この記事のポイント
 UI微調整や局所リファクタなど即時フィードバックが要る作業にCodex-Sparkが最適、1,000トークン/秒超で待ち時間ゼロのペアプロ実現
UI微調整や局所リファクタなど即時フィードバックが要る作業にCodex-Sparkが最適、1,000トークン/秒超で待ち時間ゼロのペアプロ実現- 設計や大規模改修は通常Codex、短時間の反復作業はSparkという役割分担が有効、両モデル併用で開発ワークフローの生産性を最大化
- 現時点はChatGPT Proユーザー限定の研究プレビュー、全社導入は避けPro契約の開発者でパイロット評価から始めるのが合理的
- マルチモーダル入力には非対応のため、画像を含むUI設計のレビューにはCodex-Sparkではなく通常Codexや他のマルチモーダルモデルを選択すべき
- Cerebras WSE-3専用ハードウェア最適化はAPIの安定供給・スケーラビリティに影響する可能性、依存度を見極めて本格採用を判断

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
OpenAIは2026年2月、リアルタイムの対話型コーディングに特化した新モデル「GPT-5.3-Codex-Spark」を発表しました。Cerebras Systemsの専用チップを活用することで1,000トークン/秒を超える推論速度を実現し、従来のAIアシスタントでは難しかった「ほぼ待ち時間のない」ペアプログラミング体験を提供します。
本記事では、長時間タスクを得意とする従来のCodexモデルとの役割分担や、具体的なユースケース、さらに専用ハードウェアによる高速化の仕組みについて、2026年2月時点の情報を基に体系的に解説します。
✅最新モデル「GPT-5.5」については、以下の記事をご覧ください。
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説
✅2026年6月9日、AnthropicがMythos-class初の一般公開モデル「Claude Fable 5」を発表しました。Opus 4.8の上位に位置する新最上位モデルの詳細はこちら。
▶︎Claude Fable 5とは?Mythos 5との違いや料金、使い方を解説
目次
「Codex本体による長時間タスク」×「Sparkによる対話編集」のハイブリッド運用
チーム開発でのSparkの位置づけ(レビュー補助/プロトタイピングなど)
既存ツールチェーン(Git/CI/CD/Issueトラッカー)との組み合わせ
GPT-5.3-Codex-Sparkとは?

GPT-5.3-Codex-Spark(以下、Codex-Spark)は、OpenAIが2026年2月12日に公開したリアルタイムの対話編集に最適化したコーディング向けモデルです。
既存のGPT-5.3-Codexよりもモデル規模を絞り、Cerebras Systemsの専用チップ上で稼働させることで、「とにかく速い対話型コーディング体験」を目指した位置づけになります。

GPT-5.3-CodexとCodex-Sparkの違い
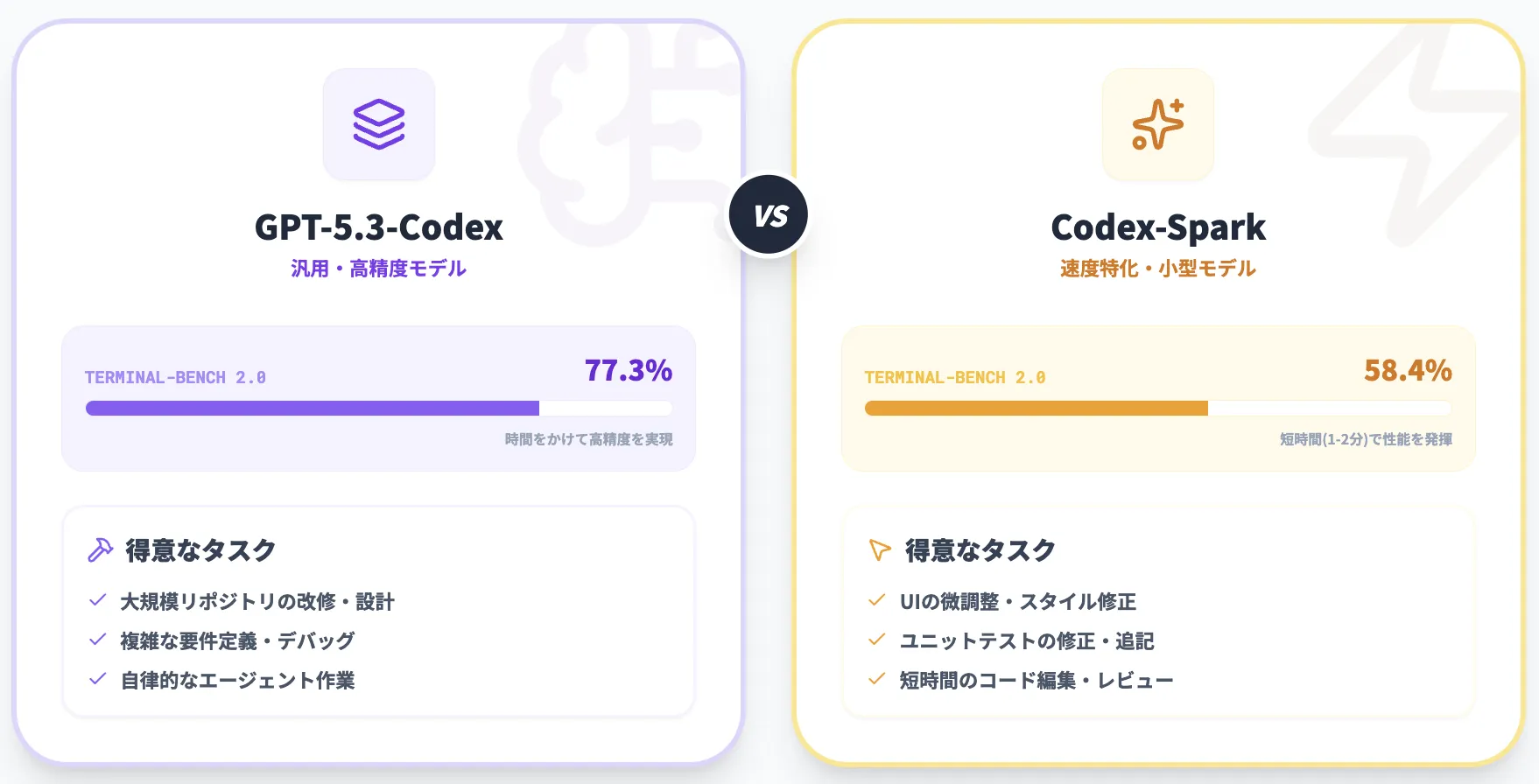
この節では、GPT-5.3-CodexとCodex-Sparkの違いを、性能・用途・他社モデルとの関係という3つの観点から整理します。
どちらか一方を選ぶというよりは、「どう組み合わせると開発フローがスムーズになるか」を考えるイメージが近いです。
モデルサイズ・性能・用途の比較
ベンチマークから見える違いを、簡単に表にまとめると次のようになります。
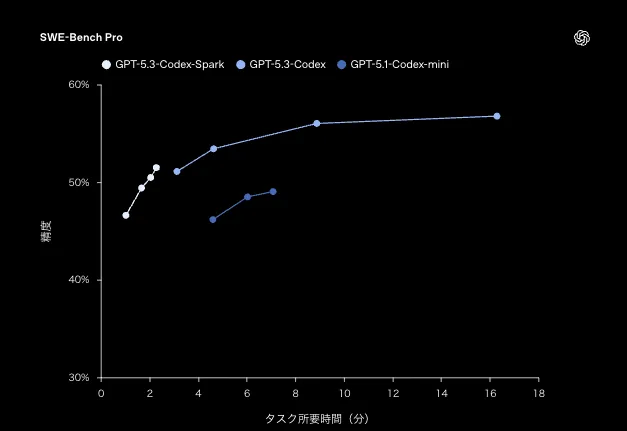
SWE-Bench Pro:正答率×タスク所要時間(分)の比較(GPT-5.3-Codex-Spark / GPT-5.3-Codex / GPT-5.1-Codex-mini)*
| 項目 | GPT-5.3-Codex | GPT-5.3-Codex-Spark |
|---|---|---|
| モデル設計 | フルサイズのCodex(汎用コーディング向け) | Codexの小型・高速版(速度特化) |
| 主な用途 | 長時間タスク、エージェント的な開発作業 | 短時間の編集、UI調整、ターゲットテスト |
| SWE-Bench Pro | タスク時間をかけるほど精度が伸び、最終的に50%台半ば付近まで到達(所要時間は数分〜十数分のレンジ) | 1〜2分程度の短時間側で50%前後まで到達(短い反復に寄せた挙動) |
| Terminal-Bench 2.0 | 77.3% | 58.4% |
SWE-Bench Proは「精度」と「タスク所要時間」のトレードオフを曲線で示しています。Sparkは短時間での反復に寄せた設計、Codexは時間を使って“伸び”を取りに行く設計として整理しやすいです。
また、Terminal-Bench 2.0では、GPT-5.3-Codexが77.3%、Codex-Sparkが58.4%、**GPT-5.1-Codex-miniが46.1%**というスコアが示されています。
この結果だけを見ると、Sparkは最高精度を狙うというより、「一定の精度を保ちつつ、体感速度を最大化する」方向にチューニングされている、といえます。
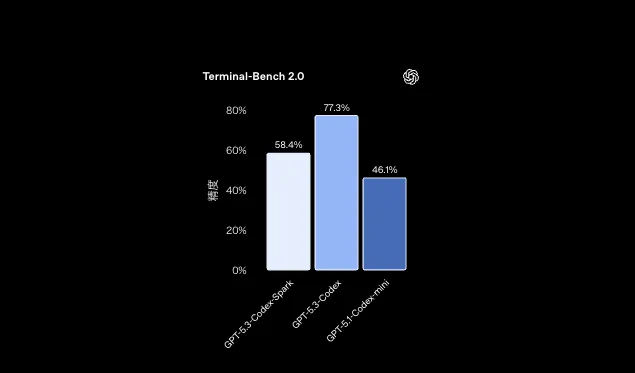
Terminal-Bench 2.0:モデル別 精度(GPT-5.3-Codex-Spark / GPT-5.3-Codex / GPT-5.1-Codex-mini)
通常版とSparkの使い分け
両者の性格を踏まえると、次のような使い分けが現実的です。
-
GPT-5.3-Codex向きのタスク
- 大規模リポジトリ全体の改修やアーキテクチャ変更。
- 仕様書・議事録・Issueを横断した「要件の再整理」。
- 数十〜数百ステップに及ぶ自律的なデバッグや最適化。
>
-
Codex-Spark向きのタスク
- すでに動いているUIের細かい調整やスタイル修正。
- 既存コードの一部関数のリファクタリングや型の整理。
- 特定ユニットテストだけを素早く修正・追記する作業。
実務では、設計や大規模改修をGPT-5.3-Codex側で行い、日々の小さな修正やコードレビューをCodex-Sparkで回す、といった「二段構え」のワークフローが想定しやすいです。
Codex-Sparkのアーキテクチャ
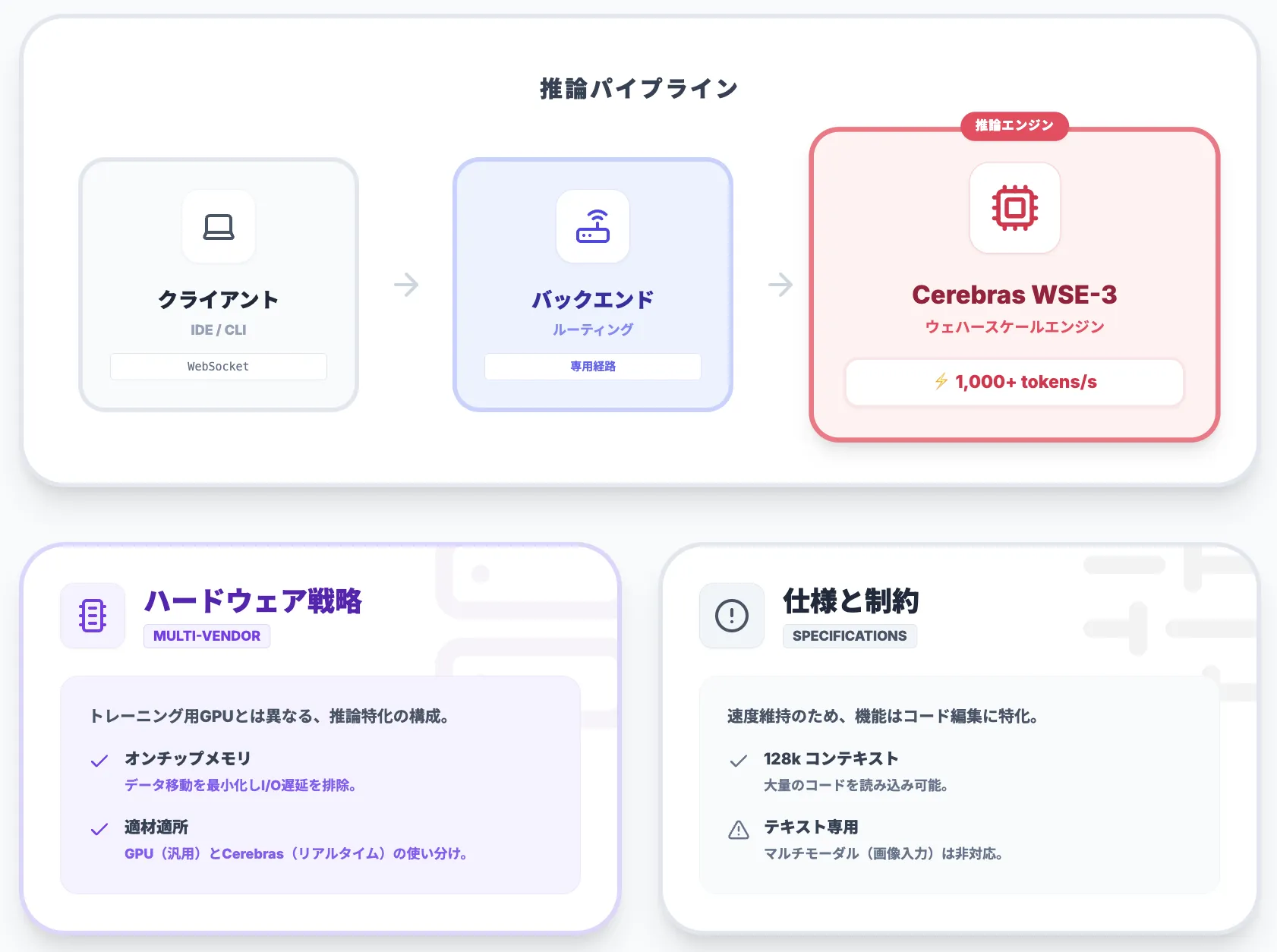
ここでは、Codex-Sparkを支えるアーキテクチャとハードウェア構成を概観します。
ポイントは、「モデル自体の設計」と「Cerebrasハードウェアとの組み合わせ」に分けて理解することです。
Cerebras WSEベースの提供とマルチベンダー戦略
Codex-Sparkは、Cerebras Systemsの**Wafer Scale Engine 3(WSE-3)**上で動くことが明言されています。
WSEは、通常は複数のGPUで構成されるクラスターを「1枚の巨大なウエハー上のチップ」で置き換える発想のアーキテクチャです。
OpenAIはこれまでNVIDIAベースのGPUクラスターを中核に据えてきましたが、Codex-Sparkの登場は、推論スタックの一部にCerebrasのような専用ハードウェアを組み合わせ、低レイテンシの体験を最適化する取り組みの一例として位置づけられます。
- トレーニングや汎用推論:引き続きGPUが中心。
- 低レイテンシが最優先のリアルタイム推論:Cerebrasを含む専用ハードウェアを活用。
という棲み分けが、公表されている情報から読み取れる方向性です。
高スループット/低レイテンシ最適化のポイント
Cerebras WSE-3は、チップ上に大容量メモリと多数の演算コアを搭載し、「チップ外へのデータ移動を最小限にする」ことを目指した設計になっています。
LLM推論のボトルネックになりがちなI/Oレイテンシを抑えられるため、Codex-Sparkは1,000トークン/秒超のスループットを実現できるとされています。
推論パイプラインのイメージは、次のように整理できます。
- IDEやCLIからのリクエストを、低オーバーヘッドなプロトコル(WebSocketなど)でCodexバックエンドに送信。
- Codexバックエンドが、対象ワークロードをCerebrasクラスタにルーティング。
- WSE上でトークン生成を行い、ストリーミングレスポンスとしてクライアントに逐次返却。
この構造により、「最初の1トークンが出てくるまでの時間」と「その後のトークン生成速度」の両方を最適化しています。
コンテキストウィンドウとテキスト専用モデルとしての制約
Codex-Sparkは現時点で128kトークンのコンテキストウィンドウを持つテキスト専用モデルであり、マルチモーダル入力には対応していません。
これは、以下のような意図を持った割り切りと考えられます。
- コードベースや関連ドキュメントを大量に読み込みつつも、リアルタイム性を維持したい。
- UIスクリーンショットや設計図の画像を直接読ませるよりも、「コードとテキストコメント」の組み合わせに集中させる。
将来的には、より大きなコンテキストやマルチモーダル対応を行う計画も示されていますが、当面は「コードとテキストに特化した高速モデル」として捉えるのが現実的です。
Codex-Sparkの強み
次に、開発者視点で「Codex-Sparkを使うと何が変わるのか」を具体的な機能レベルで見ていきます。
ここでは、特に日常のコーディング作業に直結する3つのユースを中心に整理します。
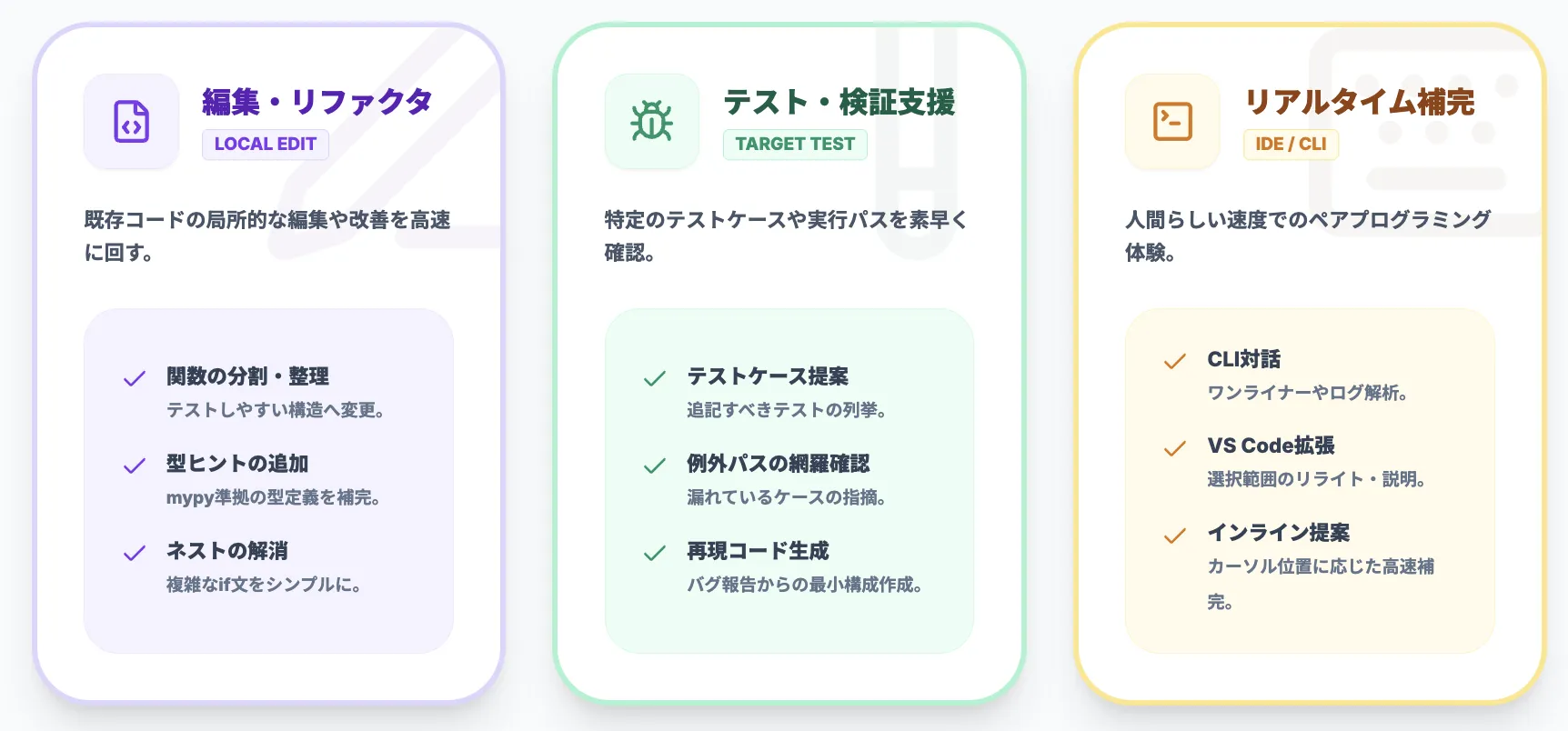
既存コードの編集・リファクタリング・局所的な修正
Codex-Sparkが最も強みを発揮するのは、「すでに存在するコード」の局所的な編集です。
長い関数を分割したり、型注釈を追加したりといった作業を、対話形式で素早く回すことができます。
代表的なパターンとしては、次のようなものがあります。
- 「この関数を2つに分割して、テストしやすい構造にしてほしい」
- 「このファイル一式に型ヒントを追加し、mypyで通るように修正して」
- 「このif文のネストを浅くする形でリファクタリングしてほしい」
返ってくる提案をその場で微調整しながら、「少し書いて、すぐ試す」というサイクルを高速に回せるのがポイントです。
ターゲットテストや実行パスの見直し支援
長いテストスイートを毎回全部走らせるのは非現実的ですが、Codex-Sparkは特定のテストケースや実行パスだけを素早く確認する用途に向いています。
たとえば、次のような使い方が想定されます。
- 「この変更に関係しそうなテストケースだけ列挙して、追記すべきテストを提案してほしい」
- 「この関数の例外パスに対応するテストが足りているか、テストコードから判断してほしい」
- 「このバグ報告を踏まえて、再現する最小ケースとテストコード案を出してほしい」
Codex-Sparkはデフォルトでは自動でテストを実行せず、「最小限の編集を提案すること」に焦点を当てていると報じられています。
IDE/CLIでのリアルタイム補完・ペアプロ体験
Codex-Sparkは、Codexアプリだけでなく、CLIやVS Code拡張機能からも利用できます。
- CLI/ターミナル
- ワンライナーのスクリプト生成、ログの解析、短い補助関数の生成を、コマンドラインから対話的に実行。
- ワンライナーのスクリプト生成、ログの解析、短い補助関数の生成を、コマンドラインから対話的に実行。
- VS Code拡張機能
- エディタ上で、選択範囲に対するリライト/コメント生成/説明を即座に得る。
- カーソル位置に応じたインライン提案を高速に受け取り、ペアプロのような感覚で作業。
従来もエディタ補完型のAIツールは多数存在しましたが、Codex-Sparkは応答速度を徹底的に上げることで、より「人間らしいペアプロ体験」に近づけることを狙っています。

Codex-Sparkの利用シナリオ
ここからは、「どの場面でCodex-Sparkを挟むと開発フローがスムーズになるか」を、実務シナリオの観点で整理します。
単体で使うよりも、他のモデルやツールと組み合わせてワークフローを組むことが前提です。
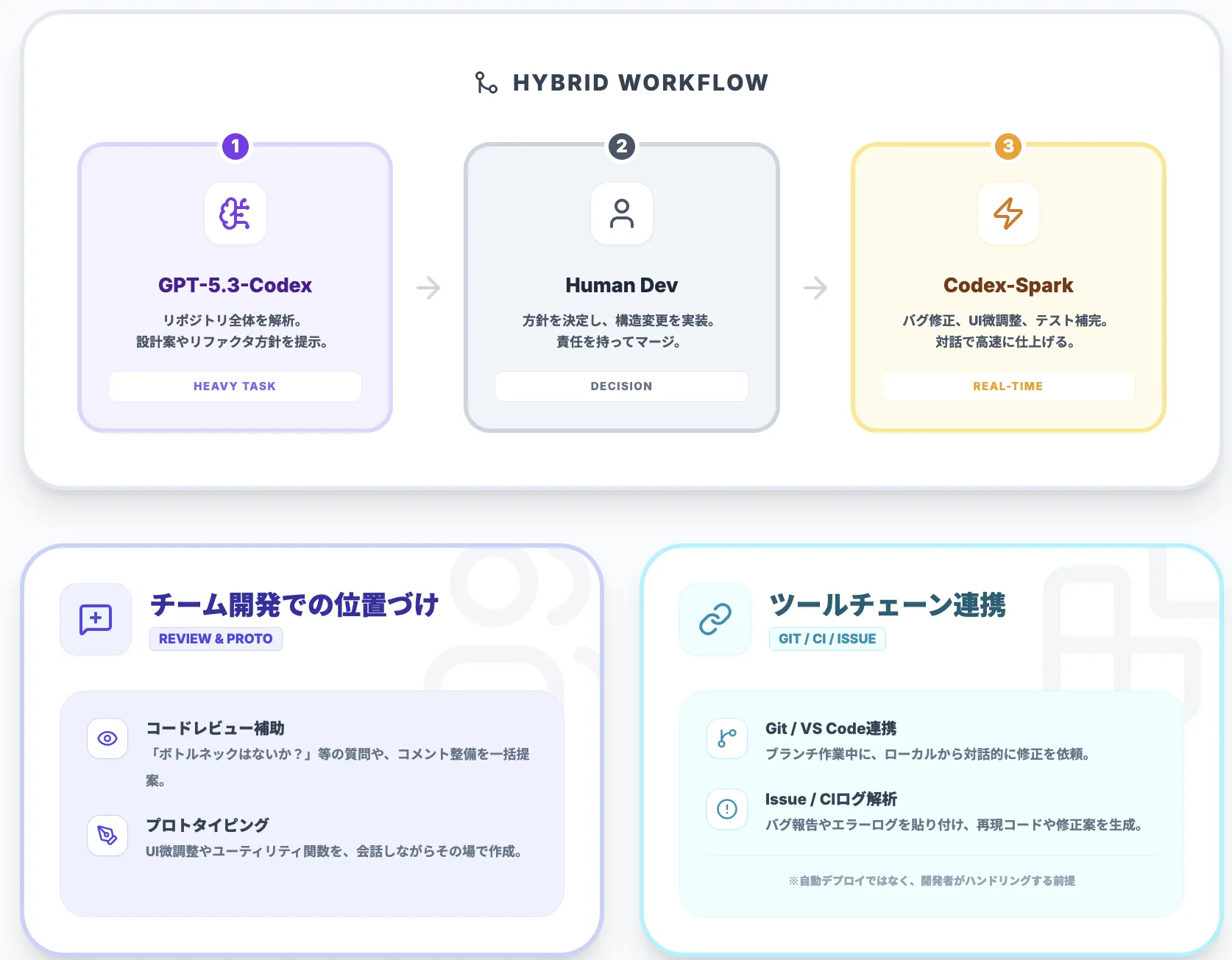
「Codex本体による長時間タスク」×「Sparkによる対話編集」のハイブリッド運用
1つの典型的なパターンは、設計や大改修をGPT-5.3-Codexで行い、その後の細かな修正をSparkで回すという二段構えです。
イメージとしては次のような流れになります。
- GPT-5.3-Codexに対して、リポジトリ全体や仕様書を読ませ、リファクタリング方針や設計案を出してもらう。
- その結果を踏まえたうえで、人間の開発者が大きな構造変更を実装する。
- 実装後の細かなバグ修正やUI調整、テスト補完をCodex-Sparkに任せる。
これにより、「重い思考」はフルサイズのCodexに、「細かい反復作業」はSparkに任せるという分担が成立します。
チーム開発でのSparkの位置づけ(レビュー補助/プロトタイピングなど)
チーム開発では、次のような使い方が考えられます。
-
コードレビューの補助
- レビュアーが気になる箇所を選択し、「ここがパフォーマンス上ボトルネックにならないか?」といった質問をSparkに投げる。
- コメント文やdocstringの整備を、Sparkに一括で提案させる。
-
プロトタイピング
- UI側の微調整を高速に試して、ユーザーテスト前に複数パターンを出しておく。
- 小さなユーティリティ関数やスクリプトを、会話しながらその場で書いてしまう。
Sparkは「大きな判断をする」よりも「人間が決めた方向性を素早く形にする」ことに向いているため、レビュー会や設計議論と組み合わせると役割がはっきりします。
既存ツールチェーン(Git/CI/CD/Issueトラッカー)との組み合わせ
現時点でCodex-Spark自体がGitやCI/CDと直接統合されているわけではありませんが、次のような組み合わせが想定されます。
- GitHub/GitLab上のブランチで作業しつつ、ローカルのVS CodeからSparkに対話的に修正を依頼。
- Issueトラッカー(Jiraなど)に書かれたバグ報告を引用し、再現コードやテストケース案をSparkに生成させる。
- CIの失敗ログをCLIで貼り付け、原因候補と修正パッチ案を素早く出してもらう。
重要なのは、「Sparkが自動で本番にデプロイする」のではなく、「開発者が意思決定とマージを握り続ける」前提でツールチェーンに組み込むことです。
Codex-Sparkの料金・利用制限
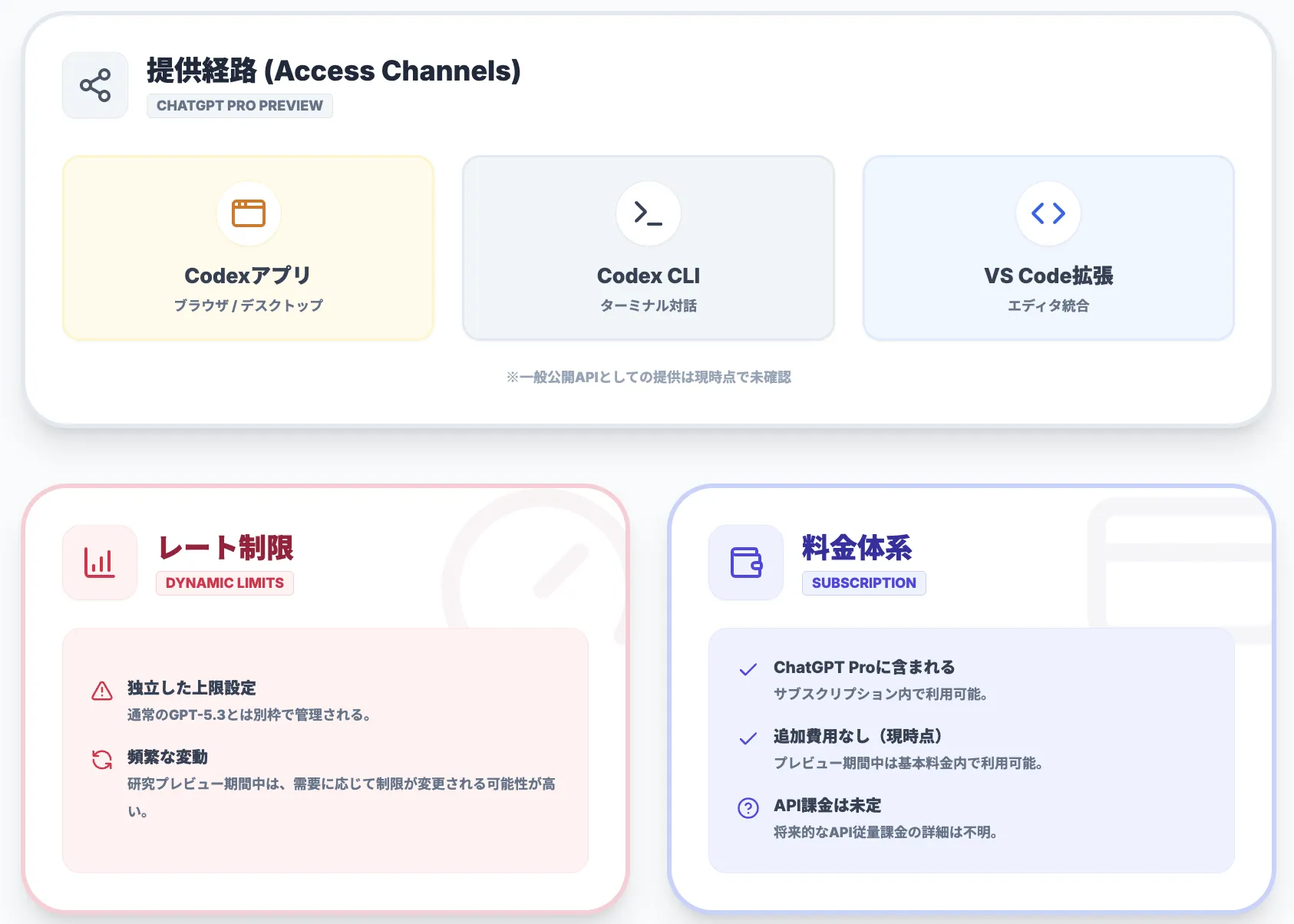
Codex-SparkはChatGPT Proユーザー向けの研究プレビューとして、以下の経路で提供されています。
- Codexアプリ(ブラウザ/デスクトップ)
- Codex CLI
- VS Code拡張機能
Codex-Spark一部の開発パートナーに対しては、限定的にAPIでも提供されているとされていますが、一般開発者向けの公開APIとしての提供は現時点では確認できません。
レート制限・提供範囲
Codex-Sparkは、専用の低レイテンシハードウェア上で動作する都合上、通常のGPT-5.3系モデルとは別のレート制限が適用されています。
- ChatGPT Pro内でも、Codex-Sparkの利用には独立した上限があり、需要に応じて調整される。
- 研究プレビュー期間中は、挙動や制限が比較的よく変更される可能性がある。
料金そのものはChatGPT Proのサブスクリプションに含まれる形ですが、将来的にAPI利用の課金体系がどのようになるかは、現時点では明示されていません。

Codex-Spark利用時の注意点とベストプラクティス
最後に、Codex-Sparkを実務に取り入れる際に意識しておきたいポイントをまとめます。
特に、従来のLLMコーディングツールとは異なる挙動や注意点に着目します。
リアルタイムモデル特有の挙動
Codex-Sparkは、「最小限の編集を高速に提案する」という設計方針が強く意識されています。
そのため、次のような点を前提にしておくと戸惑いが少なくなります。
- デフォルトではテストの自動実行を行わず、「パッチ案」や「修正候補」の提示にとどまる。
- 一度に大規模な書き換えを指示すると、速度のメリットが薄れ、誤りの検出もしにくくなる。
- 「この部分だけ直して」「この関数だけ分割して」といった細かい指示の方が、モデルの設計意図に合っている。
リアルタイム性が高いぶん、「小さく試してすぐ巻き戻す」運用を前提にすることで、開発者側のストレスも軽減されます。
セキュリティ/コンプライアンス観点
Codex-Sparkに限らず、クラウド上のAIモデルにコードを送信する場合は、次のような点に注意が必要です。
- 機密性の高いコード(暗号実装/シークレットキー/顧客固有ロジックなど)を、そのまま外部モデルに送信しない。
- どうしても送信する必要がある場合は、組織としてのデータ保護方針や契約条件(DPA/BCRなど)を確認する。
- セキュリティレビューの一環として、「どのクラスの情報までCodex-Sparkに送ってよいか」を明文化する。
OpenAI側でもエンタープライズ向けにデータ保持ポリシーやコンプライアンス基準を公表していますが、最終的な責任は導入組織側にあるため、自社のガイドラインとセットで運用することが重要です。
生産性指標とPoCの進め方
Codex-Sparkは「爆速」であることが大きくフィーチャーされていますが、速度が必ずしも生産性の向上に直結するとは限りません。
導入時には、次のような観点でPoC(試験導入)を行うと良いでしょう。
- 特定のチーム/プロジェクトを対象に、「1タスクあたりの所要時間」「レビューにかかる時間」「バグ再発率」などを導入前後で比較する。
- GPT-5.3-Codex単体、Codex-Spark単体、両者の併用など複数パターンを試し、「どの組み合わせが最もバランスが良いか」を計測する。
- 開発者の主観的な満足度(ストレス・集中のしやすさ・「待ち時間」の感覚)もあわせてヒアリングする。
こうした定量・定性評価を行うことで、「速いけれど合わない」「一部チームには非常に相性が良い」といった実態が見えてきます。
AIコーディングの効率化を開発チーム全体のAI化に広げる

AI業務自動化ガイドで導入プロセスを確認
Codex-Sparkのような高速AIコーディングツールが個人の開発体験を変える一方で、組織全体の生産性を高めるにはAIの導入設計が不可欠です。AI総合研究所のガイドでは、Microsoft環境での業務プロセス全体のAI化手順を220ページで整理しています。
AIコーディングの高速化を開発プロセス全体のAI活用に展開するなら
Codex-Sparkが実現する1,000トークン/秒超のリアルタイムコーディングは、個人開発者の体験を変えるだけでなく、開発チーム全体のワークフローをAIで効率化する起点になります。コード生成・レビュー・テスト・ドキュメント作成まで、開発プロセスの各段階にAIを組み込むことで、チーム全体の生産性を底上げできます。
AI総合研究所では、開発プロセスを含む業務全体へのAI導入を段階的に進める支援を行っています。AIコーディングツールの導入を起点に、組織的なAI活用を設計されたい方は、AI業務自動化ガイドで実践的な導入手順をご確認ください。
AIコーディングの効率化を開発チーム全体のAI化に広げる
AI業務自動化ガイドで導入プロセスを確認
Codex-Sparkのような高速AIコーディングツールが個人の開発体験を変える一方で、組織全体の生産性を高めるにはAIの導入設計が不可欠です。AI総合研究所のガイドでは、Microsoft環境での業務プロセス全体のAI化手順を220ページで整理しています。
まとめ
GPT-5.3-Codex-Sparkは、超高速なリアルタイムコーディング体験に特化したCodexファミリーの新モデルです。
CerebrasのWafer Scale Engine 3を活用することで、1,000トークン/秒超の推論速度と低レイテンシを実現し、「少し直してはすぐ試す」という開発のリズムを強化することを狙っています。
一方で、従来のGPT-5.3-Codexに比べると「速度と正確性のトレードオフ」があり得ることを前提に、適用範囲を見極める必要があります。
なお、2026年3月5日にリリースされたGPT-5.4では、Codex系モデルのコーディング能力が汎用フラグシップモデルに統合されており、Codex-Sparkの「高速・対話的なコーディング」とGPT-5.4の「高精度な推論」を用途に応じて使い分ける選択肢が広がっています。
そのため、長時間タスクやアーキテクチャ設計は従来モデル、局所的な修正やUI調整はSparkといった、役割の分担が前提になります。
導入を検討する際は、次の3点を軸に考えると整理しやすくなります。
- どのプロセスで待ち時間がボトルネックになっているか(レビュー、UI調整、テスト補完など)。
- 自社のセキュリティ/コンプライアンス要件とクラウドAI利用の整合性。
- PoCを通じて、速度向上が実際の生産性にどこまで寄与するか。
Codex-Sparkは、単体で「すべてを置き換える」モデルではなく、既存のCodexや他社のコードモデルと組み合わせて初めて価値を発揮する存在と言えます。
まずはChatGPT Pro環境で手元のプロジェクトに試し、開発チームのワークフローにどの程度フィットするかを見極めたうえで、APIやエンタープライズでの本格導入を検討していくのが現実的な進め方になるでしょう。







