この記事のポイント
 マルチプロバイダーLLM運用企業はOpen Responses移行が第一候補、API差分吸収と切替・フェイルオーバーを低コストで実現
マルチプロバイダーLLM運用企業はOpen Responses移行が第一候補、API差分吸収と切替・フェイルオーバーを低コストで実現- Chat Completions APIからの移行は段階的が最適、統一スキーマで既存コードを大きく壊さずエージェントループへ拡張可能
- ベンダーロックイン回避に有効、OpenAI・Anthropic・Googleを同一インターフェースで扱えモデル選定の柔軟性が向上
- 構造化出力やマルチモーダル入力が標準仕様に含まれているため、将来のエージェント開発基盤として採用しておけば追加の仕様変更コストを最小化できる
- ゲートウェイ層でのルーティング設計と監査ログの整備を導入初期に行うべき。ガバナンス要件を後回しにすると、本番運用時のセキュリティリスクが拡大する

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
2026年1月、OpenAIのResponses APIをベースにしたLLM APIの標準仕様「Open Responses」が公開されました。これは、ベンダーごとに断片化していたツール呼び出しやストリーミング仕様を統一し、複数のAIプロバイダーを横断して利用できるオープンなインターフェースを提供するための取り組みです。
本記事では、Chat Completionsからの移行メリットや、エージェント型ワークフローにおける具体的な仕様、さらにマルチプロバイダー運用を前提とした企業導入の設計ポイントについて、最新情報を基に解説します。
目次
Open Responsesとは?LLM API標準化の概要
Open ResponsesとResponses APIの関係
なぜ「Chat Completions」からの移行が議論されているのか
Open Responsesで標準化される範囲/されない範囲
互換性レベル(Core / Optional / Extensions)と対応マトリクスの考え方
Open Responsesとは?LLM API標準化の概要
Open Responsesは、複数のLLM(Large Language Model:大規模言語モデル)プロバイダーのAPIを横断して利用できるようにするための、オープンソース仕様+エコシステムです。
2026年1月15日に公開され、OpenAIのResponses APIの設計思想をベースにしつつ、ベンダーニュートラルな標準インターフェースとして定義されています。

各LLMプロバイダの対応状況

2026年1月時点では、Open Responses自体は仕様(Specification)・OpenAPIリファレンス・Acceptance Testsなどを公開しており、実装やエコシステム側では以下のような動きが見られます。
- OpenAI:Open Responsesを発表し、Responses APIをベースにした標準化の方向性を提示
- Hugging Faceなど:Open Responses準拠の導線(例:ルーティングや検証ツール、互換エンドポイントの提供)を進めている
- ローカルLLMツール/推論基盤(例:LM Studio、Ollama、vLLMなど):Open Responses互換の入出力形状に合わせる動きが出てきている
- その他:今後の対応予定・コミュニティによるアダプター実装が進行中
今後は、「まずはゲートウェイ/プロキシ(ルーター)がOpen Responsesを話すようになる → 裏側で各プロバイダーAPIへマッピング」という流れで、徐々に採用が広がっていく可能性が高いと考えられます。
Open Responsesの背景と位置づけ
まずは、Open Responsesが生まれた背景と、OpenAI Responses APIや従来のChat Completionsとの関係を整理します。
Open ResponsesとResponses APIの関係
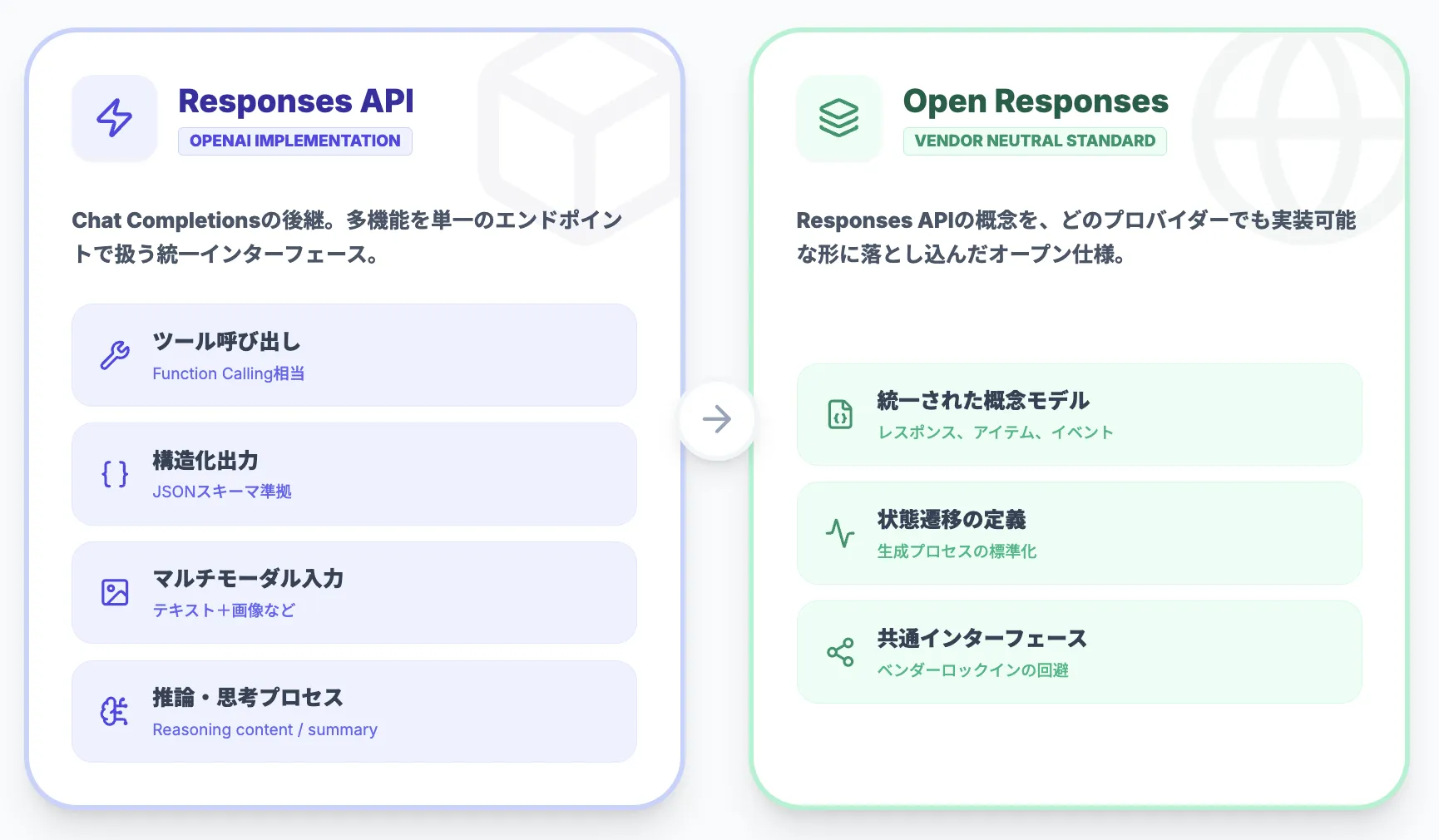
Responses APIは、Chat Completionsの後継として設計された、統一的なLLMインターフェースです。
テキスト生成だけではなく、以下のような機能を同じエンドポイントで扱えることが特徴です。
- ツール呼び出し(Function Calling相当)
- 構造化出力(JSONスキーマに沿った出力)
- マルチモーダル入力(テキスト+画像など)
- 推論関連の出力(reasoning summary、必要に応じて暗号化されたreasoningコンテンツ)やストリーミングイベント
Open Responsesは、このResponses APIで整理された概念(レスポンス、アイテム、イベント、状態遷移など)を取り込みつつ、「どのプロバイダーでも共通して実装できる形」に落とし込んだ仕様です。
イメージとしては、OpenAI独自の実装仕様をベンダーニュートラルなオープン仕様に一般化したもの、という位置づけになります。
なぜ「Chat Completions」からの移行が議論されているのか
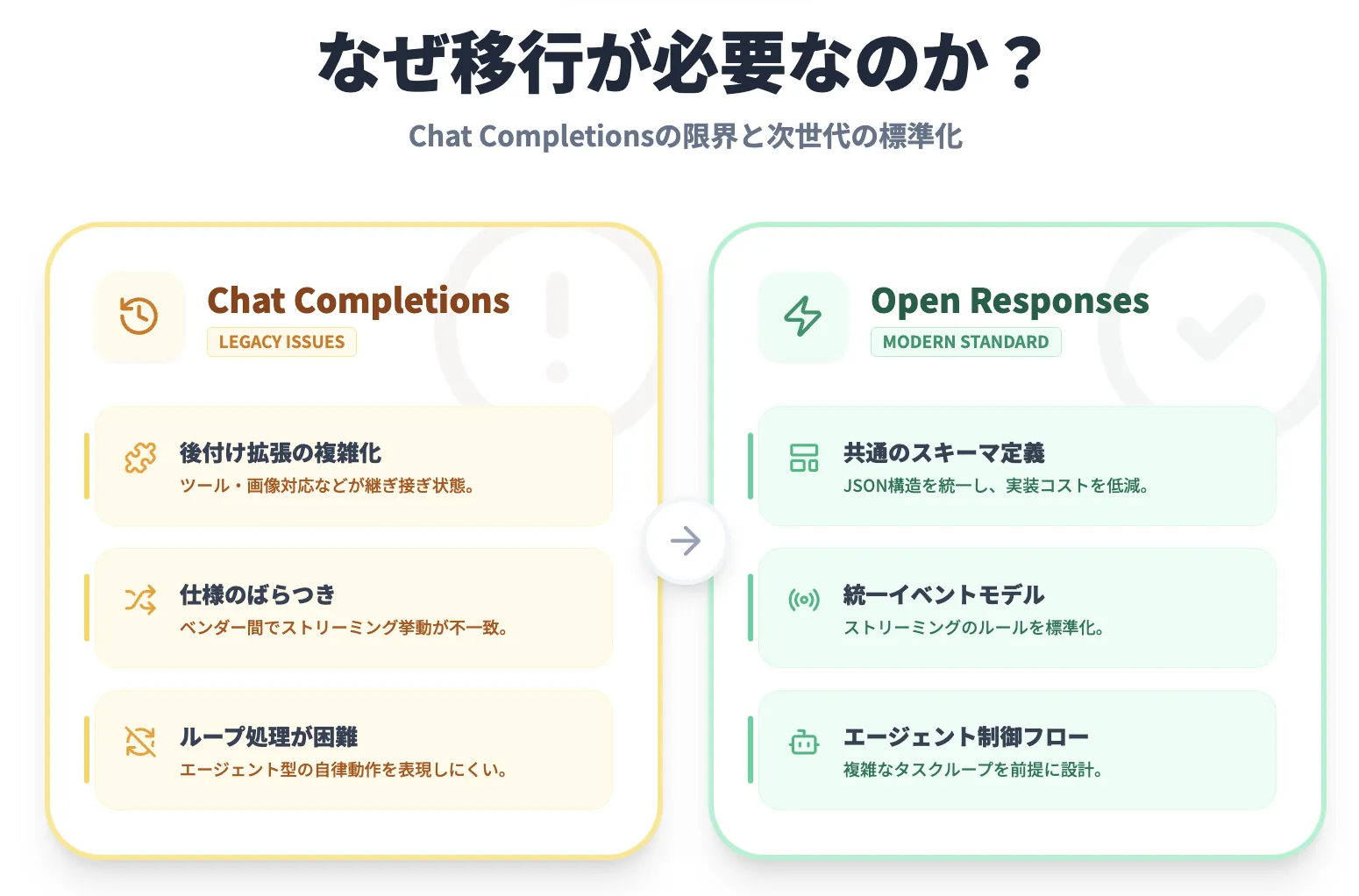
従来広く使われてきたChat Completions APIは、チャットボット型の対話には十分でしたが、近年主流になりつつあるエージェント型ワークフローにはいくつか課題がありました。
- ツール呼び出し・ストリーミング・マルチモーダルなどが後付け&ベンダーごとに微妙に違う
- 「どのイベントがいつ返ってくるか」のルールが曖昧で、ストリーミングの扱いがプロバイダーごとにばらつく
- エージェントループ(ツールを呼び出しながら複数ステップでタスクを進める)を表現しづらい
結果として、「似たようなことをしているのに、ベンダーごとにJSON形式やイベントが違う」状態になり、マルチプロバイダー対応やベンダー切り替えのコストが高止まりしていました。
Open Responsesは、この状況に対して以下の要素を定義することで、「Chat Completionsの限界を超えた世代の標準API」を目指しています。
- 共通のスキーマ
- 共通のストリーミングイベントモデル
- エージェント向けの制御フロー表現
これらが揃うことで、ベンダー間の差分を吸収しやすくなると期待されています。
Open Responsesで標準化される範囲/されない範囲
Open Responsesは「ベンダー差分をなくす」取り組みですが、現実には "標準化できる範囲" と "差分が残る範囲" が明確に分かれます。
ここを先に押さえると、導入判断と設計がブレにくくなります。
標準化される(共通化しやすい)範囲
以下の領域は、Open Responsesで共通化されやすい部分です。
- リクエスト/レスポンスの基本形(入力、出力、メタ情報の持ち方)
- ツール呼び出しの基本形(ツール定義、ツールコール、ツール結果の戻し方)
- セマンティックイベントによるストリーミング(イベント名、状態遷移、Itemの追加など)
- マルチモーダルや構造化出力の「表現の器」(どのフィールドで表すか、など)
これらはプロバイダー間で共通の「型」として扱えるようになります。
標準化されにくい(差分が残りやすい)範囲
一方で、以下の領域は標準化が難しく、差分が残りやすい部分です。
- モデル固有機能(独自パラメータ、独自ツール、独自の安全制御)
- 品質・ふるまい(同じプロンプトでも出力が揺れる/得手不得手が異なる)
- 課金・レート制限・SLA・データ取り扱い条件(契約・運用の領域)
- ストリーミング粒度やイベントの"中身"の差(同じイベント名でも情報量が違う等)
したがって、Open Responsesは「すべてが完全に同一になる標準」ではなく、互換のコアを揃えた上で、差分はルーター/アダプタ層のポリシーで吸収する前提の仕様だと整理すると安全です。
Open Responsesの仕様とアーキテクチャ
次に、Open Responsesの中核となる仕様やアーキテクチャを整理します。
メッセージ・ツール呼び出し・ストリーミングのモデル

Open Responsesでは、やり取りの最小単位として**Item(アイテム)**という概念が定義されています。
Itemは、以下のような要素をまとめて表現するための抽象化です。
- テキストメッセージ(user / assistant)
- ツール呼び出し(関数の引数や戻り値)
- 画像や他メディアなどのコンテンツ
- 推論に関する情報(raw reasoningを返すかはプロバイダー依存。summary/encrypted_contentなどが使われる)
これらはすべて「Item」として扱われ、入力にも出力にも載せられる双方向のコンテキスト単位として設計されています。
ストリーミングについても、Open Responsesでは「セマンティックイベント」として定義されます。
従来の「テキストdeltaだけのストリーミング」ではなく、状態遷移や意味のあるイベントの列としてストリーミングを扱う点が特徴です。具体的には以下のようなイベントが定義されています。
- 「response.in_progress」
- 「response.output_item.added」
- 「response.completed」
- 「response.failed」
これにより、「どのタイミングでどの情報が来るか」をクライアント側で予測しやすくなり、ビューやログの実装が楽になるメリットがあります。
エージェントループ
Open Responsesは、**推論 → ツール呼び出し → 結果反映 → 再推論…**という「エージェントループ」をAPIとして扱いやすくする設計になっています。
1つのレスポンス呼び出しの中で、モデルがツールを呼び出し、結果を受け取り、再度推論し…という繰り返しを、1つのAPI呼び出しとして表現できます。
ループ回数の上限は「max_tool_calls」のようなパラメータで制御し、「tool_choice」で呼び出し可能なツールを制約できます。
内部ツール/外部ツール
ツールは「外部ツール(クライアント側で実行)」と「内部ツール(プロバイダー側で実行)」の2系統が想定されており、設計上の責務分界がここで決まります。

外部ツール(クライアント実行)中心の設計
外部ツールは、モデルが「ツールを呼び出す意思」を出し、実行はアプリケーション(または別のMCPサーバー等)側で行うパターンです。この方式には以下のような特徴があります。
- 実行環境や権限をアプリ側で厳密に管理しやすい
- 監査ログやDLPを自社基準に寄せやすい
その一方で、ツール実行・再試行・タイムアウト・冪等性などをアプリ側で実装する必要があります。
内部ツール(プロバイダー実行)中心の設計
内部ツールは、ツールの実行がプロバイダー基盤側に組み込まれており、プロバイダーがループを回し続けて完了までを一括で処理できるパターンです。
アプリ側は「許可するツール」と「上限(max_tool_calls等)」を渡すだけで、複数ステップ処理を1リクエストとして抽象化しやすくなります。
その一方で、実行の内側がブラックボックス化しやすく、監査・可観測性・データ取り扱いのポリシー設計が重要になります。
この設計により、複雑なエージェント処理を"1つの呼び出し"として抽象化しやすい点が、Chat Completions時代との大きな違いです。
Open Responsesの主要機能と特長
Open Responsesの仕様を踏まえ、開発者・企業にとっての主なメリットを整理します。
マルチプロバイダー対応とポータビリティ
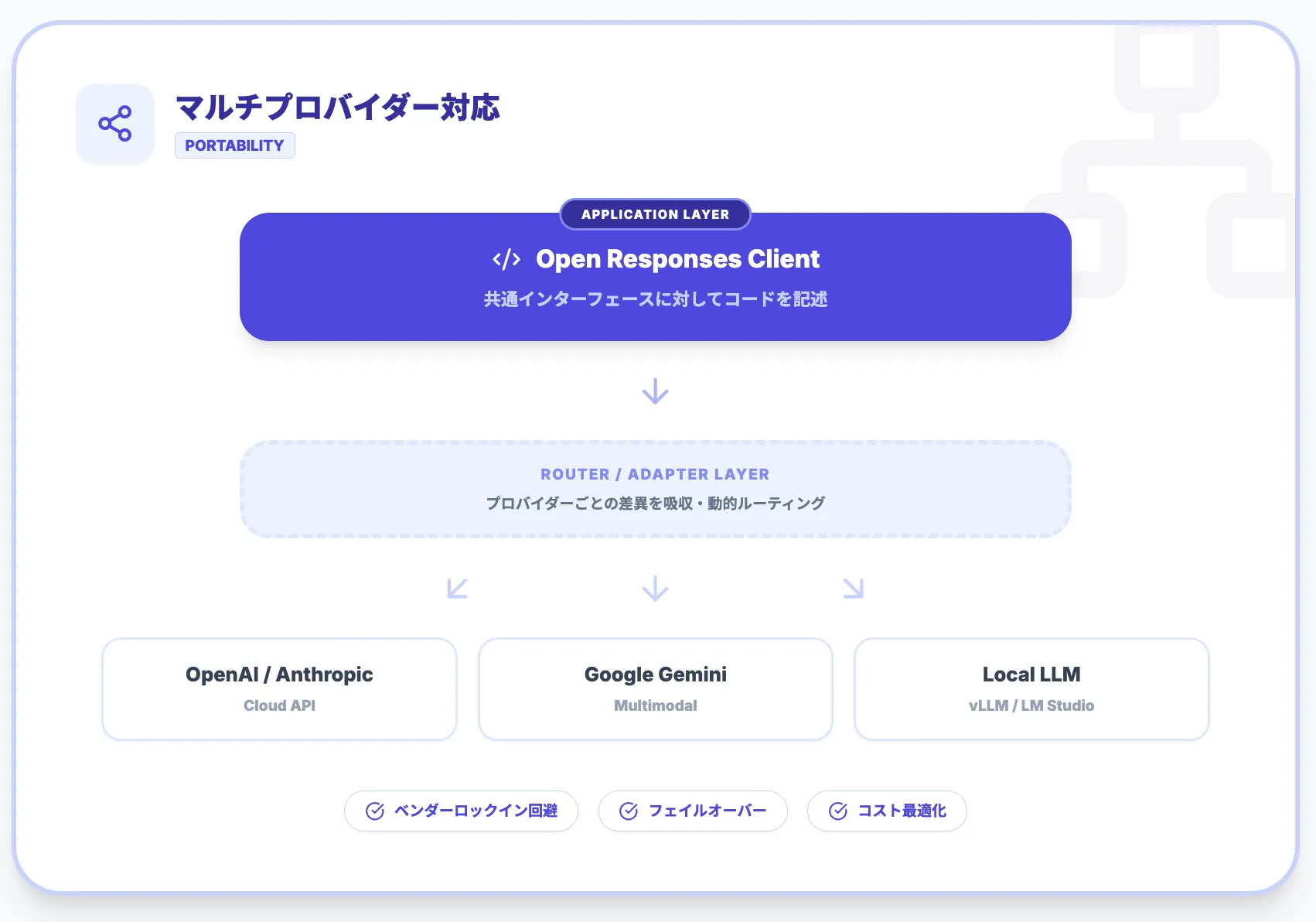
Open Responsesの最大の特徴は、**マルチプロバイダー対応(プロバイダーアグノスティック)**です。
1つのOpen Responsesスキーマに従ったリクエスト/レスポンスを、複数のバックエンドにマッピングできるように設計されています。
対応が想定されているプロバイダーは以下のとおりです。
- OpenAI
- Anthropic
- Google Gemini
- ローカルLLM(vLLM / LM Studioなど)
プロバイダーごとの細かい違いは、ゲートウェイ/プロキシ(ルーター)やアダプタ層が吸収する前提で、アプリケーションコード自体は「Open Responses対応クライアント」に対して書く、という分離が可能です。
これにより、以下のような運用がアプリケーション側の変更を最小限に抑えて実現しやすくなります。
- 「まずはOpenAIでPoC → 本番は自社GPUクラスターのローカルLLM」という移行
- ベンダーダウン時に別プロバイダーへフェイルオーバー
- タスクごとに最適なモデルへ動的ルーティング(ルーター側のポリシー変更)
構造化出力・ツール統合・マルチモーダル対応

Open Responsesは、Responses APIで導入された以下のような機能セットを前提に設計されています。
-
構造化出力
JSONスキーマや型定義に沿った出力を行うためのフィールドを標準化し、「LLMから直接、パース済みの構造データを受け取る」前提の設計を取りやすくします。
-
ツール統合(Tool Calling)
外部API・データベース・コード実行などを、ツールとして定義し、モデルが自律的に呼び出せるようにするためのItemとイベントモデルが仕様として定義されています。
-
マルチモーダル対応
テキストだけでなく、画像・音声など複数モダリティの入力を共通のスキーマで表現できるため、「ベンダーごとに画像の指定方法が違う」といった問題を緩和できます。
こうした機能群を、単なる"テキストストリームの標準化"に留まらない、「エージェント時代のAPI標準」として整理している点が、Open Responsesの特徴です。

Open Responsesのユースケース

ここからは、実際にどのような場面でOpen Responsesが効いてくるかを、ユースケースベースで整理します。
エージェント型アプリケーション開発での活用
エージェント型アプリケーション(Agentic Application)では、以下のような要件が一般的です。
- 外部ツールを何度も呼び出しながら、複数ステップでタスクを完遂する
- 中間結果や推論の要約などをログとして残す
- 失敗時に再開できるよう、状態を外部ストレージに持たせる
Open Responsesは、これらの要件を「API仕様のレベルで共通化」するための仕組みを提供しています。具体的には以下の要素です。
- アイテム(Item)ベースのコンテキスト管理
- セマンティックイベントによるストリーミング
- ツール呼び出しを前提にしたAPI形状(max_tool_calls等)
結果として、特定プロバイダー向けに書いたエージェントロジックを別プロバイダーに載せ替えたり、ルーター側で「このユースケースは高速だが小さめのモデル」「このユースケースは高精度モデル」と切り替えたりする運用がしやすくなります。
マルチプロバイダー運用・フェイルオーバーでの活用
企業利用でありがちなニーズとして、以下のような要件があります。
- コスト/レイテンシ/精度のバランスを見ながら複数モデルを使い分けたい
- あるクラウドリージョンやベンダー障害時に、別プロバイダーへ自動フェイルオーバーしたい
- 国やリージョンごとに、使えるクラウド・モデルが異なる
Open Responsesでは、プロバイダー(Model Provider)とルーター(Router)を明確に切り分ける思想が採用されており、ルーター側でどのプロバイダーへリクエストを送るか、どのようなポリシーで切り替えるかを制御する前提になっています。
アプリケーションはOpen Responses準拠のリクエストを送り、あとはルーターの設定を変えることで、以下のような運用を実現しやすくなります。
- A/Bテスト
- 段階的なモデル切り替え
- SLAやコストを考慮したルーティング
互換性レベル(Core / Optional / Extensions)と対応マトリクスの考え方
Open Responsesは「互換」を掲げますが、実務上は "どのレベルの互換を狙うか" を先に決めないと、期待値がズレやすくなります。ここでは運用しやすい整理を提示します。

Core(必須として揃えたい領域)
Coreは、互換性の基盤となる必須領域です。以下の要素が含まれます。
- 入力と出力の基本形(Item、role、contentなどの基礎)
- セマンティックイベント(最低限の開始/進行/完了/失敗と、Item追加)
- ツール呼び出しの基本形(外部ツール前提でも動く形)
Optional(可能なら揃える領域)
Optionalは、用途によって対応を検討する領域です。以下の要素が含まれます。
- 構造化出力の厳密運用(JSONスキーマの強制、バリデーション運用など)
- マルチモーダルの取り回し(画像/音声など、対応範囲の差が出やすい)
- 推論に関する付帯情報(summary/encrypted_contentなどの取り扱い)
Extensions(差分を許容して取り込む領域)
Extensionsは、ベンダー固有の拡張を扱う領域です。以下の要素が含まれます。
- ベンダー固有の追加パラメータ(生成制御、安全制御、独自最適化など)
- ベンダー固有の内部ツール(プロバイダー基盤に組み込まれた機能)
- ローカル推論基盤特有の設定(バッチ、KVキャッシュ、量子化など)
:::
*拡張を安全に扱うための設計指針
拡張の扱い方を誤ると、結局ベンダーロックインが再発します。企業利用では、次のようなルールを先に置くと安全です。
- **拡張は"アプリが直接読む"のではなく、アダプタ層で正規化してから使う
- *監査上必要なもの/機微情報を含む可能性があるものは、収集・マスキング・保存期間を明確化する
- 拡張依存の機能はフォールバックを用意する。:ベンダー変更時に「同等機能がない」前提で代替動作を定義しておく
:::
企業導入では、まずCoreを満たすことを最優先にし、Optionalは「用途が固まったら段階導入」、Extensionsは「使うならアダプタ層で吸収」を基本方針にすると設計が安定します。
Open Responses導入ステップと移行パターン
ここでは、既存実装からの移行と、新規プロジェクトでの導入パターンを整理します。
既存Chat Completions実装からの移行ステップ
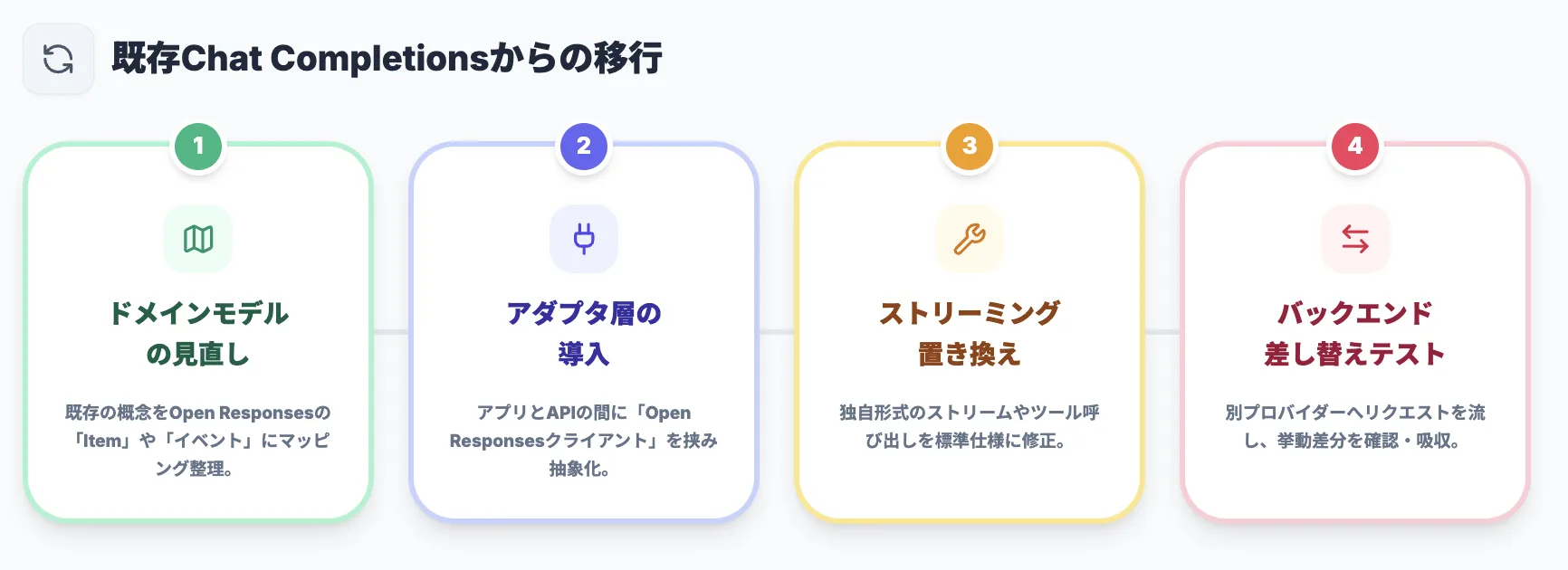
既にChat Completionsや各社独自APIでアプリケーションを構築している場合、現実的な移行ステップの一例は次のとおりです。
-
ドメインモデルの見直し
現在の「メッセージ」「ツール呼び出し」「中間結果」などの概念を洗い出し、Open ResponsesのItemやイベントにどうマッピングできるかを整理します。
-
アダプタ層(Open Responsesクライアント)の導入
アプリケーションからはOpen Responses準拠のクライアントを呼び出し、そのクライアントが既存のChat Completionsや各社APIにリクエストを橋渡しする構成にします。
-
ストリーミング・ツール呼び出しの置き換え
従来はベンダー独自のイベントやフォーマットで扱っていたストリーミングやツール呼び出しを、Open Responsesのセマンティックイベント/Itemモデルに沿って整理します。
-
バックエンドの差し替えテスト
同じOpen Responsesリクエストを、別プロバイダーに流すテストを行い、モデルごとの挙動差や制約を洗い出します。
このように、アプリケーション側の境界に「Open Responsesクライアント」を置くことで、徐々に既存コードを移行させながら、マルチプロバイダーへの拡張を進めることができます。
新規プロジェクトでの設計パターン

新規プロジェクトでは、最初からOpen Responses前提で設計することも可能です。具体的には以下のようなアプローチが考えられます。
- API呼び出し層は、最初からOpen Responsesクライアント/ゲートウェイを前提に実装
- モデル固有の制約(最大トークン長、マルチモーダル対応可否など)は、ゲートウェイ側のポリシーやメタデータとして管理
- エージェントフレームワーク(AutoGen系・独自実装など)も、Open ResponsesのItem/イベントに依存する形で実装しておく
こうすることで、当面は特定のベンダー1社だけで運用しつつ、将来のマルチプロバイダー化やローカルLLM移行に備えたアーキテクチャを初期段階から確保できます。
Open Responsesを企業で利用する際のポイント
企業としてOpen Responsesを採用する場合、アーキテクチャだけでなく、ガバナンス面も含めて検討する必要があります。
まず結論として、企業が失敗しにくい判断軸は次のとおりです。
- マルチベンダー/マルチリージョン運用を前提にするほど、採用メリットが大きい
- 単一ベンダー運用でも「将来の切替コスト」を下げたいなら検討価値がある
- ただし「拡張依存の管理」「監査・DLP」「ツール実行の責務分界」を先に決めないと、互換の恩恵が薄れる
以下、具体的なポイントを見ていきます。

マルチクラウド・マルチベンダー戦略との相性
Open Responsesは、マルチプロバイダー前提で設計されているため、以下のようなマルチクラウド・マルチベンダー戦略と相性が良い仕様です。
- クラウド依存度を下げたい
- 特定ベンダー障害時にもサービス継続したい
- 国やリージョンごとに使えるクラウド・モデルが異なる
一方で、実際のSLAやコンプライアンス要件は各プロバイダー依存になるため、以下の点を企業側のポリシーとして明文化しておくことが重要です。
- ゲートウェイ/プロキシ(ルーター)レイヤーでのルーティングポリシー
- 監査ログの標準化(どのリクエストがどのプロバイダーに送られたか)
- データレジデンシ(どのリージョンにどのデータを送ってよいか)
ログ・監査・ガバナンス設計の注意点
Open Responsesでは、レスポンスやストリーミングがセマンティックイベントとして定義されるため、ログ・監査設計の観点では次のようなメリットがあります。
- イベント種別ごとにログを集計しやすく、「どのツールがどれくらい呼ばれているか」「どのレスポンスで失敗が多いか」などを分析しやすい
- すべてのプロバイダーを同じイベントスキーマで観測できるため、監査・可観測性の実装を共通化しやすい
その一方で、以下の点は企業側のDLP(Data Loss Prevention)やアクセス制御ポリシーと組み合わせて設計する必要があります。
- 個人情報や機密データが含まれるコンテキスト(Item)を、どの粒度でログに残すか
- 外部への持ち出し禁止情報をツール経由で呼び出していないか
失敗・再試行・冪等性(Idempotency)/タイムアウトの設計
エージェント型ワークフローはツール呼び出しを挟むため、運用で問題になりやすいのが「途中失敗」と「二重実行」です。Open Responsesを採用する場合も、ここは別途ポリシー設計が必要です。
- ストリーミング途中の失敗:部分結果(途中までのItem)をどの粒度で保存し、再開時にどこから再実行するかを決めます。
- 外部ツールの再試行と冪等性:決済・メール送信・DB更新のような"副作用"のあるツールは、再試行で二重実行事故が起きやすいので、冪等キー(idempotency key)や実行ログで防御します。
- タイムアウトの三層設計:「モデル待ち」「ツール待ち」「全体SLA」を分け、どこで打ち切るか(max_tool_calls含む)を明確にします。

API標準化の理解をマルチモデルAI運用に活かすなら
Open Responsesが示すLLM APIの標準化は、マルチプロバイダー構成でのAI活用を現実的にする重要な動きです。
複数のAIモデルを統一的に扱えるようになったことで、次のステップは「どの業務にどのモデルを組み合わせるか」という設計判断です。AI総合研究所のガイドでは、Azure OpenAIを中心としたAI基盤の設計から業務自動化の実装まで、体系的にまとめています。
AI総合研究所のガイドで、マルチモデルAI環境の業務への組み込み方をご確認ください。
LLM API標準化の知見をマルチプロバイダーAI運用に活かす

複数モデルを組み合わせた業務AI化の設計指針
API仕様の標準化を理解した次は、複数のAIモデルを組み合わせた業務自動化の設計に進みましょう。ガイドでは実務的なAI導入の進め方を解説しています。
まとめ
最後に、本記事のポイントを簡単に振り返ります。
- Open Responsesは、OpenAI Responses APIをベースにしたオープンソースのLLM API標準仕様であり、複数プロバイダーを横断する共通インターフェースを提供します。
- Item/セマンティックイベントといった概念により、ツール呼び出しやエージェントループを前提にした設計が可能になり、「エージェント時代」のAPIとして位置づけられます。
- マルチプロバイダー対応・フェイルオーバー・マルチクラウド戦略との相性が良く、ベンダーロックインを緩和しながらLLMスタックを設計できる点が企業利用の大きなメリットです。
- 既存のChat Completions実装からは、アプリケーション境界にOpen Responsesクライアントを置き、徐々に移行するパターンが現実的です。
- エコシステムは2026年時点で立ち上がりフェーズにあり、互換性検証(Acceptance Tests)やルーティング前提の設計が整備されつつあります。標準化と拡張性のバランスをどう取るかが、今後の焦点となります。
実務的には、既にエージェント基盤やLLMプラットフォームを内製している企業は、「次の大規模リファクタリング時にOpen Responses対応を検討する」スタンスが良いでしょう。これからAI基盤を構築する企業は、「初期からOpen Responses互換のクライアント/ゲートウェイを前提としたアーキテクチャを採用する」ことを検討してみてください。







