この記事のポイント
 大規模AIモデルの学習・推論をGoogle Cloud上で最適化したいならCloud TPUが有力な選択肢
大規模AIモデルの学習・推論をGoogle Cloud上で最適化したいならCloud TPUが有力な選択肢- v5eはコスト重視、v6eはTransformerや画像生成など高性能ワークロード重視で選ぶ設計
- GPUは汎用性、Cloud TPUはGoogle Cloud統合と大規模分散処理を重視する場合に相性が良い
- GKEやVertex AIと組み合わせると、TPUをMLOps基盤に組み込みやすい構成
- 導入前にはフレームワーク対応、リージョン、予約・コミット、データ転送を合わせて確認する判断

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Cloud TPUは、GoogleがAIモデルの学習・推論向けに設計した専用アクセラレータを、Google Cloud上で利用できるサービスです。大規模言語モデル、画像生成、レコメンド、科学計算など、行列演算が多いAIワークロードで性能とコスト効率を高めやすい点が特徴です。
本記事では、Cloud TPUの基本概念、v5eとv6eの違い、GPUやVertex AIとの使い分け、GKEでの運用、導入事例、料金体系までを整理します。
✅Googleの最新動画生成AIモデル「Gemini Omni」については、以下の記事をご覧ください。
Gemini Omniとは?その性能や使い方、料金体系を徹底解説!
Cloud TPUとは?Google Cloud上で使えるAI専用アクセラレータ
Cloud TPUは、Googleが開発したTPU(Tensor Processing Unit)をGoogle Cloud上で利用できるAIアクセラレータサービスです。GPUが画像処理や汎用並列計算にも広く使われるのに対し、TPUはニューラルネットワークで多用される行列演算を高速化する目的で設計されています。

Google CloudのCloud TPU製品ページでは、Cloud TPUはAIモデルの学習と推論の両方に最適化されたカスタムAIアクセラレータとして説明されています。
GeminiやGoogle検索、Googleフォト、Google Mapsなど、GoogleのAIアプリケーションを支える基盤としても使われています。
Cloud TPUを使うと、PyTorch、JAX、TensorFlowといった主要なAIフレームワーク上で、大規模モデルの学習、ファインチューニング、推論を実行できます。
さらに、Google Kubernetes Engine(GKE)やVertex AIと組み合わせることで、単なるチップ利用ではなく、ジョブ管理やMLOpsの運用環境まで含めて構成しやすい点が特徴です。

TPUとGPUの違い
Cloud TPUを検討するときに最初に整理すべきなのは、TPUとGPUの役割の違いです。
GPUは汎用性が高く、画像処理、HPC、生成AI、推論サーバーなど幅広い用途で使われます。一方、TPUはGoogleがニューラルネットワーク向けに設計したASICで、行列演算、大規模分散、Google Cloud上のAIワークロードに寄せて最適化されています。
以下の表で、実務上の違いを整理します。
| 観点 | GPU | Cloud TPU |
|---|---|---|
| 主な強み | 汎用性、CUDAエコシステム、対応ツールの多さ | Google Cloud統合、大規模分散、AI行列演算への最適化 |
| 向く用途 | 幅広いAI開発、既存GPUコードの活用、NVIDIA前提の推論基盤 | JAX/PyTorch/TensorFlowでの大規模学習・推論、Google Cloud上のAI基盤 |
| 運用面 | GPUインスタンスやKubernetes構成を柔軟に組みやすい | TPU PodやGKE、Vertex AIと組み合わせて大規模構成を組みやすい |
| 注意点 | 供給、価格、GPUメモリ、ドライバ管理が課題になりやすい | 対応フレームワーク、リージョン、トポロジー選定を確認する必要がある |
既存コードやライブラリがNVIDIA GPUを前提にしている場合はGPUが自然です。逆に、Google Cloud上で大規模な学習・推論を回し、JAXやPyTorch/XLAなどTPU向けの実行環境を使えるなら、Cloud TPUが有力な候補になります。
Ironwood TPUとの関係
Cloud TPUには複数世代があり、2026年時点ではv5e、v5p、v6e(Trillium)、Ironwoodなどが文脈に応じて登場します。本記事ではGCP候補一覧のテーマに合わせ、v5eとv6eを中心に扱います。
Ironwoodは第7世代TPUとして別テーマで詳しく扱うべき内容です。性能数値やGoogleのAIインフラ戦略まで見たい場合は、既存記事のGoogle TPU「Ironwood」とは?第7世代の性能や特徴、GPUとの違いを解説を参照してください。
Cloud TPUが必要になる理由
Cloud TPUが必要になるのは、AIモデルの規模が大きくなり、単一GPUや小規模GPUクラスタでは学習・推論のコスト、時間、運用負荷が重くなるためです。特に、大規模言語モデル、レコメンド、画像生成、音声、科学計算のように、同じ種類の演算を大量に回す処理では、アクセラレータの選び方がプロジェクト全体の速度とコストを左右します。

大規模学習の時間を短縮する

大規模モデルの学習では、1回の実験に数日から数週間かかることがあります。モデルサイズやデータ量が増えるほど、チップ単体の性能だけでなく、チップ間通信、ストレージ、ジョブスケジューリング、失敗時の再実行まで含めた全体設計が重要になります。
Google Cloudの製品ページでは、Cloud TPUが大規模学習、基盤モデルのファインチューニング、大規模推論の3つを主要用途として挙げています。特にMultislice trainingやGKEとの統合は、数百から数千チップ規模のジョブを扱うための選択肢になります。
推論コストを抑える
生成AIでは学習だけでなく、推論のコストも無視できません。モデルを社内外のアプリケーションで継続的に呼び出す場合、1リクエストあたりの遅延、スループット、稼働率、予約コストが積み上がります。
Cloud TPU v5eは、Google Cloudの製品ページでコスト効率の高い中〜大規模学習・推論向けTPUとして位置づけられています。すべてのワークロードでGPUより安いと断定するべきではありませんが、TPU向けに最適化できるモデルであれば、推論単価とスケールの両面で検証する価値があります。
Google Cloud上のAI基盤に寄せる
Cloud TPUは、単体のアクセラレータではなくGoogle CloudのAI基盤として使うと価値が出やすいサービスです。Vertex AIでモデル開発や推論を管理する、GKEで分散ジョブを運用する、BigQueryやCloud Storageにあるデータを学習基盤へ流す、といった全体設計とセットで検討します。
このため、導入判断では「GPUとTPUのベンチマーク」だけを見るのではなく、自社のAI開発環境、モデル実装、データ基盤、MLOpsの運用体制まで含めて考える必要があります。
Cloud TPUの主要バージョンとv5e/v6eの違い
Cloud TPUの主要バージョンを理解すると、どの世代を選ぶべきか判断しやすくなります。ここでは、GCP上でよく比較対象になるv5eとv6eを中心に整理します。
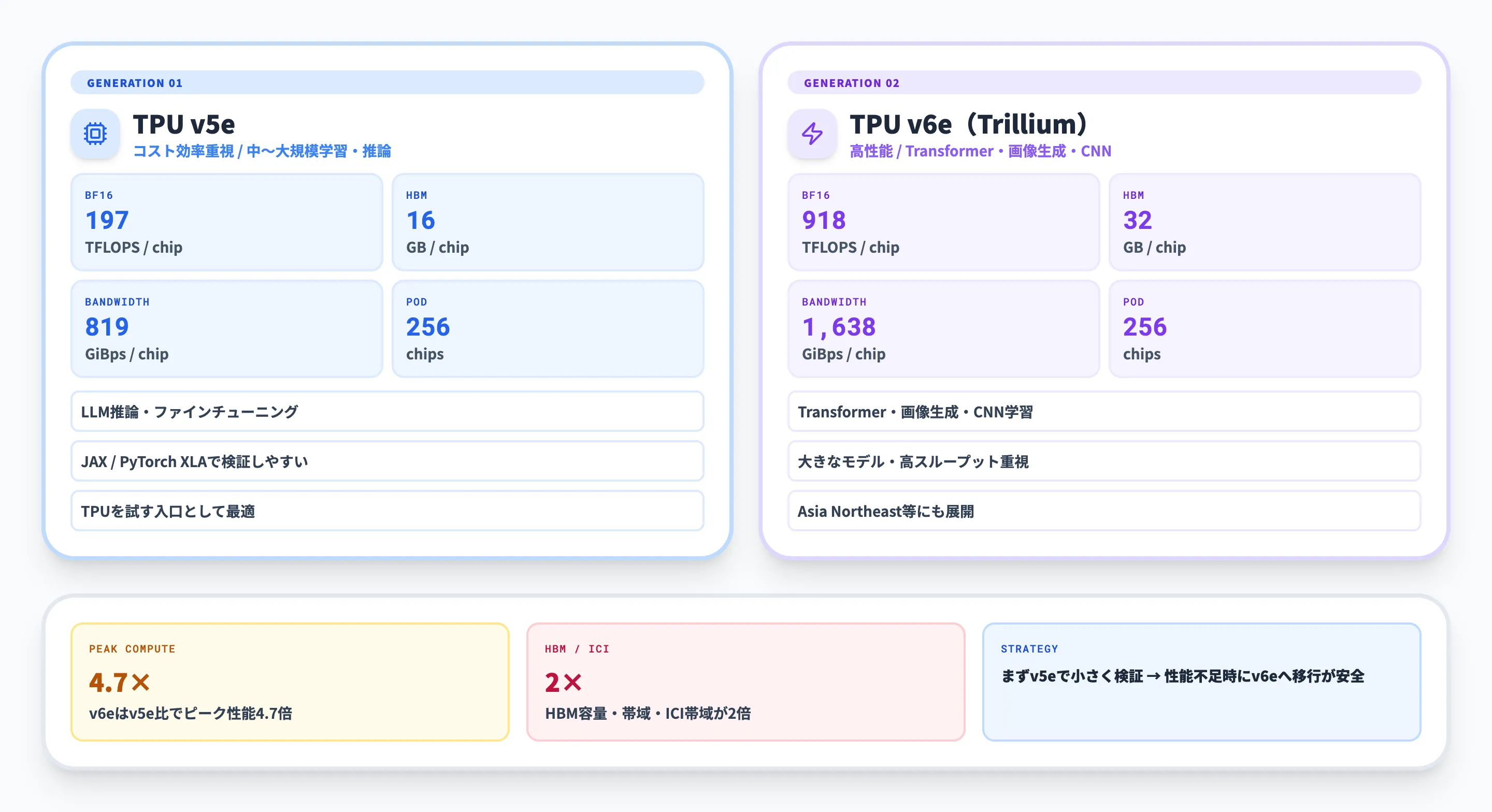
Google CloudのTPU v6eドキュメントでは、v6eはTrilliumとしても知られ、APIやログ上ではv6eと呼ばれると説明されています。v6eは256チップのPodを基本に、Transformer、画像生成、CNNの学習、ファインチューニング、推論に最適化されています。
主要な違いを表で整理します。
| 観点 | TPU v5e | TPU v6e(Trillium) |
|---|---|---|
| 位置づけ | 中〜大規模の学習・推論をコスト効率よく始める世代 | v5eの後継にあたる高性能世代 |
| 主な用途 | LLM推論、ファインチューニング、汎用的なAIワークロード | Transformer、画像生成、CNNの学習・推論 |
| チップあたりBF16ピーク性能 | 197 TFLOPS | 918 TFLOPS |
| チップあたりHBM容量 | 16GB | 32GB |
| チップあたりHBM帯域 | 800 GiBps | 1,638 GiBps |
| Podサイズ | 256チップ | 256チップ |
| 選び方 | コスト効率と導入しやすさを重視 | より大きなモデル、より高いスループットを重視 |
この表だけを見るとv6eを選びたくなりますが、実務では料金、リージョン、予約可否、既存コードの最適化状況が効きます。まずv5eで小さく検証し、性能やメモリ帯域が不足する場合にv6eへ上げる、という進め方が安全です。
v5eが向いているケース
v5eは、コスト効率を重視してCloud TPUを試したい場合に候補になります。Google CloudのTPU v5eドキュメントでは、v5eの1チップあたりBF16ピーク性能は197 TFLOPS、HBM容量は16GB、HBM帯域は800 GiBpsとされています。
特に、既存の大規模GPU基盤をすぐ置き換えるのではなく、JAXやPyTorch/XLAで一部ワークロードを検証し、学習時間や推論単価を比較したい場合に向いています。v5eは「TPUを試す入口」として見やすい世代です。
v6eが向いているケース

v6eは、Trillium世代のTPUとして、より高い演算性能とメモリ帯域が必要なケースに向きます。Google CloudのTrillium発表ブログでは、v6eはv5eと比べてチップあたりピーク演算性能が4.7倍、HBM容量と帯域、ICI帯域がそれぞれ2倍になったと説明されています。
モデルサイズ、コンテキスト長、バッチサイズ、分散並列の設計によっては、単純なチップ単価よりも、完了時間やチップ利用率のほうが重要になります。v6eは、学習・推論の時間短縮がビジネス上の制約になっている場合に検討しやすい選択肢です。

Cloud TPUの使い方
Cloud TPUの使い方は、大きく分けるとGKEで運用する方法と、Vertex AIなどのマネージド基盤に寄せる方法があります。どちらが正解かは、チームのMLOps体制と既存の運用基盤によって変わります。
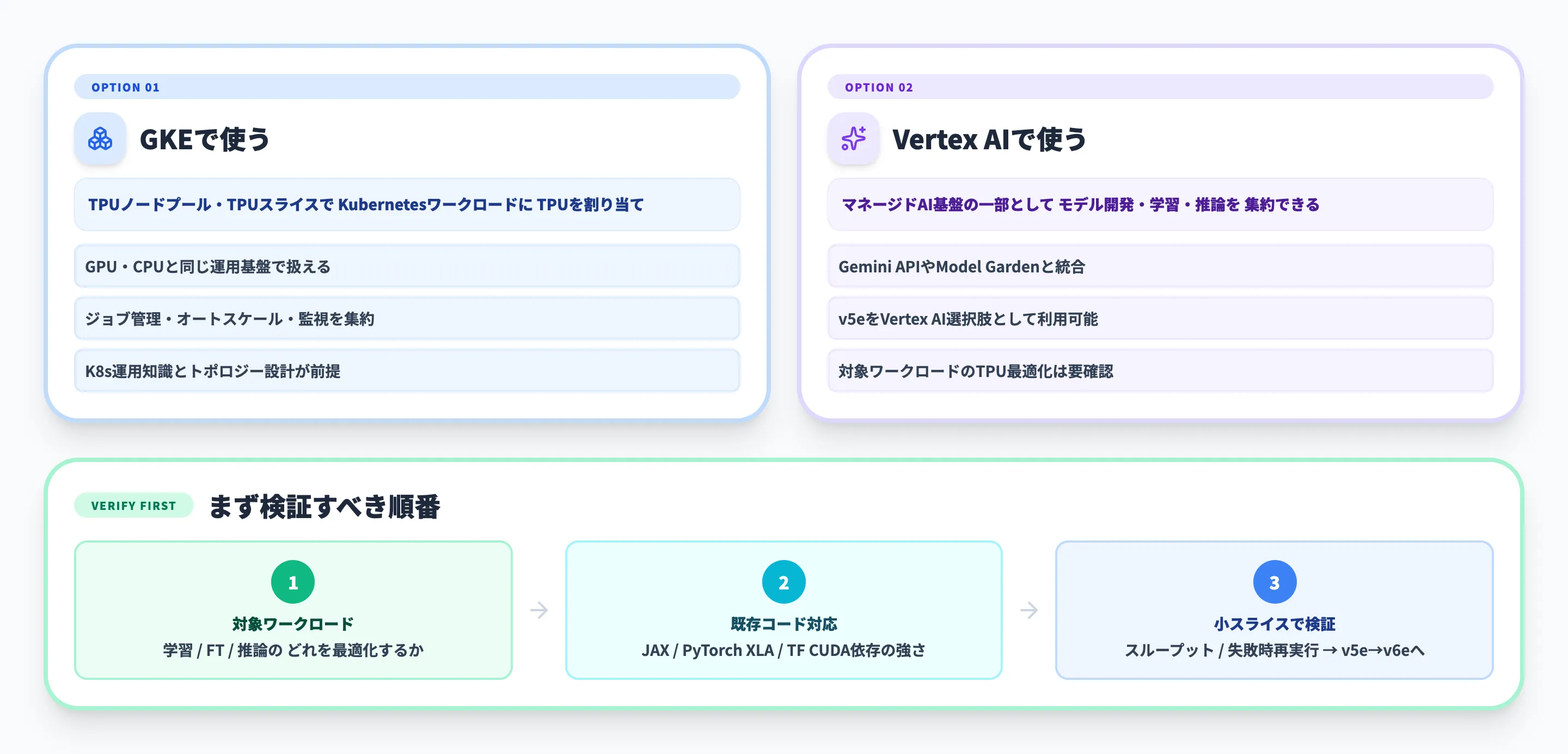
GKEで使う
GKEを使う方法は、Kubernetes上でAIワークロードを運用している企業に向いています。Google CloudのGKEでTPUを使うドキュメントでは、TPUノードプールやTPUスライスを使って、KubernetesワークロードにTPUを割り当てる流れが説明されています。
GKEでCloud TPUを扱うメリットは、GPUやCPUのワークロードと同じ運用基盤で、ジョブ管理、オートスケール、監視、デプロイを設計しやすいことです。一方で、Kubernetesの運用知識、TPUのトポロジー、ジョブ失敗時の再実行設計が必要になります。
Vertex AIで使う
Vertex AIを使う方法は、モデル開発・学習・推論をマネージド基盤に寄せたい場合に向いています。Google Cloudの製品ページでは、Cloud TPU v5eをVertex AIと組み合わせて使える選択肢として案内しています。
すでにGemini APIやModel GardenをVertex AI上で使っている場合、Cloud TPUを単体のインフラとしてではなく、AI基盤の一部として見ると設計しやすくなります。ただし、すべてのモデルや配信パターンが自動的にTPU最適化されるわけではないため、対象ワークロードごとの確認は必要です。
まず検証すべき順番
実務では、いきなり大規模Podを確保するより、小さい構成で性能と運用の見通しをつけるほうが安全です。検証では、次の順番で確認すると判断しやすくなります。
-
対象ワークロードを絞る
学習、ファインチューニング、推論のどれを最適化したいのかを決めます。対象を絞らず「TPUが速いか」を見ると、比較結果が使えなくなります。
-
既存コードの対応状況を見る
JAX、PyTorch/XLA、TensorFlowなど、Cloud TPUで動かしやすい実行環境に乗せられるか確認します。CUDA依存が強いコードは、移植コストが大きくなる場合があります。
-
小さいスライスで性能を見る
まずは小規模構成で、スループット、レイテンシ、チップ利用率、失敗時の再実行を確認します。その後、v5eからv6e、単一ホストから複数ホストへ段階的に広げます。
この順番で進めると、TPUの性能だけでなく、チームが本番運用できるかも同時に見えてきます。
AI基盤を業務運用へ

TPU検証後の実装設計
Cloud TPUで大規模AI基盤を検証した後は、モデルを業務フロー、権限管理、実行ログまで含めて運用に載せる設計が必要です。AI Agent HubのLPで、AI基盤を業務実装へつなげる全体像をご確認ください。
Cloud TPUの活用事例
Cloud TPUの事例を見ると、単なるチップ性能ではなく、大規模データ処理、推論コスト、運用の安定性が成果に直結していることが分かります。ここではGoogle Cloudの公式事例から、比較的読み取りやすい2件を紹介します。
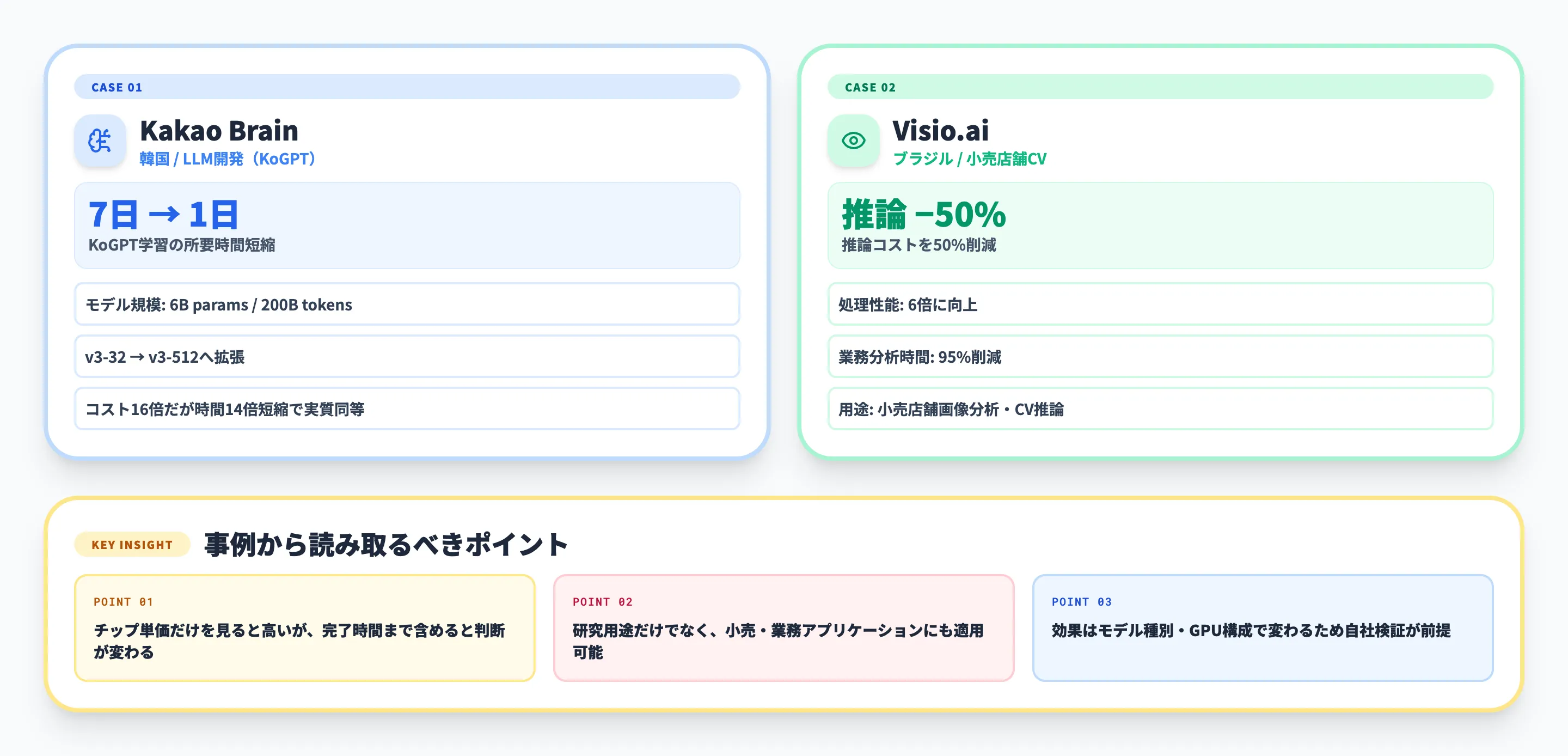
Kakao Brain
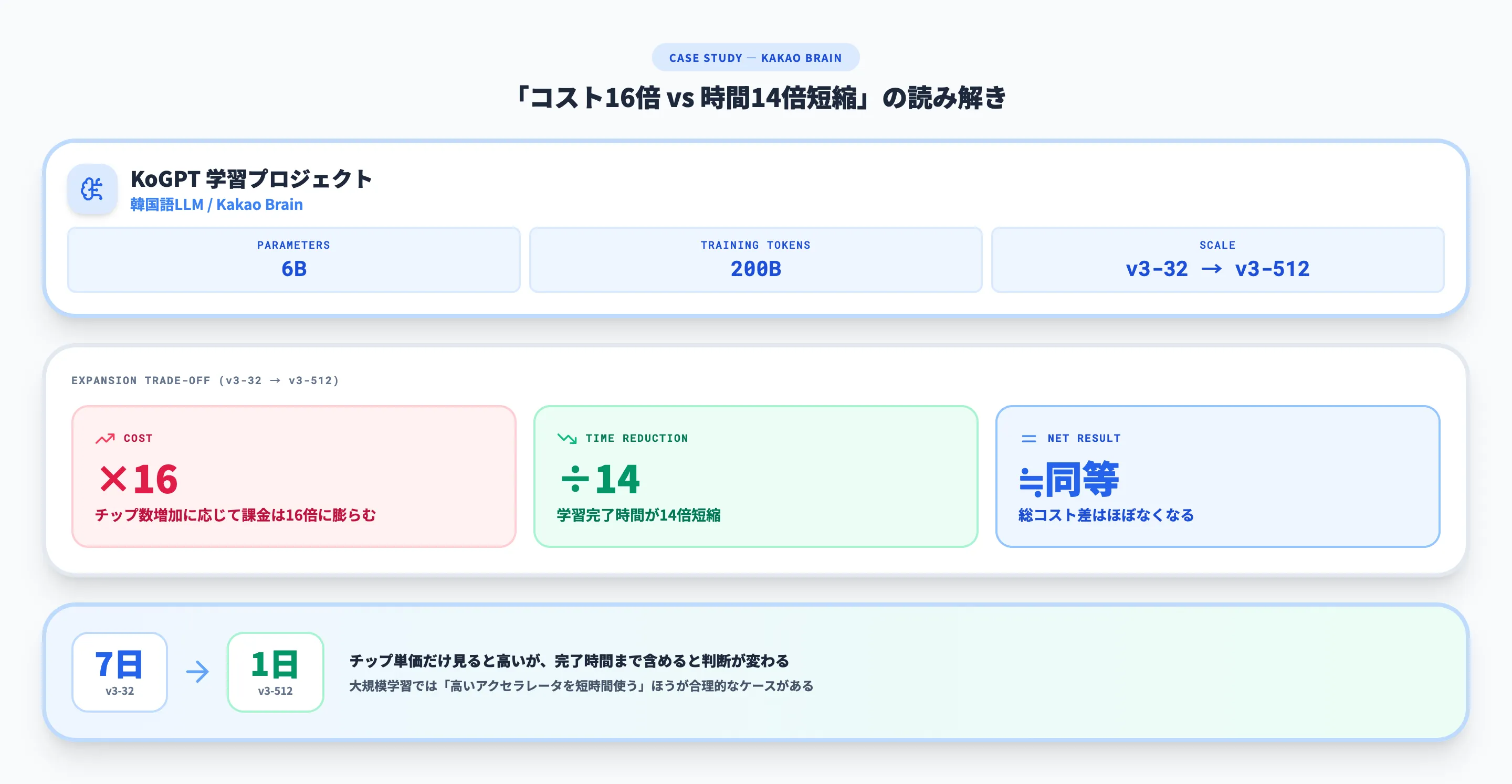
韓国のAI研究開発企業であるKakao Brainは、韓国語の自然言語処理モデルKoGPTの開発にCloud TPUを活用しました。Kakao Brainの公式事例では、6Bパラメータと200Bトークンの学習を扱い、作業完了時間を7日から1日に短縮したことが紹介されています。
同事例では、v3-32からv3-512へ拡張した際に、コストは約16倍でもタスク完了時間が約14倍短縮され、結果としてコスト差がほぼなくなるという説明もあります。これは「チップ単価だけを見ると高いが、完了時間まで含めると判断が変わる」典型例です。
Visio.ai
ブラジルのVisio.aiは、小売店舗向けのコンピュータビジョン製品でCloud TPUを活用しました。Visio.aiの公式事例では、推論コストを50%削減し、処理性能を6倍に高め、顧客の業務分析時間を95%削減したことが紹介されています。
この事例は、Cloud TPUが研究用途だけでなく、小売店舗の画像分析やオペレーション改善のような業務アプリケーションにも使われることを示しています。ただし、同じ効果を得られるかは、モデルの種類、画像処理パイプライン、データ量、既存GPU構成によって変わるため、自社ワークロードでの検証が前提です。
Cloud TPUと関連サービスの違い
Cloud TPUは、GPU、Vertex AI、Model Garden、Gemini APIなどと同じAI基盤の文脈で語られますが、役割は異なります。混同すると、インフラを選ぶ話と、モデルを使う話がずれてしまいます。

以下の表で、関連サービスとの違いを整理します。
| 比較対象 | 主な役割 | Cloud TPUとの違い |
|---|---|---|
| GPU | 汎用的な並列計算アクセラレータ | Cloud TPUはGoogle設計のAI向けASICで、Google Cloud上の学習・推論に最適化 |
| Vertex AI | モデル開発・学習・推論の統合AI基盤 | Cloud TPUはVertex AIなどから使う計算リソースの一部 |
| Model Garden | 基盤モデルの発見・利用 | Cloud TPUはモデルそのものではなく、モデルを動かすインフラ |
| Gemini API | GeminiモデルをAPIで利用 | Cloud TPUを直接運用せずにモデル機能を使う選択肢 |
| Compute Engine GPU | GPU付きVM | Cloud TPUはTPU PodやTPU VMとして使う別系統のアクセラレータ |
アプリケーション開発者がGeminiモデルを呼び出したいだけなら、Gemini APIやVertex AIのマネージド機能で十分な場合があります。Cloud TPUを直接検討すべきなのは、独自モデルの学習・推論、基盤モデルのファインチューニング、大規模レコメンドや画像生成など、計算基盤そのものが制約になっている場合です。
Cloud TPUを使う前の注意点
Cloud TPUは強力な選択肢ですが、GPUの代わりにそのまま差し替えれば必ず速く安くなる、というサービスではありません。導入前には、フレームワーク、リージョン、予約、データ転送、運用体制を確認する必要があります。

フレームワーク対応を確認する
Cloud TPUはPyTorch、JAX、TensorFlowなどに対応していますが、GPU向けに最適化された既存コードがそのまま最適性能で動くとは限りません。特に、CUDA依存のカスタムカーネル、GPU前提の推論エンジン、外部ライブラリを多用している場合は、移植や検証に時間がかかる可能性があります。
導入判断では、モデルの演算特性とコードの移植コストを分けて見てください。演算上はTPUに向いていても、運用コードの移植が重いなら、GPUで継続したほうが早いケースもあります。
リージョンと予約を確認する
Cloud TPUは世代ごとに利用できるリージョンやゾーンが異なります。Google CloudのTPUリージョンとゾーンドキュメントでは、TPUの種類ごとに利用可能な場所が整理されています。
v6eはAsia Northeastなどのリージョンにも展開されていますが、v5eは提供地域が異なります。料金やレイテンシだけでなく、学習データの保管場所、組織のデータガバナンス、必要なチップ数の確保まで合わせて確認する必要があります。
チップ単価だけで判断しない
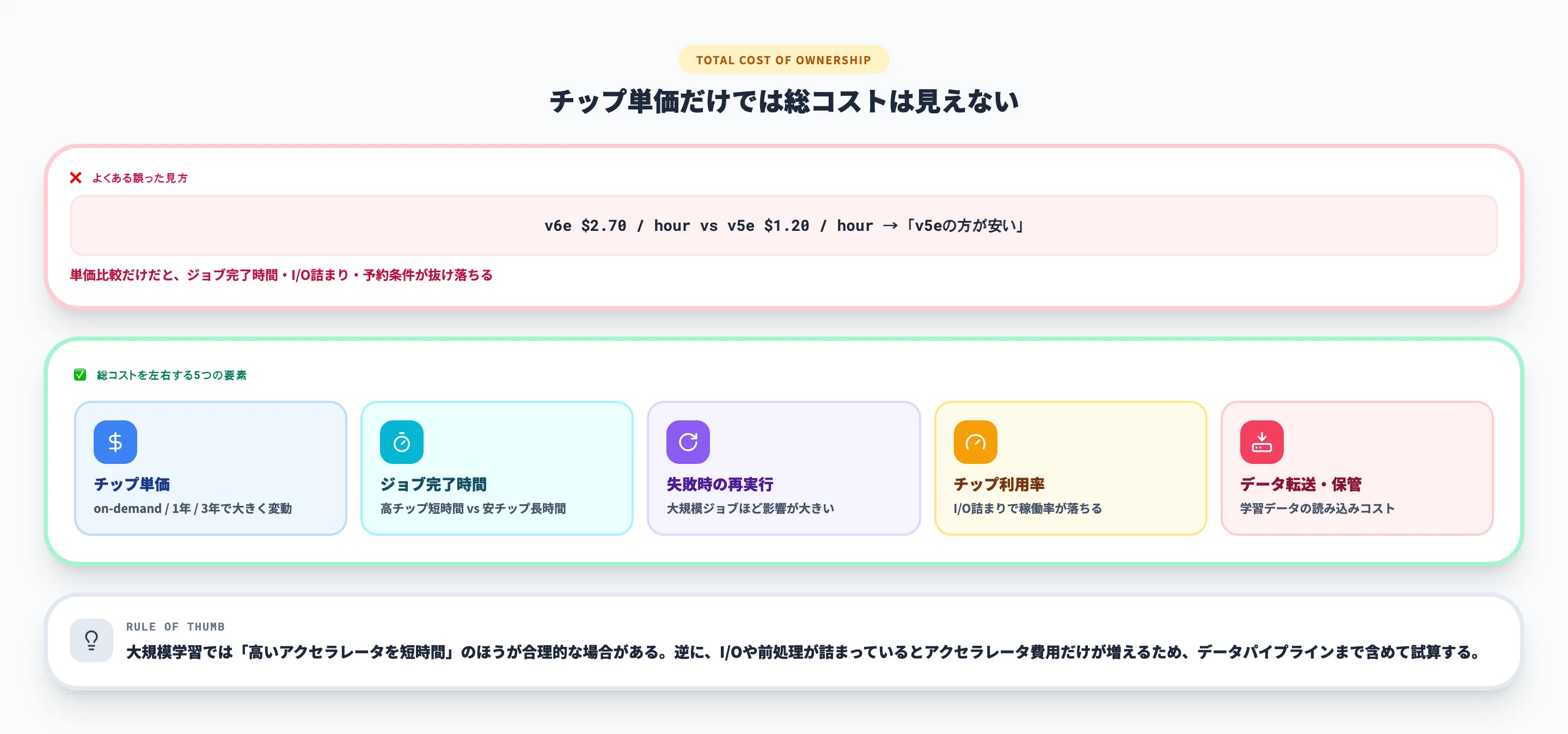
Cloud TPUのコストはチップ時間で発生します。ただし、実務で見るべきなのは単価だけではありません。ジョブ完了時間、失敗時の再実行、チップ利用率、データ読み込みの詰まり、予約の取り方によって、総コストは大きく変わります。
特に、大規模学習では「高いアクセラレータを短時間使う」ほうが「安いアクセラレータを長時間使う」より合理的な場合があります。逆に、チップを確保してもI/Oや前処理が詰まっていると、アクセラレータ費用だけが増えるため注意が必要です。
Cloud TPUの料金
Cloud TPUの料金は、基本的にチップ時間単位で発生します。2026年4月時点では、世代、リージョン、オンデマンド利用、1年または3年のコミットメントによって単価が変わります。
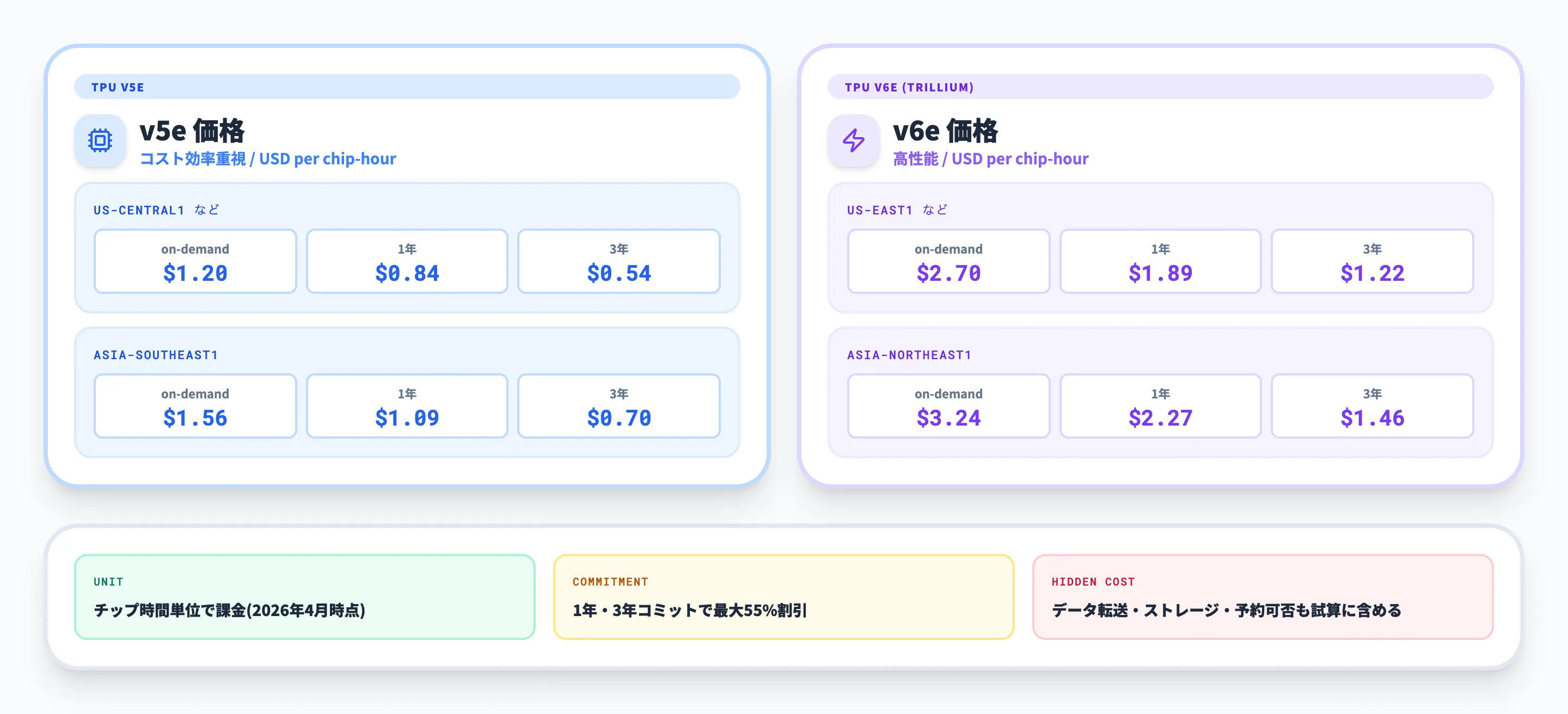
Google CloudのCloud TPU pricingページでは、すべてのCloud TPU料金はチップ時間単位と説明されています。代表的な価格例を整理すると以下の通りです。
| TPU世代 | リージョン例 | オンデマンド目安 | 1年コミット目安 | 3年コミット目安 |
|---|---|---|---|---|
| v5e | us-central1など | 1.20ドル/チップ時間 | 0.84ドル/チップ時間 | 0.54ドル/チップ時間 |
| v5e | asia-southeast1 | 1.56ドル/チップ時間 | 1.09ドル/チップ時間 | 0.70ドル/チップ時間 |
| v6e | us-east1など | 2.70ドル/チップ時間 | 1.89ドル/チップ時間 | 1.22ドル/チップ時間 |
| v6e | asia-northeast1 | 3.24ドル/チップ時間 | 2.27ドル/チップ時間 | 1.46ドル/チップ時間 |
価格はリージョンと時期によって変わるため、実際の見積もりでは最新の料金表を確認してください。特に日本企業の場合、v6eをTokyoリージョンで使うのか、v5eを別リージョンで使うのかによって、単価だけでなくデータ配置やガバナンスの判断も変わります。
料金を見るときは、チップ単価だけでなく、ジョブが何時間で完了するか、必要なチップ数はいくつか、予約やコミットメントを使えるか、データ転送やストレージ費用が別途かかるかまで含めて見積もる必要があります。

Cloud TPUの検証をAI基盤運用につなげるなら
Cloud TPUで学習や推論の性能が出ても、それだけで業務の成果につながるわけではありません。大規模AI基盤を社内で使うには、モデルの実行結果をどの業務フローへ接続するか、誰が実行できるか、ログや承認をどう残すかまで設計する必要があります。
AI Agent Hubは、既存のクラウド環境やAI基盤を前提に、業務システム連携、権限管理、実行ログの整備を支援するAIエージェント基盤です。Cloud TPUで検証したモデル活用を、研究・PoCで止めずに業務プロセスへ接続するための運用設計を考える材料になります。
AI総合研究所の専任チームが、AI基盤の検証結果を業務実装に落とし込む設計を支援します。まずは無料の資料で、AI Agent Hubの全体像をご確認ください。
AI基盤を業務運用へ
TPU検証後の実装設計
Cloud TPUで大規模AI基盤を検証した後は、モデルを業務フロー、権限管理、実行ログまで含めて運用に載せる設計が必要です。AI Agent HubのLPで、AI基盤を業務実装へつなげる全体像をご確認ください。
まとめ|Cloud TPUは大規模AIの計算基盤を選ぶ選択肢
Cloud TPUは、Google Cloud上でAIモデルの学習・推論を高速化するための専用アクセラレータです。特に大規模言語モデル、画像生成、レコメンド、コンピュータビジョンのように、行列演算と分散処理が重要なワークロードで検討しやすい選択肢です。
v5eはコスト効率を重視した中〜大規模ワークロード向け、v6eはTrillium世代としてより高い演算性能とメモリ帯域を求める用途向けです。ただし、GPUより常に優れるわけではなく、フレームワーク対応、コード移植、リージョン、チップ確保、データ転送まで含めて比較する必要があります。
まずは、Cloud TPUに載せたいワークロードを1つに絞り、小さい構成でv5eまたはv6eを検証してください。その結果をもとに、GKEやVertex AIでの運用、本番推論のスケール、業務アプリケーションへの接続まで段階的に設計するのが現実的です。







