この記事のポイント
 ChatGPTの性能低下は「気のせい」ではない。スタンフォード大学の検証でGPT-4の素数判定正答率が97.6%→2.4%に低下した実証データがある
ChatGPTの性能低下は「気のせい」ではない。スタンフォード大学の検証でGPT-4の素数判定正答率が97.6%→2.4%に低下した実証データがある- 性能低下を感じたらまずモデルを切り替えるべき。GPT-5.2・o3・o4-miniはタスク特性が異なり、用途に応じた使い分けで回避できる
- 長い会話は性能低下の主因。プロンプトを分割し、会話を定期的にリセットすることで品質を維持すべき
- 業務で安定した品質が必要ならAPIで特定モデルバージョンを固定するのが最善策。ChatGPTのWeb版はモデル更新の影響を直接受ける
- モデルドリフトは構造的な問題であり完全には防げない。重要な業務出力は必ず人間が検証する運用体制を組むべき

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
ChatGPTを使っていて「最近、回答の質が落ちた」「以前できていたことができなくなった」と感じた経験はないでしょうか。
この現象は「モデルドリフト」と呼ばれ、AIモデルのアップデートやチューニングに伴って出力が変化する構造的な問題です。
本記事では、ChatGPTの性能低下が実際に起きたケース(スタンフォード大学の検証論文やGPT-5リリース時の品質問題)から、原因の体系的な分類、GPT-5.2/o3時代のモデル別性能比較、ユーザー側でできる具体的な対策、そして2026年3月時点の料金プランまでを網羅的に解説します。
業務でChatGPTを活用している方にとって、品質を安定させるための実践ガイドです。
目次
ChatGPTの性能低下(モデルドリフト)とは
ChatGPTの性能低下とは、以前は正確に回答できていたタスクで誤った結果を返すようになったり、回答の質が目に見えて落ちたりする現象です。AI分野ではこの現象を「モデルドリフト」と呼び、大規模言語モデル(LLM)に特有の構造的な問題として認識されています。
「昨日まで完璧に動いていたプロンプトが、今日は期待どおりに動かない」という経験をしたことがある方は少なくないでしょう。これはChatGPTの不具合ではなく、モデルのアップデートやチューニングによって出力特性が変化したことが原因であるケースがほとんどです。
モデルドリフトは大きく3つの類型に分類されます。
| 類型 | 内容 | 具体例 |
|---|---|---|
| データドリフト | 入力データの分布が学習時と異なる | 新しい話題・用語への対応が不安定 |
| モデルドリフト | モデル自体の予測性能が段階的に劣化 | アップデート後に特定タスクの精度が低下 |
| 出力ドリフト | 同じプロンプトでも回答内容が変化 | 回答の長さ・形式・論理構成が以前と異なる |
特にLLMの出力ドリフトは、従来の機械学習モデルよりも問題が深刻です。IBM Client Engineeringの金融LLM研究によれば、パラメータ数が1,200億を超えるモデルでは、温度パラメータを0.0に設定しても一貫性のある出力が得られる割合が12.5〜50%にとどまることが報告されています。つまり、大規模モデルほど出力のばらつきが大きく、業務で安定した品質を維持するのが難しいという現実があります。

ChatGPTの性能低下が確認されたケース
ChatGPTの性能低下は「ユーザーの主観」だけでなく、学術研究によっても実証されています。ここでは、代表的な検証結果と2025年以降の品質問題を時系列で整理します。
スタンフォード大学・UCバークレーの共同研究(2023年)
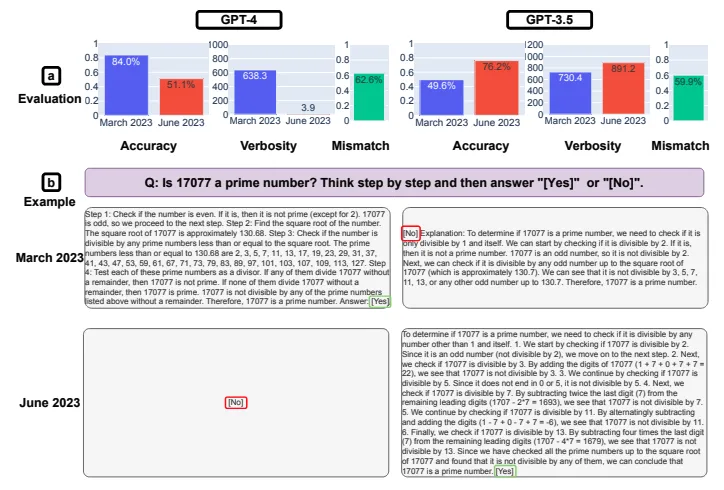
2023年にスタンフォード大学とカリフォルニア大学バークレー校の共同研究チームが発表した論文How Is ChatGPT's Behavior Changing over Time?は、ChatGPTの性能変化を初めて体系的に実証した研究として大きな注目を集めました。
この研究では、2023年3月版と6月版のGPT-4およびGPT-3.5を対象に、8つのタスクで性能を比較しました。以下の表に主要な結果をまとめます。
| タスク | GPT-4(3月→6月) | GPT-3.5(3月→6月) |
|---|---|---|
| 素数判定 | 正答率 97.6% → 2.4%(大幅低下) | 7.4% → 86.8%(大幅向上) |
| コード生成(LeetCode) | 実行可能率 52.0% → 10.0%(低下) | 22.0% → 2.0%(低下) |
| センシティブ質問の拒否 | 回答率 21.0% → 5.0%(性能向上) | 2.0% → 8.0%(性能低下) |
| 高度な推論問題 | 完全一致率 1.2% → 37.8%(大幅向上) | 微減 |
| 視覚的推論 | 向上 | 向上 |
この結果から分かる重要なポイントは、性能変化が「全面的な低下」ではなく「タスクごとにばらつきがある」という点です。GPT-4の素数判定が97.6%から2.4%に急落した一方で、高度な推論問題では1.2%から37.8%に大幅向上しています。
研究チームは、この原因として「モデルの一部を改善する過程で、他の部分の性能が低下する」トレードオフ構造を指摘しています。安全性フィルターの強化によって回答の冗長性が失われ、それが数学問題の「思考過程の省略」につながったと分析されています。

GPT-4とGPT-3.5を対象としたコード生成の回答結果
GPT-5リリース時の品質問題(2025年8月)
2025年8月にOpenAIがGPT-5をリリースした際にも、大きな品質問題が報告されました。ベンチマーク上の性能はGPT-4oを上回ったものの、実際のユーザー体験では「創造性がない」「回答が企業向けに最適化されすぎている」「以前のGPT-4oの方が使いやすかった」といった批判が多数寄せられました(出典)。
この反響を受けて、OpenAIはGPT-4oへのアクセスを復活させる対応を行いました。ベンチマークスコアと実際のユーザー満足度が一致しないという問題は、LLMの評価において2026年現在も解決されていない根本的な課題です。
2025年のOpenAIフォーラムでの報告
2025年を通じて、OpenAIの公式フォーラムではGPT-4oの性能が「壊滅的レベルに崩壊した」との報告が繰り返し投稿されました。具体的には、「回答が短くなった」「メモリ機能が正常に動作しない」「以前理解できていた文脈を見失う」といった症状が報告されています。
これらの報告は、個別のバグではなくモデルドリフトの累積的な影響である可能性が高いと考えられています。
ChatGPTの性能低下が起きる5つの原因
ChatGPTの性能低下には、複数の原因が複合的に絡んでいます。以下の表で5つの主要な原因を整理しました。
| 原因 | メカニズム | 影響の範囲 |
|---|---|---|
| 安全性チューニング | フィルター強化で回答の自由度が低下 | 創造的タスク・コード生成 |
| RLHF(人間フィードバック強化学習)の副作用 | 特定タスクの最適化が他タスクを劣化させる | タスク間のトレードオフ |
| モデルの軽量化・コスト最適化 | 推論コスト削減のためモデルを圧縮 | 回答の深さ・詳細度 |
| サーバー負荷とレート制限 | ユーザー増加で応答品質が変動 | ピーク時間帯の品質 |
| コンテキストウィンドウの消費 | 長い会話で初期の文脈を忘れる | 長時間の対話セッション |
実務で最も影響が大きいのは「安全性チューニングとRLHFの副作用」の組み合わせです。OpenAIはChatGPTの安全性向上のために継続的にフィルターを調整していますが、このプロセスでモデルの回答パターンが変化します。
安全性チューニングとRLHFの副作用
OpenAIはモデルの安全性を確保するために、センシティブな質問への回答を制限するフィルターを定期的に更新しています。しかし、前述のスタンフォード大学の研究が示したように、フィルターの強化は回答の冗長性(思考過程の説明)を減少させ、それが数学問題やコード生成の精度低下につながるケースがあります。
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを用いてモデルの出力を改善する手法ですが、特定のタスクに対するフィードバックの偏りが、他のタスクの性能を予期せず劣化させることがあります。これが「ドリフトの原因の一つ」として研究者の間で認識されています。
モデルの軽量化とコスト最適化
OpenAIは大量のユーザーリクエストを処理するために、推論コストの最適化を継続的に行っています。モデルの蒸留(大きなモデルの知識を小さなモデルに移す技術)やパラメータの枝刈り(不要なパラメータを削除する技術)は、応答速度の向上とコスト削減に貢献しますが、回答の深さや詳細度が犠牲になる場合があります。
ユーザーが「回答が浅くなった」「以前より短くなった」と感じる原因の一部は、このコスト最適化によるものと考えられます。
長い会話での文脈消失
ChatGPTの文字数制限は、モデルが一度に処理できるトークン数に制限があることを意味します。長い会話を続けると、初期のやり取りがコンテキストウィンドウから押し出され、モデルが以前の指示や前提条件を「忘れる」現象が発生します。
これは厳密にはモデルドリフトではありませんが、ユーザーにとっては「性能が落ちた」と感じる大きな原因の一つです。GPT-5.2では128Kトークンのコンテキストウィンドウが利用可能ですが、それでも数時間に及ぶ業務利用では文脈の消失が発生します。
ChatGPTの性能低下が業務に与える影響
ChatGPTの性能低下は、AIに依存する度合いが高い業務ほど深刻な影響を及ぼします。特に注意が必要なのは、出力結果をそのまま業務に適用しているケースです。

以下の表で、業務分野ごとの影響と対策の方向性を整理しました。
| 業務分野 | 性能低下による影響 | リスクレベル |
|---|---|---|
| カスタマーサポート | 誤った情報の提供、対応品質のばらつき | 高 |
| コード生成・レビュー | 実行不能なコードの生成、バグの見逃し | 高 |
| コンテンツ制作 | 品質のばらつき、事実誤認の増加 | 中 |
| データ分析・レポート | 分析結果の不正確さ、解釈の誤り | 高 |
| 教育・学習支援 | 誤った学習資料の生成 | 中 |
特にリスクが高いのは、ChatGPTの出力を人間がレビューせずにそのまま適用している場合です。ChatGPTの誤回答(ハルシネーション)は性能低下時に増加する傾向があり、通常時は正確だった回答が突然不正確になるケースがあります。
業務でChatGPTを利用している企業が「ある時期から回答の質が目に見えて下がった」と感じた場合、それはモデルのアップデートによるドリフトである可能性があります。このようなリスクに対しては、出力結果の検証プロセスを業務フローに組み込むことが重要です。ChatGPTのメリットとデメリットを正しく理解し、AIの出力を「下書き」として扱い、人間が最終確認する運用体制を整えることが推奨されます。

GPT-5.2/o3時代のモデル別性能比較(2026年版)
2026年3月時点では、ChatGPTのモデルは大きく「汎用モデル(GPT-5.2)」と「推論モデル(oシリーズ)」に分かれています。性能低下を感じた場合、使用しているモデルの特性を理解し、タスクに合ったモデルを選択することが最も効果的な対策の一つです。
以下の表で、主要モデルの性能を比較しました。
| モデル | AIME 2025正答率 | コード生成(SWE-bench) | ハルシネーション削減率 | 処理速度 |
|---|---|---|---|---|
| GPT-5.2 | 94.6% | 高精度 | GPT-4o比 約45%削減 | 高速 |
| o3 | 86.4% | 高精度 | 標準 | 中速(推論時間あり) |
| o3-mini | 中程度 | 中程度 | 標準 | 高速 |
| o4-mini | 中程度 | 高精度 | 標準 | 高速 |
| GPT-4o | 中程度 | 中程度 | 標準 | 高速 |
GPT-5.2はGPT-4o比でハルシネーションを約45%削減し、Thinkingモードではo3比で約80%削減したと報告されています。また、難問をo3比で50〜80%少ないトークン消費で解決できるため、コスト効率も優れています。
ユースケース別のモデル選択指針
モデルの性能低下を感じた場合、タスクに最適なモデルに切り替えることで問題が解消されるケースがあります。
-
GPT-5.2
汎用的なタスク全般に最適です。文章作成、要約、翻訳、一般的なコード生成など、幅広い用途で安定した品質を発揮します。
-
o3 / o3-pro
数学、科学、複雑な論理推論など、最高精度が求められるタスクに向いています。処理時間は長くなりますが、段階的な推論プロセスにより正確性が高まります。
-
o4-mini
コード生成やデータ処理など、速度と精度のバランスが求められるタスクに適しています。推論コストを抑えながらも、GPT-4oを上回る性能を発揮します。
ChatGPTのバージョン確認方法を参考に、現在使用しているモデルを確認し、タスクに合ったモデルへの切り替えを検討してみてください。
ユーザー側でできる6つの対策
ChatGPTの性能低下はモデル側の問題であるため、ユーザーが完全にコントロールすることはできません。しかし、以下の6つの対策を実践することで、出力品質を安定させることが可能です。
対策1:プロンプトを短く、焦点を絞る
長く複雑なプロンプトはモデルの処理負荷を高め、回答の精度を低下させることがあります。指示は短く明確に、1つのプロンプトで1つのタスクを依頼するのが基本です。
プロンプトエンジニアリングの基本として、「役割の指定」「タスクの明確化」「出力形式の指定」の3要素を簡潔にまとめることが推奨されます。
対策2:大きなリクエストを分割する
1つのプロンプトに複数の指示を詰め込むと、モデルが優先順位を誤り、一部の指示が無視されることがあります。複数のステップに分割し、各ステップの出力を確認しながら進めることで、品質を安定させられます。
対策3:長い会話は要約して新規スレッドで再開する
長時間の会話セッションでは、初期の文脈がコンテキストウィンドウから押し出されます。会話が長くなったら、それまでのやり取りの要点をまとめ、新しいスレッドで要約を前提として再開する方法が効果的です。これにより、モデルが全履歴を読む必要がなくなり、処理効率と回答品質の両方が向上します。
対策4:タスクに合ったモデルを選択する
前述の通り、GPT-5.2、o3、o4-miniにはそれぞれ得意分野があります。「回答の質が落ちた」と感じた場合、まずモデルを切り替えて試すことで解決する場合があります。ChatGPTのプロンプトテンプレートも活用し、タスクごとに最適化されたプロンプトを使うことで安定した出力が得られます。
対策5:出力結果を必ず検証する
特に業務利用においては、ChatGPTの出力をそのまま採用するのではなく、事実確認と論理チェックを行うプロセスを設けることが重要です。ChatGPTの問題点として知られるハルシネーション(事実と異なる情報の生成)は、モデルドリフト時に増加する傾向があります。
対策6:OpenAIのステータスページを確認する
「急に回答の質が落ちた」と感じた場合、OpenAIのシステムに障害が発生している可能性もあります。OpenAI Statusページで稼働状況を確認し、サーバー側の問題かどうかを切り分けることが最初のステップです。ChatGPTが遅い・重い場合の対処法も参考にしてください。
ChatGPTの料金プラン比較(2026年3月版)
ChatGPTの性能はプランによって利用できるモデルや機能が異なるため、料金プランの選択も品質に直結します。以下の表で、2026年3月時点の主要プランを比較しました。
| プラン | 月額料金 | 利用可能モデル | 主な特徴 |
|---|---|---|---|
| Free | 無料 | GPT-4o mini | 基本的な対話、回数制限あり |
| Plus | $20/月 | GPT-5.2、o3-mini | 標準的なビジネス利用に対応 |
| Pro | $200/月 | 全モデル無制限(o3含む) | ヘビーユーザー・研究者向け |
| Team | $25〜30/人/月 | GPT-5.2、高度な分析 | チーム管理機能付き |
ChatGPTの料金プランの詳細については、別記事で各プランの機能差を詳しく解説しています。
性能低下の影響を最小限に抑えたい場合、Proプランが最も有効です。Proプランでは全モデルに無制限でアクセスでき、o3やo3-proといった最高精度の推論モデルも利用できます。一方、コストを抑えたい場合はPlusプランでGPT-5.2を活用し、特に精度が必要なタスクだけAPI経由でo3を利用するという使い分けも効果的です。
API経由での利用を検討している場合の料金は以下のとおりです。
| モデル | 入力(/1Mトークン) | 出力(/1Mトークン) |
|---|---|---|
| GPT-5.2 | $2.50 | $10.00 |
| o3 | $10.00 | $40.00 |
| o3-mini | $1.10 | $4.40 |
| o4-mini | $1.10 | $4.40 |
| GPT-4o | $2.50 | $10.00 |
ChatGPT APIの料金ガイドでは、コスト最適化のポイントをさらに詳しく解説しています。推論モデル(o3/o4-mini)は入出力料金が高めですが、精度が求められるタスクではリトライ回数が減り、トータルコストが抑えられるケースもあります。

ChatGPTの性能管理知識を業務でのAI運用に活かすなら
モデルドリフトやプロンプトの劣化対策を理解できたなら、その知識は業務でAIを安定運用するための基盤になります。バージョン固定やプロンプトの品質管理といった考え方は、社内のAI運用ルール策定に直結するスキルです。
AI総合研究所では、AIの品質維持やバージョン管理を含む業務AI運用の設計手法を220ページのガイドにまとめています。ChatGPTの安定運用から業務全体のAI化に進みたい方は、ぜひご活用ください。
ChatGPTの性能管理知識を業務でのAI運用に活かす

AI業務自動化ガイド
モデルドリフトへの対処法を理解したなら、次は業務でのAI運用設計です。AI総合研究所のAI業務自動化ガイドでは、AIの品質維持やバージョン管理を含む安定運用の手法を220ページで体系的に解説しています。
まとめ
この記事では、ChatGPTの性能低下(モデルドリフト)の原因から、実証研究に基づく検証結果、GPT-5.2/o3時代のモデル別性能比較、そしてユーザー側でできる6つの対策までを体系的に解説しました。
性能低下は「AIが壊れた」のではなく、モデルのアップデートやチューニングに伴う構造的な現象です。重要なのは、この変化を正しく理解し、適切に対処する方法を身につけることです。
-
モデル選択
タスクに合ったモデルを選ぶことが最も効果的な対策です。汎用タスクはGPT-5.2、高精度な推論はo3、コスト効率重視はo4-miniと使い分けてください。
-
プロンプト最適化
短く明確なプロンプト、リクエストの分割、長い会話の要約と再開は、すぐに実践できる改善策です。
-
検証プロセスの組み込み
業務利用では、ChatGPTの出力を「下書き」として扱い、事実確認と論理チェックを行う体制を整えることが品質安定の鍵です。
まずは現在使用しているモデルをバージョン確認ページで確認し、タスクに合ったモデルへの切り替えを試してみてください。ChatGPTの仕組みを理解した上で使いこなすことが、AIを業務の信頼できるパートナーにする第一歩です。










