この記事のポイント
 需要予測は、在庫管理や売上計画において極めて重要な業務プロセスである
需要予測は、在庫管理や売上計画において極めて重要な業務プロセスである- Pythonを使うことで、精度の高い予測モデルを柔軟かつ自動化された形で構築できる
- 代表的な手法として、ARIMAやProphetなどの時系列分析、XGBoostやLSTMといった機械学習手法がある
- 予測精度を高めるには、特徴量の工夫や過学習対策、外部要因の活用が効果的
- 実装した予測モデルは、Excelや業務システムと連携することで実務に即した形で活用できる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
需要予測は、在庫管理や仕入れ計画に不可欠な技術です。
本記事では、Pythonを使った需要予測の基本から実装手順までを、時系列分析や機械学習の手法とともにわかりやすく解説します。
エクセルやVBAからの脱却を目指す担当者にも役立つ内容です。
需要予測をPythonで実装する方法とは?

需要予測
需要予測をPythonで実装する方法とは、Pythonのライブラリや統計・機械学習アルゴリズムを用いて、将来の需要を数値的に予測する手法です。ExcelやVBAに比べて、より高精度かつ自動化された分析が可能になります。
需要予測は、製品の在庫管理や仕入れ計画、人的リソースの最適化など、多くの業務において重要な役割を果たします。特に近年では、過去データに基づく傾向分析だけでなく、天候・曜日・イベント情報などの外的要因も加味した高度な予測が求められるようになってきました。
Pythonはこの需要予測に適した言語のひとつです。理由は以下の通りです。
- 豊富なライブラリ群:
pandasやscikit-learn、statsmodels、Prophetなどを活用できる - 柔軟なデータ処理能力:さまざまな形式のデータを取り込み、加工・可視化が可能
- 自動化との相性が良い:定期的な予測処理をスクリプトで実行できる
この記事では、需要予測の基本からPythonでの実装手順、代表的なアルゴリズム、実務への応用までを順を追って解説していきます。エンジニアだけでなく、業務改善を担う現場担当者の方にも役立つ内容です。

需要予測をPythonで行うメリットとは?
需要予測をPythonで行う最大のメリットは、「高精度な予測モデルを、比較的容易に構築・自動化できる点」にあります。従来はExcelやVBAで手作業による分析が一般的でしたが、Pythonを使うことでその限界を超えることが可能になります。
Excel・VBAとの違い
以下に、Excel/VBAとPythonによる需要予測の違いを比較します。
| 項目 | Excel・VBA | Python |
|---|---|---|
| 処理の自動化 | マクロで対応可(限定的) | 完全自動化が可能 |
| モデルの種類 | 移動平均や回帰などに限定 | ARIMA、XGBoost、LSTMなど多数 |
| データ量の対応力 | 数千行〜数万行が限界 | 数百万行以上も処理可能 |
| 外部連携 | 手作業・VBAに依存 | API・クラウドとの連携が容易 |
Pythonによる自動化・高精度化の強み
Pythonを使えば、例えば以下のような高度な処理も現実的に可能です。
- 曜日や祝日、気温などの外部データを取り込んだ予測
- 過去の販売データをもとにしたモデルの定期更新(学習の自動化)
- 欠品リスクを数値で可視化し、事前にアラートを出す仕組み
このように、Pythonによる需要予測は業務の属人化を防ぎつつ、データドリブンな意思決定を可能にします。
需要予測の代表的な手法とアルゴリズム
需要予測では、目的やデータの特性に応じて複数の手法を使い分けることが重要です。ここでは、主に以下の3つのカテゴリに分類される代表的な予測アルゴリズムについて紹介します。
時系列モデル(ARIMA、Prophet)
時系列モデルは、過去の需要データの時間的変化に着目して未来を予測する手法です。特に以下の2つがよく使われます。
| モデル名 | 特徴 |
|---|---|
| ARIMA(自己回帰和分移動平均) | トレンドや周期性を持つ時系列に対応。統計モデルの基本。 |
| Prophet(Facebook開発) | 年間・週次の季節性、祝日などのイベント影響も考慮可能。実装が簡単で精度も高い。 |
これらのモデルは、定期的な売上や在庫の変動を扱う場面に強みを持ちます。
回帰モデル・決定木系アルゴリズム(XGBoost、Random Forest)
複数の要因が需要に影響を与えている場合は、教師あり学習のアルゴリズムが有効です。特に、以下のモデルが実務で広く使われています。
| モデル名 | 特徴 |
|---|---|
| 線形回帰 | 需要と要因の関係が直線的な場合に有効。 |
| ランダムフォレスト | 決定木を多数組み合わせて予測精度を向上。特徴量の重要度分析にも有用。 |
| XGBoost(勾配ブースティング) | 精度が高く、欠損値への耐性もあり、実務利用に適する。 |
これらは、「天気」「曜日」「広告施策」「在庫数」など、複数の変数をもとにした需要予測に適しています。
深層学習モデル(LSTM、Transformer)
より複雑で非線形な需要パターンや長期的な依存性を考慮する場合は、深層学習(ディープラーニング)を用いた手法が検討されます。
| モデル名 | 特徴 |
|---|---|
| LSTM(長短期記憶ネットワーク) | 時系列データにおける長期依存関係を学習可能。売上や気象データなどに強い。 |
| Transformer | 自然言語処理で有名だが、時系列予測にも応用可能。高速かつ高精度。 |
深層学習は大量データがある場合や、複雑なパターンを捉えたい場合に効果を発揮します。ただし、チューニングや学習コストが高いため、事前の目的整理が重要です。
Pythonによる需要予測を実際に行ってみましょう
ここでは、Pythonを用いて需要予測モデルを構築する一連の手順を解説します。
実行後はこのように需要予測のグラフが作成されます。
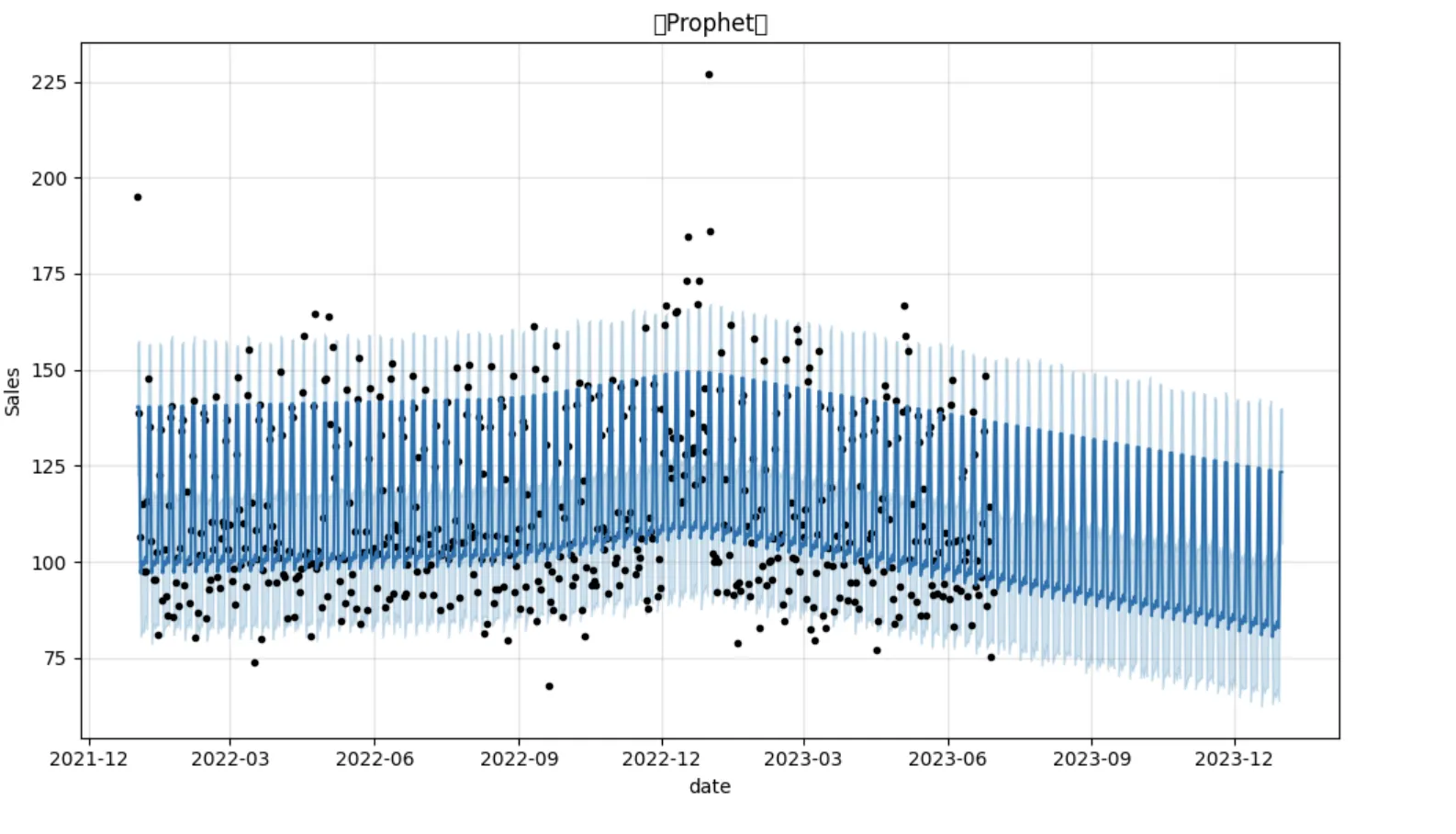
実行データ
ステップ①:データの準備と前処理
まずは予測に使用するデータを用意します。代表的なデータとしては以下のようなものがあります。
- 過去の売上実績(商品別、日別、週別など)
- 商品カテゴリ・単価・在庫情報
- 日付、曜日、祝日フラグ
- 気温・天候などの外部要因(任意)
仮のデータを今回は用意します。
import pandas as pd
import numpy as np
from prophet import Prophet
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error
dates = pd.date_range(start="2022-01-01", end="2023-12-31", freq="D")
holidays = pd.to_datetime([
"2022-01-01", "2022-05-03", "2022-05-04", "2022-05-05", "2022-12-31",
"2023-01-01", "2023-05-03", "2023-05-04", "2023-05-05", "2023-12-31"
])
np.random.seed(42)
sales = 100 + np.random.normal(0, 10, len(dates))
day_of_week = dates.dayofweek
sales += np.where(day_of_week >= 5, 40, 0)
sales += np.where(dates.month == 12, 30, 0)
sales += np.where(dates.isin(holidays), 50, 0)
temperature = 20 + 5 * np.sin(np.linspace(0, 10*np.pi, len(dates))) + np.random.normal(0, 1, len(dates))
df = pd.DataFrame({
"date": dates,
"sales": np.maximum(sales, 0).round(1),
"dayofweek": day_of_week,
"month": dates.month,
"is_holiday": dates.isin(holidays).astype(int),
"temperature": temperature.round(1)
})
次に、データの欠損値や異常値を処理します。たとえば、以下のような前処理が一般的です。
- 欠損値の補完(平均値・中央値・ゼロ埋めなど)
- 外れ値の除外または調整
- 日付の正規化(datetime型への変換)
- カテゴリ変数の数値化(one-hotエンコーディング)
df_prophet = df[["date", "sales"]].rename(columns={"date": "ds", "sales": "y"})
# 訓練データ:2022-01-01 ~ 2023-06-30、テスト:それ以降
train = df_prophet[df_prophet["ds"] <= "2023-06-30"]
test = df_prophet[df_prophet["ds"] > "2023-06-30"]
ステップ②:モデルの選定と学習
予測の目的に応じて適切なモデルを選びます。たとえば以下のように分類できます。
| モデル | 想定シナリオ |
|---|---|
| ARIMA / Prophet | 時系列データに明確な周期性・トレンドがある |
| XGBoost / ランダムフォレスト | 気温や曜日など複数の要因が影響している |
| LSTM | 複雑な時系列パターンが存在し、大量のデータがある |
以下はProphetを使った簡単な実装例です。
# ================================
# Step 3: Prophetモデル学習・予測
# ================================
model = Prophet()
model.fit(train)
# 予測期間を指定(全体で予測)
future = model.make_future_dataframe(periods=len(test))
forecast = model.predict(future)
ステップ③:予測結果の評価と可視化
予測モデルを評価するために、以下のような指標がよく使われます。
- MAE(Mean Absolute Error:平均絶対誤差)
- RMSE(Root Mean Square Error:二乗平均平方根誤差)
- MAPE(Mean Absolute Percentage Error:平均絶対パーセント誤差)
評価用にデータを訓練データとテストデータに分割し、予測精度を確認します。
# ================================
# Step 4: 精度評価と可視化
# ================================
# テストデータの期間のみに絞る
forecast_test = forecast[forecast["ds"].isin(test["ds"])]
mae = mean_absolute_error(test["y"].values, forecast_test["yhat"].values)
print(f"MAE(平均絶対誤差): {mae:.2f}")
# グラフ描画
model.plot(forecast)
plt.title("需要予測(Prophet)")
plt.xlabel("日付")
plt.ylabel("売上予測")
plt.tight_layout()
plt.show()
また、予測結果をグラフで可視化することで、傾向やズレを直感的に確認できます。

Prophetによる予測結果の解釈
需要予測モデルを構築した後は、予測結果のグラフを適切に読み解くことが重要です。ここでは、Facebook Prophetによる予測出力グラフの見方とその意味を解説します。
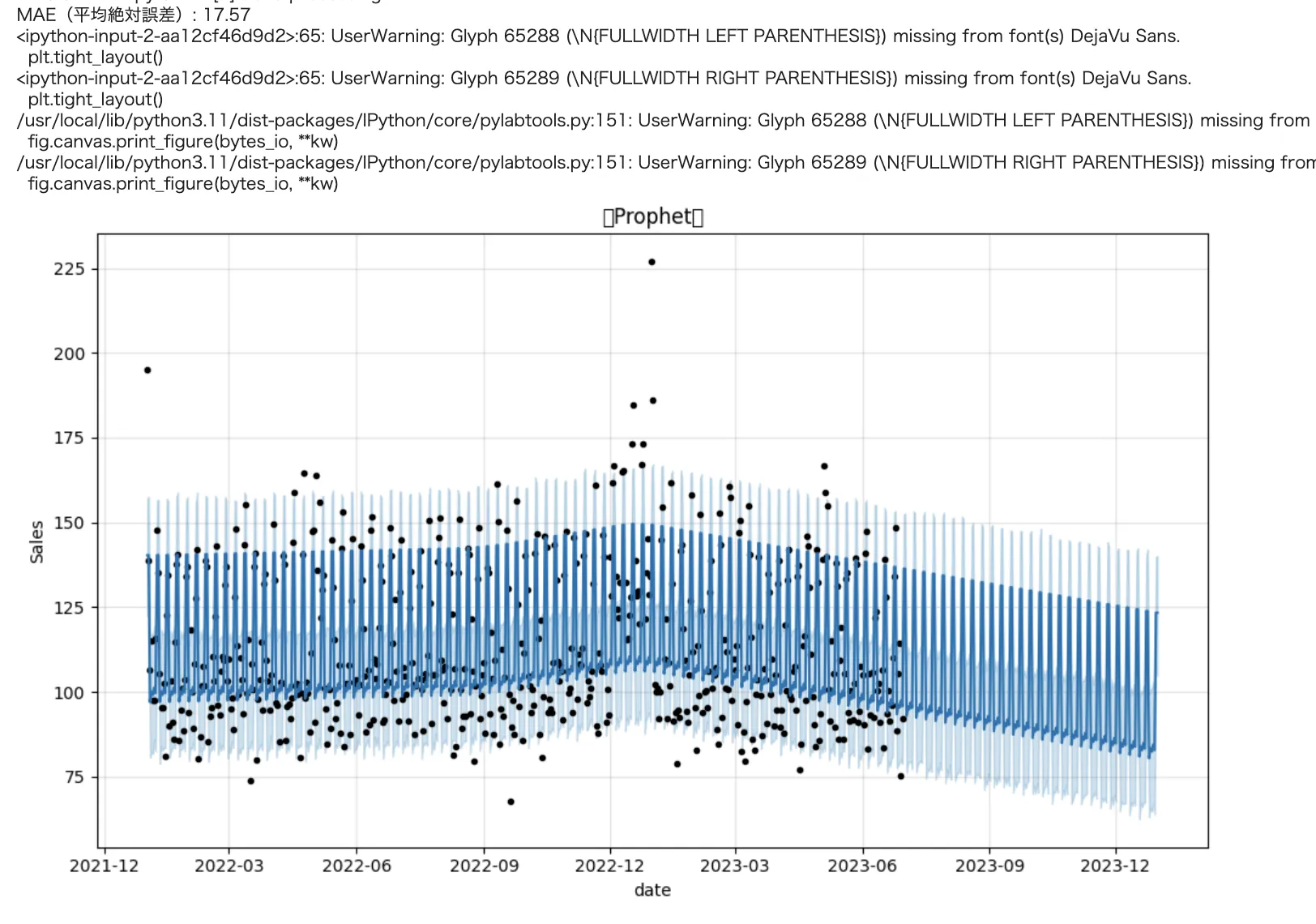
今回の出力結果
グラフに含まれる要素
Prophetの出力グラフには、以下の要素が含まれています。
- 黒い点(●):実際の売上データ(観測値)
- 青い実線:Prophetによる予測値(yhat)
- 青い帯:予測の信頼区間(予測の不確実性を表す範囲)
- 横軸:日付(タイムライン)
- 縦軸:売上数量(sales)
このグラフは、過去の売上データをもとに将来の傾向を予測したものであり、予測がどれだけ実データに近いかを視覚的に確認できます。
予測結果の読み取りポイント
以下の観点からグラフを解釈できます。
-
訓練期間(2022〜2023年6月)は予測と実測値が概ね一致
→ モデルは一定の精度で過去の傾向を捉えています。予測線と黒点のズレが小さいほどモデルの信頼性が高いと判断できます。 -
テスト期間(2023年7月以降)は信頼区間が広がる傾向
→ 時間が先に進むにつれて、将来の予測には不確実性が増すため、青い帯(信頼区間)も広くなります。これは正常な挙動です。 -
12月の売上増加傾向を正しく学習
→ Prophetは月ごとの季節性(12月の繁忙期など)を自動的に学習します。年末の予測線が持ち上がっていることから、モデルがこのパターンを正しく把握しているとわかります。
実務への応用:在庫発注や売上予測への活用
Pythonによる需要予測は、業種を問わず多くの実務で活用可能です。特に「在庫発注」や「売上予測」の場面では、意思決定の精度とスピードを大きく向上させます。
業種別の活用例(小売、製造、飲食など)
以下に、業種ごとの代表的な活用パターンを示します。
| 業種 | 活用シーン | 主な効果 |
|---|---|---|
| 小売業 | 商品別の販売予測 → 過剰在庫や欠品の回避 | 発注業務の効率化、廃棄削減 |
| 製造業 | 部材の使用量予測 → 生産計画の最適化 | 生産コストの抑制、納期遵守率の向上 |
| 飲食業 | 食材需要の予測 → 適切な仕入れ | フードロス削減、在庫圧縮 |
| ECサイト | キャンペーン時の需要予測 | サーバー負荷対策、在庫確保 |
たとえば、案件が多く発生する時期に特定資材の需要が増加する場合、その傾向を過去データから把握し、発注数量を自動で調整するといった使い方ができます。
既存システムとの連携(API化、Excel出力など)
構築したPythonモデルは、以下のような形で業務システムに組み込むことで、実用的な運用が可能になります。
- Excel連携:予測結果を
openpyxlやpandasでExcel出力し、既存の帳票に組み込み - API化:
FastAPIやFlaskでモデルをAPI化し、社内の発注システムから呼び出し - 定期実行:
cronやWindowsタスクスケジューラと組み合わせ、毎週・毎月の自動予測
# Excel出力の例
df_forecast.to_excel("予測結果.xlsx", index=False)
既存のExcelベース業務から段階的に移行したい企業でも、Pythonモデルを補助ツールとして活用することで、スムーズな導入が可能です。

Python需要予測の実装力を業務プロセス全体のAI化に展開するなら
Pythonで需要予測モデルを構築できるスキルは、業務全体のAI化を推進する強力な武器です。
予測モデル単体で終わらせず、予測結果を発注システムや在庫管理に自動連携する仕組みまで設計することで、業務プロセス全体の効率が飛躍的に向上します。AI総合研究所のガイドでは、個別のAI実装から業務横断的な自動化への拡張方法を解説しています。
AI総合研究所のガイドで、Python実装から業務全体のAI化プランへの展開方法をご確認ください。
Python需要予測の実装力を業務全体のAI化に展開する

予測モデルから業務自動化への橋渡し
Pythonで需要予測を実装できるようになった次は、予測結果を発注や在庫管理に自動連携する仕組みを検討しましょう。ガイドでは業務プロセスへのAI導入手順を解説しています。
まとめ:Pythonで始める需要予測の第一歩
需要予測は、在庫管理や発注業務の効率化、売上向上に直結する重要な取り組みです。Pythonを活用すれば、統計的手法から機械学習・深層学習まで、幅広いアプローチで高精度な予測を実現できます。
本記事では、以下の観点から需要予測の実装方法を解説しました。
- Pythonでの需要予測の全体像と利点
- 時系列・回帰・深層学習など代表的なアルゴリズム
- 実装の基本ステップとコード例
- 実務での応用と既存業務との連携方法
まずは、小規模なデータでProphetやXGBoostなど扱いやすいライブラリを使って試すことから始めてみましょう。そして、継続的な改善と業務との統合により、精度と使い勝手を両立した予測システムの構築を目指すことができます。
今後、社内のデータ活用をさらに進めたい方にとって、需要予測はPythonによるAI導入の「第一歩」として非常に有効なテーマです。
AI総合研究所では企業の需要予測・在庫管理システムの構築・AI導入を支援していますので、ぜひお気軽にご相談ください。










