この記事のポイント
 ChatGPTの性能はNVIDIA GPU抜きには成立しない。GPT-1から5まで全世代がNVIDIA上で学習されており、両社は事実上の一体関係にある
ChatGPTの性能はNVIDIA GPU抜きには成立しない。GPT-1から5まで全世代がNVIDIA上で学習されており、両社は事実上の一体関係にある- GPU投資を検討するならH100/H200世代が現時点の最適解。Blackwellは2026年後半から本格普及、Vera Rubinは2027年以降
- OpenAIとNVIDIAの10GWパートナーシップ(最大1,000億ドル投資)はAI産業史上最大級。両社の関係は今後さらに深化する
- 自社でGPUを買うよりクラウドGPU(Azure・AWS・GCP)を使うべき。ChatGPTサブスクの方がほとんどの用途でコスパが高い
- ローカルAIを試すならNVIDIAのChatRTXが最も手軽。RTX 40シリーズ以上のGPU搭載PCがあれば無料で利用できる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
NVIDIAのGPUは、ChatGPTをはじめとする大規模言語モデルの計算基盤として不可欠な存在です。2026年現在、NVIDIAの時価総額は約4.4兆ドルに達し、データセンター部門の年間売上は1,938億ドルを記録しています。
本記事では、NVIDIAのGPUがChatGPTをどのように支えているのか、GPU世代別の性能比較、OpenAIとの10GWパートナーシップの最新動向、クラウドGPU料金まで、2026年3月時点の最新情報を網羅的に解説します。
ChatGPTの最新モデル「GPT-5」については、以下の記事をご覧ください。
ChatGPT-5(GPT-5)とは?使い方や料金、回数制限について解説!
目次
Microsoft/OpenAI:世界初のGB300 NVL72クラスタ
通信・クラウドインフラ:Deutsche TelekomとOracle
ChatGPTとNVIDIAの関係とは

ChatGPTの画像
NVIDIAのGPUは、ChatGPTの開発・運用を支える計算基盤として中核的な役割を果たしています。OpenAIは2016年にNVIDIAから世界初のDGX-1 AIスーパーコンピュータの寄贈を受け、この時点からNVIDIAのGPUを基盤としたAIモデル開発を本格的に開始しました。GPT-1からGPT-5に至るまで、すべての世代のモデルがNVIDIAのGPU上で学習されています。
2026年3月時点で、NVIDIAの時価総額は約4.4兆ドル(約660兆円)に達し、世界最大の企業となっています。この成長を牽引しているのがデータセンター部門で、2026年度(2026年1月期)の年間売上は1,938億ドルと全体売上2,159億ドルの約90%を占めています。NVIDIAの事業の大半は、ChatGPTのようなAIモデルを動かすためのGPUとインフラに支えられているのです。
両社の関係は単なるハードウェア供給にとどまりません。2025年9月にはOpenAIとNVIDIAが合計10ギガワット規模のAIインフラ構築に関する戦略的パートナーシップを発表しました。NVIDIAはこのプロジェクトに最大1,000億ドルの投資意向を示しており、AI産業史上最大級の提携として注目を集めています。ChatGPTとNVIDIAの関係は、もはや「顧客とサプライヤー」ではなく、AI産業の成長を共に推進するパートナーという位置付けです。
【関連記事】
ChatGPT(チャットGPT)とは?日本語での始め方や料金、使い方を徹底解説!

NVIDIAのGPUがChatGPTを動かす仕組み

NVIDIAのロゴ
ChatGPTのような大規模言語モデルを動かすには、膨大な計算処理能力が必要です。このセクションでは、NVIDIAのGPUがどのようにChatGPTの学習と推論を支えているのかを解説します。
GPU並列処理とAI学習の関係
CPUが数個から数十個のコアで逐次的に処理を行うのに対し、NVIDIAのGPUは数千から数万のCUDAコアを搭載し、大量のデータを同時に並列処理できます。大規模言語モデルの学習では、数兆個のパラメータに対して行列演算を繰り返す必要があり、この処理はGPUの並列計算能力と極めて高い相性を持っています。
さらに、NVIDIAのGPUにはTensor Coreと呼ばれるAI専用の演算ユニットが搭載されています。Tensor Coreは混合精度演算(FP16、FP8、FP4)に対応しており、精度を維持しながら計算速度を大幅に向上させます。最新のBlackwellアーキテクチャでは、FP4精度で最大20ペタフロップスという処理能力を実現しています。
NVIDIAが提供するCUDAプラットフォームは、GPU上でのプログラミングを容易にするソフトウェア基盤です。PyTorchやTensorFlowといった主要なAIフレームワークはすべてCUDAに最適化されており、事実上のAI開発標準となっています。この強力なソフトウェアエコシステムが、NVIDIAのGPUがAI分野で圧倒的なシェアを持つ理由の一つです。
【関連記事】
GPUとは?その種類や特徴、活用分野をわかりやすく解説!
CUDAとは?主要機能やインストール方法、使い方を解説!
学習フェーズと推論フェーズの違い
大規模言語モデルの運用には「学習」と「推論」という2つのフェーズがあり、それぞれ求められるGPUリソースが大きく異なります。以下の表で、両フェーズの特性を整理しました。
| 項目 | 学習フェーズ | 推論フェーズ |
|---|---|---|
| 目的 | モデルのパラメータ最適化 | ユーザーへの応答生成 |
| GPU数 | 数千〜数万台 | 数百〜数千台 |
| メモリ要件 | 非常に高い(モデル全体+勾配) | 中程度(モデル+KVキャッシュ) |
| 処理時間 | 数週間〜数ヶ月 | ミリ秒〜秒単位 |
| 重視される指標 | スループット(学習速度) | レイテンシ(応答速度) |
| 頻度 | モデル更新時のみ | 24時間365日常時稼働 |
ChatGPTの場合、学習は新モデルのリリース時に集中的に行われますが、推論は世界中のユーザーからのリクエストに対して常時実行されています。OpenAIのCEOであるSam Altman氏は、同社のGPU規模が2025年末までに「100万台をはるかに超える」と言及しており、この大半が推論用途に使用されています。ChatGPTの日次推論コストは数十万ドル規模と推定されており、推論の効率化がビジネス上の最重要課題となっているのです。
【関連記事】
大規模言語モデル(LLM)とは?その仕組みやAIとの違い、活用例を解説
ディープラーニングとは?その仕組みや種類、機械学習との違いを解説
ChatGPTの仕組みとは?全体像や図解で基礎から解説!
NVIDIA GPU世代別性能比較(2026年版)

NVIDIA H100 Tensor コア GPUの画像 (出典)NVIDIA
NVIDIAのデータセンター向けGPUは、2020年のA100から2026年のVera Rubinまで急速な進化を遂げています。以下の表で、各世代のGPUの主要スペックを比較しました。
| 項目 | A100(2020年) | H100(2022年) | B200(2024年) | B300(2025年) | Vera Rubin(2026年下半期) |
|---|---|---|---|---|---|
| アーキテクチャ | Ampere | Hopper | Blackwell | Blackwell Ultra | Rubin |
| トランジスタ数 | 540億 | 800億 | 2,080億 | 2,080億超 | 3,360億 |
| メモリ | 80GB HBM2e | 80GB HBM3 | 192GB HBM3e | 288GB HBM3e | 288GB HBM4 |
| メモリ帯域幅 | 2TB/s | 3.35TB/s | 8TB/s | 8TB/s | 22TB/s |
| FP8性能 | 非対応 | 3.96PFLOPS | 9PFLOPS | 10PFLOPS超 | 非公開 |
| FP4性能 | 非対応 | 非対応 | 20PFLOPS | 15PFLOPS | 50PFLOPS |
| TDP | 400W | 700W | 1,000W | 1,400W | 非公開 |
| H100比 学習性能 | 0.3倍 | 1倍 | 4倍 | 6倍超 | 10倍超 |
(参考)NVIDIA Blackwell Architecture
特に注目すべきは、世代間の推論性能の飛躍的な向上です。B200はH100と比較して推論性能が最大30倍に向上しており、ChatGPTのような常時稼働のAIサービスにとって大幅なコスト削減につながります。さらに2026年下半期に出荷予定のVera Rubinは、Blackwellと比較してトークンあたりの推論コストを10分の1に削減できるとNVIDIAは発表しています。
消費電力の増大も見逃せないポイントです。A100の400WからB300の1,400Wへと3.5倍に増加しており、データセンターの電力供給と冷却システムの設計が重要な課題となっています。GB200 NVL72システムは液冷方式を採用し、72基のGPUを1つのラックに収めることで、FP4精度で合計1,440ペタフロップスの性能を実現しています。つまり、GPU単体の性能向上だけでなく、ラック単位でのシステム設計が次世代AI基盤の鍵を握っているのです。
【関連記事】
TensorRTとは?対応GPUやインストール方法、使い方を解説!
NPUとは?その必要性やGPU・CPUとの違いをわかりやすく解説
RTX Pro 6000 Blackwellとは?性能・仕様・活用法を徹底解説
OpenAIのインフラ戦略と10GWパートナーシップ
OpenAIは、ChatGPTの急成長に伴い、AIインフラの規模を過去に例のないペースで拡大しています。このセクションでは、OpenAIのGPU調達戦略と、NVIDIAとの大規模パートナーシップの最新状況を解説します。
GPUフリートの規模拡大
OpenAIのGPU保有規模は、ChatGPTの普及に伴って急速に拡大しています。以下の表で、その推移を時系列で整理しました。
| 時期 | GPU規模 | 主要GPU | 主な供給元 |
|---|---|---|---|
| 2023年 | 約2.5万台 | A100 | Microsoft Azure |
| 2024年前半 | 約25万台 | H100 | Azure、Oracle |
| 2024年末 | 約46万台 | H100、H200 | Azure、Oracle、CoreWeave |
| 2025年末目標 | 100万台超 | H100、H200、GB200 | Azure中心 |
| 2026年以降 | 数百万台 | GB300、Vera Rubin | 複数プロバイダー |
わずか3年間でGPU保有台数が2.5万台から100万台超へと40倍に拡大している点は、ChatGPTの利用規模がいかに急速に成長しているかを示しています。OpenAIのテキサス州データセンターは単一施設として世界最大規模の約300メガワットの電力容量を持ち、2026年半ばまでに1ギガワットへの拡張が計画されています。さらに、トランプ政権の支援のもと発表されたStargateプロジェクトでは、約200万チップ・5ギガワット規模のAIインフラを目指しており、AIインフラの規模は国家的プロジェクトの水準に達しています。
【関連記事】
ChatGPT-5(GPT-5)とは?使い方や料金、回数制限について解説!
10GWパートナーシップの現状
2025年9月、OpenAIとNVIDIAは合計10ギガワットのNVIDIAシステムを展開する戦略的パートナーシップの趣意書(LOI)を締結しました。NVIDIAはこのプロジェクトに対し、1ギガワットごとに段階的に最大1,000億ドルを投資する意向を表明しています。
(参考)OpenAI and NVIDIA Strategic Partnership
第1段階として、NVIDIA Vera Rubinプラットフォームによる1ギガワットの展開が2026年下半期に予定されています。ただし、2026年2月時点でCNBCの報道によると、正式契約の締結には至っておらず、NVIDIA社内からOpenAIのビジネスモデルに対する懸念の声も上がっているとされています。一方、2026年3月のGTC 2026では、NVIDIAがGroq社を約200億ドルで買収したことを発表し、推論専用プロセッサの新アーキテクチャ「LPX」を公開するなど、両社の協力関係には新たな展開も見られます。
【関連記事】
OpenAI o3(ChatGPT o3)とは?使い方や料金、制限について解説!
o4-miniとは?主な特徴や使い方、料金体系を解説
カスタムチップ開発とNVIDIA依存の変化
OpenAIはNVIDIAへの依存度を下げるため、独自のカスタムAIチップの開発を進めています。Broadcomと共同開発しているXPUチップはTSMCの3nmプロセスで製造され、2026年下半期の量産開始を目標としています。発注規模は100億ドル超とされ、元GoogleカスタムチップリーダーのRichard Ho氏が開発を指揮しています。
さらに、OpenAIはCerebras(100億ドル超の契約)やAMDとも提携を進めており、NVIDIA・AMD・Broadcom・Cerebrasを合わせた合計インフラ目標は26ギガワットに達します。これは単一ベンダーへの依存リスクを分散しつつ、推論コストの最適化を図る戦略です。企業がAIインフラを検討する際も、特定のGPUベンダーに依存しすぎないマルチベンダー戦略の視点が重要になっています。

NVIDIAのGPU活用事例
NVIDIAのGPUは、OpenAI以外にも幅広い業界で活用されています。ここでは、2025年から2026年に発表された主要な活用事例を紹介します。
Microsoft/OpenAI:世界初のGB300 NVL72クラスタ
Microsoft Azureは2026年3月、OpenAIのワークロード向けに世界初の大規模GB300 NVL72スーパーコンピューティングクラスタを構築したことを発表しました。4,600基以上のBlackwell Ultra GPUがQuantum-X800 InfiniBandで接続されており、AIモデルの学習と推論の両方で業界最高水準の性能を提供しています。
(参考)Microsoft Azure delivers the first large-scale cluster with NVIDIA GB300 NVL72
このクラスタは、OpenAIが次世代モデルの開発を加速するための基盤となるだけでなく、Azure上でNVIDIA GPUを活用するすべての企業顧客にとっても恩恵をもたらす技術実証となっています。
製薬・ヘルスケア:Eli LillyとMerck
製薬業界でもNVIDIA GPUの活用が急速に進んでいます。Eli Lillyは2025年10月にBlackwell Ultra GPUを導入し、2026年1月にはNVIDIAとの10億ドル規模の共同イノベーションラボの設立を発表しました。製薬業界におけるAI共同研究として過去最大規模のプロジェクトです。
Merckは2025年12月にNVIDIAと提携し、約1,100万分子のデータで事前学習されたKERMTモデルを開発しました。このモデルは低分子創薬の候補化合物探索を大幅に加速させるもので、従来数年かかっていた探索プロセスを数週間に短縮できる可能性があります。AI創薬の領域では、GPUによる分子シミュレーションの高速化が研究開発のスピードを根本的に変えつつあります。
通信・クラウドインフラ:Deutsche TelekomとOracle
Deutsche Telekomは2025年11月、ミュンヘンのデータセンターに1,000台以上のDGX B200システム(最大10,000基のBlackwell GPU)を配備するプロジェクトを発表し、2026年第1四半期に稼働を開始しました。欧州の通信事業者がAIインフラに大規模投資を行う先駆的な事例です。
Oracleは、「業界最大のクラウドAIスーパーコンピュータ」と位置付けるOCI Zettascale10をNVIDIAのAIインフラで構築しました。このような大規模クラウドGPUインフラの整備により、企業がオンプレミスで高額なGPUを購入しなくても、クラウド経由でAI開発に必要な計算リソースを柔軟に利用できる環境が整いつつあります。
【関連記事】
日本のAI導入状況は?現状や実際の導入事例、メリットデメリットを解説
機械学習とは?その種類や主な手法、実装方法をわかりやすく解説!
ローカルAI・エッジAIとNVIDIA
NVIDIAは大規模データセンター向けGPUだけでなく、個人のPC上で動作するローカルAIや、端末側で処理を行うエッジAIの分野でも重要な役割を果たしています。
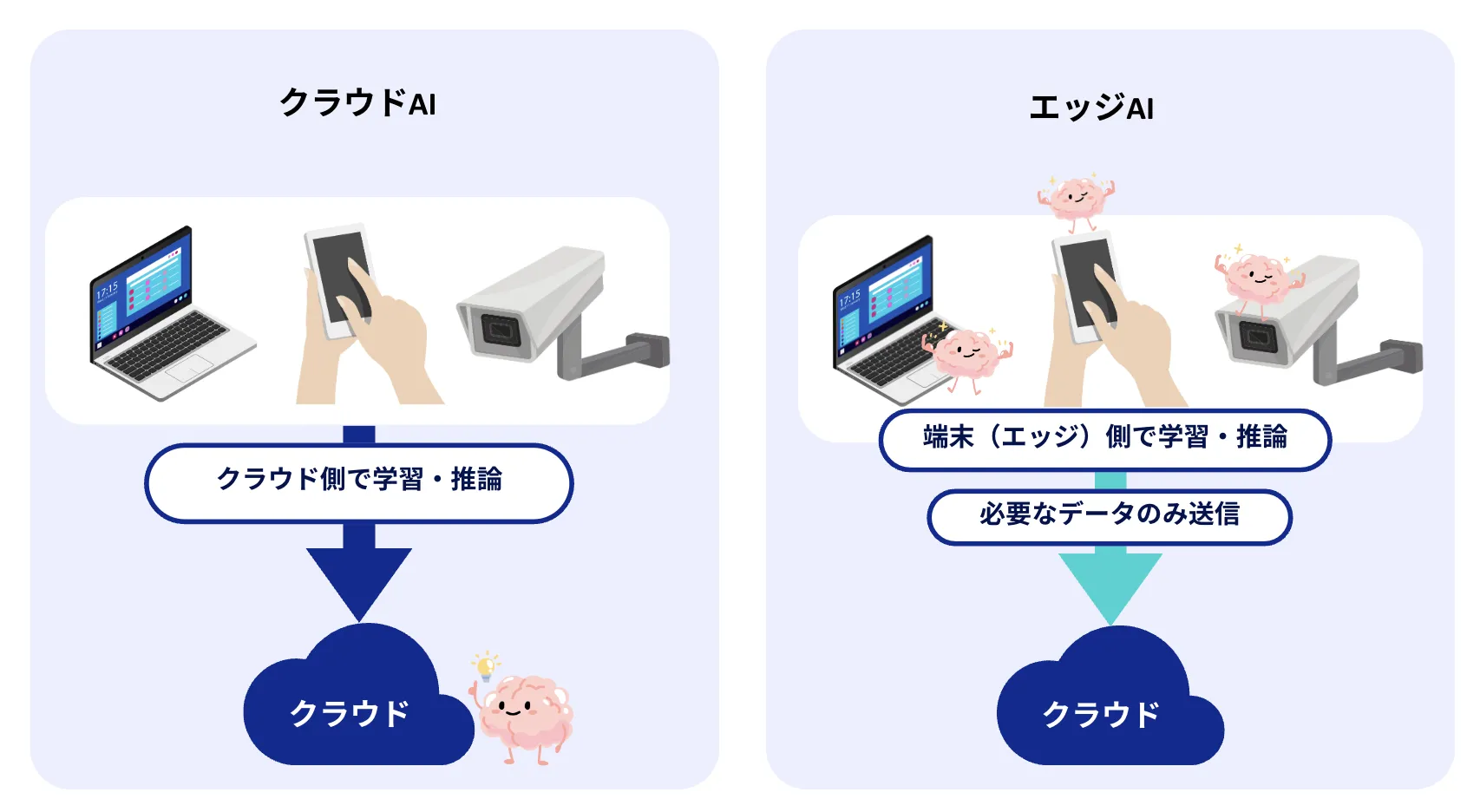
エッジAIとクラウドAIの違い
ChatRTXとローカルLLM

ローカルLLMとは
NVIDIAが提供するChatRTX(旧Chat with RTX)は、NVIDIA製のGeForce RTXグラフィックカードを搭載したWindows PC上で動作するローカルRAGチャットボットツールです。インターネット接続なしで、PC内のファイルやドキュメントを学習データとして活用し、パーソナライズされた回答を生成できます。
ChatRTXの最新バージョン0.5では、Meta Llama 3.1 8B NIMをデフォルトモデルとして採用し、NVIDIA NIMsとTensorRT-LLMによるRTXアクセラレーションを活用しています。対応GPUはGeForce RTX 30シリーズ以降(VRAM 8GB以上)で、RTX 50シリーズ(5080/5090、VRAM 16GB以上)にも対応しています。テキスト、PDF、Wordファイルに加え、JPEG、GIF、PNGなどの画像ファイルもCLIPモデルを通じて検索・対話が可能です。
(参考)NVIDIA ChatRTX
なお、ChatRTXのGitHubリポジトリは2026年1月にアーカイブされ、読み取り専用となっています。NVIDIAがローカルAI戦略を見直している可能性がありますが、ツール自体は引き続き利用可能です。ローカルLLMは、機密データを外部に送信せずにAIを活用したい企業にとって有力な選択肢であり、NVIDIAのGPUがその基盤技術を支えています。
【関連記事】
ローカルLLMとは?メリットやおすすめモデル、導入方法を解説
エッジAIとJetsonシリーズ
エッジAIは、データの発生源である端末上で直接AI処理を実行する技術です。クラウドAIがデータセンターで集中処理を行うのに対し、エッジAIはリアルタイム性とプライバシー保護が求められる場面に適しています。以下の表で、エッジAIとクラウドAIの主な違いを整理しました。
| 項目 | エッジAI | クラウドAI |
|---|---|---|
| 処理場所 | 端末・デバイス上 | データセンター |
| 代表的なNVIDIA製品 | Jetsonシリーズ | H100、B200、GB200 |
| 応答速度 | ミリ秒単位(超低レイテンシ) | 数十ミリ秒〜秒(ネットワーク遅延あり) |
| プライバシー | データが端末に留まる | データをクラウドに送信 |
| 計算能力 | 限定的 | 事実上無制限にスケール可能 |
| 適用例 | 自動運転、工場ライン検査、ロボティクス | ChatGPT、画像生成AI、大規模学習 |
| コスト構造 | ハードウェア初期投資 | 従量課金(使った分だけ) |
NVIDIAのJetsonシリーズは、エッジAI向けの小型高性能モジュールです。自動運転車のリアルタイム物体検出、工場での品質検査、ロボットの自律制御など、インターネット接続が不安定な環境や即座の応答が求められる場面で広く活用されています。NVIDIAはJetsonとデータセンターGPUの両方でCUDAエコシステムを共有しており、クラウドで学習したモデルをエッジデバイスに効率的に展開できる一貫した開発環境を提供しています。
【関連記事】
NVIDIA Jetsonとは?主な特徴や性能比較、活用事例を解説
クラウドAIとは?エッジAIとの違いやメリット、活用事例を解説!

GPU・AI基盤の理解を業務へのAI導入に活かす

生成AIの業務活用を体系的に学べるガイド
NVIDIAのGPUがAIを支える仕組みを理解した今こそ、自社の業務にAIを導入する具体的な手順を検討するタイミングです。AI総合研究所では、AI基盤の知識を実際の業務改善に結びつけるための導入ガイドを無料で提供しています。
NVIDIA GPU・ChatGPT料金比較(2026年3月版)
AI導入を検討する企業にとって、GPUインフラのコストは重要な判断材料です。ここでは、クラウドGPUサービスの料金とChatGPTのサブスクリプション料金を比較します。
以下の表は、主要クラウドプロバイダーにおけるGPUインスタンスの1時間あたりの料金です(2026年3月時点、オンデマンド価格)。
| プロバイダー | GPU | 1時間あたり料金(USD) | 備考 |
|---|---|---|---|
| Microsoft Azure | H100(NC H100 v5) | 約$6.98 | OpenAIの主要インフラ |
| AWS | H100(P5) | 約$3.90 | 2025年6月に44%値下げ |
| Google Cloud | H100 | 約$3.00 | オンデマンド |
| Lambda | H100 | $2.99 | スタートアップ向け |
| DataCrunch | H100 | $1.99 | 最安値クラス |
| DataCrunch | B200 | $3.99 | Blackwell対応 |
| RunPod | B200 | 約$5.87 | Blackwell対応 |
AWSが2025年6月にH100インスタンスの価格を44%引き下げたことで、大手クラウドでもGPUコストが大幅に低下しています。スポットインスタンスを利用すれば、オンデマンド価格からさらに60%から90%の割引が可能です。また、NVIDIA DGX Cloudはサブスクリプション形式で月額36,999ドルから提供されており、大規模な学習ワークロードに対応しています。
ChatGPTのサブスクリプション料金と合わせて確認することで、GPUを自前で用意してモデルを動かすコストとChatGPTを利用するコストの比較が可能になります。
| プラン | 月額料金(USD) | 主な特徴 |
|---|---|---|
| ChatGPT Free | 無料 | GPT-4o(制限あり) |
| ChatGPT Plus | $20 | GPT-4o、GPT-5、画像生成 |
| ChatGPT Pro | $200 | 無制限アクセス、o3推論モデル |
| ChatGPT Team | $25〜30/ユーザー | チーム管理、データ非学習保証 |
| ChatGPT Enterprise | カスタム | SSO、監査ログ、専用サポート |
たとえば、ChatGPT Proの月額200ドルで利用できるGPT-5やo3モデルの推論処理を自社のクラウドGPU上で再現しようとすると、H100インスタンス1台で月額約2,100ドルから5,000ドル(24時間稼働の場合)のコストがかかります。独自モデルの開発やカスタマイズが不要であれば、ChatGPTのサブスクリプションの方が圧倒的にコスト効率が高いと言えます。一方、機密データの取り扱いやモデルのファインチューニングが必要な場合は、クラウドGPUやローカルGPUの導入が合理的な選択です。
【関連記事】
ChatGPT APIの料金ガイド 2026年3月最新版 モデル別料金一覧とコスト削減のポイント
ChatGPT料金完全ガイド!GPT-5・GPT-4o・Proプラン徹底比較
ChatGPT-4とは?できることや料金、GPT-3.5との違いを徹底解説!
ChatGPTが遅い・重いのは時間帯のせい?原因別の対処法を解説
GPU・AI基盤の理解を業務へのAI導入に活かすなら
NVIDIAのGPUがChatGPTを支える仕組みを知ると、AI技術が膨大な計算資源の上に成り立っていることが見えてきます。一方で、企業がAIを業務に取り入れる際には、GPUの調達よりも「どの業務にAIを適用するか」の設計が出発点になります。
AI総合研究所では、AI基盤の技術的な理解を前提に、業務プロセスへのAI導入を段階的に進めるための実践ガイドを無料で提供しています。GPU・AI技術の全体像を把握した今、次は自社業務でのAI活用を具体的に検討してみてください。
GPU・AI基盤の理解を業務へのAI導入に活かす
生成AIの業務活用を体系的に学べるガイド
NVIDIAのGPUがAIを支える仕組みを理解した今こそ、自社の業務にAIを導入する具体的な手順を検討するタイミングです。AI総合研究所では、AI基盤の知識を実際の業務改善に結びつけるための導入ガイドを無料で提供しています。
まとめ
NVIDIAのGPUは、ChatGPTの開発・運用を支える計算基盤として不可欠な存在です。A100からBlackwell、そしてVera Rubinへと世代を重ねるごとに、AI処理の速度・効率・コストパフォーマンスが飛躍的に向上しています。OpenAIとの10GWパートナーシップに代表されるように、AI産業のインフラ規模は国家レベルのプロジェクトへと発展しており、NVIDIAのGPUがAI産業の中核を担い続けることは間違いありません。
一方で、OpenAIが独自チップの開発を進めているように、NVIDIA一社に依存するリスクを認識し、マルチベンダー戦略を採る動きも広がっています。企業がAI導入を検討する際は、まずChatGPTのAPIやサブスクリプションで自社の業務に適用可能かを検証し、独自モデルが必要な場合はクラウドGPUの無料枠やトライアルを活用して段階的に導入を進めることを推奨します。
具体的には、次の3ステップで検討を始めることができます。
-
Step 1 ChatGPTのAPI検証
ChatGPT APIを使って自社の業務データで精度を検証します。多くのユースケースでは、既存モデルのAPI利用が最もコスト効率に優れています
-
Step 2 クラウドGPUでのカスタムモデル検証
API利用では精度やセキュリティ要件を満たせない場合、AWSやAzureのクラウドGPUインスタンスで独自モデルの構築を検討します
-
Step 3 本格的なAIインフラの構築
大規模なAIワークロードが継続的に発生する場合、NVIDIA DGX Cloudやオンプレミスの専用GPUサーバーの導入を計画します
【関連記事】
AIガバナンスとは?企業に必要な理由・導入方法を徹底解説










