この記事のポイント
 LLMのAPIコストを即座に削減したいなら、JSONからTOONへの置き換えを第一候補にすべき
LLMのAPIコストを即座に削減したいなら、JSONからTOONへの置き換えを第一候補にすべき- 公式ベンチマークで39.6%のトークン削減を実現しており、大量データを扱うシステムほどコスト削減効果が有効
- データ構造に応じた4つの表現パターンの使い分けが最適な削減率を引き出す鍵であり、一律適用は避けるべき
- Semantic KernelやPython/TypeScriptで実装が容易なため、既存のAIパイプラインへの段階的導入に最適
- 月間数十万円以上のLLM利用費がある企業なら、年間で数百万円規模のコスト削減が見込めるため早期検討すべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
「LLMのAPIコストが高い…」「AIの応答が遅い…」AIを本格的に活用する企業が直面するこの課題は、実はAIに送るデータの「形式」に原因があるかもしれません。
その解決策として、LLMとの通信に最適化された新しいデータ形式「TOON (Token-Oriented Object Notation)」が注目されています。これは、JSONの冗長性を排除し、公式ベンチマークで39.6%のトークン削減を実現する革新的なアプローチです(データ構造によって40-60%以上の削減も可能)。
本記事では、この「TOON」について、その基本から具体的な使い方までを徹底的に解説します。
JSONとの違い、4つの表現パターン、Semantic Kernelなどでの実装例、そして実務で導入するためのベストプラクティスまで、詳しくご紹介します。
目次
なぜTOONが注目されるのか? JSONの限界とLLM 時代の新しい要件
パターン3:オブジェクト配列(テーブル形式)- TOON の最大の力
Semantic KernelやAIエージェント開発でTOONを活用する実践的なアプローチ
Python での実装例:Semantic Kernel プラグイン内での TOON 活用
JavaScript/TypeScript での実装例:API レスポンスの効率化
JSON の方が向いている場面(無理にTOONを使うべきではないケース)
TOON 導入のベストプラクティス:実務的な導入手順と運用のコツ
3. チームトレーニング:TOON の仕組みと使用シーンの共有
TOON とは?
TOON(Token-Oriented Object Notation)とは、大規模言語モデル(LLM)との通信を効率化するために設計された、新しいデータシリアライゼーション形式です。
JSON と同じデータモデル(オブジェクト、配列、プリミティブ型)を保持しながら、トークン使用量を 30-60% 削減することで、LLM 利用時のコスト低減と応答速度の向上を実現します。
TOON は単なる「コンパクトな記法」ではなく、LLM が自然に理解しやすい構造を備えた、AIネイティブなデータ形式として設計されています。
つまり、「JSONという人間向けの汎用フォーマット」から「LLM向けに最適化されたフォーマット」への進化を意味しているのです。

なぜTOONが注目されるのか? JSONの限界とLLM 時代の新しい要件
JSON は 1999 年に登場して以来、インターネットのデータ交換フォーマットとして標準的地位を確立してきました。しかし、LLM 利用が急速に増加する現在、その冗長性が課題になり始めています。
この問題は、単なる「技術的な好みの問題」ではなく、企業の実運用コストに直結する重大な課題なのです。
JSON の冗長な記法が何をもたらすのか
JSON の構文を詳しく見ると、冗長な記号が多いことがわかります。一見すると「これは当たり前」と思えるかもしれませんが、LLMに大量のデータを送信する場合、この冗長性が積み重なって、予想外のコスト増加と処理遅延を引き起こします。
以下は、シンプルなユーザー情報を JSON で表現した例です。
{
"user": {
"id": 1,
"name": "Alice Johnson",
"email": "alice@example.com",
"age": 28,
"city": "Bengaluru"
}
}
このシンプルなユーザー情報を表現するために、JSON では以下の記号が使用されています。
- 波括弧 「{}」:オブジェクトの始まりと終わり
- コロン 「:」 :キーと値の分離(1 個所につき 1 トークン)
- カンマ 「,」 :要素の分離
- ダブルクォート 「"」 :文字列の囲い込み(キーごと、値ごと)
これらの記号は、構造を明確にするには必要ですが、LLM にとっては冗長です。AI モデルは視覚的な「縦方向のインデント」や「位置情報」から構造を理解できるため、括弧やクォートは不要なのです。
しかも、この問題は単一のレコード扱う場合は目立ちませんが、100件、1000件、10000件のデータセットになると、冗長性の影響は指数関数的に増加します。
たとえば、100件の従業員データをJSONで送信する場合、括弧とクォート だけで数百トークンが消費されてしまいます。これは「無駄」ではなく、そのまま企業の IT コストに転化するのです。
LLM 時代のデータ形式の課題:コスト、速度、効率性
企業がLLMをビジネスに組み込む際、直面する課題は以下の通りです。
コスト増加
データサイズが大きいほど、API 利用コストが増加します。特に、複雑なビジネスプロセスでは、複数回のAPI呼び出しが発生するため、トークン削減による効果は累積します。100回のAPI呼び出しで40%のトークン削減ができれば、年間数千ドルのコスト削減が実現できるのです。
応答遅延
トークン数が多いほど、LLM の処理時間が長くなる傾向があります。リアルタイムシステムを構築している場合、このレスポンスタイムの短縮は、ユーザー体験の向上に直結します。
コンテキストウィンドウの圧迫
各 LLM は「思考領域」の大きさが制限されており、このエリア内に入力データとシステムプロンプト、さらに過去の会話履歴などが全て入る必要があります。無駄なトークンで圧迫されることで、実際の「思考」に使える領域が減少し、複雑なタスク対応能力が低下するのです。
これらの課題が、LLM専用の効率的なデータ形式の必要性を生み出し、TOONの開発につながったのです。
つまり、TOON は「単なる最適化」ではなく、「LLM 時代の企業システム運用を実現するための必須技術」として位置づけられるべき存在といえます。
TOONの基本要素:データ構造に応じた4つの表現パターン
TOON は、単一のフォーマットではなく、データの構造に応じて異なるパターンを使い分ける設計になっています。それぞれのパターンは、特定の場面で最大の効率性を発揮するように最適化されています。
正しいパターンを選択することで、効率化の効果を最大化できます。
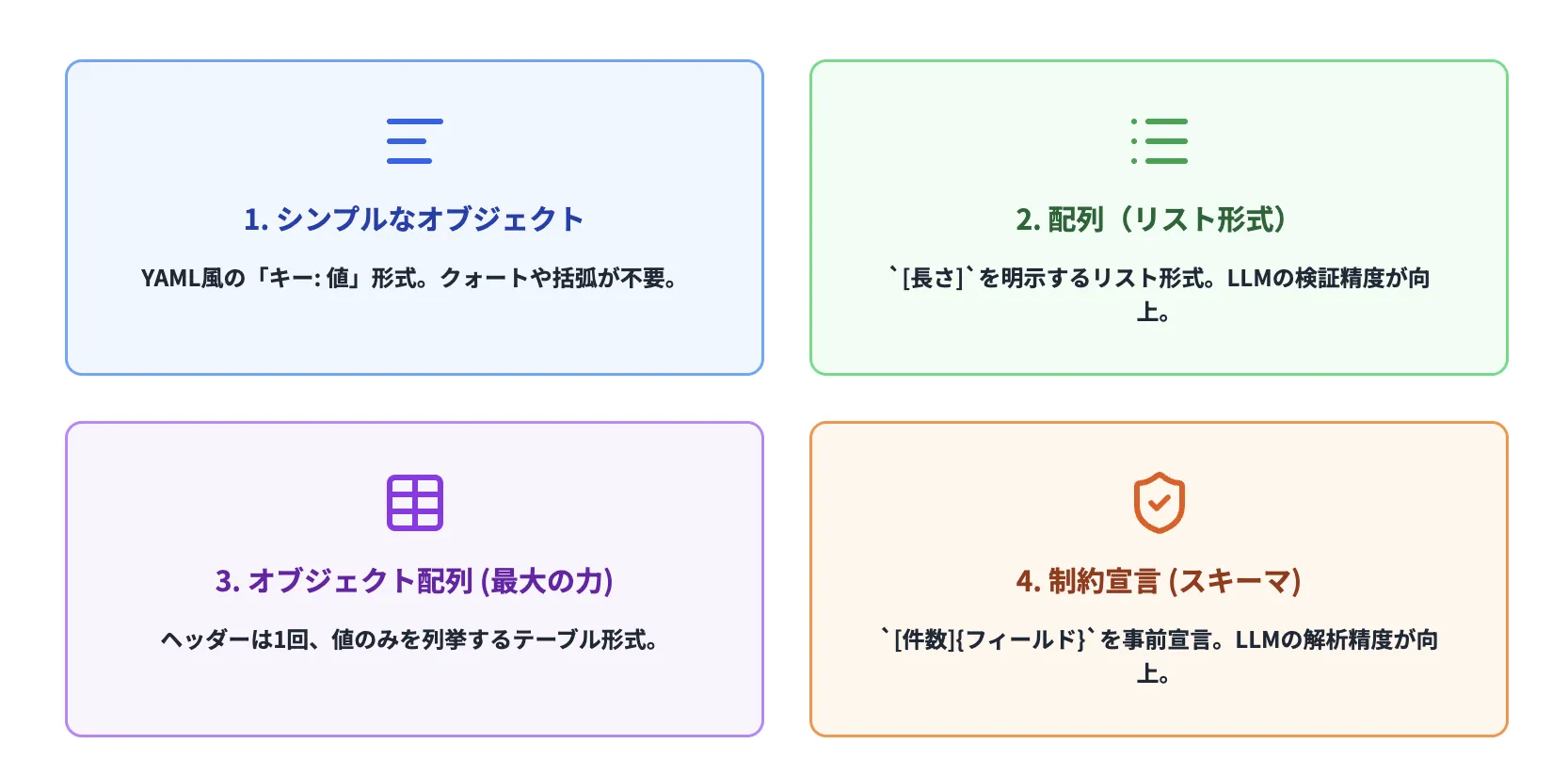
パターン1:シンプルなオブジェクト(キー・バリュー形式)
オブジェクトのフィールドが限定的で、ネストが浅い場合、TOON は YAML に近い形式を使用します。この形式では、各行に「キー: 値」という形で情報を記述し、階層はインデント(行の左側の空白)で表現します。
たとえば、ユーザーの基本情報を表現する場合、TOON では以下のように記述します。
name: Alice Johnson
email: alice@example.com
age: 28
city: Bengaluru
このシンプルな形式がもたらす効果は大きいです。ダブルクォートと波括弧が不要になり、その分のトークン数が削減されます。
実務的には、ユーザープロフィール、基本的な設定情報、簡単なメタデータなど、単層で構造が単純なデータはこのパターンで十分です。複雑な階層構造がない場合は、このパターンを採用することで、自動的にトークン削減の効果が得られるのです。
パターン2:配列(リスト形式)
複数の値を列挙する場合、TOON は角括弧内にコンマ区切りで記述します。この方式は、単純なリストには極めて効果的です。
たとえば、カラーパレットや地域リストなど、単純な値の集合を表現する場合は以下のようになります。
colors[4]: red, green, blue, yellow
同じデータを JSON で表現すると、以下のようになります。
{
"colors": ["red", "green", "blue", "yellow"]
}
TOON のこのパターンでは、括弧とクォートの数を最小化しながら、構造は明確に保持されています。さらに、[4] という「配列の長さ」を明示することで、LLM は事前に「4個の要素がある」ことを知ることができ、検証精度が向上します。
このパターンは、タグの集合、カテゴリリスト、選択肢リストなど、単純な値の集合に対して特に有効です。
パターン3:オブジェクト配列(テーブル形式)- TOON の最大の力
同一の構造を持つオブジェクトが複数ある場合、TOON はテーブル形式でこれらを表現します。これが、TOON の「最も効果的」なパターンです。なぜなら、このパターンこそが、LLM 利用において最も頻繁に発生する「大量の構造化データ」を最も効率的に表現できるからです。
テーブル形式では、まず「配列名[件数]{フィールド一覧}:」というヘッダーを記述し、その後に各レコードを行として記述します。以下は、3人のユーザー情報を表現した例です。
users[3]{id,name,email,role}:
1,Alice Johnson,alice@example.com,admin
2,Bob Smith,bob@example.com,user
3,Carol White,carol@example.com,user
同じデータを JSON で表現した場合、以下のように記述する必要があります。
{
"users": [
{
"id": 1,
"name": "Alice Johnson",
"email": "alice@example.com",
"role": "admin"
},
{
"id": 2,
"name": "Bob Smith",
"email": "bob@example.com",
"role": "user"
},
{
"id": 3,
"name": "Carol White",
"email": "carol@example.com",
"role": "user"
}
]
}
ここで注目すべきは、JSON では各レコードごとに波括弧、各フィールドごとにコロン、キー全体をクォートで囲む、という処理が繰り返されます。これらの冗長性は、レコード数が増えるほど増幅されます。
一方、TOON のテーブル形式では、フィールド情報は 1 度だけ記述し、後は値のみを列挙するという極めてシンプルな構造になります。
このパターンでは、JSON と比べて 50-60% のトークン削減が可能です。つまり、100件のレコードであれば、うち 50-60件分のトークンを節約できるということです。
パターン4:制約宣言(スキーマ情報)
TOON の強力な特徴の一つが、配列内のフィールドを事前に宣言するという仕組みです。上記の例では、「users[3]{id,name,email,role}:」という記述で、「3 件のユーザー、それぞれ id、name、email、role を持つ」という情報を LLM に事前に伝えています。
この宣言がもたらす効果は、単なる「形式的な記述」ではなく、LLM の処理能力向上に直結しています。具体的には、LLM はこの情報から以下を事前に理解できます。
- 配列要素の個数:「3件あるから、3行のデータが来る」と予測できる
- 各要素が持つフィールド:「各行は4つの値を持つ」と予測できる
- フィールドの順序と名前:「最初が id、次が name」というパターンを認識できる
この事前情報が、LLM のデータ解析精度を大幅に向上させるのです。公式ベンチマークでは、TOONは JSON よりも4 ポイント以上の精度向上を示しています。つまり、同じデータを扱う場合、TOONで正しく解析される確率がJSON より高いということです。
実務的には、これは「エラー率の低下」を意味します。LLM が間違ったデータ解析をするリスクが低下することで、下流の自動化処理の信頼性が向上し、最終的には企業システム全体の安定性が高まるのです。
Semantic KernelやAIエージェント開発でTOONを活用する実践的なアプローチ
Semantic Kernel や他の AI フレームワークを使用する際、プラグイン内でのデータ処理でも TOON の効果は大きいです。特に、複雑なワークフローで大量のデータを扱う場合、TOON による効率化が全体のパフォーマンスに影響します。
AIエージェント開発は、複数ステップのプロセスで大量のデータが行き来する構造になっています。
たとえば、顧客データ分析エージェントの場合、顧客マスターデータの取得、過去の取引履歴の検索、分析結果の生成、結果のレポート化という複数ステップが存在します。各ステップでデータが LLM に送信されるため、TOON による削減効果が複数回発生し、トータルのコスト削減になるのです。
Python での実装例:Semantic Kernel プラグイン内での TOON 活用
Semantic Kernel のプラグイン内で TOON を使用する実例を見てみましょう。顧客リストを処理して、特定の条件に合致する顧客を抽出するプラグインを考えます。
このプラグインでは、大量の顧客データが入力されるため、TOON による効率化が効果的です。
from semantic_kernel.functions import kernel_function
from toon import encode, decode
class DataProcessingPlugin:
@kernel_function(
description="顧客リストを処理し、購買実績が一定以上の顧客を抽出します。"
"入力データは TOON 形式で受け付け、TOON 形式で結果を返すことで、"
"トークン使用量を削減しながら、エージェント間のデータ交換を効率化します"
)
def process_customer_list(self, customer_data: str) -> str:
# ステップ1:TOON 形式で受け取ったデータをPython の辞書に変換
customers = decode(customer_data)
# ステップ2:ビジネスロジック:購買実績が 5 回以上の顧客をフィルタリング
# これにより、分析対象を高価値顧客に限定し、LLM の処理効率を向上
filtered_customers = [c for c in customers if c['purchase_count'] > 5]
# ステップ3:結果を TOON 形式で返すことで、下流のエージェントに渡す際のトークン削減
result_toon = encode({
"filtered_count": len(filtered_customers),
"customers": filtered_customers
})
return result_toon
# Kernel に登録
kernel = Kernel()
kernel.add_plugin(DataProcessingPlugin(), plugin_name="data_processing")
このアプローチの利点は複数あります。
-
プラグイン間のデータ交換が TOON で行われるため、エージェント全体のトークン消費が削減される
大規模な顧客リストを扱う場合、複数のプラグインを経由してデータが移動します。各段階で TOON による効率化が発生するため、総合的なコスト削減効果は非常に大きくなるのです。
-
フィルタリング処理により、LLM に送信されるデータ量が削減される
500件の顧客データから、購買実績が 5 回以上の高価値顧客 100件だけを抽出することで、次のステップで LLM が処理すべきデータ量が 80% 削減されます。これは、トークン削減だけでなく、LLM の分析精度向上にも貢献するのです。
JavaScript/TypeScript での実装例:API レスポンスの効率化
次に、Node.js 環境での使用例を見てみましょう。AI エージェントが複数の外部 API を呼び出し、その結果を統合して処理する場合、TOON による効率化が特に有効です。
import { encode, decode } from "@toon-format/toon";
// 複数の外部 API から大規模なレスポンスを取得し、効率的に処理
async function processApiResponse(jsonData: any): Promise<string> {
// ステップ1:JSON → TOON に変換
// API レスポンスは通常 JSON 形式だが、LLM に送信する直前に TOON に変換
const toonData = encode(jsonData);
// ステップ2:TOON 形式で LLM に入力
// これにより、入力トークンが削減され、コスト低下と処理速度向上の両立が可能
const prompt = `以下のデータを分析して、主要なトレンドを抽出してください:\n${toonData}`;
const response = await callLLM(prompt);
// ステップ3:処理結果も TOON 形式で返す
// 下流のプロセスでも効率性を保持
return response;
}
// 定期的な大規模データ同期での TOON 活用
async function syncLargeDataset(dataset: any[]): Promise<void> {
// 1,000件以上のデータを扱う場合、TOON の効果は顕著
const toonCompressed = encode(dataset);
// この段階で既に 40-60% のサイズ削減が実現
// さらに、後続の処理でのトークン削減も期待できる
await sendToLLM(toonCompressed);
}
このアプローチが有効なシナリオは、複数のデータソースから集めた大量のデータを、AI エージェントが一度に処理するという場合です。
たとえば、営業管理システム、顧客管理システム、取引履歴システムから各 1,000 件ずつ、合計 3,000 件のデータを取得して分析する場合、TOON を使用することで全体のトークン削減率は 50%を超えることも珍しくありません。

TOONの実装パターン:段階的な導入方法
TOON を実装する際の、難易度別のパターンを紹介します。プロジェクトの複雑度に応じて、段階的に導入することが可能です。
無理に全面切り替えするのではなく、段階的に導入することで、リスク最小化と効果最大化の両立が実現できます。

パターン1:単純な置き換え(難易度:低)
既存の JSONをTOONに置き換えるだけの簡単な例です。実装コストが最も低く、すぐに効果が実感できます。
従来の方法では、JSON データをそのまま使用していました。
# 従来の方法(JSON)
import json
data = json.dumps({"name": "Alice", "age": 30, "city": "Tokyo"})
TOON への変更は、極めてシンプルです。ライブラリを import して、encode 関数を使用するだけです。
# TOON への変更(1行のみの変更)
from toon import encode
data = encode({"name": "Alice", "age": 30, "city": "Tokyo"})
この場合、学習コストはほぼゼロで、既存コードへの影響も最小限です。さらに、自動的にトークン削減効果が得られるため、「導入効果が見える」という心理的なメリットもあります。
パターン2:配列データの効率化(難易度:中)
複数の同一構造オブジェクトを扱う場合、TOON の真価が発揮されます。ここで初めて、TOON の「テーブル形式」の威力を実感することになります。
たとえば、売上データを処理する場合を考えましょう。各行が「日付、商品、数量、売上」という同一フィールド構造を持つデータセットです。このような場合、TOON はこれらのデータをテーブル形式で表現することで、最大 60% のトークン削減を実現できます。
from toon import encode, decode
# 売上データ(複数件の同一構造レコード)
sales_data = {
"quarter": "Q4",
"records": [
{"date": "2025-11-01", "product": "Widget A", "quantity": 50, "revenue": 5000},
{"date": "2025-11-02", "product": "Widget B", "quantity": 75, "revenue": 7500},
{"date": "2025-11-03", "product": "Widget A", "quantity": 60, "revenue": 6000},
]
}
# TOON 形式で効率的に表現
# encode() 関数が自動的に最適な形式を選択
toon_output = encode(sales_data)
# 出力は以下のようになります:
# quarter: Q4
# records[3]{date,product,quantity,revenue}:
# 2025-11-01,Widget A,50,5000
# 2025-11-02,Widget B,75,7500
# 2025-11-03,Widget A,60,6000
このパターンでの効果は大きいです。3件のレコードという小規模な例でも、JSON との比較で明らかなトークン削減が実現します。そして、これが 100 件、1,000 件と増えるにつれ、削減効果は指数関数的に増加するのです。
パターン3:動的な構造変換(難易度:高)
データソースによって構造が異なる場合、TOON と JSON を併用して柔軟に対応します。このパターンは、企業内に複数のデータソース(CSV、SQL、API など)が存在する場合に有効です。
from toon import encode, decode
import pandas as pd
import requests
def convert_data_source(source_type: str, raw_data: any) -> str:
"""複数のデータソースを統一的に TOON 形式に変換する関数"""
if source_type == "csv":
# CSV ファイルを Pandas で読み込み、TOON 形式に変換
# これにより、CSV 出力データを自動的に効率化できる
df = pd.read_csv(raw_data)
json_data = df.to_dict(orient="records")
return encode(json_data)
elif source_type == "sql":
# SQL クエリ結果をそのまま TOON に変換
# データベース出力の効率化が可能
results = db.query(raw_data)
return encode(results)
elif source_type == "api":
# REST API からの JSON レスポンスを TOON に変換
# 複数の API 結果を統合する際に効果的
response = requests.get(raw_data)
return encode(response.json())
else:
# その他のデータソースも同じパターンで対応
return encode(raw_data)
このアプローチにより、データソースが複数あっても、統一的に TOON 形式で LLM に入力できます。企業システムでは通常、複数のデータソースから情報を集約して分析することが多いため、このパターンは実務的に非常に有用です。
TOONとJSONの使い分け
TOON は万能ではなく、適切に使い分けることが重要です。実務では「TOON を無理に使う」よりも「用途に応じて使い分ける」ことが成功の鍵になります。
それぞれが適しているシナリオを正しく判断することで、開発効率と実行効率の両方を最適化できるのです。

TOON が向いている場面
TOON が本当に価値を発揮する場面は、以下のような特性を持つデータです。
| 場面 | 詳細な説明 | トークン削減率 | 実務的価値 |
|---|---|---|---|
| 均一な配列データ | 同一フィールド構造が繰り返される場合(顧客リスト、商品カタログ、ログレコード) | 50-60% | 最高 |
| ログデータ分析 | サーバーログ、アクセスログなど、時系列の均質なデータ | 55-65% | 高 |
| CRM・ユーザーデータ | テーブル形式の顧客情報、ユーザープロフィール | 40-50% | 高 |
| 財務レポート | 定型的な数値データ、売上集計、予算管理データ | 45-55% | 高 |
| API レスポンス | 複数件の構造化データを返すレスト API | 50-60% | 高 |
これらの場面では、TOON を使用することで確実にコスト削減と処理速度の向上が期待できます。重要なのは、「データが「テーブル形式」で表現できるか」「多数の同一構造レコードを含んでいるか」という 2 点を判断基準にすることです。
JSON の方が向いている場面(無理にTOONを使うべきではないケース)
一方、以下の場面では JSON の方が適切です。ここで重要なのは、「TOON の方が優れている」という思い込みを避けることです。
| 場面 | 理由 | 代替案 |
|---|---|---|
| 深くネストされたデータ | 階層構造が複雑な場合、TOON の効果が薄い。むしろ JSON の方が効率的 | JSON を使用、または構造の簡潔化を検討 |
| 非均一な配列 | 要素ごとにフィールド数が異なる場合、テーブル形式が使用できない | JSON または部分的な TOON 使用 |
| 外部システム連携 | JSON が標準的な連携フォーマットの場合、変換コストが無駄 | JSON を継続使用 |
| 一度限りのデータ処理 | トークン削減の相対的効果が小さい(数百トークン程度) | JSON で十分 |
| 人間による読み込み | JSON の方が汎用的で理解しやすい。TOON は LLM 向け | JSON を使用 |
重要なのは「データの特性に応じた柔軟な選択」です。すべてを TOON で統一するのではなく、各タスクに最適なフォーマットを選ぶことが、実務レベルでの最大効率を生み出します。
実際、最も実用的なアプローチは「大規模な配列データは TOON、その他の場面では JSON という使い分け」です。
TOON 導入のベストプラクティス:実務的な導入手順と運用のコツ
TOON を企業システムに導入する際、押さえておくべきポイントを紹介します。これらの実践的な指針に従うことで、導入時のトラブルを最小化し、スムーズな運用が可能になります。
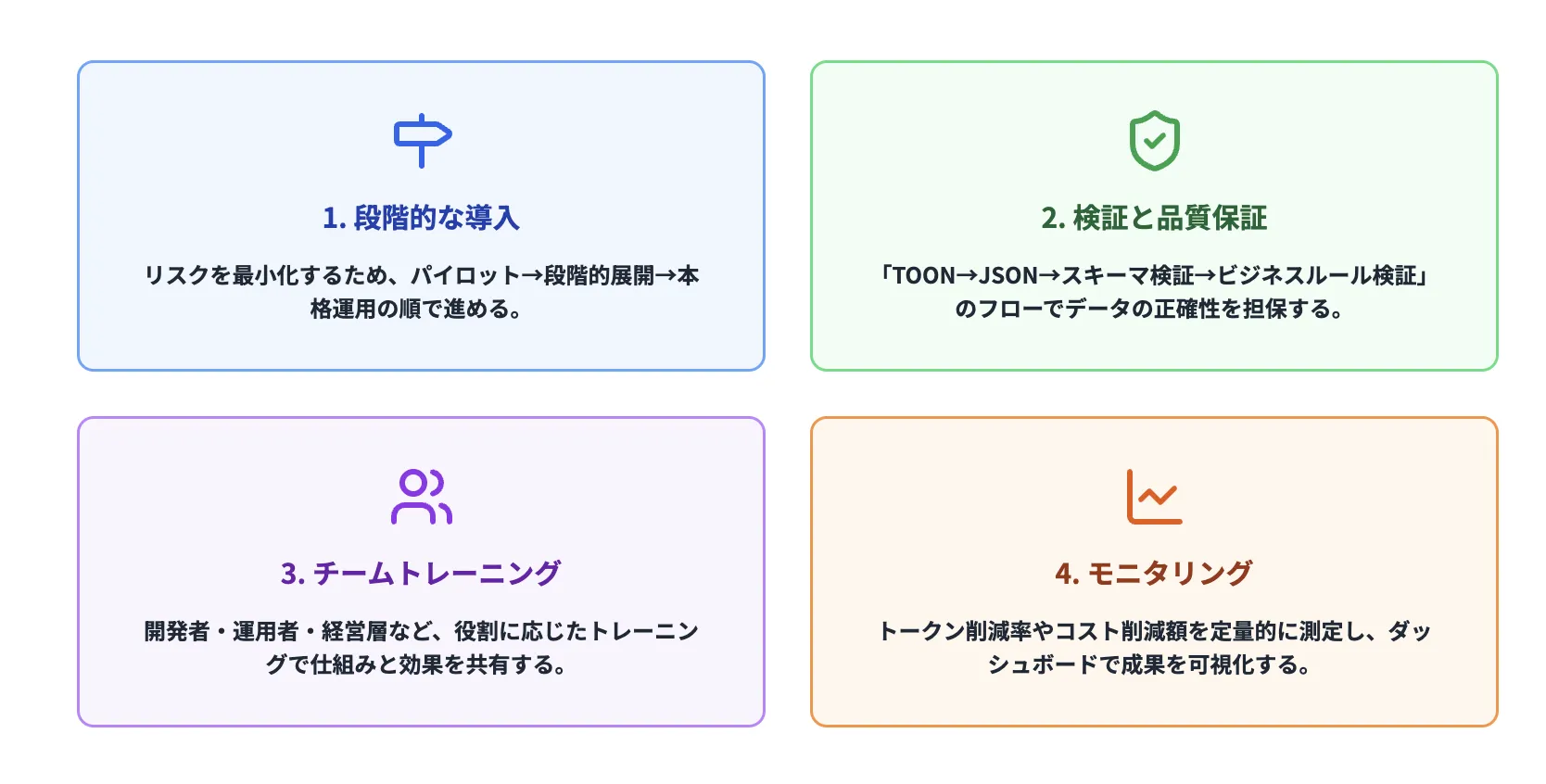
1. 段階的な導入:すぐに全面切り替えは避けるべき理由
多くの企業が陥る罠が「すべてを TOON に切り替える」という判断です。これは、既存システムに対する影響が大きく、テスト不足による予期しないトラブルを招きやすいため、絶対に避けるべきアプローチです。正しいアプローチは、以下のような段階的な導入です。
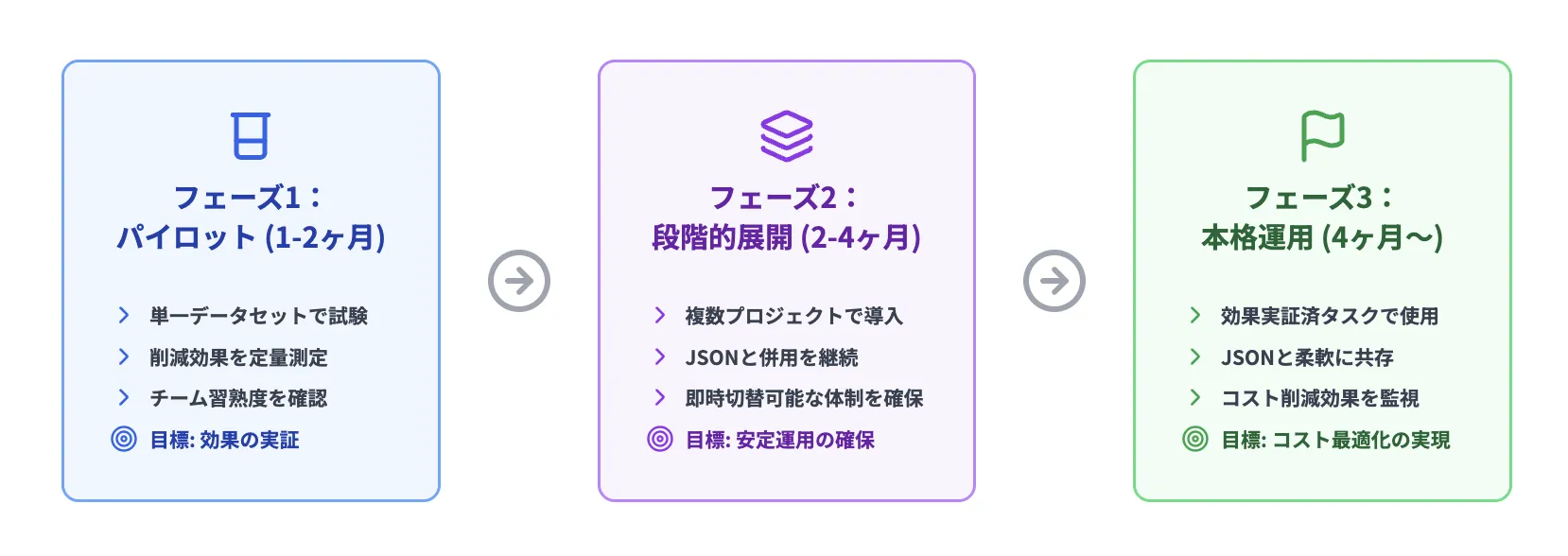
TOON導入のロードマップ
このアプローチのメリットは、「失敗のリスク最小化」と「成功の実績化」の両立です。小さく始めて、成功が見えてから拡大することで、組織内の「TOON に対する信頼度」も自然に高まるのです。
2. 検証と品質保証:データの正確性を担保するフロー
TOON を使用する際、必ずデータの正確性を検証する仕組みが必要です。AI エージェントが誤ったデータを処理してしまう危険を避けるため、以下のような検証フローを確立することが重要です。
def process_with_validation(toon_data: str) -> dict:
"""TOON→JSON→検証→結果」という安全なフロー"""
# ステップ1:TOON を JSON に変換
# 変換エラーをキャッチし、データの整形を試みる
try:
json_data = decode(toon_data)
except ValueError as e:
raise ValueError(f"TOON 形式のパース失敗:{e}")
# ステップ2:スキーマ検証
# 期待されるフィールドがすべて存在し、データ型が正しいか確認
if not validate_schema(json_data, expected_schema):
raise ValueError("スキーマ検証に失敗。データ構造が想定と異なります")
# ステップ3:ビジネスロジック検証
# 単なるデータ型チェックではなく、ビジネスルール(例:年齢は 18 以上など)をチェック
if not validate_business_rules(json_data):
raise ValueError("ビジネスルール検証に失敗。データが不正な状態です")
# ステップ4:結果を TOON に変換して返す
# 次のステップでも効率性を保持するため、出力も TOON 形式で返す
return encode(json_data)
このフローにより、「TOON による効率化」と「品質保証」の両立が可能になります。
3. チームトレーニング:TOON の仕組みと使用シーンの共有
TOON はシンプルですが、チーム全体が理由と効果を理解していないと、適切に使用できません。以下のような層別トレーニングが有効です。
開発者向けトレーニング
- データ構造の設計段階で TOON を検討するポイント
- テーブル形式の活用方法
- JSON との使い分け判断基準
運用者向けトレーニング
- ログやレポート出力時の TOON 形式への変換方法
- トークル数の計測方法
- トラブル発生時の対応手順
経営層向けプレゼン
- トークン削減がもたらすコスト削減の実績値
- LLM 利用コストの最適化戦略
- 業界内での競争優位性
4. モニタリング:削減効果の継続的な測定と改善
導入効果を定量的に測定することで、継続的な改善につながります。さらに、社内での「TOON への理解と信頼度」を高めるためにも、数値化された成果の可視化が重要です。
class TOONMetrics:
def __init__(self):
self.json_tokens = 0
self.toon_tokens = 0
self.savings_rate = 0.0
self.cost_savings = 0.0
def measure_conversion(self, data: dict):
"""JSON と TOON のトークン数を比較測定"""
json_data = json.dumps(data)
toon_data = encode(data)
# トークン数を計測(GPT の tokenizer を使用)
json_token_count = count_tokens(json_data)
toon_token_count = count_tokens(toon_data)
# 累積値を更新
self.json_tokens += json_token_count
self.toon_tokens += toon_token_count
# 削減率をパーセンテージで計算
self.savings_rate = (1 - self.toon_tokens / self.json_tokens) * 100 if self.json_tokens > 0 else 0
# コスト削減額を計算(GPT-4 の料金ベース)
# 入力トークン:$0.03/1K トークン
token_savings = self.json_tokens - self.toon_tokens
self.cost_savings = (token_savings / 1000) * 0.03
# ダッシュボードに報告
log_metrics({
"json_tokens": self.json_tokens,
"toon_tokens": self.toon_tokens,
"savings_rate": self.savings_rate,
"cost_savings": self.cost_savings
})
このメトリクスを月次でダッシュボード化することで、「TOON 導入の効果」が誰の目にも明らかになり、組織全体でのコスト削減への取り組みが加速するのです。

トークン効率化の知見を業務AI導入のコスト最適化に活かすなら
TOONのようなトークン効率化技術への理解は、AI導入コストの最適化に直結する実践的な知見です。トークン削減による年間数千ドル規模のコスト削減効果は、業務プロセス全体へのAI導入を経済的に後押しします。
AI総合研究所では、コスト最適化を考慮した業務プロセスへのAI導入を段階的に進めるための実践ガイドを無料で提供しています。トークン効率化の知見を活かしたAI導入戦略を確認してみてください。
LLM通信の効率化知見を業務へのAI導入コスト最適化に活かす

AI業務自動化ガイド
TOONのようなトークン効率化技術は、AI導入コストを直接削減する手段です。コスト最適化の知見を活かしながら、業務プロセスへのAI導入を段階的に進めるための実践ガイドをまとめました。
まとめ
TOON(Token-Oriented Object Notation)は、LLM 時代の必然的な進化であり、単なる「データ圧縮形式」ではなく、「AI との効率的な通信手段」です。JSON が「人間中心」のデータフォーマットである一方、TOON は「AI 中心」のデータフォーマットとして設計されています。この転換がもたらす実務的な価値は、単なるトークン削減にとどまらず、LLM 時代における企業競争力の向上に貢献するのです。
これまで説明してきた内容を、3 つの価値提案にまとめます。
TOON が解決する 3 つの課題
1. LLM 利用コストの削減
30-60% のトークン削減により、同じ処理でも大幅なコスト低下が実現できます。特に大規模データセットを扱う企業では、月単位で数千ドルのコスト削減につながります。さらに、複数プロジェクトでこれを実施すれば、年間十万ドル単位のコスト削減も可能です。
2. 応答速度と処理効率の向上
トークン数が少なくなることで、LLM の処理時間が短縮され、リアルタイムシステムでのレスポンス時間が改善されます。これは、ビジネスプロセスの迅速化、ユーザー体験の向上、さらには「AI を使った意思決定の高速化」につながり、競争優位性を生み出します。
3. AI と既存システムの統合効率化
TOON は JSON と相互変換可能であり、既存システムに大きな変更を加えることなく、段階的に導入できます。段階的導入のパターンに従えば、リスク最小化での導入が可能です。さらに、複数のデータソース(CSV、SQL、API など)を統一的に TOON 形式に変換するパターンを確立することで、企業内のデータ活用の効率化も同時に実現できるのです。
次のステップ
TOON の導入を検討している企業や開発者は、以下のステップで進めることをお勧めします。
-
小規模なパイロットから開始
単一のログファイルやレポートデータで試してみることが重要です。実装の容易さと削減効果を実感できます。 -
削減効果を定量的に測定
TOON 導入前後でトークン数を計測し、実際のコスト削減を数値化します。この実績が、組織内での推進力になります。 -
段階的に他のプロジェクトへ展開
成功したケースから始めて、複雑なユースケースへと拡張していきます。










