この記事のポイント
 自動運転のシーン理解にはセマンティックセグメンテーションが第一候補
自動運転のシーン理解にはセマンティックセグメンテーションが第一候補- 医療画像の領域分割ならU-Netが精度・実績の両面で有力な選択肢
- リアルタイム処理が必要ならDeepLabV3+かSegFormerを優先すべき選択肢
- 同一クラス内の個体識別が不要なタスクではインスタンスセグメンテーションより低コストで導入できる実務的な手法
- 計算リソースが限られる場合はFCNベースの軽量モデルから段階的に精度を上げるのが実務的

Microsoft AIパートナー、LinkX Japan代表。東京工業大学大学院で技術経営修士取得、研究領域:自然言語処理、金融工学。NHK放送技術研究所でAI、ブロックチェーン研究に従事。学会発表、国際ジャーナル投稿、経営情報学会全国研究発表大会にて優秀賞受賞。シンガポールでのIT、Web3事業の創業と経営を経て、LinkX Japan株式会社を創業。
セマンティックセグメンテーションとは、画像内のすべてのピクセルにクラスラベル(道路・車・建物など)を割り当て、各領域が何を表しているかをピクセル単位で理解するコンピュータビジョン技術です。
本記事では、セマンティックセグメンテーションの定義・他の手法との違い、FCN・U-Net・DeepLab・SegFormerなどの代表的アーキテクチャ、DeepLabV3を用いた実装例、医療診断・自動運転での活用事例まで体系的に解説します。
目次
FCN (Fully Convolutional Networks)
医療分野での画像診断支援(爪部メラノーマ診断支援ソフトウェア「MelaNailScan」)
セマンティックセグメンテーションとは?
セマンティックセグメンテーションは、画像処理やコンピュータビジョンの分野で、各ピクセルに意味的なラベルを付与するタスクとして注目されています。
セマンティックセグメンテーションとは、画像内の各ピクセルに対して「クラス」ラベルを割り当てる手法です。
ここで、「セグメンテーション」とは、画像を意味のある複数の領域に分割することを指します。

セグメンテーションとは

画像セグメンテーションとは
デジタル画像をピクセル単位で、オブジェクトごとに分割する技術のことを指します。
これにより、画像中の各物体は何か、その境界はどこかを詳細に把握できます。
画像セグメンテーションの種類
画像セグメンテーションは、画像認識技術の種類の1つでしたが、画像セグメンテーションの中でも複数の種類が存在します。
主要な3つの手法についてまとめた表は以下のようになります。
| 項目 | セマンティックセグメンテーション | インスタンスセグメンテーション | パノプティックセグメンテーション |
|---|---|---|---|
| 定義 | 各ピクセルに対してカテゴリラベルを割り当てる | 同一クラス内の各物体を個別に識別し、境界情報を抽出 | セマンティックとインスタンスの手法を統合し、全ピクセルにクラスおよび個別識別情報を付与する |
| 目的 | 画像全体の意味的構造を把握する | 同一クラス内の複数オブジェクトを個別に区別する | 画像全体の意味と個々のオブジェクトの両方を一貫して把握する |
| 出力形式 | クラスごとの領域マップ | 各物体の境界ボックスまたはマスク情報 | セマンティックな領域マップと個別マスクの統合出力 |
| 応用例 | 自動運転、シーン解析 | セキュリティ監視、ロボットの物体把握 | シーン理解、包括的な画像解析 |
各手法は、目的や出力が異なり、シーン理解のレベルに応じて使い分けられます。
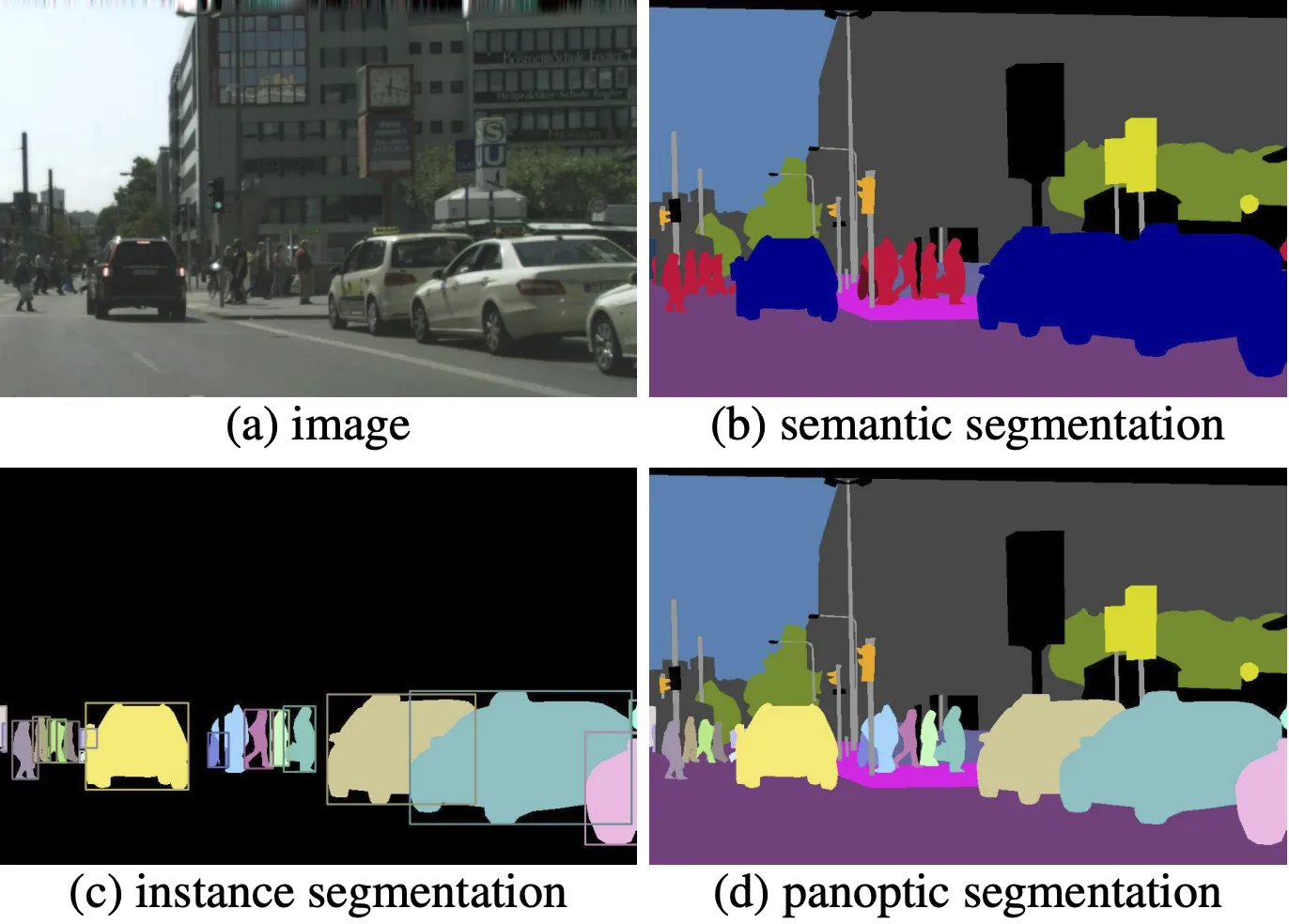
-
セマンティックセグメンテーション 画像( b )
画像内の各ピクセルに対して「クラス」ラベルを割り当てる手法です。
例: 全ての道路部分を同一ラベルに分類 -
インスタンスセグメンテーション 画像( c )
同一クラス内の複数の物体を個別に識別し、各物体ごとに境界を抽出します。
例: 複数の車を個々に分離して認識 -
パノプティックセグメンテーション 画像( d )
セマンティックセグメンテーションとインスタンスセグメンテーションを統合し、画像全体の各ピクセルに対してクラスラベルと個別オブジェクト識別情報を同時に付与します。
例: 道路部分はひとまとめに、車はそれぞれ個別に識別
セマンティック検索との違い
セマンティックセグメンテーションとセマンティック検索は、いずれも「意味 (セマンティック) 」に着目する技術ですが、対象や応用分野が大きく異なります。
以下の表は、それぞれの技術の主な違いをまとめたものです。
| 項目 | セマンティックセグメンテーション | セマンティック検索 |
|---|---|---|
| 定義 | 画像内の各ピクセルに対して「クラス」ラベルを割り当てる技術 | クエリと文書間の意味的関連性を考慮して、関連情報を検索・提示する技術 |
| 対象 | 画像(ピクセル単位のデータ) | テキスト、文書、ウェブページなど |
| 主な技術 | 畳み込みニューラルネットワーク(CNN)、FCN、U-Net、DeepLabなど | 自然言語処理(NLP)、BERT、transformers、単語・文の埋め込み表現など |
| 出力形式 | セグメンテーションマスク(各ピクセルに対するラベル付け) | ランキングされた検索結果、関連文書の提示 |
| 応用例 | 自動運転、医療画像解析、監視システム | 検索エンジン、レコメンデーション、カスタマーサポートチャットボット |
このように、セマンティックセグメンテーションは画像解析においてピクセルレベルのラベル付けを行う技術であるのに対し、セマンティック検索はテキストデータ間の意味的関連性に基づいて情報を検索する技術です。用途や対象が異なるため、目的に応じた技術選択が重要です。
セマンティック検索についてはセマンティック検索とは?仕組み・活用事例・RAGとの関係を解説で詳しく解説しています。
セマンティックセグメンテーションの仕組み
セマンティックセグメンテーションでは、画像内の各ピクセルに意味的なラベル(例:道路、建物、人など)を付ける必要があります。以下の代表的な技術は、それぞれ異なるアプローチでこの課題に対応しています。
FCN (Fully Convolutional Networks)
全層畳み込みネットワークとも呼ばれ、一般的なCNNの全結合層を、1x1の畳み込み層で置き換えることで、画像サイズを保持したままピクセル単位での分類ができるようになります。
これにより、入力画像のサイズを固定する必要がなくなり、様々な画像サイズに柔軟に対応できます。
セマンティックセグメンテーションの基本形として、多くの後続手法の土台となっています。
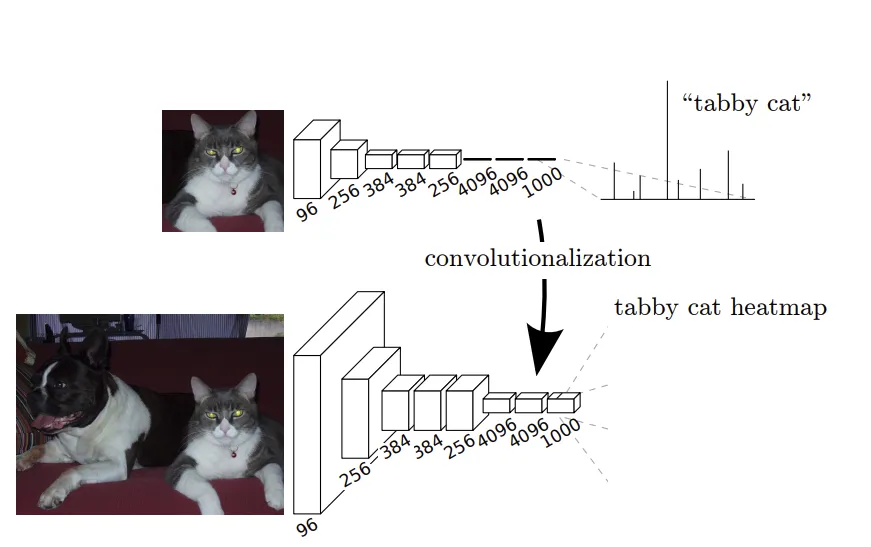
参考: Fully Convolutional Networks for Semantic Segmentation
SegNet
Encoder-Decoder型のFCN です。
Encoderでは画像から特徴を抽出し、Decoderではその特徴マップを元に元画像サイズへ復元します。
SegNetの特徴は、プーリング時のインデックス情報を保持し、それをDecoderで使うことで、位置情報を高精度に復元できる点にあります。
そのため、境界線が明確で構造を正確に捉える必要がある場面に適しています。

参考: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
U-Net
Encoder-Decoder型のFCNでありながら、 スキップ接続(skip connection) を取り入れた構造が特徴です。
これにより、低次元の詳細情報(エッジやテクスチャ)を、上位の抽象的な意味情報と結合できるようになっています。
医療画像や衛星写真など、少ないデータで高精度なセグメンテーションが必要な分野で特に活用されます。
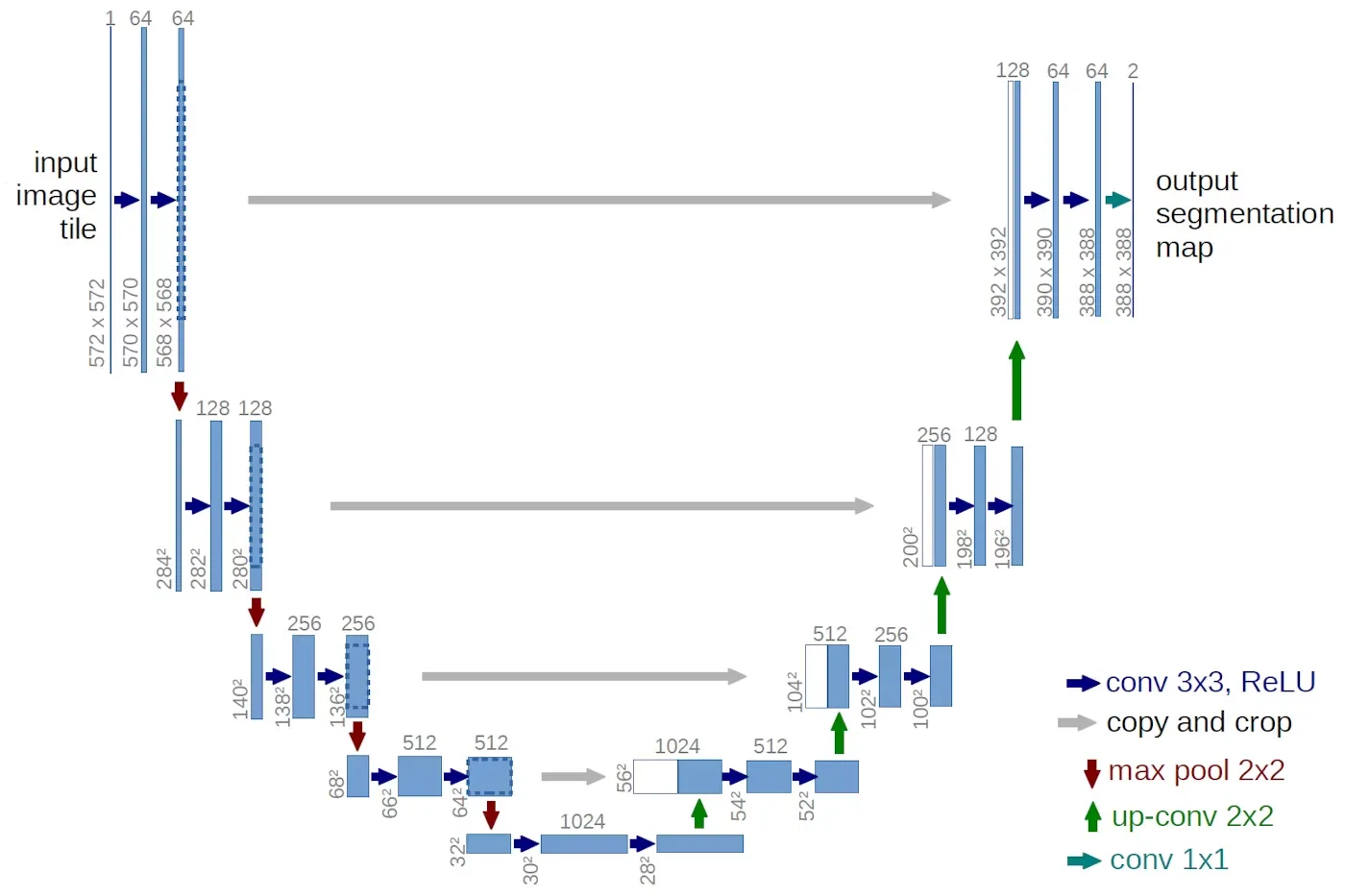
参考: U-Net: Convolutional Networks for Biomedical Image Segmentation
DeepLab (v1〜v3+)
FCNをベースに、より高精度で解像度の高いセグメンテーションを実現するために進化してきたシリーズです。
-
v1では、Atrous Convolution(空洞畳み込み)を導入し、解像度を落とさずに**広い受容野(receptive field)**を確保。
-
v2では、ASPP(Atrous Spatial Pyramid Pooling)を導入し、異なるスケールの特徴を同時に取得。
-
v3+ では、Encoder-Decoder構造とスキップ接続を導入し、U-Net的な構造に近づいています。
これらの工夫により、都市風景や自然画像など、複雑なシーンでも高精度に対応できます。
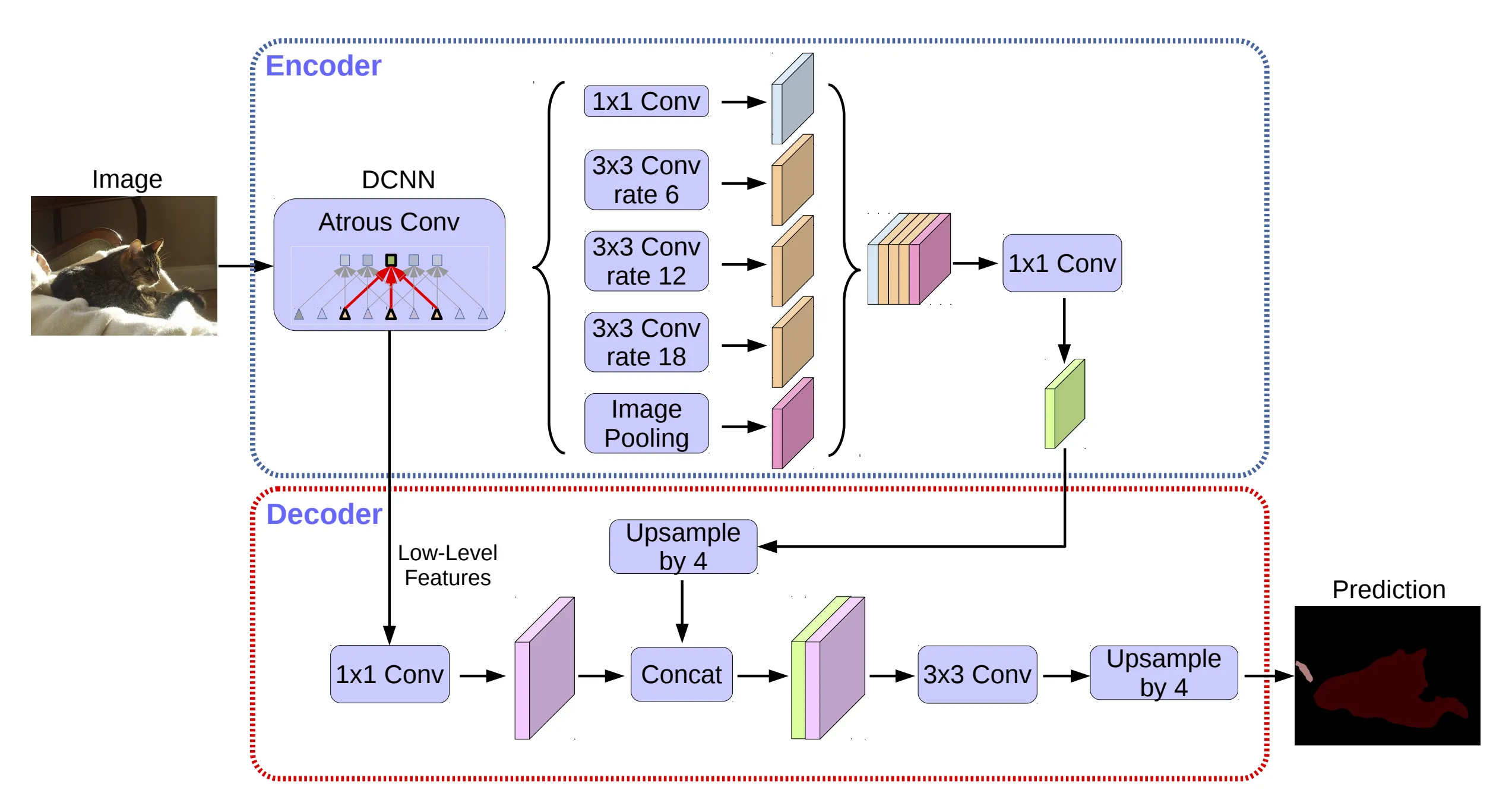
参考: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
SegFormer
Transformerをベースとした新しいアーキテクチャです。
EncoderではHierarchical Transformerを使ってマルチスケールの特徴を抽出し、Decoderでは軽量なMLP(多層パーセプトロン)でそれらを統合します。
最大の特徴は、位置情報(Positional Embedding)を使わずに高精度な空間認識を実現している点です。さらに、グローバルな文脈情報を同時に捉えられるため、複雑な構造や遠距離の関係も理解できます。
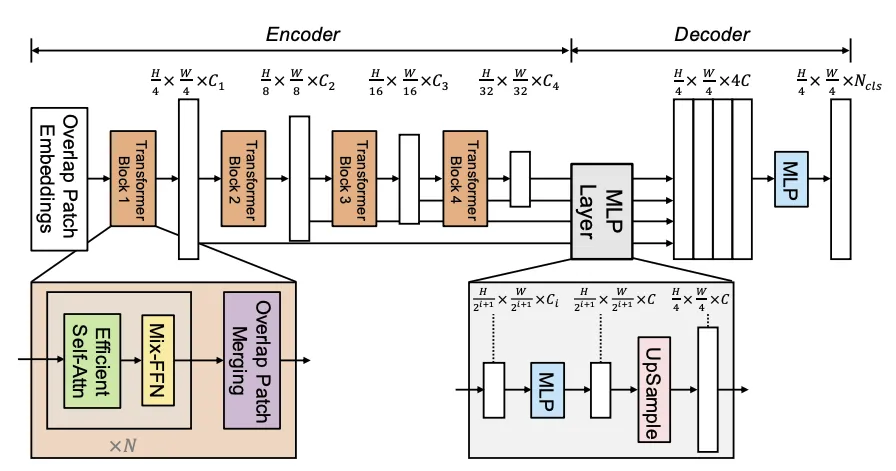
*参考: SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
このように、セマンティックセグメンテーションは、タスクの特性や必要な精度、計算資源に応じて、さまざまな技術が使い分けられています。
FCNを起点として、構造を工夫したSegNetやU-Net、広範囲の文脈を捉えるDeepLabやSegFormerまで、目的に応じたアーキテクチャ選定が精度向上の鍵となります。最新の手法とベンチマーク結果はPapers with Codeのセマンティックセグメンテーションで比較できます。
セマンティックセグメンテーションを実際に使ってみましょう
実際に、セマンティックセグメンテーションを実装してみます。
ここでは、代表的な手法の1つである、DeepLab v3を使用した実装例を紹介します。事前学習モデルの詳細はPyTorch HubのDeepLabV3ドキュメントで確認できます。
使用環境およびライブラリ
- 実行環境: Google Colaboratory
- Python: 3.11.11
- CUDA 12.4
- PyTorch: 2.6.0+cu124
- torchvision: 0.21.0+cu124
- NumPy: 2.0.2
使用するデータセット
今回の実装では、VOC2012セグメンテーションデータセットを使用します。
OC 2012は、各画像に対してピクセル単位のクラスラベルが付与されており、セマンティックセグメンテーションのタスクに適したデータセットです。
PyTorchの torchvision.datasets.VOCSegmentation を利用することで、自動ダウンロードと前処理が容易に行えます。
使用モデル
- DeepLabv3 (ResNet101バックボーン)
本実装では、事前学習済みのDeepLabv3 ResNet101をベースにし、最終出力層をVOC用(21クラス、背景含む)に変更しています。
DeepLabv3は、多段階のスケール情報を効果的に捉える仕組みを持ち、高精度なセマンティックセグメンテーションを実現します。
コード構成
本記事のコードは、以下の3つのセルに分割しています。
-
データ準備
VOC 2012セグメンテーションデータセットのダウンロードと、入力画像およびターゲットマップの前処理(リサイズ、正規化、Tensor化)を実施します。 -
Training(学習)
DeepLabv3モデルの構築、出力層の微調整、データローダーを用いた学習ループを実装します。
学習中の損失や検証結果を表示し、学習済みモデルを保存します。 -
Inference(推論と可視化)
学習済みモデルを読み込み、検証画像に対する推論を実施します。
元画像、予測されたセグメンテーションマップ、正解ラベルを並べて表示し、結果を確認します。
以下に、それぞれのコードセルを順に掲載していきます。
- データ準備
pythonコード全文
import os
import numpy as np
from PIL import Image
import torch
from torchvision import transforms
from torchvision.datasets import VOCSegmentation
import matplotlib.pyplot as plt
# 入力画像用の前処理(リサイズ、Tensor化、正規化)
input_transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# セグメンテーションマップ用の変換(リサイズ:最近傍補間、numpy化→tensor化)
target_transform = transforms.Compose([
transforms.Resize((512, 512), interpolation=Image.NEAREST),
transforms.Lambda(lambda x: torch.from_numpy(np.array(x, dtype=np.int64)))
])
# VOC 2012 セグメンテーションデータセットのダウンロード先
voc_root = '/content/VOCdevkit'
# 学習用データセット(自動ダウンロード)
train_dataset = VOCSegmentation(root=voc_root,
year='2012',
image_set='train',
download=True,
transform=input_transform,
target_transform=target_transform)
# 検証用データセット
val_dataset = VOCSegmentation(root=voc_root,
year='2012',
image_set='val',
download=True,
transform=input_transform,
target_transform=target_transform)
print("VOC 2012 Segmentation dataset downloaded.")
print("Train dataset size:", len(train_dataset))
print("Val dataset size:", len(val_dataset))
- Training(学習)
pythonコード全文
### Training
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
# ハイパーパラメータ
num_epochs = 5 # デモ用に短めに
batch_size = 4
learning_rate = 1e-4
num_classes = 21 # VOC 2012 のクラス数(背景含む)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# DataLoader の作成
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
# torchvision の DeepLabv3 (ResNet101) を事前学習済みで読み込み,出力層を VOC 用に変更
model = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=True)
model.classifier[4] = nn.Conv2d(256, num_classes, kernel_size=1)
if model.aux_classifier is not None:
model.aux_classifier[4] = nn.Conv2d(256, num_classes, kernel_size=1)
model = model.to(device)
# 損失関数(VOC はラベル 255 が無視ラベルとして扱われることが多いので ignore_index=255)
criterion = nn.CrossEntropyLoss(ignore_index=255)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
print("Starting training...")
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, (images, targets) in enumerate(train_loader):
images = images.to(device)
targets = targets.to(device)
outputs = model(images)['out'] # 出力は辞書型 ('out' キー)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if (i+1) % 2 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {running_loss/2:.4f}")
running_loss = 0.0
# 簡易バリデーション
model.eval()
val_loss = 0.0
with torch.no_grad():
for images, targets in val_loader:
images = images.to(device)
targets = targets.to(device)
outputs = model(images)['out']
loss = criterion(outputs, targets)
val_loss += loss.item()
val_loss /= len(val_loader)
print(f"Epoch [{epoch+1}/{num_epochs}], Validation Loss: {val_loss:.4f}")
# 学習済みモデルの保存
torch.save(model.state_dict(), "deeplabv3_voc.pth")
print("Training complete and model saved.")
- Inference(推論と可視化)
pythonコード全文
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
import torch.nn as nn
# --- 表示用補助関数 ---
def unnormalize(img_tensor):
"""
入力画像の正規化を解除して [0,1] の範囲に戻す
"""
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img = img_tensor.cpu().numpy().transpose(1, 2, 0)
img = std * img + mean
img = np.clip(img, 0, 1)
return img
# VOC 2012 用カラーパレット(21クラス)
voc_label_colors = np.array([
[0, 0, 0],
[128, 0, 0],
[0, 128, 0],
[128, 128, 0],
[0, 0, 128],
[128, 0, 128],
[0, 128, 128],
[128, 128, 128],
[64, 0, 0],
[192, 0, 0],
[64, 128, 0],
[192, 128, 0],
[64, 0, 128],
[192, 0, 128],
[64, 128, 128],
[192, 128, 128],
[0, 64, 0],
[128, 64, 0],
[0, 192, 0],
[128, 192, 0],
[0, 64, 128]
], dtype=np.uint8)
def decode_segmap(segmentation):
"""
segmentation: (H x W) のクラスインデックス配列
return: (H x W x 3) のRGB画像
"""
# ignore label 255 を背景(0)に置き換え
segmentation = np.where(segmentation == 255, 0, segmentation)
return voc_label_colors[segmentation]
# --- データセットの再読み込み(推論用) ---
from torchvision.datasets import VOCSegmentation
from torchvision import transforms
from PIL import Image
# 入力とターゲットの前処理は学習時と同様に定義
input_transform = transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
target_transform = transforms.Compose([
transforms.Resize((512, 512), interpolation=Image.NEAREST),
transforms.Lambda(lambda x: torch.from_numpy(np.array(x, dtype=np.int64)))
])
voc_root = '/content/VOCdevkit'
val_dataset = VOCSegmentation(root=voc_root,
year='2012',
image_set='val',
download=False, # 既にダウンロード済み
transform=input_transform,
target_transform=target_transform)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=2, shuffle=False, num_workers=2)
# --- モデルの読み込み ---
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
num_classes = 21
model = torchvision.models.segmentation.deeplabv3_resnet101(pretrained=False)
model.classifier[4] = nn.Conv2d(256, num_classes, kernel_size=1)
if model.aux_classifier is not None:
model.aux_classifier[4] = nn.Conv2d(256, num_classes, kernel_size=1)
# strict=False を指定して余分な aux_classifier のキーを無視する
model.load_state_dict(torch.load("deeplabv3_voc.pth", map_location=device), strict=False)
model = model.to(device)
model.eval()
# --- 推論と可視化 ---
with torch.no_grad():
images, targets = next(iter(val_loader))
images = images.to(device)
outputs = model(images)['out']
preds = torch.argmax(outputs, dim=1).cpu().numpy()
# 元画像の正規化解除
original_images = [unnormalize(img) for img in images.cpu()]
targets_np = targets.cpu().numpy()
for i in range(len(original_images)):
pred_color = decode_segmap(preds[i])
gt_color = decode_segmap(targets_np[i])
fig, axs = plt.subplots(1, 3, figsize=(18, 6))
axs[0].imshow(original_images[i])
axs[0].set_title("Original Image")
axs[0].axis('off')
axs[1].imshow(pred_color)
axs[1].set_title("Predicted Segmentation")
axs[1].axis('off')
axs[2].imshow(gt_color)
axs[2].set_title("Ground Truth")
axs[2].axis('off')
plt.show()
実行結果
実行結果は以下のようになりました。
飛行機の画像では、飛行機の領域をかなり正確に認識し、背景を除外して機体のみをうまく抽出できていることがわかります。
正解データの比較しても、細かな部分以外はほぼ正しく予測できています。
電車の画像では、中央付近で、実際には空間がある部分を電車と誤って予測しているなど、多少の誤認識が見られます。
正解画像と比較して、モデルの推論が全体の大枠をとらえつつも、細かい境界線で課題が残っていることが確認できます。
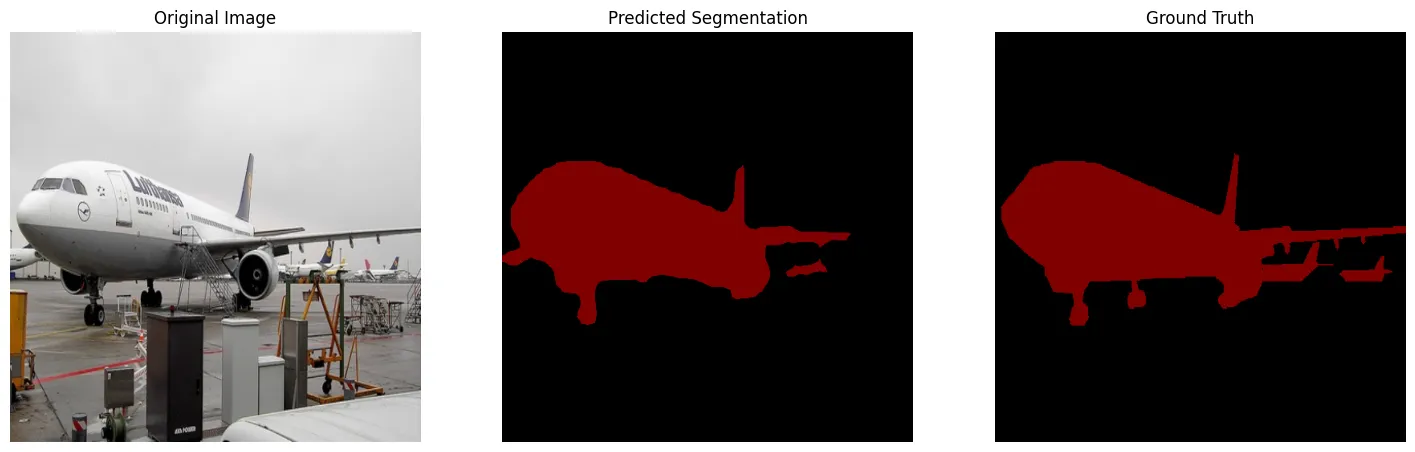
実行結果 (画像1枚目)
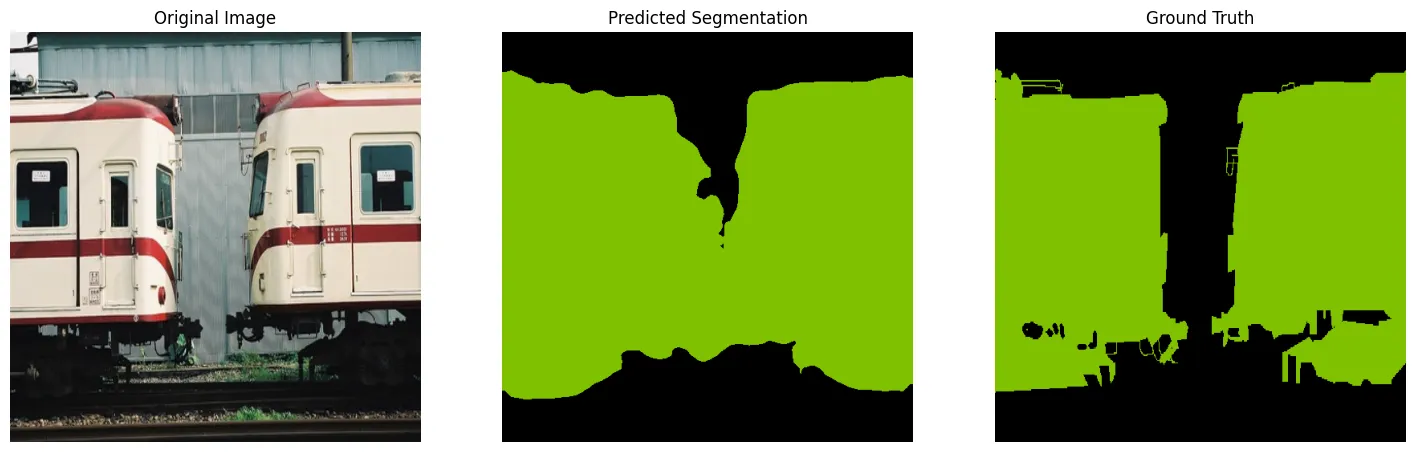
実行結果 (画像2枚目)

セマンティックセグメンテーションの活用事例
セマンティックセグメンテーションは、ITや医療など、多くの業界で活用されています。
特に、物体認識の中でも、「種類」や「位置」だけでなく「形状」や「範囲」まで詳細に理解しなければならない分野で活用されています。
ここでは、実際の活用事例を紹介します。
医療分野での画像診断支援(爪部メラノーマ診断支援ソフトウェア「MelaNailScan」)
爪部メラノーマは、爪に生じる皮膚がんの一種であり、早期発見が治療成績に大きく影響します。
従来、医師は爪の画像から病変を特定するために、手作業で爪の領域を切り出して分析する必要がありました。この作業は専門性が高く、労力や時間がかかる上に、診断者の経験により精度が変動する問題がありました。
そこで、「MelaNailScan」では、セマンティックセグメンテーションを活用したAIを導入しました。
このAIモデルは、撮影された爪画像の各ピクセルを「爪部分」「背景」などの領域に自動分類することで、正確かつ効率的に爪の領域だけを抽出します。これにより、
- 診断に必要な前処理時間が短縮
- 誰が行っても安定した品質を実現
- 医師が診断そのものに集中できる環境を提供
といったメリットをもたらしました。特に、AIの精度は数千枚以上の画像を用いて訓練されており、臨床現場での実用性が高いことが実証されています。
自動運転技術の向上
自動運転車の安全な運行には、車両が周囲の状況をリアルタイムで正確に認識する能力が不可欠です。
セマンティックセグメンテーションは、自動運転技術の核となる環境認識システムの一部を担っています。
具体的には、カメラやLiDARなどから取得した画像データを用いて、道路上のあらゆる要素(車両、歩行者、自転車、信号機、道路標識、道路境界線など)をピクセル単位で分類します。これにより、
- 車両が正確に周囲の状況を理解
- 歩行者や障害物を迅速かつ正確に検知
- 信号や標識を見落とすことなく安全な走行ルートの確保
ができます。
また、最新のAIモデル(例: DeepLabシリーズ、HRNet)は、リアルタイム性を重視しつつも精度を高める方向で発展しており、実際にTeslaやWaymoなどの自動運転車開発企業において広く導入されています。自動運転向けセグメンテーションのベンチマークはCityscapesデータセットが標準として広く使われています。
画像認識AIの信頼性向上(パナソニック「FlowEneDet」)
画像認識を行うAIモデルが実際の社会で使われる際、「未知の物体」を誤認識してしまうことが大きな課題となります。例えば、医療や運転支援など重要な場面で予期しない物体に誤ったラベルを付けることは重大な事故につながる恐れがあります。
パナソニックが開発した技術「FlowEneDet」は、セマンティックセグメンテーションを行った後のモデルに追加される仕組みで、AIが「学習していない未知の物体」を認識した際に、それを「未知」として分類し、誤ったラベル付けを防ぐ仕組みを持っています。
具体的には、
-
セグメンテーションで認識した物体に対して、各ピクセル単位のラベルの「不確かさ」を評価
-
認識の信頼度が低い(不確かな)物体領域を自動的に検出し、「未知の物体」として再分類
-
誤認識を減らし、AIの安全性・信頼性を向上させる
といった仕組みが導入されています。
この技術により、未知の状況に対してもAIが安全に対応できるようになり、特に安全性が求められる分野(自動運転、ロボット支援、医療診断)での利用促進につながると期待されています。

画像認識技術の知見を業務AI化の次のステップに活かすなら
セマンティックセグメンテーションのようなCV技術を理解することで、「AIが画像を理解して判断する」という能力の現在地が見えてきます。この知見を起点に、画像検査・品質管理といった現場系の業務だけでなく、データ処理やレポート生成などバックオフィス業務へのAI適用を検討する企業が増えています。
AI総合研究所のAI業務自動化ガイドでは、画像認識に限らず幅広い業務領域でのAI導入ステップと適用パターンを体系的に整理しています。技術理解を深めた次のアクションとして、自社のどの業務からAIを適用すべきかを見極める参考にしてください。
画像認識技術の知見をAI業務化の第一歩に

CV技術の評価から業務適用への橋渡し
画像セグメンテーションのようなCV技術を理解した次のステップは、自社業務のどの領域にAIを適用するかの判断です。業務領域ごとのAI導入パターンを整理したガイドです。
まとめ
本記事では、セマンティックセグメンテーションの定義から画像セグメンテーションの種類、代表的なアーキテクチャ(FCN・U-Net・DeepLab・SegFormer)、DeepLabV3を用いた実装例、医療・自動運転での活用事例まで体系的に解説しました。
この記事で得られる3つの価値は以下の通りです。
-
ピクセル単位の画像理解技術の全体像
セマンティックセグメンテーションは画像内の各ピクセルにクラスラベルを割り当てる技術であり、インスタンスセグメンテーション・パノプティックセグメンテーションとの使い分けを理解することで、タスクに最適な手法を選定できます。 -
用途に応じたアーキテクチャ選定の指針
FCNを起点に、境界精度ならSegNet、少データ高精度ならU-Net、複雑シーンならDeepLab、グローバル文脈理解ならSegFormerと、各アーキテクチャの強みを把握することで、精度・速度・計算コストのトレードオフに基づいた選定ができます。 -
実装から活用事例までの実践的知識
DeepLabV3によるVOC2012データセットの実装例により、学習から推論・可視化までの流れを把握できます。医療診断支援(MelaNailScan)や自動運転での実用例は、自社のコンピュータビジョンプロジェクトへの応用を検討する際の参考になります。
セマンティックセグメンテーションの導入を検討する場合は、まず対象タスクで「クラス分類のみで十分か、個体識別も必要か」を判断し、適切な手法を選定するところから始めてください。










