この記事のポイント
 v4.0は2028年9月廃止予定。新規開発には推奨されず、移行計画は2026年9月までに策定すべき
v4.0は2028年9月廃止予定。新規開発には推奨されず、移行計画は2026年9月までに策定すべき- 文書OCRならDocument Intelligence、画像中の文字読み取りならVision Readと機能が明確に分かれている
- Japan Eastではv4.0のCaptions機能が利用不可。画像キャプション生成にはv3.2かリージョン変更が必要
- Free(F0)は毎分20トランザクションまで無料。PoC段階の精度検証ならF0で十分
- Goodwillの事例では商品リスティング業務を35%以上効率化。画像からの情報抽出は実績のある活用領域

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
Azure AI Vision(旧Computer Vision)は、Microsoftが提供する画像分析・OCR・物体検出などの機能を備えたクラウドAIサービスです。
2024年のブランド再編を経て、現在は「Azure Vision in Foundry Tools」として提供されています。
本記事では、画像分析v4.0とv3.2の機能差分、Document Intelligenceとの使い分け、活用事例、料金体系、そして2028年9月に予定されているv4.0の廃止スケジュールと移行先まで、2026年4月時点の最新情報をもとに解説します。
目次
マルチモーダル埋め込み(Multimodal Embeddings)
Azure AI Visionのバージョン比較(v4.0とv3.2)
Azure AI VisionとDocument Intelligenceの使い分け
小売・EC:商品リスティングの自動化(Goodwill of Orange County)
空港運営:画像からの情報抽出(Prague Airport)
Azure AI Visionとは?
Azure AI Visionは、Microsoftが提供する画像分析・OCR(光学文字認識)・物体検出などの機能を備えたクラウドAIサービスです。画像や動画をAPIに送信するだけで、AIが被写体のタグ付けや文字の読み取り、人物の検出などを自動で行います。

Azure AI Visionの概要:定義・名称変遷・4つの機能カテゴリ
もともとは「Computer Vision」という名称でAzure AI Servicesの一部として提供されていましたが、MicrosoftのAIサービス再編に伴い名称が変遷しています。2026年4月時点では、Azure AI Foundryのツール群の一部として「Azure Vision in Foundry Tools」が正式名称です。ただし、Azureポータル上では引き続き「Computer Vision」としてリソースが作成されるため、ドキュメントによって表記が異なる場合があります。
Computer Visionからの名称変遷
Azure AI Visionは、Azure Cognitive Servicesの一部として2015年に登場しました。以降、Microsoftのブランド戦略に合わせて名称が段階的に変わっています。
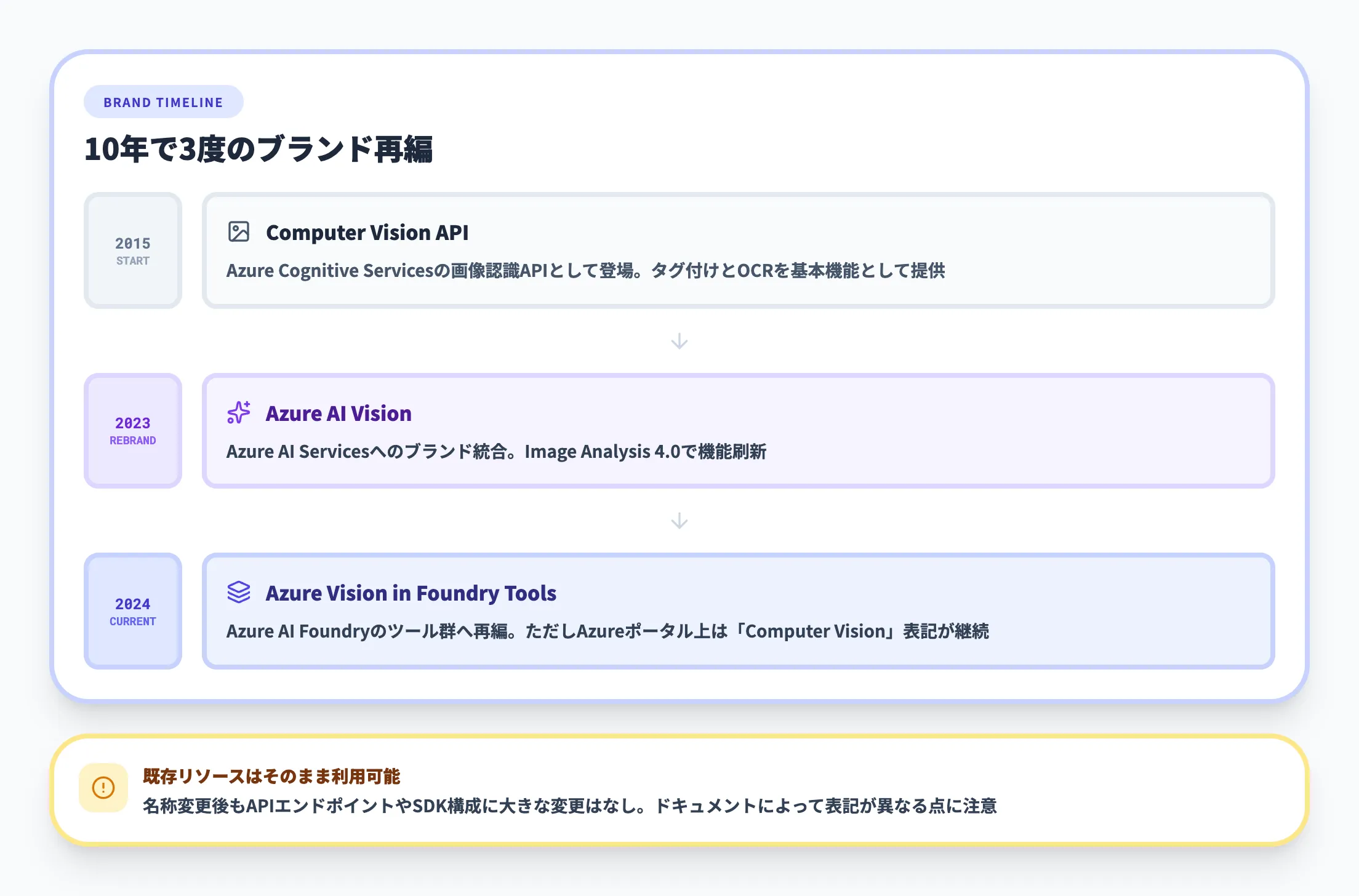
2015年Computer Vision API → 2023年Azure AI Vision → 2024年Foundry Tools統合
| 時期 | 名称 | 位置づけ |
|---|---|---|
| 2015年〜 | Computer Vision API | Cognitive Servicesの画像認識API |
| 2023年 | Azure AI Vision | Azure AI Servicesへのブランド統合 |
| 2024年〜 | Azure Vision in Foundry Tools | Azure AI Foundryのツール群に再編 |
名称が変わっても、APIのエンドポイントやSDKの基本構成に大きな変更はありません。既存のComputer Visionリソースはそのまま利用を続けられます。
Azure AI Visionでできること
Azure AI Visionは、大きく分けて3つの機能カテゴリを提供しています。
-
画像分析(Image Analysis)
画像に写っている物体のタグ付け、キャプション生成、人物検出、スマートクロップなどを行います。
-
OCR(光学文字認識)
画像中の印刷文字や手書き文字を読み取り、テキストデータとして出力します。印刷テキストは164言語、手書きテキストは英語・日本語・中国語簡体字・韓国語・フランス語・ドイツ語・イタリア語・ポルトガル語・スペイン語の9言語に対応しています。
-
マルチモーダル埋め込み(Multimodal Embeddings)
画像とテキストをベクトル化し、意味的な類似度で画像検索を行えるようにします。102言語に対応しています。
これらの機能はREST APIまたはSDK(Python、C#、Java、JavaScript)を通じて利用でき、コードを書かずに試せるVision Studioも用意されています。

Azure AI Visionの主な機能
Azure AI Visionが提供する機能は、APIのバージョンによって利用できる範囲が異なります。ここでは、2026年4月時点で利用可能な主要機能を解説します。

画像分析・OCR・マルチモーダル埋め込み・Vision Studioの4機能カテゴリ
画像分析(Image Analysis)
Image Analysis APIは、画像に写っている内容をAIが自動で解析する機能群です。1回のAPI呼び出しで複数の分析を同時に実行できます。
v4.0とv3.2で利用できる機能は以下のとおりです。
| 機能 | v4.0 | v3.2 | 概要 |
|---|---|---|---|
| タグ付け(Tags) | ○ | ○ | 画像内の物体やシーンにタグを自動付与 |
| 物体検出(Objects) | ○ | ○ | 物体の位置をバウンディングボックスで返す |
| キャプション生成(Captions) | ○ | ○ | 画像の内容を自然言語で説明 |
| Dense Captions | ○ | × | 画像内の各領域ごとにキャプションを生成 |
| 人物検出(People) | ○ | × | 人物の位置と信頼度スコアを返す |
| スマートクロップ | ○ | ○ | 指定アスペクト比で最適なトリミング領域を提案 |
| テキスト読み取り(OCR) | ○ | × | 画像内のテキストを同期的に読み取り |
| ブランド検出 | × | ○ | ロゴから商用ブランドを識別 |
| 有名人・ランドマーク認識 | × | ○ | ドメイン固有のコンテンツを識別 |
| アダルトコンテンツ検出 | × | ○ | 不適切なコンテンツを検出 |
| 色彩分析 | × | ○ | 画像の配色や支配的な色を分析 |
v4.0ではAIモデルが刷新され、タグ付けやキャプション生成の精度が向上しています。一方、ブランド検出や有名人認識など一部の機能はv3.2にしか存在しないため、ユースケースに応じたバージョン選定が必要です。

v4.0とv3.2で利用できる画像分析機能の差分
OCR(光学文字認識)
Azure AI VisionのOCR機能(Read API)は、画像中の印刷文字および手書き文字を読み取ります。
主な特徴は以下のとおりです。
-
対応言語
印刷テキストは164言語、手書きテキストは英語・日本語・中国語簡体字・韓国語・フランス語・ドイツ語・イタリア語・ポルトガル語・スペイン語の9言語に対応しています。
-
v4.0の同期OCR(一般画像向け)
v4.0ではImage Analysis APIの一部として同期的にOCRを実行できます。対象は写真や看板、スクリーンショットなど一般画像で、物体検出とテキスト読み取りを1回のAPI呼び出しで同時に処理できるため、処理フローがシンプルになります。
-
v3.2 ReadのPDF/TIFF対応
JPEG、PNG、BMP、PDF、TIFFの入力を受け付けるのはv3.2のRead APIです。PDFは最大2,000ページ(Free tierは2ページ)まで処理可能ですが、文書ファイルのOCR用途では後述のDocument Intelligence Readが公式で推奨されています。
なお、請求書やレシート、契約書といった定型文書、PDF・Office文書・HTMLのOCR処理には、Azure AI Document IntelligenceのRead APIが公式に推奨されています。Vision側は写真や画像中のテキスト抽出にフォーカスし、文書系はDocument Intelligenceに寄せるのがMicrosoftの案内する使い分けです。両者の詳細は後述のセクションで解説します。

用途別の3つのOCR選択肢:v4.0同期OCR・v3.2 PDF/TIFF・Document Intelligence Read
【関連記事】
おすすめのAI-OCRサービスを徹底比較!選び方・利用時の注意点も紹介
マルチモーダル埋め込み(Multimodal Embeddings)
v4.0で提供されるマルチモーダル埋め込み機能は、画像とテキストを同じベクトル空間にマッピングする機能です。
テキストクエリに意味的に近い画像を検索する、いわゆる「セマンティック画像検索」を実現できます。従来のキーワードベースの画像検索では画像にメタデータやタグを事前に付与する必要がありましたが、マルチモーダル埋め込みを使えば「赤い車が走っている写真」のような自然言語で直接検索できます。
2024年2月のAPIアップデートで多言語モデルが追加され、102言語のテキストで画像を検索できるようになりました。商品画像のカタログ検索や社内画像資産の整理など、大量の画像から必要なものを素早く見つけたい場面で活用できます。
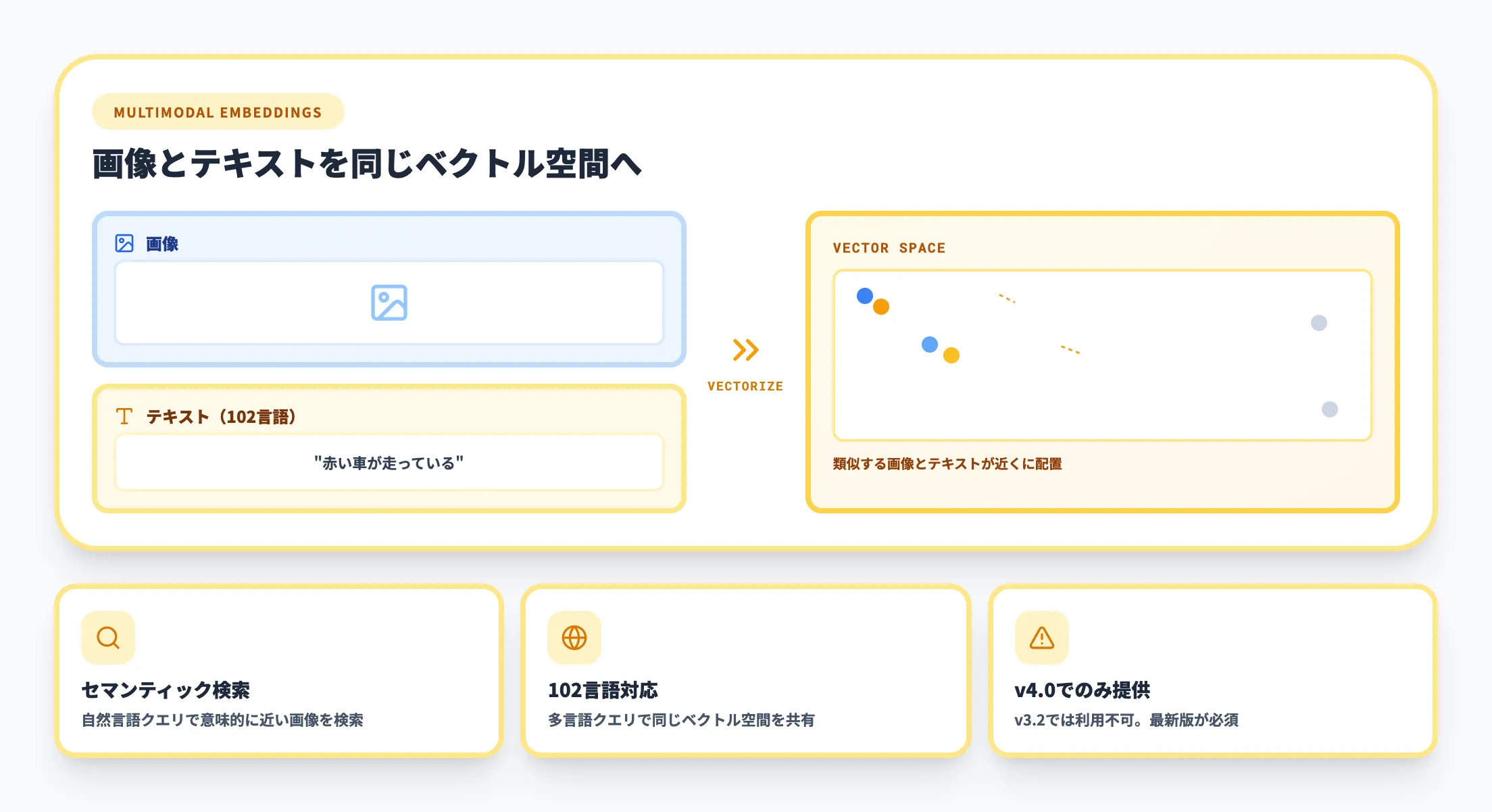
画像とテキストを同じベクトル空間にマッピングし102言語でセマンティック検索
Vision Studio
Vision Studioは、ブラウザ上でAzure AI Visionの各機能をコードなしで試せるGUIツールです。
画像をアップロードするだけで、タグ付け・キャプション生成・OCR・人物検出などの結果をその場で確認できます。PoC(概念実証)の初期段階で精度や応答速度を検証する際に有用です。SDKやREST APIでの開発に進む前に、Vision Studioで自社データの分析精度を確認しておくことで、開発の手戻りを防げます。
【関連記事】
おすすめのAI画像認識サービスを比較!実際の使用例や活用事例も紹介
Azure AI Visionのバージョン比較(v4.0とv3.2)
Azure AI Visionには2つのAPIバージョンが並存しており、どちらを選ぶかで使える機能やリージョンが変わります。ここでは、選定に必要な3つの軸で違いを整理します。
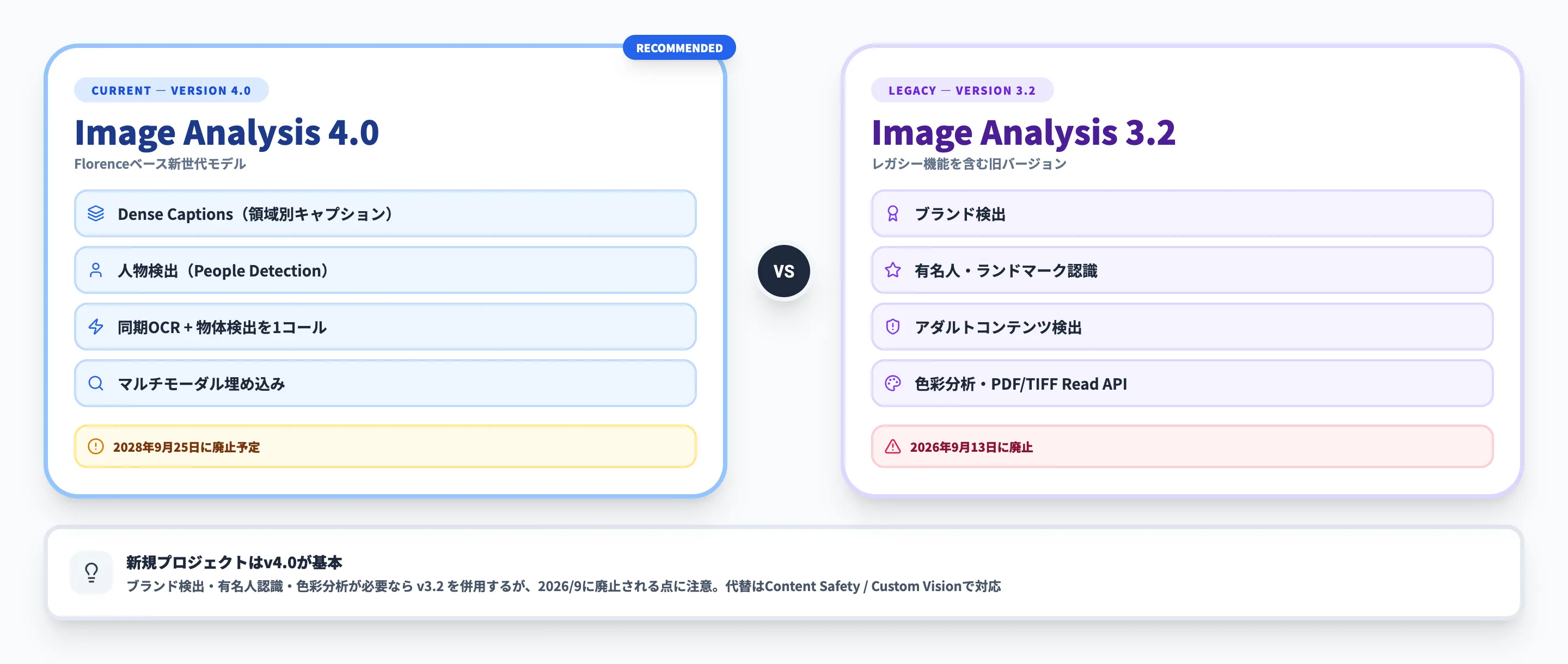
v4.0(推奨)とv3.2の主な特徴と廃止スケジュールの比較
機能の違い
前述の機能表のとおり、v4.0ではAIモデルの刷新によりOCR同期実行やDense Captionsなどの新機能が追加されています。v3.2にはブランド検出・有名人認識・色彩分析・アダルトコンテンツ検出といった固有の機能が残っています。
Microsoftの公式ガイドでは「v4.0でユースケースがカバーできるならv4.0を使い、v4.0が対応していない機能が必要ならv3.2を使う」と推奨しています。
ただし、v4.0は2028年9月25日に廃止が予定されているため、新規開発でv4.0を前提にした設計を行う場合は、廃止後の移行先も含めた計画が必要です。詳細は「廃止スケジュールと移行ガイド」のセクションで解説します。
リージョン対応状況
v4.0の一部機能は、利用可能なAzureリージョンが限定されています。日本のユーザーに影響が大きいのはCaptions機能のリージョン制限です。
以下は主要リージョンの対応状況です。
| リージョン | 画像分析(Captions除く) | Captions(v4.0) | マルチモーダル埋め込み |
|---|---|---|---|
| East US | ○ | ○ | ○ |
| West Europe | ○ | ○ | ○ |
| Southeast Asia | ○ | ○ | ○ |
| Japan East | ○ | × | ○ |
| Korea Central | ○ | ○ | ○ |
Japan East(東日本)リージョンでは、v4.0の画像分析やマルチモーダル埋め込みは利用できますが、Captions(キャプション生成)とDense Captions機能はサポートされていません。日本国内のデータセンターでキャプション生成を使いたい場合は、v3.2のDescriptions機能を使うか、East USなど対応リージョンにリソースを作成する必要があります。

主要リージョンと機能の対応状況:Japan EastではCaptions系が利用不可
この制限に関する最新情報はImage Analysis公式ドキュメントのRegion availabilityセクションで確認できます。
入力仕様の違い
バージョンによってAPIに送信できるファイルの仕様も異なります。
| 項目 | v4.0 | v3.2 |
|---|---|---|
| 対応フォーマット | JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF, MPO | JPEG, PNG, GIF, BMP |
| 最大ファイルサイズ | 20 MB | 4 MB |
| 画像サイズ | 50×50〜16,000×16,000 px | 50×50〜16,000×16,000 px |
v4.0はWEBPやTIFFなど対応フォーマットが広がり、ファイルサイズの上限も5倍に拡大しています。高解像度の写真や大きなスキャン画像を扱う場合はv4.0の方が制約が少なくなります。一方、v3.2でも一般的なJPEG/PNG画像の処理には十分対応しており、4MB以内の画像であればバージョン間の差は小さいです。
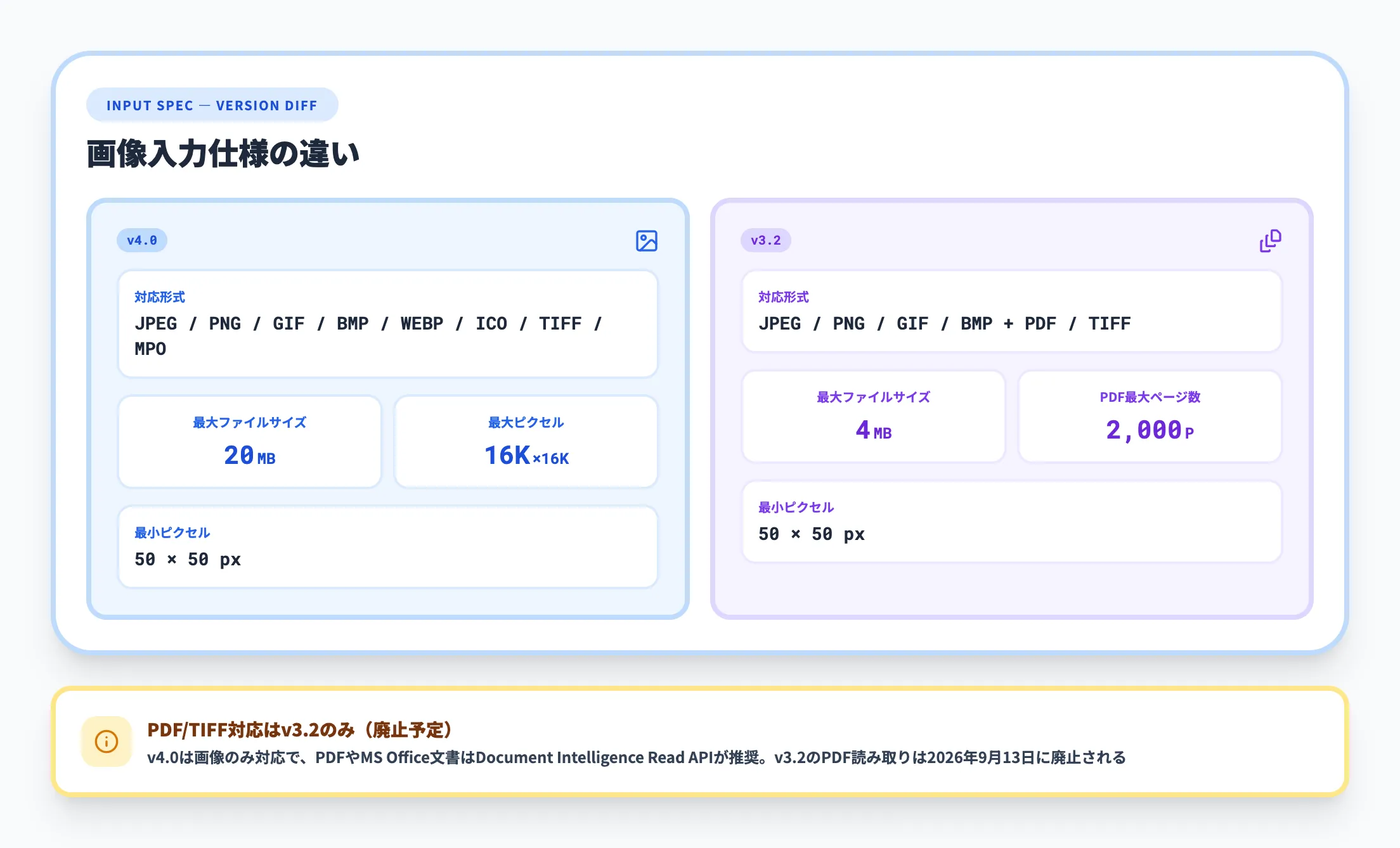
v4.0とv3.2の対応フォーマット・最大ファイルサイズの比較
Azure AI VisionとDocument Intelligenceの使い分け
Azure AI VisionとAzure AI Document Intelligenceは、どちらもOCR(文字読み取り)機能を持っていますが、得意領域が明確に異なります。このセクションでは、OCR用途でどちらを選ぶべきかの判断基準を解説します。
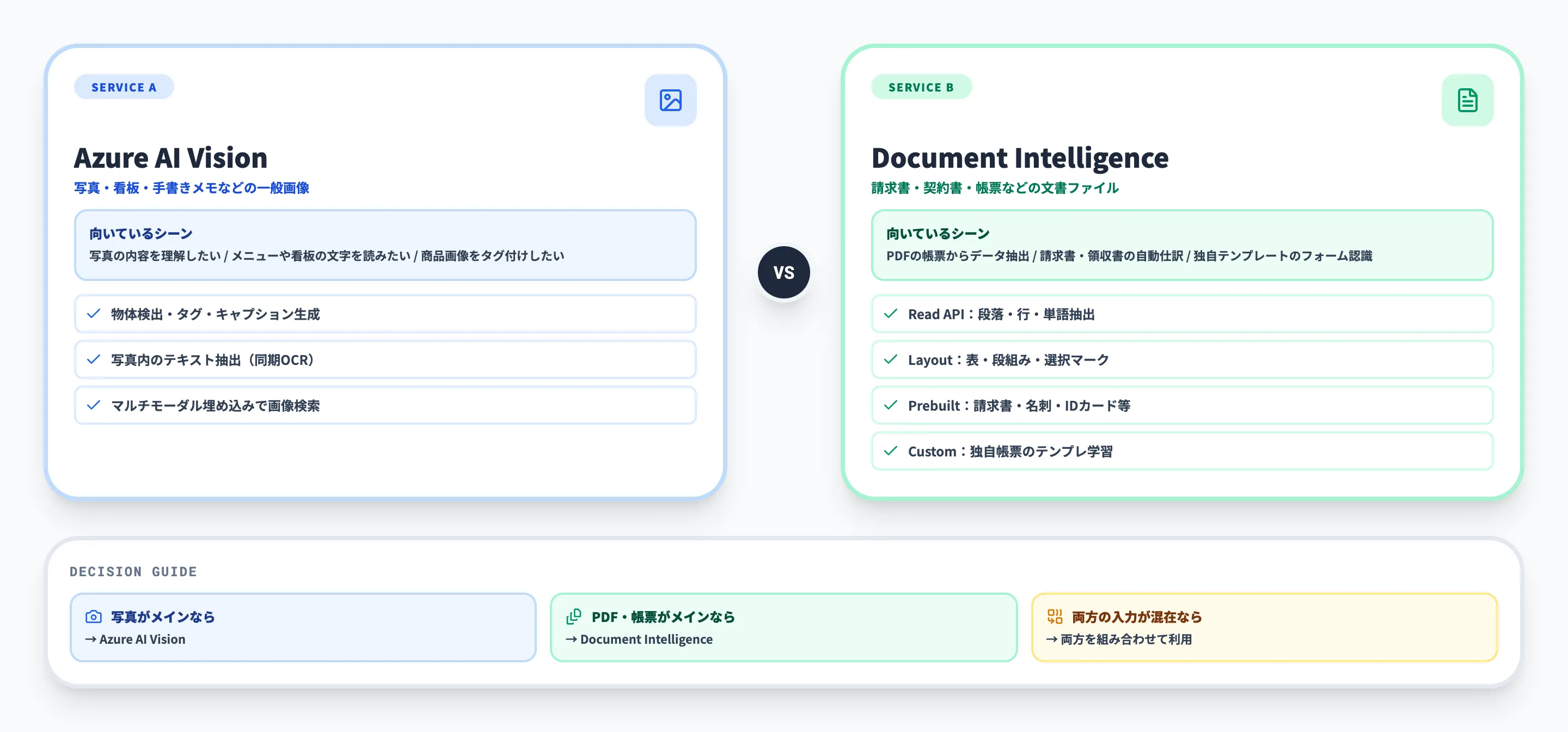
写真は Vision、PDF・帳票は Document Intelligence という使い分け
両サービスの違いを以下の表で比較します。Document Intelligenceは複数のモデルを使い分ける構成のため、Read APIとそれ以外(Layout・Prebuilt・Custom)に分けて整理します。
| 比較軸 | Azure AI Vision(Read API) | Document Intelligence |
|---|---|---|
| 得意な入力 | 写真、看板、メニュー、手書きメモなど | 請求書、レシート、契約書、フォームなどの文書 |
| Read API | テキスト行+バウンディングボックス | テキスト・段落・行・単語・言語の抽出(OCR) |
| Layoutモデル | なし | 表・段組み・選択マークなどページ構造を認識 |
| Prebuiltモデル | なし | 請求書・レシート・名刺・IDカード等の専用モデル |
| Customモデル | なし | テンプレートモデル・ニューラルモデルで独自帳票に対応 |
Document IntelligenceのRead APIだけでテーブル抽出やキー・バリュー抽出ができるわけではない点に注意が必要です。表やフォーム構造を読みたい場合はLayoutモデル、定型帳票はPrebuiltモデル、独自フォーマットはCustomモデルというように、用途別に専用モデルを選んで組み合わせます。
Microsoftの公式ドキュメントでは、以下の使い分けが推奨されています。
- 写真や画像中のテキスト読み取り → Azure AI VisionのRead API
- 文書(請求書・フォーム等)の構造化読み取り → Document IntelligenceのRead/Layout/Prebuilt/Customモデル
たとえば、工場の製造ラインで撮影した部品ラベルの文字を読み取る場合はVision Read、経理部門が受領した請求書のデータを勘定科目ごとに構造化したい場合はDocument IntelligenceのPrebuilt請求書モデル、独自フォーマットの帳票を学習させたい場合はCustomモデルが適しています。
両方のOCRが必要なシステムでは、入力データの種類に応じてAPIを振り分けるアーキテクチャが一般的です。前段で画像か文書かを判定するルーティング層を設け、画像はVision Read、文書はDocument Intelligenceの該当モデルに振り分けることで、それぞれのAPIの強みを活かせます。

Azure AI Visionの活用事例
Azure AI Visionは、小売・製造・スポーツなど幅広い業界で導入されています。ここでは、Microsoftが公開している導入事例から、画像分析とOCRの代表的な活用パターンを紹介します。

Goodwill・CATRION・Prague Airportの3つの代表的な活用パターン
小売・EC:商品リスティングの自動化(Goodwill of Orange County)
米国の非営利団体Goodwill of Orange Countyは、ECサイトShopGoodwill.comの出品作業にAzure AI Visionを導入しています。
出品担当者が衣類を撮影すると、Azure AI Custom Visionがアイテムの種類(レディースブラウス、メンズジャケットなど)を自動識別し、Azure AI VisionのOCR機能がラベルや値札の情報を読み取ります。抽出されたデータはLLM(大規模言語モデル)に渡され、商品説明文が自動生成されます。
この仕組みにより、リスティング作成時間の35〜45%を占めていた調査・執筆作業が削減されました。同社の衣類月間売上は約900万ドルで、AIツールの全社展開により月間売上1,200万ドル超への伸長が見込まれています。
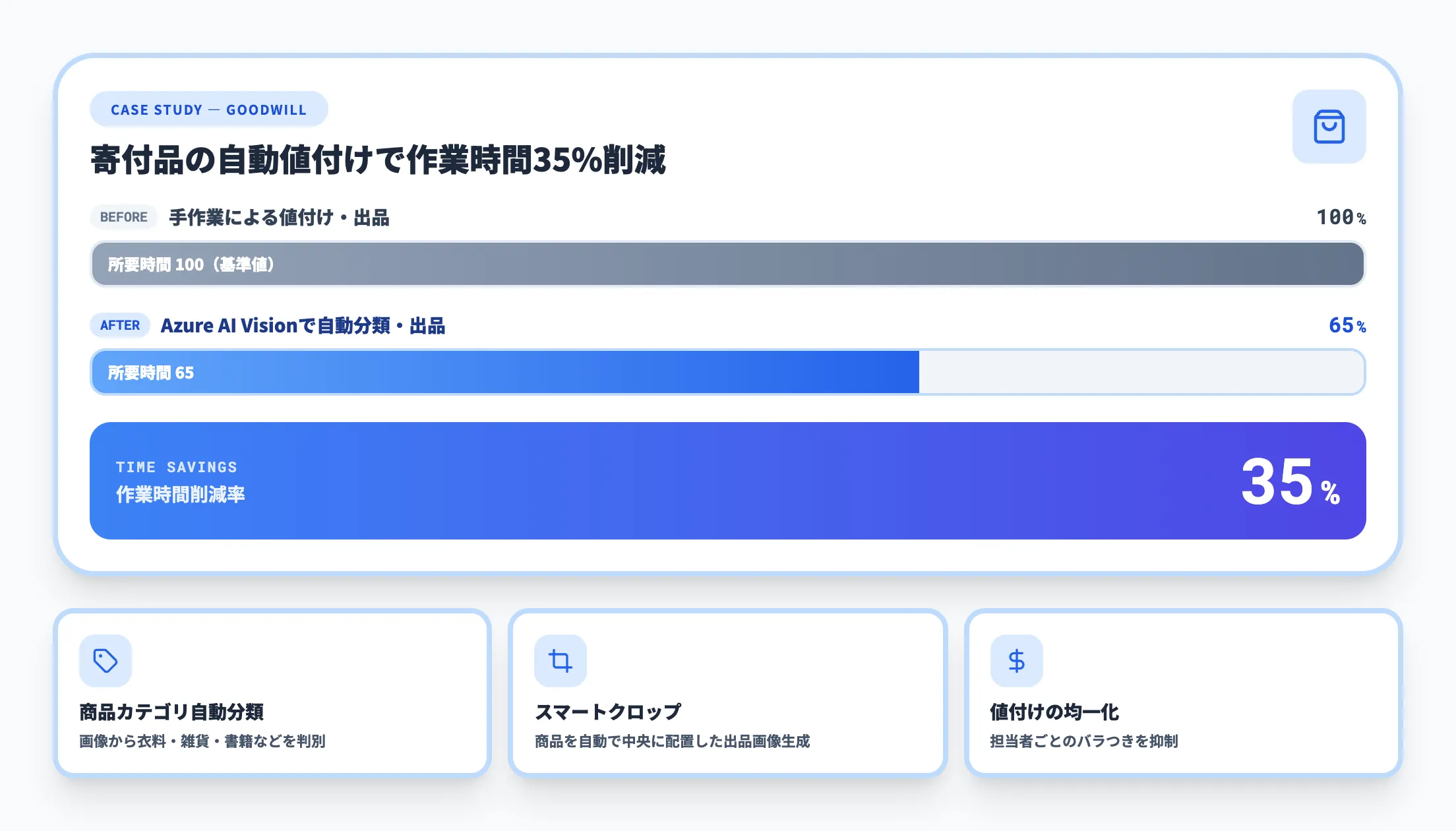
寄付品の自動値付けと出品作業の効率化(時間削減35%)
また、画像分析による作業負担の軽減により、発達障害や身体障害を持つスタッフがEC業務に従事できるようになったことも成果のひとつです。
食品サービス:請求書検証の自動化(CATRION)
食品サービス企業のCATRIONは、Azure AI Visionを使ってPDFやスキャン画像からの請求書データ抽出と検証を自動化しています。導入前は人手で行っていた照合作業のレビュー時間を3分の2に短縮する成果を上げています。
空港運営:画像からの情報抽出(Prague Airport)
MicrosoftのAzure Vision製品ページでは、Prague AirportがAzure AI VisionのOCRと画像分析を組み合わせ、空港運営の効率化とセキュリティ強化を実現している事例が紹介されています。
これらの事例に共通するのは、「人が目視で確認していた画像やスキャン画像の情報を、AIが自動で抽出・分類し、後続の業務フローに接続する」という活用パターンです。特に画像内のテキスト抽出や商品分類のように、大量の画像を均質な品質で処理する必要がある業務で効果が出やすくなっています。
毎月数千枚以上の画像や帳票を人手で処理しているなら、まずは一部のデータでVision StudioやFree(F0)ティアを使い、現行の手作業とAIの処理精度を比較してみることで、導入効果を定量的に把握できます。
【関連記事】
AI-OCRの活用事例10選!導入メリットや業界別の導入事例を解説
画像OCRから業務フロー接続まで自動化

読み取りの先の業務をAIエージェントが代行
画像やスキャン文書のOCR結果を手作業で転記していませんか。AI Agent Hubなら、読み取りから業務システムへの入力・仕訳・承認フローまで、AIエージェントが自社テナント内で自動実行します。
Azure AI Visionの使い方
Azure AI Visionを利用するには、Azureリソースの作成、APIキーの取得、APIの呼び出しという3ステップで進めます。
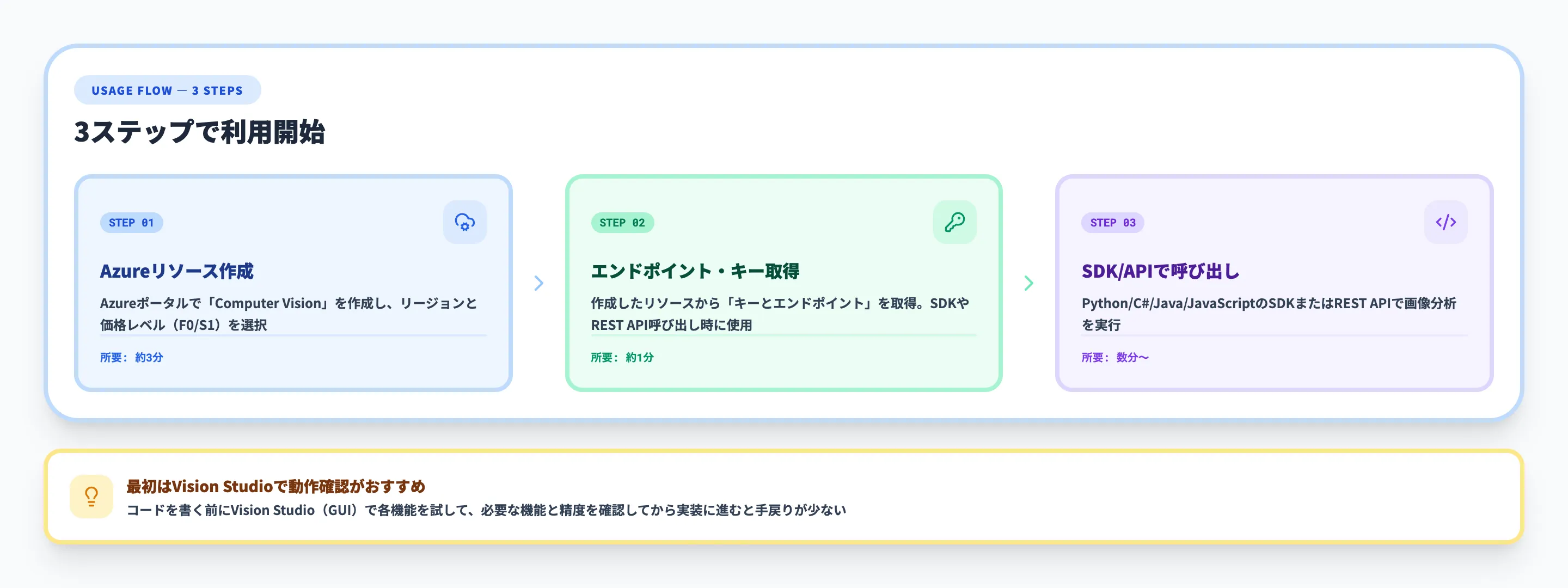
リソース作成 → エンドポイント取得 → SDK/API呼び出しの3ステップ
Azureリソースの作成
まず、AzureポータルでComputer Visionリソースを作成します。
リソース作成時の主な設定項目は以下のとおりです。
-
リソースグループ
既存のグループを選択するか、新規作成します。
-
リージョン
Japan East(東日本)が一般的ですが、v4.0のCaptions機能を使う場合はEast USなど対応リージョンを選択する必要があります。
-
価格レベル
Free(F0)またはStandard(S1)を選択します。F0は毎分20トランザクションまでの制限がありますが、PoC段階の検証には十分です。
まず、Azure PortalでComputer Visionを検索します。
Azure Portalのマーケットプレイスで「Computer Vision」を検索している画面
基本情報を入力し、リソースを作成します。
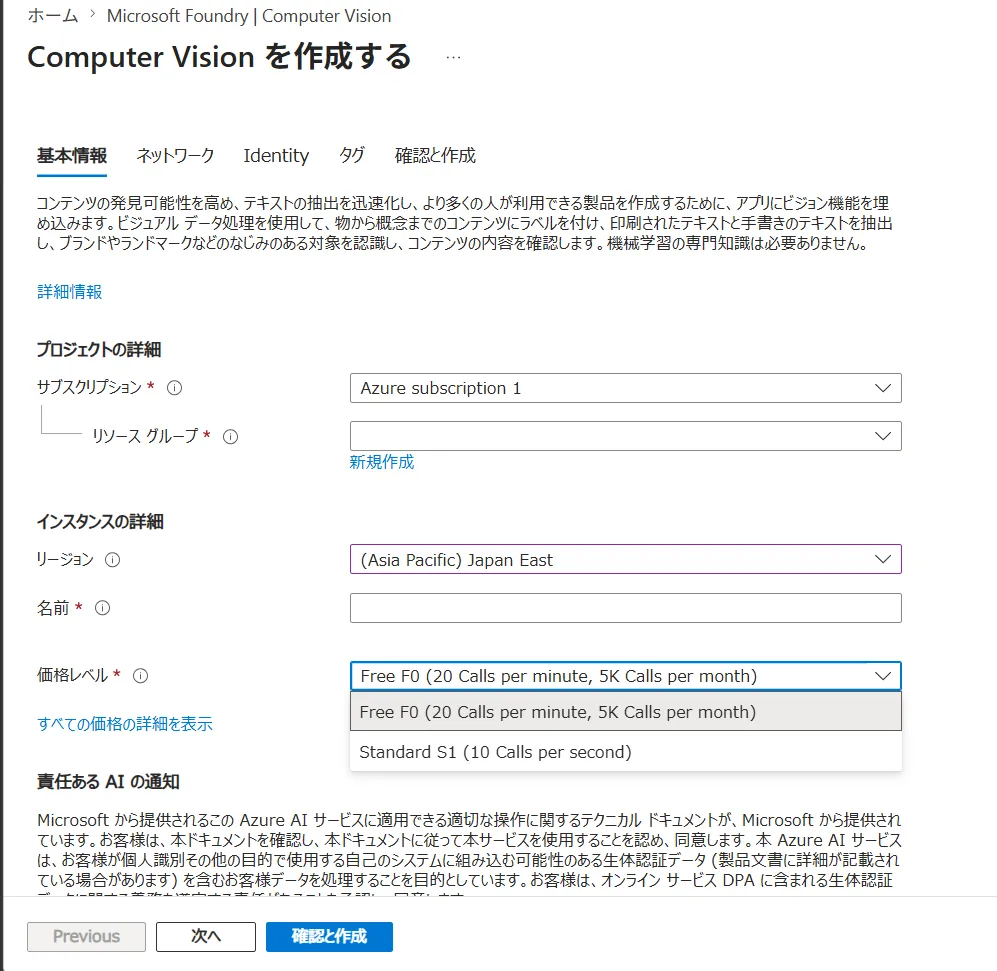
リソース作成の基本タブでリージョンや価格レベルを設定している画面
リソースの作成が完了したら、概要画面を確認します。
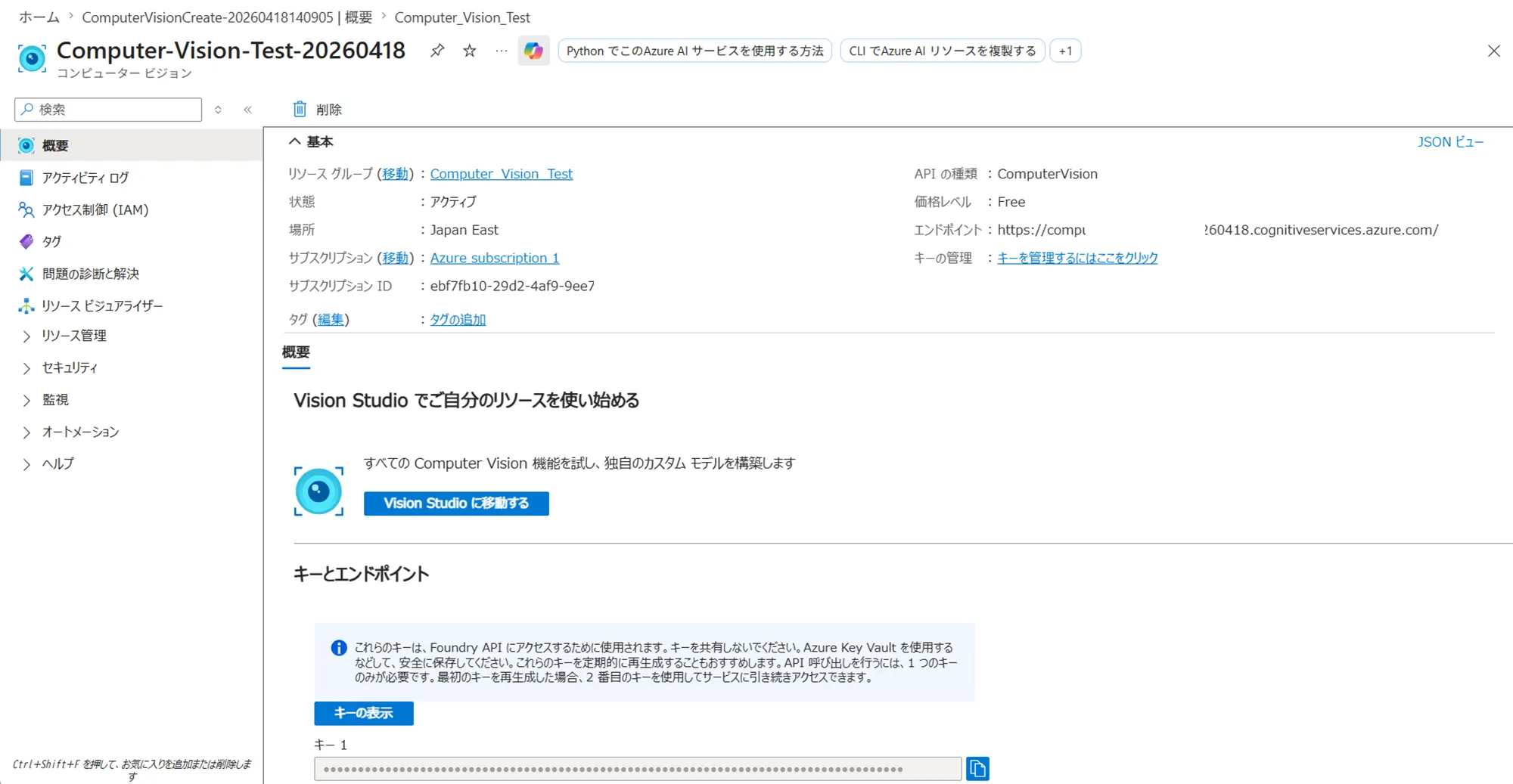
Computer Visionリソースのデプロイ完了後の概要画面
最後に、APIキーとエンドポイントを確認します。
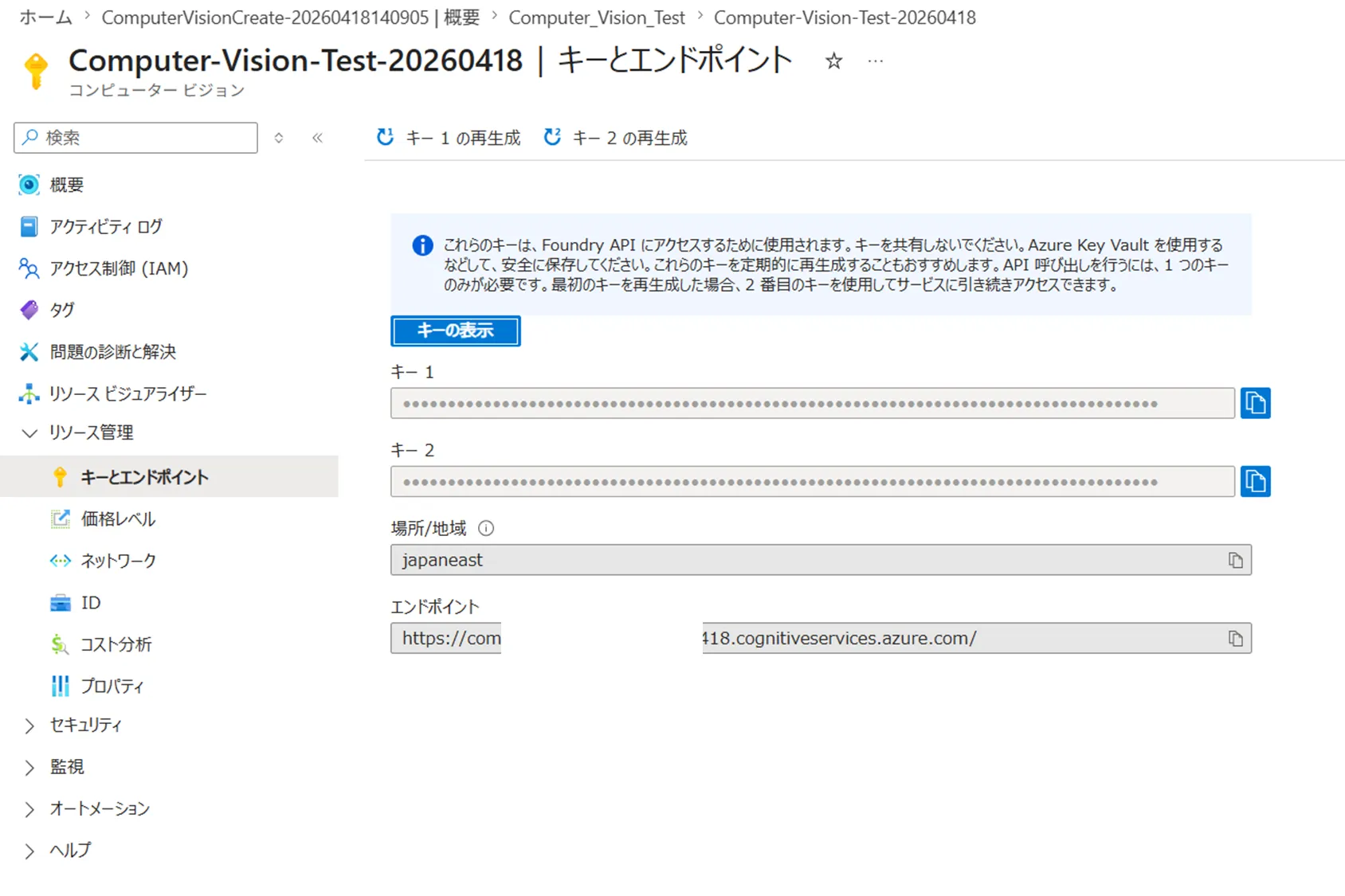
エンドポイントURLとAPIキーが表示されている画面
リソースが作成されると、エンドポイントURLとAPIキーが発行されます。
APIの呼び出し(Python)
Python SDKを使った画像分析の基本的な流れは以下のとおりです。
from azure.ai.vision.imageanalysis import ImageAnalysisClient
from azure.ai.vision.imageanalysis.models import VisualFeatures
from azure.core.credentials import AzureKeyCredential
client = ImageAnalysisClient(
endpoint="https://<your-endpoint>.cognitiveservices.azure.com/",
credential=AzureKeyCredential("<your-key>")
)
result = client.analyze_from_url(
image_url="https://example.com/sample.jpg",
visual_features=[
VisualFeatures.CAPTION,
VisualFeatures.TAGS,
VisualFeatures.OBJECTS,
VisualFeatures.READ,
],
)
print(result.caption.text)
for tag in result.tags.list:
print(f"{tag.name}: {tag.confidence:.2f}")
このコードでは、1回のAPI呼び出しでキャプション生成・タグ付け・物体検出・テキスト読み取りを同時に実行しています。v4.0の同期APIにより、複数の分析を1リクエストで完結させられる点がポイントです。
SDKはPython、C#、Java、JavaScriptが公式にサポートされています。REST APIでの直接呼び出しも可能で、curlやPostmanからのテストもできます。
Vision Studioでの試用
コードを書かずに機能を試したい場合は、Vision Studioを使います。
ブラウザ上で画像をアップロードするだけで、タグ付け、キャプション生成、OCR、人物検出などの結果を即座に確認できます。APIの仕様を把握したうえで本格的な開発に移る際の出発点として有効です。
Vision Studioを使うには、Azureサブスクリプションとcomputer Visionリソースが必要です。Free(F0)ティアのリソースでも利用できるため、Azureアカウントさえあれば追加費用なしで試せます。
ステップ1: Vision Studioにアクセス
Vision Studioにアクセスします。
Vision Studioのトップ画面で分析カテゴリが一覧表示されている状態
ステップ2: リソースの紐付け
初回アクセス時は、事前に作成したFaceリソースを紐付けます。サブスクリプションと対象リソースを選択してください。
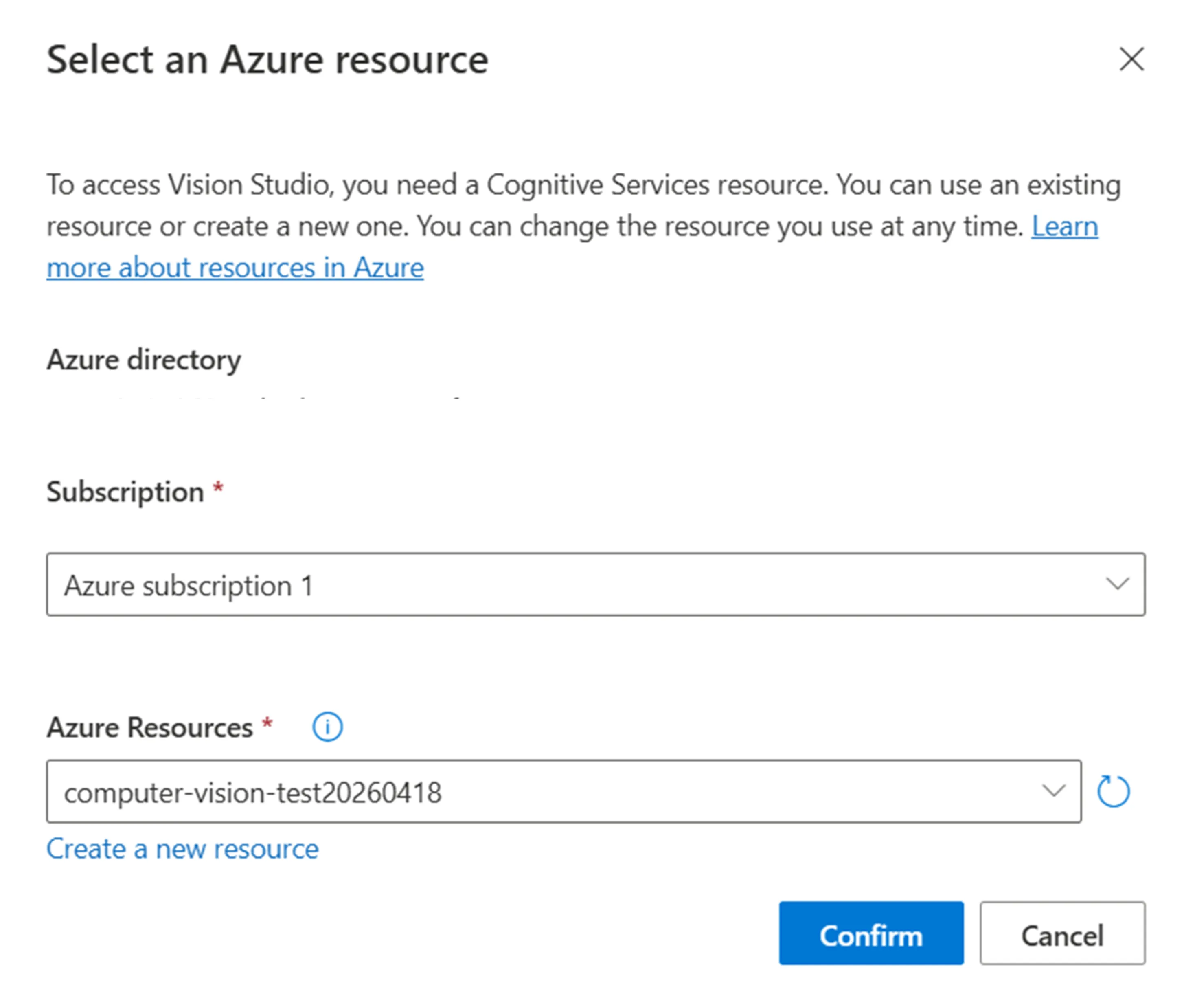
サブスクリプションとFaceリソースを選択する設定ダイアログ
ステップ3: 顔検出機能を選択
Faceカテゴリから「Detect faces in an image」を選択します。
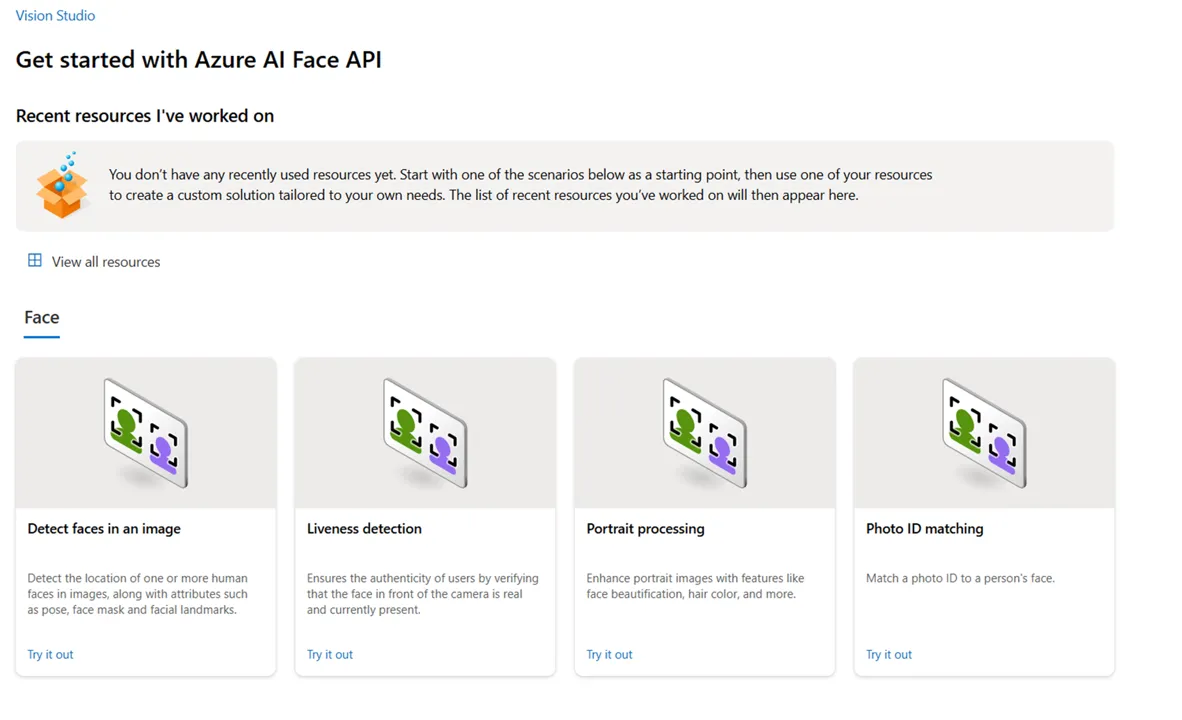
Faceカテゴリ内の機能一覧が表示されている画面
ステップ4: 画像をアップロード
顔が写っている画像をアップロードします。サンプル画像を使うことも可能です。
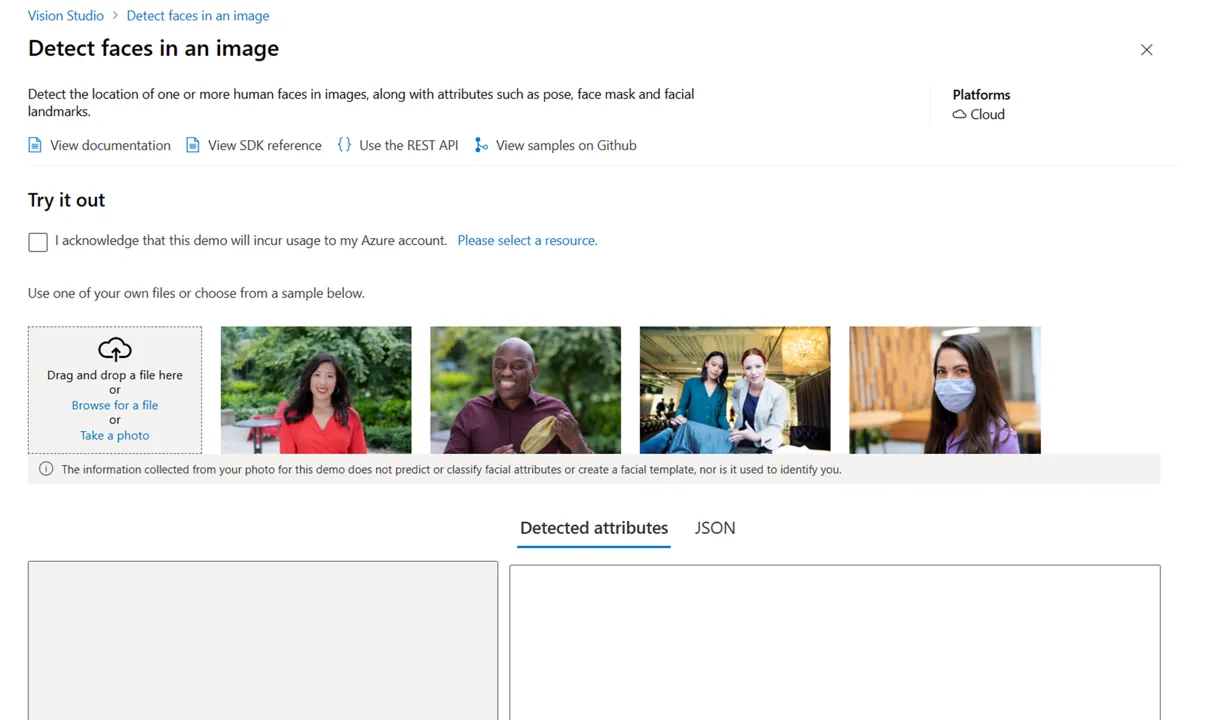
顔画像をアップロードした状態の画面
ステップ5: 顔検出結果の確認
分析を実行すると、顔の位置がバウンディングボックスで表示され、検出結果を確認できます。
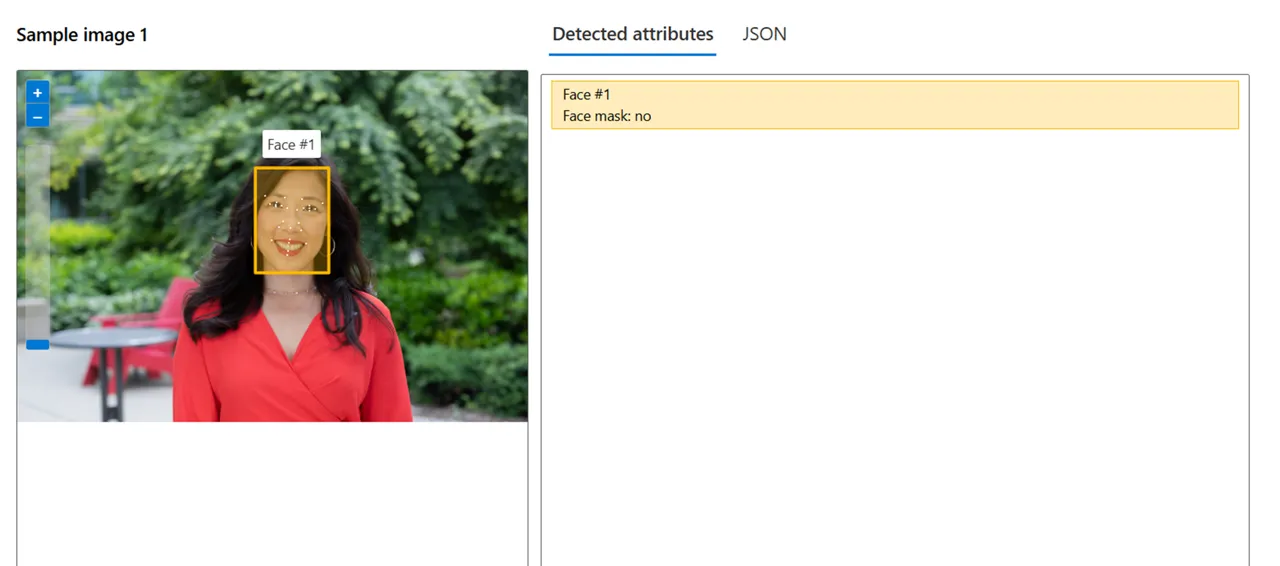
顔の位置にバウンディングボックスが表示された分析結果画面
ステップ6: JSONレスポンスの確認
開発時に役立つJSON形式のレスポンスも確認できます。APIの出力構造を把握する際に有効です。
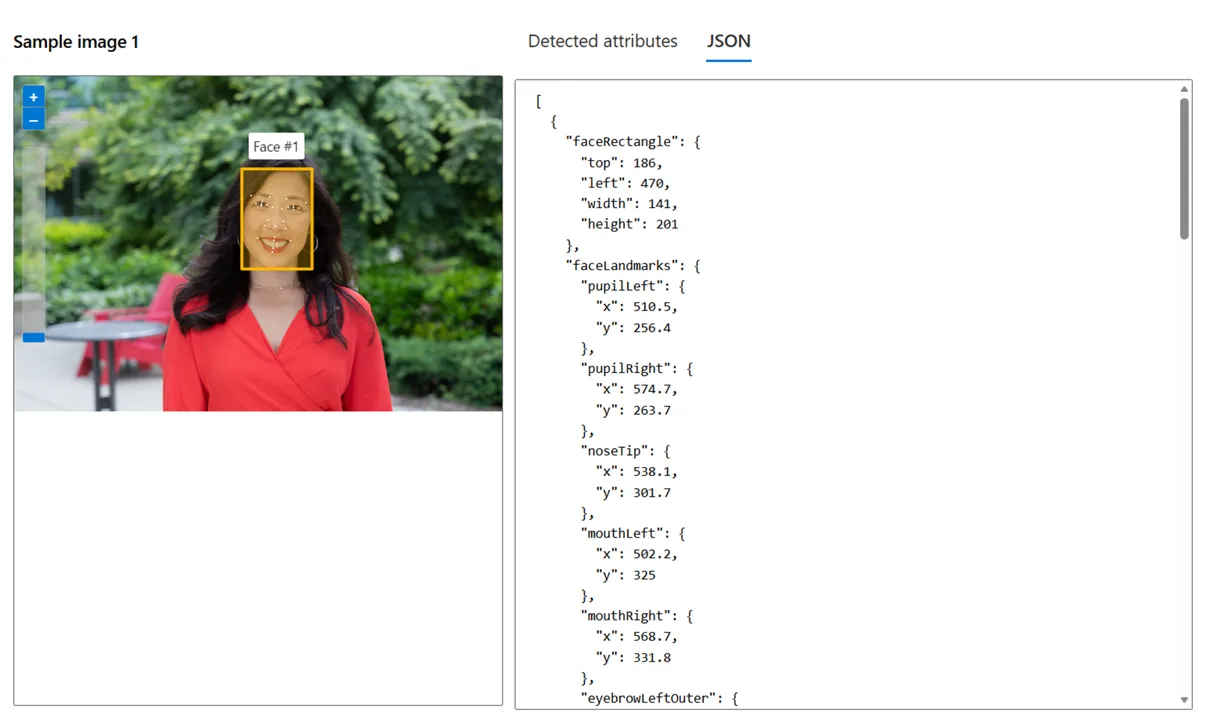
顔検出結果のJSONレスポンスが表示されている画面
Azure AI Visionの廃止スケジュールと移行ガイド
Azure AI Visionは2026年4月時点で利用可能ですが、Image Analysis 4.0を含む複数の機能が段階的に廃止される予定です。新規導入を検討している場合も、既存システムで利用している場合も、廃止スケジュールと移行先の把握は欠かせません。
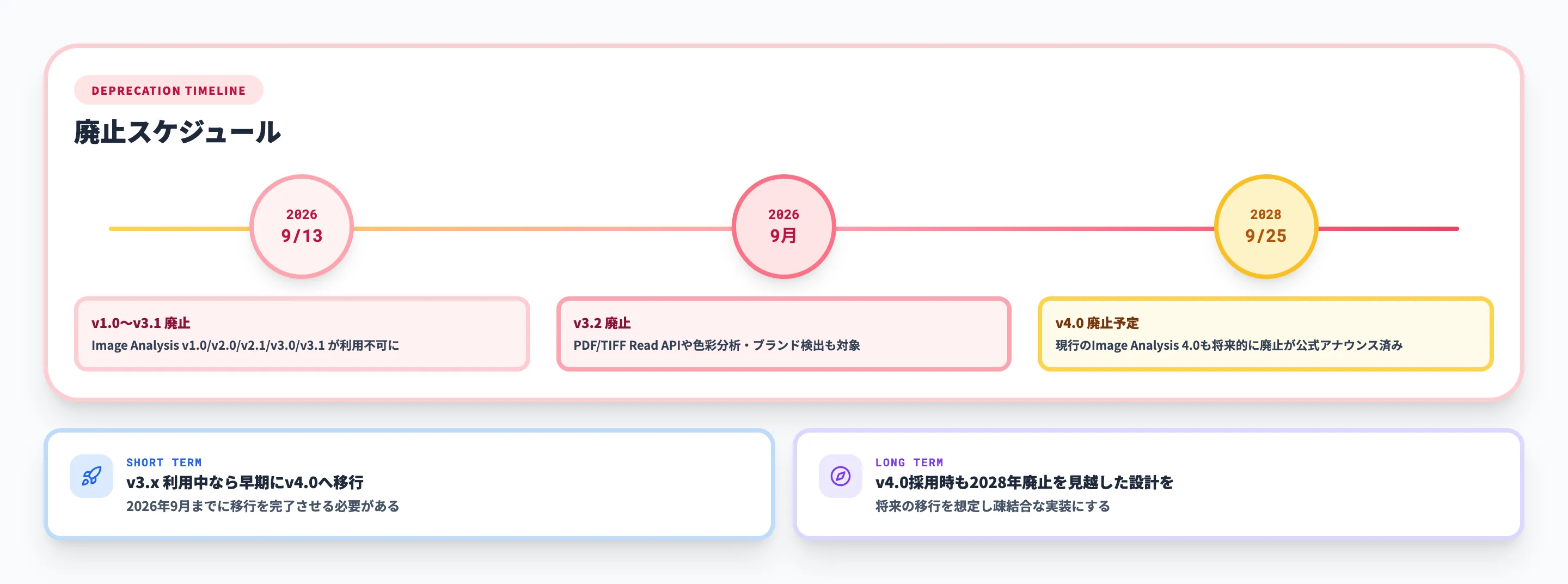
2026年9月v3.x廃止 → 2028年9月v4.0廃止のタイムライン
廃止済みの機能(2025年3月31日)
以下の機能は2025年3月31日にすでに廃止されており、APIへのリクエストは失敗します。
- Custom Image Classification(カスタム画像分類)
- Custom Object Detection(カスタム物体検出)
- Product Recognition(棚分析)
- Background Removal / Segment API(背景除去)
これらはいずれもImage Analysis 4.0のプレビュー機能として提供されていたもので、GA(一般提供)には至りませんでした。カスタムモデルが必要な場合は、Azure AI Custom VisionまたはAzure ML AutoMLへの移行が必要です。
v3.2以前の廃止(2026年9月13日)
Image Analysis v1.0、v2.0、v2.1、v3.0、v3.1は、2026年9月13日に廃止されます。この日以降、旧バージョンのAPIエンドポイントへのリクエストは失敗します。
v3.2はこの時点では引き続き利用可能ですが、v3.2固有の機能(ブランド検出、有名人認識など)の長期的な提供保証はありません。旧バージョンを利用中のシステムは、2026年9月までにv3.2またはv4.0への移行が必要です。
v4.0全体の廃止(2028年9月25日)
Image Analysis 4.0は2028年9月25日に廃止されます。これにはタグ付け、キャプション生成、物体検出、OCR、マルチモーダル埋め込みなど、v4.0のすべてのGA機能が含まれます。
Microsoftは移行ガイドを公開しており、2026年9月25日までに移行計画を策定することを推奨しています。
移行先の対応表
公式の移行ガイドでは、機能ごとに以下の代替サービスが案内されています。
| 廃止される機能 | 推奨される移行先 |
|---|---|
| OCR / テキスト読み取り | Azure AI Document IntelligenceのRead API |
| 画像分析全般(タグ・キャプション・物体検出) | Azure AI Foundry上のGPTモデル、Azure AI Content Understanding |
| 顔検出 | Azure AI Face API |
| マルチモーダル埋め込み | Cohere Embed v4、SigLIP、Florence 2 |
| カスタムモデル(分類・検出) | Azure AI Custom Vision、Azure ML AutoML |
| 背景除去 | Florence 2のRegion to Segmentation、BiRefNet |
注目すべきは、画像分析の移行先としてGPTモデル(マルチモーダルLLM)やContent Understandingが推奨されている点です。専用の画像分析APIから汎用的なマルチモーダルAIへと移行する流れが、Microsoft自身の移行ガイドにも明確に表れています。

v3.2廃止機能ごとの推奨移行先:Document Intelligence・Content Safety・Custom Visionなど
OCRについては、Document Intelligenceへの一本化が進む方向です。既にVision ReadよりもDocument Intelligence Readの方が機能・精度ともに優位なユースケースが多く、OCR目的でAzure AI Visionを新規採用するよりも、Document Intelligenceを選ぶ方が移行リスクを回避できます。
現在Azure AI Visionを使っている場合の優先度としては、OCR機能をDocument Intelligenceに移行するのが最も着手しやすく、効果も高いステップです。画像分析(タグ付け・物体検出等)はGPTモデルやContent Understandingの成熟度を見ながら2027年以降に段階的に移行するのが現実的です。
Azure AI Visionの注意点と導入判断のポイント
Azure AI Visionを導入する際に押さえておくべき制約事項と、よくある判断の迷いどころを整理します。
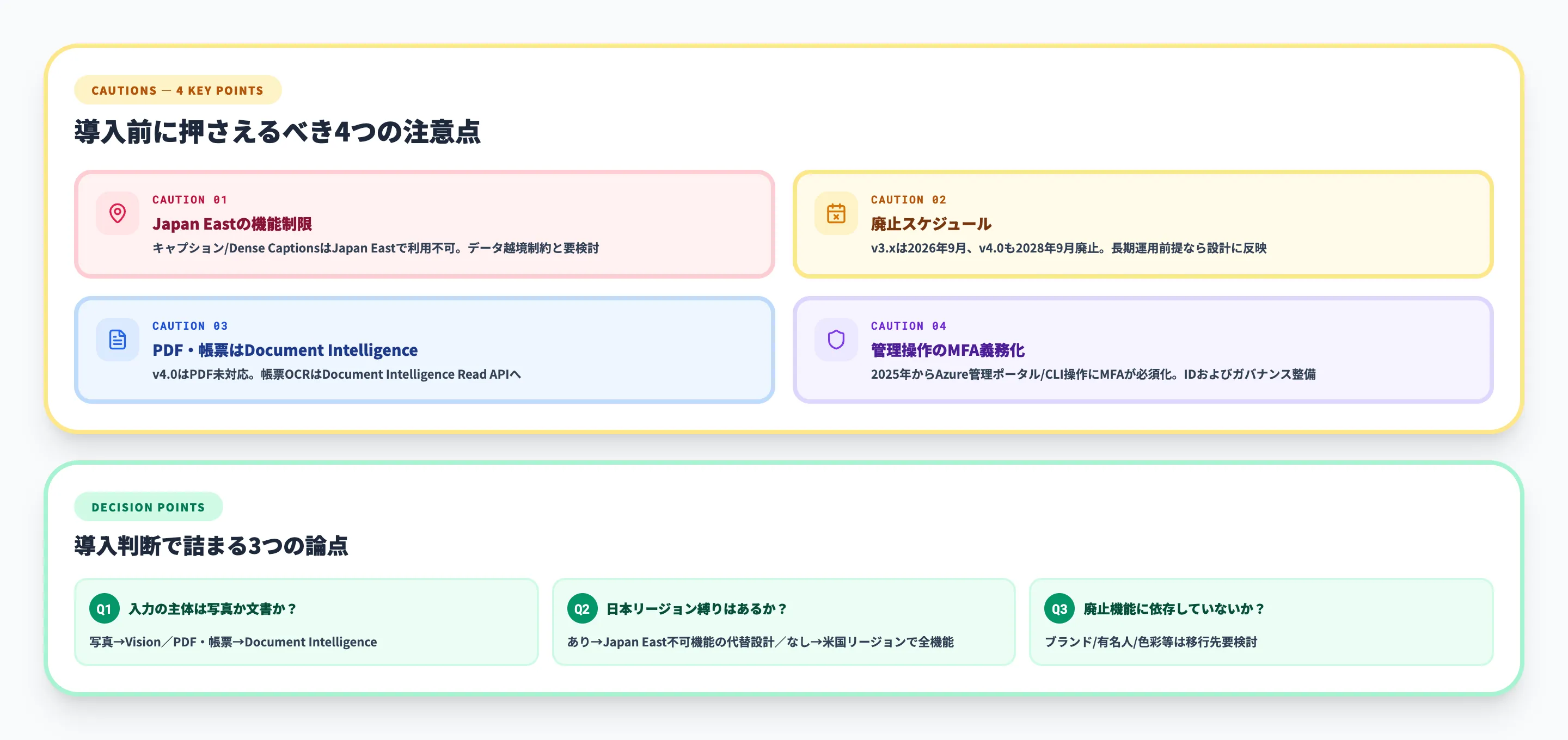
4つの注意点と導入判断で詰まる3論点の全体像
Japan Eastリージョンの制限
日本国内のデータセンター(Japan East)でAzure AI Visionを利用する場合、v4.0のCaptions(キャプション生成)機能とDense Captions機能が利用できません。
キャプション生成が業務要件に含まれる場合は、以下のいずれかで対応する必要があります。
- v3.2のDescriptions機能を使う(Japan Eastで利用可能)
- East USなどCaptions対応リージョンにリソースを作成する(レイテンシ増加を許容する場合)
- Azure OpenAI ServiceのGPTモデル(GPT-4oなど)のマルチモーダル入力でキャプションを生成する
データの国外送信に制約がある場合は、v3.2の利用またはGPTモデルの利用を検討してください。

Japan East と East US で利用可能な機能の違い
TPS(秒間トランザクション数)の制限
Azure AI Visionの各ティアにはTPS制限があります。
| ティア | TPS制限 |
|---|---|
| Free(F0) | 毎分20トランザクション |
| Standard(S1) | 毎秒20トランザクション |
S1のTPS制限はAzureサポートへの申請で引き上げ可能です(50 TPS以上)。急激なリクエスト増加時には429エラー(Too Many Requests)が返されるため、バッチ処理を行う場合はリトライロジックとレート制御の実装が必要です。
導入判断で詰まる論点
Azure AI Visionの導入検討で判断に迷いやすい3つのポイントを整理します。
Vision ReadかDocument Intelligence Readか
画像中のテキストを読み取りたい場合に、どちらのRead APIを選ぶかが最初の分岐点です。判断基準は入力データの形式で分かれます。入力が「写真やスクリーンショット」ならVision Read、「請求書や契約書などの文書ファイル」ならDocument Intelligence Readを選びます。両方の入力が混在するシステムでは、ファイル種類に応じたルーティングを設計してください。
v4.0を今から採用すべきか
v4.0は2028年に廃止予定のため、今からv4.0を前提にした大規模開発を始めるのはリスクがあります。新規開発の場合は、v4.0で検証しつつ、移行先として推奨されているDocument IntelligenceやGPTモデルへの切り替えも視野に入れた設計が望ましいです。既存システムの改修ならv4.0を使いつつ、2027年中に移行計画を立てるのが現実的なスケジュールです。
Azure AI VisionかGPTモデルか
GPT-4oなどのマルチモーダルLLMも画像分析が可能になっています。タグ付けやキャプション生成であればGPTモデルでも実現できますが、1画像あたりのコストはAzure AI Visionの方が大幅に低く、月間数万枚以上を処理する大量処理にはAzure AI Visionが有利です。一方、画像の内容について自然言語で質問応答したい場合や、分析の柔軟性を重視する場合はGPTモデルの方が適しています。
Azure AI Visionの料金
Azure AI Visionは従量課金制を採用しており、API呼び出し数(トランザクション数)に応じて料金が発生します。無料枠も用意されているため、小規模な検証から始められます。
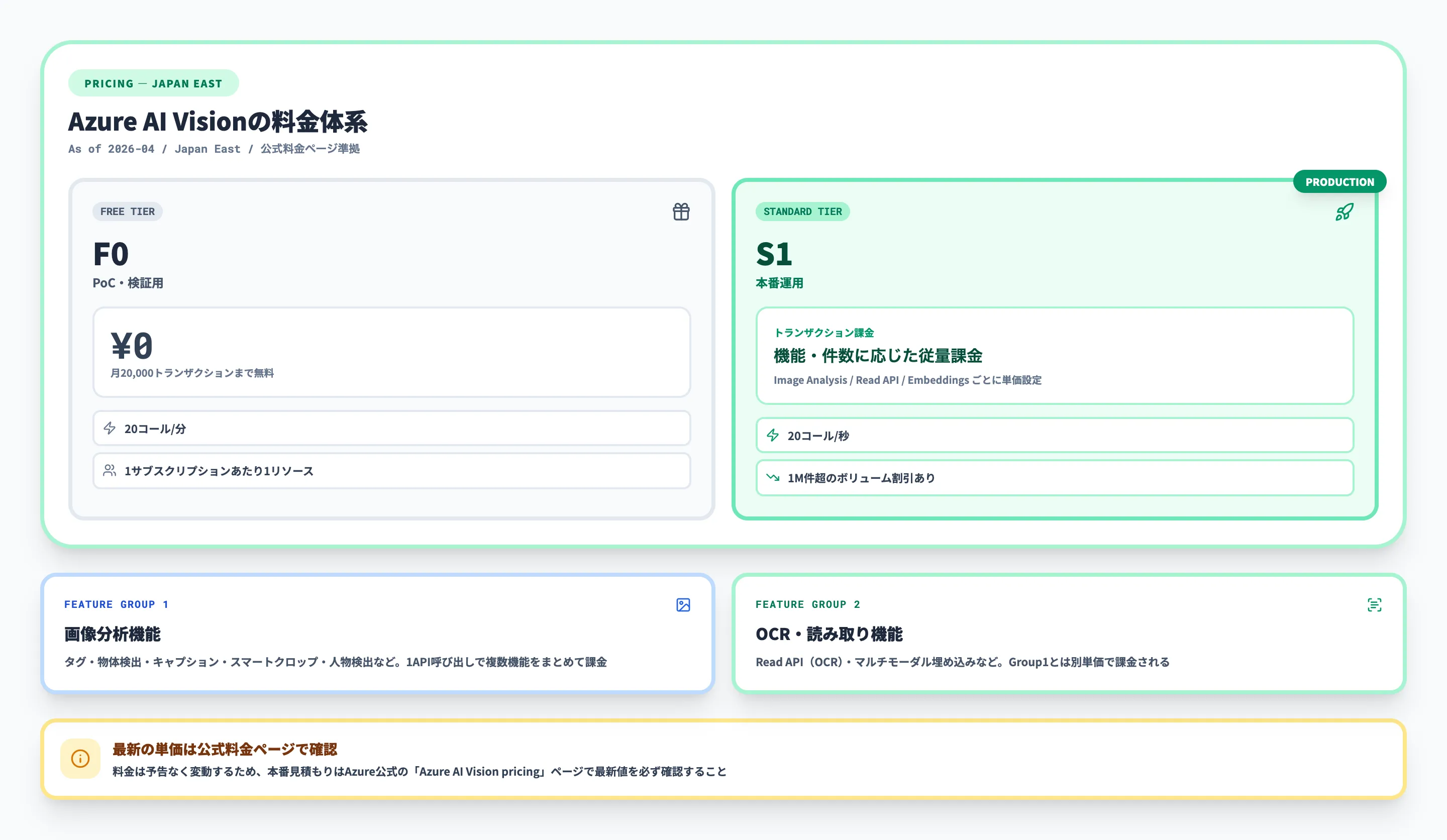
F0(無料)/S1(本番)の料金体系と機能グループ別の課金構造
料金ティアの構成
Azure AI Visionには、Free(F0)とStandard(S1)の2つの料金ティアがあります。
| 項目 | Free(F0) | Standard(S1) |
|---|---|---|
| トランザクション制限 | 毎分20トランザクション | 毎秒20トランザクション |
| ファイルサイズ上限(v4.0) | 20 MB | 20 MB |
| 用途 | PoC・小規模検証 | 本番運用 |
Free(F0)は商用利用にも制限はありませんが、スループットが毎分20トランザクションに制限されるため、本番環境での大量処理には向きません。まずはF0で精度検証を行い、要件を満たすことを確認してからS1に移行するのが一般的な進め方です。
Standard(S1)の料金体系
Standard(S1)の料金はAPI機能のグループによって異なります。以下は2026年4月時点の参考価格です(Japan Eastリージョン基準)。
| 機能グループ | トランザクション数 | 1,000トランザクションあたりの料金(税抜) |
|---|---|---|
| Group 1(Tag, Detect Objects等) | 0〜100万件 | 約150円 |
| Group 1(Tag, Detect Objects等) | 100万〜1,000万件 | 約97円 |
| Group 2(Captions, Dense Captions等) | 0〜100万件 | 約224円 |
大量処理が見込まれる場合は、コミットメントティア(月単位の処理件数を事前に確約する方式)も用意されています。50万トランザクション/月のコミットメントで月額約56,000円が目安です。
1日1,000枚の画像をGroup 1の機能で処理する場合、月間約3万トランザクションとなり、月額コストは約4,500円です。処理量が多い場合はボリュームディスカウントとコミットメントティアを比較し、コスト効率の良い方を選んでください。
料金は変動する可能性があるため、最新情報はAzure Vision公式料金ページで確認してください。

画像データの読み取りを業務フローに直結させるなら
Azure AI VisionやDocument Intelligenceで画像やスキャン文書を読み取っても、その結果を業務システムに手作業で転記していては効率化の効果は限定的です。OCRの精度が上がるほど、「読み取りの先」にある業務処理の自動化がボトルネックになります。
AI Agent Hubは、OCRで抽出したデータを基幹システムへの入力・仕訳・承認フローまでAIエージェントが自動実行するエンタープライズAI基盤です。Azure環境で構築・運用が完結する設計のため、画像データが外部に流出するリスクを排除できます。
- AI-OCR Agentが領収書・請求書の読み取りから仕訳まで自動化
画像やスキャン文書をAI-OCR Agentが読み取り、抽出した金額・日付・取引先情報を経費仕分けAgentが勘定科目に自動分類します。SAP ConcurやfreeeなどのERPにそのまま連携でき、手入力の手間とミスを同時に削減します。
- 読み取りから基幹システム投入まで人の手を介さない
自動入力Agentが、OCRで構造化したデータをDynamics 365やSalesforceなどの業務システムに直接投入します。Human-in-the-Loopの仕組みにより、AIの判定結果をTeams上で承認・差戻しでき、完全自動と人間判断のバランスを業務ごとに調整できます。
- 使い慣れたMicrosoft環境をそのまま活用
Teams・Excel・Outlookなど既存ツールの延長でAIエージェントが動作。新しいツールの学習コストはゼロです。
- データは100%自社テナント内に保持
AIの学習対象から完全除外。Azure Managed Applicationsとして自社テナント内で動作が完了する設計です。
AI総合研究所の専任チームが、画像OCRから業務システム連携までのAIエージェント設計を支援します。まずは無料の資料で、自社の画像処理業務にどう適用できるかご確認ください。
画像OCRから業務フロー接続まで自動化
読み取りの先の業務をAIエージェントが代行
画像やスキャン文書のOCR結果を手作業で転記していませんか。AI Agent Hubなら、読み取りから業務システムへの入力・仕訳・承認フローまで、AIエージェントが自社テナント内で自動実行します。
まとめ
Azure AI Visionは、画像分析・OCR・マルチモーダル埋め込みという3つの機能カテゴリを通じて、画像からの情報抽出を自動化するクラウドAIサービスです。
2026年4月時点で押さえておくべきポイントは以下の3点です。
-
v4.0は2028年9月に廃止予定
新規開発でv4.0を採用する場合は、Document IntelligenceやGPTモデルへの移行も視野に入れた設計が求められます。特にOCR用途ではDocument Intelligenceへの移行優先度が高い状況です。
-
Japan Eastリージョンの機能制限を確認
v4.0のCaptions機能はJapan Eastでは利用できません。キャプション生成が必要な場合は、v3.2のDescriptions機能や他リージョンの利用、GPTモデルによる代替を検討してください。
-
用途に応じた使い分けが重要
写真や画像の文字読み取りにはVision Read、文書の構造化読み取りにはDocument Intelligence、画像内容の自然言語理解にはGPTモデルと、それぞれ最適なサービスが異なります。
画像データの活用は、商品画像の自動タグ付けから帳票処理、セキュリティ監視まで多岐にわたります。まずはFree(F0)ティアとVision Studioで自社の画像データを使った精度検証から始め、業務要件に合ったAPI構成を設計してみてください。










