この記事のポイント
 Gemini 3 Flashは、Gemini 3 Pro級の推論能力を低レイテンシ・低コストで提供するGoogleの最新モデル
Gemini 3 Flashは、Gemini 3 Pro級の推論能力を低レイテンシ・低コストで提供するGoogleの最新モデル- SWE-bench Verifiedで78%を記録するなど、コーディングやエージェントタスクにおいて実務レベルの性能を発揮
- thinking_levelやmedia_resolutionパラメータにより、タスクの難易度に応じて思考量やマルチモーダル解析の深さを調整可能
- Geminiアプリや検索AI Modeのデフォルトモデルとして採用され、一般ユーザーから開発者まで幅広く利用可能
- API利用では入力$0.50/出力$3.00(100万トークン)と安価でありながら、トークン効率とスループットが大幅に改善されている

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2025年12月17日、Googleは新モデル「Gemini 3 Flash」を発表しました。Gemini 3 Proと同世代のフロンティア級の知能を持ちながら、レイテンシとコストを大きく抑えた、いわば「速度重視のGemini 3」です。
本記事では、このGemini 3 Flashの特徴・性能・料金・使い方・ユースケース、そしてGemini 3 Proや従来モデルとの違いまで、ビジネス・開発の両面から整理して解説します。
目次
スピードとトークン効率:Gemini 2.5 Pro比で「3倍速・トークン30%減」を狙う設計
価格と性能のバランス:LMArena×価格で見るパレートフロンティア
Gemini API / Google AI Studio / Gemini CLI
開発者向け:vibe coding とエージェント型コーディング
Gemini 3 Pro / Deep Thinkとの使い分け
Gemini 2.5 Flash / Flash Liteからの移行
Gemini 3 Flashとは?
Gemini 3 Flashとは、Googleが2025年12月17日に発表した「Gemini 3」世代の最新モデルで、フロンティア級の知能を「速さ」と「低コスト」に最適化した汎用LLMです。
同じGemini 3ファミリーの「Gemini 3 Pro」と同等クラスの推論性能を維持しながら、レスポンスの速さとスループット(単位時間あたりの処理件数)を大きく引き上げた設計になっています。
公式ブログでは「frontier intelligence built for speed(速さのために設計されたフロンティア級の知能)」と表現されており、
- 高度な推論・マルチモーダル理解
- 低レイテンシ
- 低めのトークン単価
を同時に満たす「実務で回しやすい標準モデル」として位置づけられています。
従来のGemini 2.5 Flashが「軽量・高速モデル」だったのに対し、Gemini 3 Flashは軽さを保ったままフラッグシップ級の知能に引き上げた後継と考えるとイメージしやすいです。
Gemini 3シリーズの中での立ち位置
Gemini 3ファミリーの主なモデルと役割を整理すると、次のようになります。
-
Gemini 3 Pro
精度最優先のフラッグシップモデル。Deep Thinkモードと組み合わせることで、数学・科学・研究用途などの難問に強みを発揮します。
-
Gemini 3 Flash
Pro級の知能を維持しつつ、レスポンス速度とコストを最適化した「実務向け汎用モデル」。大量のチャットやAPIリクエストをさばく用途に向きます。
-
Gemini 3 Deep Think(Proの思考モード)
レイテンシとトークンを犠牲にしてでも、最大限の推論精度を出したいときの“長考モード”。研究や高度な意思決定支援向けです。
この中でGemini 3 Flashは、Geminiアプリや検索のAI Modeにおけるデフォルトモデル(標準モデル)として採用されるワークホース的なポジションを担っています。
「ときどき最高性能を叩くのがPro/Deep Think」「日常的に大量に回すのがFlash」という分担で考えると、現場でのモデル選定が整理しやすくなります。
Gemini 3 Flashの性能・アーキテクチャ概要

Gemini 3 Flashは、Gemini 3シリーズの中でも「速度とスケールを重視しながら、知能レベルは妥協しない」ことを目標に設計されたモデルです。
公式ブログでも、複雑な推論・科学知識・数学・マルチモーダル理解・コーディング・長いコンテキストといった幅広い領域で、より大きなフロンティアモデルと肩を並べつつ、Gemini 2.5 Proを大きく上回る性能が示されています。
ここでは、公開されているベンチマークと、速度・トークン効率・コスト構造の観点からGemini 3 Flashの特徴を整理します。
ベンチマークで見るGemini 3 Flashの性能
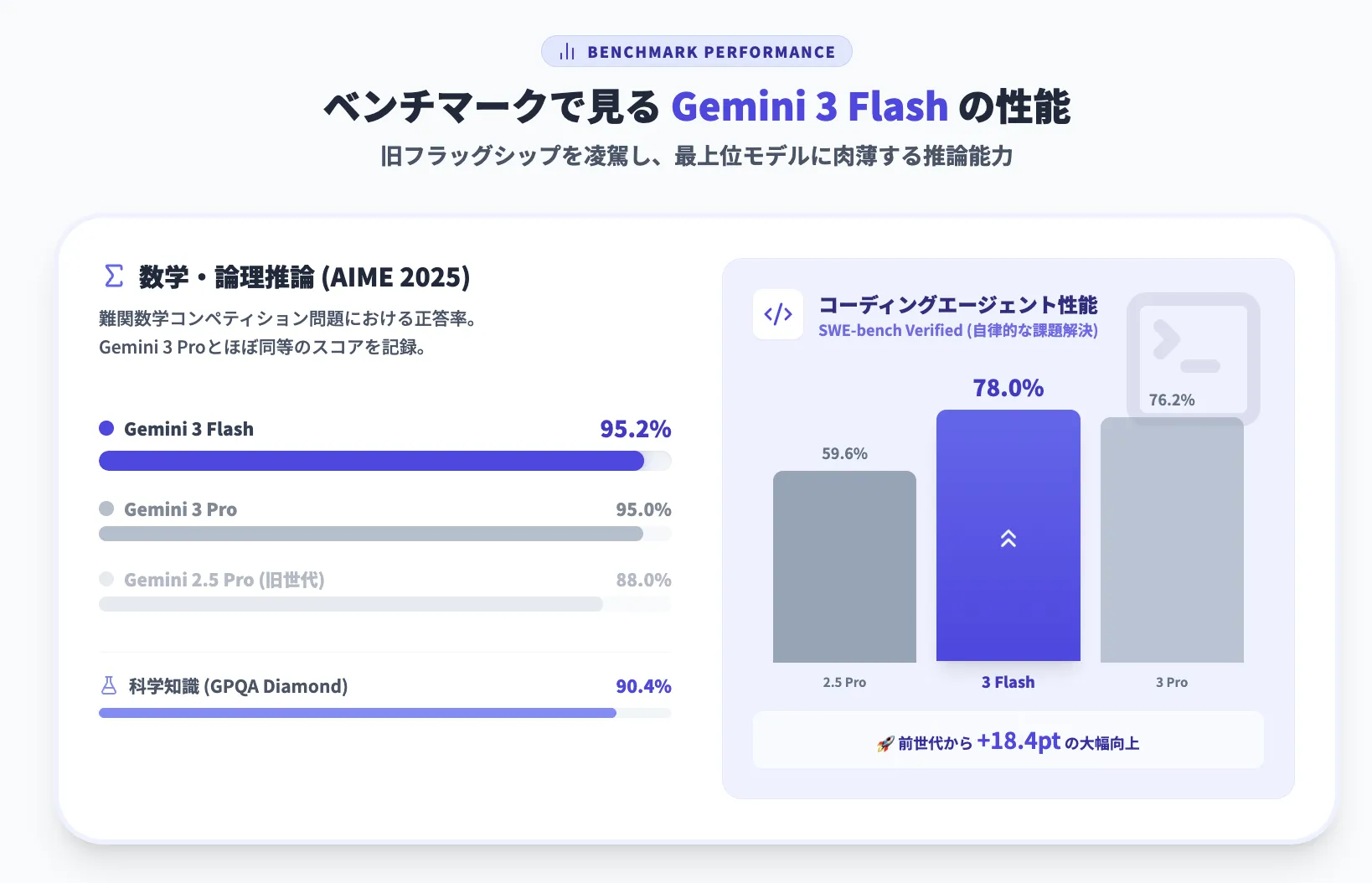
まずは、公式に公開されている主なベンチマーク結果を整理します。
数値を見ると、いわゆる「教科書問題」だけでなく、博士レベルの難問やマルチモーダルタスクまで、総合的に高い水準にあることが分かります。
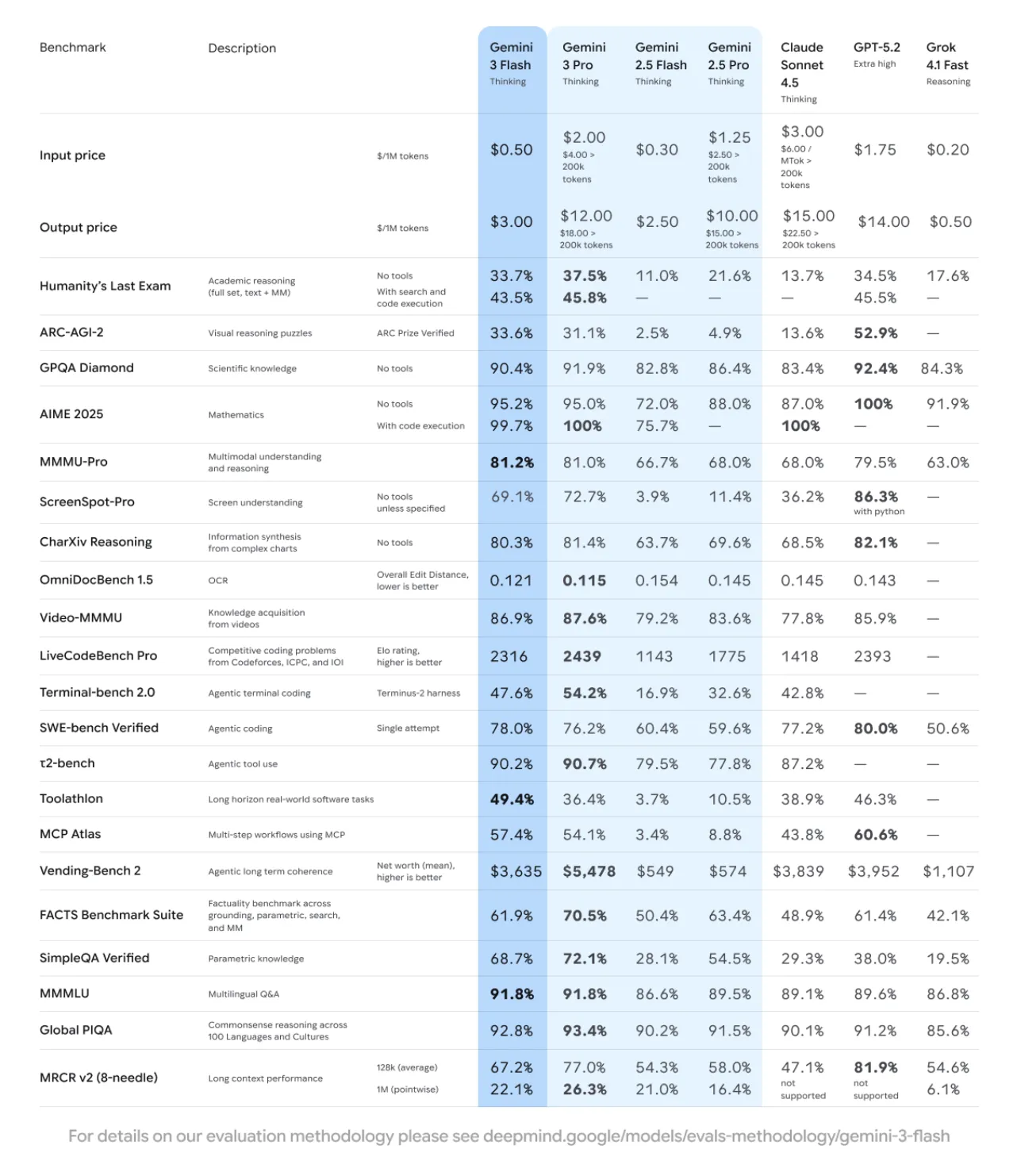
参考: Google DeepMind「Gemini 3 Flash」ベンチマーク表
この図は、学術推論・科学知識・数学・マルチモーダル推論・コーディング・ロングコンテキストなど、幅広いベンチマークにおける各モデルのスコアと価格を一覧にしたものです。
Gemini 3 Flashは、「Gemini 3 Proとほぼ同等の推論性能を持ちながら、2.5 Proを大きく上回る」というポジションにあります。
代表的な指標を、主要モデルとあわせて抜粋すると次のようになります(いずれもThinking系モデル同士の比較・値が高いほど良い)。
| ベンチマーク | Gemini 3 Flash | Gemini 3 Pro | Gemini 2.5 Pro | GPT-5.2 Extra high | Claude Sonnet 4.5 |
|---|---|---|---|---|---|
| Humanity’s Last Exam(学術推論, no tools) | 33.7% | 37.5% | 21.6% | 34.5% | 13.7% |
| GPQA Diamond(科学知識, no tools) | 90.4% | 91.9% | 86.4% | 92.4% | 83.4% |
| AIME 2025(数学, no tools) | 95.2% | 95.0% | 88.0% | 100% | 87.0% |
| MMMU-Pro(マルチモーダル推論) | 81.2% | 81.0% | 68.0% | 79.5% | 68.0% |
| SWE-bench Verified(エージェントコーディング) | 78.0% | 76.2% | 59.6% | 80.0% | 77.2% |
※数値はいずれも2025年12月時点で公開されている公式ベンチマーク結果をもとにしたものです。
この表から読み取れるポイントは、ざっくり次のとおりです。
-
総合推論
Humanity’s Last ExamやGPQA Diamondなど博士レベル試験で、Gemini 3 ProやGPT-5.2 Extra highに肉薄しつつ、Gemini 2.5 ProやClaude Sonnet 4.5を大きく上回る水準
-
数学・論理タスク
AIME 2025で95.2%を記録し、Gemini 3 Proとほぼ同水準かつ従来モデルより一段上のレンジに位置する数学・論理タスク性能
-
マルチモーダル推論
画像・チャート・図表を含むMMMU-Proで81.2%と、Gemini 3 Proとほぼ同等スコアを示すフラッグシップ級のマルチモーダル推論性能
-
コーディングエージェント性能
SWE-bench Verifiedで78.0%とGemini 3 Pro(76.2%)やClaude Sonnet 4.5(77.2%)と同クラスの精度を出しつつ、Gemini 2.5 Proを大きく引き離すコーディングエージェント性能
また、ロングコンテキスト性能を測る**MRCR v2(128k・1Mコンテキスト)**でも、Gemini 3 Flashは128k平均で67.2%、1M pointwiseで22.1%と、2.5 ProやClaude Sonnet 4.5より一段高いレンジのスコアを出しています。
大規模ドキュメントの要約や長時間会議の議事録処理などでも、十分実用的なレベルと考えられます。
スピードとトークン効率:Gemini 2.5 Pro比で「3倍速・トークン30%減」を狙う設計
Gemini 3 Flashのもう一つの特徴は、「フロンティア級の推論能力を保ったまま、レイテンシとトークン効率を徹底的に最適化している」点です。ここでは、その中核となるdynamic thinkingの仕組みと、実際の挙動イメージを整理します。
dynamic thinkingの概要

Gemini 3 Flashでは、プロンプトの難易度に応じて内部の思考量を自動で増減させる dynamic thinking と呼ばれる仕組みが導入されています。
ポイントを整理すると、次のような動きをするアーキテクチャです。
- プロンプト内容に基づくタスク難易度の内部推定
- 難易度に応じたThinkingトークン量・思考ステップ数の自動調整
- レイテンシとトークンコストを抑えるリソース配分の最適化
この結果として、簡単な要約や書き換えのようなタスクでは思考トークンを抑え、複雑なコード解析や長文ドキュメントの読解では必要に応じて思考を深くすることで、「どのタスクにどれだけ計算リソースを割くか」を自動的にコントロールできる設計になっています。
Googleの説明によると、実際の標準的なトラフィックで測定した場合、Gemini 3 FlashはGemini 2.5 Pro比で約3倍の速度を実現しつつ、平均して約30%少ないトークンで同等以上の品質を出せるようチューニングされています。
実際の挙動例:Dynamic thinking有効時のFlash vs 2.5 Pro
このdynamic thinkingを有効にした状態で、同じSVGイラスト生成タスクをGemini 3 FlashとGemini 2.5 Proに投げた比較が、次の図です。
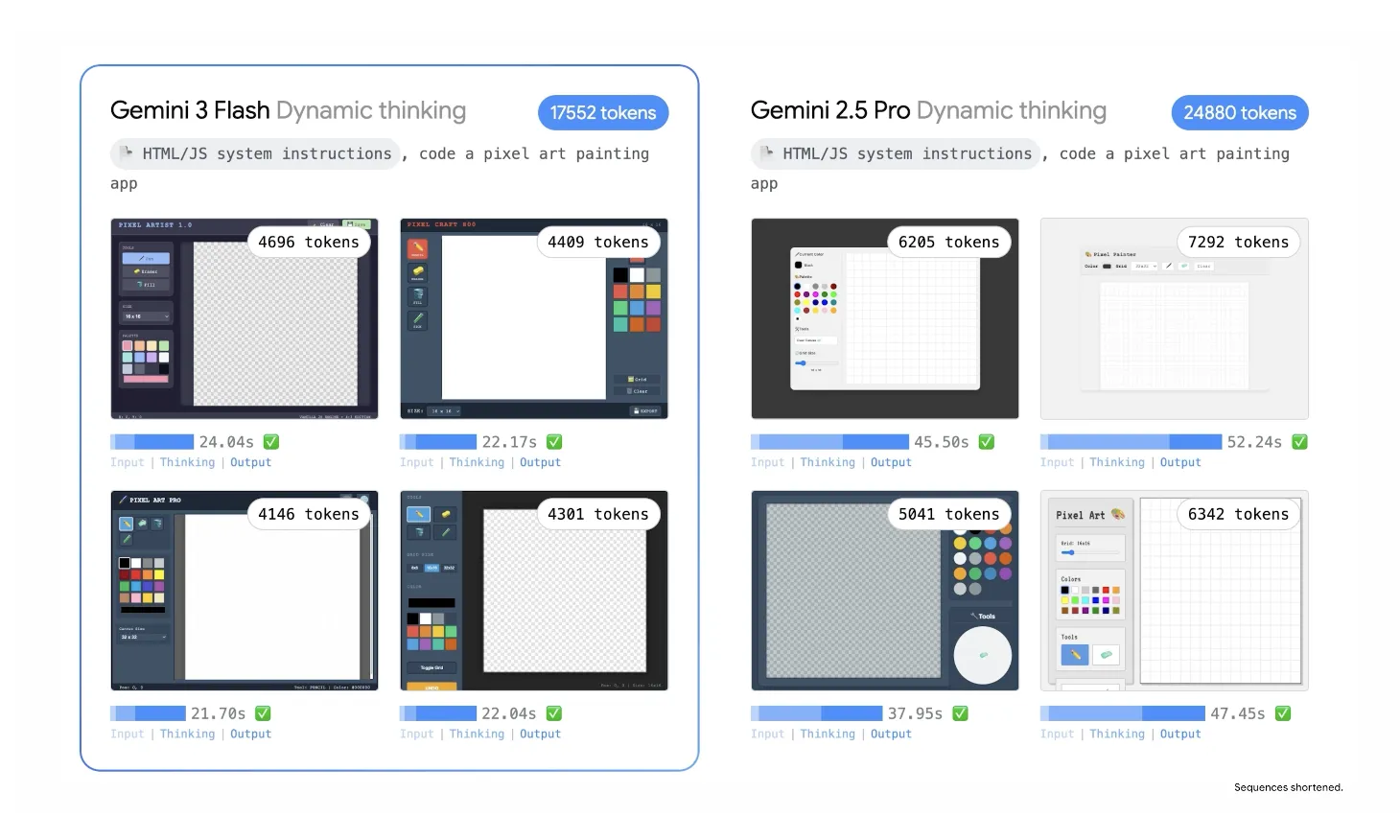
同じSVGイラスト生成タスクをDynamic thinkingで実行したときの、Gemini 3 FlashとGemini 2.5 Proのトークン数・所要時間の比較イメージ
このデモ例では、Golden Gate Bridge風のSVGイラストをDynamic thinkingで複数枚生成しています。
数値を見ると、両モデルの性格差が分かりやすくなります。
- Gemini 3 Flash の場合
1枚あたりのThinking時間はおおむね 17〜19秒台 に収まり、出力トークン数も 3,400〜3,700トークン前後 で安定しています。
- Gemini 2.5 Pro の場合
同様のタスクで 50〜70秒台 程度のThinking時間がかかり、出力トークン数も 6,000〜8,000トークン台 まで膨らむケースが多く見られます。
このように、同じ種類のタスクをこなすために必要な時間・トークンをどこまで削れるかという観点で見ると、Gemini 3 Flashが「実運用を強く意識したチューニング」を受けていることが分かります。
価格と性能のバランス:LMArena×価格で見るパレートフロンティア
最後に、「どのモデルがコストに対してどれくらい強いのか」を、価格と人間評価の両面から見ておきます。
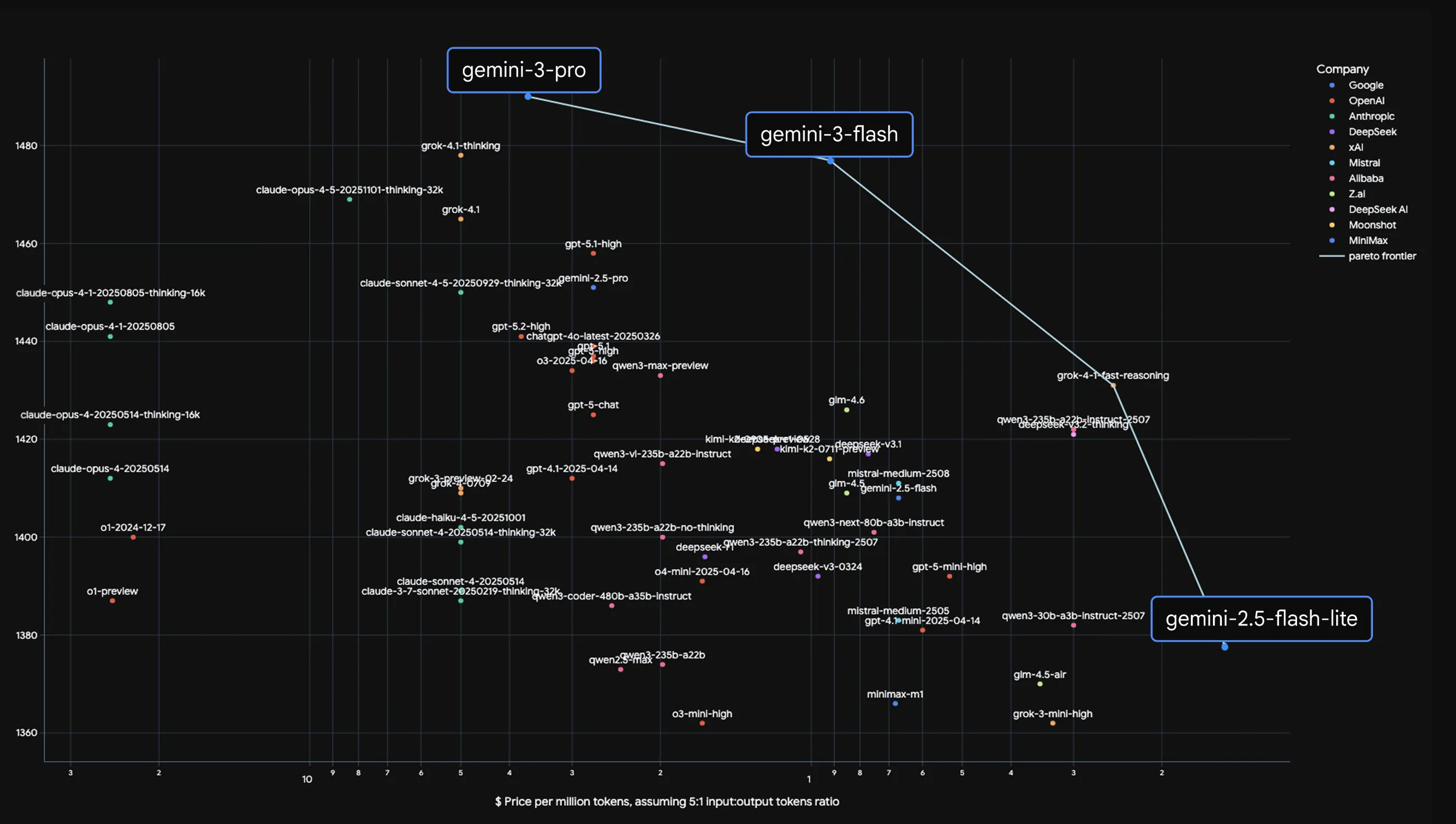
この図は、各モデルの**LMArena Eloスコア(総合的人間評価)と価格($/M tokens)**をプロットしたもので、右上に行くほど「高性能だが高価」、左下に行くほど「安いが性能も控えめ」という意味になります。
Gemini 3 Flashは、Gemini 3 ProとGemini 2.5 Flash Liteを結ぶパレートフロンティア上に位置しており、「性能とコストのバランスが良いモデル」として設計されていることが分かります。
競合モデルとの価格比較
価格面のざっくり比較は次のとおりです(テキスト生成向けThinkingモデル、1Mトークンあたり)。
| モデル | 入力価格 | 出力価格 | 特徴のイメージ |
|---|---|---|---|
| Gemini 3 Flash | $0.50 | $3.00 | フロンティア級の推論性能と高速・低コストを両立 |
| Gemini 3 Pro | $2.00 | $12.00 | 最高性能だがコストも高め |
| Gemini 2.5 Pro | $1.25 | $10.00 | 旧フラッグシップ。現在はGemini 3系列に徐々に置き換わりつつある |
| GPT-5.2 Extra high | $1.75 | $14.00 | 非常に高性能だが、出力価格は最上位クラス |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 高精度だが単価はやや高め |
| Grok 4.1 Fast | $0.20 | $0.50 | 低価格・高速だが、推論性能はフラッグシップ級より一段下 |
見て分かるとおり、Gemini 3 Flashは出力$3/M tokensという価格帯で、GPT-5.2 Extra highやClaude Sonnet 4.5と同等〜一部ベンチマークで上回る性能を出しつつ、コストは約1/4〜1/5に抑えています。
一方で、純粋な価格だけならGrok 4.1 Fastの方が安価ですが、総合推論性能やマルチモーダル性能ではGemini 3 Flashの方が一段上に位置します。
そのため、実務でのざっくりした使い分けとしては次のようなイメージになります。
- Gemini 3 Pro
「ベンチマークで最強クラスを取りに行きたい」「Deep Think前提の難問解決」を重視するケース
- Gemini 3 Flash
「高い精度は欲しいが、レイテンシとコストも重要」という業務プロダクトやエージェント基盤の主力モデル
- Gemini 2.5 Flash Lite / Grok 4.1 Fastなど
「品質よりもスループットとコストを優先する大量生成タスク」向け
Gemini 3 Flashは、この中で「フロンティア級モデルをプロダクションで回すための現実解」というポジションを狙っている、と整理できます。
Gemini 3 Flashの料金
Gemini 3 Flashを使うときの料金は、大きく「Geminiアプリ(チャット)」「検索AI Mode」「開発者向けAPI」の3レイヤーで考えると整理しやすくなります。
Geminiアプリの料金

Gemini 3 Flashは無料プランを含む全てのプランで利用可能ですが、どこまでヘビーに使えるか・どの機能まで解放されるかは「Google AI Pro / Ultra」といったサブスクプランで変わります。
以下は、日本向けの代表的なプランと、Gemini 3 Flash利用のイメージです。
| プラン | 月額料金(日本向けの目安) | 主な特徴 |
|---|---|---|
| 無料版(Googleアカウントのみ) | 無料 | ・Geminiアプリでの基本利用 ・検索のAI Modeでの基本利用 ・高負荷の利用にはレート制限あり |
| Google AI Pro | 約 ¥2,900/月 | ・Gemini 3 Pro / Flashの利用上限が拡大 ・長文のやり取りやファイル添付などヘビーユースを想定 |
| Google AI Ultra | 約 ¥36,400/月 | ・Deep Thinkなどの上位機能への早期アクセス ・大幅に緩い利用上限 ・研究・クリエイティブ用途も想定 |
各料金プランの詳細は、以下の記事で詳しく解説しています。
Geminiの料金プランを比較!無料・有料版の違いと選び方【2025年最新】
また、法人向けプラン(Google Workspace)の料金体系については、以下の記事をご覧ください。
Google Workspaceの料金体系を徹底比較!支払い方法やプラン別の違いを紹介
Gemini 3 Flash APIの料金
アプリや自社サービスにGemini 3 Flashを組み込む場合は、Gemini API(Google AI Studio / Antigravity / Vertex AI / Gemini Enterprise)経由で利用します。この場合は、トークン課金ベースの料金体系になります。
代表的な料金は次のとおりです(テキスト・マルチモーダル利用の例)。
| モデル | 用途 | 入力トークン (Input) | 出力トークン (Output) | 補足 |
|---|---|---|---|---|
| Gemini 3 Flash | 高速対話・エージェント・インタラクティブアプリ | $0.50 / 100万トークン | $3.00 / 100万トークン | オーディオ入力は $1.00 / 100万トークン。2.5 Proより大幅に安価かつ高速なポジションです。 |
Gemini 3 Flashは、同じGoogle系のフラッグシップモデルであるGemini 3 Proと比べて、価格は安く、速度は速いが、推論の「最大値」はやや抑えめという設計になっています。そのため、次のような考え方で使い分けるイメージになります。
- Flash寄りが向いているケース
日常的なチャット、RAGベースの社内Q&A、リアルタイム性の高いエージェント、インタラクティブUIなど。
- Pro / Deep Think寄りが向いているケース
研究レベルの難問、複雑な数式や証明、長期的なプランニング、極端に長いコンテキストを扱うタスクなど。
Gemini 3 Flashの使い方
Gemini 3 Flashは、一般ユーザー向けのGeminiアプリから、開発者向けのAPIやAntigravityまで、かなり広いチャネルで提供されています。
ここでは、「どこで・どう使えるのか」を簡単に整理します。
Geminiアプリ(モバイル / Web)
Geminiアプリでは、モデルピッカーから「高速モード」を選択することでGemini 3 Flashを利用できます。
Google検索のAI Mode
Google検索のAI Modeでも、Gemini 3 Flashが標準モデルとして採用されています。
従来はGemini 2.5 Flashが使われていましたが、順次Gemini 3 Flashに置き換えられています。
AI Modeでは、検索クエリに対して
- 要点を整理した回答
- 表・リスト・カード形式の「Generative UI」
- ローカル情報や最新ニュースを組み合わせた提案
などを提示してくれます。Gemini 3 Flashに置き換わることで、回答の質とスピードの両方が向上するとされています。
Gemini API / Google AI Studio / Gemini CLI
開発者向けには、次のようなチャネルでGemini 3 Flashが利用できます。
- Gemini API(Google AI Studio)
Webコンソールからプロンプトを試しつつ、バックエンドではGemini 3 Flashを指定してアプリに組み込めます。
【関連記事】
Google AI Studioとは?使い方や料金、商用利用を解説!【無料】
-
Gemini CLI
ターミナルからGemini 3 Flashを呼び出し、コード生成やログ解析を高速に行えます。CLI向けにもFlashは提供されており、SWE-bench Verified 78%の性能を活かしたエージェントコーディングが可能です。
【関連記事】
Gemini CLIとは?使い方や料金、Claude Codeとの違いをわかりやすく解説! -
Google Antigravity
エージェントファーストなIDEとして、Gemini 3 Flashを使ったコーディング・エージェントや業務フロー自動化を構築可能です。
【関連記事】
【Google】Antigravityとは?設定方法や使い方、料金体系を解説
いずれも、thinking_levelやmedia_resolutionなどのパラメータを指定することで、推論量やマルチモーダル処理の深さを調整できます。
Vertex AI / Gemini Enterprise
企業向けには、Google Cloudおよび新開発プラットフォーム経由で利用できます。
- Vertex AI
企業アプリケーションやバッチ処理でGemini 3 Flashを使いたい場合は、Vertex AIのモデルガーデンからGemini 3 Flash Previewを選択して利用します。
- Gemini Enterprise
社内検索やドキュメント要約など、業務アプリにAIを組み込むソリューションとして提供されます。
このように、個人利用からエンタープライズまで、ほぼすべてのレイヤーでGemini 3 Flashを利用できるのが大きな特徴です。
Gemini 3 Flashのユースケース・活用シナリオ
Gemini 3 Flashは「Pro級の推論」と「Flash級の速度・コスト」のバランスが良いため、かなり幅広いユースケースに向きます。ここでは代表的なシナリオをいくつか取り上げます。

日常タスク・個人利用:学習・計画・情報整理
Gemini 3 Flashは、一般ユーザー向けにも無料で提供されているため、日常的な学習や計画タスクでの利用が想定されています。
具体的には、次のような場面で活用しやすいモデルです。
- 勉強ノートや講義動画の要約、理解度チェック用クイズの作成
- 旅行・イベント・家計管理などの計画づくり
- 画像・動画・音声メモをまとめて、行動計画やTODOリストに変換
Gemini 3 Flashはマルチモーダル推論が得意なため、「動画+メモ+画像」といった混在入力からでも、まとまったプランやレポートを作るのに向いています。
開発者向け:vibe coding とエージェント型コーディング
開発者にとっては、Gemini 3 Flashはvibe coding(会話ベースでの開発)やエージェント型コーディングの中核モデルになり得ます。
- IDEやCLIからのコード生成・修正
- テストケースの自動生成やログ解析
- 既存コードベースを読み込んだうえでのリファクタリング提案
SWE-bench Verifiedで78%というスコアを出していることからも、実際のコードリポジトリを扱うタスクで高い成功率が期待できます。
業務利用:データ抽出・レポート生成・検索体験の高度化
業務システムや自社アプリに組み込む場合、Gemini 3 Flashは「速くてそこそこ安いが、知能レベルはフラッグシップ級」という特性が効いてきます。
- 請求書・契約書・議事録などからのデータ抽出と構造化
- ダッシュボードやBIツールと連携したレポート生成
- サイト内検索・FAQボットの回答品質向上
特に、検索や社内ナレッジの分野では、Google自身がGemini 3 FlashをAI Modeに採用していることからも、検索体験の高度化に向いたモデルと位置づけられていることが分かります。
画像・動画・インタラクティブ体験
Gemini 3 Flashは、画像や動画をリアルタイムに解析しながら回答するユースケースにも対応しています。公式デモでは、次のような事例が紹介されています。
- 手書きのスケッチを解析しながら、ユーザーの意図を推測してアプリUIをその場で作り替える
- 画像内のUI要素を理解し、インタラクティブなオーバーレイ(ボタンや説明ラベル)を生成する
- 短いゲーム動画を解析し、リアルタイムで攻略のヒントを出すゲーム内アシスタント
動きの速いゲーム画面を解析しながら、プレイ中にアドバイスを返すようなシナリオは、従来の大規模モデルではレイテンシの面で難しかった領域です。
Gemini 3 Flashは、こうした**「リアルタイム性+深い理解」が必要なマルチモーダル体験**を狙ったモデルと言えます。
Gemini 3 Flashと他モデルの比較・使い分け指針
最後に、Gemini 3 Flashと他モデルをどう使い分けるかを整理しておきます。ここでは、Gemini 3 Pro / 2.5シリーズ / 他社モデルとの比較観点をまとめます。

Gemini 3 Pro / Deep Thinkとの使い分け
Gemini 3 ProやDeep Thinkは、最大限の精度が必要なシナリオに向いた「ハイエンド」モデルです。一方でGemini 3 Flashは、次のような場面で選ばれやすくなります。
- リクエスト数が多いWebサービス・SaaS
- レスポンス速度が重要なインタラクティブUIやゲーム
- 一般ユーザー向けチャットボット・FAQ・学習アプリ
「品質最優先ならGemini 3 Pro、コストと速度のバランス重視ならGemini 3 Flash」というのが基本の切り分けになります。
Deep Thinkモードが必要な超難問(研究用途や数理最適化など)ではPro側を使い分け、日常的な問い合わせやUI生成などはFlashで回す、という設計が現実的です。
Gemini 2.5 Flash / Flash Liteからの移行
Gemini 2.5 FlashやFlash Liteを既に使っている場合、次の観点で乗り換えを検討できます。
- 並列リクエストが多くスループットを上げたい
- コーディングやマルチモーダル処理の成功率を上げたい
- thinking_level・media_resolutionを使った細かいコントロールが欲しい
価格だけを見ると2.5 Flashの方が安いですが、Gemini 3 Flashは3倍速・30%少ないトークンをうたっており、実運用での「コスト/成功率」のバランスはむしろ有利になる可能性があります。
OpenAI / Anthropic / xAIなど他社モデルとの比較視点
Gemini 3 FlashはLMArenaなどのサードパーティ評価でも、主要なフロンティアモデルと同等クラスのEloスコアを出しつつ、価格帯はやや低めに設定されています。
他社モデルとの比較では、
- 価格($/M tokens)
- レイテンシとスループット
- thinking_level / media_resolutionのような制御性
- Google検索やAndroid / Chromeとの統合のしやすさ
といった観点で、どこを重視するかによって選択肢が変わってきます。 Googleエコシステムを中心に据える場合、Gemini 3 Flashは「最初に検討すべき汎用モデル」になりそうです。
よくある質問(FAQ)
ここでは、Gemini 3 Flashに関して想定される質問をいくつかピックアップし、簡単に整理します。
Q1. Gemini 3 Flashは無料で使えますか?
GeminiアプリやAI Mode(検索)では、多くのユーザーが追加料金なしでGemini 3 Flashの恩恵を受けられます。一方、API経由で大規模に利用する場合は、前述のトークン単価に基づく課金が発生します。
Q2. Gemini 3 Proと比べて、どれくらい性能が落ちますか?
ベンチマークによってはGemini 3 Proの方が高スコアですが、SWE-bench VerifiedのようにFlashが上回る指標もあります。一般的なアプリケーションでは「Proとほぼ同等か、タスクによっては上回る」ケースもあるため、実際にはタスクの種類ごとに比較テストをするのが安全です。
Q3. 既存の2.5 Flashから移行するメリットは?
推論性能とマルチモーダル性能が向上しているうえに、トークン効率も改善されているため、同じ品質をより少ないトークンで実現できる可能性があります。レイテンシも改善されているため、体感速度の点でもメリットが大きいモデルです。
Q4. thinking_levelやmedia_resolutionは必ず設定した方がいいですか?
必須ではありませんが、コストと品質のバランスを最適化したい場合は設定推奨です。
thinking_levelは「どれくらいじっくり考えさせるか」、media_resolutionは「画像や動画をどの深さで読むか」を決めるパラメータなので、業務アプリやエージェント用途では、要件に合わせて調整しておくとよいでしょう。
まとめ:Gemini 3 Flashは「実務で回すフロンティア級モデル」
Gemini 3 Flashは、次のような特徴を持つモデルです。
- Gemini 3 Pro級の推論性能を維持しながら、低レイテンシ・低コストに最適化されている
- **SWE-bench Verified 78%**など、実務に近いベンチマークでも高いスコアを記録している
- GeminiアプリとAI Modeのデフォルトモデルとして、一般ユーザーにも幅広く提供されている
- thinking_level / media_resolutionにより、推論量と視覚処理の深さを細かく制御できる
「とにかく一番賢いモデルを単発で叩く」だけであればGemini 3 Proや他社フロンティアモデルも選択肢ですが、**日常的・継続的に使う“仕事道具としてのモデル”**を選ぶなら、Gemini 3 Flashはかなり有力な候補になります。
まずはGeminiアプリやAI Modeで挙動を試しつつ、開発や業務への本格導入を検討してみてください。





