この記事のポイント
 無料版でもPDF直接アップロードに対応し、1日3ファイルの制限内でGPT-5.5での要約・翻訳・抽出が可能
無料版でもPDF直接アップロードに対応し、1日3ファイルの制限内でGPT-5.5での要約・翻訳・抽出が可能- 有料プランは3時間ごとに最大80ファイル、1ファイル512MB・2Mトークンまで扱える設計
- 画像PDFの図表理解・厳密な引用元特定はChatGPTでは限界があり、Enterprise・OCR・別ツール併用が現実解
- 機密PDFはEnterprise・Business(旧Team)・APIを選択しデータ学習を回避、無料/Plusはオプトアウト設定が必須
- ユースケース別にプロンプトを設計し、Copilot・Gemini・Claudeと使い分けるのが業務利用の最適解

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTにPDFを読み込ませる機能は、無料版から法人向けEnterpriseまで全プランで利用でき、現在はGPT-5.5世代まで実装が進んだ業務の必須機能になっています。
要約・翻訳・データ抽出・複数文書の比較・校正までを1つのチャットで完結でき、長尺PDFを日常業務に組み込める実用段階に到達しています。
本記事では、2026年6月時点の最新情報をもとに、PDFを読み込ませる具体的な手順・読み込ませた後にできること/できないこと・プラン別の制限と対応形式・ユースケース別のプロンプト設計・読み込めない時の対処法・機密PDFのセキュリティ対策・Microsoft CopilotやGeminiなど他AIサービスとの比較まで体系的に解説します。
目次
ChatGPTでPDFを読み込ませた後にできること・できないこと
ChatGPTのPDF読み込み機能 2024〜2026年の主要アップデート
ChatGPTにPDFを読み込ませる方法の全体像
ChatGPTにPDFを読み込ませる手段は、2026年6月時点で直接アップロード・テキスト貼り付け・URL読み込み・カスタムGPT/Projectsの4系統に整理できます。
最も使い勝手が良いのは、チャット入力欄からPDFファイルを直接アップロードする方法です。OpenAI公式のFile Uploads FAQに明記されているとおり、無料プランからChatGPT Enterpriseまでの全プランで利用でき、PDFのテキストを抽出して要約・翻訳・抽出・分析に活用できる設計です。
本セクションでは、まず4方式の使い分けの一覧を示し、業務利用での主軸をどこに置くかを整理します。
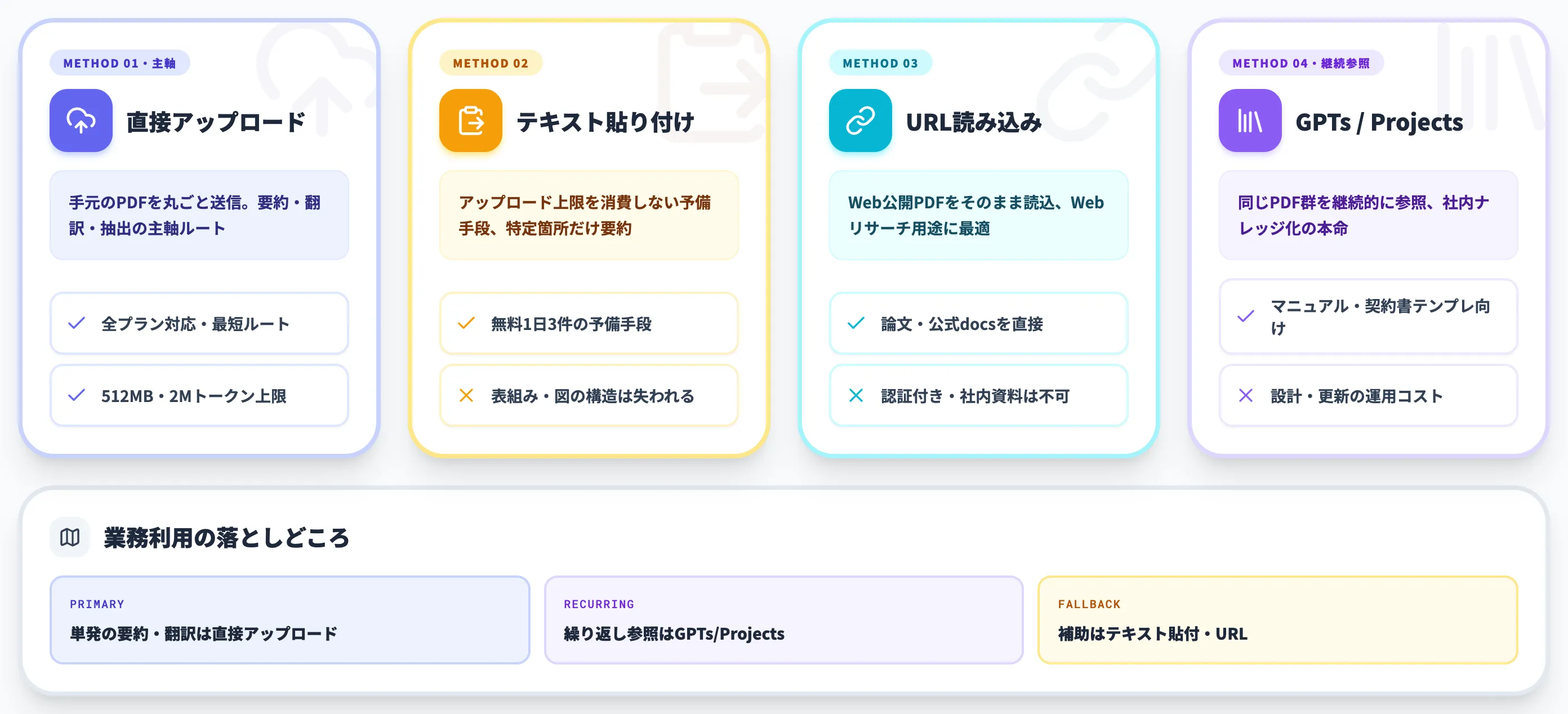
4つの読み込み方法と使い分け
現行の4つの読み込み方法は、それぞれ向き不向きがはっきり分かれます。以下の表で、用途別の選び方を整理しました。
| 方法 | 向いている場面 | 制約 |
|---|---|---|
| 直接アップロード | 手元のPDFを丸ごと読み込ませたい・要約や翻訳が主目的 | ファイルサイズ・トークン上限あり |
| テキスト貼り付け | アップロード上限を消費したくない・特定箇所だけ要約させたい | 表組み・図のレイアウトは伝わらない |
| URL読み込み | Web上に公開されたPDFをそのまま読ませたい | 認証・地域制限・JS依存サイトは取得不可 |
| カスタムGPT/Projects | 同じPDF群を継続的に参照させたい・社内ナレッジ化 | 設計・更新の運用コストが発生 |
業務でPDFを処理する場合の現実解は、単発の要約・翻訳なら直接アップロード、繰り返し参照するナレッジ系はカスタムGPTかProjectsという使い分けです。テキスト貼り付け方式は無料版で1日のアップロード上限(後段で詳述)に近づいた時の予備手段、URL読み込みはWebリサーチ用途、と棲み分けると業務途中で詰まりにくくなります。
旧Plugin手順を引きずらない

旧ChatGPT Pluginsは終了済みで、後継としてGPTs(カスタムGPT)とConnectorsが導入されています。Ask Your PDF・Link Reader・MixerBox ChatPDFといった当時の人気プラグインを前提にした古い解説記事に従うと、最初の数ステップで詰まります。
本記事はPlugin廃止後の現行運用を前提に整理しているため、まずは直接アップロードから試すのが最短ルートです。詳細な時系列は後段の制限・仕様セクションで振り返ります。

ChatGPTでPDFを読み込ませる具体的な手順
PDFをChatGPTに読み込ませる操作はシンプルで、PC・スマホのどちらでも数ステップで完了します。
ただし、無料プランと有料プランで挙動が若干違うため、本セクションではPC直接アップロード→スマホアプリ→カスタムGPT/Projects経由の順に手順を整理します。テキスト貼り付け・URL方式は補助的な扱いとして最後にまとめます。

PCでPDFを直接アップロードする手順
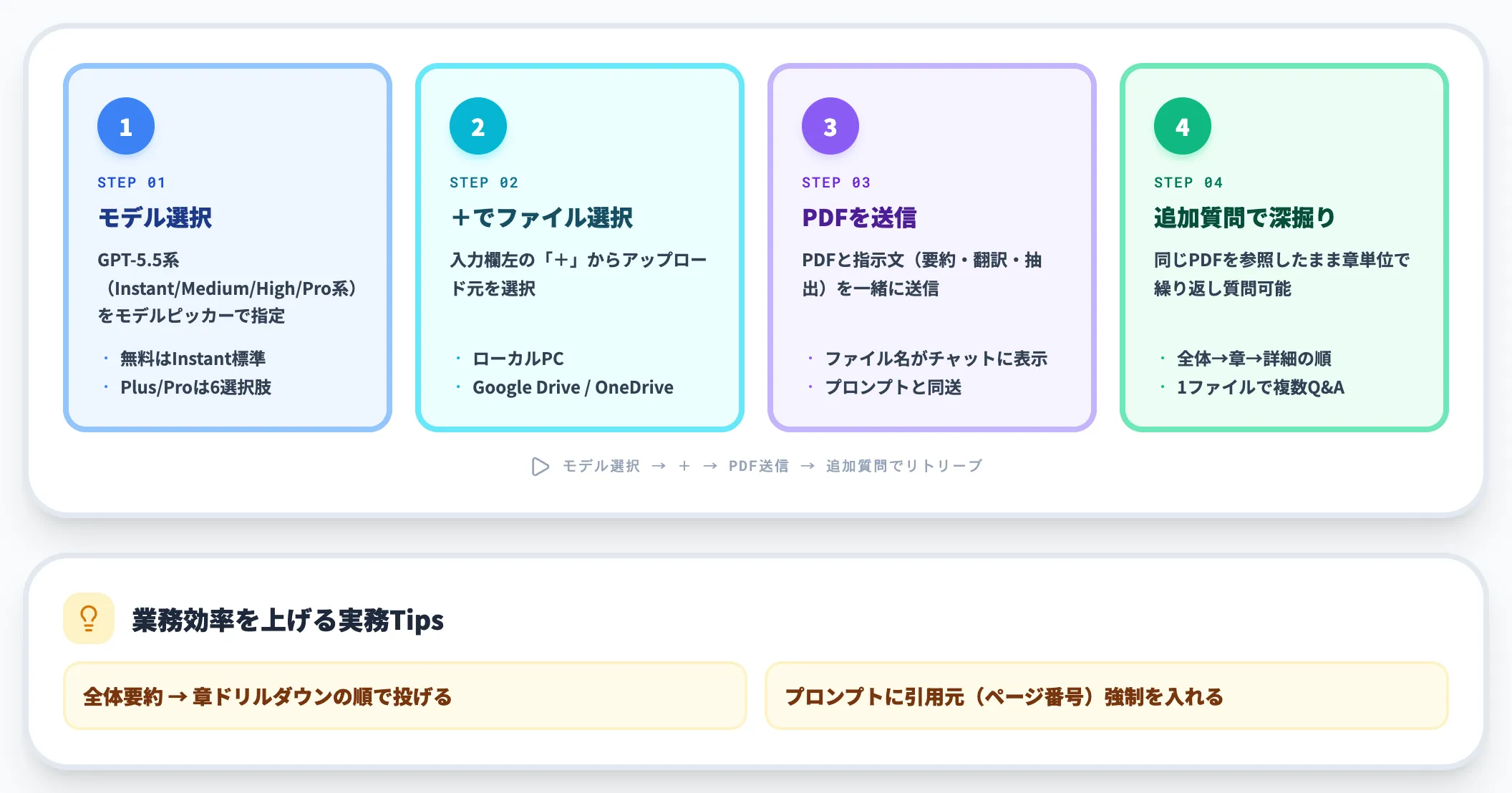
最も基本的な方法です。ChatGPT公式にログインしてから、以下の4ステップで完了します。
-
モデルを選択
画面上部のモデルセレクタからGPT-5.5系のPDF対応モデルを選びます。2026年6月10日のモデルピッカー刷新で、Plus/Proユーザーは Instant・Medium・High と、Pro限定の Extra High・Pro Standard・Pro Extended から選択する形式になりました。無料プランは Instant が標準、Enterprise/Edu系では旧表記(Auto/Instant/Thinking/Pro)が残るワークスペースもあります。
-
入力欄左の「+」をクリック
チャット入力欄左側のアイコンから「ファイルをアップロード」または「コンピューターからアップロード」を選択します。Google Drive・OneDriveに保存したPDFも同じUIから読み込めます。
-
PDFを選択して送信
ローカルのPDFを選択し、要約・翻訳・抽出などの指示文(プロンプト)と一緒に送信します。アップロードが完了するとファイル名がチャット欄に表示されます。
-
追加質問でリトリーブ
PDFの内容に対して追加質問すると、ChatGPTは同じファイルを参照して回答を返します。1ファイルで複数質問を繰り返せるので、まず全体要約を取り、章単位でドリルダウンする運用が効率的です。
このシンプルさが、Plugin廃止後にChatGPTのPDF処理が「外部サービスを噛ませる必要のない標準機能」として定着した理由です。
スマホアプリでPDFを読み込ませる場合
ChatGPTアプリ(iOS/Android)でも同様にPDFを扱えます。手順自体はPCと同じで、入力欄左の「+」からカメラ・写真・ファイルの選択肢が表示されます。
「ファイル」を選ぶと、iCloud Drive・Google Drive・Dropboxなどのクラウドストレージや、端末ローカルのPDFが選択できます。出張先や移動中に長文PDFを要約する用途に向いています。
ただし、スマホ画面では長文の回答が読みづらいため、PC側でアップロード→スマホ側で続き読みという運用がストレスが少ない実用形になります。チャット履歴は同期されるため、デバイスをまたいだ作業に支障はありません。
カスタムGPT・Projects経由で繰り返し参照する
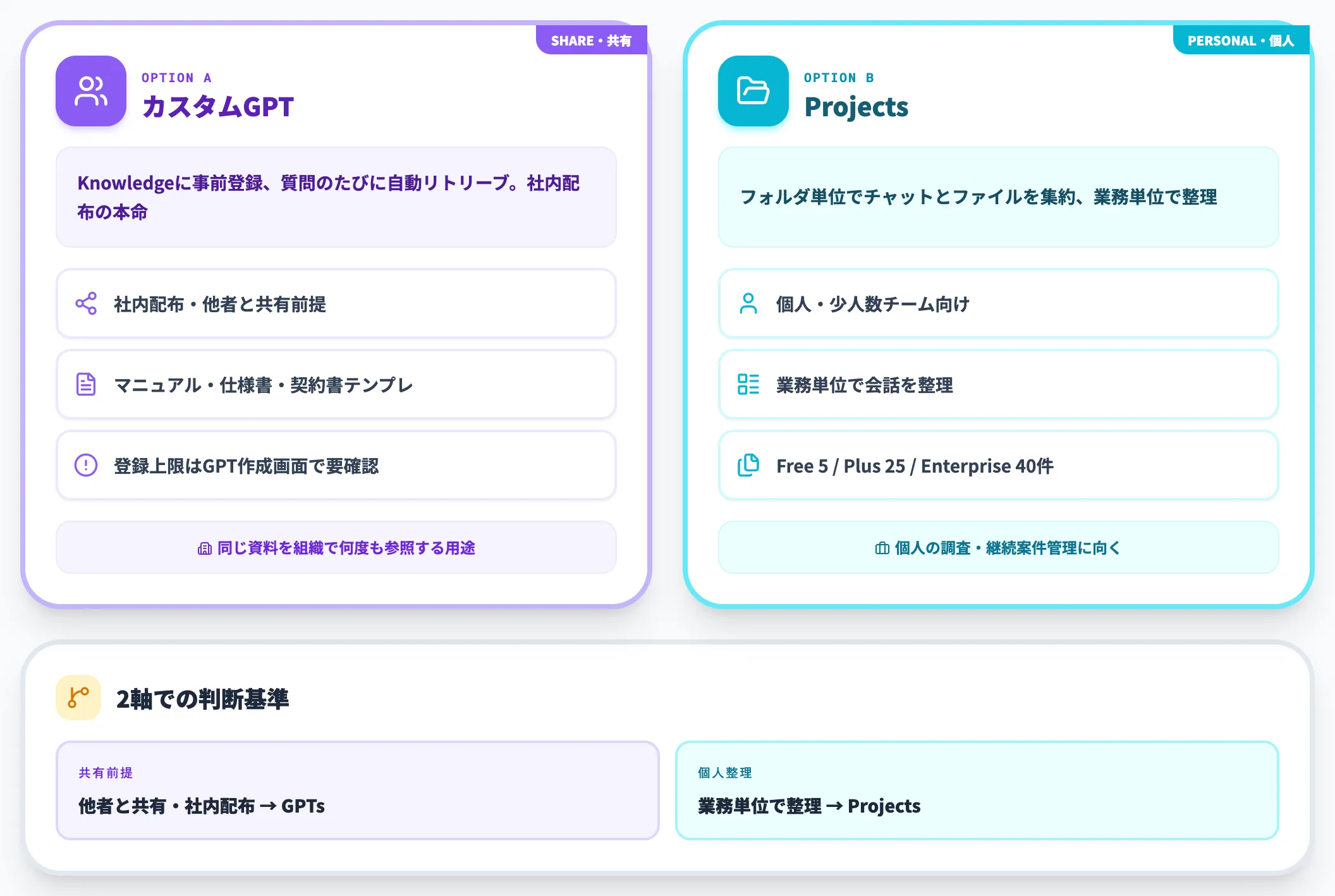
特定のPDF群を継続的に参照させたい場合、カスタムGPTかProjects(無料プランを含む各プランで利用可能)を使う方法が向いています。
カスタムGPTは、Knowledge(ナレッジ)としてPDFを事前登録でき、ユーザーが質問するたびに自動でリトリーブされます。社内マニュアル・製品仕様書・契約書テンプレートのような「同じ資料を何度も参照する」業務に適した設計です。なお登録可能ファイル数は公式ヘルプの記載値とFile Uploads FAQで差分があるため、最新の上限はGPT作成画面で確認してください。
Projectsは、フォルダ単位でチャットとファイルをまとめる機能で、公式のProjectsページでは Free 5・Go/Plus 25・Edu/Pro/Business(旧Team)/Enterprise 40 ファイル/プロジェクトとされています。
両者の違いは、「他者と共有する前提か」と「業務単位で会話を整理したいか」の差です。社内配布ならGPTs、個人や少人数のチーム運用ならProjectsが扱いやすい選択になります。
テキスト貼り付け・URL読み込みの位置づけ
直接アップロード以外の2方式は、現在の業務利用では補助的な位置づけになります。
-
テキスト貼り付け
PDFからテキストを直接コピーしてチャット欄に貼り付ける方法です。アップロード回数を消費しないため、無料プランで1日3ファイルの上限を使い切った後の予備手段になります。ただし、表組み・図表のレイアウトが失われるため、構造を持つ文書では精度が落ちます。長文の場合はChatGPTの文字数制限にも注意が必要です。
-
URL読み込み
Web上に公開されたPDFのURLを貼り付ける方法です。GPT-5.5系のWeb検索機能と組み合わせて、論文サイトや公式ドキュメントのPDFを直接読ませることが可能です。認証付き・地域制限・JS依存サイトでは取得に失敗するため、社内資料には向きません。
業務の主軸は直接アップロード、補助はテキスト貼り付け、Webリサーチ用途のみURL読み込みという順序で考えるのが現実的です。
ChatGPTでPDFを読み込ませた後にできること・できないこと
PDFを読み込ませた後の能力範囲を最初に押さえておくと、業務組み込み時の期待値ズレを避けられます。
ChatGPTは「PDFを読めれば何でもできる魔法のツール」ではなく、得意領域と苦手領域がはっきり分かれます。本セクションでは、業務で実際に通る用途と、別ツールや前処理が必要な用途を切り分けます。

ChatGPTがPDFで実現できること
ChatGPTがPDFを読み込んだ後の代表的な用途は、以下のように整理できます。
-
全文要約・章別要約
論文・契約書・調査レポート・議事録などのテキスト中心PDFを、読み手のレベルに合わせて要約。章単位で粒度を変えた要約も同じチャット内で繰り返せます。
-
多言語翻訳
英語・中国語・スペイン語など主要言語のPDFを日本語に翻訳。専門用語の業界慣例指定で訳語ゆらぎを抑えられます。
-
データ・固有名詞・数値の抽出
決算書・調査資料・カタログから、企業名・金額・日付・スペック値などの構造化情報を表形式で抽出。
-
複数文書の比較分析
契約書の差分、複数年度の決算書、競合資料の3社比較など、1メッセージで最大20ファイルまでの並列比較が可能。
-
校正・リライト
誤字脱字・冗長表現の指摘、文体トーンの統一、業界文書のリライト案生成。
-
Q&A形式の対話的リトリーブ
「○○については何が書いてある?」「○章の結論を3行で教えて」のような、検索+要約のハイブリッド質問。
-
レポート作成支援
読み込ませたPDFをソースに、社内向けの要約レポート、メール文、議事メモ案などを自動生成。
これらは「テキストとして表現できる情報」がPDF内に存在する限り、安定して再現できる領域です。
ChatGPTがPDFで不得意なこと・できないこと
一方で、ChatGPTには明確な限界もあります。期待しすぎると業務で事故るポイントを以下に整理します。
-
画像主体のスキャンPDFの内容理解
紙資料をスキャンしただけのPDFは、内部的に画像のみで構成されているため、テキスト抽出ができません。OCR前処理が必須になります。
-
図表・グラフの内容理解
標準プラン(Free・Plus・Pro・Business)はPDF内の画像を捨ててテキストだけを読みます。ChatGPT EnterpriseのVisual Retrieval for PDFを除き、グラフの数値や図の構造は伝わりません。
-
複雑な数式・化学式の正確な再現
LaTeXソースが埋め込まれていないPDFでは、上付き・下付き・特殊記号の解釈ミスが発生しやすく、数式の厳密な転記は人手確認が必要です。
-
厳密な引用元の特定
ページ番号や章番号の言及は精度100%ではなく、ハルシネーション(事実誤認)が混ざることがあります。法的文書や論文の引用には人手の二次確認が必須です。
-
リアルタイム情報の参照
PDFは固定されたスナップショットです。アップロード時点で古い情報が含まれていても、ChatGPTは「現時点の最新情報」として扱ってしまうため、日付や情報鮮度の指示が別途必要になります。
-
無条件に安全な機密処理
プラン選定とオプトアウト設定を整えない限り、機密PDFをそのまま投入するのはリスクがあります。詳細は機密PDFのセキュリティ対策セクションで整理します。
つまり、ChatGPTのPDF処理は**「テキスト情報の高度な操作」は得意、「視覚情報の解釈」「事実の厳密な保証」「未設定での機密保持」は限界がある**という性質です。この境界線を理解したうえで、プロンプト設計・前処理ツール・プラン選定を組み合わせるのが業務利用の現実解になります。
ChatGPTでPDFを扱うプランと制限・対応形式
ChatGPTでPDFを業務利用する前に押さえるべきが、プラン別の制限・ファイルサイズ・トークン上限・対応形式です。
ここでの理解が浅いと、業務途中で「20MBのPDFがアップロードできない」「画像主体のスキャンPDFが読み込めない」といったトラブルに直面します。本セクションでは、OpenAI公式のFile Uploads FAQを一次情報として、料金体系と仕様変更履歴も含めて整理します。
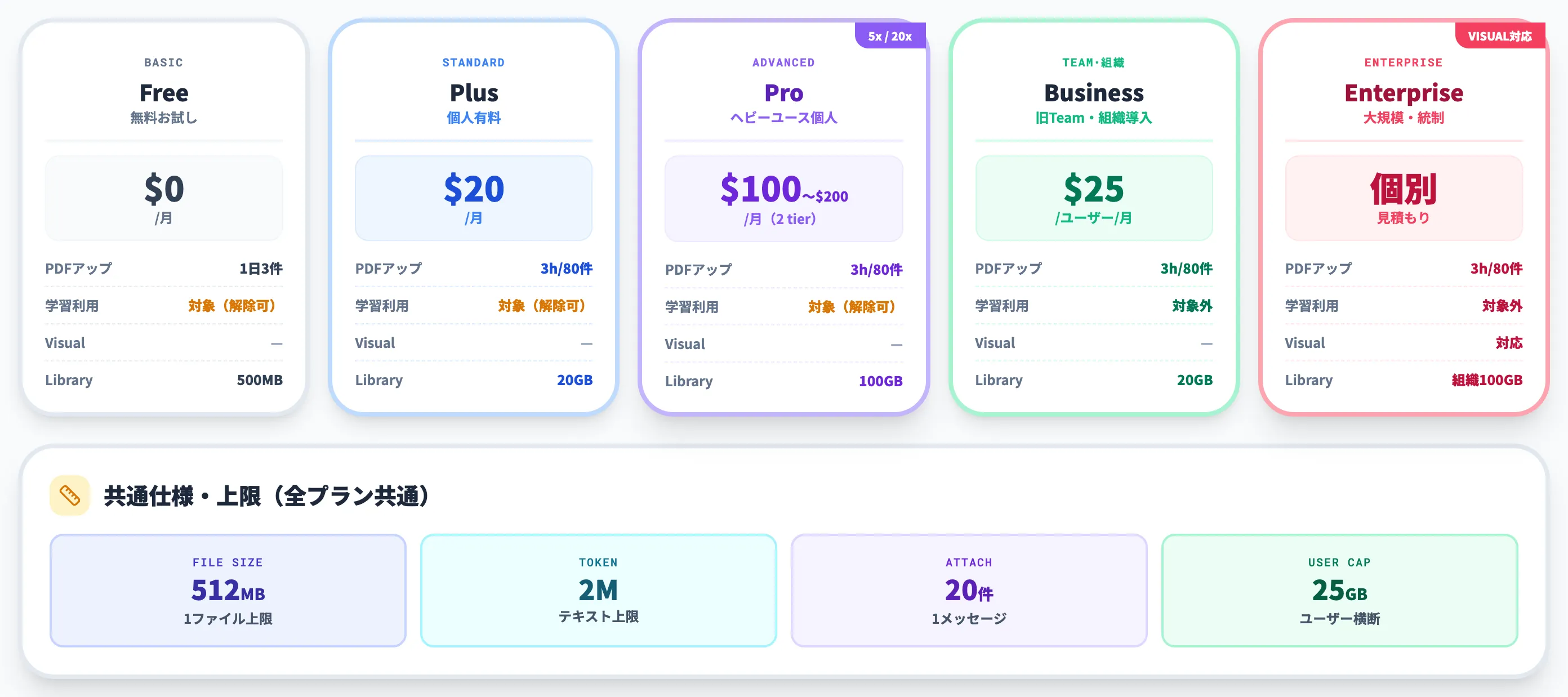
プラン別のPDF処理能力比較
ChatGPTの主要プランごとのPDF処理能力を表に整理しました。料金は2026年6月時点の標準価格です。
| プラン | 料金(月額) | アップロード上限(期間) | データ学習への利用 |
|---|---|---|---|
| Free(無料) | $0 | 1日3ファイル | デフォルトで利用される(オプトアウト可) |
| ChatGPT Plus | $20 | 3時間ごとに最大80ファイル | デフォルトで利用される(オプトアウト可) |
| ChatGPT Pro | $100(Plusの5倍枠)/$200(Plusの20倍枠) | 3時間ごとに最大80ファイル | デフォルトで利用される(オプトアウト可) |
| ChatGPT Business(旧Team) | $25/ユーザー(年払いは$20/ユーザー/月) | 3時間ごとに最大80ファイル | 学習に利用されない |
| ChatGPT Enterprise | 個別見積もり | 3時間ごとに最大80ファイル | 学習に利用されない+Visual Retrieval for PDF対応 |
2025年8月29日にChatGPT TeamはChatGPT Businessへ改名されています。改名時点では価格・機能・上限に変更はありませんでしたが、2026年4月以降はBusiness公式ページで座席種別や現行料金の追加が入っているため、契約前に最新条件を確認する運用が必要です。2026年以降の契約・請求書・社内文書はBusinessの名称で扱う運用が標準です。
無料プランは1日3ファイルという厳しい制限がありますが、同じGPT-5.5系を使えるためPDFの要約・翻訳・抽出を試すこと自体は可能です。ただし利用量・文脈長・モデル選択(Pro 2 tier・Plus/Pro限定モデル)の自由度では有料プランが有利で、Plus以上は3時間で80ファイルまで処理できるため、調査・リサーチ業務でPDFを大量に流し込む使い方に耐えます。プラン別の機能差の詳細はChatGPTの無料版と有料版の違いもあわせて参照してください。
ファイルサイズ・トークン上限の制約

PDFのアップロードには、サイズとトークン量の両方に上限があります。OpenAI公式FAQに明記されている主要な数値は以下のとおりです。
| 制限項目 | 上限値 | 補足 |
|---|---|---|
| 1ファイルのサイズ | 512MB | スプレッドシートは約50MB、画像は20MB |
| テキスト・ドキュメントのトークン量 | 2Mトークン/ファイル | スプレッドシートには適用なし |
| アップロード利用キャップ(ユーザー) | 25GB | チャット・GPTs・Projects横断のキャップ |
| アップロード利用キャップ(組織) | 100GB | BusinessやEnterpriseの組織単位キャップ |
| Library保存容量(プラン別) | Free 500MB/Go 4GB/Plus・Business 20GB/Pro 100GB | 日次添付・チャット上限とは別に管理される保存容量、Libraryに残るファイルが対象 |
| 1メッセージあたりの添付数 | 20ファイル | 2026年2月の上限拡張で10→20に |
| カスタムGPTのナレッジファイル | 作成画面の表示上限を参照 | File Uploads FAQと「Creating and editing GPTs」で記載差分あり |
| Projectsのファイル数 | Free:5/Go・Plus:25/Edu・Pro・Business・Enterprise:40 | 公式Projectsページ準拠(2026年6月時点) |
**実務で最初に詰まりやすいのが「2Mトークン上限」**です。テキスト中心のPDFなら100ページ程度は数MB・数十万トークンに収まるため通常は問題になりませんが、議事録の音声起こしを束ねたPDFや、英日対訳の大量文書では2Mトークンに近づくケースがあります。詰まったらPDFを章単位に分割するのが最短の対処になります。
対応ファイル形式と画像処理の挙動
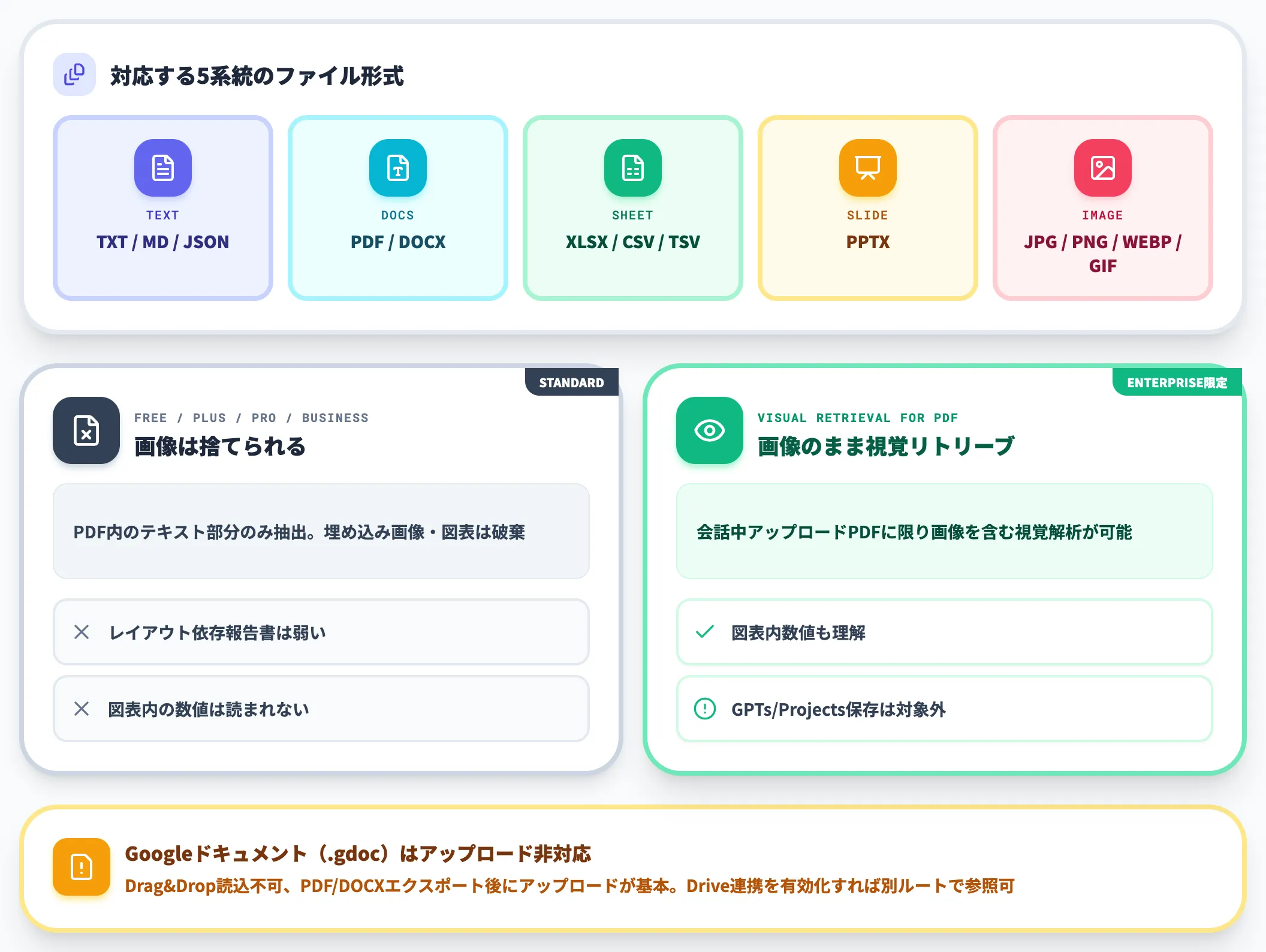
ChatGPTがアップロードで受け取れる主な形式は、OpenAI公式の対応形式一覧で以下のように整理されています。
- テキスト系:TXT・MD・JSON
- ドキュメント系:PDF・DOCX
- スプレッドシート系:XLSX・XLS・CSV・TSV
- プレゼンテーション系:PPTX
- 画像系:JPG・PNG・WEBP・GIF(GPT-5.5系のVision対応モデル)
注意したいのが、画像を含むPDFの扱いです。標準プラン(Free・Plus・Pro・Business)はPDFのテキスト部分のみを抽出し、埋め込まれた画像は捨てられます。レイアウトに依存する報告書や、画像メインのスキャンPDFを直接アップロードしても、図の内容には触れられません。
ChatGPT Enterpriseに限り、Visual Retrieval for PDF機能が利用でき、PDF内の画像も視覚的にリトリーブできます。なおVisual Retrievalの対象は会話中にアップロードしたPDFであって、GPTsのKnowledgeやProjectsに保存したPDFはテキストベース処理のままです。図表入りの社内資料を継続的に扱う前提なら、Enterprise契約がコスト面で正当化されやすい領域です。
なお、OpenAI公式はGoogleドキュメント(.gdoc)はアップロード方式では非対応と明記しています。Drag&Dropでは読み込めないため、PDFまたはDOCXにエクスポートしてからアップロードする運用が基本です。なおChatGPTのGoogle Drive連携を有効化すれば、Drive内のDocs/Sheets/Slidesを別ルートで参照させることができます。
ChatGPTのPDF読み込み機能 2024〜2026年の主要アップデート
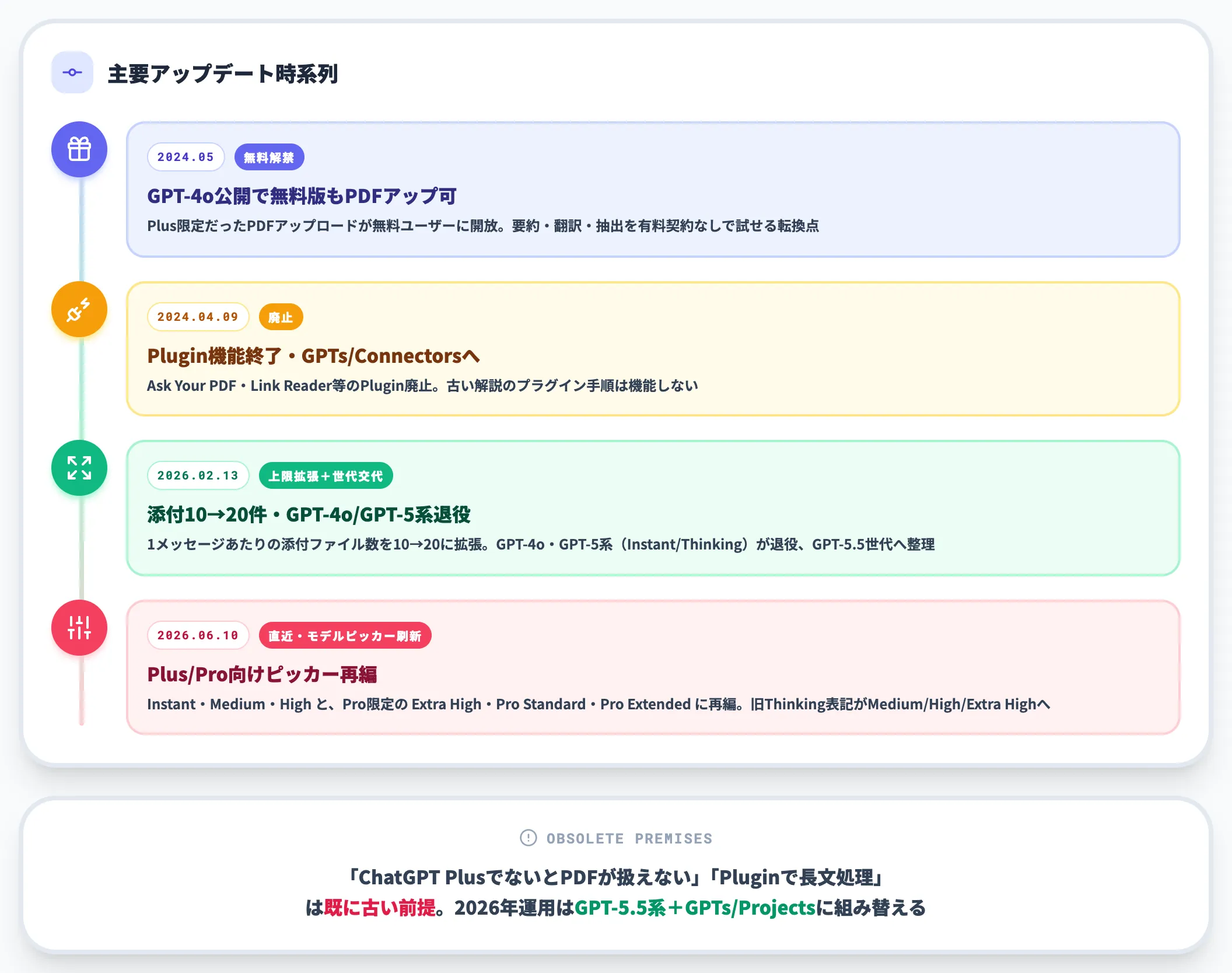
PDF読み込みは2024年以降に前提が大きく変わっています。古い解説記事のままだと「使えない方法」を選んでしまうため、主要な変化を時系列で押さえておきます。
-
2024年5月:GPT-4o公開で無料版にもファイルアップロード解禁
それまでChatGPT Plus限定だったPDFアップロード機能が、無料ユーザーにも開放されました(OpenAIのGPT-4o発表)。要約・翻訳・抽出を有料契約なしで試せるようになった転換点です。なおGPT-4o自体は2026年2月13日にChatGPTから退役済みで、現行はGPT-5.5系が中心です。
-
2024年4月9日:Plugin機能の終了
Ask Your PDF・Link Reader・MixerBox ChatPDFなどのChatGPT Pluginsは提供を終了し、後継としてGPTs(カスタムGPT)とConnectorsが導入されました。古い記事で紹介されているPlugin手順は、現在は機能しません。
-
2026年2月13日:アップロード上限の拡張
ChatGPTのリリースノートで、1メッセージあたりの添付ファイル数が10から20に拡張されました。長尺PDFを分割投入する運用が現実的になっています。
-
2026年2月13日:GPT-4o・GPT-5(Instant/Thinking)等の退役
OpenAI公式で、ChatGPTのモデルピッカーはGPT-5.5系に整理されました。旧モデルを使っていた会話やGPTsも後継モデルへ移行され、現行のGPT-5.5系を前提にPDF処理を行う運用へ変わっています。
-
2026年6月10日:モデルピッカーの簡素化
OpenAIリリースノートで、Plus/Pro向けのモデルピッカーが Instant・Medium・High と、Pro限定の Extra High・Pro Standard・Pro Extended に再編されました。旧Thinking Standard/Extended/HeavyはそれぞれMedium/High/Extra Highへ。Enterprise/Edu系では旧表記が残るケースがあるため、組織内の解説資料は両表記を併記するのが安全です。
これらの変化を踏まえると、「ChatGPT PlusでないとPDFが扱えない」「Pluginを使えば長文も処理できる」といった2023〜2024年前半の前提は、すでに古い情報になっています。
ChatGPTでPDFを活用するユースケース別プロンプト
ChatGPTにPDFを読み込ませた後、何を指示するかで成果物の質が大きく変わります。
漠然と「要約して」と投げるだけでは、章ごとの粒度や重視する観点が伝わらず、出力が表層的になりがちです。本セクションでは、業務でよく使う5つのユースケース別にプロンプト設計の型を提示します。
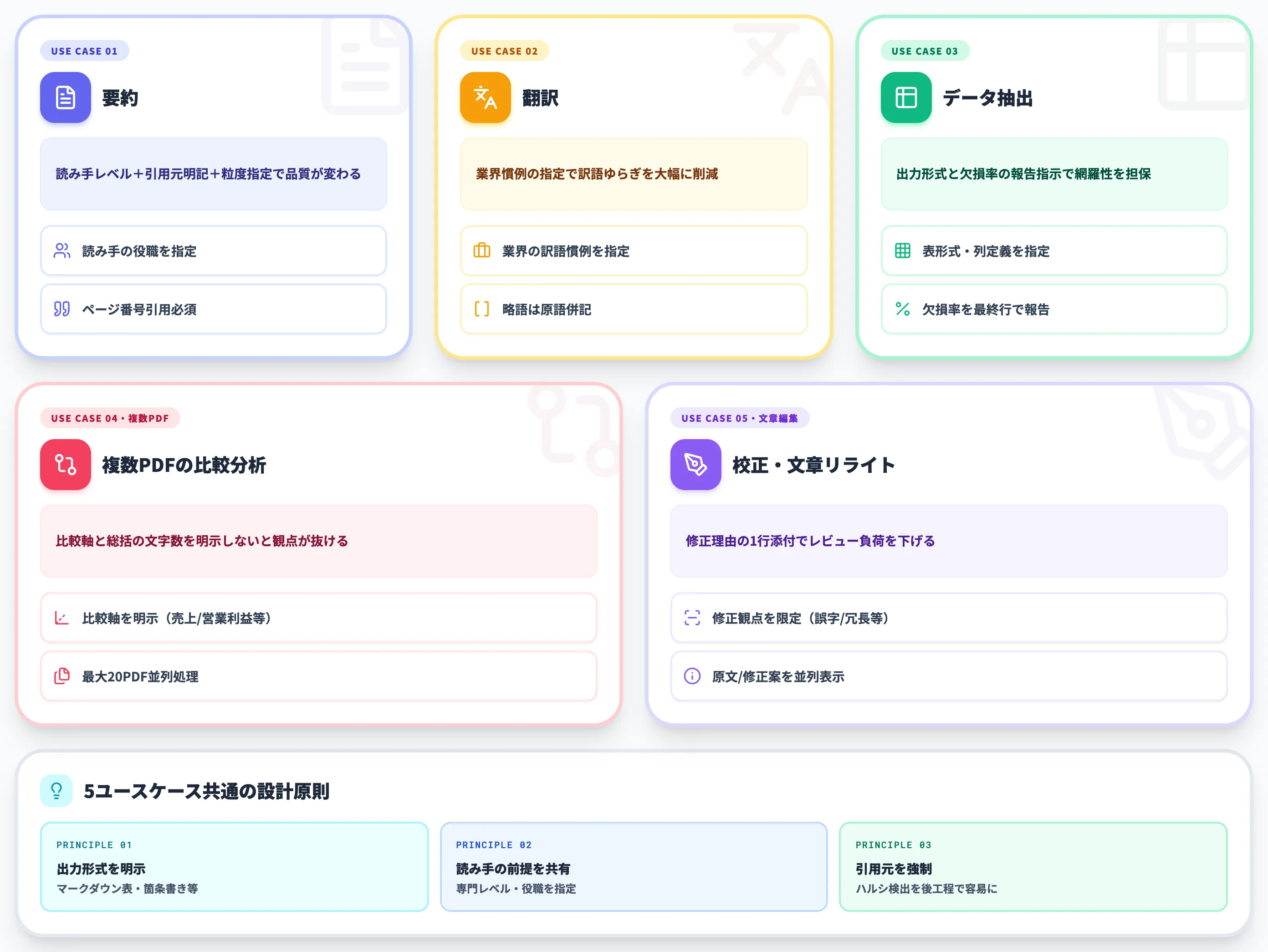
PDFの要約
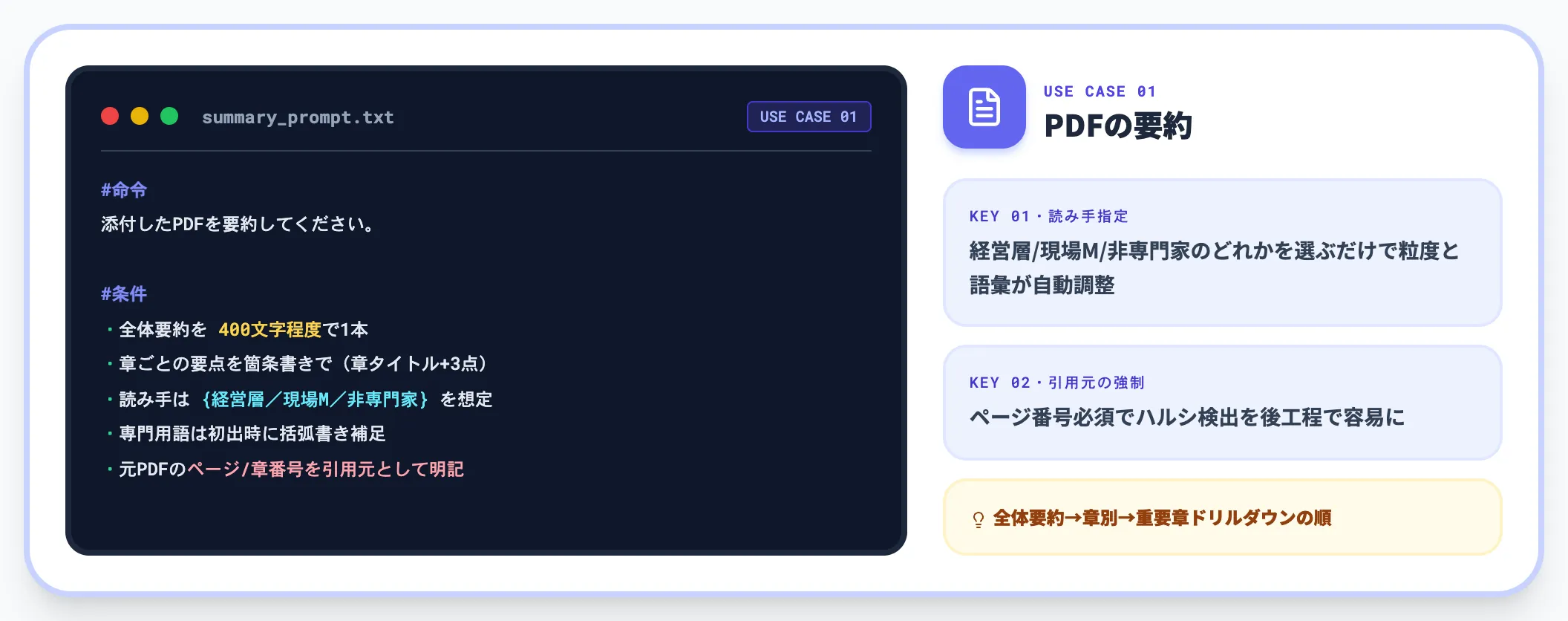
要約は最も使われる用途ですが、出力の粒度・観点・読み手を指定するかで品質が変わります。詳細はChatGPTを活用した要約のやり方で個別に解説していますが、PDF要約に最低限入れたい要素は以下のとおりです。
#命令
添付したPDFを要約してください。
#条件
・全体要約を400文字程度で1本
・章ごとの要点を箇条書きで(章タイトル+3点の要点)
・読み手は{経営層/現場マネージャー/非専門家}を想定
・専門用語が出てきたら初出時に括弧書きで補足
・元PDFのページ番号または章番号を引用元として明記
このプロンプトは、**「読み手のレベル」と「引用元の明記」**を必ず指示するのがコツです。ページ番号の明記を求めると、ハルシネーション(事実誤認)を後から検出しやすくなります。
PDFの翻訳

英文の論文・契約書・調査レポートを日本語化するときに、翻訳精度を上げる定石があります。詳細はChatGPTで翻訳を行う方法で扱っていますが、PDF翻訳に特化した型は以下のようになります。
#命令
添付したPDFを日本語に翻訳してください。
#条件
・原文の段落構造を保持する
・専門用語は{業界名}の慣例に沿って訳語を選ぶ
・固有名詞・略語は初出時にカタカナ+原語併記(例:エクスポージャー(exposure))
・図表のキャプションは「【図1】〜」のように番号付きで残す
・原文の意図が曖昧な箇所は「(原文:xxx)」として注記
専門用語の訳語ゆらぎは、業界ごとの慣例を指定するだけで大幅に減ります。法律・金融・医療など語彙が固定された業界では、この一行を入れるかどうかで読みやすさが別物になります。
PDFからのデータ抽出
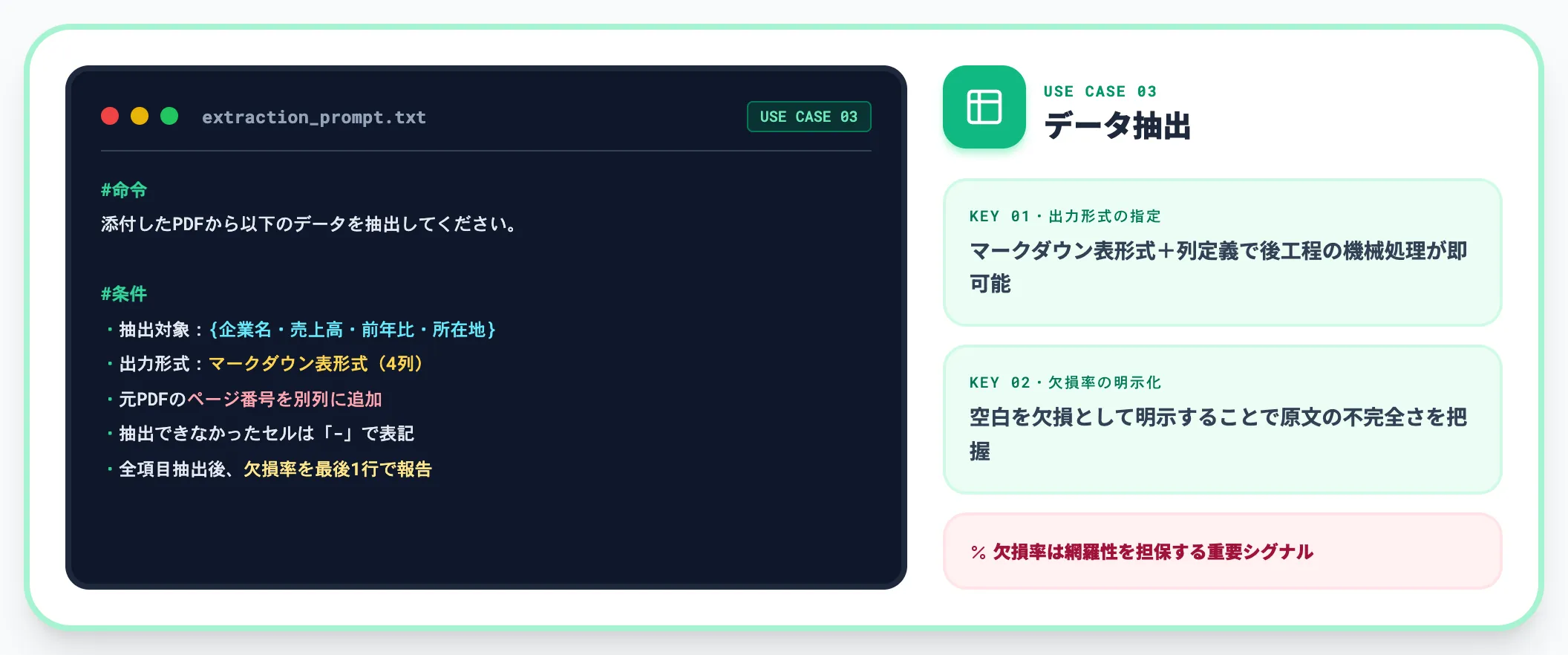
調査資料や決算書から表組み・固有名詞・数値だけを取り出したい場合に有効な型です。出力形式を表構造で指定するのがポイントになります。
#命令
添付したPDFから以下のデータを抽出してください。
#条件
・抽出対象:{企業名・売上高・前年比・所在地}
・出力形式:マークダウンの表形式(4列)
・元PDFのページ番号を別列に追加
・抽出できなかったセルは「-」で表記
・全項目を抽出した後、欠損率を最後に1行で報告
**「抽出できなかった項目を空白にせず欠損として明示」**させると、PDFのOCR品質や原文の不完全さを把握できます。網羅性を担保したいリサーチ業務では、この欠損率の確認が後工程の精度を左右します。
複数PDFの比較分析
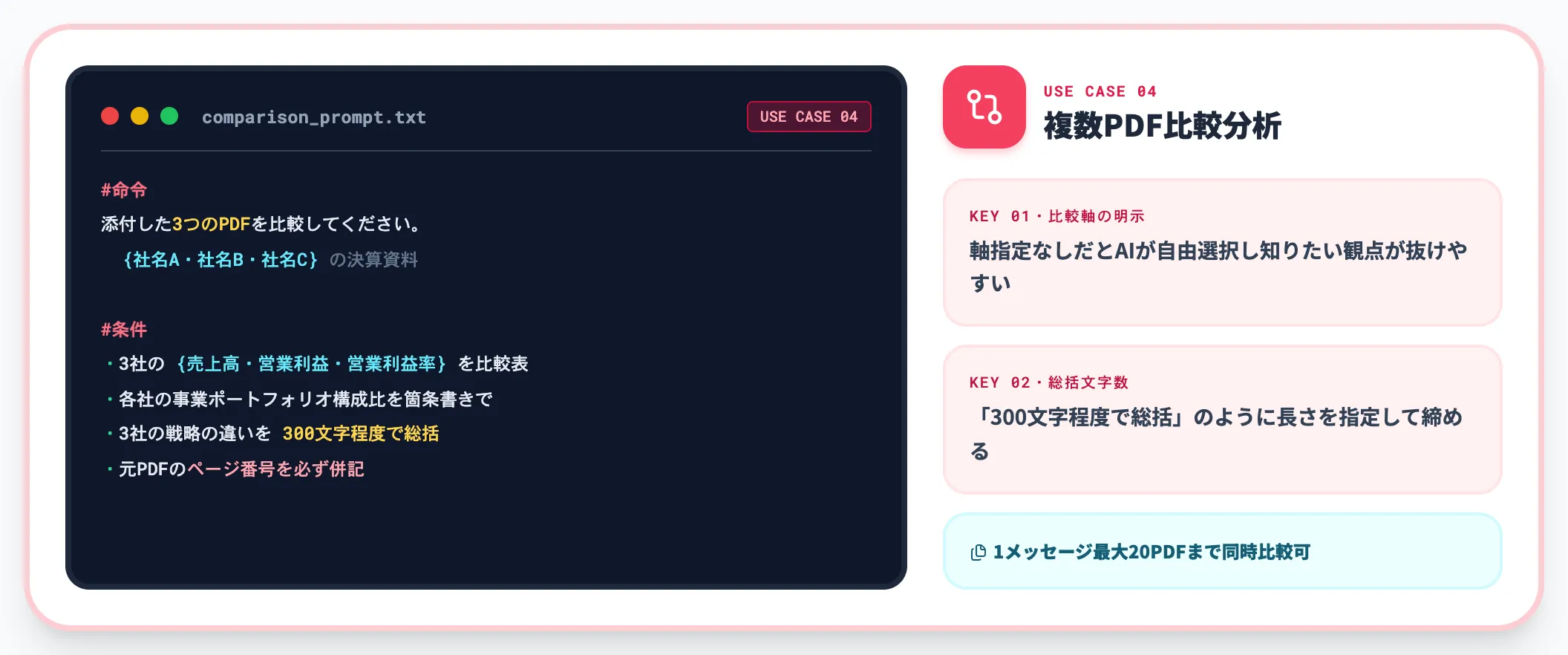
契約書の差分・複数年度の決算書・競合資料の比較など、2件以上のPDFを並べて読ませる用途です。直接アップロードは1メッセージあたり最大20ファイルまで対応します。
#命令
添付した3つのPDF({社名A・社名B・社名C}の決算資料)を比較してください。
#条件
・3社の{売上高・営業利益・営業利益率}を比較表で出力
・各社の事業ポートフォリオの構成比を箇条書きで整理
・3社の戦略の違いを300文字程度で総括
・元PDFのページ番号を必ず併記
比較系は**「比較軸」と「総括の文字数」**を明示するのが効果的です。軸を指定しないと、ChatGPTが自由に項目を選び、知りたかった観点が抜けるケースが頻発します。
PDFの校正・文章リライト
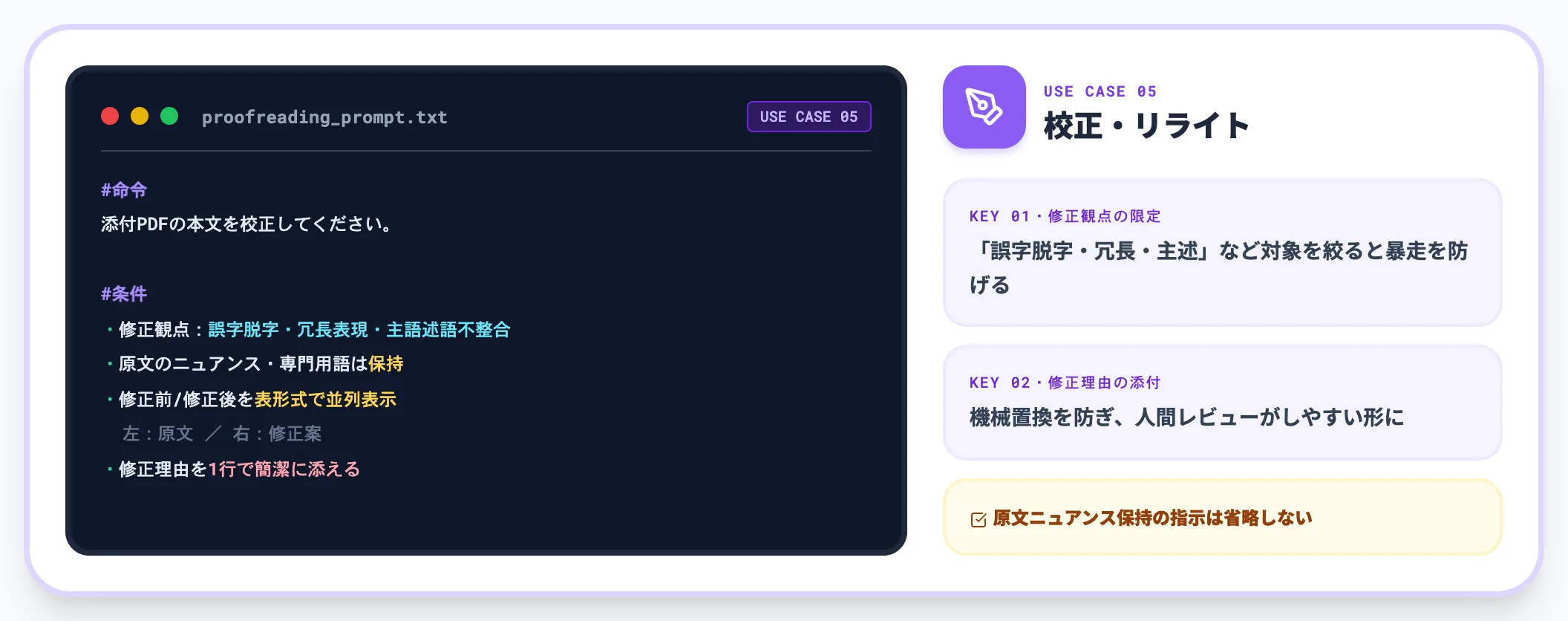
文章校正・リライト用途では、修正観点と保持すべき要素を明確に分けて指示します。文章校正全般のコツはChatGPTで文章校正する方法を参照してください。
#命令
添付PDFの本文を校正してください。
#条件
・修正観点:誤字脱字・冗長表現・主語述語の不整合
・原文のニュアンス・専門用語は保持する
・修正前と修正後を表形式で並列表示(左:原文/右:修正案)
・修正理由を1行で簡潔に添える
**「修正理由を1行で添える」**を入れると、出力が機械的な置換になりにくく、人間がレビューしやすい形になります。ニュアンスを残したい文章校正では、機械翻訳的な置換は逆に作業負担を増やすため、この一行を省略しないのが実務的なコツです。

ChatGPTがPDFを読み込めない時の原因と対処法
PDFをアップロードしようとして「ファイルを処理できません」「読み取れません」というエラーが返ることは珍しくありません。
原因は大きく4つに分類でき、原因ごとに対処法が異なります。本セクションでは出現頻度の高い順に整理します。
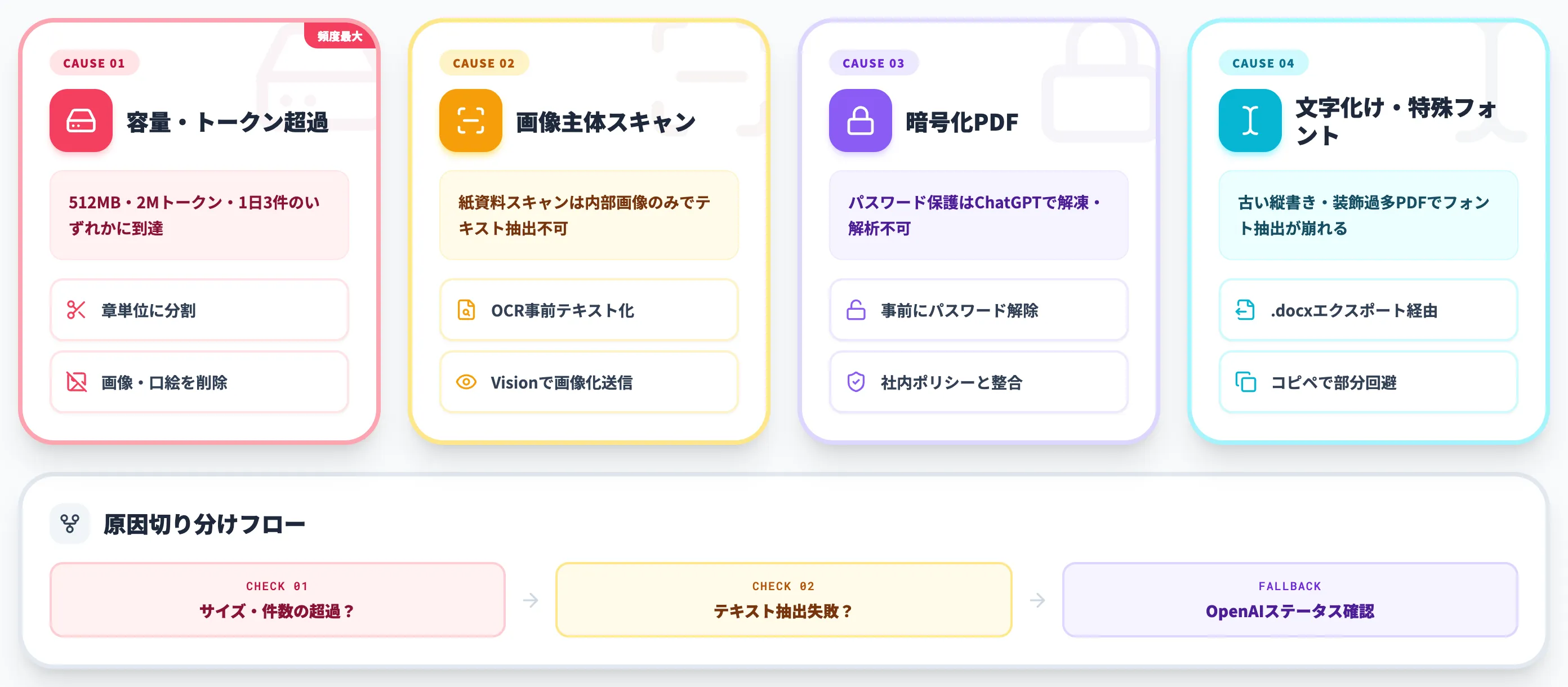
容量・トークン上限の超過
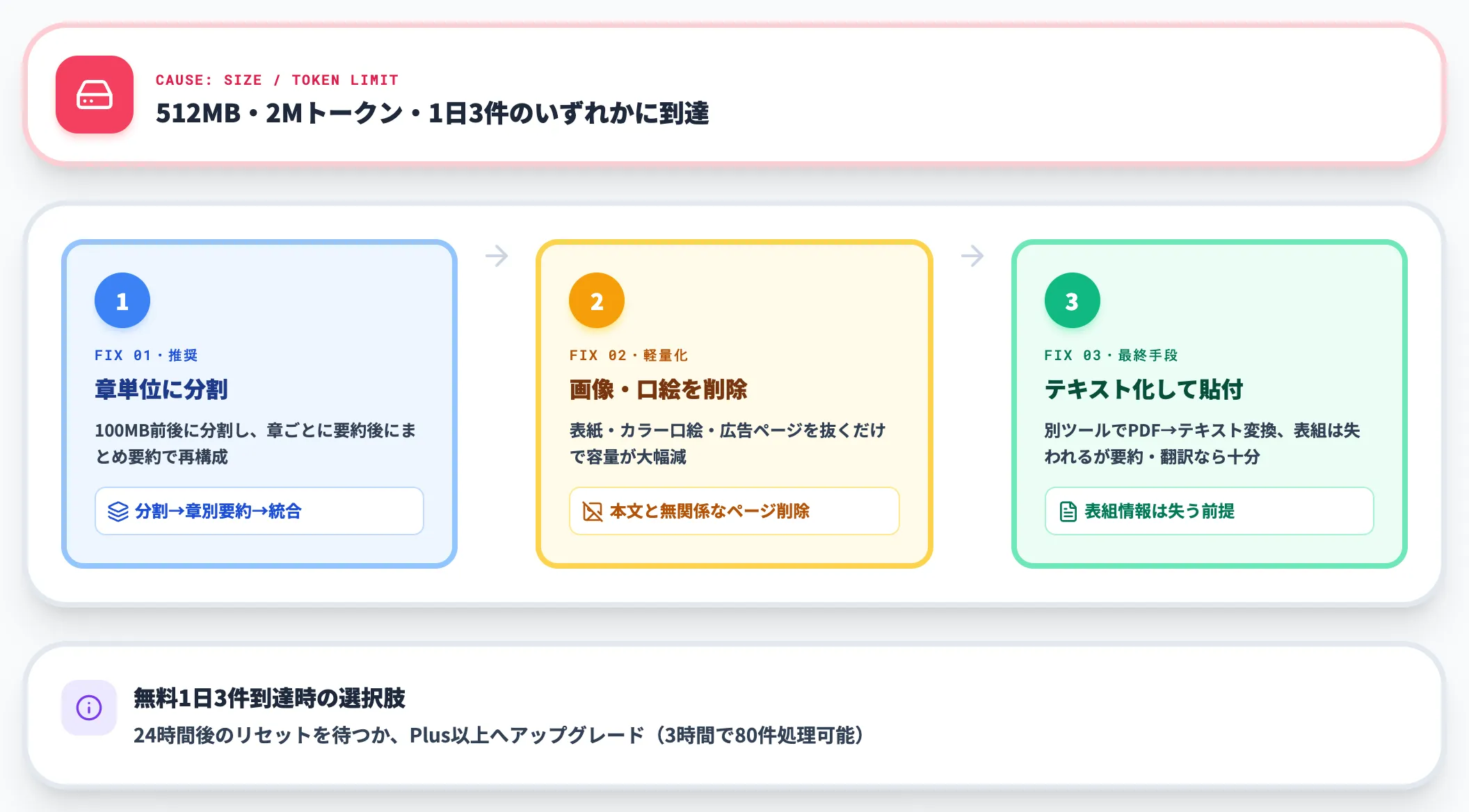
最も多い失敗パターンです。512MBのサイズ上限、または2Mトークンのテキスト上限に到達したケースで起こります。
対処は以下のいずれかになります。
- PDFを章単位に分割:100MB前後を目安に分割し、複数回に分けてアップロードする。要約は章ごとに依頼してから、最後にまとめ要約をもう一度書かせるのが定石
- 画像主体のページを削除:本文と関係ない表紙・カラー口絵・広告ページを抜くだけでサイズが大幅に減ることがある
- PDFをテキスト化:別ツールでPDF→テキスト変換を行い、テキストだけを貼り付ける。表組みは失われるが要約・翻訳だけなら十分
無料プランで1日3ファイルの制限に到達した場合は、24時間後にリセットされるまで待つか、有料プランへのアップグレードが現実解になります。
画像主体のスキャンPDF
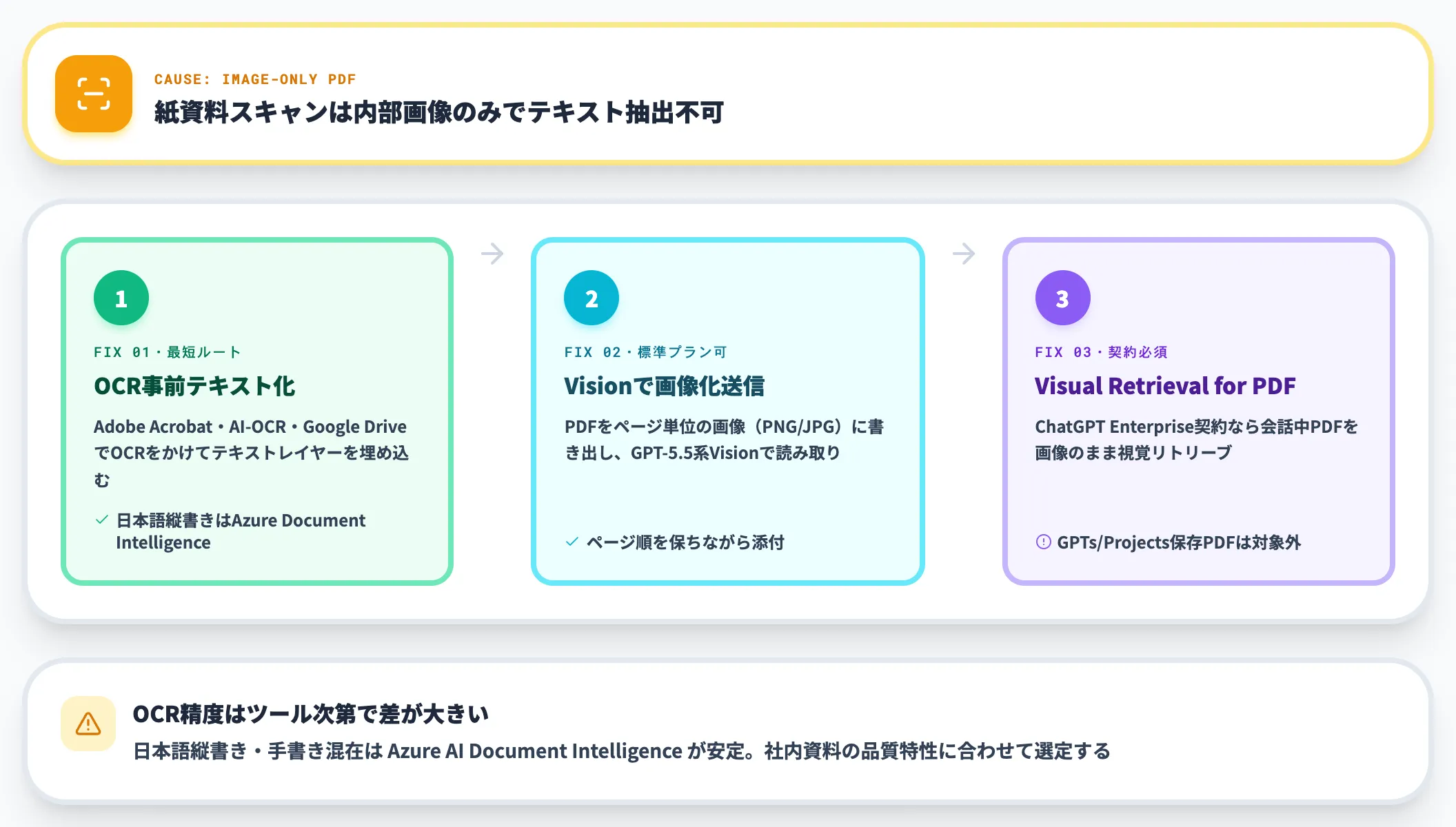
紙資料をスキャンしてPDF化した文書は、内部的に画像のみで構成されていることが多く、テキスト抽出ができません。標準プランではエラーにならずに「PDFは確認しましたが内容が読み取れません」のような応答が返ります。
対処は以下の流れになります。
- OCRで事前テキスト化:Adobe Acrobat・AI-OCR・Google Drive(PDF→Googleドキュメント変換)などでOCRをかけ、テキストレイヤーを埋め込む
- GPT-5.5系のVision機能で画像として読ませる:PDFをページ単位の画像(PNG・JPG)に書き出して順番にアップロードすると、Vision機能で画像内テキストを読み取れる
- Enterprise契約のVisual Retrieval for PDFを使う:ChatGPT Enterpriseなら、会話中にアップロードしたPDFに限り画像を含むまま視覚的にリトリーブできる(GPTs Knowledge・Projectsの保存ファイルはテキスト処理のまま)
画像PDFのOCR精度はツール次第で大きく変わります。日本語の縦書き・手書きが混ざる場合はAzure AI Document Intelligenceが安定する傾向が見られます。
パスワード保護・暗号化PDF
セキュリティ設定されたPDFは、ChatGPTが解凍・解析できません。エラーは「ファイルが暗号化されています」のような明示的なメッセージで返ります。
対処は単純で、PDFのパスワードを解除してからアップロードします。Adobe Acrobat・PDF24などのツールで解除が可能です。社外秘指定の暗号化PDFを安易に解除するのは情報管理上のリスクが大きいため、この処理は社内ポリシーと整合させる必要があります。
文字化け・特殊フォント
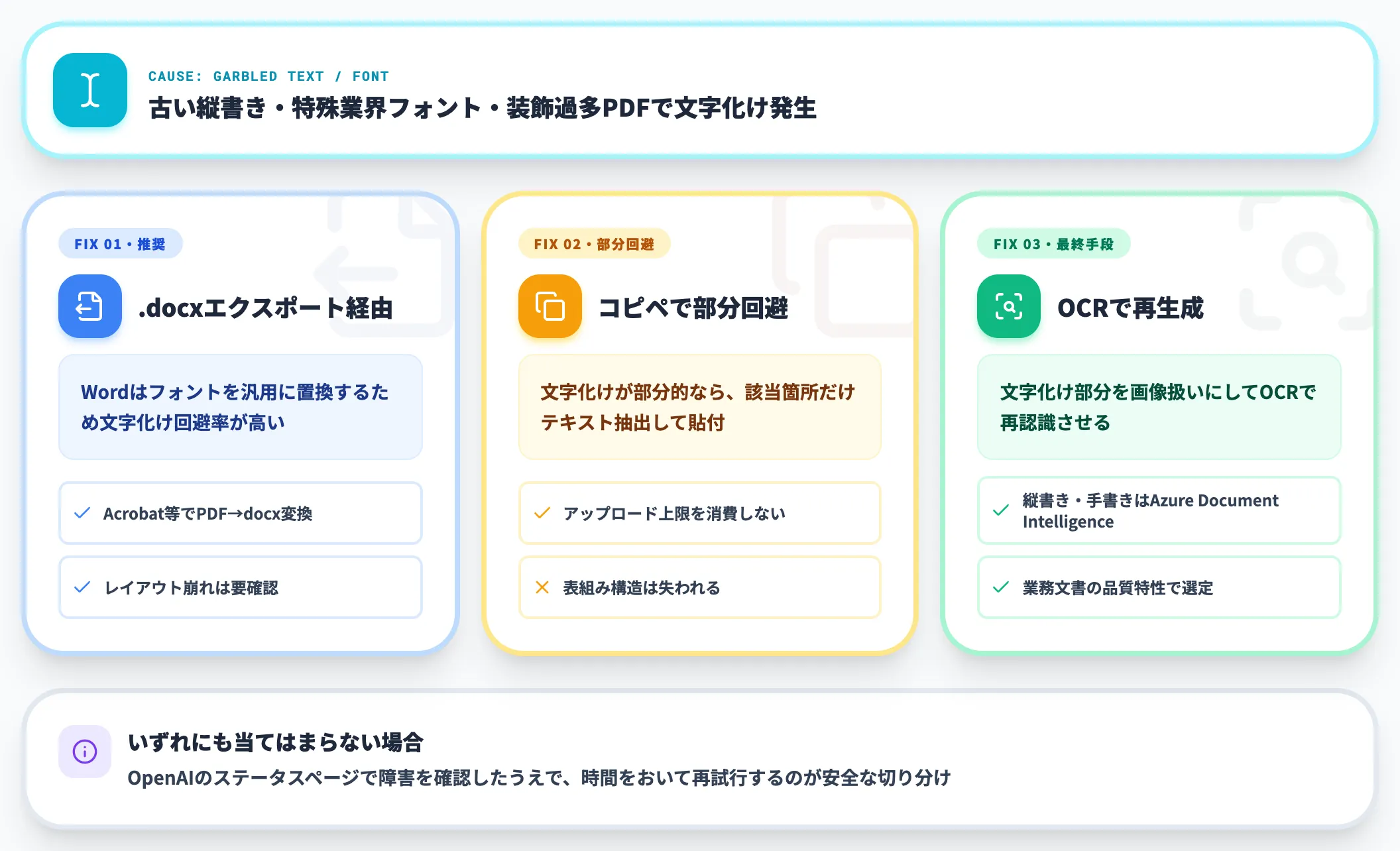
PDF内のフォントがChatGPTの抽出処理で文字化けするケースもあります。古い縦書き文書、特殊な業界フォント、HTMLから生成された装飾過多なPDFで起こりやすい現象です。
対処は以下のとおりです。
- PDFをWord(.docx)にエクスポートしてアップロード:Wordはフォントを汎用的なものに置き換えるため、文字化けが起きにくい
- コピー&ペースト方式に切り替え:文字化けが部分的なら、当該箇所だけテキストを抜き出してチャット欄に貼り付ける
- OCRで再生成:上記OCR手順と同じで、文字化けする部分を画像扱いにして再認識させる
これら4つのいずれにも当てはまらない場合は、OpenAIのステータスページで障害が発生していないか確認したうえで、しばらく時間をおいて再試行するのが安全な切り分けになります。
機密PDFをChatGPTで扱うときのセキュリティ対策
社内資料・契約書・顧客データを含むPDFをChatGPTに投入する場面では、データ漏洩リスクと利用規約の両面を押さえる必要があります。
ここを軽視すると、後から「業務で扱った機密PDFがOpenAIのモデル学習に流れていた」「個人情報保護法・GDPRに抵触する運用になっていた」というインシデントに発展するリスクがあります。本セクションでは、AI総合研究所が企業のAI導入支援で実際に提案している運用設計を整理します。
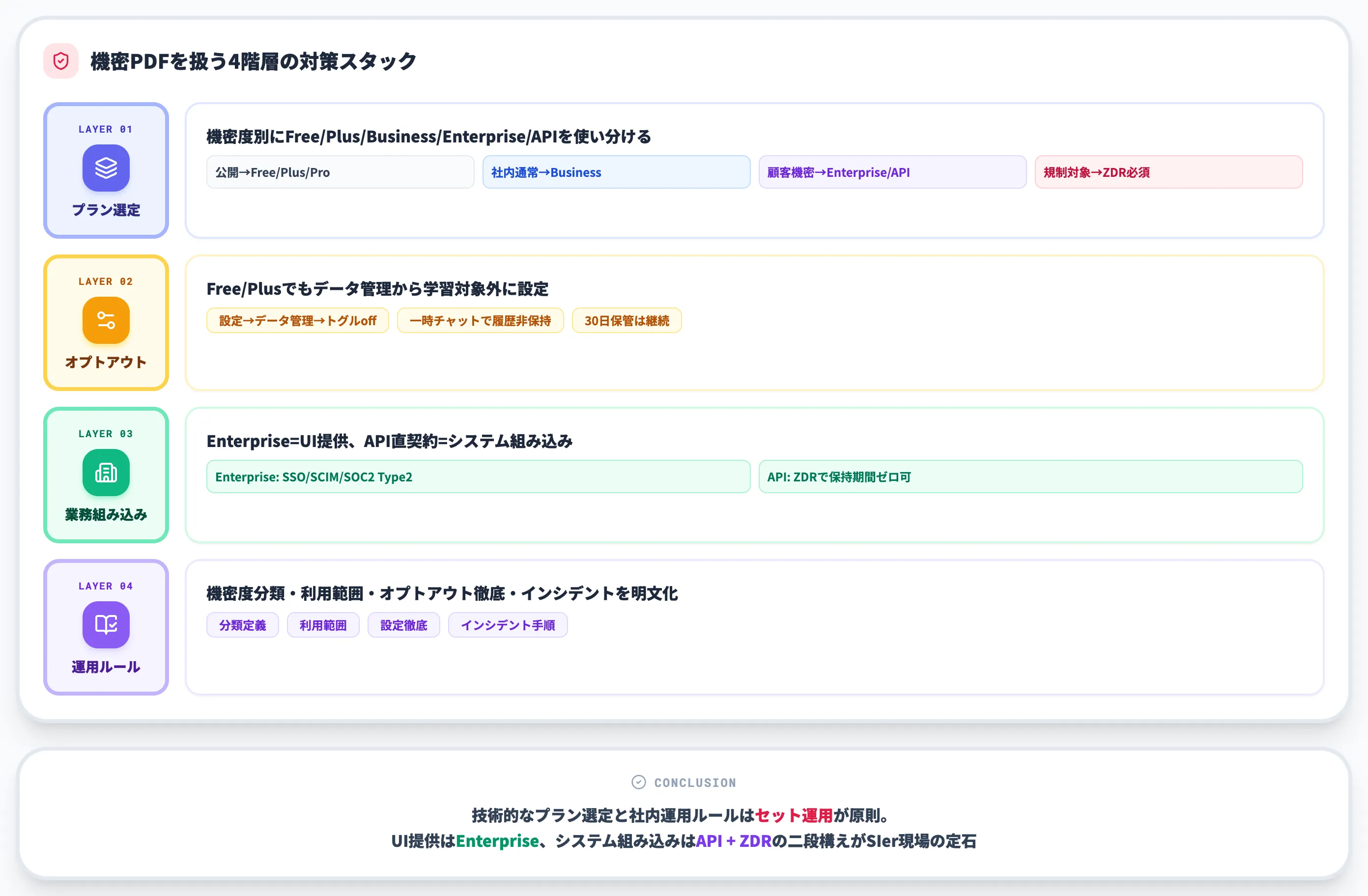
機密度別のプラン選定

機密度に応じてプランを使い分けるのが、最も実用的なリスク回避策です。以下の表で、機密度別の推奨プランを整理しました。
| 機密度 | 推奨プラン | 理由 |
|---|---|---|
| 公開情報(IR資料・公式プレスリリース等) | Free・Plus・Pro | データ学習に使われても情報価値が変わらない |
| 社内通常文書(議事録・部門マニュアル等) | Business(旧Team)・Plus(オプトアウト設定) | 学習回避が必要、Businessならデフォルトで学習対象外 |
| 顧客情報・契約書・財務データ | Enterprise・API直契約 | データ学習対象外+SSO・SCIM・SOC2準拠 |
| 規制対象データ(医療・金融機密等) | Enterprise・API+ZDR契約 | Zero Data Retentionでデータ保持自体を回避 |
多くの企業で見落とされがちなのが、Plusプランの扱いです。Plusはオプトアウト設定をすることで「データを学習に使わない」状態にできますが、デフォルトでは学習対象になります。設定を組織内で徹底できない場合は、最初からBusiness(旧Team)以上に揃えるほうが事故が起きにくくなります。詳細はChatGPTに自社データを学習させる方法でも別途解説しています。
オプトアウト設定の手順
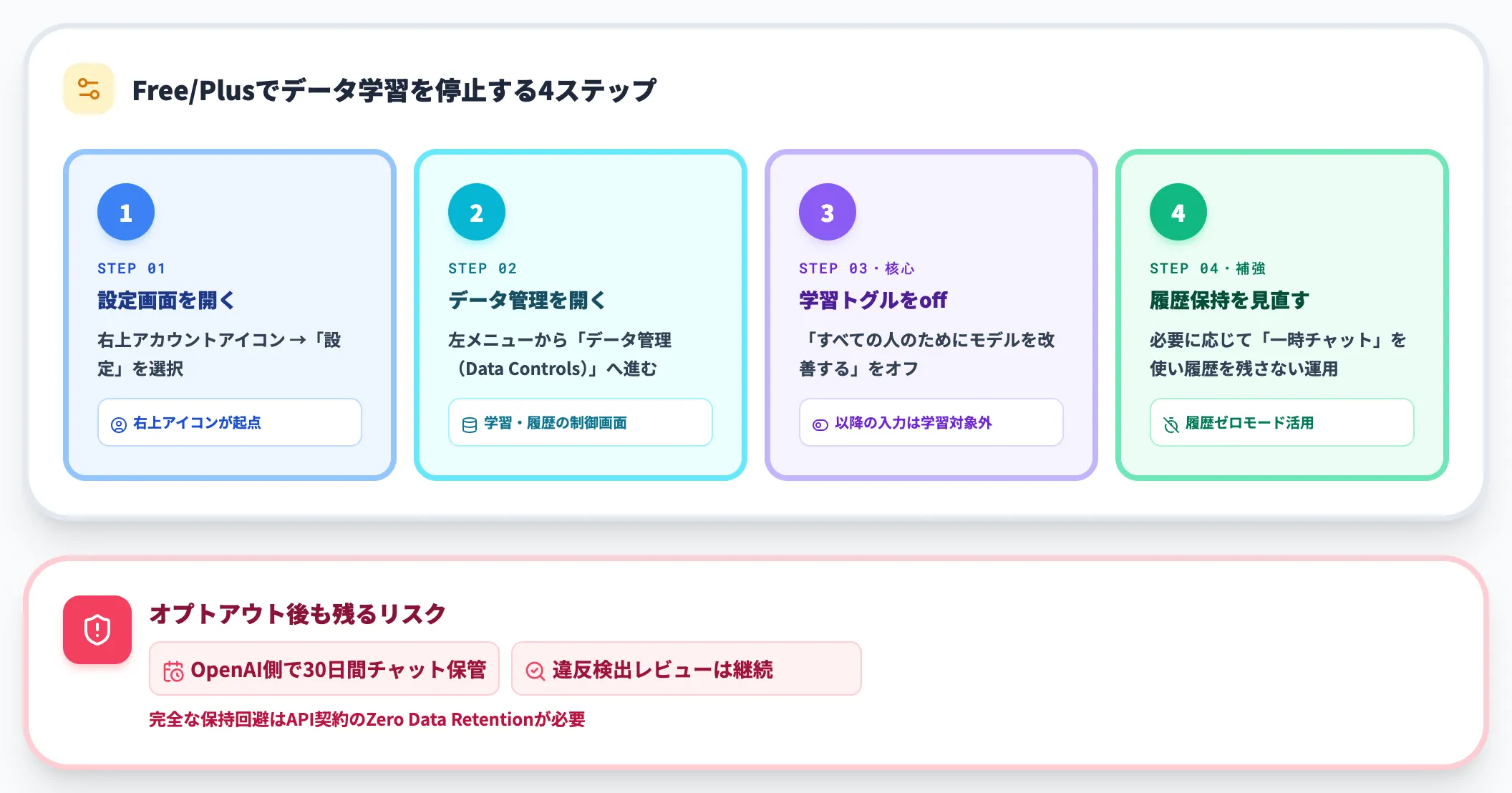
無料プラン・Plusプランでも、データ学習への利用を停止することができます。手順は以下のとおりです。
- 設定画面を開く:右上のアカウントアイコン → 「設定」を選択
- データ管理(Data Controls)に進む:左メニューから「データ管理」を開く
- 「すべての人のためにモデルを改善する」をオフ:このトグルをオフにすると、以降のチャット・アップロード内容がモデル学習に使われなくなる
- チャット履歴の保持期間を確認:必要に応じて「一時チャット」を活用し、履歴を残さない運用にする
オプトアウト後も、OpenAI側でのチャット履歴の30日保管・違反検出のためのレビューは継続されます。完全にデータ保持を回避したい場合は、API契約でのZero Data Retention(ZDR)オプションが必要になります。
Enterprise・APIの選択基準
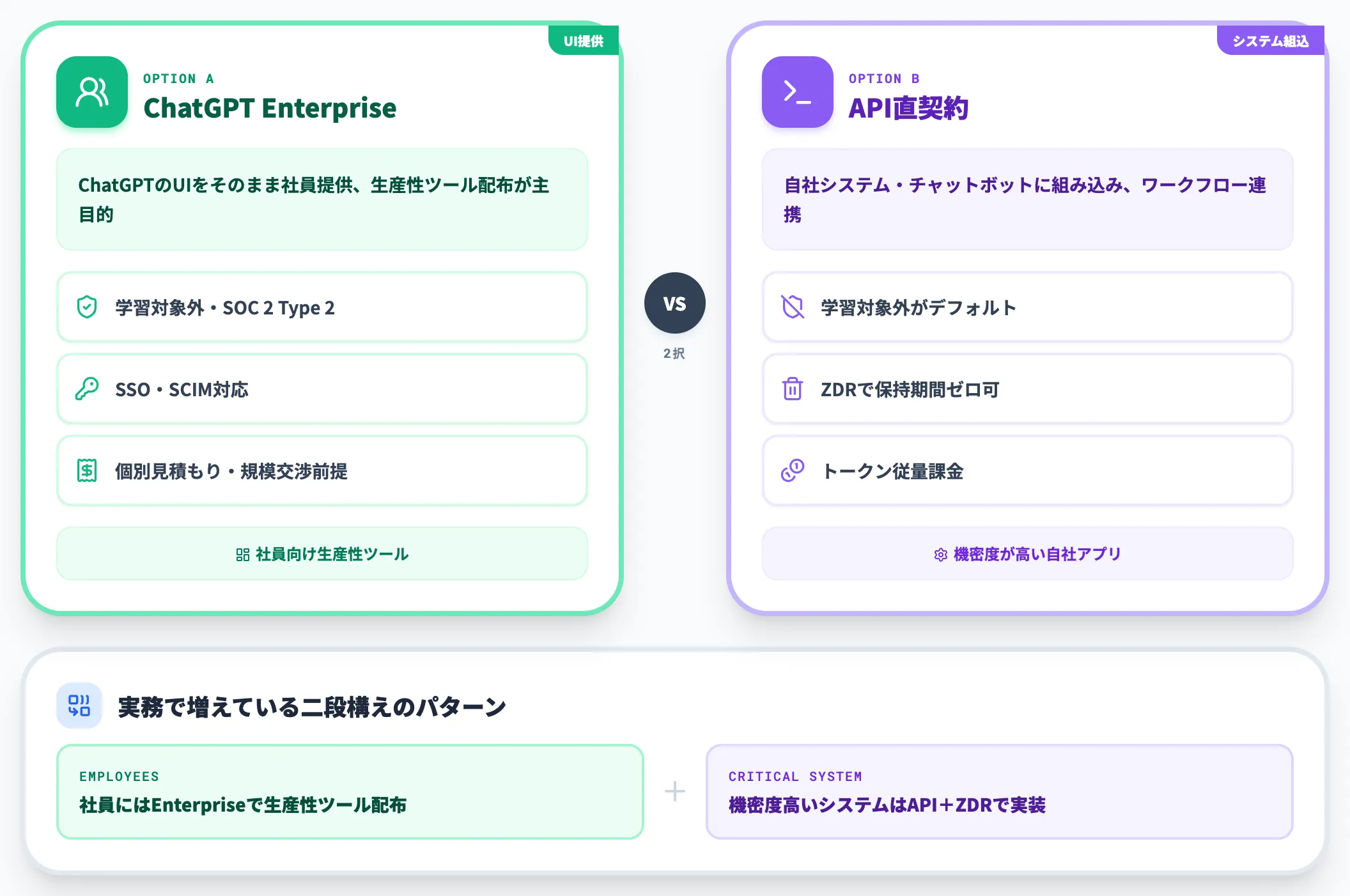
機密情報を扱う前提でAIを業務組み込みするなら、Enterprise契約またはAPI経由の選択がほぼ必須になります。両者の違いを以下に整理します。
-
ChatGPT Enterprise
契約段階でデータ学習対象外、SSO・SCIM・SOC 2 Type 2準拠、長期チャット履歴の組織管理が可能です。ChatGPTのUIをそのまま社員に提供したい場合に向きます。料金は個別見積もりで、規模に応じた条件交渉が前提になります。
-
API直契約
自社システムやチャットボットに組み込む構成。デフォルトでデータ学習対象外、ZDRオプションで保持期間ゼロも選べます。ChatGPTのUIではなく、自社のアプリやワークフローからPDF処理させる用途に適しています。料金はChatGPT API(OpenAI API)のトークン課金です。
**「UI提供ならEnterprise、システム組み込みならAPI」**という整理が、AI総研の支援現場でも一番繰り返し提案する判断軸になっています。両方を併用する企業も増えており、社員にはEnterpriseで生産性ツールを配布しつつ、機密度が高いシステムはAPI+ZDRで実装する二段構えが現実解として定着しつつあります。
社内運用ルールの整備
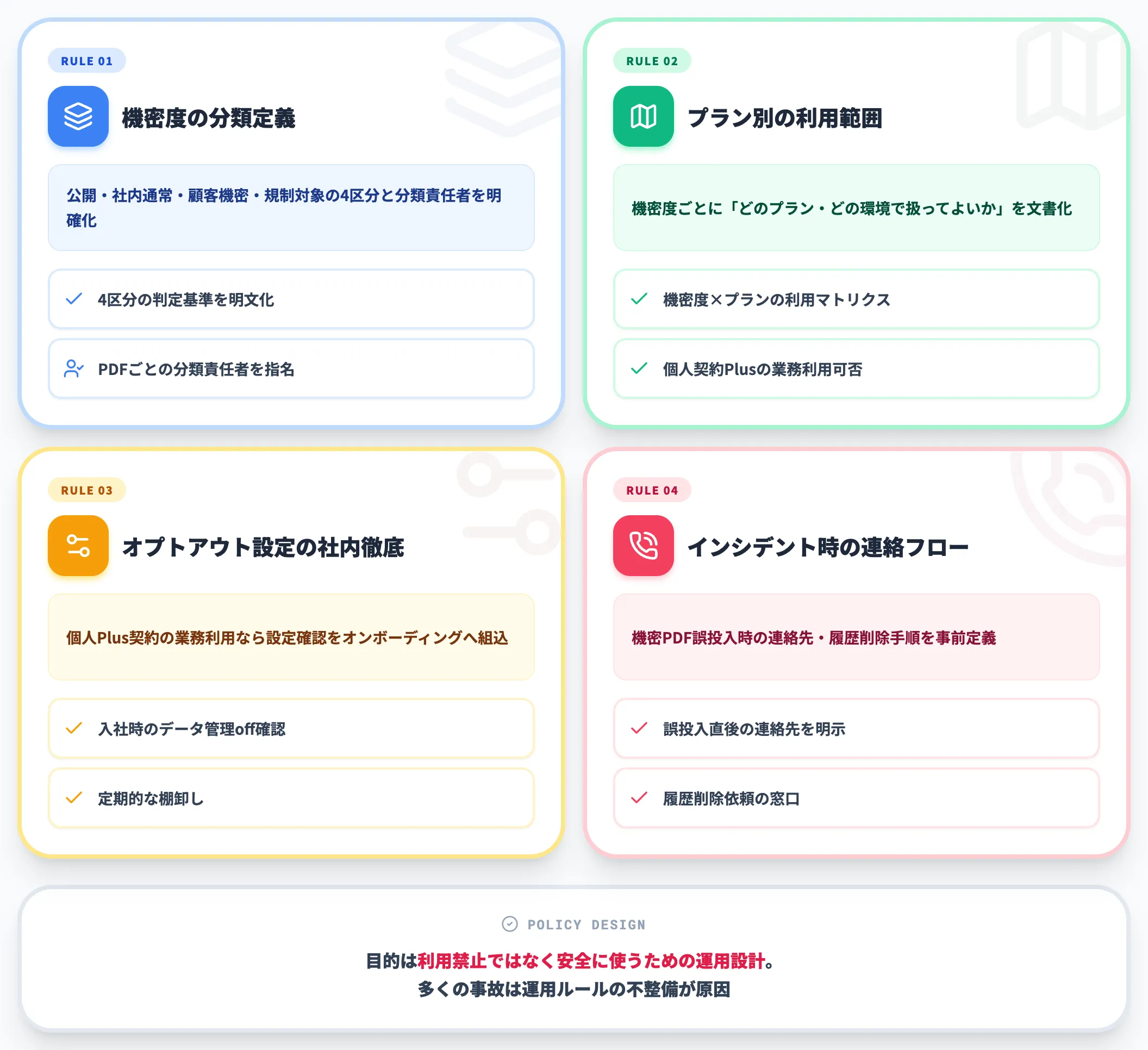
技術的なプラン選定と並行して、社内運用ルールの明文化も避けて通れません。最低限詰めるべきは以下の項目です。
- 機密度の分類定義:公開情報・社内通常・顧客機密・規制対象を明確に区分し、PDFごとに分類する責任者を決める
- プラン別の利用範囲:機密度ごとに「どのプラン・どの環境で扱ってよいか」を明文化する
- オプトアウト設定の社内徹底:個人のChatGPT Plus契約の業務利用を許す場合、オプトアウト設定の確認をオンボーディングに組み込む
- インシデント時の連絡フロー:機密PDFを誤投入してしまった場合の連絡先・履歴削除手順を事前に定義する
これらは「ChatGPTを禁止する」ためのルールではなく、「安全に使うための運用設計」です。ChatGPTのセキュリティリスクで扱っている事例の多くは、利用禁止ではなく運用ルールの整備不足が原因で発生しています。
ChatGPT以外でPDFを扱えるAIサービスとの比較
ChatGPT以外にもPDFを読み込めるAIサービスは複数あり、用途によっては別サービスのほうが効率的なケースがあります。
業務で「ChatGPT一択」と決め打ちする前に、代表的な4つのサービスとの違いを押さえておくと、ツール選定の判断軸が明確になります。本セクションでは、Microsoft Copilot・Gemini・Claude・NotebookLMの4軸で比較します。
4サービスの特徴比較
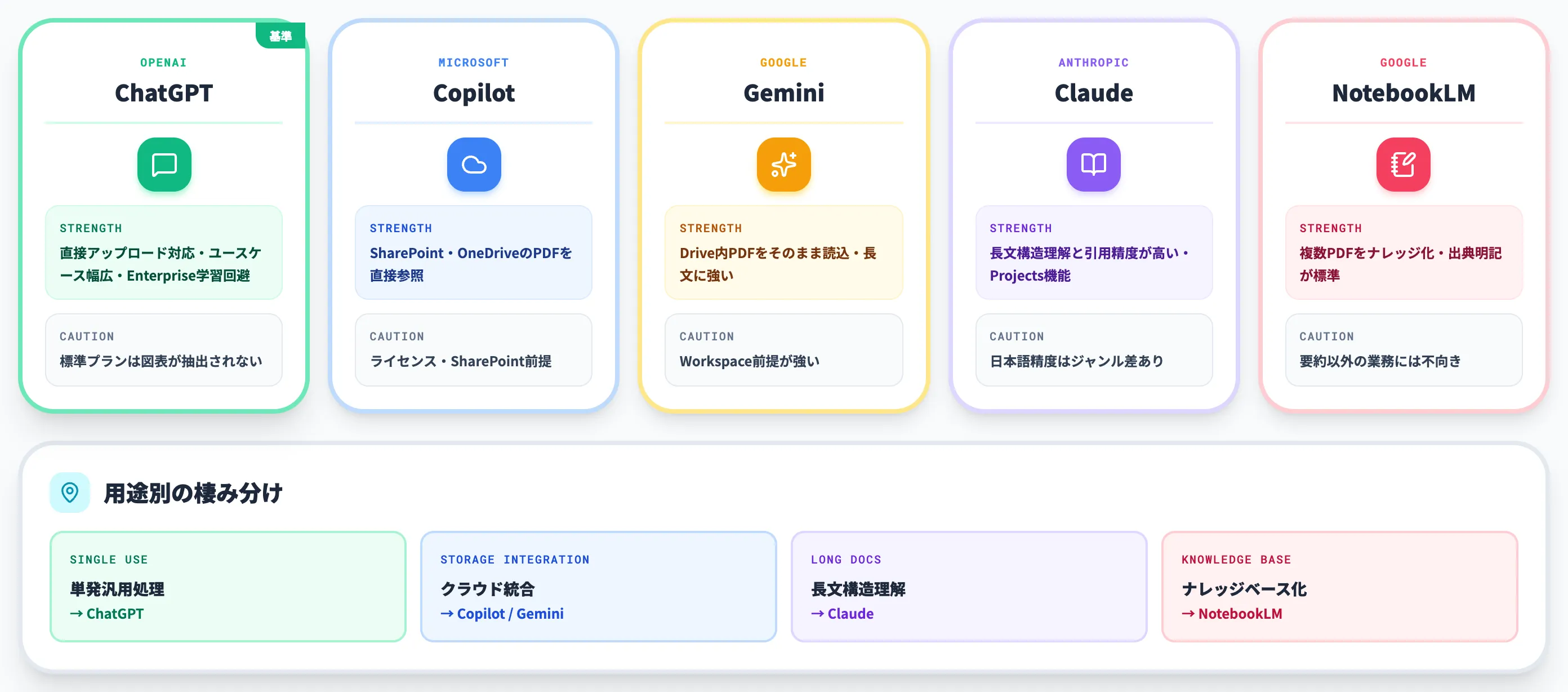
以下の表で、PDF読み込みに関する各サービスの特徴を整理しました。
| サービス | 強み | 留意点 |
|---|---|---|
| ChatGPT | 直接アップロード対応、ユースケースが幅広い、Enterpriseでデータ学習回避 | 標準プランは画像PDFの図表が抽出されない |
| Microsoft Copilot | Microsoft 365 Personal/Family または職場・学校アカウント+Copilotライセンス環境なら、SharePoint・OneDrive内PDFを直接参照 | ライセンス条件次第、SharePoint運用との一体性が前提 |
| Gemini | Google Drive内PDFをそのまま読み込み、長文の保持に強い | Workspaceとの組み合わせ前提が強い |
| Claude | 長文文書の構造理解と引用精度が高い、Projects機能で継続参照 | 日本語精度は文書ジャンルで差が出る |
| NotebookLM | 複数PDFを束ねたナレッジベース化、出典明記が標準動作 | 文書数の上限あり、要約以外の業務は不向き |
この比較から見えるのは、**ChatGPTは「単発の汎用処理に強い」、Copilot/Geminiは「自社のクラウドストレージ統合に強い」、Claudeは「長文の構造理解に強い」、NotebookLMは「ナレッジベース化に強い」**という棲み分けです。1サービスで全部やろうとせず、用途で使い分けるのが現実的な落とし所になります。
ケース別の選び方
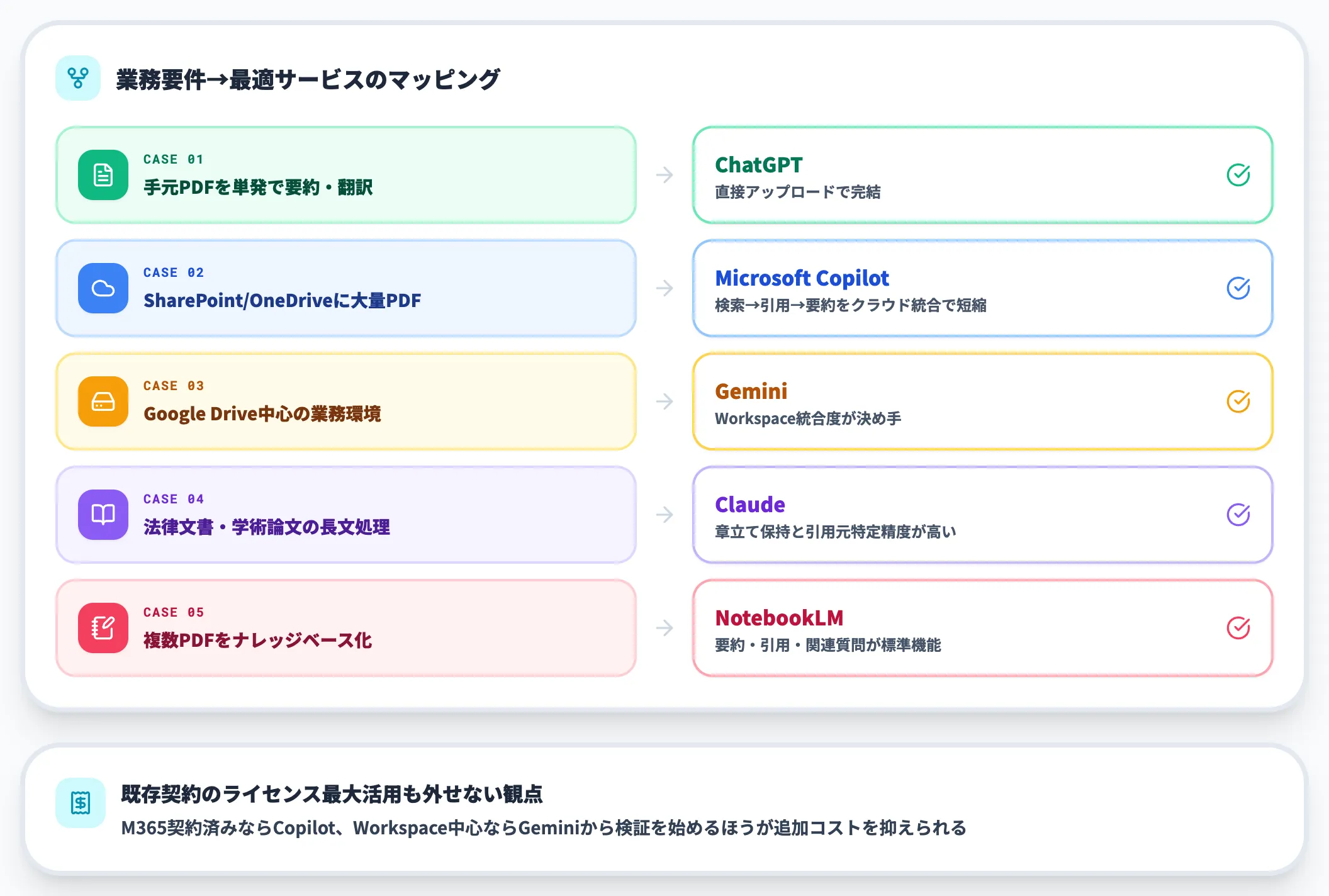
実務で迷いやすいケース別に、AI総合研究所がSIerとして支援してきた経験からの推奨を整理します。
-
手元のPDFを単発で要約・翻訳したい
ChatGPTの直接アップロードで完結します。アカウント契約のシンプルさと、要約・翻訳・抽出のプロンプト資産がそのまま流用できる強みがあります。
-
SharePoint/OneDriveに大量PDFが集約されている
Microsoft Copilotが本命です。検索→引用→要約の流れがクラウドストレージ統合で短縮され、ChatGPTで毎回アップロードする手間が消えます。
-
Google Drive中心の業務環境
Geminiが第一候補です。Drive内のPDF・スプレッドシート・ドキュメントを横断的に参照でき、Workspaceとの統合度が決め手になります。
-
法律文書・学術論文のように長文かつ構造が重要
Claudeを試す価値があります。Anthropicのアプローチは長文の章立てを保持しやすく、引用元の特定精度が高い傾向です。
-
複数PDFをまとめてナレッジベース化したい
NotebookLMが向いています。要約・引用・関連質問の生成が標準機能として揃っており、研究や調査の中間成果物として使えます。
ツール選定では「自社で契約済みのライセンスを最大活用する」観点も外せません。すでにMicrosoft 365契約があるならCopilot、Google Workspace中心ならGeminiから検証を始めるほうが、追加コストが抑えられます。
専用PDFツールとの違い
ChatPDFのようなPDF専用ツールも依然として存在しますが、業務利用での位置づけは変わりました。
汎用LLM(ChatGPT/Gemini/Claude)が無料でPDF読み込みに対応するようになった結果、専用ツール固有の優位性はかなり狭まっています。専用ツールが今でも有効なのは、PDF閲覧UIに最適化されたインターフェース(ハイライト機能、引用位置の可視化、ページプレビュー)が必要な研究・学術用途に限定されつつあります。
業務の主用途が要約・翻訳・抽出であれば、汎用LLM側で完結させたほうが、運用コストと習熟の手間が抑えられます。

PDF処理のAI活用を業務プロセス全体のAI化に発展させるなら
ChatGPTでPDFを要約・翻訳・抽出できるようになると、それは「単発の文書処理」を超えて、業務プロセス全体をAI化する起点になります。
機密度別プラン選定とユースケース別プロンプト設計の型ができれば、契約書のレビュー・調査資料の比較整理・社内マニュアルの多言語化・経費精算書類の自動整理など、文書を扱う業務はあらゆる部署でAI化候補になります。
AI総合研究所では、PoCから全社展開までの設計・部門別ユースケース・統制とセキュリティのチェックポイントを220ページの「AI業務自動化ガイド」にまとめて無料公開しています。PDF処理から業務AI化を始めたい企業の最初の一歩として活用してください。
PDF要約から業務プロセス全体のAI化に広げる

文書処理の効率化を起点にAI業務自動化を定着させる
ChatGPTでPDFを要約・翻訳できるようになると、契約書レビュー・調査資料の比較・社内文書の多言語化まで業務AI化の対象が一気に広がります。AI総合研究所では、PoCから全社展開までの設計・部門別ユースケース・統制とセキュリティのチェックポイントを220ページの「AI業務自動化ガイド」にまとめています。
まとめ
本記事では、ChatGPTにPDFを読み込ませる方法を2026年6月時点の最新情報で整理しました。要点を改めて整理します。
-
読み込み方法は直接アップロード・テキスト貼り付け・URL・カスタムGPT/Projectsの4系統。業務の主軸は直接アップロード、繰り返し参照はカスタムGPTかProjects、補助としてテキスト貼り付けという使い分けが現実的
-
操作はPC・スマホアプリともに「+」ボタンからの数ステップで完結。Plugin廃止後はカスタムGPT・Projectsが継続参照の本命になっており、古い手順を引きずらないことが効率化の前提
-
PDFを読み込ませた後の能力は得意領域と苦手領域が明確。テキスト情報の操作(要約・翻訳・抽出・比較・校正)は得意、図表理解・厳密な引用・リアルタイム情報・未設定での機密保持には限界がある
-
プラン別の制限はアップロード上限とサイズ・トークン上限で大きく異なる。FreeはVisual Retrieval対象外で1日3ファイル、Plus以上は3時間で80ファイル、1ファイル512MB・2Mトークンが目安で、長尺PDFは章単位分割が定石
-
ユースケース別のプロンプト設計で出力品質が変わる。要約・翻訳・抽出・比較・校正のいずれも、読み手のレベルと出力形式の指定が品質の決め手
-
画像主体のスキャンPDFはOCR前処理、暗号化PDFはパスワード解除が読み込み成功の前提。文字化けはWordエクスポートやコピペ方式への切り替えで多くが解決
-
機密PDFは機密度別にFree/Plus/Business(旧Team)/Enterprise/APIを使い分け、顧客情報・契約書はEnterpriseかAPI直契約、規制対象データはZDRオプションが標準。オプトアウト設定の社内徹底と運用ルール明文化が事故防止の本筋
-
Microsoft Copilot・Gemini・Claude・NotebookLMとの使い分けで、自社のクラウドストレージ・長文構造・ナレッジベース化の要件に応じて最適解が変わる
PDF読み込みは、AI業務活用の入口として最も投資対効果が高い領域のひとつです。まずは手元のPDFを1本、直接アップロードして要約させるところから始めて、業務プロセス全体のAI化への足がかりにしてください。










