この記事のポイント
 ChatGPTの回答は「正しい情報」ではなく「もっともらしい情報」であり、業務利用では必ず一次情報で裏取りすべき
ChatGPTの回答は「正しい情報」ではなく「もっともらしい情報」であり、業務利用では必ず一次情報で裏取りすべき- GPT-5.4はハルシネーション33%減だが完全解消は不可能なため、推論モデル(o3等)との併用が第一候補
- 法律・医療・金融の専門分野ではChatGPT単体の回答を意思決定に使ってはならない(裁判所制裁206件超の実例あり)
- ハルシネーション対策はウェブ検索ONとプロンプトへの「根拠URLを提示して」指示の組み合わせが最も実用的
- 企業導入時はPlus以上のプランでGPT-5.4 Thinkingを使い、回答精度とコストのバランスを取るべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTは週間アクティブユーザー9億人を擁する世界最大のAIサービスですが、その回答の正確性は保証されていません。AIが事実と異なる情報を自信を持って生成する「ハルシネーション」は、2026年3月時点の最新モデルGPT-5.4でも完全には解消されていません。
本記事では、ChatGPTの誤回答が発生する原因をOpenAIの最新研究に基づいて解説し、具体例・モデル別比較・法律分野の裁判事例・実践的な対策までを網羅的に紹介します。
ChatGPTの新料金プラン「ChatGPT Go」については、以下の記事をご覧ください。
ChatGPT Goとは?料金や機能、広告の仕様、Plus版との違いを解説
最新モデル「GPT-5.5」については、以下の記事をご覧ください。
GPT-5.5とは?使い方や料金、GPT-5.4との違いを解説
ChatGPTの誤回答(ハルシネーション)とは
ChatGPTが事実と異なる情報を、あたかも正しいかのように自信を持って回答する現象は「ハルシネーション(幻覚)」と呼ばれています。2026年3月時点で、最新のGPT-5.4を含むすべての大規模言語モデル(LLM)において、ハルシネーションは完全には解消されていません。

ChatGPTの最新情報は2022年1月まで
上のスクリーンショットは、旧モデルにおいて学習データの時点制限が原因で誤った回答が生成された例です。現在のChatGPTにはウェブ検索機能が搭載されていますが、ウェブ検索を使わない場合や、検索結果の解釈を誤る場合には、依然として誤回答が発生します。

ChatGPTの誤回答の3つの類型
ChatGPTの誤回答を理解するために、発生パターンを以下の3つに分類して整理しました。
| 類型 | 概要 | 典型例 |
|---|---|---|
| 事実誤認型 | 存在しない事実を断定的に述べる | 架空の判例引用、存在しない論文の生成 |
| 文脈逸脱型 | 質問の意図からずれた回答をする | 文字数指定の無視、話題のすり替え |
| 情報混合型 | 複数の事実を混ぜて新たな誤情報を生成する | 2つの人物の経歴を混同、異なる製品の仕様を合成 |
事実誤認型は最も深刻で、架空の法律判例をもっともらしく引用するケースが法律分野で問題化しています。文脈逸脱型は、長い会話や複雑な条件指定で発生しやすく、情報混合型は類似する概念が学習データに存在する場合に起きやすい特徴があります。
【関連記事】
ChatGPTが嘘をつくのはなぜ?その原因と対策方法を解説
ChatGPTが誤回答する原因(2026年最新研究)
ChatGPTの誤回答は単なる「バグ」ではなく、大規模言語モデル(LLM)の設計原理に根差した構造的な問題です。OpenAIが2025年9月に発表した研究論文「Why Language Models Hallucinate」は、ハルシネーションの根本原因を体系的に分析しています。
ChatGPTの学習データと確率的生成の限界
ChatGPTは膨大なテキストデータから「次に来る可能性が最も高いトークン(単語の断片)」を予測する仕組みで動作しています。つまり、モデルが選んでいるのは「正しい回答」ではなく「もっともらしい回答」です。この本質的な違いが、ハルシネーションの第一の原因です。
学習データに関しても複数の制約があります。まず、訓練データには時点の制限があり、モデルが学習していない期間の情報については正確に回答できません。2026年3月時点のChatGPTにはウェブ検索機能が搭載されていますが、検索結果の解釈を誤るケースや、ウェブ検索が無効化されている状態では、依然として古い情報に基づく誤回答が発生します。加えて、訓練データ自体に含まれる誤情報や偏りも、モデルの回答精度に影響を与えています。
「知らない」と言えない構造的問題
OpenAIの研究が指摘する最も重要な知見は、現在のLLMの学習・評価プロセスが「推測」を報酬として与えている構造的問題です。ベンチマークは正答率のみを測定するため、モデルが「わかりません」と正直に回答するよりも、推測でも回答した方がスコアが高くなります。
この構造が、モデルに「知らないことでも自信を持って回答する」インセンティブを与えています。つまり、何千もの評価問題に対して、不確実でも推測するモデルの方が、慎重に「不明」と答えるモデルよりもリーダーボードで上位に来るのです。OpenAIはこの問題を解決するために、既存のベンチマークのスコアリング方法を修正する「社会技術的な対策」が必要だと主張しています。
一方、Claudeを開発するAnthropicは、不確実な場合に回答を拒否するアプローチを採用しており、ハルシネーション率は低い代わりに回答拒否率が高いという特性を持っています。
【関連記事】
ChatGPTの仕組みとは?全体像や図解で基礎から解説!
ChatGPTの誤回答パターンと具体例
ここでは、ChatGPTの誤回答がどのような場面で発生するかを、実際のスクリーンショットを交えて具体的に示します。
事実と異なる情報の生成
学習データの時点制限による誤回答は、刻々と変動する情報を扱う際に特に顕著です。以下は、ChatGPTにドル円の為替レートについて質問した際の誤回答例です。
ChatGPTは「2024年現在の1ドルは約100円前後」と回答しましたが、実際の2024年5月2日の為替レートは1ドル約155円でした。

ChatGPTの回答による2024年のドル円相場
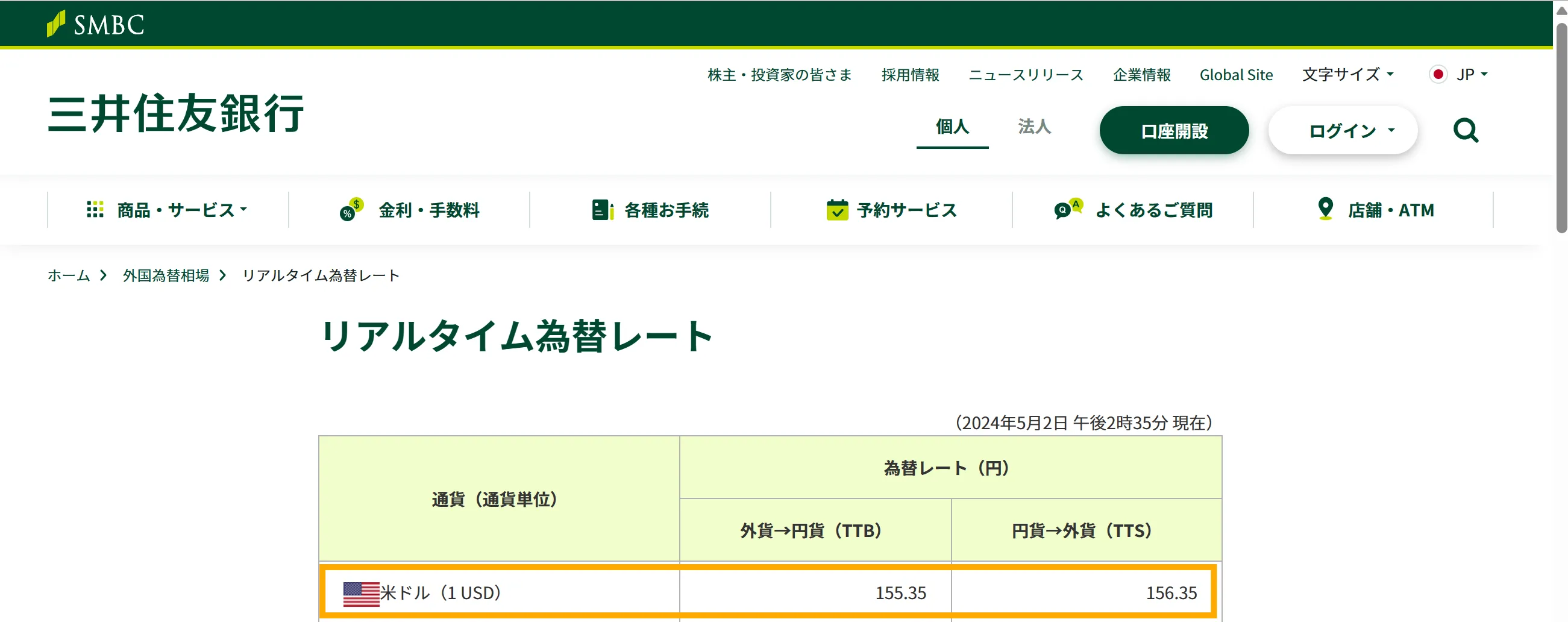
実際の2024年のドル円相場
もう1つの例として、男子マラソンの世界記録に関する質問を示します。ChatGPTは「2時間1分39秒、エリウド・キプチョゲ選手」と回答しましたが、2024年5月時点ではケルビン・キプタム選手が2時間35秒の世界新記録を更新していました。

ChatGPTで調べた男子マラソンの世界記録
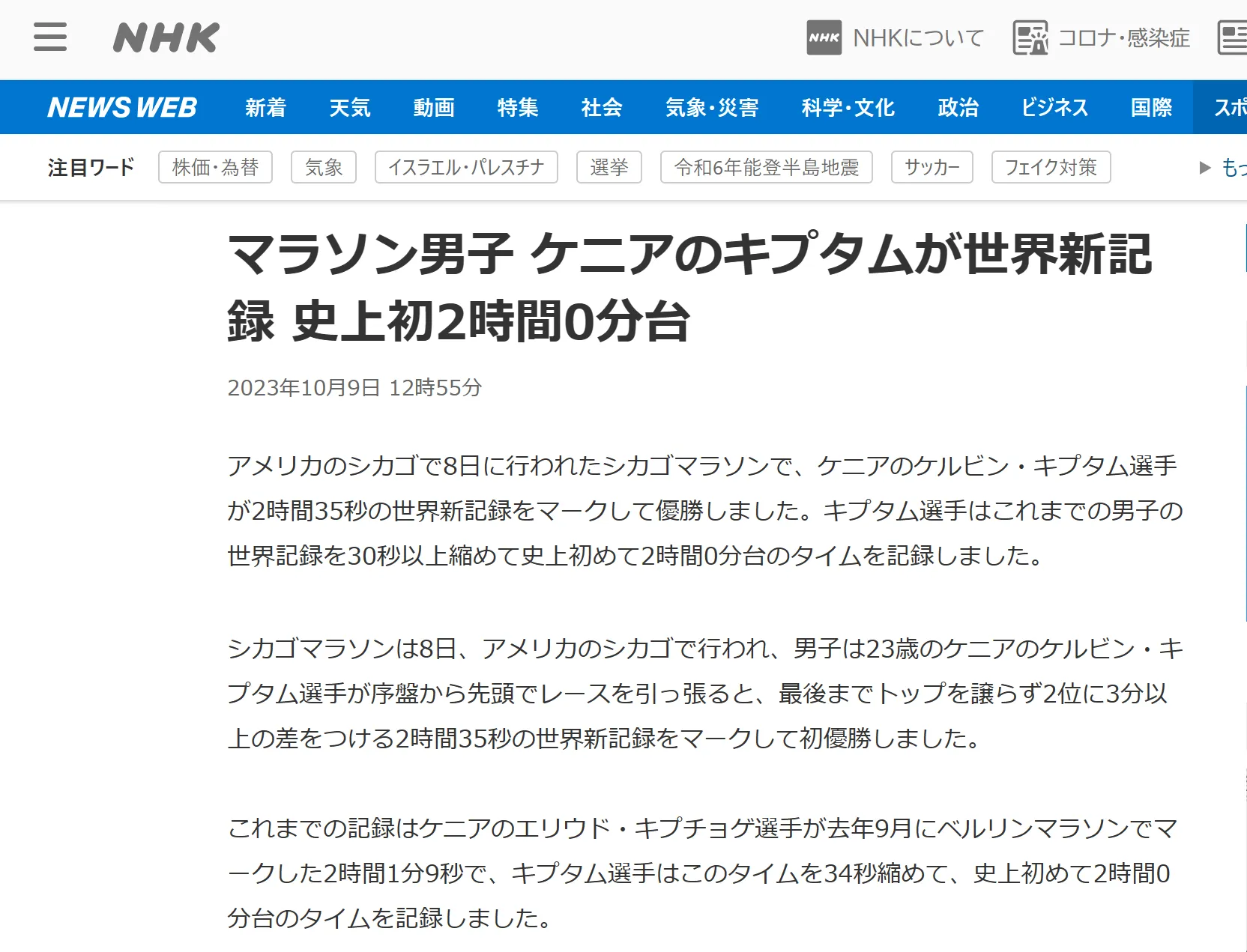
実際の男子マラソンの世界記録
これらのスクリーンショットは旧モデル(GPT-3.5/GPT-4)での検証結果です。2026年3月時点のChatGPTにはウェブ検索機能が搭載されており、リアルタイムの為替レートやスポーツ記録については検索経由で正確な情報を取得できるようになっています。ただし、ウェブ検索を使わない質問モードや、無料プランの旧モデルを使用する場合には、同様の誤回答が依然として発生する可能性があります。
【関連記事】
ChatGPTの学習データはいつまで?最新情報を取得する方法を解説
文脈理解と指示遵守の限界
ChatGPTは、特に数値条件や出力形式の指定において、ユーザーの意図通りに回答できないことがあります。以下は、「タンザニアの食事に関する情報を400文字で教えて」とリクエストした際に、448文字の回答が返ってきた例です。
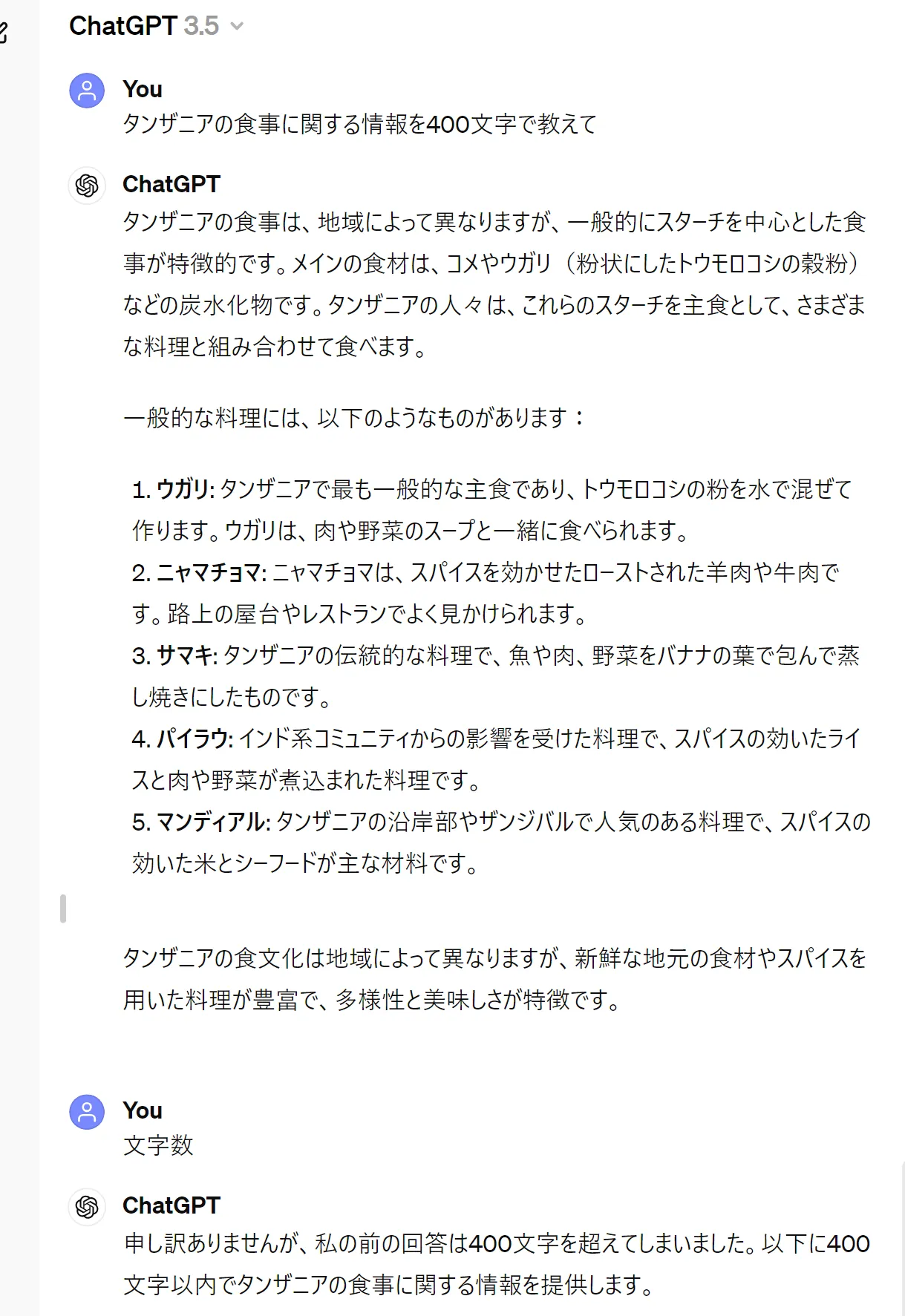
400文字でに対して400文字をオーバーする回答
LLMはテキストを「トークン」単位で処理しており、文字数を正確にカウントする能力は限定的です。対策として、「320文字から400文字以内で」のように具体的な範囲を指定すると精度が向上します。

320文字~400文字で回答に対して320文字の回答
GPT-5以降のモデルではこうした指示遵守能力が大幅に改善されていますが、文字数の厳密な制御は依然としてLLMが苦手とする領域の一つです。
【関連記事】
ChatGPTが文字数指定を守らない?その対処法を徹底解説!
専門分野への対応の難しさ
訓練データに十分な情報が含まれていないニッチな分野や専門領域では、ChatGPTの誤回答率が特に高くなります。以下は、登山業界では有名なミャンマー最高峰のカカボラジ山についてChatGPTに質問した例です。
ChatGPTは「一般的でない」との回答を返しましたが、実際にはNational Geographicが特集を組むほどの有名な山です。

ChatGPTによるカカボラジに関する回答
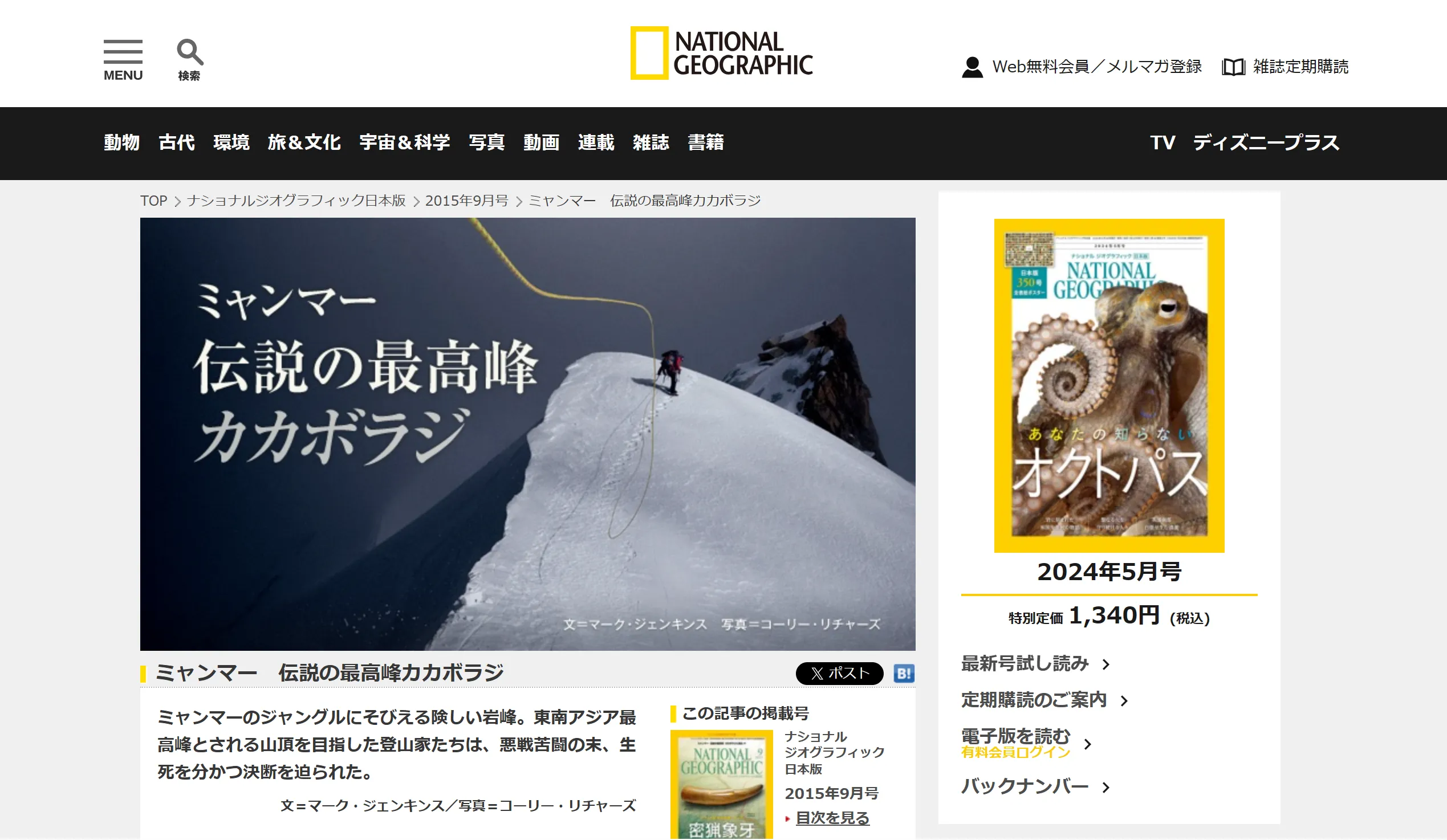
National Geographicによるカカボラジの説明
こうした事例は、ある領域では「常識」とされる情報でも、訓練データにおけるその情報の出現頻度が低ければ、モデルが正確に学習できないことを示しています。専門分野の情報をChatGPTに確認する場合は、必ずその分野の一次資料や専門家の見解と照合することが重要です。
ChatGPTのモデル別ハルシネーション率比較(2026年版)
ChatGPTの誤回答は、使用するモデルによって大きく異なります。OpenAIが公開しているベンチマークデータと独立評価機関の分析をもとに、主要モデルのハルシネーション性能を比較しました。
| モデル | ハルシネーション改善 | 主な評価データ | ウェブ検索 |
|---|---|---|---|
| GPT-4o | 基準モデル | SimpleQA正答率約44% | 対応 |
| GPT-5 | GPT-4o比で事実誤り45%減 | SimpleQA正答率46%(検索なし)、95.1%(検索+思考) | 対応 |
| GPT-5.2 | GPT-5から改善 | ARC-AGI-1で90%突破 | 対応 |
| GPT-5.3 Instant | GPT-5比ハルシネーション26.8%減 | 虚偽主張の低減に特化 | 対応 |
| GPT-5.4 | GPT-5.2比で虚偽主張33%減 | フル回答のエラー率18%減 | 対応 |
| o3 / o4-mini | 推論でGPT-4o比80%減 | 段階的推論による事実検証 | 対応 |
GPT-5のSimpleQAベンチマークでは、ウェブ検索なしの場合は正答率46%にとどまる一方、ウェブ検索と思考モードを組み合わせると95.1%まで向上します。この差は、LLMの知識だけに頼ることの限界と、外部情報ソースとの組み合わせの重要性を端的に示しています。
GPT-5.4のハルシネーション改善
GPT-5.4は、OpenAIが「最も事実に正確なモデル」と位置づけています。ユーザーが事実誤りを報告したプロンプトセットでの評価では、GPT-5.4の個別の主張がGPT-5.2と比較して33%虚偽になりにくく、回答全体としてもエラーを含む確率が18%低下しています。
(参考)OpenAI's GPT-5.4 doubles down on safety
GPT-5.4のSafety Cardでは、サイバーセキュリティ分野における高度な能力への対策が初めて実装され、推論の透明性に関する研究も公開されています。ただし、33%の改善があっても完全にゼロにはなっていない点は認識しておく必要があります。
競合AIとのハルシネーション比較
ChatGPT以外の主要AIサービスのハルシネーション状況も確認しておくことで、用途に応じた使い分けの判断材料になります。
| サービス | ハルシネーション率(AA-Omniscience) | 特徴 |
|---|---|---|
| ChatGPT(GPT-5.4) | ベンチマーク公開済み(SimpleQA) | ウェブ検索との組み合わせで高精度 |
| Claude(Sonnet 4.6) | 約38%(Sonnet 4.5の48%から改善) | 不確実な場合は回答を拒否する設計 |
| Gemini(3.1 Pro) | 約50%(Gemini 3 Proの88%から改善) | 単一アップデートで最大の改善幅 |
Claudeは不確実な質問に対して「わかりません」と回答する率が高い代わりに、回答した場合の正確性が最も高い傾向にあります。一方、Geminiは3.1 Proで前世代から88%→50%とハルシネーション率を大幅に改善しましたが、依然として50%程度の課題が残っています。用途に応じて、汎用的な質問にはChatGPT(ウェブ検索ON)、正確性が最優先の場面ではClaude、Google Workspace連携が必要な場合はGeminiという使い分けが実務的です。
【関連記事】
ChatGPT-5(GPT-5)とは?使い方や料金、回数制限について解説!
推論モデル(reasoningモデル)とは?仕組みや学習モデルとの違いを徹底解説

ChatGPTの誤回答が引き起こすリスク
ChatGPTの誤回答は、個人的な調べ物で「ちょっと違った」程度であれば大きな問題にはなりません。しかし、業務や専門分野で検証なしに使用した場合、深刻な実害が発生しています。
法律分野の裁判所制裁事例
ChatGPTの誤回答が最も深刻な問題を引き起こしている分野の一つが法律です。AIが生成した架空の判例を裁判所に提出し、制裁を受ける事例が急増しています。
AIハルシネーション事例データベースによると、2025年末時点でAIが生成した架空のコンテンツが裁判所で問題となったケースは206件を超えています。その増加ペースも加速しており、2025年前半は週に2件程度だったものが、後半には1日2〜3件のペースに達しています。
具体的な事例として、MyPillow CEO Mike Lindellの弁護を担当した2名の弁護士が、ChatGPTで作成した書面にハルシネーションによる架空の判例を含めたまま提出し、1人あたり3,000ドルの制裁金を科されたケース(2025年7月)があります。カナダのKo v. Li事件では、存在しない判例を引用した弁護士が法廷侮辱罪に問われました。
(参考)AI Hallucinations Strike Again: Two More Cases
法律分野だけでなく、AIの誤回答を検証せずに業務で使用することは、企業の信用失墜や法的責任につながるリスクがあります。業務報告書、提案書、コンプライアンス関連文書にChatGPTの出力をそのまま使用することは、事実上「検証なしの引用」と同等のリスクを伴います。
医療・金融・教育への影響
法律以外の分野でも、ChatGPTの誤回答が実害を引き起こすリスクは高まっています。
-
医療
ChatGPTに症状を相談して自己診断に利用するケースが増えていますが、誤った医療情報は直接的な健康被害につながります。PMC(PubMed Central)に掲載された研究では、GPT-5で医療分野のハルシネーションが顕著に減少したと報告されていますが、医療従事者による検証なしでの利用は依然として推奨されていません
-
金融
投資判断や市場分析にChatGPTを使用する場合、誤った数値や過去のデータに基づく予測が損失につながる可能性があります。財務データは正確性が生命線であり、AIの出力を投資判断の唯一の根拠にすることは避けるべきです
-
教育
学生の86%がAIを学業に使用している中で、AIが生成した誤った情報をそのまま学習してしまうリスクが指摘されています。教育現場では、AIリテラシーの一環として「AIの出力を検証する習慣」を育てることが急務となっています
業務でChatGPTを日常的に使用しているにもかかわらず、出力の検証プロセスを定めていないチームは少なくありません。特に法律・医療・金融のような正確性が求められる分野では、AI出力のレビュー体制を組織として整備することが、リスク管理の第一歩です。
【関連記事】
ChatGPTのセキュリティリスクとは?実際の事例を踏まえて対策を解説
AI活用における倫理問題とは?実際の事例や解決策を解説
ChatGPTの誤回答を減らす対策
ChatGPTのハルシネーションを完全にゼロにすることはできませんが、適切な使い方によってリスクを大幅に低減できます。ここでは、実践的な7つの対策を紹介します。
プロンプト設計による精度向上
ChatGPTへの質問方法を工夫するだけで、誤回答の発生率を下げることができます。以下の4つのテクニックが有効です。
-
質問を具体的かつ限定的にする
「日本経済について教えて」ではなく「2026年1月の日本のGDP成長率の速報値を教えて」のように、対象・期間・情報の種類を明確にします
-
ステップバイステップの思考を指示する
「まず前提条件を確認し、次にデータを整理し、最後に結論を述べてください」のように段階的な思考を促すと、論理的な飛躍による誤回答が減少します
-
出典の明示を求める
「回答に含まれる事実には出典URLを付けてください」と指示することで、モデルが架空の情報を生成するリスクを低減できます。ただし、AIが生成した「出典URL」自体がハルシネーションである可能性もあるため、URLの存在確認は必須です
-
回答の確信度を表明させる
「各項目について、確信度を高・中・低で示してください」と指示することで、モデルが不確実な情報を明示するようになります
プロンプトエンジニアリングのテクニックを習得することは、ChatGPTの誤回答リスクを管理する上で最もコストの低い対策です。
ウェブ検索・推論モデル・RAGの活用
プロンプト設計に加えて、ChatGPTの機能やモデル選択を工夫することで、ハルシネーションをさらに低減できます。
-
ウェブ検索機能をONにする
GPT-5のSimpleQAベンチマークでは、ウェブ検索なしの正答率46%に対し、検索+思考モードでは95.1%に向上します。最新情報や数値データを扱う質問では、ウェブ検索を有効にすることが最も効果的な対策です
-
推論モデル(o3/o4-mini)を活用する
o3やo4-miniなどの推論特化モデルは、段階的に思考してから回答を生成するため、事実誤りがGPT-4o比で最大80%減少します。数学・科学・論理的な質問では推論モデルの使用を推奨します
-
RAG(検索拡張生成)を導入する
企業が独自のデータベースや文書をChatGPTに接続するRAGアーキテクチャを導入することで、社内の正確な情報に基づいた回答を生成できます。API経由での利用が前提となりますが、社内ナレッジベースとの連携により業務文脈での誤回答を大幅に抑制できます
-
ファクトチェックの習慣化
最終的には、AIの出力を人間が検証する体制が不可欠です。特に外部公開する文書やビジネス上の意思決定に使用する場合は、複数の情報源との照合を必ず行ってください。Microsoft Copilotのように回答にソースリンクを表示するAIツールも、ファクトチェックの効率化に有効です
【関連記事】
ChatGPTの性能低下の原因とは?その原因や影響、対策について解説
AIガバナンスとは?企業に必要な理由・導入方法を徹底解説

AIの誤回答対策を業務での安全なAI活用に活かす

ハルシネーション対策を業務AI導入の基盤に
ChatGPTの誤回答リスクとその対策を理解した方は、業務でAIを安全に運用する素地が整っています。220ページの実践ガイドで、リスク管理を組み込んだ業務AI導入の手順を確認できます。
ChatGPT料金比較(2026年3月版)
ChatGPTの誤回答を減らすためには、用途に応じたプランとモデルの選択が重要です。以下の表で、2026年3月時点のサブスクリプションプランを比較しました。
| プラン | 月額料金(USD) | 利用可能モデル | ハルシネーション対策の観点 |
|---|---|---|---|
| Free | 無料 | GPT-4o mini(制限付き) | 旧モデルのためハルシネーション率が高い |
| Go | $8 | GPT-5.2 Instant | ハルシネーション26.8%減のGPT-5.3相当 |
| Plus | $20 | GPT-5.2/5.4フルアクセス | GPT-5.4で最高精度、ウェブ検索・推論モデル利用可 |
| Pro | $200 | 全モデル無制限 | o3-proの最大推論+GPT-5.4で最高精度 |
| Team | $25〜30/ユーザー | GPT-5利用増量 | チーム共有ワークスペース |
| Enterprise | カスタム | 全モデル無制限 | データプライバシー保護+専任サポート |
誤回答のリスクを最小化したい場合は、GPT-5.4とウェブ検索が利用できるPlusプラン以上の利用を推奨します。無料プランやGoプランでも基本的な質問には対応できますが、業務利用で正確性を重視する場合は上位プランの検討が必要です。
API利用の場合、GPT-5.4 Thinking(入力$2.50/100万トークン、出力$15.00/100万トークン)が最も正確性の高いモデルです。コスト効率を重視する場合はGPT-5(入力$1.25/100万トークン、出力$10.00/100万トークン)が推奨されます。推論モデルのo3/o4-miniは内部的に「推論トークン」を消費するため、可視出力以上のコストが発生する点に注意が必要です。
【関連記事】
ChatGPT APIの料金ガイド 2026年3月最新版 モデル別料金一覧とコスト削減のポイント
ChatGPT料金完全ガイド!GPT-5・GPT-4o・Proプラン徹底比較
AIの誤回答リスクを理解した上で業務へのAI導入を設計するなら
ハルシネーションのメカニズムと対策を理解した方は、業務でAIを活用する際のリスク管理も冷静に設計できます。「どの業務はAIに任せて安全か」「どの場面で人間のチェックを入れるべきか」を判断する力は、AI導入プロジェクトの成功に直結します。
AI総合研究所では、AIのリスク対策を組み込んだ業務AI導入の実践ガイドを公開しています。220ページの資料で、誤回答リスクを抑えながら業務効率を上げるAI導入手順を確認できます。
ハルシネーション対策の知識を持った方に、AI総合研究所のガイドが安全な業務AI化を支援します。
AIの誤回答対策を業務での安全なAI活用に活かす
ハルシネーション対策を業務AI導入の基盤に
ChatGPTの誤回答リスクとその対策を理解した方は、業務でAIを安全に運用する素地が整っています。220ページの実践ガイドで、リスク管理を組み込んだ業務AI導入の手順を確認できます。
まとめ
ChatGPTの誤回答(ハルシネーション)は、LLMの設計原理に根差した構造的な問題であり、GPT-5.4で33%の改善が実現したとはいえ、完全な解消には至っていません。法律分野では架空の判例引用による裁判所制裁が206件を超え、医療・金融・教育分野でも検証なしの利用によるリスクが顕在化しています。
一方で、ウェブ検索を有効にすることでSimpleQAベンチマークの正答率が46%から95.1%に向上するように、適切な使い方を選ぶことで誤回答のリスクは大幅に低減できます。ChatGPTを業務で安全に活用するために、以下の3ステップから始めることを推奨します。
-
Step 1 出力の検証ルールを決める
チーム内で「ChatGPTの出力は必ず一次ソースで検証してから使用する」というルールを明文化します。特に法律・医療・金融に関する内容は、専門家のレビューを必須とします
-
Step 2 モデルと機能を使い分ける
最新情報の質問にはウェブ検索ON、論理的な分析には推論モデル(o3/o4-mini)、正確性最優先の場面ではGPT-5.4のThinkingモードと、用途に応じたモデル選択を徹底します
-
Step 3 組織のAIガバナンスを整備する
AI出力のレビュープロセス、利用可能な業務範囲の定義、インシデント発生時の対応フローをAIガバナンス体制として整備します










