追加のLM Linkと2026年6月のLocally iOSアプリ対応で揃ったiPhone⇄Mac連携など、社内基盤としての完成度が上がっている
-
MCP連携は0.3.17で実装、2026年4月の0.4.10でOAuth対応となり、認証付きの社内MCPサーバーとも接続できる段階に到達した
-
2026年5月の0.4.15でTensor Parallelism対応となり、マルチGPUで大規模モデルを検証・一部運用する選択肢が増えた。本番運用に持ち込む場合はvLLM等との比較検証が前提。LM Studio Hub のTeam organization/LM Studio Enterpriseで組織展開の選択肢も用意されている
-
ライセンスは2025年7月8日以降、個人および社内業務利用(personal and / or internal business purposes)が無料。社内検証から社内本番運用までは申請不要。ただし外部向けSaaS/ASP/再配布などはApp Termsで禁止される範囲のため、組み込み利用や組織でのSSO・モデル/MCP/プラグイン統制・プライベート共同利用が必要な場合にEnterpriseを検討する
-
Ollamaとの使い分けは「GUIで触りたい・PoC・社内RAG・Apple Silicon中心」ならLM Studio(0.4.0+のllmster/headlessで常駐運用も射程)、「Docker・既存運用エコシステム・コンテナ運用」ならOllama/vLLMという棲み分けが現実的
個人検証ツールという以前の整理は、2026年のLM Studioには合いません。商用無料化・MCP対応・マルチGPU・モバイル拡張が出揃い、社内のローカルLLM活用を始めるなら最初に手に取る一本として、ポジションが明確に固まりつつあります。まずは手元のPCにインストールして、社内文書を1〜2件読み込ませるところから試してみるのが、最も実用的な第一歩になります。










