この記事のポイント
 画像の部分編集やスタイル維持が必要なら、テキストのみの画像生成AIよりFLUX.1 Kontextが第一候補
画像の部分編集やスタイル維持が必要なら、テキストのみの画像生成AIよりFLUX.1 Kontextが第一候補- モデル選びは「反復編集ならpro」「タイポグラフィや精密描画ならmax」「軽量・実験用途ならdev」で使い分けるべき
- 従来比最大8倍の推論速度を実現しており、インタラクティブな試行錯誤ワークフローに適している
- キャラクターやデザインの一貫性を保ったまま複数シーンを生成できるため、マンガ・広告・ブランド素材制作に有効
- KreaAI・LeonardoAI・Freepikなど主要プラットフォームで利用可能。API経由の組み込みにも対応している

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
テキストと画像の両方を理解して、リアルな編集や一貫した画像生成ができるAIをご存じですか? FLUX.1 Kontextは、画像を自然言語で自在に操作できる新しいマルチモーダルモデルです。本記事では、その構造・機能・モデルごとの違い・活用事例・評価結果まで、実例とともに詳しく解説します。
AI総合研究所では、AI導入の伴走支援を行っています。
お気軽にご相談ください。
FLuxシリーズの最新モデル「Flux.2」については、こちらの記事をご覧ください。 ▶︎Flux.2とは?主な特徴や使い方、料金体系をわかりやすく解説!
目次
FLUX.1とFLUX.1 Kontextの違い:文脈理解による次世代モデルへの進化
FLUX.1 Kontextのモデル別の違い:pro / max / dev の比較
FLUX.1 Kontext [pro]:反復編集に強い汎用モデル
FLUX.1 Kontext [max]:タイポグラフィと精密生成に特化
FLUX.1 Kontext [dev]:研究開発向けの軽量モデル
FLUX.1 Kontextによるキャラクター一貫性と反復編集の実例
図:一羽の鳥キャラクターから複数キャラクターによる物語的展開へ
FLUX.1 Kontextとは?
FLUX.1 Kontext(フラックス・ワン・コンテキスト)とは、テキストと画像を組み合わせたマルチモーダルなプロンプトにより、高速かつ柔軟に画像を生成・編集できるAIモデル群です。
従来の画像生成AIは、主にテキストだけを入力として画像を生成する「Text-to-Image(テキストから画像)」方式が主流でした。しかし、FLUX.1 Kontextは「テキスト+画像」の文脈(コンテキスト)を理解して画像を生成・編集するという大きな進化を遂げています。

このモデル群は、開発元であるBlack Forest Labs(BFL)が提供する画像生成プラットフォーム「FLUXシリーズ」の最新モデルとして、以下のような特徴を持ちます。
- 入力画像の一部を保ちながら、テキストで編集指示ができる「ローカル編集」
- 特定のキャラクターやデザイン要素を複数のシーンに一貫して反映
- スタイルを保持しながら、新しい画像を生成する「スタイル参照生成」
- 生成・編集の高速化(従来比最大8倍)
これにより、ユーザーは単なる画像生成にとどまらず、プロンプトベースで直感的かつ段階的な画像編集を行うことが可能になります。たとえば「彼女の顔にあるものを消して」→「彼女は今、晴れたフライブルクの街で自撮りしている」→「そこに雪が降ってきた」といったように、段階的に編集を重ねながらも、キャラクターの外観やスタイルを維持したまま創作を進められる点が大きな特徴です。

FLUX.1とFLUX.1 Kontextの違い:文脈理解による次世代モデルへの進化
FLUX.1 Kontextは、ベースモデルであるFLUX.1を拡張し、画像の文脈理解・編集・生成を統合的に行えるよう設計されたモデルです。以下に、両者の技術的な違いと進化点を整理し、図を交えてわかりやすく解説します。
| 比較項目 | FLUX.1 | FLUX.1 Kontext |
|---|---|---|
| 入力 | テキストのみ | テキスト+文脈画像 |
| 処理構造 | Double + Single Stream | 同様だがToken結合と時間オフセットを導入 |
| トークン処理 | 一括処理(画像・文混在) | 文脈トークンと出力トークンを論理的に分離 |
| 位置情報 | 3D RoPE(t=0固定) | 3D RoPE + 仮想タイムステップ |
| 学習目標 | 画像生成 | 画像生成+編集+スタイル保持 |
| モデル例 | FLUX.1 | FLUX.1 Kontext [pro], [max], [dev] |
【関連記事】
FLUX.1とは?使い方や料金、プロンプトを徹底解説!【画像生成AI】
1.モデル構造の違い:文脈画像の扱い
FLUX.1は主にテキストプロンプトをもとに新規画像を生成します。一方、FLUX.1 Kontextは「テキスト+文脈画像」の組み合わせを理解し、編集・追加・スタイル転写などの操作が可能です。
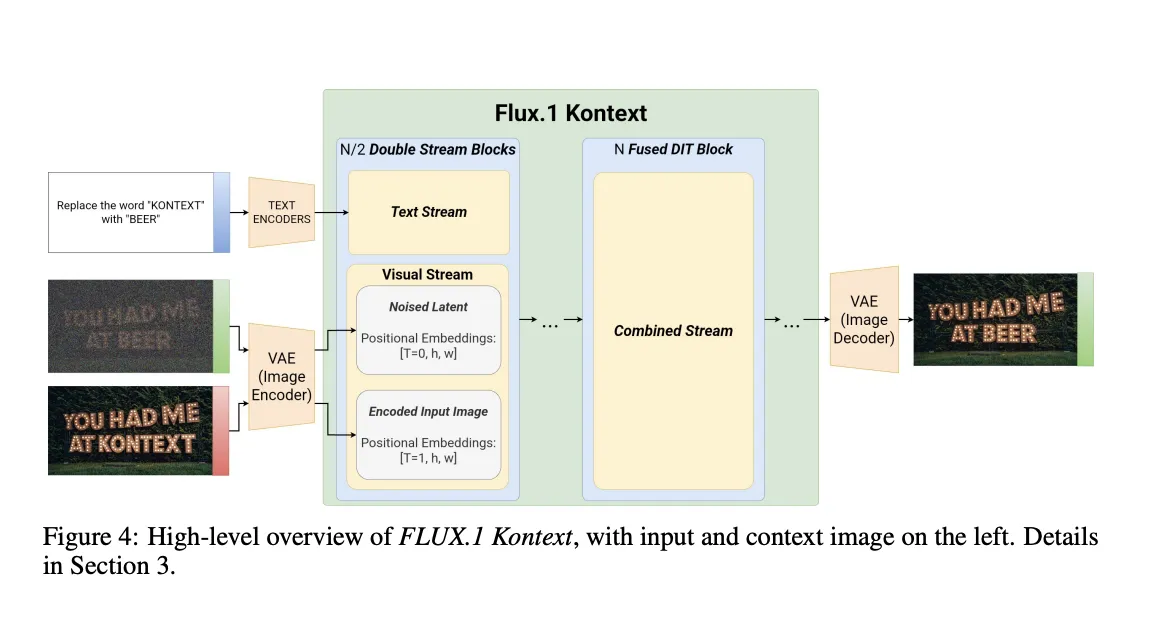
図1:FLUX.1 Kontextの高レベル構造(Figure 4)
左から順に、入力画像(context image)、編集指示文(command)、そして最終的に生成されるターゲット画像。文脈画像が与えられることで、モデルは「何を・どう編集するか」を理解し、出力画像に反映します。
2. トークン構成とポジショナル処理の違い
Kontextでは、画像を潜在トークン列に変換し、それに**3次元の位置情報(3D RoPE)を埋め込みます。さらに、文脈画像には時間ステップオフセット(t=1,2,3,...)**を加えることで、出力画像との論理的な区別を可能にします。
| トークン例 | 時間軸 | 高さ | 幅 |
|---|---|---|---|
| 出力画像 | t = 0 | h | w |
| 文脈画像1 | t = 1 | h | w |
| 文脈画像2 | t = 2 | h | w |
この工夫により、複数の文脈画像が扱いやすくなり、シーン内のスタイル・配置・特徴を統一したまま生成を続けることが可能になります。
3. DiTブロックの最適化と効率化
FLUX.1とKontextの両方に共通するDiT(Denoising Transformer)ブロックですが、Kontextではさらに高速化と安定性を追求した構成になっています。
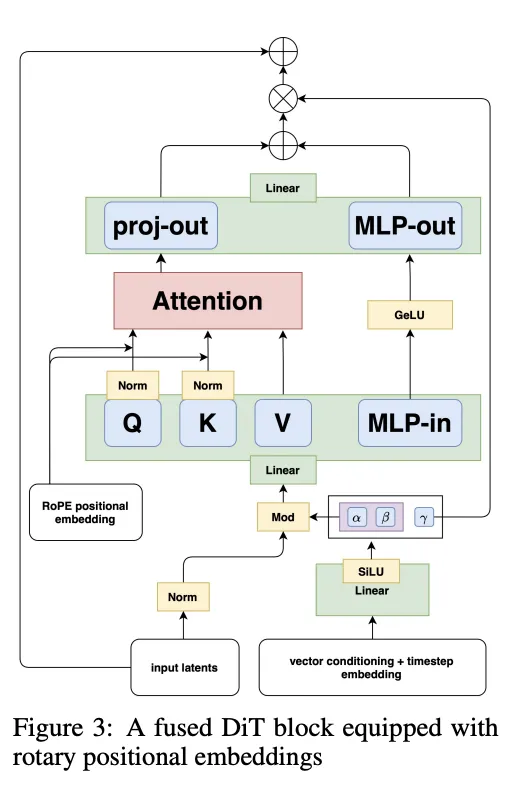
図2:FLUX.1/Fused DiT Blockの構造(Figure 3)
テキストと画像のトークンが統合され、Attention層・MLP・位置埋め込み(RoPE)・Modulation(α, β, γ)によって意味理解と画素制御が融合されます。
FLUX.1 Kontextでは、これに加えて以下の改良が加えられています:
- Fused Feed-forward Blocks による演算効率向上
- 3D RoPE の空間-時間埋め込み((t, h, w))
- Modulationのパラメータ数削減による軽量化
4. 学習目標の違いと応用範囲の拡大
FLUX.1は、主に「テキスト → 画像」のマッピングを学習しますが、FLUX.1 Kontextでは以下のような条件付き生成が学習目標になります:
ここで:
- x:ターゲット画像(出力)
- y:文脈画像(任意)
- c:自然言語による編集指示
この学習設計により、画像の細部を残したまま、部分編集やスタイル変換が可能になります。
FLUX.1 Kontextの主な特徴
FLUX.1 Kontextは、従来の画像生成AIとは一線を画す、多彩で高度な機能を備えたマルチモーダルモデルです。本セクションでは、特に注目すべき6つの特徴を整理し、それぞれの実用的な価値を明確に解説します。
1. テキストと画像を同時に理解できる“マルチモーダル入力”
FLUX.1 Kontextでは、自然言語プロンプトに加えて、画像そのものをコンテキスト(文脈)として活用できます。たとえば、既存画像に対して「このスタイルで別シーンを生成して」といった使い方が可能です。
- ✅ 例:夕焼けの風景画像 →「このスタイルで、森の中に犬がいるシーンを作って」
2. キャラクターや構造の“一貫性”を維持
一度登場させたキャラクターやオブジェクトの外見を、異なるシーンや角度でも維持できるのがFLUX.1 Kontextの強みです。これは、ストーリー仕立ての画像や連続シーンを作成する際に非常に有効です。
- ✅ 用途:マンガ、絵本、ブランド広告など
3. 特定箇所だけを変更できる“ローカル編集”
画像全体を作り直すのではなく、顔の向きだけを変える、看板の文字だけを変更するといった「ピンポイント編集」が可能です。従来はこうした部分編集には高度なツールやスキルが必要でしたが、Kontextでは自然言語で完結します。
- ✅ 例:「彼女の顔をカメラに向ける」「背景だけ夜にする」
4. スタイル参照機能:画像の“雰囲気”を引き継ぐ
1枚の参考画像からアートスタイルやカラーパレット、構図の特徴を抽出し、異なるシーンに適用できます。これはいわゆる**Style Transfer(スタイル転写)**を、自然言語と統合した形で実現したものです。
- ✅ 例:水彩画風の街 →「このスタイルで、猫が佇む裏路地を描いて」
5. 高速な推論とインタラクティブな応答性
FLUX.1 Kontextは、最大で従来比8倍の推論速度を実現しており、インタラクティブな画像生成・編集にも適しています。API経由でもGUI(BFL Playground)でも、高速なレスポンスが創作プロセスを途切れさせません。
- ✅ 実行環境:KreaAI、LeonardoAI、Freepikなど
6. ステップバイステップの“反復編集”に対応
生成後の画像をそのまま次のプロンプトに使って、少しずつ改良していく反復的なワークフローが可能です。生成内容を“積み上げる”ように進められるため、試行錯誤がしやすく、完成イメージに近づけやすいのが特徴です。
- ✅ 例:
Step 1:「女性の顔からマスクを消す」
Step 2:「晴れた日のフライブルクの街に移動」
Step 3:「街に雪を降らせる」
FLUX.1 Kontextのモデル別の違い:pro / max / dev の比較
FLUX.1 Kontextは、用途やユーザー層に応じて複数のモデルバリエーションを展開しています。ここでは、それぞれのモデルの特徴をわかりやすく比較し、どのような利用目的に適しているのかを明確に解説します。
🔽 各モデルの比較表
以下に、FLUX.1 Kontextのモデルごとの機能比較をまとめます。
| 項目 | [pro] | [max] | [dev](β) |
|---|---|---|---|
| 対応プロンプト形式 | テキスト+画像 | テキスト+画像 | テキスト+画像 |
| 局所編集(部分変更)対応 | ◎ | ○ | ◎ |
| スタイル保持性能 | ◎ | ◎ | ○ |
| タイポグラフィ性能 | ○ | ◎ | △ |
| 推論速度(低レイテンシ) | ◎ | ◎ | ○(軽量) |
| 利用可能性 | 一般公開 | 一般公開 | 限定公開中 |
| 提供プラットフォーム | KreaAI, OpenArtなど | 同左 | FAL, HuggingFaceなど予定 |
FLUX.1 Kontext [pro]:反復編集に強い汎用モデル
- 特長:最もバランスのとれたモデル。画像の局所編集・全体編集・新規生成すべてに対応。
- 対応入力:テキスト+画像(文脈画像)
- ユースケース:プロンプトベースで画像を繰り返し改良していくワークフロー(例:SNSコンテンツ、プロダクトデザイン案)
✅ 編集を繰り返しても、スタイルやキャラクターの一貫性を保つように設計されており、最も推奨されるモデルです。
FLUX.1 Kontext [max]:タイポグラフィと精密生成に特化
- 特長:プロンプト忠実度が高く、文字生成(例:“KONTEXT”と書かれた看板)やシーン構成の忠実さが求められる用途に強い。
- 描画品質:より高解像度/高忠実度な出力に最適化
- ユースケース:広告画像、ポスター、UIモックなど、細部表現が求められるデザイン作業
✅ 速度と品質を高いレベルで両立しており、「見たままに描く」性能に秀でています。
FLUX.1 Kontext [dev]:研究開発向けの軽量モデル
- 特長:オープンウェイトで提供予定の12B規模の軽量Diffusion Transformer。開発者や研究者向け。
- 利用形態:Private Beta(申請制)、API or カスタム環境での展開を想定
- ユースケース:カスタムファインチューニング、モデル評価、安全性検証など
✅ FLUX.1のエンコード/デコード互換性を維持しており、カスタマイズ性が高く、R&D用途に適しています。
補足:導入可能なプラットフォーム
すべてのモデルは、以下のようなプラットフォーム経由で利用可能です(一部は順次展開中):
- GUIベース:KreaAI, Freepik, LeonardoAI, Lightricks
- API/実装向け:Replicate, Runware, DataCrunch, TogetherAI, ComfyOrg
- 開発者向け公開:FLUX.1 Kontext [dev]は HuggingFace 経由で予定
FLUX.1 Kontextによるキャラクター一貫性と反復編集の実例
以下の画像は、FLUX.1 Kontextが同じキャラクターを文脈に応じて一貫して表現しながら、段階的に異なるシーンへ展開していく様子を示しています。

図:一羽の鳥キャラクターから複数キャラクターによる物語的展開へ
-
(b):「鳥がバーでビールを飲んでいる」
一羽のキャラクターから物語が始まります。 -
(c):「鳥が2羽になった」
同一の外見・装備(VRゴーグル)を持ったペアが登場し、視点が広がります。 -
(d):「背後から見る」
視点変更にもかかわらず、キャラクターの特徴が維持されています。 -
(e):「映画館にいる2羽の鳥」
背景が大きく変わっても、表情・ポーズが自然に変化し、物語が続いていることが明確です。 -
(f):「2羽の鳥がスーパーで買い物」
服装や体型、表情などを崩さず、日常的なシーンに移行。 -
(g):「成功を祝っている」
最後はオフィスのような場面で、両羽を挙げて感情豊かに締めくくられています。
このように、FLUX.1 Kontextは
- キャラクターの特徴を保ったまま、異なるシーンやアングルへ移行
- 反復プロンプトによりストーリー性のある画像列を段階的に構築
- 構図や環境を変更しながらも、視覚的な一貫性と自然さを維持
といった高度な制御を実現しています。
この機能は、ストーリーボード作成、絵本・漫画制作、教育コンテンツの一貫演出などに極めて有効です。

FLUX.1 Kontextの活用シーンとユースケース
FLUX.1 Kontextは、画像の生成と編集を柔軟かつ高速に行えるため、ビジネス、創作、教育などさまざまな分野で実用的に活用されています。このセクションでは、代表的な活用シーンを具体例とともに紹介します。
活用シーンまとめ
| 活用領域 | ユースケース例 | 対応モデル |
|---|---|---|
| プロダクト試作 | 色・柄のバリエーション生成 | [pro] |
| アート・創作 | スタイル参照による異なるシーンの生成 | [pro], [max] |
| 広告・SNS | タイポグラフィ変更、背景編集 | [max] |
| 教育・絵本制作 | キャラクター一貫性を持つストーリー構成 | [pro] |
| EC・販促画像 | 背景除去、部分抽出、素材のディテール表現 | [pro] |
- 女の人の動きを変える

女の人の動きの変化
- 一貫性のあるまま画像の変化
Flux Kontext Pro does pretty amazing AI haircuts - workflow on glif below pic.twitter.com/O5r9CkhzmX
— fabian (@fabianstelzer) June 3, 2025
- 古い写真画像のクリーンアップ
Flux Kontext is absolutely brilliant on restoring old photographs.
— Umesh (@umesh_ai) June 1, 2025
Some tips ⤵️ pic.twitter.com/PRttLHNNro
- 写真のスタイルを変える
Flux Kontext is blowing my mind!
— Ramón Teleco (@ramonteleco) May 30, 2025
Here are 5 use cases for applying AI as a designer 👇
1⃣ Change the hairstyle pic.twitter.com/ooz465DB5j
- リアルデザインのアシスタント
Flux Kontext is the most powerful design tool you’re not using (yet).
— NITISH JAIN (@MastersNitish) June 2, 2025
Most people think Flux is just for dev workflows.
But in the hands of architects and interior designers?
It becomes a real-time, logic-powered design assistant. pic.twitter.com/04AXnVAquU
FLUX.1 Kontextのベンチマーク評価結果
FLUX.1 Kontextは、その性能を定量的に検証するために独自のベンチマーク「KontextBench」で評価されています。ここでは、主に次の2点に注目して結果を紹介します:
FLUX.1 Kontextは、以下の6タスクで性能を評価されました。
| タスク名 | 内容の概要 |
|---|---|
| Text-to-Image Generation | テキストからの画像生成 |
| Image-to-Image Editing | 入力画像とテキスト指示による編集 |
| Character Preservation | キャラクターの外見一貫性の保持 |
| Style Reference Generation | 入力画像のスタイルを保持した別シーンの生成 |
| Local Editing | 一部だけを改変する編集 |
| Prompt Following | 指示文への忠実な画像出力 |
これらのタスクで、FLUX.1 Kontext [pro] は他の最先端モデル(例:GPT-Image系、SDXL系)と比較されました。
結果ハイライト(品質編)
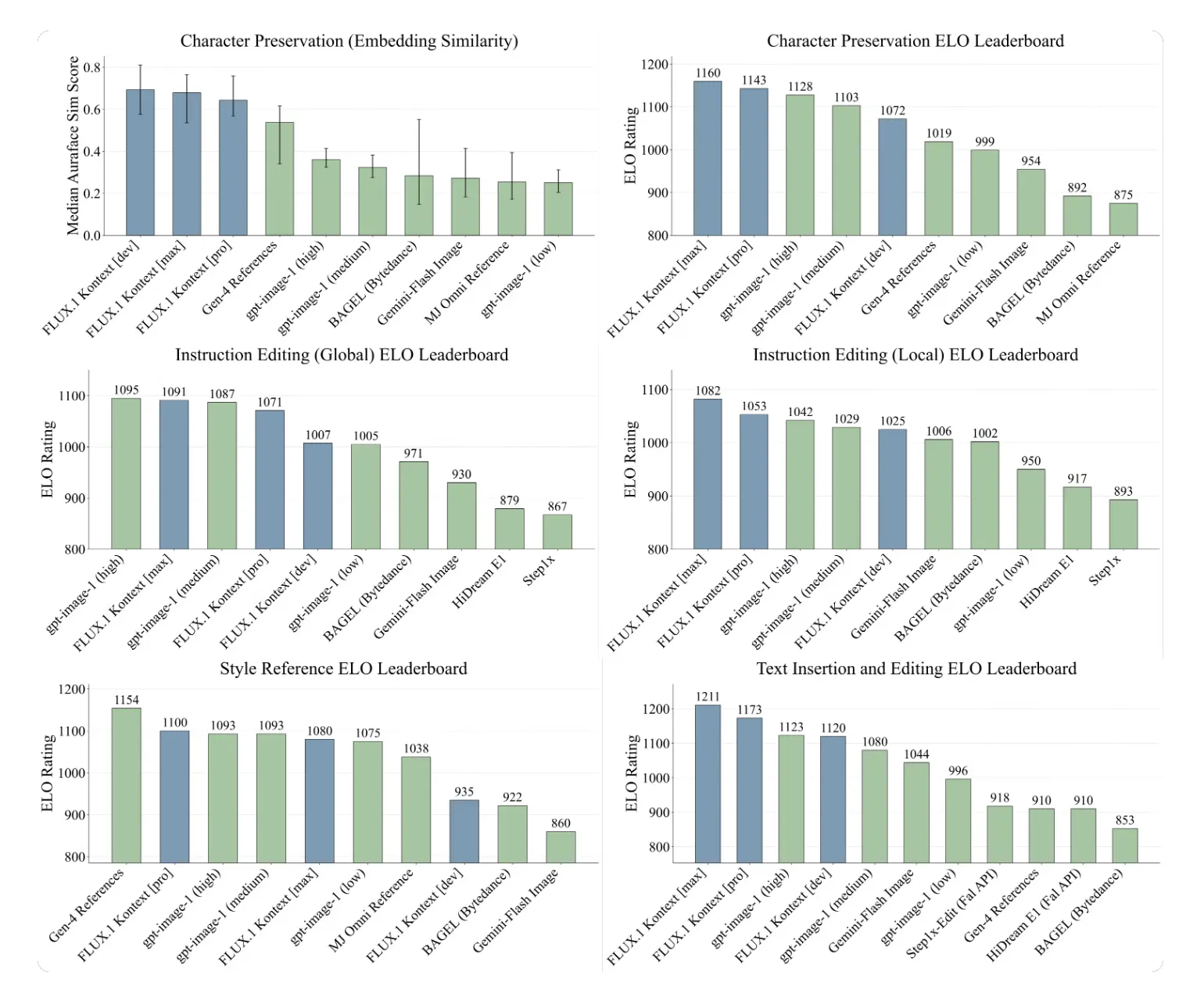
結果
- Text Editing(テキスト編集)とCharacter Preservation(キャラ一貫性)で最高スコア
- すべての6タスクで上位にランクインし、一貫した高評価を記録
- 特に「スタイル参照生成」では、指定したスタイルを保ったまま異なる構図のシーンを高精度で再構成
※実際の図表では、各タスクごとのランキングやスコア(例:Fidelity, Diversity)においてFLUX.1 Kontextが上位帯に位置しています。
結果ハイライト(速度編)
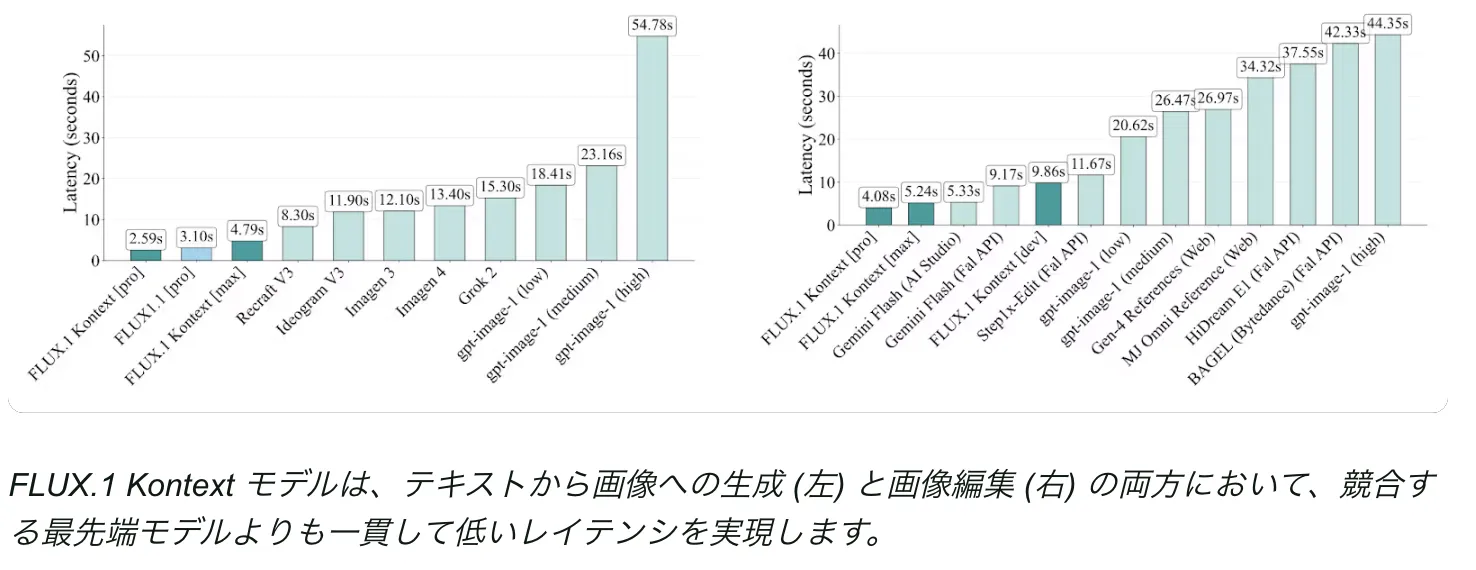
結果2
推論レイテンシの評価では、以下のような結果が得られました。
| モデル名 | Text-to-Imageレイテンシ | Image Editingレイテンシ |
|---|---|---|
| GPT-Image系 | 約3.2秒 | 約3.8秒 |
| FLUX.1 Kontext [pro] | 約0.4〜0.6秒(最大8倍高速) | 約0.5秒前後 |
- FLUX.1 Kontextは、他の最先端モデルと比べて最大8倍の高速化を実現
- API環境においても、リアルタイム応答性が高く、インタラクティブ編集に適していることが確認されています
FLUX.1 Kontextはどこで使える?プラットフォームと利用方法の実情
FLUX.1 Kontextは、研究開発レベルの先端技術でありながら、すでに一般ユーザーから開発者、法人まで幅広い層に向けて開かれています。使い方は大きく「ノーコードで使えるGUIサービス」と「API経由の組み込み利用」に分かれており、用途に応じて選ぶことが可能です。
まず、特別な知識がなくても試せるのがGUI型プラットフォームです。たとえばKreaAIやLeonardo.AIでは、テキストや画像をアップロードし、簡単な指示文を入力するだけで、FLUX.1 Kontextの画像生成機能が体験できます。SNS向け画像の量産、キャラクターの一貫性を保ったシリーズ作成など、プロンプトベースの操作で完結できる点が魅力です。
以下に、主要なGUI対応プラットフォームを一覧でまとめます。
| プラットフォーム名 | 特長 | 主なユーザー層 |
|---|---|---|
| KreaAI | 編集応答が高速。生成品質が高く、スタイル保持に強み | デザイナー、広告担当者 |
| Leonardo.AI | キャラ一貫性とポーズ制御に優れ、商用にも対応 | ゲーム制作、漫画家 |
| Freepik | 写真・商品素材の編集に強く、EC用途と親和性が高い | マーケティング担当 |
| Lightricks | 簡単操作でSNS投稿向け画像を作成可能 | インフルエンサー |
一方で、システムに組み込んで使いたい企業や開発者にとっては、API提供が重要になります。FLUX.1 KontextはReplicateやTogetherAIを通じてAPIでも利用可能であり、画像やテキストを送信するだけで編集済みの画像が返ってきます。業務アプリや社内ツールに組み込むのにも適しています。
APIベースの提供環境は以下のとおりです。
| 提供先プラットフォーム | 特長 | 想定用途 |
|---|---|---|
| Replicate | PythonやNode.jsで簡単に呼び出せる | PoC、プロト開発 |
| TogetherAI | 高速・安定したAPIで業務用途に適する | 本番環境での画像生成 |
| Runware | モバイル・エッジ推論など高速処理向け | インタラクティブアプリ |
| ComfyOrg | ComfyUIと連携し、ノードベースで構成可能 | ノーコード画像生成ワークフロー |
| DataCrunch | 自社モデルとの併用や負荷分散構成が可能 | ハイブリッド運用 |
さらに、研究やカスタム開発を行いたいユーザー向けには、「FLUX.1 Kontext [dev]」という軽量モデルも用意されています。これは12B規模のDiffusion Transformerで、HuggingFaceなどでの公開が予定されています。Private Betaとしての申請制ですが、独自データでのファインチューニングや安全性評価にも活用できます。
このように、FLUX.1 Kontextは単なる技術実験にとどまらず、実務に活かせる形で提供されているのが最大の特徴です。用途が明確であれば、目的に応じた導入手段が必ず見つかります。

画像生成AIの活用ノウハウを業務全体のAI化に広げるなら
FLUX.1 Kontextのような画像生成AIを業務に取り入れ始めた企業の次のステップは、クリエイティブ領域以外の業務にもAIを適用することです。データ集計・レポート生成・承認フローなど、定型的なバックオフィス業務はAIエージェントが代行できる段階に来ています。
AI総合研究所のAI業務自動化ガイドでは、どの業務領域から着手すべきか、段階的な導入ステップと効果測定の考え方を整理しています。画像生成AIで実感した「AIの業務適用力」を、組織全体の生産性向上につなげる参考としてご活用ください。
画像生成AIの知見を業務AI化に活かす

まとめ
FLUX.1 Kontextは、テキストと画像を同時に入力し、文脈を理解した画像の生成・編集を可能にする先進的なマルチモーダルAIです。従来の「テキスト→画像」生成とは異なり、文脈画像をもとにスタイルを継承した新規シーンを作成したり、キャラクターの外見を保ったまま複数シーンを展開するなど、高い一貫性と自由度を両立した画像操作を実現しています。
FLUX.1 Kontextは、編集や生成のたびにモデルの応答速度が落ちることもなく、最大8倍の高速処理でリアルタイムな作業にも対応可能です。複数のモデル(pro / max / dev)が提供されており、クリエイティブ制作から製品開発、教育、ECにいたるまで、幅広い実用例に対応します。
高品質な画像生成・編集をシームレスに実現したい企業・制作者にとって、FLUX.1 Kontextは次世代の選択肢と言えるでしょう。
AI総合研究所では、FLUX.1 Kontextの導入支援や活用方法についてのコンサルティングも行っています。興味のある方は、ぜひお問い合わせください。










