この記事のポイント
 MDP・報酬関数・価値関数による最適行動の数理的導出基盤
MDP・報酬関数・価値関数による最適行動の数理的導出基盤- Q学習・DQN・PPO等のアルゴリズムと状態空間に応じた使い分け
- シミュレータ上でのオフライン学習による低コスト・低リスクな検証手法
- AlphaGo・自動運転・鉄道運航計画・化学プラント等の実応用事例
- 報酬関数のビジネスKPI直結設計とPoC→本番展開の導入手順

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
強化学習は、エージェントが環境との相互作用を通じて報酬を最大化する行動方策を学習する機械学習手法です。本記事では、MDP・ベルマン方程式・TD学習の理論基盤からQ学習・DQN・PPOなどのアルゴリズム選定、AlphaGo・自動運転・鉄道運航計画・化学プラント運転の活用事例まで体系的に解説します。
強化学習とは
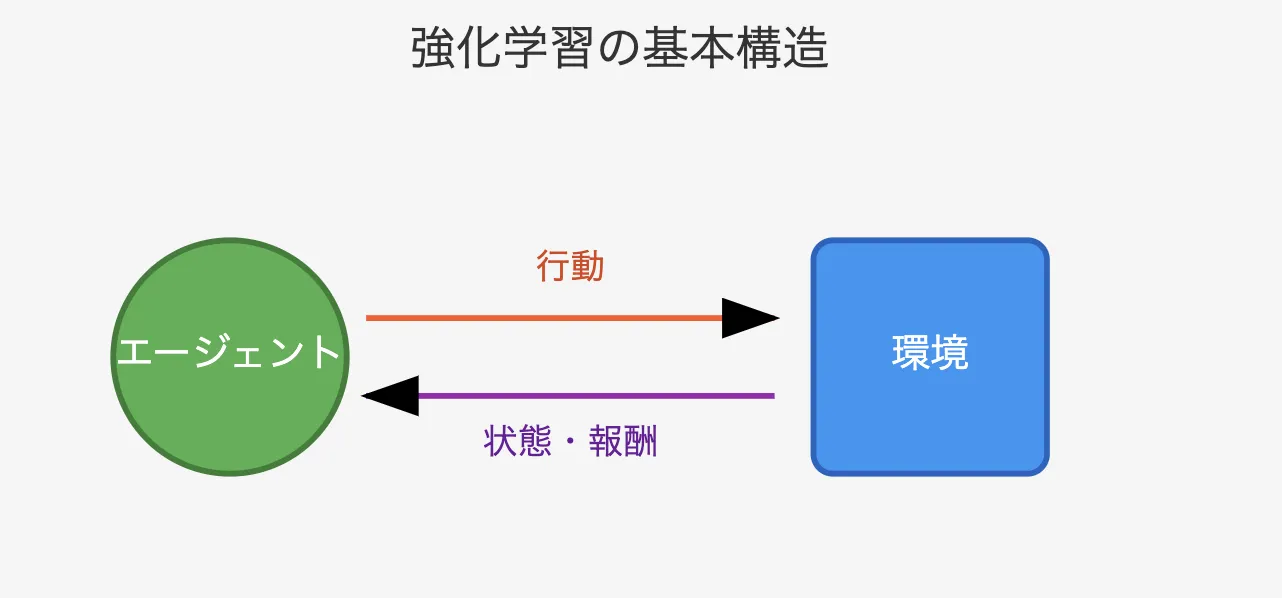
強化学習の基本構造
強化学習は、機械学習の一分野で、エージェント(学習主体)が環境との相互作用を通じて「報酬」を最大化するための行動(ポリシー)を学習する手法です。
従来の教師あり学習とは異なり、明確な正解ラベルがなくとも、エージェントが試行錯誤を通じて学習を進めます。

強化学習の理論
ここでは強化学習の理論を解説します。
まず大きく、以下のように分かれ、それぞれが強化学習の重要な役割を果たしています。
- MDPは強化学習の理論的基盤を提供し、状態、行動、報酬の関係を定義します。
- 環境モデルは、MDPの一部(PとR)を具体化し、手法の選択に影響を与えます。
- ベルマン方程式と価値関数は、最適な行動選択を行うための数理的ツールです。
- TD学習は、価値関数を効率的に学習する実践的な手法です。
- アルゴリズムは、これらを統合し、具体的な問題を解決するための実装を提供します。
- 基本要素は、MDPを基にした実践的な学習の流れを示します。
こうして全体が有機的に結びつき、強化学習の理論と応用が一貫して理解できます。
少し複雑に見えますが、以下でわかりやすく解説します。
強化学習の基盤:マルコフ決定過程(MDP)と基本要素
マルコフ決定過程(MDP)は、強化学習の問題を数学的に定式化するための基盤です。
エージェントが環境とどのように相互作用し、状態、行動、報酬がどのように関連するかを明確にします。これにより、強化学習の理論的枠組みが整います。
MDPは、強化学習における環境とエージェントの関係を以下の要素で定式化します。
マルコフ決定過程(MDP)の要素
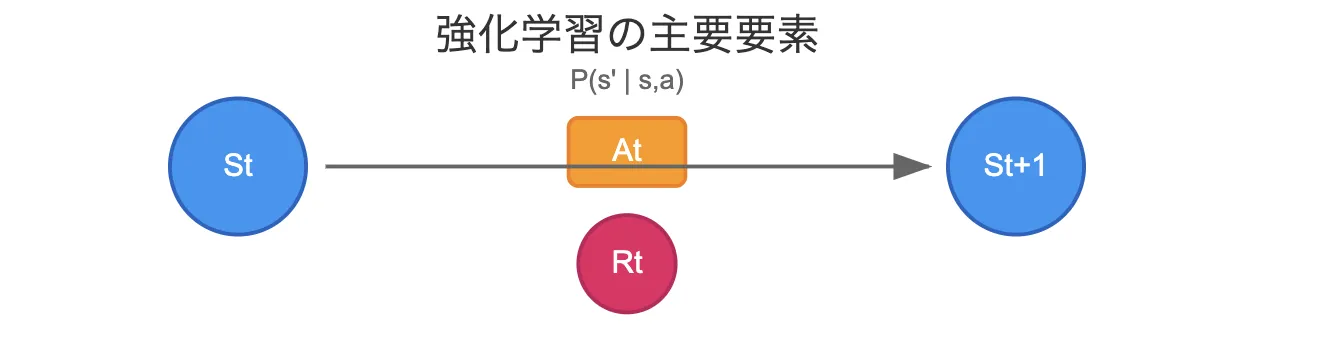
MDP要素
-
状態(S: State)
エージェントが観測する現在の環境の情報。たとえば、ゲームの画面の状況やロボットの位置など。 -
行動(A: Action)
エージェントが選択可能な行動。たとえば、「移動」「攻撃」などの操作。 -
状態遷移確率(P: Transition Probability)
エージェントがある状態で特定の行動を取ったとき、次にどの状態に遷移するかの確率分布。環境の変化をモデル化します。 -
報酬関数(R: Reward Function)
特定の状態や行動に対してエージェントが受け取る報酬を定義。目標の達成度を数値化します。 -
割引率(γ: Discount Factor)
将来の報酬をどの程度重視するかを決める係数。短期的な成果を優先するか、長期的な目標を重視するかを調整します。
環境モデルとMDPの関係
MDPの要素には、環境そのものを表現する部分が含まれています。
特に以下の2つが重要です。
- 状態遷移確率(P)
環境がどのように変化するかを数学的に表す。
- 報酬関数(R)
環境から得られる評価を数値化する。
環境モデルとは、これらの情報(PとR)を明示的に表現したものです。環境モデルがあれば、シミュレーションを通じてエージェントの方策を改善できます(モデルベース手法)。一方、環境モデルが不明であれば、エージェントは直接環境と相互作用しながらデータを収集し、学習を進めます(モデルフリー手法)。
ベルマン方程式と価値関数
ベルマン方程式は、最適な行動選択を行うための数理的ツールであり、価値関数を定義し、それを更新するための理論的な基盤を提供します。
価値関数を計算することで、エージェントは各行動がどの程度有益かを評価できます。
TD学習(Temporal Difference Learning)
TD学習は、ベルマン方程式を基に、経験から価値関数を効率よく更新する手法です。実際の試行錯誤を通じて学習を進める上で重要です。
- TD学習は、経験を基に逐次的に価値関数を更新します。
- 方策オン型(例: SARSA) は、現在の方策に基づいてデータを収集し、学習を行います。
- 方策オフ型(例: Q学習) は、他の方策で得たデータも活用します。
強化学習のアルゴリズム
アルゴリズムは、MDPや価値関数、TD学習の理論を基に実際の問題を解決するための具体的な実装を提供します。
アルゴリズムの種類
- 価値ベース手法: Q学習やSARSAなど、価値関数を更新して最適方策を学びます。
- 方策ベース手法: PPOやA3Cなど、方策そのものを最適化します。
- モデルベース手法: AlphaGoやSimPLeなど、環境モデルを活用して学習効率を向上させます。
これらの過程が結びつくことによって精度の高い強化学習プロセスが実行されます。

強化学習の実行プロセスと具体例
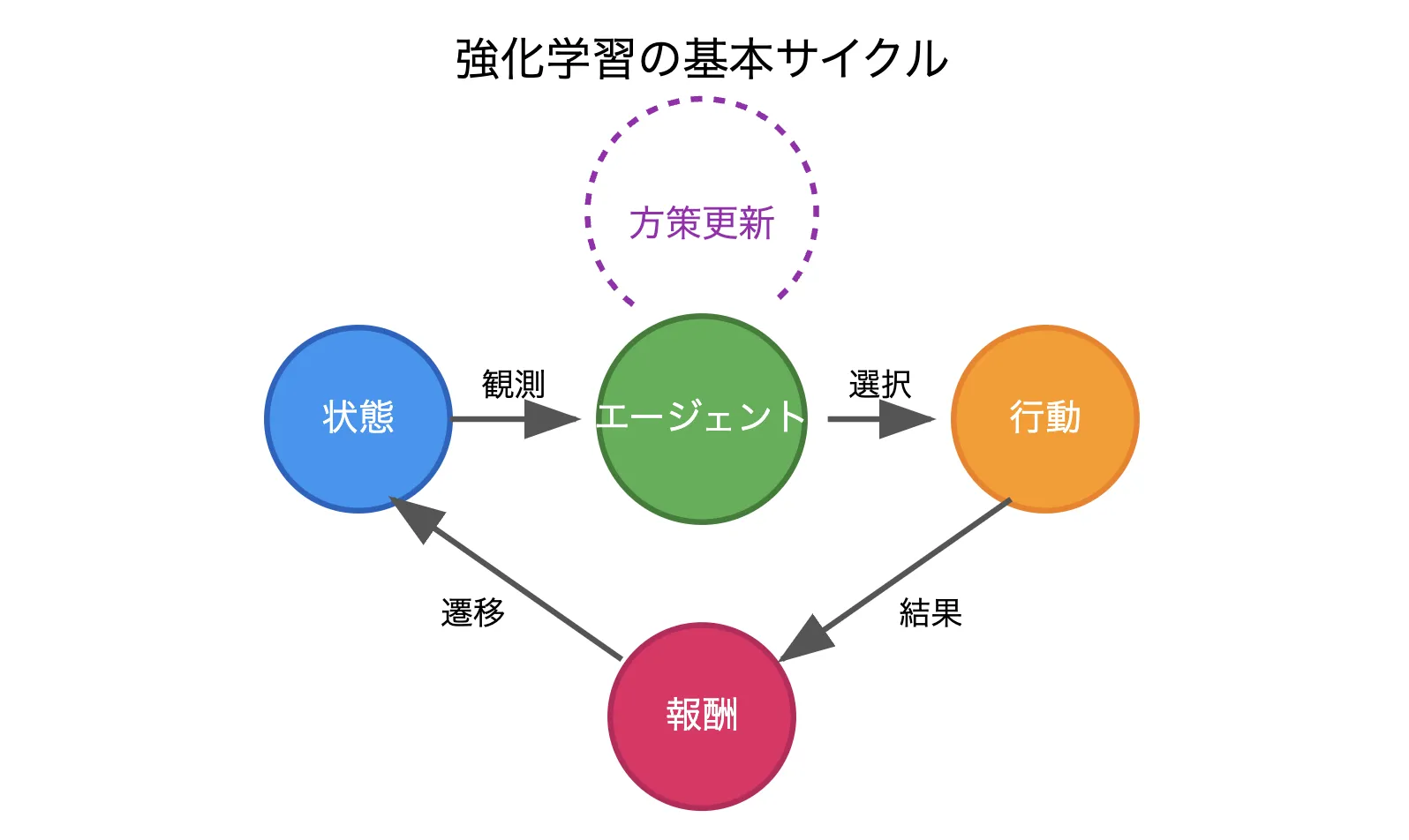
強化学習の基本要素
MDPの理論に基づき、強化学習では次の基本要素を通じて学習が進行します。
エージェントはある「状態(State)」を観測し、「行動(Action)」を選択し、その結果として「報酬(Reward)」を得るというプロセスになります。
エージェントは得られた報酬を手掛かりに行動方策(Policy)を更新し、長期的な報酬最大化を目指します。
具体例
たとえば、ゲームでは画面上の情報を状態とし、「移動」「攻撃」といった行動をとり、成功すればスコアという報酬を獲得、これを積み重ねて最適な戦略を確立します。
具体的な例を示します。
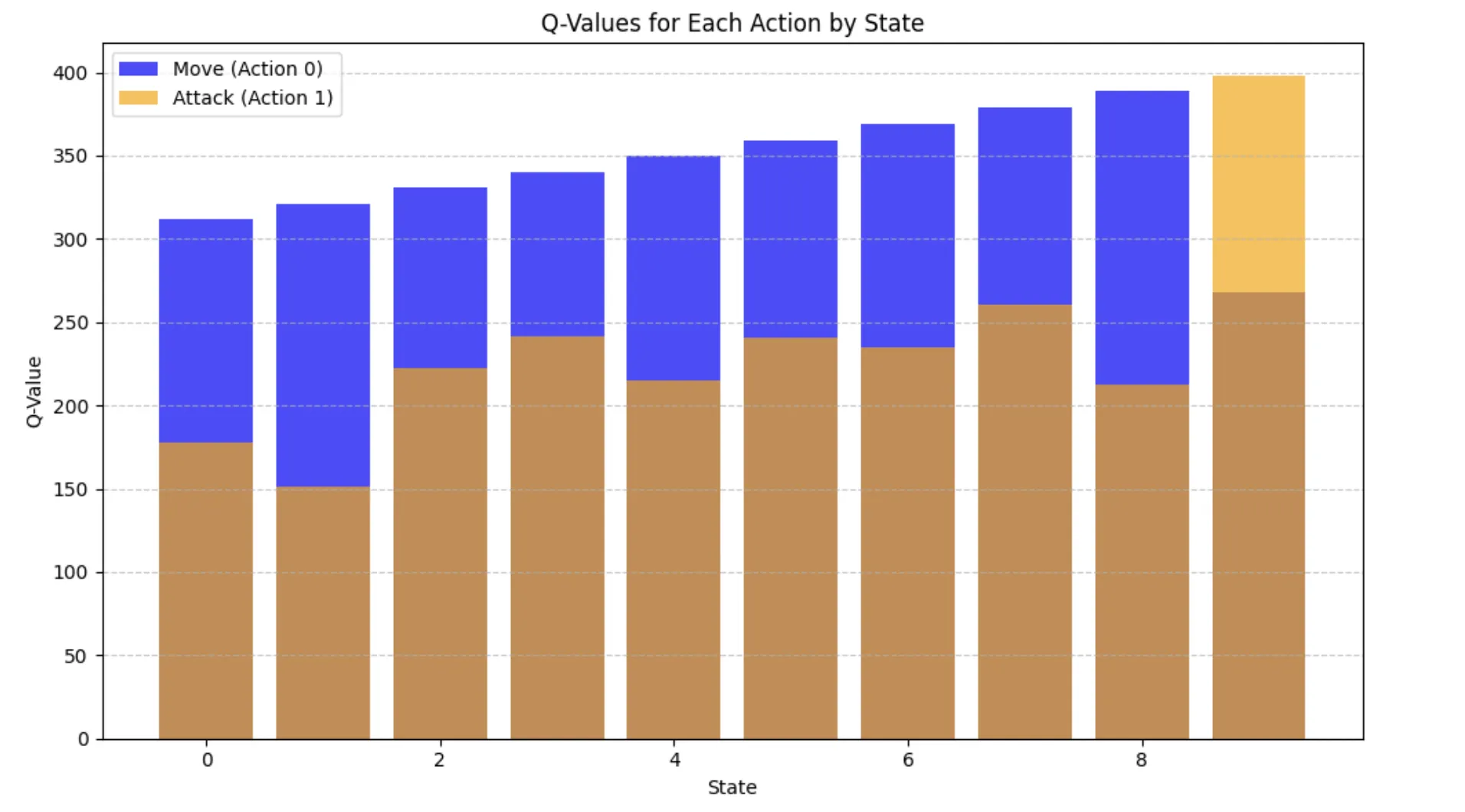
強化学習結果イメージ
以下はゲーム上で移動もしくは攻撃をした時に最適な戦略を実行した結果です。
このシナリオをゲームに例えると、以下のような戦略を学んだことを意味します。
- ゲームの目標:
ゴール(状態9)にたどり着いて敵を倒す(攻撃)ことで高得点を得る。
- 学んだ戦略:
最初はゴールに向かって移動(Move)。
ゴールに着いたら攻撃(Attack)して得点。
実際に強化学習をやってみよう
ではこの結果を、実際にGoogle Colabで簡単な強化学習シミュレーションとして実装します。
この例では、エージェントが「移動」と「攻撃」を行い、報酬を獲得して最適な行動を学習します。
以下に、ゲームのような環境で強化学習エージェントが動作するコードを示します。
# 必要なライブラリをインストール
!pip install matplotlib gym
# ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
import random
import gym
# 簡単なカスタム環境を作成
class SimpleGameEnv(gym.Env):
def __init__(self):
super(SimpleGameEnv, self).__init__()
self.state = 0 # 初期状態
self.action_space = gym.spaces.Discrete(2) # 0: Move, 1: Attack
self.observation_space = gym.spaces.Discrete(10) # 状態は0-9の範囲
self.done = False
def reset(self):
self.state = 0
self.done = False
return self.state
def step(self, action):
reward = 0
if action == 0: # Move
self.state = min(self.state + 1, 9)
reward = 1 if self.state == 9 else 0
elif action == 1: # Attack
reward = 10 if self.state == 9 else -1
self.done = self.state == 9 and action == 1
return self.state, reward, self.done, {}
# 環境の初期化
env = SimpleGameEnv()
# Q学習エージェントを訓練する関数
def train_q_learning(env, episodes=500, alpha=0.1, gamma=0.99, epsilon=0.1):
q_table = defaultdict(lambda: np.zeros(env.action_space.n))
for episode in range(episodes):
state = env.reset()
done = False
while not done:
if random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # Explore
else:
action = np.argmax(q_table[state]) # Exploit
next_state, reward, done, _ = env.step(action)
q_table[state][action] = q_table[state][action] + alpha * (
reward + gamma * np.max(q_table[next_state]) - q_table[state][action]
)
state = next_state
return q_table
# Q学習の実行
q_table = train_q_learning(env)
# 状態ごとの価値関数(Q値)を可視化
states = list(range(10))
q_values_move = [q_table[s][0] for s in states] # Q-value for Move
q_values_attack = [q_table[s][1] for s in states] # Q-value for Attack
# 棒グラフを描画
plt.figure(figsize=(10, 6))
plt.bar(states, q_values_move, label="Move (Action 0)", alpha=0.7, color='blue')
plt.bar(states, q_values_attack, label="Attack (Action 1)", alpha=0.7, color='orange')
plt.xlabel("State")
plt.ylabel("Q-Value")
plt.title("Q-Values for Each Action by State")
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
上記と同じグラフを簡単に実装できます。
強化学習の活用事例
強化学習は実際に多くの分野で活用されています。
ここでは、その活用事例を紹介します。
囲碁:AlphaGo
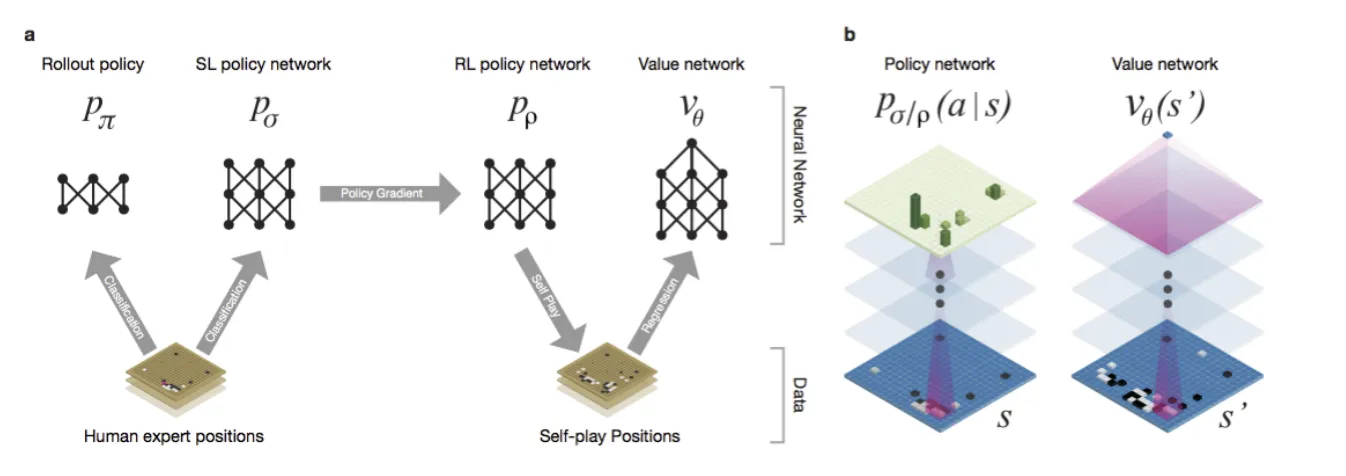
AlphaGo参考:Mastering the Game of Go with Deep Neural Networks and Tree Search
Google DeepMindが開発したコンピュータ囲碁プログラムです。
最先端のモンテカルロツリー検索プログラムで、ランダムにセルフプレイゲームを何千回にも及んでシミュレートします。
従来の囲碁プログラムに対して99.8%の勝率を達成しました。また、欧州チャンピオン(ファン・フイ)に対して5対0で勝利を収めました。
将棋:elmo
瀧澤誠が開発したコンピュータ将棋ソフトです。
2017年にはコンピュータ将棋協会(CSA)世界チャンピオンとなりました。
引用元:https://www.science.org/doi/10.1126/science.aar6404
自動運転車両(AV)
Googleが2010年に自動運転プログラムを発表した後、交通渋滞を緩和し、ドライバーの注意を解放し、エネルギーを節約するという利点から、近年世間の注目を集めています。
複雑な3車線区間ではCFと車線変更動作の両方を組み合わせた統合モデルを学習し、平均速度が2.4%向上しました。
引用元:https://doi.org/10.1016/j.trc.2019.08.011
鉄道運航計画
鉄道路線を再現するシミュレータ、強化学習によるダイヤ作成手法が開発されています。
開発首都圏の複線路線を想定した仮想路線で検証し、実用的な時間で全区間のダイヤを自動で作成できます。
事故や自然災害等に、ダイヤの修正・再作成を迅速に行えます。
引用元:https://www.jstage.jst.go.jp/article/pjsai/JSAI2022/0/JSAI2022_1G4OS22a04/_pdf/-char/ja
化学プラントの運転
以下の3要素に強化学習を適用することで、現実のプラントにおける運転支援AIを実現しました。
(1) 現在のプラントの状態の正確な把握
(2)目標状態に移行するために最適な操作手順の生成
(3)外乱等により目標とのズレが生じた際の迅速な補正
引用元:https://www.tandfonline.com/doi/full/10.1080/18824889.2022.2029033

強化学習の仕組みを理解したなら業務へのAI導入を設計する
強化学習のMDPや報酬関数の概念を理解すると、AIが「試行錯誤から最適な行動を学ぶ」仕組みが業務のどの領域に適用できるかが見えてきます。在庫管理の自動最適化、物流ルートの動的制御、広告配信の自動チューニングなど、状況に応じた判断が求められる業務にAIを活用する基盤がここにあります。
AI総合研究所では、強化学習を含むAI技術の知識を業務プロセスの自動化に結びつけるための「AI業務自動化ガイド」を無料で提供しています。技術選定から導入まで、220ページで業務AI化の全体像を解説しています。
強化学習の知識を業務へのAI導入計画に活かす

動的意思決定の自動化から業務プロセスのAI化へ
強化学習のMDP・報酬設計・価値関数の知識は、在庫最適化やスケジューリングなど業務の動的意思決定をAI化する基盤です。220ページの実践ガイドで、AI技術の理解を業務自動化に結びつける手順を具体的に解説しています。
まとめ
強化学習を導入することで、以下の3つの価値が得られます。
-
ルールベースでは困難な動的意思決定の自動化
MDP・報酬関数・価値関数の理論的基盤により、在庫最適化・経路制御・プラント運転など、状態が刻々と変化する環境での最適行動を自動的に学習できます。 -
シミュレータ活用による安全かつ低コストな検証
実環境での試行錯誤はコストとリスクが高いため、シミュレータ上でのオフライン学習から開始し、十分な精度を確認した上で実環境に移行できます。 -
AlphaGo・自動運転等の実績が示す幅広い応用可能性
囲碁・将棋などのゲームAIから自動運転車両・鉄道運航計画・化学プラント運転まで、試行回数を十分に確保できる領域で高い成果が実証されています。
導入を検討する際は、まず対象業務のシミュレータ環境を構築し、報酬関数をビジネスKPIに直結させた上でPoCを実施、効果測定後に本番環境へ段階的に展開する手順が有効です。










