この記事のポイント
 API非提供のWebサービス自動化を検討する企業はGemini 2.5 Computer Useが第一候補、UI操作をAIが代行する唯一無二のアプローチ
API非提供のWebサービス自動化を検討する企業はGemini 2.5 Computer Useが第一候補、UI操作をAIが代行する唯一無二のアプローチ- 「観察→思考→行動」の反復ループにより、複数システムをまたぐ業務フローの自動化が可能。RPA導入が難しかった領域に有効
- ベンチマークで競合を上回る高精度と低レイテンシを両立しており、実務レベルの自動化精度が期待できる
- Gemini 2.5 Proと同一料金で追加コスト不要。既にGoogle AI StudioやVertex AIを利用中の企業は、すぐに検証を始めるべき
- ただし、機密情報を扱うUI操作では安全性ガイドラインの遵守が不可欠。スクリーンショット経由でのデータ漏洩リスクは避けるべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「Web上の定型作業をAIに任せたい」「APIがないWebサービスを自動化したい」——そんなニーズに応える、Google DeepMindの革新的なAIモデル「Gemini 2.5 Computer Use」が登場しました。
これは、AIが人間のように画面を「見て」、クリックやタイピングといった操作を自律的に実行する、UI操作に特化したAIです。しかし、その具体的な仕組みや性能、そして安全な使い方について、まだ知らない方も多いのではないでしょうか。
本記事では、この「Gemini 2.5 Computer Use」について、その全貌を徹底的に解説します。
基本的な動作フロー、ベンチマークで示された性能、安全性への取り組み、料金体系、そして開発者向けの実装方法まで、詳しくご紹介します。
ChatGPTの新料金プラン「ChatGPT Go」については、以下の記事をご覧ください。
ChatGPT Goとは?料金や機能、広告の仕様、Plus版との違いを解説
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
Gemini 2.5 Computer Useとは?
Gemini 2.5 Computer Useは、Google DeepMindが2025年10月7日に発表した、UI(ユーザーインターフェース)操作に特化したAIモデルです。
Gemini 2.5 Proの高度な視覚理解能力と推論能力をベースに構築されており、Webページやモバイルアプリケーションを人間と同じように「見て」「操作する」ことができます。
Gemini 2.5 Computer Useのイメージ (参考:Google
現在、Google AI StudioとVertex AIを通じてプレビュー版として提供されており、開発者は「gemini-2.5-computer-use-preview-10-2025」というモデルIDでAPIにアクセスできます。
このモデルの最大の特徴は、スクリーンショットを入力として受け取り、クリック、タイピング、スクロールといった具体的なUI操作を返すことで、人間が行うようなブラウザ操作やアプリ操作を自動化できる点にあります。

従来のAPIとの決定的な違い
これまで、AIモデルがソフトウェアと連携する際は、主に構造化されたAPI(Application Programming Interface)を通じて行われてきました。例えば、データベースからデータを取得したり、特定の機能を呼び出したりする場合です。
しかし、実際のデジタル業務には、APIが存在しないタスクが数多く存在します。
なぜUI操作が必要なのか
実世界のタスクの多くは、グラフィカルなユーザーインターフェースを通じてのみ実行可能です。具体的には以下のようなケースです。
- フォームへの入力と送信: Webフォームに情報を入力し、送信ボタンをクリックする必要があるタスク
- ドロップダウンやフィルターの操作: 複雑な検索条件を設定したり、UI要素を操作してデータを絞り込むタスク
- ログイン後の操作: 認証が必要なWebサイトやアプリケーション内での作業
- 複数システム間の連携: 異なるWebサービスをまたいでデータをコピー・ペーストするような作業
Gemini 2.5 Computer Useは、これらの「人間がブラウザで行う作業」をAIが代行できるようにすることで、真の意味でのワークフロー自動化を実現します。
Gemini 2.5 Computer Useの仕組み
Gemini 2.5 Computer Useを理解する上で最も重要なのは、その動作プロセスです。このモデルは、単発の質問応答ではなく、「観察→思考→行動→観察...」という反復的なサイクルで動作します。人間がブラウザで作業をする際に、画面を見て、考えて、クリックして、結果を確認して...というプロセスを繰り返すのと同じです。
このセクションでは、Computer Useがどのように動作し、どのような情報をやり取りし、どのようにタスクを完了させるのかを詳しく解説します。
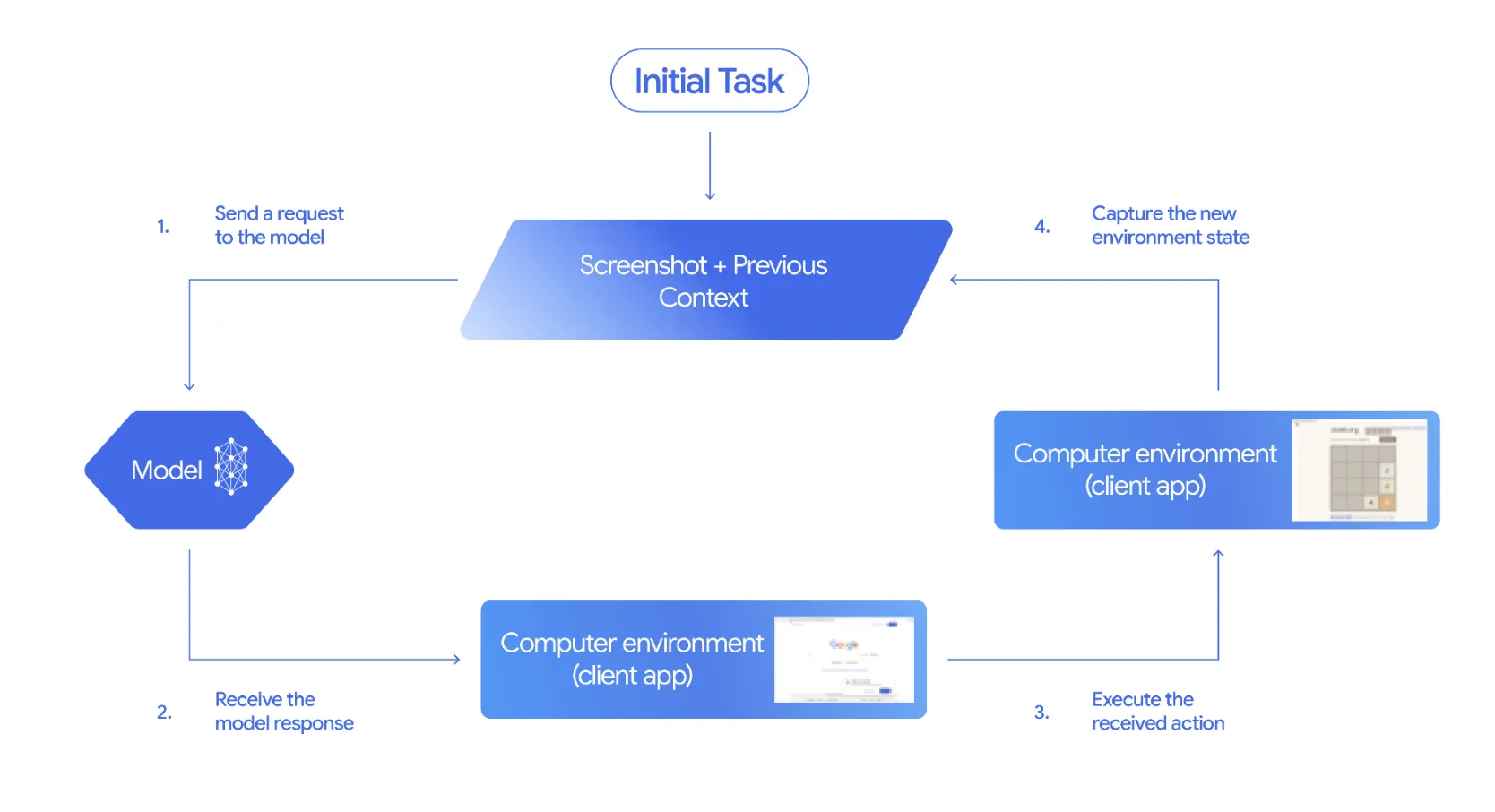
基本的な動作フロー
Gemini 2.5 Computer Useは、「エージェントループ」と呼ばれる反復的なプロセスで動作します。これは、観察→思考→行動→観察...というサイクルを繰り返すことで、複雑なタスクを段階的に完了させる仕組みです。
入力情報
モデルは、タスクを実行するために以下の3つの情報を受け取ります。
- ユーザーリクエスト: 「この商品を検索して最安値を見つけて」といった自然言語での指示
- スクリーンショット: 現在のGUI環境の視覚情報。モデルはこれを「見る」ことで画面の状態を理解します
- 過去のアクション履歴: これまでに実行した操作の記録。文脈を維持するために使用されます
出力:UI操作コマンド
モデルは入力を分析し、次に実行すべきUI操作を「function_call」として返します。例えば、「座標(371, 470)にテキストを入力する」「座標(500, 300)をクリックする」といった具体的な指示です。
下の図は、このプロセス全体の流れを示しています。
Gemini 2.5 Computer Useの動作フロー (参考:Google
このループは、タスクが完了するか、エラーが発生するか、安全システムが介入するまで継続します。
computer_useツールの機能
Gemini APIでComputer Useを利用する際は、「computer_use」という特別なツールをリクエストに含めます。このツールには、以下の機能が備わっています。
サポートされるUI操作
モデルは、15種類以上のUI操作を実行できます。基本的なクリックやタイピングから、ドラッグ&ドロップ、スクロール、キーボードショートカットまで、人間がブラウザで行うほとんどの操作が可能です。
詳細な操作リストについては、後述の「サポートされている全UI操作」セクションで解説します。
カスタム関数の追加
開発者は、標準のUI操作に加えて、独自のカスタム関数を定義できます。例えば、モバイル環境向けに「アプリを起動する」「長押しする」「ホーム画面に戻る」といった関数を追加することで、Computer Useの機能をブラウザ以外の環境にも拡張できます。
除外関数の指定
逆に、特定のUI操作をモデルに使わせたくない場合は、「excluded_predefined_functions」パラメータで除外できます。
例えば、モバイルアプリ開発の場合、ブラウザ固有の操作(open_web_browser、navigate など)を除外することで、モデルの動作を目的の環境に最適化できます。
エンドユーザー確認メカニズム
購入ボタンのクリックやCookieの受け入れなど、リスクを伴う可能性のある操作を実行する前に、モデルは「safety_decision」フィールドで「ユーザー確認が必要」と通知することがあります。
これにより、意図しない操作を防ぐことができます。
実行プロセスの詳細
エージェントループの各ステップを詳しく見ていきましょう。
ステップ1:モデルへのリクエスト送信
クライアント側のコードは、ユーザーの目標、現在の画面のスクリーンショット、そして「computer_use」ツールを含むリクエストをモデルに送信します。
ステップ2:モデルからのレスポンス受信
モデルは画面を分析し、次に実行すべきアクションを決定します。レスポンスには通常、以下が含まれます。
- テキストでの説明(「検索バーにテキストを入力します」など)
- 実行すべき「function_call」(具体的なUI操作)
- 必要に応じて「safety_decision」(安全性の判断)
ステップ3:アクションの実行
クライアント側のコードは、受信した「function_call」を解析し、実際の環境(例:Playwrightで制御されているブラウザ)で操作を実行します。
座標は正規化された値(0-999の範囲)で返されるため、実際のピクセル座標に変換する必要があります。
ステップ4:新しい状態のキャプチャ
アクション実行後、クライアントは新しいスクリーンショットと現在のURLを取得し、これを「FunctionResponse」としてモデルに返します。
モデルはこの新しい情報を使って、次のアクションを決定します。
終了条件
このループは、以下のいずれかの条件で終了します。
- タスク完了: モデルがユーザーの目標を達成したと判断した場合
- エラー発生: 技術的な問題や予期しないページ構造により操作が失敗した場合
- 安全性による停止: 安全システムが危険な操作を検出し、ブロックした場合
- ユーザー判断による中断: ユーザーが明示的にプロセスを停止した場合
Gemini 2.5 Computer Useの性能と主要な進化点
AI技術の進化において、ベンチマークスコアは重要な指標ですが、実際のビジネス価値は「どれだけ実用的か」で決まります。
Gemini 2.5 Computer Useは、複数の独立したベンチマークで競合を上回る成績を記録しただけでなく、実際のWebサイトを使ったデモで、その実用性を明確に示しています。
このセクションでは、客観的な性能評価と、実際にどのようなタスクをこなせるのかを、具体例とともに解説します。
ベンチマーク結果
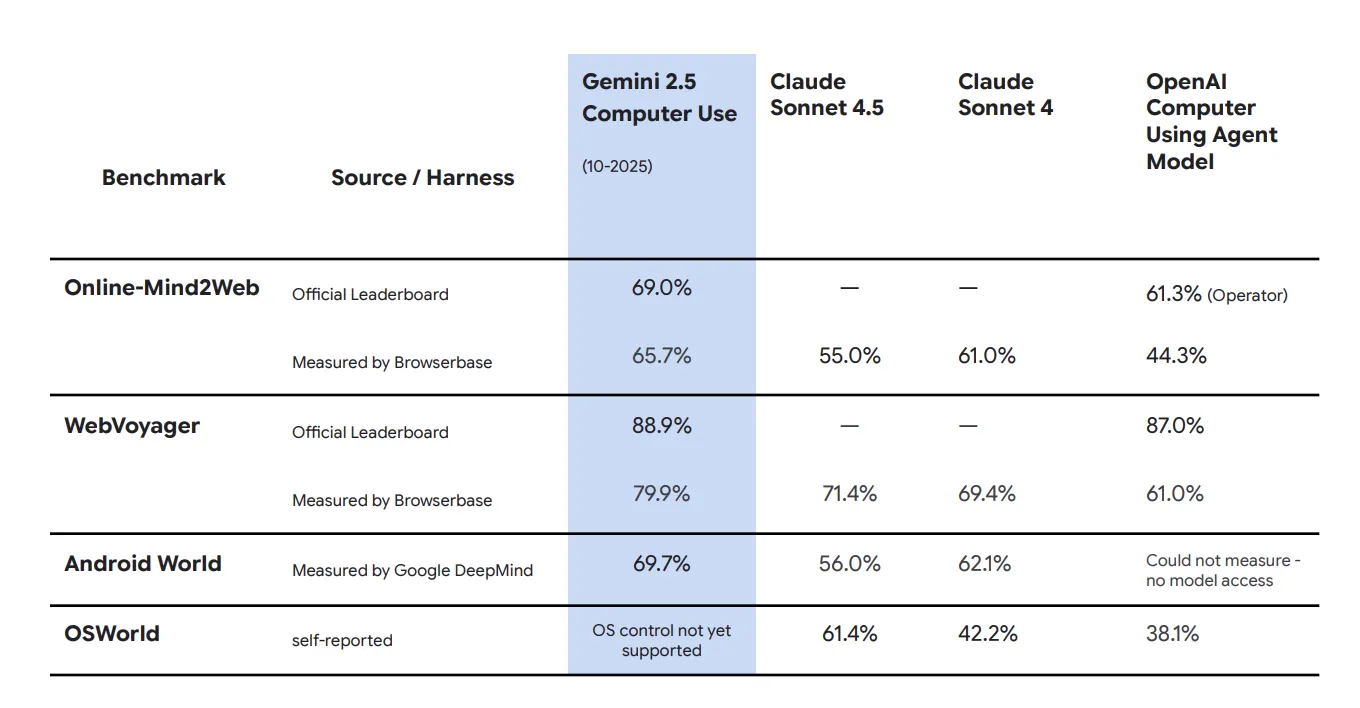
Gemini 2.5 Computer Useは、複数の主要なベンチマークで優れた性能を示しています。以下は、公式発表されたスコアと、独立した評価機関Browserbaseによる測定結果です。
Gemini 2.5 Computer Useのベンチマーク結果 (参考:Google)
-
Online-Mind2Web
実際のWebサイト上でのタスク実行能力を測定するベンチマークです。Gemini 2.5 Computer Useは、公式リーダーボードで69.0%、Browserbaseによる独立評価では65.7%のスコアを記録しました。
これは、Claude Sonnet 4.5の55.0%(Browserbase測定)やClaude Sonnet 4の61.0%を上回る成績です。
-
WebVoyager
より複雑なWeb閲覧タスクを評価するベンチマークで、Gemini 2.5 Computer Useは公式で88.9%、Browserbaseの測定で79.9%という高いスコアを達成しました。
これは、競合であるOpenAI Computer Using Agentの87.0%(公式)や61.0%(Browserbase)を大きく上回っています。
-
AndroidWorld
モバイルアプリケーションの制御能力を測定するベンチマークです。Google DeepMindによる測定で69.7%のスコアを記録し、Claude Sonnet 4.5の56.0%、Claude Sonnet 4の62.1%を上回りました。
レイテンシと精度のバランス
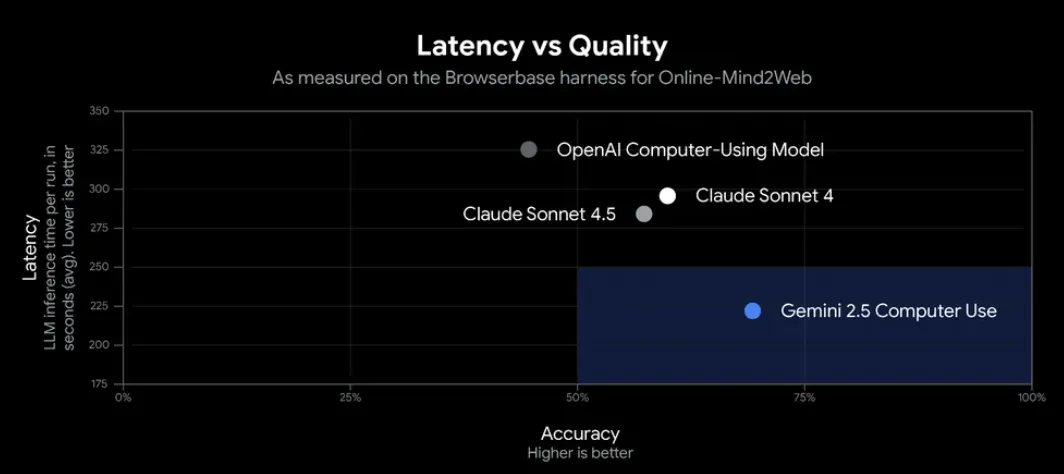
AIモデルの実用性を測る上で、精度だけでなく「どれだけ速く応答できるか」も重要な指標です。Gemini 2.5 Computer Useは、この両面で優れたバランスを実現しています。
Gemini 2.5 Computer Useは低レイテンシで高精度を実現 (参考:Google
Browserbaseによる評価では、Gemini 2.5 Computer Useは約225秒のレイテンシで70%以上の精度を達成しました。これは、精度を維持しながら、競合モデルよりも大幅に高速であることを意味します。
この「速くて正確」という特性は、実際のビジネスシーンでAIエージェントを活用する際に非常に重要です。ユーザーを待たせることなく、確実にタスクを完了できるからです。
実際のデモ事例
Google DeepMindは、Computer Useモデルの実力を示すために、実際のWebサイトを使った2つのデモを公開しています。
ペットスパCRMデモ
タスク内容
「カリフォルニア在住のペットの情報をフォームサイトから取得し、別のスパ管理CRMシステムにゲストとして登録。さらに、10月10日午前8時以降に専門家Anima Lavarとのフォローアップ予約を設定する」
このデモでは、モデルは以下の複雑な操作を自律的に実行しました。
- 最初のWebサイト(https://tinyurl.com/pet-care-signup)にアクセス
- カリフォルニア在住のペットを検索・特定
- 必要な情報をコピー
- 2つ目のWebサイト(スパCRM)に移動
- ゲスト登録フォームに情報を入力
- 予約システムで適切な日時と担当者を選択
- 予約を確定
実用性の評価
このデモは、Computer Useが単一のWebサイト内での操作だけでなく、複数のシステムをまたいだ業務フローを理解し、実行できることを示しています。
実際のビジネスシーンでは、こうした「システムAからデータを取得してシステムBに入力する」といった作業は非常に多く、その自動化は大きな生産性向上につながります。
付箋ボード整理デモ
タスク内容
「アートクラブのメンバーがブレインストーミングした付箋をカテゴリ別に整理する。各付箋を適切なセクションにドラッグして配置する」
このデモでは、以下の能力が実証されました。
- 各付箋の内容を理解する能力
- カテゴリの意味を把握する能力
- ドラッグ&ドロップという複雑なUI操作を正確に実行する能力
UI理解力の実証
このデモが示すのは、Computer Useが単純なクリックやタイピングだけでなく、視覚的に複雑なUIレイアウトを理解し、適切な位置に要素を移動させるといった高度な操作も可能だということです。
安全性への取り組み
Gemini 2.5 Computer Useのような強力な機能を持つAIは、同時に新しいリスクも生み出します。Google DeepMindは、「責任あるAI」を最初から組み込むアプローチを採用し、複数のレイヤーで安全性を確保しています。
Computer Useが抱える3つの主要リスク
Google DeepMindは、System Cardにおいて、Computer Useが抱える主要なリスクを3つに分類しています。
1. ユーザーによる意図的な悪用
悪意のあるユーザーが、Computer Useを使って以下のような行為を行う可能性があります。
- システム整合性の侵害: アプリケーションやOSの設定を不正に変更する
- セキュリティ侵害: パスワードやAPIキーなどの機密情報を窃取する
- CAPTCHA回避: ボット対策を突破して大量の自動操作を行う
- 医療機器の制御: 人命に関わる医療機器を不適切に操作する
2. モデルの予期しない動作
AIモデルが、ユーザーの意図を誤解したり、Web
ページの内容を誤って解釈したりすることで、意図しない結果を引き起こす可能性があります。
例えば、間違ったボタンをクリックしたり、誤ったフォームに入力したりすることで、データの削除や誤った購入といった問題が発生する可能性があります。
3. Web環境での脅威
Computer Useは画面に表示された情報を信頼するため、以下のような攻撃に脆弱です。
- プロンプトインジェクション: Webページに埋め込まれた悪意のある指示をモデルが実行してしまう
- フィッシング詐欺: 「アンケートに答えると無料でiPhoneがもらえる」といった詐欺サイトの指示に従ってしまう可能性
実装されている安全機能
これらのリスクに対処するため、Gemini 2.5 Computer Useには複数の安全メカニズムが組み込まれています。
モデル組み込みの安全機能
モデルのトレーニング段階で、上記の3つのリスクに直接対処する安全機能が組み込まれています。これにより、モデル自体が危険な操作を避けるように学習されています。
ステップ毎の安全性サービス
モデルが提案する各アクションは、実行される前に、モデル外部の安全性サービスによって評価されます。このサービスは、推論時(inference-time)に動作し、リアルタイムで危険な操作を検出します。
開発者向け制御機能
開発者は、システムインストラクション(システムプロンプト)を使って、エージェントの動作をさらに細かく制御できます。
例えば、「購入ボタンをクリックする前に必ずユーザーに確認を求める」「医療関連のサイトでは操作を実行しない」といったルールを明示的に指定できます。
高リスク操作の制限リスト
Google DeepMindが特に注意を促しているのは、以下のような操作です。
- システム整合性を侵害する可能性のある操作
- セキュリティを侵害する操作
- CAPTCHAやその他のボット対策を回避する操作
- 医療機器やその他の重要なシステムを制御する操作
開発者は、これらの操作がアプリケーションの要件に含まれないように設計することが強く推奨されています。
safety_decision機能
Computer Useの安全システムの中核を担うのが、「safety_decision」フィールドです。
require_confirmationの仕組み
モデルがリスクの高い操作を実行しようとする場合、レスポンスの「function_call」内に「safety_decision」フィールドが含まれ、「decision」が「require_confirmation」に設定されます。
以下は、CAPTCHAの「私はロボットではありません」チェックボックスをクリックしようとした際のレスポンス例です。
{
"function_call": {
"name": "click_at",
"args": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "CAPTCHAチャレンジが検出されました。'私はロボットではありません'チェックボックスをクリックし、その後の検証手順を完了する必要があります。",
"decision": "require_confirmation"
}
}
}
}
ユーザー確認フローの実装
「require_confirmation」を受け取った場合、開発者はエンドユーザーに対して、そのアクションを実行してよいか確認を求める必要があります。これは、利用規約で義務付けられています。
ユーザーが確認した場合のみ、アクションを実行し、「FunctionResponse」に「safety_acknowledgement: true」を含めてモデルに返します。
ユーザーが拒否した場合は、アクションを実行せず、エージェントループを終了するか、別のアプローチを試みます。
safety_acknowledgementの返却
ユーザーが確認した場合、クライアント側のコードは以下のように「FunctionResponse」を構築します。
function_response = FunctionResponse(
name="click_at",
response={
"url": current_url,
"safety_acknowledgement": "true" # ユーザーが確認したことを明示
},
parts=[...]
)
これにより、モデルは「ユーザーの承認を得た上でアクションが実行された」ことを認識し、次のステップに進むことができます。
開発者への推奨事項
Google DeepMindは、開発者に対して以下のベストプラクティスを推奨しています。
安全なサンドボックス環境での実行
Computer Useエージェントは、必ず隔離された環境で実行してください。具体的には、以下のような環境が推奨されます。
- サンドボックス化された仮想マシン(VM)
- Dockerなどのコンテナ環境
- 制限された権限を持つ専用ブラウザプロファイル
これにより、万が一モデルが予期しない操作を実行した場合でも、ホストシステムや本番環境への影響を最小限に抑えることができます。
ローンチ前の徹底的なテスト
プロダクション環境にデプロイする前に、以下の観点で徹底的にテストしてください。
- 様々なエッジケースでの動作確認
- エラー時の挙動検証
- 安全性チェックの動作確認
追加の安全対策
モデル組み込みの安全機能に加えて、アプリケーションレベルでも以下の対策を実装することが推奨されます。
- 入力サニタイズ: ユーザー入力やWeb上のテキストをサニタイズし、プロンプトインジェクションのリスクを軽減
- 許可リスト・ブロックリストの活用: アクセス可能なWebサイトを制限したり、危険なサイトへのアクセスをブロック
- オブザーバビリティとロギング: すべてのアクションを詳細にログに記録し、問題発生時に追跡可能にする
- 環境管理: GUI環境を一貫した状態に保ち、予期しないポップアップや通知がモデルを混乱させないようにする
これらの対策を組み合わせることで、Computer Useの強力な機能を、安全かつ責任ある形で活用することができます。
Gemini 2.5 Computer Useの料金体系
Gemini 2.5 Computer Useは、Gemini 2.5 Proと同じ料金体系を採用しているため、Computer Use機能を使用するための追加料金は発生しません。これは、開発者にとって非常にコスト効率の良い選択肢となっています。
API料金
Gemini 2.5 Computer UseのAPI料金は、トークンベースで課金されます。料金は入力トークン数に応じて2段階に分かれています。
| トークン数 | 入力料金(/1M tokens) | 出力料金(/1M tokens) |
|---|---|---|
| ≤200K トークン | $1.25 | $10 |
| >200K トークン | $2.50 | $15 |
Computer Use専用の追加料金なし
重要なポイントは、Computer Use機能を使用しても、Gemini 2.5 Pro標準版と同じ料金が適用されるということです。追加のプレミアム料金は発生しません。
課金タグでComputer Use使用状況を分離可能
Vertex AIを使用している場合、課金タグ(billing tags)を適用することで、Computer Use関連のコストを他のGemini 2.5 Proの利用と分けて追跡することができます。これにより、Computer Useがどれだけのコストを消費しているかを正確に把握できます。
他モデルとの料金比較
Gemini 2.5 Computer Useが、他の主要AIモデルと比較してどの程度コスト競争力があるかを見てみましょう。
| モデル | 入力料金(/1M tokens) | 出力料金(/1M tokens) | 備考 |
|---|---|---|---|
| Gemini 2.5 Computer Use | $1.25 | $10 | ≤200K時 |
| Gemini 2.5 Pro(標準) | $1.25 | $10 | 同一料金 |
| Claude 3.7 Sonnet | $3 | $15 | Computer Use機能あり |
| GPT-4o | $2.50 | $10 | Computer Use機能なし |
| OpenAI o3-mini | $1.10 | $4.40 | Computer Use機能なし |
Gemini 2.5 Computer Useは、Claude 3.7 Sonnetと比較すると入力が半額以下、出力も安価です。また、Computer Use機能を提供していない他のモデルと比較しても競争力のある価格設定となっています。
コストパフォーマンスの評価
ベンチマーク性能(Online-Mind2Webで69.0%、WebVoyagerで88.9%)を考慮すると、Gemini 2.5 Computer Useは、性能とコストのバランスにおいて非常に優れた選択肢と言えます。
無料枠と制限
Google AI Studioでの無料利用枠
Google AI Studioを通じてGemini 2.5 Computer Useを利用する場合、無料枠が提供されています。ただし、プレビュー版のため、厳格なレート制限が適用されます。
レート制限の詳細
プレビュー版では、以下のようなレート制限が適用される可能性があります(具体的な数値は、Googleアカウントの設定やプロジェクトによって異なります)。
- リクエスト数の制限(RPM: Requests Per Minute)
- 1日あたりのリクエスト数制限
- トークン使用量の制限
詳細なレート制限については、Google AI Studioのダッシュボードで確認できます。
プレビュー版としての制限事項
現在はプレビュー版のため、以下の点に注意が必要です。
- モデルの動作が予告なく変更される可能性がある
- レート制限が将来変更される可能性がある
- 本番環境での重要なタスクには使用しないことが推奨される

Gemini 2.5 Computer Useの使い方
Gemini 2.5 Computer Useを実際に使い始めるには、開発環境の準備からエージェントループの実装まで、いくつかのステップが必要です。このセクションでは、初めて触る開発者でも実装できるように、段階的に解説します。
開発環境の準備
Google AI StudioまたはVertex AIへのアクセス
まず、以下のいずれかのプラットフォームにアクセスする必要があります。
- Google AI Studio: 個人開発者やプロトタイピングに最適。無料枠あり
- Vertex AI: エンタープライズ向け。本番環境での利用に推奨
必要なAPIキーの取得手順
Google AI Studioを使用する場合の手順:
- Google AI Studioにアクセス
- Googleアカウントでサインイン
- 左側のメニューから「Get API key」をクリック
- 新しいAPIキーを生成
Vertex AIを使用する場合は、Google Cloudプロジェクトを作成し、Vertex AIを有効化する必要があります。
推奨開発環境
Computer Useを快適に開発するための推奨環境は以下の通りです。
- Python: 3.8以降
- Playwright: ブラウザ自動化ライブラリ
- Google Generative AI SDK: Gemini APIとの通信用
- 推奨画面サイズ: 1440x900(モデルが最も最適化されている解像度)
基本的な実装方法
必要なライブラリのインストール
まず、必要なPythonライブラリをインストールします。
# Google Generative AI SDKのインストール
pip install google-generativeai
# Playwrightのインストール
pip install playwright
# Playwrightブラウザのインストール
playwright install
最小限の実装例
以下は、Computer Useを使用する最小限のコード例です。
from google import genai
from google.genai import types
from google.genai.types import Content, Part
# クライアントの初期化
client = genai.Client(api_key="YOUR_API_KEY")
# Computer Useツールの設定
generate_content_config = types.GenerateContentConfig(
tools=[
types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER
)
)
]
)
# リクエストの送信
contents = [
Content(
role="user",
parts=[
Part(text="GoogleでAIについて検索してください")
]
)
]
# モデルIDに注意:computer-use専用モデルを指定
response = client.models.generate_content(
model='gemini-2.5-computer-use-preview-10-2025',
contents=contents,
config=generate_content_config
)
print(response)
重要なポイント
- モデルIDは必ず「gemini-2.5-computer-use-preview-10-2025」を使用
- 他のGemini 2.5モデルではComputer Useツールは使用できません
- 「environment」パラメータで環境タイプを指定(現在はBROWSERのみ)
Browserbaseのデモ環境で試す
コードを書く前に、Computer Useがどのように動作するかを体験したい場合は、Browserbaseが提供するデモ環境が便利です。
デモ環境へのアクセス方法
- Browserbaseのデモページにアクセス
- サンプルタスクを選択または独自のタスクを入力
- 実行ボタンをクリック
基本的な操作の流れ
デモ環境では、以下の流れでComputer Useの動作を確認できます。
- タスク入力
- モデルが画面を分析
- 実行するアクションがリアルタイムで表示される
- 結果の確認
サンプルタスクの実行
デモ環境では、以下のようなサンプルタスクを試すことができます。
- 「Wikipediaでトヨタについて検索し、本社所在地を教えて」
- 「Google Shoppingで1000ドル以下のノートPCを3つ見つけて」
- 「GitHub上で特定のリポジトリを検索し、スター数を確認して」
これらを試すことで、Computer Useがどの程度複雑なタスクをこなせるかを体感できます。

【開発者向け】実装時の重要ポイント
Computer Useを本番環境で使用する際には、単純なAPI呼び出し以上の実装が必要です。このセクションでは、実用的なエージェントを構築するための重要なポイントを解説します。
エージェントループの構築
基本構造
実用的なComputer Useエージェントは、以下の4ステップを繰り返すループで構成されます。
- リクエスト送信: ユーザーの目標と現在のスクリーンショットをモデルに送信
- レスポンス受信: モデルが提案するアクションを受け取る
- アクション実行: Playwrightなどを使って実際にブラウザを操作
- 状態キャプチャ: 新しいスクリーンショットとURLを取得し、次のリクエストに含める
会話履歴の管理方法
Computer Useは会話の文脈を維持するため、各ターンの内容を履歴として保持する必要があります。
# 会話履歴の初期化
contents = [
Content(role="user", parts=[
Part(text="タスクの説明"),
Part.from_bytes(data=screenshot, mime_type='image/png')
])
]
# ループ内で履歴に追加
response = client.models.generate_content(...)
contents.append(response.candidates[0].content) # モデルの応答を追加
# アクション実行後、FunctionResponseを追加
contents.append(
Content(role="user", parts=[Part(function_response=fr)])
)
ターン数制限の設定
無限ループを防ぐため、最大ターン数を設定します。
turn_limit = 10 # 最大10ターンで終了
for i in range(turn_limit):
# エージェントループの処理
if task_completed:
break
座標の正規化と変換
Computer Useモデルは、画面サイズに依存しない正規化された座標(0-999の範囲)を返します。これを実際のピクセル座標に変換する必要があります。
def denormalize_x(x: int, screen_width: int) -> int:
"""正規化されたx座標を実際のピクセル座標に変換"""
return int(x / 1000 * screen_width)
def denormalize_y(y: int, screen_height: int) -> int:
"""正規化されたy座標を実際のピクセル座標に変換"""
return int(y / 1000 * screen_height)
# 使用例
if function_call.name == "click_at":
actual_x = denormalize_x(args["x"], 1440)
actual_y = denormalize_y(args["y"], 900)
page.mouse.click(actual_x, actual_y)
サポートされている全UI操作
Computer Useモデルは、以下の15種類以上のUI操作をサポートしています。実装時には、これらすべてを適切に処理する必要があります。
ブラウザ操作系
| 操作名 | 説明 | 引数 |
|---|---|---|
open_web_browser |
Webブラウザを開く | なし |
navigate |
指定URLへ移動 | url: 移動先URL |
search |
検索エンジンのホームページへ | なし |
go_back |
ブラウザの戻るボタン | なし |
go_forward |
ブラウザの進むボタン | なし |
マウス操作系
| 操作名 | 説明 | 引数 |
|---|---|---|
click_at |
指定座標をクリック | x, y: 座標(0-999) |
hover_at |
指定座標にホバー | x, y: 座標(0-999) |
drag_and_drop |
ドラッグ&ドロップ | x, y: 開始座標destination_x, destination_y: 終了座標 |
キーボード操作系
| 操作名 | 説明 | 引数 |
|---|---|---|
type_text_at |
テキスト入力 | x, y: 座標text: 入力テキストpress_enter: Enter押下(デフォルト: true)clear_before_typing: 事前クリア(デフォルト: true) |
key_combination |
キーボードショートカット | keys: キーの組み合わせ(例: "Control+C") |
スクロール操作系
| 操作名 | 説明 | 引数 |
|---|---|---|
scroll_document |
ページ全体のスクロール | direction: "up", "down", "left", "right" |
scroll_at |
特定要素のスクロール | x, y: 座標direction: 方向magnitude: スクロール量(デフォルト: 800) |
その他
| 操作名 | 説明 | 引数 |
|---|---|---|
wait_5_seconds |
5秒待機 | なし |
カスタムユーザー定義関数
標準のUI操作に加えて、独自の関数を定義できます。これは、モバイル環境やブラウザ以外の環境に対応する際に特に有用です。
モバイル環境への拡張
以下は、Android環境向けにカスタム関数を追加する例です。
from google.genai import types
def open_app(app_name: str, intent: Optional[str] = None):
"""アプリを起動する"""
return {"status": "requested_open", "app_name": app_name, "intent": intent}
def long_press_at(x: int, y: int):
"""指定座標を長押し"""
return {"x": x, "y": y}
def go_home():
"""ホーム画面に戻る"""
return {"status": "home_requested"}
# 関数宣言の作成
custom_functions = [
types.FunctionDeclaration.from_callable(client=client, callable=open_app),
types.FunctionDeclaration.from_callable(client=client, callable=long_press_at),
types.FunctionDeclaration.from_callable(client=client, callable=go_home),
]
# Computer Useツールと一緒に使用
config = types.GenerateContentConfig(
tools=[
types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER,
excluded_predefined_functions=["open_web_browser", "navigate"]
)
),
types.Tool(function_declarations=custom_functions)
]
)
ブラウザ機能の除外
モバイル環境では、ブラウザ固有の機能が不要なため、「excluded_predefined_functions」で除外します。
excluded_functions = [
"open_web_browser",
"search",
"navigate",
"hover_at",
"scroll_document",
"go_forward",
"go_back",
"key_combination",
"drag_and_drop"
]
computer_use_tool = types.Tool(
computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER,
excluded_predefined_functions=excluded_functions
)
)
エラーハンドリングと安全性
リトライロジック
ネットワークエラーやページ読み込みの遅延に対応するため、リトライロジックを実装します。
import time
def execute_action_with_retry(action_func, max_retries=3):
"""アクション実行をリトライ付きで行う"""
for attempt in range(max_retries):
try:
result = action_func()
# ページの読み込みを待つ
page.wait_for_load_state(timeout=5000)
time.sleep(1)
return result
except Exception as e:
if attempt == max_retries - 1:
raise e
time.sleep(2) # リトライ前に待機
タイムアウト設定
長時間応答がない場合のタイムアウトを設定します。
try:
page.wait_for_load_state(timeout=10000) # 10秒でタイムアウト
except TimeoutError:
print("ページ読み込みがタイムアウトしました")
# エラー処理
安全性の確認フロー
「safety_decision」をチェックし、ユーザー確認が必要な場合は適切に処理します。
def check_safety_decision(function_call):
"""安全性の判断をチェック"""
if 'safety_decision' in function_call.args:
decision = function_call.args['safety_decision']
if decision['decision'] == 'require_confirmation':
print(f"確認が必要: {decision['explanation']}")
user_input = input("実行しますか? (y/n): ")
if user_input.lower() != 'y':
return False
return True
# 使用例
if not check_safety_decision(function_call):
print("ユーザーがアクションを拒否しました")
break # ループを終了
# アクションを実行
execute_action(function_call)
# FunctionResponseにsafety_acknowledgementを含める
function_response = types.FunctionResponse(
name=function_call.name,
response={
"url": page.url,
"safety_acknowledgement": "true" # ユーザーが承認したことを明示
},
parts=[
types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(
mime_type="image/png",
data=page.screenshot(type="png")
)
)
]
)
エラー発生時の対応
アクション実行中にエラーが発生した場合の処理も重要です。
def execute_function_calls(candidate, page, screen_width, screen_height):
"""関数呼び出しを実行し、結果を返す"""
results = []
for part in candidate.content.parts:
if not part.function_call:
continue
function_call = part.function_call
fname = function_call.name
args = function_call.args
print(f"実行中: {fname}")
try:
# アクションを実行
if fname == "click_at":
actual_x = denormalize_x(args["x"], screen_width)
actual_y = denormalize_y(args["y"], screen_height)
page.mouse.click(actual_x, actual_y)
elif fname == "type_text_at":
actual_x = denormalize_x(args["x"], screen_width)
actual_y = denormalize_y(args["y"], screen_height)
text = args["text"]
press_enter = args.get("press_enter", False)
page.mouse.click(actual_x, actual_y)
page.keyboard.press("Meta+A") # 全選択
page.keyboard.press("Backspace") # 削除
page.keyboard.type(text)
if press_enter:
page.keyboard.press("Enter")
# その他のアクション...
page.wait_for_load_state(timeout=5000)
time.sleep(1)
results.append((fname, {})) # 成功
except Exception as e:
print(f"エラー: {fname}の実行中に問題が発生 - {e}")
results.append((fname, {"error": str(e)}))
return results
Gemini 2.5 Computer Useの今後の展開
Gemini 2.5 Computer Useは現在プレビュー版として提供されており、いくつかの制限事項を抱えています。しかし、これらは今後のアップデートで改善される見込みです。
デスクトップOS制御への対応
現在、Computer UseモデルはWebブラウザとモバイルUIに最適化されており、デスクトップOSレベルの操作にはまだ対応していません。WindowsのエクスプローラーやmacOSのFinderといったネイティブアプリケーションを直接制御することは、現時点では難しい状況です。
今後のアップデートでは、WindowsやmacOSのネイティブアプリケーションの制御、Linux環境でのサポート、そしてiOSを含むより高度なモバイル制御への対応が進むことが予想されます。これにより、Webブラウザだけでなく、デスクトップ全体のワークフロー自動化が可能になります。
安定性と信頼性の向上
プレビュー版という性質上、現時点ではいくつかの注意点があります。モデルの動作や応答フォーマットが予告なく変更される可能性があり、レート制限も厳しく設定されています。また、エラーやセキュリティ脆弱性が存在する可能性もあるため、Google DeepMindは重要なタスクや機密データを扱う業務、修正不可能な重大なエラーを伴う可能性のあるアクションでの使用には慎重な監督を推奨しています。
正式版リリースに向けては、これらの制約が大幅に緩和されることが見込まれます。レート制限の緩和、安定したAPIインターフェースの提供、そしてプロンプトインジェクションやフィッシング攻撃への耐性強化により、本番環境で安心して使用できるレベルの信頼性が実現されるでしょう。また、充実したドキュメントとサンプルコードの提供により、開発者がより簡単にComputer Useを活用できる環境が整うことも期待されます。
エンタープライズ対応の強化
企業での本格的な活用を見据え、エンタープライズ向けの機能強化も進むと予想されます。より詳細なアクセス制御、監査ログの強化、コンプライアンス対応機能、そしてSLA(Service Level Agreement)の提供により、大企業でも安心して導入できる体制が整うでしょう。
また、現在約225秒というレイテンシは競合と比較して優れていますが、さらなる高速化により、よりリアルタイム性が求められるタスクにも対応できるようになることが期待されます。
これらの改善により、Computer Useはプロトタイピングツールから、本番環境で信頼して使えるプロダクションレベルのサービスへと進化していくことが期待されています。
画面操作AIの自動化アプローチを業務プロセスに広げるなら
Gemini 2.5 Computer Useのような「AIがUIを操作して業務を遂行する」モデルの進化は、RPAの延長線上で業務自動化の可能性を大きく広げます。ただし実務では、画面操作に頼らずAPIやワークフローエンジンでプロセスを設計した方が、安定性・監査性の面で優位なケースも多くあります。
AI総合研究所のAI業務自動化ガイドでは、業務プロセスの自動化手法をAPI連携型・エージェント型・画面操作型に整理し、用途ごとの選定基準と導入ステップを解説しています。Computer Useの知見を実務にどう活かすかの判断材料としてご活用ください。
画面操作AIの知見を業務自動化へ

まとめ
Gemini 2.5 Computer Useは、AIがWebページやモバイルアプリを人間のように操作できる革新的なモデルです。複数のベンチマークで競合を上回る性能を示し、低レイテンシで高精度な動作を実現しています。
Google社内では既にUI自動テストで60%以上の自動復旧率を達成し、アーリーアクセスユーザーからも高い評価を得ています。Gemini 2.5 Proと同じ料金体系で利用でき、追加コストなしでComputer Use機能が使えるのも大きな魅力です。
現在はプレビュー版ですが、ワークフロー自動化やUIテスト効率化など、幅広い分野での活用が期待されています。AI総合研究所では、Computer Useを含むAIエージェントの企業導入を支援しています。ぜひお気軽にご相談ください。










