この記事のポイント
 LLMのトークンコスト削減を最優先課題とするなら、DeepSeek-OCRの「光学的圧縮」アプローチを検討すべき。テキストを画像化して圧縮する革新的な手法
LLMのトークンコスト削減を最優先課題とするなら、DeepSeek-OCRの「光学的圧縮」アプローチを検討すべき。テキストを画像化して圧縮する革新的な手法- 大量文書のOCR処理にはDeepEncoderの活用が最適。高解像度の文書画像を少数のビジョントークンに変換し、既存モデル比で大幅なコスト削減が可能
- グラフ・化学式・多言語文書(約100言語)を扱う業務には特に有効。構造的解析「ディープパーシング」で従来手法では困難だった精度を実現
- オープンソースのため、自社環境へのカスタマイズ導入が第一候補になる。ソースコードとモデル重みが公開済み
- 本番運用にはまだ検証が必要なため、即座の全面移行は避けるべき。まずはPoCでトークン削減効果を実測するのが現実的

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入DX推進を支援。
「AIにもっと長い文章を読ませたいけど、処理が遅くてコストも高い…」LLMが抱えるこの「長期コンテキスト問題」に、全く新しいアプローチで挑むモデルがDeepSeek-AIから登場しました。それが「DeepSeek-OCR」です。
このモデルは、テキストを一度「画像」として捉え直し、圧縮することで、計算効率を飛躍的に高める「光学的圧縮」という革新的なコンセプトを提唱しています。
本記事では、この「DeepSeek-OCR」について、その全貌を徹底的に解説します。
核心技術である「DeepEncoder」の仕組み、驚異的な性能、そして「光学的圧縮」が拓くAIの未来まで、詳しくご紹介します。
最新モデル「DeepSeek V3.2」については、こちらの記事で詳しく解説しています。 ▶︎DeepSeek-V3.2とは?使い方や料金、ベンチマーク性能を徹底解説!
目次
DeepSeek-OCRとは?
DeepSeek-OCRは、AI企業DeepSeek-AIが開発した、テキスト情報を効率的に扱うための視覚言語モデル(VLM)です。その核心には、大規模言語モデル(LLM)が抱える長期コンテキストの課題を解決する可能性を秘めた「光学的圧縮 (Contexts Optical Compression)」というコンセプトがあります。

LLMの「長期コンテキスト問題」を解決する新アプローチ
今日のLLMは、一度に処理できる情報量(コンテキスト長)が長くなるほど、計算量が二乗で増加する「長期コンテキスト問題」を抱えています。この問題により、非常に長い文書の読解や、過去の対話履歴をすべて記憶することが困難になっています。
DeepSeek-OCRは、この課題に対して、テキストをそのまま処理するのではなく、一度「画像」として扱うという新しい視点を提供します。
このアプローチにより、計算コストを抑えながら、より多くの情報を効率的に処理することを目指します。
テキストを画像に変換して圧縮する「光学的圧縮」
「光学的圧縮」とは、テキスト情報を文書画像として2次元情報にマッピングし、それをビジョンエンコーダ(画像認識AI)を通して少数の「ビジョントークン」に圧縮する技術です。
例えば、1000語の文章が数千のテキストトークンになるのに対し、それを一枚の画像として捉えれば、わずか数百のビジョントークンで表現できる可能性があります。
DeepSeek-OCRは、この圧縮されたビジョントークンから元のテキストを正確に復元する(OCR)ことで、このコンセプトの有効性を実証しています。
高性能OCRと研究コンセプトを両立したVLM
DeepSeek-OCRは、単なる実験的なコンセプトモデルではありません。そのアーキテクチャは、実際の文書解析タスクにおいて非常に高い性能を発揮するように設計されています。
研究としての新規性と、実用的なOCRツールとしての堅牢性を両立させている点が、このモデルの大きな特徴です。後述する性能評価では、既存の多くのモデルを少ない計算資源で上回る結果を示しています。
DeepSeek-OCRの技術的な仕組み
DeepSeek-OCRの優れた性能は、独自に設計されたアーキテクチャによって実現されています。ここでは、その核心技術である「DeepEncoder」を中心に、モデルがどのようにして高効率・高精度な処理を可能にしているのかを解説します。
モデルの全体構成:DeepEncoderとMoEデコーダー
DeepSeek-OCRは、大きく分けて2つのコンポーネントで構成されています。一つは画像から特徴を抽出・圧縮するエンコーダ、もう一つは圧縮された情報からテキストを生成するデコーダーです。
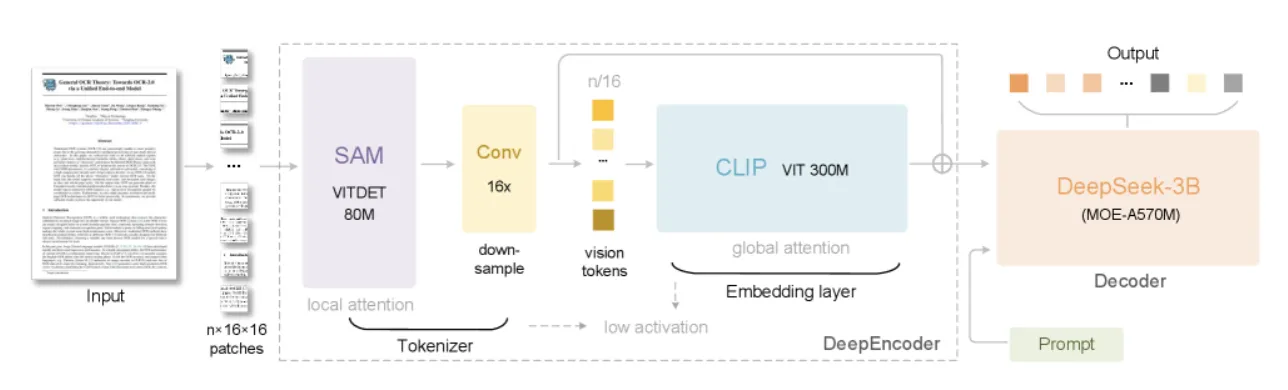
DeepSeek-OCRのアーキテクチャ全体像。 SAM、16倍コンプレッサー、CLIPを直列に繋いだ独自の「DeepEncoder」が、入力された文書画像を高効率に圧縮する。 (参考:DeepSeek-OCR: Contexts Optical Compression)
- DeepEncoder (エンコーダ):
高解像度の文書画像を、計算コストを抑えながら少数のビジョントークンに変換する役割を担います。
- DeepSeek-3B-MoE (デコーダー):
DeepEncoderから受け取ったビジョントークンを解釈し、元のテキスト情報を正確に復元します。MoE (Mixture of Experts) 形式を採用しており、推論効率が高い点が特徴です。
核心技術「DeepEncoder」の3つのコンポーネント
このモデルの心臓部である「DeepEncoder」は、性質の異なる既存モデルを巧みに組み合わせた、3段階の直列構造になっています。
- SAM (Segment Anything Model): ウィンドウアテンションを主体とし、高解像度の画像から局所的な特徴を効率的に抽出
- 16x トークンコンプレッサー: SAMから出力された大量のビジョントークンを、畳み込み層を用いて16分の1に圧縮
- CLIP (Contrastive Language–Image Pre-training): 全体的なアテンションを主体とし、圧縮されたトークンから画像全体の文脈的な知識を抽出
この設計により、計算負荷の高いグローバルアテンション(CLIP)への入力情報量を大幅に削減し、高解像度入力と低計算コストの両立を実現しています。
既存エンコーダの課題とDeepEncoderの優位性
従来のVLMで採用されてきたビジョンエンコーダには、それぞれ一長一短がありました。DeepEncoderは、これらの課題を克服するように設計されています。
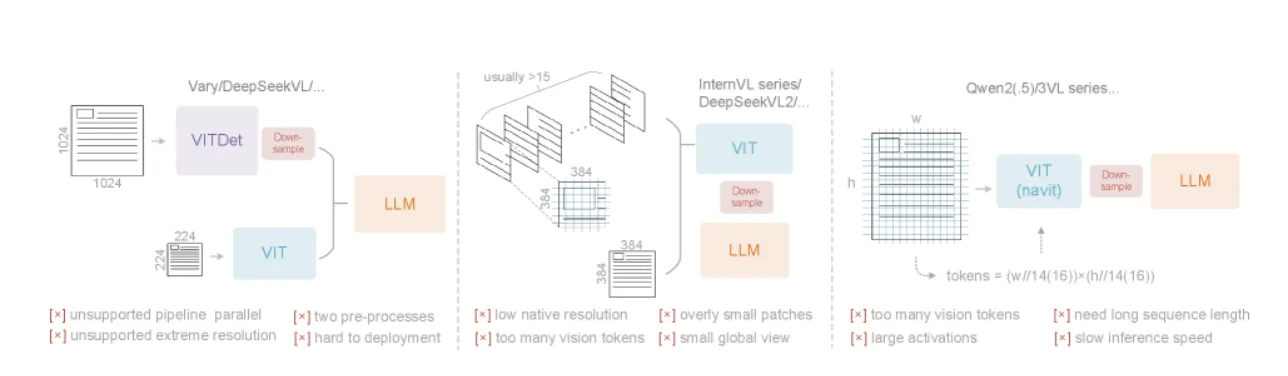
既存の主要なVLMエンコーダの比較。 Vary、InternVL、Qwen2-VLシリーズといった既存モデルのエンコーダが持つ、それぞれの課題を示しています。(参考:DeepSeek-OCR: Contexts Optical Compression)
以下に、既存の代表的なエンコーダタイプとDeepEncoderの比較をまとめます。
| エンコーダタイプ | 代表モデル | メリット | デメリット | DeepEncoderによる解決策 |
|---|---|---|---|---|
| デュアルタワー | Vary | パラメータ制御が容易 | 2つの前処理が必要で複雑 | 単一パイプラインで処理を簡素化 |
| タイルベース | InternVL2 | 超高解像度に対応可能 | トークン数が過剰に増加 | 高いネイティブ解像度で分割を抑制 |
| アダプティブ解像度 | Qwen2.5 | 柔軟な解像度に対応 | GPUメモリ消費量が大きい | トークン圧縮でメモリ負荷を軽減 |
この表から分かるように、DeepEncoderは先行するアプローチの利点を組み合わせ、欠点を補うバランスの取れた設計と言えます。
多様な解像度を使い分ける「マルチ解像度モード」
DeepSeek-OCRは、処理する文書の特性や要求される精度に応じて、入力解像度を柔軟に切り替えられる複数のモードを備えています。
論文で示されている主なモードとその仕様は以下の通りです。
| モード名 | ネイティブ解像度 | 出力トークン数 | 処理方法 | 主な用途 |
|---|---|---|---|---|
| Tiny | 512×512 | 64 | リサイズ | 低解像度・シンプルな文書 |
| Small | 640×640 | 100 | リサイズ | 標準的な文書、性能テスト |
| Base | 1024×1024 | 256 | パディング | 高解像度・複雑なレイアウト |
| Large | 1280×1280 | 400 | パディング | より高い精度が求められる文書 |
| Gundam | 640(n枚)+1024 | n×100+256 | タイル化+パディング | 新聞など超高解像度の文書 |
この機能により、ユーザーは性能とコストの最適なバランスを選択でき、モデルの実用性を大きく高めています。
DeepSeek-OCRの性能評価
DeepSeek-OCRは、その独創的なコンセプトだけでなく、実際のベンチマークテストにおいても優れた結果を示しています。
ここでは、具体的なデータを基に、その圧縮能力と実用的なOCR性能を検証します。
驚異的な圧縮・復元能力:圧縮率10倍で精度97%
「光学的圧縮」がどれほど有効かを測るため、Foxベンチマークを用いて、テキストの圧縮率とOCR精度の関係が評価されました。結果は非常に有望なものでした。
テキストトークン数をビジョントークン数の10倍程度に圧縮した場合でも、約97%という高い精度で元のテキストを復元。さらに、圧縮率が20倍に達する厳しい条件下でも、約60%の精度を維持しており、このアプローチのポテンシャルの高さを示しています。
実用的なOCR性能:最少トークンでSOTAを達成
実世界の多様な文書に対応する能力を測るOmniDocBenchにおいて、DeepSeek-OCRは既存の主要モデルと比較されました。
以下の表は、主要なエンドツーエンドモデルとの性能(編集距離:値が低いほど高精度)と使用トークン数の比較です。
| モデル | 平均使用トークン数 | 性能 (編集距離) |
|---|---|---|
| MinerU2.0 | 6790 | 0.133 |
| GOT-OCR2.0 | 256 | 0.287 |
| DeepSeek-OCR (Small) | 100 | 0.221 |
| DeepSeek-OCR (Gundam) | 795 | 0.127 |
この結果から、DeepSeek-OCRが既存モデルより大幅に少ないビジョントークンで、同等以上の性能(State-of-the-Art, SOTA)を達成していることが分かります。
文書タイプ別の性能比較
DeepSeek-OCRは、文書の種類によって最適な解像度モードが異なります。例えば、「スライド」のようなシンプルな文書は少ないトークンで高い性能を発揮しますが、「新聞」のように情報が密集した文書は、より多くのトークンを必要とします。
| 文書タイプ | Smallモード (100トークン) | Gundamモード (~800トークン) |
|---|---|---|
| 書籍 | 0.085 | 0.035 |
| スライド | 0.111 | 0.085 |
| 金融レポート | 0.079 | 0.289 (※注) |
| 新聞 | 0.744 | 0.122 |
※金融レポートのGundamモードの数値は論文の記載に基づく
このように、文書の特性に応じてモードを使い分けることで、効率的に高い精度を得られることが示されています。
DeepSeek-OCRでできること【応用例】
※リード文:DeepSeek-OCRは、単に紙の文字をデジタル化するだけではありません。文書内に含まれる多様なコンテンツを構造的に理解し、データとして活用するための高度な能力を備えています。
文書内の図表を構造化する「ディープパーシング」
「ディープパーシング (Deep Parsing)」とは、文書内の図や表などを、その意味や構造を保ったままデータ化する機能です。
-
グラフのデータ抽出: 金融レポート内の棒グラフや折れ線グラフを解析し、その数値をHTMLのテーブル形式で出力します。

金融レポート内のグラフをHTMLテーブルに変換する例 (参考:DeepSeek-OCR: Contexts Optical Compression)
-
化学式のSMILES形式への変換: 科学論文などに記載された化学構造式を認識し、機械可読なSMILES形式の文字列に変換します。
!化学構造式をSMILES形式に変換する例](<スクリーンショット 2025-10-30 15.52.46.png>)
化学構造式をSMILES形式に変換する例 (参考:DeepSeek-OCR: Contexts Optical Compression)
-
幾何学図形の解析: 図形問題の図を解析し、線分や頂点の座標といった構造的な情報を抽出します。

幾何学図形を構造的に解析する例 (参考:DeepSeek-OCR: Contexts Optical Compression)
約100言語に対応する多言語OCR機能
英語や中国語といった主要言語はもちろんのこと、多様な言語の学習データを用いることで、約100言語の文書認識に対応しています。
アラビア語やシンハラ語など、文字体系が大きく異なる言語でも、レイアウトを保持したまま高精度なOCRが可能です。

アラビア語文書のOCR例 (参考:DeepSeek-OCR: Contexts Optical Compression)
OCRだけじゃない!一般的な画像理解タスク
DeepSeek-OCRは、その基盤となっているCLIPモデルの能力を継承しており、OCR以外の汎用的な画像理解タスクも実行できます。
- 画像の説明文生成 (キャプション)
- 物体検出
- 指示された領域の特定 (グラウンディング)
これにより、文書内の写真やイラストの内容を理解するなど、より幅広い応用が可能になります。

一般的な画像内の物体を検出する例 (参考:DeepSeek-OCR: Contexts Optical Compression)

DeepSeek-OCRの利用方法
DeepSeek-OCRは、研究コミュニティへの貢献と技術の普及を目的として、ソースコードと学習済みモデルが公開されています。ここでは、その利用方法について紹介します。
オープンソースでコードとモデルを公開
DeepSeek-OCRのソースコードとモデルの重みは、以下のGitHubリポジトリで公開されており、誰でも自由にダウンロードして利用することができます。
- 公式GitHubリポジトリ: http://github.com/deepseek-ai/DeepSeek-OCR
ライセンス条件を確認の上、自身の研究や開発プロジェクトに組み込むことが可能です。
大規模な学習データ生成ツールとしての活用
DeepSeek-OCRは、その高い処理能力から、LLMやVLMの事前学習に用いるための大規模なデータセットを生成するツールとしても非常に有効です。
論文によれば、単一のA100-40G GPUを使用した場合、1日あたり20万ページ以上の文書を処理できると報告されており、データ収集・加工のプロセスを大幅に効率化できます。
「光学的圧縮」が拓くAIの未来
DeepSeek-OCRが提唱する「光学的圧縮」は、単なるOCR技術の改良に留まらず、今後のLLMアーキテクチャやAIの「記憶」のあり方そのものに影響を与える可能性を秘めています。
人間の「忘却」を模倣した長期記憶メカニズム
人間の記憶は、古い情報ほど詳細が失われ、要点だけが残るという特徴があります。この「忘却」のプロセスは、脳が情報を効率的に管理するための重要な機能です。
「光学的圧縮」は、このメカニズムをAIで模倣するアプローチに応用できると期待されています。
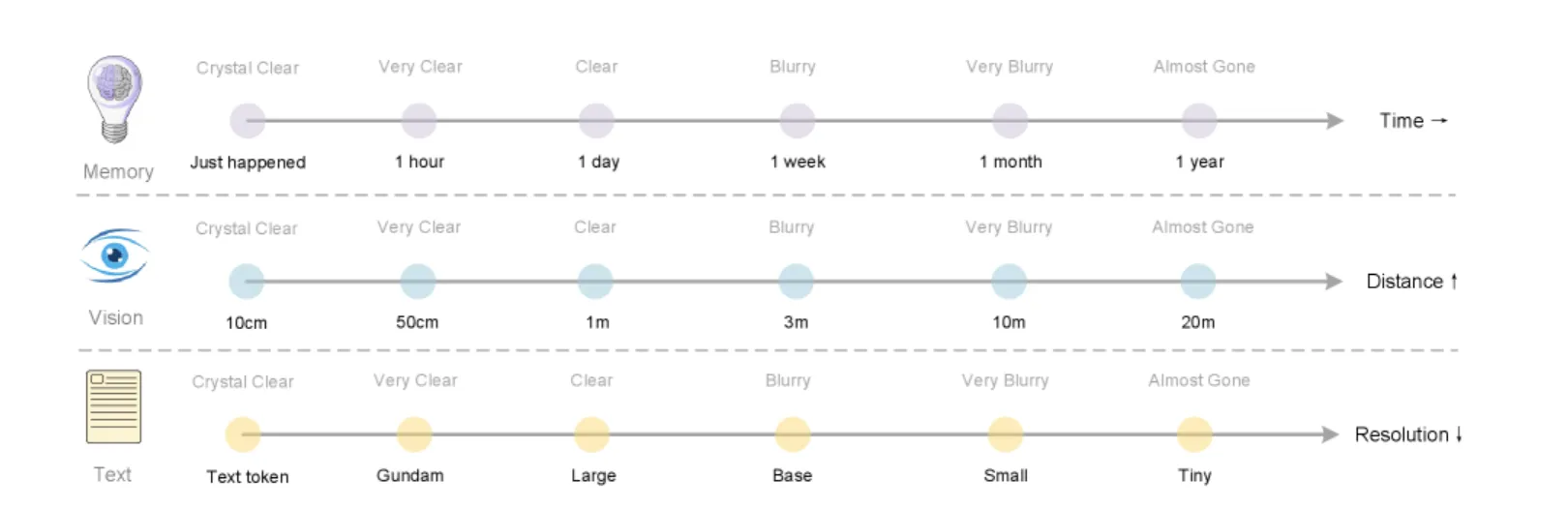
「光学的圧縮」による忘却メカニズムの概念図。 人間の記憶が時間と共に曖昧になるように(上)、古い情報ほど画像の解像度を落として圧縮率を高める(下)ことで、効率的な長期記憶を実現するアイデアを示しています。(参考:DeepSeek-OCR: Contexts Optical Compression)
- 直近の対話履歴 (記憶): 高解像度の画像として保持し、詳細な情報を維持する。
- 古い対話履歴 (記憶): 時間の経過と共に画像の解像度を段階的に下げ、より少ないトークンで要点を圧縮して保持する。
このように情報の重要度に応じてリソース配分を動的に変えることで、AIがより効率的に長期記憶を管理できる可能性があります。
理論上「無限のコンテキスト」への挑戦
現在のLLMは、有限のコンテキストウィンドウという制約を持っています。しかし、光学的圧縮のようなアプローチを発展させることで、この制約を乗り越える道筋が見えてきます。
古い情報を低解像度で圧縮し続けることで、計算コストの爆発を抑えながら、理論上は無限に情報を保持し続けるアーキテクチャが考えられます。これは、AIが真に長期的な文脈を理解するための、有望な研究開発の方向性の一つと言えるでしょう。

OCR技術の進化を業務プロセスの自動化に広げるなら
DeepSeek-OCRの光学的圧縮が示すように、文書処理のAI技術は従来のOCRを超えた新しい段階に入っています。この技術進化を、請求書や契約書の処理にとどまらず、業務プロセス全体のAI自動化へと結びつけることで、より大きな効率化が実現できます。
AI総合研究所では、文書処理の自動化から業務プロセス全体のAI化まで、段階的に進めるための実践ガイドを無料で提供しています。OCR技術の知見を活かした業務自動化の全体像を確認してみてください。
OCR技術の進化を業務プロセスの自動化に結びつける

AI業務自動化ガイド
DeepSeek-OCRのような次世代OCR技術は、文書処理の自動化だけでなく業務プロセス全体へのAI適用を加速させます。OCRを起点とした業務自動化の段階的な進め方をガイドにまとめました。
まとめ
本記事では、テキストを画像として圧縮する「光学的圧縮」という革新的なコンセプトを提唱するモデル、DeepSeek-OCRについて解説しました。
最後に、本記事の要点をまとめます。
- 核心コンセプト: LLMの長期コンテキスト問題を解決するため、テキストを画像化して圧縮する「光学的圧縮」を提唱。
- 独自技術: 高効率なビジョンエンコーダ「DeepEncoder」により、高解像度入力と低計算コストを両立。
- 高性能: 既存モデルを大幅に下回る最少のビジョントークンで、最先端(SOTA)のOCR性能を達成。
- 多機能性: グラフや化学式の構造的解析、約100言語への対応など、実用性の高い機能を多数搭載。
- 将来性: AIの長期記憶メカニズムや「無限コンテキスト」の実現に向けた、新しいアプローチを提示。
DeepSeek-OCRは、今日の文書解析の課題を解決する強力なツールであると同時に、未来のAIアーキテクチャの可能性を切り拓く、重要な一歩となるモデルです。










