この記事のポイント
 経営層への説明責任が求められる場面では統計学を選ぶべき。「なぜそうなるか」を因果関係で示せるのは統計学だけ
経営層への説明責任が求められる場面では統計学を選ぶべき。「なぜそうなるか」を因果関係で示せるのは統計学だけ- 予測精度を最大化したいなら機械学習が最適。大量データからのパターン抽出は統計学では対応しきれない
- 実務ではEDA(探索的データ分析)に統計手法を使い、予測モデルに機械学習を適用する組み合わせが最も有効
- データ量が少ない初期フェーズでは統計学から始め、データ蓄積後に機械学習へ移行する段階的アプローチを取るべき
- 「どちらか一方」ではなく両方を使い分けられるデータ人材の育成が、データドリブン経営の成否を分ける

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
機械学習と統計学は、どちらもデータから知見を引き出す技術ですが、その目的とアプローチは異なります。機械学習は「予測精度の最大化」を、統計学は「データの構造理解と因果関係の解釈」を重視します。
本記事では、両分野の定義・主要手法の比較から、Irisデータセットを使った実践例、ビジネスシーンでの使い分け判断基準、さらにデータ分析に使える主要ツールと料金まで、体系的に解説します。
データ分析の手法選びに迷っている方は、自社の課題に合ったアプローチを見極める参考にしてください。
目次
機械学習と統計学の違いとは
機械学習と統計学は、どちらもデータから知見を引き出す技術ですが、目的とアプローチが根本的に異なります。
一言で表すなら、機械学習は「予測精度の最大化」を目指し、統計学は「データの構造理解と因果関係の解釈」を重視する分野です。
 AIおける機械学習の立ち位置
AIおける機械学習の立ち位置
機械学習はAI(人工知能)の一分野であり、データからパターンを自動的に学習し、新しいデータに対して予測や分類を行うシステムの開発に焦点を当てた手法です。一方の統計学は、データを収集・分析・解釈するための方法論を体系化した数学の一分野です。
以下の表で、両者の主な違いを整理しました。
| 項目 | 機械学習 | 統計学 |
|---|---|---|
| 目的 | 予測精度の最大化(「何が起きるか」を当てる) | データの構造理解・因果関係の解釈(「なぜそうなるか」を説明する) |
| アプローチ | アルゴリズムがデータからパターンを自動学習し、予測モデルを構築する | 数理モデルの仮定に基づき、仮説検定や推定で結論を導く |
| データ量 | 大量のデータほど精度が向上する傾向がある | 小さなサンプルからでも母集団について有意な結論を導ける |
| モデルの解釈性 | ブラックボックスになりやすい(特にディープラーニング) | モデルの係数や p値で結果を説明しやすい |
| 典型的な手法 | ニューラルネットワーク、ランダムフォレスト、XGBoost | 回帰分析、分散分析(ANOVA)、仮説検定 |
| 主な用途 | 画像認識、自然言語処理、レコメンド、需要予測 | 臨床試験の効果検証、マーケティングのA/Bテスト、政策評価 |
この比較から分かるのは、両者は競合関係ではなく補完関係にあるという点です。実務のデータ分析では、まず統計学的な手法(EDA=探索的データ分析)でデータの特性を把握し、その上で機械学習モデルを構築して予測に活用する——この組み合わせが主流になっています。

統計学の基礎と主要手法
統計学は、データを元にして意思決定を行うための数学的手法を提供する学問です。大きく「記述統計」と「推測統計」の2つに分かれます。
記述統計と推測統計
-
記述統計
データセットの特徴を要約し、全体像を把握するための手法です。平均、中央値、標準偏差、ヒストグラムなどを使ってデータの分布を可視化します。
-
推測統計
標本データから母集団全体の特性を推定する手法です。サンプルが全体を代表しているかどうかを確率論に基づいて判断します。
以下の表で、統計学の主要な手法をまとめました。
| 手法 | 説明 | 活用場面 |
|---|---|---|
| 記述統計 | 平均・中央値・標準偏差でデータを要約 | データの全体像把握 |
| 仮説検定 | 特定の仮説が統計的に有意かを検証 | 施策の効果検証(A/Bテスト等) |
| 回帰分析 | 変数間の関係性をモデル化し予測 | 売上予測、因果分析 |
| 分散分析(ANOVA) | 複数群間の平均値の差を検証 | 複数条件の比較実験 |
| 主成分分析(PCA) | 多次元データの主要な変動を抽出 | 次元削減、データの可視化 |
| ベイズ推定 | 事前知識とデータを組み合わせて推定 | 不確実性の定量化 |
これらの手法はビジネス、医学、政策策定、科学研究など幅広い領域で使われています。特に「なぜこの結果が出たのか」「この施策に効果があったのか」を説明する必要がある場面では、統計学的手法が不可欠です。

機械学習の基礎と主要手法
機械学習は、データからパターンを自動的に学習し、新しいデータに対して予測や分類を行う技術です。学習方法によって大きく4つのカテゴリに分かれます。
学習方法による分類
-
教師あり学習
正解ラベル付きのデータを使ってモデルを訓練し、新しいデータのラベルを予測する手法です。スパムメール判定や売上予測が代表例です。
-
教師なし学習
ラベルなしのデータからパターンやグループを発見する手法です。顧客セグメンテーションや異常検知に使われます。
-
強化学習
環境からのフィードバック(報酬)をもとに最適な行動を学習する手法です。ゲームAIやロボット制御で活用されています。
-
ディープラーニング
多層のニューラルネットワークを使い、画像・音声・テキストなどの複雑なデータから特徴を抽出する手法です。自然言語処理や画像認識の精度を飛躍的に向上させました。
代表的なアルゴリズム
以下の表で、機械学習の代表的なアルゴリズムと特徴をまとめました。
| アルゴリズム | カテゴリ | 特徴 |
|---|---|---|
| ランダムフォレスト | 教師あり | 複数の決定木を組み合わせ、過学習を抑えながら高精度な予測を実現 |
| XGBoost / LightGBM | 教師あり | 勾配ブースティング手法。構造化データの予測コンペで広く使われる |
| SVM | 教師あり | 特徴空間内で最適な境界線を見つけて分類。小〜中規模データに適する |
| k-最近傍法(kNN) | 教師あり | 最も近いk個のデータをもとに分類。シンプルだが計算コストが高い |
| k-平均法 | 教師なし | データをk個のクラスタに分割。顧客セグメンテーションの定番 |
| CNN | 深層学習 | 画像データの特徴を自動抽出。画像認識・物体検出に特化 |
| Transformer | 深層学習 | 自己注意機構でテキストの文脈を捉える。LLMの基盤技術 |
選択するアルゴリズムは、データの種類(構造化 or 非構造化)、データ量、求められる精度と解釈性のバランスによって異なります。


機械学習と統計学の使い分け
実務でデータ分析に取り組む際、「機械学習と統計学のどちらを使うべきか」は頻出の悩みです。ここでは判断基準を整理します。
統計学が適している場面
-
因果関係を明らかにしたいとき
「この施策によって売上が上がったのか」のように、原因と結果の関係を検証する場面では、仮説検定や回帰分析などの統計手法が適しています。
-
データが少ないとき
統計学は小さなサンプルサイズでも、適切な検定手法を選べば有意な結論を導けます。臨床試験や社会調査では数十〜数百件のデータで分析を行うことも珍しくありません。
-
意思決定の根拠を説明する必要があるとき
経営会議や規制当局への報告では「なぜこの結論に至ったか」の説明が求められます。統計モデルの係数やp値は、その説明材料として機能します。
機械学習が適している場面
-
予測精度を最大化したいとき
レコメンドエンジン、広告配信の最適化、需要予測など、「ロジックは問わず、とにかく精度が高ければよい」場面では機械学習が力を発揮します。
-
大量のデータがあるとき
データ量が増えるほど精度が向上するのが機械学習の特性です。数百万〜数億件のトランザクションデータやログデータの分析に適しています。
-
非構造化データを扱うとき
画像、テキスト、音声といった非構造化データの分析は、ディープラーニングをはじめとする機械学習の得意分野です。
実務では「組み合わせ」が主流
多くのデータサイエンスプロジェクトでは、まず統計学的な手法(EDA)でデータの全体像を把握し、変数間の関係性や外れ値を確認したうえで、機械学習モデルを構築して予測に活用する——という流れが標準的です。どちらか一方だけで完結するケースの方が少ないのが実態です。
統計学と機械学習の実践例
ここでは、機械学習の分野で広く知られているIris(アヤメ)データセットを使い、統計学的な分析と機械学習による予測の流れを具体的に示します。
Irisのデータセット
統計学的分析(EDA)
まずChatGPTのデータ分析機能を使い、基礎統計量を算出します。
プロンプトは以下のとおりです。
これらのデータを統計学的分析を行ってください。基礎統計をしっかり出して表形式にまとめてください。
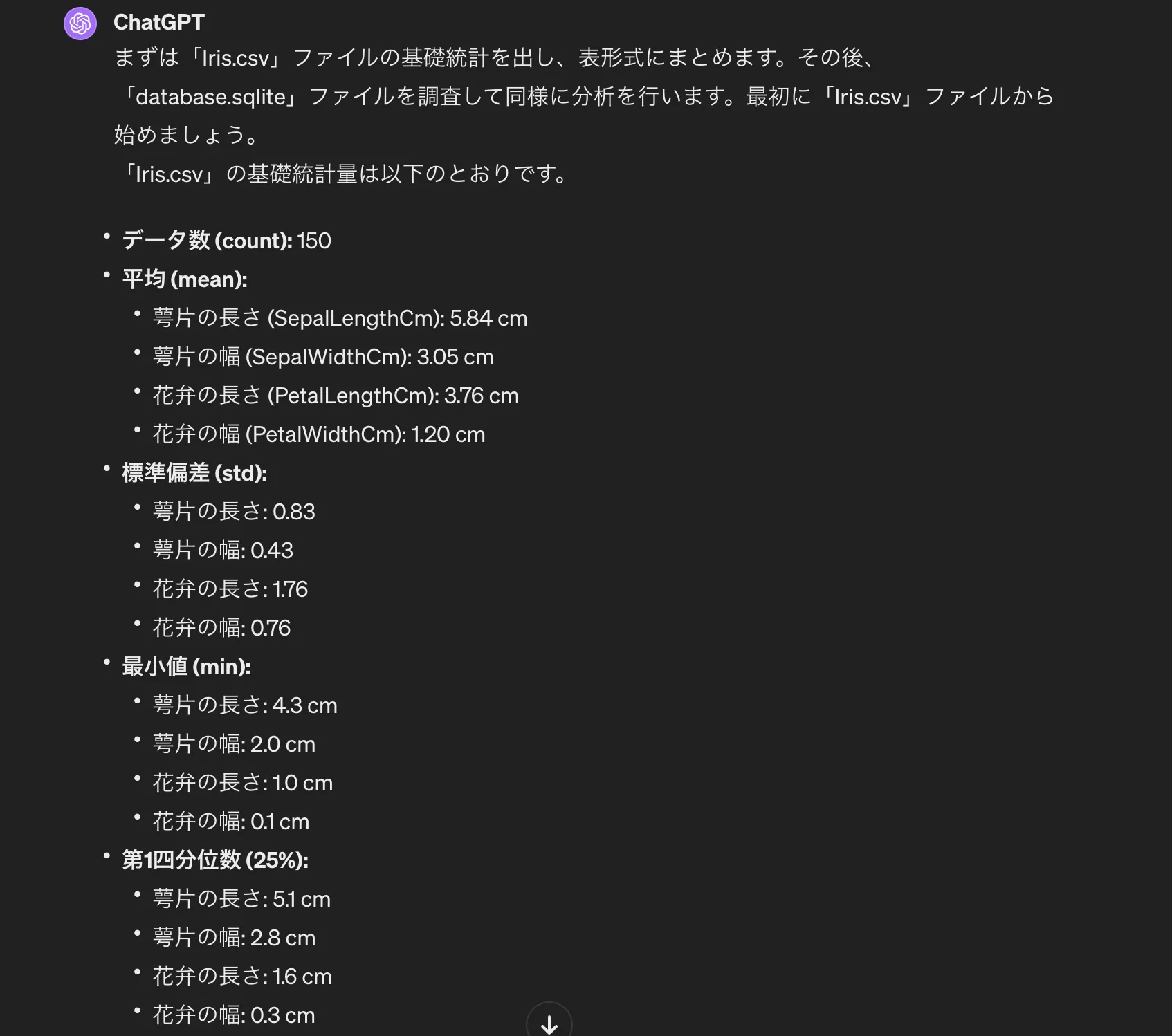
ChatGPTによる基礎統計量
以下がデータセットの基礎統計量です。
| 統計量 | 萼片の長さ (cm) | 萼片の幅 (cm) | 花弁の長さ (cm) | 花弁の幅 (cm) |
|---|---|---|---|---|
| データ数 | 150 | 150 | 150 | 150 |
| 平均 | 5.84 | 3.05 | 3.76 | 1.20 |
| 標準偏差 | 0.83 | 0.43 | 1.76 | 0.76 |
| 最小値 | 4.3 | 2.0 | 1.0 | 0.1 |
| 第1四分位数 | 5.1 | 2.8 | 1.6 | 0.3 |
| 中央値 | 5.8 | 3.0 | 4.35 | 1.3 |
| 第3四分位数 | 6.4 | 3.3 | 5.1 | 1.8 |
| 最大値 | 7.9 | 4.4 | 6.9 | 2.5 |
花弁の長さの標準偏差(1.76)が他の特徴量に比べて大きく、種類間で最も差が出やすい変数であることが読み取れます。
次に分散分析(ANOVA)で、3種類のアヤメ間に統計的に有意な差があるかを検証しました。
| 特徴 | p値 | Setosa中央値 | Versicolor中央値 | Virginica中央値 |
|---|---|---|---|---|
| 萼片の長さ | < 0.01 | 5.0 cm | 5.9 cm | 6.5 cm |
| 萼片の幅 | < 0.01 | 3.4 cm | 2.8 cm | 3.0 cm |
| 花弁の長さ | < 0.01 | 1.5 cm | 4.35 cm | 5.55 cm |
| 花弁の幅 | < 0.01 | 0.2 cm | 1.3 cm | 2.0 cm |
すべての特徴量でp値が0.01未満となっており、3種類間には統計的に有意な差があることが確認できます。特に花弁の長さと幅は、種類ごとの中央値の差が大きいため、分類に有効な変数だと判断できます。
機械学習モデルの構築
統計分析の結果を踏まえ、ランダムフォレストで分類モデルを構築します。
ランダムフォレストを行って。きちんと精度も示してください。

ランダムフォレスト結果
上記のとおり、高い精度で分類ができています。
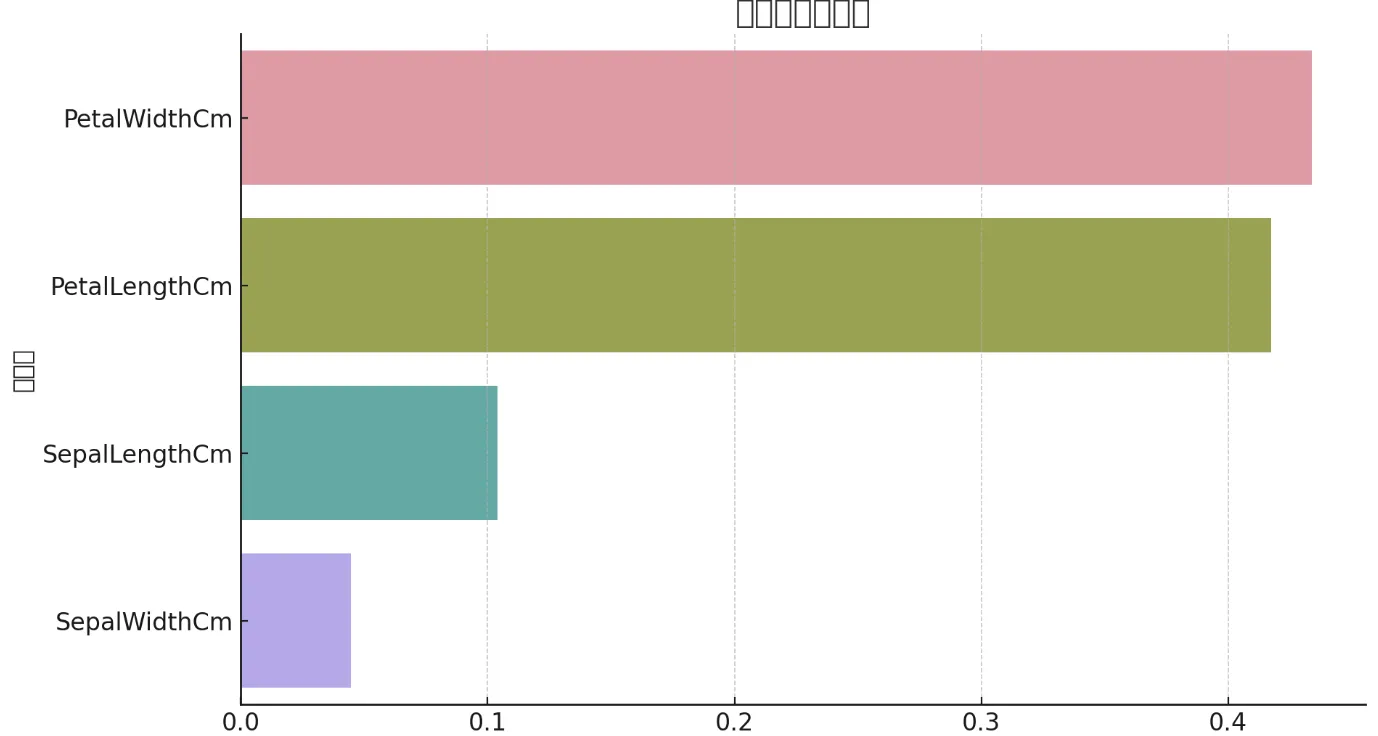
特徴量の重要度グラフ
特徴量の重要度を見ると、統計分析で示唆されたとおり花弁の幅と花弁の長さが最も重要な変数であることが確認できます。統計学で「どの変数に差があるか」を把握し、機械学習で「実際にどの程度正確に分類できるか」を検証する——この2段階の流れが、データ分析の基本パターンです。
データ分析に使えるツールと料金
機械学習や統計分析を実践するためのツールにはさまざまな選択肢があります。以下の表で代表的なツールを比較しました。
| ツール | 用途 | 料金(2026年2月時点) |
|---|---|---|
| Python + scikit-learn | 統計分析・機械学習の定番。無料で高機能 | 無料(オープンソース) |
| R | 統計分析に特化。学術分野で広く使用 | 無料(オープンソース) |
| Google Colaboratory | ブラウザ上でPythonを実行。GPU利用も可能 | 無料(Pro: 月額$11.79) |
| ChatGPT | データ分析機能でCSV読み込み→統計分析→可視化まで対応 | Free / Plus $20/月 / Pro $200/月 |
| Azure Machine Learning | エンタープライズ向けMLプラットフォーム | 従量課金(計算リソースに応じた課金) |
個人や小規模チームであれば、PythonとGoogle Colaboratoryの組み合わせで十分に始められます。企業で本格的にMLOpsを回す場合は、Azure Machine LearningやAWS SageMakerなどのマネージドサービスが運用効率の面で有利です。

【無料DL】AI業務自動化ガイド(220P)

Microsoft環境でのAI活用を徹底解説
Microsoft環境でのAI業務自動化・AIエージェント活用の完全ガイドです。Microsoft環境でのAI業務自動化の段階設計を詳しく解説します。
まとめ
本記事では、機械学習と統計学の違い、それぞれの主要手法、使い分けの判断基準、Irisデータセットを使った実践例、分析ツールの比較を解説しました。
機械学習は「何が起きるか」を高精度に予測する技術、統計学は「なぜそうなるか」をデータから説明する学問です。どちらが優れているかではなく、目的に応じて使い分ける——あるいは組み合わせる——のが実務の正解です。
まずは自社のデータを使ってEDA(探索的データ分析)から始め、統計的な特性を把握したうえで、予測が必要な場面に機械学習を適用する流れを試してみてください。










