この記事のポイント
 GLM-5は、総パラメータ744B・アクティブ40BのMoE構造を採用し、約28.5Tトークンの事前学習を経たオープンウェイトのフラッグシップモデル
GLM-5は、総パラメータ744B・アクティブ40BのMoE構造を採用し、約28.5Tトークンの事前学習を経たオープンウェイトのフラッグシップモデル- コーディングやエージェント性能に特化しており、SWE-bench VerifiedなどのベンチマークでClaude Opus 4.5等の競合モデルと同等の水準を記録
- MITライセンスで公開されているため、商用利用や再配布が可能であり、自社インフラでのセルフホスト運用によって機密情報の保護やコスト最適化を図りやすい
- 長期的なタスク遂行能力や複雑なシステム設計の支援を想定したAgentic Engineering向けの設計がなされており、単発のチャットボットを超えた開発パートナーとして機能する
- 企業導入にあたっては、中国発モデル特有のデータ越境や輸出管理リスク、および大規模モデルを運用するためのインフラ要件を慎重に評価する必要がある

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
中国発のAI企業Z.ai(旧Zhipu AI)は、第5世代の大規模言語モデル「GLM-5」を公開しました。これは744Bという大規模なパラメータを持ちながら、MoE構造によって推論コストを抑制し、コーディングや長期エージェントタスクにおいてクローズドな最上位モデルに迫る性能を実現したフラッグシップモデルです。
本記事では、GLM-5の技術的な仕様やSWE-benchなどのベンチマーク結果、オープンウェイトならではの運用メリットに加え、中国製チップでの学習背景やデータ越境リスクといった企業導入時に考慮すべきガバナンス上のポイントについて、2026年2月時点の情報を基に体系的に解説します。
目次
744B MoE(40Bアクティブ)構成と疎なアテンション系の設計
Huawei Ascendなど“非NVIDIA”環境も意識した提供
ソフトウェアエンジニアリング:コード生成・リファクタリング・レビュー
Agentic Engineering:長期タスク・業務フロー自動化
GPT-5.2・Claude Opus・Gemini系との位置づけ
DeepSeek V3系・Kimi系など他オープンモデルとの比較ポイント
GLM-5とは?Z.aiの新フラッグシップモデル概要
GLM-5は、中国発のAI企業Z.ai(智谱/Zhipu AI)が公開した第5世代の大規模言語モデルシリーズです。
オープンウェイト(重み公開)でありながら、コーディングとエージェント性能でクローズドの最上位モデルに迫る水準を狙ったフラッグシップとして位置づけられています。
GLM-5のアーキテクチャとモデル仕様
ここでは、GLM-5の内部構造や学習条件、コンテキスト長、ハードウェア要件など、技術的な仕様面を整理します。
MoE構造や“非NVIDIA環境も意識したデプロイ”といった特徴は、企業の導入・評価方針にも影響します。
744B MoE(40Bアクティブ)構成と疎なアテンション系の設計
GLM-5は、総パラメータ744B/アクティブ40BのMixture-of-Expertsモデルとして公開されています。
- 合計パラメータ数:744B(約7,440億)
- 推論時アクティブパラメータ:40B(約400億)
- MoE構造:多数のエキスパートから、トークンごとに一部のみを選択して計算
さらに、長コンテキスト処理時の計算コストを抑えるために、疎なアテンション系の手法(DeepSeek Sparse Attentionに言及)を採用していると説明されています。
この構成により、大規模なパラメータ数と実行時コストの抑制を両立する設計になっています。
学習データ規模・精度形式・コンテキスト長
GLM-5は次のような条件で事前学習・提供が行われています。
- 事前学習データ量:約28.5Tトークン
- 重み精度:BF16(標準)に加え、推論向けにFP8等の提供が言及される
- コンテキスト長:最大200K級(長文処理を前提にした設計)
フル精度(BF16)版を「重みだけ」で見積もると、744B × 2byte ≒ 約1.5TB級になります。
セルフホストする場合は、マルチGPUサーバー/推論クラスタ前提での設計が現実的です。
Huawei Ascendなど“非NVIDIA”環境も意識した提供
GLM-5は、推論(inference)用途で「中国国内の国産チップを含む環境」を意識した提供が報じられています。
また、モデルのデプロイガイドでは、NVIDIA以外のアクセラレータ環境(例:Huawei Ascend NPU)に触れた記載も見られます。
ここは技術面だけでなく、地政学やサプライチェーンの観点からも検討テーマになりやすい領域です。
一方で「学習をどのハードウェアで行ったか」まで断定するには、一次情報の粒度が足りないケースがあるため、運用判断に使う場合は公式資料と報道の両方を突き合わせてください。
GLM-5の特徴:コーディングとエージェント性能
GLM-5の最大の訴求ポイントは、ソフトウェアエンジニアリング領域での性能と、長期エージェントタスクでの安定した挙動です。
ここでは、公式の公開情報(モデルカード等)を中心に、特徴を整理します。
コーディングベンチマークとオープンウェイト上位水準
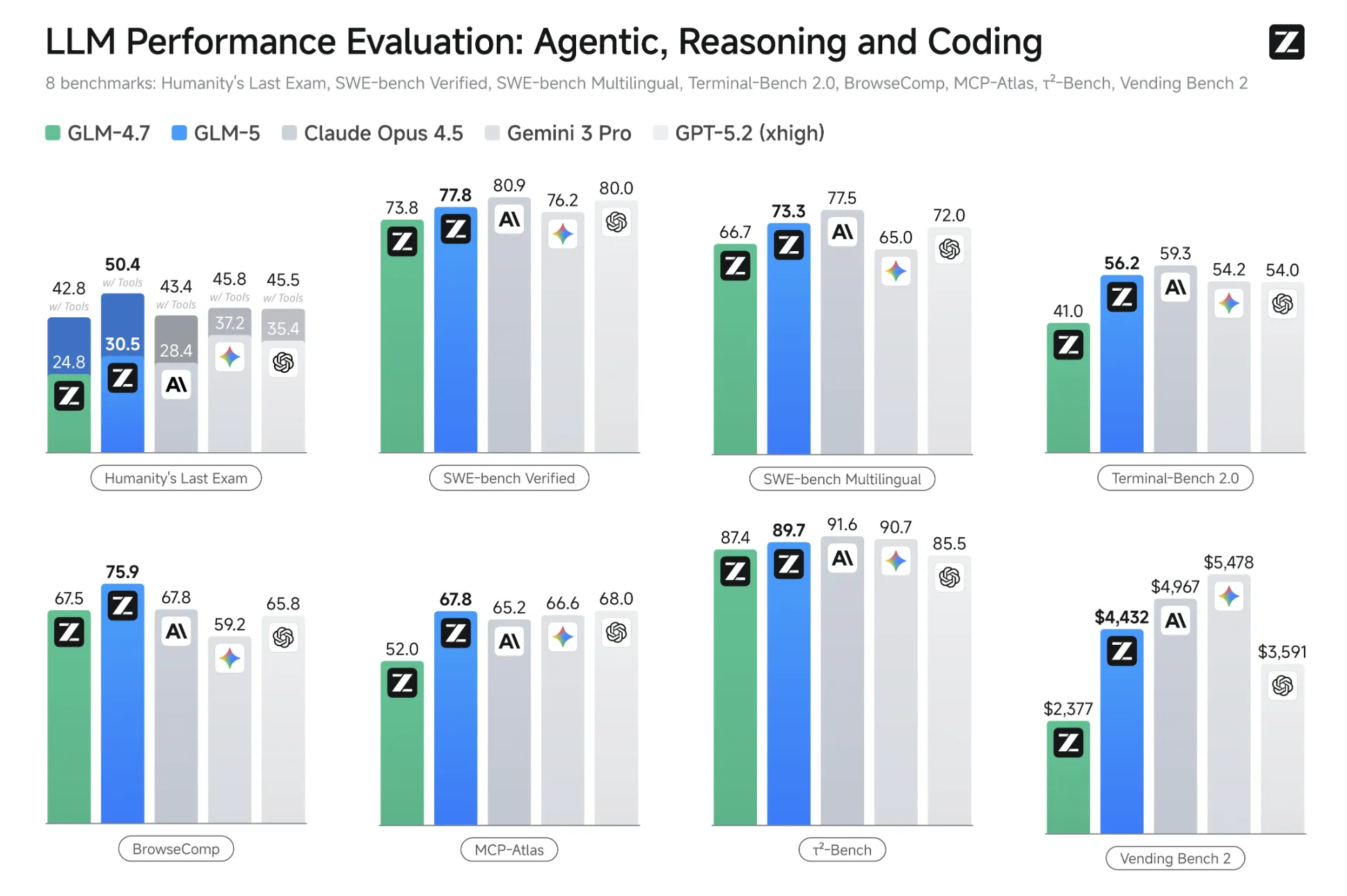
LLM Performance Evaluation: Agentic, Reasoning and Coding(8ベンチ比較)
GLM-5は、SWE-bench Verifiedなどのコーディングベンチマークで、公開モデルとして上位水準のスコアが示されています。
公式にまとまった比較図では、たとえば次のような結果が提示されています。
- SWE-bench Verified:77.8(GLM-4.7の73.8から上昇。比較図ではClaude Opus 4.5=80.9、GPT-5.2=80.0)
- SWE-bench Multilingual:73.3(GLM-4.7の66.7から上昇)
- Terminal-Bench 2.0:56.2(GLM-4.7の41.0から上昇)
このため、「コーディング性能は、クローズド最上位に近い領域まで迫っている(ただし項目によって差は残る)」という整理が現実的です。
一方で、モデル自体が大きいため、軽量モデルと比較すると推論レイテンシやスループットで不利になる場面があります。
「1回の呼び出しでどこまでタスクを進めてくれるか」という観点で見ると、トークン単価だけではない“効率面のトレードオフ”も意識した設計が必要です。
長期タスク・システム設計におけるエージェント性能
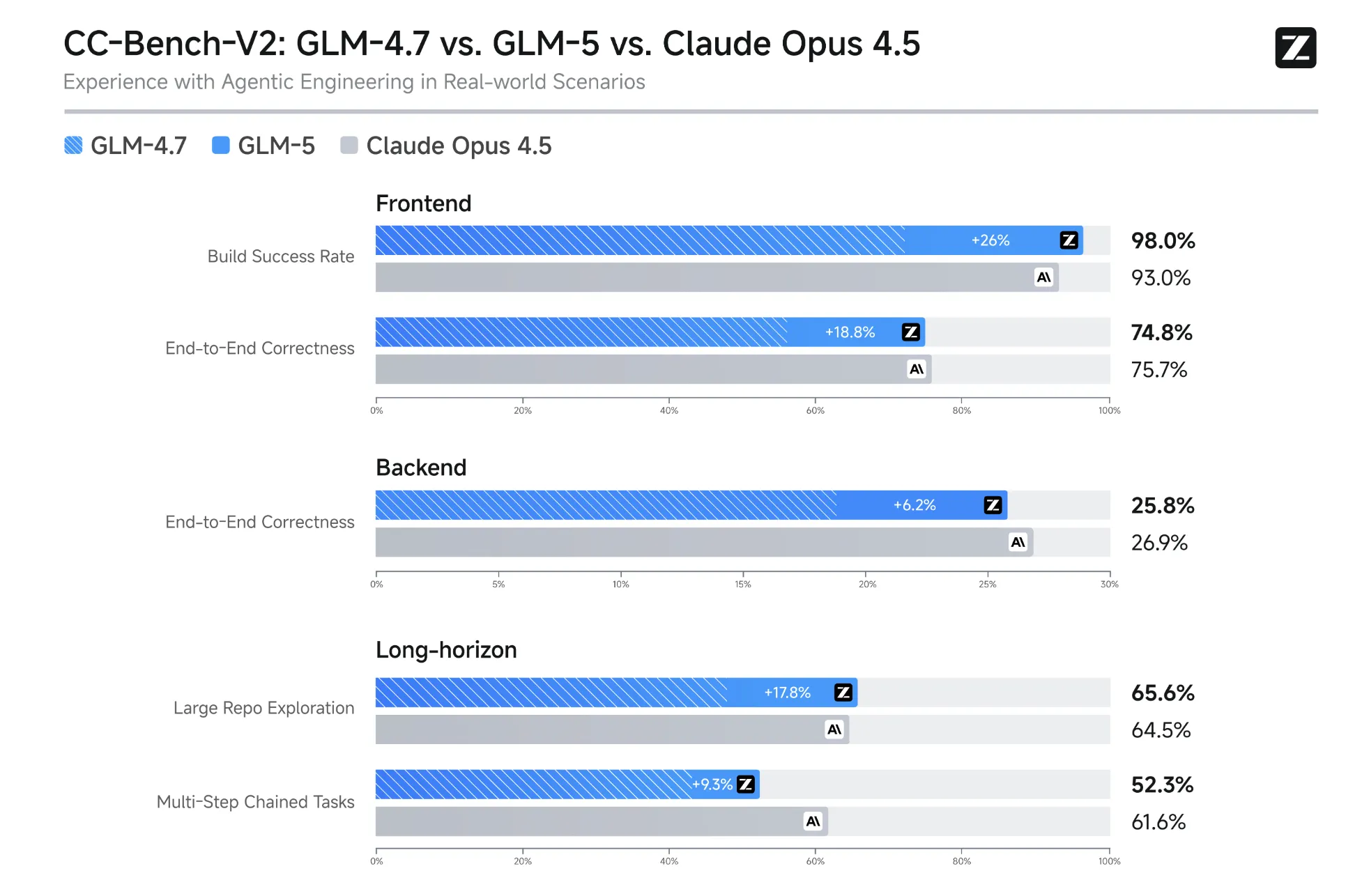
CC-Bench-V2(Agentic Engineering in Real-world Scenarios)
GLM-5は、長期タスク・複雑なシステム設計を対象にした“エージェント的な仕事”での性能も重視されています。
BrowseCompやMCP-Atlasなど、ツール実行やブラウジングを伴う指標でもスコア上昇が示されています。
- BrowseComp:75.9(GLM-4.7=67.5)
- MCP-Atlas:67.8(GLM-4.7=52.0)
- t^2-Bench:89.7(GLM-4.7=87.4)
ただし、Frontend/Backend/Long-horizonで「得意・不得意」が分かれるため、“総合で常に勝つ”ではなく“特性を見る図”として置くのが安全です。
たとえば「Build Success Rate」は高い一方で、「Multi-Step Chained Tasks」のような項目では他モデルが上回る場面も示されており、 エージェント性能は“単一スコア”ではなくタスクタイプで見たほうが判断しやすいことが分かります。
また、以下はシミュレーションを通じて資金を増やすタイプの指標で、長期運用の挙動差が可視化されています。
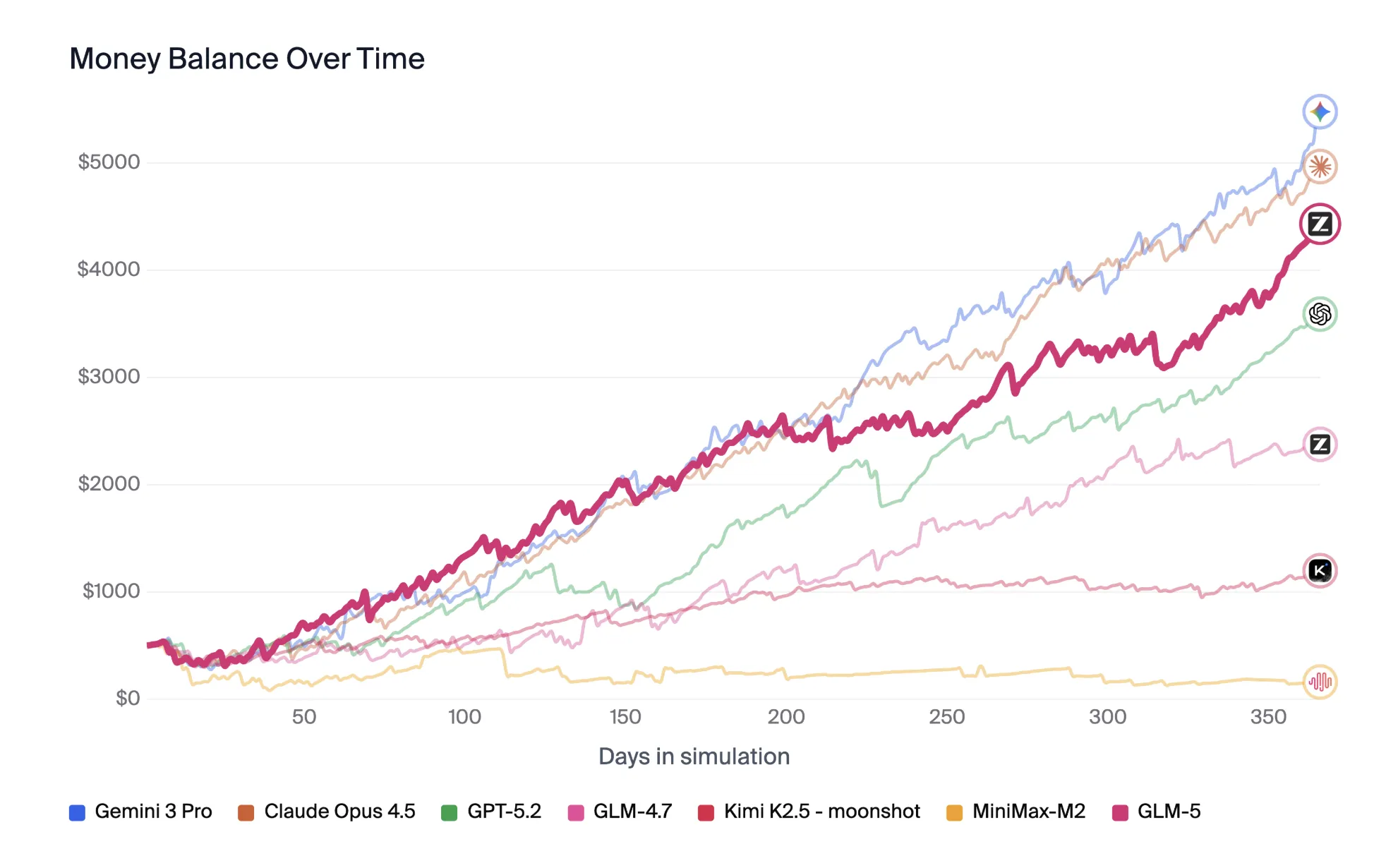
幻覚率・安定性・安全性
GLM-5は、ハルシネーション(事実誤認の生成)削減にも重点を置いて調整されています。
ただし、外部の評価はベンチや設定で揺れやすく、運用時の安全性はプロンプト設計・ガードレール・ログ監査などとセットで検証することが重要になります。
- 「分からないときに無理に答えない(abstainする)」挙動が強化される方向性は、各社モデルで一般に見られるトレンド
- コーディングやツール実行系では、エラーを踏まえた自己修正の挙動が観察されることがある
- 一方で、雑談や創作タスクでは、モデル特性上の癖も出やすいため個別検証が必要
GLM-5の料金
ここでは、GLM-5をどのような形で利用できるのか(API/サブスク/オープンウェイト/ローカル実行)と、料金・ライセンス面を整理します。
Z.ai APIの従量課金
| モデル | 入力 | キャッシュ入力 | 出力 |
|---|---|---|---|
| GLM-5(テキスト) | $1.00 / 1M tokens | $0.20 / 1M tokens | $3.20 / 1M tokens |
| GLM-5-Code(コード) | $1.20 / 1M tokens | $0.30 / 1M tokens | $5.00 / 1M tokens |
- キャッシュ入力ストレージ:期間限定で無料(無料条件は更新される可能性あり)
GLM Coding Plan(サブスク)
GLM-5は、APIの従量課金とは別に、GLM Coding Plan(DevPack)のサブスクリプションでも提供されています。
これは「IDE/コーディング用途のツール連携」を主眼にしたプランで、**Monthly / Quarterly(-10%)/ Yearly(-30%)**といった形態です。
| プラン | Monthly | Quarterly(-10%) | Yearly(-30%) |
|---|---|---|---|
| Lite | $10 / month | $27 / quarter | $84 / year |
| Pro | $30 / month | $81 / quarter | $252 / year |
| Max | $80 / month | $216 / quarter | $672 / year |
プランの主な位置づけ
-
Lite
軽量ワークロード向け。20以上のコーディングツール(Claude Code、Cursor、Cline、Kilo Code など)に対応。
-
Pro
Liteの5倍の使用量。複雑なワークロード向け。新モデル/機能への優先アクセス。Liteより 40%〜60%高速 と記載。Vision Analyze / Web Search / Web Reader / Zread MCP へのアクセスを含む。 -
Max
Pro の4倍の使用量。高負荷・大規模利用向け。ピーク時間帯の性能保証、最速の新モデル/機能アクセスなどを含む。
ローカル・オンプレミス導入時の前提・必要スペック
GLM-5はオープンウェイトモデルとして公開されており、MITライセンスの下で利用できます。
Hugging Faceなどのモデルリポジトリに、BF16版・FP8版など複数のバリエーションが登録されています。
- ライセンスがMITであるため、商用利用・再配布・改変が広く認められている
- モデル重みを自社環境に持ち込み、オンプレミスやプライベートクラウドで運用可能
- OSSコミュニティによる量子化版・最適化版も多数登場している
クローズドモデルと異なり、「自社のインフラ上で完全に閉じた形で運用する」選択肢を取りやすい点が、GLM-5の大きな利点の一つです。
おおよその必要スペック
フル精度(BF16)版のGLM-5をセルフホストする場合、モデルサイズが非常に大きいため、現実的にはマルチGPUサーバーや専用の推論クラスタが前提になります。
- BF16フルモデル:1.5TB級のメモリ/ストレージを前提とした構成
- FP8/2bit量子化モデル:数百GBクラスのVRAM構成で運用可能な事例が報告
- 1bit量子化など、さらに圧縮したモデルは精度・安定性とのトレードオフが大きく、個別検証が必要
GLM-5の主なユースケース
GLM-5は汎用LLMとしてさまざまな用途に使えますが、とくにエンジニアリング領域とエージェント用途で強みを持つモデルです。
ここでは、代表的なユースケースを整理します。
ソフトウェアエンジニアリング:コード生成・リファクタリング・レビュー
GLM-5のコーディング性能は、公式比較図でも上位水準が示されています。
想定される活用例:
- フロントエンド〜バックエンドまでを含むフルスタックなコード生成
- 既存コードベースのリファクタリング案や性能改善案の提示
- テストコードの生成、既存テストの補強、CI/CD定義の作成支援
- ログやスタックトレースを読み解き、根本原因の推定と修正パッチの提案
特に、「一度エラーを出した後、自分でログを読み直して修正を試みる」といった挙動が観察されることがあり、単発のスニペット生成を超えた“ペアプロ相手”としての振る舞いが期待されています。
Agentic Engineering:長期タスク・業務フロー自動化
GLM-5は、Agentic Engineering(エージェント前提のシステム設計)向けの基盤モデルとしても位置づけられています。
具体的なシナリオの例:
- 要件定義→設計→実装→テスト→ドキュメント化までを含む長期タスクの自動化
- データ分析・可視化・レポート作成・スライド化までを一気通貫で行うアシスタント
- チケット管理ツールやワークフローエンジンと連携し、継続的に業務改善提案を行うエージェント
長時間連続して動くエージェントは、モデルの“安定した推論”や“目標の維持”が求められます。
GLM-5はこの領域を強く意識して設計されたモデルであり、公式比較でも長期タスク系の指標が提示されています。
日本語・多言語での利用とチューニングの方向性
GLM-5は多言語対応をうたっており、日本語を含む多言語での利用が想定されています。
企業利用では、GLM-5をベースモデルとしてRAG(検索拡張生成)やLoRAなど軽量なファインチューニングを組み合わせ、自社ドメインに特化したアシスタントを構築するパターンが現実的です。
GLM-5と他モデルの比較・選定の考え方
ここでは、GLM-5を他の代表的モデルと比較し、「どのポジションで採用すべきか」を考えるための視点を整理します。
GLM-4.7・GLM-4.6Vとの比較
同一ベンダー内の比較としては、GLM-4.7(テキストモデル)およびGLM-4.6V(マルチモーダルモデル)との関係が重要です。
- GLM-4.7
- テキスト中心の汎用モデルで、コーディングやエージェント実行の安定性を強化した位置づけ。
- テキスト中心の汎用モデルで、コーディングやエージェント実行の安定性を強化した位置づけ。
- GLM-4.6V
- 画像入力などに対応したマルチモーダルモデル。認識系タスクに強み。
- 画像入力などに対応したマルチモーダルモデル。認識系タスクに強み。
- GLM-5
- 744B/40BのMoEへスケールし、エージェント的なエンジニアリング用途を強く意識したフラッグシップ。
したがって、「マルチモーダルが必須ならGLM-4.6V」「コーディングとエージェントを最重視するならGLM-5」という棲み分けが現時点では自然です。
GPT-5.2・Claude Opus・Gemini系との位置づけ
クローズドなフロンティアモデルとの比較では、GLM-5は次のようなポジションと整理できます。
- 性能面
- コーディング・エージェント系ベンチで差が小さい項目もある一方、項目によってはクローズド側が上回る。
- コーディング・エージェント系ベンチで差が小さい項目もある一方、項目によってはクローズド側が上回る。
- コスト面
- 公式Pricingでは入力$1/出力$3.2(1M tokens)で、最上位クローズドより低価格帯に置かれることが多い。
- オープンウェイトであるため、自前ホスティングによるコスト最適化余地も大きい。
- 機能面
- 公式にはテキスト中心の位置づけで、ワークスペース統合やマルチモーダル体験はクローズドSaaS側が有利になりやすい。
このため、「UIやマルチモーダル体験は既存のSaaSに任せ、バックエンドのエージェント・コーディング用にはGLM-5を使う」といった役割分担を前提に設計するパターンも考えられます。
DeepSeek V3系・Kimi系など他オープンモデルとの比較ポイント
他のオープンウェイト勢との比較では、DeepSeek V3系やMoonshot AIのKimi系が比較対象になります。
単純にスコアだけで決めるというより、「既存のツールチェーンとの相性」「利用したいAPIプラットフォームがどのモデルを優先サポートしているか」といった実務的な観点も含めてモデル選定を行う必要があります。
GLM-5を検討する際の注意点
ここからは、GLM-5を導入候補として検討する際に、意識しておきたいポイントを整理します。
中国発モデル特有のリスク(制裁・データ越境・コンプライアンス)
GLM-5の開発元は、米国の制裁や輸出規制の文脈で言及されるなど、地政学的なリスク要因を抱えます。
これはGLM-5に限った話ではありませんが、中国発のフロンティアモデルを業務利用する際には、次の観点を事前に検討しておく必要があります。
- データ越境の扱い
- クラウドAPIを使う場合、自社データがどの地域のデータセンターで処理されるか。
- 個人データや機密情報を送信してよいかどうか、社内ポリシーや規制との整合性。
- 制裁・輸出管理リスク
- 将来的な規制強化により、特定リージョンや特定企業との取引制限が生じる可能性。
- 監査・説明責任
- モデル出力の根拠説明、ログ保全、第三者監査などの要件にどう対応するか。
これらは法律・コンプライアンス・情報セキュリティの領域とも重なるため、IT部門だけでなく法務・リスク管理部門と連携して方針を定めることが重要です。
コスト・性能・運用の観点からの適合性
GLM-5はトークン単価だけ見ると魅力的ですが、エージェントワークフローで「長時間・大量トークン」を使う場合、総コストは相応の規模になります。
-
ケースごとのコスト比較
- 単発のQ&A/要約タスクは、より軽量なモデルや他社SaaSでも十分なケースが多い。
- 長期エージェントや大規模コードベースを扱うタスクだけGLM-5に振り分ける設計にできるか
-
運用の複雑さ
- オープンウェイトモデルを自社で運用する場合のMLOps・監視・アップデートコスト。
- 精度設定(BF16/FP8等)やバージョン管理、評価の手間。
-
社内スキルとのフィット
- エージェントフレームワーク・ツール呼び出し・ガードレール設計を担当できるチームがいるか。
「他モデルとのA/B比較」「タスク別モデル切り替え」「RAG+エージェント構成での実運用テスト」などを通じて、GLM-5が最も効果を発揮する領域を見極めることが重要です。
まとめ
最後に、GLM-5のポイントを簡単に振り返ります。
- GLM-5は、744B/40BのMoE構造と約28.5Tトークンの事前学習を背景に、オープンウェイト陣営の中でトップクラスの性能を狙ったフラッグシップモデルです。
- コーディング・エージェント分野では、公式比較図でも強いスコアが示されており、項目によってはクローズド最上位と差が小さい領域まで迫っています。
- オープンウェイト+MITライセンスで公開されているため、自社インフラ上でのセルフホストや、API/自前運用を組み合わせた柔軟なアーキテクチャ設計が可能です。
一方で、次のような観点には注意が必要です。
- 中国発モデルとしてのデータ越境・制裁リスク、コンプライアンス要件への対応。
- フル精度での自前運用を行う場合のインフラ要件・運用コスト。
- エージェント前提のワークロードで、実際にどこまで「人の仕事」を代替・拡張できるかという定量評価。
現実的な進め方としては、
- 既存のGPT/Claude/Gemini環境と並行して、GLM-5を特定ユースケースの候補として試す。
- コーディングタスクやエージェントワークフローでA/Bテストを行い、品質・レイテンシ・コストを比較する。
- 問題なければ、RAGや社内ツール連携を含めたアーキテクチャを設計し、オープンウェイトの利点(コスト最適化・カスタマイズ性)を段階的に活かしていく。
というステップが考えられます。
GLM-5は、「オープンウェイトでもここまで到達できる」という意味でインパクトの大きいモデルです。
ただし、どれほどモデルが高性能になっても、インフラ・データ・業務プロセス・人材・ガバナンスといった“AI Ready”の土台が整っていなければ、十分な価値は引き出せません。
自社のユースケースと制約条件を整理しながら、**「どのレイヤーでGLM-5を使うと最も効果的か」**を冷静に見極めることが、これからのモデル選定のポイントになります。





