この記事のポイント
 日本語NLPの起点となる形態素解析の理解が、検索・翻訳・チャットボットなどAI活用全般の設計判断の土台
日本語NLPの起点となる形態素解析の理解が、検索・翻訳・チャットボットなどAI活用全般の設計判断の土台- Pythonで手軽に始めるならJanome、業務精度を求めるならMeCabかSudachi、Java検索基盤にはKuromojiという用途別の最適解
- Google Colabなら環境構築不要で即座に試せる、MeCab×unidic-liteによる最短の実装ルート
- 単語境界の曖昧さ・活用形の多さ・同音異義語という日本語3大課題を踏まえたツール選定の判断基準
- 検索精度向上・感情分析・文書要約という3大応用の理解が、自社データ活用の具体的な第一歩

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
形態素解析とは、自然言語の文を意味のある最小単位(形態素)に分割し、品詞や活用形を特定する自然言語処理の基礎技術です。英語と異なり単語間にスペースがない日本語では、検索エンジン・音声認識・チャットボット・テキストマイニングなどあらゆる言語処理の起点として不可欠な処理です。
本記事では、形態素解析の基本概念から日本語固有の難しさ、MeCab・Sudachi・Janome・Kuromojiの4大ツール比較、Google Colabでの実装手順、そして検索精度向上・感情分析・文書要約といった実務応用までを体系的に解説します。
ツール選定から実装まで、形態素解析の全体像を把握するための実践ガイドです。
形態素解析とは?
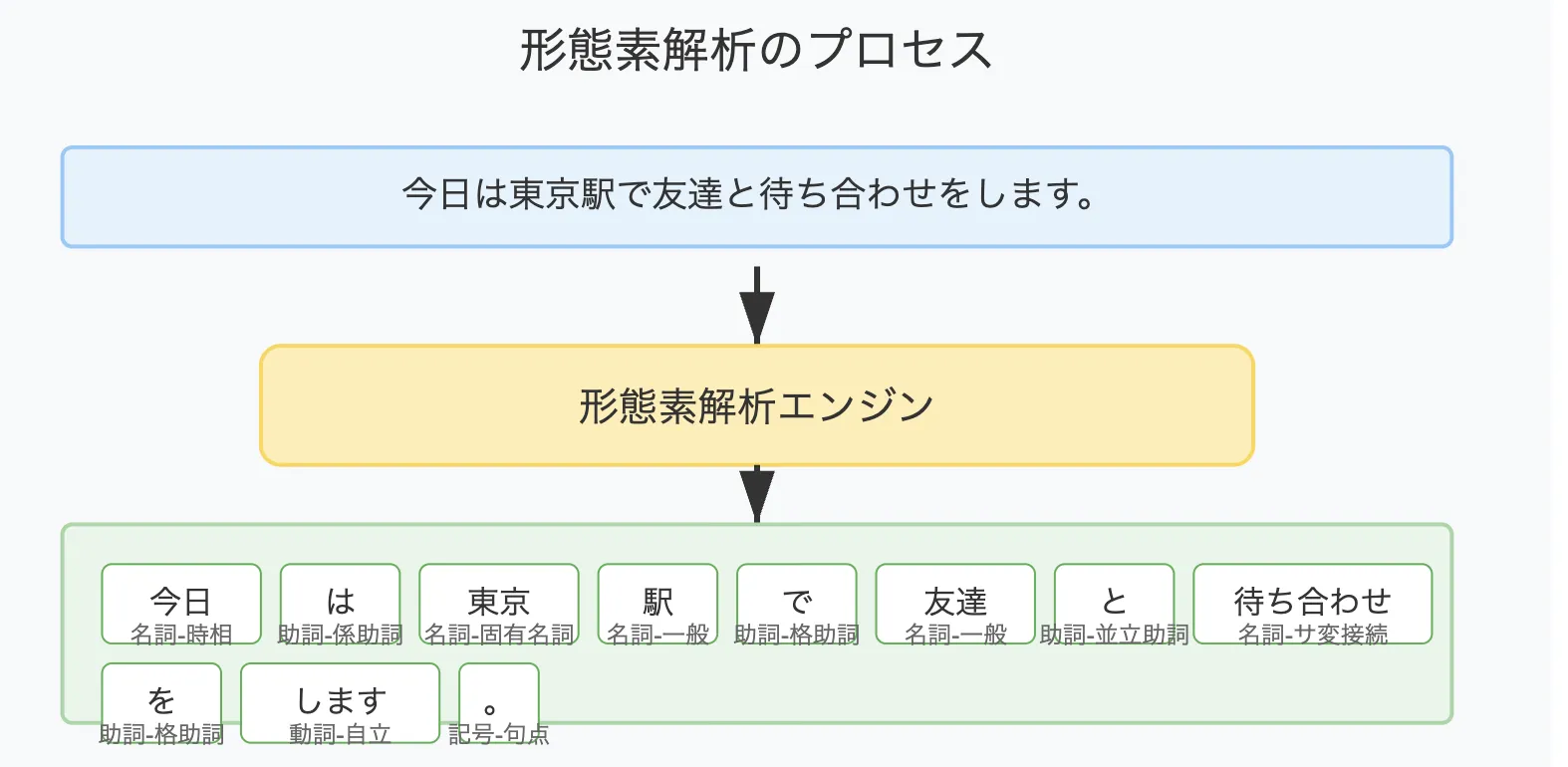
形態素解析のプロセスとイメージ
IT用語辞典 e-Wordsの定義では、形態素解析とは自然言語を意味のある最小単位=形態素(morpheme)に分解し、それぞれの品詞などを分析する処理です。
特に日本語のように単語の区切りが明確でない言語においては、形態素解析は非常に重要なステップです。
たとえば「私は学生です。」という文を形態素解析すると、次のように分割されます。
| 単語 | 品詞 | 説明 |
|---|---|---|
| 私 | 名詞 | 話し手を表す主語 |
| は | 助詞 | 主語を強調 |
| 学生 | 名詞 | 職業や属性を表す語 |
| です | 助動詞 | 丁寧な述語表現 |
| 。 | 記号 | 句点(文の終わり) |

なぜ形態素解析が重要なのか?
形態素解析は、コンピュータが日本語を「理解できる形」にするための最初の変換ステップです。
言葉を単語レベルに細かく分けて、それぞれが「名詞」なのか「動詞」なのかといった情報を付けていきます。
この処理は、実は多くの身近なサービスの裏側で活躍しています。
-
検索エンジンの精度向上
→ 「走った」「走る」「走りたい」などの違いを吸収して、同じ意味を探せるようにします。
検索エンジンが “あなたの言いたいこと”を理解する力が上がります。 -
音声認識・自動翻訳の基礎処理
→ 音声をテキストに変換した後、形態素解析で「意味のかたまり」に分けて初めて文法が読めます。 -
チャットボットやAIアシスタントの自然な会話
→ 「明日は雨?」という短い文でも、「明日」「雨」というキーワードを正しく認識できます。
こうした認識が、的確な応答や判断の土台となります。 -
SNS解析やレビュー分析(テキストマイニング)
→ 「最高!」「全然ダメ」といった文章から、評価の言葉を抜き出して集計します。
形態素解析が、データの見える化の起点になります。
📌 たとえるなら…
形態素解析は、文章という“ごちゃまぜの材料”を、用途ごとにきれいに分類・ラベリングして並べる作業。
料理でいえば、下ごしらえや材料カットのようなもの。ここが正確だと、その後の処理も失敗しづらくなります。
主要な形態素解析ツール(初心者〜業務用まで)
形態素解析を行うには専用のツールが必要です。ここでは、日本語の自然言語処理でよく使われる4つの代表的ツールを紹介します。
| ツール名 | 特徴と向いている用途 | リンク |
|---|---|---|
| MeCab | 非常に高速で高精度。多くの辞書と連携できるため、研究・実務の両方で使われています。 → 「まずはMeCabで試す」が定番**。 |
公式ページ |
| Sudachi | 固有名詞や社名など、少し難しい単語もきれいに扱えます。 さらに、分割粒度を3段階(A/B/C)から選べるのが特徴。 → 業務文書の解析や商品名抽出などに強い。 |
GitHub |
| Janome | Pythonで動く、軽量で手軽なツール。インストールも簡単なので初心者にもおすすめ。 → 教育用途や検証的なプロジェクト向き。 |
公式ページ |
| Kuromoji | Javaベースで、Elasticsearchなどの全文検索エンジンと一緒に使いやすい。 → 検索システムや大規模処理に組み込みやすい。 |
公式ページ |
💡どれを使えばいいか迷ったら
→「Pythonで手軽に始めたい」なら Janome
→「業務向けの高精度がほしい」なら MeCab or Sudachi
→「Javaと組み合わせたい」なら Kuromoji
実際にやってみた:Google Colabで形態素解析(MeCab × Python)
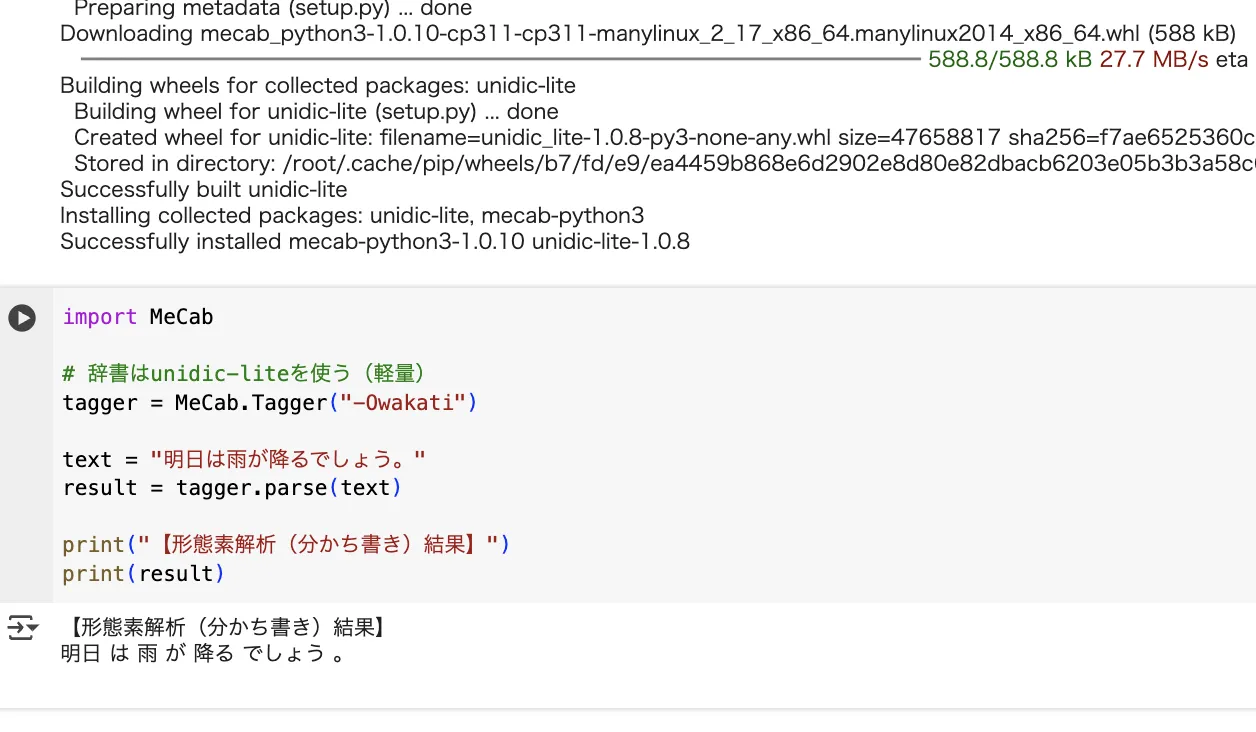
実際の出力画面
ここでは、Google Colab上でMeCabとunidic辞書を使って形態素解析を実行する方法を紹介します。Colabならインストール不要で手軽に試せます。
ステップ1 環境構築(初回のみ)
# MeCabと必要な辞書をインストール
!apt install -y mecab libmecab-dev mecab-ipadic mecab-ipadic-utf8
!pip install mecab-python3 unidic-lite
ステップ2 形態素解析を実行
import MeCab
# 辞書はunidic-liteを使う(軽量)
tagger = MeCab.Tagger("-Owakati")
text = "明日は雨が降るでしょう。"
result = tagger.parse(text)
print("【形態素解析(分かち書き)結果】")
print(result)
出力例(分かち書き)
明日 は 雨 が 降る でしょ う 。
このように、文章が自然な単位で分かち書きされており、後続の品詞分類やキーワード抽出に活用できます。
日本語の形態素解析はなぜ難しいのか?
簡単な言語で形態素解析をやってみましたが、日本語は形態素解析がとても難しい言語の一つです(Wikipedia「形態素解析」も参照)。
理由は主に以下の3つです。
1. 単語の区切りがない(スペースが存在しない)
英語では単語ごとにスペースがありますが、日本語にはそれがありません。
例
英語:I am a student.
日本語:私は学生です。
このため、どこで単語が始まり、どこで終わるのかを文脈から推測しなければならないという大きな課題があります。
2. 語形変化・活用が多い
日本語の動詞・形容詞は語尾が変化します。
「行く」「行った」「行こう」「行かない」...
これらはすべて「行く」という一つの意味に由来しますが、形が大きく異なるため、元の形(原形)を見抜く必要があります。これを原形化や語幹抽出と呼び、形態素解析の大事なステップです。
3. 同音異義語・意味の曖昧さが多い
たとえば「はし」は、以下のように複数の意味があります:
- 橋(構造物)
- 箸(食事に使う道具)
- 端(はじっこ)
どの意味かを判断するには、前後の文脈を踏まえる必要があります。これを**語の曖昧性解消(Word Sense Disambiguation)**といい、高度な解析が求められます。

形態素解析器がどう対応しているのか?
こうした日本語の難しさに対して、形態素解析ツール(MeCabやSudachiなど)は以下のような工夫をしています:
| 問題 | 対応方法 |
|---|---|
| 単語の区切りが曖昧 | 大規模な辞書や統計モデル(例えばCRFや機械学習)を使って、もっとも自然な分かち方を選ぶ |
| 活用形が多い | 辞書に活用のルールを持たせ、語幹と活用語尾を分けて解析 |
| 意味の曖昧性 | 形態素解析だけでは限界があるため、後続の構文解析や文脈解析と連携して補完する |
このように、現代の形態素解析ツールは辞書と統計モデルを組み合わせることで日本語の複雑さに対応しています。ただし完全な精度を実現するには、構文解析や文脈解析といった後続処理との連携が重要です。
形態素解析とワードクラウドの違いとは?
形態素解析とワードクラウドは、どちらもテキストを扱う技術ですが、目的も処理も全く異なるものです。
ワードクラウドは、文章や文書の中でよく使われている単語を視覚的に表現する方法です。
単語の出現頻度に応じてフォントサイズを変えることで、ひと目で「どんな語が重要か」がわかるのが特徴です。
例:SNS投稿やアンケートの自由記述欄の可視化、PR資料のキービジュアルなどに使われます。
形態素解析との比較
| 比較項目 | ワードクラウド | 形態素解析 |
|---|---|---|
| 主な目的 | 単語の頻度を可視化する | 単語の意味・品詞・構造を分析する |
| 出力 | 単語とその出現頻度 | 単語(形態素)、品詞、活用形、原形など |
| 用途 | 可視化・印象づけ | 言語処理の前処理・構文理解 |
| 処理粒度 | 単語レベル(ただし表記ゆれに弱い) | 文法レベルでの正確な分割と分析 |
| 連携可能性 | 形態素解析の結果をもとに作成できる | ワードクラウド作成の前処理として使われることが多い |
このように使い分けることで、テキストデータをより深く理解し、効果的に活用できます。
形態素解析の応用事例
形態素解析は、日本語を「意味のある単語のかたまり」に分けてくれる技術です。実はこれ、検索エンジンからAIアシスタントまで、あらゆる“言葉を扱うシステム”の土台になっています。ここでは、実際の活用例をわかりやすく紹介します。
1. 検索エンジンでの「言い換え」対応と検索精度アップ
たとえばあなたが「カフェで勉強したい」と検索したとします。形態素解析を使うと、「カフェ」「勉強」といったキーワードが正しく取り出されます。
さらに重要なのは、「勉強した」「勉強する」「勉強中」といった表現の違いを同じ意味として認識できることです。これは言葉の“変化形”を正しく見抜けるからで、検索エンジンのヒット精度が上がる大きな要因になります。
✅ 専門用語でいうと、語幹の抽出(原形への変換) と呼ばれる処理です。
2. 商品レビューの感情分析(ポジティブ?ネガティブ?)
「このカメラ、画質は良いけど電池が持たない」といった口コミ。
形態素解析を使えば、「良い」「持たない」といった感情を表す言葉を抜き出せます。
こうして、レビューの中にある「ポジティブ」「ネガティブ」の評価を機械が自動で判断できるようになります。
✅ 特に、形容詞や副詞といった “感情のニュアンス”を持つ単語の抽出 に強みを発揮します。
3. 文書要約やキーワード抽出で、要点をつかむ
大量の文章から重要な単語や内容を要約する処理でも、形態素解析は最初に使われます。
たとえばレポートから「売上」「要因」「増加」といった名詞や、「改善する」「変動する」といった動詞を抽出し、その組み合わせからキーワードや要点を自動的にピックアップします。
✅ 名詞や動詞といった “中身のある単語=コンテンツ語”を選び出す下地 になるのです。
自然言語処理の基礎を理解したなら業務データのAI活用を計画する
形態素解析のツール選定やPythonでの実装を体験すると、テキストデータをAIが処理する仕組みが具体的に理解できます。顧客の問い合わせ分類、製品レビューの感情分析、社内ドキュメントの自動タグ付けなど、テキスト処理の知識は業務のAI活用に直接結びつくスキルです。
AI総合研究所では、NLP技術を含む業務のAI活用を体系的に進めるための「AI業務自動化ガイド」を無料で公開しています。テキスト処理の知識を業務改善に応用する具体的な手順を220ページで解説しています。
自然言語処理の知識を業務へのAI導入に結びつける

形態素解析の理解からテキストデータのAI活用へ
形態素解析で学んだ日本語テキスト処理の知識は、社内文書の自動分類やFAQ検索の精度向上、顧客の声分析など業務で直接役立ちます。220ページの実践ガイドで、Microsoft環境での業務プロセスの自動化を段階的に進める手順を具体的に解説しています。
まとめ
本記事では、形態素解析の基本概念からツール選定、実装手順、応用事例までを解説しました。ここで得られる価値は大きく3つあります。
1つ目は、形態素解析の仕組みと日本語固有の課題を理解することで、NLPプロジェクトの設計精度が上がる点です。単語境界の曖昧さ・活用形の多さ・同音異義語という3つの課題を把握しておけば、ツール選定やチューニングの方向性を的確に判断できます。
2つ目は、MeCab・Sudachi・Janome・Kuromojiの4ツールの特性を把握することで、用途に応じた最適な選択ができる点です。Pythonで手軽に試すならJanome、業務精度ならMeCabかSudachi、Java検索基盤にはKuromojiと、目的に合わせた使い分けが実務効率を左右します。
3つ目は、検索精度向上・感情分析・文書要約という3大応用パターンの理解が、自社データ活用の具体的な設計につながる点です。形態素解析は単独技術ではなく、後続処理の品質を決定づける基盤処理です。
次のステップとして、まずはGoogle ColabでMeCab×Pythonの実装例を動かし、自社の業務テキスト(FAQ・レビュー・社内文書など)を対象に解析精度を確認してみてください。目的に応じたツール選定→小規模データでの検証→本番データへの段階的適用という流れで、形態素解析を実務に組み込むことをおすすめします。











