この記事のポイント
 スクリプト保守からAIエージェント運用へ主軸が切り替わるのが2026年の節目
スクリプト保守からAIエージェント運用へ主軸が切り替わるのが2026年の節目- 技術はLLM抽出・AIエージェント・LLM-Ready Scraping API・ノーコード自動化の4スタックで捉える
- 中小規模はノーコード自動化+Scraping API、大規模はAIエージェント+クラウド統合が第一候補
- 国内ではPigData年3,000万円削減・楽天楽楽リサーチャー、海外ではZapier/Retell/Firecrawl連携が公開
- 著作権・利用規約・幻覚リスク・コスト暴走の4軸でガード設計しないとPoCで詰まる

Microsoft MVP・AIパートナー。LinkX Japan株式会社 代表取締役。東京工業大学大学院にて自然言語処理・金融工学を研究。NHK放送技術研究所でAI・ブロックチェーンの研究開発に従事し、国際学会・ジャーナルでの発表多数。経営情報学会 優秀賞受賞。シンガポールでWeb3企業を創業後、現在は企業向けAI導入・DX推進を支援。
AIによるデータ収集の自動化は、これまで「ルールベースのスクレイピングを書いてはサイト構造の変更で壊す」を繰り返してきた領域を、LLMとAIエージェントで根本から組み替える流れに入っています。
2025年6月のOpenAI MCP connector提供開始(当初はDeep Research向け)と2025年10月17日のChatGPT BusinessでのBeta対応、2025年10月のChatGPT Atlas発表、AIエージェント+n8nのようなノーコード自動化の成熟により、エンジニアでなくても運用に乗せられる選択肢が一気に広がりました。
本記事では、データ収集の自動化を構築する実務フロー全体像、4つの技術スタック、主要ツールの選定と料金、実装5ステップ、国内外の導入事例、PoCで詰まる判断軸までを2026年6月時点の最新情報で解説します。
目次
LLM-Ready Web Scraping API(取得層のSaaS化)
LLM-Ready Web Scraping APIの主要サービス
LLM-Ready Scraping APIの料金(年契約時の月割換算)
PigData:展示会・不動産モニタリングで年3,000万円削減
SmapraTracker:EC競合価格モニタリングで1回あたり約3時間削減
AIでデータ収集を自動化する実務フロー全体像
AIによるデータ収集の自動化は、単発のスクレイピング業務ではなく、「対象棚卸し → ツール選定 → 抽出スキーマ設計 → 定期実行 → ガバナンス」の5ステップを業務サイクルとして回す段階に来ています。
これまでのスクレイピング・RPAは「ページが変わったら作り直す/属人スクリプトを夜中にメンテする」というやり方が一般的で、規模が伸びるほど運用負債が膨らんでいました。OpenAIによるMCP(Model Context Protocol)connectorの提供開始(2025年6月4日・Deep Research向け)と2025年10月17日のChatGPT BusinessでのBeta対応、2025年10月のChatGPT Atlas発表、FirecrawlのようなLLM-Ready Scraping APIの成熟により、構造変化を意味で吸収する設計が現実的になりました。

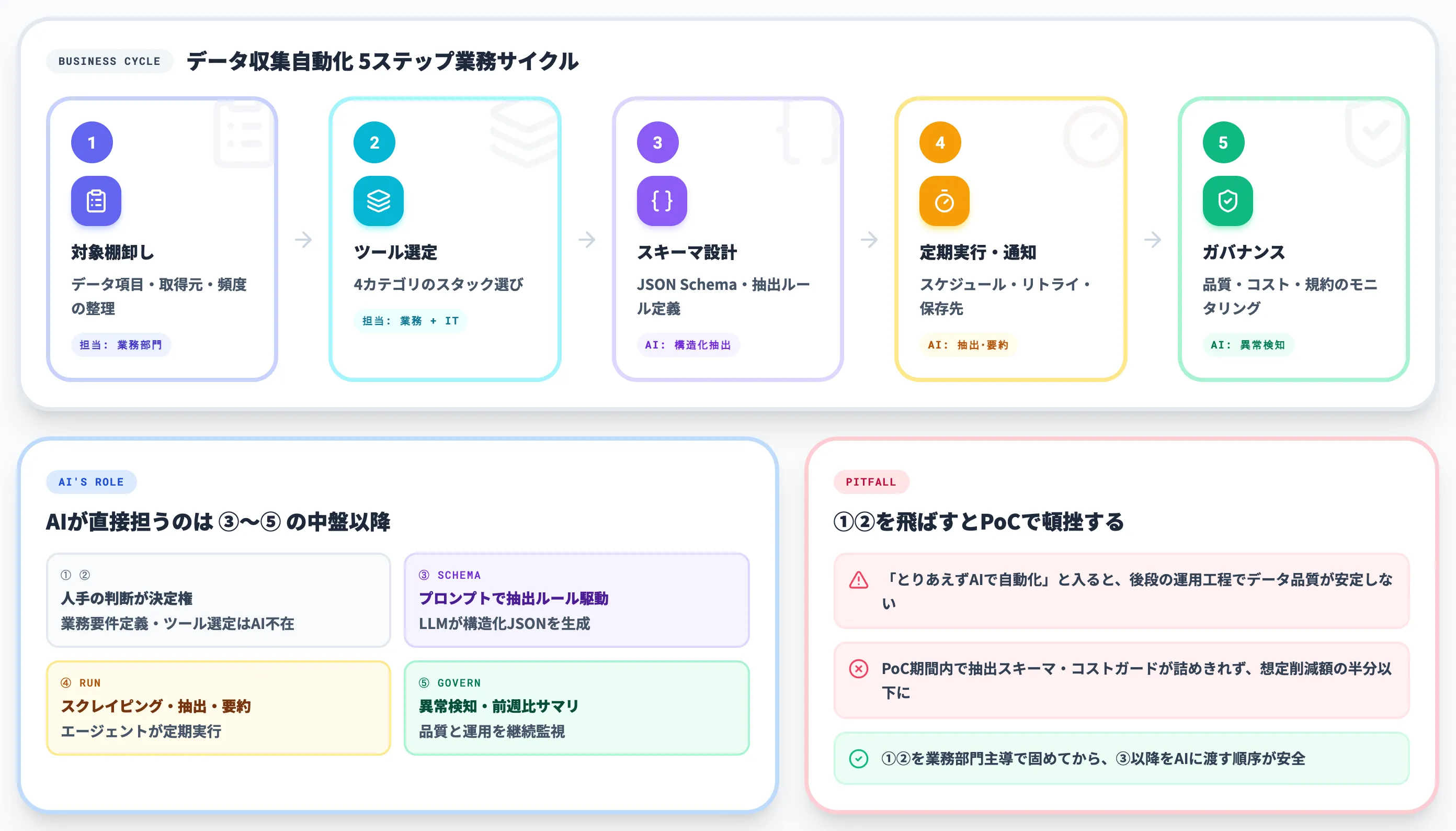
データ収集自動化の業務サイクル5ステップ
以下の表で、AIによるデータ収集の自動化を業務サイクルとして回すときの5ステップを整理しました。
| ステップ | やること | AIが担う役割 | 主な担当 |
|---|---|---|---|
| ①対象棚卸し | データ項目・取得元・頻度の整理 | (担当しない・人手で要件定義) | 業務部門 |
| ②ツール選定 | 4カテゴリのスタック選び | (担当しない・人手で設計判断) | 業務部門+IT |
| ③抽出スキーマ設計 | JSON Schema・抽出ルールの定義 | プロンプトでのスキーマ駆動抽出 | IT+業務部門 |
| ④定期実行・通知 | スケジュール・リトライ・保存先 | スクレイピング・抽出・要約 | IT |
| ⑤ガバナンス | 品質・コスト・規約のモニタリング | 異常検知・前週比サマリ | 業務部門+IT |
5ステップを通して見ると、AIが直接担うのは③〜⑤の中盤以降であり、①②の業務要件定義・ツール選定は人手の判断が決定権を持ちます。ここを飛ばして「とりあえずAIで自動化してみよう」とPoCに入ると、後段の運用工程でデータ品質が安定せず、PoC期間で頓挫します。
業務インパクトの目安
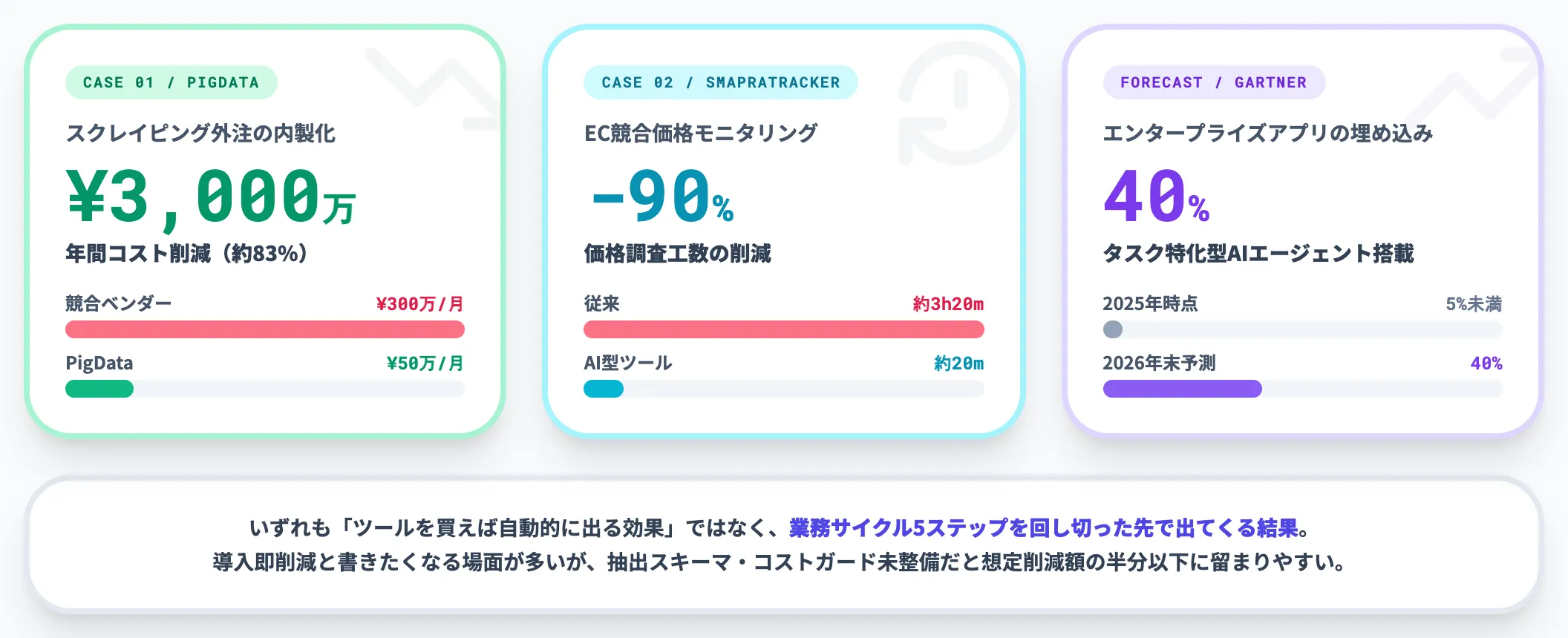
データ収集の自動化が回り始めた企業の公開数値を見ると、規模感は明確です。
- AIスクレイピング基盤を提供するPigDataは、競合する別ベンダーが月額300万円規模で受託していた領域を月額50万円で提供し、年間で約3,000万円(約83%)のコスト削減を顧客側で実現したと公表しています
- ECの競合価格モニタリング領域では、AI型ツール「SmapraTracker」を導入することで価格調査工数を最大90%以上削減(1回あたり約3時間20分→約20分)できると報告されています
- Gartnerは2026年末までに40%のエンタープライズアプリにタスク特化型AIエージェントが組み込まれる(2025年は5%未満)と予測しており、データ収集領域はその主戦場の1つになる見込みです
これらの数値は「ツールを買えば自動的に出る効果」ではなく、業務サイクル5ステップを回し切った先で出てくる結果です。経営層への稟議段階では「導入即削減」と書きたくなる場面が多いものの、実装途中で抽出スキーマやコストガードを詰めないと、想定削減額に対して半分以下しか出ないケースが現場でよく見られます。
データ収集をAIに任せる4つの技術スタック
AIによるデータ収集の自動化を構成する技術は、4層のスタックで整理すると全体像がブレません。
それぞれが解いている課題と、組み合わせ方の典型を順に見ていきます。
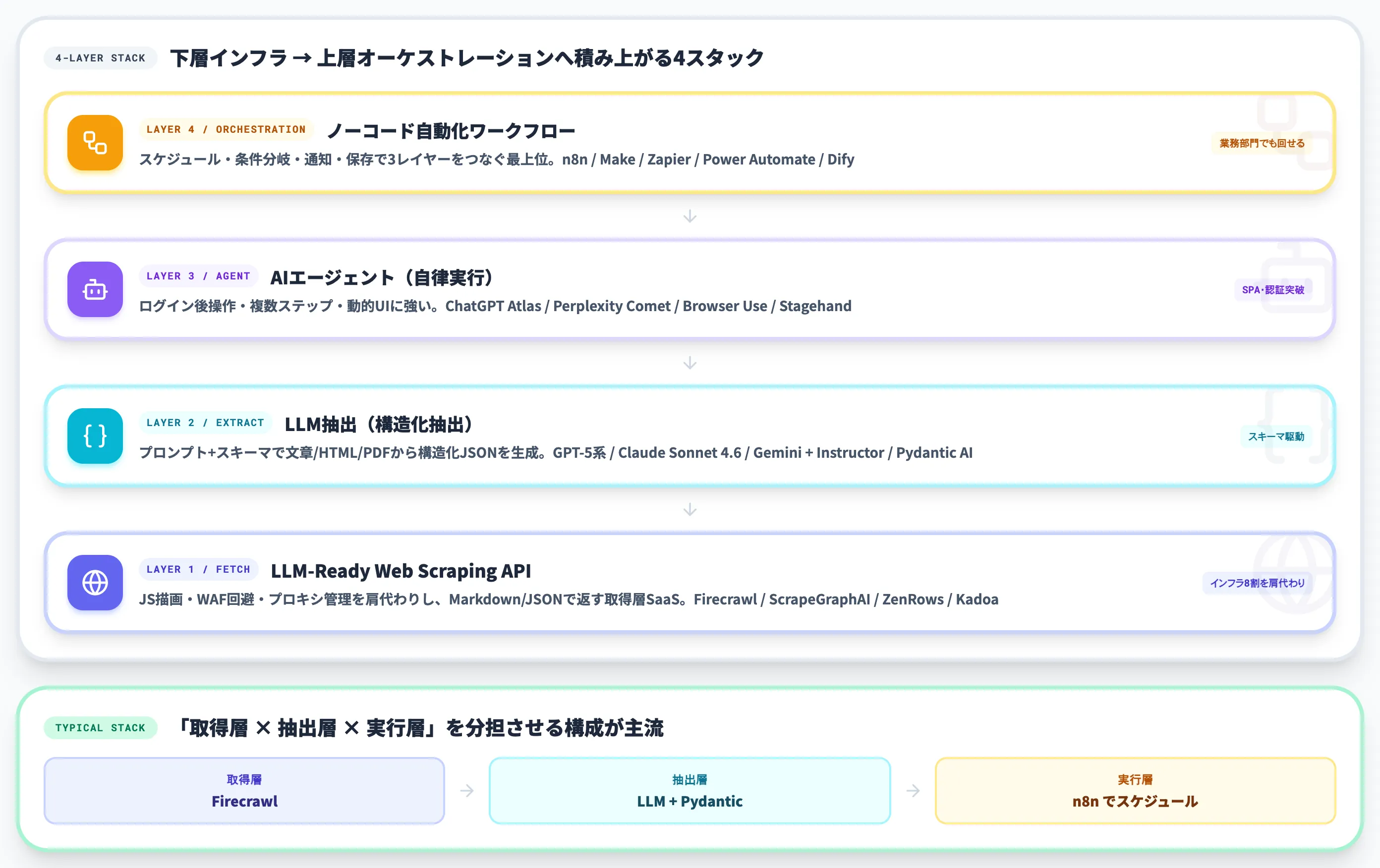
LLM抽出(構造化抽出レイヤー)

最も小さな単位の技術が、LLMに自然言語でスキーマを渡して、文章・HTML・PDFから構造化データを抜き出す構造化抽出です。
「商品名・価格・在庫ステータスをJSONで返して」というプロンプトを渡すと、GPT-5系やClaude Sonnet 4.6、Geminiなどの汎用LLMが該当箇所を読み解いてJSONを生成します。構造が安定しないページにも対応できる点が、固定セレクタを書く従来型との根本的な違いです。
近年はInstructorやPydantic AIのようなライブラリが標準化を進めており、開発者は期待する出力スキーマ(Pydanticモデル)を渡すだけで、スキーマ準拠した構造化出力を得られます。
LLM抽出は単独でも使えますが、後述のScraping APIやAIエージェントと組み合わせて「取得層・抽出層・実行層」を分担させる構成が主流です。
AIエージェント(自律実行レイヤー)
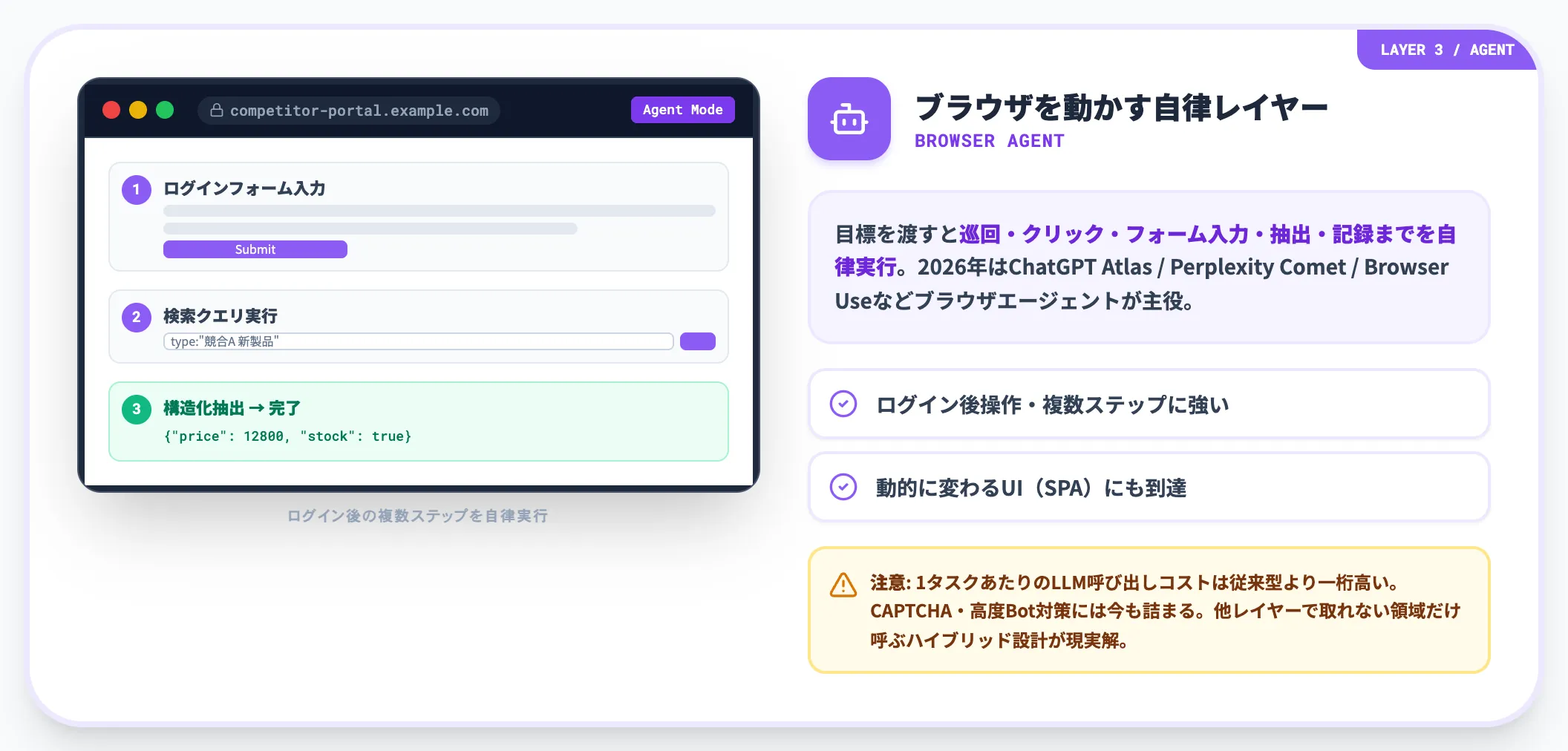
AIエージェントは、目標を渡すと自律的にWebを巡回・クリック・フォーム入力・抽出・記録までを実行する自律実行レイヤーです。2026年は「ブラウザエージェント」が業界の主役になっています。
OpenAI Operatorは2025年7月17日にChatGPT agentへ統合され、Operator research previewはChatGPT agent発表後にsunset(終了)されました。代わって2025年10月にエージェント型ブラウザ「ChatGPT Atlas」がリリースされ、Perplexity Comet、オープンソースのBrowser Use・Stagehandが同レイヤーの選択肢として並びます。
AIエージェントが特に効くのは、ログイン後の操作、複数ステップのトランザクション、動的に変わるUIを含む収集です。従来型スクレイピングが手も足も出ないSPA(Single Page Application)にも、ブラウザを実際に動かす力技で到達できます。
ただしAIエージェントは1タスクあたりのLLM呼び出しコストが従来型より一桁高く、CAPTCHAや高度なBot対策には今でも詰まります。全件をエージェントに任せるより、他レイヤーで取れない領域だけエージェントを呼ぶハイブリッド設計が現実解です。
【関連記事】
自律型AIエージェントとは?その仕組みや自動化との違い、活用事例を解説
LLM-Ready Web Scraping API(取得層のSaaS化)
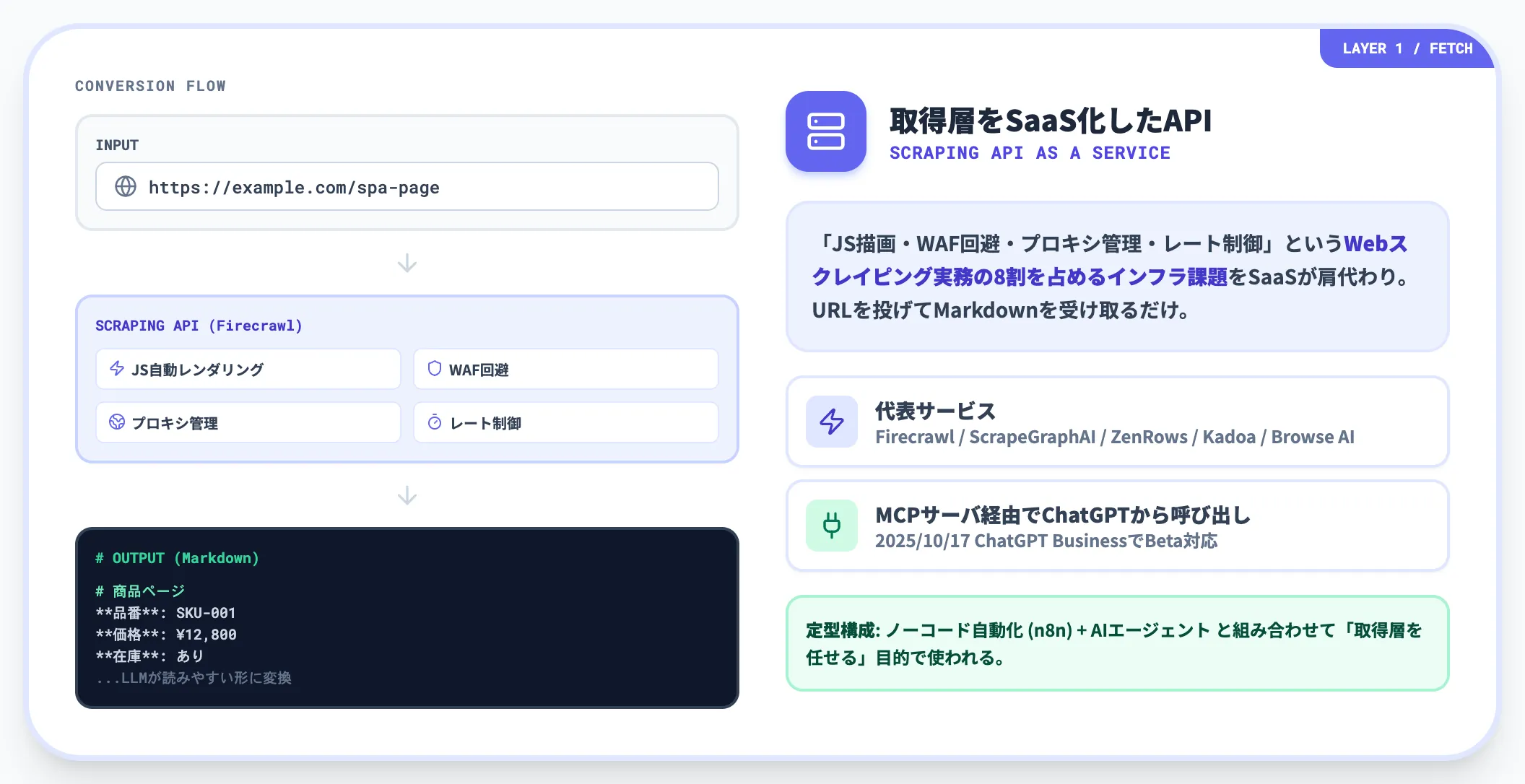
3つ目が、Webサイトを「LLMが読みやすい形(Markdown・構造化JSON)」に変換して返すAPIサービス、いわゆるLLM-Ready Scraping APIです。代表格はFirecrawl・ScrapeGraphAI・ZenRows・Kadoa・Browse AI。
このレイヤーが解いているのは「JavaScript描画・WAF回避・プロキシ管理・レート制御」という、Webスクレイピング実務の8割を占めるインフラ課題です。Firecrawl公式は「JSを自動レンダリングし、SPAでもページ全文を返す」と説明しており、エンジニアはURLを投げてMarkdownを受け取るだけで済みます。
OpenAIは2025年6月にMCP(Model Context Protocol)のconnectorをDeep Research向けに提供開始し、2025年10月17日にはChatGPT BusinessでMCP connectorのBeta対応を公表しました。
対応はプラン・用途で段階的に拡大している状況ですが、FirecrawlのようなScraping APIをMCPサーバ経由でChatGPTから呼び出すルートが現実的な選択肢として整い始めています。
このレイヤーは、後述のノーコード自動化やAIエージェントと組み合わせて「取得層を任せる」目的で使われるのが定型です。
ノーコード自動化ワークフロー(オーケストレーション層)
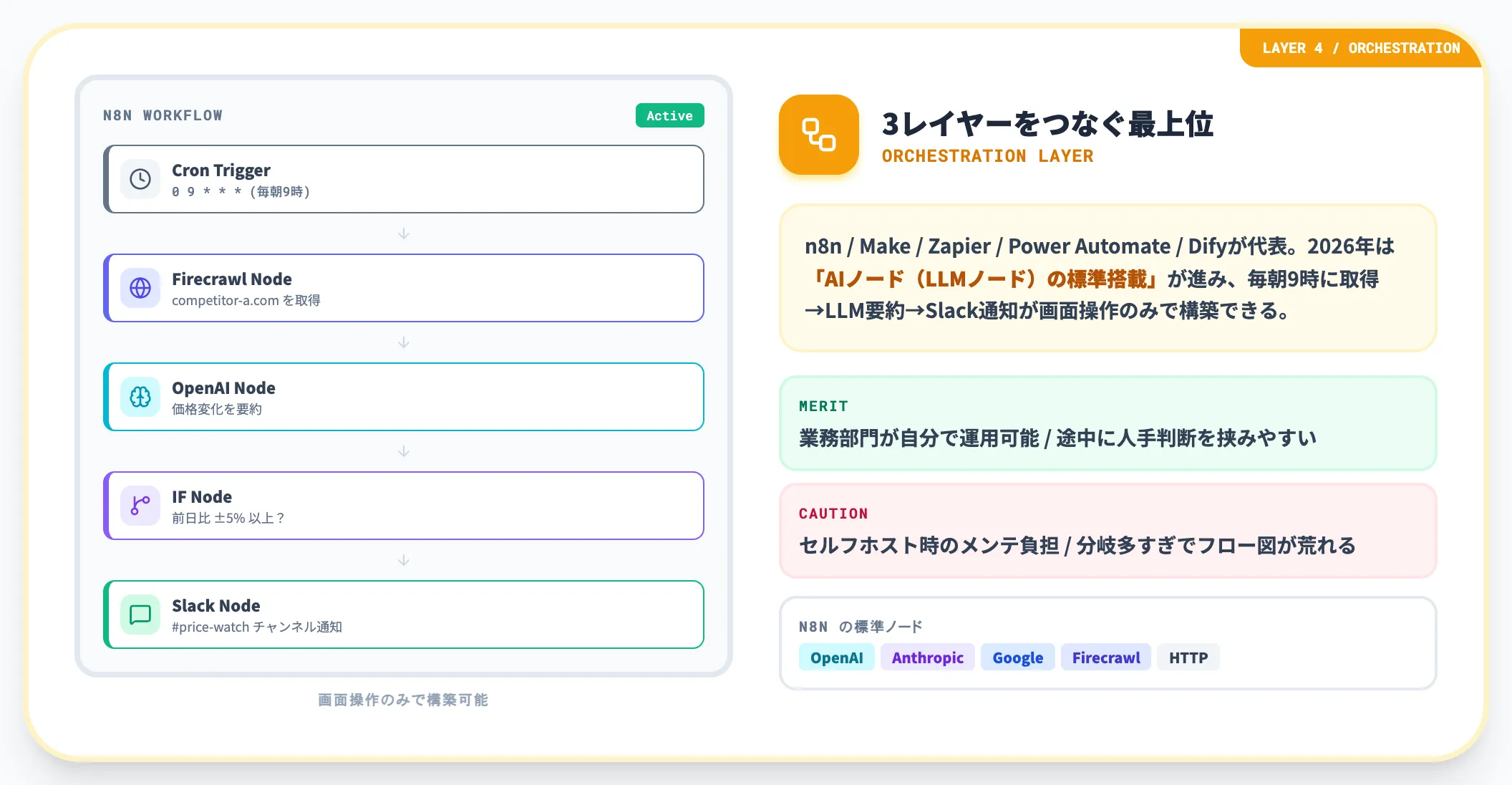
最後が、上記3レイヤーをスケジュール・条件分岐・通知・保存などのワークフローでつなぐオーケストレーション層です。代表ツールはn8n・Make(旧Integromat)・Zapier・Microsoft Power Automate・Difyなど。
このレイヤーの2026年の進化は「AIノード(LLMノード)の標準搭載」です。n8nは公式に「OpenAI/Anthropic/Google各社のLLMノード」と「Firecrawl/HTTPノードによる外部API呼び出し」を標準提供しており、毎朝9時に競合サイトを取得→LLMで要約→Slackに通知というワークフローを画面操作のみで構築できます。
ノーコード自動化のメリットは「業務部門でも回せる」「途中で人手判断を挟みやすい」点です。一方でセルフホスト運用時のメンテナンス負担や、複雑な分岐条件を可視化しすぎてフロー図が荒れる課題もあります。
【関連記事】
AIワークフローとは?自動化ツールの選び方と業務効率化の活用事例を解説
データ収集の自動化に使う主要ツール
ここからは、前セクションの4スタックに対応する形で、実務で選択肢に上がる主要ツールをカテゴリ別に紹介します。
カテゴリごとに代表サービスを並べ、選定のヒントを各ツール1段落で添えます。

LLM-Ready Web Scraping APIの主要サービス
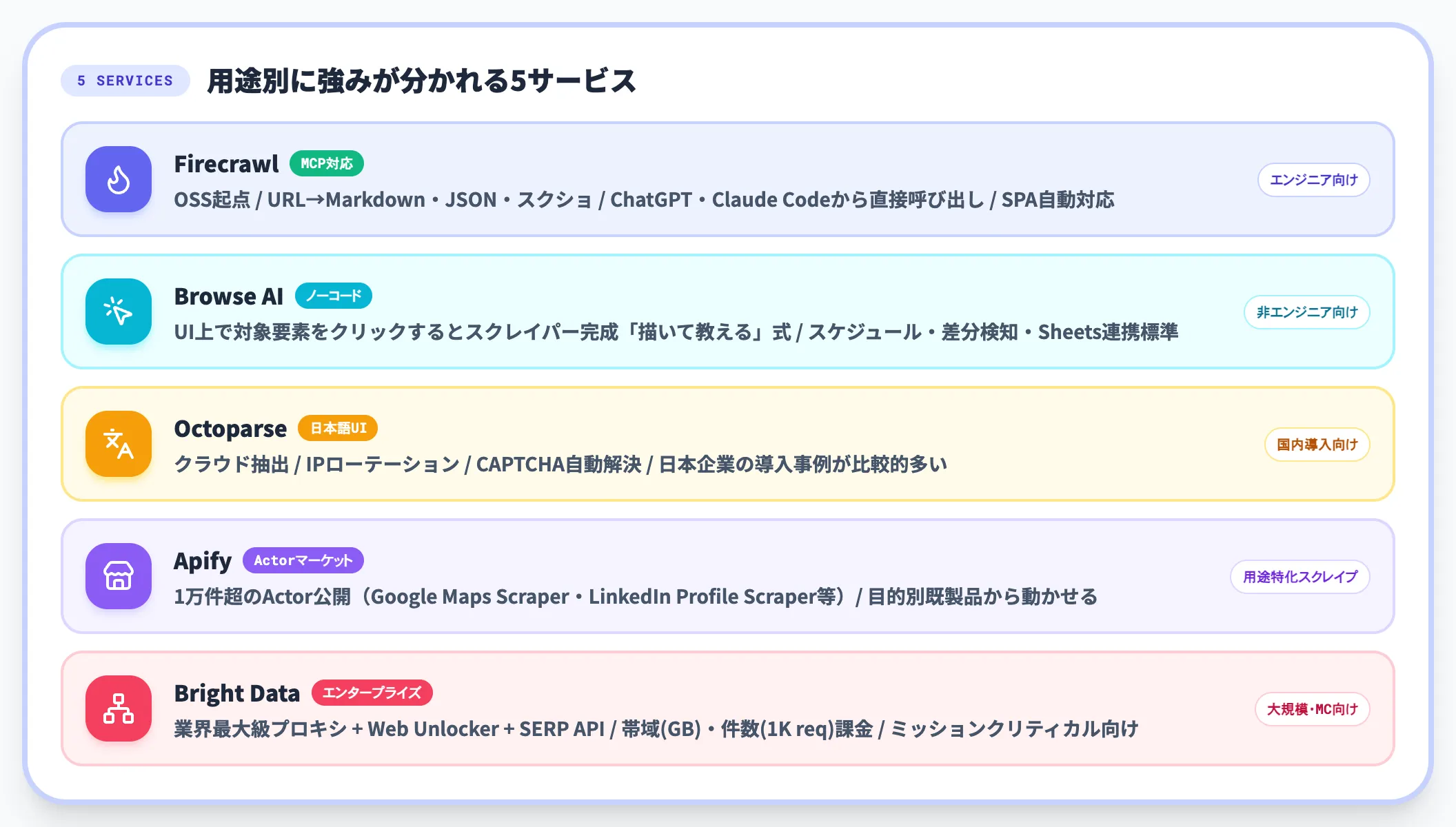
Web上の情報を「LLMが扱える形」に変換して返すAPI型サービスです。エンジニアが自社プロダクトに組み込む使い方と、ノーコード自動化ツール経由で呼び出す使い方の両方に対応します。
-
Firecrawl
オープンソース起点のScraping API。URLを投げるとMarkdown/構造化JSON/スクリーンショットで返す。MCPサーバ提供ありで、ChatGPT・Claude Code等から直接呼び出し可能。SPAやJS描画にも自動対応。
-
Browse AI
非エンジニア向けのノーコードScraper。UI上で対象要素をクリックするとスクレイパーが完成する「描いて教える」スタイル。スケジュール実行・差分検知・Google Sheets連携が標準装備。
-
Octoparse
日本語UI対応のスクレイピングプラットフォーム。クラウド抽出・IP rotation・CAPTCHA自動解決などのインフラ機能が手厚く、日本企業の導入事例が比較的多い。
-
Apify
スクレイピングActor(個別スクリプト)のマーケットプレイス+プラットフォーム。1万件超のActor(Google Maps Scraper・LinkedIn Profile Scraper等)が公開されており、目的別の既製品から動かせる。
-
Bright Data
業界最大級のプロキシネットワーク+Web Unlocker+SERP API。大規模・ミッションクリティカル用途に強い。料金は帯域(GB)または件数(1K request)課金で、エンタープライズ寄り。
AIブラウザエージェントの主要サービス
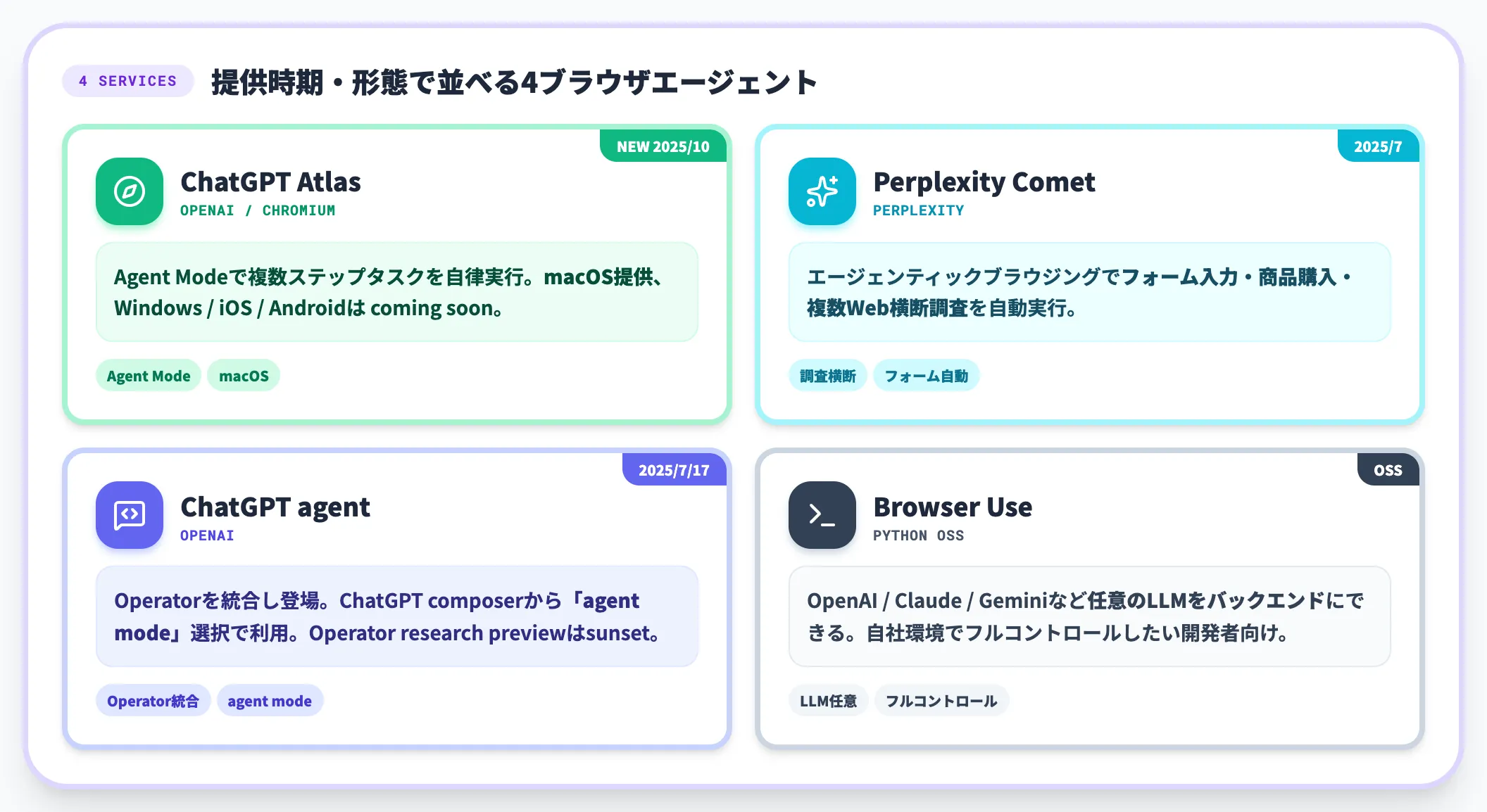
ブラウザを実際に動かして自律的にタスクを遂行するレイヤーです。ログイン後の操作や、複数ステップのトランザクションを伴う収集で威力を発揮します。
-
ChatGPT Atlas(OpenAI)
2025年10月リリース、ChromiumベースのAIブラウザ。Agent Modeで複数ステップのタスクを自律実行する。公式アナウンス時点ではmacOS提供で、Windows/iOS/Androidは「coming soon」として今後提供予定とされている。
-
Perplexity Comet
Perplexityが2025年7月にリリースしたAIブラウザ。エージェンティックブラウジング機能でフォーム入力・商品購入・複数Webソース横断調査を自動実行する。
-
ChatGPT agent(OpenAI)
2025年7月17日にOperatorを統合する形で登場。ChatGPTのcomposerから「agent mode」を選択することで利用できる。Operator research previewはChatGPT agent発表後にsunsetされている。
-
Browser Use(OSS)
PythonベースのオープンソースAIブラウザエージェント。OpenAI/Claude/Geminiなど任意のLLMをバックエンドにできる柔軟性が魅力で、自社環境でフルコントロールしたい開発者向け。
ノーコード自動化ワークフローの主要サービス
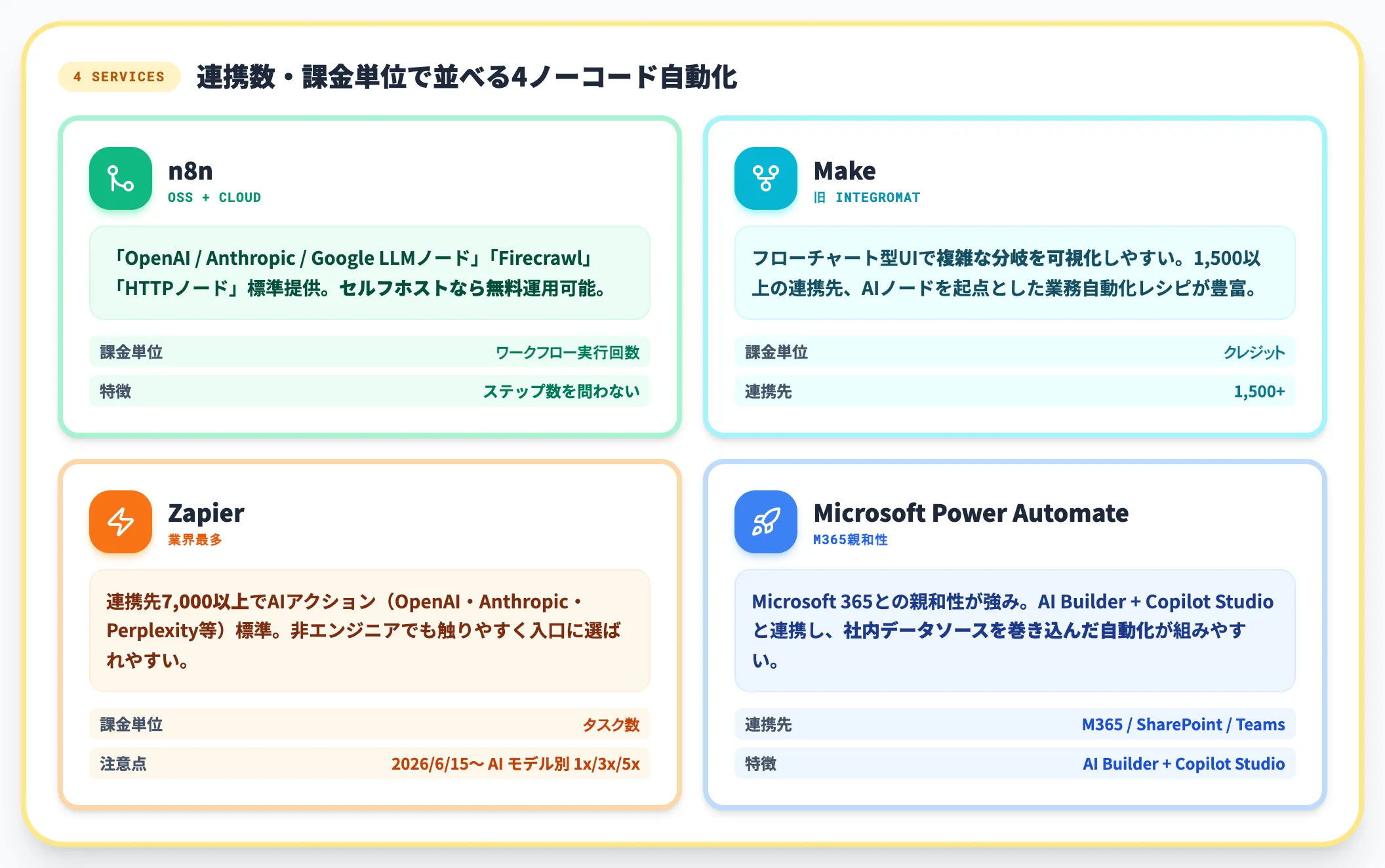
LLM抽出・Scraping API・通知などをスケジュール/条件分岐でつなぐオーケストレーション層です。業務部門が自分で運用に乗せられる選択肢として、2026年は実装の重心がここに移っています。
-
n8n
オープンソース+商用クラウド両対応。「OpenAI/Anthropic/Google LLMノード」「Firecrawlノード」「HTTPノード」を標準提供し、AIワークフローを画面操作のみで構築可能。セルフホスト時は無料運用も可能。
-
Make(旧Integromat)
フローチャート型UIで複雑な分岐を可視化しやすい。1,500以上の連携先を持ち、AIノードを起点とした業務自動化のレシピが豊富。
-
Zapier
連携先7,000以上で業界最多。AIアクション(OpenAI・Anthropic・Perplexity等)も標準提供。非エンジニアでも触りやすく、入口として選ばれやすい。
-
Microsoft Power Automate
Microsoft 365との親和性が強み。AI Builder+Copilot Studioとの連携で、社内データソースを巻き込んだ自動化が組みやすい。
【関連記事】
ノーコードで実現するAIエージェント活用とツール比較完全ガイド
統合プラットフォーム・AIエージェント基盤
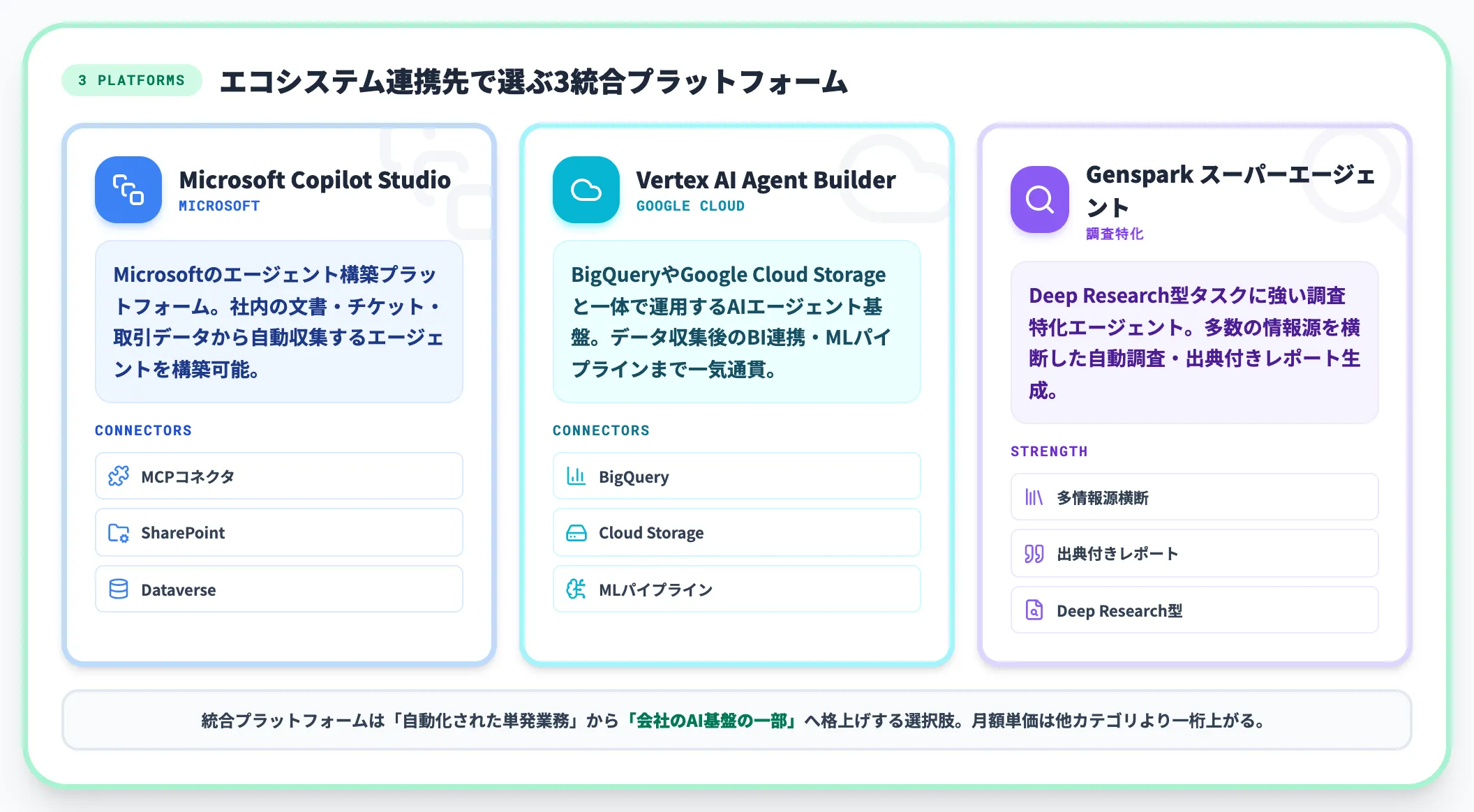
データ収集を単発のタスクではなく、社内の業務基盤に組み込みたい場合は統合プラットフォーム型を選ぶことになります。
-
Microsoft Copilot Studio
Microsoftのエージェント構築プラットフォーム。MCPコネクタ・SharePoint・Dataverseと連携し、社内の文書・チケット・取引データから自動収集するエージェントを構築できる。
-
Google Vertex AI Agent Builder
Vertex AI Agent Builderは、BigQueryやGoogle Cloud Storageと一体で運用するAIエージェント基盤。データ収集後のBI連携・MLパイプラインまで一気通貫で組める。
-
Genspark スーパーエージェント
Gensparkスーパーエージェントは調査特化のエージェント。Deep Research型タスク(多数の情報源を横断した自動調査・出典付きレポート生成)に強い。
統合プラットフォームは、データ収集を「自動化された単発業務」から「会社のAI基盤の一部」に格上げする選択肢です。次のH2で扱う料金体系でも、月額単価が他カテゴリより一桁上がる傾向があります。
AIスクレイピング系ツールの料金体系
ツール選定で最初に直面するのが料金体系の違いです。代表サービスの料金を、レイヤー別にまとめます。各社とも年契約と月契約で月額が異なり、価格改定も頻繁なため、契約前には必ず各社公式pricingページで最新の月払い/年払い区分を確認してください。
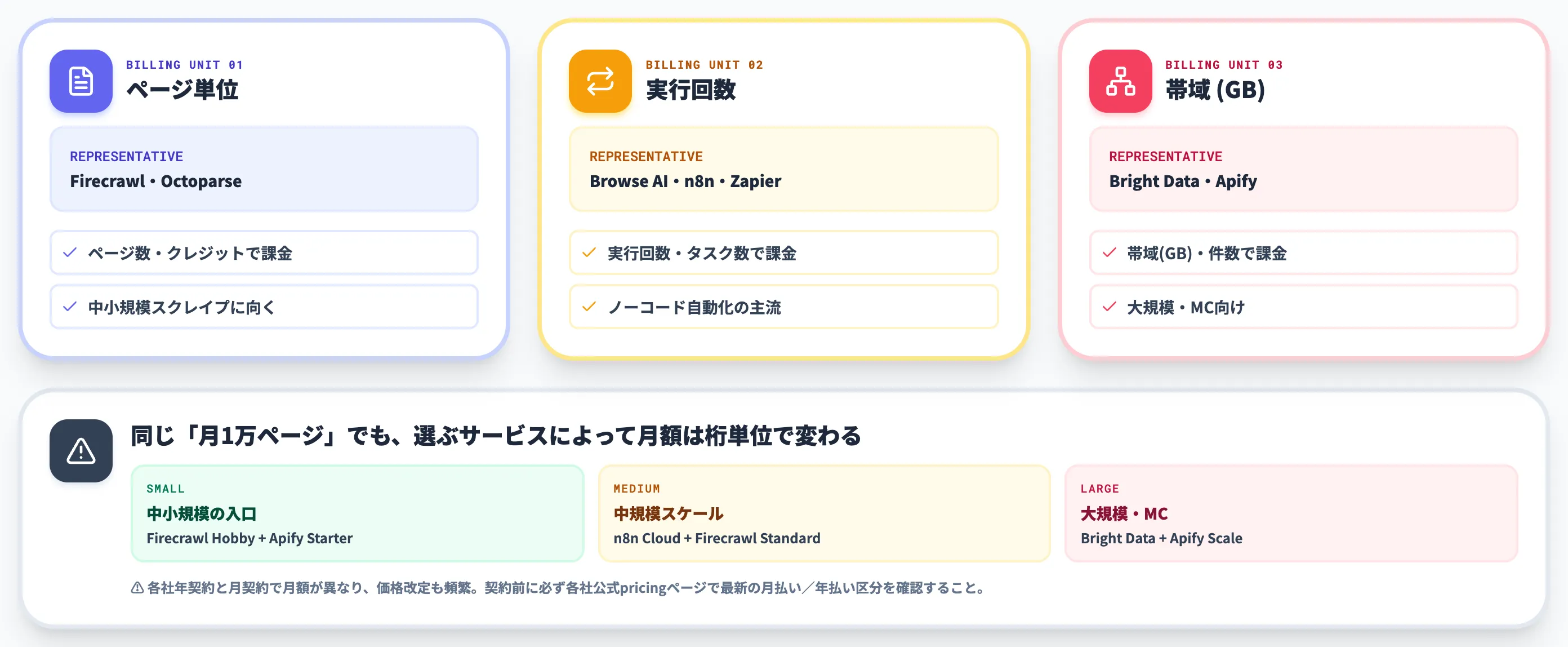
LLM-Ready Scraping APIの料金(年契約時の月割換算)

以下の表で、Scraping APIの代表サービスの料金プランを整理しました(年契約時の月割換算)。
| サービス | 無料プラン | 入門プラン | 中規模プラン | 課金単位 |
|---|---|---|---|---|
| Firecrawl | $0(1,000クレジット/月) | Hobby $16/月(5,000) | Standard $83/月(100,000) | ページ数(クレジット) |
| Browse AI | $0(年600クレジット) | Personal $19/月(年契約) | Professional $69/月(年契約) | クレジット(実行回数) |
| Octoparse | $0(10タスク) | Standard $69/月(年契約) | Professional $249/月(年契約) | タスク・行数 |
| Apify | $0($5クレジット) | Starter $29/月 | Scale $199/月 | プリペイドクレジット |
| Bright Data | なし(PAYG) | Residential Proxy PAYG $8/GB(キャンペーン時は割引表示あり) | 月額コミットでGB単価が下がる($7/$6/$5/GB レンジ) | 帯域(GB)/件数 |
料金体系で重要なのは、ページ単位(Firecrawl型)・実行回数単位(Browse AI型)・帯域単位(Bright Data型)のどれで課金されるかです。同じ「月1万ページ」でも、選ぶサービスによって月額が桁単位で変わります。
中小規模ならFirecrawl Hobby・Apify Starterあたりが入口として軽く、大規模・ミッションクリティカルになるとBright Data・Apify Scale級が現実解になります。
ノーコード自動化ツールの料金
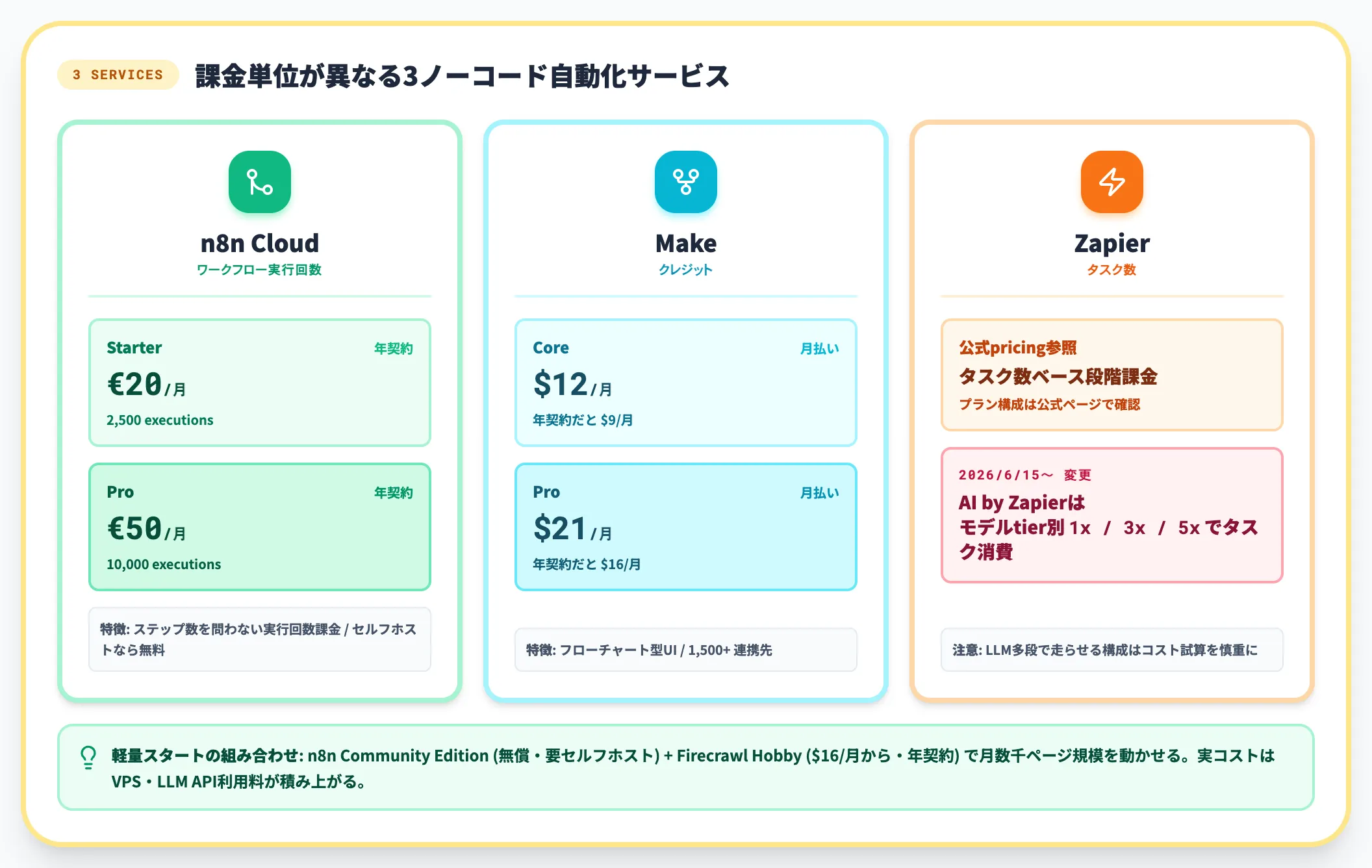
ノーコード自動化ツール側の料金は、ワークフロー実行数(execution)・クレジット・タスク数など、サービスごとに課金単位が異なります。代表3サービスを以下に整理します。
| サービス | 入門プラン | 中規模プラン | 課金単位 |
|---|---|---|---|
| n8n Cloud | Starter €20/月(年契約時・2,500 executions) | Pro €50/月(年契約時・10,000 executions) | ワークフロー実行回数 |
| Make | Core $12/月(月払い・年契約だと$9/月) | Pro $21/月(月払い・年契約だと$16/月) | クレジット |
| Zapier | プラン構成は公式pricingページ参照(タスク数ベースの段階課金) | 同上 | タスク数(2026年6月15日以降AI by Zapierはモデルtier別に1x/3x/5xでタスク消費) |
n8nは「ステップ数を問わない実行回数課金」「セルフホストなら無料」が特徴で、複雑なAIワークフローを多段で組むほど割安です。Zapierは2026年6月15日以降、AI by Zapierがモデルtierに応じて1ステップで1x/3x/5xのタスクを消費する課金体系に変わったため、LLM呼び出しを多段で走らせる構成だとコスト試算を慎重にやり直す必要があります。
セルフホスト前提なら、n8n Community Edition(無償・要セルフホスト環境)+Firecrawl Hobby($16/月から・年契約)の組み合わせで、月数千ページ規模のスクレイピングを軽量に動かせます。実コストはこれにVPS・サーバ運用費・LLM API利用料が積み上がるため、自社環境の運用費込みで試算してください。

AIブラウザエージェントの料金と隠れコスト
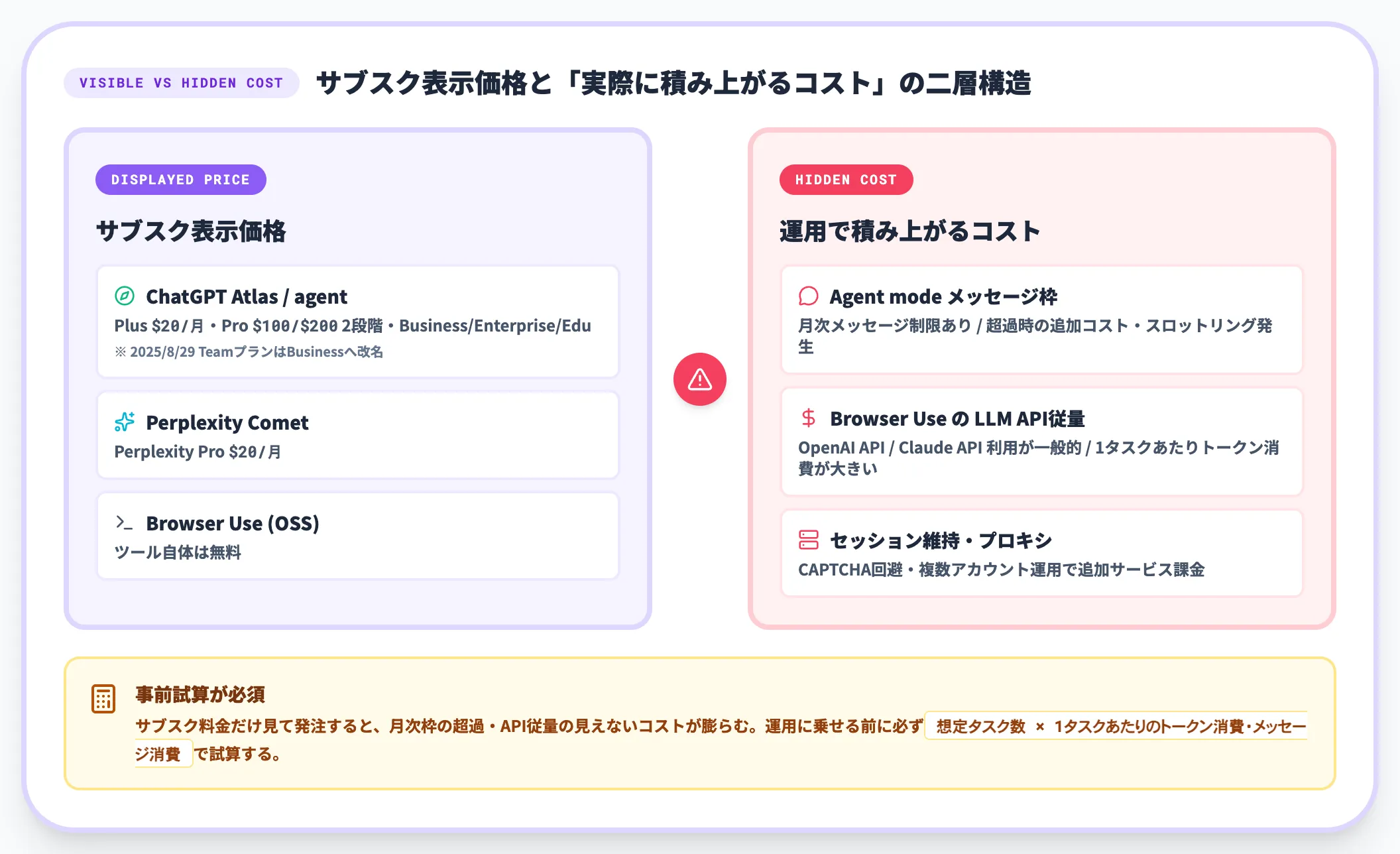
ブラウザエージェント系は、サブスクリプション内のagent mode利用が中心です。Business/Enterpriseでは柔軟課金の契約形態もあり、Eduは管理者設定・提供条件に従って利用します。OSS型のみAPI従量課金が前面に出ます。
-
ChatGPT Atlas / ChatGPT agent
ChatGPT Plus $20/月、ChatGPT Pro $100/$200の2段階、Business/Enterprise/Eduで利用可能。なお2025年8月29日にTeamプランはBusinessへ改名されている。Agent modeは月次メッセージ制限があり、API従量よりサブスク内の利用枠で運用するのが基本。
-
Perplexity Comet
Perplexity Pro $20/月で利用可能。
-
Browser Use(OSS)
ツール自体は無料、バックエンドLLMのAPI従量課金が実コスト。OpenAI APIまたはClaude API利用が一般的。
ブラウザエージェントは「サブスク単価では安く見える」が、Agent modeの月次メッセージ枠を超える運用を想定する場合や、Browser UseのようなOSS型でLLM APIを直接叩く構成の場合は、運用に乗せる前に必ず「想定タスク数 × 1タスクあたりのトークン消費・メッセージ消費」で試算する必要があります。試算なしでサブスク料金だけ見て発注すると、月次枠の超過や、API従量の見えないコストが膨らみます。
データ収集自動化を構築する5ステップの実装手順
ツールを揃えても、業務に乗せるには工程の順序が決定的です。AI総研の支援現場で標準化している5ステップを順に解説します。
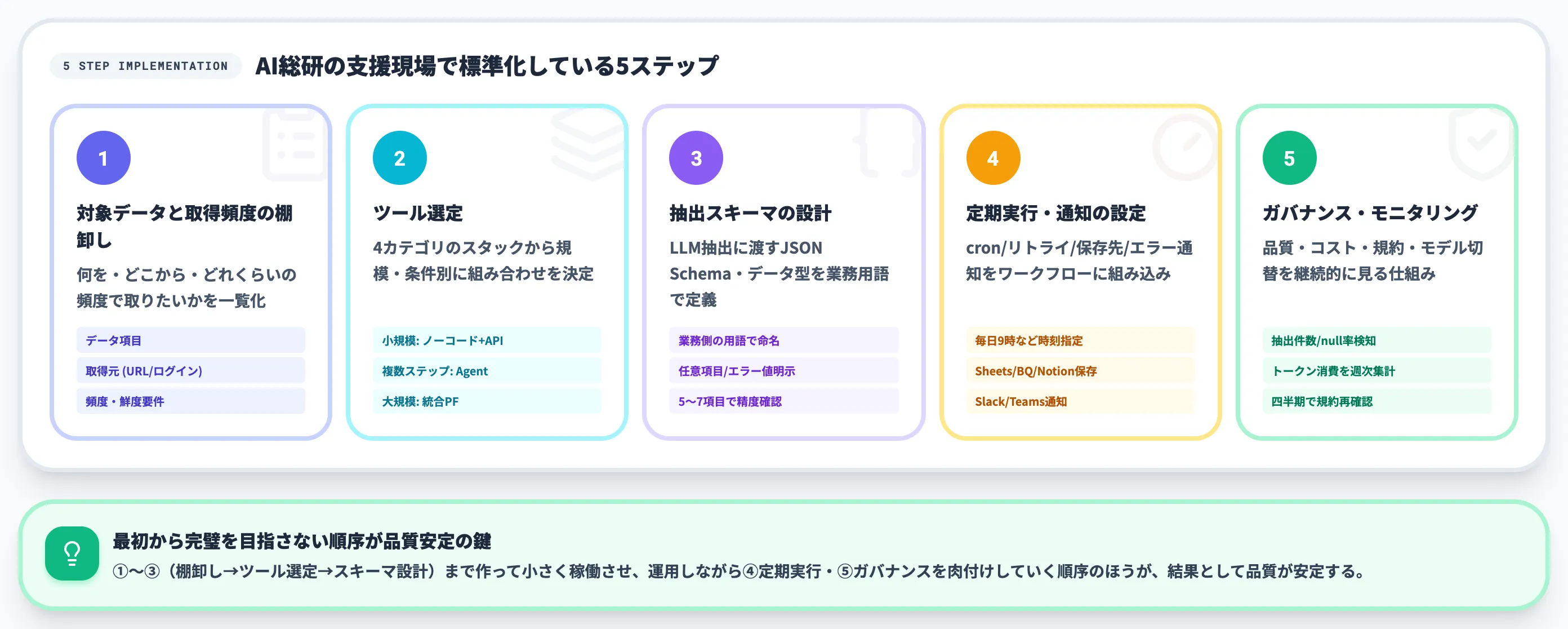
対象データと取得頻度の棚卸し

最初に手をつけるのは「何を・どこから・どれくらいの頻度で取りたいか」の棚卸しです。
具体的には、以下の3点を一覧で書き出します。
-
データ項目
取得したい列名(商品名/単価/在庫/発売日 等)
-
取得元
URL一覧、ログイン要否、API有無
-
頻度・鮮度要件
リアルタイム/日次/週次/月次
この棚卸しを飛ばすと、後工程でツールを選んでから「実は競合A社のサイトはログイン必須だった」「データが日次更新ではなく週次更新だった」といった追加要件が出てきて、設計のやり直しが頻発します。
棚卸し時点で、データ項目数が多すぎる・鮮度要件がバラバラ・取得元が30サイト超といった兆候が見えたら、フェーズを分けて段階導入する設計に切り替えるタイミングです。
ツール選定(規模・条件別の推奨スタック)
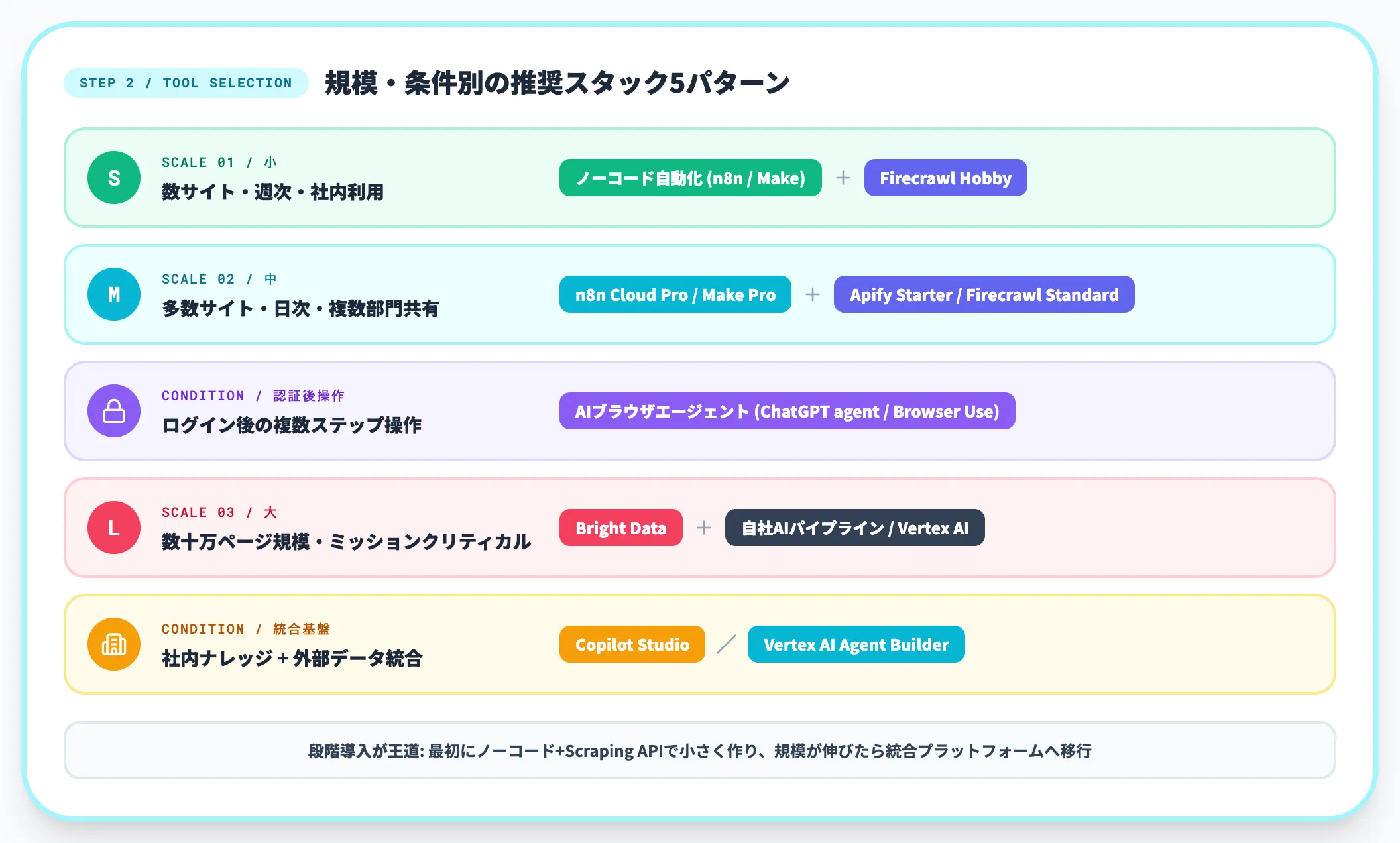
棚卸し結果から、前セクションの4カテゴリのどれを組み合わせるかを決めます。判断の典型パターンは以下のとおりです。
| 規模・条件 | 推奨スタック |
|---|---|
| 数サイト・週次・社内利用 | ノーコード自動化(n8n/Make)+ Firecrawl Hobby |
| 多数サイト・日次・複数部門共有 | n8n Cloud Pro/Make Pro+ Apify Starter/Firecrawl Standard |
| ログイン後の複数ステップ操作 | AIブラウザエージェント(ChatGPT agent/Browser Use) |
| 数十万ページ規模・ミッションクリティカル | Bright Data+ 自社AIパイプライン/Vertex AI |
| 社内ナレッジ+外部データ統合 | Copilot Studio/Vertex AI Agent Builder |
このマッピングはあくまで初期判断の起点です。実際は「最初にノーコード+Scraping APIで小さく作り、規模が伸びたら統合プラットフォームへ移行する」段階導入が王道になります。
抽出スキーマの設計
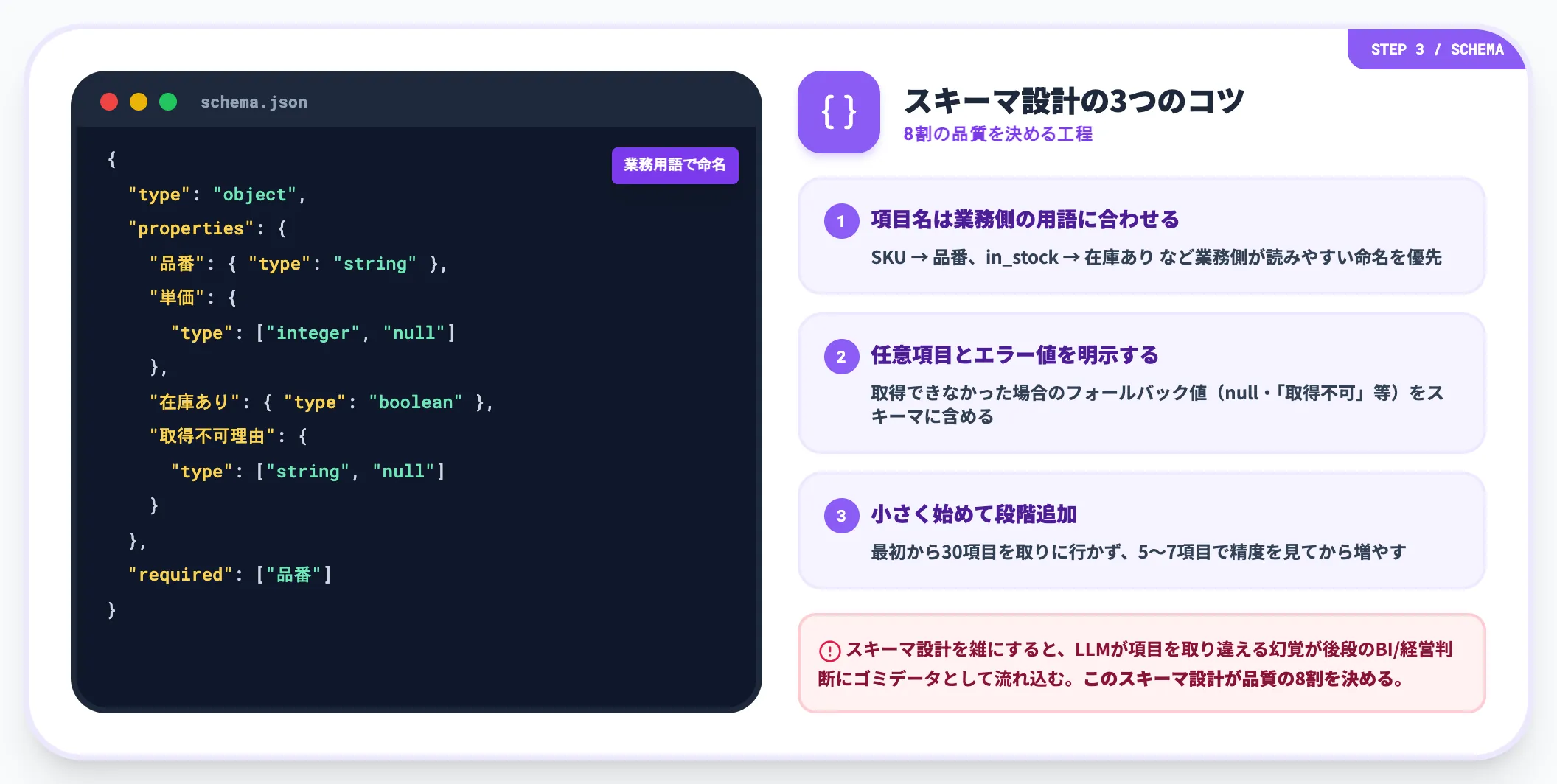
ツールを決めたら、LLM抽出に渡すスキーマを設計します。スキーマとは「商品名・単価・在庫数を、それぞれ string/number/boolean で返す」というJSON Schemaやデータ型定義を指します。
スキーマ設計のコツは3点です。
-
項目名は業務側の用語に合わせる
SKUを「品番」、in_stockを「在庫あり」など、業務側が読みやすい命名を優先する
-
任意項目とエラー値を明示する
取得できなかった場合のフォールバック値(null・「取得不可」等)をスキーマに含める
-
小さく始めて段階追加
最初から30項目を取りに行かず、5〜7項目で精度を見てから増やす
スキーマ設計を雑にしたまま定期実行に乗せると、LLMが項目を取り違える幻覚が紛れ込み、後段のBIや経営判断にゴミデータが流れ込みます。次のH2の落とし穴セクションでも触れますが、このスキーマ設計が品質の8割を決めます。
定期実行・通知の設定
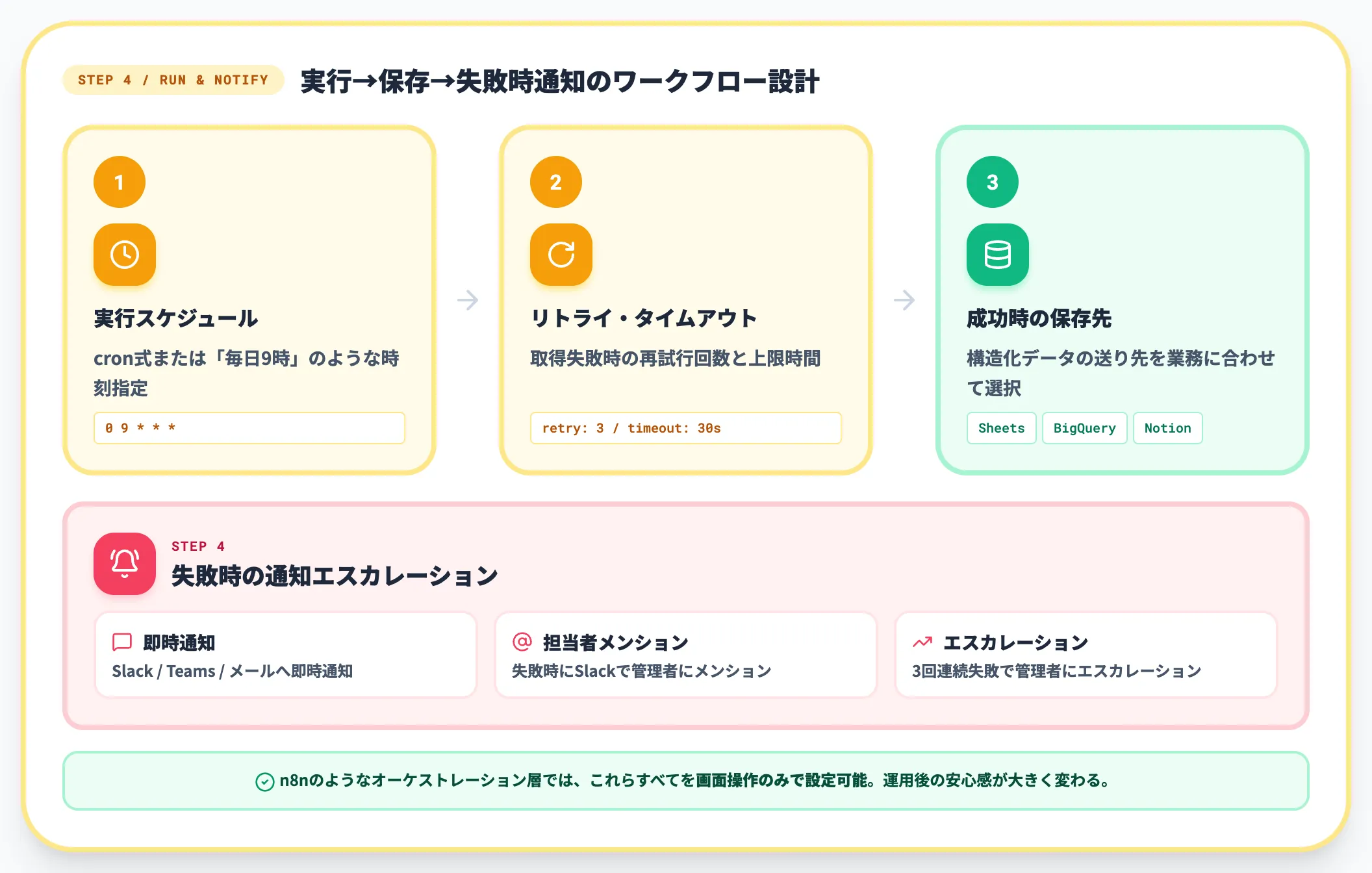
抽出スキーマができたら、定期実行とエラー時通知の仕組みをワークフローに乗せます。
具体的には以下を設計します。
-
実行スケジュール
cron式または「毎日9時」のような時刻指定
-
リトライ・タイムアウト
取得失敗時の再試行回数と上限時間
-
成功時の保存先
Google Sheets/BigQuery/Notion/Slack
-
失敗時の通知
Slack/Teams/メールへの即時通知
n8nのようなオーケストレーション層では、これらすべてを画面操作のみで設定できます。「失敗時にSlackへ通知+管理者にメンション」「3回連続失敗で管理者にエスカレーション」などの設計を入れておくと、運用に乗ったあとの安心感が大きく変わります。
ガバナンス・モニタリング

最後に、データの品質と運用ガバナンスを継続的に見る仕組みを整えます。
-
品質モニタリング
抽出件数・null率・前週比の異常検知をダッシュボード化する
-
コスト監視
LLM API・Scraping APIのトークン/クレジット消費を週次で集計する
-
法務・規約レビュー
取得元サイトの利用規約・robots.txt変更を四半期で再確認する
-
モデル切替対応
バックエンドLLMの新モデル登場時の精度評価ループ
5ステップは、いずれも「やらないと運用が回らないが、最初から完璧にやろうとすると着手できない」性質があります。AI総研の支援現場では、棚卸しからスキーマ設計まで作って小さく稼働させ、運用しながら定期実行・ガバナンスを肉付けしていく順序のほうが、結果として品質が安定する傾向にあります。
【関連記事】
AI業務自動化|PoC止まりを突破する全社展開ロードマップと統合基盤の設計
データ収集自動化の国内・海外導入事例
ここからは、AIによるデータ収集の自動化が実際にどう業務に乗っているかを、国内外の公開事例で見ていきます。出典のあるものに絞り、業務領域別に整理しました。

PigData:展示会・不動産モニタリングで年3,000万円削減
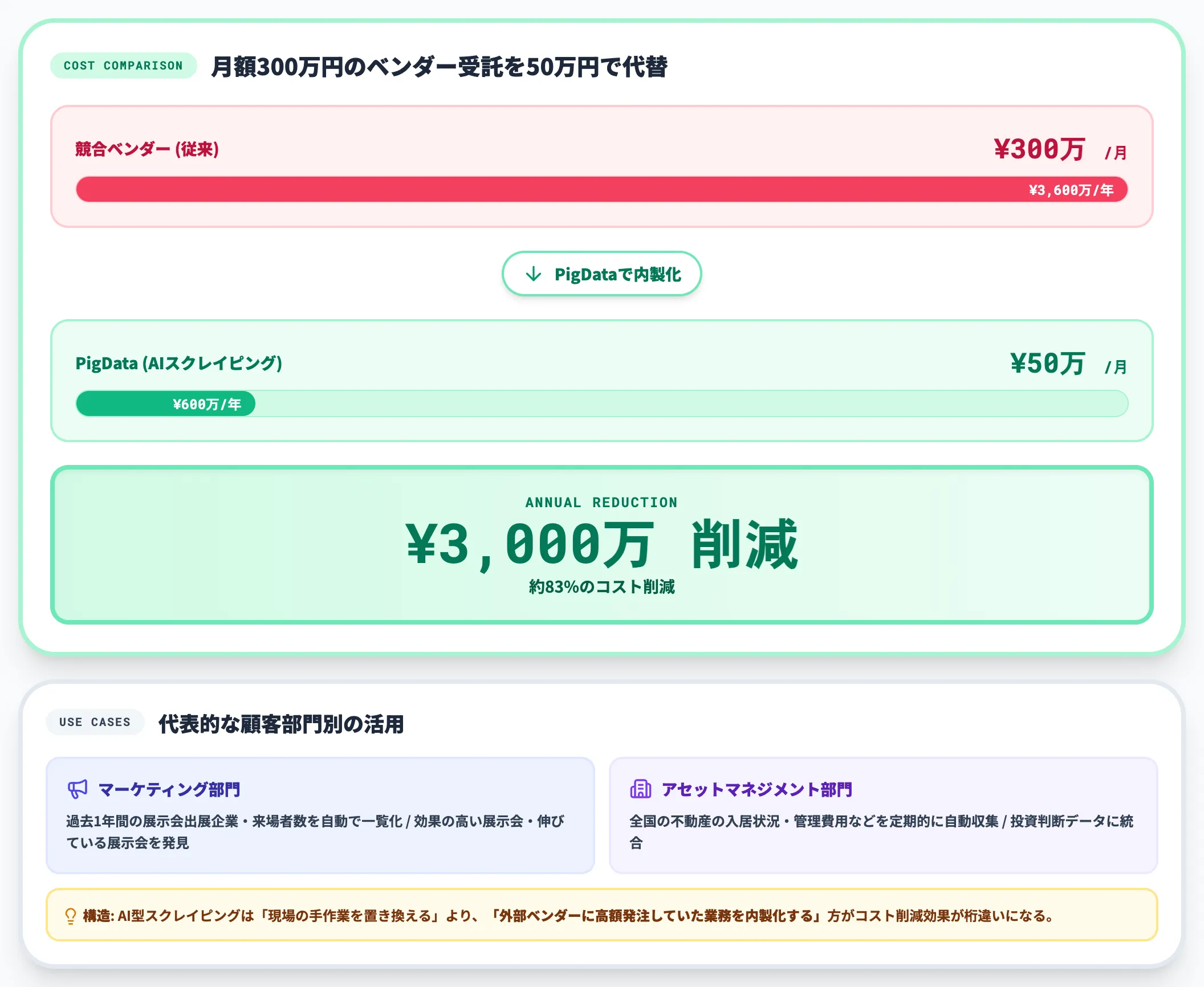
PigData(株式会社インディゴデータ)は、Webスクレイピングをサービス提供する国内ベンダーで、AIスクレイピングソリューションを公開しています。
公開されている代表的な顧客部門別の活用は以下のとおりです。
- マーケティング部門:過去1年間の展示会出展企業・来場者数を自動で一覧化し、効果の高い展示会・伸びている展示会を発見
- アセットマネジメント部門:全国の不動産の入居状況・管理費用などを定期的に自動収集し、投資判断データに統合
同社の公表では、競合する別ベンダーが月額約300万円(年約3,600万円)で受託していたスクレイピング業務をPigDataが月額約50万円(年約600万円)で代替し、顧客側で年間約3,000万円(約83%)のコスト削減を実現したと報告されています。
ここから読み取れるのは、AI型のスクレイピングは「現場が手作業でやっていた業務」を置き換えるよりも、「外部ベンダーに高額で発注していた業務」を内製化するほうがコスト削減効果が桁違いになる、という構造です。
楽天インサイト:楽楽リサーチャーで調査分析を自動化
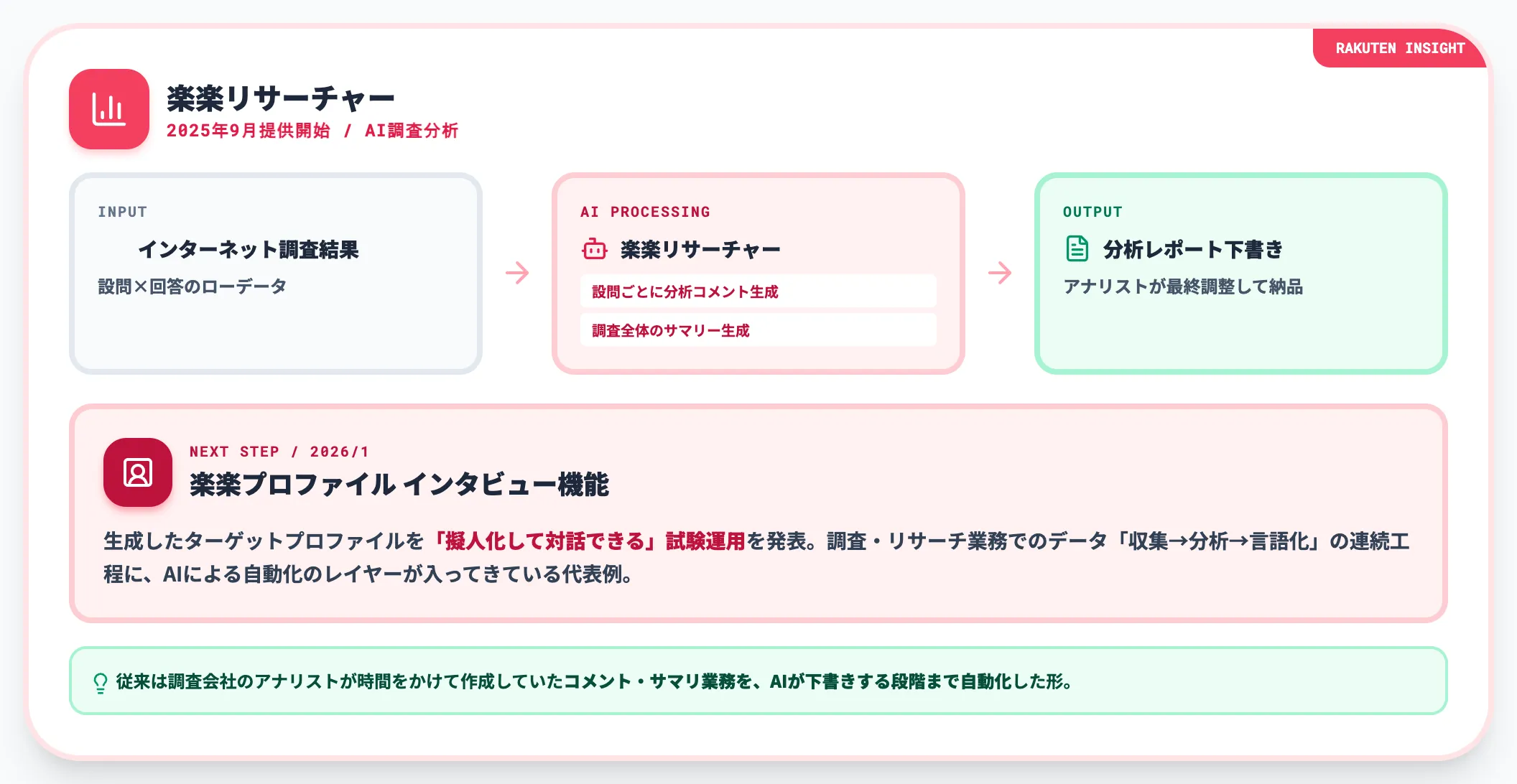
楽天グループの調査会社楽天インサイトは、2025年9月にAIアシスタント搭載の調査分析ツール「楽楽リサーチャー」を提供開始しました。
このツールは、インターネット調査結果に対して、AIが設問ごとの分析コメントと、調査結果全体のサマリーを自動生成します。従来は調査会社のアナリストが時間をかけて作成していたコメント・サマリ業務を、AIが下書きする段階まで自動化した形です。
楽天インサイトはさらに、2026年1月に同シリーズの「楽楽プロファイル」のインタビュー機能で、生成したターゲットプロファイルを「擬人化して対話できる」試験運用を発表しています。
調査・リサーチ業務でのデータ「収集→分析→言語化」の連続工程に、AIによる自動化のレイヤーが入ってきている代表例です。
SmapraTracker:EC競合価格モニタリングで1回あたり約3時間削減
![]()
ECの競合価格モニタリング領域では、AI型ツール「SmapraTracker」が代表的な選択肢です。
楽天・Amazon・Yahoo!といった主要モール、自社EC、海外サイトまで、追跡対象のURLを登録するだけで毎日自動収集する仕組みで、価格調査の工数を最大90%以上削減できると報告されています。検証例では1回あたり約3時間20分かかっていた調査が約20分に短縮されています。
EC・小売領域では「競合の値動きを翌日には把握する」スピードが利益率を直接左右するため、データ収集の自動化は単なる工数削減ではなく、価格戦略の精度を上げる意思決定インフラとして機能します。
Zapier・Retell・Athena Intelligence:Firecrawlを組み込んだAI機能(海外)
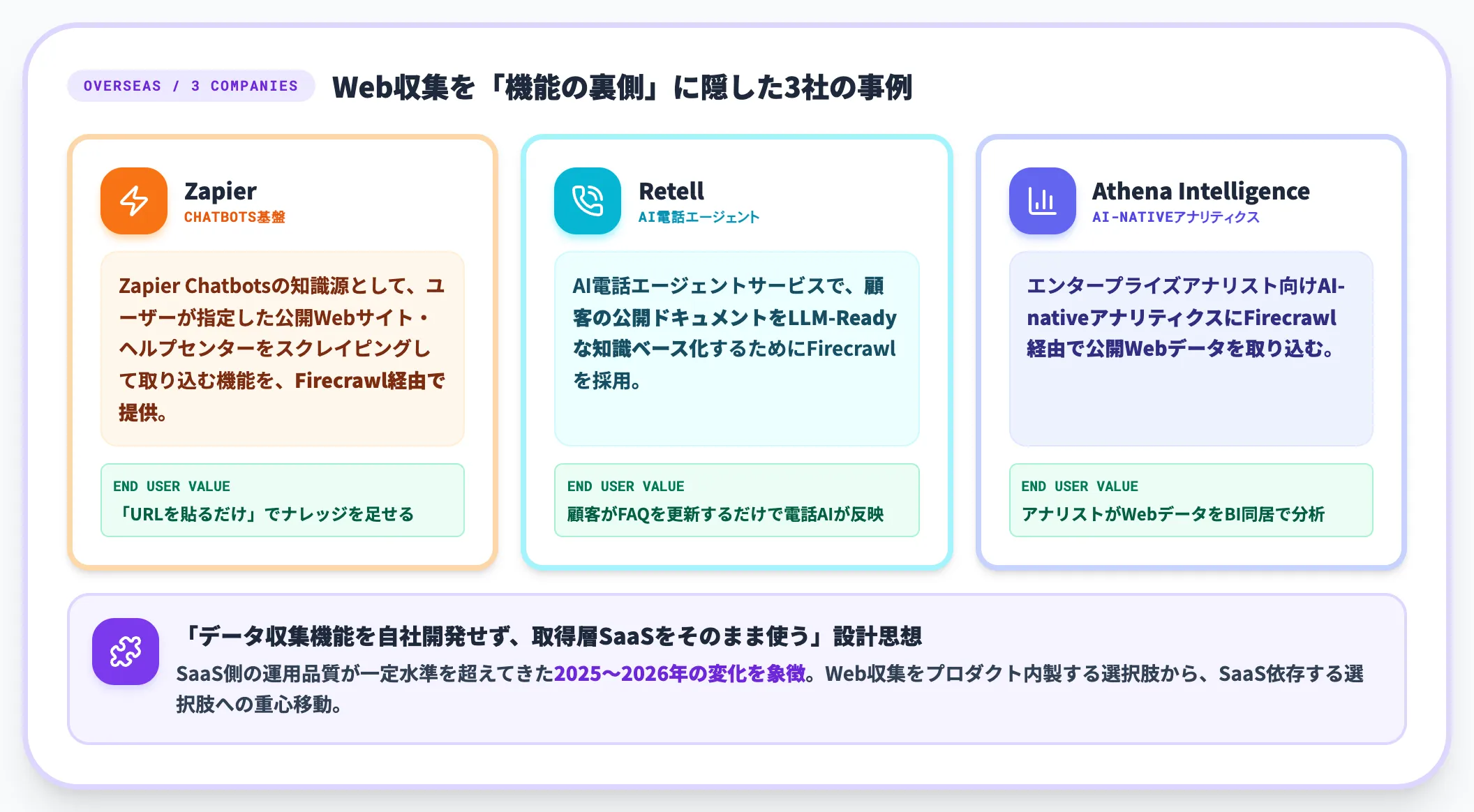
海外では、LLM-Ready Scraping APIのFirecrawlを自社プロダクトに組み込む形で、Web収集を「機能の裏側」に隠した事例が増えています。
- Zapier:Zapier Chatbotsの知識源として、ユーザーが指定した公開Webサイト・ヘルプセンターをスクレイピングして取り込む機能を、Firecrawl経由で提供。エンドユーザーは「URLを貼るだけ」でナレッジを足せる
- Retell:AI電話エージェントサービスで、顧客の公開ドキュメントをLLM-Readyな知識ベース化するためにFirecrawlを採用
- Athena Intelligence:エンタープライズアナリスト向けAI-nativeアナリティクスにFirecrawl経由で公開Webデータを取り込む
これらは「データ収集機能を自社で開発せず、Firecrawlのような取得層SaaSをそのまま使う」設計思想の例です。SaaS側の運用品質が一定水準を超えてきた2025〜2026年の変化を象徴しています。
業界全体の動向:Gartnerによる2026年予測
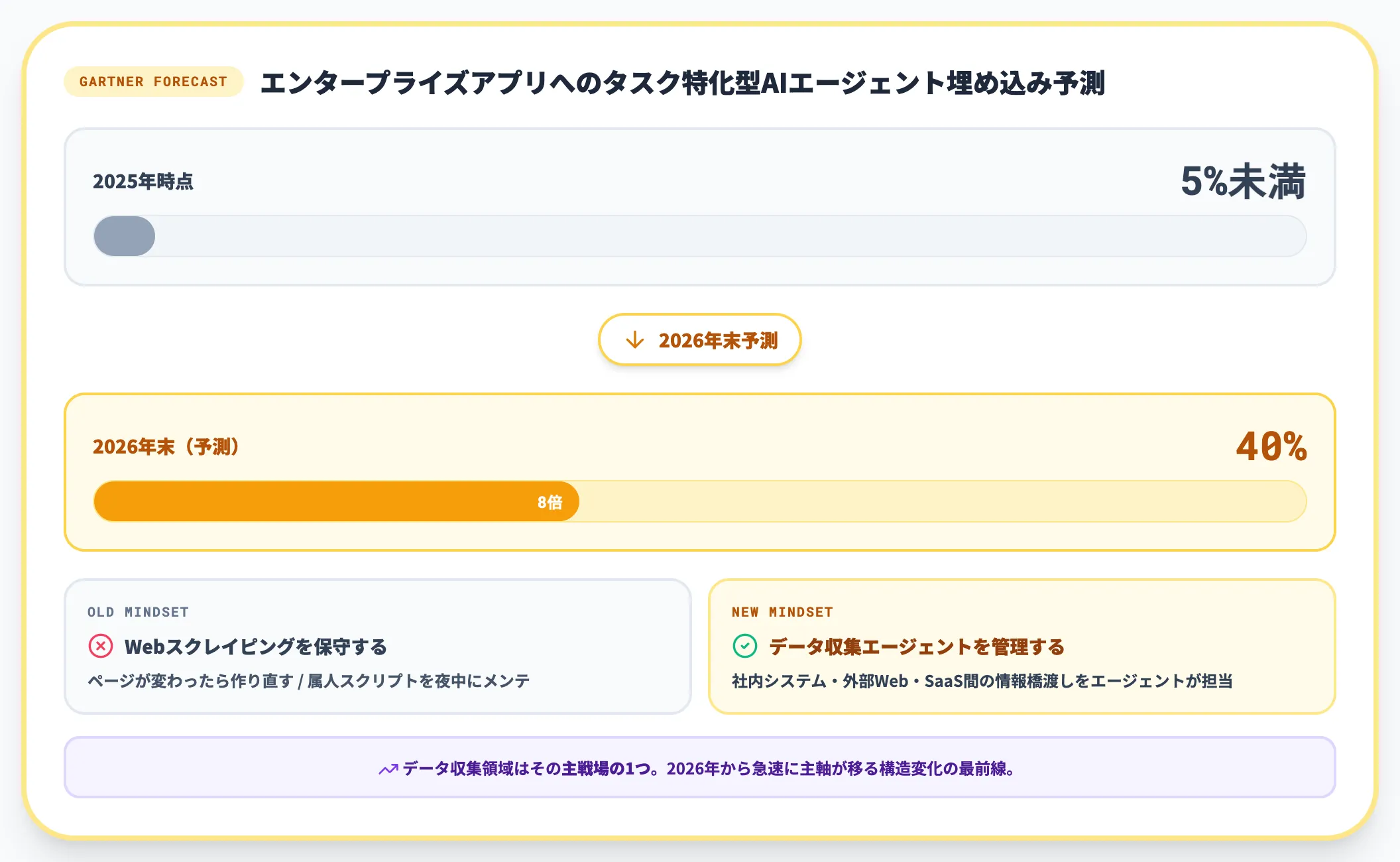
個別事例だけでは見えない業界全体の現在地として、Gartnerの予測は外せません。
Gartnerは「2026年末までに40%のエンタープライズアプリにタスク特化型AIエージェントが組み込まれる(2025年は5%未満)」と予測しています。データ収集領域はその主戦場の1つで、社内システム・外部Web・SaaS間の情報橋渡しを担うエージェントが急増する見込みです。
ここから読み取れるのは、「Webスクレイピングを保守する」発想は2026年から急速に古くなり、「データ収集エージェントを管理する」発想に主軸が移る、という構造変化です。
AIスクレイピングで起きる落とし穴と回避策
ここまで業務インパクト・スタック・ツール・事例とメリット中心に整理してきましたが、AI活用型のデータ収集には固有の落とし穴があります。
法務・データ品質・コスト・セキュリティの4軸で、起きやすいパターンと回避策を順に整理します。
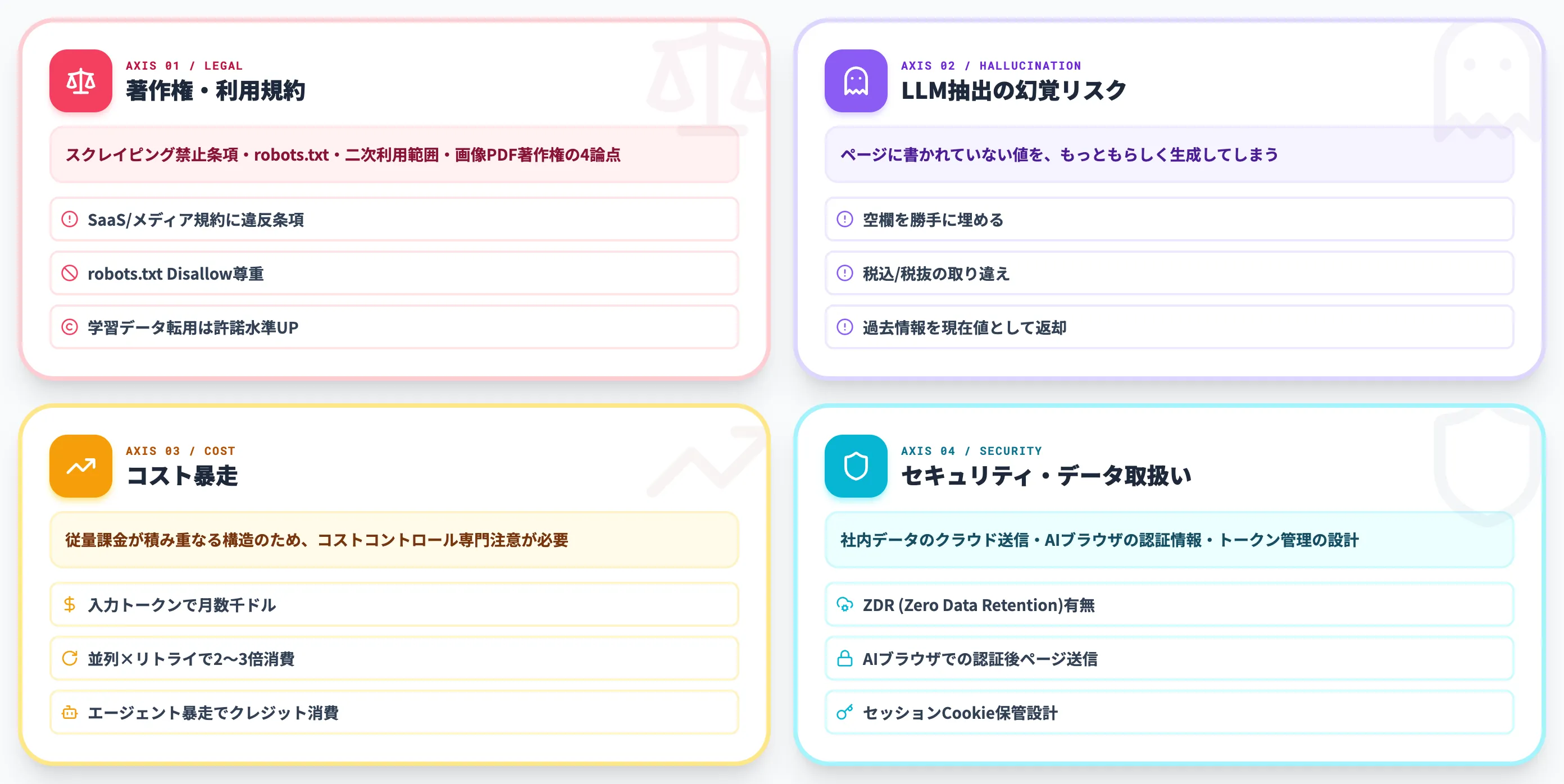
著作権・利用規約・robots.txtの解釈

スクレイピング全般に共通する論点ですが、AI活用型ではいくつかの追加注意があります。
-
対象サイトの利用規約
多くのSaaS・メディアサイトの利用規約には「スクレイピング・自動収集を禁止」する条項が含まれている。法人利用で違反した場合のリスクは個人利用より大きい
-
robots.txtの尊重
robots.txtに「Disallow」と書かれているパスは原則アクセスしない。AIエージェントもこれを尊重する設計にすべき
-
データの二次利用範囲
取得したコンテンツを社内分析に使うのと、自社サイトに掲載する/生成AIの学習データに使うのでは、必要な許諾水準が変わる
-
画像・PDFの著作権
テキスト抽出に加えて画像・PDFファイル自体を保存する場合、著作権の取り扱いがより厳格になる
2026年時点では、AI事業者と権利者団体の交渉が継続中の論点が多く、「明示的に禁止されていなければOK」という解釈は危険です。AI総研の支援現場では、社内法務とのレビューを設計フェーズに必ず1回挟むことを推奨しています。
LLM抽出の幻覚(ハルシネーション)リスク
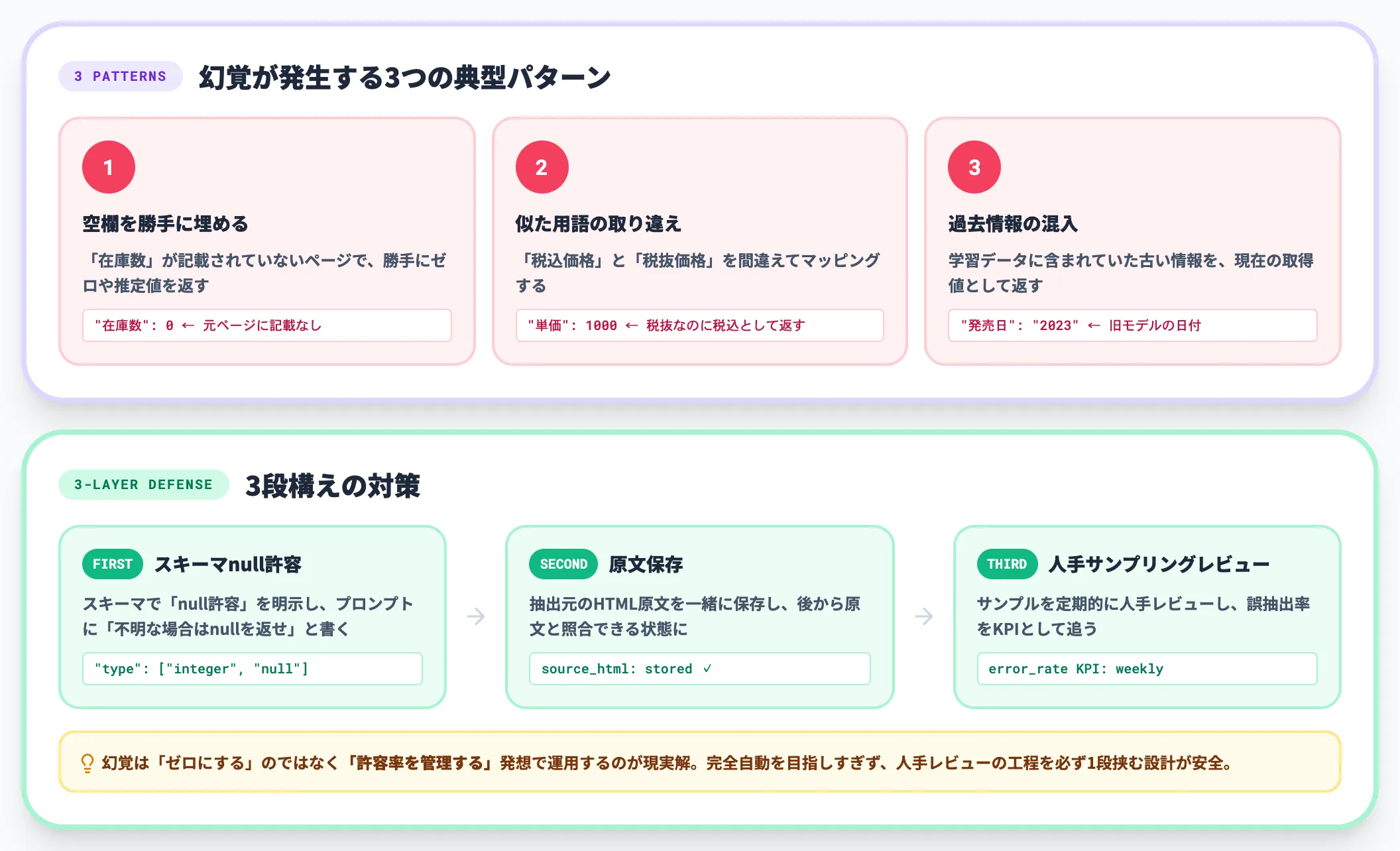
LLM抽出は柔軟性が高い反面、「ページに書かれていない値を、もっともらしく生成してしまう」幻覚リスクがあります。
具体的な発生パターンは以下です。
-
空欄を埋めてしまう
「在庫数」が記載されていないページで、勝手にゼロや推定値を返す
-
似た用語の取り違え
「税込価格」と「税抜価格」を間違えてマッピングする
-
過去情報の混入
学習データに含まれていた古い情報を、現在の取得値として返す
対策は3段構えです。第一に、スキーマで「null許容」を明示し「不明な場合はnullを返せ」とプロンプトに書く。第二に、抽出元のHTML原文を一緒に保存して、後から原文と照合できる状態にする。第三に、サンプルを定期的に人手でレビューし、誤抽出率をKPIとして追う。
幻覚は「ゼロにする」のではなく「許容率を管理する」発想で運用するのが現実解です。完全自動を目指しすぎず、人手レビューの工程を必ず1段挟む設計が安全です。
コスト暴走の典型パターン

AI活用型は従量課金が積み重なる構造のため、コストコントロールに専門の注意が必要です。
-
LLMトークン課金
抽出対象ページが長文だと、入力トークンだけで月数千ドルに膨らむ
-
Scraping APIクレジット
ページ数 × 同時並列数 × 失敗時リトライで、想定の2〜3倍消費するケースが頻発
-
エージェントの暴走
AIエージェントが「目的達成のために」予想外の追加ページを巡回し続け、クレジットが空になる
対策として、必ず「月次予算アラート」と「利用上限」をAPI管理画面側で設定すべきです。各サービスで予算アラート、利用上限、クレジット/レート制限の設定可否・粒度は異なるため、OpenAI/Anthropic/Firecrawlなど利用予定のサービスごとに管理画面で個別に確認してください(例: Anthropicの Spend limits 設定)。
セキュリティ・データ取扱い
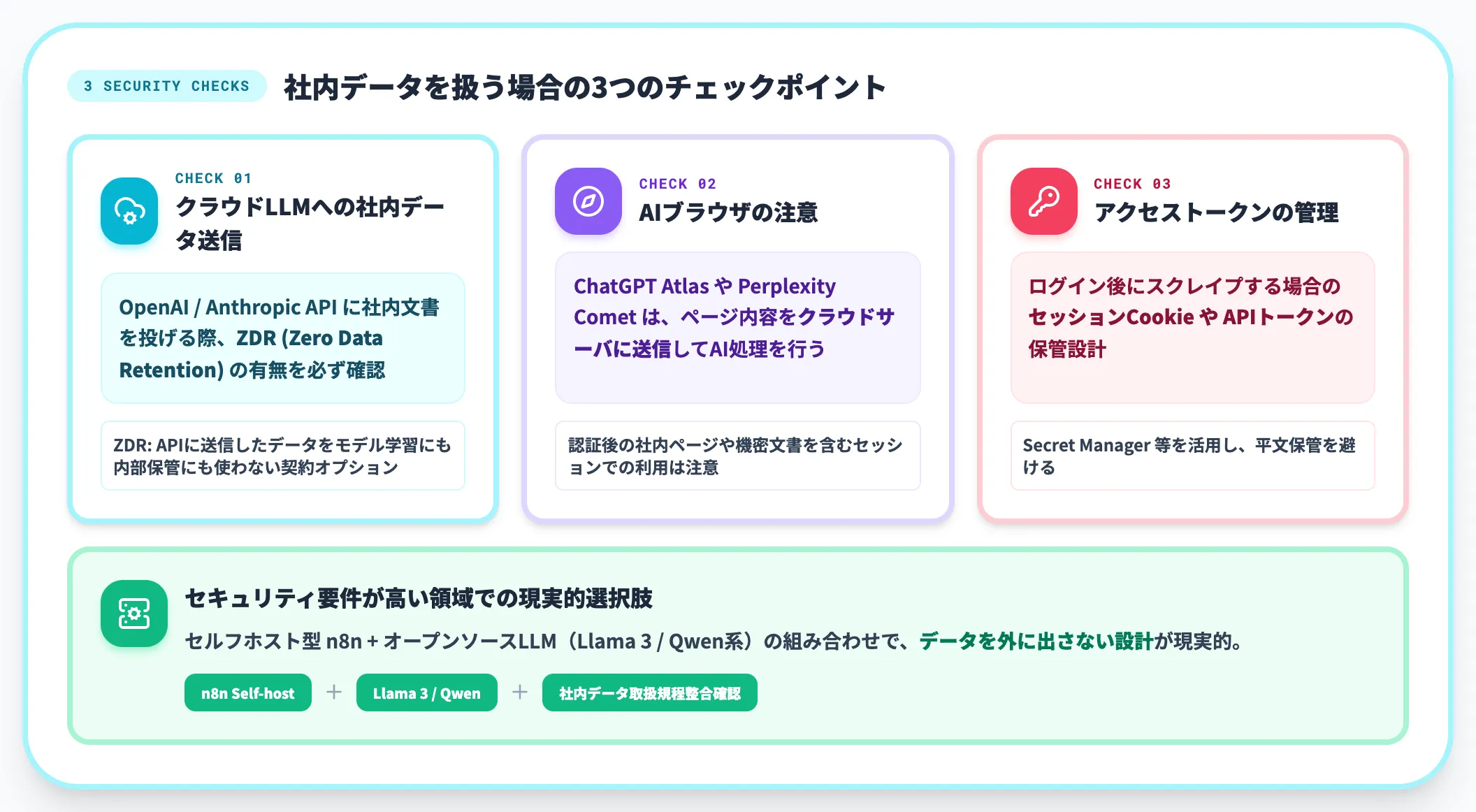
社内データを扱う場合、データ取扱いの設計も避けて通れません。
-
クラウドLLMへの社内データ送信
OpenAI/Anthropic APIに社内文書を投げる際、ZDR(Zero Data Retention:APIに送信したデータをモデル学習にも内部保管にも使わない契約オプション)の有無を必ず確認する
-
AIブラウザの注意
ChatGPT AtlasやPerplexity Cometは、ページ内容をクラウドサーバに送信してAI処理を行うため、認証後の社内ページや機密文書を含むセッションでの利用には注意が必要
-
アクセストークンの管理
ログイン後にスクレイプする場合のセッションCookieやAPIトークンの保管設計
セキュリティ要件が高い領域では、セルフホスト型のn8n+オープンソースLLM(Llama 3/Qwen系)の組み合わせで、データを外に出さない設計が現実的な選択肢になります。社内データ取扱規程との整合確認を、設計の最初のチェックポイントに置くことを推奨します。
データ収集自動化のPoCで詰まる3つの判断軸
最後に、AI総研が支援現場で実際に詰まりやすいと感じる判断軸を3つに整理します。一般的なメリット・デメリット論の外側にある、ケース別の決定の話です。

自動化範囲と人手レビューの線引き

AIエージェントが自律実行できる範囲が広がるほど、どこまで自動化し、どこから人手判断を残すかの線引きが運用品質を決めます。
実務的には、以下の3レイヤーに分けて考えると判断がブレません。
-
完全自動化レイヤー
取得・抽出・保存までAIに任せる。社内の参照用ダッシュボード・営業の競合監視など、誤りがあっても致命的でない用途
-
半自動レイヤー
AIが抽出した後、業務担当が承認して初めて反映される。経営判断データ・顧客への提示資料に流れる用途
-
人手主体レイヤー
AIは「候補提示」までで、判断は人手。法務・コンプライアンス関連、機密性の高いデータの取り扱い
多くの企業で「全部完全自動化」を目指してPoCが頓挫するパターンを見ます。最初の1年は半自動レイヤーを主軸に置き、データの安定性が見えてから完全自動を増やしていく順序が安全です。
スキーマ変更耐性と再学習コスト
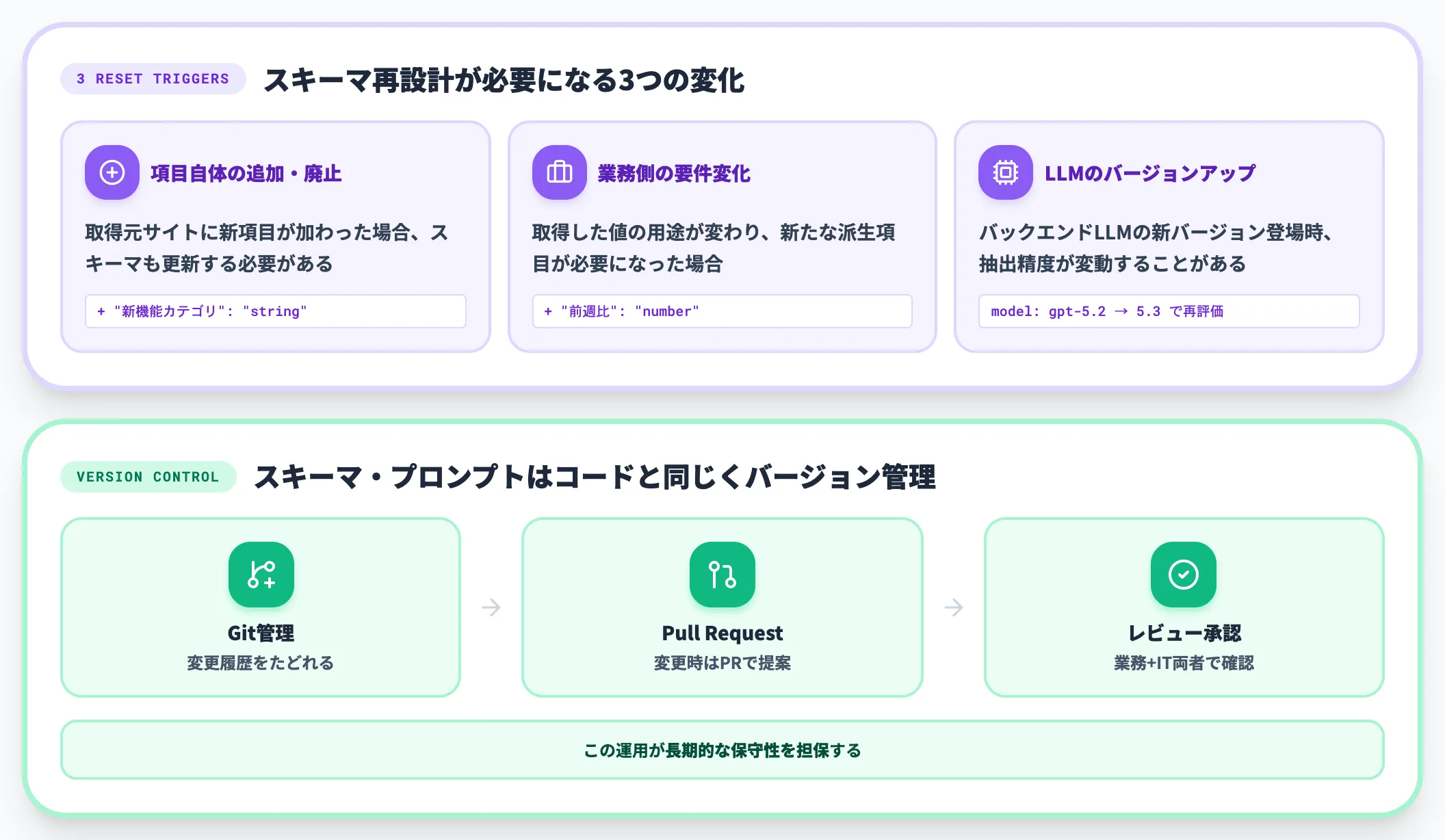
AI抽出の強みは「ページ構造の変化に強い」ですが、これは「無限に強い」わけではありません。具体的には、以下の変化に対しては再設計が必要になります。
-
項目自体の追加・廃止
取得元サイトに新項目が加わった場合、スキーマも更新する必要がある
-
業務側の要件変化
取得した値の用途が変わり、新たな派生項目が必要になった場合
-
LLMのバージョンアップ
バックエンドLLMの新バージョン登場時、抽出精度が変動することがある
そのため、抽出スキーマ・プロンプトはコードと同じくバージョン管理し、変更履歴をたどれる状態を保つことを推奨します。Gitリポジトリでスキーマ定義を管理し、変更時はPull Request+レビューを通すような運用が、長期的な保守性を担保します。
「過剰AI化」を避ける見極め

最後の論点は、AI活用型 vs 従来型の使い分けです。
冒頭で触れたとおり、AI活用型は「構造変化への耐性」「非構造データへの対応」で従来型を上回ります。一方で、「APIが用意されている公開データ」「定型フォーマットのCSV取り込み」のような領域では、AIを噛ませる必要がないどころか、AI経由のほうがコスト高・精度低になるケースもあります。
判断軸の例を以下に整理します。
| 状況 | 推奨スタック |
|---|---|
| 取得元が公式APIを提供している | 直接API呼び出し(AI不要) |
| HTMLが構造化されており変化が少ない | 従来型スクレイピング+簡易チェック |
| HTMLが揺らぐ・非構造文章を読む必要がある | LLM抽出+Scraping API |
| ログイン・複数ステップ操作が必要 | AIブラウザエージェント |
| 数百サイト超・多部門展開 | 統合プラットフォーム(Copilot Studio/Vertex AI) |
「AIで自動化する」と言い切るより、「AIを噛ませる価値が高い領域だけAI化する」発想のほうが、長期コストとデータ品質の両面で安定します。AI総研の支援現場では、PoC設計時にこの判断軸を1枚のマップに整理し、ステークホルダー間で握ることから始めるケースが増えています。

データ収集の自動化から、AI業務自動化の全体設計へ
ここまで紹介したデータ収集の自動化は、AI業務自動化のうち最も着手しやすい入口です。
「自社で毎日30分以上手動でやっている情報収集」を1つ自動化できると、見える景色は確実に変わります。一方、その先で本当に効いてくるのは、収集したデータをどの業務判断に流すか、どの部門で巻き取るか、どの粒度で全社共有するか、というAI業務自動化の全体設計です。
AI総研では、Microsoft Copilot Chat → Microsoft 365 Copilot → Copilot Studio → Azure AI Foundry/AI Agent Hub の段階導入を、部門別ユースケースのBefore/Afterと合わせて整理した220ページの実践ガイドを公開しています。
データ収集の自動化を「点」で終わらせず、業務判断・意思決定までつながる「線」として設計したい方は、以下から無料でダウンロードしてご活用ください。
データ収集の自動化を全社のAI業務効率化につなげる

PoCから全社展開までの設計を1冊で
AIによるデータ収集の自動化は、AI業務自動化のうち最も着手しやすい入口です。AI業務自動化ガイド(220ページ)では、PoC設計から全社展開までの進め方、部門別ユースケース、運用上の統制・セキュリティのチェックポイントを整理しています。
まとめ
本記事では、AIによるデータ収集の自動化について、実務フロー全体像・4つの技術スタック・主要ツールの分類と料金・実装5ステップ・国内外事例・PoCで詰まる判断軸までを2026年6月時点の最新情報で整理しました。
要点を1行ずつ振り返ります。
- 実務フロー:5ステップ業務サイクル(棚卸し→ツール選定→スキーマ設計→定期実行→ガバナンス)として回す
- 技術スタック:LLM抽出/AIエージェント/LLM-Ready Scraping API/ノーコード自動化の4層で組み合わせる
- 主要ツール:Firecrawl・Browse AI・ChatGPT Atlas・n8n・Copilot Studio等をカテゴリ別に使い分ける
- 料金:ページ単位・実行回数単位・帯域単位の課金軸を踏まえてランニングを試算する
- 国内外事例:PigData年3,000万円削減・楽天楽楽リサーチャー・SmapraTracker工数90%削減・海外Zapier/Retell/Athena
- 落とし穴:著作権・利用規約・幻覚リスク・コスト暴走・データ取扱いの4軸でガード設計する
- PoCで詰まる論点:自動化範囲の線引き/スキーマ変更耐性/「過剰AI化」の見極め
最初の一歩としては、自社で毎日30分以上手動の情報収集をかけているタスクを1つ選び、ノーコード自動化+Scraping APIの組み合わせで小さく試すところから始めるのが現実的です。
AIによるデータ収集の自動化は、単独で完結する施策ではなく、その先の業務判断・意思決定・AI業務基盤につながる入口になります。本記事の整理が、自社のスタックを設計する際の判断材料になれば幸いです。










